hitomarukonpaku / twspace-crawler Goto Github PK
View Code? Open in Web Editor NEWScript to monitor & download Twitter Spaces 24/7
Script to monitor & download Twitter Spaces 24/7

![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")
















































































































I noticed that on a space that has already ended and there was a recording still available, the following command did not successfully download the recording: twspace-crawler --env ./.env --config ./config.json --id <space_id>. Specifically, it did nothing after it successfully got the chat access token.
I managed to download the recording with no problem after passing in --force. Is there no check for a Space's state to see if it is Ended and by not passing in --force it immediately goes to monitoring the Space instead of retrieving the recording?
Hi, I get this error:
[ERROR] [UserManager] getUsersByUsernames: Request failed with status code 403 | {"requestId":"667a0f54-c312-4e81-91b5-67792c142147","response":{"data":{"client_id":"27283493","detail":"When authenticating requests to the Twitter API v2 endpoints, you must use keys and tokens from a Twitter developer App that is attached to a Project. You can create a project via the developer portal.","registration_url":"https://developer.twitter.com/en/docs/projects/overview","title":"Client Forbidden","required_enrollment":"Appropriate Level of API Access","reason":"client-not-enrolled","type":"https://api.twitter.com/2/problems/client-forbidden"}}}
The error started today. It worked before and I tried to use a new project.
Hello there,
is it possible to make my script to only Selectively download only [Audio] Files?
I don't need either text chat nor the jsonl file ?
I'm currently trying to test your service.
I installed the application. However, I tried to simple execute node ./dist/index.js --user myTwitterAccount.
then tried to open twitter space and closed it. But nothing was downloaded nor anything happen any ideas?
Can't install it.

I am quite upset about what Qelon has done to Twitter. I used to be able to download spaces but I am no longer able. I wanted this to work, I went through and followed the instructions for setup. Is it just me, or are there truly issues? When I initiate a space download I am met with this: getSpaceMetadata: Invalid value "undefined" for header "x-csrf-token" | {"requestId" Any help would be appreciated. Thank you kindly.
I know I can noti's if someone's in a space - so is there any way to record spaces by attendance rather than hosting? Like record all the spaces I show up as an attendee to?
Suggestion.
Add Node 14 install commands to the documentation.
We are thousands of programmers who never used Nodejs before. And it can clearly be done incorrectly.
Install Node 14:
sudo apt install curl
curl -sL https://deb.nodesource.com/setup_14.x | sudo bash -
sudo apt install -y nodejs
The username could change while the userID will always stay the same
2023-10-27T12:43:34.602Z | [INFO] [UserListWatcher] Watching...
2023-10-27T12:43:35.668Z | [INFO] [SpaceWatcher@1ZkJzjPZPzqJv] Watching...
2023-10-27T12:43:35.670Z | [INFO] [SpaceWatcher@1ZkJzjPZPzqJv] Space url: https://twitter.com/i/spaces/1ZkJzjPZPzqJv
2023-10-27T12:43:36.072Z | [ERROR] [SpaceWatcher@1ZkJzjPZPzqJv] getAudioSpaceByRestId: Request failed with status code 404
--env .env with proper credentials. I'm getting 401 error:
getUserByScreenName: Request failed with status code 401
In the Discord webhook, the title of the space is being displayed as undefined. This happens when a space does not have a title and therefore no title key within the space's data.
See
twspace-crawler/src/utils/SpaceUtil.ts
Line 18 in f1428fc
Twitter's front-end sets the space's title in such cases to the display name of the space owner. We could do the same by falling back on
twspace-crawler/src/utils/SpaceUtil.ts
Line 26 in f1428fc
When I'm fetching the audioSpaces, from https://api.twitter.com/graphql/xjTKygiBMpX44KU8ywLohQ/AudioSpaceById
The api returns:
{"errors":[{"message":"The following features cannot be null: responsive_web_uc_gql_enabled, responsive_web_enhance_cards_enabled, responsive_web_edit_tweet_api_enabled, spaces_2022_h2_spaces_communities, tweetypie_unmention_optimization_enabled, verified_phone_label_enabled, longform_notetweets_consumption_enabled, vibe_api_enabled, spaces_2022_h2_clipping, interactive_text_enabled, responsive_web_graphql_timeline_navigation_enabled, tweet_with_visibility_results_prefer_gql_limited_actions_policy_enabled, view_counts_everywhere_api_enabled, responsive_web_text_conversations_enabled, graphql_is_translatable_rweb_tweet_is_translatable_enabled, standardized_nudges_misinfo, responsive_web_twitter_blue_verified_badge_is_enabled, view_counts_public_visibility_enabled","extensions":{"name":"BadRequestError","source":"Client","code":336,"kind":"Validation","tracing":{"trace_id":"5aa0e1ad62b688ff"}},"code":336,"kind":"Validation","name":"BadRequestError","source":"Client","tracing":{"trace_id":"5aa0e1ad62b688ff"}}]}
But the parameters that are mentioned are not null.
I'm calling:
const { data } = await axios.get(url, {
headers,
params: {
variables: {
id: spaceId,
isMetatagsQuery: true,
withSuperFollowsUserFields: true,
withDownvotePerspective: false,
withReactionsMetadata: false,
withReactionsPerspective: false,
withSuperFollowsTweetFields: true,
withReplays: true,
},
features: {
spaces_2022_h2_clipping: true,
spaces_2022_h2_spaces_communities: true,
responsive_web_twitter_blue_verified_badge_is_enabled: true,
verified_phone_label_enabled: false,
view_counts_public_visibility_enabled: true,
longform_notetweets_consumption_enabled: false,
tweetypie_unmention_optimization_enabled: true,
responsive_web_uc_gql_enabled: true,
vibe_api_enabled: true,
responsive_web_edit_tweet_api_enabled: true,
graphql_is_translatable_rweb_tweet_is_translatable_enabled: true,
view_counts_everywhere_api_enabled: true,
standardized_nudges_misinfo: true,
tweet_with_visibility_results_prefer_gql_limited_actions_policy_enabled: false,
responsive_web_graphql_timeline_navigation_enabled: true,
interactive_text_enabled: true,
responsive_web_text_conversations_enabled: false,
responsive_web_enhance_cards_enabled: false,
},
},
})
```
hello,
you must have noticed that the subtitles file generally remains empty at 0kb. to get the cc you have to go to the Space and activate it via the ... "activate subtitles" from there this unlocks the problem for the current Space. is it possible via the code to modify it so that the api asks the cc to activate without needing to do it on Space? THANKS
Is there a way to download just the audio? Monitoring, master url extraction goes fine, but it stops at the chat access token.
I am still trying to figure out how to properly use this tool as I was under the impression it downloads the space in real-time. When I tried it first using twspace-crawler --env ./.env --config ./config.json --id <space_id> it found the space but did not start downloading it yet. After taking a closer look at the README and reading it in full I misunderstood the functionality.
It's written "Monitor user(s) indefinitely, wait for live Space and download when Space ended". I tried passing in --force to force it to download the space which it did. However, it kept fetching the space and attempting to re-download it as the terminal kept monitoring the same user. Furthermore, the downloaded file did not seem to be re-written after all those calls.
The reason for this I believe is due to the ffmpeg command. ffmpeg by default does not overwrite an existing file and asks you either to rename the file or overwrite it via -y flag which twspace-crawler does not use.
It would be nice if either
--overwrite
--download-segments
Due to bad ffmpeg metadata formatting. I have a patch, this is a tracking issue.
or use @ffmpeg-installer/ffmpeg
node -v
v16.11.1
2021-12-17T08:19:13.781Z | [�[32mINFO�[39m] [SpaceCaptionsDownloader@1YqKDqaobPAGV] Downloading captions to 211217081913 (1YqKDqaobPAGV) CC.jsonl
2021-12-17T08:19:13.815Z | [�[32mINFO�[39m] [SpaceCaptionsDownloader@1YqKDqaobPAGV] Downloading chunk 1
2021-12-17T08:19:15.466Z | [�[32mINFO�[39m] [SpaceCaptionsDownloader@1YqKDqaobPAGV] Downloading chunk 2
2021-12-17T08:19:16.061Z | [�[32mINFO�[39m] [SpaceCaptionsDownloader@1YqKDqaobPAGV] Downloading chunk 3
2021-12-17T08:19:16.668Z | [�[32mINFO�[39m] [SpaceCaptionsDownloader@1YqKDqaobPAGV] Downloading chunk 4
2021-12-17T08:19:17.314Z | [�[32mINFO�[39m] [SpaceCaptionsDownloader@1YqKDqaobPAGV] Downloading chunk 5
2021-12-17T08:19:18.092Z | [�[32mINFO�[39m] [SpaceCaptionsDownloader@1YqKDqaobPAGV] Downloading chunk 6
2021-12-17T08:19:18.464Z | [�[32mINFO�[39m] [SpaceCaptionsDownloader@1YqKDqaobPAGV] Downloading chunk 7
2021-12-17T08:19:18.978Z | [�[32mINFO�[39m] [SpaceCaptionsDownloader@1YqKDqaobPAGV] Downloading chunk 8
2021-12-17T08:19:19.531Z | [�[32mINFO�[39m] [SpaceCaptionsDownloader@1YqKDqaobPAGV] Downloading chunk 9
2021-12-17T08:19:20.125Z | [�[32mINFO�[39m] [SpaceCaptionsDownloader@1YqKDqaobPAGV] Downloading chunk 10
2021-12-17T08:19:20.800Z | [�[32mINFO�[39m] [SpaceCaptionsDownloader@1YqKDqaobPAGV] Downloading chunk 11
2021-12-17T08:19:21.437Z | [�[32mINFO�[39m] [SpaceCaptionsDownloader@1YqKDqaobPAGV] Downloading chunk 12
2021-12-17T08:19:22.047Z | [�[32mINFO�[39m] [SpaceCaptionsDownloader@1YqKDqaobPAGV] Downloading chunk 13
2021-12-17T08:19:22.748Z | [�[32mINFO�[39m] [SpaceCaptionsDownloader@1YqKDqaobPAGV] Downloading chunk 14
2021-12-17T08:19:23.333Z | [�[32mINFO�[39m] [SpaceCaptionsDownloader@1YqKDqaobPAGV] Downloading chunk 15
2021-12-17T08:19:23.971Z | [�[32mINFO�[39m] [SpaceCaptionsDownloader@1YqKDqaobPAGV] Downloading chunk 16
2021-12-17T08:19:24.373Z | [�[32mINFO�[39m] [SpaceCaptionsDownloader@1YqKDqaobPAGV] Downloading chunk 17
2021-12-17T08:19:25.020Z | [�[32mINFO�[39m] [SpaceCaptionsDownloader@1YqKDqaobPAGV] Downloading chunk 18
2021-12-17T08:19:25.616Z | [�[32mINFO�[39m] [SpaceCaptionsDownloader@1YqKDqaobPAGV] Downloading chunk 19
2021-12-17T08:19:26.347Z | [�[32mINFO�[39m] [SpaceCaptionsDownloader@1YqKDqaobPAGV] Downloading chunk 20
2021-12-17T08:19:26.917Z | [�[32mINFO�[39m] [SpaceCaptionsDownloader@1YqKDqaobPAGV] Downloading chunk 21
2021-12-17T08:19:27.366Z | [�[32mINFO�[39m] [SpaceCaptionsDownloader@1YqKDqaobPAGV] Downloading chunk 22
2021-12-17T08:19:28.792Z | [�[32mINFO�[39m] [SpaceCaptionsDownloader@1YqKDqaobPAGV] Downloading chunk 23
2021-12-17T08:19:29.727Z | [�[32mINFO�[39m] [SpaceCaptionsDownloader@1YqKDqaobPAGV] Downloading chunk 24
2021-12-17T08:19:30.539Z | [�[32mINFO�[39m] [SpaceCaptionsDownloader@1YqKDqaobPAGV] Downloading chunk 25
2021-12-17T08:19:31.157Z | [�[32mINFO�[39m] [SpaceCaptionsDownloader@1YqKDqaobPAGV] Downloading chunk 26
2021-12-17T08:19:32.357Z | [�[31mERROR�[39m] [SpaceCaptionsDownloader@1YqKDqaobPAGV] Request failed with status code 503
Is this case normal? It always happens for running lives, sometimes for ended lives.
twspace-crawler --url https://twitter.com/i/spaces/1ZkJzbWyoqZJv
2022-02-13T20:15:48.881Z | [INFO] ================================================================================
2022-02-13T20:15:48.883Z | [INFO] Version: 1.11.1
2022-02-13T20:15:48.884Z | [INFO] Starting in url mode | {"url":"https://twitter.com/i/spaces/1ZkJzbWyoqZJv"}
2022-02-13T20:15:48.884Z | [VERBOSE] [SpaceDownloader] Playlist path: "/home/USR/twdl/download/2202132015.m3u8"
2022-02-13T20:15:48.885Z | [VERBOSE] [SpaceDownloader] Audio path: "/home/USR/twdl/download/2202132015.m4a"
(node:30337) UnhandledPromiseRejectionWarning: TypeError: Cannot read property '0' of null
at Function.getFinalPlaylistName (/usr/lib/node_modules/twspace-crawler/dist/utils/PeriscopeUtil.js:9:42)
at Function.getFinalPlaylistUrl (/usr/lib/node_modules/twspace-crawler/dist/apis/PeriscopeApi.js:21:71)
at processTicksAndRejections (internal/process/task_queues.js:95:5)
at async SpaceDownloader.download (/usr/lib/node_modules/twspace-crawler/dist/modules/SpaceDownloader.js:33:32)
(Use node --trace-warnings ... to show where the warning was created)
(node:30337) UnhandledPromiseRejectionWarning: Unhandled promise rejection. This error originated either by throwing inside of an async function without a catch block, or by rejecting a promise which was not handled with .catch(). To terminate the node process on unhandled promise rejection, use the CLI flag --unhandled-rejections=strict (see https://nodejs.org/api/cli.html#cli_unhandled_rejections_mode). (rejection id: 1)
(node:30337) [DEP0018] DeprecationWarning: Unhandled promise rejections are deprecated. In the future, promise rejections that are not handled will terminate the Node.js process with a non-zero exit code.
I don't know how to fix such problem
if someone faced it or if I installed something wrong please guide me to fix it
for a while, i'd have to try 4 or 5 times before captions would actually download, now they never do, they fail with 503... I think i remember when looking deeper something to do with rate limiting, so maybe the code needs to be updated to honor the rate limiting.
Hi,
when i try twspace-crawler --user Name i have a problem:
root@raspberrypi:/home/pi# twspace-crawler --user test_test
2022-06-04T00:21:05.142Z | [INFO] ================================================================================
2022-06-04T00:21:05.149Z | [INFO] Version: 1.11.8
2022-06-04T00:21:05.654Z | [INFO] Starting in user mode | {"userCount":1,"users":["test_test"]}
2022-06-04T00:21:05.728Z | [INFO] [UserWatcher@test_test] Watching...
and after nothin...
I do it with a real name (here i replace it with test for the question...) :)
Why i never seen when people start space ?
Thank you
Just installed it but couldn't get it to download my own Twitter Spaces. What am I doing wrong?
$ twspace-crawler --id 1lPKqbYrAonGb
2024-03-13T01:16:55.448Z | [INFO] ================================================================================
2024-03-13T01:16:55.448Z | [INFO] Version: 1.12.9
2024-03-13T01:16:56.036Z | [INFO] Starting in space id mode | {"id":"1lPKqbYrAonGb"}
2024-03-13T01:16:56.036Z | [INFO] [SpaceWatcher@1lPKqbYrAonGb] Watching...
2024-03-13T01:16:56.036Z | [INFO] [SpaceWatcher@1lPKqbYrAonGb] Space url: https://twitter.com/i/spaces/1lPKqbYrAonGb
2024-03-13T01:16:56.039Z | [ERROR] [SpaceWatcher@1lPKqbYrAonGb] getAudioSpaceById: Cannot read properties of undefined (reading 'config')
2024-03-13T01:16:57.572Z | [ERROR] [SpaceWatcher@1lPKqbYrAonGb] getAudioSpaceByRestId: Request failed with status code 404
2024-03-13T01:16:57.573Z | [ERROR] [SpaceWatcher@1lPKqbYrAonGb] AudioSpace metadata not found
2024-03-13T01:16:57.579Z | [INFO] [SpaceWatcher@1lPKqbYrAonGb] Retry watch in 10000ms
2024-03-13T01:17:07.580Z | [INFO] [SpaceWatcher@1lPKqbYrAonGb] Watching...
2024-03-13T01:17:07.581Z | [INFO] [SpaceWatcher@1lPKqbYrAonGb] Space url: https://twitter.com/i/spaces/1lPKqbYrAonGb
2024-03-13T01:17:07.585Z | [ERROR] [SpaceWatcher@1lPKqbYrAonGb] getAudioSpaceById: Cannot read properties of undefined (reading 'config')
2024-03-13T01:17:08.513Z | [ERROR] [SpaceWatcher@1lPKqbYrAonGb] getAudioSpaceByRestId: Request failed with status code 404
2024-03-13T01:17:08.514Z | [ERROR] [SpaceWatcher@1lPKqbYrAonGb] AudioSpace metadata not found
2024-03-13T01:17:08.515Z | [INFO] [SpaceWatcher@1lPKqbYrAonGb] Retry watch in 10000ms
Hi,
I noticed that users with undescores are not scanned by the crawler.
I would be happy to help (but not sure how to setup a devenv and how to capture data for unit testing).
Thibault
data: { code: 200, message: 'Forbidden.' }
When I'm hitting the https://api.twitter.com/1.1/guest/activate.json with the bearer token AAAAAAAAAAAAAAAAAAAAANRILgAAAAAAnNwIzUejRCOuH5E6I8xnZz4puTs=1Zv7ttfk8LF81IUq16cHjhLTvJu4FA33AGWWjCpTnA
It returns forbidden. Can I get some help? I might be missing something.
Hello there 🌵
Firstly, thanks for all your hard work 🧑💼
I suspect you did a typo or commented something out that is the cause of the error.
I'm not a pro at programming yet so I may be wrong though.
I followed the install instructions + installed node with sudo apt install node (The Ubuntu console gave me the command)
Ubuntu 20.04
Python 3.9
node --version: v10.19.0
ffmpeg version 4.4.1-0 ubuntu120.04.sav0 Copyright (c) 2000-2021 the FFmpeg developers built with gcc 9 (Ubuntu 9.3.017ubuntu120.04)
New anaconda environment
Git clone repo a few hours ago.
The error:
Person_1 etc. = left out for the purpose of OPSEC
(twspace-crawler) judo@judo-VM:~/twspace-crawler$ node ./dist/index.js --user Person_1,Person_2,Person_3,Person_4
/home/judo/twspace-crawler/dist/utils/PeriscopeUtil.js:18
return data.match(chunkIndexPattern)?.map((v) => Number(v)) || [];
^
SyntaxError: Unexpected token .
at Module._compile (internal/modules/cjs/loader.js:723:23)
at Object.Module._extensions..js (internal/modules/cjs/loader.js:789:10)
at Module.load (internal/modules/cjs/loader.js:653:32)
at tryModuleLoad (internal/modules/cjs/loader.js:593:12)
at Function.Module._load (internal/modules/cjs/loader.js:585:3)
at Module.require (internal/modules/cjs/loader.js:692:17)
at require (internal/modules/cjs/helpers.js:25:18)
at Object.<anonymous> (/home/judo/twspace-crawler/dist/apis/PeriscopeApi.js:8:25)
at Module._compile (internal/modules/cjs/loader.js:778:30)
at Object.Module._extensions..js (internal/modules/cjs/loader.js:789:10)
(twspace-crawler) judo@judo-VM:~/twspace-crawler$ node ./dist/index.js --user RichardHeartWin,FundingGym,Hexologist31,HexOrca
/home/judo/twspace-crawler/dist/utils/PeriscopeUtil.js:18
return data.match(chunkIndexPattern)?map((v) => Number(v)) || [];
^
Hey,
since few days all files CC captions are empty... do you know what is the problem ?
Thank you
User undefined due to user changed protected status mid stream
{"rest_id":"1vAxRkbpqXkKl","state":"Running","media_key":"28_1507007548024516614","created_at":1648133572933,"started_at":1648133575936,"updated_at":1648133576596,"is_employee_only":false,"is_locked":false,"conversation_controls":0,"total_participated":0,"total_replay_watched":0,"creator_results":{"result":{"__typename":"User","id":"VXNlcjoxMzQ5NzA1MTI2Mzg3MjI0NTc5","rest_id":"1349705126387224579","affiliates_highlighted_label":{},"has_nft_avatar":false,"legacy":{"created_at":"Thu Jan 14 13:09:26 +0000 2021","default_profile":true,"default_profile_image":false,"description":"ひなゆです。illust。基本創作たまに版権。パーカーとサメとシャチとネコ多いです。お仕事のご連絡は[email protected] かDMまで!サブ垢→@tsukino_63 skeb→ https://t.co/9QFh1EwGPq","entities":{"description":{"urls":[{"display_url":"skeb.jp/@tsukino_hinayu","expanded_url":"https://skeb.jp/@tsukino_hinayu","url":"https://t.co/9QFh1EwGPq","indices":[100,123]}]},"url":{"urls":[{"display_url":"pixiv.net/users/76920612","expanded_url":"https://www.pixiv.net/users/76920612","url":"https://t.co/dTUqj7Ozjg","indices":[0,23]}]}},"fast_followers_count":0,"favourites_count":5997,"followers_count":5192,"friends_count":221,"has_custom_timelines":true,"is_translator":false,"listed_count":77,"location":"水族館と猫カフェ","media_count":35,"name":"雛夕 月ノ。@固ツイ把握お願いします💦","normal_followers_count":5192,"pinned_tweet_ids_str":["1494054740388290563"],"profile_banner_extensions":{"mediaColor":{"r":{"ok":{"palette":[{"percentage":67.93,"rgb":{"blue":232,"green":232,"red":232}},{"percentage":23.75,"rgb":{"blue":128,"green":123,"red":117}},{"percentage":2.27,"rgb":{"blue":58,"green":48,"red":44}},{"percentage":1.98,"rgb":{"blue":178,"green":162,"red":117}},{"percentage":0.62,"rgb":{"blue":36,"green":37,"red":92}}]}}}},"profile_banner_url":"https://pbs.twimg.com/profile_banners/1349705126387224579/1641301487","profile_image_extensions":{"mediaColor":{"r":{"ok":{"palette":[{"percentage":51.92,"rgb":{"blue":218,"green":219,"red":220}},{"percentage":27.24,"rgb":{"blue":65,"green":63,"red":62}},{"percentage":9.61,"rgb":{"blue":131,"green":132,"red":119}},{"percentage":4.97,"rgb":{"blue":110,"green":114,"red":125}},{"percentage":0.42,"rgb":{"blue":135,"green":135,"red":173}}]}}}},"profile_image_url_https":"https://pbs.twimg.com/profile_images/1484483261548023810/GXFXn3VG_normal.jpg","profile_interstitial_type":"","protected":false,"screen_name":"tsukino_hinayu","statuses_count":7468,"translator_type":"none","url":"https://t.co/dTUqj7Ozjg","verified":false,"withheld_in_countries":[]}}}}
{"rest_id":"1vAxRkbpqXkKl","state":"Ended","title":"無言多めさぎょー。スピーカー相互さんのみ","media_key":"28_1507007548024516614","created_at":1648133572933,"started_at":1648133575936,"ended_at":"1648148556421","updated_at":1648148557700,"is_employee_only":false,"is_locked":false,"conversation_controls":0,"total_participated":58,"total_replay_watched":0,"creator_results":{"result":{"__typename":"UserUnavailable","reason":"Protected"}}}
Matterbridge is a tool that works as a non-platform-specific chat bridge between many communications platforms. It preserves threading/attachments/etc as much as it can.
I see that you support discord, but you could use the matterbridge API to support everything they support :)
https://github.com/42wim/matterbridge/wiki/Api
Thanks for the great tool!
i start the twspace crawler and it only print the message like this ,please help
2023-07-01T08:33:20.986Z | [ERROR] [UserManager] getUserByScreenName: Invalid value "undefined" for header "x-csrf-token" | {"username":"achan_UGA"}
As of right now, the script that extracts the captions needs to be fixed. This might be because the JSON from which the captions are usually extracted no longer contains the captions.
Title
I've created a space that can only be viewed on the Twitter app, but on the mobile web and PC web it looks like a deleted space, and I can only hear and see it on the app. Is there a solution?..
Hello, since 2 days i have this message...
Do you know what is the problem ? i don't have problem since 1 year but since 2 days i havethis message...
(i try to do another account but it's similar)
It'll be impossible with free account developers ?
Thank you.
[ERROR] [UserManager] getUsersByUsernames: Request failed with status code 403 | {"requestId":"16fbde9b-5874-423c-bfc5-7528f0eqa215","response":{"data":{"client_id":"27841039","detail":"When authenticating requests to the Twitter API v2 endpoints, you must use keys and tokens from a Twitter developer App that is attached to a Project. You can create a project via the developer portal.","registration_url":"https://developer.twitter.com/en/docs/projects/overview","title":"Client Forbidden","required_enrollment":"Appropriate Level of API Access","reason":"client-not-enrolled","type":"https://api.twitter.com/2/problems/client-forbidden"}}}
I can do "twspace-crawler --id 1ldxxxxxxxx " for catch 1 space manualy but impossible to do "--env --config" with the config.json for autocatch... :((
Node version: 14.18.2
twspace-crawler version: dd2dada (v1.8.0)
After watching an user for 3 hours, UserWatcher started getting 403's.
Log:
$ node dist/index.js -d --user akaihaato
2022-01-13T07:57:08.916Z | [INFO] ================================================================================
2022-01-13T07:57:08.919Z | [DEBUG] Args | {"debug":true,"user":"akaihaato"}
2022-01-13T07:57:08.919Z | [INFO] Starting in user mode | {"users":["akaihaato"]}
2022-01-13T07:57:08.920Z | [DEBUG] [UserManager] add | {"usernames":["akaihaato"]}
2022-01-13T07:57:08.920Z | [DEBUG] [UserManager] --> fetchUsersByScreenName
2022-01-13T07:57:08.928Z | [DEBUG] [ConfigManager] --> getGuestToken
2022-01-13T07:57:09.552Z | [DEBUG] [ConfigManager] <-- getGuestToken | {"guestToken":"1481535776458690564"}
2022-01-13T07:57:09.557Z | [DEBUG] [UserManager] --> getUserByScreenName 1 | {"username":"akaihaato"}
2022-01-13T07:57:10.163Z | [DEBUG] [UserManager] <-- getUserByScreenName 1 | {"username":"akaihaato"}
2022-01-13T07:57:10.164Z | [DEBUG] [UserManager] <-- fetchUsersByScreenName
2022-01-13T07:57:10.164Z | [INFO] [UserWatcher@akaihaato] Watching...
2022-01-13T07:57:10.165Z | [DEBUG] [UserWatcher@akaihaato] --> getUserTweets
2022-01-13T07:57:11.520Z | [DEBUG] [UserWatcher@akaihaato] --> getAudioSpaceById | {"id":"1mrxmalLejgxy"}
2022-01-13T07:57:11.520Z | [DEBUG] [UserWatcher@akaihaato] <-- getUserTweets | {"spaceIds":["1mrxmalLejgxy"]}
2022-01-13T07:57:12.160Z | [DEBUG] [UserWatcher@akaihaato] <-- getAudioSpaceById | {"id":"1mrxmalLejgxy","state":"Ended"}
2022-01-13T07:57:41.520Z | [DEBUG] [UserWatcher@akaihaato] --> getUserTweets
2022-01-13T07:57:42.843Z | [DEBUG] [UserWatcher@akaihaato] <-- getUserTweets | {"spaceIds":["1mrxmalLejgxy"]}
2022-01-13T07:58:12.844Z | [DEBUG] [UserWatcher@akaihaato] --> getUserTweets
2022-01-13T07:58:14.160Z | [DEBUG] [UserWatcher@akaihaato] <-- getUserTweets | {"spaceIds":["1mrxmalLejgxy"]}
2022-01-13T07:58:44.161Z | [DEBUG] [UserWatcher@akaihaato] --> getUserTweets
2022-01-13T07:58:45.674Z | [DEBUG] [UserWatcher@akaihaato] <-- getUserTweets | {"spaceIds":["1mrxmalLejgxy"]}
2022-01-13T07:59:15.674Z | [DEBUG] [UserWatcher@akaihaato] --> getUserTweets
2022-01-13T07:59:17.072Z | [DEBUG] [UserWatcher@akaihaato] <-- getUserTweets | {"spaceIds":["1mrxmalLejgxy"]}
2022-01-13T07:59:47.073Z | [DEBUG] [UserWatcher@akaihaato] --> getUserTweets
2022-01-13T07:59:48.414Z | [DEBUG] [UserWatcher@akaihaato] <-- getUserTweets | {"spaceIds":["1mrxmalLejgxy"]}
2022-01-13T08:00:18.414Z | [DEBUG] [UserWatcher@akaihaato] --> getUserTweets
2022-01-13T08:00:19.860Z | [DEBUG] [UserWatcher@akaihaato] <-- getUserTweets | {"spaceIds":["1mrxmalLejgxy"]}
...
2022-01-13T10:55:08.454Z | [DEBUG] [UserWatcher@akaihaato] --> getUserTweets
2022-01-13T10:55:09.827Z | [DEBUG] [UserWatcher@akaihaato] <-- getUserTweets | {"spaceIds":["1mrxmalLejgxy"]}
2022-01-13T10:55:39.827Z | [DEBUG] [UserWatcher@akaihaato] --> getUserTweets
2022-01-13T10:55:41.289Z | [DEBUG] [UserWatcher@akaihaato] <-- getUserTweets | {"spaceIds":["1mrxmalLejgxy"]}
2022-01-13T10:56:11.289Z | [DEBUG] [UserWatcher@akaihaato] --> getUserTweets
2022-01-13T10:56:12.605Z | [DEBUG] [UserWatcher@akaihaato] <-- getUserTweets | {"spaceIds":["1mrxmalLejgxy"]}
2022-01-13T10:56:42.605Z | [DEBUG] [UserWatcher@akaihaato] --> getUserTweets
2022-01-13T10:56:44.087Z | [DEBUG] [UserWatcher@akaihaato] <-- getUserTweets | {"spaceIds":["1mrxmalLejgxy"]}
2022-01-13T10:57:14.088Z | [DEBUG] [UserWatcher@akaihaato] --> getUserTweets
2022-01-13T10:57:14.635Z | [ERROR] [UserWatcher@akaihaato] getSpaces: Request failed with status code 403
2022-01-13T10:57:44.636Z | [DEBUG] [UserWatcher@akaihaato] --> getUserTweets
2022-01-13T10:57:45.231Z | [ERROR] [UserWatcher@akaihaato] getSpaces: Request failed with status code 403
2022-01-13T10:58:15.231Z | [DEBUG] [UserWatcher@akaihaato] --> getUserTweets
2022-01-13T10:58:15.786Z | [ERROR] [UserWatcher@akaihaato] getSpaces: Request failed with status code 403
2022-01-13T10:58:45.786Z | [DEBUG] [UserWatcher@akaihaato] --> getUserTweets
2022-01-13T10:58:46.333Z | [ERROR] [UserWatcher@akaihaato] getSpaces: Request failed with status code 403
2022-01-13T10:59:16.333Z | [DEBUG] [UserWatcher@akaihaato] --> getUserTweets
2022-01-13T10:59:16.887Z | [ERROR] [UserWatcher@akaihaato] getSpaces: Request failed with status code 403
2022-01-13T10:59:46.889Z | [DEBUG] [UserWatcher@akaihaato] --> getUserTweets
2022-01-13T10:59:47.452Z | [ERROR] [UserWatcher@akaihaato] getSpaces: Request failed with status code 403
2022-01-13T11:00:17.452Z | [DEBUG] [UserWatcher@akaihaato] --> getUserTweets
2022-01-13T11:00:17.997Z | [ERROR] [UserWatcher@akaihaato] getSpaces: Request failed with status code 403
2022-01-13T11:00:47.999Z | [DEBUG] [UserWatcher@akaihaato] --> getUserTweets
2022-01-13T11:00:48.537Z | [ERROR] [UserWatcher@akaihaato] getSpaces: Request failed with status code 403
2022-01-13T11:01:18.538Z | [DEBUG] [UserWatcher@akaihaato] --> getUserTweets
2022-01-13T11:01:19.075Z | [ERROR] [UserWatcher@akaihaato] getSpaces: Request failed with status code 403
2022-01-13T11:01:49.075Z | [DEBUG] [UserWatcher@akaihaato] --> getUserTweets
2022-01-13T11:01:49.637Z | [ERROR] [UserWatcher@akaihaato] getSpaces: Request failed with status code 403
...
2022-01-13T12:53:48.594Z | [DEBUG] [UserWatcher@akaihaato] --> getUserTweets
2022-01-13T12:53:49.115Z | [ERROR] [UserWatcher@akaihaato] getSpaces: Request failed with status code 403
2022-01-13T12:54:19.116Z | [DEBUG] [UserWatcher@akaihaato] --> getUserTweets
2022-01-13T12:54:19.649Z | [ERROR] [UserWatcher@akaihaato] getSpaces: Request failed with status code 403
Hello,
When a space is ended it's possible to retrieve a space ? Because i want retrieve a space but i've error 404...
thank you.
Twitter update their APIs again and now nothing is publicy visible.
Will try to fix later
UPDATED: PLEASE READ INSTALLATION for more detail
Been getting Error code 429 after a day or two - I need to nail down the time frame. Guessing there's some sort of API token time out? Is there anyway to code it where if it detects this it auto restarts the service? Error below...
I get a bunch of these and eventually gets hung with a spaces URL and starts throwing 404s
2023-03-17T09:52:11.733Z | [ERROR] [UserListWatcher] getSpaces: Request failed with status code 429 | {"requestId":"7a580cad-6d39-449b-a6ce-04e939221224","response":{"data":{"title":"Too Many Requests","detail":"Too Many Requests","type":"about:blank","status":429},"headers":{"date":"Fri, 17 Mar 2023 09:52:11 UTC","perf":"7626143928","server":"tsa_b","set-cookie":["guest_id_marketing=v1%3A167904673173096689; Max-Age=63072000; Expires=Sun, 16 Mar 2025 09:52:11 GMT; Path=/; Domain=.twitter.com; Secure; SameSite=None","guest_id_ads=v1%3A167904673173096689; Max-Age=63072000; Expires=Sun, 16 Mar 2025 09:52:11 GMT; Path=/; Domain=.twitter.com; Secure; SameSite=None","personalization_id="v1_dy3wQXs5Llnzrao1YoIj5g=="; Max-Age=63072000; Expires=Sun, 16 Mar 2025 09:52:11 GMT; Path=/; Domain=.twitter.com; Secure; SameSite=None","guest_id=v1%3A167904673173096689; Max-Age=63072000; Expires=Sun, 16 Mar 2025 09:52:11 GMT; Path=/; Domain=.twitter.com; Secure; SameSite=None"],"api-version":"2.61","content-type":"application/json; charset=utf-8","cache-control":"no-cache, no-store, max-age=0","content-length":"92","x-access-level":"read","x-frame-options":"SAMEORIGIN","x-transaction-id":"033183acfc66aa59","x-xss-protection":"0","x-rate-limit-limit":"300","x-rate-limit-reset":"1679047260","content-disposition":"attachment; filename=json.json","x-content-type-options":"nosniff","x-rate-limit-remaining":"275","strict-transport-security":"max-age=631138519","x-response-time":"11","x-connection-hash":"e8213dd39ff82c155977688a21641e14cabe54b07e281f20631a29bfa2c0a7fb","connection":"close"}}}
I probably have ran into some problems with Ubuntu 22.04 LTS 🤔
The crawler can grab the meta info but not being able to download any m4a audiofile.
| Env | Ver |
|---|---|
| pnpm | 7.18.0 |
| Node.js | 18.2.1 |
| twspace-crawler | 1.11.10 |
| FFmpeg | 5.0.1 |
I have tested this and confirmed that it happens on my Ubuntu machines (both x86_64 and aarch64, 22.04.1 LTS).
Strangely, everything works fine on my MacBook (Apple Silicon, 2021, Ventura 13.0.1).
Here's the log on my Ubuntu machine
$ twspace-crawler --url https://prod-fastly-ap-northeast-1.video.pscp.tv/Transcoding/v1/hls/SvvyS_Hr2uetdvBKLMcK-BWeT2I8BHq-3c5ZpoABD5tHCNCjaWZus3Uufrxb9BJFhQH9jS-6LDz5Nm4uh4mxrg/non_transcode/ap-northeast-1/periscope-replay-direct-prod-ap-northeast-1-public/audio-space/master_playlist.m3u8 -d
2022-12-05T12:12:04.784Z | [INFO] ================================================================================
2022-12-05T12:12:04.788Z | [INFO] Version: 1.11.10
2022-12-05T12:12:05.601Z | [DEBUG] Args | {"url":"https://prod-fastly-ap-northeast-1.video.pscp.tv/Transcoding/v1/hls/SvvyS_Hr2uetdvBKLMcK-BWeT2I8BHq-3c5ZpoABD5tHCNCjaWZus3Uufrxb9BJFhQH9jS-6LDz5Nm4uh4mxrg/non_transcode/ap-northeast-1/periscope-replay-direct-prod-ap-northeast-1-public/audio-space/master_playlist.m3u8","debug":true}
2022-12-05T12:12:05.603Z | [DEBUG] env.TWITTER_AUTHORIZATION=
2022-12-05T12:12:05.604Z | [DEBUG] env.TWITTER_AUTH_TOKEN=
2022-12-05T12:12:05.605Z | [INFO] Starting in playlist url mode | {"url":"https://prod-fastly-ap-northeast-1.video.pscp.tv/Transcoding/v1/hls/SvvyS_Hr2uetdvBKLMcK-BWeT2I8BHq-3c5ZpoABD5tHCNCjaWZus3Uufrxb9BJFhQH9jS-6LDz5Nm4uh4mxrg/non_transcode/ap-northeast-1/periscope-replay-direct-prod-ap-northeast-1-public/audio-space/master_playlist.m3u8"}
2022-12-05T12:12:05.607Z | [DEBUG] [SpaceDownloader] constructor | {"originUrl":"https://prod-fastly-ap-northeast-1.video.pscp.tv/Transcoding/v1/hls/SvvyS_Hr2uetdvBKLMcK-BWeT2I8BHq-3c5ZpoABD5tHCNCjaWZus3Uufrxb9BJFhQH9jS-6LDz5Nm4uh4mxrg/non_transcode/ap-northeast-1/periscope-replay-direct-prod-ap-northeast-1-public/audio-space/master_playlist.m3u8","filename":"2212051212","subDir":""}
2022-12-05T12:12:05.607Z | [VERBOSE] [SpaceDownloader] Playlist path: "/home/aozaki/download/2212051212.m3u8"
2022-12-05T12:12:05.608Z | [VERBOSE] [SpaceDownloader] Audio path: "/home/aozaki/download/2212051212.m4a"
2022-12-05T12:12:05.609Z | [DEBUG] [SpaceDownloader] download | {"originUrl":"https://prod-fastly-ap-northeast-1.video.pscp.tv/Transcoding/v1/hls/SvvyS_Hr2uetdvBKLMcK-BWeT2I8BHq-3c5ZpoABD5tHCNCjaWZus3Uufrxb9BJFhQH9jS-6LDz5Nm4uh4mxrg/non_transcode/ap-northeast-1/periscope-replay-direct-prod-ap-northeast-1-public/audio-space/master_playlist.m3u8"}
2022-12-05T12:12:06.091Z | [INFO] [SpaceDownloader] Final playlist url: https://prod-fastly-ap-northeast-1.video.pscp.tv/Transcoding/v1/hls/SvvyS_Hr2uetdvBKLMcK-BWeT2I8BHq-3c5ZpoABD5tHCNCjaWZus3Uufrxb9BJFhQH9jS-6LDz5Nm4uh4mxrg/non_transcode/ap-northeast-1/periscope-replay-direct-prod-ap-northeast-1-public/audio-space/playlist_16776578390500222618.m3u8
2022-12-05T12:12:06.093Z | [VERBOSE] [SpaceDownloader] Audio is saving to "/home/aozaki/download/2212051212.m4a"
2022-12-05T12:12:06.093Z | [VERBOSE] [SpaceDownloader] ffmpeg -protocol_whitelist file,https,tls,tcp -i https://prod-fastly-ap-northeast-1.video.pscp.tv/Transcoding/v1/hls/SvvyS_Hr2uetdvBKLMcK-BWeT2I8BHq-3c5ZpoABD5tHCNCjaWZus3Uufrxb9BJFhQH9jS-6LDz5Nm4uh4mxrg/non_transcode/ap-northeast-1/periscope-replay-direct-prod-ap-northeast-1-public/audio-space/playlist_16776578390500222618.m3u8 -c copy /home/aozaki/download/2212051212.m4a
Hi, thanks for making this tool, I am giving it a try but encountered the following error on both Windows and Ubuntu:
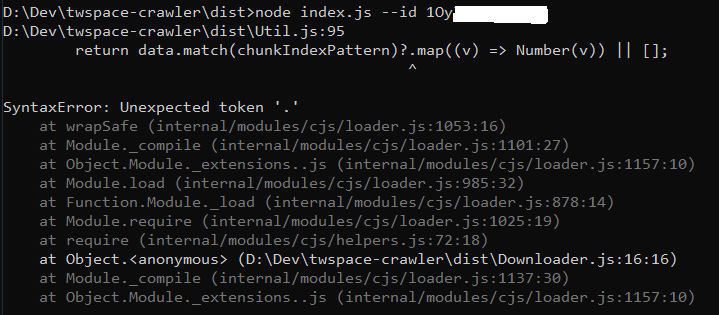
I tried with --user, --config or --id, all result in the same error.
Would it be possible or is it possible to batch spaces (as I'm not sure how it multithreads, I know its captured more than one space at once for me) or do them as a queue where you could input twspace-crawler --id spaceoneid,spacetwoid,space3id etc. I've been doing them as one offs. And not sure if this is correct.
Hello,
Do you know what is the problem please ?
Thank you.
2023-08-15T10:56:04.897Z | [ERROR] [SpaceWatcher@1dRKZMdLMrvxB] getAudioSpaceById: Request failed with status code 404
2023-08-15T10:56:04.937Z | [ERROR] [SpaceWatcher@1dRKZMdLMrvxB] getAudioSpaceByRestId: Request failed with status code 404
2023-08-15T10:56:04.939Z | [ERROR] [SpaceWatcher@1dRKZMdLMrvxB] AudioSpace metadata not found
2023-08-15T10:56:04.942Z | [INFO] [SpaceWatcher@1dRKZMdLMrvxB] Retry watch in 10000ms
2023-08-15T10:56:04.953Z | [ERROR] [SpaceWatcher@1eaKbraQLArKX] getAudioSpaceById: Request failed with status code 404
2023-08-15T10:56:04.977Z | [ERROR] [SpaceWatcher@1eaKbraQLArKX] getAudioSpaceByRestId: Request failed with status code 404
2023-08-15T10:56:04.982Z | [ERROR] [SpaceWatcher@1eaKbraQLArKX] AudioSpace metadata not found
Since yesterday I noticed on my Raspberry that the @ followed in the config.json work even when they are not host of the spaces (before the @ had to be the host of the space to trigger the capture), on the other hand on my PC the system has not changed, it only captures if the @ starts the space.
Do you know why ?
ps: FYI I prefer the new @ tracking system (capturing the space even if the @ doesn't host it).
I'm on 1.11.13 on Raspberry and PC.
Thank you
It would be cool if there would be a way to trigger scripts after a space got downloaded completely. That way people could write additional plugis, I for example would want to write a plugin that automatically uploads the files to GDrive via rclone, others might want to move the files to a path for a webserver...
If the host of a space has a private account, there's no Discord webhook sent for whatever reason but also the file(s) don't get properly organized. I tested it by hosting a space with a private account, and using the auth of my other account that follows it.

twspace-crawler/src/utils/SpaceUtil.ts
Line 22 in 430247d
but for protected accounts the value of creator_results is
"creator_results": {
"result": {
"__typename": "UserUnavailable",
"reason": "Protected"
}
}I think we should modify SpaceUtil's functions to mitigate a protected account such as by adding a check to SpaceUtil#getHostUsername and other relevant functions. Despite create_results being unavailable we could utilize audiospace.participants.admins[0] instead as from my gathering that is always the host. Even though the account is protected, we can pull relevant data such as user and display names as well as the user's id and avatar (src/interfaces/Twitter.interface.ts#L69).
By using this information and adding checks, we could derive the appropriate information and be able to send the webhook with no problem as well as organizing the files accordingly.
I can help work on this but I will be busy until the next 12 hours or so.
Hello I'm trying to setup the script to monitor users and record spaces without me keep monitoring them myself
so I followed the guide you posted and did this comamnd
twspace-crawler --env ./.env --config ./config.json
all I can see in the log file inside logs folder
is this
2022-02-22T18:11:40.010Z | [INFO] ================================================================================
2022-02-22T18:11:40.019Z | [INFO] Version: 1.11.3
2022-02-22T18:11:43.370Z | [INFO] ================================================================================
2022-02-22T18:11:43.380Z | [INFO] Version: 1.11.3
2022-02-22T18:11:46.723Z | [INFO] ================================================================================
2022-02-22T18:11:46.732Z | [INFO] Version: 1.11.3
2022-02-22T18:11:50.067Z | [INFO] ================================================================================
2022-02-22T18:11:50.076Z | [INFO] Version: 1.11.3
2022-02-22T18:11:53.411Z | [INFO] ================================================================================
2022-02-22T18:11:53.420Z | [INFO] Version: 1.11.3
2022-02-22T18:11:56.757Z | [INFO] ================================================================================
2022-02-22T18:11:56.766Z | [INFO] Version: 1.11.3
2022-02-22T18:12:00.105Z | [INFO] ================================================================================
2022-02-22T18:12:00.115Z | [INFO] Version: 1.11.3
so how can I know for sure it's working here
It would be nice if the download directory wouldnt be hardcoded to [workdir]/download but set via the .env file to any folder (default to [workdir]/download if not set would still be important)
It would be cool to have the bot edit its Space live posts to "Space ended", maybe with a custom field "End Text" where people could add an info about how to optain the finished space (Like: "Head over to some.website/spaces to get the archive")
Info about editing Webhook messages: https://discord.com/developers/docs/resources/webhook#edit-webhook-message
Ok another random question. Is it possible since I believe the audio are individual streams from participants to just capture the audio of a single participant - like if i wanted to record my own space and isolate my own voice for sampling/cuts without others talking over me? Sometimes I want to do subclips but someone talks over or buries something I said and I want to just pull my or one other persons audio for editing.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.