hiroi-sora / paddleocr-json Goto Github PK
View Code? Open in Web Editor NEWOCR离线图片文字识别命令行windows程序,以JSON字符串形式输出结果,方便别的程序调用。提供各种语言API。由 PaddleOCR C++ 编译。
License: Apache License 2.0
OCR离线图片文字识别命令行windows程序,以JSON字符串形式输出结果,方便别的程序调用。提供各种语言API。由 PaddleOCR C++ 编译。
License: Apache License 2.0



























































































































作者您好,就是我算一个新手,想知道的就是可不可以在另外一个项目中直接使用c++调用exe文件,然后返回json到另外一个项目

对于上图这种的识别结果是两行哦,有什么好的方式或是模型,让他们输出成一个结果么?
{
"code": 100,
"data": [{
"box": [[84, 35],[393, 35],[393, 53],[84, 54]],
"score": 0.9679305553436279,
"text": "Driving in areas where salt or other"
}, {
"box": [[84, 66],[331, 66],[331, 84],[84, 84]],
"score": 0.9162040948867798,
"text": "corrosive materials are used"
}]
}
谢谢

python调用启动时,仅初始化只有100M左右,正常。
当ocr方法调用多次时,paddleOCR-json.exe进程的内存逐步飙到七百多M,而且,你停止调用ocr,内存并不会释放
import dxcam
import time
import cv2
PPOCR_api_module_path = './api'
sys.path.append(PPOCR_api_module_path)
from PPOCR_api import GetOcrApi
PADDLEOCR_JSON_PATH = "./PaddleOCR-json/PaddleOCR-json.exe"
time.sleep(2)
text_region = (426, 79, 510, 99)
camera = dxcam.create(output_color='BGR')
frame = camera.grab(region=text_region)
# cv2.imwrite('./results.png', frame)
frame_bytes = frame.tobytes()
results = ocr.runBytes(frame_bytes)
# results = ocr.run('./../results.png')
ocr.printResult(results)图片识别失败。错误码:301,错误信息:Base64 data imdecode failed.
按照“方式1. 传统构建”方法构建,已经按照PaddleOCR官方“Visual Studio 2019 Community CMake 编译指南”成功编译得到了ppocr.exe,并将项目的project_files\cpp_infer下include和src两个目录中的文件替换到了官方工程相同路径中,再次打开sln项目文件重新build,报了一堆错误,例如:
严重性 代码 说明 项目 文件 行 禁止显示状态
错误(活动) E1696 无法打开 源 文件 "nlohmann/json.hpp"
错误(活动) E0725 名称必须是命名空间名
错误(活动) E0020 未定义标识符 "json"
错误(活动) E0020 未定义标识符 "json"
错误(活动) E0020 未定义标识符 "json"
错误(活动) E0020 未定义标识符 "json"
错误(活动) E0276 后面有“::”的名称一定是类名或命名空间名
错误(活动) E0020 未定义标识符 "json"
错误 C2062 意外的类型“int”
错误 C2059 语法错误:“{”
错误 C2334 “{”的前面有意外标记;跳过明显的函数体
错误 C2530 “PaddleOCR::Classifier::gpu_id”: 必须初始化引用
......
看了一下,感觉是缺少了一些头文件所导致。对比了项目project_files和官方工程生成的的CMakeLists文件,确实不太一样,项目project_files\cpp_infer下src中的CMakeLists文件多了很多依赖的package。
所以,简单的将include和src两个目录中的文件替换到了官方工程相同路径,是否不可行?是否还漏了其他步骤?还是说文件合并后,还需要重新用cmake构建一次项目?
你好,请问在Linux(Ubuntu20.04)环境下是否可以正常编译打包?谢谢!
e[37m--- fused 0 elementwise_add with relu activatione[0m
e[37m--- fused 0 elementwise_add with tanh activatione[0m
e[37m--- fused 0 elementwise_add with leaky_relu activatione[0m
e[37m--- fused 0 elementwise_add with swish activatione[0m
e[37m--- fused 0 elementwise_add with hardswish activatione[0m
e[37m--- fused 0 elementwise_add with sqrt activatione[0m
e[37m--- fused 0 elementwise_add with abs activatione[0m
e[37m--- fused 0 elementwise_add with clip activatione[0m
您好,感谢,汇报下
1、顺时针90°图片读完,行错位了
2、请问Win Server 2012不能直接运行是吗?
请问可以支持其他语言吗?比如意大利语。
有计划关键信息抽取(SER、RE)的支持吗
我在Win10平台CMD窗口下执行CLI命令运行到"退出前暂停程序"这一步骤时窗口会显示"Press any key to continue . . .", 但如果想采用DOS重定向符方式生成文本文件 (即 >xxx.txt ),那么这一句话就不会在窗口显示,而是输出到 xxx.txt 中了,这时候看CMD窗口会让人很懵B,由于没有显示那句话,看上去像是还在运行中,或者是卡死了,我又查看了 xxx.txt 的文件大小显示为0,结果我傻等了好一会见还是没动静只好选择点Esc或中断键放弃,这时候发现 xxx.txt 文件生成成功了(也就是大小已经不是0了),实际是由于按了任意键,所以退出了暂停状态,搞了大半天我才明白这是怎么一回事。
为了解决以上问题,我到Issues查看了一下,发现作者回复其他问题时有提到过 -use_system_pause (退出前暂停程序) 说这一参数可以关闭,我尝试了一下(例如: PaddleOCR_json.exe -use_system_pause=0 -image_dir="D:\OCR.jpeg"),发现没有用,依然会“退出前暂停程序”。
我又查看了"详细使用说明", 以我的理解总结为,PaddleOCR_json.exe 支持的CLI命令格式只有两个参数 -use_debug、-image_dir ,而其它在说明中提到的参数都是属于 -use_debug= 的子参数,是不能单独拿出来用的,我尝试了一下(例如: PaddleOCR_json.exe -use_debug=0 -image_dir="D:\OCR.jpeg"),确实关闭了"退出前暂停程序",但又出现了新的问题,文本内容不是能直接采用的明文了,而是转成了转ASCII编码(\u前缀格式 好像正确应该是叫Unicode 统一码/万国码),还是再另想办法转回明文,汗!!!
我觉得"退出前暂停程序"这一步骤真的有点多余,如果能取消的最好,如果不能,那么能不能把它从子参数中提出来,变成单独可执行参数,也就是改成:PaddleOCR_json.exe 支持的CLI命令格式有三个参数 -use_debug、-image_dir、-use_system_pause
你好,我按照你的教程编译成一个exe,然后通过python可以调用执行。但是我编译成一个动态dll,再通过python调用的时候就一直报错。报错信息如下:
PreconditionNotMetError: The third-party dynamic library (mklml.dll) that Paddle depends on is not configured correctly. (error code is 182)
不知道你试过编译dll么,会不会遇到同样的错误。
(node:1920) DeprecationWarning: file property is deprecated and will be removed in v5.
(Use electron --trace-deprecation ... to show where the warning was created)
error Error: spawn PaddleOCR_json.exe ENOENT
at ChildProcess._handle.onexit (node:internal/child_process:283:19)
at onErrorNT (node:internal/child_process:478:16)
at process.processTicksAndRejections (node:internal/process/task_queues:83:21) {
code: 'ENOENT',
syscall: 'spawn PaddleOCR_json.exe',
spawnargs: [ '-config_path="models\config_chinese.txt"', '--use_debug=0' ]
}
控制面板 -> 6Rb?g


版本: PaddleOCR-json.v1.2.1
运行环境:win11
调用方法如图所示:
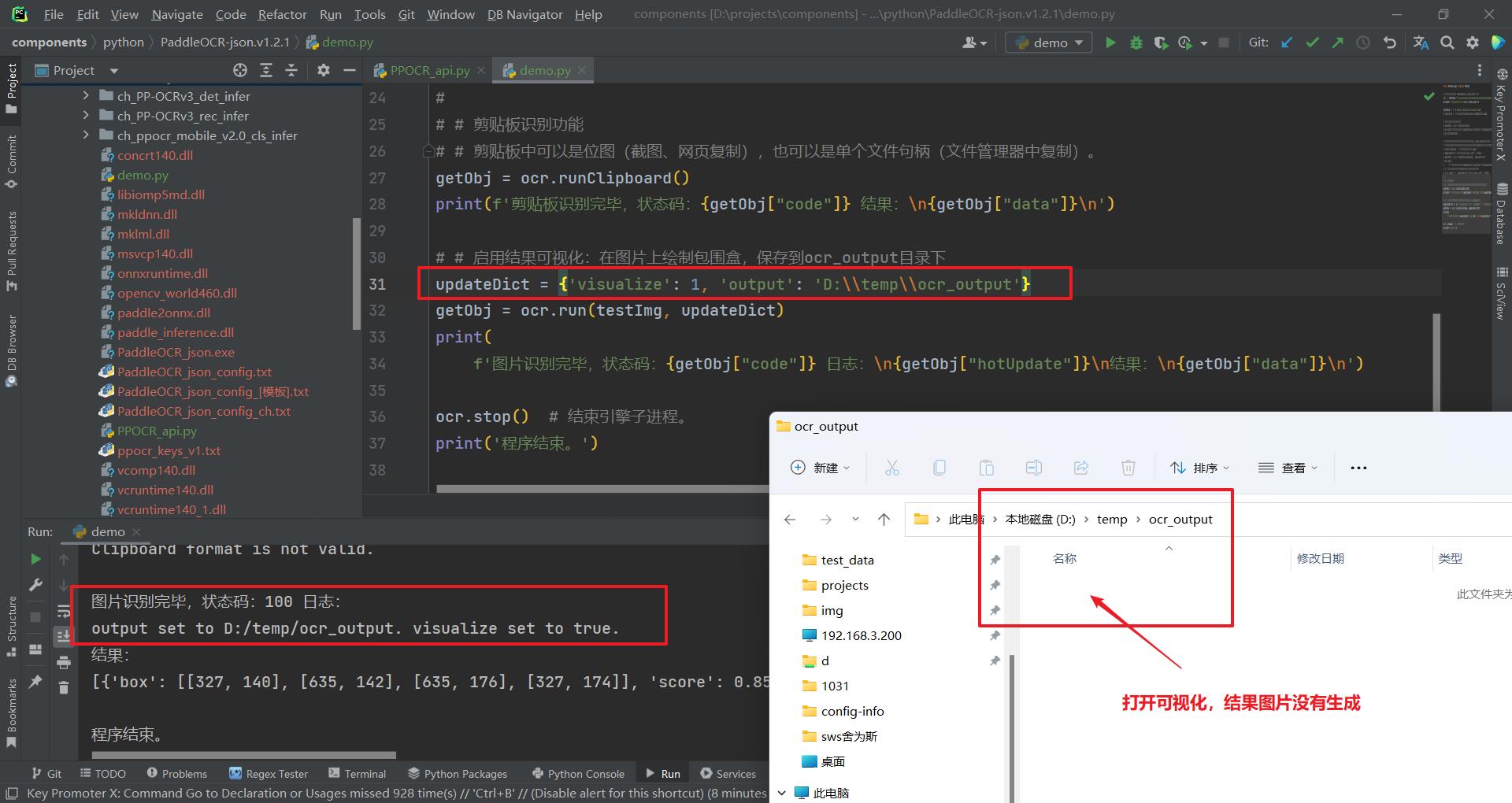
OCR识别正常,但在指定的输出目录中没看到结果图片
output_dir 的值试过 'D:/temp/ocr_output' 和 'D:\temp\ocr_output' ,一样没看到图片。
请帮忙看看哪里操作有问题,谢谢。
我有一种图片:

这个图片是992*48的
使用paddle0cr识别结果是:
{code=100, data=[RecognizedText{text='天单,', box=[8, 0][132, 3][132, 39][8, 36], score=0.8951358795166016}, RecognizedText{text='墙壁和地板', box=[662, 7][894, 7][894, 37][662, 37], score=0.9648885726928711}, RecognizedText{text='伯', box=[933, 7][980, 7][980, 36][933, 36], score=0.41533949971199036}, RecognizedText{text='大', box=[454, 18][628, 13][628, 28][454, 33], score=0.26688411831855774}], msg='null', hotUpdate='null'}
可以看到识别了四部分,并且检测框的高度分别是36,30,29,15,这些检测框过小导致识别结果错误。
我使用paddleocr官方模型,不开启文本检测,只做识别时:
('天里,我甚至尝试过拆掉屋顶、墙壁和地板,但', 0.977444589138031)
这时候可以完全识别正确。
我尝试关闭det=false参数好像也不起作用
我用的vb语音,需要自己构建json格式进行管道参数传递。我想知道json格式的结构。能否打印一份json格式的例子,这样我就知道怎么传递参数了。py的我不了解谢谢。
在“返回值说明”下添加以下内容 (也许我写得不太对,你看着修改^_^)
300 JSON转储失败了. 编码错误
data为字符串:JSON dump failed. Coding error.
原因:命令行调用方式采用了 方式1:启动参数,通过-image_dir参数传入的图片路径中包含有中文,需修改成不含中文的路径才行
use_debug=1 就正常
现在文本都不是可视字符了
PaddleOCR-json v1.2.1
OCR init completed.
{"code":100,"data":[{"box":[[384,6],[403,6],[403,23],[384,23]],"score":0.8491007089614868,"text":"\u53e3"},{"box":[[28,8],[121,8],[121,22],[28,22]],"score":0.9404433369636536,"text":"\u8ff7\u96fe\u901a4.4.20"},{"box":[[443,6],[462,6],[462,23],[443,23]],"score":0.7332991361618042,"text":"X"},{"box":[[35,69],[54,69],[54,90],[35,90]],"score":0.27678585052490234,"text":"8"},{"box":[[287,69],[310,69],[310,91],[287,91]],"score":0.6947178840637207,"text":"C"},{"box":[[99,71],[162,71],[162,92],[99,92]],"score":0.9988619685173035,"text":"icyfox"},{"box":[[371,69],[411,69],[411,92],[371,92]],"score":0.994987964630127,"text":"\u767b\u51fa"},{"box":[[99,131],[222,131],[222,151],[99,151]],"score":0.9241697788238525,"text":"\u4eab\u53d7\u65e0\u9650\u901f\u5ea6"},{"box":[[342,130],[422,132],[422,153],[342,151]],"score":0.8816037178039551,"text":"\u9a6c\u4e0a\u8d2d\u4e70\uff01"},{"box":[[231,319],[350,319],[350,347],[231,347]],"score":0.9966230988502502,"text":"\u8fde\u63a5\u6210\u529f"},{"box":[[231,356],[392,356],[392,374],[231,374]],"score":0.8895745277404785,"text":"0.00k274ms0.0%"},{"box":[[152,400],[198,400],[198,447],[152,447]],"score":0.9788767695426941,"text":"+"},{"box":[[212,408],[348,408],[348,435],[212,435]],"score":0.9950642585754395,"text":"\u745e\u58eb/\u82cf\u9ece\u4e16"},{"box":[[149,462],[333,462],[333,479],[149,479]],"score":0.9467524886131287,"text":"ch-zrh-01.exits.geph.io"},{"box":[[196,655],[287,655],[287,679],[196,679]],"score":0.9990895986557007,"text":"\u66f4\u6539\u4f4d\u7f6e"},{"box":[[217,721],[266,721],[266,749],[217,749]],"score":0.9995450973510742,"text":"\u65ad\u5f00"},{"box":[[388,814],[417,814],[417,841],[388,841]],"score":0.327283650636673,"text":"*"},{"box":[[61,840],[101,842],[100,865],[60,863]],"score":0.9298021197319031,"text":"\u6982\u89c8"},{"box":[[226,845],[259,845],[259,862],[226,862]],"score":0.893752932548523,"text":"\u901a\u77e5"},{"box":[[388,845],[419,845],[419,861],[388,861]],"score":0.9994618892669678,"text":"\u8bbe\u7f6e"}]}
OCR exit.
这是什么问题?

config_path [] does not exist.
[ERROR] det_model_dir [models/ch_PP-OCRv3_det_infer] does not exist. rec_model_dir [models/ch_PP-OCRv3_rec_infer] does not exist.

PaddleOCR_json 跑一段时间后,服务异常,返回null值,不知道如何解决?
if (strget != "" && score != 0 && count != 0) { // 确定识别内容存在
}else{
当识别的内容不存在的时候,这里没有对应的空值设置 ,在返回结果那你的boxs取了i。是不是会造成的错位,返回来的box不是对应的
}
可以加个QQ397720544吗,我也在用这paddleocr,有些东西要请教下?
想识别并纠正图像的方向
建议提供restfull接口调用方式
在使用pip默认安装的“pillow10.0.0”模块下,PPOCR_visualize.py中77行“w, h = ttf.getsize(text)”报错,恢复到“pillow 9.2”正常。
原因为pillow已经在新版本中删除了FreeTypeFont.getsize()方法,变更为新的方法FreeTypeFont.getbbox()。
具体见文档:https://pillow.readthedocs.io/en/stable/releasenotes/9.2.0.html

cmake 按步骤下来报错
CMake Error in CMakeLists.txt:
OUTPUT containing a "#" is not allowed.
然后我把 cpp下的CMakeLists.txt 里面的# Note: libpaddle_inference_api.so/a must put before libpaddle_inference.so/a 删除后,依然提示这个错误。vs版本和opencv版本和文章中的一样,cmake版本为3.27.0-rc4
这个项目 用到了 PaddleOCR-json ,主要演示了Rust+QT 开发 OCR 桌面软件的可行性。
你好,我想请问一下作者使用的什么软件打包的?
我目前想打包一个深度学习的Python代码lama,可是一直打包不成功
我是使用了nuitka和pyinstaller,可惜都没有成功,使用nuitka打包了1个多小时,内存积累到了将近10g,导致最后内存不足失败
我正常跑是可以的,但是不能打包出来
这是我的打包命令
nuitka --standalone --show-memory --mingw64 --show-progress --windows-icon-from-ico=./favicon.ico --output-dir=out ./bin/predict.py
所以我想请教一下作者是如何打包PaddleOcr的?
我的目标是将python库打包成一个命令行功能工具
| 键名称 | 默认值 | 值说明 |
|---|---|---|
| addr | -1 | 指定开展服务的端口。传入0时随机端口,传入1~65535则设为该端口。 |
| port | loopback | 可选值:loopback仅在本地环回(127.0.0.1)开展服务。any在本机任何可用ip地址开展服务。 |
请问,如果输入的图片已经是单行的文本,是否有参数可设置,跳过文本检测模型,直接使用文本识别模型呢?这样是不是可以加快运行速度?
有些问题想请教一下。
1.1如果用cmake软件编译
我在编译paddleocr的过程中,发现作者自定义的include文件夹下,并没有包含config.h。
并且还有其它一些微小的错误。
1.2如果用vs2019中的cmake编译,则会由于无法添加paddle的include文件目录,导致paddle_api.h不能正确导入,也会导致编译失败。
2.请问作者在程序中,是否使用了gpu?
如果使用了gpu,那我应该在CUDA_LIB以及CUDNN_LIB填写什么项的地址。
本人工程经验太少,希望各位大神能帮帮小弟解惑。
Traceback (most recent call last):
File "threading.py", line 950, in bootstrap_inner
File "threading.py", line 888, in run
File "keyboard_generic.py", line 58, in process
File "keyboard_init.py", line 218, in pre_process_event
File "keyboard_init_.py", line 649, in
File "main.py", line 135, in show_message
File "question_to_answer.py", line 21, in init
File "ocr_api.py", line 47, in init
Exception: OCR init fail.
请问我的代码打包为pyinstaller的时候运行会报错,但是本地运行是ok的
作者大大有望增加支持PHP调用接口范例吗
我看现在的 C++ 代码有一部分是 GBK 编码的(这也是 Visual Studio 默认的),应该全部改成 UTF8 编码。
我之后想移植到 Linux 上,编码应该统一

大佬,可以添加c++推理调用sast模型吗?我这里训练出SAST高精度模型,但只能应用python上。是否可以支持?可以交流下吗?有偿也可以
各位开发者,大家好!我是PaddleOCR-json的作者。
PaddleOCR-json刚刚更新了v1.3测试版本,重构了部分代码,让任务流程更清晰,功能分类明确,更适合二次开发工作。对多平台兼容专门做了优化,绑定平台的代码都分离出来单独封装。理论上,移植其他平台,只需要重写少数几个跟进程交互及文件读取有关的函数即可。
另外,考虑到管道交互的潜在的限制性(缓冲区有限,及无纠错机制),v1.3新增了通过TCP交互的方式,在不同平台上也许能提供更稳定和可靠的服务。不过考虑到本项目的初衷是纯本地的应用,而且我的后端开发经验也不足,所以暂未考虑HTTP服务器等更高层的网络交互机制。
现在诚邀有Linux开发经验的人员参与本项目,负责移植Linux的工作。过程中,有任何跟项目流程及功能有关的疑问,都可以在这个issue下提出,我会尽力帮助你。
v1.3中,我重写了全部项目文档,希望这些文档会对你有帮助:
argument = {"config_path": "models/congfig_en.txt"} # 指定使用英文库
congfig这里写错啦,调半天= =
想请问一下进程该如何结束。
我使用如下代码创建子进程:
def OCR_text_threading(srcfile):
argument = {'config_path': "models/config_chinese.txt"}
ocr = GetOcrApi("./PaddleOCR-json_v.1.3.0/PaddleOCR-json.exe", argument)
try:
res = ocr.run(srcfile)
except Exception as e:
print(f'OCR_text_threading 循环失败: {e}')
res = 0
ocr.ret.kill()
# ocr.exit()
if res['code'] == 100:
textBlocksNew = tbpu.run_merge_line_h_m_paragraph(res['data'])
s = ""
for i in range(len(textBlocksNew)):
s1 = textBlocksNew[i]['text']
s += s1
print(s)
clipboard.copy(s)
def OCR_text(srcfile):
print(srcfile)
try:
my_thread = threading.Thread(target=OCR_text_threading, args=(srcfile,))
print(my_thread)
my_thread.start()
except Exception as e:
print(f'Thread 循环失败: {e}')
return某图片路径为:Z:\0722pz\0680_20230727110609_00.jpg
单次执行可成功。但是二次执行会爆出找不到文件的错误,重启重新识别正常:
<Thread(Thread-3 (OCR_text_threading), initial)>
Exception in thread Thread-3 (OCR_text_threading):
Traceback (most recent call last):
File "F:\language\miniconda3\lib\threading.py", line 1016, in _bootstrap_inner
self.run()
File "F:\language\miniconda3\lib\threading.py", line 953, in run
self._target(*self._args, **self._kwargs)
File "E:\MyCode\python\picture-crop\main - v0.3.py", line 429, in OCR_text_threading
ocr = GetOcrApi("./PaddleOCR-json_v.1.3.0/PaddleOCR-json.exe", argument)
File "E:\MyCode\python\picture-crop\PPOCR_api.py", line 199, in GetOcrApi
return PPOCR_pipe(exePath, argument)
File "E:\MyCode\python\picture-crop\PPOCR_api.py", line 35, in __init__
self.ret = subprocess.Popen( # 打开管道
File "F:\language\miniconda3\lib\subprocess.py", line 971, in __init__
self._execute_child(args, executable, preexec_fn, close_fds,
File "F:\language\miniconda3\lib\subprocess.py", line 1440, in _execute_child
hp, ht, pid, tid = _winapi.CreateProcess(executable, args,
FileNotFoundError: [WinError 2] 系统找不到指定的文件。
Exception ignored in: <function PPOCR_pipe.__del__ at 0x000001D24FCD6A70>
Traceback (most recent call last):
File "E:\MyCode\python\picture-crop\PPOCR_api.py", line 122, in __del__
self.exit()
File "E:\MyCode\python\picture-crop\PPOCR_api.py", line 103, in exit
self.ret.kill() # 关闭子进程
AttributeError: 'PPOCR_pipe' object has no attribute 'ret'ocr.ret.kill() 似乎不起作用。该如何结束进程?

支持把项目部署在win 7上吗
windows作为socket server ,python和golang的客户端连接socket可以连上但是服务端报错接收数据大小不足导致json解析失败
我是php,使用proc_open创建的进程,发现proc_close并不能实际关闭paddleocr进程,proc_terminate也不能关闭,必须通过proc_get_status获取到pid,然后手动执行taskkill /F /T /PID ***才可以。
是原始设计就需要这么做吗?还是我的姿势不对啊
识别结果如何合并成完整的文本呢? 我用的是java,返回了很多box, 但是我想把他合并成一整段文本
非Python开发者,纯业余小白,为了解决日常办公需求写了个Powershell脚本,如果运行"PaddleOCR_json.exe 图片路径"能够直接返回JSON结果比较方便调用。不知道能不能满足鄙人的这个需求,万分感谢!


win10 v1.2.1
如图片方式调用时,第一次会乱码,之后调用没有问题
希望批处理调用时能传入多个图片路径,或者取消输出后的Press any key to continue
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.