To the previous ML exercise - Neural Networks
In this exercise we will touch the world of Machine Learning.
Machine learning is a branch of Artificial Intelligence (AI) and computer science which focuses on the use of data and algorithms to imitate the way that humans learn, gradually improving its accuracy.
In the first part, we will implement the K-Means algorithm.
The implementation will be based on the NumPy package only.
In the second part, we will implement the PCA algorithm (Pricipal Component Analysis) on the MNIST dataset.
As in the first part, the implementation will be based on the NumPy package only.
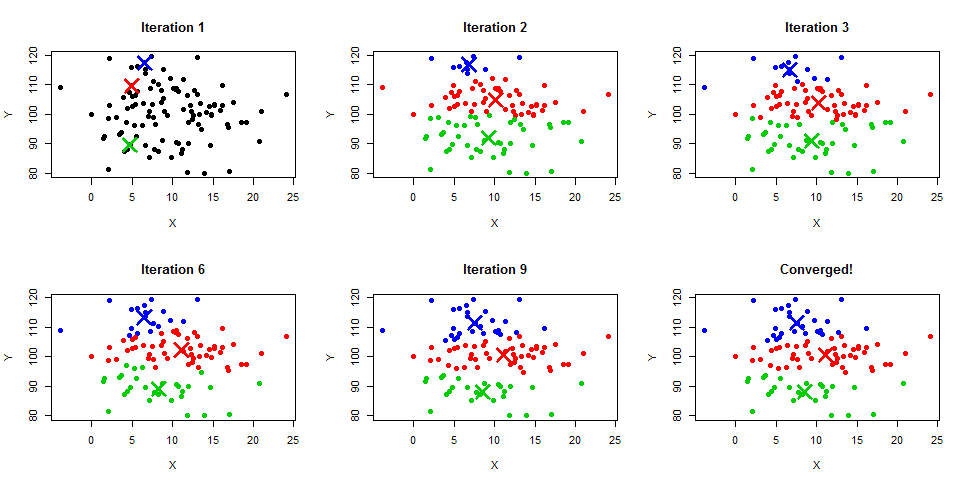
K-means clustering is a known unsupervised machine learning algorithm that is used to solve the clustering problems. Meaning, its purpose is to group a set of data points into clusters based on similarity. The number of groups is represented by K.
First we need to decide how many clusters we want to create. This is called the "k" value.
Next, we choose k random points in space to serve as the initial centroids of the clusters. These points are center of each cluster.
Then, we measure the distance between each data point and each centroid, and assign each point to the nearest cluster based on this distance.
Once all data points have been assigned to a cluster, we recalculate the centroid of each cluster by taking the mean of all data points in that cluster.
We repeat this process until the centroids no longer move significantly or until we reach a predetermined number of iterations.
In the end, we would have k clusters of points based on similarity.
This problem is NP-Hard, but there is a mathematical proof that the algorithm converges and therefore a sufficiently good approximate result can be reached.
You can read more about K-Means here.
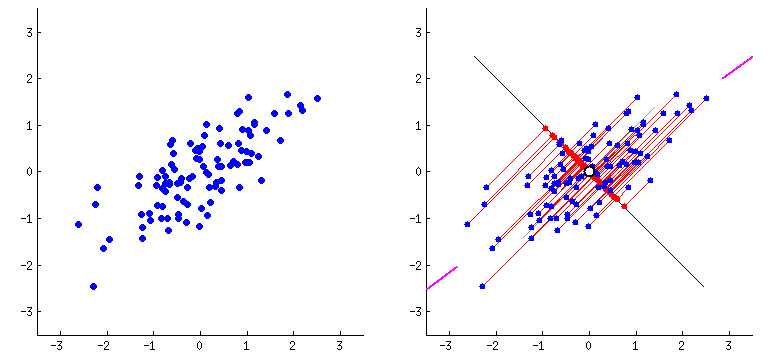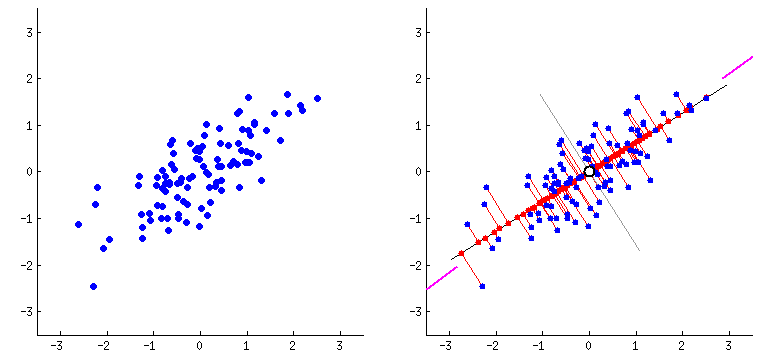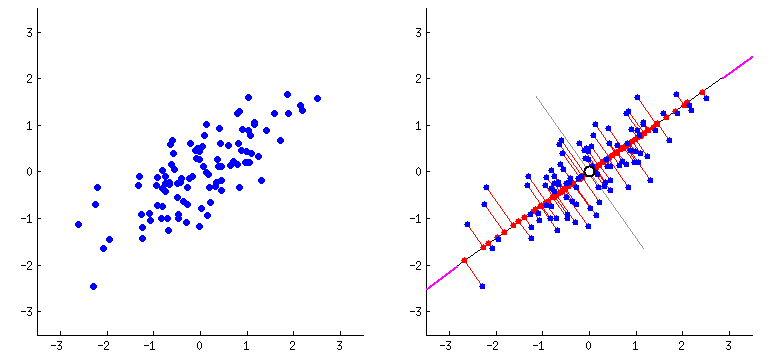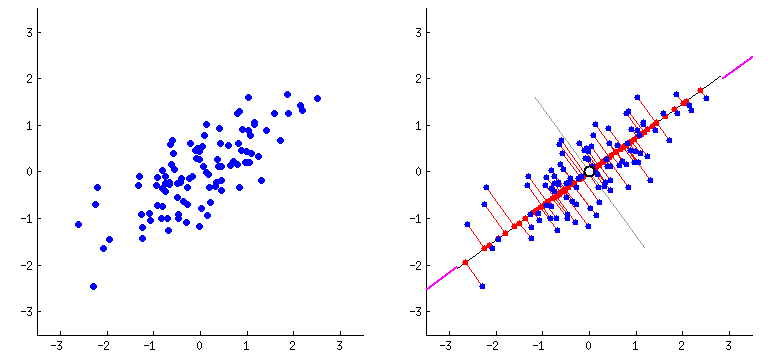
Principal component analysis (PCA) is a popular technique for analyzing large datasets containing a high number of dimensions/features per observation (i.e there is a lot of data to take into account).
It is likely that some of the data are less important and will not be too significant in the calculation process, so the idea behind PCA is to remove these parts and take into account only the significant features that interest us. This way our data can be interpreted more easily and quickly.
In short, we can achieve this by projecting the samples into a lower dimensional space and then projecting them back into the original dimension. If we project to a dimension that is too low, we can lose vital information. Therefore, the dimension to project to should be chosen wisely. If so, we will omit only the less important features and in addition we will get rid of noises.
In the second part of the notebook, you can see how the choice of the dimension affects the solution.
You can read more about PCA (Principal component analysis) here.
In the ML tasks, and in particular in this task, we will use Google Colab to run the code in an iterative and convenient way.
To preview the notebook, you can click on KMeans_PCA.ipynb in this repository.
In the notebook you can find a detailed explanation about the algorithms and the code step by step.
To run the code, first clone the repository to your computer with git clone https://github.com/ido106/KMeans-PCA.git, then drag the notebook (KMeans_PCA.ipynb) to your Google Drive.
Enjoy !
