google / active-qa Goto Github PK
View Code? Open in Web Editor NEWLicense: Apache License 2.0
License: Apache License 2.0
Hi,
Thanks for releasing the code for active-qa.
After browsing the code, I did not find Monte-Carlo Sampling in the training stage. It seems that each training instance consists of only one 「query, reformulated_query, reward」 tuple. Therefore, the reward is the same for each token in one reformulated query.
I don't know whether the suspicion is right. If it is right, what will model perform with or without Monte-Carlo sampling? Maybe using only one instance for Monte Carlo sampling is like the relation between stochastic gradient descent and gradient descent?
Thank you
When I run this code in Jupyter, that error show up for me:
!python -m px.environments.bidaf_server
--port=10000
--squad_data_dir=./data/squad
--bidaf_shared_file=./data/bidaf/shared.json
--bidaf_model_dir=./data/bidaf
The import can't be completed, I guess, because doesn't have the file to import.
In px/proto I can't found it.
I'm using Python 2.
Thank you for your interesting paper & open-sourcing it!
Running the code given in: #9 (comment) but getting a grpc.FutureTimeoutError:
python2 reformulate.py
Num encoder layer 2 is different from num decoder layer 4, so set pass_hidden_state to False
# hparams:
src=source
tgt=target
train_prefix=None
dev_prefix=None
test_prefix=None
train_annotations=None
dev_annotations=None
test_annotations=None
out_dir=/tmp/active-qa/reformulator
# Vocab file data/spm2/spm.unigram.16k.vocab.nocount.notab.source exists
using source vocab for target
# Use the same embedding for source and target
Traceback (most recent call last):
File "reformulate.py", line 10, in <module>
environment_server_address='localhost:10000')
File "/root/active-qa/px/nmt/reformulator.py", line 130, in __init__
use_placeholders=True)
File "/root/active-qa/px/nmt/model_helper.py", line 171, in create_train_model
trie=trie)
File "/root/active-qa/px/nmt/gnmt_model.py", line 56, in __init__
trie=trie)
File "/root/active-qa/px/nmt/attention_model.py", line 65, in __init__
trie=trie)
File "/root/active-qa/px/nmt/model.py", line 137, in __init__
hparams.environment_server, mode=hparams.environment_mode))
File "/root/active-qa/px/nmt/environment_client.py", line 152, in make_environment_reward_fn
grpc.channel_ready_future(channel).result(timeout=30)
File "/root/active-qa/venv/local/lib/python2.7/site-packages/grpc/_utilities.py", line 134, in result
self._block(timeout)
File "/root/active-qa/venv/local/lib/python2.7/site-packages/grpc/_utilities.py", line 84, in _block
raise grpc.FutureTimeoutError()
grpc.FutureTimeoutError
Does the gRPC server have to run in order to use the Reformulator or am I missing something else here?
Are you running the environment server before running the reformulator code?
Originally posted by @graviraja in #15 (comment)
Kindly help me on how to run the environment server before running the reformulator code?
I've also tried changing environment_server_address=None. Still the same issue.
In reformulator_and_selector_training.py file, eval_utils module needs to be imported by "from px.utils import eval_utils". However, there is no utils module in the px folder. Could you please upload this file?
I'm trying to download the pretrained model file of reformulator(translate.ckpt-6156696.zip) and returns forbidden access (403).
https://storage.cloud.google.com/pretrained_models/translate.ckpt-6156696.zip
Can you provide a public link for this file?
I am trying to get the reformulations from the reformulator but I get all nonsensical reformulations like this-

My questions were- ['how can i apply for nsa?', 'what is the minimum working hours required for a day?']
I used this code to get the reformulations-
from px.nmt import reformulator
from px.proto import reformulator_pb2
questions = ['how can i apply for nsa?', 'what is the minimum working hours required for a day?']
reformulator_instance = reformulator.Reformulator(
hparams_path='px/nmt/example_configs/reformulator.json',
source_prefix='<en> <2en> ',
out_dir='path/to/reformulator_dir',
environment_server_address='localhost:10000')
# Change from GREEDY to BEAM if you want 20 rewrites instead of one.
responses = reformulator_instance.reformulate(
questions=questions,
inference_mode=reformulator_pb2.ReformulatorRequest.GREEDY)
# Since we are using greedy decoder, keep only the first rewrite.
reformulations = [r[0].reformulation for r in responses]
print reformulations
When running in a ipython notebook
reformulator = reformulator.Reformulator(
hparams_path='px/nmt/example_configs/reformulator.json',
source_prefix='<en> <2en> ',
out_dir='/tmp',
environment_server_address='localhost:10000')AttributeError: 'DiverseBeamSearchDecoder' object has no attribute '_coverage_penalty_weight'
When running via the cli:
python -m px.nmt.reformulator_and_selector_training \
--environment_server_address=localhost:10000 \
--hparams_path=px/nmt/example_configs/reformulator.json \
--enable_reformulator_training=true \
--enable_selector_training=false \
--train_questions=$SQUAD_DIR/train-questions.txt \
--train_annotations=$SQUAD_DIR/train-annotation.txt \
--train_data=data/squad/data_train.json \
--dev_questions=$SQUAD_DIR/dev-questions.txt \
--dev_annotations=$SQUAD_DIR/dev-annotation.txt \
--dev_data=data/squad/data_dev.json \
--glove_path=$GLOVE_DIR/glove.6B.100d.txt \
--out_dir=$REFORMULATOR_DIR \
--tensorboard_dir=$OUT_DIR/tensorboard
AttributeError: 'DiverseBeamSearchDecoder' object has no attribute '_coverage_penalty_weight'
This should be set in the parent object as per https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/seq2seq/python/ops/beam_search_decoder.py#L338
Not clear on what is missing
Reformulator Training
We first train reformulator from a model pretrained on UN and Paralex datasets. It should take a week on a single P100 GPU to reach ~42 F1 score on SearchQA's dev set.
@rodrigonogueira4 How to make the model (pretrained on UN and Paralex datasets) from scratch on a different dataset ?
flake8 testing of https://github.com/google/active-qa on Python 3.7.0
$ flake8 . --count --select=E901,E999,F821,F822,F823 --show-source --statistics
./px/environments/docqa.py:72:20: E999 SyntaxError: invalid syntax
async=0,
^
1 E999 SyntaxError: invalid syntax
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/tmp/pip-build-OSBzO1/numpy/setup.py", line 31, in <module>
raise RuntimeError("Python version >= 3.5 required.")
RuntimeError: Python version >= 3.5 required.
----------------------------------------
Command "python setup.py egg_info" failed with error code 1 in /tmp/pip-build-OSBzO1/numpy/
Ubuntu 16.04.6 LTS (GNU/Linux 4.4.0-165-generic x86_64)
I am using ActiveQA Github repository to generate questions and answers. right now i am looking for checkpoints for selector training (Pre-trained Models),actually i was unable to download from activeqa readme file so could you provide public link.
https://storage.cloud.google.com/pretrained_models/selector.zip
All prior steps went fine. Running the gRPC environment server errors out. Thoughts?
Running Python 2.7.14 :: Anaconda custom (x86_64) on CPU
Full stack trace:
python -m px.environments.bidaf_server
--port=10000
--squad_data_dir=data/squad
--bidaf_shared_file=data/bidaf/shared.json
--bidaf_model_dir=data/bidaf/
I0514 14:08:35.730832 140735704388480 bidaf_server.py:195] Loading server...
Traceback (most recent call last):
File "/Users/david/anaconda/lib/python2.7/runpy.py", line 174, in _run_module_as_main
"main", fname, loader, pkg_name)
File "/Users/david/anaconda/lib/python2.7/runpy.py", line 72, in _run_code
exec code in run_globals
File "/Users/david/active-qa/px/environments/bidaf_server.py", line 227, in
app.run(main)
File "/Users/david/anaconda/lib/python2.7/site-packages/absl/app.py", line 300, in run
_run_main(main, args)
File "/Users/david/anaconda/lib/python2.7/site-packages/absl/app.py", line 251, in _run_main
sys.exit(main(argv))
File "/Users/david/active-qa/px/environments/bidaf_server.py", line 207, in main
debug_mode=FLAGS.debug_mode), server)
File "/Users/david/active-qa/px/environments/bidaf_server.py", line 84, in init
debug_mode=debug_mode)
File "/Users/david/active-qa/px/environments/bidaf_server.py", line 107, in _InitializeEnvironment
debug_mode=debug_mode)
File "px/environments/bidaf.py", line 95, in init
self.config, dataset, True, data_filter=data_filter)
File "third_party/bi_att_flow/basic/read_data.py", line 199, in read_data
shared = json.load(fh)
File "/Users/david/anaconda/lib/python2.7/json/init.py", line 291, in load
**kw)
File "/Users/david/anaconda/lib/python2.7/json/init.py", line 339, in loads
return _default_decoder.decode(s)
File "/Users/david/anaconda/lib/python2.7/json/decoder.py", line 364, in decode
obj, end = self.raw_decode(s, idx=_w(s, 0).end())
File "/Users/david/anaconda/lib/python2.7/json/decoder.py", line 380, in raw_decode
obj, end = self.scan_once(s, idx)
ValueError: Unterminated string starting at: line 1 column 1781596155 (char 1781596154)
Hello, I am just beginning the training of the selector, and would like to share some odd-looking reporting with you to see if it is expected and/or ignorable, or something possibly problematic. The most confusing report is that of the termination for 'deadline_exceeded', though the server still appears to be answering as tf_logging reports truncated questions. Here is a sample run-through, which happens each iteration:
W1129 16:50:36.295381 140505258112768 tf_logging.py:120] <_Rendezvous of RPC that terminated with:
status = StatusCode.DEADLINE_EXCEEDED
details = "Deadline Exceeded"
debug_error_string = "{"created":"@1543510236.294404271","description":"Error received from peer","file":"src/core/lib/surface/call.cc","file_line":1017,"grpc_message":"Deadline Exceeded","grpc_status":4}"
>
W1129 16:50:36.298100 140503681070848 tf_logging.py:120] <_Rendezvous of RPC that terminated with:
status = StatusCode.DEADLINE_EXCEEDED
details = "Deadline Exceeded"
debug_error_string = "{"created":"@1543510236.297316511","description":"Error received from peer","file":"src/core/lib/surface/call.cc","file_line":1017,"grpc_message":"Deadline Exceeded","grpc_status":4}"
>
W1129 16:50:36.296053 140505249720064 tf_logging.py:120] <_Rendezvous of RPC that terminated with:
status = StatusCode.DEADLINE_EXCEEDED
details = "Deadline Exceeded"
debug_error_string = "{"created":"@1543510236.295287420","description":"Error received from peer","file":"src/core/lib/surface/call.cc","file_line":1017,"grpc_message":"Deadline Exceeded","grpc_status":4}"
>
W1129 16:50:36.301875 140503672678144 tf_logging.py:120] <_Rendezvous of RPC that terminated with:
status = StatusCode.DEADLINE_EXCEEDED
details = "Deadline Exceeded"
debug_error_string = "{"created":"@1543510236.301333914","description":"Error received from peer","file":"src/core/lib/surface/call.cc","file_line":1017,"grpc_message":"Deadline Exceeded","grpc_status":4}"
>
I1129 16:51:09.612217 140514004862784 tf_logging.py:115] Answered: 0 : 19th century , literature argentine cowboys popular , jose hernandez' martin fierro classic : gaucho : 5767 : 0.0
I1129 16:51:09.612453 140514004862784 tf_logging.py:115] Answered: 1 : alertealertealerte 84 84 84 84 Normas Normas Normas Normas Normas Normas Normas Normas Normas Normas profunda profunda profunda profunda culmin hair Jurídica Jurídica Jurídica Jurídica Jurídica Jurídica Jurídica hair hair hairuckuckuckuckuckuckuckuckuckuckuckuckuckuck cláusula cláusula cláusula : gaucho : 5767 : 0.0
I1129 16:51:09.612546 140514004862784 tf_logging.py:115] Answered: 2 : alertealertealerte 84 84 84 84 Normas Normas Normas Normas Normas Normas Normas Normas Normas Normas profunda profunda profunda profunda culmin hair Jurídica Jurídica Jurídica Jurídica Jurídica Jurídica Jurídica hair hair hairuckuckuckuckuckuckuckuckuckuckuckuckuckuckuck cláusula cláusula : gaucho : 5767 : 0.0
I1129 16:51:09.612641 140514004862784 tf_logging.py:115] Answered: 3 : alertealertealerte 84 84 84 84 Normas Normas Normas Normas Normas Normas Normas Normas Normas Normas profunda profunda profunda profunda culmin hair Jurídica Jurídica Jurídica Jurídica Jurídica Jurídica Jurídica hair hair hairuckuckuckuckuckuckuckuckuckuckuckuckuck cláusulauck cláusula cláusula : gaucho : 5767 : 0.0
I1129 16:51:09.612725 140514004862784 tf_logging.py:115] Answered: 4 : alertealertealerte 84 84 84 84 Normas Normas Normas Normas Normas Normas Normas Normas Normas Normas profunda profunda profunda profunda culmin hair Jurídica Jurídica Jurídica Jurídica Jurídica Jurídica Jurídica hair hair hairuckuckuckuckuckuckuckuckuckuckuckuckuck cláusula cláusula cláusula cláusula : gaucho : 5767 : 0.0
I1129 16:51:09.612806 140514004862784 tf_logging.py:115] Answered: 5 : alertealertealerte 84 84 84 84 Normas Normas Normas Normas Normas Normas Normas Normas Normas Normas profunda profunda profunda profunda culmin hair Jurídica Jurídica Jurídica Jurídica Jurídica Jurídica Jurídica hair hair hairuckuckuckuckuckuckuckuckuckuckuckuck cláusulauck cláusula cláusula cláusula : gaucho : 5767 : 0.0
I1129 16:51:09.612886 140514004862784 tf_logging.py:115] Answered: 6 : alertealertealerte 84 84 84 84 Normas Normas Normas Normas Normas Normas Normas Normas Normas Normas profunda profunda profunda profunda culmin hair Jurídica Jurídica Jurídica Jurídica Jurídica Jurídica Jurídica hair hair hairuckuckuckuckuckuckuckuckuckuckuckuckuckuck cláusulauck cláusula : gaucho : 5767 : 0.0
I1129 16:51:09.612967 140514004862784 tf_logging.py:115] Answered: 7 : alertealertealerte 84 84 84 84 Normas Normas Normas Normas Normas Normas Normas Normas Normas Normas profunda profunda profunda profunda culmin hair Jurídica Jurídica Jurídica Jurídica Jurídica Jurídica Jurídica hair hair hairuckuckuckuckuckuckuckuckuckuckuckuck cláusulauckuck cláusula cláusula : gaucho : 5767 : 0.0
I1129 16:51:09.613049 140514004862784 tf_logging.py:115] Answered: 8 : alertealertealerte 84 84 84 84 Normas Normas Normas Normas Normas Normas Normas Normas Normas Normas profunda profunda profunda profunda culmin hair Jurídica Jurídica Jurídica Jurídica Jurídica Jurídica Jurídica hair hair hairuckuckuckuckuckuckuckuckuckuckuck cláusulauckuck cláusula cláusula cláusula : gaucho : 5767 : 0.0
I1129 16:51:09.613131 140514004862784 tf_logging.py:115] Answered: 9 : alertealertealerte 84 84 84 84 Normas Normas Normas Normas Normas Normas Normas Normas Normas Normas profunda profunda profunda profunda culmin hair Jurídica Jurídica Jurídica Jurídica Jurídica Jurídica Jurídica hair hair hairuckuckuckuckuckuckuckuckuckuck cláusulauckuckuck cláusula cláusula cláusula : gaucho : 5767 : 0.0
I1129 16:51:09.613209 140514004862784 tf_logging.py:115] Time to make 1344 environment calls: 153.337013006```
Hi @willnorris ,
Actually I am running your project in the process of 2-way processing while run this comand python -m third_party.bi_att_flow.squad.prepro
--glove_dir=$GLOVE_DIR
--source_dir=$SQUAD_DIR
the process is killed in the middle like this " 66%|██████▌ | 59663/90834 [12:42<33:24:15, 3.86s/it]Killed
"
can you tell me whether the system configuration issue or any this else actually before killed my system was struct for 3 minutes and later when i open the command prompt its show's me that your process is killed can you tell me the what's the reason behind this...
Thanks and Regards,
Manikantha Sekhar..
Happy Codding......
How do I use only Reformulator with checkpoint of the reformulator https://storage.cloud.google.com/pretrained_models/translate.ckpt-6156696.zip
hi, loved the repo. failed to download pre-trained models using the links in readme.
checkpoint of the reformulator
and checkpoint of the selector
are there new updated links?
thanks in advance, a.
Collecting sentencepiece (from -r requirements.txt (line 11))
Using cached https://files.pythonhosted.org/packages/1b/87/c3c2fa8cbec61fffe031ca9f0da512747520bec9be7f886f748457daac31/sentencepiece-0.1.83.tar.gz
Complete output from command python setup.py egg_info:
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "c:\users\zzj04\appdata\local\temp\pip-install-vxmbno\sentencepiece\setup.py", line 29, in <module>
with codecs.open(os.path.join('..', 'VERSION'), 'r', 'utf-8') as f:
File "c:\python27\lib\codecs.py", line 898, in open
file = __builtin__.open(filename, mode, buffering)
IOError: [Errno 2] No such file or directory: '..\\VERSION'
OS Name Microsoft Windows 10 Pro
Version 10.0.17763 Build 17763
Python 2.7.16 (v2.7.16:413a49145e, Mar 4 2019, 01:30:55) [MSC v.1500 32 bit (Intel)] on win32
When running Selector Training section, px.nmt.reformulator_and_selector_training module requires answers files (shown below). However, train_data is not provided in configurations. Neither the answers file is not generated after preprocessing squad data using python -m searchqa.prepro
--searchqa_dir=$DATA_DIR/SearchQA
--squad_dir=$SQUAD_DIR.
Could you please give some help on how to fix this issue.
questions, annotations, docid_2_answer = read_data(
questions_file=FLAGS.train_questions,
annotations_file=FLAGS.train_annotations,
answers_file=FLAGS.train_data,
preprocessing_mode=FLAGS.mode)
dev_questions, dev_annotations, dev_docid_2_answer = read_data(
questions_file=FLAGS.dev_questions,
annotations_file=FLAGS.dev_annotations,
answers_file=FLAGS.dev_data,
preprocessing_mode=FLAGS.mode,
max_lines=FLAGS.max_dev_examples)
Hello!
Could you please provide some info when/how do I know training is finished for reformulator_and_selector_training?
If the training is finished, how can I directly use to trained model for query reformulator?
Could you please provide a trained model for reformulator_and_selector_training as you did for reformulator?
Thanks!
Hi Every one ,
I followed README.md file and follow the instruction given their to run the program/code mean while i got an error while running tis command python -m searchqa.prepro --searchqa_dir=$DATA_DIR/SearchQA --squad_dir=$SQUAD_DIR i got an error
Traceback (most recent call last):
File "searchqa/prepro.py", line 165, in
app.run(main)
File "/home/launchship/my_name/lib/python3.6/site-packages/absl/app.py", line 299, in run
_run_main(main, args)
File "/home/launchship/my_name/lib/python3.6/site-packages/absl/app.py", line 250, in _run_main
sys.exit(main(argv))
File "searchqa/prepro.py", line 145, in main
assert os.path.exists(FLAGS.searchqa_dir)
AssertionError
could any one solve this problem that helps me a lot
Thanks and Regards,
Manikantha Sekhar.
Happy Codding..
Hi @dberlin ,
I had run Full code in System but at last i downloaded the pretrained transalate checkpoints and sector modules and placed in the select folders but my concern is how to test my own text file or any other documents file (which contains the paragraph) to generate the questions and answers format could help me to come with an output
Thanks and Regards,
Manikantha Sekhar.
Happy Codding....
Would be great to have docker image.
For a custom document and a question related to that document, i can run reformulator for that question and can get the multiple reformulations. But how can i get the answers for those reforumlations using that custom document and get the best answer using pretrained selector model ?
I was wondering where I can find (or if you plan to release) the Selector pre-trained models that achieved ~47.5 F1 score
Hi @willnorris @cdibona @christianbuck @dberlin @j5b
Actually i am running the command
'python -m px.nmt.reformulator_and_selector_training --environment_server_address=localhost:10000 --hparams_path=px/nmt/example_configs/reformulator.json --enable_reformulator_training=true --enable_selector_training=false --train_questions=$SQUAD_DIR/train-questions.txt --train_annotations=$SQUAD_DIR/train-annotation.txt --train_data=data/squad/data_train.json --dev_questions=$SQUAD_DIR/dev-questions.txt --dev_annotations=$SQUAD_DIR/dev-annotation.txt --dev_data=data/squad/data_dev.json --glove_path=$GLOVE_DIR/glove.6B.100d.txt --out_dir=$REFORMULATOR_DIR --tensorboard_dir=$OUT_DIR/tensorboard'
then i am getting an error like "tensorflow.python.framework.errors_impl.NotFoundError: /train-questions.txt; No such file or directory"
but in squad directory folder i am having the train-question.txt file but again it showing me the error file not found could you help me
Thanks & Regards,
Manikantha Sekhar
Are you running the environment server before running the reformulator code?
https://github.com/google/active-qa/issues/15#issue-407744369
@graviraja @JohannesTK I'm getting the above error even after running the environment server.
Please anyone help fixing it..
Screenshot for gRPC Environment server
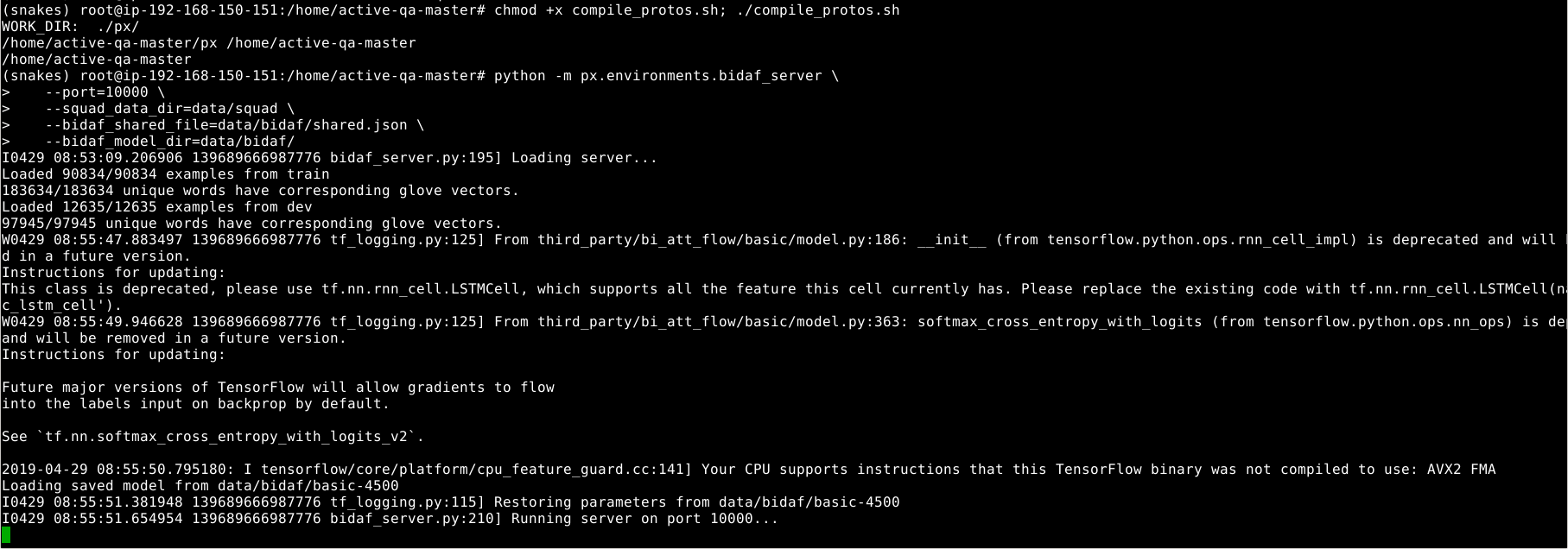
I have not seen this kind of training and inference , can I use just raw text files to get the model to come up with questions. Thus building a qa bot.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.