hxwfromdjtu / blog Goto Github PK
View Code? Open in Web Editor NEW🌈 技术博客,记录日常工作学习的整理~欢迎star
🌈 技术博客,记录日常工作学习的整理~欢迎star






































































































select select/poll epoll
摘自《NodeJS深入浅出》
select poll epoll都是I/O多路复用的一种机制。fd_set到�内核空间__pollwait函数,I/O操作的过程中,当前进程就被挂在等待队列中,直到操作完成,当前进程就再次被释放出来socket_poll方法,进而根据情况调用tcp_poll,udp_poll或者datagram_poll。若fd_set很大的时候,操作开销会特别大。poll机制和select运行的机制上没有区别,但是poll是基于l链表来存储的文件描述符,所以没有最大连接数的限制。epoll既然是以上两种方案的改进版,自然没有以上方案的缺点。
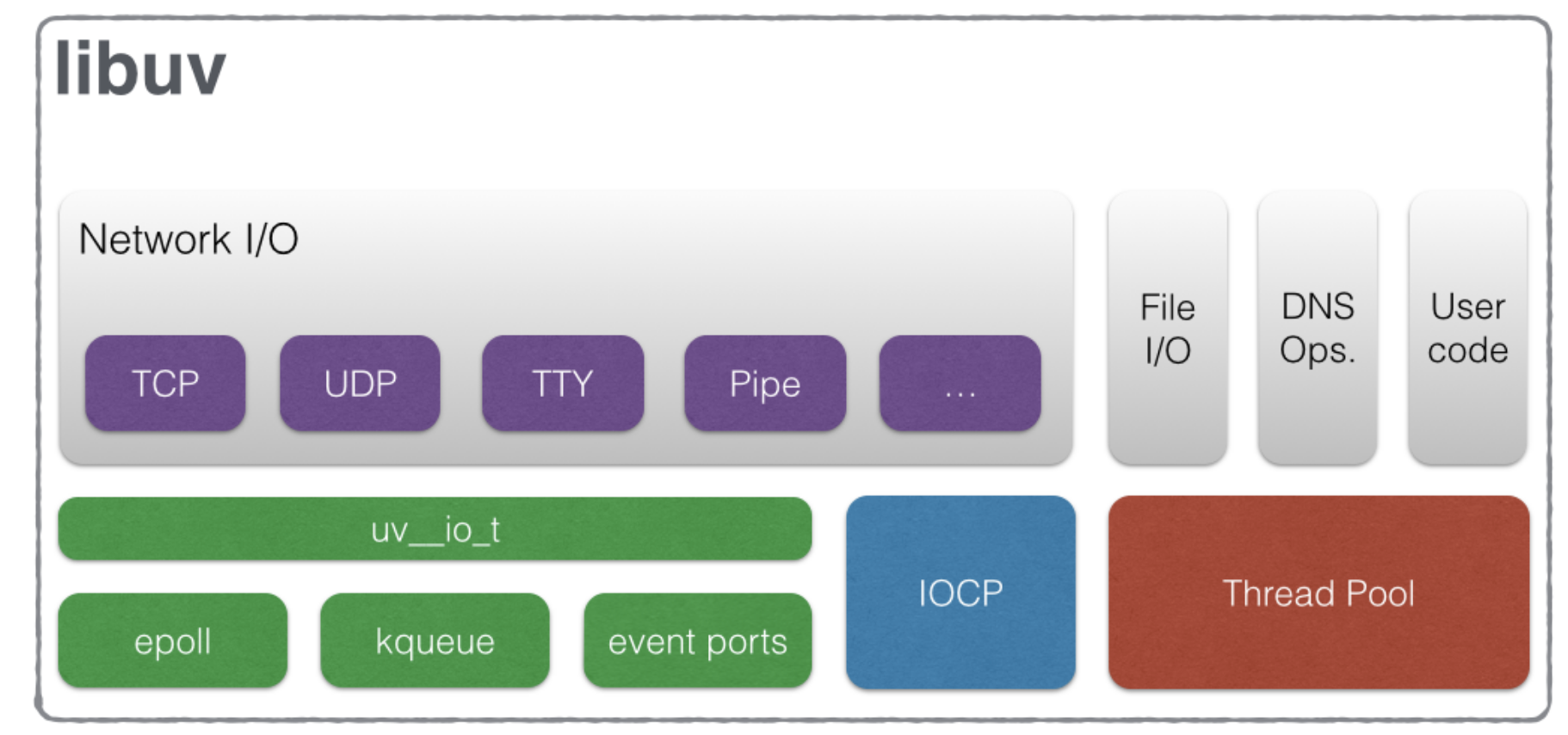
epoll_create:用于创建一个epoll句柄epoll_ctl:用于注册要�监听的事件类型epoll_wait:则是等待事件的发生重复拷贝" 那么在Windows平台下的状况如何呢?而实际上,Windows有一种独有的内核异步IO方案:IOCP。IOCP的思路是真正的异步I/O方案,调 用异步方法,然后等待I/O完成通知。IOCP内部依旧是通过线程实现,不同在于这些线程由系统内核接手管理。IOCP的异步模型与Node.js的异步 调用模型已经十分近似。"
以上文字摘自《异步I/O - NodeJS深入浅出 第三章》
[1] select、poll、epoll之间的区别总结[整理]
[2] Java 与 NIO
[3] 《异步I/O - NodeJS深入浅出 第三章》
[4] IO模型及select、poll、epoll和kqueue的区别
前面一篇文章聊过了最常用的跨域手段 CORS (跨域资源共享)。这次再看看工作中其他的跨域资源获取手段,proxy 和 JSONP。
同源策略的是浏览器本身管理资源的安全策略,并且以域来划分管理。但是当企业发展、业务变得繁杂之后,一个页面需要的资源来源,可能是数十个。
与每个接口的提供方进行进行沟通,让其进行在响应中添加对应的 Access-Controll-Allow-xxxx 的响应头是在过于繁琐,万一自己网站的域名做了调整,又需要对所有的接口提供方进行更新。
通过一个中间服务器为我们的 web服务 进行请求转发。Proxy 与数据接口之间可以直接调用,Proxy Server 与 web应用 之间且存在的跨域问题,只需要使用一次 跨域响应头 的设置即可。
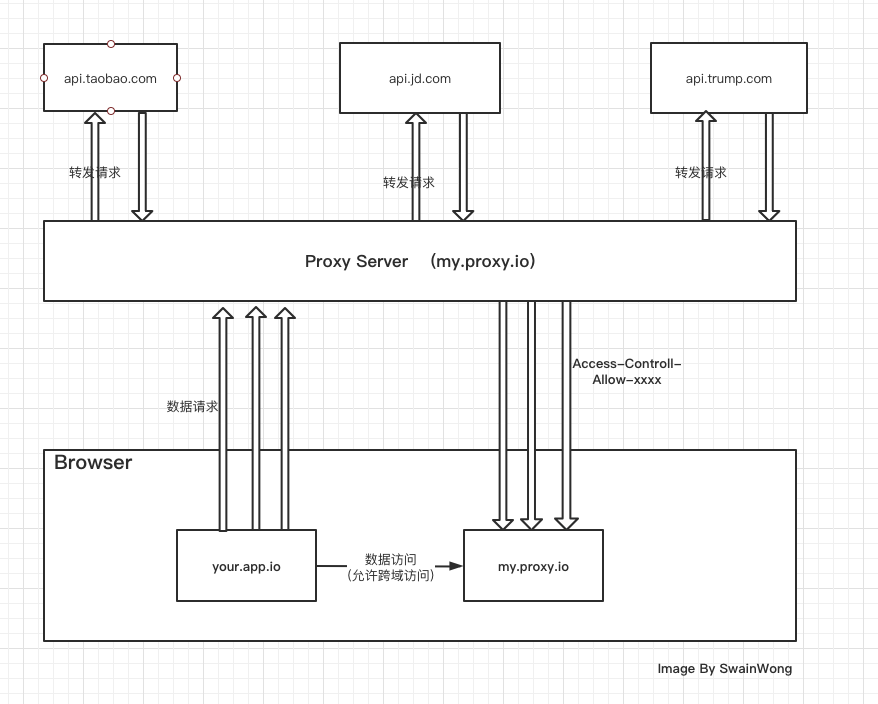
Proxy Server 是一个最简化的 http Server,不进行任何的业务处理,只对请求原封不动地转发,对相应数据也原封不动地返回给请求方。
常用的实际方案是 Node.js 转发 与 nginx 转发,为啥选她俩?因为足够轻量足够快,前端可以闭环。
cors-anywhere 是一个开箱即用的 Node.js 转发服务,专门为中转请求而设计。前端开发将其部署到自己的服务器上
return axios.get('https://cors-anywhere.your-server.com/https://api.other-domain.com/price', {
params: { ids: tokens.join(',') },
withCredentials: false,
})#进程, 可更具cpu数量调整
worker_processes 1;
events {
#连接数
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
#连接超时时间,服务器会在这个时间过后关闭连接。
keepalive_timeout 10;
# gizp压缩
gzip on;
# 直接请求nginx也是会报跨域错误的这里设置允许跨域
# 如果代理地址已经允许跨域则不需要这些, 否则报错(虽然这样nginx跨域就没意义了)
add_header Access-Control-Allow-Origin *;
add_header Access-Control-Allow-Headers X-Requested-With;
add_header Access-Control-Allow-Methods GET,POST,OPTIONS;
# srever模块配置是http模块中的一个子模块,用来定义一个虚拟访问主机
server {
listen 80;
server_name localhost;
# 根路径指到index.html
location / {
root html;
index index.html index.htm;
}
# localhost/api 的请求会被转发到192.168.0.103:8080
location /api/ {
rewrite ^/b/(.*)$ /$1 break; # 去除本地接口/api前缀, 否则会出现404
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_pass ?; # 转发地址
}
# 重定向错误页面到/50x.html
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
}
假设代理服务始终是麻烦的,JSONP 方案的灵活性这体现了出来。淘宝、天猫、京东的等电商网站的首页数据,无一例外地使用了 JSONP 的数据请求方式。
原理则是“欺骗浏览器”,告诉浏览器我用换这个script 标签获取回来的只是一些执行脚本,并不是数据,而让浏览器不进行资源访问的域限制。

[1] JSONP - Wikipedia
[2] 跨源资源共享(CORS) - MDN
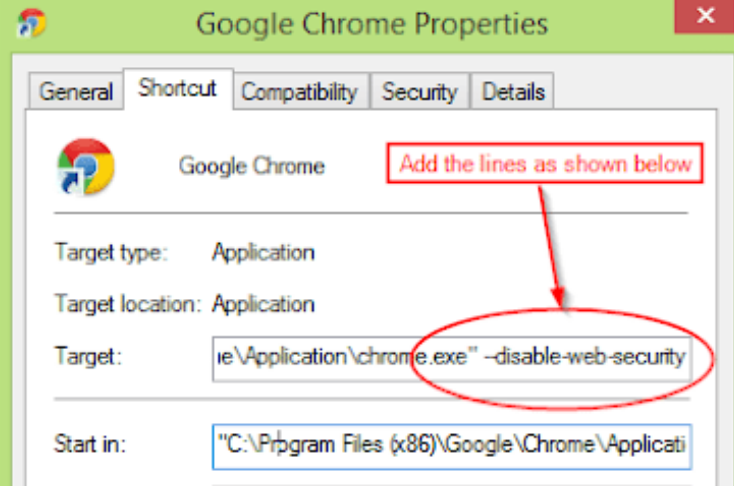
实习时第一次接触浏览器同源策略问题,是前后端准备联调需要访问后端Api,呆头呆脑的我再浏览器上发送了好久的 xhr 请求,却一直不成功.....头都麻了

一起实习的小伙伴让我在Chrome的启动程序上,加上--disable-web-security的小尾巴禁用掉同源策略,轻松加愉快地直接解决了问题......
作为web开发者,工作中不同阶段、不同场景都会遇到跨域的情况。这篇笔记📒在博客中也随着工作学习的推进,一次次地更新内容,更新自己对跨域这一问题的认识。
以下内容最后更新于2020.10,前文内容略有删改。由于这个问题体系比较繁杂,本片文章仅涉及
浏览器同源策略的由来为什么要同源策略,不设置会有什么安全问题。为什么客户端没有同源策略呢一些特殊的跨域场景想了解项目中如何进行跨域设置的小伙伴,请关注下一篇文章。
同源策略(same-origin policy)是一个重要的安全策略,它用于限制一个origin的文档或者它加载的脚本如何能与另一个源的资源进行交互。它能帮助阻隔恶意文档,减少可能被攻击的媒介。 --- MDN
资源URL的以下三项中都相同时才认为两个资源是同源的
协议: 比如http、https、ws、wss域名: 包括主域名和子域名,需要做到全匹配。端口号localStorage、IndexedDB 是浏览器常用的本地化存储方案,两者都是以源进行分割。每一个源下的脚本,都只能够访问同源中的缓存数据,不能实现跨域访问。Cookie的匹配规则与上面二者又略有差异,主要差异在于子域的cookie会默认使用在父域上。详细的规则可以参考另一篇笔记 浏览器原理 - 缓存之cookieDOM 如果两个网页不同源,就无法拿到对方的DOM。Telegram登录,授权Button是一段插入<Iframe>的脚本。Ifream本身的域名是auth.telegram.io。那么域名为abc.io的业务页面,则不能Ifream中的DOM进行访问。图片、css、js资源外,无法通过网络请求访问不同域的资源JSONP、CORS和Websocket的形式进行。SOP 本质上 SOP 并不是禁止跨域请求,而是浏览器在请求后拦截了请求的回应无论是在PC还是移动设备商,你的 Chrome 和 Firefox 是所有网站应用的载体。
你在访问 淘宝网 的时候,相当于从 www.taobao.com 的服务器上下载了 对应的 html、css、js资源,页面也从 api.taobao.com (JSONP 也好, CORS 也罢)获取了商品数据。
页面 JavaScript 把获取到的热门商品数据 缓存到了 本地的 localstorage 中,用于优化体验。
你点击登陆时,通过访问 api.taobao.com/login 接口完成了授权登录,服务器下发 Token 到 cookie 中。
同样的,在京东、在亚马逊、在你的个站、甚至在恶意网站进行访问后,网站的数据都会被下载到设备本地,并且通用 浏览器 这一个应用所管理着。
接触过客户端的同学一定知道,在安卓 和 iOS上的两个App的本地数据,没有对方的允许是不能够直接本访问的,控制权在于App开发方本身,而提供保障的则是系统(Android 和 iOS)本身。
相同的情况类比一下,把浏览器当做系统本身(Chrome Book 请给我打钱),把各个站点相当于“系统上”的一个个App。
下面的页面各位 FEer一定很熟悉,这是Chrome浏览器对于页面中所有加载的静态资源的域名划分。
想想一下,不仅仅是静态的资源。WebStorage、Cookie、IndexDB,在浏览器层面上都是以域这一概念来划分管理的。而且这个划分管理行为,就是在浏览器本地生效,和服务器、其他客户端没有直接关系。
你在 your.company.com 对 data.abc.com 发起数据请求,通常我们会遇到浏览器跨域访问的提示,你的代码拿不到 返回的数据。
但其实对于跨域请求,浏览器并不是直接阻止了此次请求的发出,也没有隔断数据的返回。仅仅是阻止了你尝试跨越 “域” 这个本地 “沙箱” 去访问其他域 下刚刚获取回来的数据 罢了。
你的业务代码在 your.company.com 域下,请求回来的数据在 data.abc.com 域下,是不是?
你品品,你再品
在以前的理解中,我们总容易把跨域想想得跟服务端有很大关系,因为服务端总是要去设置什么 Access-Control-Allow-Origin 巴拉巴拉的好几个响应头(我猜你已经熟读全文,并能够默写了)。
总的来说,我们要将 页面HTML 脚本 样式 字体 等静态资源,和接口返回的数据都同等视为资源,而资源在浏览器的管理下,就是以域区划分管理的。
在同源策略中,<img> <script> 不受跨域访问限制 (熟悉的 打点上报 和 JSONP),是因为浏览器本地开放了这些途径返回的资源的访问权限。
而我们常见的 跨域响应头 们,相当于告诉了浏览器,这几个资源的管理权限应该 根据跨域响应头 来设置,所以本地的其他域下的 JavaScript 代码才能够访问得到这些返回的数据。
[1] 浏览器的同源策略 - MDN
[3] CORS - MDN
知乎上的疑问,也搬运一下过来 知乎原帖 - 为什么只有浏览器(或JS)是有所谓的同源策略? - SwainWong的回答 - 知乎

NODE_CHANNEL_FD告诉子进程这个IPC的文件描述符Domain Socket,所以与网络中的socket表现类似。SO_REUSEADDR 选项,使得不同进程可以就相同的网卡和端口进行监听newconn的内部消息,并附带客户端句柄net.Socket 创建实例,执行距离业务逻辑,并且返回NODE_UNIQUE_ID进行判断是否处于master进程 cluster.isWorker = ('NODE_UNIQUE_ID' in process.env)
cluster.isMaster = (cluster.isWorker === false)NODE_UNIQUE_IDSO_REUSEADDR 为1,实现多个子进程共享端口uncaughtException 事件,事件发生时利用IPC 通知父进程自己准备退出了SUICIDE消息后,马上创建新的worker进程,进行补位SUICIDE 消息后,子进程服务器关闭(停止接收新连接),所有已有的连接断开之后,使用process.exit(1)进行退出agent 进程PM2 模块是 cluster 模块的一个包装层,尽量将 cluster 模块抽象封装,让用户像是使用单进程一样部署多进程 Node 应用
"Node.js 从最一开始就支持模块化编程。然而,在 web,模块化的支持正缓慢到来。在 web 存在多种支持 JavaScript 模块化的工具,这些工具各有优势和限制。webpack 基于从这些系统获得的经验教训,并将_模块_的概念应用于项目中的任何文件。"
从 Webpack 4对模块化的面数来看,深知自己的历史任务深重,所以扛起了所有的前端几乎所有的模块化方案:
ES6的 import 与 export 语句CommonJS 的 require 与 module.exportsAMD 的 define 与 require 语句CMD 的 definecss/less/sass 中的 @import 语句根据CommonJS规范,全局中可以直接取到exports、require、module这三个经典的变量。再加上运行环境为node,所以多加两个__filename与__dirname
Webpack根据以上的基本需要,将当前模块封装在一个块级作用域中,并将这些变量当做模块的全局变量传入。
(function(exports, require, module, __filename, __dirname){
// YOUR MODULE CODE
});CommonJS规范下,代码是在运行时才确定依赖关系的,所以webpack在实现上也是依照规范去做。只能在打包编译的时候加入完整的模块到最后的bundle中,无法实现Tree Shaking.
对于ES6 Module的编译过程静态化处理,Webpack也以文件为维度对模块进行划分,得到module1、module2、module3等,最后还有入口模块moduleEntry。
这里的设计思维,有点像是
Javascript的作用域链.
// moduleA.js
export const A = 'A value'
// moduleB.js
export const B = 'B value'
// moduleC.js
export const C = 'C value'
// app.js
import { A } from './es6/moduleA'
import { B } from './es6/moduleB'
import { C } from './es6/moduleC'
console.log('==== entry.js ======')
console.log(A)
console.log(B)我们把app.js作为打包入口,则会得到以下结构的代码
// 入口模块
(function (modules) {
function webpackRequire(moduleId) {
// ...
}
webpackRequire(1);
})([module1, module2, module3, moduleEntry]);Webpack编译后的代码中,使用__webpack_require__()方法进行模块的调度,相当于Node.js版实现中的require()方法。
/******/ // The require function
/******/ function __webpack_require__(moduleId) {
/******/
/******/ // 使用内存进行模块缓存
/******/ if(installedModules[moduleId]) {
/******/ return installedModules[moduleId].exports;
/******/ }
/******/ // 若没有命中缓存,则新创建一个 module 实例
/******/ var module = installedModules[moduleId] = {
/******/ i: moduleId,
/******/ l: false,
/******/ exports: {}
/******/ };
/******/
/******/ // 执行模块
/******/ modules[moduleId].call(module.exports, module, module.exports, __webpack_require__);
/******/
/******/ // Flag the module as loaded
/******/ module.l = true;
/******/
/******/ // 返回模块
/******/ return module.exports;
/******/ }简单总结一下
使用了和内存进行模块单例缓存,类似于Node.js实现中的require.cache 与 Module._cache(建议和这篇文章的“源码概览”部分一起食用)
__webpack_require__参数为moduleId,该ID也为传入的模块数组下标的ID
创建模块部分,相当于Node.js 实现中的这部分内容👉
// /lib/internal/modules/cjs/loader.js#L912
const module = new Module(filename, parent); // /lib/internal/modules/cjs/loader.js#L1200
result = compiledWrapper.call(thisValue, exports, require, module,
filename, dirname);Webpack如何实现的异步加载,请参考这篇文章👉
__webpack_require__.d(其实应该为__webpack_require__.define),函数用于导出模块,也就是实现export语句的基础方法,编译后的源码如下。
__webpack_require__.d = function (exports, name, getter) {
/******/
if (!__webpack_require__.o(exports, name)) {
/******/
Object.defineProperty(exports, name, { enumerable: true, get: getter })
/******/
}
/******/
}我们在打包后的代码中,除了看到__webpack_require__.d方法的定义,也有对应的使用。蔽日我们引入了moduleA、moduleB、moduleC。
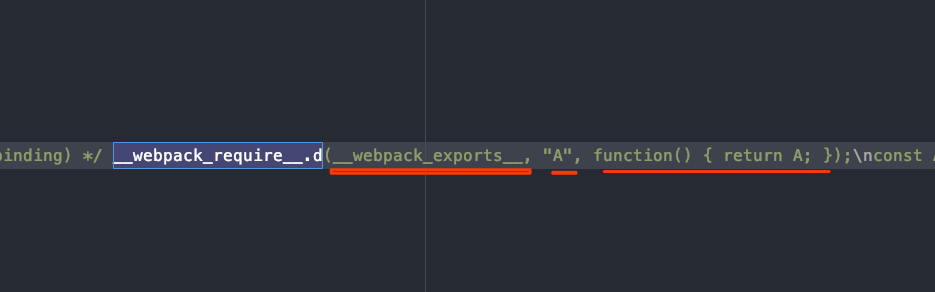
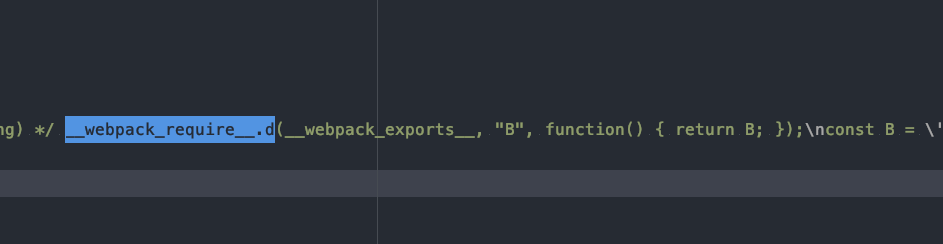
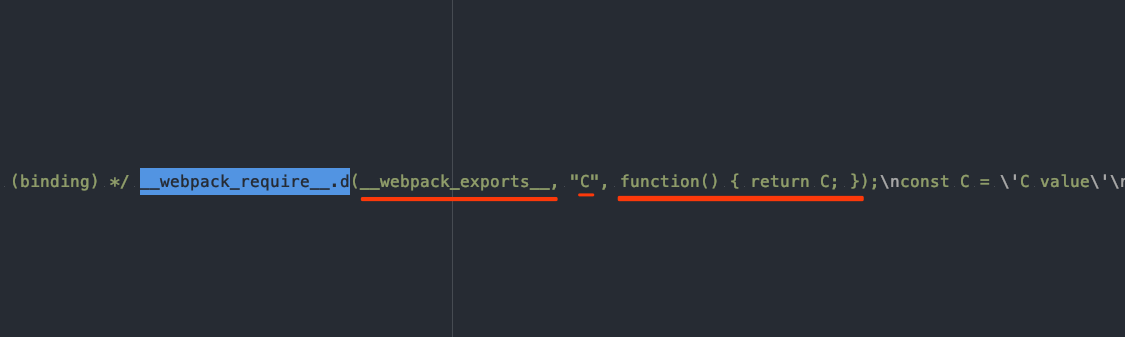
图中出现的__webpack_exports__则是表示暴露的整体对象,__webpack_require__.d负责给该对象添加属性。
打包后的代码中有这么一段代码如下,根据对应模块的类型,ES6 Module或者是CommonJS,进行不同的处理方式。
/******/
/******/ // getDefaultExport function for compatibility with non-harmony modules
/******/
__webpack_require__.n = function (module) {
/******/
var getter = module && module.__esModule ?
/******/ function getDefault () {
return module['default']
} :
/******/ function getModuleExports () {
return module
}
/******/
__webpack_require__.d(getter, 'a', getter)
/******/
return getter
/******/
}webpack还实现了AMD规范,说明熟悉的AMD引入也是可行的。
// 使用AMD规范引入模块包
require(['./list', './edit'], function(list, edit){
console.log(list)
console.log(edit)
});require.ensure 能够确保 webpack 进行打包的时候,会将异步引入的包和主包分离
// ./list/index.js
console.log('i am the separated module')
module.exports = {
abc: 123
}
// app.js
require.ensure([], function(require){
const list = require('./list');
console.log(list)
}, 'list');
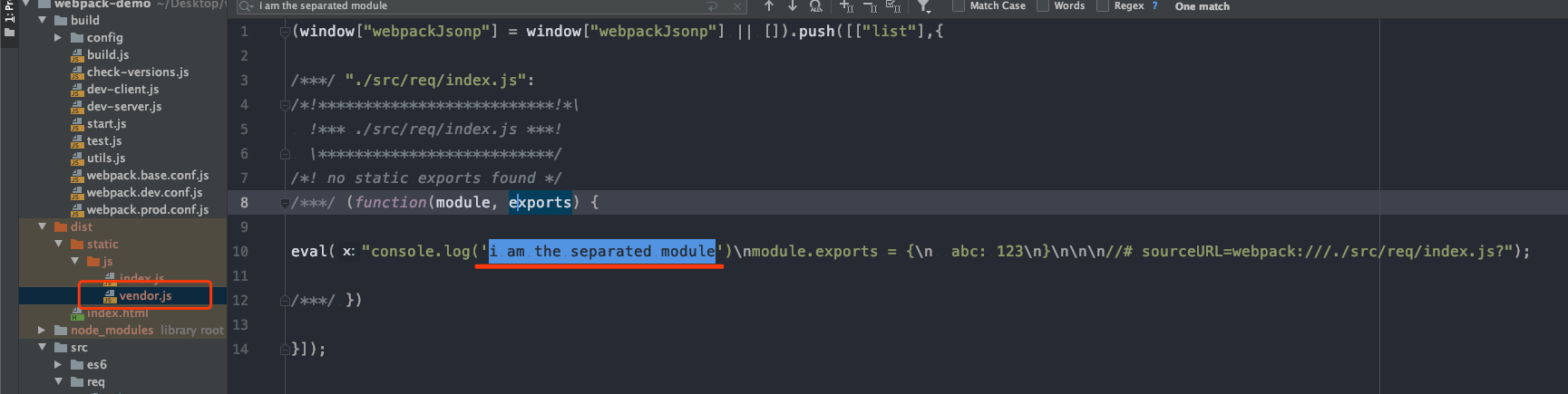
当然我们正在做 code spliting的时候一般会通过webpack.config.js来进行配置plugins或者optimization来实现

行为表现HTTP/1.1 协议里设计 100 (Continue) HTTP 状态码的的目的是,在客户端发送 Request Message 之前,HTTP/1.1 协议允许客户端先判定服务器是否愿意接受客户端发来的消息主体(基于 Request Headers)。
设计含义client 和 server 在 post (较大)数据之前,允许双方“握手”,如果匹配上了,Client 才开始发送(较大)数据。操作如果 client 预期等待“100-continue”的应答,那么它发的请求必须包含一个 " Expect: 100-continue" 的头域!
客户端 Request Header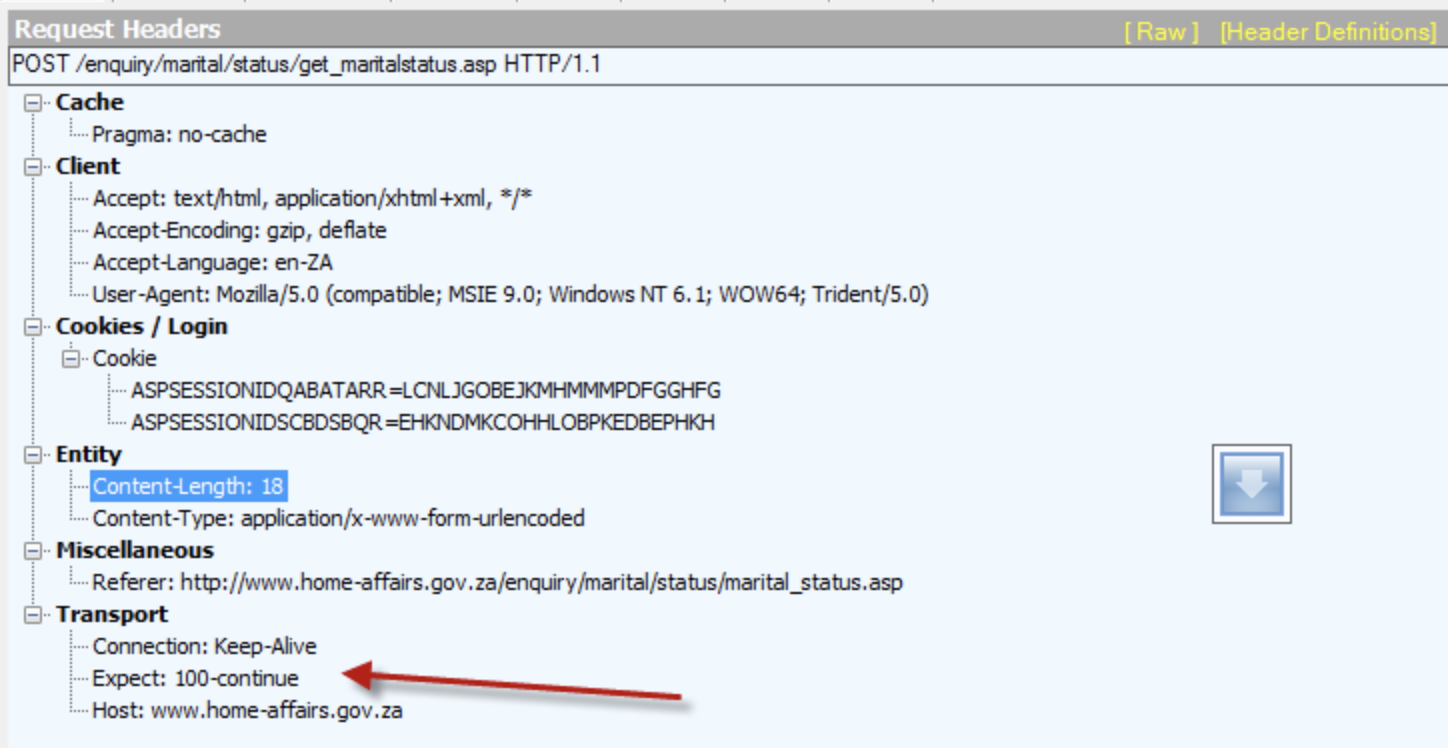
服务端处理
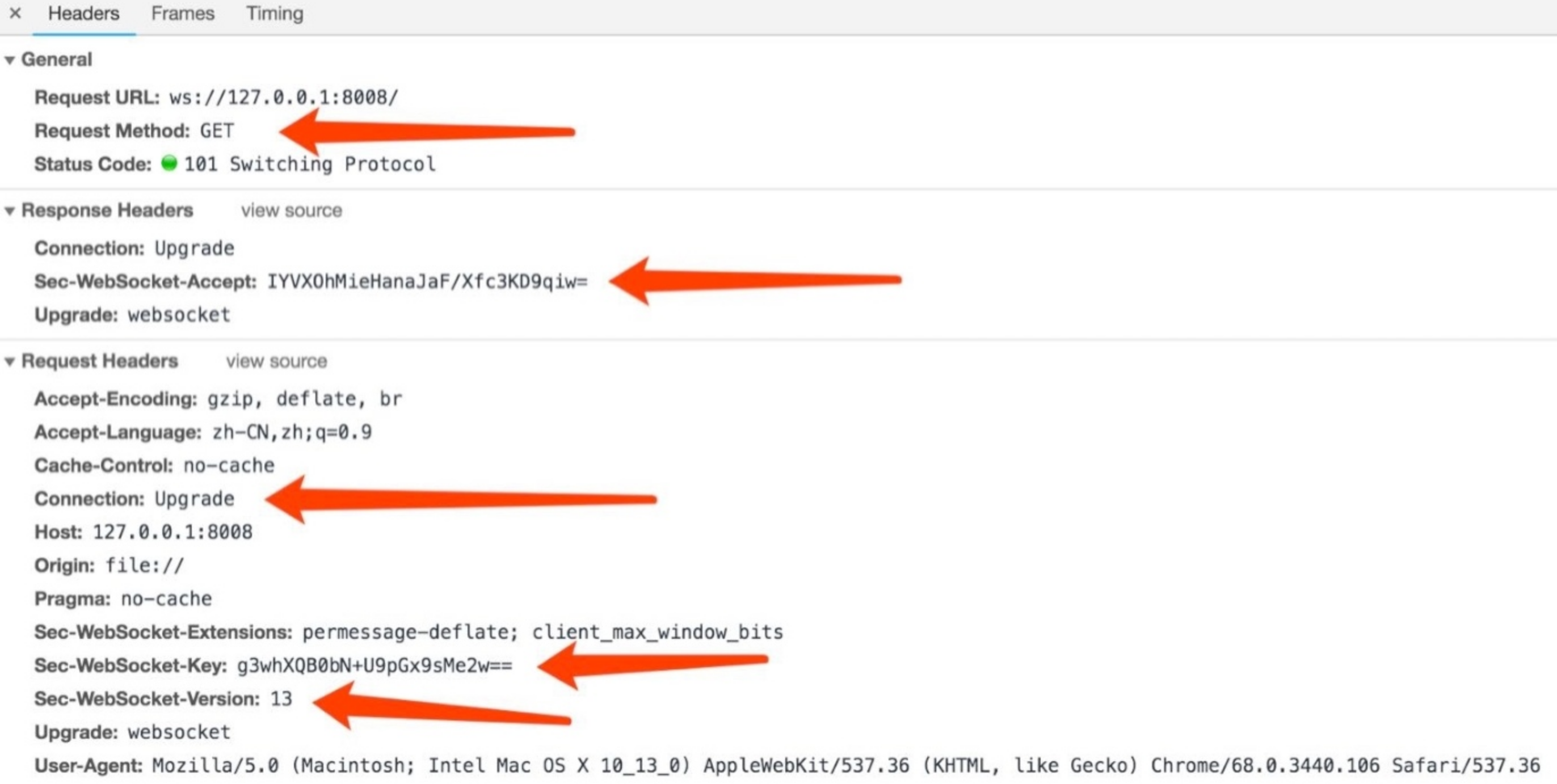
表示访问当前资源需要更换协议进行数据传输,比如 Websocket 握手连接。
2xx 一类的状态码,表示你的请求已经被服务器正确地处理了,没有遇到其他问题,服务器选择性地返回一些内容
请求被服务器成功处理,服务器会根据不同的请求方式返回结果
请求已经被实现,而且有一个新的资源已经依据请求的需要而建立,且其 URI 已经随Location 头信息返回。
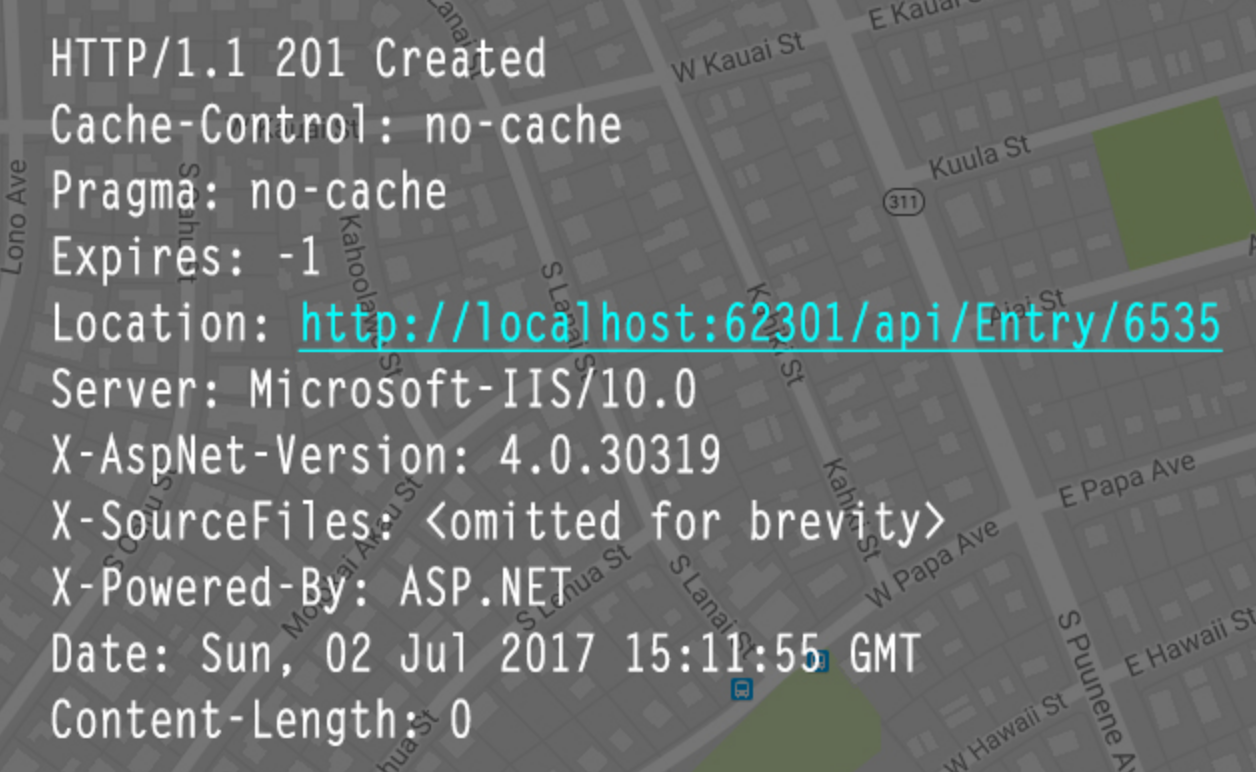
200 状态下,没有实体返回的区别在于,浏览器处理 204 的状态码,只是回去读取报文头的更新信息UA 是一个浏览器,请求的时候是<a href="xxx">标签形式,204 则不会发生页面跳转,相对应 200 下则会发生跳转。
RFC的描述原文

范围请求,而服务器只成功处理了其中的一部分range字段,而服务端的报文中,必须包含由,Content-Range指定的实体内容(entity)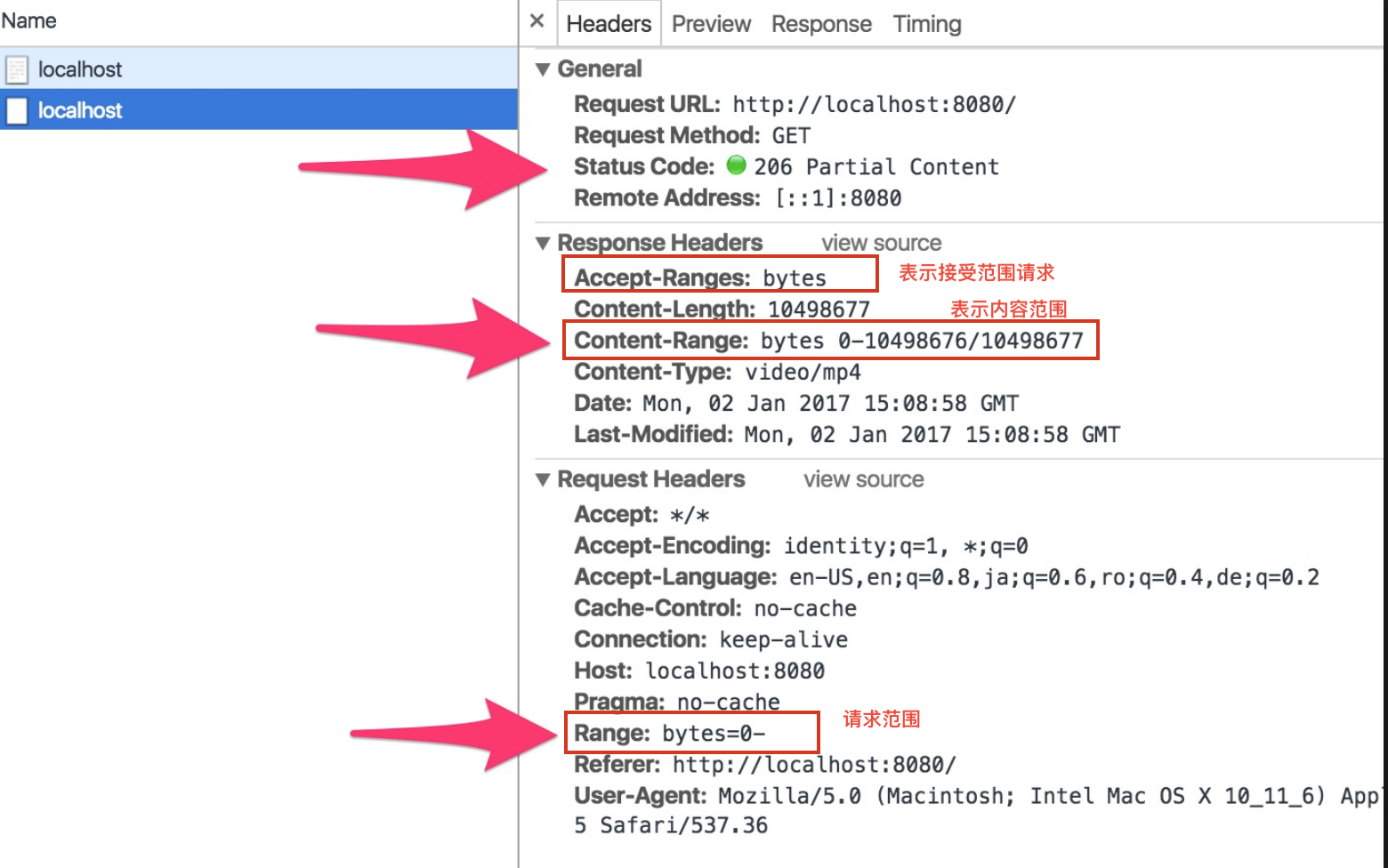
Range字段含义增强校验If-Modified和If-Match这两套去保证分段的资源是可靠的,资源在分段过程中没有被修改
�If-Range去请求,总是跟 Range 头部一起使用。If-Range浏览器告诉 WEB 服务器
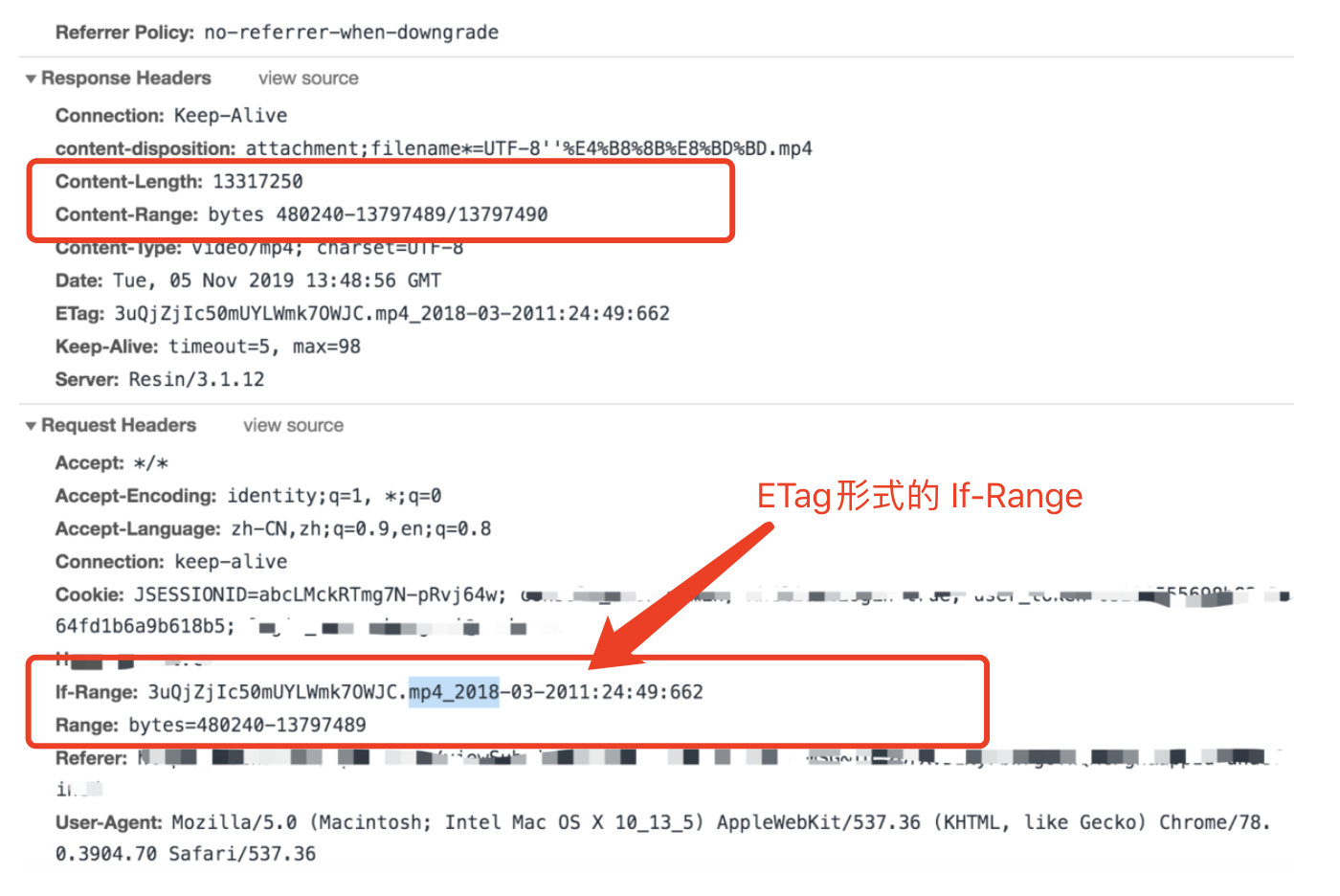
范围请求详细过程请参考这篇文章👉
表示服务器端已经接受到了请求,必须对请求进行一些特殊的处理之后,才能够顺利完成此处请求
请求的资源已经被永久地重定向了,301 状态码的出现表示请求的URL对应的资源已经被分配了新的定位符。
Location字段中明确指出新的URILocation字段以外,还需要在相应体中,附上新的 URI 的链接文本POST 请求的话,服务端若是使用重定向,则需要经过客户的同意301 来说,资源除非额外指定,否则默认都是可缓存的。我们使用http访问一些只接受 https �资源的时候,浏览器设置了自动重定向到 https,那么首次访问就会返回 301 的状态码。
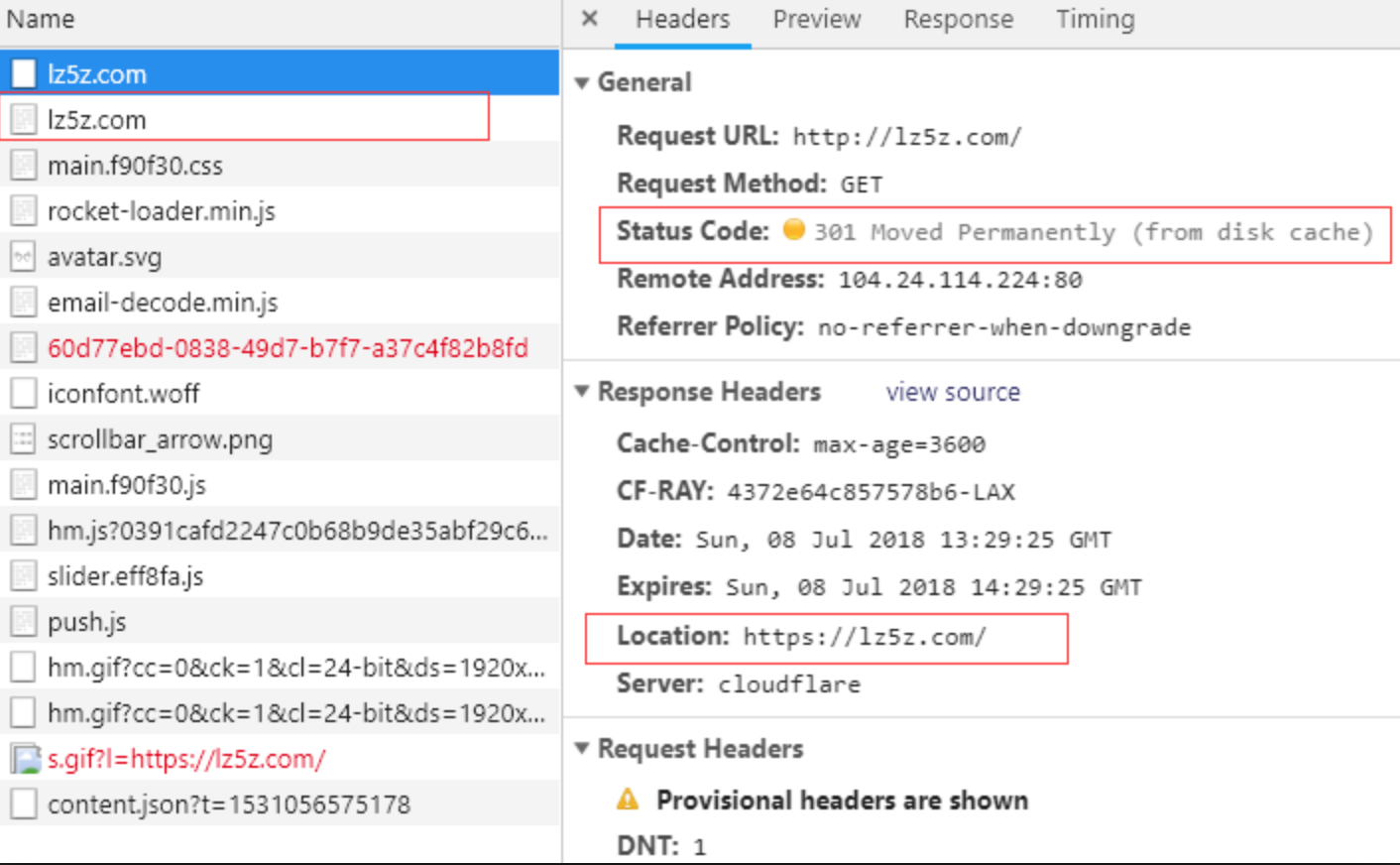
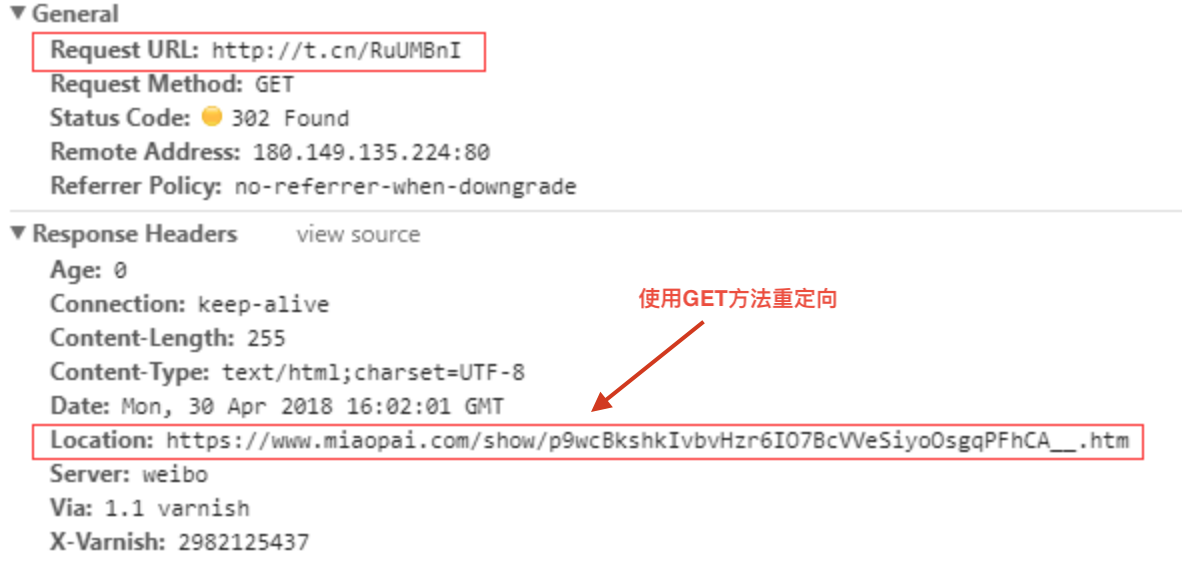
301状态码意思几乎一样,不同点在于302是临时的重定向,并只对本次的请求进行重定向URI 收藏了起来,不去修改书签中的指向。302 响应等同于 303 响应,并且在重定向的时候,使用 GET 方式返回报文中Location字段指明的URLCache-Control 或 Expires 中进行了指定的情况下,这个响应才是可缓存的。我们使用的网站短地址,访问的时候就会临时重定向到我们压缩前地址指向的页面。
(http 1.1)303 状态码同样处理为 302,而且是直接将非 GET、HEAD请求改为 GET 请求。GET 形式去进行
(http1.1)302 状态码
http1.0和http 1.1都规定,若客户端发送的是非 GET 或者 HEAD 请求,响应头中携带 301 或 302 的时候,浏览器不会自动进行重定向,而需要询问用户,因为此时请求的情况 很可能 已经发生变化。
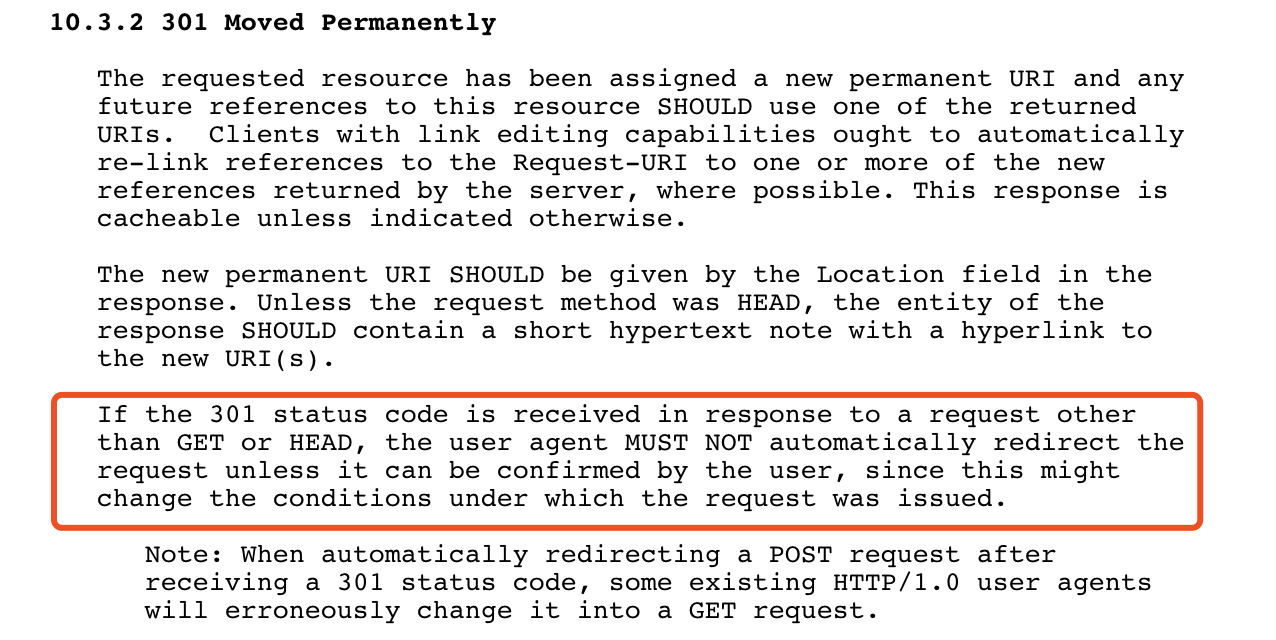


但是实际上,所有的浏览器都会默认把 POST 请求直接改为 GET 请求。
�对于301状态码,搜索引擎在抓取新内容的同时,也将旧网址替换为重定向后的网址。而对于302状态码则会保留旧的网页内容。
兼容性:服务端考虑准备使用303的时候,一般还是会使用302代替,因为要兼容许多不支持http 1.1的浏览器,而对与要进行 307 返回的时候,浏览器一般会将要重定向的 URL 放到 response.body 中,让用户去进行下一步操作。
303和307的存在,就是细化了http 1.0中302的行为,归根结底是由于 POST(等对服务器有伤害的请求)方法的非幂等属性引起的。


304 状态码返回时,不包含任何响应的主题部分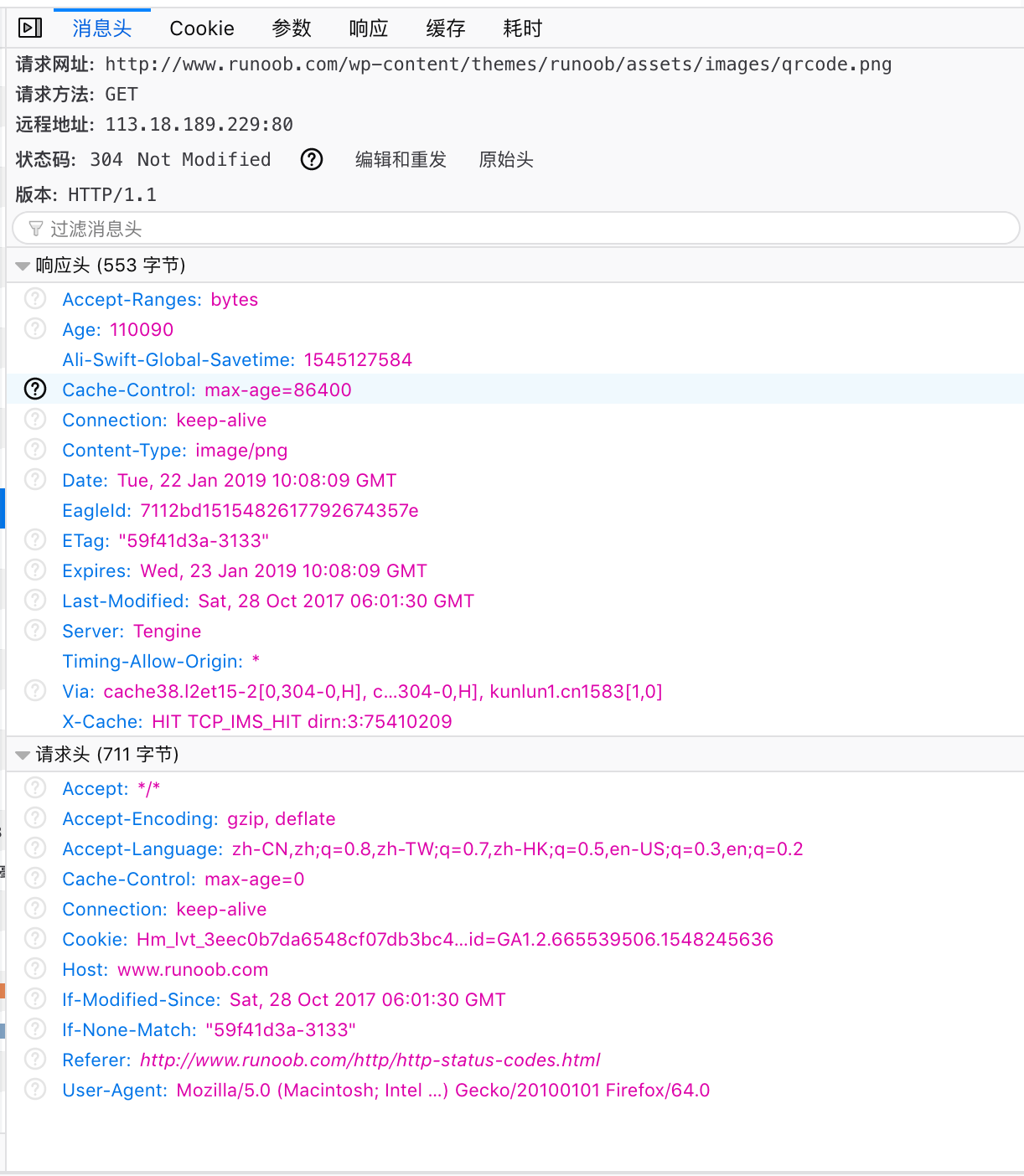
表示该请求报文中存在语法错误,导致服务器无法理解该请求。客户端需要修改请求的内容后再次发送请求。
一般也可以用于用户提交的表单内容不完全正确,服务端也可以用 400 来响应客户端
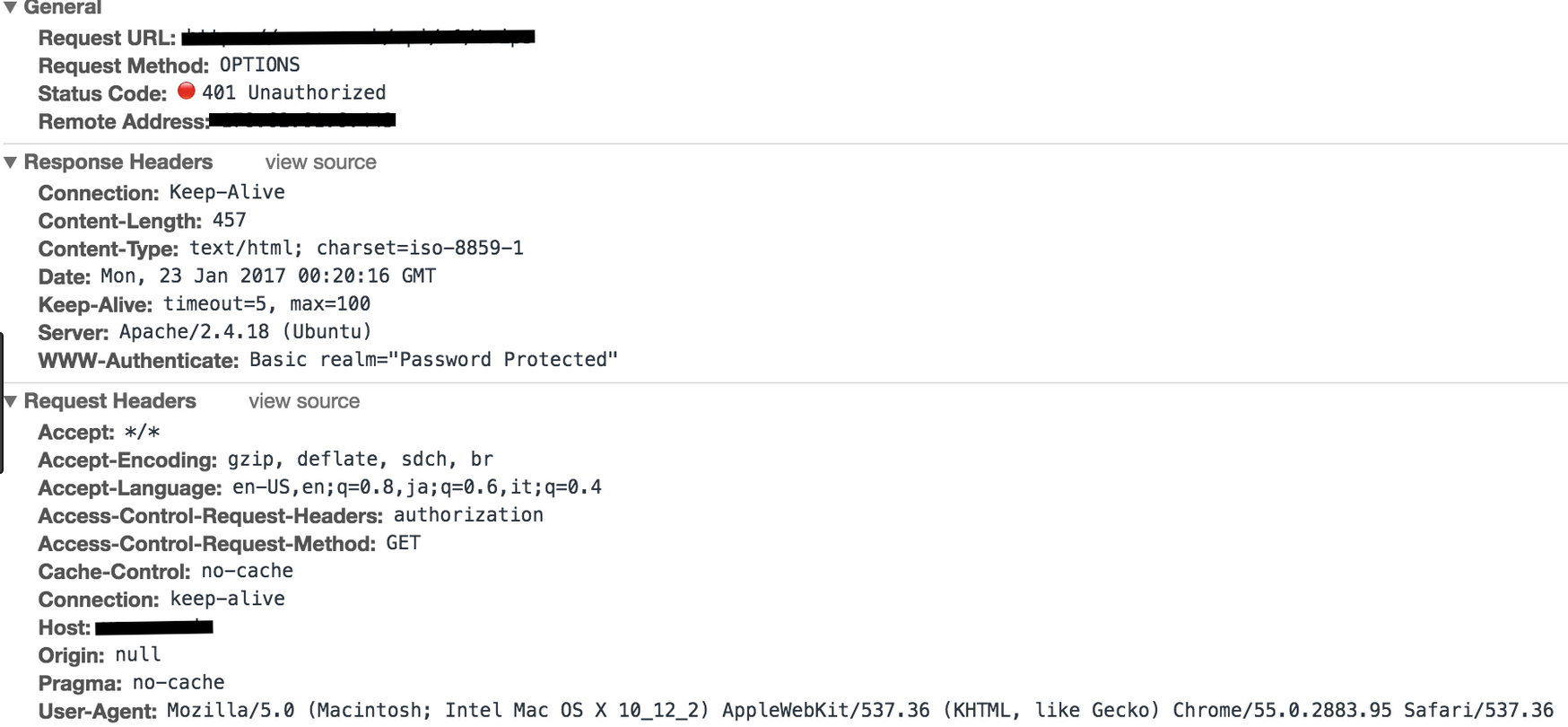
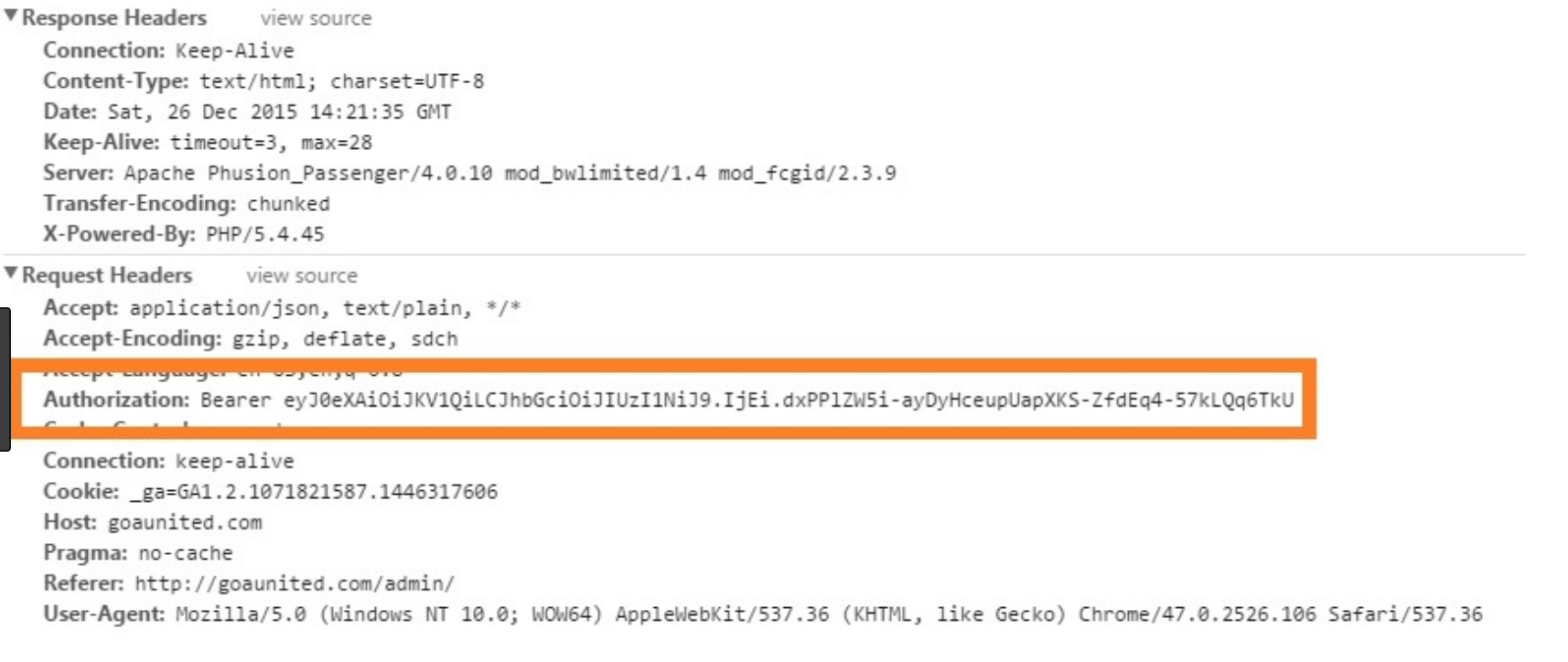
www-authenticate:Basic表示一种简单的,有效的用户身份认证技术。
http 基本认证保护的资源。401 状态,要求客户端提供用户名和密码进行认证。(验证失败的时候,响应头会加上WWW-Authenticate: Basic realm="请求域"。)
401 Unauthorized
WWW-Authenticate: Basic realm="WallyWorld"
Base64进行编码后,采用非加密的明文方式传送给服务器。
Authorization: Basic xxxxxxxxxx.
401状态,要求重新进行认证。
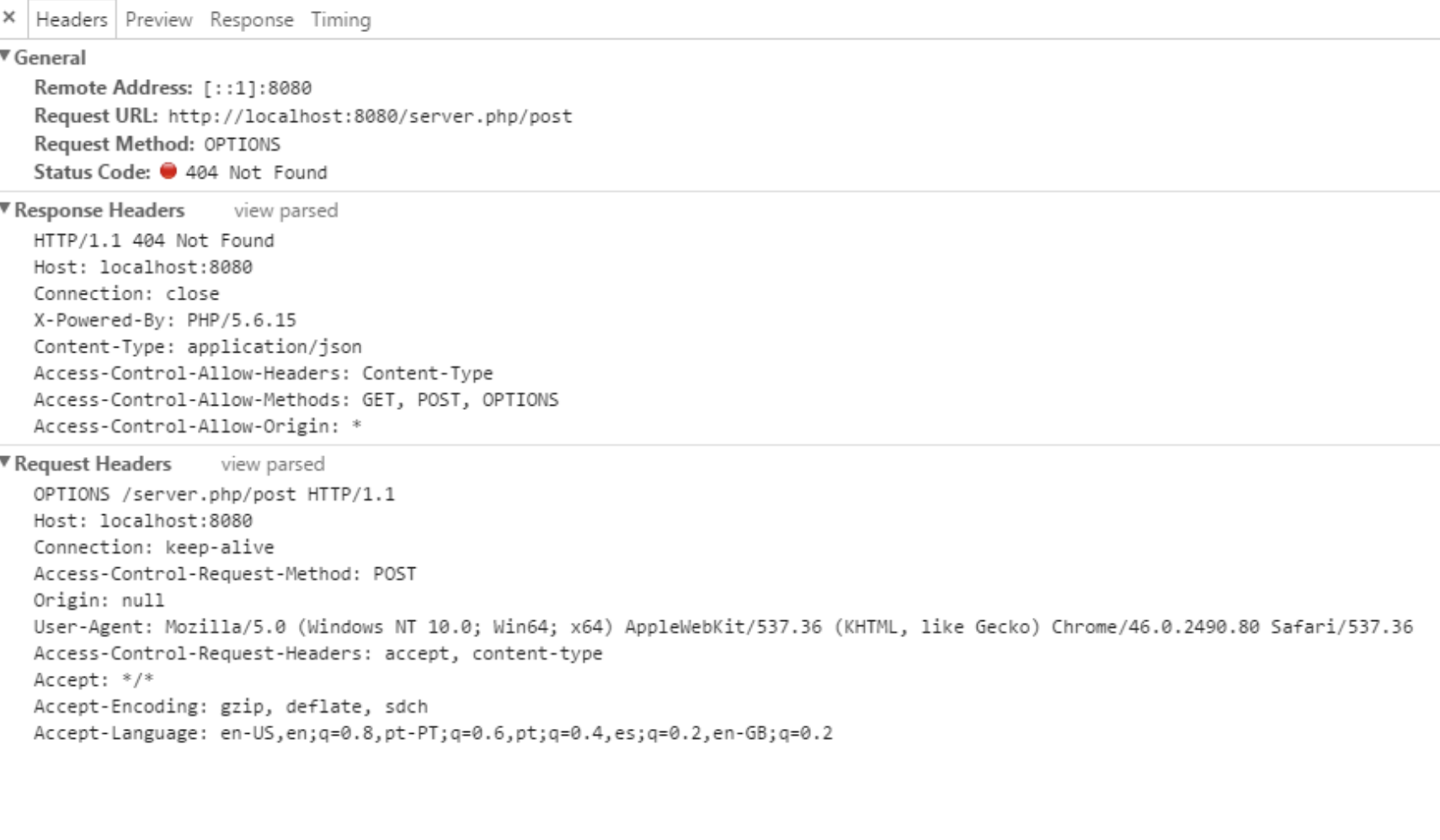
表示该资源不支持该形式的请求方式,在Response Header中返回 Allow 字段,携带支持的请求方式
在请求报文中的If-xxx字段发送到服务端后,服务端发现没有匹配上。比如,If-Match:asfdfsdzxc,希望匹配ETag值。
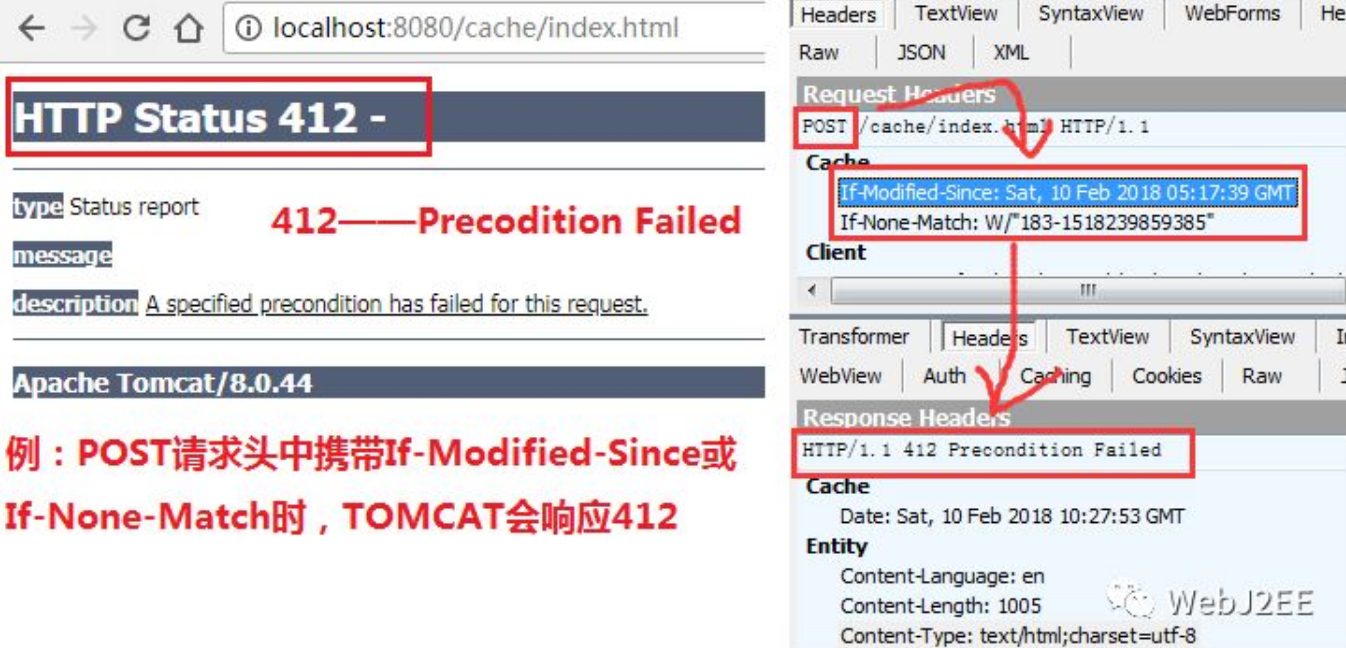
我们先来看看RFC是怎么定义的...

在请求头Expect中指定的预期内容无法被服务器满足,或者这个服务器是一个代理服务器,它有明显的证据证明在当前路由的下一个节点上,Expect 的内容无法被满足。

表示服务器端在处理客户端请求的时候,服务器内部发生了错误
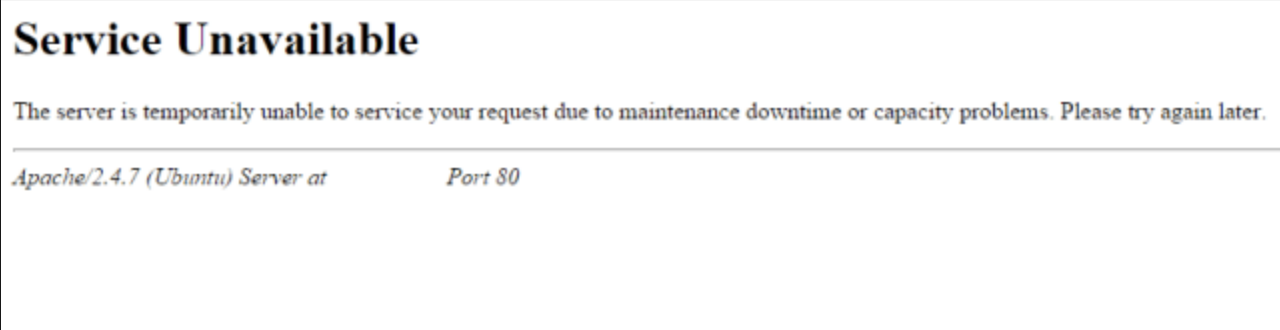
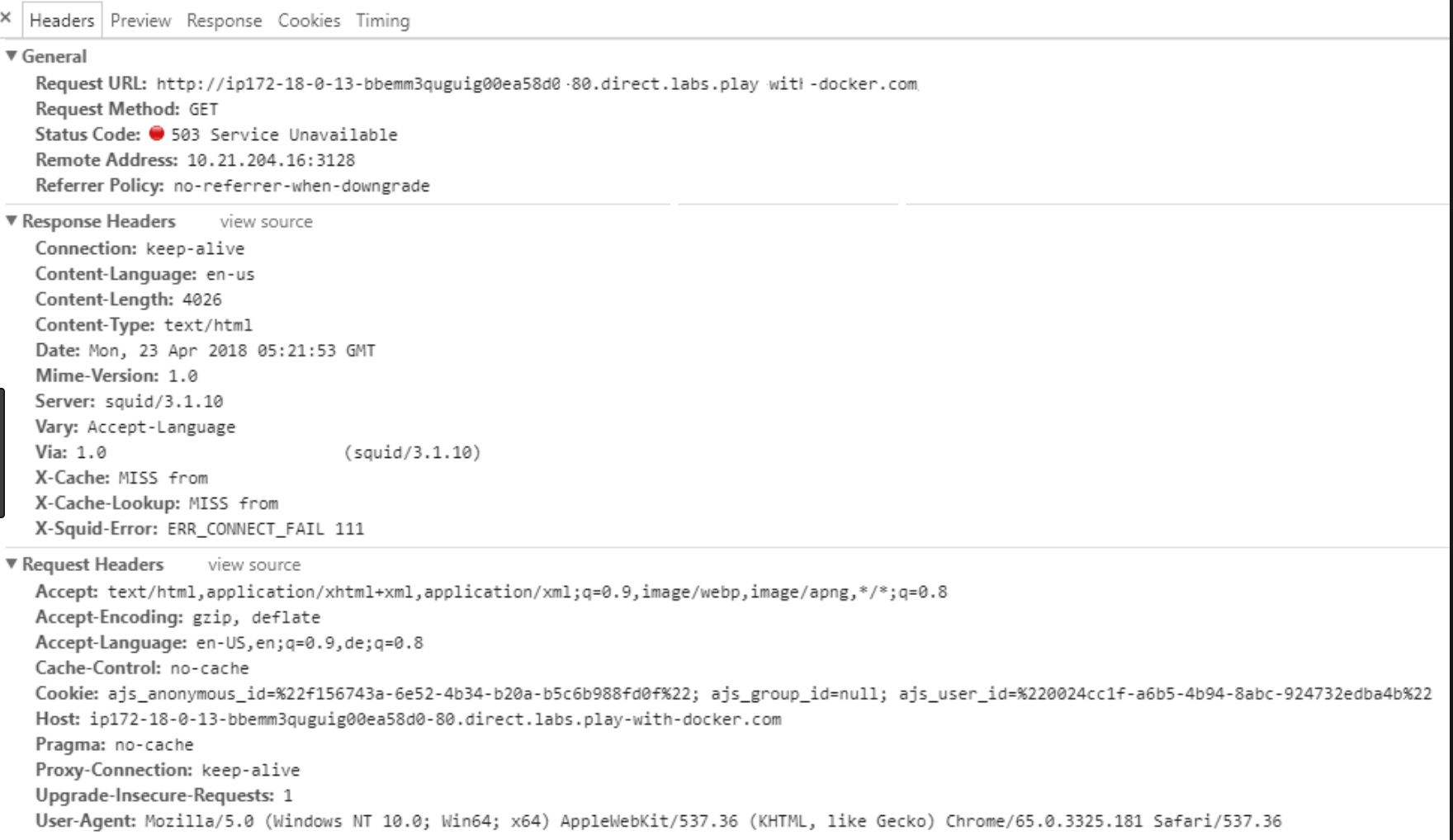
一般表示连接服务器的便捷路由器出问题了,导致请求不能到达。我们最常见的应该是这个页面

然后资源请求的时候,详细的报文

Ctrl + F5 进行强制刷新,多次从服务器重新拉取数据,排除是网关服务器偶尔波动引起的该状态码表示服务器已经处于一个超负荷的一个状态,或者是所提供的服务暂时不能够正常使用
若服务器端能够事先得知服务恢复时间的话,可以在返回503状态码的同时,把恢复时间写入Retry-After字段中
常见的页面形式
注意,要是503的报文返回时,没有携带Retry-After�的报文头,那么客户端应将次返回处理为500
[1] 100 continue 的秘密
[2] http状态码 -百度百科
[3] 301与302
[4] websocket探秘
[5] 200/204/206-302/303/307 -cnblog
[6] HTTP状态码302、303和307的故事
[7] RFC- HTTP1.1
[8] 206断续下载
[9] 断点续传-http协议里Header参数Range
上一篇主要总结了鉴权、签名、心跳的问题,这次我们着重过一下在封装请求库时遇到的以下问题。
1.对调用方透明,尽可能使用Promise封装
2.实现请求与响应的中间件
3.实现订阅机制
完整的demo代码在这里👉👉👉
export class RainbowWebsocket {
protected _serverUrl: string // 远端地址
protected _ws: WebSocket // 原生ws实例
constructor (option: IOption) {
// 初始化
this._serverUrl = option.url
this._ws = new WebSocket(this._serverUrl)
}
// 处理请求
request (data: any): Promise<any> {}
// 处理相应
response (msg: string) {}
}export interface IPromise {
resolve: Function,
reject: Function,
method: string
}
protected _promises: Map<string, IPromise> // 请求记录哈希表 export interface IRequest {
id: string,
jsonrpc: string,
method: string,
data: any
}request (data: any): Promise<any> {
return new Promise((resolve, reject): void => {
const payload = Object.assign(data, {
id: uniqueId(pkg.name + '-'),
jsonrpc: JSON_RPC_VERSION
})
// 登记请求
this._promises.set(data.id, {
resolve,
reject,
method: payload.method,
})
// 发送请求
this._ws.send(this._toDataString(data))
})
}export interface IResponse {
id: string,
jsonrpc: string,
method: string,
data: any,
errCode: number,
}
// error code
export enum ErrorCode {
SUCCESS = 0
}this._ws.onmessage = event => {
console.log(event.data)
// 简单的检测过后,进行相应处理
if (event.data && typeof event.data === 'string' && event.data.includes(JSON_RPC_VERSION)) {
this.response(event.data)
}
}response (msg: string) {
try {
const res: IResponse = JSON.parse(msg)
// 取出对应的响应
const promise: IPromise = this._promises.get(res.id)
// 删除对端已响应的promise
this._promises.delete(res.id)
// 根据errno决定执行哪一个reject还是resolve
if (res.errCode !== ErrorCode.SUCCESS) {
// 执行请求登记时的 resolve function
promise.reject(res.errCode)
}
else {
// 执行请求登记时的 resolve function
promise.resolve(res.data)
}
}
catch (err) {
this._logger.error('response msg parse fail')
return
}
}public interceptors: {
request: InterceptorManager
response: InterceptorManager
} _requestInterceptorExecutor (payload) {
let _payload = payload
this.interceptors.request.forEach((handler: Function) => {
_payload = handler(_payload)
})
return _payload
}
_responseInterceptorExecutor (payload) {
let _payload = payload
this.interceptors.response.forEach((handler: Function) => {
_payload = handler(_payload)
})
return _payload
}request (data: any): Promise<any> {
return new Promise((resolve, reject): void => {
// 拼接生成payload
// 通过请求拦截器
const _payload = this._requestInterceptorExecutor(payload)
// 登记请求 .....
// 若ws连接达成,则先缓存请求 ......
// 发送请求
this._ws.send(this._toDataString(data))
})
}
response (msg: string) {
const res: IResponse = JSON.parse(msg)
// 解析数据 ....
// 删除处理过的promise记录 .....
// 响应中间件
const _res = this._responseInterceptorExecutor(res)
// 根据errno决定执行哪一个reject还是resolve
}websocket建立需要时间,但作为接口层的调用方并不关心这些事,即使在websocket信道连通前发出的请求,也可以顺利发出。
protected _waitingQueue: Array<any> // websocket 未建立的时候,缓存请求request (data: any): Promise<any> {
return new Promise((resolve, reject): void => {
// 登记请求
// ........
// 若ws连接达成,则先缓存请求
if (this._ws.readyState === WEBSOCKET_STATE.CONNECTING) {
this._waitingQueue.push(payload)
return
}
// 发送请求
this._ws.send(this._toDataString(data))
})
}this._ws.onopen = event => {
this._logger.log(`RainbowWebsocket connected to ${this._serverUrl} successfully......`)
// ws通道联通后,发送前期未发送的请求(缓存队列中的请求,都已经注册登记过了,所以不需要再次登记)
this._waitingQueue.forEach(payload => {
this._ws.send(this._toDataString(payload))
})
}我们在使用http请求库(比如axios),发送了请求等待响应过程中,突然发现网络发生了异常,我们通常会收到不同的错误码,比如404等。
this._ws.onclose = event => {
this._logger.log(`RainbowWebsocket has close ......`)
// 将所有未处理的请求都reject调
for (const record of this._promises) { // 遍历Set
const request = record[1]
request.reject(ErrorCode.DISCONNECT)
}
}通知类型的通信,并不存在一发一收的对应机制,自然也不需要使用this._promises用于存储。但是通知自然是需要一个监听机制的存在。
import * as EventEmitter from 'eventemitter3'
export class RainbowWebsocket extend EventEmitter {
// .....
}response () {
this.$emit('notify')
}request (data: any, isNotify = false): Promise<any> {
return new Promise((resolve, reject): void => {
// data处理......
// 通过请求拦截器......
if (!isNotify) {
// 登记请求
this._promises.set(data.id, {
resolve,
reject,
method: _payload.method
})
}
// 若ws连接尚未达成,则先缓存请求......
// 发送请求......
})
}response (msg: string) {
try {
const res: IResponse = JSON.parse(msg)
const promise: IPromise = this._promises.get(res.id)
// todo: 删除处理过的promise......
// 响应中间件
const _res = this._responseInterceptorExecutor(res)
// 判断是否是通知性的消息
if (isNotifyMsg(res)) {
// 使用事件机制进行通知
this.emit(`notify:${ res.method }`, res.data)
}
else {
// todo: 根据errno决定执行哪一个reject还是resolve
if (_res.errCode !== ErrorCode.SUCCESS) {
promise.reject(_res.errCode)
}
else {
promise.resolve(_res.data)
}
}
}
catch (err) {
this._logger.error('response msg parse fail')
return
}
}const apiServer = new RainbowWebsocket({port: 9527, host: 'localhost'})
apiServer.on('notify:balance', data => {
// do something you like...
})koa-compose 作为koa实现中间件串联功能的关键函数,值得我们细细品味,话不多说先送上👉源码,别惊讶确实只有这么多行....
'use strict'
/**
* Expose compositor.
*/
module.exports = compose
/**
* Compose `middleware` returning
* a fully valid middleware comprised
* of all those which are passed.
* 👉 原文译: 将所有中间件组合,返回一个包含所有传入中间件的函数
*
* @param {Array} middleware
* @return {Function}
* @api public
*/
function compose (middleware) {
// 传入middware的必须为数组
if (!Array.isArray(middleware)) throw new TypeError('Middleware stack must be an array!')
// 任意数组元素也都必须为函数
for (const fn of middleware) {
if (typeof fn !== 'function') throw new TypeError('Middleware must be composed of functions!')
}
// 返回一个每个中间件依次串联的函数闭包
// 其实第一次调用 return fnMiddleware(ctx).then(handleResponse).catch(onerror); 时并没有传入第二个next参数,当然也传入不了
return function (context, next) {
// last called middleware #
// 这里的 index 是用于防止在一个中间件中重复调用 next() 函数,初始值设置为 -1
let index = -1
// 启动递归,遍历所有中间件
return dispatch(0)
// 递归包装每一个中间件,并且统一输出一个 Promise 对象
function dispatch (i) {
// 注意随着 next() 执行,i、index + 1、当前中间件的执下标,在进入每个中间件的时候会相等
// 每执行一次 next (或者dispatch) 上面三个值都会加 1
/* 原理说明:
* 当一个中间件中调用了两次 next方法,第一次next调用完后,洋葱模型走完,index的值从 -1 变到了 middlewares.length,
* 此时第一个某个中间件中的 next 再被调用,那么当时传入的 i + 1 的值,必定是 <= middlewares.length 的
*/
if (i <= index) return Promise.reject(new Error('next() called multiple times'))
// 通过校验后,index 与 i 的值同步
index = i
// 取出一个中间件函数
let fn = middleware[i]
// 若执行到了最后一个,(其实此时的next也一定为undefined),我认为作者是为何配合下一句一起判断中间件的终结
if (i === middleware.length) fn = next
// 遍历到了最后一个中间件,则返回一个 resolve 状态的 Promise 对象
if (!fn) return Promise.resolve()
try {
// 递归执行每一个中间件,当前中间件的 第二个 入参为下一个中间件的 函数句柄
// 这里注意:每一个 next 函数,都是下一个 dispatch函数,而这个函数会返回一个 Promise 对象
return Promise.resolve(fn(context, dispatch.bind(null, i + 1)));
} catch (err) {
// 中间件执行过程中出错的异常捕获
return Promise.reject(err)
}
}
}
}接下来是手摸手教你写 compose , 要是上面的看懂了,就节省时间不必往下看了 👻👻👻
前面的一些类型判断语句也就不做过多描述。
if (!Array.isArray(middlewares)) throw new TypeError('Middlewares must be an array')
for (const fn of middlewares) {
if (typeof fn !== 'function') {
throw new TypeError('item of middlewares must be an functions')
}
} return function (context) {
function dispatch(i) {
let fn = middlewares[i] // ① 取出当前的中间件,fn指向每一个中间件
if (!fn) return // ④ 为递归设定终结条件
fn(context) // ② 执行当前中间件
return dispatch(i + 1)// ③ 形成初步的递归调用
}
return dispatch(0) // ④ 设定一个递归启动点
}// 简单准备第三个中间件
const mid1 = () => console.log('mid1')
const mid2 = () => console.log('mid2')
const mid3 = () => console.log('mid3')
const fnx = compose([mid1, mid2, mid3])
fnx() // mid3 mid2 mid1next表示开启下个中间件的函数句柄bind对dispatch进行函数改造 return function (context, next) {
function dispatch(i) {
let fn = middlewares[i]
if (!fn) return
// ⑤ 改造当前中间件执行时传入的参数,将下一个中间件的含数句柄,作为第二个参数 next 传入
return fn(context, dispatch.bind(null, i + 1))
}
return dispatch(0)
}const mid1 = (ctx, next) => {
console.log('mid1')
setTimeout(()=>{
console.log('mid1 wait for 2s')
next()
}, 2000)
console.log('mid1 after')
}
const mid2 = (ctx, next) => {
console.log('mid2')
setTimeout(()=>{
console.log('mid2 wait for 2s')
next()
},2000)
console.log('mid2 after')
}
const mid3 = function (ctx, next) {
console.log('mid3')
console.log('mid3 after')
}
const fnx = compose([mid1, mid2, mid3])
fnx() // 输出结果我就不写了,你猜猜是什么研究清楚第二阶段的测试输出后,我们基本将异步中间件串联起来。那么源码中,dispatch函数,无论走哪一个分支,为何一定都要返回一个Promise对象呢?
想了好久不得其解,就把源码中返回Promise部分改为同步,跑了一下koa自带的测试用例。
# koa
$ npm run test 1) app.context
should merge properties:
Uncaught TypeError: Cannot read property 'then' of undefined
at Application.handleRequest (lib/application.js:166:29) // 👈👈 点开这里看了看
at Server.handleRequest (lib/application.js:148:19)
at parserOnIncoming (_http_server.js:779:12)
at HTTPParser.parserOnHeadersComplete (_http_common.js:117:17)
[use `--full-trace` to display the full stack trace]// application.js #line 160
handleRequest(ctx, fnMiddleware) {
const res = ctx.res;
res.statusCode = 404;
const onerror = err => ctx.onerror(err);
const handleResponse = () => respond(ctx);
onFinished(res, onerror);
// 上面的错误堆栈,追踪到的就是这里 #line 166 👇👇👇
return fnMiddleware(ctx).then(handleResponse).catch(onerror);
}
// application.js #line 141
callback() {
const fn = compose(this.middleware);
if (!this.listenerCount('error')) this.on('error', this.onerror);
const handleRequest = (req, res) => {
const ctx = this.createContext(req, res);
return this.handleRequest(ctx, fn);
};
return handleRequest;
}不难看出抛出错误的#line 161 fnMiddleware指的就是 compose之后的结果。说明在koa中,将所有中间件串联起来之后,希望得到的是一个thenable的对象。我们则需要继续添加对Promise的支持
return function (context, next) {
function dispatch(i) {
let fn = middlewares[i]
if (i === middlewares.length) fn = next
// ⑧ 调用最后一个中间件
if (!fn) return Promise.resolve()
try {
// ⑥ 成功调用
return Promise.resolve(fn(context, dispatch.bind(null, i + 1)))
} catch (err) {
// ⑦ 成功过程出错
return Promise.reject()
}
}
return dispatch(0)
}我们知道一次深入到最内层,再原路返回到最外层,就是一次完整的洋葱模型。对于代码设计中的index 与 i 的关系,也是一个设计巧妙的宝盒。如下测试代码,在mw1中调用多次next函数
async function mw1 (context, next) {
console.log('===== middleware 1 =====')
next()
next() // 预计这里是会爆出一个错误,但是为什么呢?是如何工作的呢?
}
function mw2 (context, next) {
console.log('===== middleware 2 =====')
next()
}
async function mw3 (context, next) {
console.log('===== middleware 3 =====')
}
如上图我们可以知道,用index去标记i曾经到达过的最深层词的中间件的下标,那么就能有效防止再原路返回时,每个中间件再次出触发next深入深层次的情况。
return function (context, next) {
let index = -1 // ⑨ 表示初始的层次
function dispatch(i) {
// 10 当前调用的层次,是否小于曾经到过的最大层次(变相判断这一个中间件的next是否已经调用过了)
if (i <= index) return Promise.reject('next cant not be invoke multiple time')
// 11 通过了上面的校验,就标记本次到达的最深层次
index = i
let fn = middlewares[i]
if (i === middlewares.length) fn = next
if (!fn) return Promise.resolve()
try {
return Promise.resolve(fn(context, dispatch.bind(null, i + 1)))
} catch (err) {
return Promise.resolve()
}
}
return dispatch(0)
}若还是不太明白上面写法的原理,那我们来看看compose 组合 middlewares后的结果会是什么样子。
const [mid1, mid2, mid3] = middlewares
// compose 可以理解为
const fnMiddleware = function(ctx) {
return Promise.resolve(
mid1(ctx, function next () {
return Promise.resolve(
mid2(ctx, function next () {
return Promise.resolve(
mid3(ctx, function next() {
return Promise.resolve()
})
)
})
)
})
)
}[1] Koa源码 - github
[2] 大家觉得 Koa 框架还有什么不足的地方吗? - Starkwang的回答 - 知乎
基于上一篇cookie的基本使用场景和用法,这回来记录下项目关于cookie中遇到的问题和解决方案。
cookie解决的基本问题是http的无状态性,项目中大多数的场景也利用这个特性用于标记用户。
auth token标明用户的登录态。ssid token,并通过整个广告联盟中的网站中上报的ssid token,收集用户的访问行为。简单滴说,session 是什么呢?
Session是一个临时的进程组群,目的是去完成一些任务,是直接存储在内存中的。OS接收到新任务的时候,就会调度进程去执行任务。Session会话。Session 一般有效期设置为20min,若超时时间内没有数据交互,服务器就会将Session对应的资源删除。当客户端首次向服务端请求的时候,服务端维护一个Session,生成一个sessionid,值可以随意约定,就是一个用于标记session的值。
server 通过 http 响应客户端,客户端接收到了并保存在Cookie中。
客户端结束掉了请求连接,服务端就会释放掉这些进程对资源的占用,本次会话的状态会被暂时保存在一个文件中,在一定的时间内,服务端会保留这个文件。
在超时时间范围内,客户端每次访问该域名都会用cookie携带sessionid到服务端。服务端再根据sessionid找对应的Session,并且根据这个状态中记录的内容,打开对应的资源。
cookieSession 并不能够被共享我们来逐个解决下这些问题。
cookie的情况下,用户访问服务器页面时,服务器可以下发token到前端,前端使用cookie以外的 web storage 技术进行 token 存储。Session不能共享的问题时,高速缓存工具就是首选,比较热门的有 Redis Memcached 等IP或者浏览器型号等等。明文信息 = 随机生成字符串 + 客户端独有信息后,通过服务端独有的私钥进行加密,最终生成下发的token.号分割
Header.Payload.Signature {
"alg": "HS256",
"typ": "JWT"
}{
"user_id":"8192qhgb6kmoh3bypbc9wp146jusho",
"session_id":"81928yaqk1sccfgwze4k718338z3ae",
"platform":"wechat",
"roles":"",
"props": {"botId":"850444981"},
"exp":1606291794,
"iat":1603699794
}私钥保存在服务器,以下是生成秘钥的示例。HMACSHA256(base64UrlEncode(header) + "." +base64UrlEncode(payload),secret)《浏览器原理 - 缓存之cookie》 这篇文章中聊到SameSite时提到了,欧美国家因为隐私安全问题,对Google涉及使用第三方Cookie来追踪用户行为的操作,进行了巨额的罚金。
SameSite属性的实现,将Lax规则设置为默认规则。token,在跨站条件下直接无法发送。
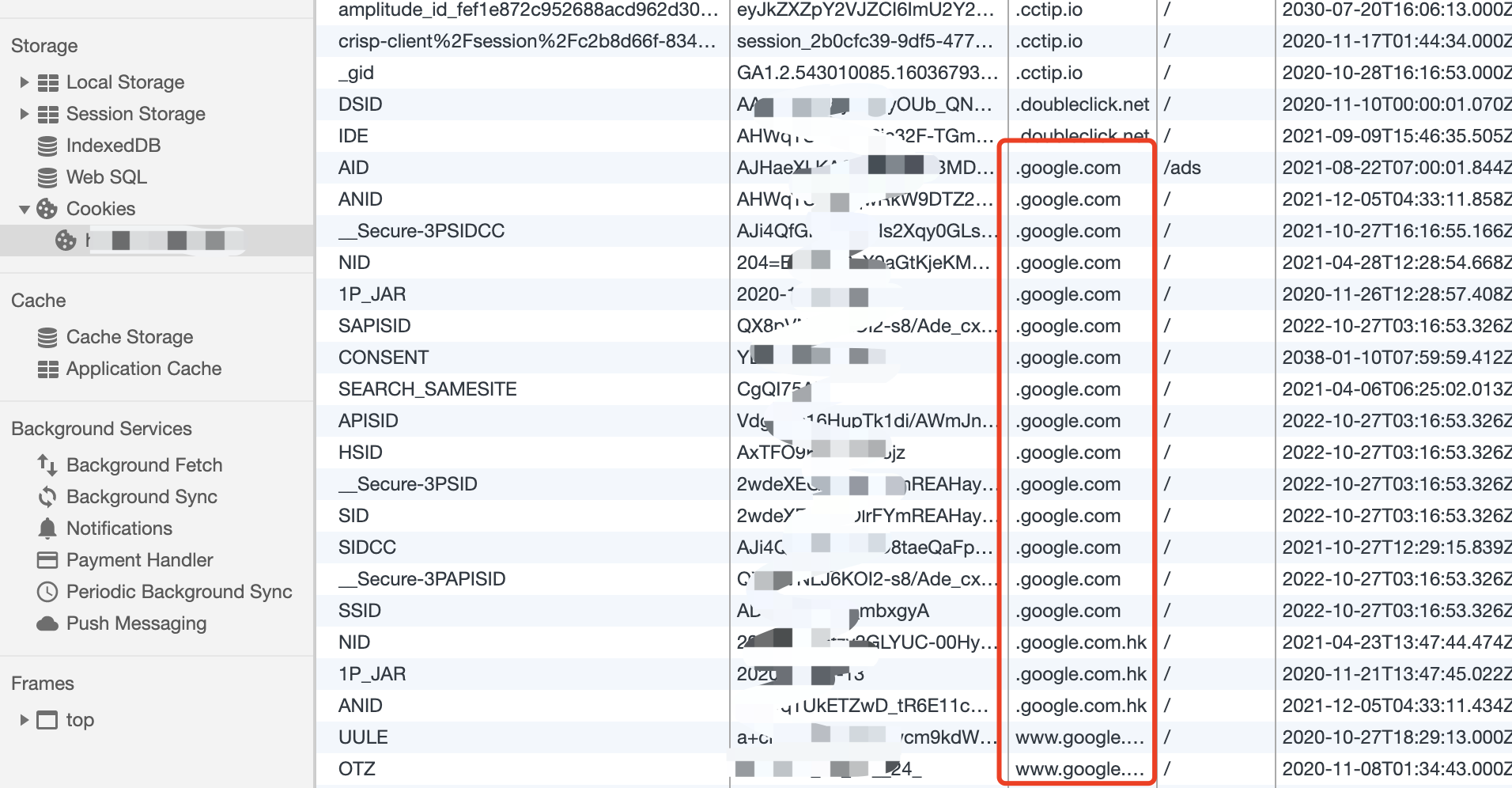
某个 cookie 对应的 domain 值,和当前页面服务器所在的 doamin 不属于一个站点。那么对于这个站点来说,这个 cookie 就是一个第三方cookie。
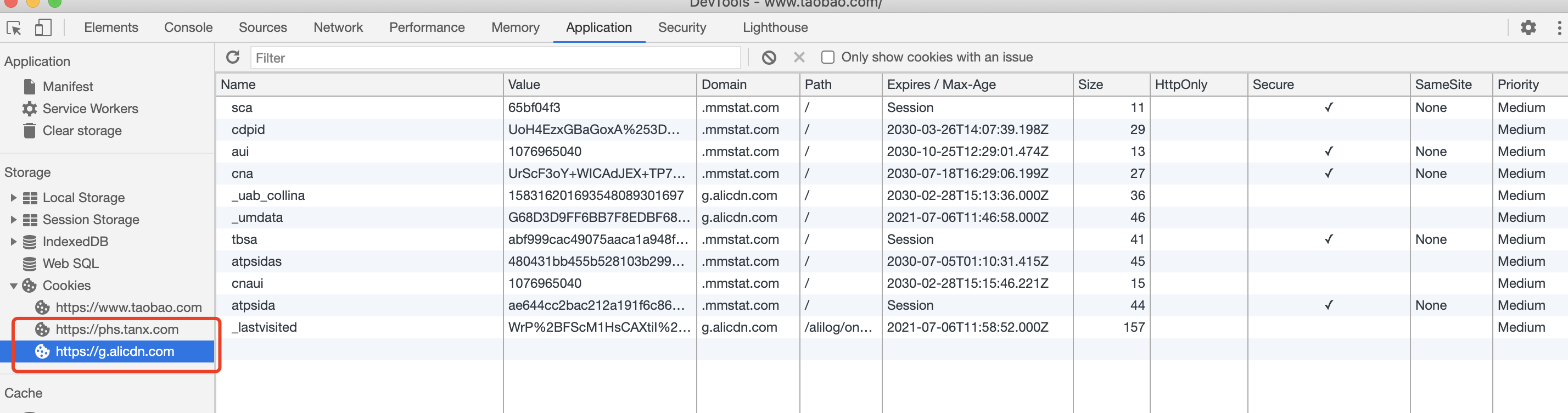
若上图,在淘宝主页面下,就存在hps.tanx.com和g.alicdn.com两个第三方cookie。分别是阿里旗下的阿里妈妈营销平台和阿里CDN。
在旧版(Chrome 80之前)的Chrome浏览器中,默认只在无痕窗口中禁用第三方cookie。
通过设置SameSite字段
2020年秋天,SameSite 默认值改为Lax已经在逐步推广,这意味着除了超链接 pre-fetch 之外,所有的跨站请求都不再携带cookie。
说了这么多,像是欧美人和几家浏览器巨头在做商业利益和人权之间的权衡,远远影响不到我们。可事实真是这样吗?
广告营销
从上面阿里妈妈数据平台的第三方 cookie 看出,用户行为收集,数据分析,广告精准投放已经成为大多数平台类的主要收入。而他们标记用户的主要手段就是,在目标网站插入用户信息的脚本。
前端打点上报
与上述问题相同,使用过Google Analysis的童鞋应该知道,原理其实和广告追踪一样。更像是一种正义的数据收集 [滑稽脸.png]
第三方登录受影响
许多使用iframe嵌入第三方域的授权登录都将因为之前没有设置SameSite这个字段,而被浏览器升级导致默认为Lax,进而导致之前的Cookie而失效。 (抱歉,👇这个图我又用了一次)
作为下发授权的网站,需要默认更新你的设置cookie策略,声明式地将SameSite设置为None。
非同站的跨域请求
queen,那么前端通常页面部署在my.queen.io,api的域名通常为api.queen.io和login.queen.io,这种情况不受到SameSite的影响。api,调用兄弟部门的api, 则日常的CORS请求中携带对方域名的cookie就会出现问题,不仅仅是withCredentials = true可以解决问题的。SameSite=None第三方选择显式关闭 SameSite 属性,将其设为 None时,前提是必须同时设置 Secure 属性, 标明 Cookie 只能通过 HTTPS 协议发送,否则无效。
[1] JSON Web Token 入门教程
[2] 当浏览器全面禁用三方 Cookie - 知乎 by conard
[3] Cookie 的 SameSite 属性
[4] SameSite cookies - MDN
无论是BS时代还是CS时代,计算机诞生之初安全问题就一直是重中之重。安全也从来都是们大课题,是你出招我接招的武功比拼。本文仅结合当前见识过的一些招数,管中窥豹地去记录一些日常。
每一次成功的攻击,看似都是多个低概率事件结果。但墨菲定律告诉我们,会发生的事迟早会发生。
面向安全问题,自己问问自己:
linux环境,那前端代码的宿主浏览器和node本身你又了解多少呢?XSS的温床吗?cookie可以根据domain字段判断是否携带。那Same Site、secure和第三方cookie又了解多少呢?XSS、CSRF之外,网络劫持、非法调用又该如何防范呢?安全是一个体系,在恶意攻击面前,每一端每一环都是至关重要。程序从前端到后端,需要把安防这套组合拳打好配合,每个环节都至关重要。
CSRF (Cross-Site-Request-Forgery),中文称之为跨站点伪造攻击。主要流程如下
受害者在正常网站登录,并保存登录态到cookie中。攻击者诱导受害者进入事先准备好的第三方网站。攻击者准备好的第三方网站的恶意脚本中,会向被攻击网站发送跨站请求。被攻击网站中留下的cookie注册凭证,通过受攻击网站的后端用户检验。转移资产、查询敏感信息等)。受害者可能就不小心点击了一个恶意连接,打开的页面一闪而过,攻击可能就完成了。Get请求CSRF攻击,通常会埋藏在恶意网站中的一个图片链接中,或者给出一个超链接引诱用户点击。
img请求可以绕过浏览器同源策略限制<!-- 自动发起请求 -->
<img src="https://safebank.com/assets/change-verify-phone?new_number=1345678901">
<!-- 引诱用户点击 -->
<a href="https://safebank.com/assets/change-verify-phone?new_number=1345678901"></a>更换用户绑定的安全手机号。没错,利用的是你当前浏览器中cookie中的身份token做的身份验证。POST类型的CSRF
<form action="https://safebank.com/assets/change-verify-phone">
<input type="hidden" name="new_phone" value="1345678901">
<input type="hidden" name="other_param" value="xxxxx">
</form>
<script>
document.forms[0].submit() // auto submit
</script>表单自提交请求仍然能够轻松模拟POST请求,并且不阻碍浏览器携带用户token。http协议的同学,也知道GET与POST在请求上其实是相同的,只是两端的读取方式上不一致罢了。CORS类型的CSRFCORS不也是归类到POST或者GET吗?
Response Header中的 Access-Controll-Allow-Origin的时候,为什么不建议设置为*的原因。*意味着来自所有域的脚本,都可以对这个借口进行跨域访问,多增加了一层风险。
知己知彼,从上面的总结可以看出CSRF的特点
第三方网站,除非你的网站已经被XSS攻击了。cookie信息,只是借用你的cookie而已针对CSRF特点,我们针对性可以做出防范:
直接阻止外域访问
cookie中的token。添加外域获取不到的信息到请求中
CSRF-Token 方案。都知道http请求是无状态、无连接的,每一次请求的信息都携带在了请求与相应头中,大家是否还记得Origin和Referer这两个Request Header呢?
The Origin request header indicates where a fetch originates from. It doesn't include any path information, but only the server name. It is sent with CORS requests, as well as with POST requests. It is similar to the Referer header, but, unlike this header, it doesn't disclose the whole path.
The Referer request header contains the address of the page making the request. When following a link, this would be the url of the page containing the link. When making AJAX requests to another domain, this would be your page's url. The Referer header allows servers to identify where people are visiting them from and may use that data for analytics, logging, or optimized caching
以上分别是是MDN对Origin 和 Referer 的描述,都可以标明当前请求的来源,而Referer更详细。但我们更需要关心的是这二者发送与不发送的情况。
POST请求下携带CORS请求也不会写带Origin请求头302重定向之后的请求中,不包含Origin请求头IE 6和IE 7下,使用location.href或者window.open进行跳转都不携带refererOrigin 或者 Referer 属于自己的白名单中,则直接拒绝访问。简单粗暴地处理,会有以下问题:
Origin和Referer请求头是不完全可靠,只能够借助这两个请求头进行初步防御。搜索引擎跳转访问页面的时候,referer一定会是搜索引擎的域名。会拒绝掉正常流量。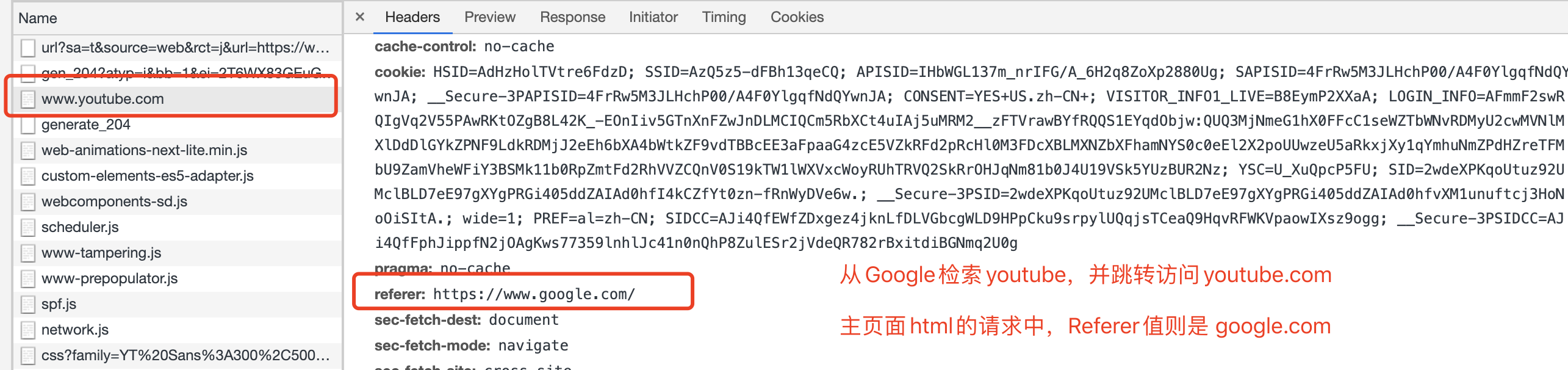
XSS攻击后,那么攻击方就会很粗暴地成为你自己的Origin了。要说读取Origin/Referer Header信息像是检查你的车票,那么CSRF Token则像是则是检查你的身份证了。区别就在于你能够拿出一些,别人拿不出来的东西,以证明该请求的合法性。
CSRF Token(一般为随机字符串和时间戳的哈希),服务器存储一份,下发给客户端一份。CSRF 攻击者利用,不再使用Cookie存储和提交CSRF Token请求参数中携带这个CSRF Token
beforeSend的intercepter中统一添加Token的合法性,决定是否要处理此请求
时间戳是否超过有效期Token是页面级别的,在大型网站中session存储大量的CSRF Token压力是巨大的。Redis作为多台服务器的公共存储空间页面为维度去处理Token,工作量巨大。<a>标签跳转、<form>提交,则需要手动添加CSRF Token回想我们使用金融类的App时候,就算你已经登录了,在支付的时候也需要再次输入支付密码呢?这里面的支付密码和验证码,其实就相当于支付这个请求的CSRF Token。这个方法适用于少数关键的几个接口。
{
email_verify_code: "1213"
password: "250f78769f22a8c43a2b767fde4b093fbbcdc28bd7ecac4bad883a4b0fcf30e3"
timestamp: 1603684913776
value: "2"
}在业务处理中去验证token的有效性极大地添加了开发工作量。那么有没有更轻便的形式完成简单的CSRF Token工作呢?尝试一下流程:
signKey,作为后续加密使用。// app.config.ts
const CSRFTokenInfo = {
appName: 'bank',
signKey: 'ajhsbdkjasu123123bjsbkd'
}signKey和请求参数,生成请求的signature:
path、当前时间timestamp、本应用的idappName作为、签名参数signKey作为准备参数md5进行加密生成signature// request.interceptor.ts
export function signRequest (config: RequestConfig) {
const key = CSRFTokenInfo.signKey
const timestamp = Date.now()
const fullPath = [(config.baseURL || '').replace(/\/$/, ''), (config.url || '').replace(/^\//, '')].join('/')
const path = new URL(fullPath).pathname
// 明文签名
const text = `app=${CSRFTokenInfo.appName}×tamp=${timestamp}&path=${path}&signature=${key}`
// 加密签名
const signMessage = md5(text)
// 绑定到请求头中
config.headers['x-service-app'] = CSRFTokenInfo.appName
config.headers['x-service-timestamp'] = timestamp
config.headers['x-service-signature'] = signMessage
return config
}input(app、timestamp)与output(signature)通过请求头传递到后端
// other request header...
x-service-app: bank
x-service-signature: 12dsf222ssdf312d334sddzxczxcz
x-service-timestamp: 1403691292039nginx + 本地脚本校验的形式完成前端请求中携带的app、timestamp 与 signature参数,结合nginx中拦截到的请求path,和前端一样重新计算一次signature,并且比对结果timestamp字段则另外再加一个防重放时间的检测signKey两端该如何同步呢?
CSRF Token不同,这次我们反向去考虑问题app.config.ts中配置的signKey加入到发布脚本中ci机器一般拥有ssh到正式环境的权限。ci发布流程完成后。执行特定的script以启动服务器上更新signKey为前端本地的值。
# build 项目 .....
# reload 项目 ....
# 更新signKey
python xxx/xxx/update-sign-key.py -- bank ajhsbdkjasu123123bjsbkdsignKey的更新是由前端驱动的,只有在发版的时候才会更新,实时性并不如第一种方案。nginx层处理,可以大量减少后端同学的开发工作量。所谓成也Cookie,败也Cookie。CSRF则是利用浏览器的这个规则漏洞建立起来的攻击方式。前面说到,安全每一个环节都有责任,那么作为前端主要运行环境的浏览器,是否也可以在Cookie规则上进行优化呢?
时间来到了2020年秋天,SameSite Cookie已经被大多数浏览器所支持了,甚至于有“浏览器全面禁止第三方Cookie”的传闻(连接),这里推荐一个小工具给大家测试自己浏览器的Same-Site Cookie支持情况,传送门==>
将cookie中授权 token的same-site属性设置为Strict则可以直接防止CSRF的发生。
根据上面的总结,CSRF攻击,通常有以下的特点
img作为CSRF请求时,Request Header中的MIME Type为图片,而想要窃取的数据返回的MIME Tpye一般为plain/text、json等文本信息事小而不为。被攻击时,每一个环节都不是无辜的。CSRF请求[1] HTTP headers 之 host, referer, origin
[2] 浏览器的沙箱模式
[3] 前端优化 - by Alex 百度
[4] 前端安全系列(二):如何防止CSRF攻击? - 美团技术团队
[5] CSRF 漏洞的末日?关于 Cookie SameSite 那些你不得不知道的事
CommonJS、AMD 不同, 而ES6 尝试在语言层面上实现了模块化的功能CommonJS 与 AMD 都需要程序运行时才能够知道模块之间的依赖关系。而ES 6 Module要做到的是尽量的静态化,在编译时就确定模块的依赖关系,以及输出和输出的内容。
export命令规定的是对外的接口,起的作用必须是与模块内部建立起一以对应的关系。
export语句输出的接口,与其对应的是动态绑定的关系,模块内部值的变化,会引起外部引用的变化。
例子一:
// modulesA.js
export const number = 3
export function add () {
number ++
}
// app.js
import { number, add } from 'moduleA'
console.log(number) // 3
add()
console.log(number) // 4例子二:
// moduleA.js
class ModuleA {
this.name = 'moduleA'
this.getName = function () {
return this.name
}
}
export const objA = new ModuleA()
// a.js
import { objA } from 'moduleA'
objA.name = 'name has been changed'
// b.js
import { objA } from 'moduleA'
setTimeout(() => {
console.log(objA.name) // 'name has been changed'
})以上两个例子都可以说明,模块内部,引用方拿到的模块引用,都是指向同一个内存空间,任意一方改变了内存空间存储的值,那么任意一方取到的都是最新的值。
ES6 Module的初衷是实现静态分析模块化,所以export必须处于模块顶层中,不能处于块级作用域内。
import会在静态解析时,会因为变量提升解拆分成声明与赋值两个部分。
console.log(abc)
import { abc } from 'module.js' // 并不会报错
与
export相类似,同样遵循ES 6静态模块分析的设计初衷,import语句同样不能处于块级作用域中,导出的值也不能够是需要运算后得出的结果。
import命令输入的变量都是只读的,因为本质上来说,引入的是输入接口。改变引用本身,则会破坏模块之间的引用关系。
原则上不允许修改接口,但可以修改接口里面的值,其他的模块也能够拿到修改后的值,但是我们不推荐这样做,因为这样的修改是不可以追踪的。
如下例子:
// common.js
export const config = {
port: '8899',
host: '123.77.33.56'
}
// a.js
import { config } from 'common.js'
config.port = '1234' // 不会报错
//b.js
import { config } from 'common.js'
console.log(config.port) // 一脸懵逼地拿到了 1234这个值,b的开发者回去看 common.js 又发现不了问题一下的语句,仅仅会执行
my.module模块的内容,但并不会引入任何代码。
import 'my-module'import * as myModule from 'my-module'优先解析
./与../等相对路径,直接写模块名称则需要根据配置文件的规则来约定。
$ node --experimental-modules a.mjs # 这里用node来运行一下比如出现以上循环引用的情况下,a.js为入口moduleB被首先加载
ES 6 Module的最终目的是要取代CommonJS 与 AMD,一统天下。那么在运行时的模块化中,使用import()函数来替代require()方法。import() 与 import 语句不一样,前者产生的是运行时执行的异步加载,后者产生的是静态的连接关系。
import()进行异步加载,方法返回的是一个Promise对象,那么显而易见的require()则是一个运行时同步加载的过程。
// 异步加载
import list from './list';
// 同步加载
const list = require('./list');因为
import()是运行时执行,显而易见的我们可以用于做code spliting。
const router = new VueRouter({
routes: [
{
path: '/foo', component: import('./Foo.vue'),
path: '/bar', component: import('./Bar.vue'),
}
]
})详细请参考👉这里
使用
export default相当于对外暴露了一个名为 default的变量,变量的值直接跟在export default后面。
使用
export from可以实现模块转发,(表面上相当于是import 与 export的结合),但要实际进行静态解析的时候,当前模块是没有引入目标对象的。
// moduleA
export { foo, bar } from 'moduleB'
console.log(foo) // error中间模块转发接口的时候,可以对接口进行改名
export { default as myModule } from 'that-module'
export * as myModule from 'that-module'<script type="module" src="./foo.js" type="module"></script>
<!-- 效果类似于 -->
<script src="./foo.js" defer></script>
defer关键字表示脚本的执行延迟到文档加载完成之后。

module关键字也能够使得JS在DOM加载完后才执行,兼容性不如前者,IE封杀,edge 16+,FF60+,Chrome 61+
当二者同时出现的时候,执行顺序是一般脚本 > module脚本 > defer脚本 > DOMContentLoaded事件
Javascript是一门具有垃圾回收机制的编程语言,程序员大部分情况下不用手动去操心内存管理的问题。
和EvemtLoop类似,虽然我们不能直接地去操控垃圾清理的执行与停止,但充分了解了V8的垃圾回收机制后吗,在编码上能够有意识地去较少GC的影响。相当于武林高手虽然绑上了手脚,但仍然能够识破别人的招式,以守为攻。
本文主要分为两个部分,① 先了解V8与内存的关系,② 再延展开去了解V8对内存的管理(清理)。
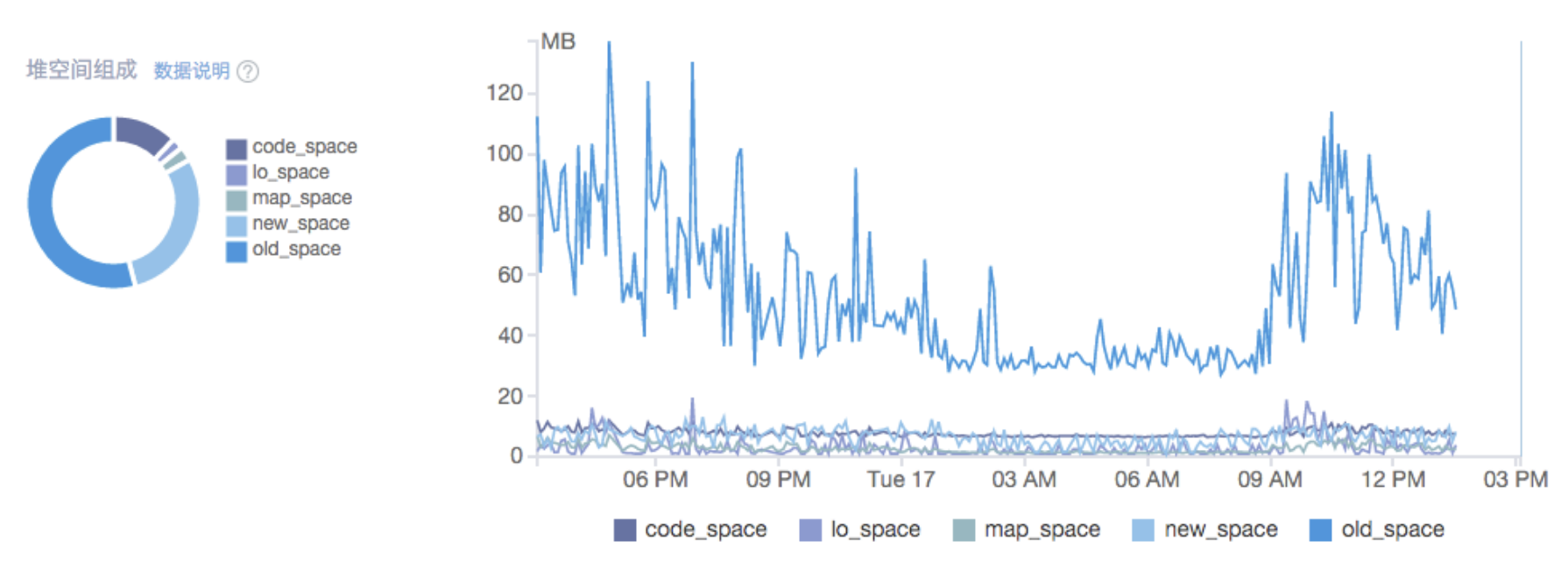
V8创始之初是设计为新一代Chrome的内核,作为浏览器所需要的内存当然就不需要太大,这从系统安全和浏览器本身需求两个角度去考虑的。V8自身的垃圾回收机制,若分配的内存过大,单次的垃圾回收时间则会过长,这是在服务端Node.js和前端浏览器都不可以接受的。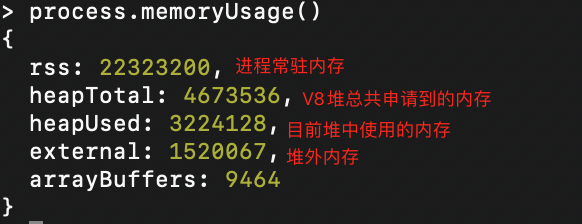
heapTotal 和 heapUsed 分别代表已申请到的堆内存大小,和当前的使用量。external 代表 V8 管理的,但绑定到 C++ 对象的内存使用情况。rss: 全称是resident set size,是驻留集大小, 是给这个进程分配了多少物理内存(占总分配内存的一部分),包含所有的 C++ 和 JavaScript 对象与代码。'os.freemem()': os.freemem(), // 返回系统空闲内存的大小, 单位是字节
'os.totalmen': os.totalmem(), // 返回系统总共内存的大小
堆外内存指的是那些OS分配给Node.js进程使用的内存资源,但却不是通过V8内核进行分配的内存,称之为堆外内存。
这种情况是因为在浏览器Api中,对于大多数场景不需要使用过度的内存,而Node.js在服务端的场景,需要处理网络I/O流,则需要更大的内存,常见的有BufferAPI。
V8的内存分为老生代和新生代,新生代较小,用于保存新产生的小的对象,老生代用于保存大对象和�经历多次回收仍未回收的对象。V8可支配堆内存大小。
新生代使用Scavenge算法进行回收。其实现核心是Cheney算法。
From空间中所有能从GC Root对象到达的对象(说明仍该对象仍存活)复制到To区。对象晋升机制,直接移动到老生代中。
To空间的使用率已经超过了25%。Scavenge回收,却没有被淘汰掉的semispace内存会被释放掉。semispace空间对调。老生代中GC使用的是标记清除(Mark Sweep)策略 和 标记整理(Mark Compact)�策略。
Mark Sweep执行过程Mark Compact执行过程V8中会将这两种方法进行结合,在大多数情况下使用的是Mark Sweep,而在发生对象晋升而老生代空间连续不足的情况下,Mark Compact才会被触发。
incremental marking与lazy swaeeping为了减低全堆垃圾回收带来的全停顿,V8从标记到清除也都进行了改进,使得原本需要长时间的GC工作,得以分段实行。
DOM节点内存泄漏DOM 树和 JavaScript 代码都不引用某个 DOM 节点,该节点才会被作为垃圾进行回收。Node.js服务端端开发时,尽可能减少内存进行的使用。定时器 和 事件监听 要记得及时清除。Node.js中尽量使用 stream 和 buffer来操作大文件,而不是使用内存一旦数据不再使用,最好通过将其值设置为null来释放其引用,这个做法叫做解除引用(dereferencing)
一般会针对全局对象的属性进行解除引用操作,局部变量会在离开执行环境的时候自动被解除引用。
解除引用后并不会马上释放内存,只是相当于打上了一个标记,本轮GC回收的时候,会直接将指向null的数据原所占内存释放掉。
已知delete关键字也可以删除对象的一个属性,但不推荐使用
let const var fun声明的量,都不能都够使用delete去删除false,然后相当无操作configurable:false,那么也是不能够被删除的。delete相对于null操作范围基本限定在对象的属性上,能够实现资源回收的优化也仅限于对象的属性上。无论是V8下的浏览器还是Node.js其内存分配制度是极其相似的,Node.js仅仅在其使用场景需要处理大文件I/O的情况下增加了堆外内存的相关API。
因为没有实际去排查过V8在生产环境下的内存问题,接下来的文章就去看看Node.js和浏览器下如何排查内存隐患吧。
[1]《Javascript 高级程序设计 第三版》
[2] 浅谈Chrome中的垃圾回收 -博客园
[3]《Nodejs深入浅出》
[4] javascript 中的 delete
在计算机的世界中,浮点数的表示范围优先。浮点数只是可以近似的标识一个数而已。与许多其他编程语言不同,JavaScript 并未定义不同类型的数字数据类型,而是始终遵循国际 IEEE 754 标准,将数字存储为双精度浮点数。
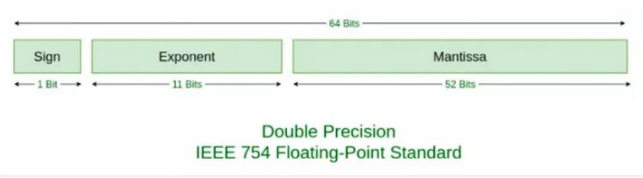
用2去除十进制整数,可以得到一个商和余数;再用2去除商,又会得到一个商和余数,如此进行,直到商为零时为止,然后把先得到的余数作为二进制数的低位有效位,后得到的余数作为二进制数的高位有效位,依次排列起来。
用2乘十进制小数,可以得到积,将积的整数部分取出,再用2乘余下的小数 部分,又得到一个积,再将积的整数部分取出,如此进行,直到积中的小数部分为零,或者达到所要求的精度为止。然后把取出的整数部分按顺序排列起来。
接下来我们手动尝试一下10.3 + 12.4这个组合,我先帮你在Chrome devtool测试了一下



整数部分: 10 ==> 1010
小数部分: 0.3 ==> 01 0011 0011 0011 0011 ......
科学计数表示: 1.010010011001100110011... x 103
基准偏移量 + 偏移量(可能为负喔)。100 0000 00100100 1001 1001 1001 1001 1001 1001......按照Double Float Precision IEEE 754的格式拼起来就是0 100 0000 0010 0100 1001 1001 10001 1001 1001......
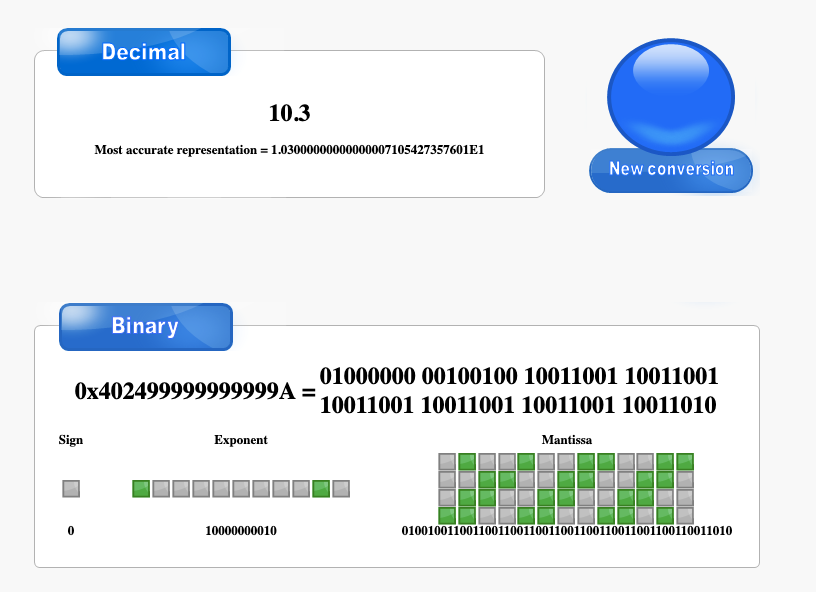
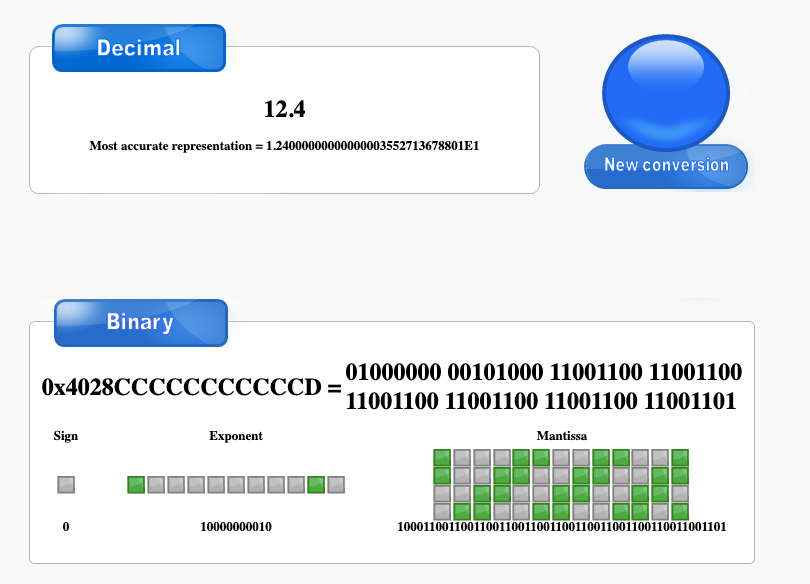
按照上面IEEE 双精度的表示法,两个数字分别如下,然后进行尾数求和
0 100 0000 0010 0100 1001 1001 1001 1001 1001...
0 100 0000 0010 1000 1001 1001 1001 1001 1001...
——————————————————————————————————————————————————
1101 0011 0011 0011 0011 0010
然后进行的是尾数的规格化: 1101 0011 0011 0011 0011 0010 ===> 0110 1001 1001 1001 1001 1001,其实就是把末尾的0给去掉了,前面补0。
因为mantissa(尾数部分)的固定长度为52位,最多可以表示252 + 1(也即是9007199254740992)个数字,用科学技术法来表示也就是9.007199254740992 x 10 16
在控制台我们可以测试到
(0.1).toPrecision(16) // "0.1000000000000000"
(0.1).toPrecision(17) // "0.10000000000000001"
(0.1).toPrecision(18) // "0.100000000000000006"
(0.1).toPrecision(20) // "0.10000000000000000555"
(0.2).toPrecision(16) // "0.2000000000000000"
(0.2).toPrecision(17) // "0.20000000000000001"
(0.2).toPrecision(18) // "0.200000000000000011"
(0.3).toPrecision(16) // "0.3000000000000000"
(0.3).toPrecision(17) // "0.29999999999999999"
(0.3).toPrecision(20) // "0.29999999999999998890"所以,我们平时看到的 0.1 并不是只有 0.1,看到的 0.3也不一定够0.3,只是显示精度作怪而已。
// 以定点表示法或指数表示法表示的一个数值对象的字符串表示,四舍五入到 precision 参数指定的显示数字位数。
numObj.toPrecision(precision)// 使用定点表示法表示给定数字的字符串。
numObj.toFixed(digits)其实,precision是指从小数点开始从左往右开始数,第一个不为0的数字开始计数。而fixed是指小数点后开始算的位数。
显而易见,在IEEE体系中,二进制只能够近似地表示某个浮点数数值。比如0.3,使用标准的转换方式,我们永远也达不到终止条件---小数位为0。在存储空间有限的情况下,无尽的循环到达边界时,就不得不进行类似十进制的四舍五入进位了。
在实际项目中,直接使用float、double进行金额数值运算也就有可能出现未知的情况,在许多语言中会有Decimal数据类型(例如Python)。而在JavaScript中则是推荐使用Decimal.js
相比较于其他浏览器本地存储,cookie的特点在于符合匹配规则,则自动携带。服务端与客户端双方都可以写入。Cookie 的存在使得基于无状态的HTTP协议下,储存信息成为了可能。
首先定义一下,cookie是一段记录用户信息的字符串,一般保存在客户端的内存或者硬盘中。
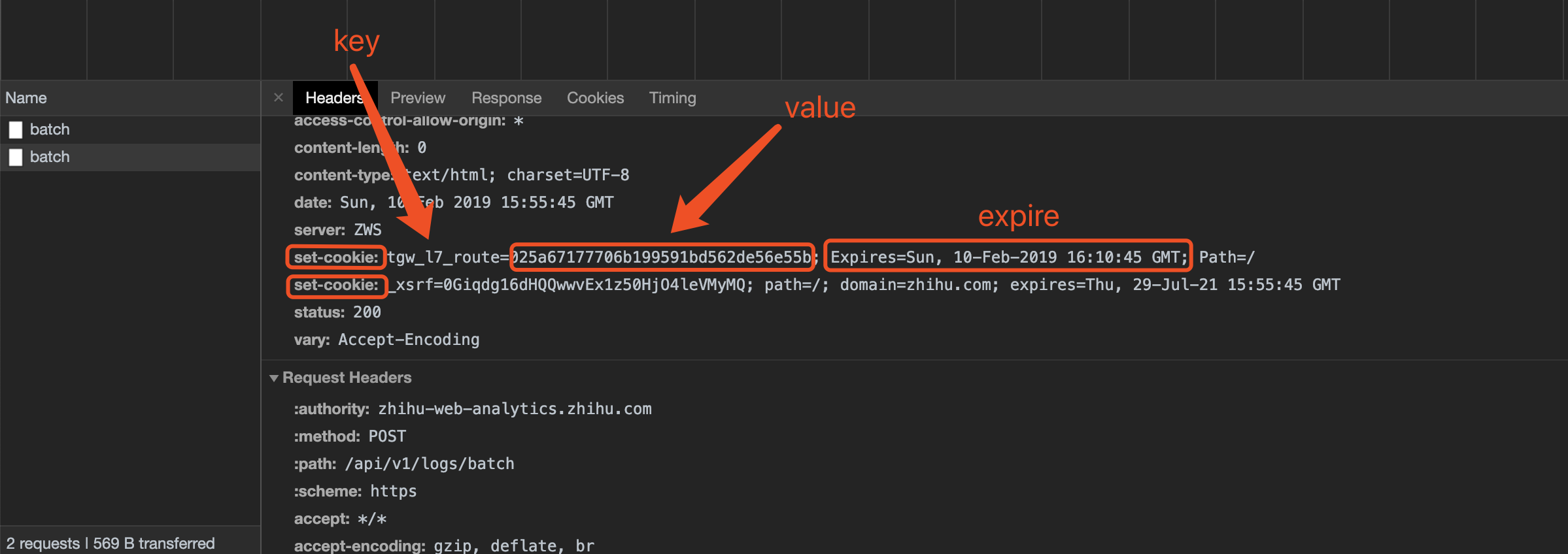
cookie的创建是由服务端的响应头,其中带着set-cookie的字段,来对客户端进行cookie设置。
| 属性名 | 作用 |
|---|---|
| Name | 表示cookie的名称 |
| Value | 字段表示cookie的值 |
| size | 表示cookie的大小 |
| 属性名 | 作用 |
|---|---|
| domain | 表示cookie有效的域,默认值为当前域名 |
| path | 字段表示cookie有效的路径,默认值为/表示全匹配。 |
若不显示设置cookie的domain值,则浏览器会处理为生成一个只对当前域名有效的cookie。比如在map.baidu.com下,我们生成了一个cookie,但没有指定domain值,那么这个cookie,只有在访问map.baidu.com时候有效,而abc.map.baidu.com和user.map.baidu.com都是拿不到的。
domain为www.abc.com,path为/sale/img,则只有匹配www.abc.com/sale/img路径的资源才可以读取cookie。模式匹配,也就是向后匹配,上面的例子也能匹配www.abc.com/sale/img/qqq/ss| 属性名 | 作用 |
|---|---|
| Expire / Max-Age | 表示为cookie的有效时间,默认值session,也就是指浏览器session,也就是用户关闭浏览器就会清除掉这个cookie。 |
| Secure | 表示该cookie在安全的协议下才会生效 |
| HttpOnly | 只用于http请求,本地脚本不能够读写 |
| SameSite | 标明该cookie是否在跨站点请求时发送 |
cookie只会在�https协议或者ssl等安全协议下进行发送。document.cookie = "username=cfangxu; secure"cookie只会在http请求传输的时候携带SameSite 用于限制第三方cookie的使用, 在 a.com 下发起对 b.com 的请求,cookie携带与否,将取决于SameSite这个属性。
Strict 表示绝对禁止所有的跨站cookieNone 则表示不启用该规则Lax, 限制强度介于 Strict 和 None 之间, 相对于Strict仅允许以下三种情况的cookie携带
<a href="..."></a> 连接跳转<link rel="prerender" href="..."/> 预加载<form method="GET" action="..."> GET形式的表单same origin,但 same site中的 site,指的则是有eTLD + 1,其中 eTLD 指的是 effective top-level domain(有效顶级域名)github.com .gov.uk .org.uk也是有效顶级域名。参考👉这份名单你在闲逛某个网站A的时候,使用管理工具查看cookie,发现除了本域下的cookie,还经常存在某些知名搜索网站的cookie。
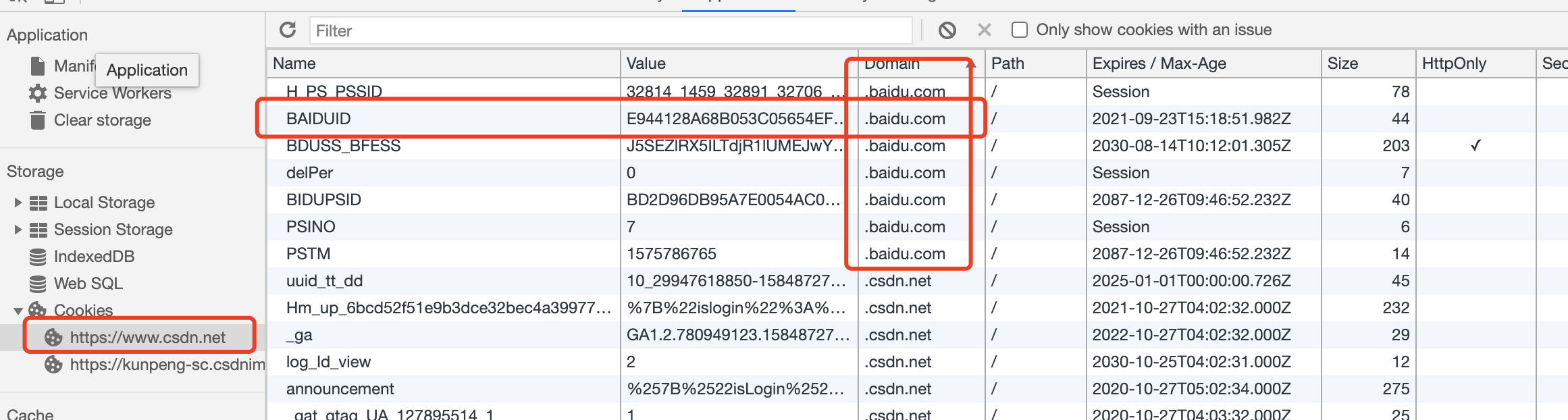
这并不是什么秘密了,而是搜索网站跟踪手机用户习惯的主要手段。
比如你的网站加入了某某广告联盟,则在你的网站中加入上报脚本,告知广告联盟这个用户来过这里,帮助联盟构建更完整的用户画像。
CORS调用部署在其他站点的第三方API存在影响关于域的设置,👆前面讲解domain部分有介绍。
cookie中的domin设置的跨域是指跨子域名都不可以访问,例如www.baidu.com和map.baidu.com是不可以跨域进行读取内容的。(看上述domain第一条规则)

首先服务端要返回Access-Control-Allow-Credentials表明允许跨域请求携带cookie,并且Allow-Control-Allow-Origin字段也不能模糊的表示为*,而要写明cookie发送的域
再者,客户端也要设置请求的携带cookie
// 原生ajax请求设置跨域携带cookie
var xhr = new XMLHttpRequest();
xhr.withCredentials = true;读取cookie可以使用docuemnt.cookie

document.cookie = 'userId=xusfh123; maxAge=5000;path=/;secure'写入cookie也是用的是这个属性,但要注意,但是不支持同时设置多个cookie,需要分开多次调用设置属性值。
删除一个cookie的方法就是把对应字段的cookie值置空。
当服务器想共享cookie值给所有二级域名的时候,我们的cookie就应该设置为共同的上一级域名。比如.baidu.com(常用于单点登录)。建议设置cookie时候,都带上.通配符号,如.a.b.c.baidu.com。
一个服务器能够设置domian的有效的范围是,从自身域名开始,向上追溯到一级域名。比如a.b.c.baidu.com能够设置有效的cookie-domain是.a.b.c.baidu.com、.b.c.baidu.com、.c.baidu.com、.baidu.com。
不能够跨上级域名设置其他域的子域。不能够设置.a.u.c.baidu.com。例如如下:
set-cookie中,domain字段为 .dashboard.swain.com"this. set-cookie domain attribute was invalid with regards to the current host URL".的错误这就是一个跨子域设置cookie的实例,正确的方式应该设置domain为.swain.com
在不domain下的cookie即使同名也不会覆盖,若在同一个domain下,同名的cookie后者会覆盖前者。
secure与http-only都象征着更高的对应cookie条目的更高安全级别,当前cookie已经添加了对应安全策略的时候,更低安全策略的cookie写入相对于是无法无盖已存在的旧cookie值。
因为cookie会跟随请求自动发送的特性,所以浏览器对对一个域的cookie总大小和数目都有着不同的限制。
| 浏览器 | 数目(个/域) | 每域下的cookie总大小限制 | 其他 |
|---|---|---|---|
| Firefox | 50个 | 4k | |
| Chrome | 53个 | 4k | |
| Safari | 无限制 | 4k | |
| IE 7+ | 50个 | <4k | 超长则截断,超过数目则使用LRU淘汰 |
| IE 6 | 20个 | <4k | 超长则截断,超过数目则使用LRU淘汰 |
| Opera | 30个 | 4k |
cookie当做我们的本地数据仓库使用,而仅仅去存储一些用户的id,sessionID之类的身份验证性的简单数据。cookie 需要注意对应的有效范围、有效期、安全生效条件等属性SameSite的支持情况,有可能对于你的应用导致致命的bug。接下来会结合安全、隐私方向,说说最常见的用cookie作为用户身份标识,遇到的问题和解决方案。
[1] 从url中解析出域名、子域名和有效顶级域名 - alsotang
[2] 干掉状态:从 session 到 token
[3] 正确使用cookie中的domain
我们知道在浏览器渲染中,页面渲染有几个关键的时刻比如说First Paint、DOMContentLoaded、Onload以及可交互时间。
打开我们亲爱的淘宝页面,使用devtools中的Performance面板录制一段从初始加载到完成的过程,可以看出各个资源的下载和执行的过程,也能看到Chrome给我们标出了所需要注意的几个关键时间点。
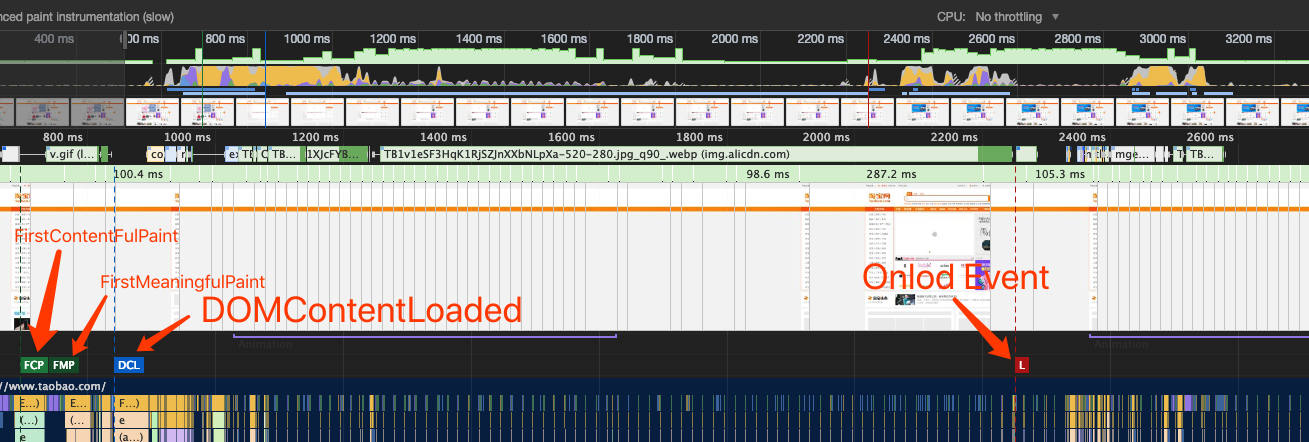
直接看字面意思,就是DOM的内容加载(解析)完毕了。而据我们之前所知,页面中脚本(无论是外链还是内联)的执行都会阻碍DOM的解析,也就是说脚本的执行,会延迟DOMContentLoaded事件的到来。

如上图所示,DOM的解析阻塞于脚本的加载,而脚本的加载也受限于脚本前面的css加载完成后才会执行,在任何情况下,DOMContentLoaded的触发不需要等待图片或者其他任何资源的加载完成。
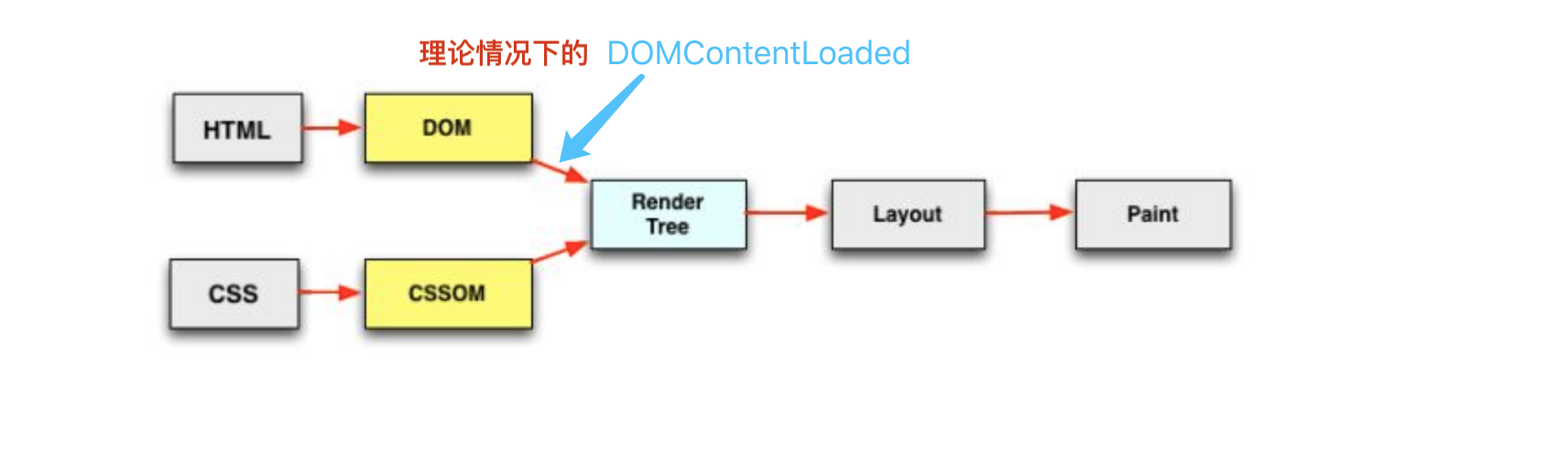
这里插一个题外话,async标明的脚本不知道何时会加载完,而后立即执行,所以DOMContentLoaded事件也不会等它。但type=module和defer标明的<script>标签脚本一定会先于DOMContentLoaded事件。
以下代码都是我们熟悉的用于监听DCL事件
// jQuery
$(document).ready(function(){......}); // 或者
$(function(){...});
// 原生
document.addEventListener('DOMContentLoaded',function(){......})首先回答是不可以的。
因为DCL的定义是整个文档都加载完成,当然也包括body外,HTML内的script标签。
但是我们要是把script标签放到了header中,往细说是阻塞了body的解析,那么body中有啥?当然就是我们页面的主要内容结构啦。
理论上浏览器会等待DOM和CSSOM都解析完生成RenderTree才开始布局和绘制,但是现代的浏览器,为了减少白屏等待的时间,都会进行HTML局部的渲染。
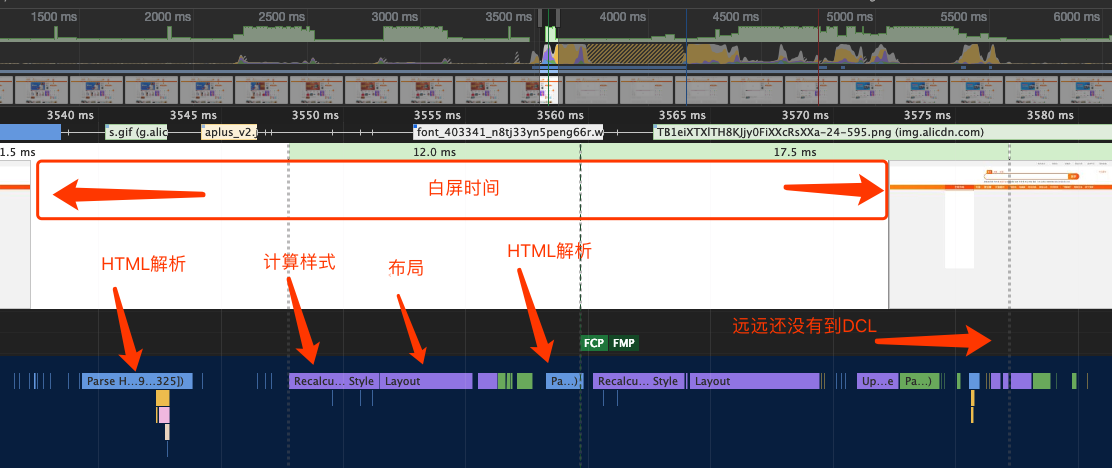
上面的截图同样来自于淘宝首页,我们可以看到在DOMContentLoaded之前,就已经触发了FirstPaint,页面空白的时间的不到30ms。但是DOM远远没有解析完,只是部分完成了。这个过程中,我们发现并没有表示script执行的黄色片段。
下面我们来看看www.hoopchina.com 虎扑网的首页
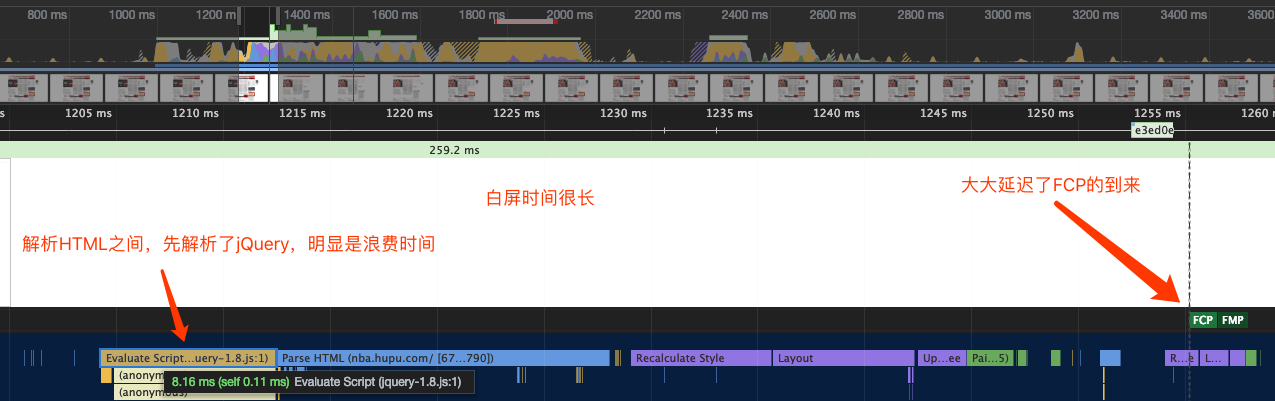
�所以我们将script标签写在header中则会阻塞body的解析,也就是会阻碍First Paint的到来,也就是说用户看到的白屏时间会更长。
所以呢,js代码沉底,只是提前 First Content Paint 的时间,而不是减少 DOMContentLoaded 的时间。
看到图中红色的块块了吗?...在ie 6-8下,请做以下兼容
document.onreadystatechange=function(){
/*dom加载完成的时候*/
if(document.readyState=='complete'){
fn&&fn();//处理事情
}
};�既然上面提到了FirstPaint那么我么就先说说First�Paint相关的知识。
首先呢,Chrome 的devtools给我们细微的划分了FirstPaint为First ���Contentful Paint(首次有内容的渲染)和First Meaningful Paint(首次有效的渲染)。
使用 window.performace.getEntriesByType 这个api可以检测到这两个阶段的开始时间。
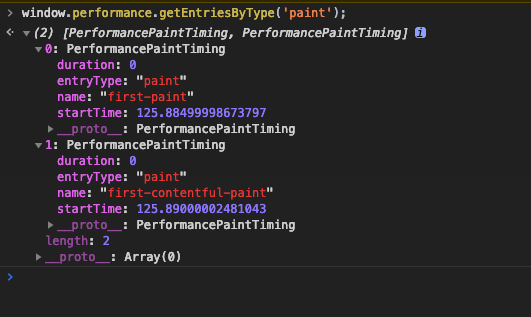
FirstPaint 表示的是页面上第一个像素被绘制上去的时刻,有可能是背景颜色。
FirstContentfulPaint 表示的是浏览器第一个DOM节点渲染到品目上的时间。
从上面的测试结果也可以看出来,二者之间的间距非常非常之小,但这两者共同决定了我们常说的白屏时间。
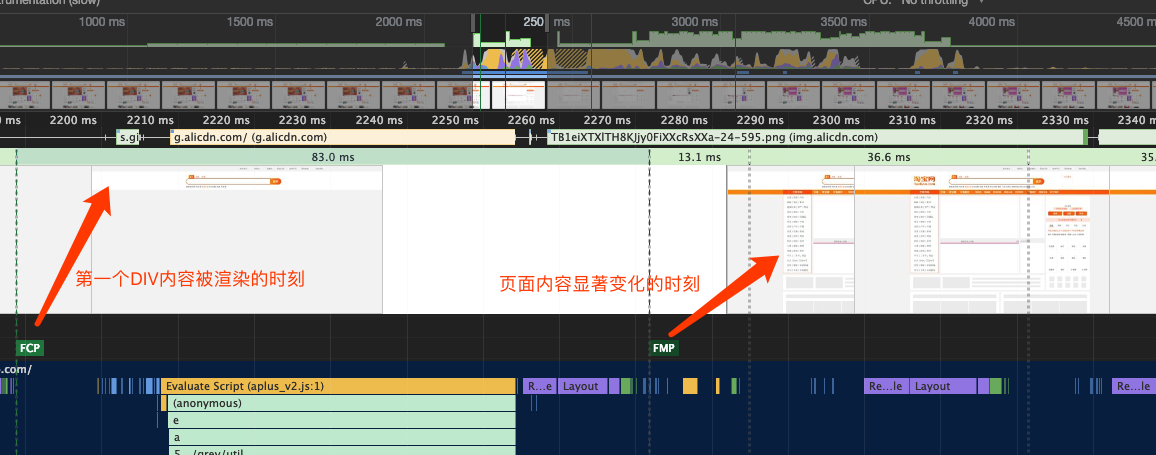
FMP在chrome下的定义是,浏览器计算页面的内容高度或者说是内容多少变化最大的一个时刻,和我们通常意义上将的首屏内容(不包括滚动下滑的内容)意义相近。内容有没有意义,也只是我们网站开发者才能够知道的,所以我们能够根据这一条规则进行优化。
还是来看看淘宝首页的情况吧,FCP的时候出现了顶部的搜索框,FMP的时候基本完成了骨架屏的渲染。
我们知道浏览器中的Javascript是单线程的,浏览器的渲染机制也规定了,UI渲染、�JS执行和用户操作一个时刻只能够执行一种,一定会有一个先后顺序。(宏任务微任务的概念看这里,传送门👉)
既然用户的操作会被JS的执行和UI渲染所阻塞,既然也不能完全避免这样的情况,我们就需要将这样的占用时间尽量缩短,或者说是切割。也就是说将长的JS代码执行任务,切割成小的执行任务。
从人的感受上来说,用户给出的操作最好在100ms内要得到操作反馈,否则就会让用户感觉到卡顿或者说不爽。
其实就是“可交互时间”的英文翻译,我们常简称为TTI。定义上来说,指的是用户看到了页面的大部分内容(近似于FMP)之后,准备进行用户操作,但是此时的主线程又被JS的执行所占用着,想输入,想点击但是都得不到浏览器的响应。
借用一张图来表示,图不是我自己画的....来源在这
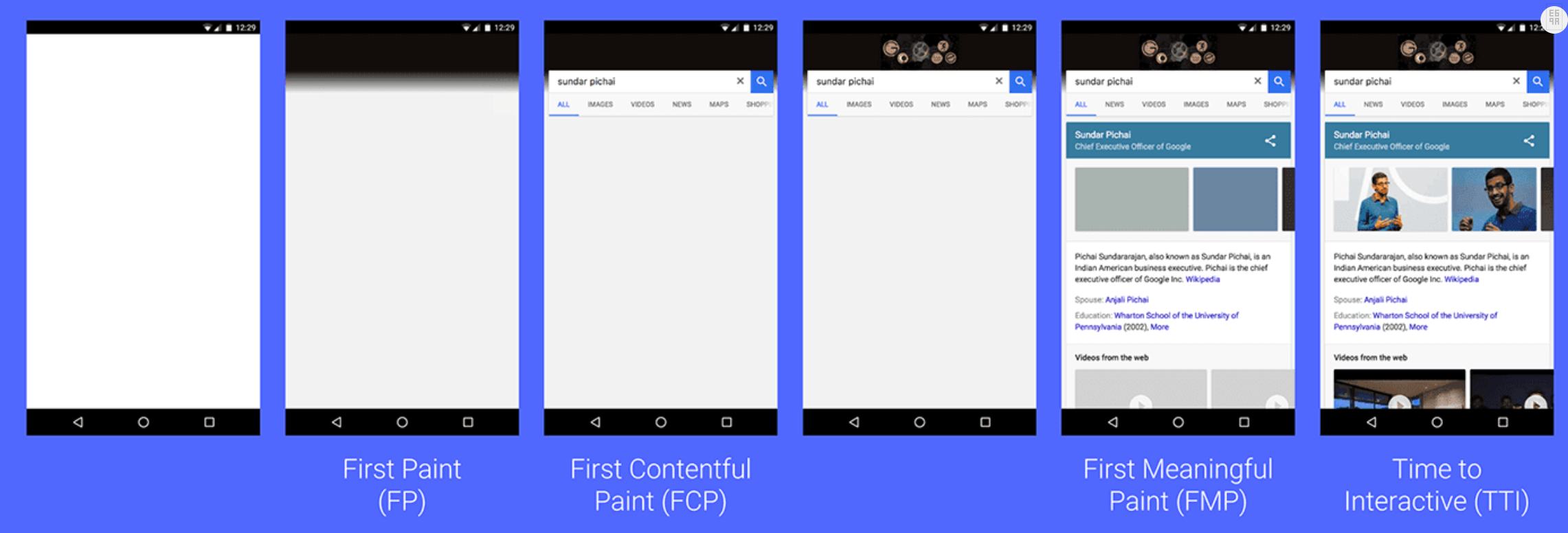
在文章首部的图中,我们发现DOMContentLoaded之后还有一个Onload Event,它表明的是页面上所有的资源(图片、音频、视屏)都被加载完的时刻,就会触发onload事件,并且它是固定会晚于DCL时刻的。因为onload是指DOM中的所有资源,而影响DCL只有CSS和JS这两种资源的加载与执行。

重要的是,也能确保使用async标记的script被加载并且执行完,假如我们的一些业务代码是依赖于这些异步加载的第三方库的,则不会出现业务代码操作失败。
但因为图片、视屏这一类的资源一般都是加载时间较长,所以onload事件的使用,需要谨慎,否则会大大拖延业务代码的执行。
对应到代码上,就是使用JS去监听window.onload事件
window.onload=function(){
document.getElementById("bg").style.backgroundColor="#F90"; //DOM操作
// 或者其他任意业务代码
}总结一下,其实前端性能优化,就是服务于用户的感受的,说白了就是用户要感觉到爽,那么我们能不能够从交互的角度来量化一下用户的感受呢?
以下是几个当你打开一个页面后,脑子里会�闪过的几个念头...
| 闪过的念头 | 白话描述 | 内部因素 |
|---|---|---|
| 咦?访问成功了吗? | 用户看到了页面切换,看到了白屏?不知道服务器是否有响应? | FirstPaint、FirstContentfulPaint |
| 内容加载完了吗? | 用户陆续看到了内容,但不知道页面内容加载完了没有? | FirstMeaningfulPaint |
| 我可以动鼠标点击了吗? | 页面看起来时加载完了,但是用户不知道自己可以操作了吗? | Time To Interact |
| 爽不爽? | �整个流程下来,页面是否闪烁,内容上下乱跳,让用户有一个直观的感受,爽与不爽? | 是否有长任务占用主线程,onload之后是否又频繁造成重排 |
回看Timeline,阻塞FP和FCP的就是head标签中的css和Javascript,但是有些css确实首屏需要的(key-css的概念,看这里👉)则仍需要保留在head中避免频繁重排,Javascript脚本则可以放心地沉到body底部或者defer、async。
使用http缓存本地资源,减少请求时间也是很重要的一点。
FMP是关键内容的出现,或者是大部分内容出现的时间。在这一点上客户端的渲染能力,远远比不上服务端的渲染能力,所以首推SSR。
TTI强调的点是交互,那么我们要消除或者减少的是页面UI渲染和JS脚本执行。
DCL之前去加载执行,而不是让用户看到了页面再去等待加载时间,因为用户看到白屏至少不会想要去操作,或者说用户看到了所有内容就会立刻想去操作,若得不到反馈,会极为的不爽。TTL最后的这一条优化,可以根据网站功能类型的不同去做不同优化,不要墨守成规。
在非首屏情况下,大体不会有渲染的问题,但是用户的行为会触发javascript的执行,比如说复杂的JS计算也是会导致用户操作的卡顿,页面进入假死状态。
web-worker进行多线程计算,然后返回结果到主线程。过去两年的时间有幸可以去主导多个 toC 的 web 项目,随着用户量的不断增大,也就让“朗读并背诵全文”的全前端优化手段们得到了实践的机会。
项目的基本信息:
nuxt.jsGoogle AnalyticsSentry接下来说说自己在过去一年多里,优化项目是如何在项目中落地。
随着项目功能模块地增多、用户量也在不断地积累,运营同学那边收到用户的反(to)馈(cao)越来越多...
*xxx is great, but the xxx on web sometime drive me crazy... 😡
一个帮我们推广应用的大V 在推广视频中,面对首页的 8s 加载时间,竟然习以为常地吹起了口哨,平静地向粉丝说 “Dont worry, It just usually take a while.”
天天忙着改 bug 的我们组还没来得及看运营小姐姐的的消息,就被老板在群里 艾特了。
@前端组-ALL 这样的体验,凭我们凭什么留住用户???
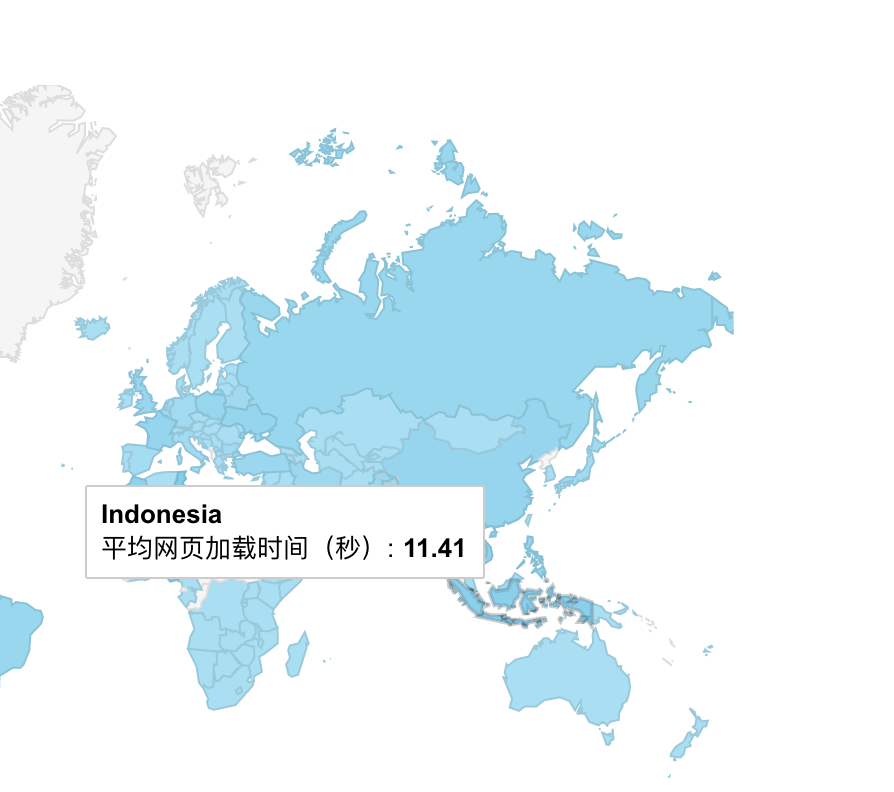
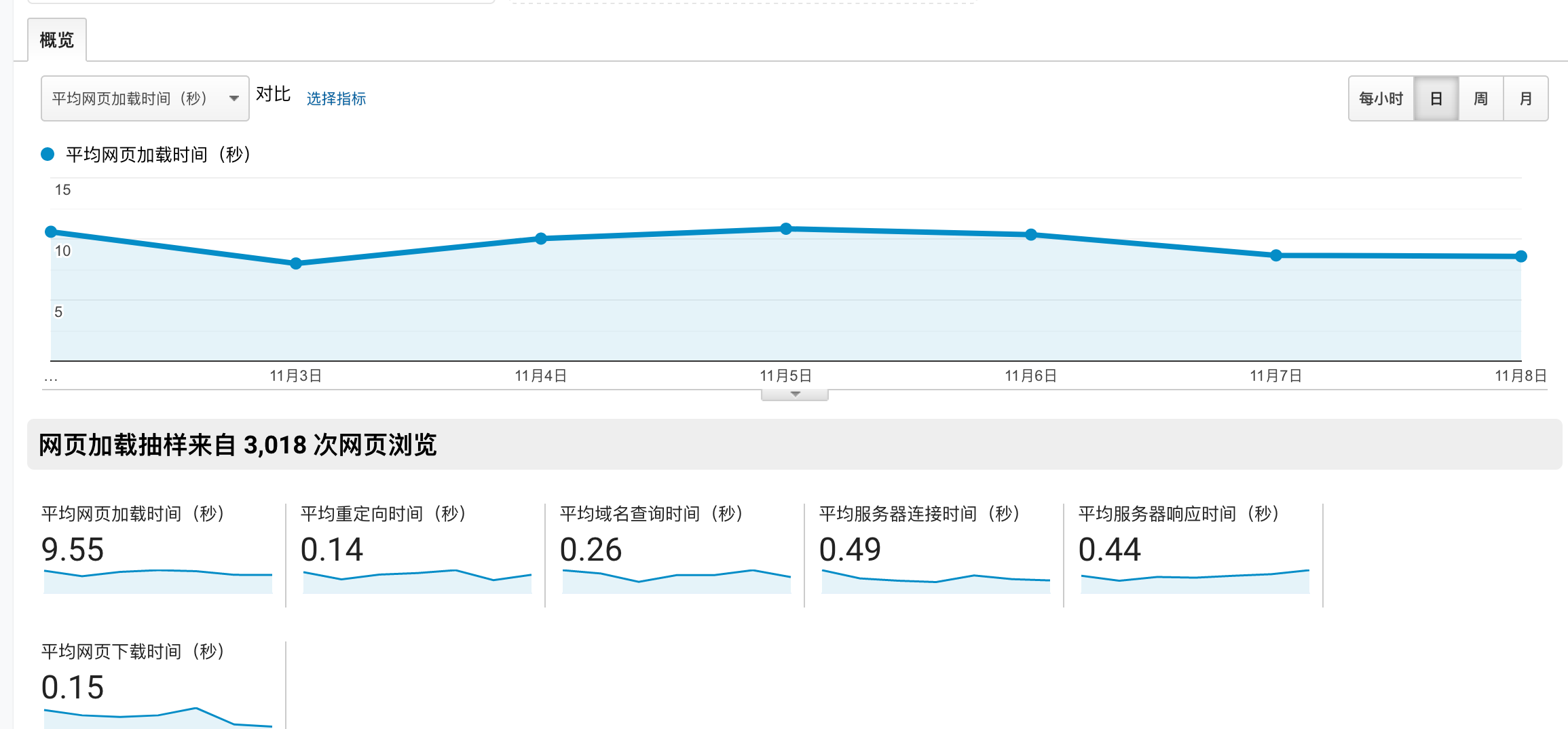
两张图重重地砸在了我的脸上,将近 10s 的平均加载时间,和主要用户来源马来西亚的加载时间甚至达到了 11.41s。
随手打开线上的项目主页,就碰到了和 大V 哥一样的尴尬.....,nuxt 的loading 足足占据了屏幕 15s 才缓缓出现内容。

要我自己是用户早就关掉了......
冤有头债有主,解铃也还需寄铃人嘛。既然是 “平均网页加载时间” 惹了众怒,那就查查 Google Analysis 对这个词儿是如何定义的吧。 传送门👉

Google Analytics 的描述和我们web开发中的 load 事件基本一致。
当整个页面及所有依赖资源如样式表和图片都已完成加载时,将触发load事件。 --- MDN
通过具体分析得知,有以下几个点影响了我们的 load 时间...
iframe页面,但由于各个国家墙的原因,这个脚本静态会加载失败Javascript 文件大小太大,网络加载速度也很慢,直接导致了用户看到大大的loading图标过久。你一定也遇到过首屏是列表页,每个列表项上都有一个或者多个图片需要加载,大量的图片同时加载时间十分不确定,同时渲染到 DOM 上也会造成页面的卡顿。
老问题了,方法也多:
多数情况下,这部分脚本的加载,不会影响到首屏的主观体验。但当首屏加载完成,用户主动去触发该功能时,需要做好所对应功能 “加载未完成” 等提示。
const targetScript = document.getElementById('targetScript')
targetScript && targetScript.onload = () => {
const authIframe = document.getElementById('auth-iframe')
authIframe && authIframe.onload = () => {
loaded = true
}
}在自己合适的地方自定义 page load 事件,这样使得 Google Analytics 上的数据更直观。
ga('send', 'timing', 'JS Dependencies', 'load', timeSincePageLoad);因为实际上我们需要的是 TTI (可交互时间)。这部分内容可以参考这篇笔记 👉
资源加载速度慢有两个方面,一个是资源本身体积过大,二是网络传输速度太慢。
webpack打包优化网上的资料很多,这里就不拓展开讲了。这次只是习惯性地运行一次 analyser,便可以发现那个眨眼的 lodash.js

// 全部引入
import { toNumber, sortby } from 'lodash-es'
// 改为单独引入
import toNumber from 'lodash.toNumber'
import sortby from 'lodash.sortby'上面的一顿操作后,JavaScript 文件的大小的到了控制,但海外用户反映还是慢慢慢慢慢慢慢慢慢慢慢慢.....
这时候针对性地上了一个部分地区的 CDN 服务。域名配置的是 static-xxx.io。
根据 Nuxt.js 的文档(传送门👉)配置一下,发布前尝试一下连通性...就可以发到线上试试啦。
export default {
build: {
publicPath: 'https://static-xxx.io/_nuxt/'
}
}实际效果也比较明显
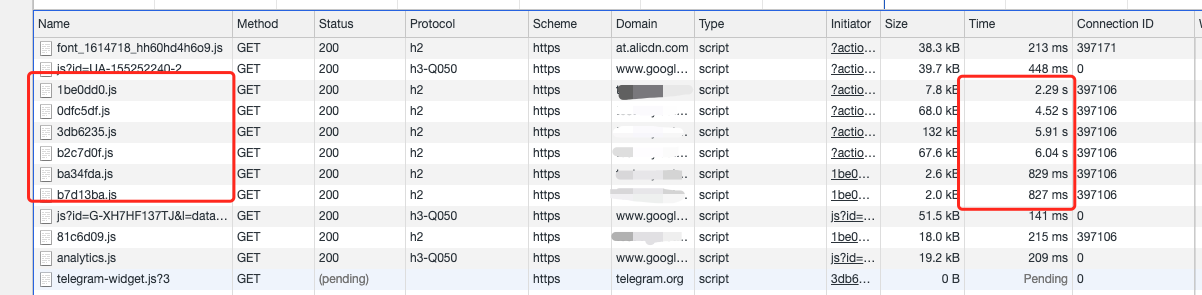
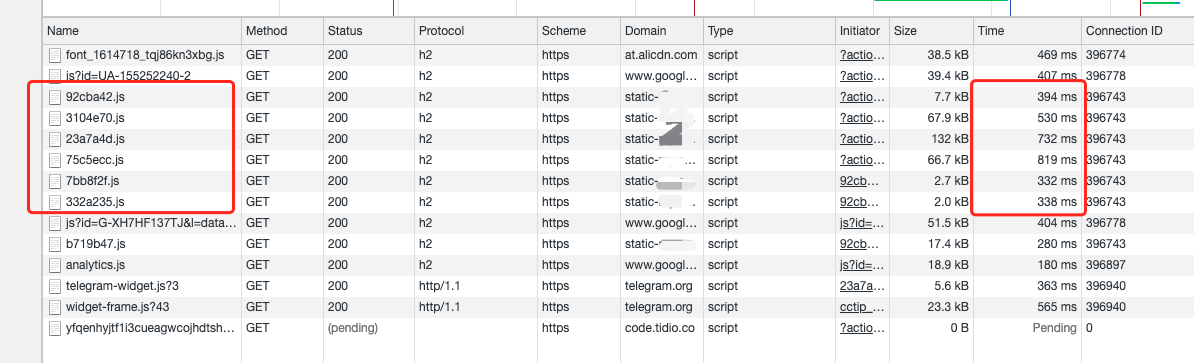
随着 Web 应用的不断复杂化,早就已经不是填写一个表单就离开的那个时代了。特别是在移动端使用你的 web 服务时,总是想要体会到和原生 App 一样的感受。此时,本地缓存就变得越来越重要了。
无论是作为用户还是开发者,你是不是也受够这无穷无尽 loading。滥用 loading 作为你页面的遮羞布,长此以往只会让你的页面越来越不可用。
ajax 或者 websocket 进行静默地数据更新loading 进行数据更新,更新后也缓存到本地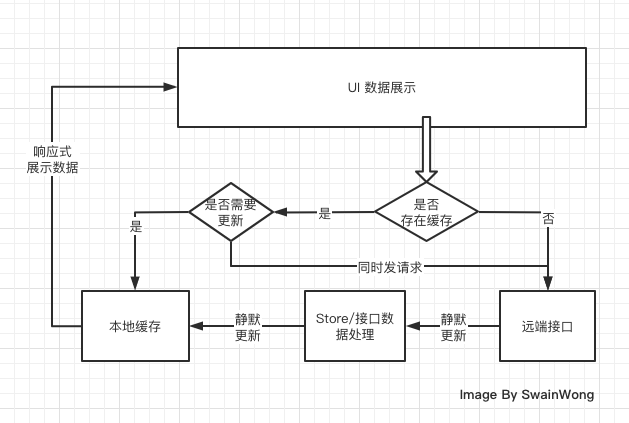
对于 loading 提醒的其他建议,可以看看这篇笔记
针对于数据实时性要求强的业务模块,请求的信道的搭建时间已经远远地超过了数据的实时性本身。这次使用的是 websocket 的解决方案。
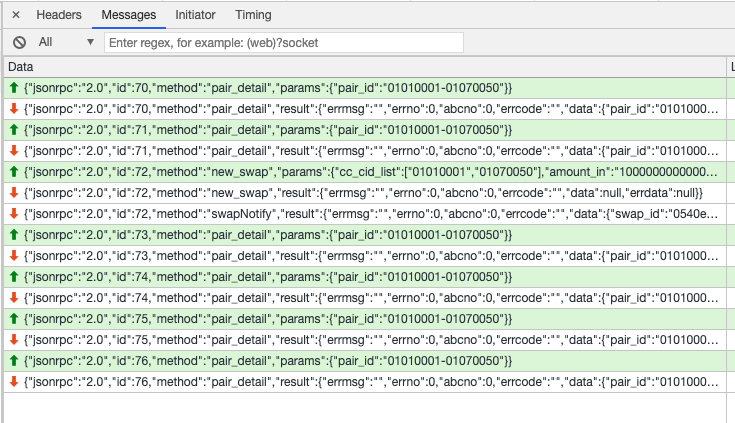
在减少了请求我收的同时,也带来了一些问题:
http 请求不兼容具体操作请参考这篇笔记👉
数据请求一般要求下都是发送的非简单请求,这其中就会包括预请求的时间。使用 Access-Control-Max-Age: xxx 减少预请求的次数。
详细的原理请参看这篇笔记👉
prefetch 是浏览器的一种机制,可以利用空闲时间提前先帮你下载好 未来 可能需要的资源。
dns-prefetch 可以帮助我们在用户仅仅访问主页的情况先,优先帮助用户完成 DNS 查询,并缓存结果再浏览器中。
<!-- 十分可能访问页面 -->
<link rel="dns-prefetch" href="https://doc.xxx.io/" >
<link rel="dns-prefetch" href="https://home.xxx.io/" >
<!-- 肯定会用到的接口URL -->
<link rel="dns-prefetch" href="https://api.xxx.io/" >
<link rel="dns-prefetch" href="https://login.xxx.io/" >类似于 http 2.0的 server push的意思,前端也可以要求浏览器提前把需要的 css 、font 等资源提前下载到缓存中。并结合资源的 max-age 和 expire 缓存策略达到跨页面使用。
<link rel="prefetch" href="telegram.auth.com/123ahisdhu2.js" />MDN 连接: [dns-prefetch] [prefetch]

最近工作室的官网准备要上线了,也因为 https 的普遍使用,https 的原理读得多了,现在就来实操一次,为网站建立 https 证书吧。
以腾讯云(免费)申请流程为例子
nginx版本
请根据自己的服务器平台选择证书包

使用scp等方法把证书放到服务器的conf目录,例如
$ scp xxxss.com_bundle.crt xxxss.com.key xxx.xxx.xxx.xx:/usr/local/nginx/conf/cert
with-http_ssl_module 模块在你安装nginx的目录下(这里要注意,不是/usr/local/nginx这个,一般会是nginx.10.x.x带版本号的那个,下面有一个configure可执行文件),用它来安装这个ssl模块

$ ./configure --with-http_ssl_module
然后在同样目录下执行make命令
$ make
然后备份之前的nginx,再将新配置的nginx覆盖掉旧的
$ cp /usr/local/nginx/sbin/nginx /usr/local/nginx/sbin/nginx.bak
$ cp objs/nginx /usr/local/nginx/sbin/nginx
哦对了~👆上面这个覆盖文件会需要你停止当前的nginx,避免你又查了,给你搬运过来了
$ nginx -s quit # 等待当前程序执行完后退出
$ nginx -s stop # 强制停了吧
server {
listen 443;
server_name xxxxxxxx.club; # 此处为您证书绑定的域名。
ssl on; # 设置为on启用SSL功能。
location / {
proxy_pass http://nuxtSSR; # 前面配置的一个前端项目
}
# SSL 证书配置
ssl_certificate cert/1_woniuhuafang.club_bundle.crt; # 您证书的文件名。
ssl_certificate_key cert/2_woniuhuafang.club.key; # 证书的私钥文件名。
ssl_session_timeout 5m;
# 使用此加密套件。
ssl_ciphers ECDHE-RSA-AES128-GCM-SHA256:ECDHE:ECDH:AES:HIGH:!NULL:!aNULL:!MD5:!ADH:!RC4;
ssl_protocols TLSv1 TLSv1.1 TLSv1.2; # 修改protocols。
ssl_prefer_server_ciphers on;
}
搞定之后检测一下语法没问题就重启happy吧
$ nginx -t # check 一下
$ nginx
哇咔咔,小锁头被解开啦 🙃

[warn] the "ssl" directive is deprecated, use the "listen ... ssl" directive instead
移除 ssl on配置,修改listen 443 为 listen 443 ssl

在请求的资源很多的情况下,http1.x是会同时打开6~8个tcp链接,所以我们在前端机操作的时候,就有了压缩合并css/js资源,使用雪碧图这样的�优化方案。
而http2使用单一的长链接去加载所有资源。有效地减少了tcp握手所带来的时延,特别是当请求使用了ssl加密请求时,握手次数会大大增加。
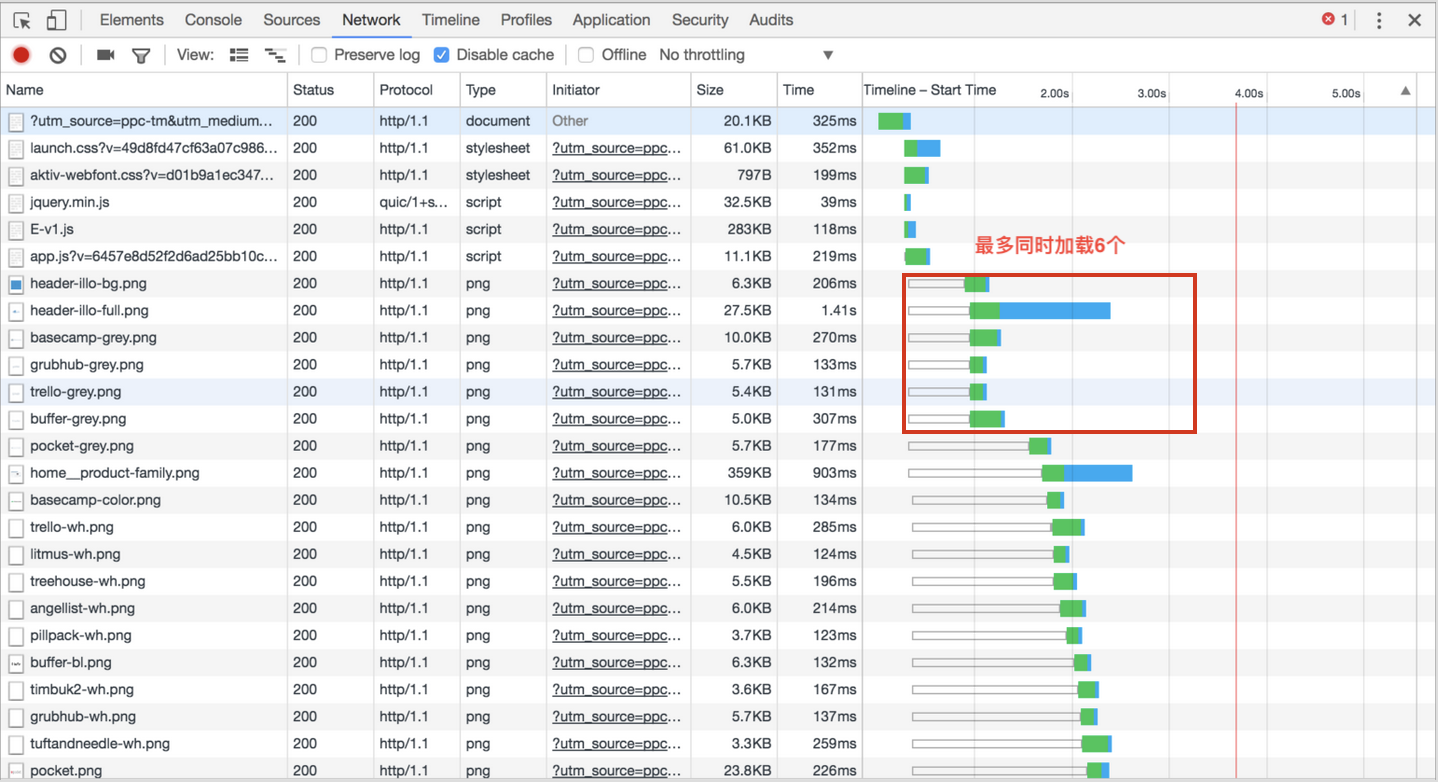
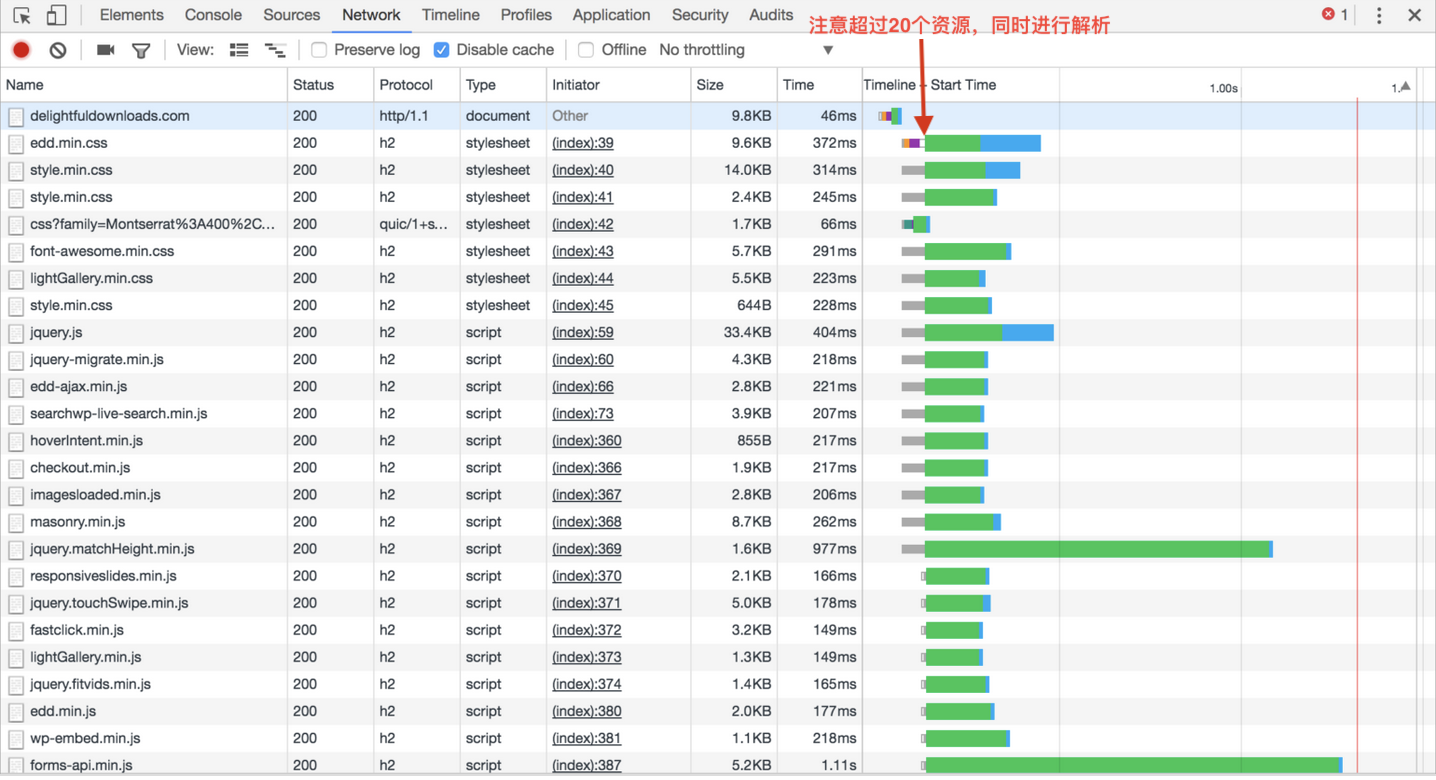
结合上面图说明,http2.0 可以同时对多个资源进行请求,不受 6~8 链接的限制,图中看出,服务器接收到请求的时间是一样的,而根据不同的资源做出的响应时间长度不一样而已。
浏览器所在的操作系统,对半开连接数有限制,用于保护 TCP/IP 协议栈资源不被迅速消耗殆尽。所以浏览器不会同时发送过多的 tcp 链接
浏览器操作启动一个 tcp 链接都需要一个开启一个线程,若同时创建过多线程,性能会下降的很严重。而综合考量 6~8 个 tcp 链接(线程),并且在 http 1.1 下的keep-alive 机制,这些链接(线程)是可以被复用的,减少开销。
对于服务器来说,同时能够接受的请求数目也是有限的。这时候,作为一个 client,不进行作恶就很关键了,作恶你就和恶意程序没有区别了。所以浏览器是选择性的减少同时连接的数目。
每次的TCP链接,都会涉及到一个慢启动过程,也就是连接建立之后,数据线是慢慢地传,然后数据窗口再慢慢地增大,传输速度才达到稳定峰值。
而http2减少tcp的连接数为1次,大大减少了冷启动的滑动窗口的次数。
HTTP 2.0 把每一个资源的传输叫做流 Stream,每一个流都有他的唯一 id 称之为stream ID。
每一个流就像是一批货物,都有自己的编号,每个数据流最后都被切分为数据帧(frame)。同一种货物(最后要拼装在一起的不同frame)要遵循 FIFO 的原则去传输,但是不同种货物之间,可以相互穿插,先后出发。
流id的是递增的已关闭的流的编号在当前连接不能复用,避免在新的流收到延迟的相同编号的老的流的帧。所以流的编号是递增的。

frame传输若把每次建立 TCP 连接,称之为修路的话,那么 http2 则只修了一条路,然后把不同文件请求的 data 切分为多个二进制 Frame,头部信息放在 HEADER FRAME,数据体存放在 data Frame 中,装在不同的的货车上,然后让他们同时在修好的道路上跑,充分利用了道路的宽度,也充分利用了现有的宽带带宽。

HTTP/2规定了多种类型的帧
| 名称 类型 | 帧代码 | 作用 |
|---|---|---|
| DATA | 0x0 | 一个或多个DATA帧作为请求、响应内容载体 |
| HEADERS | 0x1 | 报头主要载体,请求头或响应头,同时呢也用于打开一个流,在流处于打开"open"或者远程半关闭"half closed (remote)"状态都可以发送。 |
| PRIORITY | 0x2 | 表达了发送方对流优先级权重的建议值,在流的任何状态下都可以发送,包括空闲或关闭的流。 |
| RST_STREAM | 0x3 | 表达了发送方对流优先级权重的建议值,任何时间任何流都可以发送,包括空闲或关闭的流。 |
| SETTINGS | 0x4 | 设置帧,接收者向发送者通告己方设定,服务器端在连接成功后必须第一个发送的帧。 |
| PUSH_PROMISE | 0x5 | 服务器端通知对端初始化一个新的推送流准备稍后推送数据 |
| PING | 0x6 | 优先级帧,发送者测量最小往返时间,心跳机制用于检测空闲连接是否有效。 |
| GOAWAY | 0x7 | 一端通知对端较为优雅的方式停止创建流,同时还要完成之前已建立流的任务。 |
| WINDOW_UPDATE | 0x8 | 流量控制帧,作用于单个流以及整个连接,但只能影响两个端点之间传输的DATA数据帧。但需注意,中介不转发此帧。 |
| CONTINUATION | 0x9 | 用于协助HEADERS/PUSH_PROMISE等单帧无法包含完整的报头剩余部分数据。 |
针对不同类型的资源,HTTP2 进行了不同程度的优先传输。比如页面传输中的,script和link会被优先传输,而类似于图片这种较大的文件优先级则降低。
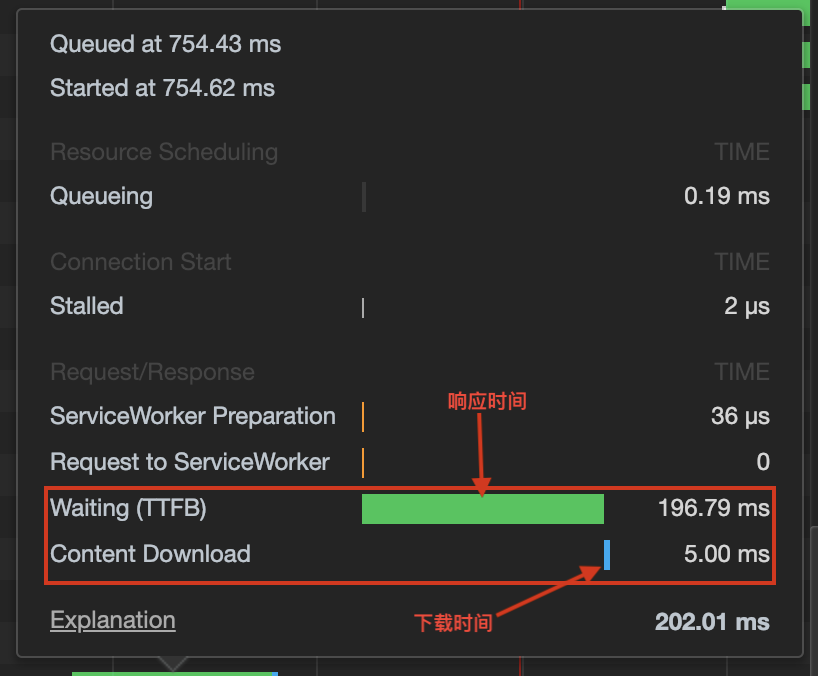
在 http1.x 中,我们可以直接在报文中看到报文头的内容,便于开发人员调试。但随着https 的普及,SSL 加密传输也是 plain text 变成了二进制,明文调试也不存在。

上图是我们尝试发送一个 hello world 字符串,整个数据体�加上报文头,一共超过了300个字符,浪费了很多的大小
header内容HTTP使用HPACK压缩来说压缩头部,减少了报文的大小。具体实现是将报文头中常见的一些字段变成一个索引值index,也就是维护一张静态索引表,例如把method:POST,user-agent,协议版本等,对应成一个index值。
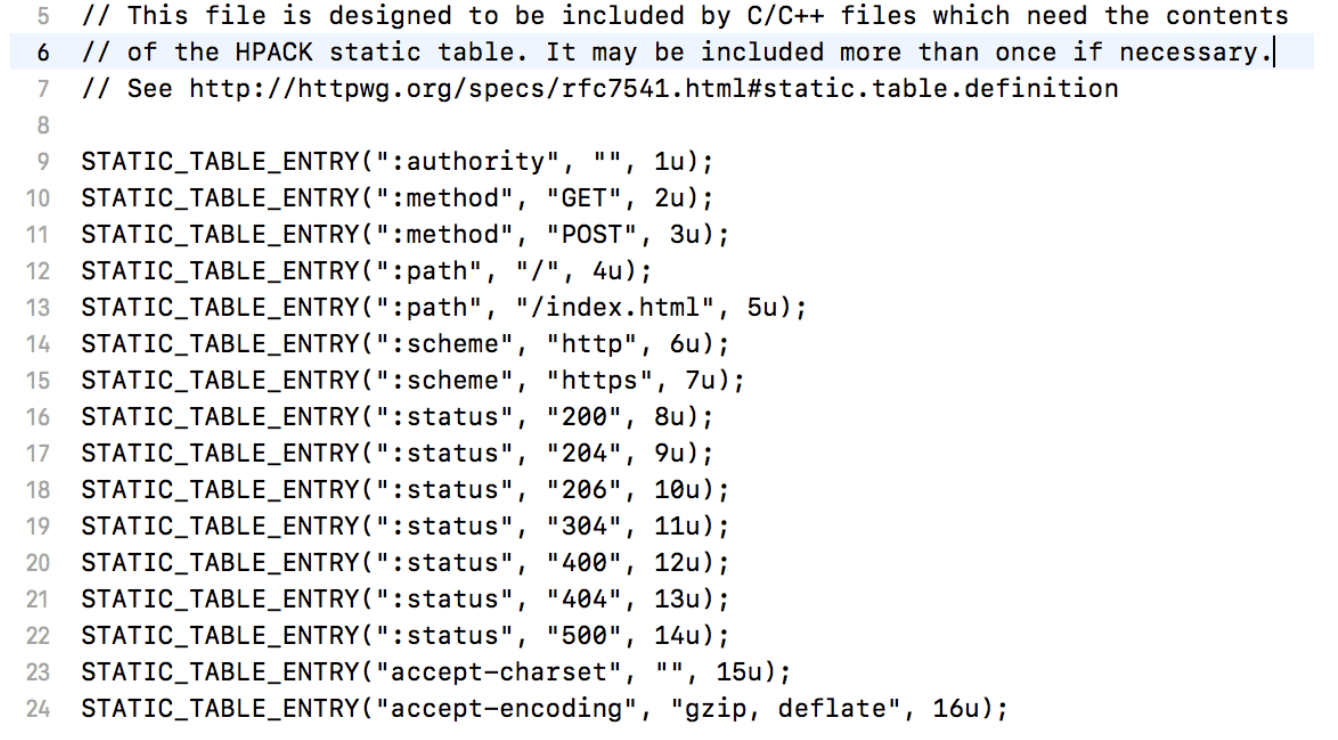
静态索引表是固定的。
浏览器下的系统目录下的 http2.0 静态表格
静态表格一共有61个常用字段搭配。
动态索引表功能类似于静态索引表,动态索引表的索引存放在静态索引表中。请求发现了新内容,则在动态索引表中建立新的索引。
那么我们的动态表格的索引,就从 62 开始计算。有新字段增加,就用最小的索引去记录它,而不是使用大的索引。
table_.push_front(entry);对于经常变化的内容,类似于“资源路径”,HPACK压缩则使用Huffman编码进行压缩。
因为请求的文件过大,超过一个TCP报文时,会被分成几个TCP报文进行传输,压缩能够有效的减少TCP传输的数目。
压缩规范格式为
key长度 + key + value长度 + value比如 Method:OPTION可以被翻译压缩为:
0206 6a6b 6f64 6a69在客户端请求想服务端请求过一个资源"A"后,而服务端"预先"知道,客户端很有可能也会需要另一个资源"B"。
那么服务端就会在客户端请求“B”之前,主动将资源“B”推送给客户端
## nginx 配置文件
location = /html/baidu/index.html { ## 表示在访问这个地址的时候
# 主动向客户端推送以下资源
http2_push /html/baidu/main.js?ver=1;
http2_push /html/baidu/main.css;
http2_push /html/baidu/image/0.png;
http2_push /html/baidu/image/1.png;
http2_push /html/baidu/image/2.png;
http2_push /html/baidu/image/3.png;
http2_push /html/baidu/image/4.png;
http2_push /html/baidu/image/5.png;
http2_push /html/baidu/image/6.png;
}根据上图的配置,客户端请求 /html/baidu/index.html 页面的时候,服务器不会马上返回页面的信息,而是首先将所配置资源以数据帧的形式,与客户端建立多条Stream。
这样可以有效减少资源所需的响应时间,而浏览器收到服务器的主动推送,就可以直接进行下载阶段。
“缓存推送”需要客户端显式地允许服务端提供该功能。即使允许了“主动推送”,客户端仍能够传送 "RST_STREAM" 帧来终止这种主动推送服务。
事实上呢,线上服务的静态资源都是托管于 CDN 的,想要享受 Server Push 的福利只能依赖于 CDN 服务商支持 Server Push 的功能。
frame,充分利用带宽http1.x 时代,强行将多个文件杂糅到成一个文件,分文件请求,使得文件缓存更有效命中。
[2] 从Chrome源码看HTTP/2
[3] HTTP2 帧的分类
[5] http2.0优先级
[6] Node HTTP/2 Server Push 从了解到放弃
[7] Exploring Differences Between HTTP Preload vs HTTP/2 Push
使用直接赋值的方式,我们得到的效果一般就是浅拷贝,因为复制的只是对象和数组的引用地址。
let a = {key:123};
let b = a;
b; // {key:123}
a === b; // true💎 常用方法:array.slice(0) 和 array.concat()
只对数组进行了第一层的完全拷贝,第二层以及内部若存在对象或者数组,则也都只是复制了对象的引用。
💎 常用方法:Object.assign
Object.assign拷贝的是属性值,假如源对象对属性是一个指向对象的引用,也只会拷贝那个对象的引用值。
let a = {key:124,aa:{key2:456}};
let b = Object.assign({},a);
b; // {key:123,{key2:456}}
b === a; // false
b.aa = {key3:789};
a.aa; //{key3:789};实现的效果仍然是首层内容的完全拷贝,对于第二层及以后都是只复制引用地址。
只复制第一层的拷贝,适用于只有单层内容(数组或者对象)的拷贝,速度快,不需要迭代。
深拷贝是要对对象以及对象的所有子对象进行拷贝。
使用JSON.stringfy() + JSON.parse进行转换
JSON.parse转换为JSON对象,并且分配一个新的对象。JSON.parse()这个方法,只能够正确地处理 Number、String、Array等能够被json格式正确表达的数据结构。但是,undefined、function、Symbol 会在转换过程中被忽略。在项目中我们要深拷贝一个复杂对象,首选的肯定是lodash的cloneDeep
let obj = {a:1,b:'xxx'};
let copyObj = JSON.parse(JSON.stringify(obj));使用方法很简单,源码的解读网上也有很多,这里就不赘述了,总体来说离不开以下几个关键点
// 判断是否复杂对象
const isComplexObj = data => {
const type = typeof data
return data !== null && (type === 'object' || type === 'function')
}
// 准确判断每一种对象的类型
function getType(target) {
return Object.prototype.toString.call(target);
}
// 判断是否复杂类型,需要继续深入递归
const isIterative = data =>{
let typeString = Object.prototype.toString.call(data);
const iterateTypes = ['[object Array]', '[object Object]', '[object Map]', '[object Set]']
return iterateTypes.includes(typeString)
}
// 获取一个一个复杂类型的原始值
const initComplexObj = data => {
const creator = data.constructor
return new creator()
}
// 拷贝方法主函数
const deepCopy = function(target, currentMap = new WeakMap()) { // 使用WeakMap,使得currentMap与其内部属性是一个弱用关系,占用的内存不需要手动去释放
// 处理原始类型
if (!isComplexObj(target)) {
return target // 原始类型不做多余处理,直接进行返回
}
// 初始化复杂对象的初始值
const cloneTarget = initComplexObj()
// 检测当前复杂对象是否已经被拷贝过了
if (currentMap.get(target)) {
return currentMap.get(target)
}
// 使用WeakMap记录当前对象已经被处理了
currentMap.set(target, cloneTarget) ;
// 注意: 可遍历对象中,所有子元素的类型我们不清楚,所以要不断调用cloneDeep来确定,这里就触发了递归的点
if (isIterative(target)) {
// 复杂对象 - 可遍历对象 - Map的处理
if (getType(target) === '[object Map]') {
target.forEach((value, key) => {
cloneTarget.set(key, deepCopy(value, currentMap))
})
return cloneTarget
}
// 复杂对象 - 可遍历对象 - Set 的处理
if (getType(target) === '[object Set]') {
target.forEach(value => {
cloneTarget.add(deepCopy(value, currentMap))
})
return cloneTarget
}
// 复杂对象 - 可遍历对象 - 数组、JS对象 的处理
for (let attr in source) {
cloneTarget[attr] = deepCopy(target[attr], currentMap);
}
return cloneTarget;
}
else {
// 复杂对象 - 不可遍历对象
// Symbol 这个笔者认为是伪需求,拷贝出来的另一个Symbol又有何意义呢
// Date 自己查查api吧,不难但是常见
// RegExp 通过 source属性拿到正则的规则
/** function
* 重点是要通过 func.prototype 去判断出是否箭头函数
* 若是则使用 eval去生成即可
* 若不是则通过正则解析出函数参数,通过new Function重新构造
*/
// ....... 还有好多其他类型不多说了
return cloneTarget
}
}深度拷贝算法是浏览器内核,某些API需要进行深拷贝时候的内部处理方法,暂未直接对外开放,但我们可以借用这几个API来实现深拷贝。先看看MDN的描述👇传送门
The structured clone algorithm copies complex JavaScript objects. It is used internally to transfer data between Workers via postMessage(), storing objects with IndexedDB, or copying objects for other APIs. It clones by recursing through the input object while maintaining a map of previously visited references, to avoid infinitely traversing cycles.
// target = obj
const {port1, port2} = new MessageChannel();
port2.onmessage = ev => resolve(ev.data);
port1.postMessage(obj);// target = obj
history.replaceState(obj, document.title);
const copy = history.state;当然,这部分知识不建议在生产中使用,权当是拓展自己的视野。
[1] The structured clone algorithm
[2] JavaScript 深拷贝性能分析 - 掘金
[3] lodash源码浅析之如何实现深拷贝
[4] 如何写出一个惊艳面试官的深拷贝?

Javascript的事件环,主要就在理解宏任务和微任务这两种异步任务
| 任务类型 | 事件类型 | 优先级 |
|---|---|---|
| 宏任务 | setTimeOut 、 setInterval 、 setImmediate 、 I/O 、 各种callback、 UI渲染 、messageChannel等 |
主代码块 > setImmediate > postMessage > setTimeOut/setInterval |
| 微任务 | process.nextTick 、Promise 、MutationObserver 、async(实质上也是promise) |
process.nextTick > Promise > MutationOberser |
我们常常把EventLoop中分为 内存、执行栈、WebApi、异步回调队列(包括微任务队列和宏任务队列)
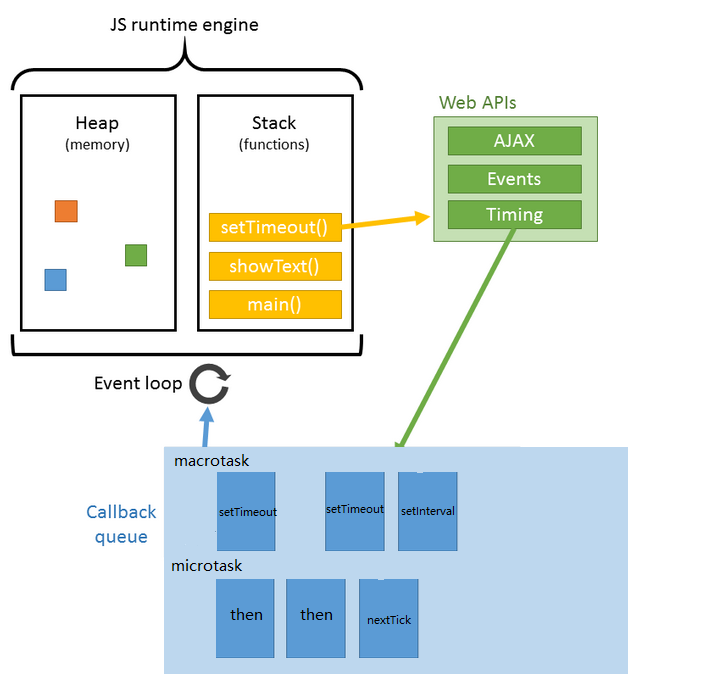
简单用代码表示一下过程
for (macroTask of macroTaskQueue) {
// 1. Handle current MACRO-TASK
handleMacroTask();
// 2. Handle all MICRO-TASK
for (microTask of microTaskQueue) {
handleMicroTask(microTask);
}
}1️⃣ Javascript内核加载代码到执行栈
2️⃣ 执行栈依次执行主线程的同步任务,过程中若遇调用了异步Api则会添加回调事件到回调队列中。且微任务事件添加到微任务队列中,宏任务事件添加到宏任务队列中去。直到当前执行栈中代码执行完毕。
3️⃣ 开始执行当前所有微任务队列中的微任务回调事件。 (:smirk:注意是所有哦,相当于清空队列)
4️⃣ 取出宏任务队列中的第一条(先进先出原则哦)宏任务,放到执行栈中执行。
5️⃣ 执行当前执行栈中的宏任务,若此过程总又再遇到微任务或者宏任务,继续把微任务和宏任务进行各自队伍的入队操作,然后本轮的宏任务执行完后,又把本轮产生的微任务一次性出队都执行了。
6️⃣ 以上操作往复循环...就是我们平时说的eventLoop了
综合一下....特点是
⭕️ 微任务队列操作,总是会一次性清空队列
⭕️ 宏任务队列每次只会取出一条任务到执行栈中执行
let promiseGlobal = new Promise(resolve=>{
console.log(1)
resolve('2')
})
console.log(3)
promiseGlobal.then(data=>{
console.log(data)
let setTimeoutInner = setTimeout(_=>{
console.log(4)
},1000)
let promiseInner =new Promise(resolve=>{
console.log(5)
resolve(6)
}).then(data=>{
console.log(data)
})
})
let setTimeoutGlobal = setTimeout(_=>{
console.log(7);
let promiseInGlobalTimeout = new Promise(resolve=>{
console.log(8);
resolve(9)
}).then(data=>{
console.log(data)
})
},1000) 建议不要直接拷贝到 控制台跑...大家先想想:smirk:
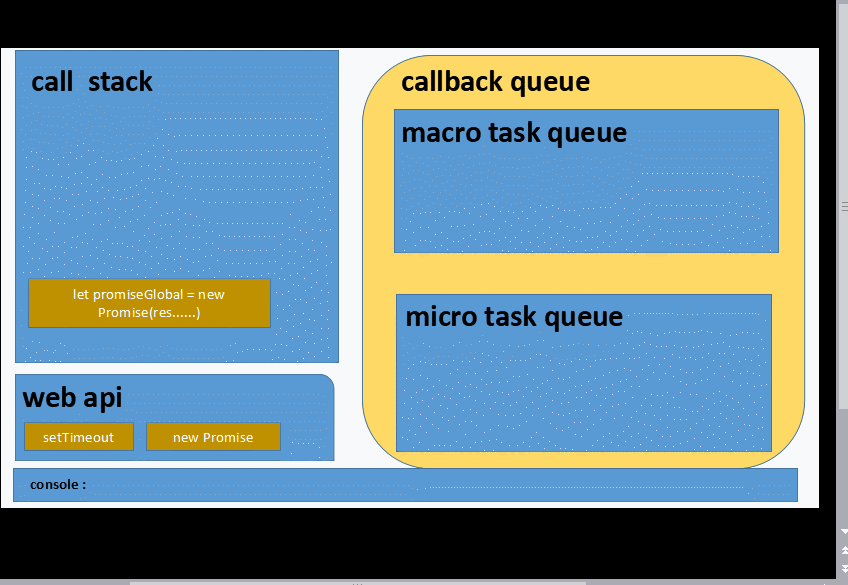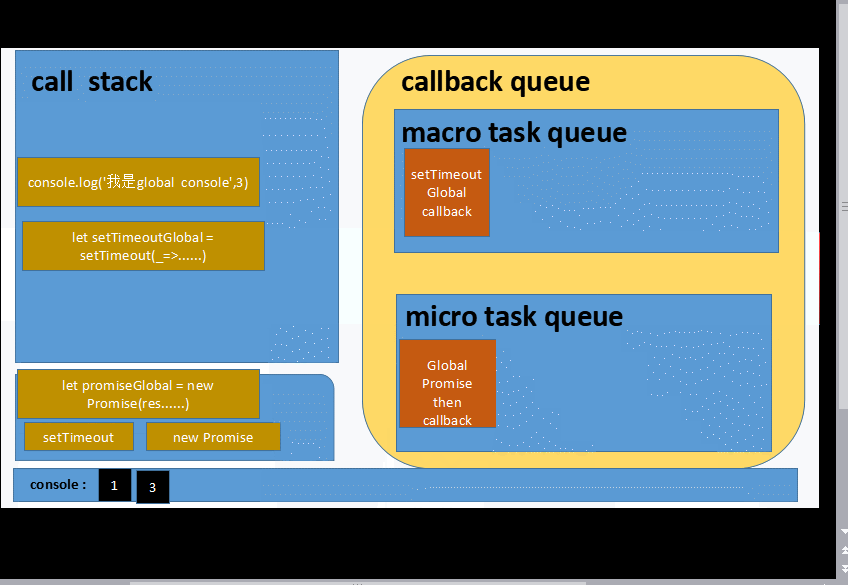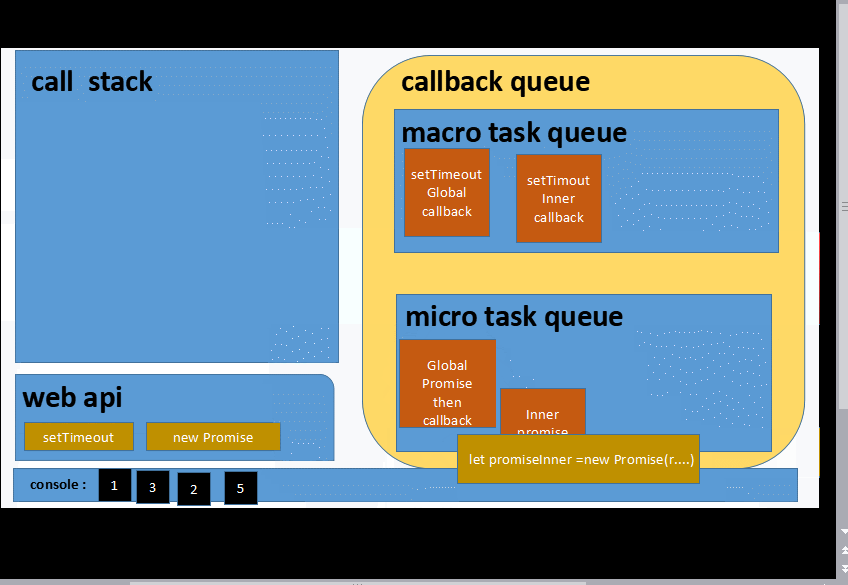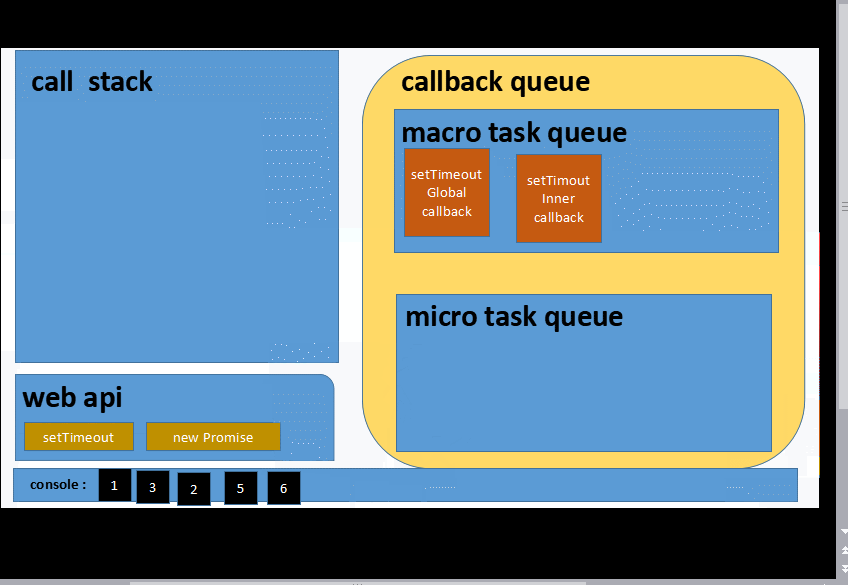
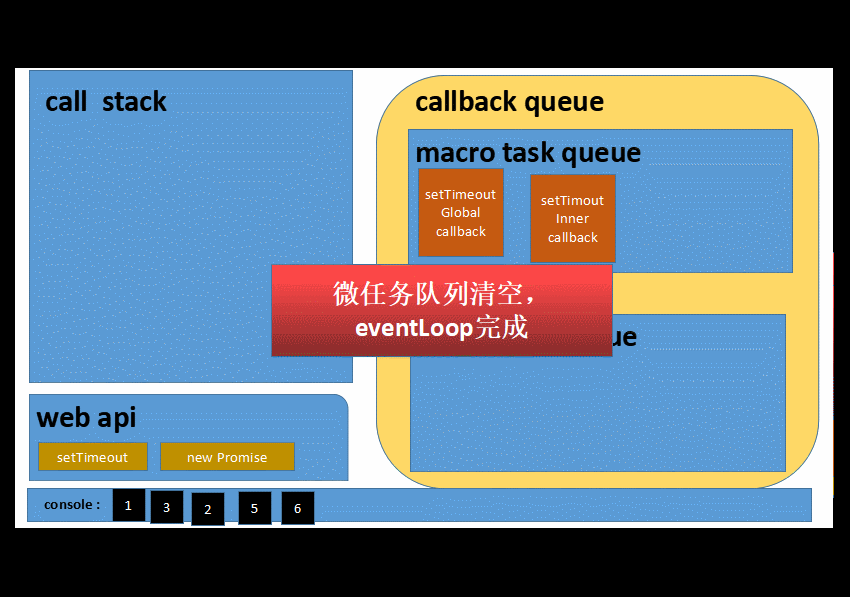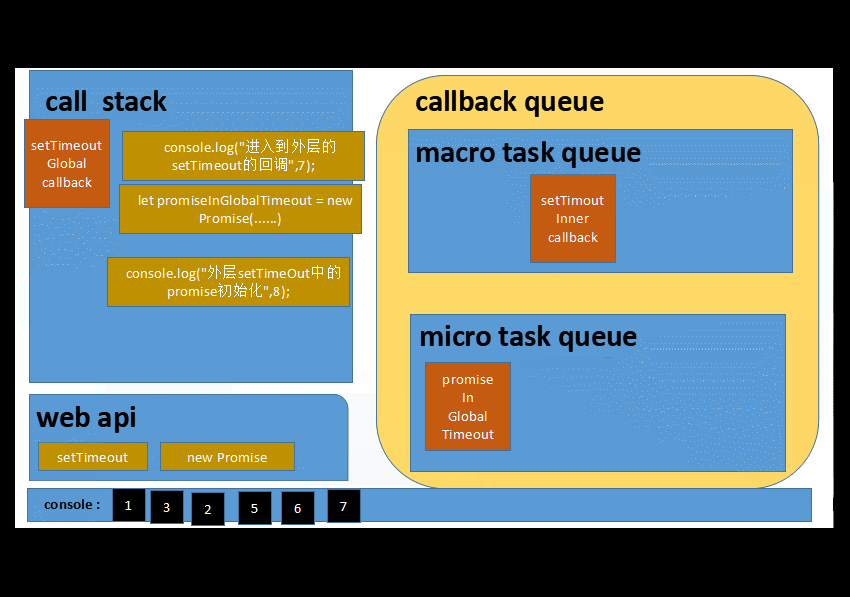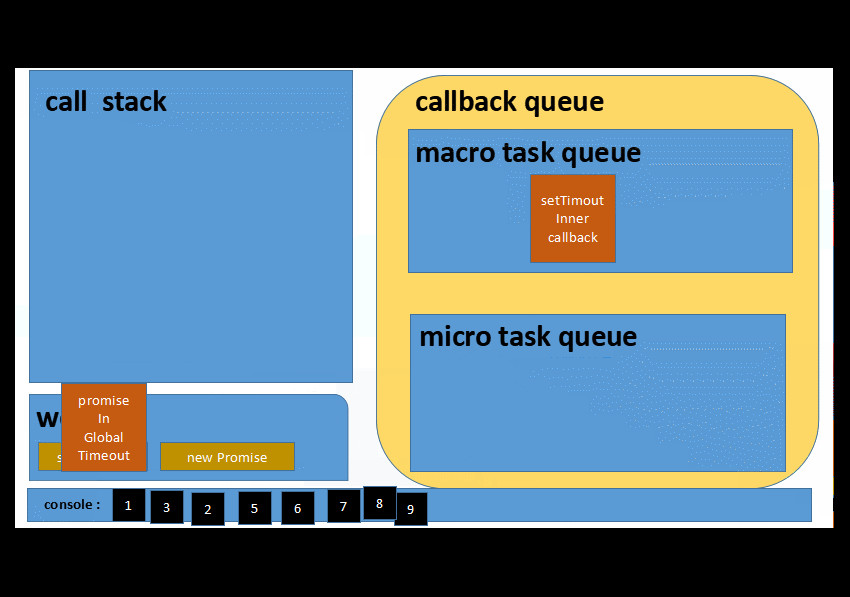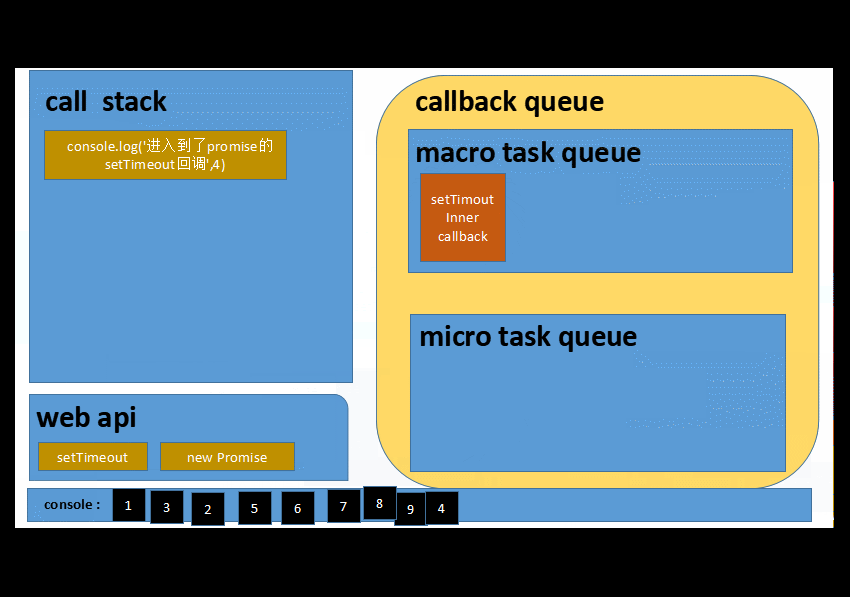
1 3 2 5 6 __ 等待一秒___ 7 8 9 4
let mc = new MessageChannel();
let p1 = mc.port1, p2 = mc.port2;
setTimeout(function(){
let pro2 = new Promise(resolve=>{
resolve()
})
pro2.then(data=>{
console.log('pro2');
})
},0)
console.log('first round');
p1.onmessage = function(data){
let pro3 = new Promise(resolve=>{
resolve()
})
pro3.then(data=>{
console.log('pro3');
})
console.log(data);
}
p2.postMessage("message form port2")
p2.postMessage("message form port2 second")
let pro1 = new Promise((solve)=>{
console.log('pro1 inner');
solve()
})
pro1.then(data=>{
console.log('pro then')
});
setTimeout函数到时间了,为啥一直不去执行。A: setTimeOut的回调会被放到任务队列中,需要当前的执行栈执行完了,才会去执行执行任务队列中的内容。出现setTimeout回调不及时,说明在执行栈中出现了阻塞,或者说执行代码过多。
A:常见的vue.$nextTick会把事件直接插入到当前微任务队列的中
[1] 实现异步的Api
[2] vue 的nextTick
[3] vue 的DOM更新机制
CommonJS 引入的是模块值一个拷贝ES 6 module引入的是暴露对象的引用,本质上是暴露了一个指向对应内存空间的指针,模块内部值改变,外部引用值也会改变。在模块中 CommonJS的this指向当前模块
而ES 6 module中this指向的是undefined。
同时,ES 6模块中也不存在
arguments、require、module、exports、__filename、__dirname这些对象
执行阶段也有import()语句来对补充空缺CommonJS加载模块使用的require()是同步加载的。ES6 Module中的import()方法,返回的是一个Promise对象,属于异步加载。文件名以.mjs结尾的文件,代码中可以出现import 或者 export等ES 6模块代码,Nodejs引擎也会将其当做ES 6 Module进行处理。
文件名以.cjs结尾的文件,Node.js引擎会将采用CommonJS加载该模块。
若文件后缀仅仅为.js,则需要搭配package.json配置文件中的type字段来标志自身的模块编写规范。
{
"main": "./dist/index.js", // 后缀没有指明是 cjs 还是 mjs
"type": "module" // 标明是ES6 模块
}Node.js版本 v13.2之后直接支持了ES 6 Module,可以采用package.json中exports字段,对模块入口进行指定。{
"exports": {
"require": "./main.cjs", // CommonJS 入口
"default": "./main.js" // ES 6 入口
}
}其原理是exports字段为.路径声明了一个别名,这里的.也就是指模块入口。
{
"type": "module",
"main": "./dist/index.cjs", // 用于 CommonJS 识别
"exports": {
"require": "./index.cjs",
"default": "./index.mjs"
}
}ES6 module加载CommonJS不能够做到单一输出的加载,只能够整体进行加载,因为CommonJS的模块化是运行时加载的,而ES6 Module则是在编译时进行的加载。
// moduleA.cjs
module.exports = {
bar: 123,
foo: 456s
}
// app.mjs
import { bar } from "moduleA.cjs" // error笔者最近到和朋友的讨论中,聊到了关于 微信扫码相关的设计流程:
大家可以自己先想想这个过程,去京东的授权页下打开 DevTools 看看
已知微信扫码登录设计是遵循 OAuth 2.0 协议 进行设计的,我们可以先从去深入了解 OAuth 2.0 的内容。
授权服务器 使用重定向的方式下发 code 时,有可能出现不使用 https 的安全请求方式的情况App Secret 进行加密,称之为 statecode 时,会将 state 参数进行解密, 并且扔回给第三方应用App Secret 进行加密还原,与自身本地存储的作比较整个过程相当于利用 App Secret,在第三方应用的角度,对授权服务器身份进行了确认
与上述问题类似,授权服务器 同样不能够确认请求授权的身份是否为签约的第三方应用,直接下发 Access Token 则过于草率。
授权服务器 会进行一次性票据的下发APP Secret,对 App Ids 和 下发的 code 生成一个加密内容,发送给授权服务器App Id 找到 App Secret 对应的私钥,并尝试对内容进行解密,若成功则标明发起授权方是合法用户Access Token 到第三方应用提供的页面使用一次性票据 code, 而不是直接下发 Access Token,相当于 授权服务器 与 发起授权的第三方 进行了一次认证,确保申请 Access Token请求到的发起者是经过事先签约的,而不是拦截了请求的攻击者。
Access Token 的结构是以 JWT 的形式而存在的,则资源服务器可以快速验证 Access Token的有效性,而不用通过访问 授权服务器 确认结果。大量减少了授权服务器的访问压力。Resource Server 作为资源访问的认证Access Token 的过期时间比较短
资源服务器 进行即可Refresh Token 由 授权服务器 下发,由 授权服务器 进行验证Refesh Token 是拥有较长过期时间的,不需要被设置无效Access Token 过期时,客户端使用 Refresh Token 向 授权服务器 获取一个新的 Access Token在 OAuth 体系中表示 下发的 Access Token 对应可以访问的资源范围。系统设计中,划分的标准一般为某个权限组、策略组。
用户选择 微信扫码登录 后,显示二维码的页面,我们着重关注两部分
将参数进行解析,使用 Javscript 代码进行表示
const url = 'https://open.weixin.qq.com/connect/qrconnect'
const url_query = {
appid: 'wx827225356b689e24&state',
state: 'C14C6845B4FD3C50F786170C53578D23B3528AEF1154F8304F333200F287D7351AA05BAF998CAE44DF27D76C4995B8B0',
redirect_uri: 'https%3A%2F%2Fqq.jd.com%2Fnew%2Fwx%2Fcallback.action%3Fview%3Dnull%26uuid%3Dbba3111a8de7458c9ff6c152e3bb9ee1',
response_type: 'code',
scope: 'snsapi_login'
}appid 应用唯一标识redirect_uri 授权成功时重定向的URL,请使用 urlEncode 对链接进行处理response_type 表示当前的权限下发方式,固定为 codescope 应用授权作用域state 用于保持请求和回调的状态,授权请求后原样带回给第三方。可用于防止csrf攻击(跨站请求伪造攻击),建议第三方带上该参数,可设置为简单的随机数加session进行校验
使用工具进行解码读取内容:
不难得出结论:
uuid用户扫码后,页面上二维码下方提示当前已进入了 等待确认 的状态。

但天知道用户啥时候才会进行 确认/取消 操作呢?好奇的我们打开浏览器的控制台
向服务器轮询当前扫码操作的结果。http 连接返回结果。

[1] https://zhuanlan.zhihu.com/p/110127600
[2] https://zhuanlan.zhihu.com/p/22325152
[3] https://zhuanlan.zhihu.com/p/109101311
[4] Access Token & Refresh Token 详解以及使用原则
[5] OAuth2.0 详解 - Dreamgoing
<meta pre-fetch> 二级页面DNS预查询
js,css混淆压缩
使用gulp grunt 或者 webapck等前端工具将多个js文件合并在一起
图片使用雪碧图
CDN服务商可以再离用户最近的云服务器上,部署所需要的静态资源,然后发送给客户。
key-css在首页展示的时候,将首屏关键的css提取出来,并使用内嵌的形式加入页面,剩余部分使用外链的形式。
HTTP 2.0改为使用单一TCP链接,数据的传输改为使用流的形式,充分利用了带宽,减少了RTT的次数。也消除了浏览器对同一个域下资源的同时请求只能存在6~8个的限制。(当然我们也可以在服务端,将不同的资源放在不同的服务器中)
强缓存可以有效地减少RTT次数,而协商缓存也能够有效地减少网络传输的负载。
尽量减小数据包的大小
将页面的多个接口在接入层进行合并,减少网络请求的次数。
首屏数据直接结合DOM�后,直接输出字符串到客户端,而不需要使用异步去请求数据。
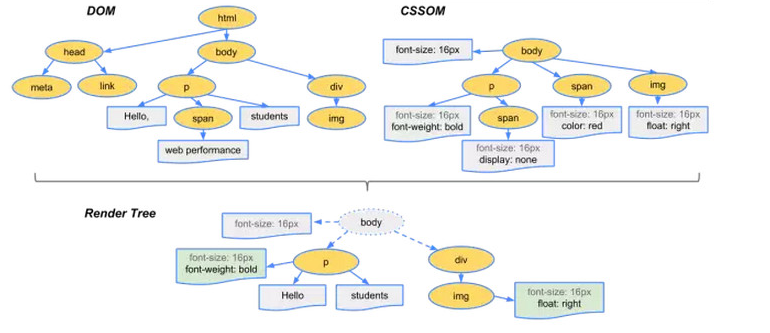
�因为浏览器的渲染规则,渲染页面需要CSS生成一个稳定的CSSOM,与DOM一起组成Render Tree。
而script的下载和执行都会阻塞UI的渲染,所以一般将script标签放到DOM结构末尾。
每一次我们使用选择器去获取DOM元素的时候,都需要经历一个查询的过程,时间不长,但是当批量操作出现的时候,�耗时就变得可观了。
let button = document.getElementByClassName('trigger-btn');
button.onclick = fucntion(){};
otherFun(button);
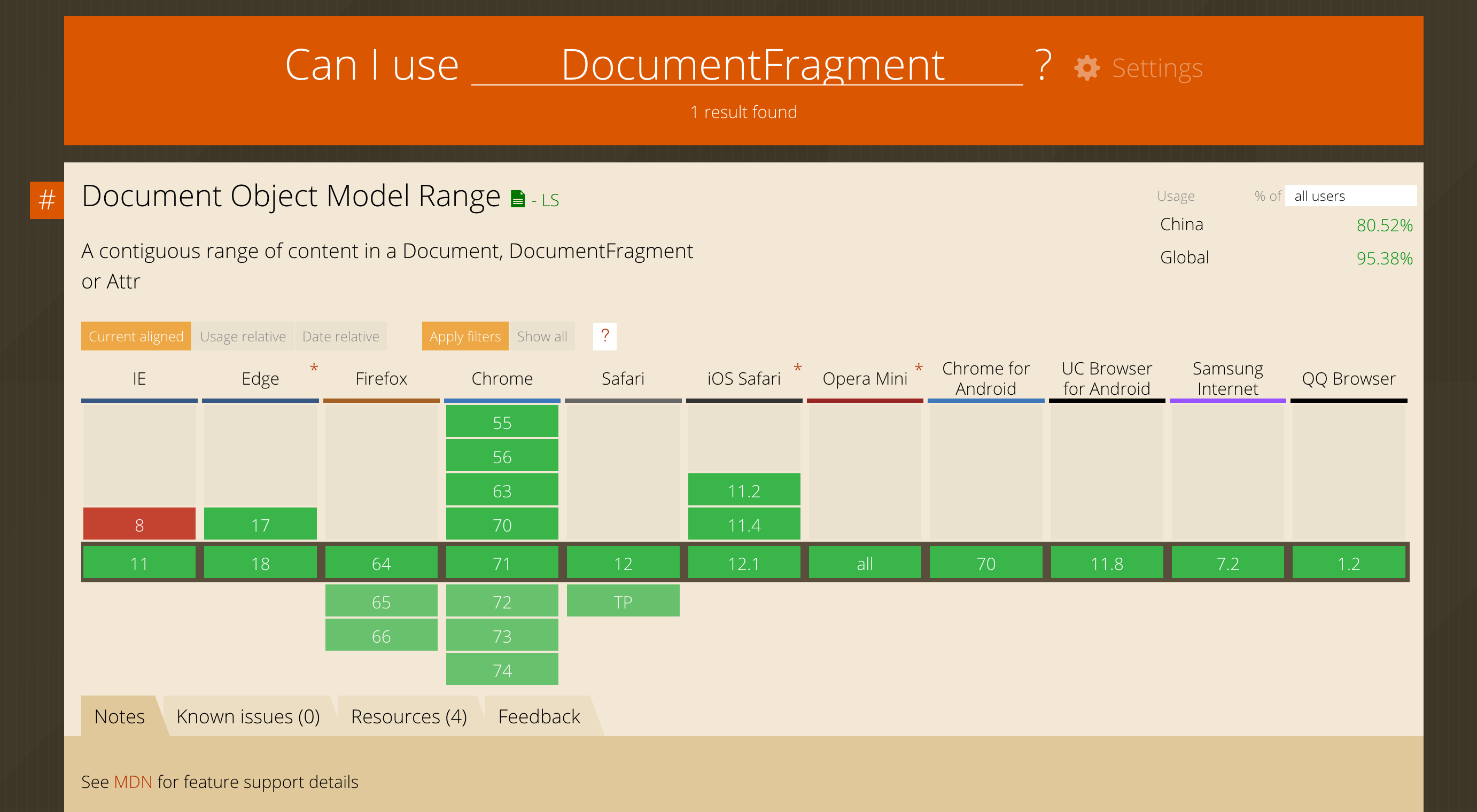
button.id = 'newId'; // 尽量复用前面的引用减少直接操作DOM的次数,也就是将DOM操作进行合并(使用DocumentFragment技术,mdn文档传送门👉
兼容性:IE系列基本不支持 Chrome>55 FF>64
原理就是这么个原理,但是经过大家的测试,貌似兼容性不太好,并且实验效果并没有提升多少效率,暂不推荐使用。
事件节流,频繁频繁的事件,一点要做节流处理,避免js的执行阻塞UI操作。
若后端使用的是node,我们还可以在加载较慢的主页面中,使用SSR直接在node拼装好前端也买�所需要的DOM和数据的结合体,直接交给浏览器渲染,而不用通过前端异步请求数据去渲染数据。�有效减少RTT次数。
VUE-SSR传送门👉
模块中有大量的图片加载时,大量图片同时挂在到节点上,浏览器UI渲染线程就会特别忙...抽不出空来执行其他UI渲染(页面假死),或者是其他Javascript�计算(内容延迟)。
使用图片的懒加载,有许多优秀的现成的工具,其原理是超出视窗(可以自定)范围的图片咱不挂在到DOM上,也就不会触发下载和渲染,等到用户滚动窗口,再根据视窗位置去挂载IMG标签,下载图片资源,渲染图片资源。
浏览器的渲染是单线程,Javascript的大量计算会阻塞UI渲染,使用新建web worker新开启一个进程来进行耗时的计算操作,可以大大减少对UI渲染的阻塞。
当页面�有大量DOM节点的时候,�大量使用范围选择器,会引起CSS选择器查询事件累计加长。
❤️ 性能优化需要数据作为支持,而前端的性能数据的收集,依赖于我们在项目中的埋点。
❤️ 建立数据分析平台,收集大量的监控数据,进行分析。
❤️ 根据分析结构优化代码,然后再继续监测。
[1] 页面优化与安全 - by 掘金
本文的主角是decorator,字面意思是装饰器。前端的同学大概都知道,它当前处于stage 2阶段(草案原文),可以用babel进行转码后进行使用。
使用过Angular 2或者Nest.js(或者Midway.js)的同学,一定对@Component、@Inject、@ViewChild和@get()、@post()、@provide()不陌生。
了解设计模式的同学,大概还记得修饰器模式这东西,也许至今也还分不太清楚它和代理模式的差别。
但这次,我们想要追本溯源,从AOP、IOC和descriptor这些东西说起,认识一下修饰器这个熟悉的陌生人。
在正文开始之前,我们先来一个需求,我们将陆续用不同阶段的思维去实现这个要求。
要求是:已知一个超过10几个人维护的代码,在不修改原函数的情况下,如何实现在每个函数执行后打印出指定内容的一行日志。
In computing, aspect-oriented programming (AOP) is a programming paradigm that aims to increase modularity by allowing the separation of cross-cutting concerns. It does so by adding additional behavior to existing code (an advice) without modifying the code itself, instead separately specifying which code is modified via a "pointcut" specification.
以上是维基百科对AOP的基本解释,主要着重于以下几点
横切关注点与中体业务的进一步分离。现有代码的基础上,通过在切入点增加通知的方式实现。与主体业务没有这么密切的代码对主题代码的入侵。了解过Javascript 高阶函数的同学,可能见到过以下方式对👆题目需求的实现。
// 注意在执行 after的时候,原函数也会被一并执行
Function.prototype.after = function(afterfn){
let _self =this;
return function(){
// 执行原方法
let result = _self.apply(this,arguments);
// 额外添加 after 函数的执行
afterfn.apply(this,arguments);
return result;
}
}实现过程本身不做过多解释,主要思维是将要添加的行为和目标函数(主函数)包装到了一起,实现了不对原函数(主函数)入侵的预期,但写法上仍不够优雅。
在《Spring实战》第四章中提到了
散布于应用中多处的功能(日志、安全、事务管理等)被称为横切关注点。
把横切关注点与业务逻辑分离是AOP要解决的问题。
在Spring中的AOP实现,给调用者的实际已经是经过加工的对象,开发者表面上调用的是Fun方法,但其实Spring为你做的是a + b + c --> Fun -->d + e + f 的调用过程。这里的abcdef都是函数动态的编入点,也就是定义中描述的pointcut。
我们称这种切入方式为运行时织入。
// 基本实现代码
try{
try{
//@Before
method.invoke(..);
}finally{
//@After
}
//@AfterReturning
} catch() {
//@AfterThrowing
}控制反转,是面向对象编程中的一种设计原则,可以用来减低计算机代码之间的耦合度。其中最常见的方式叫做依赖注入,还有一种方式叫“依赖查找”。通过控制反转,对象在被创建的时候,由一个调控系统内所有对象的外界实体,将其所依赖的对象的引用传递给它。
以上是来自于维基百科对”控制反转“的基本解释。那么,我们如何实现一个控制反转呢,需要了解以下几个关键步骤。
所谓IOC容器,它的作用是:在应用初始化的时候自动处理对类的依赖,并且将类进行实例化,在需要的时候,使用者可以随时从容器中去除实力进行使用,而不必关心所使用的的实例何时引入、何时被创建。
const container = new Container()有了容器,我们需要将”可能会被用到“的对象类,绑定到容器上去。
class Rabbit {}
class Wolf {}
class Tiger {}
// 绑定到容器上
container.bind('rabbit', Rabbit)
container.bind('wolf', Wolf)
container.bind('tiger', Tiger)const rabbit = container.get('rabbit')
const wolf = container.get('wolf')
// 对象的创建有可能是一个异步的过程,所以这里采用 getAsync 表示经过异步调用才能够完成的实例获取
const tigger = container.getAsync('tiger')在tc 39 - decorator原文中,笔者没有找到总结性的描述语句。这里分别引用Python和TS中对decorator这一特性的描述。
A Python decorator is a function that takes another function, extending the behavior of the latter function without explicitly modifying it.
Python装饰器是一种 能拓展另一个函数行为而不明确地修改原函数 的函数。
Decorators provide a way to add both annotations and a meta-programming syntax for class declarations and members.
装饰器(Decorator)是一种与类(class)相关的语法,用来注释或修改类和类方法。
Python - decorator中可以看出,其着重在extending与without explicitly modifying it上,基本上沿用了AOP的设计**。
类的装饰 、 类方法的装饰。从内向外执行function longHair(target) {
target.isLongHair = true;
}
// 金发女郎,一般都是长头发
@longHair
class Blonde {
// ...
}
Blonde.isLongHair // true// 修改 descriptor.writable 使得对象不可被修改
function readonly(target, name, descriptor){
descriptor.writable = false;
return descriptor;
}
class Blonde {
@readonly
name() { return `${this.first} ${this.last}` }
}我们把上面这一堆东西扔到babel中试了一下,得到以下内容。
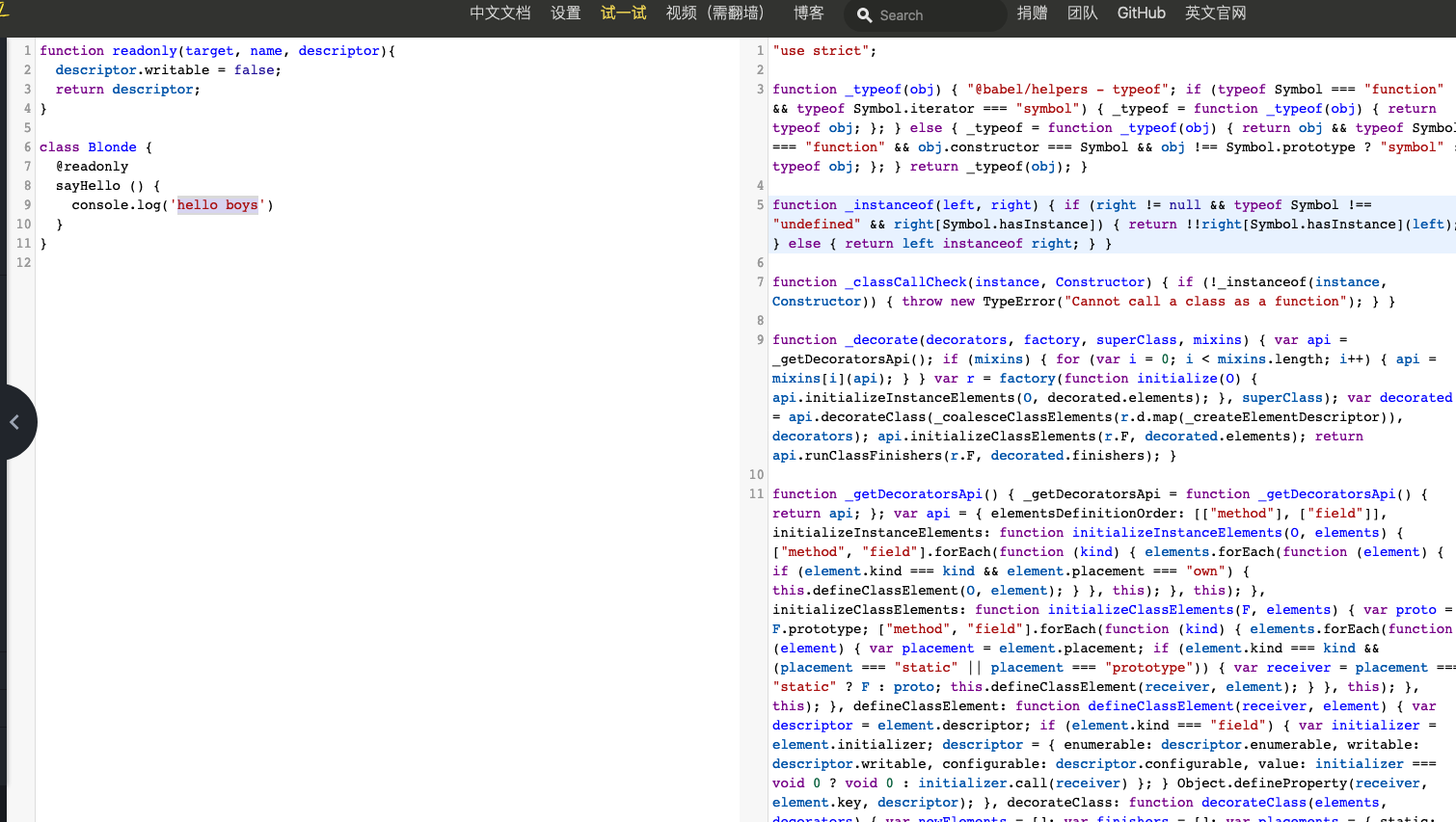
最后最显眼的地方出现了 Class 的 babel 实现,有兴趣的同学可以看这里的全部源码
// 对类本身的修饰
var Blonde = _decorate([longHair], function (_initialize) {
var Blonde = function Blonde () {
_classCallCheck(this, Blonde)
_initialize(this)
}
return {
F: Blonde,
d: [{
kind: 'field',
decorators: [readonly], // 对类方法的修饰
key: 'abc',
value: function value () {
return 12
}
}]
}
})
// 经过多次调用后......
for (var i = decorators.length - 1; i >= 0; i--) {
// 函数本身
var obj = this.fromClassDescriptor(elements)
// decorators 逐个被执行,传入的参数是一个类的模拟对象 { kind: 'class', elements: elements.map(this.fromElementDescriptor, this) }
var elementsAndFinisher = this.toClassDescriptor((0, decorators[i])(obj) || obj)
}从前面的转码实验看出 ,Decorator语法转为ES 5后,其实就是使用Object.defineProperty(target, name, description)进行的。
针对前面的例子,其实就是执行了。
let descriptor = {
value: function(){console.log('hello boys~')},
enumerable: false,
configurable: true,
writeable: true
};
// 此处也对应上述 babel 转码后展示的最后一行代码
descriptor = readonly(Blonde.prototype,'sayHello',descriptor)||descriptor;
Object.defineProperty(Blonde.prototype,'sayHello',descriptor);细心的你已经发现,decorator方法的参数 与 Object.defineProperty一模一样。这是因为Javascript中的decorator的设定就是后者的拦截器。
首先获取到原对象上的descriptor对象属性(非额外添加的那些),然后再执行修饰器自身,实现对原descriptor添加属性。类似于这样
function readonly () {
let descriptor = Object.getOwnPropertyDescriptor(constructor.prototype, 'sayHello')
Object.defineProperty(constructor.prototype, 'sayHello', {
...descriptor, // 保留原来的对象
writable: false, // 进行新的修改
})
}针对一开始的问题,我们也写一个Javascript版本的解决方案吧
const logger = type => {
return (target, name, description) => {
const originFun = description.value; // 取出原方法
description.value = (...args) => {
console.info('ready')
let ret
try {
ret = originFun.apply(target, args) // 执行方法,并将this指向原函数
console.log('excuted success')
} catch (err) {
console.log('excuted error')
}
return ret
}
}
}看完了上面的内容,我们只要简单地回想一下代理模式的定义,就能轻松梳理出二者的异同点。
代理模式: 为其它对象提供一种代理以控制对这个对象的访问。
实际应用: 图片代理下载、缓存计算等
装饰模式:动态地给一个对象添加一些额外的职责。
实际应用:日志模块、模块鉴权等
区别有以下几点:
更详细的例子,推荐参考这篇文章
我们日常开发中,还会有一些功能用Decorator能够优美的实现,比如类型检查、单位转换、字段映射、方法鉴权、代替部分注释`等。
midway.js 封装了许多装饰器,部分是用于实现IOC,如 @provide与@inject
import { provide, inject } from 'midway' // 这里 midway 也是转发了
@provide()
export class FlowerService {
@inject()
flowerMobel;
async getFlowerInfo () {
return this.flowerModel.findByIds([12,28,31])
}
}
// 封装了和 koa-router 所支持的多种请求方法相对应的修饰器
@get、@post、@del、@put、@patch、@options、@head、@all依赖注入只是IOC思维实现的一种表现,而装饰器只是依赖注入的一种实现手段。[1] �我们来聊聊装饰器 -by 讶羽
[2] JS 装饰器实战 -by 芋头
[3] ES6 教程 -by 阮一峰
[4] ES7 Decorator 装饰器 | 淘宝前端团队
[5] 什么是面向切面编程AOP? - 柳树的回答 - 知乎
执行环境 ➡️ 作用域链 ➡️ 变量对象
每个执行环境都有一个[ [scope] ]变量,指向对象的的作用域链,作用域链上的每个栏位都存放着对应的函数空间的变量对象。
函数在创建的时候,会创建一个执行环境(excution context)对内部对象,他定义了一个函数执行时的环境
函数每次执行时,执行环境都是独一无二的,多次调用就有多个执行环境。每个人执行环境都有自己的作用域链,用于解析标志符
每个执行环境都有一个与之关联的变量对象(variable object),环境中定义的所有变量和函数都保存在这个对象中
全局环境是最外围的一个执行环境,随着ECMAScript的真实环境变化而变化,常见的是global和window
某个执行中的代码执行完毕,该环境被销毁,保存在其中的所有变量和函数定义也随之销毁。
[ [scope] ]和执行期上下文虽然保存的都是作用域链,但是不相同。[ [scope] ]属性在函数创建的时候产生,会一直存在每个函数都有自己的执行环境,每当执行流进入一个函数时,当前函数的环境就会被推入一个环境栈中。当函数执行完后,栈将其环境弹出,把控制权返回给外层执行环境。
[[SCOPE]]上。[[scope]],并把当前函数的活动对象,追加到取出的全局对象中,形成新的作用域链,再次存入[[SCOPE]]。在ES6的let之前,javascript是没有块级作用域的
if(false){
var abc = 123;
}
console.log(abc)使用var的abc声明提升到了作用域顶端,这里的所谓if作用域是不存在的,其实就是�外层的顶级作用域。
var name = "Andy";
function changeGlobalName(){
let innerName = "innerName"
name = "Jacky"
function changeInnerName(){
let tempName = "innerInnerName";
innerName = "changeByInnerInner"
}
changeInnerName()
}
changeGlobalName()执行环境 与 作用域链window (name changeGloalName)
:arrow_up: :arrow_up:
changeGlobalName (arguments inner changeInnerName)
:arrow_up: :arrow_up:
changeInnerName (arguments tempName)
⬆️
Javascript的作用域只有:全局作用域和函数作用域。with 和 catch 语句。在严格模式下,with是被禁止使用的。全局环境只能够访问全局环境中定义的 变量 和 函数,而不能直接访问局部环境中的任何数据;
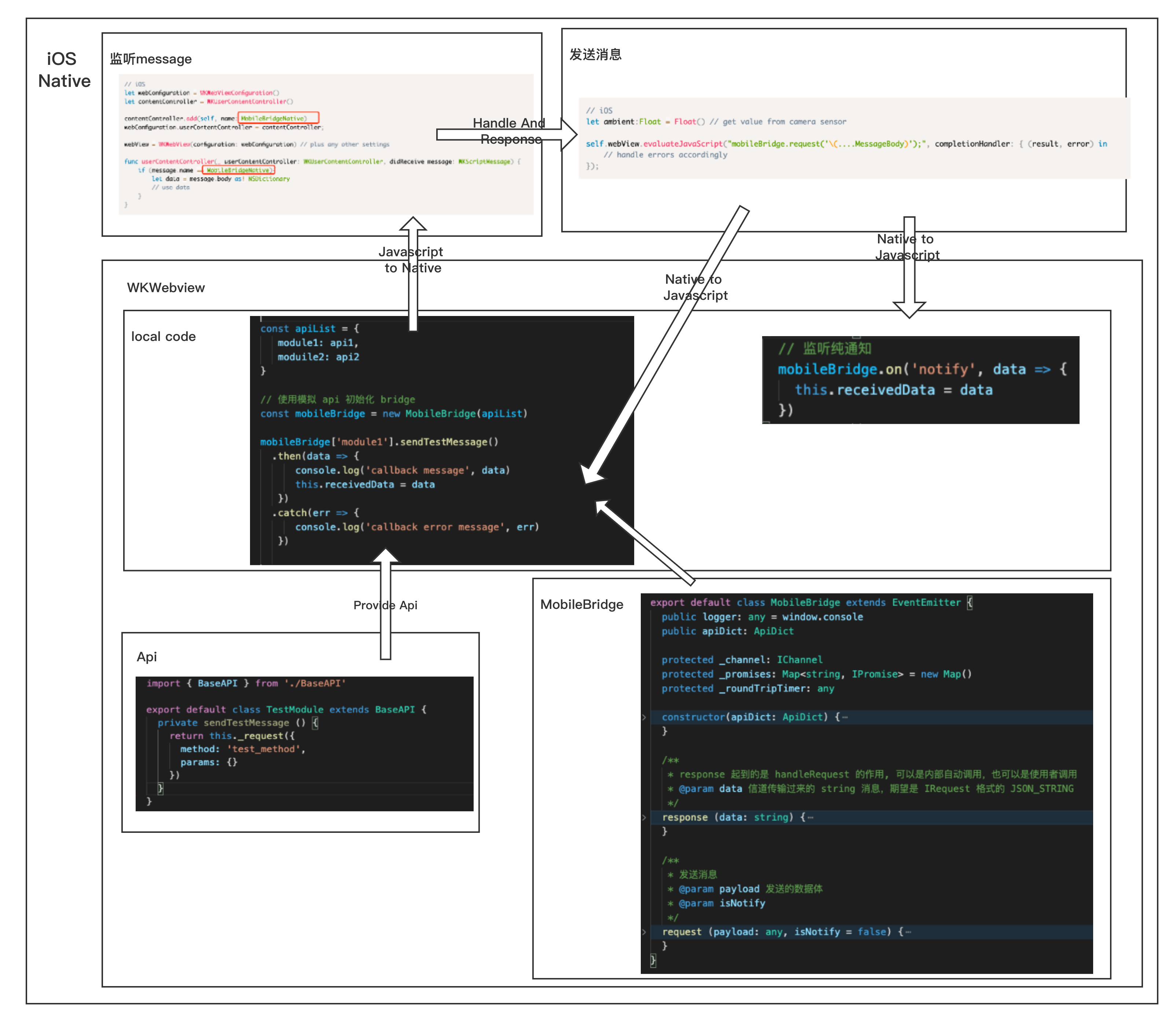
一个客户端webview中加载的h5应用与Native通信工具,持续完善中....传送门 👉👉
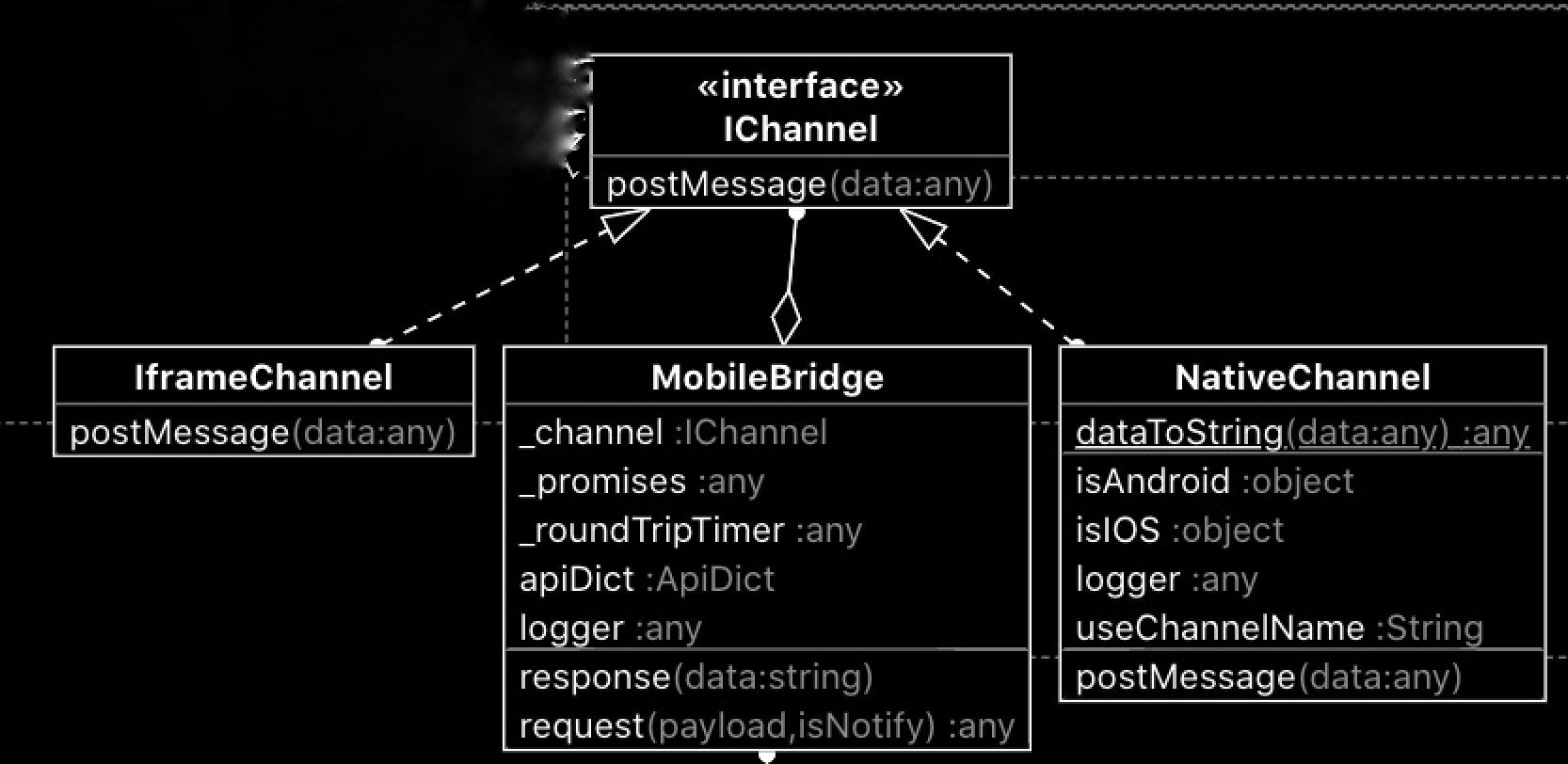
[1] window.postMessage - MDN
[2] logger-level - github
[3] webpack - ts-loader
[4] JavaScript WebView and iOS
[5] JSON-RPC 2.0
最近在做一个行情模块,后端同学建议直接上websocket练练手,也符合业界基操。这里就记录一些开发中遇到了一些问题,聊一聊解决方案。这里不再去一点点陈列websocket的知识点,主要会围绕项目的痛点来说。
ps: 食用本文时,建议出发点需要向下沉,从传输层开始思考,做类似http(应用层)需要完成的事。
| 端 | 语言 | 框架(lib) | 环境 |
|---|---|---|---|
| 后端 | Go | gin | CentOS |
| 前端 | TS | axios | 浏览器 |
项目当前的前后端选型如上表,因为websocket是一个基于tcp的应用层协议,就像http客户端服务器约定的请求头、响应头、cookie等约定,和一发一收交互形式,websocket在使用的时候相当于将这部分约定的权利,重新交给了我们开发者。
那么如果考虑使用websockt的lib进行项目构建时,则需要考察该方案在两端是否都有实现的方案,
| 框架(lib) | 服务端支持(Go) | 浏览器支持 | 周下载量 | 包大小 | 其他 |
|---|---|---|---|---|---|
| socket.io | ✅ go-socket.io | ✅ | 3,309,990 | 55.9 kB | 支持策略退化到Polling |
| ws | ✅ | ❌ | 25,770,149 | 110 kB |
因为这次的模块是websocket尝鲜,所以没有考虑太多,最后决定前端这边使用浏览器原生支持Websocket对象,根据这次的要求进行简答的封装,先趟趟坑,正式上线后再慢慢考察框架。
开工前,几个前端小伙伴做到了一起,提出了自己对这个SDK的期望。
websocket还是http,请自己在接口层封装好。lib,req和res的interceptor还是要有的吧。axios都习惯了,接口返回的是一个请求的Promise,这次也最后保持一致吧办公室不大,后端的同学也听到了讨论,附和到:
信道复用实现无刷新请求。可别忘啦,后期我们还是要做服务端消息推送的。deadline了...嘚嘞,上马开工...
项目当前的鉴权是依赖用户登录后,服务端下发用户token到cookie中,搭配header中的某个字段进行使用。
由于websocket在传输数据的时候,并不存在和http协议一样的cookie、request header机制。但信道建所用的请求,仍是http请求,你也一定见过这个请求的报文。
const crypto = require('crypto');
// 生成 websocket AcceptKey
function generateAcceptKey (websocketReqKey: string): string {
const magic = '258EAFA5-E914-47DA-95CA-C5AB0DC85B11';
return crypto.createHash('sha1')
.update(websocketReqKey + magic)
.digest('base64');
}const headerParser = require('parse-headers')
const server = net.createServer(socket => {
socket.on('data', async chunk => {
const headers = headerParser(Buffer.from(chunk).toString())
// 检测到是 websocket 建立信道的请求
if (headers['upgrade'] && headers['sec-websocket-key']) {
const secWebSocketAccept = generateAcceptKey(headers['sec-websocket-key'])
const cookies = header['cookie']
// 请求用户服务身份验证
const authorized = await checkAuth(cookie.authToken)
if (authorized) {
socket.write('HTTP/1.1 101 Web Socket Protocol Handshake\r\n' +
'Upgrade: WebSocket\r\n' +
'Connection: Upgrade\r\n' +
'Sec-WebSocket-Accept: ' + secWebSocketAccept + '\r\n' +
'\r\n');
} else {
socket.write('HTTP/1.1 403 Unauthorized\r\n' +
'\r\n');
}
} else {
socket.write('data')
}
})
}).listen(serverConfig.port, serverConfig.host);ps: 对应的框架实现,可以参考ws - npm模块的verifyClient的用法,传送门👉
数据传输时的鉴权建议基于信道建立时鉴权的方案,用户第一次认证后,回传给客户端一个类似token的令牌,用户在每一次使用websocket进行数据传输时,则需要回传这个token到服务端进行验证。
ps: 没有什么神秘的,这里其实相当于实现了个手动cookie。
首先说明一点,心跳机制在RFC协议中没有做规定,原则上一个连接可以无限制时间去连接,但是我们知道,服务器的内存、打开文件数量是有限的,特别是需要在同一个时间服务更多用户,则需要及时发现并断开那些已经不在线、不活跃的连接。
ps: 比如做一个内部系统、公司大屏什么的,连接数不多,可以不需要心跳机制也行。
const ws = new WebSocket("ws://localhost:9527")
// 大家都喜欢的 ping-pong
ws.send('ping')
// 获取接口版本号来保活
ws.send({
jsonrpc: '2.0',
method: 'version',
data: null
})socket.on('data', data => {
if (data === 'ping') {
resetTimer() // 重置断开计时器
socket.send('pong') // 发送心跳返回
}
})项目开发完的总结会中,查看日志才发现webscoket连接从未因为达到过上限10 min未发送心跳包而断开,倒是发现不少60 s断开的日志。后端同学恍然大悟 ---- nginx。
proxy_read_timeout 90;
为了可以统一在业务代码中处理心跳机制,而不是通过nginx来实现,所以我们将针对websocket请求的nginx配置调整了一下
http {
server {
location /ws {
root html;
index index.html index.htm;
proxy_pass xxx.xxx.xxx.xx:9527;
proxy_http_version 1.1;
proxy_connect_timeout 4s;
proxy_read_timeout 700s; # 需要比业务心跳更长一点
proxy_send_timeout 12s;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "Upgrade";
}
}
}
你一定知道客户端关闭webcsocket的close语句
// client
const ws = new WebSocket("ws://localhost:9527")
ws.close() // 关闭连接
// server
const wss = new WebSocket.Server({ port: serverConfig.port });
wss.on('connection', function connection(ws) {
ws.on('close', function (message) {
console.log('websocket peer closed', message) // websocket peer closed 1005
})
})但是在各个种情况下断开的websocket,对端又是否能够正常知晓呢?
| 关闭场景 | 出现情况 | 己端是否知晓 | 对端是否知晓 | 备注 |
|---|---|---|---|---|
ws.close() |
程序代码主动关闭 | ✅ | ✅ | |
刷新浏览器 |
程序上下文丢失 | ❌ | ✅ | |
关闭浏览器1 |
用户点击关闭浏览器 | ❌ | ✅ | |
关闭浏览器2 |
kill 命令杀死浏览器进程 |
❌ | ✅ | |
突然断网 |
手痒拔网线 进电梯 |
❌ | ❌ | 心跳机制超时、nginx 设置超时才会被发现,若在超市范围内重新发送了心跳,则相当于没有断开过 |
若是项目验证身份的token是保存在cookie中的,并且我们知道websocket的信道建立是要通过http协议的upgrade完成的,那么也就存在浏览器中的CSRF问题。
跨域资源共享不适应于 WebSocket,WebSocket 没有明确规定跨域处理的方法。
也就是说在浏览器层面,不需要跨域访问的资源的服务器返回Access-Control-Allow-Origin的Response Header,数据仍然能够正常返回并且解析。
针对普通的CSRF问题,先前的做法是在接口的HTTP请求头中,添加自定义的请求签名自定义头字段。这样做可以基本做到发起请求的页面,是出自我们自己的业务代码,而其他伪造请求的代码,会因为得不到签名字段而被后端拦截掉。
相同的,也想在websocket 信道建立的请求中照葫芦画瓢。
但实践中发现,不同于http请求,websocket请求的http Connect-upgrade请求是浏览器内部发出的,市面上常见的浏览器都不支持我们对请求头进行编写、拓展、删除。
所以这个方法行不通。
来了看看rfc是如何建议我们解决问题的吧

其中蓝色部分已经支出,我们可以通过信道建立的http请求的origin字段进行校验,服务端可以直接拒绝掉非本站点发起的请求。
这次的项目虽然只是web,但我们进一步司考,若发起请求(重放请求)的攻击方环境并不是浏览器呢?是客户端,甚至是脚本拦截请求后的重放呢?
这时候,我们就需要给信道建立的http请求加上更加严格的束缚 - 一次性过期的Token。
可行的实际过程可以是:
这里补充说一下websocket请求头中的一些字段,算是项目安全决策的一些辅助知识。
Sec-WebSocket-Key: 是随机的字符串,用于后续校验。Origin: 请求源Upgrade: websocketConnection: UpgradeSec-WebSocket-Accept: 用匹配寻找客户端连接的值,计算公式为toBase64(sha1( Sec-WebSocket-Key + 258EAFA5-E914-47DA-95CA-C5AB0DC85B11 ) )258EAFA5-E914-47DA-95CA-C5AB0DC85B11 为魔术字符串,为常量。若计算不正确,或者没有返回该字段,则
websocket连接不能建立成功
websocket是基于tcp上的应用层协议,http遇到的问题websocket都会遇到,鉴权、保活、签名,这些在http都有现成基础可以操作,在websocket都需要使用者进行设计实现。
本文了解了websocket与后端部分传输信道的问题,下一篇则会着重讲讲如何实现一个简单的符合业务需求的websocket请求lib。
[1] 深入理解跨站点 WebSocket 劫持漏洞的原理及防范
[2] How to Use Websockets in Golang: Best Tools and Step-by-Step Guide
[3] WebSocket 的鉴权授权方案 - Mo Ye
[4] RFC - The WebSocket Protocol
软件项目开发在团队协作的情况下,总体的输出效率并不取决于你对项目难点的处理,更取决与你对整个流程的认识程度,以及对正确工作流的贯彻程度。
以下内容是站在一个前端开发者的角度,对整个工作留的梳理。请搭配另外两篇笔记《质量提升 之 日常开发规范沉淀》 和 《效率提升 之 小团队测试流程优化》进行食用。
方案耗时 实现难度 进行调整开发经验沉淀Api文档上的参数与返回值进行处理(模拟数据时基本处理过了)。pull request的提审安排,别让代码审查过度影响发布进度Sentry 上报记录分析用户问题工作流程的打磨是是积月累的,在实际的项目开发中,特别是在高压项目之下,能够做到灵活调整,与贯彻实施的平衡,才是真功夫。
有什么好的建议和想法,请在下面留言吧🤔
在了解Node.js内存的分配的时候,堆外内存是一个神秘的存在,仅知道它是通过Node.js中的C++代码向内存申请使用的。这其中最具代表的必须要数Node.js中的Buffer和Stream了。
Buffer字面的意义是缓冲区,暂存器,了解过操作系统组成原理的同学一定不会陌生。在计算机中,缓冲器是存储变量,方便CPU直接读取的一款存储区域。而Stream则是类比数据字节的顺序的移动像是水流一样。
作为前端工程师,在进阶学习Node.js时遇到Buffer常常比较陌生,因为虽然同是Javascript,但在浏览器场景下处理文件流、视频流是相对比较少的情况,而服务端Javascript的情况恰恰相反。
Buffer 对象用于表示固定长度的字节序列。 --- 《Node.js文档》
Buffer是一个像Array的对象,但它主要用于操作字节。 --- 《深入浅出Node.js》
Buffer类似于数组,可以使用下标访问,并且有length属性。Buffer每一个元素都是一个两位的十六进制数。
const buff = Buffer.from('swain wong')
console.log(buff) // <Buffer 73 77 61 69 6e 20 77 6f 6e 67>Buffer可以和String进行相互转换,并且可以指定字符集编码。Buffer格式的内容更便于在网络中传输,而String形式的内容更便于进行修改操作。Buffer 是一个典型的Javascript 与 C++ 结合的模块,它将性能相关部分用 C++ 实现,将非心梗相关部分用
Javascript实现。 --- 《Node.js 深入浅出》
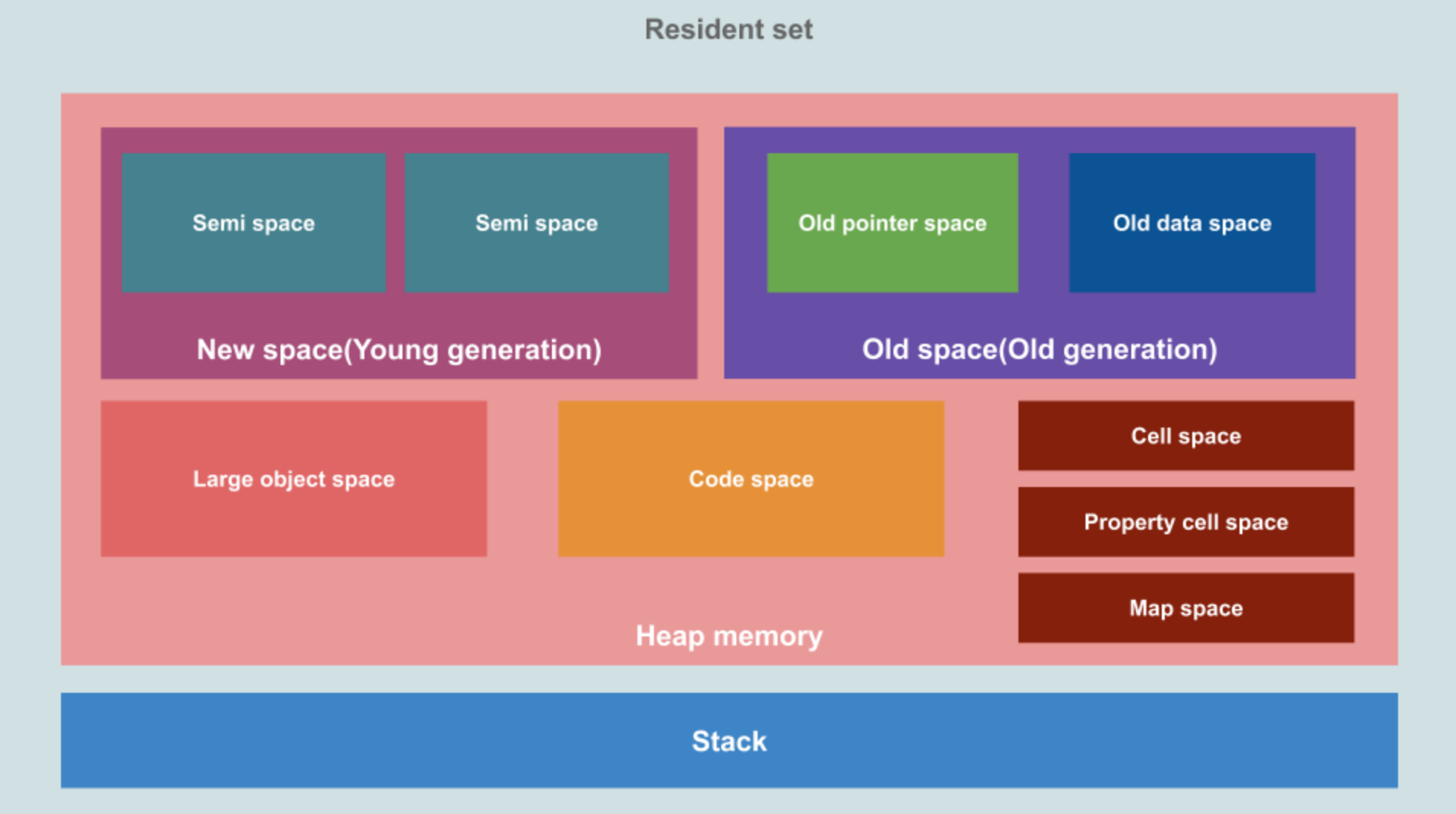
Buffer所占的内存并不受V8所支配,属于堆外内存,但包含在RSS之内。8 KB来界定大对象和小对象
流(stream)是 Node.js 中处理流式数据的抽象接口。 stream 模块用于构建实现了流接口的对象。 --- 《Node.js官网文档》
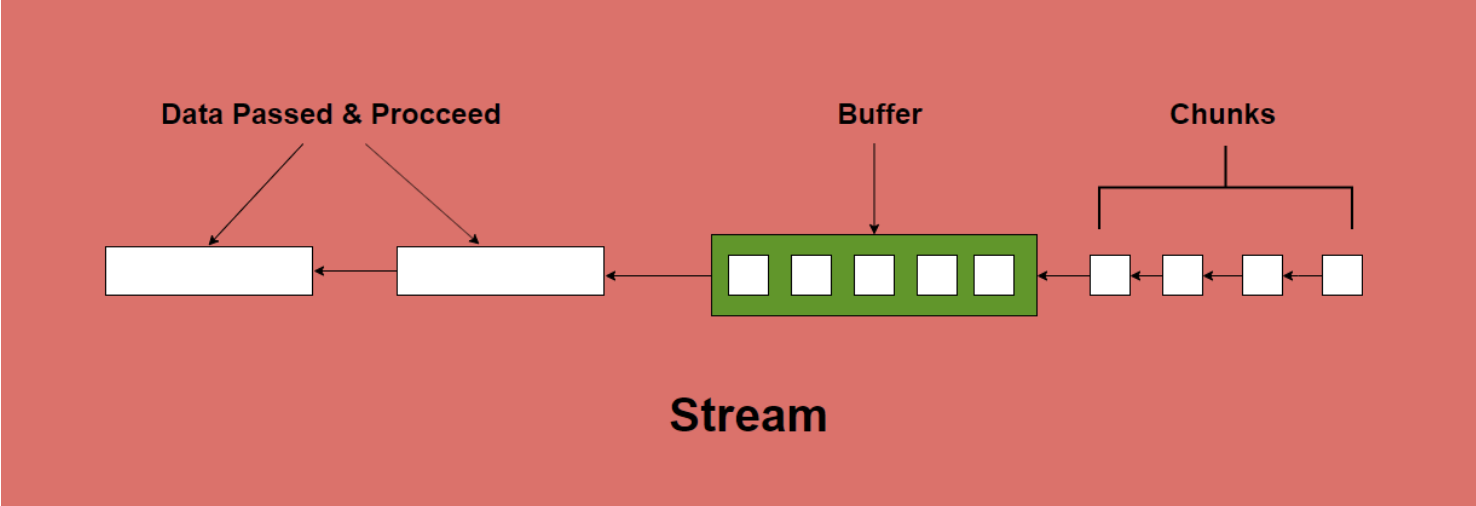
数据的流动就像是生活中水的流动褨,流是可以描述所有常见输入-输出类型数据的统一模型。就像是水流有方向,数据的排列也有方向性一样,数据流本身也具有方向性,对于某一端可写,对于另一端边仅仅可读了。
| 流种类 | 具体实现 |
|---|---|
| Writable Stream | HTTP Request(client) HTTP Response(server) fs write stream |
| Readable Stream | HTTP Response(server) HTTP Request(client) fs read stream |
Duplex 既可读又可写的流 |
TCP Sockets zlib streams crypto streams |
Treansform 在读写过程中即可以修改或者转换数据的Duplex流 |
zlib streams crypto streams |
在Node.js的API设计中,Stream被设计为事件驱动相关的,继承实现了EventEmitter。四种基本的Stream都包含有close、error、data、finish的接口用于流数据的读取。
fs 模块可用于与文件系统进行交互(以类似于标准 POSIX 函数的方式)。 --- 《Node.js官方文档》
不难看出,从Buffer到Stream再到fs模块,对数据处理的粒度是越来越大的。而Node.js在fs模块的实现上确实也是继承了上述两个模块的api来实现的。
Stream的文件流,对外暴露fs.createReadStream与fs.createWriteStreamfs.readFileSync与fs.writeFileSyncfs.readFile与fs.writeFilefs处理文件的形式,区别在于第一种的处理会将文件处理为流的形式。第二种会将文件视作一个整体,统一为整个文件分配内存大小,并将内容放入到一个大的缓冲区中。Buffer、Stream与file在后端中是很成熟的概念,且不说Node.js在服务端处理文件流的底层逻辑,仅Node.js作为前端工具链对前端文件进行打包的时候,最基础的步骤就是:读取文件内容 ==> 处理文件内容 ==> 生成处理后的内容。了解Buffer、Stream与fs对我们理解很多前端自动化工具打下了坚实的基础。
[1] 认识node核心模块--从Buffer、Stream到fs
[2] Node.js v14.13.1 文档 - fs文件系统
[3] Introduction to NodeJS Streams
进程是CPU资源分配的最小单位,是能拥有资源和独立运行的最小单位。
线程是CPU调度的最小单位,线程是建立在进程的基础上的一次程序运行,一个进程可以有多个线程。
不同进程之间也可以通信,不过代价比较大。
常说的单线程、多线程都是指在一个进程内的单和多,也就是说,敲黑板...这些多线程单线程都必须属于一个进程才行。
浏览器是多进程的,新增一个tab页面至少新增一个进程,然后操作系统会给每个进程都分配CPU和内存,一个浏览器可以有多个tab页面
那么整体来说,OS就给一个浏览器开启了多个进程,如下图
相比较单进程浏览器,多进程浏览器有以下优势:
tab 页面阻塞运行,甚至 crash 的话也整个浏览器也都跟着崩溃crash 导致整个浏览器崩溃CPU 优势简而言之,就是几大功能模块都使用单独的进程去运作,各个功能之间尽量不要相互影响。
我们作为 FEer 最关注的其实是渲染进程,因为它包括了我们开发、优化需要用到的
页面渲染 :arrow_right: JS执行 :arrow_right: 事件的循环 :arrow_right:
首先我们牢记一点,浏览器的渲染进程是多线程的。
浏览器的渲染进程包括了以下线程:
Javascript/脚本程序Tab页中无论什么时候都只有一个JS线程运行JS程序。GUI渲染线程与JS线程引擎是互斥的,当JS引擎执行的时候,GUI线程会被挂起,相当于被冻结了,GUI更新会被保存在一个队列中,等到JS引擎空闲的时候立即被执行。
所以 Javascript 脚本执行的时间过长,这样就会造成渲染不连贯,导致页面渲染加载阻塞。
setTimeout 用户点击 nextClick)的时候,JS引擎就会吧这些任务交给事件触发线程中。eventLoop)setInterval和setTimeout所在的线程XMLHttpRequest在两级后通过浏览器新开一个线程进行发起请求。用户打开了一个浏览器,会默认打开一个空的tab页面,此时与浏览器相关的会有:浏览器主进程 和 这个tab的渲染进程
浏览器输入 url ,浏览器主进程接管,开一个下载进程。
进行http请求,等待响应,获取内容。
随后将内容,通过 RenderHost 传递给 Renderer 进程,浏览器渲染渲染进程开始工作。
解析html建立DOM树
解析css ,将CSS代码解析成属性的数据及结构,然后结合DOM合并成render树
布局 render 树,重绘和重排,负责各元素尺寸、位置的计算。
浏览器会将各层的信息发送给 GPU,GPU 会将各层合成显示在屏幕上。
最后,渲染进程将渲染结果传递回给,浏览器主进程,主进程再将结果绘制出来。
面试中常常会问到,浏览器再加载JS代码的时候,页面UI渲染是否停止?重绘重排呢?
今天,我们知道了GUI渲染线程与JS引擎线程是互斥的,因为Javascript线程中可以操作DOM元素的,若果在JS修改这些元素的属性的同时渲染界面,那么渲染现成前后获得的元素数据可能就不一样了。
因此为了防止渲染会出现不同的结果,那么浏览器内核就将UI渲染(包括重绘和重排版)与JS引擎执行JS代码设置为互斥的关系,GUI的更新一般会被暂时的存放到一个异步的队列中,等待JS引擎空闲的时候再被执行(这里应该理解为GUI变动被渲染引擎执行)。
| 浏览器 | 渲染引擎 | JS引擎 |
|---|---|---|
| firefox | gecko | monkey |
| IE | Trident | Chakra |
| edge | edge | Chakra |
| Opera | Presto | Carakan |
| chrome | webkit | V8 |
| safari | webkit | SquirrelFish |
从上述的互斥关系,可以推导出,JS如果执行时间过长就会阻塞页面。
所以,要尽量避免JS执行时间过长,这样就会造成页面的渲染不连贯,导致页面渲染加载阻塞的感觉。
css是由http下载线程单独的下载线程异步下载,所以不会阻塞DOM树的解析。
但css解析,会阻塞render树进行渲染
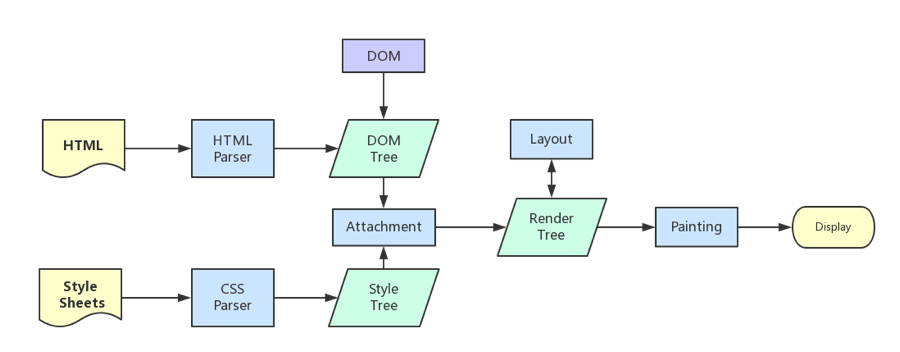
在红宝书学习webworker的时候,记住了一句
webworker是一个独立于widnow外的一个独立作用域,webworker仅仅拥有window对象上的部分属性和方法,特别是没有操作DOM的能力。而且只能透过postMessage这种特殊的方式与主JS引擎线程进行传递信息
以上是回忆...不是原文:joy:
浏览器创建worker,分配一个单独子线程,受控于主线程,而且不能够操作DOM,自然也不会与GUI渲染线程相互阻塞了。所以我们一般会使用webworker去做一些大量耗时的计算,然后通过postMessage()方法传回拥有window对象的JS引擎线程中去。并且悄悄补一句...postMessage是``异步任务,属于宏任务`,自然更不存在阻塞的问题了..
要说WebWorker是服务于一个渲染进程内的多个线程...帮助他们(JS引擎线程,GUI渲染线程)减缓压力。
那么SharedWorker就是一个浏览器内,多个tab页的多个进程的帮手,要实现服务于多个进程之间,那么SharedWorker本身也是一个依托于一个进程。
每开启一个浏览器,则多个页面会共享这个SharedWorker对象。
[2] V8与字节码
CMD 规范集合了CommonJS 和 AMD,取长补短。其最有名的实现是射雕的sea.js
define(function(require, exports, module) {
// 同步引入模块
const module2 = require('./module2')
// 异步引入模块
const module1 = require('./module3', function (module3) {
cosnole.log(module3)
})
const name = 'module1'
const getName = function () {
return name
}
// 模块暴露
module.exports.module1 = {
getName
}å
})define(function(require, exports, module) {
// 模块暴露
module.exports.module1 = {
getName
}
})AMD的不同点AMD对代码的态度是预执行CMD对代码的态度是懒执行(也就是上面说的依赖就近),比如SeaJS就是在代码需要用到包的内容时候,内核才会去异步地调用这些包。(不同于AMD所有的包都在一开始就加载)spm进行打包(spm是sea.js的打包工具)
CommonJS是一种JS模块规范。规范内容主要分为模块定义、模块引用与模块标志三个部分。Node.js的模块机制是其主要的实践。
CommonJS 规定每一个文件就是一个模块,拥有自己的作用域。文件内的变量、函数、类都是私有的,其他文件不可以直接访问到,只有通过module.exports这个神魔之井进行访问。
// 最简单的一个模块,使用node命令执行它,输出以下的内容
module.exports = {
abc: 123
}
console.log(module)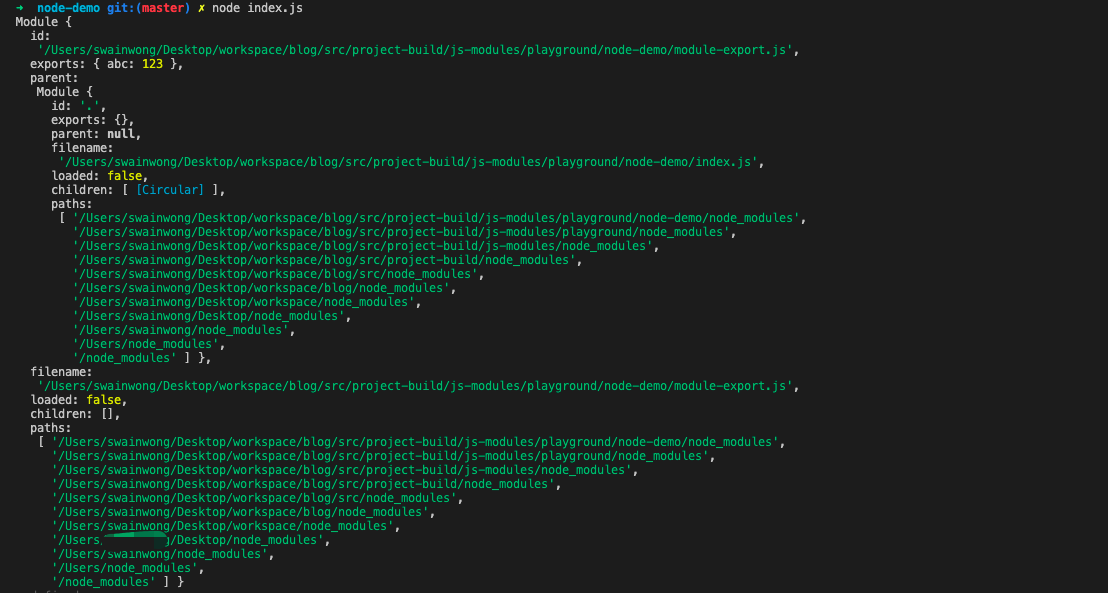
对象(👈注意这个用词)先说结论,请您放弃使用
exports,严格使用module.exports进行模块暴露
事实上,在编译的过程中Node.js对获取的Javascript文件进行了头尾包装。在头尾分别添加了
(function (exports, require, module, __filename, __dirname) {/n) 和 \n})
也就是我们常常在webpack打包之后debugger的时候看到的
(function (exports, require, module, __filename, __dirname) {
var math = require('math')
exports.area = function (radius) {
return Math.PI * radius * radius
}
})通过观察以上的产出的模块代码,不难得出以下结论:
exports对于一个模块内部来说,仅仅是一个函数形参。exports.abc = 123exports上的属性,并不会影响到外部参数。module上的exports属性指向的确实,全局上的module的exports属性,而不是内部的形参exports。所以
module.exports.abc = 123 Node.js中有一个全局性方法require()用于同步加载模块
const module1 = require('./module.js')
module1.getName() // 'module1'CommonJS中模块加载机制,require函数引入的是输出模块中module.exports的值得拷贝。也就是说,内部值的变化,外界不再能够感知到。
// moduleA.js
var innerValue = 'innerValue'
setTimeout(() => {
innerValue = 'innerValue has been changed'
}, 100)
function changeInnverValue () {
innerValue = 'innerValue has been changed by function'
}
module.exports = {
innerValue,
changeInnverValue
}
// index.js
const moduleA = require('./moduleA')
console.log('before', moduleA.innerValue) // before innerValue
moduleA.changeInnverValue()
console.log('after', moduleA.innerValue) // after innerValue
setTimeout(() => {
console.log('after timmer', moduleA.innerValue) // after timmer innerValue
}, 3000)❓❓❓ 大家想想,既然
CommonJS是运行时加载,那么内部的变动的值如何才能够被取到呢?留言区见
一个模块可能会被多个其他模块所依赖,也就会被多次加载。但是每一次加载,获取到的都是第一次运行所加载到缓存中的值,
require.cache会指向已经加载的模块。
// module-imported
module.exports = {abc: 123}
// index.js
require('./module-imported')
require('./module-imported').tag = 'i have been imported'
const moduleImported = require('./module-imported')
console.log(moduleImported.tag) // 输出 'i have been imported'
console.log(require.cache) // 输出如下图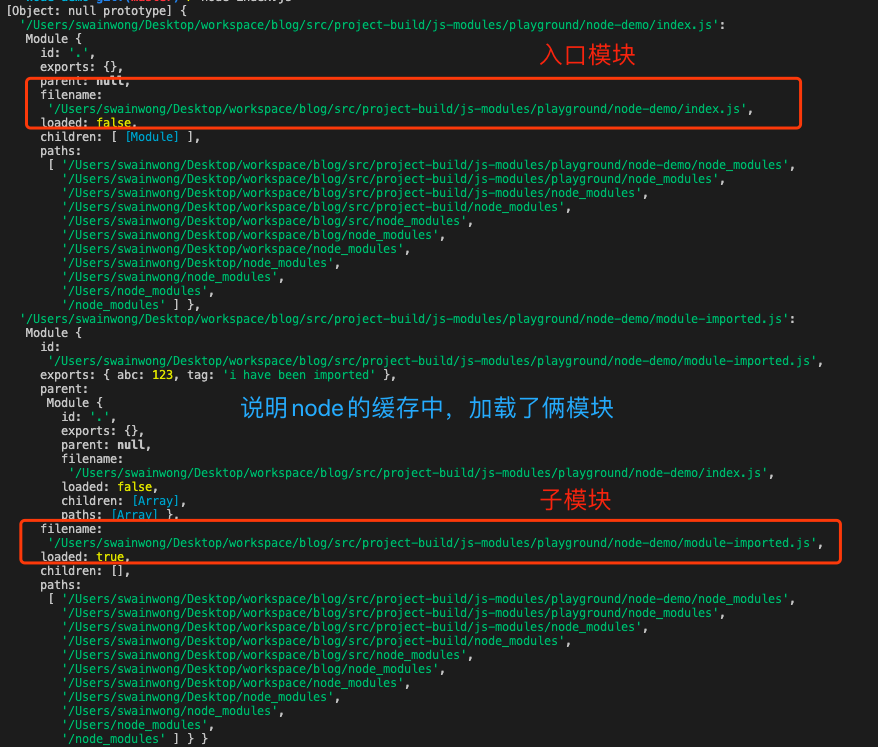
上面两个例子结合,可以说明对于同一个模块,node只会加载一次。后续的读取都是从缓存中读取出来。
对于模块缓存机制,若是存在两个同名模块,存放于不同的路径,则那么require()方法仍然会重新加载该模块,而不会从缓存中读取出来。如以下例子。
|-- node_modules
|-- module-importe.js #外层同名模块
|-- index.js #入口文件
|-- node_modules
|-- module-importe.js #内层同名模块// index.js
const moduleA = require('module-imported')
const moduleB = require('../node_modules/module-imported')
moduleA.tag = 'moduleA tagged'
moduleB.tag = 'moduleB tagged'
console.log(require.cache)
console.log(moduleA.tag)
console.log(moduleB.tag)
module.exports = {
name: 'index module'
}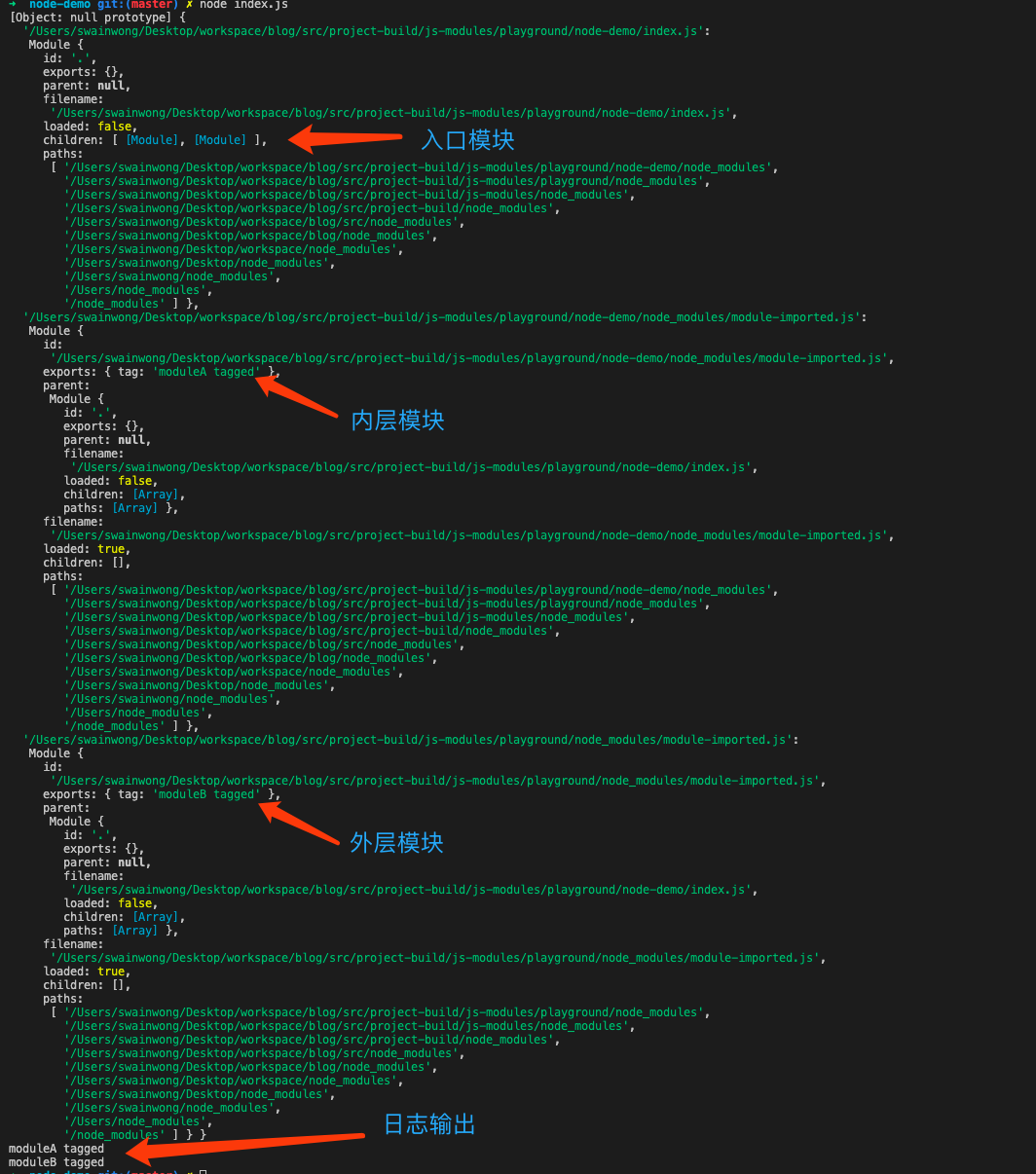
.js后缀名/开头表示绝对路径。./ 或 ../ 表示相对路径。我们同样使用上面的输出结果。可以看到路径是逐级向上寻找的过程。从当前目录下的node_modules一直寻找到根目录下的node_modules为止。逐级向上寻找的方式,FNer们是否似曾相识呢?(Javascript的原型链溯源👩🏫)
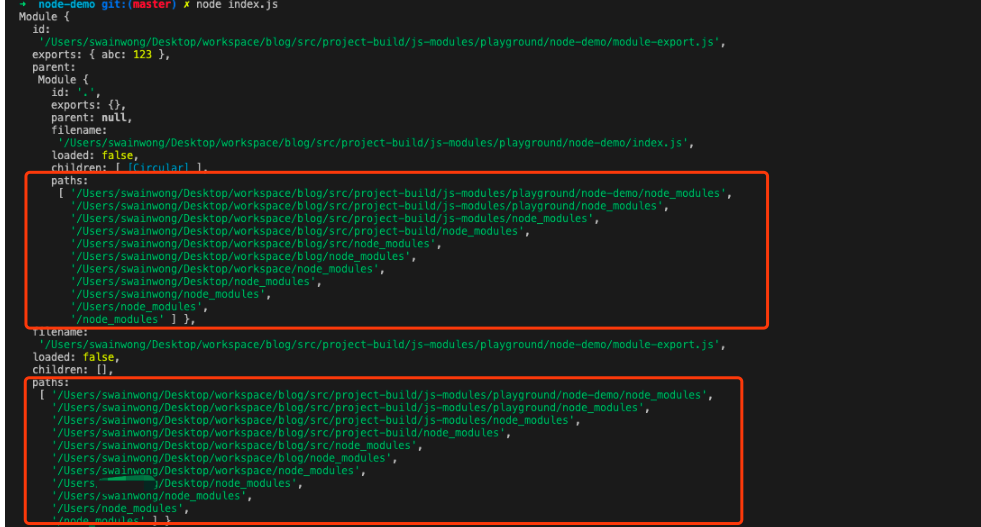
这种情况常见于我们项目开发中,引用的第三方模块包。
require()函数在解析标识符的时候,对于不指定文件拓展名的情况,Node.js按照.js、.node、.json文件的顺序补足拓展名后,再尝试进行加载。
// app.js
const abcModule = require('abcmodule')--|-- app.js
|-- node_modules
|-- abcmodule
|-- index.js
|-- package.json若在上述的逐级匹配寻找的过程中,匹配到了一个目录(如上图)。则会进把匹配到的目录当做一个模块包,首先寻找文件夹下的package.json文件(也就是模块包的配置文件)。
// 省略了一大堆其他属性
{
"author": "",
"bundleDependencies": false,
"deprecated": false,
"description": "",
"license": "BSD-2-Clause",
"main": "index.js",
"name": "http",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"version": "0.0.0"
}package.json 中的 "main" 配置项则会被指定位模块的加载入口。
"main": "not-found.js"若"main"指定的文件是不存在的,加载机制则会默认依次寻找当前目录下的index.js、index.node、inde.json 来作为文件模块的入口。
在Node.js源码中,也出现了模块定义的内应内容👉传送门。
// lib/internal/modules/cjs/loader.js #L192
function Module(id = '', parent) {
this.id = id;
this.path = path.dirname(id);
this.exports = {};
this.parent = parent;
updateChildren(parent, this, false);
this.filename = null;
this.loaded = false;
this.children = [];
}先上Node.jsb部分源码。看过Webpack编译后代码的童鞋可能不会对下面的内容陌生,Node.js实现CommonJS的方式,也是将每个文件模块都封装在一个函数作用域中,然后将常用的module、exports、module、__dirname、__filename 一一作为参数传递到作用域中。
// /lib/internal/modules/cjs/loader.js#L192
let wrap = function(script) {
return Module.wrapper[0] + script + Module.wrapper[1];
};
const wrapper = [
'(function (exports, require, module, __filename, __dirname) { ',
'\n});'
];require 引入模块 入口👉 到 出口👉Module.prototype.require = function(id) {
validateString(id, 'id');
if (id === '') {
throw new ERR_INVALID_ARG_VALUE('id', id,
'must be a non-empty string');
}
requireDepth++;
try {
return Module._load(id, this, /* isMain */ false);
} finally {
requireDepth--;
}
};Module._load()进行模块加载,传送门👉// /lib/internal/modules/cjs/loader.js#L877
Module._load = function(request, parent, isMain) {
// .....
// /lib/internal/modules/cjs/loader.js#L912
const module = new Module(filename, parent); // 新建 module 实例
// /lib/internal/modules/cjs/loader.js#L912
Module._cache[filename] = module; // 存入缓存
}Module.extensions调用处传送门👉
注意这里的实现方式使用的是 readFileSync 则说明我们需要同步地去读取文件。
// /lib/internal/modules/cjs/loader.js#L1049
Module._extensions[extension](this, filename);各种文件的处理方式:
// Native extension for .js
Module._extensions['.js'] = function(module, filename) {
if (filename.endsWith('.js')) {
const pkg = readPackageScope(filename);
// Function require shouldn't be used in ES modules.
if (pkg && pkg.data && pkg.data.type === 'module') {
const parentPath = module.parent && module.parent.filename;
const packageJsonPath = path.resolve(pkg.path, 'package.json');
throw new ERR_REQUIRE_ESM(filename, parentPath, packageJsonPath);
}
}
// 使用文件模块读取文件
const content = fs.readFileSync(filename, 'utf8');
// 编译文件内容
module._compile(content, filename);
};// /lib/internal/modules/cjs/loader.js#L1154
Module.prototype._compile = function(content, filename) {
// ...
const compiledWrapper = wrapSafe(filename, content, this);
return result;
};
// /lib/internal/modules/cjs/loader.js#L1104
function wrapSafe(filename, content, cjsModuleInstance) {
// vm.runInThisContext 用于编译和执行JavaScript代码
return vm.runInThisContext(wrapper, {
filename,
lineOffset: 0,
displayErrors: true,
importModuleDynamically: async (specifier) => {
const loader = asyncESM.ESMLoader;
return loader.import(specifier, normalizeReferrerURL(filename));
},
});
}module.exports 结果// /lib/internal/modules/cjs/loader.js#L961
return module.exports;[1]CommonJS规范 - ruanyifeng
[2]《深入浅出Node.js》 - 朴灵
[3] Node.js - github
[4] webpack 前端运行时的模块化设计与实现 - by AlienZHOU
HTML是页面的骨架,而 CSS 作为页面的衣服,才是页面展示的重要环节。
相信大家都见过,满屏id和满屏行内样式的祖传代码吧。眼花缭乱的代码..不可复用..不可修改的代码...我知道你想原地爆炸....
<div id="containerWrapper" style="height:400px;width:auto;line-height:400px;">
<div id="container" style="background-color:red;border:1px solid green;">
<!-- 更多元素 -->
</div>
</div>当然↑↑↑↑↑那种代码是你一次又一次的贪图方便直接行内修改而引起的,九层之台,始于累土,CSS的编码习惯和设计思维是需要贯穿项目本身的
现在css在日常的开发中,越来越多地被UI框架减轻压力...(其实造轮子和改样式的需求还是hin多的),熟悉前端的开发者,一般懂得以下几点:
使用class属性共享样式 ✔️
使用项目公共样式表,项目全局使用,进一步减少css代码 ❌
不使用id作为元素修饰选择器。特别是因为选择优先级的时候,不要因为追求一时爽,而放弃程序的可维护性。 ❌
不要使用嵌套过于复杂的css选择器。 ❌
编码上,我们知道css解析选择器的时候,render-tree的搜索方向是从叶子结点出发的,编码上也就是从右往左读取的,逐级进行过滤。
因为通配符选择器和树形选择器匹配到的标签过多,比较耗时。总的来说,我们要在css匹配规则最后(最右)书写比较精确的规则,以便浏览器更快地命中规则。
/* * 表示全选,相当于没说,范围太大 */
.bodyContainer * {
height:30px;
}
/* class="container"范围太大 */
.demo[class="container"]{
width:90px;
}如box-shadow/border-radius/filter/透明度/:nth-child等 CSS3 属性用起来十分爽,效果也好,但当我们要考虑性能时,如有可以接受的替代方案,则考虑性能为先。
这是个老生常谈的问题了,我们在了解浏览器渲染原理的时候,用户的一些操作,样式的先后被覆盖,影响DOM也会影响CSS,都有可能引起重绘和重排。
改变font-size和font-family
改变元素的内外边距
通过JS改变CSS类
通过JS获取DOM元素的位置相关属性(如width/height/left等)
CSS伪类激活
滚动滚动条或者改变窗口大小
当元素的外观属性,如颜色和可见度等不涉及DOM宽高的属性,改变的时候,浏览器会对页面进行重绘。
有时候这些改变时不可避免的,那么我们只好针对站在用户的角度去测试一下加载的性能。
使用chrome的devtools的performance选项中进行配置,尽量模拟用户的最差环境进行开发测试。
样式表的加载有其先后性,但是使用@import来关联样式文件,会导致样式文件下载顺序的紊乱,甚至于后续js文件下载的顺序混杂在一起,导致不可预知的后果。
使用并行的<link>标签来引入多个样式表,可以让多个样式表并行下载。
@import无论写在哪一行,都会在页面加载完再加载css,也就出现了,页面本来样式已经排布完(已经到了DOMContentLoad),然后又要去加载@import的内容,就增加了页面重新排布的可能。
详细参考这篇文章:为啥不建议使用@import?
不知道啥是DOMContentLoad?看看这里:浏览器优化�3 之 页面加载的Timeline
BEM等编码规范使用行为状态分离class命名规范,提高样式代码的可读性、修改灵活性。也是用于大型项目开发的多人合作编写CSS。
以上是编码上的优化,接下来再看看项目架构划分上的性能优化..
在众多的用户体验中,首屏加载效果是经常被提起的。在样式的表现就在,当首屏代码量较大,需要的样式代码比较多,而大量的CSS代码存放在<link href="../css/index.css">的外链样式表中,这意味着需要多一次的http请求去获取样式文件,而且因为浏览器的阻塞渲染机制,用户在外链样式表下载完成之前,不能看到他们所关心的首屏效果...
聪明的你明白,这时候我们就需要把首页(甚至只是首屏)的关键CSS代码,改为内联的形式。
这里我们会涉及到一个关键词语Critical Css如何判断哪些是关键CSS,哪些我们该作为内联样式呢?这篇文章结合了webpack+ critical css讲解了如何进行优化,《webpack_关键css》,另有时间再做总结。
(preload属性)
因为tcp存在初始拥塞窗口的的机制,想要抢先下载首屏 css,则要保证内联了css代码的首屏html代码不能过大,经过长期的经验,这个值通常为14.6kb。否则,首屏的html问件可能需要被切分几次传输,则达不到优化的效果。
内联部分的 CSS 是不会像外链 CSS 文件那样被浏览器缓存下来的。
我们通常使用<link rel="stylesheet" href="css/style.css">去引入css,这样书写的引入,被浏览器认为是需要同步引入样式表。我们知道,这样的引入方式:
因此我们有必要进行css代码的异步加载,使得这些阻塞问题不存在。
let link1 = document.createElement('link');
link1.href = '/public/staticAssets/bdmap/css/baidu_map_v2.css';
link1.rel = 'stylesheet';
document.head.appendChild(link1);使用media属性,将该属性改为不识别的值,浏览器将降低该资源的下载优先度,当完成后将值设定回原值。
<link rel="stylesheet" href="mystyles.css" media="noexist" onload="this.media='all'">使用preload属性,告知浏览器异步地去加载这个资源。需要注意preload的兼容性,我们会使用loadCss进行polyfill
<link rel="preload" href="mystyles.css" as="style" onload="this.rel='stylesheet'">兼容性
这是我们最常用的方法,减小css样式表文件的大小,能够有效地减少文件传送时间。
webpack等构建工具
{
loader: 'css-loader',
options: {
minimize: true
}
}我们的项目中,通常会产生两种多余的CSS代码
1️⃣ 两段css代码都对一个元素的同一个状态进行了修饰,一个等级高一个等级低,则肯定有一方被覆盖,被覆盖方可能就是无效css。
2️⃣ 项目公共库中还没有match的css代码,我们也认为是无效的css代码。
当然我们还是推荐使用webpack+ purifycss,官方讲解摸我,网友讲解摸我
最后,我们做一个预告,我们将在后面的文章《浏览器性能优化 5 - GPU加速》中继续讲解如何�利用图层的合成规则进一步优化我们的渲染性能。传送门👉
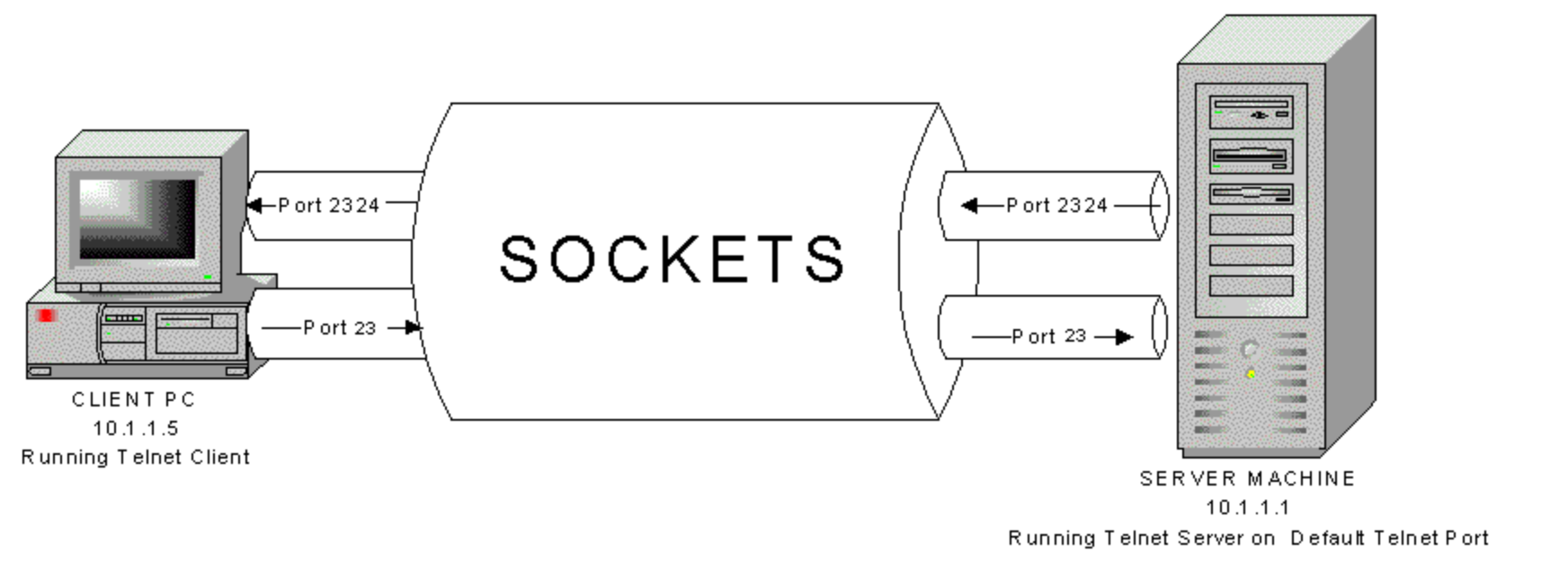
网络上的两个程序通过一个双向链接实现数据的交换,这个连接的一段被称之为socket。
socket的本质是一个编程接口,对TCP/IP进行了封装,TCP/IP也要提供可供开发者做网络开发的接口。
一台主机上多个端口,对应着不同的应用服务,每个服务都打开一个socket,并且绑定到一个端口上。
HTTP提供了封装或者显示数据的具体形式,socket是发动机,提供了网络通信的能力。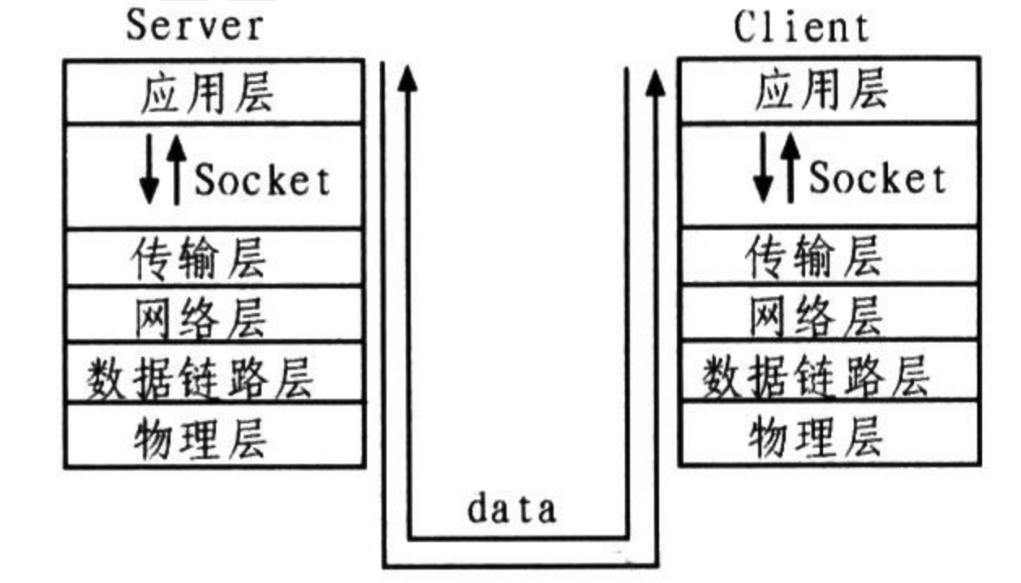
socket 是一套用于Unix进程间通信的api。IP + port 等于网络socket的地址
根据UNIX中一切皆是文件的哲学,常规意义的文件、目录、管道、socket都可以看成文件。例如,我们通常也认为TCP的Socket是一个文件流。
fd是内核提供给用户安全操作文件的标识,标识符而不像指针,你不能进行修改,只能以当做参数传递给系统不同的api,告知系统该处理哪些文件。写入和读出,也是通过对文件描述符进行read和write操作。
Socket 是一个文件,那对应就有文件描述符。每一个进程都有一个数据结构 task_struct,里面指向一个文件描述符数组,来列出这个进程打开的所有文件的文件描述符。文件描述符是一个整数,是这个数组的下标。
Socket 对应的文件 inode不是保存在物理硬盘上,而是存在于内存中。
详细的fd解释,请参考另一篇[笔记](https://github.com/HXWfromDJTU/blog/issues/12)
Socket 是网络层上的一个概念,进行的是端到端的通信。既不能够感知到应用层是什么应用,也不能感知到中间将会经过多少局域网、路由器。因而能够设置的参数只是网络层和传输层相关的参数。
| 传输层协议 | 网际协议版本 | 数据格式 |
|---|---|---|
| TCP | IPV4/6 | SOCK_STREAM |
| UDP | IPV4/6 | SOCK_DGRAM |
例如我们熟悉的nodejs中创建socket连接的参数就能看出
对于 TCP 连接,可用的 options 有:
port <number> 必须。套接字要连接的端口。
host <string> 套接字要连接的主机。默认值: 'localhost'。
localAddress <string> 套接字要连接的本地地址。
localPort <number> 套接字要连接的本地端口。
family <number> IP 栈的版本。必须为 4、 6 或 0。0 值表示允许 IPv4 和 IPv6 地址。默认值: 0。
hints <number> 可选的 dns.lookup() 提示。
lookup <Function> 自定义的查找函数。默认值: dns.lookup()。
对于diagram(udp)的 options <Object> 允许的选项是:
type <string> 套接字族. 必须是 'udp4' 或 'udp6'。必需填。
reuseAddr <boolean> 若设置为 true,则 socket.bind() 会重用地址,即使另一个进程已经在其上面绑定了一个套接字。默认值: false。
ipv6Only <boolean> 将 ipv6Only 设置为 true 将会禁用双栈支持,即绑定到地址 :: 不会使 0.0.0.0 绑定。默认值: false。
recvBufferSize <number> 设置 SO_RCVBUF 套接字值。
sendBufferSize <number> 设置 SO_SNDBUF 套接字值。
lookup <Function> 自定义的查询函数。默认值: dns.lookup()。
// TCP
var net = require("net");
var server = net.createServer(function(socket){
console.log('someone connects');
})
// UDP
const dgram = require('dgram');
const server = dgram.createSocket('udp4');根据连接启动的方式以及本地套接字要连接的目标,套接字之间的连接过程可以分为三个步骤:服务器监听,客户端请求,连接确认。
bind函数,给这个Socket赋予一个IP地址与端口。
// node.js tcp监听
server.listen(8000, function(){
console.log("Creat server on http://127.0.0.1:8000/");
})是指由客户端的套接字提出连接请求,要连接的目标是服务器端的套接字。为此,客户端的套接字必须首先描述它要连接的服务器的套接字,指出服务器端套接字的地址和端口号,然后就向服务器端套接字提出连接请求。
// node.js 创建tcp连接
const net = require('net');
const client = net.createConnection({ port: 8124 }, () => {
// 'connect' 监听器
console.log('已连接到服务器');
client.write('你好世界!\r\n');
});是指当服务器端套接字监听客户端套接字的连接请求,它就响应客户端套接字的请求,建立一个新的线程,把服务器端套接字的描述发给客户端,一旦客户端确认了此描述,连接就建立好了。而服务器端套接字继续处于监听状态,继续接收其他客户端套接字的连接请求。
在内核中,为每个Socket维护两个队列
已经建立连接的队列,处于established状态。还没有完全建立连接的队列,处于syn_rcvd的状态。在服务等待的时候,客户端仍可以通过
IP地址与端口号发起连接,并开始三次握手,内核会为其分配一个临时的端口。直到握手成功,服务端使用accept函数返回另一个socket进行处理。 --- 《趣谈网络协议》
用于监听的socket与用于数据传输的socket是两个不同的socket。这里通常称之为监听socket与已连接socket。
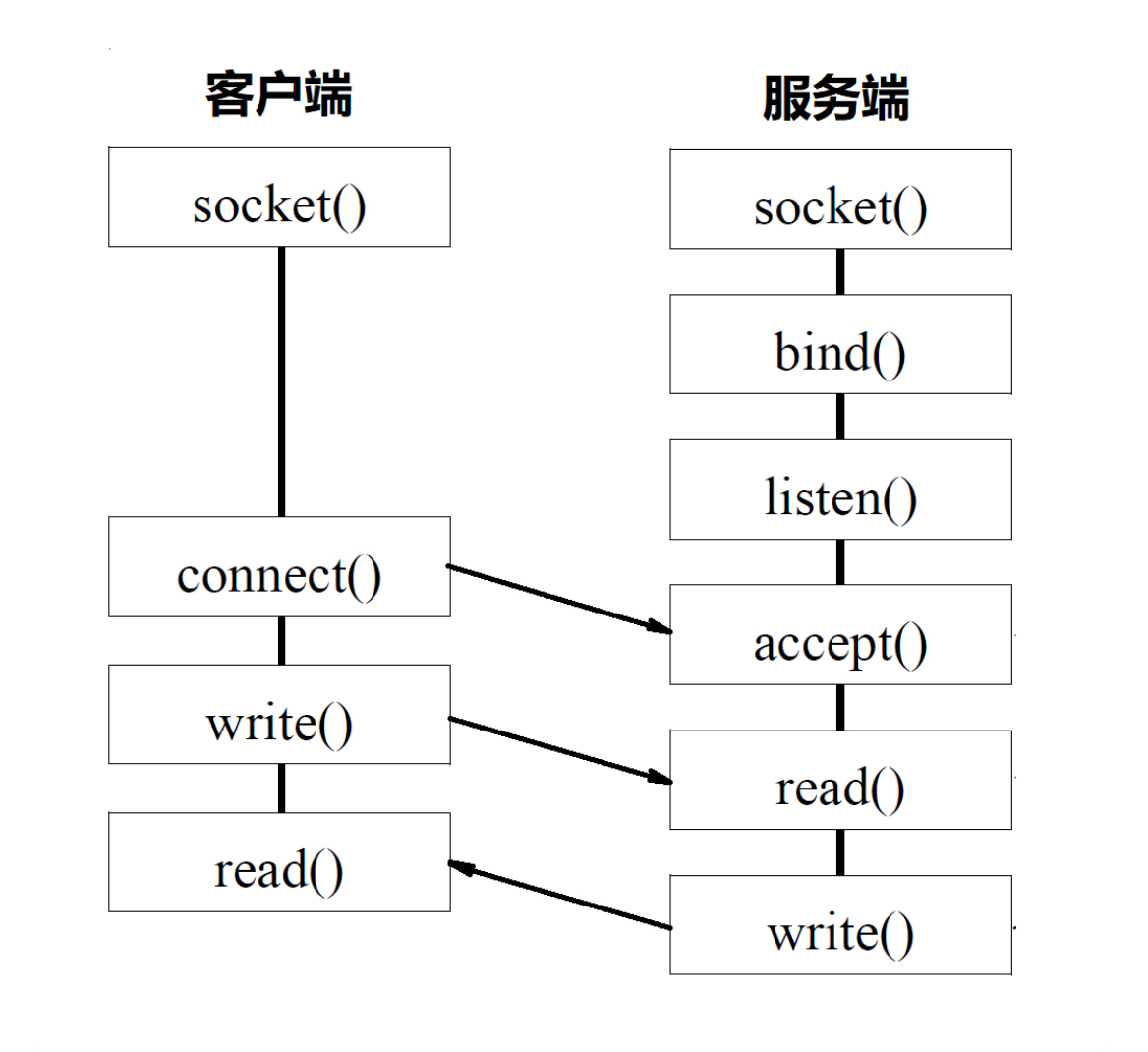
连接一旦建立,双方的socket之间的读写read 与 write就和在一台机器上俩进程之间的读写没有区别,正如一开始说的,socket是感知不到中间经过多少路由器和电缆线路的。
发送队列 与 接收队列
对于UDP来说,是无连接、无握手过程的,也就不存在了上面👆TCP连接过程的listen与connect。但是其仍需要一个IP和端口号。
// node.js 使用 dgram 模块启动 UDP 服务
const dgram = require('dgram');
const server = dgram.createSocket('udp4');
// 服务器监听 0.0.0.0:41234
server.bind(41234);sendto 和 recvfrom,都可以传入 IP 地址和端口。
// node.js 客户端通过UDP发送数据
const dgram = require('dgram');
const client = dgram.createSocket('udp4');
const msg = Buffer.from('hello world');
const port = 41234;
const host = '255.255.255.255';
client.bind(function(){
client.setBroadcast(true);
// 每次通信,都可以传入 IP 地址 和 端口
client.send(msg, port, host, function(err){
if(err) throw err;
console.log('msg has been sent');
client.close();
});
});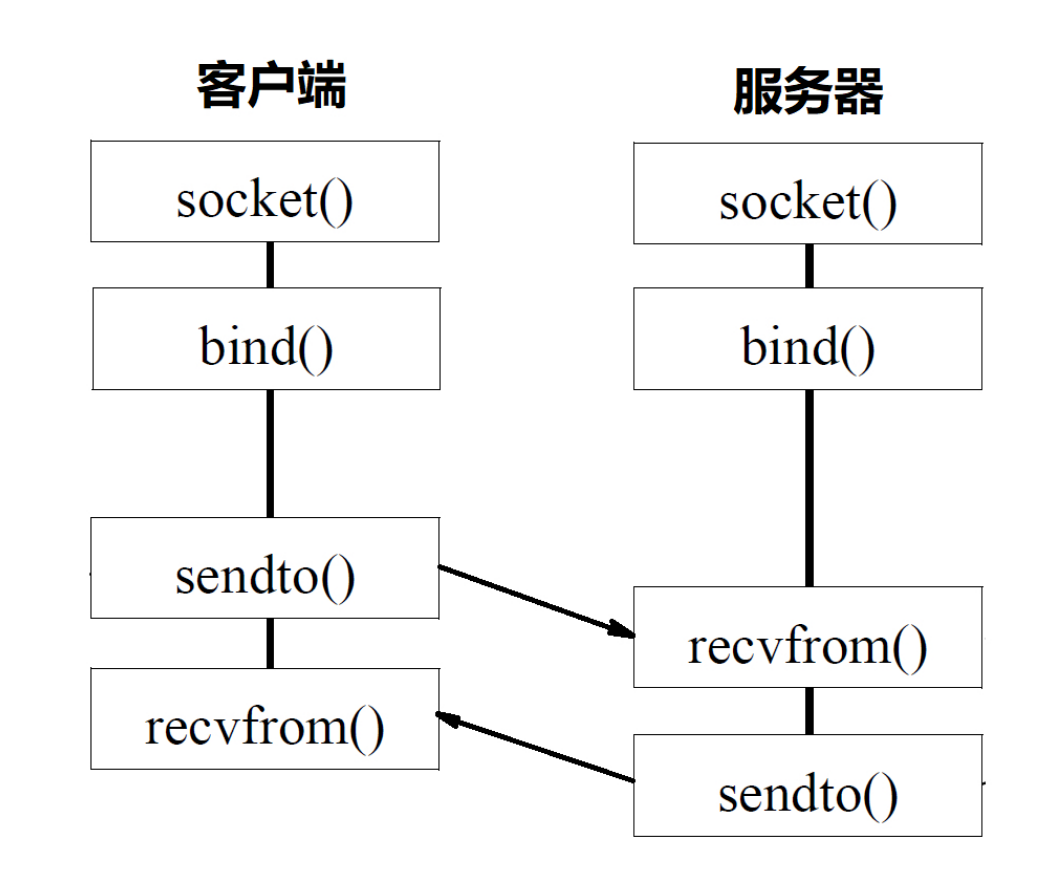
每一个TCP可以用一个四元组来唯一确定,也就是
<source_IP, source_PORT, target_IP, target_PORT>
通常服务端启动服务后,IP与Port就不再变化,但是可以承接N多个客户端的请求。这里的N是由Source_IP数目2^32个,与port数目2^16个.搭配起来的话就是2^48个,但实际上远远达不到。
备注:
IPV_4下 共有32位,则最多2^32个。TCP与UDP存储port的字段一共16位,所以最多2^16个
按照上文的理解,每一个socket都被OS当做一个文件处理,那么就有存在打开文件数的限制。
# 查看最大打开文件数
$ ulimit -n
# 设置最大打开文件数
$ ulimit -n <file-num>这里的-n参数标明修改的是单个进程可以打开的文件数
其他的参数这里也一并简单了解一下(参考文档👉)
数据段长度:ulimit -d unlimited
最大内存大小:ulimit -m unlimited
堆栈大小:ulimit -s unlimited
CPU 时间:ulimit -t unlimited
虚拟内存:ulimit -v unlimited 每一个socket都有对应的inode存储在内存中,然而计算机的内存是有限的。
Linux创建一个子进程的操作称为fork, 进程复制的主要涉及几样东西
执行了fork后,父子进程理论上是完全一样的。仅能通过fork返回值来区分,自己到底是父进程还是子进程。
// node 创建子进程的命令
const cp = require('child_process')
// 启动子进程来执行命令
cp.spawn('node', ['index.js'])
// 启动了子进程,并通过回调获得信息
cp.exec('node index.js', (err, studio, stderr) => {
// get some message
})
// 启动子进程来执行可执行文件
cp.execFile('index.js', (err, studio, stderr) => {
// get some message
})
// 仅需指定执行文件模块
cp.fork('index.js')进程的创建与销毁开销过大,则可以考虑使用轻量级得多的多线程,区别在于
已连接的socket来处理请求,从而达到并发表处理的目的。const { Worker, isMainThread, parentPort, workerData } = require('worker_threads');
return new Promise((resolve, reject) => {
const worker = new Worker(__filename, {
workerData: script
});
worker.on('message', resolve);
worker.on('error', reject);
worker.on('exit', (code) => {
if (code !== 0)
reject(new Error(`Worker stopped with exit code ${code}`));
});
});示例代码使用node的worker_threads,感兴趣的推荐这篇文章👉
无论多么厉害的一台机器,同时维护超过1w个进程,OS是无法承受的,这就是常说的C10K问题。此时I/O多路复用就出现了。有以下优点:
更多关于多路复用的问题,请关注另一篇笔记👉
AMD 是一种模块管理规范,全称是
Asynchronous Module Definition(异步模块定义)。其中一个实现则是著名的require.js。
AMD的最大特点是他的A ==> Asynchronous,规范规定模块的加载过程是异步的,不会影响侯后续的代码执行。
同步加载模块会阻塞浏览器的代码执行,是当初AMD产生的主要原因。
require(['really-big-module']);
const bigData = new BigData()
bigData.getData()
// 被模块加载阻塞的操作
console.log('some action')require(['really-big-module'], function (BigData) {
const bigData = new BigData()
bigData.getData()
});
// 同步可执行,不需要等待 really-big-module 模块的加载
console.log('some action')// 没有依赖模块的模块
define(function () {
return {
abc: 123
}
})
// 有依赖的情况
define(['module1', 'module2'], function (m1, m2) {
return {
abc: 123
}
})// 入口声明的所直接依赖的模块即可
requirejs(['module-service', 'jquery'], function (moduleService, $) {
moduleService.showMsg()
moduleService.showModuleData()
console.log($) // 打印出query的$函数
})// require.js 的模块配置
require.config({
paths: {
"jquery": "jquery.min",
"underscore": "underscore.min",
"backbone": "backbone.min"
}
});身处webpack**时期的当下前端开发时代,对这些配置项是否也有似曾相识的感觉呢?
require.js引入模块的时候,被引入的模块也需要是遵循require.js规范,否则需要使用shim配置项进行额外声明。// 比如 backbone.js 没有遵循AMD规范,则需要我们额外定义它的依赖,还要帮它指明要暴露哪些对象
require.config({
shim: {
'backbone': {
deps: ['underscore', 'jquery'],
exports: 'Backbone'
}
}
});本文主要为Node.js工作原理解析,从我们编写的Application到Node,再到v8编译解析,也会聊聊大家比较关心的Libuv和EventLoop的6阶段,所以把之前拆分开的内容,汇总到一起便于大家整体理解。
其实每一个点都可以讲上一天,本文主要为大家理清楚这几个过程间的关系,很多细节则不多赘述。
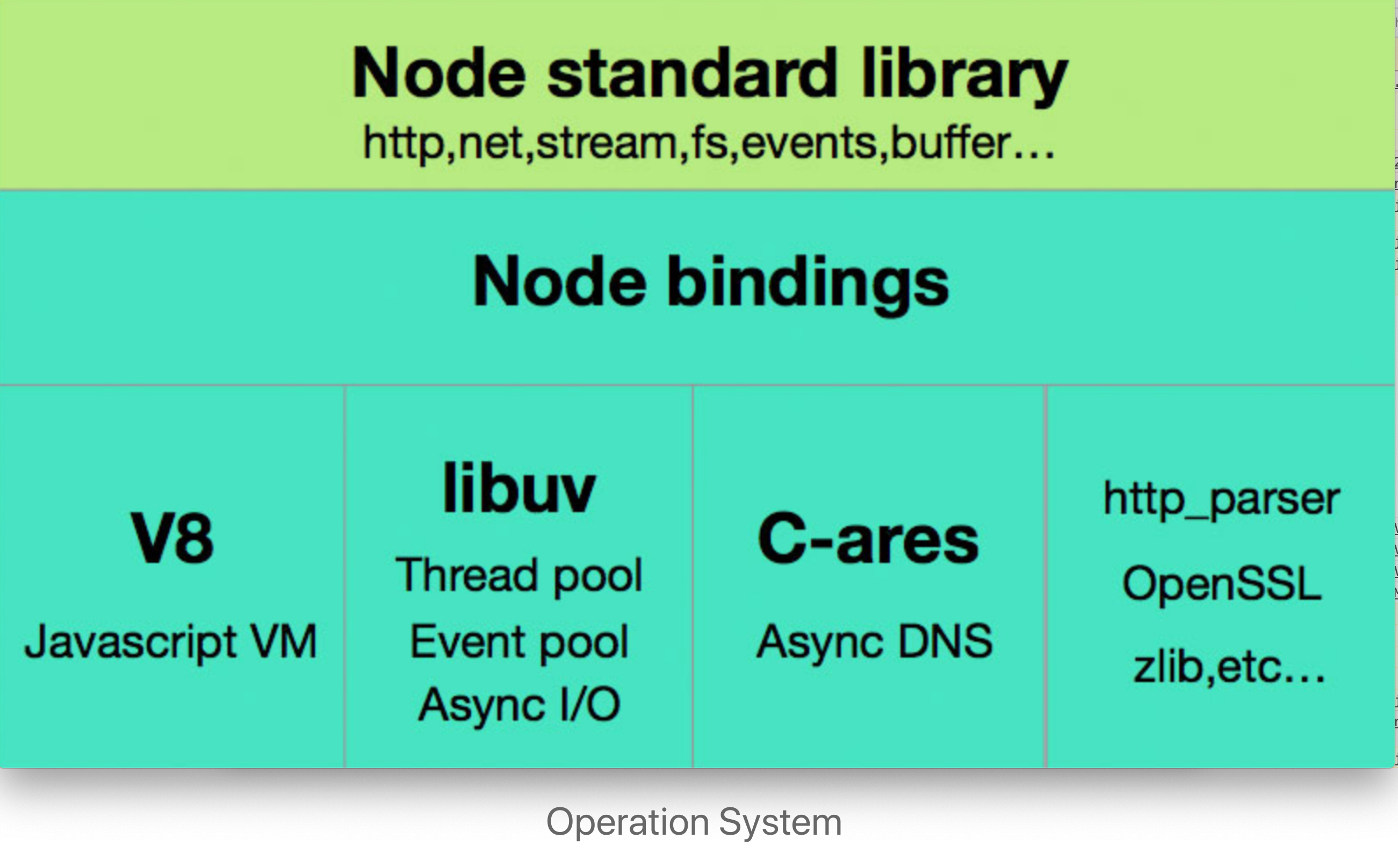
HTTP Buffer等模块这一层是支撑 Node.js 运行的关键,由 C/C++ 实现
V8不必多说相当于Nodejs的引擎(V8相关的笔记📒,传送门)
libuv 填平了多个平台的对异步I/O的不同实现,在Win平台上则是直接使用IOCP代替转让部分的功能。 (libuv的笔记📒,传送门)
C-ares 是使用C语言实现的一个异步DNS查找的一个底层库,著名的Node.js curl gevent都使用了C-ares作为底层
http_parser、OpenSSL、zlib等模块实现了一些和网络请求封装有关的东西,比如说http解析、SSL和数据压缩。
可以在node源码的/deps目录中找到都有哪些C/C++依赖
第三层的内容都是C/C++编写的依赖,在各操作系统平台下,都会直接调用系统Api去完成对应的任务。
了解了Node.js的整体架构后,不难发现架构中第三层中的各种C/C++依赖正是Node.js实现它的单线程黑魔法的关键所在,所以接下来就详细看看这些依赖们。
| 引擎 | 处理流程 | 优缺点 |
|---|---|---|
| 旧版v8 | JavaScript 代码 ---> AST ---> V8 直接执行这些未优化过的机器码 ---> 高频率过高的代码优化为机器码 | ①惰性编译,编译时间过久,影响代码启动速度 ②编译出的机器码通常为源JS代码大小的几千倍 ③使用内存、硬盘进行缓存在移动端内存占用问题明显 |
| 新版v8 | 源代码 ---> AST ---> 字节码 ---> 解释器执行字节码 | ①字节码占用空间远小于机器码,有效减少内存占用 ②将字节码转换为不同架构的二进制代码的工作量也会大大降低 ③引入字节码,使得V8 移植到不同的 CPU 架构平台更加容易 |
v8无论是在浏览器端还是Node.js环境下都会启用一个主线程(浏览器中称为为UI线程),并且维护一个消息队列用于存放即将被执行的宏任务,若队列为空,则主线程也会被挂起。
每个宏任务执行的时候,V8都会重新创建栈,所有的函数都会被压入栈中然后逐个执行,直到整个栈都被清空。
微任务的出现,是为了在多个在粒度较大的宏任务之间穿插更多的操作。微任务可以看做是一个需要异步执行的函数,执行的时机在当前的宏任务的主代码快执行完之后,在整个宏任务执行结束之前。
通俗地理解,V8 会为每个宏任务维护一个微任务队列,生成一个微任务,该微任务会被 V8 自动添加进微任务队列,等整段代码快要执行结束时,该环境对象也随之被销毁,但是在销毁之前,V8 会先处理微任务队列中的微任务。
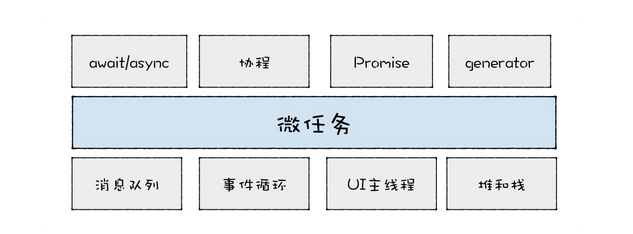
libuv 是一个高性能的,事件驱动的I/O库,这个库负责各种回调函数的执行熟顺序。童鞋们熟知的EventLoop与Thread Pool都由Libuv实现。

在 《图解 Google V8》中有一段描述十分经典,这里直接引用一下
Node 是 V8 的宿主,它会给 V8 提供事件循环和消息队列。在 Node 中,事件循环是由 libuv 提供的,libuv 工作在主线程中,它会从消息队列中取出事件,并在主线程上执行事件。
同样,对于一些主线程上不适合处理的事件,比如消耗时间过久的网络资源下载、文件读写、设备访问等,Node 会提供很多线程来处理这些事件,我们把这些线程称为线程池。
拿文件读写操作来说,如上图libuv就会启用Thread Pool中的文件读写线程进行文件读写。读写完毕后,该线程会将读写的结果包装成函数的形式,塞入消息队列中等待主线程执行。
耗时工作在工作线程完成,而工作的callback在主线程执行。
每一个node进程中,libuv都维护了一个线程池。
因为同处于一个进程,所以线程池中的所有线程都共享进程中的上线文。
线程池默认只有4个工作线程,用UV_THREADPOOL_SIZE常量控制。(翻译自文章)
并不是所有的操作都会使用线程池进行处理,只有文件读取、dns查询与用户制定使用额外线程的会使用线程池。
(配图来自libuv团队的演讲)

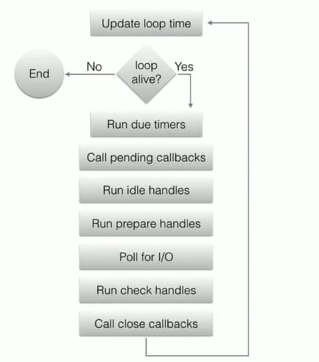
loop的状态,只有处于激活状态才会开始执行周期,若处于非激活状态,则什么都不需要做。ps: 重点看timers、poll、check这3个阶段就好,因为日常开发中的绝大部分异步任务都是在这3个阶段处理的。
int uv_run(uv_loop_t* loop, uv_run_mode mode) {
int timeout;
int r;
int ran_pending;
/*
从uv__loop_alive中我们知道event loop继续的条件是以下三者之一:
1,有活跃的handles(libuv定义handle就是一些long-lived objects,例如tcp server这样)
2,有活跃的request
3,loop中的closing_handles
*/
r = uv__loop_alive(loop);
// 假若上述三个条件都不满足,则更新 loop 里的update_times
if (!r)
uv__update_time(loop); // 更新 loop 实体的 time属性为当前时间
while (r != 0 && loop->stop_flag == 0) {
uv__update_time(loop); // 更新时间变量,这个变量在uv__run_timers中会用到
uv__run_timers(loop); // 执行timers阶段
ran_pending = uv__run_pending(loop);//从libuv的文档中可知,这个其实就是I/O callback阶段,ran_pending指示队列是否为空
uv__run_idle(loop);//idle阶段
uv__run_prepare(loop);//prepare阶段
timeout = 0;
/**
设置poll阶段的超时时间,以下几种情况下超时会被设为0,这意味着此时poll阶段不会被阻塞,在下面的poll阶段我们还会详细讨论这个
1,stop_flag不为0
2,没有活跃的handles和request
3,idle、I/O callback、close阶段的handle队列不为空
否则,设为timer阶段的callback队列中,距离当前时间最近的那个
**/
if ((mode == UV_RUN_ONCE && !ran_pending) || mode == UV_RUN_DEFAULT){
timeout = uv_backend_timeout(loop); // 这个函数调用计算除了,I/O将会阻塞多少时间
uv__io_poll(loop, timeout);//poll阶段
uv__run_check(loop);//check阶段
uv__run_closing_handles(loop);//close阶段
//如果mode == UV_RUN_ONCE(意味着流程继续向前)时,在所有阶段结束后还会检查一次timers,这个的逻辑的原因不太明确
if (mode == UV_RUN_ONCE) {
uv__update_time(loop);
uv__run_timers(loop);
}
r = uv__loop_alive(loop);
if (mode == UV_RUN_ONCE || mode == UV_RUN_NOWAIT)
break;
}
if (loop->stop_flag != 0) {
loop->stop_flag = 0;
}
return r;
}Node.js的timer与libuv的timer阶段并不是一一对应的,若多个Node.js中的timer都到期了,则会在一个libuv的timer阶段所处理。此阶段对某些系统操作(如 TCP 错误类型)执行回调。例如,如果 TCP 套接字在尝试连接时接收到 ECONNREFUSED,则某些 *nix 的系统希望等待报告错误。这将被排队以在 挂起的回调 阶段执行。
只在内部执行
poll是整个消息循环中最重要的一个阶段,作用是等待异步请求和数据,文档原话是
Acceptc new incomming connection( new socket establishment ect) and dat (file read etc)
在Node.js里,任何异步方法(除timer,close,setImmediate之外)完成时,都会将其callback加到poll queue里,并立即执行。
本阶段支撑了整个消息循环机制,主要做了两件事:
poll整个阶段过程为:
具体epoll的实现过程,可以参考另一篇笔记Socket 编程 - I/O 多路复用
这个阶段只处理setImmediate的回调函数
因为poll phase阶段可能设置一些回调,希望在 poll phase后运行,所以在poll phase后面增加了这个check phase
专门处理一些 close类型的回调,比如socket.on('close',....),用于清理资源。
Node.js中v8借助libuv来实现异步工作的调度,使得主线程则不阻塞libuv中的poll阶段,主要封装了各平台的多路复用策略epoll/kqueue/event ports等,对I/O事件的等待和到达来驱动整个消息循环。Node.js时,使用者是单线程的概念。但了解其线程池规则之后,我们仍可隐式地去使用多线程的特性,只是线程的调度完全交给了Node.js的内核。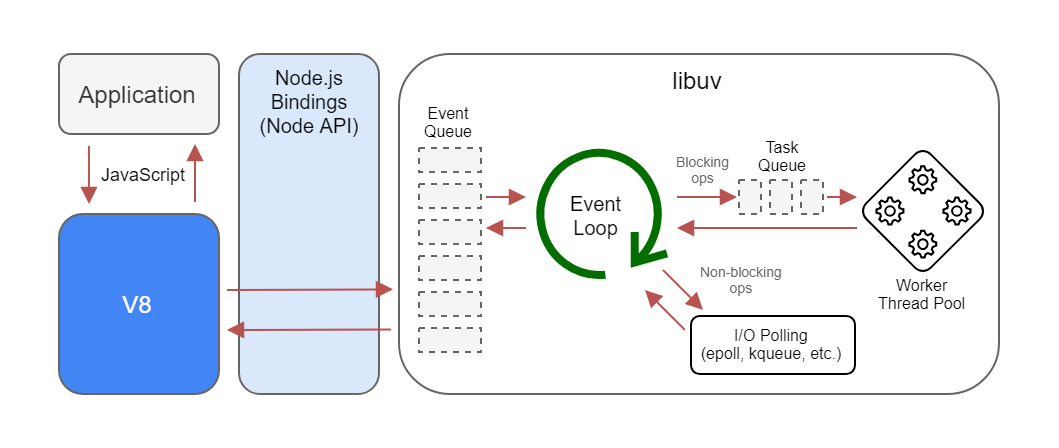
node 从 V11 版本开始,event loop 已经与浏览器趋于相同,即每个 macrotask 执行完之后,执行所有的 microtask
[1] NodeConf EU | A deep dive into libuv - Saul Ibarra Coretge
[2] libuv & Node.js EventLoop
[3] The Node.js Event Loop: Not So Single Threaded
[4] 《图解 Google V8》
[5] Introduction to libuv: What's a Unicorn Velociraptor? - Colin Ihrig, Joyent
[6] Node.js 事件循环,定时器和 process.nextTick()
上一篇笔记了解了浏览器同源策略的方方面面,随着web服务的多元化,以及前后端分离的大环境,页面与资源的分离已经是必然的事情。这次则先聊聊工作中用得最多的 CORS 策略(Corss-origin Resource Sharing)。
CORS 策略允许浏览器向跨源服务器发出获取资源,但请求既然是来源于不同于服务器的非同域。最容易出现以下问题:
同域检测 就十分有必须要了。(你是否想起了CSRF Token的概念,后文会做相应比较)。同域检测 都通过不了,则十分浪费网络带宽同域检测 的逻辑复杂程度不一,每一次都需要重新判断,也是对服务器资源的浪费针对此需求,w3c 在提出了一个预检查请求 (CORS-preflight) 的概念。但由于向下兼容的需要,只在非简单请求中启用预检查请求,而对简单请求不作额外处理。
服务端服务器可以根据这个预检查请求,来告知是否允许浏览器对原接口发起请求。
正如前文👆所提到的,其实 简单请求 仅仅是为了 w3c 为了退出新策略而强行划定的标准。在 CORS 标准推出前,浏览器与服务器的数据交互大多数是使用 <Form> 发起的,那么为了最大程度地兼容已存在的服务,则以此为界定。
参考 👉DOM Form - MDN 和 👉简单请求 - MDN, 二者的描述 和 定义也十分相近。

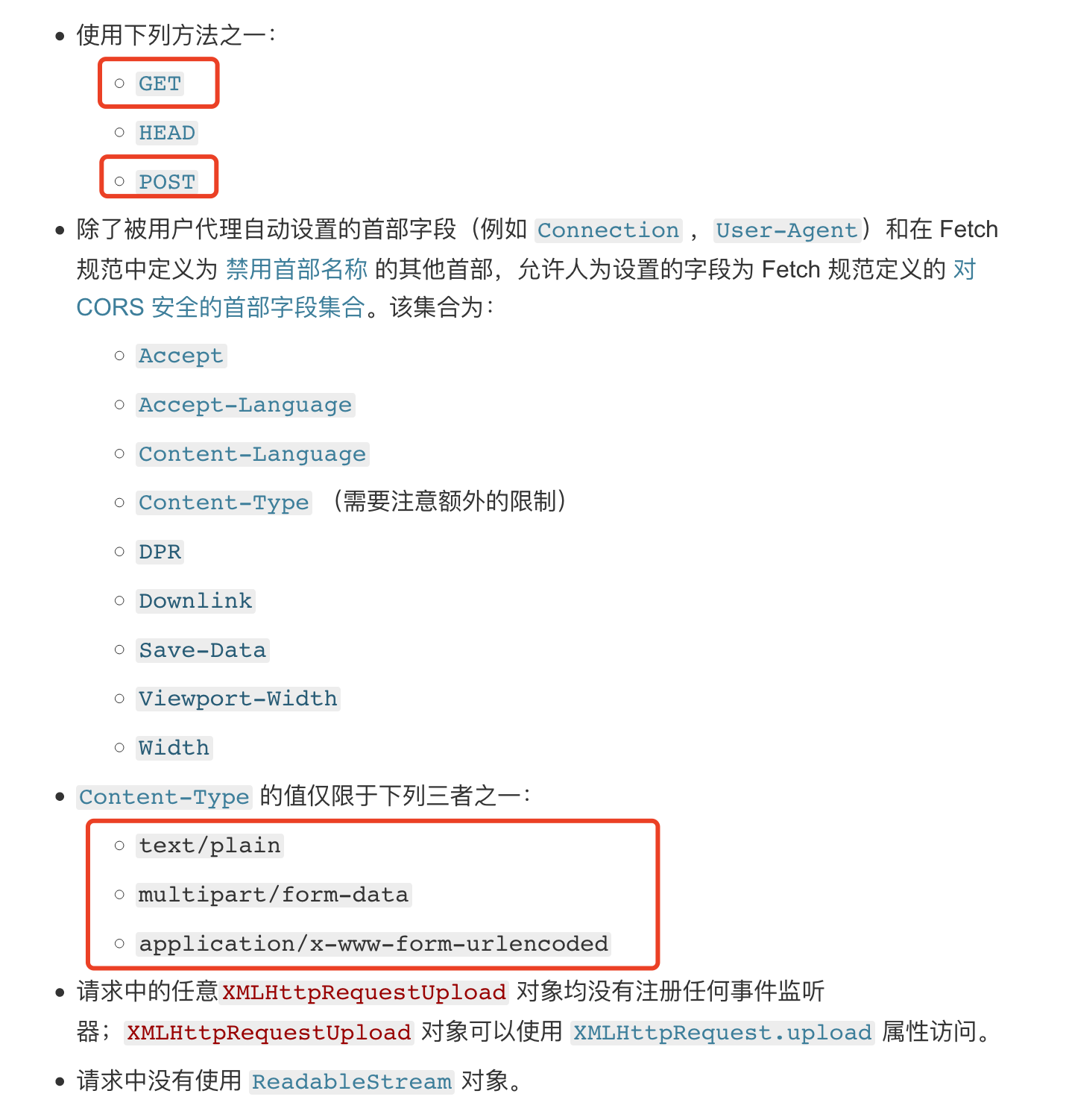
使用form标签是否可以发起这一标准,大多数情况下我们就不需要去强行记忆区分简单请求的那些复杂的method、content-type 和 header了。
很好理解的是, 非简单请求 字面意思就是 除了 简单请求 以外的其他请求。这时候,浏览器会先行发送一个请求的预检查请求。
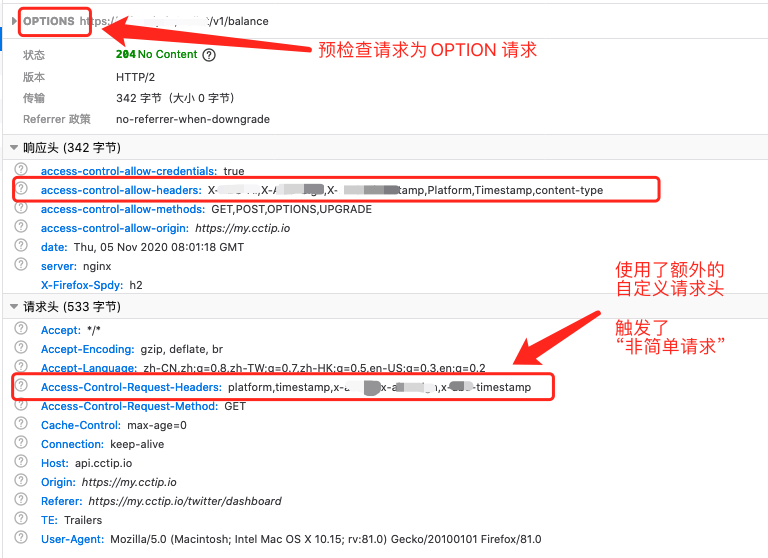
预检测请求存在的意义之一,则是减少服务器频繁执行 检查同域 逻辑,其起作用的核心则是:
Access-Control-Max-Age: xxx
在有效时间内,浏览器无须为同一请求再次发起预检请求。这一机制有效地减少了服务端执行 同域检测 逻辑的时间,节省了服务器的资源。
如果值为 -1,则表示禁用缓存,每一次请求都需要提供预检请求,即用OPTIONS请求进行检测。
Access-Control-Allow-Origin、Access-Controll-Allow-Method、Access-Controll-Allow-Header 和 Access-Control-Allow-Credentials 这几个的用法已经是老生常谈了。这里则不再赘述了。
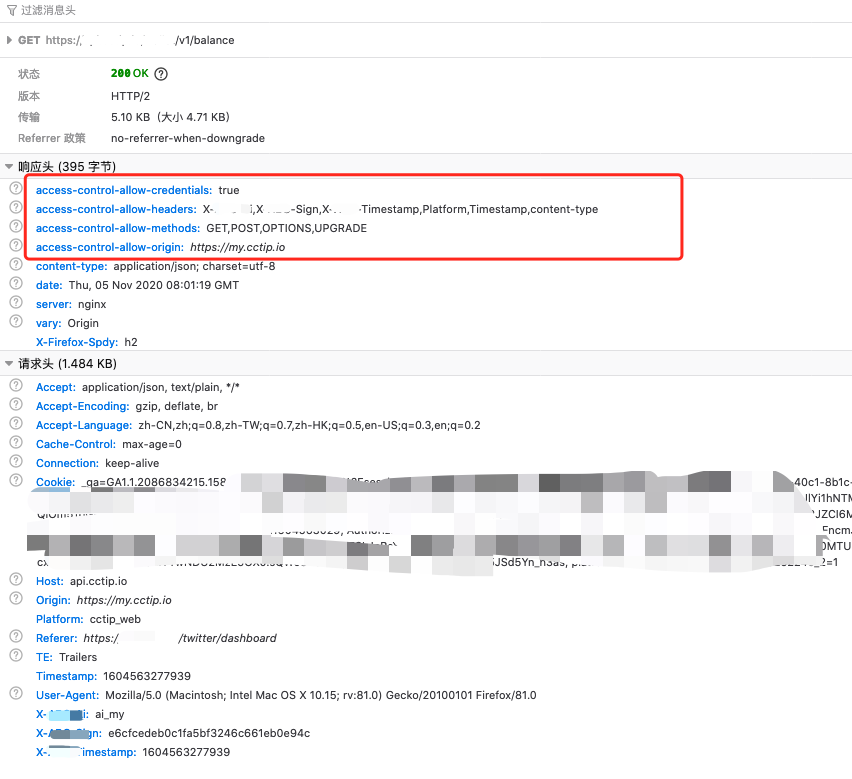
"借用"用户cookie以实现盗用用户登录态的行为,便是大家熟知的CSRF攻击。同源策略仅仅只是拦截了请求的返回,但并不会阻止跨域请求的发送。CSRF token 方案进行防范
nginx)处拒绝掉请求,否则请求仍然会被服务器处理CORS访问、或者不开启Access-Control-Allow-Credentials*。
Origin 请求头而有所不同,必须在Vary响应头中包含 Origin。关于 CSRF 原理与防范实战,请看博主的另一篇笔记,传送门👉
与 HTTP 协议相类似,w3c 提出的 CORS 也是一种约定,需要浏览器和服务器共同配合实现。对于预检测请求的结果,仍然后很多种可能的处理流程:
非简单请求。简单请求,是否就可以绕过 同源检测 了呢?curl、postman工具 和 其他脚本等发起的请求,是否不用检测了呢?在👉 CSRF 实战 笔记中,我们讲到过对于非同源请求的拦截与处理方法。结合起来 CORS 的 OPTION 预检查请求用于浏览器缓存检测结果,而CSRF Token的检测则用于做最后的防御。
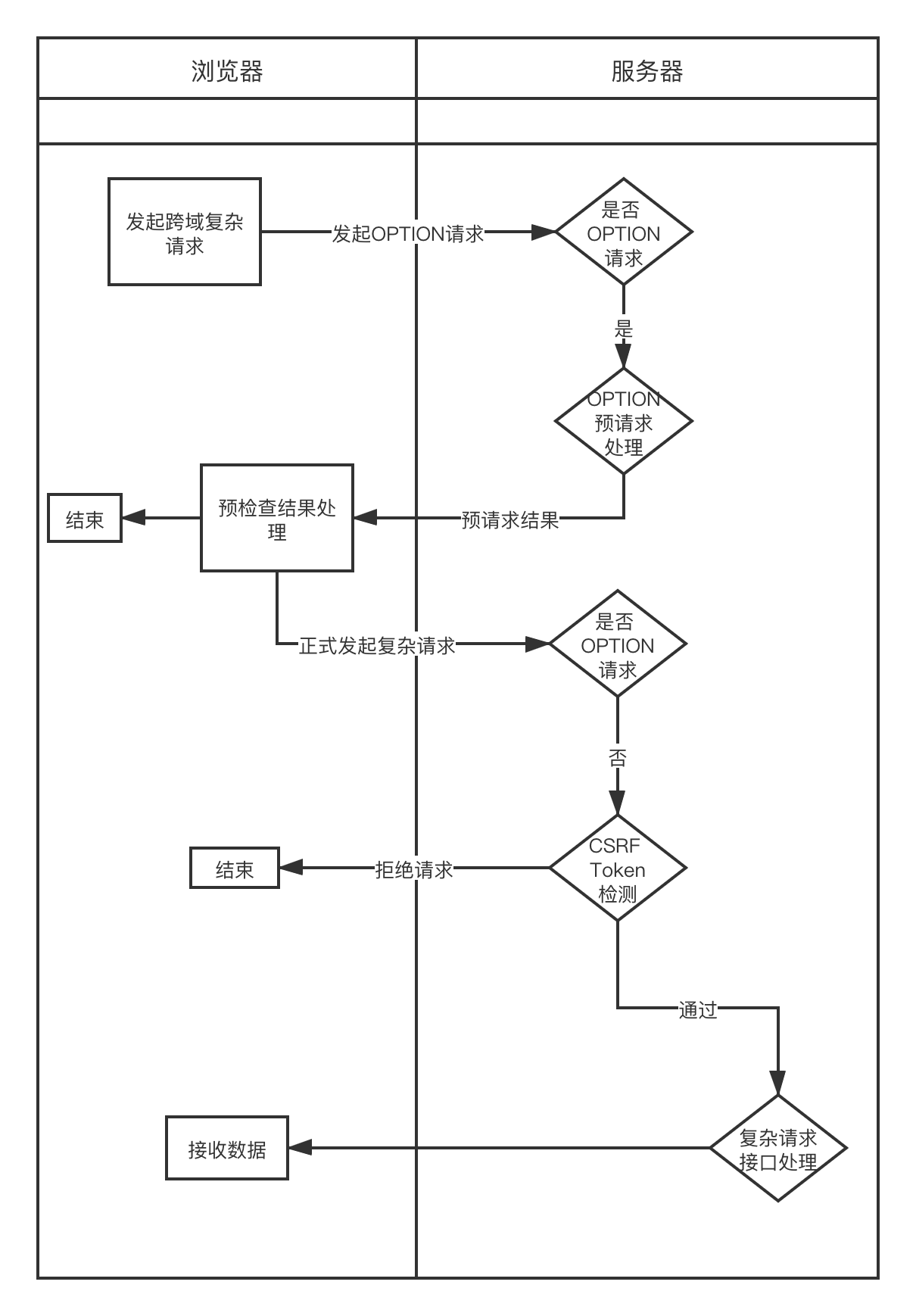
服务端的跨域处理,简单可以表示为以下的流程,感兴趣的话也可以看看kosjs/cors插件的实现过程。
// 集中处理错误
const handler = async (ctx, next) => {
// log request URL:
ctx.set("Access-Control-Allow-Origin", "yourdmain.com");
ctx.set("Access-Control-Allow-Methods", "POST, GET, OPTIONS, DELETE");
ctx.set("Access-Control-Max-Age", "86400");
ctx.set("Access-Control-Allow-Headers", "x-requested-with,Authorization,Content-Type,Accept");
ctx.set("Access-Control-Allow-Credentials", "true");
// 若有必要,请添加上其他 CSRF TOKEN 所需的响应头字段
ctx.set("X-Yourdomain-Timestamp", "x-requested-with,Authorization,Content-Type,Accept");
// 统一处理预请求
if (ctx.request.method == "OPTIONS") {
ctx.response.status = 204
}
console.log(`Process ${ctx.request.method} ${ctx.request.url}`);
try {
await next();
console.log('handler通过')
} catch (err) {
console.log('handler处理错误')
ctx.response.status = err.statusCode || err.status || 500;
ctx.response.body = {
message: err.message
};
}
};preflight 机制,使用 Access-Control-Max-Age 响应头实现预请求的缓存,减少服务器压力非简单请求,触发 preflight 机制而减小服务器压力。CSRF防护。[1] 跨源资源共享(CORS) - MDN
[2] koa跨域 - mapplat
[3] CORS 为什么要区分『简单请求』和『预检请求』? - 奇舞团
javascript没有动态作用域,而闭包的本质是动态作用域。使用闭包,只需要简单滴将一个函数定义在另一个函数内部,并将它暴露出来。要暴露一个函数,可以将它返回或者传递给其他函数。
IIFE(立即执行函数)去实现;(function($){
$.fn.pluginName = function() {
// Our plugin implementation code goes here.
};
})(jQuery); 闭包的实现原理,根本上来说是作用域链,我们还需要简单了解一下名词
变量对象 与 活动对象函数的参数 + 函数内声明的变量 + 函数内声明的函数)共同组成了函数的 变量对象,函数的变量对象在函数没有执行之前,都是不能够被访问的。活动对象,也即是环境中定义的所有变量和函数,在执行前被称作变量对象在执行后,被称为活动对象。活动对象相当于变量对象在真正执行时的另一种形式。每一个函数(包括全局和自定义函数),在词法解析阶段,都会有自己的词法作用域。当我们调用一个函数的时候,若该环境没有被js回收机制回收时,则我们仍可以通过其来引用它原始的作用域链。
var counter = (!function(){
var num = 0;
return function(){ return ++num; }
}())
var n = counter();
n();
n();
n = null; // 清空引用,等待回收var outerValue = 'globalValue';
var later;
function outFunction() {
var innerValue = 'innerGlobal';
function innerFunction(param){
console.log(outerValue,innerValue,param,outter2);
}
// 向外暴露
later = innerFunction;
}
console.log('outter2:',outter2);
outFunction();
later('paramValue');
var outter2 = 'outter2';
later('paramValue2');
// outter: undefined
// globalValue innerGlobal paramValue undefined
// globalVlaue innerGlobal paramValue2 outter2① 首次传入时,外层最fun函数的变量对象转变为活动对象时,n值为1,o未被赋值所有为undefined,所以打印出undefined
② 此时最外层fun函数内部的活动对象,n值为0,m值为undefined,o值为undefined。
所以第二次调用时,传入1,活动对象中的n值被修改为1,但①中递归返回的最内部的fun(m,n),其实是执行了fun(undefined,0) ,所以打印出来的是undefined ,然后当前此次调用返回的是fun(undefined,1)。
③第三次调用时,注意看,调用对象还是a,所以依托的环境还是①执行后的活动环境。同样输出 0
④第四次调用时,同③
anwser: undefined 0 0 0
function foo() {
// 内部参数
var something = "cool";
// 读取内部值
var another = [1, 2, 3];
function doSomething() {
console.log( something );
}
// 修改内部值
function doAnother(feeling) {
something = feeling
console.log('value has changed to ' feeling);
}
return {
doSomething,
doAnother
}
}
var F = foo();
F.doSomething(); // cool
F.doAnother("hot"); // value has changed hot
F.doSomething(); // hot①与Q1不一样的是,Q2使用的是链式调用的形式,后一次使用的是前一次调用修改后的活动环境。
② Q1中,只有第一次修改到了o的值,后三次都是继承第一次调用后的活动环境。
③ 同Q1中的②解释,第二次、第三次链式调用,都是用的是上一次返回的fun(m,n),所以四次调用的实际情况别是fun(undefined,0)、fun(undefined,1)、fun(undefined,2)、fun(undefined,3),undefined位置替代的是m的值,后三次调用的时候,分别也传入了,1、2、3来替代这个undefined的值,输入后也成功修改到了外层fun函数活动变量中的n值
anwser: undefined 0 1 2
function fun(n,o) {
console.log(o);
return {
fun:function(m){
return fun(m,n);
}
};
}
var a = fun(0); a.fun(1); a.fun(2); a.fun(3); //Q1
var b = fun(0).fun(1).fun(2).fun(3); // Q2
var c = fun(0).fun(1); c.fun(2); c.fun(3); //Q3① 注意函数调用完,若没有后续操作,当前的作用域就被释放了。若有,则后者可以延续当前的作用域中的参数。
② Q1: undefined 0 0 0 作用域始终停留在第一次 fun(0) 产生的 a 中。
③ Q2: undefined 0 1 2 后续调用延续前面的作用域。
④ Q3: undefined 0 1 1 逻辑参考 Q1 Q2
使用对象原型和使用闭包封装,在对象实例化后,和闭包环境执行之后,都能够实现面向对象来构建数据对象,实现对数据声明环境的通过特定方法操作内部数据效果。
function Viechel() {
this.speed = 100;
}
Viechel.prototype.speedUp = function() {
this.speed += 10;
}
// 实例化对象
var car = new Viechel();function viechel() {
var speed = 100;
return {
getSpeed: () => speed,
speedUp: function() {
speed += 10;
}
}
}
// 执行闭包
var car = viechel();初始化
使用闭包在执行的时候,变量对象变为活动对象的过程中,可能需要执行大量代码。而原型链的形式,在实例化的时候都只是把构造函数执行一次。也即是,在初始化的时候,原型的形式的效率更高。
调用时
在初始化之后,调用方法时,原型上的方法存放在原型链上,寻址速度会略慢。所以在调用上,闭包的形式优于原型的形式。
构建的对象实例化数量少,但是经常需要调用内部方法的时候,请使用闭包。(比如:自定义函数库,页面中banner的控制,大数据监控屏中--各个模块的数据的控制器)
若是实例化数量比较多的,一般只需要注入信息,调用方法较少的,请使用对象原型。(比如封装好的msgCard组件,时间轴组件等等)
// 一个希望封闭的对象
const privateZone = (secret) =>{
return {
get:()=>{secrte} //对往外的数据接口
}
}
var obj = private(); // 返回一个对象
var secert = obj.get(); // 使用闭包对外的接口,也就是对内部数据访问的特权方法。在调用一个函数的时候,传入了多个参数,返回时返回带少数参数的一个函数。
使用分步返回函数,可以实现参数的分步输入。
const partialApply = (fn, ...fixedArgs) => {
return function (...remainingArgs) {
// 声明时的参数,与调用时的参数合二为一
return fn.apply(this, fixedArgs.concat(remainingArgs));
};
};// 经典用法,不多解释
for(var i=0;len =btns.length;i<len;i++){
(function(i){
btns[i].inclick = function(){
alert(i)
}
})(i)
}例子实现一个图片的异步创建与加载
var report = function(src){
var img = new Image();
img.src = src;
}
report('http://api.getImgInfo');
// 当report执行完成后,img对象则被释放var report = (function(){
var img = new Image();
return function(src){
img.src = src;
}
})()[1] 闭包面试题 - 小小沧海
课本的知识,需要温故而知新,做个笔记吧
在Linux中一切皆可以看成是文件,有
普通文件、目录文件、链接文件和设备文件。 然而,进程访问文件数据必须要先“打开”这些文件。内核为了跟踪某个进程打开的文件,则用一个个文件描述符组成了一个打开文件表。
文件描述符仅是打开文件的标识,是系统内核为了高效管理已经被打开的文件所创建的索引。因为文件系统中所有的文件数目与当前打开的数目是有数量级差别的。
一个文件描述符只能够指向一个文件,但是一个文件会有多个文件描述符去描述它。
索引一般是小整数,所有执行I/�O调用的系统操作都需要通过文件描述符,文件描述符一般从3开始计算
程序刚启动的时候 0指代标准输入,1指代标准输出,2指代标准错误
POSIX标准要求,每次打开文件的时候,都必须使用最小的可用序号。下图则是Linux中某个进程的文件描述符情况。
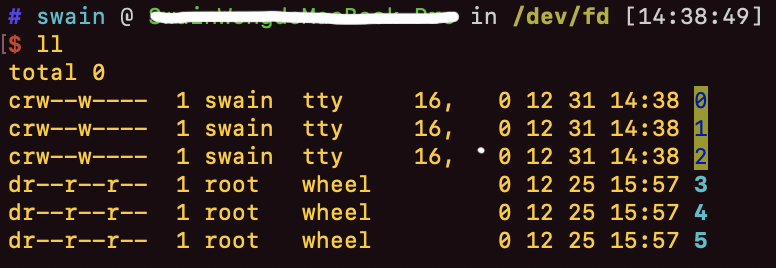
文件描述符,既然是描述符,都描述了什么内容呢?
打开文件表中移除。
一般来说,系统有多少内存就可以打开多少文件,但是一般系统在底层配置的时候会做出限制,通常是系统内存的10%。
在进程级别上,系统也会限制一个进程能够打开的最大的�文件数目,一般这个数目为1024,这个限制称之为用户级的限制。
同一个文件可以被一个进程中打开多次,也可以在不同进程中被打开
若是同个进程中,多次打开同个文件,则在i-node表中会是同一个文件。
若是不同进程下的文件描述符,�都指向了同一个系统级下的文件句柄,那么很有可能是因为进程非fork造成的。或者是一个�进程将UNIX下�穿件的文件描述符,传递给另一个进程。
两个不同的文件描述符,若指向同一个打开文件句柄,将共享同一文件偏移量。因此,如果通过其中一个文件描述符来修改文件偏移量,则也会影响当前的文件偏移量。
文件描述符标志(即,close-on-exec)为进程和文件描述符所私有。对这一标志的修改将不会影响同一进程或不同进程中的其他文件描述符
查看自身机器最大可打开链接数目:
$ ulimit -n
数据块为单位进行的。
字节序列。语义一致性,规定了多进程如何同时访问共享文件。又因为磁盘I/O和网络延迟的原因,而把这部分设计得比较宽松。基本都把数据一致性的问题,抛给了应用程序自己去解决。
毕业前几年时间一直在小公司小团队中度过,对项目组的测试流程有些总结:
主要问题有以下几种:
总体思路应该是,一个项目(需求)的测试用例文档,应该由测试组为主导,开发组、设计组、产品组进行补充,并持续补充、迭代。总体思路,简单可以概括为下面的流程图。
开发组进行项目开发的时候,需求文档+原型为主,设计图 和 基础测试用例为辅。
开发组在开发过程中,发现一些特殊逻辑、新的边界条件,也加入到云文档的“待整理用例”区。
测试用例评审会
过程总结
以上内容,都是是根据已有的工作经验和经历过团队的实际情况总结出来的。能不能借鉴,具体情况必须具体分析。
[1] 软件测试的流程
这里收集下工作中遇到的跨域问题....持续更新
博主上周给公司web项目上了CDN加速。开发使用的是nuxt.js,在nuxt.config.js的配置中很快滴配置好了static.xxx.io的CDN域名。测试后发现,所有js``css、image资源都正常,除了项目中的material-design.woff2字体文件加载失败了。
/* fallback */
@font-face {
font-family: 'Material Icons';
font-style: normal;
font-weight: 400;
src: url(./material.woff2) format('woff2');
}
问题原因: 字体文件请求是从我们自己的网站发起的,而请求的是CDN资源库上的字体文件,明显是you跨域的情况存在。
解决办法
阿里云,直接在CDN服务后台添加上跨域白名单即可。参考这里CDN服务,那就自行在对应机器上的nginx或者服务上加上返回头 Access-Control-Allow-Origin: 'your.domain.com'问题出现的过程:
target.js 文件如何解决:
给script标签增加 crossorigin 属性,让浏览器允许页面请求资源。
<script src="http://other-cdn-domain.com/static/target.js" crossorigin>参考 CORS 规范,在资源服务端返回跨域头 Access-Control-Allow-Origin: test.com
最后就可以可以在控制台中看到 跨域脚本 下的 js 执行异常了。
Allow-Origin: * 与 withCredentials = true想要跨域请求携带cookie,但服务端允许跨域的端口却是*的话,听起来就是矛盾的。

所以服务端需要同时设置二者:
add_header "Access-Control-Allow-Origin" "http://fedren.com";
add_header "Access-Control-Allow-Credentials" "true";在日常开发调试中,博主在搭配使用whistle作为代理服务器进行调试时,应用运行在Chrome 的某些版本下。后端接口返回 5xx 的异常,Chrome Dev Tool 中会显示与接口跨域调用失败一样的错误。
(截图待补充......)
不知道 whistle 是啥?去看看👉
为了项目的更好优化,为了提高浏览器的解析速率,减少页面无用的重绘,重置。
本文请结合其他笔记一起食用...
[1] 前端性能优化 - 第一曲 总览
[2] 从渲染�Timeline中深入交互优化
用户输入网址(URL),浏览器查找DNS服务器,寻找对应的ip地址
(DNS查询过程博文,传送门👉)
浏览器根据ip地址,向服务器发送获取资源的请求
服务器端返回一个HTML响应
浏览器收到返回的内容,浏览器开始解析HTML内容
HTML字符串转化成浏览器能够识别的DOM Tree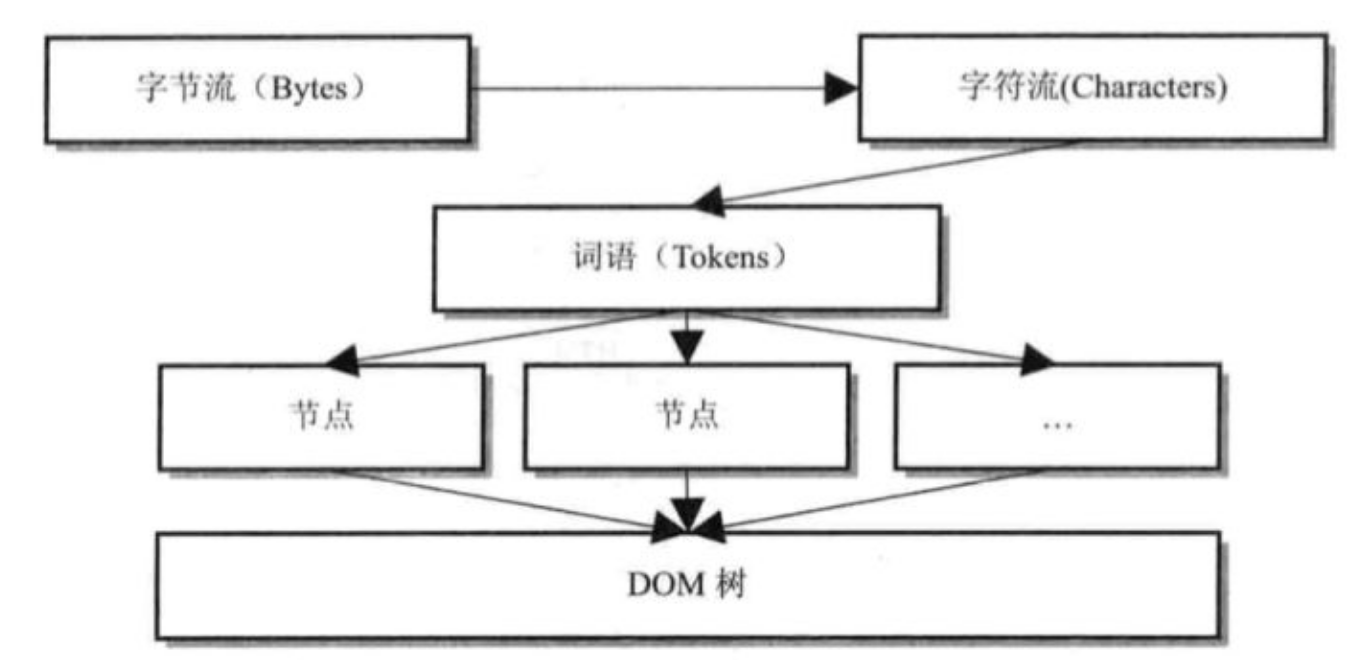
CSS内容内容生成CSSOM ��Tree (或者称之CSS Rule)CSSOM Tree 与 DOM Tree合起来生成 Render Tree准备对页面进行排布和绘制。Render Layer的概念,一个Render Layer上有N个Render Object。
最后,浏览器调用GPU进行渲染。
想了解更多内容的,请去访问我的另一篇博文《Render �Layer与GUP加速》👉
浏览器解析CSS过程不阻塞;
浏览器在代码中发现一个<img>标签引用了一张图片,向服务器发出请求。此时浏览器不会等到图片下载完,而是继续渲染后面的代码。
服务器返回图片文件,由于图片占用了一定面积(宽度高度),影响了后面段落的排布,因此浏览器需要回过头来重新渲染这部分代码;
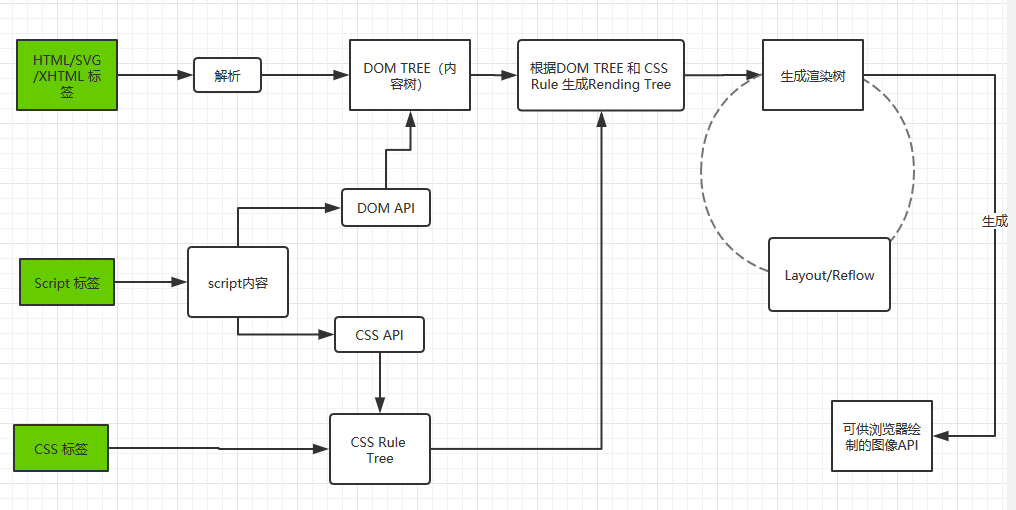
Reflow
浏览器发现某个部分的变化,影响了布局,就需要重新回去渲染。
Repaint
浏览器发现,某些变化只是改变了背景颜色,文字颜色,不影响元素周围或者内容的属性,浏览器将只会进行repaint。
Reflow 相比 Repaint更加浪费时间,也就更加影响性能。需要尽量避免。
外链css的异步加载不会阻塞HTML的解析,但会阻塞页面的渲染因为要等合成Render Tree
外链的script标签会阻塞HTML的加载,加载完后也会立即执行。内嵌的script标签的JS代码也会遇到就立即执行
执行的script内容中,有队DOM进行的操作,其中的操作有可能引起浏览器的重绘或者重新渲染。
用户若有异步的JS操作,也同样会引起浏览器的重绘或者重新渲染。(例如用户点击按钮,某个部分隐藏)
无论外链,还是内嵌。JS代码中的运行若出错,HTML会停止解析。(包括页面的渲染、其它资源的下载)
script内容放置到body标签的末尾去,最大程度避免页面加载的阻塞,也避免操作到未加载的DOM内容gulp和webpack等打包工具整合JS实现)script外链标签[1] 从URL输入到到加载完成的过程 - FEX baidu
[2] 浏览器工作原理
[3] css3硬件加速
最近在
webpack调试的时候遇到,经常遇到heap oout of menory的情况,导致调试开发工作的十分不顺利。所以决心了解一下Javascript和node的内存机制。
本篇文章先了解Javascript In Browser的内两种原始数据类型
| 类型 | 包含种类 | 存储情况 |
|---|---|---|
| 原始值 | Number boolean null undefined |
原始值存储在栈中 |
| 引用值 | Object Function Array |
引用类型的指针存储在栈中,指向存在堆中的实际对象 |
| 栈(stack) | 描述 |
|---|---|
| 结构 | 栈的优势就是存取速度比堆要快,仅次于直接位于CPU中的寄存器 |
| 值的变动 | 从一个变量向另一个变量复制基本类型的值,会创建这个值的一个副本 |
| 大小与存活时间 | 所占内存空间大小、生命周期都是固定的 |
| 堆(heap) | 描述 |
|---|---|
| 结构 | 因为在运行时动态分配内存,所以存取速度比较慢 |
| 值的变动 | 原地操作 |
| 大小与存活时间 | 可以动态地分配内存大小,生存期也不必事先告诉编译器 |
Javascript 中的 String 虽然是 原始类型,但事实上 V8 堆内使用(类似数组的)连续空间存储字符串。并且使用OneByte 和 TwoByte两类结构来做存储。
const str = 'abcdef'
// 可读
conso.log(str[2]) // c
str[2] = 'x'
// 但不可写
console.log(str) // abcdefJavascript的字符串属于基础类型,每次往字符串中加添加内容,其实在内存中都是新创建了一个新字符串对象,旧字符串对象短时间也还在内存中,但马上会被GC回收。
首先我们给一个定论,是传值。而且所有情况都只传值。
在函数传参的时候,内核是复制了一个栈帧的值作为形参的值,栈帧上存的是什么,那么我们就复制的是什么。
基本类型在基本类型传参的时候,�我们同样理解为拷贝栈帧,此时栈帧中保存的就是基本类型的值,比如说123,true,那么�形参中的栈帧保存的也是一个这样的基本类型值。
引用类型在传递引用类型的的时候。首先,实参在栈中存储的值就是一个指向堆中对应数据对象的指针,在传递函数参数的时候,将这个指针的值赋值了一份,作为形参的值。那么此时,形参的栈空间也存着一个值相同的指针,都指向了堆中的同一个对象。
// 原对象
let a = {key:123};
// 转换方式1
function changeAttr(b){
b.key = 789;
}
// 转换方式2
function changeItSelf(c){
c = {key2:888}
}
// 开始试验
changeAttr(a);
console.log(a); // {key:789}
changeItSelf(a);
console.log(a) // {key:789}我们可以看出changeAttr操作中,访问到了a中的内容,并且进行了修改。而changeItSelf中的内容并没有修改成功。来画一下当时的栈帧情况。
| 栈内存 | -- | 堆内存 | ||
|---|---|---|---|---|
| a | xxx0081270xx |
-- | xxx0081270xx |
{key:123} |
然后执行了函数changeAttr,进行了栈帧的拷贝,除了变量名字不同,值是完全的一致,所指向堆的位置也一致。也就不难明白为什么会修改到同一个对象了,以下是修改后的内存情况。
| 栈内存 | -- | 堆内存 | ||
|---|---|---|---|---|
| a | xxx0081270xx |
-- | xxx0081270xx |
{key:123} |
| b | xxx0081270xx |
而当调用changeItSelf的时候,这时候是对c的值直接进行修改,也就是赋值了a的值(也就是那个内存地址)之后,我们又用一个新的内存地址覆盖了c的值。
| 栈内存 | -- | 堆内存 | ||
|---|---|---|---|---|
| a | xxx0081270xx |
-- | xxx0081270xx |
{key:789} |
| c | a762784368wqe |
-- | a762784368wqe |
{key:888} |
所以到这里,我们坚定地继续喊出:JS函数调用的时候,形参的到的就是实参的值
这个问题其实比较绕的原因是,大多数的前端工程师不知道指针的定义
在计算机科学中,指针(英语:Pointer),是编程语言中的一类数据类型及其对象或变量,用来表示或存储一个存储器地址,这个地址的值直接指向(points to)存在该地址的对象的值。
--- 《维基百科 - 指针》
JavaScript中没有指针这个数据类型,也不能够将一个变量作为另一个变量的指针。
JavaScript中没有指针,引用的工作机制也不尽相同。在JavaScript中变量不可能成为指向另一个变量的引用。
———《你不知道的JavaScript 中卷》2.5 值和引用,第1版28页。
但是,无论语言怎么变,都脱离不了冯诺依曼模型,CPU和内存。
我们可以认为Javascript中没有指针,因为没有指针这种数据类型,也不能将一个变量指向另一个变量。
我们也可以认为JavaScript中的引用和指针是类似的一套体系,都是实际内容存储的内存空间的一个地址。
JavaScript变量赋值、传递的时候,时钟传递的是值,这个值本身是一个基础类型的内容,异或是对象的引用就交给函数解析器去理解了。
Q: JavaScript字符串的内容存储在哪里,是堆中还是栈中?
A: 你写JS里面用到的所有东西,字符串,数字,数组,对象,甚至整个代码片段(文件),在JS引擎里面都会 new 一个指针(对象引用)出来,所以如果你要问字符串在堆还是栈,那么可以说是堆。然而脚本语言引擎的目的就是为了托管内存管理,让你不用去知道到底是堆还是栈。
[1] 图1 - 链接
[2] 字符串在 V8 内的表达 - @superzheng
[3] [讨论] JavaScript中String的存储 - iteye
| 任务类型 | 事件类型 |
|---|---|
| 宏任务 | setTimeOut 、 setInterval 、 setImmediate 、 I/O 、 各种callback、 UI渲染 、messageChannel等 |
| 微任务 | process.nextTick 、Promise 、MutationObserver 、async(实质上也是promise) |
MutationObserver 接口提供了监视对DOM树所做的更改能力。它被设计为旧的MutationEvents功能的替代品。
MutationObserver是一个构造器,他能够在指定的DOM发生变化的时候被调用。
disconnect()
阻止mutationObserver示例继续接收通知。直到再次调用observe()方法开启,该观察者对象包含的回调函数都不会被调用。
observe()
配置MutationObserver在DOM更改匹配给定选项时,通过其回调函数开始接收通知。
takeRecords
从MutationObserver的通知队列中删除所有待处理的通知,并将它们返回到MutationRecord对象的新Array中。
实例
// 获取目标DOM对象
let targetNode = document.querySelector(`#id`);
// 配置所需检测对象
let config = {
attributes: true,
childList: true,
subtree: true
};
// 声明 DOM 变动后触发的回调函数
const mutationCallback = (mutationsList) => {
for(let mutation of mutationsList) {
// mutation.type 指向的是 配置项中被修改的项目名称
let type = mutation.type;
switch (type) {
case "childList":
console.log("childList被改动了");
break;
case "attributes":
console.log(`${mutation.attributeName} 这个属性名称被改动了.`);
break;
case "subtree":
console.log(`subTree这个属性被改动了`);
break;
default:
break;
}
}
};
// 使用构造器,初始实例化 MutationObserer对象
let observer = new MutationObserver(mutationCallback);
// 开启监听属性,传入监听DOM对象,和需要监听的内容
observer.observe(targetNode, config);let div = document.createElement("div")
div.id = 'targetNode'
document.body.appendChild(div)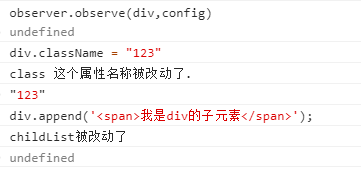
// 停止监听
observer.disconnect();process.NextTick是nodeJS中的概念,在浏览器中并不能够使用哦,node官网传送门:point_right:
准备另开一篇文章:去学习node_eventLoop,传送门:point_right:
console.log('start');
process.nextTick(() => {
console.log('nextTick callback');
});
console.log('scheduled');
// start
// scheduled
// nextTick callback注意:每次事件轮询后,在额外的I/O执行前,next tick队列都会优先执行。 递归调用nextTick callbacks 会阻塞任何I/O操作,就像一个while(true); 循环一样。
let ch = new MessageChannel()
let p1 = ch.port1;
let p2 = ch.port2;
p1.postMessage("你好我是 p1");
// port2 receive 你好我是 p1
p2.postMessage("这样啊,我是p2,吃了吗?");
// port1 receive 这样啊,我是p2,吃了吗?// 使用MessageChannel构造函数实例化了一个channel对象
var channel = new MessageChannel();
var para = document.querySelector('p');
// 获取到iframe对象
var ifr = document.querySelector('iframe');
var otherWindow = ifr.contentWindow;
// 当iframe加载完毕
ifr.addEventListener("load", iframeLoaded, false);
// 我们使用MessagePort.postMessage方法把一条消息和MessageChannel.port2传递给iframe
function iframeLoaded() {
otherWindow.postMessage('Hello from the main page!', '*', [channel.port2]);
}
//
channel.port1.onmessage = handleMessage;
function handleMessage(e) {
para.innerHTML = e.data;
}�后来笔者在工作使用到了service-worker帮助进行排序计算,所以补充一下,主页面和worker之间的通信也是是用了 MessageChannel 机制进行实现
// page.js
let worker = new Worker('./counting.js');
worker.postMessage({id:666})
worker.on('message',result=>{
rending(result); // 渲染结果
})
// counting.js
self.on('message',message=>{
let result = countintMethod(message.id);
self.postMessage(result);
})这样至少有一个好处就是能够不阻塞浏览器UI的渲染,让另一个进程去帮助我们进行计算,然后异步渲染。
几个定时器属于宏任务这个不多说。简单提一下setImmediate,它相当于setTimeout(fn,0),一般我们会将他用于把某个任务提取到异步的形式执行,而不阻塞当前任务。
window.requestAnimationFrame() 告诉浏览器——你希望执行一个动画,并且要求浏览器在下次重绘之前调用指定的回调函数更新动画。该方法需要传入一个回调函数作为参数,该回调函数会在浏览器下一次重绘之前执行 --- MDN
严格意义上来说,raf并不是一个宏任务,因为
但是查阅了相关规范之后,我们可以知道一个eventLoop的完整过程是包含这浏览器的渲染过程的,再根据上面raf的定义可以知道,ref的执行会在一个eventLoop中的微任务结束后,下一个eventloop开始前去执行。

[1] MessageChannel
[2] MutationObserver - MDN
[3] MutationObserver的使用 - 掘金
[4] requestAnimationFrame是一个宏任务么
[5] Living Standard — Last Updated 6 October 2020
不知不觉正式工作已经三年时间了,不同于自己的side-project,正式项目中更加强调流程化、标准化的工作规范。
比如淘系的《前端开发规约》,著名的雅虎35条军规等...学习参考固然重要,但能够沉淀下来成为自己的内容才更为重要。
本文会陆续补充自己在项目中犯过错,吃过亏的一些点,希望通过一次次脑海中的回荡,形成肌肉记忆...
ws错误码/错误信息可交互时间的时长
loading过程API 请求都有错误处理
错误未被吞掉。
Toast、Dialog 通知用户多个维度的逻辑相互交叉的判断时,要做到以下两点:
注释是否得当
特殊逻辑 关键逻辑 才需要添加注释代码重复出现两次或以上,就有一定会有抽象的空间
内存管理
宁愿写面条代码,也不要将一处逻辑拆离地支离破碎
decimal的处理
大单位 带精度的值进行计算。而去中心化业务中,使用小单位 不带精度的值进行计算。watch中处理主业务代码
上报数据等场景下。横向拆分 和 纵向拆分相结合action中完成[error, resData]的形式对调用方进行暴露commit粒度,思维清晰,尽量不交叉功能提交commit message必须要遵循 commit log的形。(这一点可以使用husky保证)pull request
feature时,需要单独开辟一个功能主分支单个pr的代码量,单个feature没有完成的情况下也可以提交。后续开发基于此分支为主分支,开辟子分支继续开发。pr的粒度应该维持在多个小commit(步骤/功能)所组成的一个小任务(修复一个bug,一个功能优化)等等pr已经被同事review通过的情况下,合并前不要对该分支代码进行过大改动。rebase主分支的代码feature合并到主分支时,commit过多时,建议使用git mergeCode Review,自己在提交的前,必须做足开发测试。bargin主线程进行处理[1] 阿里前端开发规范
DNS (Domain Name System 的缩写)的作用非常简单,就是根据域名查出IP地址。你可以把它想象成一本巨大的电话本,电话黄页。 使用的是UDP协议进行传输。
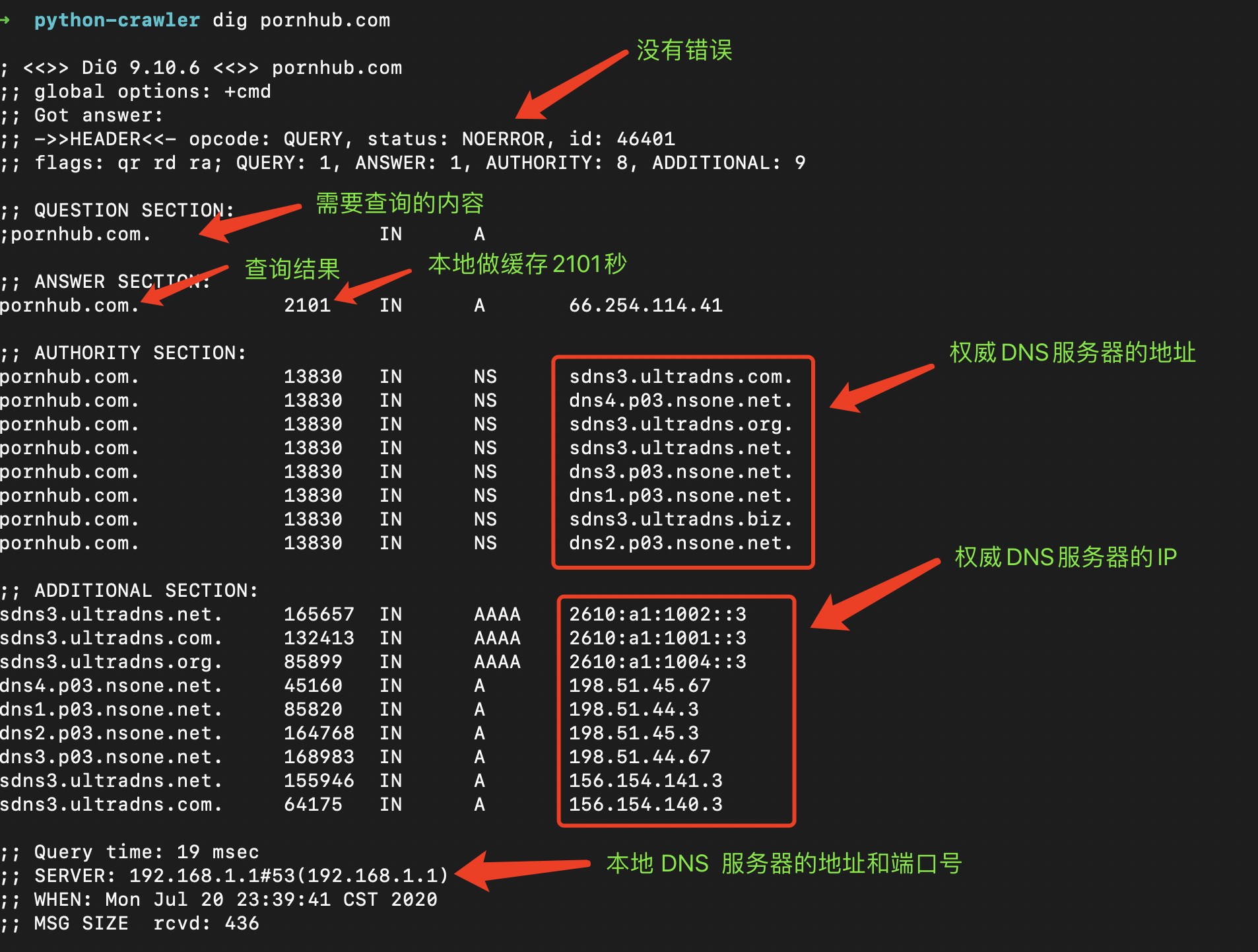
whois命令
| 域名分级 | 解析服务器 | 解析器地址存储位置 | 举例 |
|---|---|---|---|
| 根域名 | 根域名服务器 | 本地DNS服务器 | .root |
| 顶级域名 | 顶级域名服务器 | 根域名服务器中 | .com .net .cn .edu |
| 权威域名 | 各家公司自己的服务器 | 顶级域名服务器中 | .taobao .baidu .alibaba |
| 子域名 | 各公司的web服务 | map.baidu image.baidu |
先查找根域名服务器 ===> 再是顶级域名服务器 ====> 再是权威域名服务器 ====> 自身服务器子域名服务
(.root) (.com /.cn /.net) (.baidu.com /abc.cn/hupu.net) (music.baidu.com/map.baidu.com)
每一次DNS的查找结果,OS都会进行一定时间的缓存。
UNIX系统中,在/etc/resolve.conf文件中查看cDNS服务器的IP地址。Mac 使用偏好设置一样可以看到对应设置。
$ cat cat /etc/resolv.conf
每一次连接网络的时候,DNS服务器都是可以通过DHCP协议动态获取的,常用的DNS服务器一般是你接入的ISP提供的服DNS服务器。
客户端(系统)向本地DNS服务器查找ip,这个过程OS通过UDP请求向本地DNS服务器询问这个www.baidu.com对应的ip是多少。
为什么是UDP呢? 因为这时候只需要查询一个www.baidu.com的ip地址,数据量极少,不可能超过512字节,所以为了速度。
首先我们要知道两个概念,DNS主服务器和DNS辅助服务器
主服务器托管控制区域文件,该文件包含域的所有权威信息(这意味着它是重要信息的可信源,例如域的IP地址)
辅助服务器包含区域文件的只读副本,它们通过称为区域传输的通信从主服务器获取其信息。每个区域只能有一个主DNS服务器,但它可以有任意数量的辅助DNS服务器。
一台DNS服务器可以是一个区域的主要服务器,也可以是另一个区域的辅助服务器。
其实这里是要补充说明一下,DNS中也有一个地方用到了TCP协议,那就是辅助DNS服务器从区主DNS服务器中,读取该区域的DNS数据信息的时候,称之为区域传送。这个过程因为数据量比较大、而且需要保证正确性,所以这里使用到了可靠传输TCP。
所有根域名服务器都是以同一份根域文件(Root Zone file,文件名为root.zone)返回顶级域名权威服务器(包括通用顶级域和国家顶级域),文件只有2MB[31]大小。截至2017年10月9日,一共记录了1542个顶级域。对于没被收录的顶级域,是没法通过根域名服务器查出相应的权威服务器。而其他递归DNS服务器则只需要配置Root Hits文件,只包含根域名服务器的地址。
来自维基百科的词条,不多解释
说到顶级域名的制定的管理,就不得不提ICANN这个组织,他是原来美国商务部的一个机构,现在独立为一个非盈利机构,专职管理域名。👆上面根域名服务器返回的2MB文件,就是这些顶级域名与其对应服务器地址。
当然,这些服务器ICANN不会都自己进行管理,而是交给不同的服务商。
子域名服务一般由开发者自身的服务器中的web服务器来充当,比如我们熟悉的nginx。
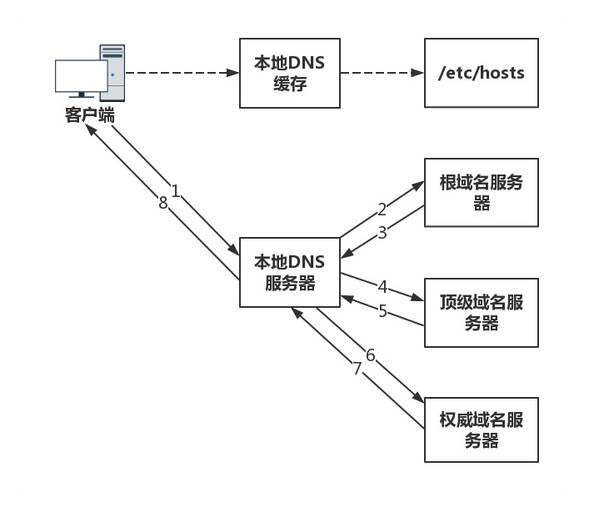
DNS的查询时间也包括在我们访问网站的响应时间内,一般为20-120毫秒的时间,所以减少DNS查询时间,是能够有效减少响应时间的方法。 MDN原文 👉
The X-DNS-Prefetch-Control HTTP response header controls DNS prefetching, a feature by which browsers proactively perform domain name resolution on both links that the user may choose to follow as well as URLs for items referenced by the document, including images, CSS, JavaScript, and so forth.
This prefetching is performed in the background, so that the DNS is likely to have been resolved by the time the referenced items are needed. This reduces latency(延迟) when the user clicks a link.
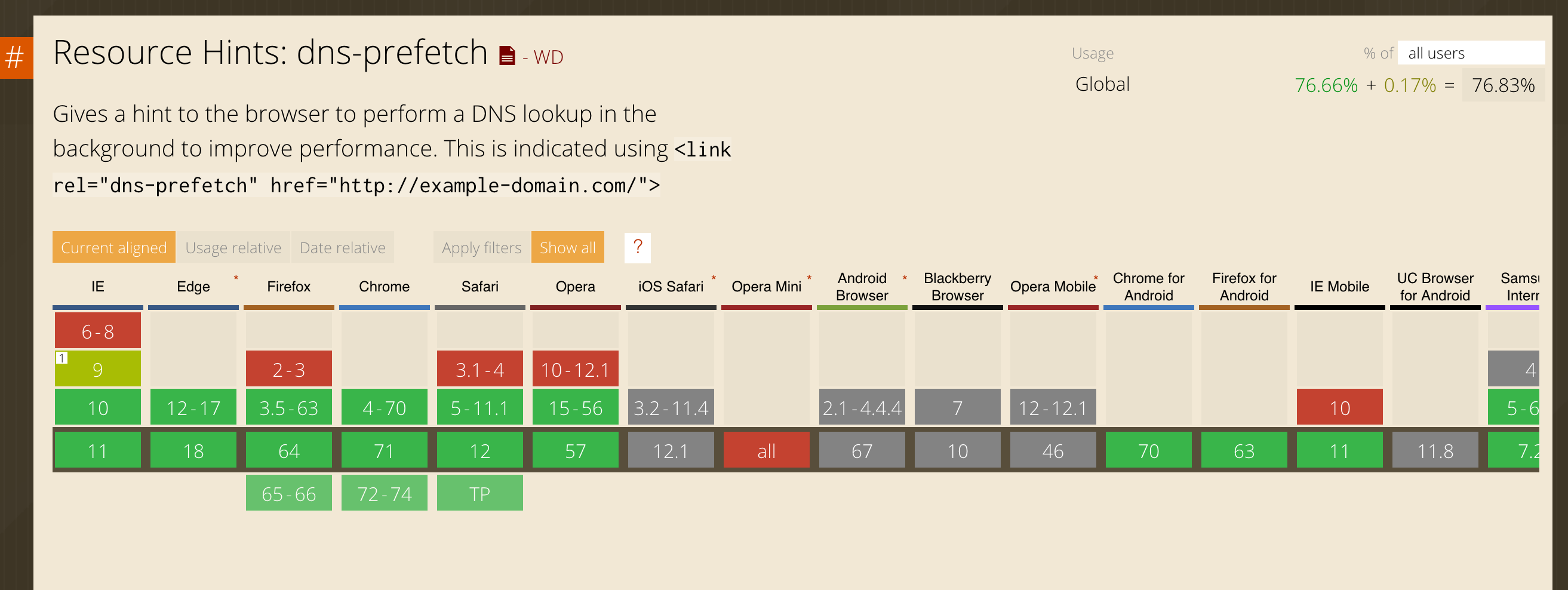
感动得流泪...IE6-8竟然都支持...
我们来看看淘宝网是怎么用prefetch的
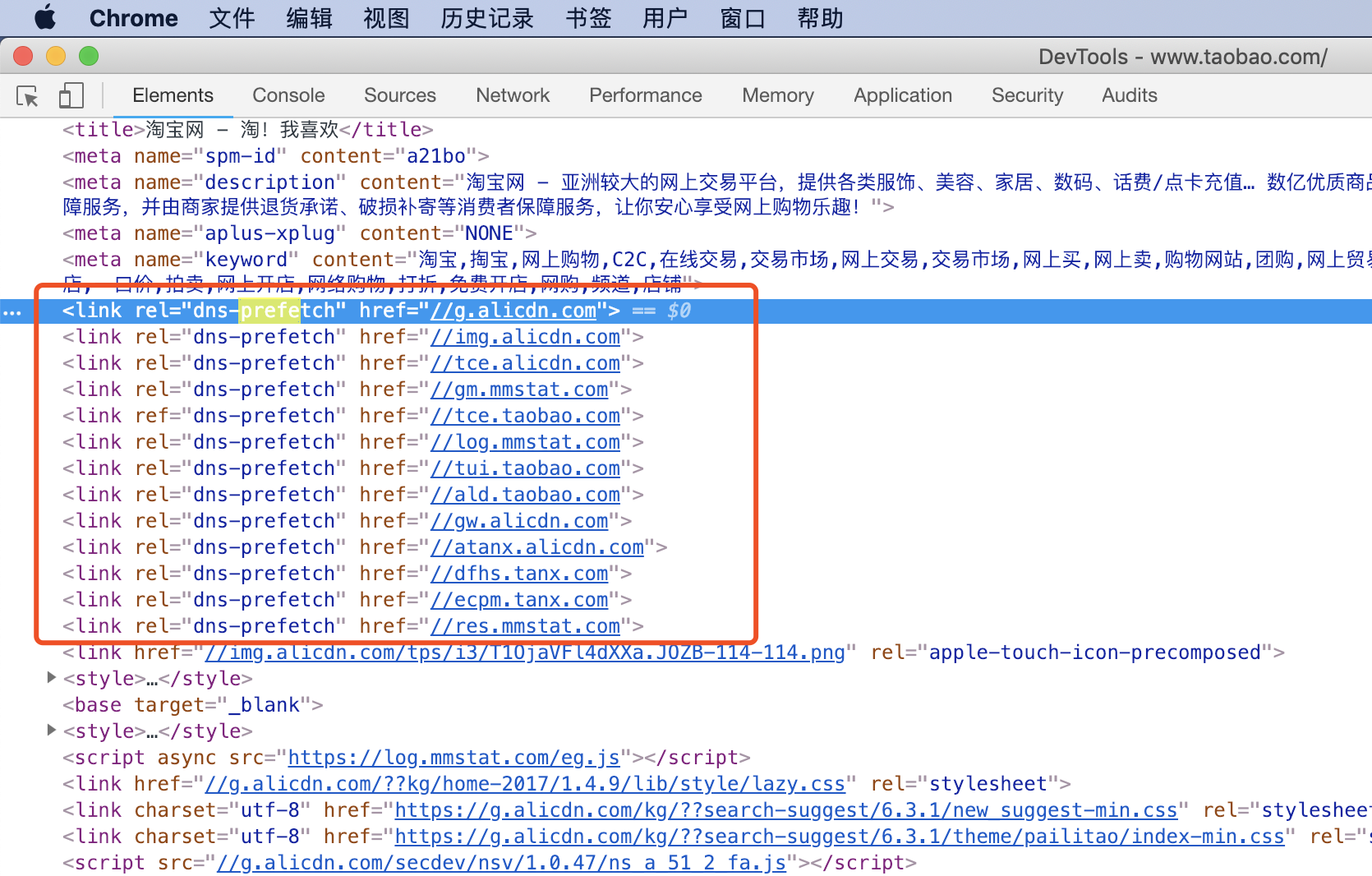
<!-- 告诉浏览器开启预请求 -->
<meta http-equiv="x-dns-prefetch-control" content="on" />
<!-- 禁用浏览器的预请求 -->
<meta http-equiv="x-dns-prefetch-control" content="off">
<!-- 进行 DNS 预请求 -->
<link rel="dns-prefetch" href="http://www.next-resource.com/"> 使用Chrome浏览器,打开chrome://histograms/DNS.PrefetchQueue这个页面,就能查看到
Manual Prefetch 这是使用dns-prefetch之前必须要先知道的知识。文档中提到

<a> <style>等带有href的标签手动pre-fetchjs跳转站外的,需要手动进行pre-fetchscript、img、font等静态资源进行pre-fetchpre-fetch<link rel="prefetch" href="login-modal-chunk.js">[1] 阮一峰 - DNS入门
[2] 前端优化与DNS
[3] 主DNS服务器与辅助DNS服务器的区别
[4] 讲讲DNS的原理?

https 全称 (Hyper Text Transfer Protocol over Secure Socket Layer),也就是在原http协议下,添加SSL(Secure Socket Layer)层https最大的亮点就是SSL层加对数据的加密💸 从原来的
http协议缺点来看:
明文传输明文传参,极其容易被第三方截取。https使用的是加密传输。MITM 中间人冒充服务器报文容被篡改
http 的URL 以http:// 开头,https以https:// 开头HTTP采用的是明文传输,而HTTPS使用的是SSL\TSL进行加密传输HTTP的默认端口是80,而HTTPS的默认端口是443<=牢记HTTPS 需要CA证书,http不需要。https协议是由SSL+http协议构建的可进行加密传输、身份认证的网络协议 要比http协议安全公钥加密只有私钥可以解开,私钥加密只有公钥能够解开cpu 消耗,相同负载下会增加带宽和服务器投入成本。CA 公司信息泄露,那么 SSL 的证书安全就无从谈起。SSL(Security Socket Layer)是一种广泛运用在互联网上的资料加密协议;TLS是SSL的下一代协议SSL证书 (Certificate) 像身分证一般可以在互联网上证明自己的身份。在资料的加密传输开始之前,服务器透过“有效”的SSL证书告诉用户端自己是值得信赖的服务器SSL大部分是收费的,但是自己生成的SSL证书又不能被浏览器所信任,即不安全。本段中(A与A',B与B')表示两对非对称加密的公钥和私钥。
pre-master中用到。客户端向服务器发送准备链接的信息(相当于打招呼), 并且告诉服务器自己支持哪些加密套件
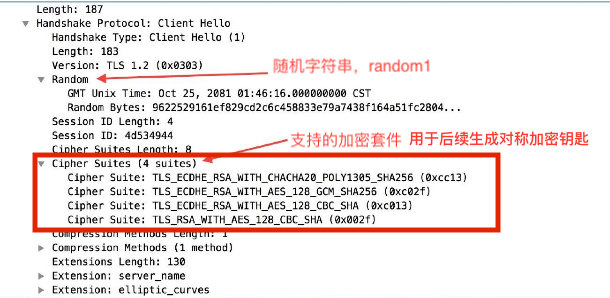
服务器响应 客户端的打招呼,返回包括
Random2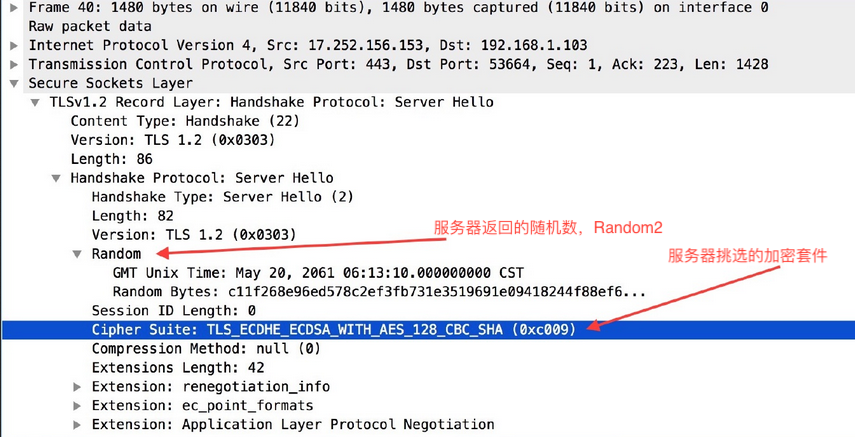
这一步是服务端将自己的证书下发给客户端,让客户端验证自己的身份,客户端验证通过后取出证书中的公钥。
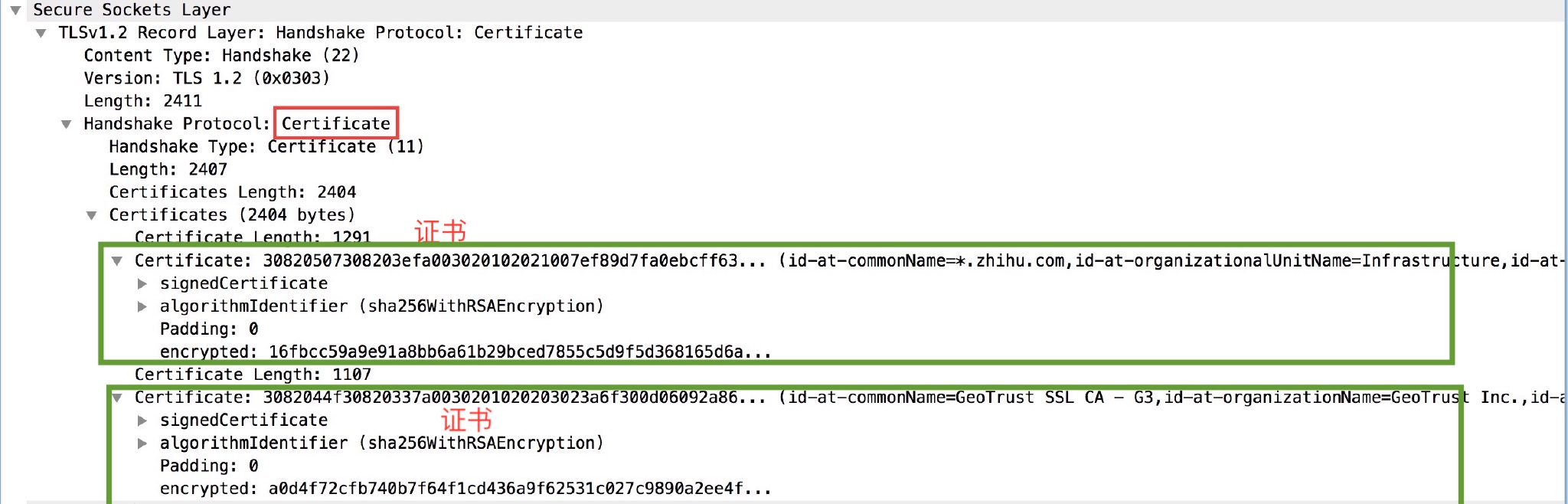
Certificate Request 是服务端要求客户端上报证书(可选)
Server Hello Done 通知客户端 Server Hello 过程结束
客户端收到服务端的证书,使用CA机构在客户端中内置的证书公钥尝试解开证书,若不能解开,则说明证书不是�真正的服务器发出的,或者证书被篡改过。
若验证通过(解得开证书),则取出证书中的服务端公钥,准备用于非对称加密pre-master。
注意:这里若证书合法性验证失败,则会告知用户改证书有风险。
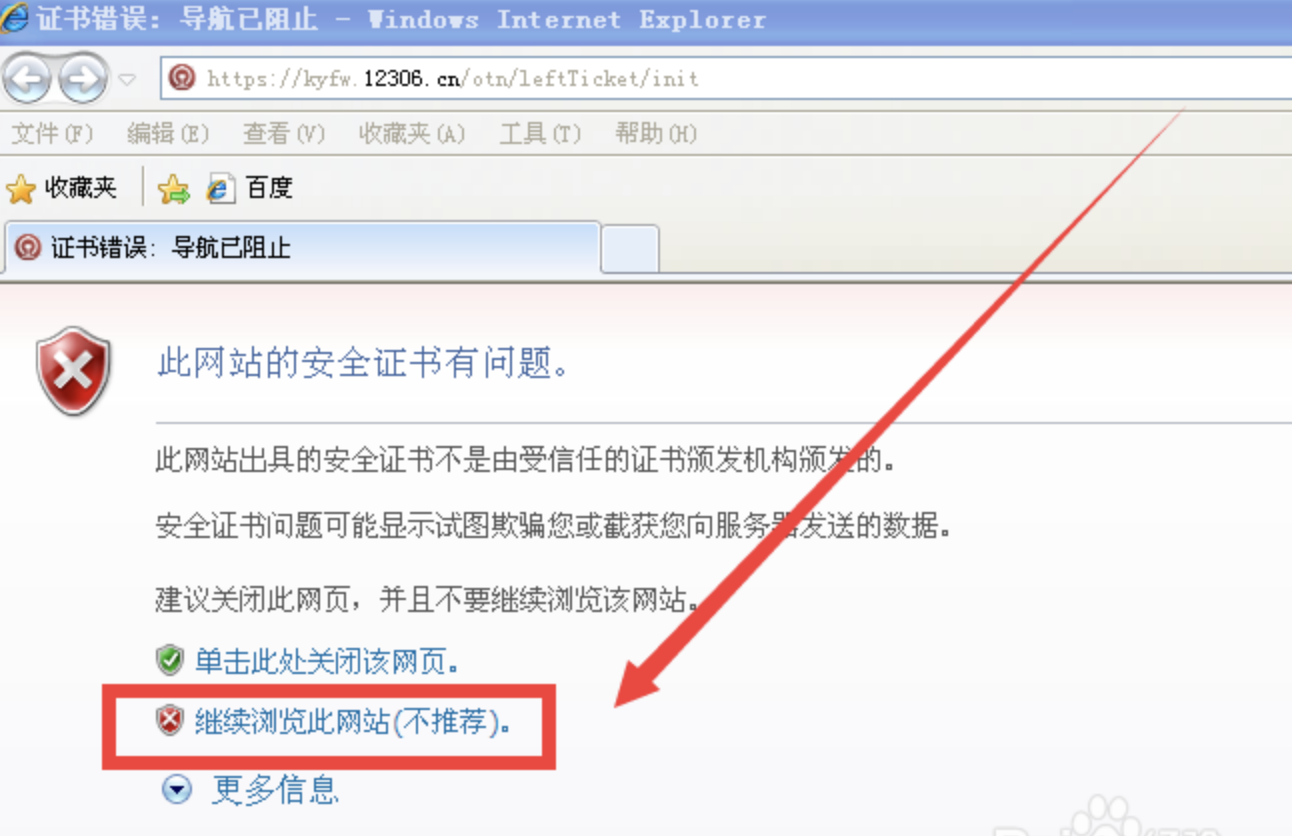
生成随机数 pre-master,并用服务端公钥(非对称加密) 加密,并发送给服务端。
双方用之前约定好的的加密套件,以 (random1 + random2 + pre-master) 作为盐,生成对称加密的会话秘钥
接下来准备开始,进行测试加密传输。
首先是客户端通知服务端后面再发送的消息都会使用前面协商出来的秘钥加密了,是一条事件消息。
再是客户端将前面的握手消息生成摘要再用协商好的秘钥加密,这是客户端发出的第一条加密消息。
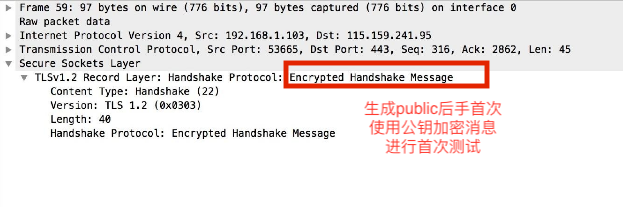
首先是服务端通知客户端后面再发送的消息都会使用加密,也是一条事件消息
再是服务端也会将握手过程的消息生成摘要再用秘钥加密,这是服务端发出的第一条加密消息
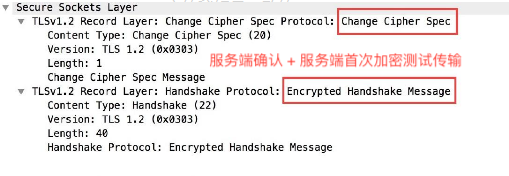
使用各自生成的对称秘钥public key正式进行对称加密数据传输。
并不是每一次的传输都需要进行这么繁杂的握手过程,每隔一定的时间才回进行重新SSL握手。
首次的client hello就附带了上一次的session ID,服务端接受到这个session ID,若能够复用则不进行重新握手。
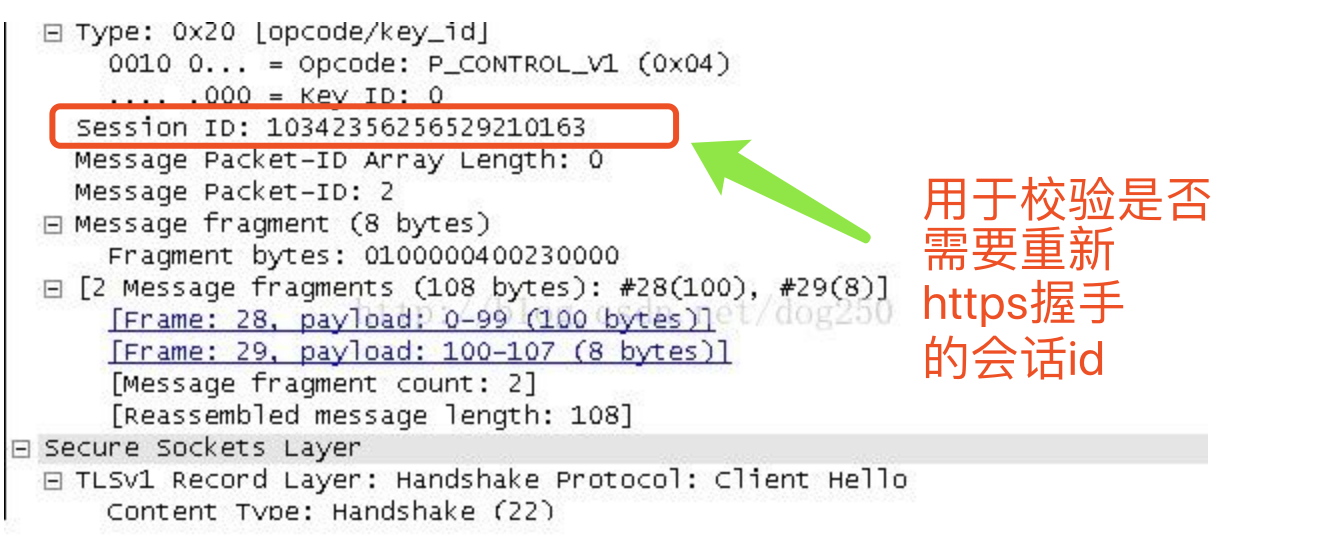
http2.0 与 https 结合,加入多路复用、服务端推送等优势。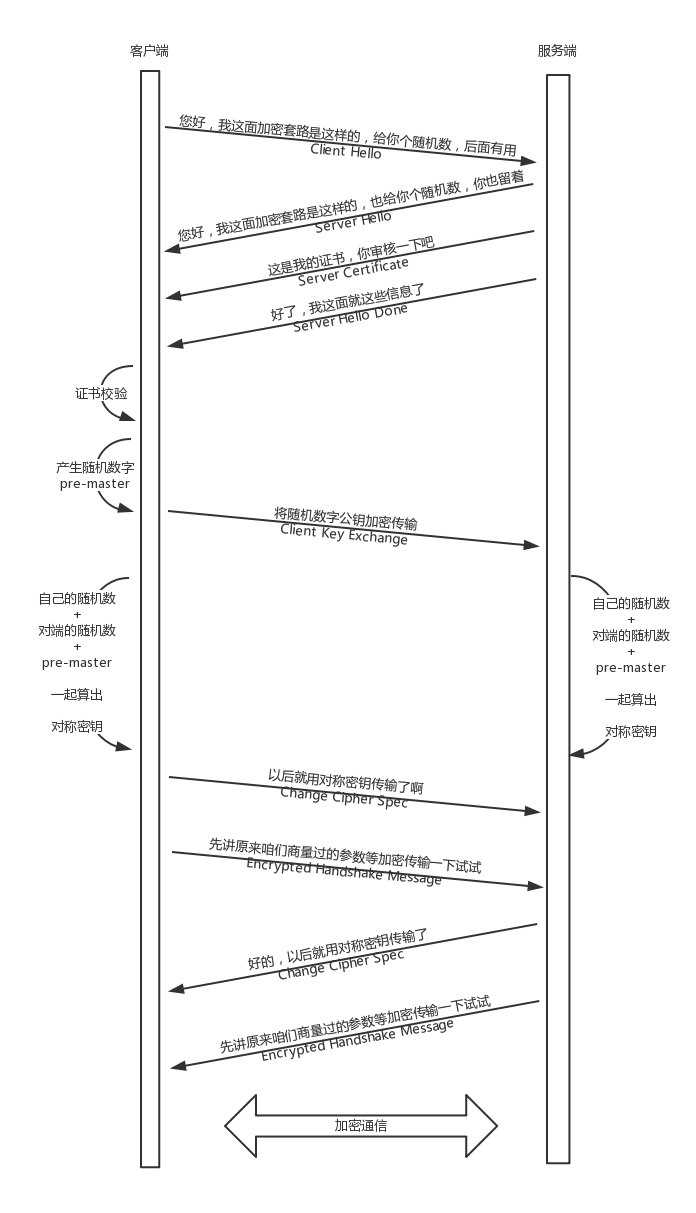
[1] SSL/TLS 握手过程详解
[2] 从http 到 https项目迁移
[3] IEEE 802.1X-PEAP认证过程分析(抓包)
new MyPromise ((resolve, reject) => {
setTimeout(() => {
console.log(111);
resolve(222);
}, 5000);
}).then((data) => {
return new MyPromise ((resolve, reject) => {
setTimeout(() => {
console.log(data);
resolve(333);
}, 3000);
});
}).then((data) => {
console.log(data);
});
这种情况下,打印出来的是
111 222 222
正确的结果应该是
111 222 333
_resolve方法有问题
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.