japila-books / apache-spark-internals Goto Github PK
View Code? Open in Web Editor NEWThe Internals of Apache Spark
Home Page: https://books.japila.pl/apache-spark-internals
License: Apache License 2.0
The Internals of Apache Spark
Home Page: https://books.japila.pl/apache-spark-internals
License: Apache License 2.0
















































































































































































































It would be great if a page about implementing custom stages (estimator transformer ) for a spark pipeline could be added to this great book. So far I could not find great documentation for this task.
Links in the description column of the BlockManager’s Internal Properties table are broken:
https://books.japila.pl/apache-spark-internals/apache-spark-internals/latest/spark-BlockManager.html
Correction: Links are broken almost on the entire page.
Executor memory is not mentioned, so people who set worker memory too low can have the Spark shell or a Spark application fail to allocate resources on the workers. The default for SPARK_EXECUTOR_MEMORY is 1024m; it can be suggested to set this a lower value.
conf/spark-env.sh:
SPARK_EXECUTOR_MEMORY=500msome_spark_app.scala:
val conf = new SparkConf()
// ...
.set("spark.executor.memory", "500m")One or more of these files can have such mentions:
spark-standalone.adocspark-shell.adocspark-first-app.adocI currently wonder what is a good configuration of spark in case a lot of memory is available (on a single node) http://stackoverflow.com/questions/43262870/spark-with-high-memory-use-multiple-executors-per-node Maybe you could put some clarifying hints into your great book.
It seems that some styling is broken
https://books.japila.pl/apache-spark-internals/overview/

https://books.japila.pl/apache-spark-internals/rdd/


Hello,
So reading the chapter:
https://jaceklaskowski.gitbooks.io/mastering-apache-spark/content/spark-logging.html
there is Log4J2 mentioned and linked (docs, etc.)
However, I have found that Apache Spark (to my surprise) uses old Log4J1.
Here is the proof:
https://github.com/apache/spark/blob/master/pom.xml#L124
The configuration remained similar between those two, so the solution is still valid, but extending it may be misleading.
Could you explain the usage of https://jaceklaskowski.gitbooks.io/mastering-apache-spark/content/spark-MemoryManager.html off heap memory better.
For me http://stackoverflow.com/questions/43330902/spark-off-heap-memory-config-and-tungsten it is unclear if off heap is enabled automatically now (2.1.0) as tungsten is enabled by default.
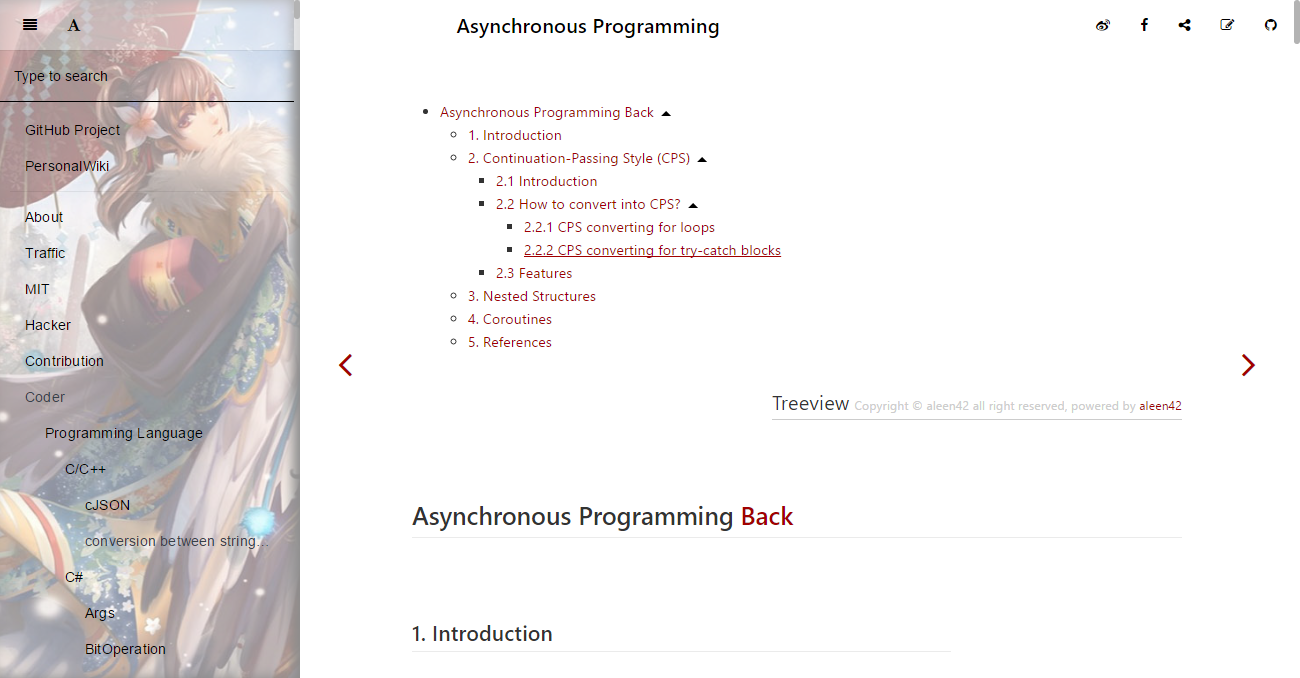
gitbook-treeview is a Gitbook plugin designed for generating structures for articles of a book. As the following picture shown, the main structure of a whole article has been clearly shown before contents, and each title has also been directed to a corresponding part. Mastering Apache Spark 2 is a large book, which has integrated with Gitbook, and I hope that the plugin can helps to enhance readability. If you like it, I hope you can star my project too, and thanks for your appreciations. As for the picture, it's an article named "Asynchronous Programming" in my personal wiki book.
From Elie:
It looks nicer but personally, I miss "real chapter like" navigation on the left. i.e 1. Spark Core 2. Spark Mllib 3. Deployments, etc.a
Hi, thanks for writing the notebooks.
In the introduction to RDD partitioning you mention that the filter operation does not preserve partitioning. But I'm looking at the source code where I see that MapPartitionsRDD is instantiated with preservesPartitioning = true.
Doesn't this conflict your statement?
Hey,
is it possible to build an HTML or PDF (preferred) version of this book for offline reading? What would be the process to do that?
Thanks
I can not find a way to download PDF of the latest book version from http://books.japila.pl/apache-spark-internals/apache-spark-internals/2.4.3
When I press Download nothing happens.
hi @jaceklaskowski ,
this is a great resource for learning and dive into spark. Thanks a lot for your book.
I want know if we can support multi language or plan in the future?
if so, I want participate in these works.
And also, is this book will be commercial used ? I mean we need pay to access?
Otherwise I can try to do something in my local for Chinese version translation, of course this need your allowed firstly.
I just a spark learner, no commercial attempt.
Thanks & Regards,
Kevin
Hi,
I am starting reading Spark source code, and I have found that the newBroadcast in the trait BroadcastFactory in the documentation is missing the serializedOnly param.
a small remark :)
I will push the MR to update it.
BTW: very nice and helpful descriptions
jaceklaskowski,you are doing a great job. I have a trouble when i am reading the book, the content is not well presented.
e.g https://books.japila.pl/apache-spark-internals/serializer/SerializationStream/
Please give me some suggestions!!! Thank you very much.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.