This blog showcases an example of Bayesian A/B testing to assess click-through rate (CTR).
Imaging the engineers of your team are working on some new feature of some product. To see users' reaction, data scientists propose A/B testing.
Taking this scenario into the real world, we split users randomly into a case (A: with new feature) and control (B: without new feature) group. Then, statistical testing would be used to determine which variant (A or B) performs better for a given conversion goal. The test is called an A/B test. Note before working on the A/B testing, we must conduct A/A testing to ensure the system works the way you think. In other words, you must run an experiment where both groups are the same.
A classical significance testing makes a decision based on p-value which is defined as the likelihood that you would see evidence stronger than what was observed, assuming the null hypothesis is true. This reflects if the different effect size is merely due to chance.
However, p-values are not without controversy. Critiques of p-Values include:
-
Interpretation: p-values are hard to interpret and often misinterpreted. The real question we care is how likely A is actually better (or the probability that the null hypothesis is true)? The issue is p-values do not provide this probability. Furthermore, one may also want to know if A is better, then how much better. Unfortunately, p-values have no clue, either. The classical significance testing can at most tell the significance of the hypotheses but not the magnitude.
-
Comparison: p-values are not straightforward to compare across studies. The power of significance test depends on sample size and effect size. For example, would you prefer to invest resources in following up a feature with a p-value of 0.002 in a study with 10 observations or a feature with a p-value of 0.02 in a study with 1,000 observations? The answers to these questions are not obvious. This is extremely true for multiple testing. For the previous click-through rate (CTR) study, we usually run repeated tests as the more data comes in. If you continuously monitor the testing and the correcting p-value, you are very likely to see an effect, even if there is none. Thus, using p-values give us an extremely high false positive rate. Of course, to avoid this, we could arbitrarily adjust our significance level [4] or just use classical Bonferroni correction. But none of them comes as elegant as Bayesian.
Next, let's see how Bayesian A/B testing can mitigate these issues.
First, what is Bayesian A/B testing? Following the standard Bayesian approach, Bayesian A/B testing updates the probability of results with prior beliefs. The updated beliefs after having seen the data are called "posterior".
For the previous example, say, we collect some data:
| Clicked | Not Clicked | |
|---|---|---|
| A: with new feature | 25 | 75 |
| B: without new feature | 15 | 85 |
One can compute conversion rates, 25% and 15%, for two groups. The prior knowledge in this are we expect a small improvement here, say, 5%. It would be unreasonable that the conversion rate will surge to 50%. So, we begin with a prior belief on conversion rate of 20%, and then update it as the data starts coming in.
To describe this belief, we choose Beta(2, 10). We can simulate observations with the posteriors of the two groups. One can clearly see two distributions overlap. Then, how can we tell which one is better? We tackle this by computing the posterior that A gets more clicks than B. We end up with this posterior of 0.95, in which case, we can conclude there is 95% chance that A is better than B.
It is also flexible for Bayesian A/B testing to reveal the magnitude of significance. We just need to simply plot density of the ratio that A beats B (left figure). Actually, it is more intuitive to illustrate this by using cumulative distribution function (CDF) (right figure) [5]. We can simulate the similar result (x is the difference of #clicks between A and B) and it shows that there is large chance that A is better.
| cdf | |
|---|---|
 |
 |
Thus, data scientists would say "ship this new feature"!
The real power of using Bayesian is that one can achieve a robust result by incorporating informative priors with limited size. We highlight this by another simulation.
Let's pretend that we know adding new features does no good. To simulate this, we generate two independent samples from Bernoulli distribution (Clicked / Not Clicked) and compute the ratio that A is better than B. We repeat this procedure until we accumulate 500 observations[6] with some replicates. Ideally, the estimates should remain close to 0 (i.e. null effect) at all times: after all, we generate data from the same distribution. In reality, this is what we have (y is the difference of #clicks between A and B):
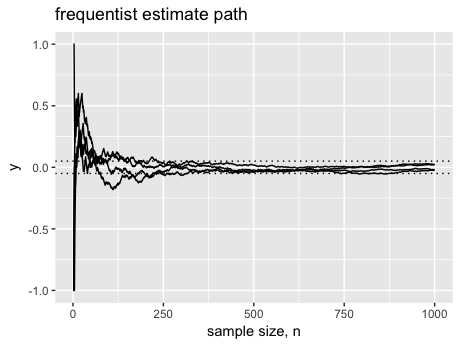

With limited sample size, frequentist estimates are rather variable which can easily get false positive results; Bayesian estimates remain robust and stay in the same state for the priors.
In this post, we have shown the ideas of doing A/B testing from a Bayesian perspective. Frequentist hypothesis testing with p-values suffers from several issues while Bayesian offers nice interpretation of uncertainty and can achieve convergence much faster with limited samples. But in some cases, it would be a challenge to specify the priors. Using an informative prior will make it an equivalent classical test.
