1、JS基础篇
1.1 原型链、对象的创建和继承
1.2 对象的浅拷贝和深拷贝
1.3 new的过程——手写new
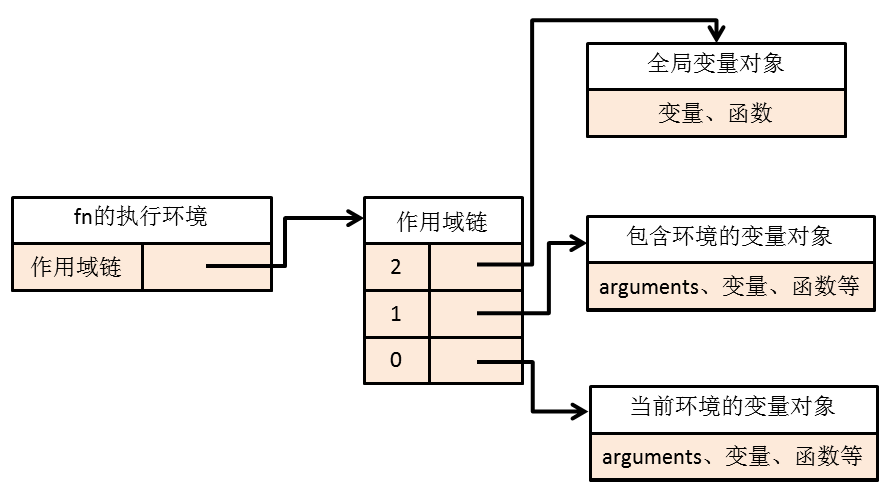
1.4 对闭包的理解(垃圾回收机制)与应用——防抖、节流、柯里化
1.5 js的异步回调、Promise及其手写
1.6 this的指向及其4种绑定规则
1.7 js设计模式之——观察者模式与发布订阅模式
2、数据结构与算法篇
2.1 栈和队列——2个栈实现队列
2.2 链表——js实现链表类及其方法
2.3 排序算法——冒泡排序 | 归并排序 | 快速排序
2.4 二叉树、堆的一些概念
2.5 二叉树类的创建及前、中、后续遍历 | 深度优先、广度优先
2.6 集合(Set)、字典(Map)、哈希表(hash)简介
3、计算机网络篇
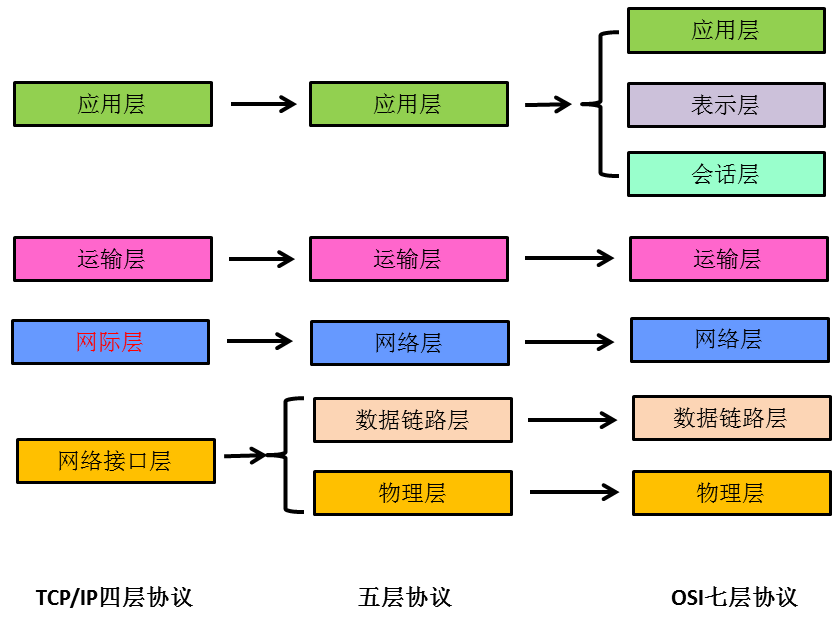
3.1 计算机网络的体系结构及其各层的作用
3.2 网络层要点
3.3 运输层要点
3.4 应用层要点
3.5 应用层协议——HTTP/1.0、1.1及2.0
3.6 密码体制及应用——HTTPS
4、HTML(5)、CSS(3)篇
4.1 HTML(5)标签
4.2 CSS选择器、单位、文本
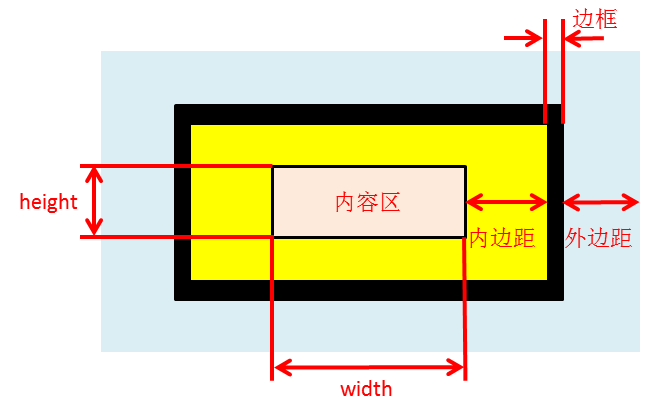
4.3 盒模型、元素分类
4.4 浮动与定位
4.5 CSS3新特性
4.6 应用
******换位子 DOM事件
5、浏览器篇
5.1 浏览器的组成
5.2 渲染引擎——重排、重绘
5.3 JS引擎——事件循环Event Loop
5.4 浏览器缓存——Cookie、sessionStorage和localStorage
5.5 浏览器内存——内存泄漏
6、网页通信篇
6.1 Ajax原理
6.2 同源策略及跨域
6.3 服务端推送Comet——长轮询、短轮询和http流
6.4 SSE和Web Sockets
6.5 用户身份识别——session和token
6.6 Web安全防范——CSRF与XSS
7、网站性能优化篇
7.1 减少HTTP请求
7.1.1 合并图片、内联图片、合并脚本和样式表
7.1.2 缓存组件——Last-Modified,Expires,Cache-Control和ETag
7.1.3 使用外部JS和CSS——为了能缓存
7.1.4 避免重定向
7.1.5 不使用@import、空的href、空的form表单method
7.2 优化网络连接
7.2.1 使用内容发布网络CDN——缩短物理传输距离
7.2.2 减少DNS查找——缩短IP查找时间
7.3 减小响应的大小
压缩组件、精简代码、删除重复
7.4 优化加载顺序
样式表放在顶部、脚本放在底部、懒加载和预加载
7.5 减少重排和重绘
避免CSS表达式、使用事件代理、防抖节流等
7.6 运算量大的代码分片执行
避免浏览器卡死 —— js代码分片执行
8、前端框架篇--Vue
8.1 前端框架设计模式——MVC、MVP、MVVM
8.2 Vue生命周期、常用API、组件通信
8.3 Vue-router——手写原生hash、history路由
8.4 Vuex
8.5 Vue原理——手写Vue核心
8.5.1 Vue工作机制——总体流程
8.5.2 Vue首次渲染——手写响应式、html编译、依赖收集
8.5.3 Vue更新渲染——手写createElement,render,diff算法
9、webpack和Node.js篇
9.1 js的模块系统——ES6与ES5的模块系统
9.2 webpack原理——loader、plugin、bundle
- 《JavaScript高级程序设计》 第三版 Nicholas C.Zakas
- 《你不知道的JavaScript》 KYLE SIMPSON
- 《学习JavaScript数据结构与算法》 第三版 Loiane Groner
- 《计算机网络》 第七版 谢希仁
- 《CSS权威指南》 第三版 Eric A.Meyer
- 《高性能网站建设指南》 Steve Souders
- 《How Browsers Work: Behind the scenes of modern web browsers》、w3school、MDN、Vue等在线文档
- SegmentFault、CSDN、简书、博客园、牛客等在线博客