jasonwu73 / blog Goto Github PK
View Code? Open in Web Editor NEW因网络原因,已自建博客站点
Home Page: https://www.wuxianjie.net
License: MIT License
因网络原因,已自建博客站点
Home Page: https://www.wuxianjie.net
License: MIT License















{
"default_config":
{
"linux": null,
"osx": null,
"windows": "Command Prompt"
},
"shell_configs":
[
{
"name": "PowerShell",
"cmd": "powershell.exe",
"env":{},
"enable": true,
"platforms": ["windows"]
}
],
"theme": "default"
}默认情况下,CentOS 7 只提供了一个 root 的账户。虽然 root 可以为我们的工作带来极大的便利性和灵活性,但也正因为该账户拥有系统的最高权限,所以也很容易造成一些安全问题(因为该用户可以随意操作整个服务器的文件系统)。
一个比较好的方案就是添加一个非特权用户来执行一些常规操作。我们应该为每个访问服务器的用户都创建一个账户,这样便于系统管理员监控和管理这些用户的活动。然而在工作中,我们的非特权用户也需要管理员权限来执行一些操作,即他们应该能通过 sudo 机制临时获取管理员权限。
下面我们就来学习下在 CentOS 7 中如何创建一个新的用户账户,分配 sudo 权限和删除用户。下面的命令以 root 用户执行为例。
创建新用户:
adduser <username>设置用户密码(只有设置用户密码后,该用户才能登录):
passwd <username>上述操作需要输入两次密码,第一次是设置密码,第二次是确认密码。
通过 gpasswd 命令将用户加入到 wheel 用户组(默认情况下,该用户组中所有用户都具有 sudo 权限)来为新用户授予访问 sudo 的权限。这是最简单也是最安全的管理 sudo 用户权限的方式。
将用户加入到 wheel 用户组:
gpasswd -a <username> wheel之后,该用户就可以通过 sudo 实现以管理员权限执行命令:
sudo <command>执行上述命令后,会提示我们需要用户密码(当前登录用户自己的密码)来确认操作。一旦密码确认通过后,本次命令就会以 root 管理员的权限来执行。
我们也可以将用户从 wheel 用户组移除:
gpasswd -d <username> wheel我们可以使用 lid 命令来查看 wheel 用户组中的成员。lid 通常用于查看某用户在哪些用户组中,但我们可以通过 -g 选项进行反操作,即查看某用户组中有哪些用户:
lid -g wheel当一个用户账户不再被使用后,最好的方式就是删除掉该账户。
使用以下命令可以删除一个用户,但不删除该用户主目录:
userdel <username>使用以下命令可以删除用户及其用户主目录:
userdel -r <username>当删除用户后,该用户也会从任何其它用户组中删除。
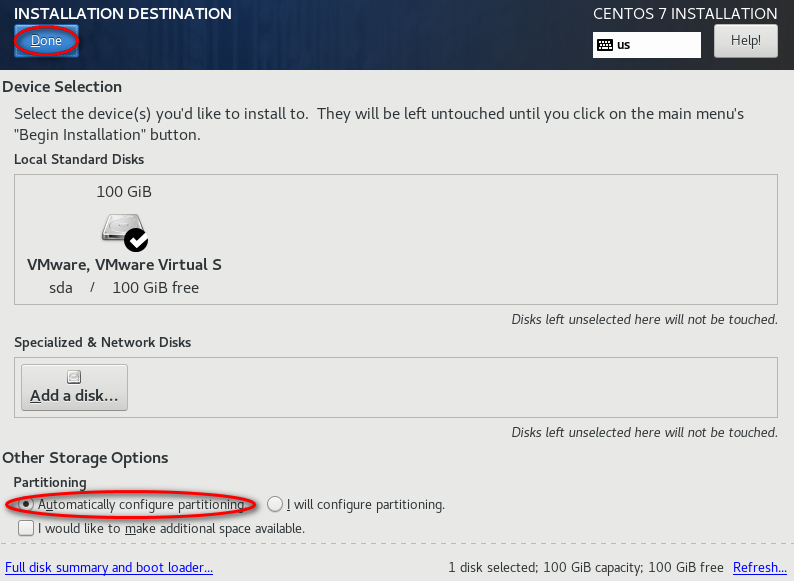
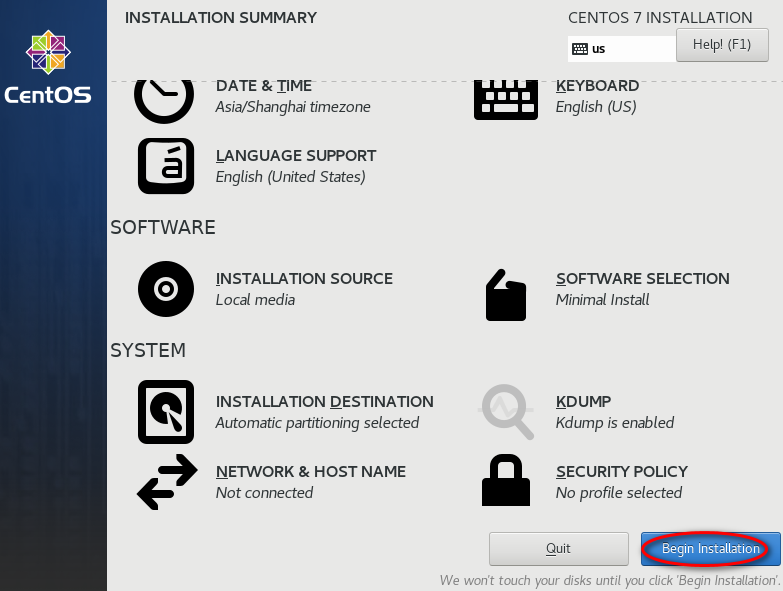
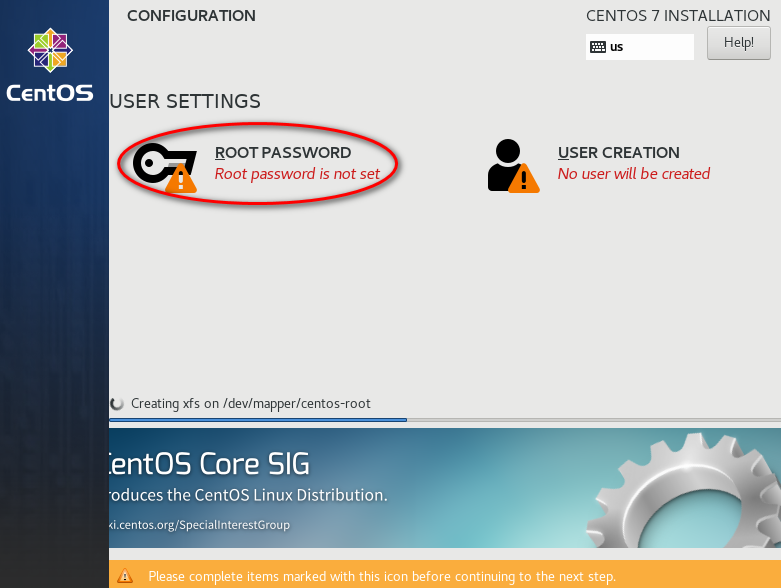
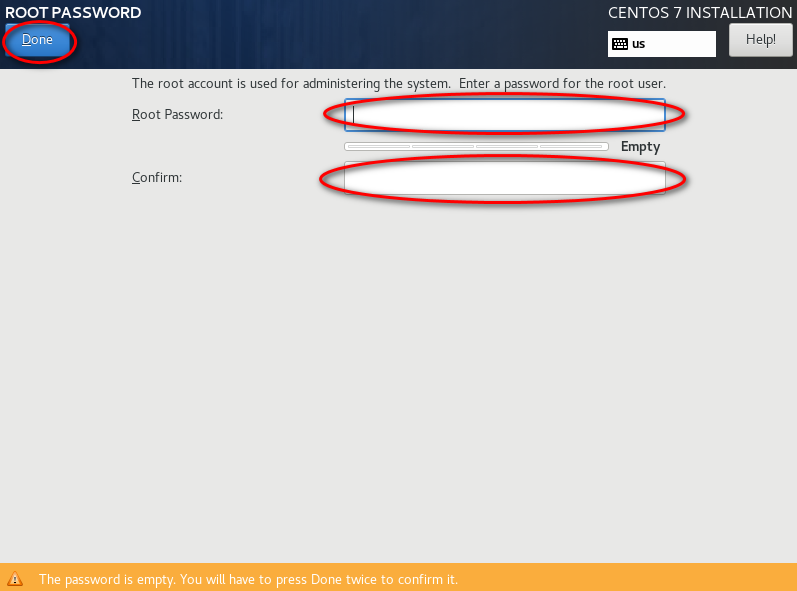
待安装完,点击“reboot”。
重启系统后,使用用户名“root”,和我们之前设置的密码即可登录系统。
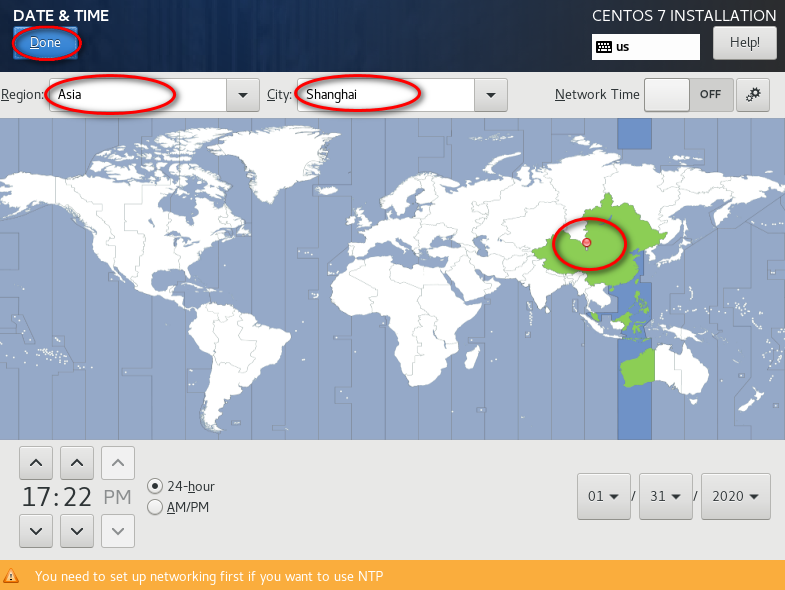
当我们安装完服务器后,不可避免地需要配置时间同步服务。在 Linux 中时间同步配置是通过 NTP(Network Time Protocol)完成的。
查看当前时区:
timedatectl status设置时区(**使用的是上海时区):
timedatectl set-timezone Asia/Shanghai有两种类型的 NTP 守护进程,分别是 chronyd 和 ntpd。
本教程同时包含了这两个 NTP 守护进程的配置方法,你只需二选其一即可(如果系统中同时运行两个 NTP 守护进程,则会导致不兼容和不稳定):
不论使用上述哪种 NTP 守护进程,都需要从 NTP 公共池选择时间服务器,比如** NTP 池(pool.ntp.org: NTP Servers in China, cn.pool.ntp.org)的是:
server 0.cn.pool.ntp.org
server 1.cn.pool.ntp.org
server 2.cn.pool.ntp.org
server 3.cn.pool.ntp.org
1)安装 chronyd 软件包:
yum install chrony -y2)编辑配置文件:
vi /etc/chrony.conf将:
server 0.centos.pool.ntp.org iburst
server 1.centos.pool.ntp.org iburst
server 2.centos.pool.ntp.org iburst
server 3.centos.pool.ntp.org iburst
修改为:
server 0.cn.pool.ntp.org iburst
server 1.cn.pool.ntp.org iburst
server 2.cn.pool.ntp.org iburst
server 3.cn.pool.ntp.org iburst
3)启动 chronyd 服务:
systemctl start chronyd4)设置当系统引导时自动启动 chronyd 服务:
systemctl enable chronyd1)安装 ntpd 软件包:
yum install ntp -y2)编辑配置文件:
vi /etc/ntp.conf将:
server 0.centos.pool.ntp.org iburst
server 1.centos.pool.ntp.org iburst
server 2.centos.pool.ntp.org iburst
server 3.centos.pool.ntp.org iburst
修改为:
server 0.cn.pool.ntp.org iburst
server 1.cn.pool.ntp.org iburst
server 2.cn.pool.ntp.org iburst
server 3.cn.pool.ntp.org iburst
3)启动 ntpd 服务:
systemctl start ntpd4)设置当系统引导时自动启动 chronyd 服务:
systemctl enable ntpd# 最大连接数,默认 200
SHOW VARIABLES LIKE '%max_connections%'
# 非交互式(程序)超时时间(秒),默认 8 小时
SHOW GLOBAL VARIABLES LIKE 'wait_timeout';
# 交互式(Navicat)超时时间(秒),默认 8 小时
SHOW GLOBAL VARIABLES LIKE 'interactive_timeout';
# 查看所有连接
SHOW FULL PROCESSLIST;
SELECT * FROM information_schema.`PROCESSLIST`;mysql -uroot -pmysql -h192.168.2.182 -P3306 -uroot -pexitquitSELECT User, Host, Plugin FROM mysql.user; ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY 'root123';FLUSH PRIVILEGES;GRANT ALL PRIVILEGES ON * . * TO 'wxj'@'%';SHOW GRANTS FOR 'wxj'@'%';REVOKE ALL PRIVILEGES, GRANT OPTION FROM 'wxj'@'%';CREATE USER 'wxj'@'%' IDENTIFIED WITH mysql_native_password BY 'qwe123';UPDATE mysql.user SET User = 'jason' WHERE User = 'wxj';ALTER USER 'jason'@'%' IDENTIFIED BY '123';DROP USER 'wxj'@'%';SHOW DATABASES;MySQL 8 以前:
CREATE DATABASE test CHARACTER SET utf8 COLLATE utf8_general_ci;MySQL 8 及以后:
CREATE DATABASE test CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci;USE test;DROP DATABASE test;CREATE TABLE users(
id INT AUTO_INCREMENT COMMENT '用户id',
create_time DATETIME COMMENT '记录创建时间',
modify_time DATETIME COMMENT '记录修改时间',
username VARCHAR(15) COMMENT '用户名',
password VARCHAR(60) COMMENT '登录密码(加密)',
is_admin TINYINT(1) COMMENT '是否管理员(1:是;0:否)',
email VARCHAR(50) COMMENT '邮箱',
PRIMARY KEY(id)
) COMMENT='系统用户表';CREATE TABLE posts(
id INT AUTO_INCREMENT,
user_id INT,
title VARCHAR(100),
body TEXT,
publish_date DATETIME DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY(id),
FOREIGN KEY(user_id) REFERENCES users(id)
);SHOW TABLES;DROP TABLE users;DESCRIBE users;SHOW COLUMNS FROM users;SHOW FULL COLUMNS FROM users;SHOW CREATE TABLE users;SELECT * FROM information_schema.TABLES WHERE TABLE_SCHEMA = 'test' AND TABLE_NAME = 'users';SELECT * FROM information_schema.COLUMNS WHERE TABLE_SCHEMA = 'test' AND TABLE_NAME = 'users';ALTER TABLE users COMMENT = '修改表注释';ALTER TABLE users MODIFY COLUMN `username` varchar(15) DEFAULT NULL COMMENT '修改列注释';ALTER TABLE users ADD COLUMN need_to_delte VARCHAR(100); ALTER TABLE users RENAME COLUMN need_to_delte TO need_d; ALTER TABLE users DROP COLUMN need_d;EXPLAIN SELECT * FROM users;SHOW INDEX FROM users;SELECT DISTINCT TABLE_NAME, INDEX_NAME FROM information_schema.STATISTICS WHERE TABLE_SCHEMA = 'test';CREATE INDEX USERNAME_INDEX ON users(username);DROP INDEX USERNAME_INDEX ON users;INSERT INTO users(create_time, modify_time,
username, password, is_admin, email)
values (now(), now(),
'Jason', 'pass123', 1, '[email protected]');INSERT INTO users(create_time, modify_time,
username, password, is_admin, email)
values (now(), now(),
'Bruce', 'pass123', 1, '[email protected]'),
(now(), now(),
'wxj', 'pass123', 1, '[email protected]');UPDATE users SET is_admin = 0 WHERE id = 2;SELECT id, username, is_admin, email FROM users ORDER BY id DESC LIMIT 0, 10;DELETE FROM users WHERE ID = 3;默认情况下,Docker 守护进程的工作有如下几个特点:
root 用户所拥有,其他用户需要 sudo 权限才能访问root 用户运行当我们使用非 root 用户执行 docker 命令时,会得到类似如下的错误:
Got permission denied while trying to connect to the Docker daemon socket at unix:///var/run/docker.sock: Get http://%2Fvar%2Frun%2Fdocker.sock/v1.40/images/json: dial unix /var/run/docker.sock: connect: permission denied
如果我们想以非 root 用户来执行 docker 命令时,可以创建一个用户组 docker,然后将用户加入到该用户组中即可。因为当 Docker 守护进程启动时,它会创建能够被 docker 用户组中成员可访问的 Unix 套接字。
1)默认情况下,Docker 已自动帮我们创建了 docker 用户组(getent group | grep docker)。如果没有,则我们可以自己创建 docker 用户组:
groupadd docker2)将当前登录用户加入到 docker 用户组中:
usermod -aG docker $USER我们可以使用 sudo lid -g docker 查看 docker 用户组中有哪些用户。
将当前用户退出系统,再重新登录,就可以使我们的用户在新加入的用户组中生效。
我们有两种方式可以退出系统:
logoutCtrl + D将当前用户以 docker 用户组的身份再次登入系统:
newgrp dockerConfigure → Plugins →
IdeaVimLombokCodotaJRebel for IntelliJPythonCVSVue.jsConfigure → Settings
Appearance & Behavior → Appearance → 钩选 Show memory indicator
Appearance & Behavior → System Settings →
Reopen last project on startupConfirm application exitOpen project in new windowSynchronize files on frame or editor tab activationSave files on frame deactivation可通过
Ctrl + Alt + Y手动同步硬盘文件
Appearance & Behavior → System Settings → Updates → 取消钩选 Automatically check updates for
Editor → General →
Change font size (zoom) with Ctrl+Mouse WheelSoft-wrap files,并添加 ; *.*Use original line's indent for wrapped parts1Ensure line feed at file end on SaveEditor → Code Style → Import Scheme → Intellij IDEA code style XML 选择 intellij-java-google-style.xml
Editor → General → Auto Import →
Add unambiguous imports on the flyOptimize imports on the fly (for current project)suncom.sunjava.awt.Listjava.sql.DateEditor → General → Appearance →
Show line numbersShow method separatorsShow whitespace可通过
Ctrl + G定位行号。
Editor → General → Console → 钩选 Use soft wraps in console
Editor → General → Editor Tabs →
Hide tabs if there is no spaceUse small font for labelsShow file extensionMark modified (*)None可通过
Ctrl + F4或鼠标中键关闭标签页。
Editor → Font →
Menlo161.2Editor → Color Scheme → Console Font →
Use console font instead of the defaultMenlo131.2Editor → Code Style →
Unix and macOS (\n)79Editor → File Encodings →
UTF-8UTF-8UTF-8Transparent native-to-ascii conversionwith NO BOMEditor → Vim Emulation → 将 Hnadler 都设置为 IDE
Version Control → 钩选 Show directories with changed descendants
Version Control → Commit Dialog → 取消钩选 Perform code analysis
Languages & Frameworks → JavaScript → JavaScript language version 选择 ECMAScript 6
Languages & Frameworks → JavaScript → Code Quality Tools →
Manual ESLint configuration
npm install -g eslintLanguages & Frameworks → Kite →
Start Kite at startupShow Kite introduction at startupLanguages & Frameworks → Style Sheets → Stylelint →
Enablenpm install -g stylelintTools → Web Browsers → 按需选择
Tools → Terminal → Shell path 选择 cmd.exe
JRebel & XRebel → JRebel Advanced → 钩选 Disable reporting
只有当你觉得 IDEA 很卡时,才需要以下配置:
1)Plugins → 不认识的统统干掉
2)Editor → Inspections → Duplicate... 复制一个默认配置,然后只保留 Error 和 Typo 的检查,并选择为 IDEA 默认的代码查检配置。
通过主菜单 Analyze → Inspect Code 手动选择默认配置文件运行检查。可进一步在 Keymap 配置快捷键,我是将
Alt + Shift + I从原绑定操作上删除,再分配给 Inspect Code。
3)Editor → Live Templates → 全部干掉
4)Editor → Intentions → 全部干掉
IDE_HOME\bin\<product>[bits][.exe].vmoptionsC:\Users\JasonWu\.IntelliJIdea2019.3\configConfigure → Edit Custom VM Options
-server
-Xms2048m
-Xmx2048m
-XX:NewSize=512m
-XX:MaxNewSize=512m
-XX:ParallelGCThreads=4
-XX:MaxTenuringThreshold=1
-XX:SurvivorRatio=8
-XX:+UseCodeCacheFlushing
-XX:+CMSClassUnloadingEnabled
-XX:+CMSParallelRemarkEnabled
-XX:CMSInitiatingOccupancyFraction=65
-XX:+CMSScavengeBeforeRemark
-XX:+UseCMSInitiatingOccupancyOnly
-XX:ReservedCodeCacheSize=256m
-Xlog:class+unload=off
-ea
-Dsun.io.useCanonCaches=false
现在的前端给人感觉就是万物皆可编译,什么编译 JavaScript,编译 CSS 啊,都已经是司空见惯的事了。今天我们更进一步,来玩玩编译图片是个什么玩意!
我们示例代码目录为:
D:.
index.css
index.html
me-comic-book.jpg
test.js
index.css 源码:
body {
background-image: url("me-comic-book.jpg");
}test.js 源码:
const compile = () => {
const file = require('fs');
const buildFileName = 'build.js';
file.writeFile(buildFileName, '', () => {});
file.readFile('./index.css', (err, data) => {
if (err) {
return console.error(err);
}
let css = String(data).replace(/\s/g, '');
const regex = /['"](.*?\.jpg)['"]/g;
let match;
while ((match = regex.exec(css))) {
const imagePath = match[1];
const imageData = file.readFileSync(imagePath);
const imageBase64 = imageData.toString('base64');
css = css.replace(imagePath, `data:image/jgp;base64,${imageBase64}`);
}
file.appendFile(buildFileName,
'var style = document.createElement("style");' +
'style.appendChild(document.createTextNode(\'' + css + '\'));' +
'document.head.appendChild(style);',
() => {});
});
};
compile();index.html 源码:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>首页</title>
</head>
<body>
<script src="build.js"></script>
</body>
</html>其中编译结果为 build.js:
var style = document.createElement("style");style.appendChild(document.createTextNode('body{background-image:url("data:image/jgp;base64,/9j/4SMHRXhpZgAATU0AKgAAAAgAEQEAAAMAAAABCRAAAAEBAAMAAAABDxyGO1O0y6bxN+L.../zEz/8mHy2P90fe0n+9Huf/9k=");}'));document.head.appendChild(style);在浏览器中打开我们的 index.html,可以看到我们的背景图片是能够正确地显示的。
这就是我们编译图片所进行的工作,将图片转为 Base64 字符串,这样做的好处有:
当然,并不是什么图片都适合转为 Base64 的。如果图片符合以下任何一个条件,那都是不适合转为 Base64 的:
直接加入系统环境变量
path,可免去以下配置。
{
"linters": {
"flake8": {
"executable": "D:/Workspace/PyEnvST3/Scripts/flake8.exe"
},
"eslint": {
"executable": "D:/Workspace/NPM/node_modules/.bin/eslint.cmd"
}
}
}[
{"id": "side-bar-files-open-with",
"children":
[
{
"caption": "Google Chrome",
"id": "side-bar-files-open-with-chrome",
"command": "side_bar_files_open_with",
"args": {
"paths": [],
"application": "C:/Program Files (x86)/Google/Chrome/Application/chrome.exe",
"extensions":".*",
"args":[]
}
},
{
"caption": "Firefox",
"id": "side-bar-files-open-with-firefox",
"command": "side_bar_files_open_with",
"args": {
"paths": [],
"application": "D:/Program Files/Mozilla Firefox/firefox.exe",
"extensions":".*",
"args":[]
}
},
{
"caption": "Internet Explorer",
"id": "side-bar-files-open-with-chrome",
"command": "side_bar_files_open_with",
"args": {
"paths": [],
"application": "C:/Program Files/internet explorer/iexplore.exe",
"extensions":".*",
"args":[]
}
},
{"caption":"-"}
]
}
]| 快捷键 | 描述 |
|---|---|
Alt + Shift + Mouse click |
指定多处光标 |
| 快捷键 | 描述 |
|---|---|
Ctrl + Alt + L |
格式化代码 |
Ctrl + F4 |
关闭当前编辑器选项卡 |
Alt + Enter |
显示意图动作和快速修复 |
Shift + Enter |
另起一行 |
Ctrl + Alt + Enter |
向上添加一行 |
Ctrl + D |
复制当前行或选定的块 |
Ctrl + Shift + U |
切换英文字符大小写 |
Ctrl + Y |
删除当前行 |
Ctrl + Q |
快速查找文档 |
Ctrl + Space |
代码补全提示 |
Ctrl + P |
参数信息 |
Ctrl + Mouse over |
简短信息 |
Ctrl + F1 |
显示错误或警告信息 |
Alt + Insert |
自动生成代码 |
Ctrl + O |
重载方法 |
Ctrl + I |
实现方法 |
Ctrl + Alt + T |
将选中的代码包围在其他语句之中 |
Ctrl + W |
递增选择代码块 |
Ctrl + Shift + W |
回退递增选择代码块的前一步操作 |
Alt + Q |
上下文信息 |
Ctrl + Shift + Enter |
完成当前语句 |
Ctrl + Alt + O |
优化 import 语句 |
Ctrl + Shift + V |
从剪贴板选择粘贴 |
Ctrl + Delete |
删除到字符串的结尾 |
Ctrl + Backspace |
删除到字符串的开始 |
Ctrl + NumPad-/+ |
折叠/展开代码块 |
Ctrl + Shift + NumPad-/+ |
折叠/展开所有 |
Ctrl + Shift + Up/Down |
上行/下移行 |
| 快捷键 | 描述 |
|---|---|
Ctrl + F |
查找 |
F3 |
查找下一处 |
Shift + F3 |
查找上一处 |
Ctrl + R |
替换 |
Ctrl + Shift + F |
在路径中查找 |
Ctrl + Shift + R |
在路径中替换 |
| 快捷键 | 描述 |
|---|---|
Ctrl + F7 |
在当前文件中查找变量的使用 |
Ctrl + Shift + F7 |
在当前文件中高亮显示变量的使用 |
Alt + F7 |
在整个项目中查找变量的使用 |
Ctrl + Alt + F7 |
显示变量在整个项目中的使用情况 |
| 快捷键 | 描述 |
|---|---|
Ctrl + F9 |
编译整个项目 |
Ctrl + Shift + F9 |
编译选定的文件、包或模块 |
Alt + Shift + F10 |
选择配置并运行 |
Alt + Shift + F9 |
选择配置并运行 |
Shift + F10 |
运行 |
Shift + F9 |
调试 |
| 快捷键 | 描述 |
|---|---|
F8 |
单步运行 |
F7 |
进入调用的方法 |
Shift + F7 |
智能进入调用的方法 |
Shift + F8 |
跳出当前方法 |
Alt + F9 |
运行到光标 |
Alt + F8 |
计算表达式 |
F9 |
继续运行 |
Ctrl + F8 |
对光标所在的行设置或清除断点 |
Ctrl + Shift + F8 |
查看断点 |
| 快捷键 | 描述 |
|---|---|
Ctrl + N |
跳转到指定类 |
Ctrl + Shift + N |
通过文件名快速查找工程内的文件 |
Ctrl + Alt + Shift + N |
通过一个字符查找函数位置 |
Alt + Right/Left |
转到下一个/前一个编辑器标签 |
Ctrl + G |
跳转到第几行 |
Ctrl + E |
弹出最近打开的文件 |
Ctrl + Shift + E |
弹出最近编辑的文件 |
Ctrl + Alt + Left/Right |
后退/前进导航 |
Ctrl + Shift + Backspace |
导航到最后一个编辑位置 |
Ctrl + B 或 Ctrl + Click |
跳转到声明 |
Ctrl + Alt + B |
跳转到实现 |
Ctrl + U |
跳转到父类方法/超类 |
Alt + Up/Down |
跳转到上一个/下一个方法 |
Ctrl + [/] |
移动到代码块的结束/开始 |
Ctrl + F12 |
弹出文件结构窗口 |
Ctrl + H |
类型层次结构 |
Ctrl + Shift + H |
方法层次结构 |
Ctrl + Alt + H |
调用层次结构 |
F2 / Shift + F2 |
下一个/前一个高亮错误 |
Alt + Home |
显示导航栏 |
Ctrl + Shift + T |
导航到相应的测试类,或者创建一个测试类 |
| 快捷键 | 描述 |
|---|---|
F11 |
设置/取消书签 |
Ctrl + F11 |
用助记符切换设置/书签 |
Ctrl + #[0-9] |
跳转到带编号的书签 |
Shift + F11 |
显示书签 |
| 快捷键 | 描述 |
|---|---|
F5 |
拷贝类 |
F6 |
移动静态成员 |
Shift + F6 |
重命名 |
Ctrl + F6 |
修改签名 |
Ctrl + Alt + M |
提取方法 |
Ctrl + Alt + V |
提取变量 |
Ctrl + Alt + F |
提取字段 |
Ctrl + Alt + C |
提取常量 |
Ctrl + Alt + P |
提取参数 |
| 快捷键 | 描述 |
|---|---|
Ctrl + K |
提交 |
Ctrl + Shift + K |
推送 |
Ctrl + T |
拉取更新 |
Ctrl + Alt + Z |
回滚修改 |
Ctrl + Alt + Shift + Down/Up |
下一个/上一个修改 |
| 快捷键 | 描述 |
|---|---|
Ctrl + Alt + Y |
手动同步硬盘上的文件 |
Ctrl + Shift + F12 |
编辑器最大化切换 |
Ctrl + Alt + S |
打开设置对话框 |
Ctrl + Alt + Shift + S |
打开项目结构对话框 |
Ctrl + Tab |
在选项卡和工具窗口之间切换 |
Ctrl + Shift + C |
复制绝对路径 |
Double Shift |
随处搜索 |
Ctrl + Shift + A |
查找操作 |
Double Ctrl |
运行任何命令 |
Alt + F12 |
打开或隐藏终端 |
Alt + Shift + I |
手动选择配置文件并运行检查(此快捷键已被我调整过) |
单一功能原则是我们在面向对象设计中非常重要的一个原则,在通过保证单一功能原则的情况下,我们的功能将变得更加容易实现和测试,并且还可以提高代码的复用性,此外还可以使得我们的代码更加简洁明了。
单一功能原则要求我们的每个类、函数和模块都只有一个单一的功能,即我们的代码只能有一个“改变的原因”。如果我们的代码会因为两个或以上完全不同的起因而发生改变,或是做了明显不同的事情,那么就违反了这个原则,并且这样的代码很可能也是设计很差的代码。
以下是一个跟踪话费余额的示例程序:
class BalanceOfPhoneReminder:
def __init__(self, balanceToRemind, balance):
self.balanceToRemind = balanceToRemind
self.balance = balance
def trackBalance(self, cost):
self.balance -= cost
if self.balanceToRemind >= self.balance:
self.logBalanceSurplus()
def logBalanceSurplus(self):
print(f'当前话费余额{self.balance}元,已不足{self.balanceToRemind}元,请及时充值')
balanceToRemind = BalanceOfPhoneReminder(15, 30)
balanceToRemind.trackBalance(10)
balanceToRemind.trackBalance(10)上面代码中的 BalanceOfPhoneReminder 即实现了追踪话费余额的功能(trackBalance),又实现了打印余额不足消息的功能(logBalanceSurplus)。现在假设我们要把打印余额更改为发送邮件,那么我们势必要修改 BalanceOfPhoneReminder 的代码,这意味着在开发完毕后,我们又得测试一遍追踪话费余额的功能。
此外,我们能够很明显地发现追踪消费和打印消息两个发生的原因是完全不同的,一个起因是余额的改变,一个起因是仅仅需要打印而已。而我们强行把这样两个本该独立的功能耦合在了一起,就使得了我们代码的可维护性大大降低,也不利于后续开发的代码可复用性。
下面我们依据单一功能原则,将打印消息的代码从跟踪话费余额的代码中抽离出来为一个单独的模块 logger.py:
def log_message(message):
print(message)然后我们跟踪话费余额的代码就可以变为:
from logger import log_message
class BalanceOfPhoneReminder:
def __init__(self, balanceToRemind, balance):
self.balanceToRemind = balanceToRemind
self.balance = balance
def trackBalance(self, cost):
self.balance -= cost
if self.balanceToRemind >= self.balance:
log_message(
f'当前话费余额{self.balance}元,'
f'已不足{self.balanceToRemind}元,请及时充值')
balanceToRemind = BalanceOfPhoneReminder(15, 30)
balanceToRemind.trackBalance(10)
balanceToRemind.trackBalance(10)通过对单一功能原则的应用,我们的代码变得更加容易维护,并且也抽离出了一个通常的打印消息模块,后面如果要修改打印消息为发送邮件也会变得更加轻松,因为我们只需对 logger.py 进行修改即可,而跟踪话费余额代码却可以原封不动。
Windows IP 变更脚本文件(批处理文件),主要涉及两个步骤:
新建文本文档,参照以下内容,按需要修改,最后保存文件,并修改文件名为 IPChanger.bat(可以是任意文件名,但要求文件扩展名必须为 .bat)。
@echo off
cls
rem 网络连接名称
set "nic=以太网"
rem 静态 IP 地址
set "ip=192.168.0.37"
set "governmentIP=192.168.166.37"
rem 子网掩码
set "subnetMask=255.255.255.0"
rem 默认网关
set "defaultGateway=192.168.0.1"
set "governmentDefaultGateway=192.168.166.1"
rem 首选 DNS 服务器
set "dns=221.12.1.227"
rem 备用 DNS 服务器
set "dns2=202.101.172.35"
:start
echo [1] 配置公司内网 IP
echo [2] 配置政务外网 IP
echo [3] 动获得 IP 地址(DHCP)
echo [4] 直接退出
set choice=
set /p choice=请输入编号,并按回车键结束:
if "%choice%"=="1" goto setStaticIP
if "%choice%"=="2" goto setGovernmentStaticIP
if "%choice%"=="3" goto setDHCP
if "%choice%"=="4" goto end
echo "%choice%" 是无效的,请重新输入
echo.
goto start
:setStaticIP
rem 网络连接名称 静态 IP 地址 子网掩码 默认网关
netsh interface ipv4 set address name=%nic% static %ip% %subnetMask% %defaultGateway%
netsh interface ipv4 add dns name=%nic% addr=%dns% > null
netsh interface ipv4 add dns name=%nic% addr=%dns2% index=2 > null
goto end
:setGovernmentStaticIP
rem 网络连接名称 静态 IP 地址 子网掩码 默认网关
netsh interface ipv4 set address name=%nic% static %governmentIP% %subnetMask% %governmentDefaultGateway%
netsh interface ipv4 add dns name=%nic% addr=%dns% > null
netsh interface ipv4 add dns name=%nic% addr=%dns2% index=2 > null
goto end
:setDHCP
rem 自动从 DHCP 服务器获取 IP 地址
netsh interface ipv4 set address name=%nic% dhcp
netsh interface ipv4 set dns name=%nic% dhcp
goto end
:end
echo.
echo 当前网络连接信息
ipconfig /all
pauseIPChanger.bat,打开右键菜单,点击 属性高级 按钮,然后勾选 用管理员身份运行(R),最后 确定IPChanger.bat,在弹出的用户账户控制中选择 是(即以管理员身份运行){
"target": "terminus_exec",
"cancel": "terminus_cancel_build",
"shell_cmd": "py -3 -u $file",
"working_dir": "$file_path",
"selector": "source.python",
"file_regex": "^[ ]*File \"(...*?)\", line ([0-9]*)",
"env": {"PYTHONIOENCODING": "utf8"}
}JDK 下载地址:https://www.oracle.com/technetwork/java/javase/downloads/index.html。
1)安装 JDK,下载并运行 .exe 可执行文件。安装 JDK 还会安装私有和公共 JRE:
D:\Program Files\Java\jdk1.8.0_241\jre)2)设置环境变量,Win key + Pause/Break -> 高级系统设置 -> 高级 -> 环境变量:
Path,在变量值起始位置添加 D:\Program Files\Java\jdk1.8.0_241\bin;查看 JDK 的安装目录:
where java。
1)下载归档二进制文件(.tar.gz)
2)根据超级用户密码将当前用户切换为超级用户:$ su - root
3)将 .tar.gz 文件移动到 JDK 的目标安装目录中(通常为 /usr/local/java)
4)解压压缩包并安装 JDK:# tar zxvf jdk-8u202-linux-x64.tar.gz
5)配置环境变量:# vi /etc/profile,在末尾添加如下内容:
export PATH=$PATH:/usr/local/java/jdk1.8.0_241/bin
6)刷新当前 Shell 环境:# source /etc/profile
7)如果要节省磁盘空间,则删除 .tar.gz 文件
8)Xshell 退出 Root Shell(无需重启):# Ctrl + D
查看 JDK 的安装目录:
$ which java。
{
"target": "terminus_exec",
"cancel": "terminus_cancel_build",
"shell_cmd": "chcp 65001 && gcc $file -o $file_base_name && $file_base_name",
"working_dir": "$file_path",
"selector": "source.c",
"file_regex": "^[ ]*File \"(...*?)\", line ([0-9]*)"
}创建对象是我们工作中极其普遍的事。比如以下代码:
class Address:
def __init__(self, zip, street):
self.zip = zip
self.street = street
def __repr__(self):
return f'Address(zip={self.zip}, street={self.street})'
class User:
def __init__(self, name, age, phone, address):
self.name = name
self.age = age
self.phone = phone
self.address = address
def __repr__(self):
return f'User(name={self.name}, age={self.age}, \
phone={self.phone}, address={self.address})'
user_1 = User('Jason', None, None, None)
print(user_1)
user_2 = User('Jason', 25, None, None)
print(user_2)
user_3 = User('Jason', 25, None, Address('310000', '杭州下城'))
print(user_3)以上这样的代码,可以算是司空见惯的了,这即可能是我们自己写的代码,也可能是我们同事写的代码。正因为创建一个对象实在是太普遍了,所以也导致了我们对这样的工作没有进行过多的考虑。但是回过头再来看我们上面的代码,比如类似 User('Jason', None, None, None) 这样的对象构造方法,对于构造一个简单对象当然没有问题,但是一旦我们需要构造一个复杂对象,我们构造方法的参数就会变得很长,且无法表现出每个参数的具体含义。这样的代码可读性不高,也显得代码不够简洁。
下面我们采用生成器模式来优化以上的代码:
class Address:
def __init__(self, zip, street):
self.zip = zip
self.street = street
def __repr__(self):
return f'Address(zip={self.zip}, street={self.street})'
class User:
def __init__(self, name, age, phone, address):
self.name = name
self.age = age
self.phone = phone
self.address = address
def __repr__(self):
return f'User(name={self.name}, age={self.age}, \
phone={self.phone}, address={self.address})'
class UserBuilder:
def __init__(self, name):
self.user = User(name, None, None, None)
def setAge(self, age):
self.user.age = age
return self
def setPhone(self, phone):
self.user.phone = phone
return self
def setAddress(self, address):
self.user.address = address
return self
def build(self):
return self.user
user_1 = UserBuilder('Jason').build()
print(user_1)
user_2 = UserBuilder('Jason').setAge(25).build()
print(user_2)
user_3 = UserBuilder('Jason') \
.setAge(25) \
.setAddress(Address('310000', '杭州下城')) \
.build()
print(user_3)现在我们的代码,可读性得到了很好的提高,代码结构也显得更加清晰。
因为我使用的是 Python 语言作为代码演示,而对于 Python 而言,我们可以不需要创建额外的构造器对象 UserBuilder,直接利用关键字参数和字典的 get() 方法来进一步简化代码:
class Address:
def __init__(self, zip, street):
self.zip = zip
self.street = street
def __repr__(self):
return f'Address(zip={self.zip}, street={self.street})'
class User:
def __init__(self, name, **kwargs):
self.name = name
self.age = kwargs.get('age')
self.phone = kwargs.get('phone')
self.address = kwargs.get('address')
def __repr__(self):
return f'User(name={self.name}, age={self.age}, \
phone={self.phone}, address={self.address})'
user_1 = User('Json')
print(user_1)
user_2 = User('Json', age=25)
print(user_2)
user_3 = User('Json', age=25, address=Address('310000', '杭州下城'))
print(user_3)摘自《中文维基百科》:
在面向对象编程领域中,依赖反转原则(Dependency inversion principle,DIP)一种特定的解耦(传统的依赖关系创建在高层次上,而具体的策略设置则应用在低层次的模块上)形式,使得高层次的模块不依赖于低层次的模块的实现细节,依赖关系被颠倒(反转),从而使得低层次模块依赖于高层次模块的需求抽象。
该原则规定:
- 高层次的模块不应该依赖于低层次的模块,两者都应该依赖于抽象接口。
- 抽象接口不应该依赖于具体实现。而具体实现则应该依赖于抽象接口。
该原则颠倒了一部分人对于面向对象设计的认识方式。如高层次和低层次对象都应该依赖于相同的抽象接口。
应用依赖反转原则同样被认为是应用了适配器模式(adapter pattern)。
假设我们有一个商店类,需要接入支付接口,一开始我们只对接了微信支付,此时的代码如下:
class Store:
def __init__(self, user):
self.__weChat = WeChat(user)
def buyBottle(self, quantity):
self.__weChat.pay(100 * quantity * 10)
def buyMaple(self, quantity):
self.__weChat.pay(350 * quantity * 10)
class WeChat:
def __init__(self, user):
self.__user = user
def pay(self, jiao):
print(f'{self.__user} 通过微信支付 {jiao} 角')
print('\n微信支付\n')
store = Store('Jason Wu')
store.buyBottle(1)
store.buyMaple(1)过了一段时间,应顾客要求,我们加入了支付宝的支付接口。此时代码如下:
class Store:
def __init__(self, user):
self.__user = user
self.__aLiPay = ALiPay()
def buyBottle(self, quantity):
self.__aLiPay.pay(self.__user, 100 * quantity)
def buyMaple(self, quantity):
self.__aLiPay.pay(self.__user, 350 * quantity)
class ALiPay:
def pay(self, user, yuan):
print(f'{user} 通过支付宝支付 {yuan} 元')
print('\n支付宝支付\n')
store = Store('Jason Wu')
store.buyBottle(1)
store.buyMaple(1)我们会发现,在加入支付宝接口后,我们修改了商店类的代码。这也就意味着,我们高层次的代码依赖于低层次的 API,每当低层次的 API 改变时,都会影响到我们的高层次代码,这使得我们的代码变得不易维护,且容易出错。
下面我们采用依赖反转原则,重构我们的代码:
class Store:
def __init__(self, payTool):
self.__payTool = payTool
def buyBottle(self, quantity):
self.__payTool.pay(100 * quantity)
def buyMaple(self, quantity):
self.__payTool.pay(350 * quantity)
class WeChatPayTool:
def __init__(self, user):
self.__weChat = WeChat(user)
def pay(self, yuan):
self.__weChat.pay(yuan * 10)
class ALiPayTool:
def __init__(self, user):
self.__user = user
self.__aLiPay = ALiPay()
def pay(self, yuan):
self.__aLiPay.pay(self.__user, yuan)
class WeChat:
def __init__(self, user):
self.__user = user
def pay(self, jiao):
print(f'{self.__user} 通过微信支付 {jiao} 角')
class ALiPay:
def pay(self, user, yuan):
print(f'{user} 通过支付宝支付 {yuan} 元')
print('\n微信支付\n')
store = Store(WeChatPayTool('Jason Wu'))
store.buyBottle(1)
store.buyMaple(1)
print('\n支付宝支付\n')
store = Store(ALiPayTool('Jason Wu'))
store.buyBottle(1)
store.buyMaple(1)此时我们的代码逼格变得更高,逻辑也更加清晰,可维护性也得到了相应的提高。
单例模式作为我们比较常用的设计模式,想必你的系统中也或多或少有所使用。单例模式要求我们的类在整个系统中始终只有一个实例对象,在创建出一个类的实例后就不再对该类进行实例对象的再创建,从而避免一些资源消耗过大的对象初始化过程被反复执行,而且也能在复用这个实例对象的同时,传递(共享)对象的信息(状态)。
my_logger.py:
class MyLogger:
def __init__(self):
self.logs = []
def log(self, message):
self.logs.append(message)
print(f'My Logger: {message}')
def countLog(self):
print(f'{len(self.logs)} Logs')first_log.py:
from my_logger import MyLogger
logger = MyLogger()
def first_log():
logger.countLog()
logger.log('First File')
logger.countLog()second_log.py:
from my_logger import MyLogger
logger = MyLogger()
def second_log():
logger.countLog()
logger.log('Second File')
logger.countLog()print_result.py:
from first_log import first_log
from second_log import second_log
first_log()
second_log()上面代码中的 first_log.py 和 second_log.py 无法共享 my_logger.py 中的属性,所以我们也无法从一个 MyLogger 的实例对象中统计所有日志。
my_logger.py:
class Singleton(type):
_instances = {}
def __call__(cls, *args, **kwargs):
if cls not in cls._instances:
cls._instances[cls] = super(Singleton, cls) \
.__call__(*args, **kwargs)
else:
cls._instances[cls].__init__(*args, **kwargs)
return cls._instances[cls]
class MyLogger(metaclass=Singleton):
def __init__(self):
self.logs = []
def log(self, message):
self.logs.append(message)
print(f'My Logger: {message}')
def countLog(self):
print(f'{len(self.logs)} Logs')应用单例模式后,first_log.py 和 second_log.py 共享了 my_logger.py 中的属性,所以我们也可以从一个 MyLogger 实例对象中统计出所有日志。
{
"target": "terminus_exec",
"cancel": "terminus_cancel_build",
"shell_cmd": "node $file",
"working_dir": "$file_path",
"selector": "source.js",
"file_regex": "^[ ]*File \"(...*?)\", line ([0-9]*)"
}Command Palette: Ctrl + Shift + P
- Reindent Lines
- Case
Goto Anything: Ctrl + P
- File Name: "xxx"
- Symbol: "xxx@Func"
- Search: "xxx#str"
- Line: "xxx:num"
Multi Cursor: Ctrl + Cursor
Multi Column Cursor: Shift + Right Click Drag Or Ctrl + Shift + Arrow
Multi Select: Ctrl + Double Click
Multi Occurrence Select: Ctrl + D
Multi Occurrence Select Skip: Ctrl + K, Ctrl + D
Split Selection Into Lines: Ctrl + Shift + L
Select Line: Ctrl + L
Select String: Ctrl + Shift + Space
Wrap Selection With Tag: Alt + Shift + W
Wrap With Emmet: Ctrl + Shift + G
Next Tab: Ctrl + Tab
Previous Tab: Ctrl + Shift + Tab
Close Current Tab: Ctrl + W
Recover Closed Tab: Ctrl + Shift + T
Close Sublime Text: Ctrl + Shift + W
Undo: Ctrl + Z
Un-Undo: Ctrl + Y Or Ctrl + Shift + Z
Increment By 1: Ctrl + Arrow
Increment By 0.1: Alt + Arrow
Increment By 10: Alt + Shift + Arrow
Lower Case: Ctrl + K, Ctrl + L
Upper Case: Ctrl + K, Ctrl + U
Find In Current File: Ctrl + F
Find In All File: Ctrl + Shift + F
Enter New Line: Ctrl + Enter
Enter Before New Line: Ctrl + Shift + Enter
Move Line Vertically: Ctrl + Shift + Arrow
Duplicate Line: Ctrl + Shift + D
Delete Line: Ctrl + Shift + K
Indent Line: Ctrl + [ or ]
Paste & Indent: Ctrl + Shift + V
Edit -> Line -> Reindent
Show Or Hide Console: Ctrl + `
Show Or Hide Side Bar: Ctrl + K, Ctrl + B
Hide Bottom Screen: Esc
Split Screen: Alt + Shift + 2
Spell Check: F6
Show Completions: Ctrl + Space
Next Modification: Ctrl + .
Previous Modification: Ctrl + ,
Revert Modification: Ctrl + K, Ctrl + Z
Toggle Diff Hunk: Ctrl + K, Ctrl + /
Goto Definition: F12
Jump Back: Alt + -
Jump Forward: Alt + Shift + -
Custom Key Binding:
- Toggle Terminus Panel: Alt + `
- Close Current Terminus: Ctrl + W
Macros:
- Begin Recoding A Macro: Ctrl + Q
- Stop Recoding A Macro: Ctrl + Q
- Playback Macro: Ctrl + Shift + Q
- Tools -> Save Macro...
Speedy Tip:
- See Unsaved Changes
- Sidebar Time Savings
- Multiple Top Level Folders
- Save a Project
本文以在 CentOS 7 中将以太网接口从 DHCP 配置为静态 IP 为例。
列出网络信息:
ip a输出(包含了以太网接口名称):
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valide_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pf ifo_fast state UP group default qlen 1000
link/ether 00:0c:29:cf:bf:d9 brd ff:ff:ff:ff:ff:ff
从上可知,系统的以太网接口名称为 ens33(你的名称很可能与我的不同)。
使用 NetworkManager 查看网络设备:
nmcli -p dev输出结果:
=====================
Status of devices
=====================
DEVICE TYPE STATE CONNECTION
-------------------------------------
ens33 ethernet disconnected --
lo loopback unmanaged --
我们可以在目录 /etc/sysconfig/network-scripts/ 中,找到一个名为 ifcfg-INTERFACENAME(其中 INTERFACENAME 就是以太网接口的名称)的配置文件。在本文例子中,该文件名为 ifcfg-ens33。
使用 vi 编辑器修改以太网接口配置文件:
vi /etc/sysconfig/network-scripts/ifcfg-ens33我们不但需要将协议从 dhcp 改为 static,还需要设置在系统启动时激活以太网接口,并添加特定 IP 地址。
1)将协议从:
BOOTPROTO=dhcp
改为:
BOOTPROTO=static
2)将系统启动时激活以太网接口的配置从:
ONBOOT=NO
改为:
ONBOOT=yes
3)然后添加我们的 IP 地址、子网掩码、网关和 DNS 地址。在文件的末尾添加如下内容:
IPADDR=192.168.2.173
NETMASK=255.255.255.0
GATEWAY=192.168.2.1
DNS1=114.114.114.114
DNS2=8.8.8.8
以上内容需按照你的网络环境进行相应的调整,然后保存文件(:wq)。
为了使最新的网络配置生效,还需重启系统的网络服务:
systemctl restart network待网络服务重启完成后。
查看 ens33 以太网接口的 IP 配置:
ip a s ens33输出:
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pf ifo_fast state UP group default qlen 1000
link/ether 00:0c:29:cf:bf:d9 brd ff:ff:ff:ff:ff:ff
inet 192.168.2.173/24 brd 192.168.2.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet6 fe80::2823:bd72:15a8:b806/64 scope link noprefixroute
valide_lft forever preferred_lft forever
查看系统路由表:
ip route show或:
ip r输出:
default via 192.168.2.1 dev ens33 proto static metric 100
192.168.2.0/24 dev ens33 proto kernel scope link src 192.168.2.173 metric 100
查看 DNS 服务器配置:
cat /etc/resolv.conf输出:
# Generated by NetworkManager
nameserver 114.114.114.114
nameserver 8.8.8.8
验证互联网连通性:
ping -c 3 www.baidu.com输出:
PING www.baidu.com (183.232.231.174) 56(84) bytes of data.
64 bytes from 183.232.231.174 (183.232.231.174): icmp_seq=1 ttl=54 time=39.0 ms
64 bytes from 183.232.231.174 (183.232.231.174): icmp_seq=2 ttl=54 time=50.7 ms
64 bytes from 183.232.231.174 (183.232.231.174): icmp_seq=3 ttl=54 time=37.4 ms
--- www.baidu.com ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2004 ms
rrt min/avg/max/mdev = 37.488/42.412/50.732/5.916 ms
一般情况下,当我们调用一个方法或判断时,通常需要非空判断。比如以下判断用户是否可登录的示例代码:
class User:
def __init__(self, user_id, username):
self.user_id = user_id
self.username = username
def login(self):
return self.username == 'Jason'
users = [User(1, 'Bruce'), User(2, 'Jason')]
def get_user(id):
for user in users:
if user.user_id == id:
return user
def print_user(id):
user = get_user(id)
default_username = 'Guest'
if user is not None and user.username is not None:
username = user.username
else:
username = default_username
print(f'您好 {username}')
if user is not None and user.login():
print('登录成功')
else:
print('登录失败')运行以上脚本,并进入 Python 交互式模式:
python -i weChat.py
>>> print_user(1)
您好 Bruce
登录失败
>>> print_user(2)
您好 Jason
登录成功
>>> print_user(3)
您好 Guest
登录失败采用空对象模式后,我们可以将代码优化为:
class User:
def __init__(self, user_id, username):
self.user_id = user_id
self.username = username
def login(self):
return self.username == 'Jason'
users = [User(1, 'Bruce'), User(2, 'Jason')]
class NoneUser:
def __init__(self):
self.user_id = -1
self.username = 'Guest'
def login(self):
return False
def get_user(id):
for user in users:
if user.user_id == id:
return user
return NoneUser()
def print_user(id):
user = get_user(id)
print(f'您好 {user.username}')
if user.login():
print('登录成功')
else:
print('登录失败')编码与解码:
常用编码:
我的测试环境编码为:
chcp 936)
TestEncoding.java 文件(UTF-8):
import java.nio.charset.Charset;
public class TestEncoding {
public static void main(String[] args) {
System.out.println("我的名字是 Jason Wu");
System.out.println("file.encoding: " + System.getProperty("file.encoding"));
System.out.println("Charset.defaultCharset(): " + Charset.defaultCharset());
}
}打开 CMD 为 GBK(chcp 936),编译上面的 Java 文件:
javac TestEncoding.java
TestEncoding.java:5: error: unmappable character for encoding GBK
System.out.println("鎴戠殑鍚嶅瓧鏄? Jason Wu");
^
1 error此时,我们发现编译出错,提示“存在 GBK 编码不可映射的字符”,且在控制台输出的中文也是乱码。
现在我们修改 CMD 为 UTF-8(chcp 65001),然后再次编译该 Java 文件:
javac TestEncoding.java
TestEncoding.java:5: error: unmappable character for encoding GBK
System.out.println("我的名字? Jason Wu");
^
1 error此时,我们发现虽然编译依旧出错,但源码中的中文内容除了中文字符 是 外都能够在控制台正确输出了,说明控制台和源码确实都是 UTF-8 编码。那为什么 javac 编译还是会报错?为什么中文字 是 还是乱码呢?
想要理解为什么 javac 编译还会报错,则需要先明白以下两个知识点:
所以对于 UTF-8 源码,如果是奇数位汉字(奇数 x 3 还是奇数,即奇数位字节),则使用 GBK 编译时就会出现字符映射失败,并输出乱码;而偶数位汉字(偶数 x 3 则是偶数,即偶数位字节),则可以正确运行。
对于上面的问题,我们只需指定 Java 编译时所使用的编码为 UTF-8 即可:
javac -encoding utf8 TestEncoding.java上面我们最后正确编译出了 TestEncoding.class 文件。接下来,我们来研究下运行该字节码文件会发生什么。
1、默认情况下的 CMD 为 GBK(chcp 936):
java TestEncoding
我的名字是 Jason Wu
file.encoding: GBK
Charset.defaultCharset(): GBK2、指定 JVM 运行时为 UTF-8,CMD 还是 GBK:
java -Dfile.encoding=utf8 TestEncoding
我的名字是 Jason Wu
file.encoding: utf8
Charset.defaultCharset(): UTF-83、修改我们的 CMD 为 UTF-8(chcp 65001),然后运行:
java TestEncoding
ҵ Jason Wu
file.encoding: GBK
Charset.defaultCharset(): GBK4、指定 JVM 运行时为 UTF-8,CMD 也是 UTF-8:
java -Dfile.encoding=utf8 TestEncoding
我的名字是 Jason Wu
file.encoding: utf8
Charset.defaultCharset(): UTF-8开闭原则是一个非常重要的面向对象设计原则,它指导我们在编写代码时要考虑对扩展开放,但对修改进行封闭,即要求我们能够在不修改原来代码的前提下,加入新的功能。
以下是一个打印问卷的示例程序:
def print_quiz(questions):
for question in questions:
print(question['description'])
if question['type'] == 'boolean':
print('1. 是')
print('2. 否')
elif question['type'] == 'multipleChoices':
for index, option in enumerate(question['options']):
print(f'{index + 1}. {option}')
elif question['type'] == 'text':
print('回答:___________________________')
print('')
questions = [
{
'type': 'boolean',
'description': '你是程序员吗?'
},
{
'type': 'multipleChoices',
'description': '以下编程语言你最喜欢哪一个?',
'options': ['Python', 'Java', 'JavaScript', 'C/C++']
},
{
'type': 'text',
'description': '你是怎么找到本博客的?'
}
]
print_quiz(questions)对于上面的代码,每当我们增加一个新类型的问答时,不但需要在 questions = [...] 中添加新内容,还需要向 print_quiz 添加新的 elif question['type'] == '?' 语句,这使得我们的代码变得很脆弱,因为每当加入一个新类型的问答都可能造成程序出错。
我们采用开闭原则重构上面的代码:
def print_quiz(questions):
for question in questions:
print(question.description)
question.printQuestion()
print('')
class BooleanQuestion:
def __init__(self, description):
self.description = description
def printQuestion(self):
print('1. 是')
print('2. 否')
class MultipleChoices:
def __init__(self, description, options):
self.description = description
self.options = options
def printQuestion(self):
for index, option in enumerate(self.options):
print(f'{index + 1}. {option}')
class TextQuestion:
def __init__(self, description):
self.description = description
def printQuestion(self):
print('回答:___________________________')
questions = [
BooleanQuestion('你是程序员吗?'),
MultipleChoices('以下编程语言你最喜欢哪一个?',
['Python', 'Java', 'JavaScript', 'C/C++']),
TextQuestion('你是怎么找到本博客的?')
]
print_quiz(questions)此时的代码,我们只需增加新的问答类,而不需要修改原来 print_quiz 中的任何代码。很明显,现在的代码不论是在健壮性还是可维护性方面,都得到了极大的提高。
{
"target": "terminus_exec",
"cancel": "terminus_cancel_build",
"shell_cmd": "chcp 65001 && javac -J-Duser.language=en -encoding utf8 -d . $file && java -Dfile.encoding=utf8 -cp . $file_base_name",
"working_dir": "$file_path",
"selector": "source.java",
"file_regex": "^[ ]*File \"(...*?)\", line ([0-9]*)"
}{
"show_function_signatures": false,
"show_help_dialog": false,
"show_hover": false,
"show_popular_patterns": true,
"start_kite_engine_on_startup": false
}命令模式是一种非常有意思的设计模式,我们可以根据该模式轻松编写动态命令链,并且可以在不修改源代码的情况下,把不同的操作组合在一起。因为在设计之初,我们就把每个命令都定义为一个独立对象,所以我们也可以很容易地实现各个对象的撤销操作。
以下是一个简易的计算器程序:
class Calculator:
def __init__(self):
self.value = 0
def add(self, value):
self.value += value
def subtract(self, value):
self.value -= value
def multiply(self, value):
self.value *= value
def divide(self, value):
self.value /= value
calculator = Calculator()
calculator.add(10)
print(calculator.value)
calculator.divide(2)
print(calculator.value)下面我们采用命令模式,对上面代码进行重构:
class Calculator:
def __init__(self):
self.value = 0
self.histories = []
def executeCommand(self, command):
self.value = command.execute(self.value)
self.histories.append(command)
def undo(self):
command = self.histories.pop()
self.value = command.undo(self.value)
class AddCommand:
def __init__(self, value):
self.value = value
def execute(self, currentValue):
return currentValue + self.value
def undo(self, currentValue):
return currentValue - self.value
class SubtractCommand:
def __init__(self, value):
self.value = value
def execute(self, currentValue):
return currentValue - self.value
def undo(self, currentValue):
return currentValue + self.value
class MultiplyCommand:
def __init__(self, value):
self.value = value
def execute(self, currentValue):
return currentValue * self.value
def undo(self, currentValue):
return currentValue / self.value
class DivideCommand:
def __init__(self, value):
self.value = value
def execute(self, currentValue):
return currentValue / self.value
def undo(self, currentValue):
return currentValue * self.value
class AddThenDivideCommand:
def __init__(self, valueToAdd, valueToDivide):
self.addCommand = AddCommand(valueToAdd)
self.divideCommnad = DivideCommand(valueToDivide)
def execute(self, currentValue):
new_value = self.addCommand.execute(currentValue)
return self.divideCommnad.execute(new_value)
def undo(self, currentValue):
new_value = self.divideCommnad.undo(currentValue)
return self.addCommand.undo(new_value)
calculator = Calculator()
# calculator.executeCommand(AddCommand(10))
# print(calculator.value)
# calculator.executeCommand(DivideCommand(2))
# print(calculator.value)
# calculator.undo()
# print(calculator.value)
# calculator.undo()
# print(calculator.value)
calculator.executeCommand(AddThenDivideCommand(10, 2))
print(calculator.value)
calculator.undo()
print(calculator.value)在采用命令模式后,我们可以在不修改原来加减乘除各命令的源代码情况下,轻松组合实现各类混合四则运算和撤销操作。
我们还可以微调上面的代码,实现链式调用:
class Calculator:
def __init__(self):
self.value = 0
self.histories = []
def executeCommand(self, command):
self.value = command.execute(self.value)
self.histories.append(command)
return self
def undo(self):
command = self.histories.pop()
self.value = command.undo(self.value)
return self
class AddCommand:
def __init__(self, value):
self.value = value
def execute(self, currentValue):
return currentValue + self.value
def undo(self, currentValue):
return currentValue - self.value
class SubtractCommand:
def __init__(self, value):
self.value = value
def execute(self, currentValue):
return currentValue - self.value
def undo(self, currentValue):
return currentValue + self.value
class MultiplyCommand:
def __init__(self, value):
self.value = value
def execute(self, currentValue):
return currentValue * self.value
def undo(self, currentValue):
return currentValue / self.value
class DivideCommand:
def __init__(self, value):
self.value = value
def execute(self, currentValue):
return currentValue / self.value
def undo(self, currentValue):
return currentValue * self.value
calculator = Calculator()
calculator.executeCommand(AddCommand(10)).executeCommand(DivideCommand(2))
print(calculator.value)
calculator.undo().undo()
print(calculator.value){
"theme": "Material-Theme-Darker.sublime-theme",
"color_scheme": "Packages/Predawn/predawn.tmTheme",
"font_face": "Menlo",
"font_options":
[
"no_round"
],
"font_size": 12,
"bold_folder_labels": true,
"caret_style": "phase",
"caret_extra_width": 1,
"close_windows_when_empty": false,
"copy_with_empty_selection": false,
"drag_text": false,
"draw_minimap_border": true,
"enable_tab_scrolling": false,
"highlight_line": true,
"line_padding_bottom": 1,
"line_padding_top": 1,
"match_brackets_content": false,
"match_selection": false,
"match_tags": false,
"open_files_in_new_window": false,
"overlay_scroll_bars": "enabled",
"preview_on_click": false,
"scroll_past_end": true,
"scroll_speed": 5.0,
"show_full_path": false,
"translate_tabs_to_spaces": true,
"trim_trailing_white_space_on_save": true,
"word_wrap": true,
"show_definitions": false,
"show_encoding": true,
"show_errors_inline": false,
"ensure_newline_at_eof_on_save": true,
"highlight_modified_tabs": true,
"default_line_ending": "unix",
"folder_exclude_patterns": [],
"file_exclude_patterns": []
}! + Tab:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
</head>
<body>
</body>
</html>link + Tab:
<link rel="stylesheet" href="">div.top + Tab 或 .top + Tab:
<div class="top"></div>div#top + Tab 或 #top + Tab:
<div id="top"></div>span[data-no="1"] + Tab:
<span data-no="1"></span>form:post + Tab:
<form action="" method="post"></form>header>nav + Tab:
<header>
<nav></nav>
</header>main+footer + Tab:
<main></main>
<footer></footer>button{提交} + Tab:
<button>提交</button>ul>li*3 + Tab:
<ul>
<li></li>
<li></li>
<li></li>
</ul>ul>li{列表项 $}*3 + Tab:
<ul>
<li>列表项 1</li>
<li>列表项 2</li>
<li>列表项 3</li>
</ul>ul>li.class-$${列表项 $}*3 + Tab:
<ul>
<li class="class-01">列表项 1</li>
<li class="class-02">列表项 2</li>
<li class="class-03">列表项 3</li>
</ul>(header>nav)+main+footer + Tab:
<header>
<nav></nav>
</header>
<main></main>
<footer></footer>bxzb + Tab:
-webkit-box-sizing: border-box;
-moz-box-sizing: border-box;
box-sizing: border-box;w10 + Tab:
width: 10px;w10em + Tab:
width: 10em;w10% + Tab:
width: 10%;在 Java 中接口作为语法的一部分,是受严格定义的。但在 Python 中,情况却非如此。
与 Java 不同,Python 中没有 interface 关键字来定义一个接口。在动态语言(如 Python、JavaScript)中,很多事情都是隐式的。我们更多关注的是对象的行为,而非它的类型。
“当看到一只鸟走起来像鸭子、游泳起来像鸭子、叫起来也像鸭子,那么这只鸟就可以被称为鸭子。”
如果我们有一个对象,它即可以像鸭子一样走路,又可以像鸭子一样嘎嘎叫,那么我们就认为这个对象是一只鸭子。这就是所谓的“鸭子类型(Duck typing)”。在运行时,我们是通过调用期望的方法来替代类型检查。当方法的调用行为符合我们的预期,那么就照常往后执行。否则,我们就认为程序出现了问题。为了安全起见,我们通常使用 try...except 代码块或使用 hasattr 来检查对象是否拥有某个方法。
在 Python 中,不论是什么类型的对象,都可以通过实现预期的方法来遵循特定的接口。这种非正式(非强制性)的接口定义被称为协议(protocol)。这样的接口通常由文档进行说明,或由约定俗成的方式进行定义。
class Zoo:
def __init__(self, animals):
self.__animals = animals
def __len__(self):
return len(self.__animals)
def __contains__(self, animal):
return animal in self.__animals
zoo = Zoo(['Tiger', 'Elephant', 'Giraffe'])
# Sized protocol
print(len(zoo))
# Container protocol
print('Giraffe' in zoo)
print('Monkey' in zoo)
print('Monkey' not in zoo)在我们上面的例子中,实现了 __len__ 和 __contains__ 方法,所以我们可以直接对 Zoo 实例使用 len 方法,使用 in 操作符检查成员。如果我们添加了 __iter__ 方法来实现迭代器协议(iterable protocol),那么我们还可以这样做:
for animal in zoo:
print(animal)但在还没有实现 __iter__ 方法前,我们尝试上面的迭代,将会得到以下错误:
TypeError: 'Zoo' object is not iterable
所以我们可以看到协议就像接口一样,可以通过实现协议所期望的方法来实现协议。
尽管在大多数情况下,通过协议实现接口都不会有什么问题,但在在有些情况下,通过协议或鸭子类型实现的非正式接口会导致一些问题。比如,Car 和 People 都有 move 方法,即使通过协议定义的接口是一样的,但是他们的行为却完全不同。而 Python 内置的 ABCs(Abstract Base Classes)模块就可以帮我们解决这个问题。
ABCs 的使用非常简单,我们定义的基类在其本质上就是一个抽象类,而在基类上定义的方法就是抽象方法。所以任何从该基类派生出来的类,都要实现这些抽象方法。此时,我们就可以说这些派生出的类是接口(基类)的实现类。此时我们就可以使用类型检查,来检查类是否实现了特定的接口。
现在回到我们之前的 Car和 People 的例子,采用 ABCs 模块实现接口:
import abc
class Car(abc.ABC):
@abc.abstractmethod
def move(self):
pass
class People(metaclass=abc.ABCMeta):
@abc.abstractmethod
def move(self):
pass
class Benz(Car):
def move(self):
print('奔驰嘟嘟嘟')
class Chinese(People):
def move(self):
print('昂首挺胸嗒嗒嗒')
@Car.register
class BMW:
pass
benz = Benz()
benz.move()
chinese = Chinese()
chinese.move()
print(f'奔驰是汽车吗?{isinstance(benz, Car)}')
print(f'**人是汽车吗?{isinstance(chinese, Car)}')
print(f'奔驰是人类吗?{isinstance(benz, People)}')
print(f'**人是人类吗?{isinstance(chinese, People)}')
bmw = BMW()
print(f'宝马是汽车吗?{issubclass(BMW, Car)}')参考链接
{
"target": "terminus_exec",
"cancel": "terminus_cancel_build",
"shell_cmd": "chcp 65001 && py -2 -u $file",
"working_dir": "$file_path",
"selector": "source.python",
"file_regex": "^[ ]*File \"(...*?)\", line ([0-9]*)"
}里氏替换原则认为父类和子类是可互换的,即原可以使用父类的所有地方都可以使用子类进行替换。
众所周知,正方形是特殊的长方形,所以在以下代码中,我们将正方形类 Square 作为长方形类 Rectangle 的子类:
class Rectangle:
def __init__(self, length, width):
self.length = length
self.width = width
def setLength(self, length):
self.length = length
def setWidth(self, width):
self.width = width
def calculateArea(self):
return self.length * self.width
class Square(Rectangle):
def __init__(self, length, width):
if length != width:
raise Exception('正方形长宽必须相等')
self.length = width
self.width = width
def setLength(self, length):
self.length = length
self.width = length
def setWidth(self, width):
self.length = width
self.width = width
def increase_rectangle_width(rectangle):
rectangle.setWidth(rectangle.width + 1)
rectangle = Rectangle(5, 5)
increase_rectangle_width(rectangle)
print(rectangle.calculateArea())
print('\n------子类替换父类后------\n')
square = Square(5, 5)
increase_rectangle_width(square)
print(square.calculateArea())但是对于上面的代码,当我们使用子类 Square 替换父类 Rectangle 后,长方形面积的计算结果和正方形的面积是不一样的,这违反了里氏替换原则。
下面我们再抽象出一个四边形类 Quadrilateral 后,然后再将长方形类 Rectangle 和正方形类 Square 都继承它:
class Quadrilateral:
def setWidth(self, width):
pass
def calculateArea(self):
pass
class Rectangle(Quadrilateral):
def __init__(self, length, width):
self.length = length
self.width = width
def setLength(self, length):
self.length = length
def setWidth(self, width):
self.width = width
def calculateArea(self):
return self.length * self.width
class Square(Quadrilateral):
def __init__(self, length, width):
if length != width:
raise Exception('正方形长宽必须相等')
self.length = width
self.width = width
def setWidth(self, width):
self.length = width
self.width = width
def calculateArea(self):
return self.length * self.width
def increase_quadrilateral_width(quadrilateral):
quadrilateral.setWidth(quadrilateral.width + 1)此后,我们可以在其他使用 Quadrilateral 的场合下,使用子类 Rectangle 或 Square 进行代替,因为不论是长方形还是正方形,在使用抽象四边形的地方都可以进行替换,而不会影响四边形本身所要表达的含义。
导入模块:
let moduleName = require('moduleName')导出模块:
exports.functionName = functionName或:
module.exports.functionName = functionName配置淘宝镜像源:
npm config set registry https://registry.npm.taobao.org配置文件位于 ~/.npmrc。
查看配置是否生效:
npm config get registrynode_modules 中的外部模块通过 npm install 安装的软件包会放至于 node_modules 目录(没有则自动创建)。
比如,我们可以通过以下命令安装 jquery:
npm install jquery之后,我们就可以在代码中使用 jquery 了:
let $ = require('jquery');
console.log($);那么我们是不是可以认为只要自己写一个模块扔到 node_modules 后,Node.js 也能识别出这个模块呢?
动手尝试一下,新建文件 node_modules/my_lib/my_lib.js:
exports.showVersion = function () {
console.log('v1.0.0');
};然后使用该模块:
let myLib = require('my_lib');
myLib.showVersion();很好,我们得到了以下错误信息:
Error: Cannot find module 'my_lib'
这说明我们自己创建的模块没有被 Node.js 识别。那要怎么做才能让我们的模块像 jquery 一样被 Node.js 识别呢?
我们将 my_lib.js 重命名为 index.js,然后再执行以上代码。此时,我们的模块就能被 Node.js 识别为一个外部模块了。
然而我们查看 node_modules/jquery 目录,并没有发现 index.js 文件,显然 jquery 不是通过这种方式实现的。但是在 juqery 目录中,我们却发现了一个 package.json 文件,查看该文件内容,我们可以看到有这么一项配置: "main": "dist/jquery.js"。这玩意看上去就很像配置一个主入口函数。OK,我们现在自己来尝试一下。
在我们的 node_modules/my_lib 目录中创建一个 package.json 文件,并写入以下内容:
{
"main": "my_lib.js"
}此时,我们发现程序能正常运行了,证明我们的猜想是正确的。pakckage.json 中的 main 字段正是指定了模块入口文件。
Node.js 要识别 node_modules 中的外部模块只要符合以下其中一个条件即可:
index.js 的文件package.json 的文件,并在该文件内配置了 main 字段Node.js 加载模块的优先级:
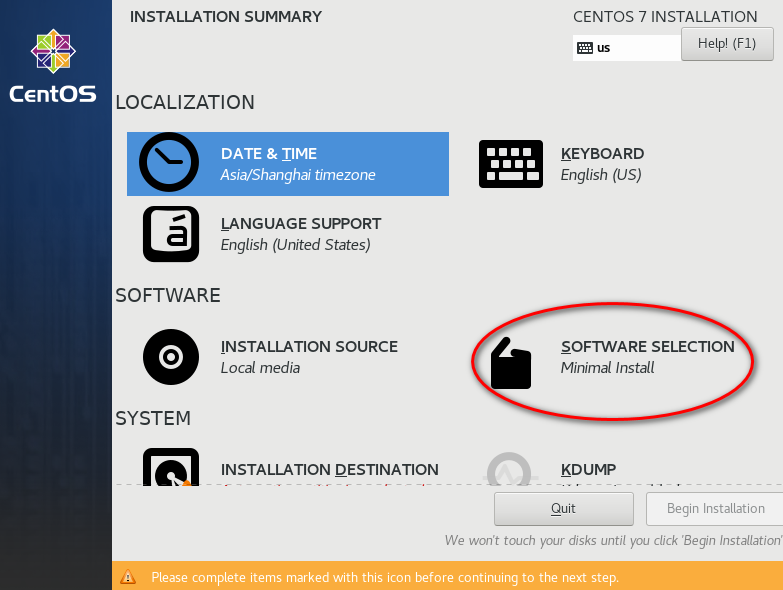
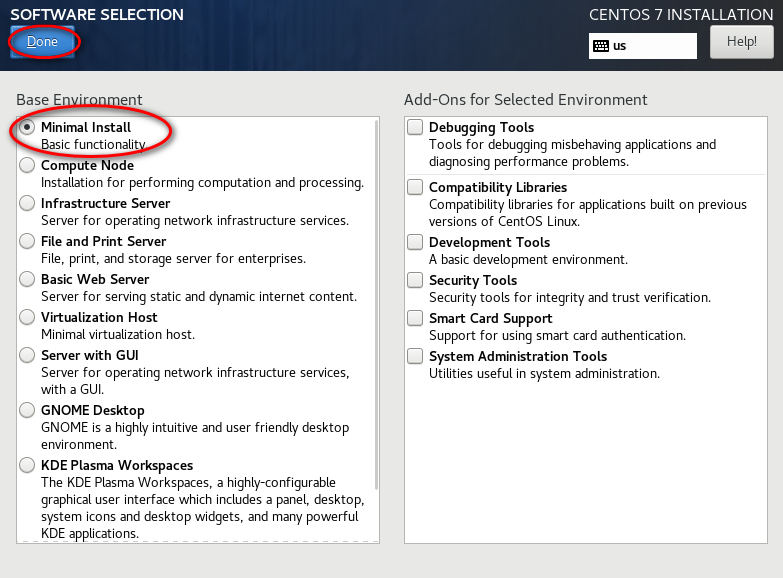
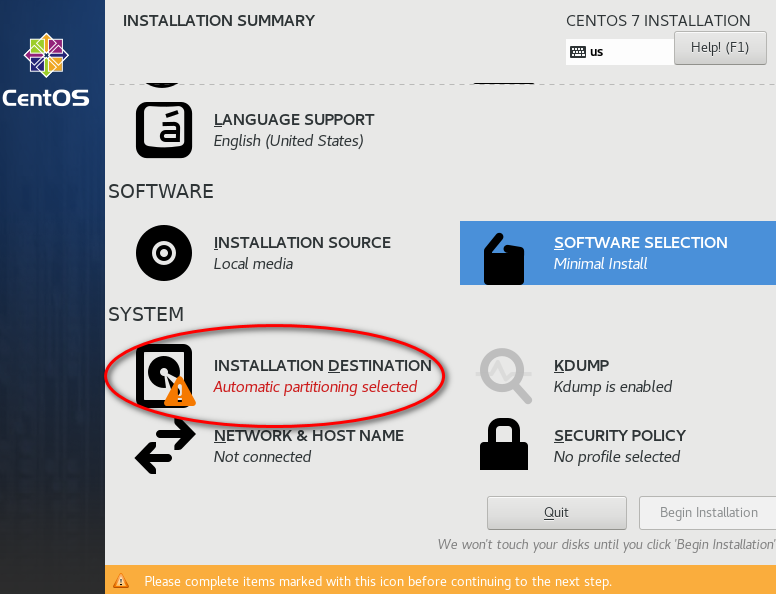
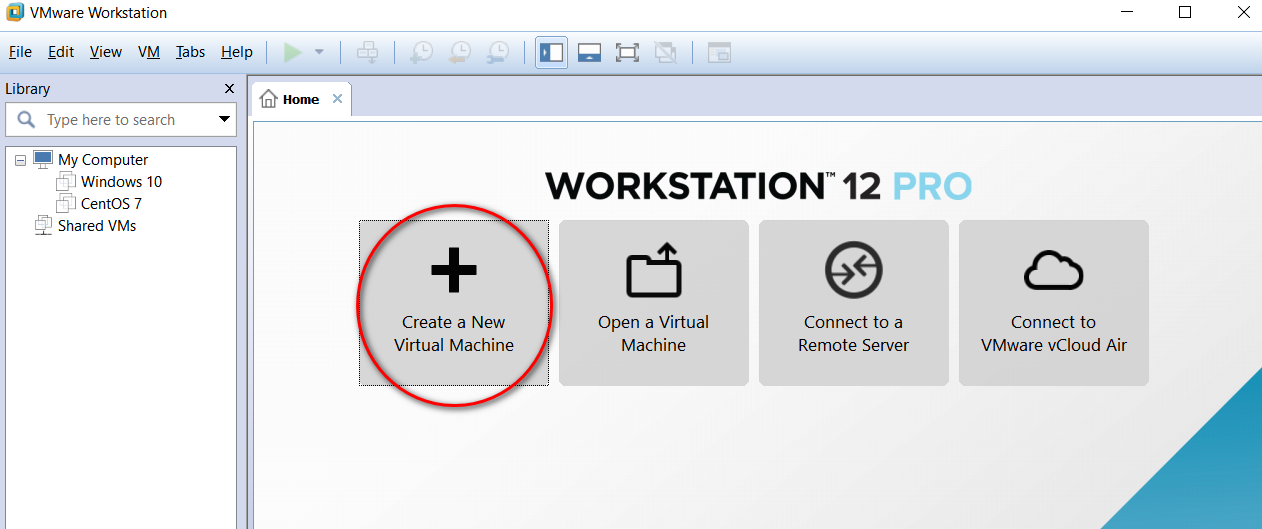
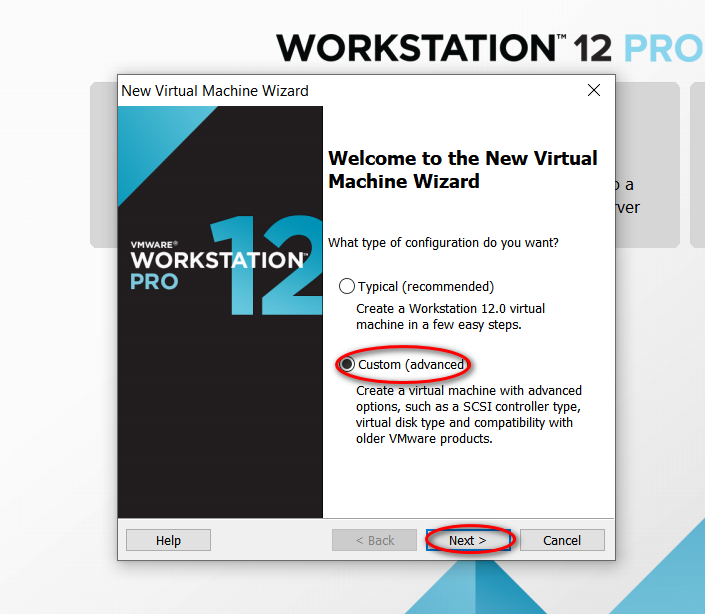
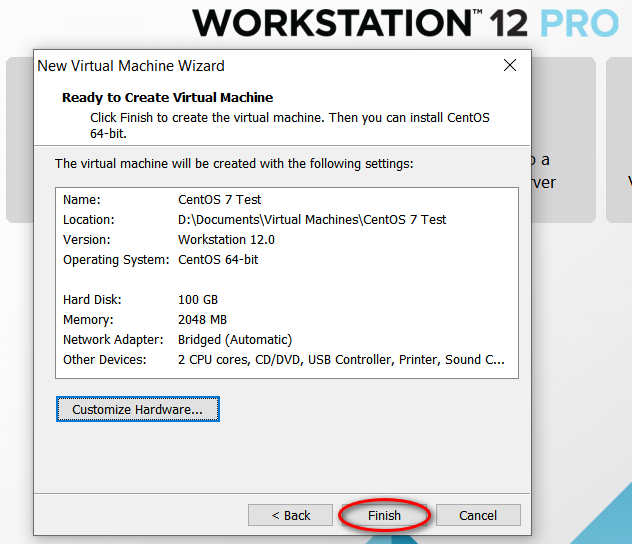
node_modules 目录中的同名文件夹以下是完整的截图,照着做就可以创建一个用于安装 CentOS 7 64 位操作系统的虚拟机(还未安全操作系统)。
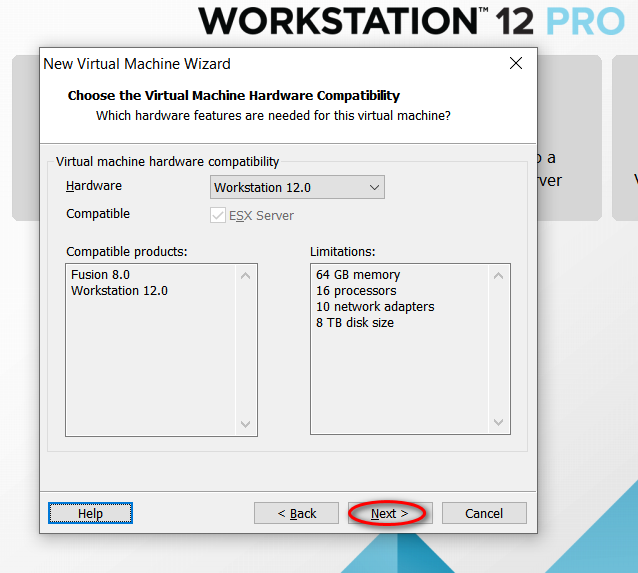
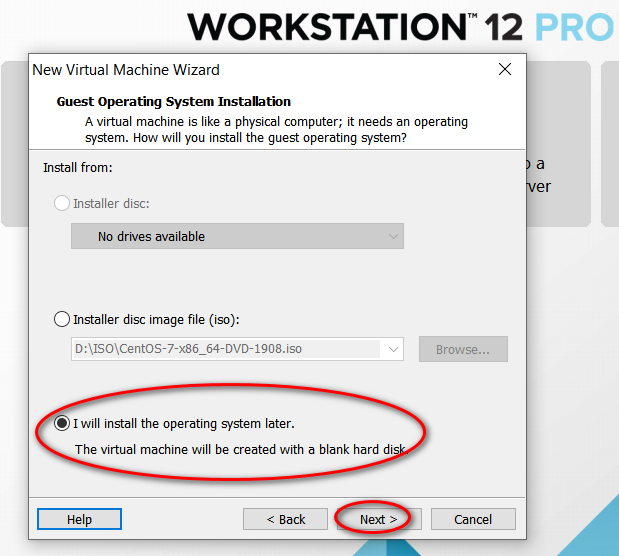
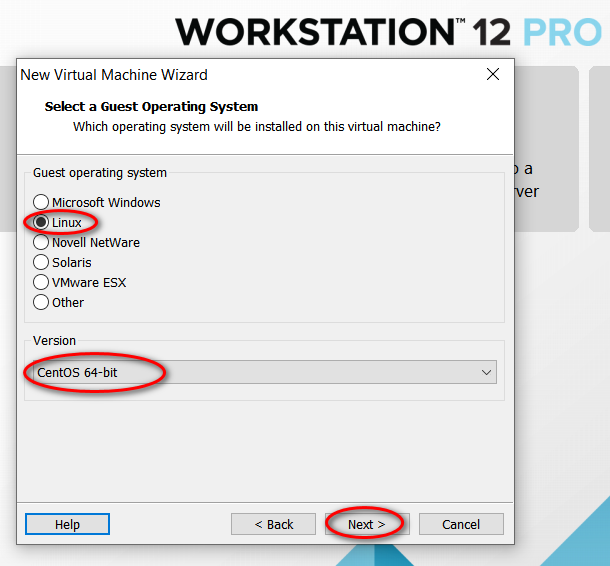
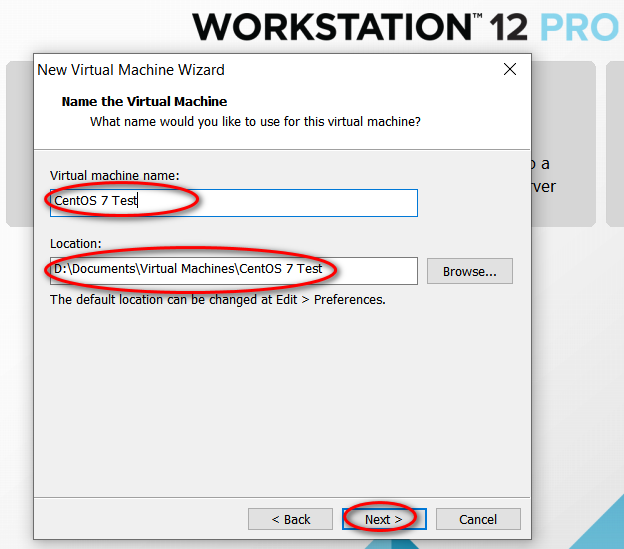
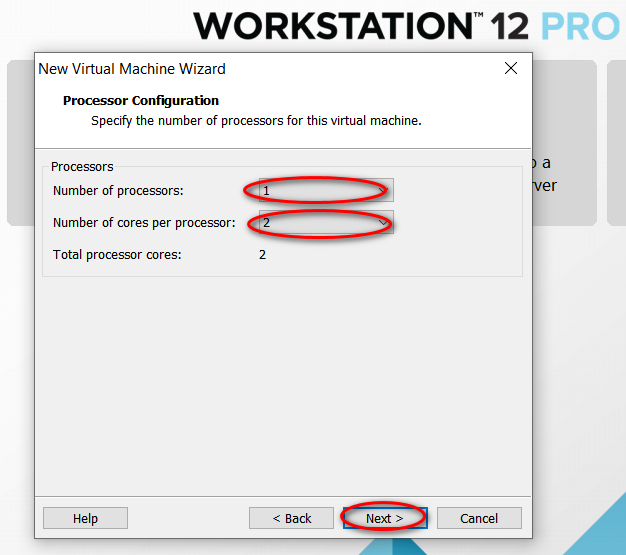
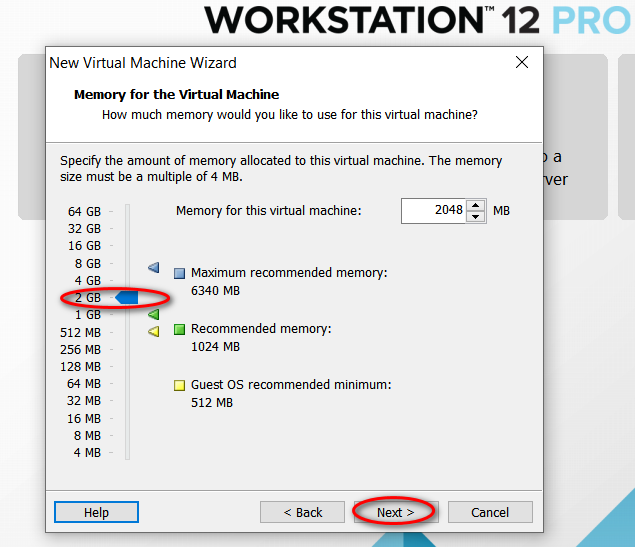
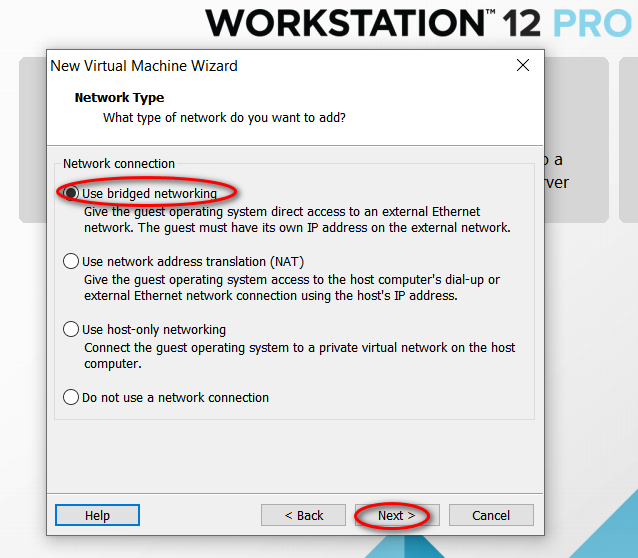
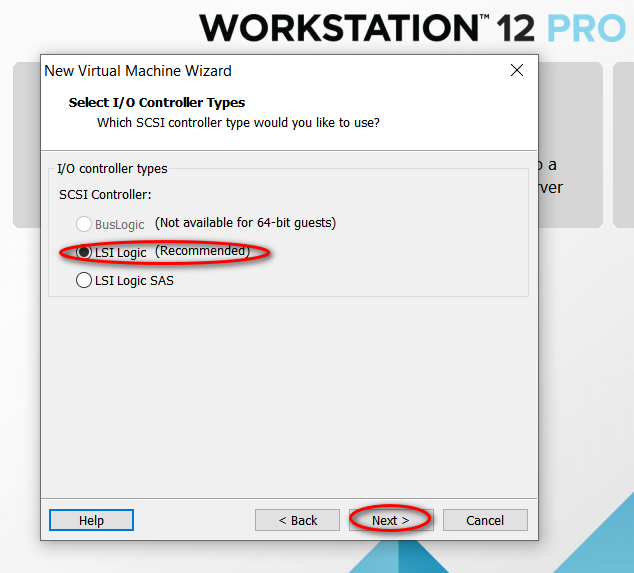
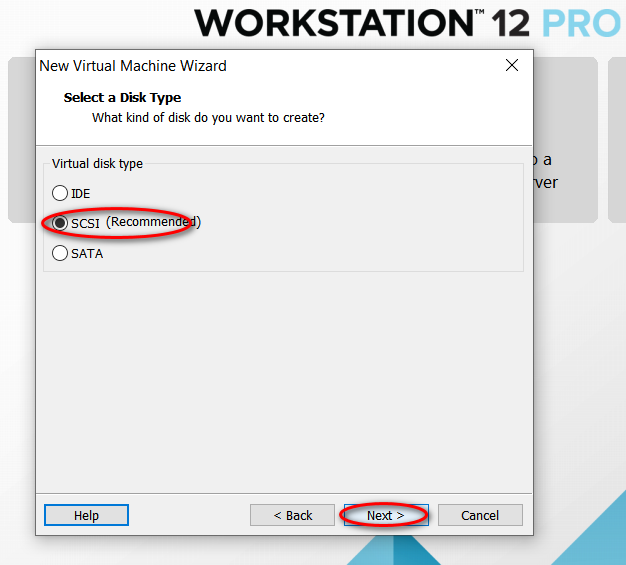
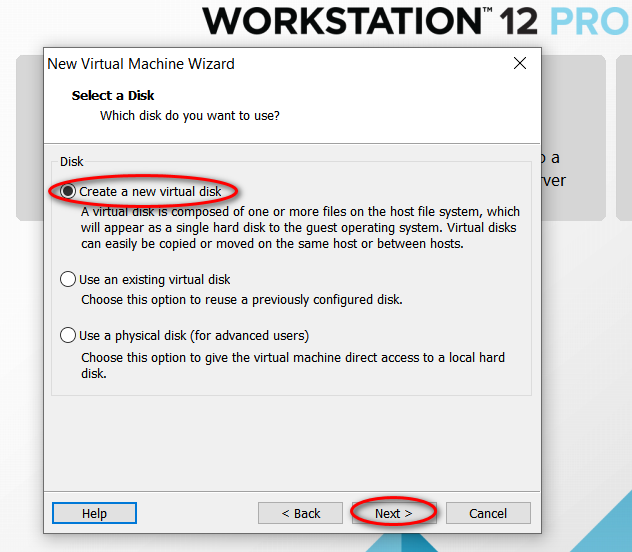
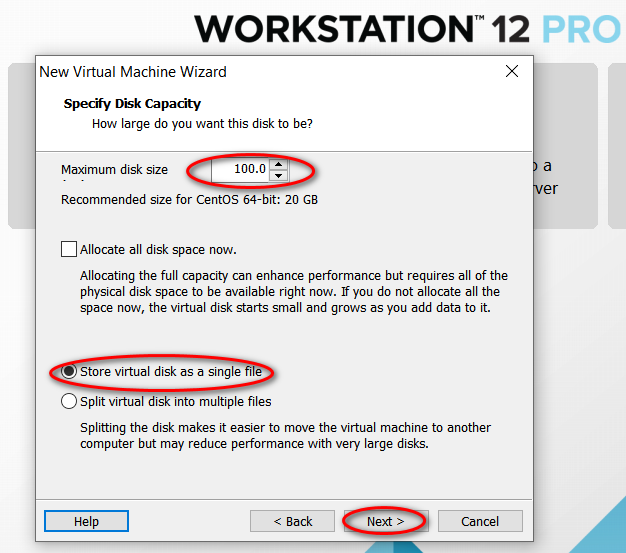
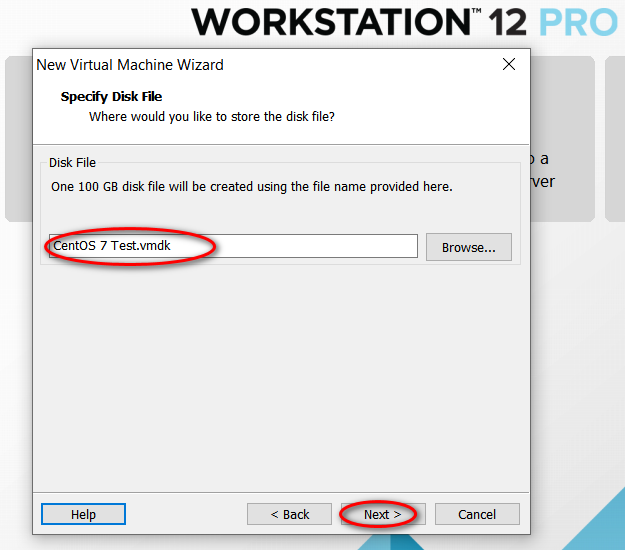
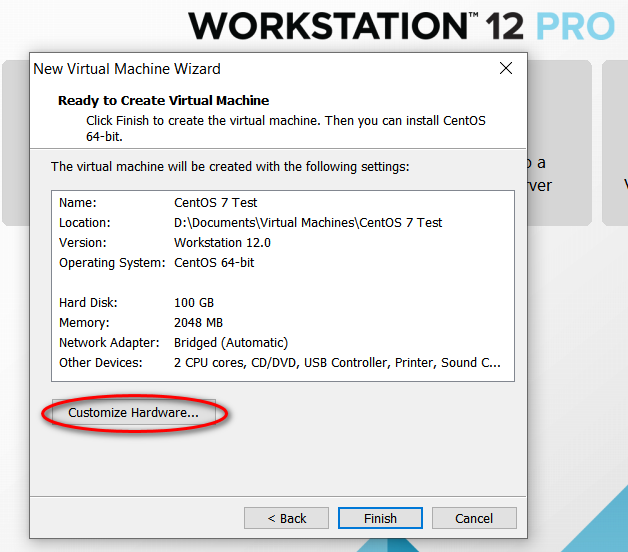
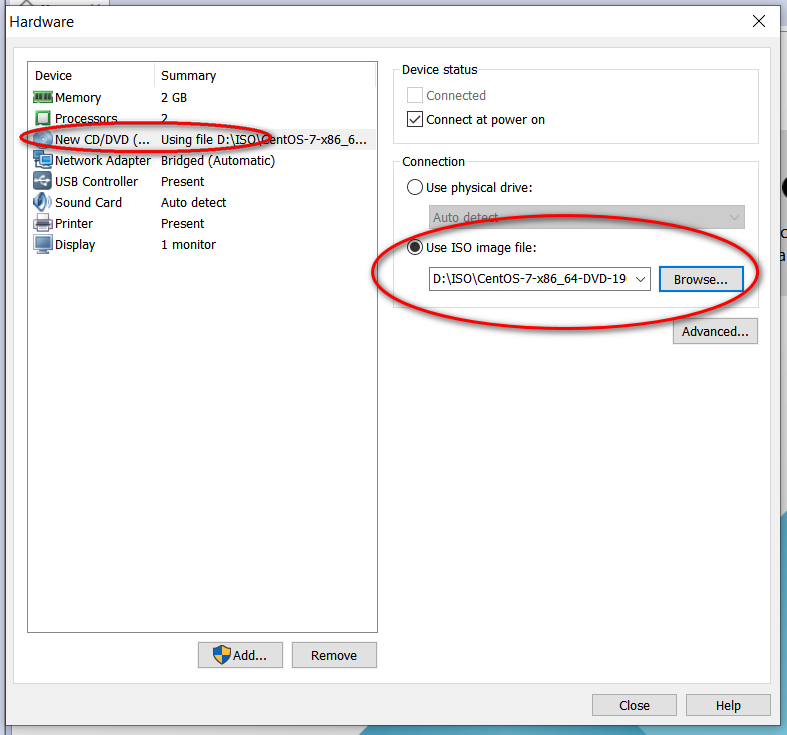
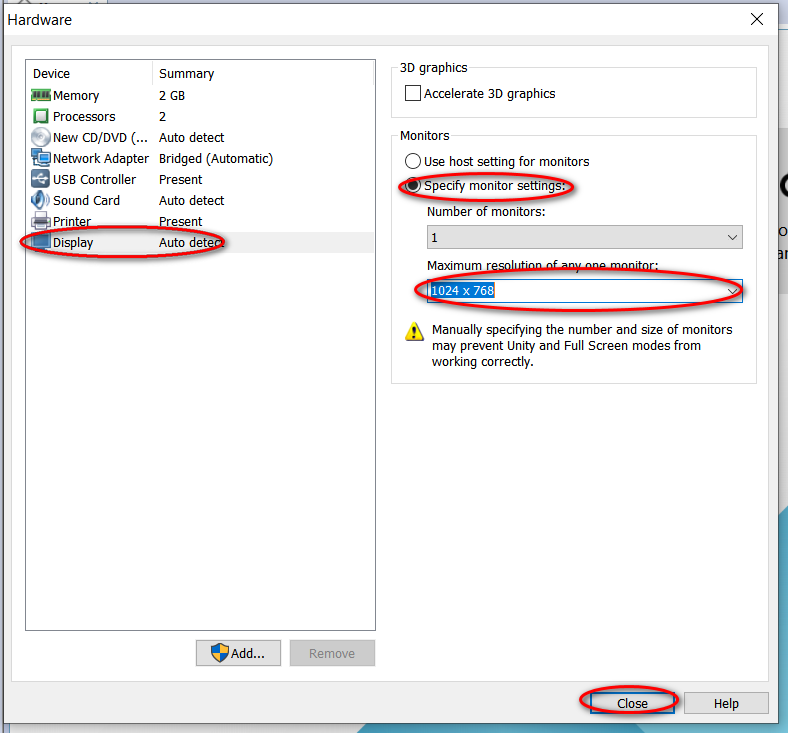
因为我的主机分辨率是 1920x1080,故设置的虚拟机最大分辨率应该要小于 1920x1080,否则可能造成在虚拟机中操作系统安装界面显示不全的问题。
外观模式是一个极其好用的设计模式,我们可以借助外观模式封装并隐藏复杂的底层实现代码,只暴露出简洁易用的上层接口。这样做的好处,不但可以使代码更加简洁、易于使用,而且也更容易对外观背后的复杂代码进行重构。
一开始我们使用的是内置模块 urllib 实现 HTTP 请求:
import urllib.request
def get_github_root_rest_api():
return urllib.request.urlopen('https://api.github.com') \
.read().decode('utf8')
def get_github_issues(username, *args):
url = 'https://api.github.com/search/issues'
query = f'{"+".join(args)}+user:{username}'
return urllib.request.urlopen(f'{url}?q={query}') \
.read().decode('utf8')
print('\nGitHub Root REST API\n')
print(get_github_root_rest_api())
print("\nJasonWu73's Issues\n")
print(get_github_issues('JasonWu73', 'MySQL', 'Docker'))后来我们升级 API,使用了 requests 模块:
import requests
def get_github_root_rest_api():
return requests.get('https://api.github.com').json()
def get_github_issues(username, *args):
url = 'https://api.github.com/search/issues'
query = f'{"+".join(args)}+user:{username}'
return requests.get(f'{url}?q={query}').json()
print('\nGitHub Root REST API\n')
print(get_github_root_rest_api())
print("\nJasonWu73's Issues\n")
print(get_github_issues('JasonWu73', 'MySQL', 'Docker'))对于上面的代码,当我们修改了使用的底层 API 时,所有使用了原 API 的方法都要进行相关调整,此外由于我们将底层 API 的调用细节都写在了功能代码中,这也加重了我们功能代码的复杂性。
下面,我们采用外观模式重构以上代码:
import urllib.request
def fetch_github_data(url, params):
if params is not None:
url = (
f'{url}?q={"+".join(params["keywords"])}'
f'+user:{params["username"]}')
return urllib.request.urlopen(url).read().decode('utf8')
def get_github_root_rest_api():
return fetch_github_data('https://api.github.com', None)
def get_github_issues(username, *args):
return fetch_github_data('https://api.github.com/search/issues', {
'username': username,
'keywords': args
})
print('\nGitHub Root REST API\n')
print(get_github_root_rest_api())
print("\nJasonWu73's Issues\n")
print(get_github_issues('JasonWu73', 'MySQL', 'Docker'))之后,当我们升级 API,使用 requests 模块替换 urllib 模块时,只需要修改 fetch_github_data 方法即可:
import requests
def fetch_github_data(url, params):
if params is not None:
url = (
f'{url}?q={"+".join(params["keywords"])}'
f'+user:{params["username"]}')
return requests.get(url).json()
def get_github_root_rest_api():
return fetch_github_data('https://api.github.com', None)
def get_github_issues(username, *args):
return fetch_github_data('https://api.github.com/search/issues', {
'username': username,
'keywords': args
})
print('\nGitHub Root REST API\n')
print(get_github_root_rest_api())
print("\nJasonWu73's Issues\n")
print(get_github_issues('JasonWu73', 'MySQL', 'Docker'))接口隔离原则指导我们要设计更小、更具体的接口,这意味着继承任何一个类都要使用这个类的所有属性和方法。而对于客户端程序来说,就是任何客户端都应该不依赖于它不使用的方法。
假设我们有一个操作系统的接口,所有操作系统都应该实现该接口:
import abc
class OperatingSystem(abc.ABC):
@abc.abstractmethod
def boot(self):
pass
@abc.abstractmethod
def powerOff(self):
pass
@abc.abstractmethod
def loadDesktop(self):
pass
class MicrosoftWindows(OperatingSystem):
def boot(self):
print('打开 Windows 操作系统')
def powerOff(self):
print('关闭 Windows 操作系统')
def loadDesktop(self):
print('载入图形化桌面程序')
class MiniCentOS(OperatingSystem):
def boot(self):
print('打开 CentOS 最小安装服务器系统')
def powerOff(self):
print('关闭 CentOS 最小安装服务器系统')
def loadDesktop(self):
raise Exception('最小安装的 CentOS 没有图形化桌面程序')
microsoftWindows = MicrosoftWindows()
microsoftWindows.boot()
microsoftWindows.loadDesktop()
microsoftWindows.powerOff()
miniCentOS = MiniCentOS()
miniCentOS.boot()
miniCentOS.powerOff()在上面的代码中,我们发现最小安装的 CentOS 系统并没有安装图形化桌面程序,但因为实现了操作系统接口,所以强制我们必须要实现 loadDesktop 抽象方法。但事实上,这个方法的实现对于最小安装的 CentOS 系统来说是完全没有必要的。
现在我们对以上代码进行优化,将 loadDesktop 这样属于图形化操作系统的抽象方法抽离至一个新接口 DesktopOperatingSystem 中:
import abc
class OperatingSystem(abc.ABC):
@abc.abstractmethod
def boot(self):
pass
@abc.abstractmethod
def powerOff(self):
pass
class DesktopOperatingSystem(abc.ABC):
@abc.abstractmethod
def loadDesktop(self):
pass
class MicrosoftWindows(OperatingSystem, DesktopOperatingSystem):
def boot(self):
print('打开 Windows 操作系统')
def powerOff(self):
print('关闭 Windows 操作系统')
def loadDesktop(self):
print('载入图形化桌面程序')
class MiniCentOS(OperatingSystem):
def boot(self):
print('打开 CentOS 最小安装服务器系统')
def powerOff(self):
print('关闭 CentOS 最小安装服务器系统')
def loadDesktop(self):
raise Exception('最小安装的 CentOS 没有图形化桌面程序')
microsoftWindows = MicrosoftWindows()
microsoftWindows.boot()
microsoftWindows.loadDesktop()
microsoftWindows.powerOff()
miniCentOS = MiniCentOS()
miniCentOS.boot()
miniCentOS.powerOff()此时,我们的 OperatingSystem 接口变得更小和更具体了,因为这个接口包含的开关机方法对于所有操作系统来说都是必须的功能,而 DesktopOperatingSystem 只是针对有图形化桌面程序的操作系统罢了。
本文测试的环境是 Microsoft Windows 10 Enterprise LTSC,版本号为 10.0.17763 N/A Build 17763。
打开 MySQL :: Download MySQL Community Server,选择 Microsoft Windows 平台, 下载 Windows (x86, 64-bit), ZIP Archive。
解压下载后的 mysql-8.0.19-winx64.zip 文件,通过 CMD 进入 mysql-8.0.19-winx64/bin 目录,执行:
mysql --version如果你遇到以下的错误:
提示 `mysql.exe` - 系统错误
由于找不到 VCRUNTIME140_1.dll,无法继续执行代码。重新安装程序可能会解决此问题。
或:
提示 `mysql.exe` - 系统错误
由于找不到 VCRUNTIME140.dll,无法继续执行代码。重新安装程序可能会解决此问题。
那么你只需安装 Microsoft Visual C++ 2015-2019 Redistributable (x64) - 14.24.28127 就可以了。
查看我们 MySQL 客户端命令行工具的版本:
mysql --version如无意外,会输出:
mysql Ver 8.0.19 for Win64 on x86_64 (MySQL Community Server - GPL)
为了后续更好的使用体验,建议将 mysql-8.0.19-winx64/bin 所在目录加入到系统环境变量 Path 中,在这之后,在 CMD 的任何目录中都可以运行 mysql 命令。
[
// Terminus
{
"keys": ["alt+`"],
"command": "toggle_terminus_panel",
"args": {
"cwd": "${file_path:${folder}}"
}
},
{
"keys": ["ctrl+w"],
"command": "terminus_close",
"context": [{ "key": "terminus_view" }]
}
]| 命令 | 描述 |
|---|---|
<cmd_builtin_command> /? |
查看命令行帮助文档 |
where <command> |
查看命令行工具所在的位置 |
| 命令 | 描述 |
|---|---|
echo %Path% |
打印环境变量 |
| 命令 | 描述 |
|---|---|
chcp |
查看当前字符编码 |
chcp 65001 |
切换为 UTF-8 |
chcp 936 |
切换为 GBK |
| 命令 | 描述 |
|---|---|
cd |
显示当前目录路径 |
cd .. |
切换至上级目录 |
c: |
切换至 C 盘 |
| 命令 | 描述 |
|---|---|
start . |
在资源管理器中打开当前目录 |
| 命令 | 描述 |
|---|---|
subl a.txt |
在 Sublime Text 3 中打开或创建文件 |
subl . |
在 Sublime Text 3 中打开当前文件夹 |
type a.txt |
查看文件内容 |
| 命令 | 描述 |
|---|---|
dir |
查看当前目录中非隐藏文件和文件夹 |
dir /ah |
查看当前目录中隐藏文件和文件夹 |
dir /a |
查看当前目录中所有文件和文件夹 |
tree |
显示当前目录的文件和目录列表 |
tree /f |
显示当前目录及其子目录中的文件和目录列表 |
| 命令 | 描述 |
|---|---|
mkdir mydir |
创建文件夹 |
type nul > my.txt |
创建空文件 |
| 命令 | 描述 |
|---|---|
move my.txt .\mydir |
移动文件 |
move .\mydir ..\ |
移动文件夹 |
| 命令 | 描述 |
|---|---|
rename my.txt me.txt |
重命名文件 |
rename mydir medir |
重命名文件夹 |
| 命令 | 描述 |
|---|---|
del /q me.txt |
删除文件 |
del /q medir |
删除文件夹中的所有文件 |
rmdir /s /q medir |
删除文件夹及其中的所有文件 |
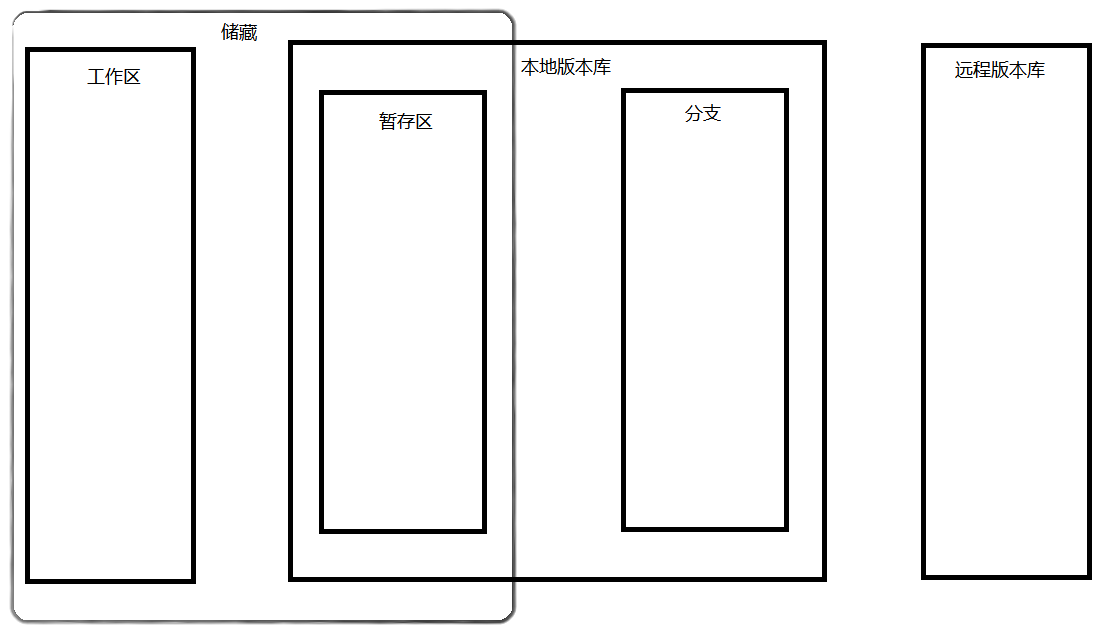
.git 目录。工作区中的文件只有先加入到暂存区才可以提交到版本库.git 目录中的 index 文件。我们也可以称暂存区为索引。只有加入到暂存区中的修改才可以被提交到版本库.git 目录,也就是 Git 的版本库从 Git - Downloads 下载最新版的 Git 工具进行安装。
个人原则是在开发环境下,尽量用新不用旧。
在安装完毕后,打开 CMD 或 Git Bash 输入以下命令,查看所安装 Git 的版本:
D:\Workspace\local-repo>git --version
git version 2.25.0.windows.1本文以 Git 2.25.0,Windows 10 为演示环境。
全局配置文件位于 ~/.gitconfig。
~代表用户主目录,参考 Linux Shell 中的~。
配置提交时的用户名:
git config --global user.name "<user name>"配置提交时的用户邮箱:
git config --global user.email "<email address>"解决 git status 无法正确显示中文文件名的问题:
git config --global core.quotepath false解决 git log 无法正确显示中文提交内容的问题:
set LESSCHARSET=utf8上述只在当前 CMD 的会话中有效,如需持久化配置,请在系统环境变量(
Win+Pause Break)中进行配置。
自定义 git lg 命令来实现更好的 git log 体验:
git config --global alias.lg "log --color --graph --pretty=format:'%Cred%h%Creset -%C(yellow)%d%Creset %s %Cgreen(%cr) %C(bold blue)<%an>%Creset' --abbrev-commit"有关上述命令中格式化部分的具体含义请查看 Git log format string cheatsheet。
配置 git commit 命令默认使用的编辑器:
git config --global core.editor "subl --wait --new-window"上面命令以 Sublime Text 3 所提供的命令行工具 subl.exe 为例。
注意,上述命令还需将 subl.exe 所在目录配置到环境变量
Path中,如:D:\Program Files\Sublime Text 3。
或配置 VS Code 为默认编辑器:
git config --global core.editor "code --wait --new-window"查看全局配置项:
git config --global --list查看特定仓库的配置项:
git config --list通过命令行打开某个命令的帮助文档:
git <command> --help或:
git help <command>.gitignore 文件就是一个普通的文本文件,里面记录了有意不需要版本控制的文件的匹配规则。
将当前目录初始化为一个本地版本库:
git init从远程版本库克隆(下载)一个本地版本库:
git clone <url>因为我们在别名一节,配置了 log 的别名 lg,故以下我们就可以直接使用 git lg 以带来更好的体验。
查看本地版本库中当前分支的提交历史:
git lg查看本地版本库中当前分支的提交历史并显示修改的统计信息:
git lg --stat
--stat也可以用于git diff。
查看本地版本库中的所有操作历史:
git reflog
git log只列出当前分支未删除的提交历史,而git reflog则可以列出所有本地版本库的操作历史。注意:
git log会同步到远程版本库,而git reflog只会保存在用户的本地版本库中。
查看当前工作状态(也会显示我们当前所工作的本地分支):
git status查看所有本地分支,并通过 * 和颜色(一般为绿色)标出我们当前所工作的本地分支:
git branch查看所有分支(本地和远程):
git branch -a1)创建一个新的本地分支:
git branch <new-branch-name>2)切换到其他分支(本地或远程):
git switch <branch-name>我们还可以使用以下命令简化操作,实现创建一个新分支,并切换到该新分支:
git switch -c <new-branch-name>将本地分支推送到远程版本库中:
git push -u <origin> <branch-name>默认情况下,
git clone只会克隆(拷贝)主分支(一般叫master)到本地。
1)查看所有的分支(本地和远程):
git branch -a上述命令显示远程分支的名称格式为
remotes/<origin>/<branch-name>,一般远程版本库命名为origin。
2)拉取远程分支:
git switch <branch-name>针对
remotes/<origin>/<branch-name>显示的远程分支,只需指定<branch-name>部分即可。
删除本地分支:
git branch -d <branch-name>上述命令要求被执行删除的分支必须符合以下几点:
如果被删除的分支存在上游分支,则该分支必须已经被完整合并入上游分支才行
如果被删除的分支不存在上游戏分支,则要求该分支不是当前正在操作(即非当前
HEAD所指向的分支)的分支才行
强制删除本地分支:
git branch -D <branch-name>
-D代表--delete --force。
删除远程版本库中名为 <branch-name> 的分支:
git push <origin> -d <branch-name>查看哪些本地分支已经合并到当前分支:
git branch --merged查看哪些本地分支还没有合并到当前分支:
git branch --no-merged将本地分支 <branch-nam> 的修改合并到当前分支中:
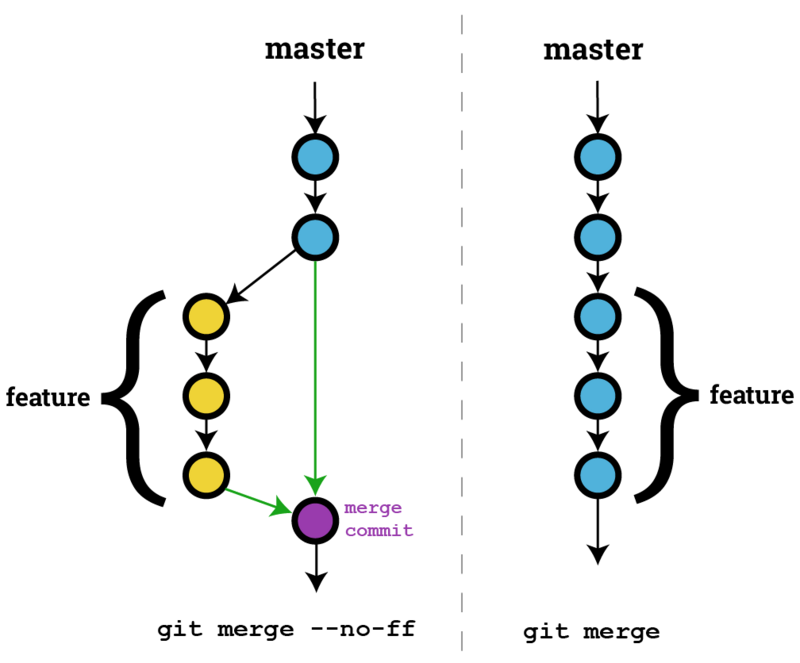
git merge --no-ff <branch-name>
--no-ff代表强制禁用 Fast forward 模式。个人建议不要使用默认的 Fast forward 模式进行合并操作,因为这种模式不利于我们对开发历史的追溯。原因如下图所示(网络图片,出处不明):
查看当前工作状态(工作区和暂存区)的完整信息:
git status查看当前工作状态(工作区和暂存区)的简短信息:
git status -s将工作区中某个文件的修改加入到暂存区:
git add <file>将工作区中某个目录的所有修改都加入到暂存区:
git add <directory>将暂存区中的所有修改都提交到本地版本库:
git commit修正最新一次的提交:
git commit --amend
--amend会改变 commit id,故应在git push到远程版本库前使用。对于已经推送到远程版本库中的修改,我们最好的做法应该是创建一个新的提交,否则可能造成团队中其他人员极大的困扰。
以暂存区中的修改为基准,查看当前工作区中的修改:
git diff以最新一次提交中的修改为基准,查看当前暂存区中的修改:
git diff --staged或使用 --staged 的同义词 --cached:
git diff --cached以最新一次提交中的修改为基准,查看当前工作区中的修改:
git diff HEAD
HEAD指向当前分支的最新一次提交,"HEAD^"指向前一次提交,"HEAD^^"指向前前一次的提交,依次类推。
以 <commit-id-1> 中的修改为基准,查看 <commit-id-2> 中的修改:
git diff <commit-id-1> <commit-id-2>温馨提示:为了避免比对时可能出现的迷惑,个人建议
<commit-id-1>应该始终指定较旧的提交,而<commit-id-2>则应该始终指定较新的提交。
撤销工作区中某个文件的修改:
git restore <file>撤销工作区中整个目录的修改:
git restore <directory>将暂存区中的修改撤回到工作区中:
git restore --staged <file>删除本地版本库中的某个提交,并将修改撤回到暂存区中:
git reset --soft <commit-id>删除本地版本库中的某个提交,并将修改撤回到工作区中:
git reset <commit-id>删除本地版本库中的某个提交,并将修改直接丢弃:
git reset --hard <commit-id>对于已经推送到远程版本库中的修改,我们最好的做法应该是创建一个新的提交,否则可能造成团队中其他人员极大的困扰。
1)查看本地版本库的所有操作历史:
git reflog2)检出需要恢复的提交,并切换到“detached HEAD”状态的分支(例如 HEAD detached at 146e594):
git checkout <commit-id>“detached HEAD”状态的分支是一个
checkout时自动创建的临时分支,当切换到其它分支时就会被自动删除。
3)从“detached HEAD”状态的分支创建一个用于恢复的分支,并切换到该分支:
git switch -c <new-branch-name>4)查看用于恢复的分支上的所有提交:
git lg5)恢复到指定的提交:
git revert <commit-id>6)切换到需要恢复提交的分支:
git switch <branch-name>7)将用于恢复的分支合并到当前分支:
git merge --no-ff <new-branch-name>从其它分支的提交历史中指定一个提交写入到当前分支:
git cherry-pick <commit id>注意:在当前分支的生成的最终提交(commit id)与选取的提交(commit id)是不同的。
在当我们本应该在开发分支上的工作,而错误地在主分支上进行了提交时,则可以利用
git cherry-pick将主分支上的该提交写入到开发分支中,最后删除主分支上的错误提交即可。
一个标签常作为一个版本的发布点(比如 v1.0 等)。
标签一旦创建就不可以被改变,它直接指向历史中的一个特定的提交。
查看所有标签(本地和远程):
git tag上述命令只会以字母顺序列出标签。
查看某个标签详细:
git show <tag name>给最新一次提交打上标签:
git tag -a <tag name>给某个提交打上标签:
git tag -a <tag name> <commit id>推送所有本地标签到远程版本库:
git push --tags删除本地标签:
git tag -d <tag name>删除远程版本库中的某个标签:
git push <origin> :<tag name>1)检出某个标签,并切换到“detached HEAD”状态的分支:
git checkout <tag name>2)从“detached HEAD”状态的分支创建一个新分支,并切换到该分支:
git switch -c <new-branch-name>用于保存当前的工作进度,以便进行更加紧急的开发或 Bug 修复工作,待紧急的工作完成后,再重新恢复该工作进度,继续开发。
将当前工作区和暂存区的所有修改存入储藏(栈顶):
git stash save "<message>"列出储藏(从新到旧)中所有的记录:
git stash list取出第一条(最新,栈顶)的工作进度进行恢复,并将该工作进度从储藏中移除:
git stash pop取出某条工作进度:
git stash apply <stash@{num}>丢弃某一条工作进度:
git stash drop <stash@{num}>丢弃全部工作进度,清空储藏:
git stash clear个人建议对远程版本库的操作规则是,不要改变远程版本库中已有的提交,所有的修改都应该在保证完整原有提交历史的情况下进行迭代。
1)添加一个地址是 <url> 并指定名称为 <origin>(origin 是约定俗成的远程版本库名)的远程版本库:
git remote add <origin> <url>2)将本地版本库推送到远程版本库:
git push -u <origin> <master>首次推送时,我们约定俗成的是将
master用作主分支名。
1)从远程版本库拉取更新:
git pull2)若有合并冲突,则先解决冲突,然后再将解决后的修改加入到暂存区,最后提交到本地版本库。
3)将本地版本库中的修改推送到远程版本库:
git push查看本地版本库所对应远程版本库的名称和地址:
git remote -v查看本地版本库与远程版本库的配置详情:
git remote show <origin>{
"target": "terminus_exec",
"cancel": "terminus_cancel_build",
"shell_cmd": "chcp 65001 && g++ $file -o $file_base_name && $file_base_name",
"working_dir": "$file_path",
"selector": "source.c,source.c++",
"file_regex": "^[ ]*File \"(...*?)\", line ([0-9]*)"
}现代的前端开发,不但需要编译 JavaScript 代码,免不了还要编译 CSS 样式文件。那么编译 CSS 样式到底是个什么意思呢,怎么连 CSS 都要编译了?
下面我们将采用一个极其粗略的代码来模拟一下所谓编译 CSS 样式是什么意思。我们代码的目录结构非常简单:
D:.
index.css
index.html
test.js
index.css 源码:
body {
background-color: grey;
}test.js 源码:
const compile = () => {
const file = require('fs');
const buildFileName = 'build.js';
file.writeFile(buildFileName, '', () => {});
file.readFile('./index.css', (err, data) => {
if (err) {
return console.error(err);
}
const css = String(data).replace(/\s/g, '');
file.appendFile(buildFileName,
'var style = document.createElement("style");' +
'style.appendChild(document.createTextNode("' + css + '"));' +
'document.head.appendChild(style);',
() => {});
});
};
compile();index.html 源码:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>首页</title>
</head>
<body>
<script src="build.js"></script>
</body>
</html>HTML 中引入了编译后的 build.js,其源码:
var style = document.createElement("style");style.appendChild(document.createTextNode("body{background-color:grey;}"));document.head.appendChild(style);我们在浏览器中打开 index.html 可以发现,虽然我们没有在 HTML 标签中引入任何样式,但最终在浏览器中的渲染却实实在在地实现了我们在 index.css 中所编写的样式要求。这是因为我们通过 Node.js 将 CSS 文件的内容编译到了 build.js 中,而在浏览器加载该 JS 文件时,又由该 JS 代码将我们的 CSS 样式插入到了 HTML <head> 标签内的 <style> 标签中。
最后我们来做个总结,所谓对 CSS 的编译,主要有以下几种类型:
{
"bootstrapped": true,
"installed_packages":
[
"A File Icon",
"All Autocomplete",
"BracketHighlighter",
"ConvertToUTF8",
"DiffView",
"EditorConfig",
"Emmet",
"MarkdownPreview",
"Material Theme",
"Package Control",
"PackageResourceViewer",
"Predawn",
"SideBarEnhancements",
"SublimeLinter",
"SublimeLinter-eslint",
"SublimeLinter-flake8",
"Terminus"
]
}运行一个简单的 Node.js 程序,测试下我们 MySQL 服务器的连通性:
const express = require('express');
const mysql= require('mysql');
const app = express();
const db = mysql.createConnection({
host: '192.168.2.173',
port: '3306',
user: 'root',
password: 'root123',
database: 'mysql'
});
db.connect();
app.get('/users', (req, res) => {
const sql = 'SELECT User, Host, Plugin FROM user';
db.query(sql, (err, result) => {
if (err) throw err;
res.send(result);
});
});
app.listen(5000, () => console.log('服务已启动'));如果我们使用的是 MySQL 8.0.4 及以后的版本,且在没有进行额外配置的情况下,不出意外地我们会得到以下的错误:
ER_NOT_SUPPORTED_AUTH_MODE: Client does not support authentication protocol requested by server; consider upgrading MySQL client
这是因为从 MySQL 8.0.4 开始,MySQL 服务器的默认身份验证插件从 mysql_native_password 更改为了 caching_sha2_password,而我们使用的 MySQL 客户端还不支持新版的身份验证插件。所以一个比较简单的解决方案就是将用户的身份验证插件改回 mysql_native_password。
查看用户所使用的身份验证插件:
mysql> SELECT User, Host, Plugin FROM mysql.user;
+------------------+-----------+-----------------------+
| User | Host | Plugin |
+------------------+-----------+-----------------------+
| root | % | caching_sha2_password |
| mysql.infoschema | localhost | caching_sha2_password |
| mysql.session | localhost | caching_sha2_password |
| mysql.sys | localhost | caching_sha2_password |
| root | localhost | caching_sha2_password |
+------------------+-----------+-----------------------+
5 rows in set (0.00 sec)上面的结果正验证了我们的猜测,下面我们就将 root 用户的身份验证插件修改为 mysql_native_password:
ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY 'root123';比较好的做法是创建非
root用户,并指定相关权限。这里,我为了测试的简单,直接使用root用户。
然后再执行我们的 Node.js 代码,访问 http://localhost:5000/users,就可以得到正确结果了。
test_list = ['a', 'b', 'c', 'd', 'e']
for index in range(len(test_list)):
print(f'Index: {index}, Value: {test_list[index]}')test_list = ['a', 'b', 'c', 'd', 'e']
for item in [(index, test_list[index]) for index in range(len(test_list))]:
print(f'Index: {item[0]}, Value: {item[1]}')enumerate()test_list = ['a', 'b', 'c', 'd', 'e']
for index, value in enumerate(test_list):
print(f'Index: {index}, Value: {value}')zip()test_list = ['a', 'b', 'c', 'd', 'e']
for index, value in zip(range(len(test_list)), test_list):
print(f'Index: {index}, Value: {value}')因为网络原因,在国内直接从 Docker Hub 拉取公有镜像的速度不容乐观,所以配置国内的镜像加速器是一个非常不错的选择。
本文以配置科大 LUG为例。
1)创建 /etc/docker/daemon.json 文件,并写入以下内容:
{
"registry-mirrors": ["https://docker.mirrors.ustc.edu.cn"]
}
2)重新加载 systemctl 配置:
systemctl daemon-reload3)重启 Docker:
systemctl restart docker4)查看镜像加速器是否配置成功:
docker info如果输出包含如下内容,就说明镜像加速器已生效:
Registry Mirrors:
https://g4ttm0i5.mirror.aliyuncs.com/
拉取最新的 MySQL 官方镜像:
docker pull mysql启动一个运行了 MySQL 服务器实例的容器:
docker run -d -p 3306:3306 --name mysql -e MYSQL_ROOT_PASSWORD=root123 -e TZ=Asia/Shanghai mysql-d:以后台模式运行容器-p 3306:3306:将容器的 3306 端口映射到宿主机的 3306 端口(hostPort:containerPort),外部主机可以直接通过 宿主机ip:3306 访问到 MySQL 数据库--name mysql:指定容器名为 mysql-e MYSQL_ROOT_PASSWORD=root123:通过向容器传递环境变量,来设置 MySQL 数据库的超级用户(root)密码为 root123-e TZ=Asia/Shanghai:设置**时区,默认为 UTC查看容器是否已启动:
dcoker container ls -a若还未启动,则执行以下命令启动容器:
docker container start mysql获取容器内 bash shell:
docker exec -it mysql bash登录容器内的 MySQL 数据库:
mysql -uroot -proot123不论是退出 MySQL 数据库的命令行还是容器内的 bash shell,都可以使用 Ctrl + D 快捷键。
1)从 Maven 官网下载最新版的 Maven,例如 apache-maven-3.6.3-bin.tar.gz。
2)将 apache-maven-3.6.3-bin.tar.gz 解压至 D:\Portable。
3)将 D:\Portable\apache-maven-3.6.3\bin 目录加入到环境变量 Path 中。
4)检验安装是否成功:mvn -v。
要想正确执行
mvn命令,首先要保证已将D:\Program Files\Java\jdk1.8.0_241\bin加入到环境变量Path中。
pom.xml~/.m2/settings.xml${maven.home}/conf/settings.xml~/.m2/settings.xml:
<?xml version="1.0" encoding="UTF-8"?>
<settings>
<localRepository>D:/MavenRepository</localRepository>
<mirrors>
<mirror>
<id>aliyunNexus</id>
<mirrorOf>central</mirrorOf>
<name>Aliyun Nexus</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</mirror>
</mirrors>
</settings>pom.xml:
<project>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<!-- 解决执行 `maven test` 时,控制台中文乱码的问题 -->
<argLine>-Dfile.encoding=UTF-8</argLine>
</properties>
</project>1)安装需要的软件包(yum-utils 提供 yum-config-manager 实用程序,存储驱动 devicemapper 需要 device-mapper-persistent-data 和 lvm2):
yum install yum-utils device-mapper-persistent-data lvm2 -y2)设定稳定版存储库:
yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo1)列出存储库中可用的 Docker CE 版本(版本号从高到低):
yum list docker-ce --showduplicates | sort -r2)安装指定版本的 Docker CE:
yum install docker-ce-<VERSION_STRING> docker-ce-cli-<VERSION_STRING> containerd.io -y若不指定版本号,则默认安装的是最新版本:
yum install docker-ce docker-ce-cli containerd.io -y此时,Docker 已经安装,且自动创建了 docker 用户组,但还未向该用户组添加任何用户。
2.1)查看 Docker 版本:
docker --version2.2)查看 docker 用户组是否存在:
getent group | grep docker2.3)查看 docker 用户组中有哪些用户:
lid -g docker查看是否已启动 Docker 服务:
systemctl status docker启动 Docker 服务:
systemctl start docker设置 Docker 服务开机自启动:
systemctl enable docker禁止 Docker 服务开机自启动:
systemctl disable docker如果当前用户不是
root用户,则需要sudo权限才能操作 Docker。
验证 Docker 是否安装成功,运行 hello-world 镜像:
docker run hello-world如果本地没有 hello-world 镜像,则上述命令会从远程镜像库拉取(下载)一个 hello-world 镜像并运行为一个新容器,否则就从本地 hello-world 镜像运行出一个新的容器。当容器运行时,它会打印一条消息,然后自动退出。
查看本地镜像:
docker image ls查看所有容器(默认只显示运行中的容器):
docker container ls -a删除容器 id 是 0b8dbf5625b5 的容器:
docker container rm 0b8dbf5625b5删除本地镜像 hello-world:
docker image rm hello-worlddocker images 与 docker image ls,docker ps 与 docker container ls ,docker rm 与 docker container rm,docker rmi 与 docker image rm 都没有区别。只是新的 docker image ls、docker container ls、docker container rm 和 docker image rm 命令为我们提供了更好的结构化命令行体验,故个人建议使用较新的 Docker 命令。因为旧的命令,指不定在将来的某个版本后就被弃用了。
后续针对 Docker 的文章,我将直接使用新版命令,类似我之前的《Git 命令行操作速学》文章,在那篇文章中,我对旧的 Git 命令甚至提都未提。
很多老人认为 JavaScript 是往浏览器一扔就可以执行的解释型语言,哪来的什么编译。但事实上就存在着像 Babel 这类 JavaScript 编译器,而且这类 JS 编译器往往还是现阶段前端开发都离不开的,那么这里对 JavaScrit 代码的编译到底是什么呢?
本文将通过一个最简单的例子来玩玩所谓的编译 JavaScript 代码,到底是在干什么事情。
以下是本文测试代码的目录树(其中比较关键的几个文件源码也在下文分别列出):
D:.
│ index.html
│ package-lock.json
│ package.json
│ test.js
│
└─node_modules
│
└─my_lib
index.js
node_modules/my_lib/index.js 源码:
exports.name = '自定义测试模块';
exports.showVersion = function () {
console.log('v1.0.0');
};test.js 源码:
const myLib = require('my_lib');
myLib.showVersion();
const compile = () => {
// 编译 `const myLib = require('my_lib');`
const file = require('fs');
const buildFileName = 'build.js';
file.writeFile(buildFileName, '', () => {});
const build = (key, value) => {
value = typeof(value) === 'string'? `'${value}'` : value;
return `var ${key} = ${value};\n`;
};
for (const key in myLib) {
file.appendFile(buildFileName, build(key, myLib[key]), () => {});
}
// 编译 `myLib.showVersion();`
file.appendFile(buildFileName, 'showVersion();\n', () => {});
};
compile();index.html 源码:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>首页</title>
</head>
<body>
<script src="build.js"></script>
</body>
</html>其中 JavaScript 编译结果,即 build.js 源码:
var name = '自定义测试模块';
var showVersion = function () {
console.log('v1.0.0');
};
showVersion();以上的代码只是粗略模拟了 JavaScript 编译到底是在做什么,实际像 Babel 这类编译器做的事肯定是要复杂太多的。
不过从以上这个粗略的代码中,我们还是可以很清楚地了解到所谓对 JavaScript 代码的编译,事实上做的只是将当前浏览器不可识别的 JS 代码转换为当前浏览器可以识别的 JS 代码(比如将 ECMAScript 2015 及以上的代码转换为浏览器可识别的旧版 JS 代码,或是将 JSX 代码转换为 JS 代码等)罢了,这和 C/C++、Java 这类编译型语言的编译是有很大不同的。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.