
Below is what you can do with this program:
- Get Instagram posts/profile/hashtag data without using Instagram API.
crawler.py - Like posts automatically.
liker.py
This crawler could fail due to updates on instagram’s website. If you encounter any problems, please contact me.
- Make sure you have Chrome browser installed.
- Download chromedriver and put it into bin folder:
./inscrawler/bin/chromedriver - Install Selenium:
pip3 install -r requirements.txt cp inscrawler/secret.py.dist inscrawler/secret.py
- Open
inscrawler/secret.pyfile. - Change the
usernameandpasswordvariables' value to the ones corresponding to your Instagram account.
username = 'my_ig_username'
password = '***********'
positional arguments:
mode
options: [posts, posts_full, profile, hashtag]
optional arguments:
-n NUMBER, --number NUMBER
number of returned posts
-u USERNAME, --username USERNAME
instagram's username
-t TAG, --tag TAG instagram's tag name
-o OUTPUT, --output OUTPUT
output file name(json format)
--debug see how the program automates the browser
--fetch_comments fetch comments
# Turning on the flag might take forever to fetch data if there are too many commnets.
--fetch_likes_plays fetch like/play number
--fetch_likers fetch all likers
# Instagram might have rate limit for fetching likers. Turning on the flag might take forever to fetch data if there are too many likes.
--fetch_mentions fetch users who are mentioned in the caption/comments (startwith @)
--fetch_hashtags fetch hashtags in the caption/comments (startwith #)
--fetch_details fetch username and photo caption
# only available for "hashtag" search
python crawler.py posts_full -u cal_foodie -n 100 -o ./output
python crawler.py posts_full -u cal_foodie -n 10 --fetch_likers --fetch_likes_plays
python crawler.py posts_full -u cal_foodie -n 10 --fetch_comments
python crawler.py profile -u cal_foodie -o ./output
python crawler.py hashtag -t taiwan -o ./output
python crawler.py hashtag -t taiwan -o ./output --fetch_details
python crawler.py posts -u cal_foodie -n 100 -o ./output # deprecated
- Choose mode
posts, you will get url, caption, first photo for each post; choose modeposts_full, you will get url, caption, all photos, time, comments, number of likes and views for each posts. Modeposts_fullwill take way longer than modeposts. [postsis deprecated. For the recent posts, there is no quick way to get the post caption] - Return default 100 hashtag posts(mode: hashtag) and all user's posts(mode: posts) if not specifying the number of post
-n,--number. - Print the result to the console if not specifying the output path of post
-o,--output. - It takes much longer to get data if the post number is over about 1000 since Instagram has set up the rate limit for data request.
- Don't use this repo crawler Instagram if the user has more than 10000 posts.
The data format of posts:

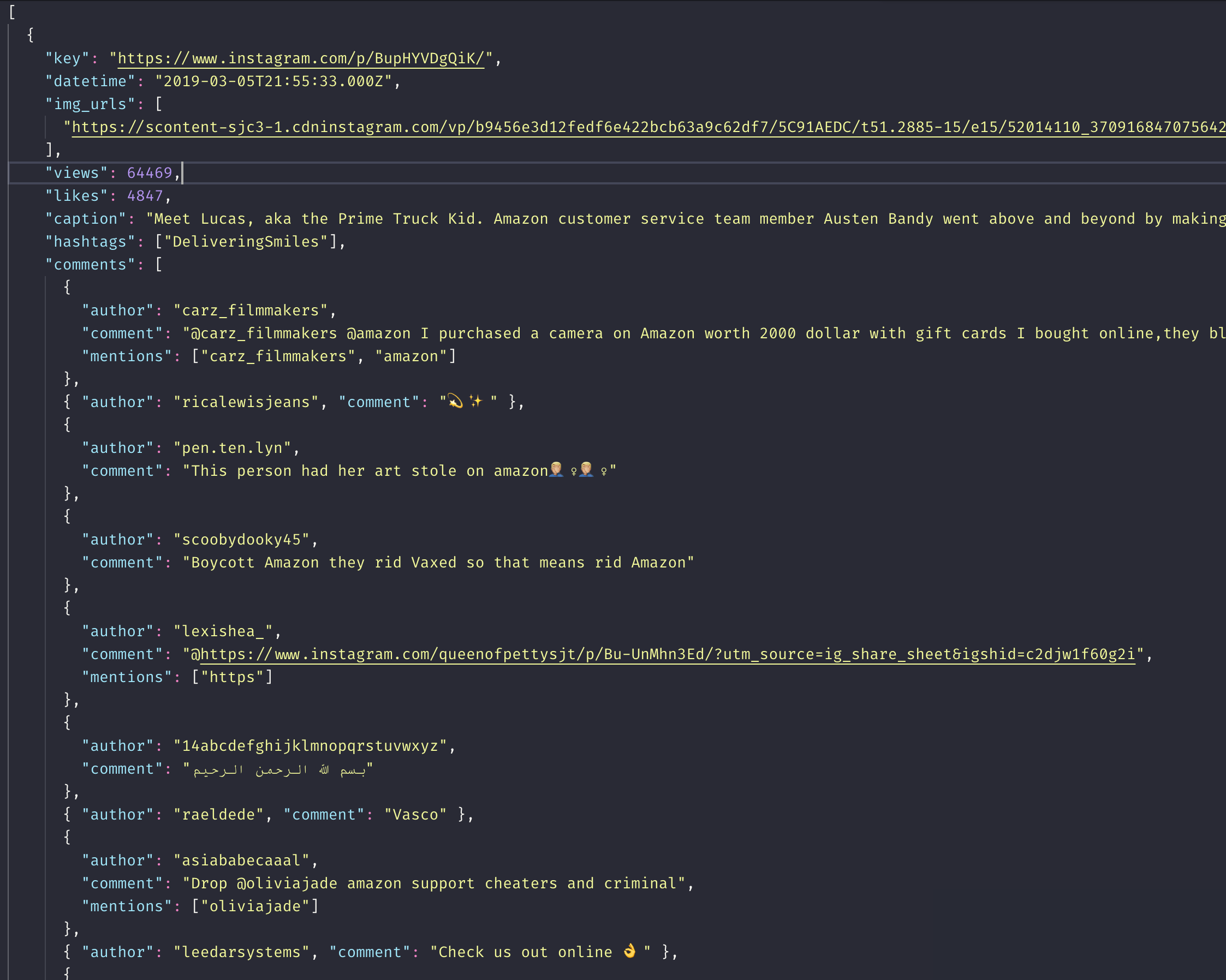
The data format of posts_full:

Set up your username/password in secret.py or set them as environment variables.
positional arguments:
tag
optional arguments:
-n NUMBER, --number NUMBER (default 1000)
number of posts to like
python liker.py foodie
























































































































































