- Lab 1
- Access cluster
- Lab 2
- Review use case
- Build a simple NiFi data flow
- Lab 3 - MiNiFi
- Enable Site2Site in NiFi
- Designing MiNiFi Flow
- Preparing the flow
- Running MiNiFi
- Lab 4 - Kafka Basics
- Creating a topic
- Producing data
- Consuming data
- Lab 5 - Integrating Kafka with NiFi
- Creating the Kafka topic
- Adding the Kafka producer processor
- Verifying the data is flowing
- Lab 6 - Storm Basics
- Creating the Kafka output topic
- Deploying the Top N topology
- Verifying the data flow
- Lab 7 - Tying it all together
- Starting the API server
- Connecting to the API server
Credentials will be provided for these services by the instructor:
- SSH
- Ambari
-
Right click to download this ppk key > Save link as > save to Downloads folder
-
Use putty to connect to your node using the ppk key:
- Connection > SSH > Auth > Private key for authentication > Browse... > Select hdf-workshop.ppk
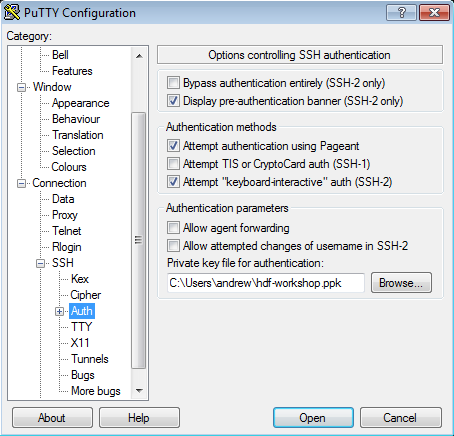
- Connection > SSH > Auth > Private key for authentication > Browse... > Select hdf-workshop.ppk
-
Create a new seession called
hdf-workshopand sure to click "Save" on the session page before logging in
-
SSH into your EC2 node using below steps:
-
Right click to download this pem key > Save link as > save to Downloads folder
-
Copy pem key to ~/.ssh dir and correct permissions
cp ~/Downloads/hdf-workshop.pem ~/.ssh/ chmod 400 ~/.ssh/hdf-workshop.pem -
Login to the ec2 node of the you have been assigned by replacing IP_ADDRESS_OF_EC2_NODE below with EC2 node IP Address (your instructor will provide this)
ssh -i ~/.ssh/training-keypair.pem ec2-user@IP_ADDRESS_OF_EC2_NODE -
To change user to root you can:
sudo su -
-
Login to Ambari web UI by opening http://{YOUR_IP}:8080 and log in with admin/hdfworkshop
-
You will see a list of Hadoop components running on your node on the left side of the page
- They should all show green (ie started) status. If not, start them by Ambari via 'Service Actions' menu for that service
- NiFi is installed at: /usr/hdf/current/nifi
Use case: We work for a social analytics company, the first product we are working on is a Meetup Analytics dashboard. To do this we want to calculate the Top N meetups happening right now and display them on a dashboard.
- Consume Meetup RSVP stream
- Extract the JSON elements we are interested in
- Split the JSON into smaller fragments
- Write the JSON to Kafka
- Analyze the data in Storm, performing a Top N on the groups
- Write the data back to Kafka
- Consume the data via a streaming API
We will run through a series of labs and step by step to achieve all of the above goals
To get started we need to consume the data from the Meetup RSVP stream, extract what we need, splt the content and save it to a file:
- Consume Meetup RSVP stream
- Extract the JSON elements we are interested in
- Split the JSON into smaller fragments
- Write the JSON files to disk
Our final flow for this lab will look like the following:
 A template for this flow can be found here
A template for this flow can be found here
-
Step 1: Add a ConnectWebSocket processor to the cavas
- Configure the WebSocket Client Controller Service. The WebSocket URI for the meetups is:
ws://stream.meetup.com/2/rsvps
- Configure the WebSocket Client Controller Service. The WebSocket URI for the meetups is:
-
Step 2: Add an Update Attribute procesor
- Configure it to have a custom property called
mime.typewith the value ofapplication/json
- Configure it to have a custom property called
-
Step 3. Add an EvaluateJsonPath processor and configure it as shown below:

-
Step 4: Add a SplitJson processor and configure the JsonPath Expression to be
$.group.group_topics -
Step 5: Add a ReplaceText processor and configure the Search Value to be
([{])([\S\s]+)([}])and the Replacement Value to be{ "event_name": "${event.name}", "event_url": "${event.url}", "venue" : { "lat": "${venue.lat}", "lon": "${venue.lon}", "name": "${venue.name}" }, "group" : { "group_city" : "${group.city}", "group_country" : "${group.country}", "group_name" : "${group.name}", "group_state" : "${group.state}", $2 } } -
Step 6: Add a PutFile processor to the canvas and configure it to write the data out to
/temp/rsvp-data
- What does a full RSVP Json object look like?
- How many output files do you end up with?
- How can you change the file name that Json is saved as from PutFile?
- Why do you think we are splitting out the RSVP's by group?
- Why are we using the Update Attribute processor to add a mime.type?
- How can you cange the flow to get the member photo from the Json and download it.
In this lab, we will learn how configure MiNiFi to send data to NiFi:
- Setting up the Flow for NiFi
- Setting up the Flow for MiNiFi
- Preparing the flow for MiNiFi
- Configuring and starting MiNiFi
- Enjoying the data flow!
NOTE: Before starting NiFi we need to enable Site-to-Site communication. To do that we can either make the change via Ambari or edit the config by hand. In Ambari the below property values can be found at http://<EC2_NODE>:8080/#/main/services/NIFI/configs . To make the changes by hand do the following:
- Open /usr/hdf/current/nifi/conf/nifi.properties in your favorite editor
- Change:
To
nifi.remote.input.host= nifi.remote.input.socket.port= nifi.remote.input.secure=truenifi.remote.input.host=localhost nifi.remote.input.socket.port=10000 nifi.remote.input.secure=false - Restart NiFi via Ambari
Now that we have NiFi up and running and MiNiFi installed and ready to go, the next thing to do is to create our data flow. To do that we are going to first start with creating the flow in NiFi. Remember if you do not have NiFi running execute the following command:
<$NIFI_INSTALL_DIR>/bin/nifi.sh start
Now we should be ready to create our flow. To do this do the following:
-
Open a browser and go to: http://<nifi-host>:<port>/nifi on my machine that url looks is http://127.0.0.1:8080/nifi and going to it in the browser looks like this:
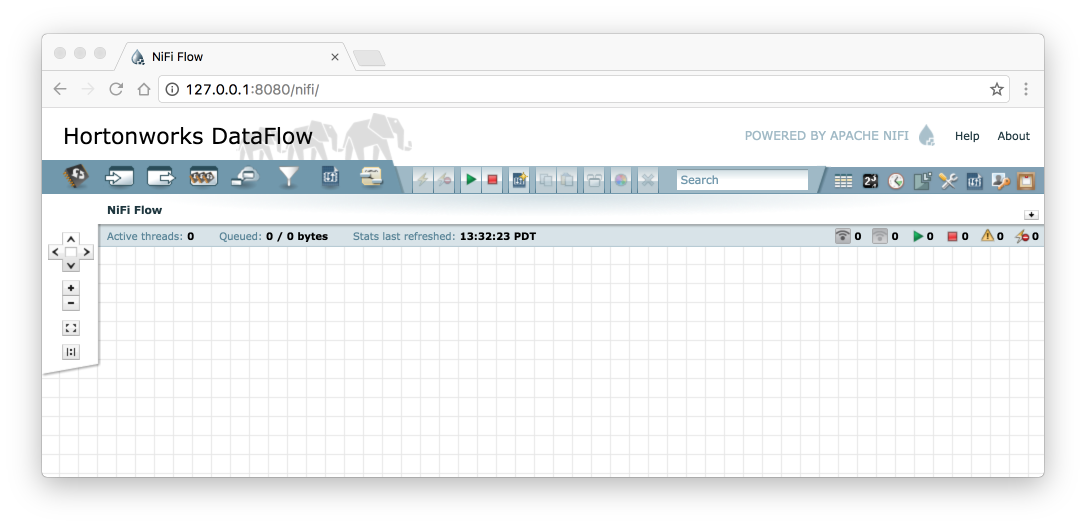 Figure 2. Empty NiFi Canvas
Figure 2. Empty NiFi Canvas -
The first thing we are going to do is setup an Input Port. This is the port that MiNiFi will be sending data to. To do this drag the Input Port icon to the canvas and call it "From MiNiFi" as show below in figure 3.
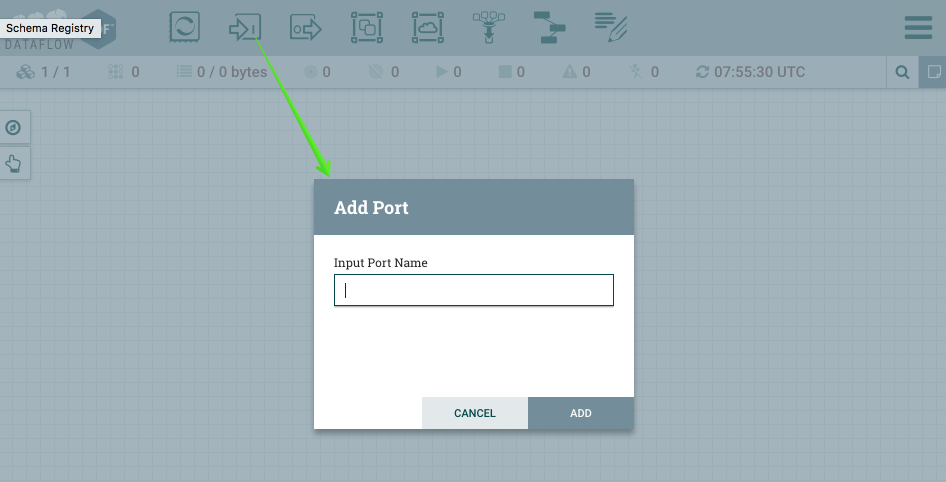 Figure 3. Adding the Input Port
Figure 3. Adding the Input Port -
Now that the Input Port is configured we need to have somewhere for the data to go once we receive it. In this case we will keep it very simple and just log the attributes. To do this drag the Processor icon to the canvas and choose the LogAttribute processor as shown below in figure 4.
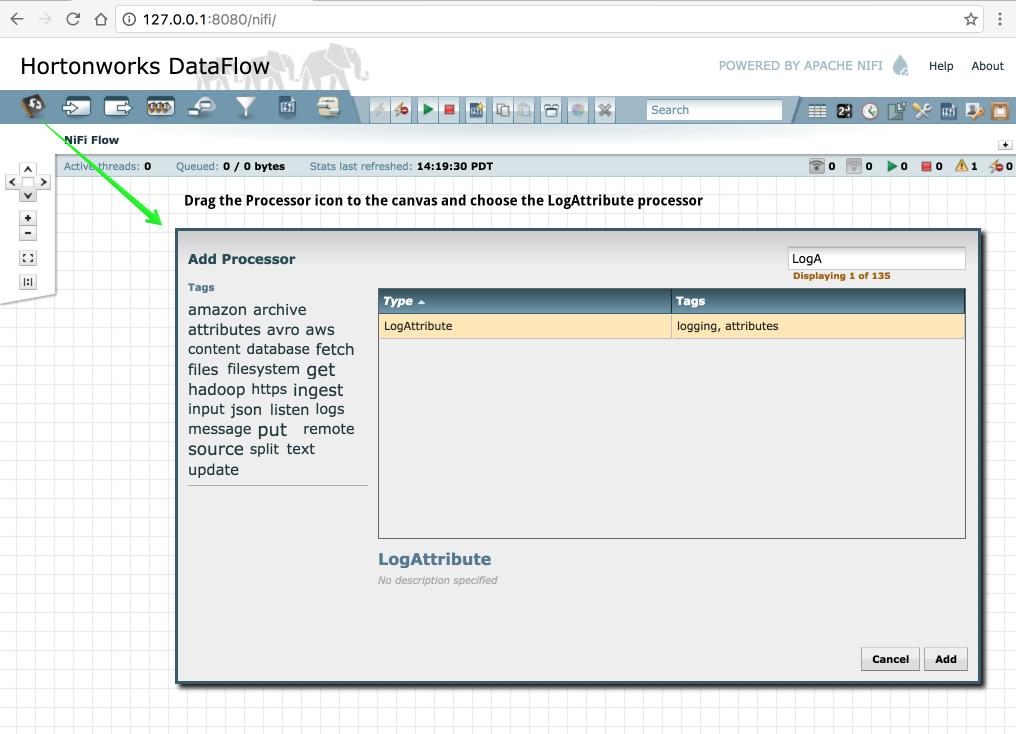 Figure 4. Adding the LogAttribute processor
Figure 4. Adding the LogAttribute processor -
Now that we have the input port and the processor to handle our data, we need to connect them. After creating the connection your data flow should look like figure 5 below.
 Figure 5. NiFi Flow
Figure 5. NiFi Flow
- We are now ready to build the MiNiFi side of the flow. To do this do the following:
- Add a GenerateFlowFile processor to the canvas (don't forget to configure the properties on it)
- Add a Remote Processor Group to the canvas as shown below in Figure 6
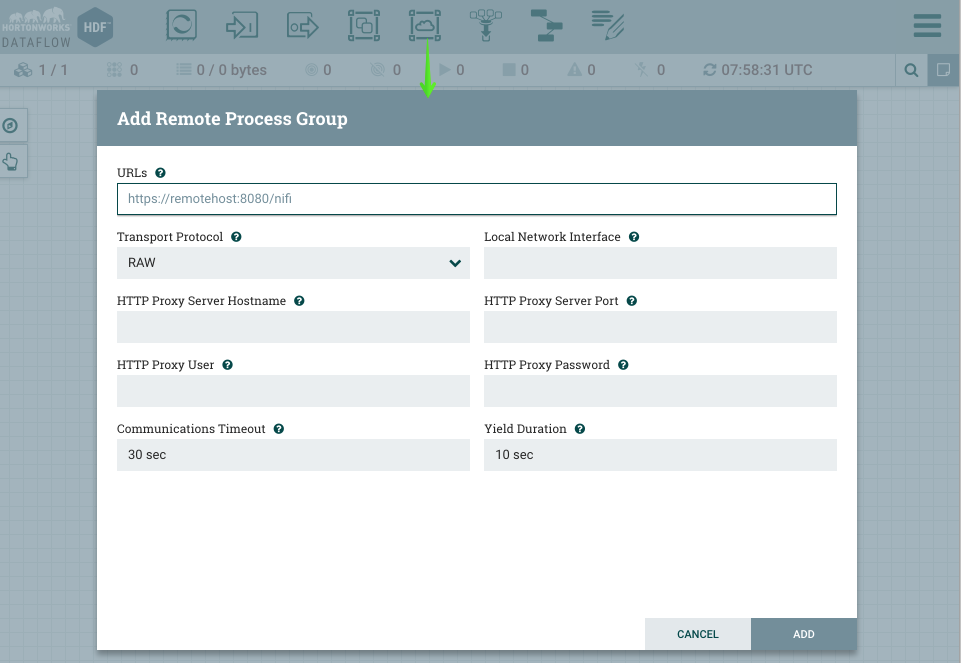
Figure 6. Adding the Remote Processor Group
- For the URL copy and paste the URL for the NiFi UI from your browser
- Connect the GenerateFlowFile to the Remote Process Group as shown below in figure 7. (You may have to refresh the Remote Processor Group, before the input port will be available)
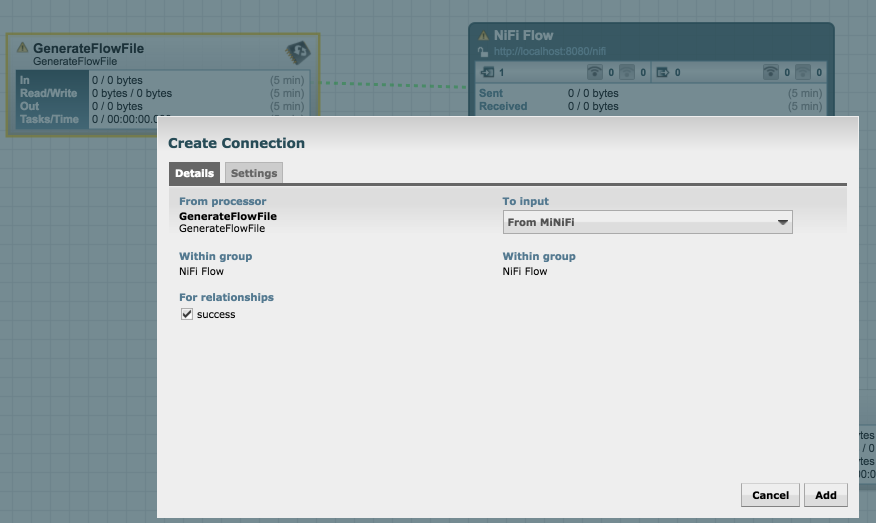
Figure 7. Adding GenerateFlowFile Connection to Remote Processor Group
- Your canvas should now look similar to what is shown below in figure 8.
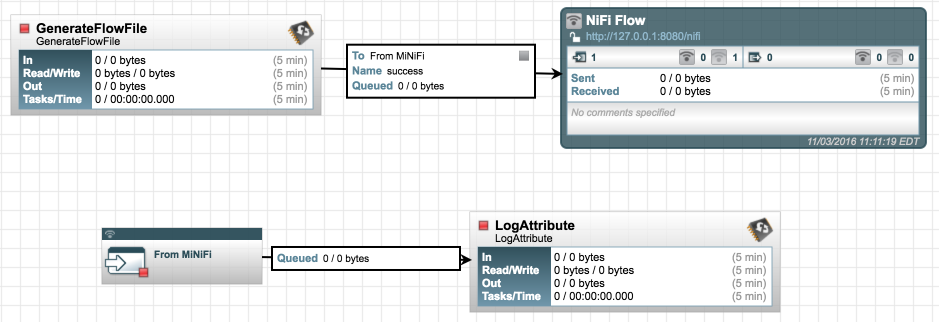
Figure 8. Adding GenerateFlowFile Connection to Remote Processor Group
- The next step is to generate the flow we need for MiNiFi. To do this do the following steps:
-
Create a template for MiNiFi illustrated below in figure 9.
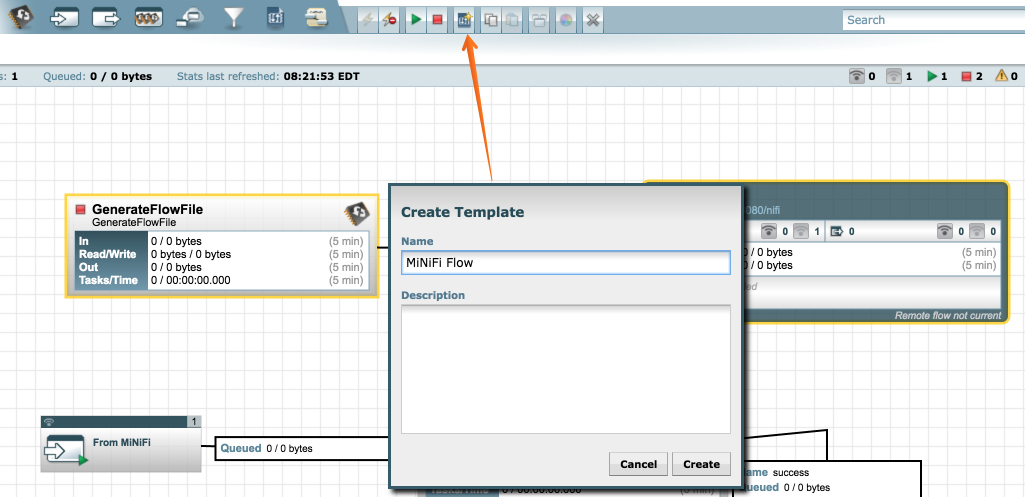 Figure 9. Creating a template
Figure 9. Creating a template -
Select the GenerateFlowFile and the NiFi Flow Remote Processor Group (these are the only things needed for MiMiFi)
-
Select the "Create Template" button from the toolbar
-
Choose a name for your template
- We now need to save our template, as illustrated below in figure 10.
Figure 10. Template button
- Now we need to download the template as shwon below in figure 11

Figure 11. Saving a template
- We are now ready to setup MiNiFi. However before doing that we need to convert the template to YAML format which MiNiFi uses. To do this we need to do the following:
-
Navigate to the minifi-toolkit directory (minifi-toolkit-0.0.1)
-
Transform the template that we downloaded using the following command:
bin/config.sh transform <INPUT_TEMPLATE> <OUTPUT_FILE>For example:
bin/config.sh transform MiNiFi_Flow.xml config.yml
-
Next copy the
config.ymlto theminifi-0.0.1/confdirectory. That is the file that MiNiFi uses to generate the nifi.properties file and the flow.xml.gz for MiNiFi. -
That is it, we are now ready to start MiNiFi. To start MiNiFi from a command prompt execute the following:
cd <MINIFI_INSTALL_DIR>
bin/minifi.sh start
You should be able to now go to your NiFi flow and see data coming in from MiNiFi.
In this lab we are going to explore creating, writing to and consuming Kafka topics. This will come in handy when we later integrate Kafka with NiFi and Storm.
- Creating a topic
-
Step 1: Open an SSH connection to your EC2 Node.
-
Step 2: Naviagte to the Kafka directory (
/usr/hdf/current/kafka-broker), this is where Kafka is installed, we will use the utilities located in the bin directory.#cd /usr/hdf/current/kafka-broker/ -
Step 3: Create a topic using the kafka-topics.sh script
bin/kafka-topics.sh --zookeeper localhost:2181 --create --partitions 1 --replication-factor 1 --topic first-topicNOTE: Based on how Kafka reports its metrics topics with a period ('.') or underscore ('_') may collide with metric names and should be avoided. If they cannot be avoided, then you should only use one of them.
-
Step 4: Ensure the topic was created
bin/kafka-topics.sh --list --zookeeper localhost:2181
- Testing Producers and Consumers
- Step 1: Open a second terminal to your EC2 node and navigate to the Kafka directory
- In one shell window connect a consumer:
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --from-beginning --topic first-topic
Note: using –from-beginning will tell the broker we want to consume from the first message in the topic. Otherwise it will be from the latest offset.
- In the second shell window connect a producer:
bin/kafka-console-producer.sh --broker-list demo.hortonworks.com:6667 --topic first-topic
-
Sending messages. Now that the producer is connected we can type messages.
- Type a message in the producer window
-
Messages should appear in the consumer window.
-
Close the consumer (ctrl-c) and reconnect using the default offset, of latest. You will now see only new messages typed in the producer window.
-
As you type messages in the producer window they should appear in the consumer window.
- Step 1: Creating the Kafka topic
- For our integration with NiFi create a Kafka topic called
meetup-raw-rsvps
-
Step 2: Add a PublishKafka_0_10 processor to the canvas. It is up to you if you want to remove the PutFile or just add a routing for the success relationship to Kafka
-
Step 3: Start the flow and using the Kafka tools verify the data is flowing all the way to Kafka.
-
Step 1: Creating the Kafka topic
- The results of our TopN computation will be written to a topic called:
meetup-topn-rsvpsUsing the Kafka tools go ahead and create this topic.
- The results of our TopN computation will be written to a topic called:
-
Step 2: Deploying the Top N topology
-
Step 3: Verifying the data flow - to do this you can use the Kafka tools or consume the data from NiFi.
- Starting the API server
- Connecting to the API server