![]()



In addition to helping you memorise, this code helps you do other things that I don't remember...
📚 Documentation: https://guiferviz.com/mnemocards
⌨️ Source Code: https://github.com/guiferviz/mnemocards
Mnemocards is a Python package originally intended for creating Anki flashcards from text files. It allows users to define a series of steps to read flashcards from any source, transform them and export them to different formats such as Anki APKG packages.
Mnemocards is designed to be fully extensible, which means that users can create their own tasks and customize the card generation process to their specific needs. Indeed, Mnemocards has the versatility to be used for purposes beyond generating Anki decks.
- Generate Anki APKG packages that you can later import into the Anki app.
- Auto generate pronunciations from the words that you are learning in any language supported by Google Translator.
- Generate flashcards from text files that can be stored in Git
repositories. This brings several positive things:
- Keep track of changes.
- Edit cards using your favourite text editor. I ❤️ VIM.
- Easily share and collaborate with others. If you know how to work with Git you can create forks and pull requests to existing repositories.
- Fully extensible architecture that allows you to define custom
transformations on a list of notes.
- Possibility to implement another way of exporting flashcards to other existing flashcards apps. Contributions are welcome.
- Possibility to create search indexes, analyze your collection of cards, create visualizations, clustering, analyze how the cards relate to each other... Contributions are welcome.
To get started with Mnemocards, you'll need to have Python >= 3.10 installed on
your computer. Then, you can install Mnemocards using pip:
$ pip install --pre mnemocardsYou can check that the installation went well by executing the following command:
$ mnemocards --version
╔╦╗╔╗╔╔═╗╔╦╗╔═╗┌─┐┌─┐┬─┐┌┬┐┌─┐
║║║║║║║╣ ║║║║ ║│ ├─┤├┬┘ ││└─┐
╩ ╩╝╚╝╚═╝╩ ╩╚═╝└─┘┴ ┴┴└──┴┘└─┘ X.Y.Z
╭────────────────────────────────╮
│ <A super mega funny joke here> │
╰────────────────────────────────╯If the joke made you laugh you can continue with this tutorial, otherwise this program is not for you and you should consider other alternatives.
Once you have Mnemocards installed, you can start creating your own flashcards. Let's start creating our own vocabulary Anki cards.
Imagine you are learning Spanish and you have a list of vocabulary like this:
| English | Spanish |
|---|---|
| Hello | Hola |
| Bye | Adiós |
If you want to use Mnemocards to generate Anki cards for those words the first thing you need to do is to create a CSV file like the following:
your_language_word,language_you_learn_word,id
Hello,Hola,9a6c9728-7f86-4e3f-9dec-a2f804bd0a76
Bye,Adiós,e600a85a-8a6b-4449-a188-f7401dc69d6b
A CSV file is a text file that represents a table. The first line is the header of the table, after that header line we have one line per row. Each column is separated from the other with a column. CSV stands for Comma-Separated Values.
The first column contains the word in your native language, in this case English. The second row is the word in the language you are learning, Spanish. The last column is a randomly generated ID.
!!! question "Why do we need an ID?"
IDs are used to uniquely identify a note in Anki. We can use the Spanish
word as an ID, but if you start studing a card and you want to make an edit
later the card will be considered as a complete new one, loosing your
progress.
For example, imagine you write *Adios* and after several days of study you
realise that your miss the accent. If you chage *Adios* to *Adiós* the
ID of that note will be different. To avoid this kind of problems I decided
to include an ID column.
Mnemocards uses a configuration file named mnemocards.yaml to define the
steps that will be used to process our flashcards. In this file, you can
specify the tasks that you want to use, the order in which they will be
executed, and any necessary parameters.
Here is an example of a simple configuration file that reads in a CSV file containing vocabulary data, and then generates an Anki APKG package:
steps:
# Read a CSV file with our spanish vocabulary.
- type: ReadCsv
path: vocabulary.csv
# Tag the generated notes and assign them to an Anki deck.
- type: mnemocards_anki.Configure
tags: spanish, languages
deck:
name: Spanish
id: 429d2604-ca8a-4c0a-9b03-38d1df5b9af7
note_type: mnemocards_anki.VocabularyNoteType
# Pronounce the spanish words using Google Translator.
- type: mnemocards_anki.Pronounce
language: es
attribute_to_pronounce: language_you_learn_word
# Save the Anki package.
- type: mnemocards_anki.Package
# Show the generated tasks in the terminal.
# Do not print the note id, the note_type and the deck to avoid cluttering the terminal.
- type: Print
ignore_regex: id|note_type|deck
# Show some stats of the generation process.
- type: StatsYou can run the configuration file using the following command:
$ mnemocards run mnemocards.ymlThis will execute the steps in the configuration file, and will generate an
Anki package named out.apkg by default. The generated file is in the same
directory as your mnemocards.yaml.
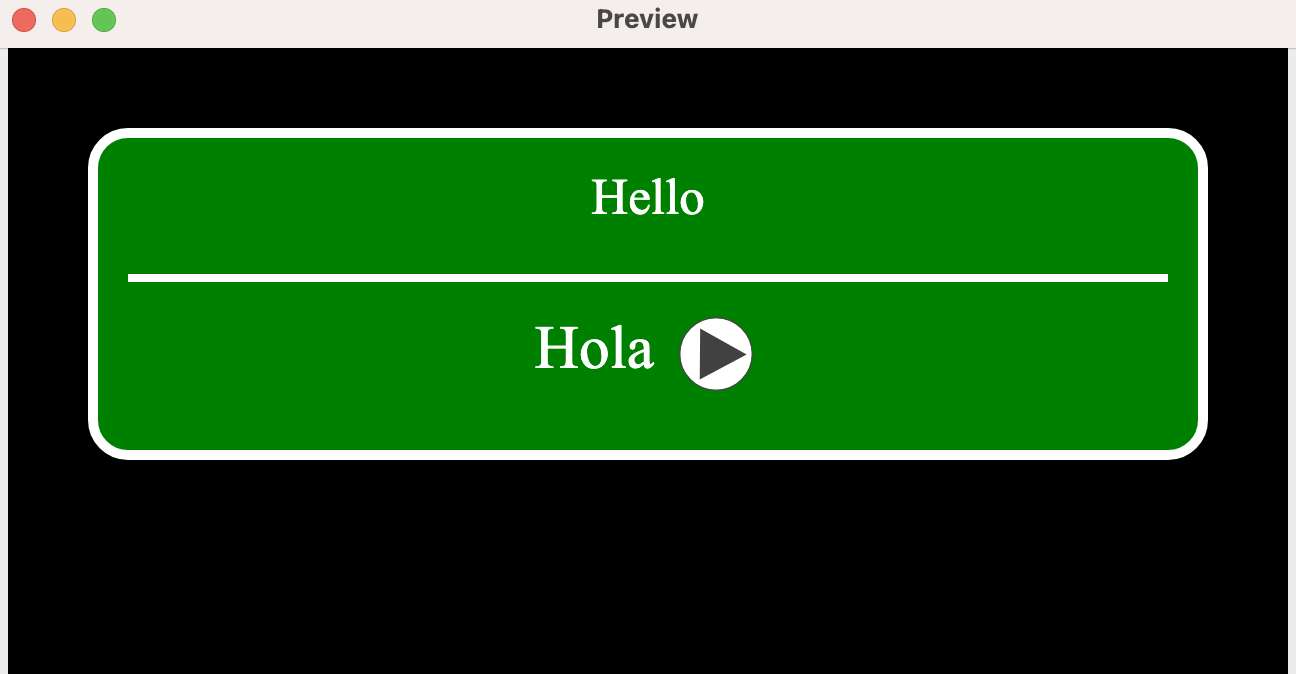
If you import the apkg file to Anki you can start studying Spanish:
If you have come this far, it is because you may have found this project interesting. Consider visiting the documentation, in particular the examples section to learn more.
As mentioned above, Mnemocards is fully extensible, so any data source you miss or any processing or analysis you want to do on your cards is more than welcome. Feel free to post your idea to start a discussion. Do not worry if you do not know how to program, there may be someone who can do it for you.
Enjoy learning!!!

![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")











































