blog's People
Stargazers

Watchers

blog's Issues
GraphQL技术分享(上)概念篇
GraphQL技术分享(上)概念篇
目录大纲
1、什么是GraphQL
- GraphQL介绍
- GraphQL生态
2、GraphQL核心概念
- Type System
- Query & Mutation
- Resolver
- Introspection
- Validation
3、能为团队带来什么
- GraphQL能提供哪些帮助
- 有哪些问题需要解决
- RPC vs REST vs GraphQL
一、GraphQL介绍
1、什么是GraphQL?
简单的说,GraphQL是由Facebook开源的一套**“用于API的查询语言”,全称是“Graph Query Language”**。

不同于数据库的SQL,GraphQL是一种前后端数据交互的规范,只是通过类似SQL查询的方式,对后端提供的接口数据,进行自定义查询,但是它的数据源需要开发者自己定义,而不是任由前端人员传入GraphQL语句,直接读取数据库。
它不局限于编程语言,任何语言都可以实现这套规范。
https://graphql.cn/code/
2、GraphQL生态
awesome-graphql上列举了Github上面开源的并且十分有用的graphql相关的服务端、客户端以及生态链相关的其他工具。
https://github.com/chentsulin/awesome-graphql
-
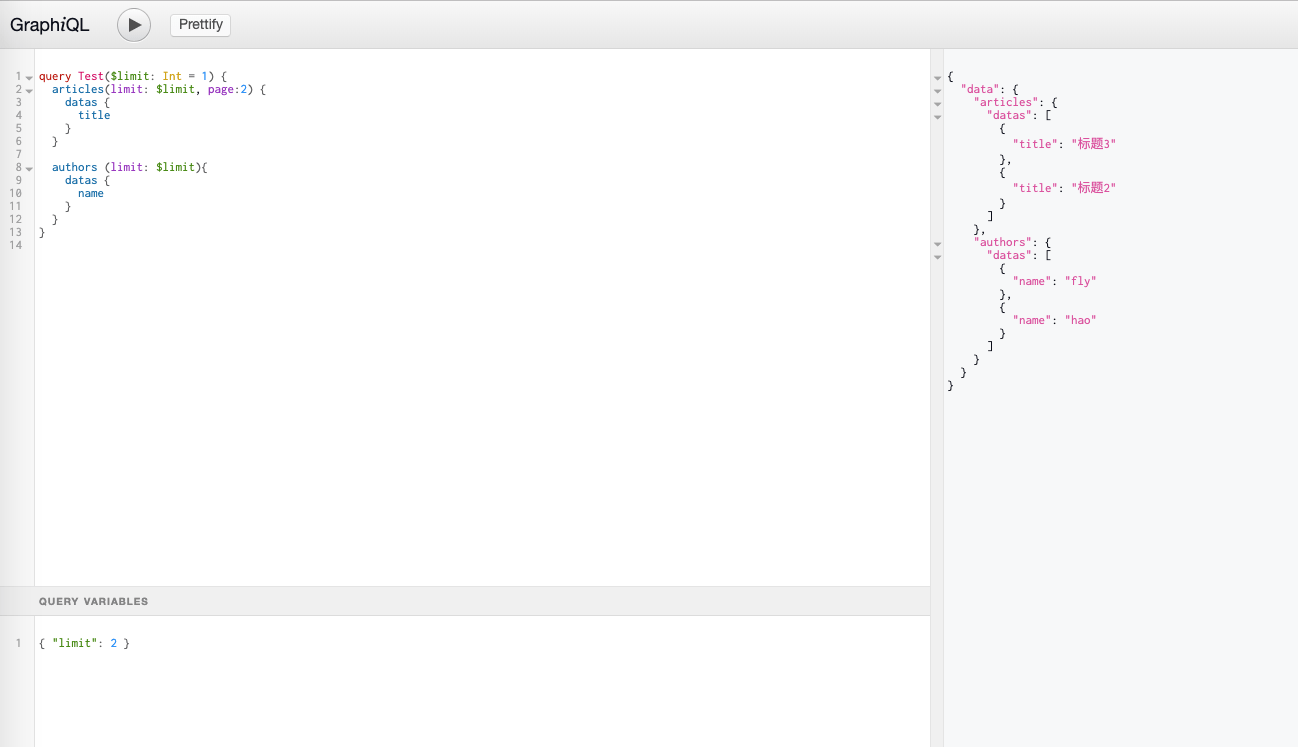
GraphiQL:
-
Graphql-Network:
-
GraphQL-Voyager:

二、GraphQL核心概念
1、Type System
GraphQL 的强大表达能力主要还是来自于它完备的类型系统,与 REST 不同,它将整个 Web 服务中的全部资源看成一个有连接的图,而不是一个个资源孤岛,在访问任何资源时都可以通过资源之间的连接访问其它的资源。
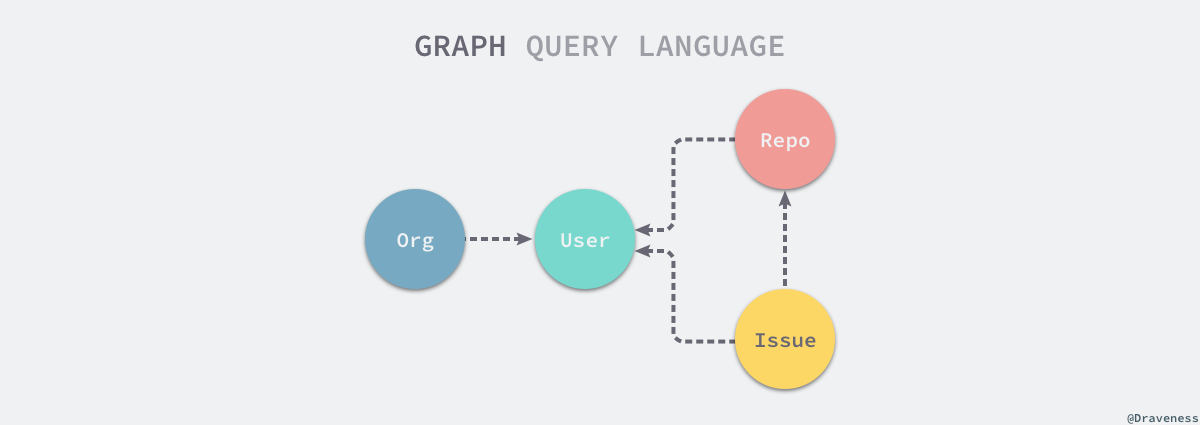
总而言之,GraphQL中的Type,就是描述和表达这些视图模型最基本的要素。
type Issue {
title: String,
content: String
}
type User {
id: String,
name: String,
age: Integer,
issue: [Issue]
}
GraphQL 不单单支持简单类型,还支持一些其他类型,如 Object, Enum, List, NotNull 这些常见的类型,还有 Interface, Union, InputObject 这几个特殊类型。
2、Query & Mutation
GraphQL的查询语法同我们现在所使用的有一大不同是,传输的数据结构并不是 JSON 对象,而是一个字符串,这个字符串描述了客户端希望服务端返回数据的具体结构。
Query,查询操作。
query fetchArticle {
article {
id,
createDate,
title,
subtitle,
content,
tags {
name,
label
}
}
}
{
"data": {
"article": {
"id": "3",
"createDate": "2016-08-01",
"title": "GraphQL基础概念",
"subtitle": "A query language created by Facebook for decribing data requirements on complex application data models",
"content": "省略...",
"tags": [{
"name": "graphql",
"label": "GraphQL"
}]
}
}
}Motation,执行修改操作。
mutation addArticle($input: Article!) {
addArticle(input: $input) {
id
title
}
}
{
"data": {
"addArticle": {
"id": "3",
"title": "GraphQL基础概念"
}
}
}在查询字段时,是并行执行,而变更字段时,是线性执行,一个接着一个。
3、Resolver
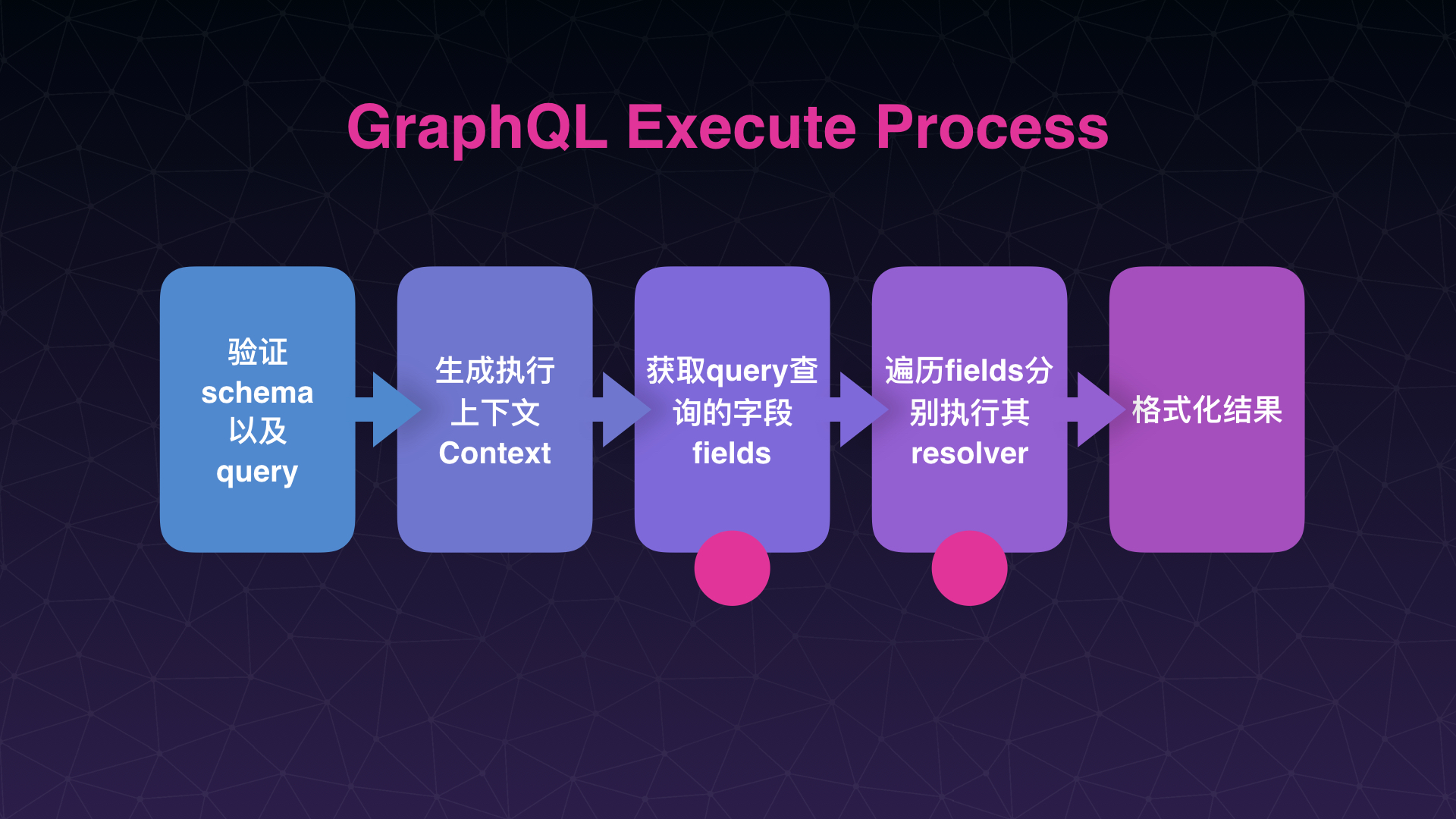
GraphQL的执行过程:
1、Validating Requests:主要是检查传入的schema、document、variables是否符合规范格式。
2、Coercing Variable Values:检查客户端请求变量的合法性,需要和schema进行对比。
3、Executing Operations:执行客户端请求的方法与之对应的resolver函数
4、Executing Selection Sets:搜罗客户端请求需要返回的字段集合
5、Executing Fields:执行每个字段,需要进行递归
参考链接:https://juejin.im/post/5ceb1e28f265da1bb80c0b70
现在让我们用一个例子来描述当一个查询请求被执行的全过程。
{
human(id: 1002) {
name
appearsIn
starships {
name
}
}
}
{
"data": {
"human": {
"name": "Han Solo",
"appearsIn": [
"NEWHOPE",
"EMPIRE",
"JEDI"
],
"starships": [
{
"name": "Millenium Falcon"
},
{
"name": "Imperial shuttle"
}
]
}
}
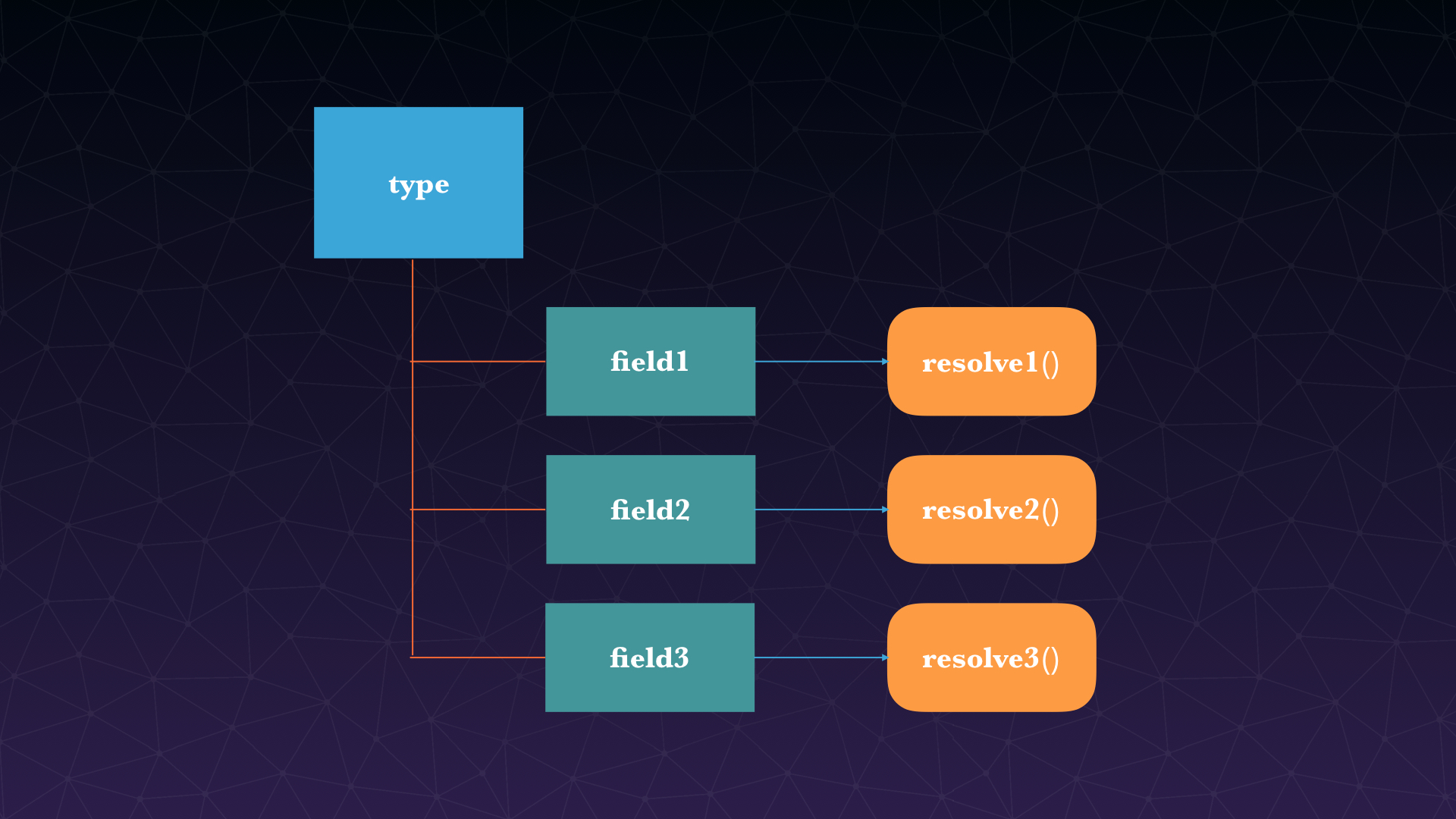
}你可以将 GraphQL 查询中的每个字段视为返回子类型的父类型函数或方法。事实上,这正是 GraphQL 的工作原理。每个类型的每个字段都由一个 resolver 函数支持,该函数由 GraphQL 服务器开发人员提供。当一个字段被执行时,相应的 resolver 被调用以产生下一个值。
如果字段产生标量值,例如字符串或数字,则执行完成。如果一个字段产生一个对象,则该查询将继续执行该对象对应字段的解析器,直到生成标量值。GraphQL 查询始终以标量值结束。
4、Introspection
我们有时候会需要去问 GraphQL Schema 它支持哪些查询。GraphQL 通过内省系统让我们可以做到这点!
{
__schema {
types {
name
}
}
}
"data": {
"__schema": {
"types": [
{
"name": "Query"
},
{
"name": "Episode"
},
{
"name": "Character"
},
{
"name": "ID"
},
{
"name": "String"
},
{
"name": "Int"
},
{
"name": "FriendsConnection"
},
{
"name": "FriendsEdge"
},
{
"name": "PageInfo"
},
{
"name": "Boolean"
},
{
"name": "Review"
},
{
"name": "SearchResult"
},
{
"name": "Human"
},
{
"name": "LengthUnit"
},
{
"name": "Float"
},
{
"name": "Starship"
},
{
"name": "Droid"
},
{
"name": "Mutation"
},
{
"name": "ReviewInput"
},
{
"name": "__Schema"
},
{
"name": "__Type"
},
{
"name": "__TypeKind"
},
{
"name": "__Field"
},
{
"name": "__InputValue"
},
{
"name": "__EnumValue"
},
{
"name": "__Directive"
},
{
"name": "__DirectiveLocation"
}
]
}
}
}- Query, Character, Human, Episode, Droid - 这些是我们在类型系统中定义的类型。
- String, Boolean - 这些是内建的标量,由类型系统提供。
- __Schema, __Type, __TypeKind, __Field, __InputValue, __EnumValue, __Directive - 这些有着两个下划线的类型是内省系统的一部分。
5、Validation
通过使用类型系统,你可以预判一个查询是否有效。这让服务器和客户端可以在无效查询创建时就有效地通知开发者,而不用依赖运行时检查。
{
hero {
...NameAndAppearancesAndFriends
}
}
fragment NameAndAppearancesAndFriends on Character {
name
appearsIn
friends {
...NameAndAppearancesAndFriends
}
}
片段不能引用其自身或者创造回环,因为这会导致结果无边界。
{
"errors": [
{
"message": "Cannot spread fragment \"NameAndAppearancesAndFriends\" within itself.",
"locations": [
{
"line": 11,
"column": 5
}
]
}
]
}三、能为团队带来什么
1、GraphQL能提供哪些便捷?
-
单一入口
简化了**“版本管理”和“路径管理”**。

-
数据聚合
这里的数据聚合,分前端和后端两种意义:
从前端的意义上来讲,可以做到多个查询接口合并成一个请求,后端解析后并行执行。
从后端的意义上讲,是封装了多个服务提供的数据。


-
避免数据冗余
我们在传统的 RESTful 处理冗余的数据字段大约有这么三种处理方式:
- 前端不去展示这些字段;
- 加一个中间层服务去筛选这些字段,然后再返回终端来展示出来;
- 前端和后端去做约定,如果说这一个接口这一个字段已经不要,可以和后端商量一下把这个删掉,但是有一种情况可能造成冗余字段删不掉的,那就是后端的同学做这个接口可能是“万能接口”,也就是说这个接口在这个页面会用,在另外一个页面也能用,在这个应用会用,在另外一个应用也可能会用,多端之间存在部分数据共享,后端同学为了方便可能会写这么一个“万能”的接口来应付这种情况,久而久之,发现字段冗余到很多了,但是随便删除又可能会影响到很多地方,导致这个接口大而不能动,所以前后端都不得不忍受它。
在GraphQL中如何去做:


-
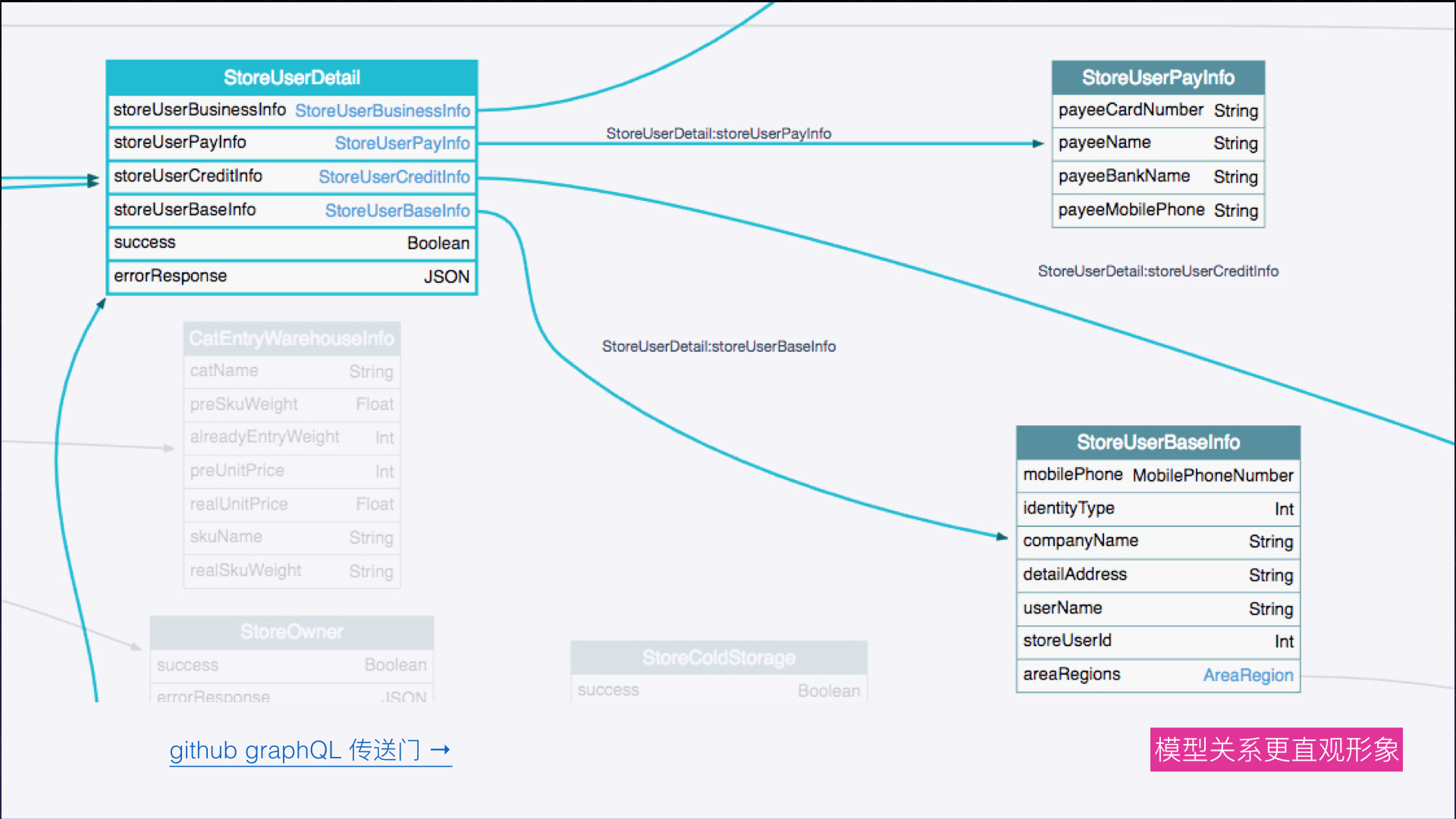
接口文档和模型关系
GraphQL 类型定义的时候我们可以对类型以及类型的属性增加描述 (description) , 这相当于是对类型做注释,当类型被编译以后就可以在相应的工具上面看到我们编辑的类型详情。
* 约束规范
GraphQL自带的参数类型效验,以及必填、选填等基础效验。
### 2、我们需要解决哪些问题
-
权限认证
基本上,有三种情况会发生:
1、已经登录的用户发出GraphQL查询,未登录的用户不可以。认证在非GraphQL节点完成。
2、所有用户都可以发出GraphQL查询,未登录用户可以使用其中的一个子集,认证在非GraphQL节点完成。
3、所有用户都可以发出GraphQL查询,认证就由GraphQL节点完成。
非GraphQL节点的处理认证:
是指在resolver执行之前,也就是请求在一个比GraphQL路由更早的中间件处理,之后,请求才会到达GraphQL代码。我们知道请求是从哪里来的。我们甚至都可以在请求到达GraphQL代码以前,把请求重定向到登录页面。
-
N+1 问题
这里的 N + 1 就是db operation的次数
# schemas/article.py class ArticleSchema(SQLAlchemyObjectType): author = graphene.Field("schemas.AuthorSchema", description="文章作者信息") def resolve_author(self, info): return AuthorManager.get_one(id=self.author_id) class Meta: model = ArticleModel description = "文章Schema"
SELECT * FROM `articles` LIMIT 0, 20; SELECT * FROM `authors` WHERE `id` = 1; SELECT * FROM `authors` WHERE `id` = 2; SELECT * FROM `authors` WHERE `id` = 3; ... SELECT * FROM `authors` WHERE `id` = N;
为了防止N+1问题,社区为GraphQL提供了一个解决方案: DataLoader。其原理就是,在需要查询数据库的时候将查询进行延迟,等到拿到所有的查询需求之后再一次性查询出来。在graphene里面,批量查询可以这样写:
# managers/author.py class AuthorsDataLoader(DataLoader): def batch_load_fn(self, ids): query = DBSession().query(AuthorModel).filter(AuthorModel.id.in_(ids)) articles = dict([(article.id, article) for article in query.all()]) return Promise.resolve([articles.get(id, None) for id in ids])
最终,仅需要两次数据库查询就完成了两个批量查询,即:
SELECT * FROM `articles` LIMIT 0, 20; SELECT * FROM `authors` WHERE `id` IN (1, 2, 3, ..., N);
-
缓存
可以提供对象的标识符以便客户端构建丰富的缓存
在基于入口端点的 API 中,客户端可以使用 HTTP 缓存来确定两个资源是否相同,从而轻松避免重新获取资源。这些 API 中的 URL 是全局唯一标识符,客户端可以利用它来构建缓存。然而,在 GraphQL 中,没有类似 URL 的基元能够为给定对象提供全局唯一标识符。
方案:使用全局唯一ID
一个可行的模式是将一个字段(如 id)保留为全局唯一标识符。这些文档中使用的示例模式使用此方法
{
starship(id:"3003") {
id
name
}
droid(id:"2001") {
id
name
friends {
id
name
}
}
}
{
"data": {
"starship": {
"id": "3003",
"name": "Imperial shuttle"
},
"droid": {
"id": "2001",
"name": "R2-D2",
"friends": [
{
"id": "1000",
"name": "Luke Skywalker"
},
{
"id": "1002",
"name": "Han Solo"
},
{
"id": "1003",
"name": "Leia Organa"
}
]
}
}
}
这是向客户端开发人员提供的强大工具。与基于资源的 API 使用 URL 作为全局唯一主键的方式相同,该系统中提供 id 字段作为全局唯一主键。
如果后端使用类似 UUID 的标识符,那么暴露这个全局唯一 ID 可能非常简单!如果后端对于每个对象并未分配全局唯一 ID,则 GraphQL 层可能需要构造此 ID。通常来说,将类型的名称附加到 ID 并将其用作标识符都很简单;服务器可能会通过 base64 编码使该 ID 不透明。
3、RPC vs REST vs GraphQL
-
RPC
优点:
轻量级的数据载体
高性能
开发人员实现简单缺点:
对外应用不够灵活
对于系统本身耦合性高
因为RPC容易实现、轻量,因此很容易造成function explosion,或者违背开闭原则。
-
REST
优点:
对于系统本身耦合性低,调用者不再需要了解接口内部处理和实现细节。
重复使用了一些 http 协议中的已定义好的部分状态动词,增强语义表现力
API可以随着时间而不断演进缺点:
缺少约束,缺少简单、统一的规范
随着功能的迭代,会造成部分接口的数据冗余
有时候调用api会比较繁琐,需要发送多条请求去获取数据
-
GraphQL
优点:
单一入口
数据聚合
避免数据冗余
接口文档和模型关系
约束规范缺点:
本身的语法相比较REST和RPC均复杂一些
实现方面需要配套 Batchcing 和 Caching 以解决性能瓶颈
仍然是新鲜事物,很多技术细节仍然处于待验证状态
十分钟搞明白 MobX + React 使用教程
MobX 是一个简单的、可扩展的、经过测试的状态管理解决方案。本教程将在十分钟内教给您介绍 MobX 的所有重要概念。
核心概念
状态是每个应用程序的核心。生成了不一致的状态或状态与本地变量的状态不同步,会造成应用程序很不容易管理,极易产生 bug。因此,许多状态管理解决方案试图限制你修改状态的方式,比如使用不可变的 state。但这会带来了一些新的问题,比如数据必须规范化,完整性约束失效等。
为了解决这些根本问题,MobX 再次使状态管理变得简单:使用它不可能产生不一致的状态。而且实现这一目标的策略很简单,就是确保一切都是从应用程序状态中自动派生出的。
MobX 处理你的应用程序状态如下图所示:

-
首先有一个 state,它可以是一个 object、array、primitives 等任何组成你程序的部分,你可以把这个想象成你应用程序的“单元格”。
-
其次就是 derivations,它一般是指可以从 state 中直接计算出来的结果。比如未完成的任务数量,也可以是稍微复杂的任务,比如渲染 html。你可以把它想象成电子表格中的“公式和图表”。
-
Reactions 和 derivations 很像,主要的区别在于 reactions 并不产生数据结果,而是自动完成一些任务,一般是和 I/O 相关的。它们可以确保 DOM 更新和网络请求在正确的时间被自动执行。
-
最后是 actions。Actions 可以改变 state 的一切,MobX 会确保所有引起应用程序状态的更改都有对应的 derivations 和 reactions 相伴,保证同步。
一个简单的 todo store
看完上面的理论,还是应该用实际例子说明一下会更直白。我们从一个简单的 todo store 开始,它维护了一个待办事项集合,我们最开始先不用 MobX。
class TodoStore { todos = [];<span class="pl-k">get</span> <span class="pl-en">completedTodosCount</span>() { <span class="pl-k">return</span> <span class="pl-c1">this</span>.<span class="pl-smi">todos</span>.<span class="pl-en">filter</span>( <span class="pl-smi">todo</span> <span class="pl-k">=></span> <span class="pl-smi">todo</span>.<span class="pl-smi">completed</span> <span class="pl-k">===</span> <span class="pl-c1">true</span> ).<span class="pl-c1">length</span>; } <span class="pl-en">report</span>() { <span class="pl-k">if</span> (<span class="pl-c1">this</span>.<span class="pl-smi">todos</span>.<span class="pl-c1">length</span> <span class="pl-k">===</span> <span class="pl-c1">0</span>) <span class="pl-k">return</span> <span class="pl-s"><span class="pl-pds">"</span><none><span class="pl-pds">"</span></span>; <span class="pl-k">return</span> <span class="pl-s"><span class="pl-pds">`</span>Next todo: "<span class="pl-s1"><span class="pl-pse">${</span><span class="pl-c1">this</span>.<span class="pl-smi">todos</span>[<span class="pl-c1">0</span>].<span class="pl-smi">task</span><span class="pl-pse">}</span></span>". <span class="pl-pds">`</span></span> <span class="pl-k">+</span> <span class="pl-s"><span class="pl-pds">`</span>Progress: <span class="pl-s1"><span class="pl-pse">${</span><span class="pl-c1">this</span>.<span class="pl-smi">completedTodosCount</span><span class="pl-pse">}</span></span>/<span class="pl-s1"><span class="pl-pse">${</span><span class="pl-c1">this</span>.<span class="pl-smi">todos</span>.<span class="pl-c1">length</span><span class="pl-pse">}</span></span><span class="pl-pds">`</span></span>; } <span class="pl-en">addTodo</span>(<span class="pl-smi">task</span>) { <span class="pl-c1">this</span>.<span class="pl-smi">todos</span>.<span class="pl-c1">push</span>({ task<span class="pl-k">:</span> task, completed<span class="pl-k">:</span> <span class="pl-c1">false</span>, assignee<span class="pl-k">:</span> <span class="pl-c1">null</span> }); }}
const todoStore = new TodoStore();
todoStore.addTodo("read MobX tutorial");
console.log(todoStore.report());todoStore.addTodo("try MobX");
console.log(todoStore.report());todoStore.todos[0].completed = true;
console.log(todoStore.report());todoStore.todos[1].task = "try MobX in own project";
console.log(todoStore.report());todoStore.todos[0].task = "grok MobX tutorial";
console.log(todoStore.report());我们创建了一个
TodoStore的实例,为了能看到每次的执行结果,每次在往TodoStore里添加了一条数据之后,都会调用一下report()方法。codepen 完整实例执行结果也和我们预想的一样,每次都输出了当前的应用程序数据集合状态结果:
"Next todo: 'read MobX tutorial'. Progress: 0/1" "Next todo: 'read MobX tutorial'. Progress: 0/2" "Next todo: 'read MobX tutorial'. Progress: 1/2" "Next todo: 'read MobX tutorial'. Progress: 1/2" "Next todo: 'grok MobX tutorial'. Progress: 1/2"如你所见,每次数据有变动时,都要手动去调用一下
report()方法是一件很麻烦的事情。设想一下,能不能像 Excel 表格一样,当某个表格的数据有变动时,图表就能自动重新计算显示结果呢。没错,这就是 MobX 要解决的问题。变成响应式
为了实现这个目标,需要把代码进行一下改动,使
todos成为一个可观测(observable)的属性。class ObservableTodoStore { @mobx.observable todos = []; @mobx.observable pendingRequests = 0;<span class="pl-en">constructor</span>() { <span class="pl-smi">mobx</span>.<span class="pl-en">autorun</span>(() <span class="pl-k">=></span> <span class="pl-en">console</span>.<span class="pl-c1">log</span>(<span class="pl-c1">this</span>.<span class="pl-smi">report</span>)); } @<span class="pl-smi">mobx</span>.<span class="pl-smi">computed</span> <span class="pl-k">get</span> <span class="pl-en">completedTodosCount</span>() { <span class="pl-k">return</span> <span class="pl-c1">this</span>.<span class="pl-smi">todos</span>.<span class="pl-en">filter</span>( <span class="pl-smi">todo</span> <span class="pl-k">=></span> <span class="pl-smi">todo</span>.<span class="pl-smi">completed</span> <span class="pl-k">===</span> <span class="pl-c1">true</span> ).<span class="pl-c1">length</span>; } @<span class="pl-smi">mobx</span>.<span class="pl-smi">computed</span> <span class="pl-k">get</span> <span class="pl-en">report</span>() { <span class="pl-k">if</span> (<span class="pl-c1">this</span>.<span class="pl-smi">todos</span>.<span class="pl-c1">length</span> <span class="pl-k">===</span> <span class="pl-c1">0</span>){ <span class="pl-k">return</span> <span class="pl-s"><span class="pl-pds">"</span><none><span class="pl-pds">"</span></span>; } <span class="pl-k">return</span> <span class="pl-s"><span class="pl-pds">`</span>Next todo: "<span class="pl-s1"><span class="pl-pse">${</span><span class="pl-c1">this</span>.<span class="pl-smi">todos</span>[<span class="pl-c1">0</span>].<span class="pl-smi">task</span><span class="pl-pse">}</span></span>". <span class="pl-pds">`</span></span> <span class="pl-k">+</span> <span class="pl-s"><span class="pl-pds">`</span>Progress: <span class="pl-s1"><span class="pl-pse">${</span><span class="pl-c1">this</span>.<span class="pl-smi">completedTodosCount</span><span class="pl-pse">}</span></span>/<span class="pl-s1"><span class="pl-pse">${</span><span class="pl-c1">this</span>.<span class="pl-smi">todos</span>.<span class="pl-c1">length</span><span class="pl-pse">}</span></span><span class="pl-pds">`</span></span>; } <span class="pl-en">addTodo</span>(<span class="pl-smi">task</span>) { <span class="pl-c1">this</span>.<span class="pl-smi">todos</span>.<span class="pl-c1">push</span>({ task<span class="pl-k">:</span> task, completed<span class="pl-k">:</span> <span class="pl-c1">false</span>, assignee<span class="pl-k">:</span> <span class="pl-c1">null</span> }); }}
const observableTodoStore = new ObservableTodoStore();
observableTodoStore.addTodo("read MobX tutorial");
observableTodoStore.addTodo("try MobX");
observableTodoStore.todos[0].completed = true;
observableTodoStore.todos[1].task = "try MobX in own project";
observableTodoStore.todos[0].task = "grok MobX tutorial";到目前为止,这段代码中并没有什么太特别的东西,但是不需要每次都调用
report()方法了。completedTodosCount会被自动从 todo list 中派生出来,使用@observable和@computed可以使对象变成一个可观测的属性。在
constructor中,使用autorun()包裹了一个输出report的函数,使 React 变成响应式
现在
report方法已经变成了傻瓜式的响应。是时候围绕着此 store 来搭建用户界面了。React 组件默认并不是响应式的。使用mobx-react模块中的@observer修饰器将 React 组件包裹起来,以达到 render 方法能够自动运行,自动同步组件内的 state 状态。这个和上面repoet方法的实现概念是不一样的。下面定义了一些 React 组件,其中仅用到了
mobx-react的@observer修饰器,就能够使每个组件可以根据相关的数据变化自动进行渲染了。你再也不需要调用 setState 方法,也不需要再指出如何用选择器去订阅应用状态的适当部分或者需要配置的高阶组件。基本上,所有的组件都会变得很聪明。但其实,它们又是用了一种看起来很“愚蠢”的声明式定义出来的。@observer class TodoList extends React.Component { render() { const store = this.props.store; return ( <div> { store.report } <ul> { store.todos.map( (todo, idx) => <TodoView todo={ todo } key={ idx } /> ) } </ul> { store.pendingRequests > 0 ? <marquee>Loading...</marquee> : null } <button onClick={ this.onNewTodo }>New Todo</button> <small> (double-click a todo to edit)</small> <RenderCounter /> </div> ); }onNewTodo = () => {
this.props.store.addTodo(prompt('Enter a new todo:','coffee plz'));
}
}@observer
class TodoView extends React.Component {
render() {
const todo = this.props.todo;
return (
<li onDoubleClick={ this.onRename }>
<input
type='checkbox'
checked={ todo.completed }
onChange={ this.onToggleCompleted }
/>
{ todo.task }
{ todo.assignee
? <small>{ todo.assignee.name }</small>
: null
}
<RenderCounter />
</li>
);
}onToggleCompleted = () => {
const todo = this.props.todo;
todo.completed = !todo.completed;
}onRename = () => {
const todo = this.props.todo;
todo.task = prompt('Task name', todo.task) || todo.task;
}
}ReactDOM.render(
<TodoList store={ observableTodoStore } />,
document.getElementById('reactjs-app')
);使用引用类型
到目前为止,我们已经创建过了可观测的对象、数组和基本类型。你可能会疑惑,在 MobX 中如何处理引用呢?在以前的示例中你可能已经注意到 todos 中有一个
assignee属性。我们现在引入一个存储了若干人物名称的store数组,以便后面能够将任务分配给他们。var peopleStore = mobx.observable([ { name: "Michel" }, { name: "Me" } ]); observableTodoStore.todos[0].assignee = peopleStore[0]; observableTodoStore.todos[1].assignee = peopleStore[1]; peopleStore[0].name = "Michel Weststrate";我们现在有了两个独立的 store。一个存储的是人名,另一个存储的是 todo 列表。
异步 action
在我们这个小小的 todo 应用中,每一件事情都是由状态衍生出来的。这使得创建异步的 action 变得非常简单,
参考链接
Git版本控制规范
Git版本控制规范
一、分支管理
分支名 环境 备注 master 生产 权限只开放给项目负责人 test 测试 定期回滚到master版本 development 开发 手动rebase master版本 developer branch... 本地 个人开发分支,随意 1. 开发者本地分支:
开发者在本地创建、修改代码后,提交到git仓库,用来备份自己开发的代码。
基于development、test、master分支,可以任意选择一支进行开发,并针对不同的场景,合并到test或development分支,部署后进行测试。
问:为什么不直接在development和test分支上进行开发?
上面提到过,test和development分支都可能会因为自动或者人为的因素回滚到master版本,为了防止不必要的合并和代码丢失,还是用个人开发分支。2. development分支
开发环境分支,在多个开发者协同工作时,方便联调。
比如A将自己代码提交到development分支,B可以从development分支拉取A提交的代码,开发完成后,统一在开发环境测试。
每次项目上线之后,development分支都需要看情况,由开发者自己决定,何时rebase到master分支,基于线上最新版本继续开发。
3. test分支
测试环境分支,主要供测试人员使用,开发者请勿在测试环境联调。
test分支需要定期还原到当前线上最新的master分支,比如每周的周一和周三晚上12点,测试人员在测试时间安排上,也尽量按照这个周期。
问:为什么test分支要定期自动回滚到master?
说白了就是一个约定,如果跟development分支一样,由开发者自己手动将分支回归到release版本,那么合代码的时候,可能不知道其他开发人员修改的内容,而导致误操作,给测试人员带来不必要的问题,所以不如直接回滚,然后让开发者自己重新提交。4. master分支
生产环境预发布时,项目负责人需要询问开发人员是否有需要上线的功能,开发人员提供自己的开发分支,该分支必须要基于最新的master版本,并且只能有一个commit提交。
在要求负责人往master合并代码的时候,需要遵守提交规范,不符合规范的提交,会被负责人打回,重新修改后再进行合并。
项目负责人确认项目合并没有问题,进行手动上线。
每次发布都应该打上对应的版本号,以及该版本详细的相关修改内容。
二、代码提交规范
开发者本地分支、development分支、test分支,理论上是不限制提交规范,用merge还是cherry-pick都可以,还是以效率为主,因为最终都要回归到master版本,所以只需要在上线提交master分支的时候,才需要对提交规范做限制。
当然,在日常工作中有一个良好的代码提交规范,对开发者而言也是一种对自我要求严格的表现。
master分支代码提交规则:
每一个开发者,需要将自己本次上线修改的所有内容,合并成一个commit。
比如你基于上次master分支进行开发,现在要提交master分支的时候,你总共有10次commit记录,那么你需要先将这10次合并成1个,并将本次功能修改的内容,一一列出,然后提交到master分支。
另外,想git操作自动生成的commit,比如merge、revert生成的记录,一律不允许存在,主要是方便跟踪和管理线上提交记录。
多次提交合并一次的实现方式:
在本地基于你当前提交并push过多次的分支explosion_duang_1,创建一个新的分支,如:
git checkout -b explosion_duang_2。
然后查看commit提交记录,回退到分支最新的一次提交(前提你要先rebase master分支),如:git reset 0bfaad4,注意,别加--hard参数,不然你代码会丢哦!
回退完之后,会发现之前所有的提交过的文件,都重新变成了未提交的,这时,你再重新执行git add files,git commit -m '1、fuck。2、fuck。...'即可。
最后,切换到master分支,git checkout master,合并刚才分支提交的commit记录,git cherry-pick 6cd9616,到此,大功告成!等等,好像还有一个问题,如果我要把我当前创建的分支提交到远程保存,那不会创建很多分支吗,会导致分支列表很乱。
的确,如果你只想用一个分支,而且在合并一次提交之前,push过多次,那么你在reset和重新add、commit之后,可以通过git push -f命令,强制覆盖远程分支的提交记录。
注意!大写的注意!普通开发人员操作公共分支尽量不要用git push -f,不然容易挨揍。。。。项目负责人合并上线:
项目负责人合并开发人员分支到master分支时,需要先检查每个开发者的commit提交记录是否合并成一个。
然后进行代码review,如果发现存在问题,要求负责开发的人员进行完善,修改没问题之后,再进行合并,注意使用cherry-pick合并,而不要使用merge。
项目负责人合并完所有人的代码之后,在进行手动上线。以上,就是git版本管理和发布的规范流程的初定稿,欢迎提问和补充。
Redux-saga使用心得总结
Redux-saga使用心得总结
最近将项目中redux的中间件,从redux-thunk替换成了redux-saga,做个笔记总结一下redux-saga的使用心得,阅读本文需要了解什么是redux,redux中间件的用处是什么?如果弄懂上述两个概念,就可以继续阅读本文。
- redux-thunk处理副作用的缺点
- redux-saga写一个hellosaga
- redux-saga的使用技术细节
- redux-saga实现一个登陆和列表样例
1.redux-thunk处理副作用的缺点
(1)redux的副作用处理
redux中的数据流大致是:
UI—————>action(plain)—————>reducer——————>state——————>UI
redux是遵循函数式编程的规则,上述的数据流中,action是一个原始js对象(plain object)且reducer是一个纯函数,对于同步且没有副作用的操作,上述的数据流起到可以管理数据,从而控制视图层更新的目的。
但是如果存在副作用,比如ajax异步请求等等,那么应该怎么做?
如果存在副作用函数,那么我们需要首先处理副作用函数,然后生成原始的js对象。如何处理副作用操作,在redux中选择在发出action,到reducer处理函数之间使用中间件处理副作用。
redux增加中间件处理副作用后的数据流大致如下:
UI——>action(side function)—>middleware—>action(plain)—>reducer—>state—>UI
在有副作用的action和原始的action之间增加中间件处理,从图中我们也可以看出,中间件的作用就是:
转换异步操作,生成原始的action,这样,reducer函数就能处理相应的action,从而改变state,更新UI。
(2)redux-thunk
在redux中,thunk是redux作者给出的中间件,实现极为简单,10多行代码:
function createThunkMiddleware(extraArgument) { return ({ dispatch, getState }) => next => action => { if (typeof action === 'function') { return action(dispatch, getState, extraArgument); }return next(action);};
}const thunk = createThunkMiddleware();
thunk.withExtraArgument = createThunkMiddleware;
export default thunk;
这几行代码做的事情也很简单,判别action的类型,如果action是函数,就调用这个函数,调用的步骤为:
action(dispatch, getState, extraArgument);发现实参为dispatch和getState,因此我们在定义action为thunk函数是,一般形参为dispatch和getState。
(3)redux-thunk的缺点
hunk的缺点也是很明显的,thunk仅仅做了执行这个函数,并不在乎函数主体内是什么,也就是说thunk使
得redux可以接受函数作为action,但是函数的内部可以多种多样。比如下面是一个获取商品列表的异步操作所对应的action:export default ()=>(dispatch)=>{ fetch('/api/goodList',{ //fecth返回的是一个promise method: 'get', dataType: 'json', }).then(function(json){ var json=JSON.parse(json); if(json.msg==200){ dispatch({type:'init',data:json.data}); } },function(error){ console.log(error); }); };从这个具有副作用的action中,我们可以看出,函数内部极为复杂。如果需要为每一个异步操作都如此定义一个action,显然action不易维护。
action不易维护的原因:
- action的形式不统一
- 就是异步操作太为分散,分散在了各个action中
2.redux-saga写一个hellosaga
跟redux-thunk不同的是,redux-saga是控制执行的generator,在redux-saga中action是原始的js对象,把所有的异步副作用操作放在了saga函数里面。这样既统一了action的形式,又使得异步操作集中可以被集中处理。
redux-saga是通过genetator实现的,如果不支持generator需要通过插件babel-polyfill转义。我们接着来实现一个输出hellosaga的例子。
(1)创建一个helloSaga.js文件
export function * helloSaga() { console.log('Hello Sagas!'); }(2)在redux中使用redux-saga中间件
在main.js中:
import { createStore, applyMiddleware } from 'redux' import createSagaMiddleware from 'redux-saga' import { helloSaga } from './sagas' const sagaMiddleware=createSagaMiddleware(); const store = createStore( reducer, applyMiddleware(sagaMiddleware) ); sagaMiddleware.run(helloSaga); //会输出Hello, Sagas!和调用redux的其他中间件一样,如果想使用redux-saga中间件,那么只要在applyMiddleware中调用一个createSagaMiddleware的实例。唯一不同的是需要调用run方法使得generator可以开始执行。
3.redux-saga的使用技术细节
redux-saga除了上述的action统一、可以集中处理异步操作等优点外,redux-saga中使用声明式的Effect以及提供了更加细腻的控制流。
(1)声明式的Effect
redux-saga中最大的特点就是提供了声明式的Effect,声明式的Effect使得redux-saga监听原始js对象形式的action,并且可以方便单元测试,我们一一来看。
- 首先,在redux-saga中提供了一系列的api,比如take、put、all、select等API ,在redux-saga中将这一系列的api都定义为Effect。这些Effect执行后,当函数resolve时返回一个描述对象,然后redux-saga中间件根据这个描述对象恢复执行generator中的函数。
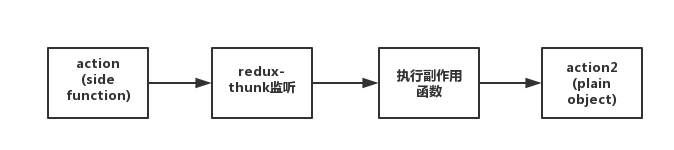
首先来看redux-thunk的大体过程:
action1(side function)—>redux-thunk监听—>执行相应的有副作用的方法—>action2(plain object)
转化到action2是一个原始js对象形式的action,然后执行reducer函数就会更新store中的state。
而redux-saga的大体过程如下:
action1(plain object)——>redux-saga监听—>执行相应的Effect方法——>返回描述对象—>恢复执行异步和副作用函数—>action2(plain object)
对比redux-thunk我们发现,redux-saga中监听到了原始js对象action,并不会马上执行副作用操作,会先通过Effect方法将其转化成一个描述对象,然后再将描述对象,作为标识,再恢复执行副作用函数。
通过使用Effect类函数,可以方便单元测试,我们不需要测试副作用函数的返回结果。只需要比较执行Effect方法后返回的描述对象,与我们所期望的描述对象是否相同即可。
举例来说,call方法是一个Effect类方法:
import { call } from 'redux-saga/effects'
function* fetchProducts() {
const products = yield call(Api.fetch, '/products')
// ...
}
上述代码中,比如我们需要测试Api.fetch返回的结果是否符合预期,通过调用call方法,返回一个描述对象。这个描述对象包含了所需要调用的方法和执行方法时的实际参数,我们认为只要描述对象相同,也就是说只要调用的方法和执行该方法时的实际参数相同,就认为最后执行的结果肯定是满足预期的,这样可以方便的进行单元测试,不需要模拟Api.fetch函数的具体返回结果。
import { call } from 'redux-saga/effects' import Api from '...'const iterator = fetchProducts()
// expects a call instruction
assert.deepEqual(
iterator.next().value,
call(Api.fetch, '/products'),
"fetchProducts should yield an Effect call(Api.fetch, './products')"
)
(2)Effect提供的具体方法
下面来介绍几个Effect中常用的几个方法,从低阶的API,比如take,call(apply),fork,put,select等,以及高阶API,比如takeEvery和takeLatest等,从而加深对redux-saga用法的认识(这节可能比较生涩,在第三章中会结合具体的实例来分析,本小节先对各种Effect有一个初步的了解)。
引入:
import {take,call,put,select,fork,takeEvery,takeLatest} from 'redux-saga/effects'
- take
take这个方法,是用来监听action,返回的是监听到的action对象。比如:
const loginAction = { type:'login' }在UI Component中dispatch一个action:
dispatch(loginAction)在saga中使用:
const action = yield take('login');可以监听到UI传递到中间件的Action,上述take方法的返回,就是dipath的原始对象。一旦监听到login动作,返回的action为:
{ type:'login' }
- call(apply)
call和apply方法与js中的call和apply相似,我们以call方法为例:
call(fn, ...args)call方法调用fn,参数为args,返回一个描述对象。不过这里call方法传入的函数fn可以是普通函数,也可以是generator。call方法应用很广泛,在redux-saga中使用异步请求等常用call方法来实现。
yield call(fetch,'/userInfo',username)
- put
在前面提到,redux-saga做为中间件,工作流是这样的:
UI——>action1————>redux-saga中间件————>action2————>reducer..
从工作流中,我们发现redux-saga执行完副作用函数后,必须发出action,然后这个action被reducer监听,从而达到更新state的目的。相应的这里的put对应与redux中的dispatch,工作流程图如下:
从图中可以看出redux-saga执行副作用方法转化action时,put这个Effect方法跟redux原始的dispatch相似,都是可以发出action,且发出的action都会被reducer监听到。put的使用方法:
yield put({type:'login'})
- select
put方法与redux中的dispatch相对应,同样的如果我们想在中间件中获取state,那么需要使用select。select方法对应的是redux中的getState,用户获取store中的state,使用方法:
const state= yield select()
- fork
fork方法在第三章的实例中会详细的介绍,这里先提一笔,fork方法相当于web work,fork方法不会阻塞主线程,在非阻塞调用中十分有用。
- takeEvery和takeLatest
takeEvery和takeLatest用于监听相应的动作并执行相应的方法,是构建在take和fork上面的高阶api,比如要监听login动作,好用takeEvery方法可以:
takeEvery('login',loginFunc)takeEvery监听到login的动作,就会执行loginFunc方法,除此之外,takeEvery可以同时监听到多个相同的action。
takeLatest方法跟takeEvery是相同方式调用:
takeLatest('login',loginFunc)与takeLatest不同的是,takeLatest是会监听执行最近的那个被触发的action。
4.redux-saga实现一个登陆和列表样例
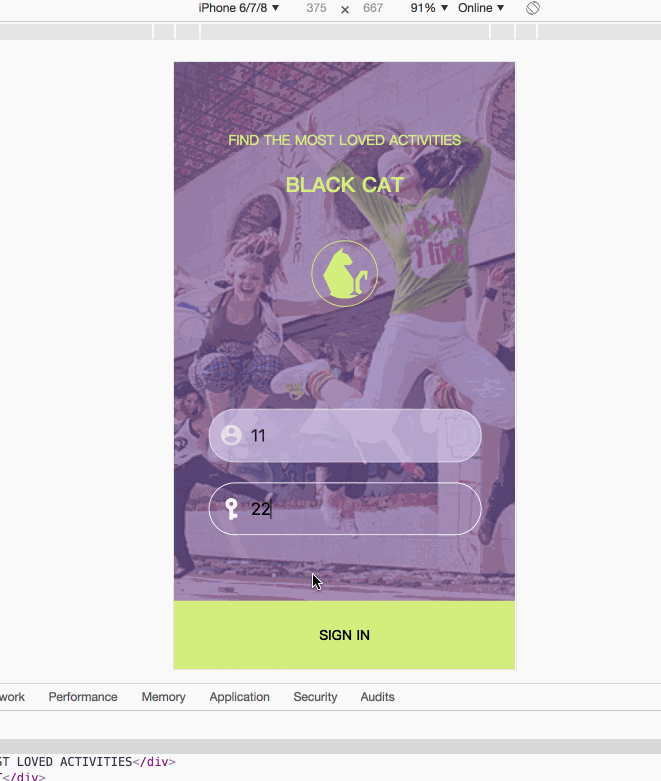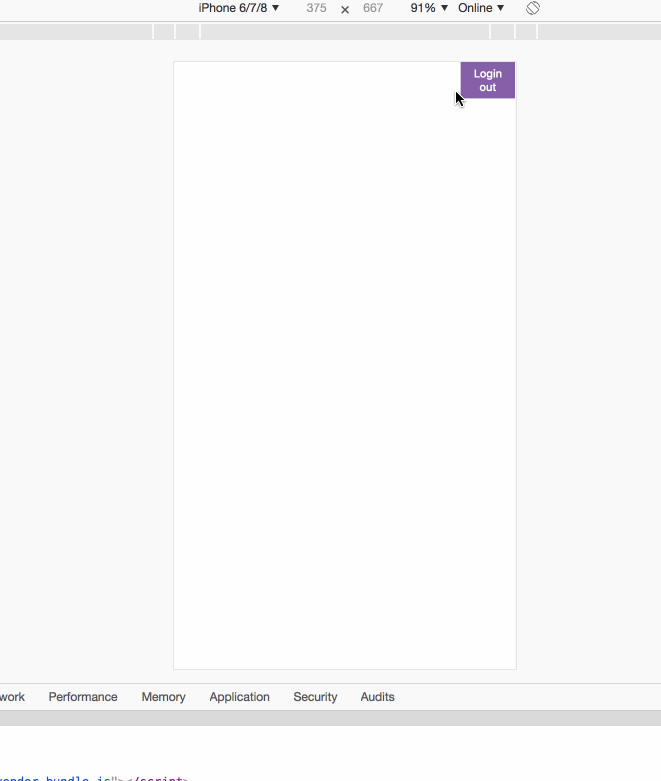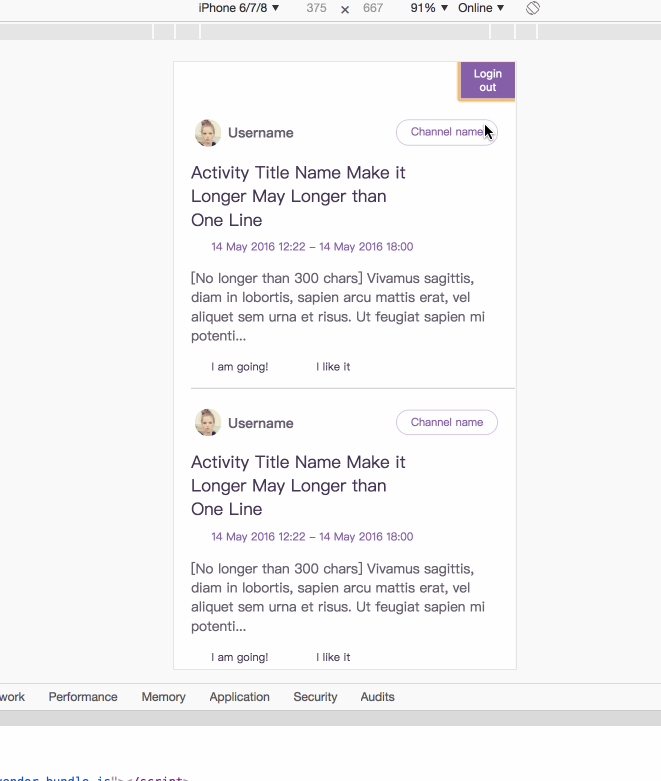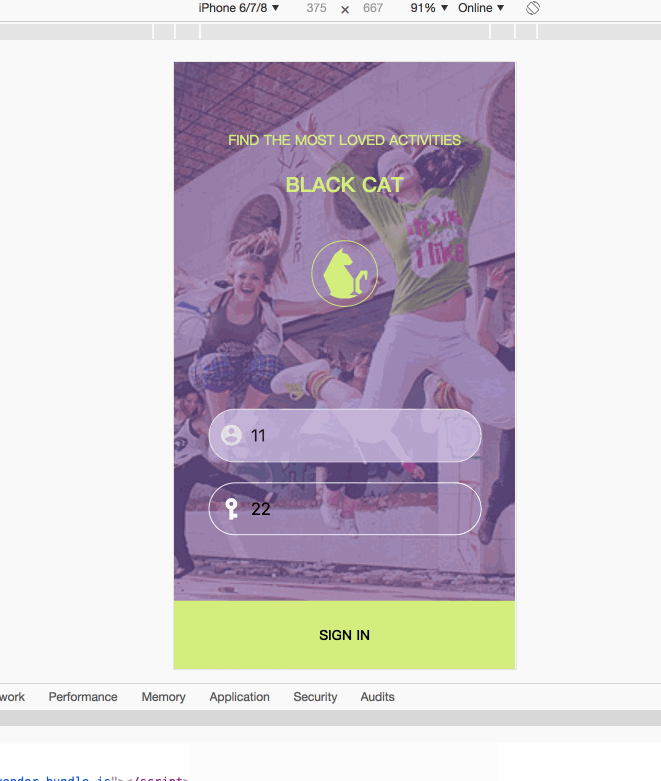
接着我们来实现一个redux-saga样例,存在一个登陆页,登陆成功后,显示列表页,并且,在列表页,可
以点击登出,返回到登陆页。例子的最终展示效果如下:
样例的功能流程图为:
接着我们按照上述的流程来一步步的实现所对应的功能。
(1)LoginPanel(登陆页)
登陆页的功能包括
- 输入时时保存用户名
- 输入时时保存密码
- 点击sign in 请求判断是否登陆成功
I)输入时时保存用户名和密码
用户名输入框和密码框onchange时触发的函数为:
changeUsername:(e)=>{ dispatch({type:'CHANGE_USERNAME',value:e.target.value}); }, changePassword:(e)=>{ dispatch({type:'CHANGE_PASSWORD',value:e.target.value}); }在函数中最后会dispatch两个action:CHANGE_USERNAME和CHANGE_PASSWORD。
在saga.js文件中监听这两个方法并执行副作用函数,最后put发出转化后的action,给reducer函数调用:
function * watchUsername(){ while(true){ const action= yield take('CHANGE_USERNAME'); yield put({type:'change_username', value:action.value}); } } function * watchPassword(){ while(true){ const action=yield take('CHANGE_PASSWORD'); yield put({type:'change_password', value:action.value}); } }最后在reducer中接收到redux-saga的put方法传递过来的action:change_username和change_password,然后更新state。
II)监听登陆事件判断登陆是否成功
在UI中发出的登陆事件为:
toLoginIn:(username,password)=>{ dispatch({type:'TO_LOGIN_IN',username,password}); }登陆事件的action为:TO_LOGIN_IN.对于登入事件的处理函数为:
while(true){ //监听登入事件 const action1=yield take('TO_LOGIN_IN'); const res=yield call(fetchSmart,'/login',{ method:'POST', body:JSON.stringify({ username:action1.username, password:action1.password }) if(res){ put({type:'to_login_in'}); } });在上述的处理函数中,首先监听原始动作提取出传递来的用户名和密码,然后请求是否登陆成功,如果登陆成功有返回值,则执行put的action:to_login_in.
(2) LoginSuccess(登陆成功列表展示页)
登陆成功后的页面功能包括:
- 获取列表信息,展示列表信息
- 登出功能,点击可以返回登陆页面
I)获取列表信息
import {delay} from 'redux-saga';
function * getList(){
try {
yield delay(3000);
const res = yield call(fetchSmart,'/list',{
method:'POST',
body:JSON.stringify({})
});
yield put({type:'update_list',list:res.data.activityList});
} catch(error) {
yield put({type:'update_list_error', error});
}
}
为了演示请求过程,我们在本地mock,通过redux-saga的工具函数delay,delay的功能相当于延迟xx秒,因为真实的请求存在延迟,因此可以用delay在本地模拟真实场景下的请求延迟。
II)登出功能
const action2=yield take('TO_LOGIN_OUT'); yield put({type:'to_login_out'});与登入相似,登出的功能从UI处接受action:TO_LOGIN_OUT,然后转发action:to_login_out
(3) 完整的实现登入登出和列表展示的代码
function * getList(){ try { yield delay(3000); const res = yield call(fetchSmart,'/list',{ method:'POST', body:JSON.stringify({}) }); yield put({type:'update_list',list:res.data.activityList}); } catch(error) { yield put({type:'update_list_error', error}); } }function * watchIsLogin(){
while(true){
//监听登入事件
const action1=yield take('TO_LOGIN_IN');const res=yield call(fetchSmart,'/login',{ method:'POST', body:JSON.stringify({ username:action1.username, password:action1.password }) }); //根据返回的状态码判断登陆是否成功 if(res.status===10000){ yield put({type:'to_login_in'}); //登陆成功后获取首页的活动列表 yield call(getList); } //监听登出事件 const action2=yield take('TO_LOGIN_OUT'); yield put({type:'to_login_out'});
}
}
通过请求状态码判断登入是否成功,在登陆成功后,可以通过:
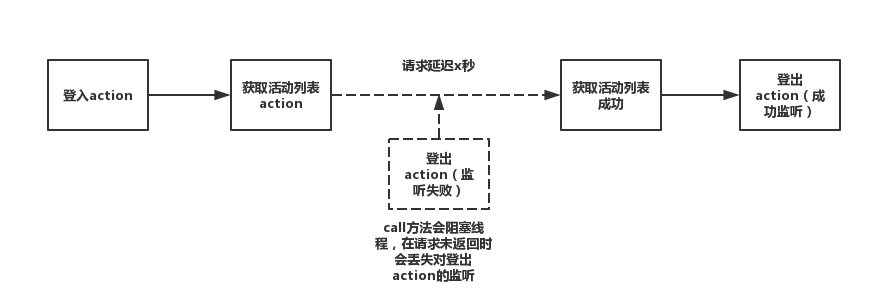
yield call(getList)的方式调用获取活动列表的函数getList。这样咋一看没有什么问题,但是注意call方法调用是会阻塞主线程的,具体来说:
在call方法调用结束之前,call方法之后的语句是无法执行的
如果call(getList)存在延迟,call(getList)之后的语句 const action2=yieldtake('TO_LOGIN_OUT')在call方法返回结果之前无法执行
在延迟期间的登出操作会被忽略。
用框图可以更清楚的分析:
call方法调用阻塞主线程的具体效果如下动图所示:
白屏时为请求列表的等待时间,在此时,我们点击登出按钮,无法响应登出功能,直到请求列表成功,展示列表信息后,点击登出按钮才有相应的登出功能。也就是说call方法阻塞了主线程。
(4) 无阻塞调用
我们在第二章中,介绍了fork方法可以类似与web work,fork方法不会阻塞主线程。应用于上述例子,我们可以将:
yield call(getList)修改为:
yield fork(getList)这样展示的结果为:
通过fork方法不会阻塞主线程,在白屏时点击登出,可以立刻响应登出功能,从而返回登陆页面。
5.总结
通过上述章节,我们可以概括出redux-saga做为redux中间件的全部优点:
统一action的形式,在redux-saga中,从UI中dispatch的action为原始对象
集中处理异步等存在副作用的逻辑
通过转化effects函数,可以方便进行单元测试
完善和严谨的流程控制,可以较为清晰的控制复杂的逻辑。
Recommend Projects
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
TensorFlow
An Open Source Machine Learning Framework for Everyone
Django
The Web framework for perfectionists with deadlines.
Laravel
A PHP framework for web artisans
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
Recommend Topics
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
web
Some thing interesting about web. New door for the world.
server
A server is a program made to process requests and deliver data to clients.
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Visualization
Some thing interesting about visualization, use data art
Game
Some thing interesting about game, make everyone happy.
Recommend Org
We are working to build community through open source technology. NB: members must have two-factor auth.
Microsoft
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba
Alibaba Open Source for everyone
D3
Data-Driven Documents codes.
Tencent
China tencent open source team.