This package shows how to make arbitrary code in Tetrad directly available in Python via JPype as part of a Python workflow. We do this by giving reusable examples of how it can be done, along with API Javadoc documentation to allow further exploration of the entire Tetrad codebase.
It also gives some simple tools that can be used in both Python and R to hide the JPype facilities for those who don't want to (or can't, in the case of R) deal directly with the Tetrad codebase.
Part of our code uses the causal-learn Python package in py-why to show how it can be integrated.
You can also integrate Tetrad code into Python by making os.system (..) calls to Causal Command; here are some examples of how to do it.
Please bear with us as we add and refine example modules and keep our code up to date. Please submit any problems or suggestions to our Issue Tracker, so that we can resolve them. In some cases it may not be obvious how to call a Tetrad class or method from Python. Please point out any difficulties you have, so that we can make it more intuitive to use for the next version.
We maintain a current version of the Tetrad launch jar, which is either the current published version or else the current published version with some adjustments. The example code will work with this current jar. Feel free to use any version of Tetrad though. All artifacts for Tetrad for the last several releases are on Maven Central, with their corresponding API Javadocs, along wth signatures to verify authenticity.
We added a method to use Tetrad algorithms in R via py-tetrad. This is work in progress.
-
It is necessary to install a JDK. For this, see our Wiki article, Setting up Java for Tetrad.
-
If JAVA_HOME is not already set to the correct location of your Java installation above, you'll need to set JAVA_HOME to the path of the Java installation you want to use for py-tetrad.
-
Make sure you are using the latest Python--at least 3.5--as required by JPype; if not, update it.
-
We use causal-learn. For installation instructions, see the Docs for the causal-learn package.
-
We use the JPype package to interface Python with Java. For installation instructions, see the Docs for the JPype box.
-
Finally, you will need to clone this GitHub repository, so if you don't have Git installed, google and install that for your machine type.
Then (for instance, on a Mac) in a terminal window, cd to a directory where you want the cloned project to appear and type the following--again, as above, make sure JAVA_HOME is set correctly to your java path:
git clone https://github.com/cmu-phil/py-tetrad/
cd py-tetrad/pytetrad
python run_continuous.py
If everything is set up right, the last command should cause this example module to run various algorithms in Tetrad and print out result graphs. Feel free to explore other example modules in that directory.
Feel free to use your favorite method for editing and running modules.
Please cite as:
Bryan Andrews and Joseph Ramsey. https://github.com/cmu-phil/py-tetrad, 2023.
[Update 12/8/22] Interested in faster and more accurate structure learning? See our new DAGMA library from NeurIPS 2022.
This is an implementation of the following papers:
[1] Zheng, X., Aragam, B., Ravikumar, P., & Xing, E. P. (2018). DAGs with NO TEARS: Continuous optimization for structure learning (NeurIPS 2018, Spotlight).
[2] Zheng, X., Dan, C., Aragam, B., Ravikumar, P., & Xing, E. P. (2020). Learning sparse nonparametric DAGs (AISTATS 2020, to appear).
If you find this code useful, please consider citing:
@inproceedings{zheng2018dags,
author = {Zheng, Xun and Aragam, Bryon and Ravikumar, Pradeep and Xing, Eric P.},
booktitle = {Advances in Neural Information Processing Systems},
title = {{DAGs with NO TEARS: Continuous Optimization for Structure Learning}},
year = {2018}
}
@inproceedings{zheng2020learning,
author = {Zheng, Xun and Dan, Chen and Aragam, Bryon and Ravikumar, Pradeep and Xing, Eric P.},
booktitle = {International Conference on Artificial Intelligence and Statistics},
title = {{Learning sparse nonparametric DAGs}},
year = {2020}
}
Check out linear.py for a complete, end-to-end implementation of the NOTEARS algorithm in fewer than 60 lines.
This includes L2, Logistic, and Poisson loss functions with L1 penalty.
A directed acyclic graphical model (aka Bayesian network) with d nodes defines a
distribution of random vector of size d.
We are interested in the Bayesian Network Structure Learning (BNSL) problem:
given n samples from such distribution, how to estimate the graph G?
A major challenge of BNSL is enforcing the directed acyclic graph (DAG) constraint, which is combinatorial. While existing approaches rely on local heuristics, we introduce a fundamentally different strategy: we formulate it as a purely continuous optimization problem over real matrices that avoids this combinatorial constraint entirely. In other words,
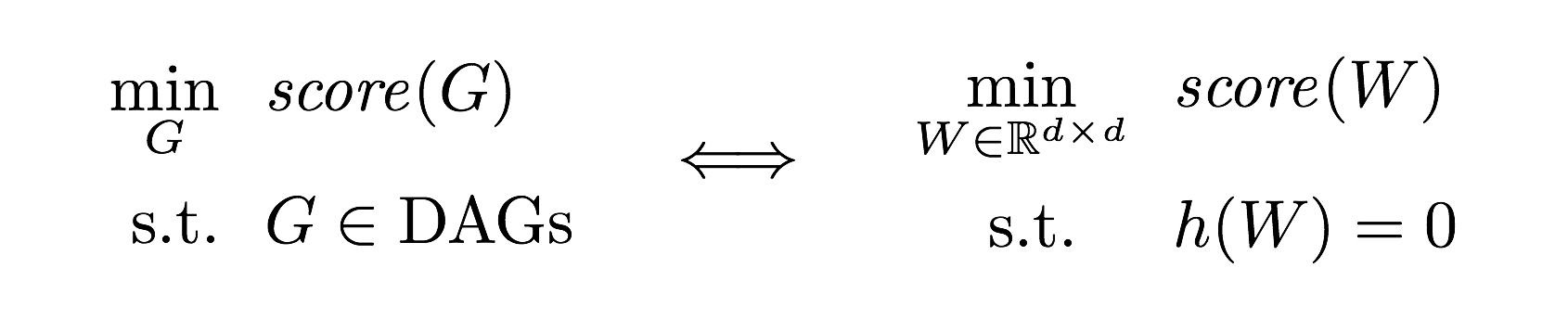
where h is a smooth function whose level set exactly characterizes the
space of DAGs.
- Python 3.6+
numpyscipypython-igraph: Install igraph C core andpkg-configfirst.torch: Optional, only used for nonlinear model.
linear.py- the 60-line implementation of NOTEARS with l1 regularization for various lossesnonlinear.py- nonlinear NOTEARS using MLP or basis expansionlocally_connected.py- special layer structure used for MLPlbfgsb_scipy.py- wrapper for scipy's LBFGS-Butils.py- graph simulation, data simulation, and accuracy evaluation
The simplest way to try out NOTEARS is to run a simple example:
$ git clone https://github.com/xunzheng/notears.git
$ cd notears/
$ python notears/linear.pyThis runs the l1-regularized NOTEARS on a randomly generated 20-node Erdos-Renyi graph with 100 samples. Within a few seconds, you should see output like this:
{'fdr': 0.0, 'tpr': 1.0, 'fpr': 0.0, 'shd': 0, 'nnz': 20}
The data, ground truth graph, and the estimate will be stored in X.csv, W_true.csv, and W_est.csv.
Alternatively, if you have a CSV data file X.csv, you can install the package and run the algorithm as a command:
$ pip install git+git://github.com/xunzheng/notears
$ notears_linear X.csvThe output graph will be stored in W_est.csv.
-
Ground truth:
d = 20nodes,2d = 40expected edges.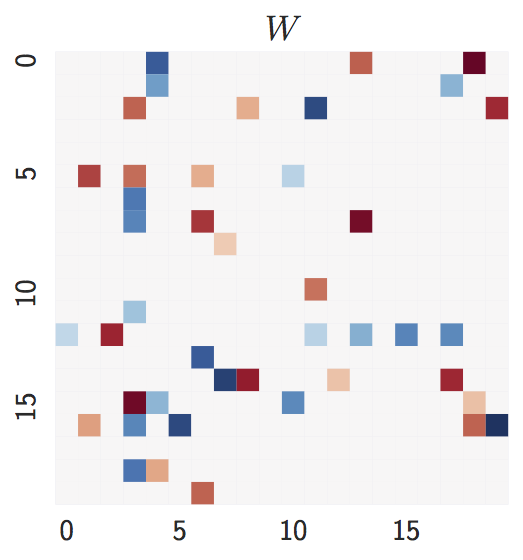
-
Estimate with
n = 1000samples:lambda = 0,lambda = 0.1, andFGS(baseline).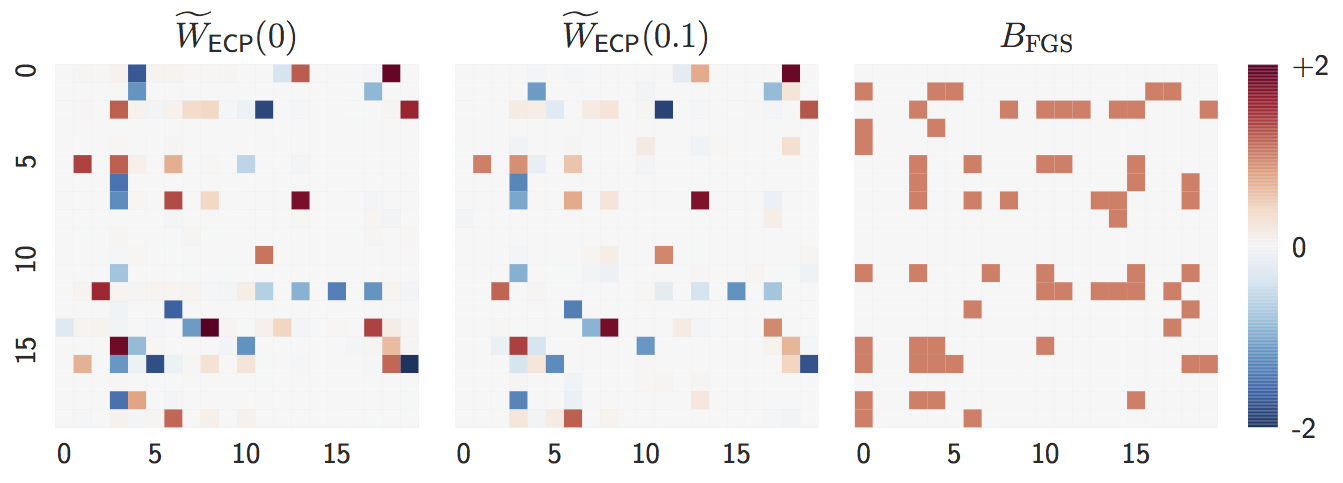
Both
lambda = 0andlambda = 0.1are close to the ground truth graph whennis large. -
Estimate with
n = 20samples:lambda = 0,lambda = 0.1, andFGS(baseline).
When
nis small,lambda = 0perform worse whilelambda = 0.1remains accurate, showing the advantage of L1-regularization.
-
Ground truth:
d = 20nodes,4d = 80expected edges.
The degree distribution is significantly different from the Erdos-Renyi graph. One nice property of our method is that it is agnostic about the graph structure.
-
Estimate with
n = 1000samples:lambda = 0,lambda = 0.1, andFGS(baseline).
The observation is similar to Erdos-Renyi graph: both
lambda = 0andlambda = 0.1accurately estimates the ground truth whennis large. -
Estimate with
n = 20samples:lambda = 0,lambda = 0.1, andFGS(baseline).
Similarly,
lambda = 0suffers from smallnwhilelambda = 0.1remains accurate, showing the advantage of L1-regularization.
- Python: https://github.com/jmoss20/notears
- Tensorflow with Python: https://github.com/ignavier/notears-tensorflow
This is an implementation of the following paper:
[1] Bello K., Aragam B., Ravikumar P. (2022). DAGMA: Learning DAGs via M-matrices and a Log-Determinant Acyclicity Characterization. NeurIPS'22.
If you find this code useful, please consider citing:
@inproceedings{bello2022dagma,
author = {Bello, Kevin and Aragam, Bryon and Ravikumar, Pradeep},
booktitle = {Advances in Neural Information Processing Systems},
title = {{DAGMA: Learning DAGs via M-matrices and a Log-Determinant Acyclicity Characterization}},
year = {2022}
}
We propose a new acyclicity characterization of DAGs via a log-det function for learning DAGs from observational data. Similar to previously proposed acyclicity functions (e.g. NOTEARS), our characterization is also exact and differentiable. However, when compared to existing characterizations, our log-det function: (1) Is better at detecting large cycles; (2) Has better-behaved gradients; and (3) Its runtime is in practice about an order of magnitude faster. These advantages of our log-det formulation, together with a path-following scheme, lead to significant improvements in structure accuracy (e.g. SHD).
Let
where
Given the exact differentiable characterization of a DAG, we are interested in solving the following optimization problem:
where
where
Let us give an illustration of how DAGMA works in a two-node graph (see Figure 1 in [1] for more details). Here
Below we have 4 plots, where each illustrates the solution to an unconstrained problem for different values of

- Python 3.6+
numpyscipypython-igraphtorch: Only used for nonlinear models.
dagma_linear.py- implementation of DAGMA for linear models with l1 regularization (supports L2 and Logistic losses).dagma_nonlinear.py- implementation of DAGMA for nonlinear models using MLPlocally_connected.py- special layer structure used for MLPutils.py- graph simulation, data simulation, and accuracy evaluation
Use requirements.txt to install the dependencies (recommended to use virtualenv or conda).
The simplest way to try out DAGMA is to run a simple example:
$ git clone https://github.com/kevinsbello/dagma.git
$ cd dagma/
$ pip3 install -r requirements.txt
$ python3 dagma_linear.pyThe above runs the L1-regularized DAGMA on a randomly generated 20-node Erdos-Renyi graph with 500 samples. Within a few seconds, you should see an output like this:
{'fdr': 0.0, 'tpr': 1.0, 'fpr': 0.0, 'shd': 0, 'nnz': 20}
The data, ground truth graph, and the estimate will be stored in X.csv, W_true.csv, and W_est.csv.
We thank the authors of the NOTEARS repo for making their code available. Part of our code is based on their implementation, specially the utils.py file and some code from their implementation of nonlinear models.
Arkhangelsky, Dmitry, et al. Synthetic difference in differences. No. w25532. National Bureau of Economic Research, 2019. https://www.nber.org/papers/w25532
https://github.com/synth-inference/synthdid




$ pip install git+https://github.com/MasaAsami/pysynthdid
This package is still under development. I plan to register with pypi after the following specifications are met.
- Refactoring and better documentation
- Completion of the TEST code
- setup
from synthdid.model import SynthDID
from synthdid.sample_data import fetch_CaliforniaSmoking
df = fetch_CaliforniaSmoking()
PRE_TEREM = [1970, 1988]
POST_TEREM = [1989, 2000]
TREATMENT = ["California"]- estimation & plot
sdid = SynthDID(df, PRE_TEREM, POST_TEREM, TREATMENT)
sdid.fit(zeta_type="base")
sdid.plot(model="sdid")
- Details of each method will be created later.
See the jupyter notebook for basic usage
-
ReproductionExperiment_CaliforniaSmoking.ipynb- This is a reproduction experiment note of the original paper, using a famous dataset (CaliforniaSmoking).
-
OtherOmegaEstimationMethods.ipynb- This note is a different take on the estimation method for parameter
omega(&zeta). As a result, it confirms the robustness of the estimation method in the original paper.
- This note is a different take on the estimation method for parameter
-
ScaleTesting_of_DonorPools.ipynb- In this note, we will check how the estimation results change with changes in the scale of the donor pool features.
- Adding donor pools with extremely different scales (e.g., 10x) can have a significant impact (bias) on the estimates.
- If different scales are mixed, as is usually the case in traditional regression, preprocessing such as logarithmic transformation is likely to be necessary
- This module is still under development.
- If you have any questions or comments, please feel free to use issues.
python setup.py sdist bdist_wheel twine upload dist/* hahray 129)
