通过多种神经网络分析大学生平日的各种行为信息是否与成绩有足够的影响。
从移动互联网发展普及至今,学生们上网已不局限在传统PC,还包括平板、手机等移动设备, 花费在各类产品的上网时间也越来越多;同时,以往我们认为学生上网的时间多消耗在休闲娱乐上,但近年来网络的学习资源越来越多,加之线上授课等教学模式的崛起,学生们为学习花费在网络上的时间也日益增多。所以, 对于今天的学生来说,上网已经是一种普遍的生活与学习方式。故本项目将采用神经网络对上网行为影响大学生成绩问题进行分类预测,分析上网行为和成绩的关联性,对学生们的上网行为加以科学引导。
通过从各方搜寻来的实际数据,关联后整理成可用数据源。
CIDP学校三届学生数据,记录了每位同学的流量日志。
| No. | loginTime | outTime | useFlow |
|---|---|---|---|
| 125011101 | 2014-05-06 11:49:00 | 2014-05-06 13:33:00 | 110.63 |
| 125011101 | 2014-05-07 18:21:00 | 2014-05-07 21:27:00 | 243.89 |
| 125011101 | 2014-05-07 13:15:00 | 2014-05-08 15:18:00 | 181.97 |
每位同学当学期的各科成绩。原始的学生成绩数据记录了多项学生信息,包括姓名、年级、学号、课程号、课程名、课程成绩和学分等。
| xh | term1 | term2 | term3 | term4 | term5 | term6 | term7 |
|---|---|---|---|---|---|---|---|
| 155011101 | 82.46 | 82.31 | 81.77 | 82.64 | 78.7 | 86.86 | 86.57 |
| 155011103 | 74.17 | 70.45 | 60.75 | 61.10 | 50.17 | 59.96 | 57.03 |
对于学习成绩,根据学生在一学期内的班级内综合成绩的排名,将排名前百分之二十的同学该学期的成绩定为A类,成绩中部百分之六十五的同学定B类,成绩尾部百分之十五的同学成绩定C类;对于上网数据信息,按照时间段进分:该学期上网流量、上网时长、月均流量、月均时长、日均流量、日均时长等。 每一个学生的学号对应着上述个人上网数据和成绩。将学生的上网行为的数据作为特征数据,成绩作为标签数据进行分析。通过匹配筛选特征数据及标签数据,对上网行为特征有缺失的和成绩标签有缺失的的样本进行忽略性去除。 成绩数据在处理前用A、B、C区间区分等级后,利用LabelEncoder进行归一化,将其对应转换为0、1、2。同时,为了进行多样测试,将BC化为一类,A、BC对应转化为0,1。
| ID | T data | T time | M data | M time | D data | D time | Grade |
|---|---|---|---|---|---|---|---|
| 135011101 | 48556.1 | 20171 | 12139.1 | 5042.7 | 404.6 | 168.1 | 1 |
| 135011102 | 11174.3 | 12674 | 2793.5 | 3168.5 | 93.1 | 105.6 | 1 |
ID学号,T data对应该学生学期总上网流量(单位:MB,下同),T time对应该学生学期总上网时长,M表示月均,D代表日均,Grade代表成绩。
除了对数据整体进行总体分析外,为了设立多组对照设计进行分析,可以通过设立不同的分类构建更多样本进行对比分析。 原始数据样本达到了近一万四千条,学生成绩分布在中部的同学居65%之多,平衡性无法保障。为了模型的稳定性,将样本分布的区间进行合理划分,使得不同成绩分布的同学的设计样本数据的比例控制在1:1:1,利用留出法而尽可能保持数据分布的一致性,避免因数据划分过程引入的额外偏差而对最终结果产生影响。
由于原数据样本量较大,使用部分条件筛选掉较异常的上网事件,确定异常的数据去除掉,剩余的事件为代表事件。这三个条件用是“或”的关系,只要一次完整的上网事件满足任意一个条件,就被判定为正常上网事件,否则即会被筛选掉。3个筛选条件如下: (1)成绩在班级显著的同学(原始数据中成绩为A)或成绩在班级中偏下的同学(原始数据中成绩为C); (2)总上网时间处于(500h-2000h)分段; (3)上网流量处于(10000MB-100000MB)分段。
在利用KREAS框架搭建深度学习模型中,为了对数据进行有效地分析和对比,采用了多种神经网络算法,对数据进行纵向分析和横向对比。在各种模型的结果对比下,MLP和LSTM的效果较好。
MLP多层感知器(Multilayer Perceptron,MLP)是一种前向反馈结构的人工神经网络,最典型的多层感知器MLP的基本结构包括包括三层:输入层、隐层和输出层,如下图所示。当数据从输入层输入,其流向从输入层到各个隐层最后到输出层,一层接一层流入。其中隐层和输出层可分别实现对输入的非线性映射/线性分类,而这分工不同但其函数可以同时学习;MLP的不同层之间是全连接的,除了输入节点,每个节点都是一个带有非线性激活函数的神经元,上一层的任何一个神经元与下一层的所有神经元都有连接。所以在多层感知器的监督训练的在线学习中,常采用BP神经网络算法误差逆传播的特点来调整网络;MLP相邻层节点之间有权重与偏置,通过不断调节权重与偏置,最后达到预期的输出值。
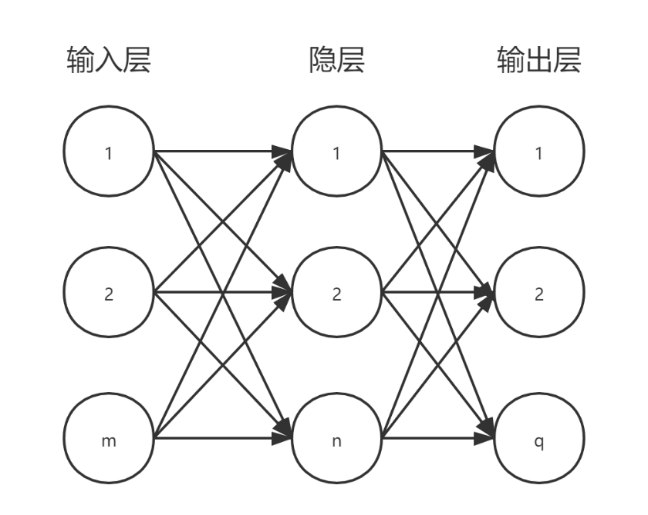
当输入层是n维向量时,就有n个神经元。 而隐藏层的神经元,则根据输入层决定。由图可知,输入层与隐藏层是全连接的。设用向量x表示输入层,则隐藏层的输出也就是$f(w^1 x+b^1)$。$w^1$是权重,$b^1$是偏置,函数f可以是常用的sigmoid函数或者tanh函数和relu函数等。
而输出层和隐藏层,本质上其实是后者为前者的多类别逻辑回归($softmax$回归)。设隐藏层的输出即就是$f(w^1 x+b^1)$为$x^1$,则输出层的输出就是$softmax(w^2 x^1+b^2)$。
至此,MLP的模型已构建完成。将上述函数合并,用公式去总结,MLP模型即为:$softmax(b^2+w^2 (s(b^1+w^1 x)))$。
由此可知,真正影响MLP模型的参数其实就为各个层之间的连接权重以及偏置、激活函数。 而MLP可使用几乎任何形式的激活函数,像很多被人熟知的sigmoid函数或tanh函数,被奉为圭臬。为了使用反向传播算法进行有效学习,激活函数限制为可微函数。
但随着深度学习算法的更新推动,像relu这样的函数作为激活函数越来越受欢迎。relu在数学上虽然不可微,但可提供伪梯度使其可分,并且在与sigmoid函数作为对比时,可使梯度下降法运行的更快,效果更好。
长短期记忆(Long short-term memory, LSTM)是一种较为特殊的循环神经网络,其主要是为了解决长序列的循环神经网络的训练过程中,可能出现的梯度消失和爆炸的问题,同时基本可以无缝地对多变量的输入问题进行有效建模。而且,在与普通循环神经网络对比时,LSTM可以在更长的序列中有更出色的表现,能在序列数据中高效地发挥其长距离依赖信息的特性,被广泛公认为适合处理文本序列数据。本设计模型的变量较多,数据量较大,且与LSTM神经网络的优势相契合,故选用LSTM作为设计。
那么LSTM比起普通循环神经网络,为什么会更强呢?LSTM其实是通过三道“门结构”来刻意处理长期依赖问题,即“记住该记住的信息、忘记该忘记的信息。”这三道“门结构”分别是“忘记门”、“输入门”和“输出门”。
忘记门是随着序列的变化,忘记掉前面的需要忘记的信息。此门的输出是一个sigmoid函数,取值范围为0-1之间,与上一时刻的细胞状态进行按位相乘,将$C_(t-1)$和
此处公式如下:$f_t=σ(W_f·[h_(t-1),x_t]+b_f)$ (1)
输入门则监控新神经元状态的信息哪些需要补充,也是sigmoid函数,取值范围为0~1之间,是与当前的神经元状态按位相乘。
此处公式如下: $C_t=f_(t)C_(t-1)+i_tC ̃_t$ (2)
输出门,最终的神经元状态加上tanh函数就是输出,也是一个sigmoid函数,取值为0~1,作用于输出,选择哪些信息可以输出。
此处公式如下:$o_t=σ(W_o [h_(t-1),x_t]+b_o))$
LSTM通过“三道门”,将长序列的训练过程保持弹性,忘掉“不该记住的”,使得最终仅输出确定需要输出的那部分。
序贯模型是深度学习中的基本模型,其以线性叠加的结构,多个网络层的线性堆而便于搭建模型。通过序贯模型,可以分别构建从头到尾的MLP神经网络和LSTM网络。 在该模型之下,MLP和LSTM准备其需要的不同形状的数据输入其不同的连接层,然后对神经网络模型的结果的准确率进行对比。
输出误差被反向传播到网络参数以适应样本输出,本质上是一个优化的过程,并逐渐趋向于最优解。但是,每次参数更新中所使用的误差需要由一个参数来控制,这个参数就是学习率,也称为步长。
为适应拟合样本的输出,输出误差被反向传播至网络参数,这就是优化的过程,实质上就是不断地呈往最优解的趋势。而学习率,可以作为一个参数以控制每次更新参数中的误差,这个误差会因为学习率的大小而受影响。前向反馈算法中学习率的公式:
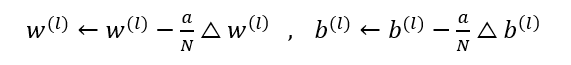
不难看出,当学习率越大时,参数受到输出误差的影响就越大,更新的就越快。所以受到异常数据的影响也就越大,整体呈发散状。而当一定轮数过后,学习率越小的时候,整体呈拟合状,收敛速度下降。当学习率过小时,就容易出现过拟合的问题。
所以,最优异的学习率不会是一个固定值,而是一个随着训练次数衰减的变化的值。也就是在训练初期,学习率比较大,随着训练的进行,学习率不断减小,直到模型收敛。
Keras学习框架提供了LearningRateScheduler的函数,作为学习率适应方法,可通过回调函数实现。将样本分为数个epoch,每个epoch中的全部数据作为一次完整的训练,使其所有被训练的数据样本都在神经网络中进行了一次正向传播和反向传播。
通过设计一个schedule函数,将optimizer作为参数传递给scheduler,使其接受epoch轮索引数作为参数输入,然后返回一个学习速率作为输出,初始设计为每过100个epoch,将学习率减小至之前的的10%。所以每次通过调用scheduler就会更新optimizer中每一个reduce_lr。
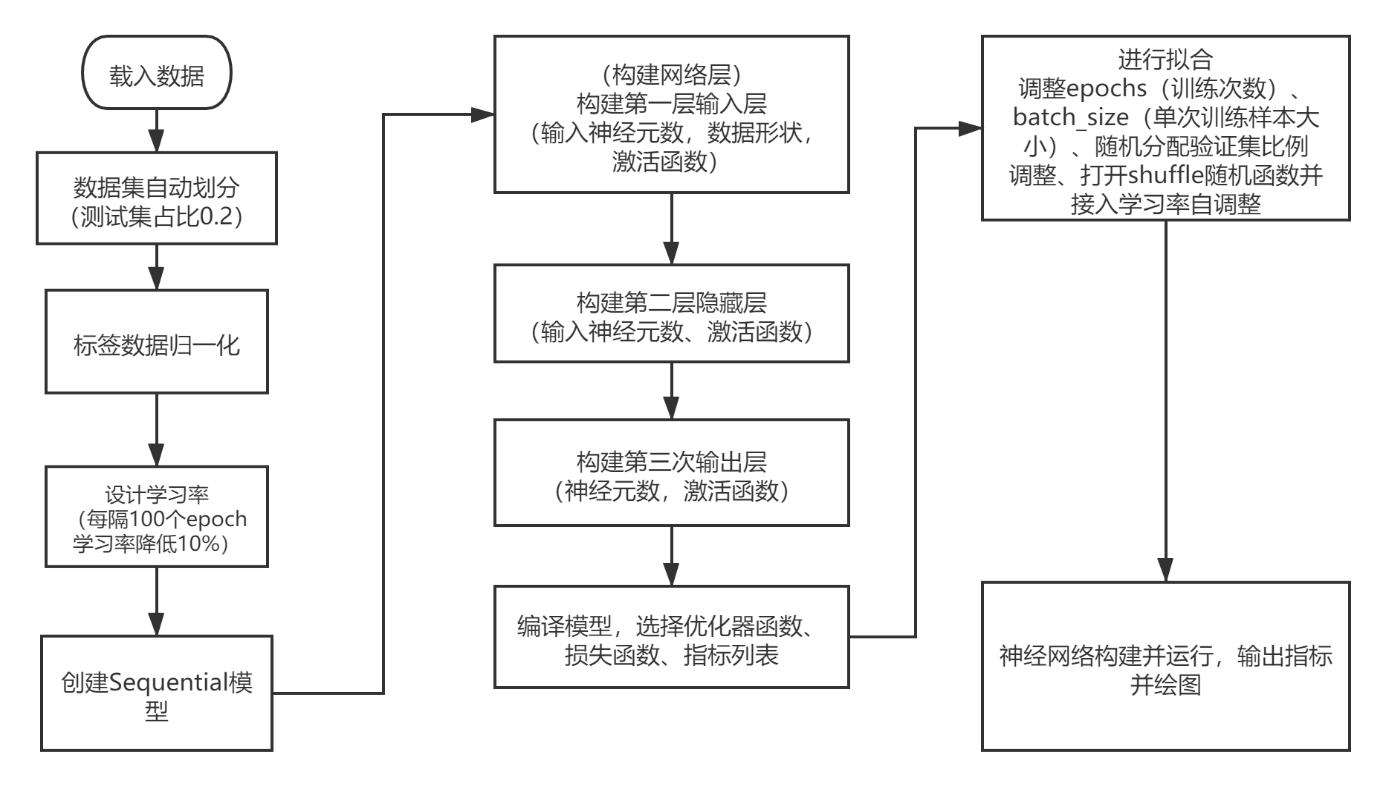
输入数据时,使用sklearn框架中的train_test_split函数对数据集进行自动划分测试集和训练集,其中测试集的比例占20%。 定义一个Sequential对象,然后用add按网络结构添加。
搭建的MLP模型由三个全连接层链接。其中效果最好的为首层和隐层使用了ReLU激活函数,输出层则使用Softmax函数。
ReLU激活函数是Rectified linear unit的简称,是如今使用率最高的激活函数。它的数学形式为$f(x)=max(0 ,1)$。当输入数值为正时,它的导数会一直为1而不衰减,因此缓解了梯度消失问题。当输入为负数时,它的导数为0。
Sigmoid函数表达式为
Sigmoid激活函数效果比ReLU函数差上很多。使用Sigmoid函数,当神经元的值无限接近于1或者0时,在反向传播计算时梯度也几乎为0。这就出现了梯度弥散问题,易导致模型参数几乎失效。故采用ReLU激活函数效果更好。
当输入层和隐含层选定ReLU激活函数时,在本设计中输出层选择了Softmax激活函数。Softmax用于多分类过程中,它将多个神经元的输出,映射到(0,1)区间内,从而来进行多分类。本模型的本质是在构建MLP神经网络模型进行分类类型设计,选用Softmax最为合适。
在开始训练模型之前,需要通过compile函数来对学习过程进行编译配置。compile可以接收三个参数:①优化器optimizer;②损失函数loss;③指标列表metrics。 optimizer选用ADAM优化器,loss选用categorical_crossentropy损失函数,指标列表选用acc函数。 在ADAM优化器和SGD优化器(随机梯度下降法)的选择中,数据统计特征明显时,SGD的收敛效果好。本设计数据特征极其不明显,变化大,故优先采用“傻瓜算法”ADAM。
由于本设计标签分类为多类模式,选用交叉熵损失函数(categorical_ crossentropy)最为合适。 指标列表选用acc函数。如果在对上网特征的识别上对应成绩的准确率良好,则说明模型有效且效果不错,同时也说明大学生上网的流量和时长确实对他们的成绩具有显著的影响。
最后对网络进行拟合,epochs(训练轮次)设置在60、将validation_split(验证集)比例设置在0.3时效果最佳,函数收敛幅度好。同时将shuffle函数设置为True,将训练的数据打乱,避免数据投入的顺序对网络训练造成影响。
在使用序贯模型进行构建标准MLP神经网络模型后,绝大部分的参数已调至最优化,可以复用刚才建立模型的参数,并对二者不同的地方进行调整,使得构建LSTM神经网络模型更容易。 LSTM模型需要的数据为3D格式,为此,需要将数据集进行一次重塑,将本来的特征重塑为[样例,时间步,特征]。 搭建LSTM模型时,第一层为LSTM层。在Keras框架中,LSTM作为输入层,将原有的上网流量、时长等的数据从表格中原有的行列作为替代,其形式为[行,1(时间步),列],研究上网时长和流量二者特征关系的联系。 其余的参数调整在追求模型的准确率后,跟MLP模型调参基本相同。
在搭建好MLP模型和LSTM模型后,进行参数调整并用数据集对二者进行测试,并尝试对原数据进行统计分析。 为了避免过拟合影响参数调整,采用已构建的标准样本测试。实验时对各项参数进行了测试对比,模型初始化已调优参数如表。
模型参数
| 参数 | 取值 |
|---|---|
| LearningRateScheduler(学习率) | 0.01 |
| Loss(损失函数) | categorical_crossentropy |
| Optimizer(优化器) | Adam |
| Metrics(指标函数) | acc |
| validation_split(验证集划分) | 0.3 |
| Epochs(最佳迭代次数) | 60 |
Batch_size数值效果对比
| Batch_size | 测试集准确率 | 测试集损失值 |
|---|---|---|
| 128 | 0.72 | 0.77 |
| 64 | 0.90 | 0.59 |
| 32 | 0.83 | 0.32 |
| 20 | 0.92 | 0.28 |
| 当batch_size调至20时,模型整体效果最佳。 |
MLP多层分感知器神经网络模型和LSTM长短期记忆人工神经网络模型分别搭建完成后,用处理好的数据进行对照设计。 当使用标准样本时,两种神经网络的准确率曲线和loss值曲线如图所示。
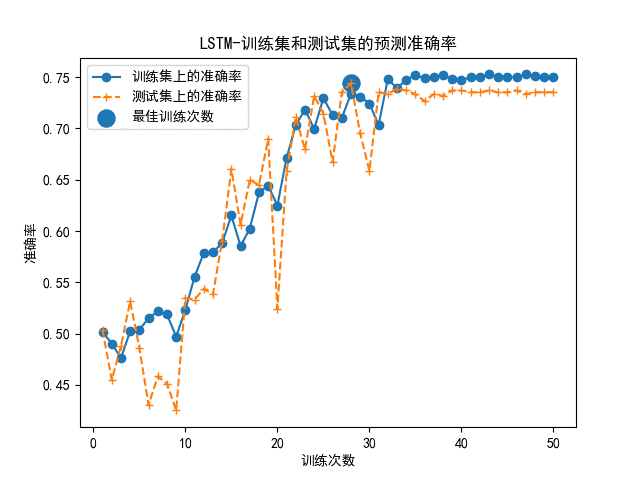
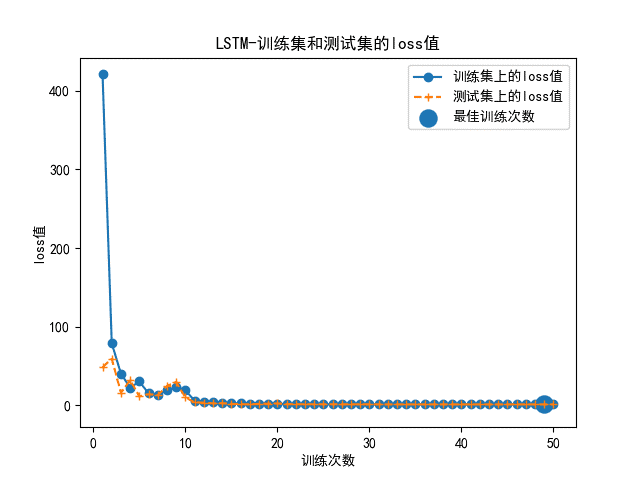
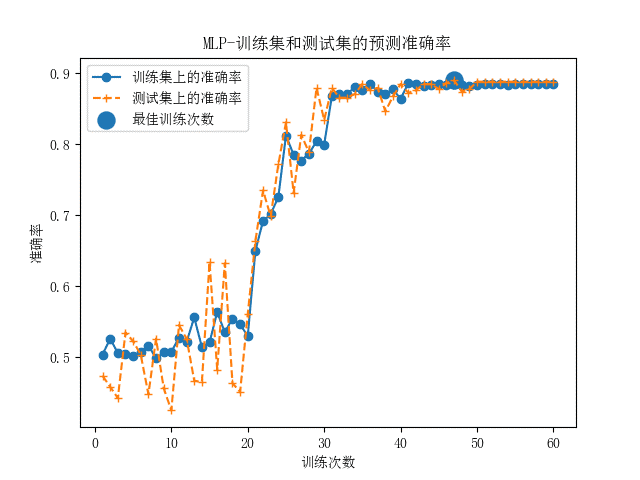
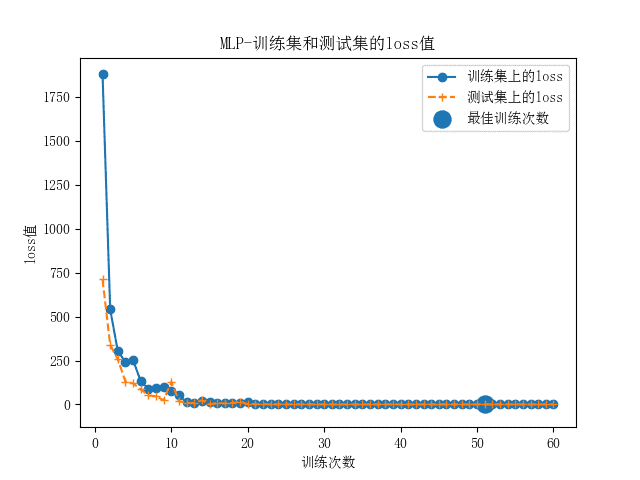
由以上的模型评估结果可以看出,两种神经网络模型结构均比较稳定,MLP的整体准确率非常高,达到了92%以上,同时损失函数也较稳定。训练次数到达10次时,测试集上的损失率到达最小值,仍可以调参来更拟合。
整体上网流量和上网时长对成绩的影响线性对比分析
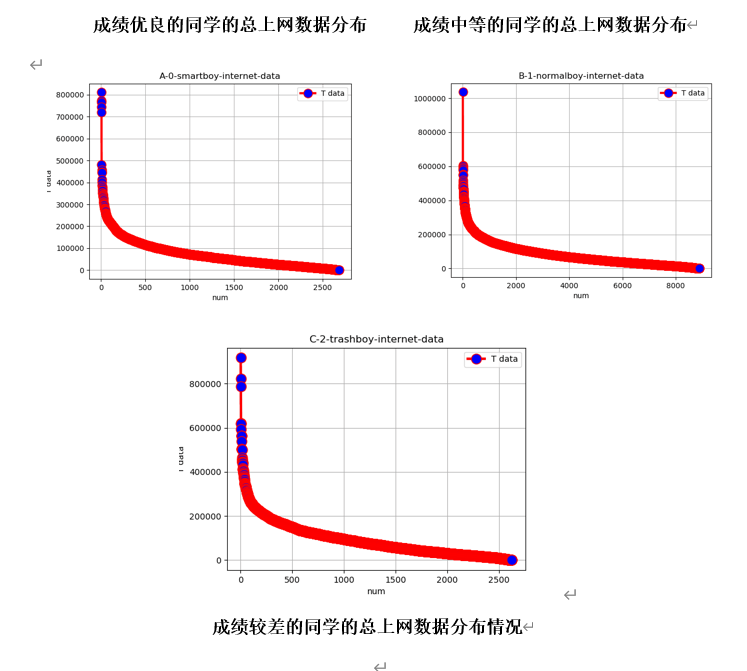
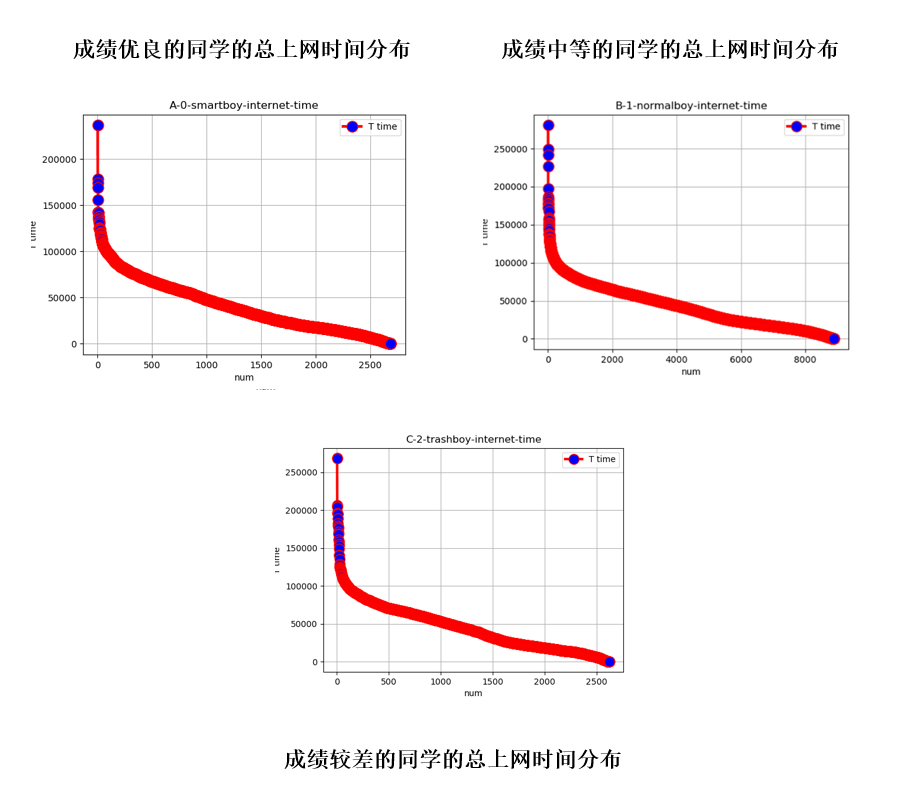
可以明显看出,当控制单一变量时各成绩分布的同学曲线曲率相似,上网时间和流量的多少对成绩好坏的影响人数还是有所差别的。成绩优异的同学整个学期的上网时长多数控制在50000分钟内,而成绩中等或较差的同学上网时长近半数在50000-250000分钟。这其实也侧面体现了上网时长对学生整体成绩的影响。如果从上网数据流量方面来看,几乎超过八成成绩优秀的同学整学期流量都控制在了100000MB之内,而成绩中等或较差的同学近六成超过了100000MB,甚至有近两成同学学期数据从200000MB向1000000MB逼近。从线性角度上来说,学生的上网特征和成绩之间着实存在关系。
