This repository contains source code for Draco, a scalable framework for robust distributed training that uses ideas from coding theory. Please check https://arxiv.org/abs/1803.09877 for detailed information about this project.
Draco is a scalable framework for robust distributed training that uses ideasfrom coding theory. In Draco, compute nodes evaluate redundant gradients that are then used by the parameter server (PS) to eliminate the effects of adversarial updates.

In Draco, each compute node processes rB/P gradients and sends a linear combination of those to the PS. This means that Draco incurs a computational redundancy ratio of r. Upon receiving the P gradient sums, the PS uses a “decoding” function to remove the effect of the adversarial nodes and reconstruct the original desired sum of the B gradients. With redundancy ratio r, we show that Draco can tolerate up to (r − 1)/2 adversaries, which is information theoretically tight.
Tested stable depdencises:
- python 2.7 (Anaconda)
- PyTorch 0.3.0 (please note that, we're moving to PyTorch 0.4.0, and 1.0.x)
- torchvision 0.1.18
- MPI4Py 0.3.0
- python-blosc 1.5.0
- hdmedians
We highly recommend installing an Anaconda environment. You will get a high-quality BLAS library (MKL) and you get a controlled compiler version regardless of your Linux distro.
We provide this script to help you with building all dependencies. To do that you can run:
bash ./tools/pre_run.sh
For running on distributed cluster, the first thing you need do is to launch AWS EC2 instances.
This script helps you to launch EC2 instances automatically, but before running this script, you should follow the instruction to setup AWS CLI on your local machine.
After that, please edit this part in ./tools/pytorch_ec2.py
cfg = Cfg({
"name" : "PS_PYTORCH", # Unique name for this specific configuration
"key_name": "NameOfKeyFile", # Necessary to ssh into created instances
# Cluster topology
"n_masters" : 1, # Should always be 1
"n_workers" : 8,
"num_replicas_to_aggregate" : "8", # deprecated, not necessary
"method" : "spot",
# Region speficiation
"region" : "us-west-2",
"availability_zone" : "us-west-2b",
# Machine type - instance type configuration.
"master_type" : "m4.2xlarge",
"worker_type" : "m4.2xlarge",
# please only use this AMI for pytorch
"image_id": "ami-xxxxxxxx", # id of AMI
# Launch specifications
"spot_price" : "0.15", # Has to be a string
# SSH configuration
"ssh_username" : "ubuntu", # For sshing. E.G: ssh ssh_username@hostname
"path_to_keyfile" : "/dir/to/NameOfKeyFile.pem",
# NFS configuration
# To set up these values, go to Services > ElasticFileSystem > Create new filesystem, and follow the directions.
#"nfs_ip_address" : "172.31.3.173", # us-west-2c
#"nfs_ip_address" : "172.31.35.0", # us-west-2a
"nfs_ip_address" : "172.31.14.225", # us-west-2b
"nfs_mount_point" : "/home/ubuntu/shared", # NFS base dirFor setting everything up on EC2 cluster, the easiest way is to setup one machine and create an AMI. Then use the AMI id for image_id in pytorch_ec2.py. Then, launch EC2 instances by running
python ./tools/pytorch_ec2.py launch
After all launched instances are ready (this may take a while), getting private ips of instances by
python ./tools/pytorch_ec2.py get_hosts
this will write ips into a file named hosts_address, which looks like
172.31.16.226 (${PS_IP})
172.31.27.245
172.31.29.131
172.31.18.108
172.31.18.174
172.31.17.228
172.31.16.25
172.31.30.61
172.31.29.30
After generating the hosts_address of all EC2 instances, running the following command will copy your keyfile to the parameter server (PS) instance whose address is always the first one in hosts_address. local_script.sh will also do some basic configurations e.g. clone this git repo
bash ./tool/local_script.sh ${PS_IP}
At this stage, you should ssh to the PS instance and all operation should happen on PS. In PS setting, PS should be able to ssh to any compute node, this part dose the job for you by running (after ssh to the PS)
bash ./tools/remote_script.sh
We currently support MNIST and Cifar10 datasets. Download, split, and transform datasets by (and ./tools/remote_script.sh dose this for you)
bash ./src/data_prepare.sh
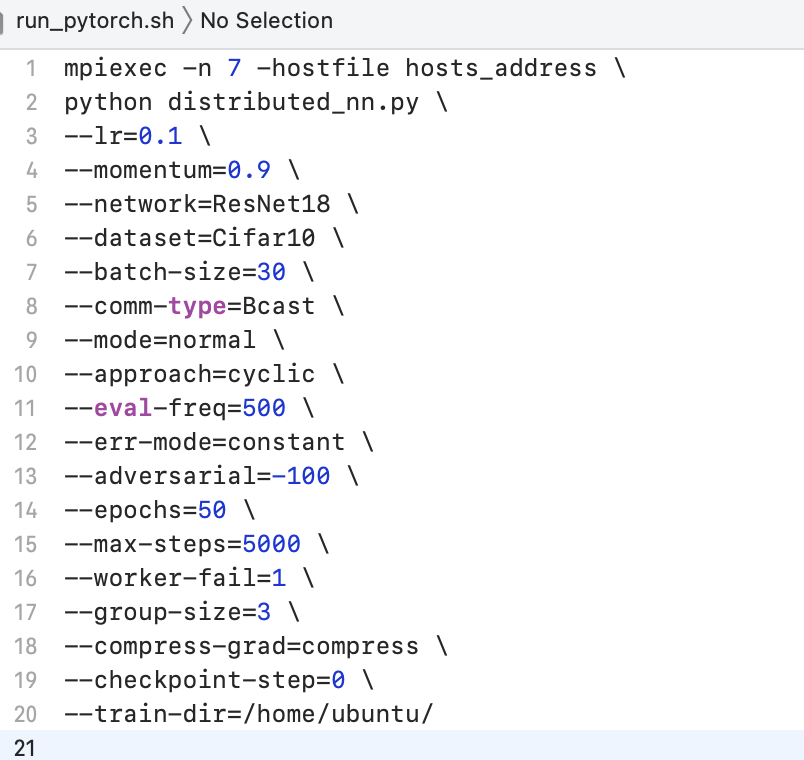
Since this project is built on MPI, tasks are required to be launched by PS (or master) instance. run_pytorch.sh wraps job-launching process up. Commonly used options (arguments) are listed as following:
| Argument | Comments |
|---|---|
n |
Number of processes (size of cluster) e.g. if we have P compute node and 1 PS, n=P+1. |
hostfile |
A directory to the file that contains Private IPs of every node in the cluster, we use hosts_address here as mentioned before. |
lr |
Inital learning rate that will be use. |
momentum |
Value of momentum that will be use. |
network |
Types of deep neural nets, currently LeNet, ResNet-18/32/50/110/152, and VGGs are supported. |
dataset |
Datasets use for training. |
batch-size |
Batch size for optimization algorithms. |
comm-type |
A fake parameter, please always set it to be Bcast. |
mode |
Update mode used on PS, e.g. geometric median, Krum, majority vote, and etc. |
approach |
Approach used in experiments, e.g. baseline method or Draco (repition code or cyclic code). |
err-mode |
Mode of simulated adversaries, reverse gradient adversary and constant adversary are currently supported. |
adversarial |
Magnitude of adversaries. |
worker-fail |
Number of adversarial nodes simulated in the cluster. |
group-size |
Used for repitition code in specific, for group size of workers. |
max-steps |
The maximum number of iterations to train. |
epochs |
The maximal number of epochs to train (somehow redundant). |
eval-freq |
Frequency of iterations to evaluation the model. |
enable-gpu |
Training on CPU/GPU, if CPU please leave this argument empty. |
train-dir |
Directory to save model checkpoints for evaluation. |
Distributed evaluator will fetch model checkpoints from the shared directory and evaluate model on validation set. To evaluate model, you can run
bash ./src/evaluate_pytorch.sh
with specified arguments.
Evaluation arguments are listed as following:
| Argument | Comments |
|---|---|
eval-batch-size |
Batch size (on validation set) used during model evaluation. |
eval-freq |
Frequency of iterations to evaluation the model, should be set to the same value as run_pytorch.sh. |
network |
Types of deep neural nets, should be set to the same value as run_pytorch.sh. |
dataset |
Datasets use for training, should be set to the same value as run_pytorch.sh. |
model-dir |
Directory to save model checkpoints for evaluation, should be set to the same value as run_pytorch.sh. |
Those are potential directions we are actively working on, stay tuned!
- Reduce the computational cost of Draco by only approximately recovering the desired gradient summation.
- Explore other coding methods that achieve the same redundancy and computation lower bounds.
- Move Draco to state-of-the-art PS (or distributed) frameworks e.g. Ray or TensorFlow.
@inproceedings{Draco,
author = {Lingjiao Chen and Hongyi Wang and Zachary Charles and Dimitris Papailiopoulos},
title = {DRACO: Byzantine-resilient Distributed Training via Redundant Gradients},
booktitle = {Proceedings of the 35th International Conference on Machine Learning, {ICML} 2018},
year = {2018},
month = jul,
url = {https://arxiv.org/abs/1803.09877},
}