joeyguo / blog Goto Github PK
View Code? Open in Web Editor NEWjoeyguo's blog 请 Watch 或 Star
Home Page: https://github.com/joeyguo/blog
joeyguo's blog 请 Watch 或 Star
Home Page: https://github.com/joeyguo/blog







































































































































































































帧动画中含有大量的图片,通过图片优化、减少图片整体大小,将能够节省资源,提高性能。下面将一一列举优化方式及解决方案。
使用 gka 一键图片优化并生成动画文件
GitHub: https://github.com/gkajs/gka
帧动画中,有些帧使用的图片其实是一模一样的。如果能让这些帧引用同一张图片,不再重复加载展示一样的图片,那将能够减少相同图片的加载。
需要做的工作:

通过裁剪图片四周的空白区域,减少图片的大小。
需要做的工作:

为了能够减少 http 请求,减少整体帧图片的大小,可以对图片进行合图处理。
需要做的工作:

空白裁剪与去重强强联合,更加强大的优化。
在帧动画中,有些帧的区别实际上只是图片内容的移动,当对这些图片进行空白裁剪后,会发现裁剪后的图片是一致的,于是可以进行图片复用

空白裁剪+去重将能达到更多场景的图片复用,特别是当存在大量的可以经过裁剪后复用的帧,那么优化的效果非常可观。
基于空白裁剪 + 去重,最终再进行合图优化

通过 空白裁剪 + 去重 + 合图 进行图片优化,能够大大减少图片资源大小。通过最终处理后的图片与图片信息文件后,编写代码还原每帧图片展示,从而进行帧动画播放。

上面一步步的图片处理以及数据信息应该如何实现呢?
使用 gka,仅需一行命令,完成下列工作
gka <dir> -t canvas # dir 为帧图片目录欢迎使用,欢迎任何意见或建议,谢谢 :D
coming soon..
在《前端资源加载失败优化》文章中,我们聊到了前端资源加载失败的监控方式,以及资源加载失败时的优化方案。通过对加载失败的资源更换域名动态重新加载、同时确保最终代码正常的执行顺序,从而有效地减少了因为资源加载失败导致的网页异常。到此,资源文件成功加载了!但加载到的是否就是正确的资源呢?是否会在加载过程中被半路劫持?此时又该如何监控?是否还能做更多的防护措施呢?本文将逐步进行分析。
流量劫持在 Web 项目中是一个老生常谈的话题了,常见的劫持方式是往 JS 代码文件中注入一段脚本,从而实现一段广告“完美”植入,而当注入的位置稍有偏差,导致代码执行异常,页面将完全不可用。

上面现象在使用以明文传输、不带加密的 HTTP 协议中经常遇到,毕竟流量在传输过程中裸奔,劫持轻而易举。HTTPS 应运而生,通过证书加密等方式保证了传输过程中的数据完整性,开启 HTTPS 后,这类劫持问题基本不复存在了。
原本以为就此安稳一生,直到有一天,钟声再次响起,有用户反馈访问页面时看到了广告、还有的打开页面后白屏。通过具体的定位分析,最终发现返回的 CDN 文件只剩一半内容。
难道 HTTPS 协议被破译了吗?其实并不是。
HTTPS 是可以有效应对流量劫持的问题,然而很多提供 HTTPS 的 CDN 服务在回源的时候采用的 HTTP 协议,流量劫持便有机可乘,那么开启全链路的 HTTPS 是否就万无一失了呢?大部分情况确实如此。但如果遇到 CDN 服务入侵、源头污染,或者用户信任了异常证书导致的中间人劫持,千里之堤,溃于蚁穴,防御之门被摧毁后,依然任人宰割。为了尽可能的安全,或许我们可以再加一道防线,那就是 SRI。
SRI 是用来校验资源是否完整的安全方案。通过为页面引用的资源指定信息摘要,当资源被劫持篡改内容时,浏览器校验信息摘要不匹配,将会拒绝代码执行并抛出加载异常,保证加载资源的完整性。
使用 SRI 只需要给页面标签添加 integrity 属性,属性值为签名算法(sha256、sha384、sha512)和摘要签名内容组成,中间用 - 分隔。

function getIntegrity() {
const hashFuncName = 'sha256';
const hash = crypto
.createHash(hashFuncName)
.update(source, 'utf8')
.digest('base64');
return hashFuncName + '-' + hash;
}我们也可以借助 webpack-subresource-integrity 轻易实现 integrity 的添加过程,保持对开发者透明。
开启 SRI,浏览器会对相关资源进行 CORS 校验,所以被加载的资源要么在同域下,要么得满足 CORS 机制(具体方式可查看 脚本错误量极致优化-监控上报与Script error 中 跨源资源共享机制( CORS ) 章节)。
至此,当资源内容被劫持篡改时,浏览器校验签名不匹配将使得异常资源不被执行,并触发加载失败。从而进入到资源加载失败的监控流程中,最终可以通过切换 CDN 域名或主域名进行加载重试,直到加载上正确资源,避免资源被劫持篡改内容后注入广告或白屏等情况。
监控及重加载的具体方式可见 《前端资源加载失败优化》。加载失败的原因有很多,那么该如何区分哪些是由 SRI 机制触发的呢?可以采用下面思路:
最终搭配上报和告警机制,当遇到劫持问题时,及时收到消息。

上面是我们遇到的劫持问题,上报量急剧上升,处理后快速下降。遇到劫持问题之后,我们该如何应对呢?
向运营商客服投诉或工信部投诉或许是个办法。不过在此之前我们可以先主动触发刷新 CDN 节点缓存的资源,避免被劫持的资源被继续访问。除此之外,对于已经缓存到异常资源的用户,特别是在不方便强制刷新页面的环境下,下次访问会先接着访问异常缓存造成二次伤害,对此通过修改文件 hash,重新发布强制刷新资源,问题得以解决。
资源内容完整(不被篡改)加载下来了,但加载的是否就都是我们需要的资源呢?是否会因为代码问题导致 XSS、或是浏览器使用了异常插件,最终导致加载了其他不需要的资源而影响业务呢?
对此,我们可以开启 CSP 机制来保证加载的是需要的资源文件、执行的是正常的脚本。
一方面通过制定 CSP 的外链白名单机制,限制了不可信域名的资源加载;另一方面通过开启 nonce 模式,确保执行的是正常的内联脚本。相关内容可以查看[《XSS终结者-CSP理论与实践》和《Csp Nonce - 守护你的 inline Script》这两篇文章。
HTTPS 可以有效应对流量劫持的问题,SRI 在资源完整性再上一道屏障,CSP 也进行了其他方面的补充。“三驾马车”为页面资源安全“保驾护航”。当然这也绝非银弹,安全之路充满着荆棘与挑战,任重道远。
以上为本文所有内容,如有不妥,恳请斧正,谢谢。
Web 项目上线后,开始开门迎客,等待着来自大江南北、有着各式各样网络状态的用户莅临。在千差万别的网络状态中,访问页面难免会遇到前端资源加载失败的情况,占比或许不高,但一遇到,轻则页面样式错乱,重则白屏打不开,影响用户体验感受,紧急情况下甚至影响了用户的工作,属于非常严重的问题。本文将围绕着前端 JS 文件从如何监控加载失败、加载失败如何优化、始终加载失败又该如何处理等问题逐一分析。
我们可以给 script 标签添加上 onerror 属性,这样在加载失败时触发事件回调,从而捕捉到异常。
<script onerror="onError(this)"></script> 并且,借助构建工具( 如 webpack 的 script-ext-html-webpack-plugin 插件) ,我们可以轻易地完成对所有 script 标签自动化注入 onerror 标签属性,不费吹灰之力。
new ScriptExtHtmlWebpackPlugin({
custom: {
test: /\.js$/,
attribute: 'onerror',
value: 'onError(this)'
}
})上述方案已然不错,但我们也试想是否可以减少 onerrror 标签大量注入呢?类比脚本错误 onerror 的全局监控方式(详见:脚本错误量极致优化-监控上报与Script error),是否也可以通过 window.onerror 去全局监听加载失败呢?
答案否定的,因为 onerror 的事件并不会向上冒泡,window.onerror 接收不到加载失败的错误。冒泡虽不行,但捕获可以!我们可以通过捕获的方式全局监控加载失败的错误,虽然这也监控到了脚本错误,但通过 !(event instanceof ErrorEvent) 判断便可以筛选出加载失败的错误。
window.addEventListener('error', (event) => {
if (!(event instanceof ErrorEvent)) {
// todo
}
}, true);通过监控数据分析,我们发现现实情况不容乐观。访问页面时存在资源加载失败的情况超过了 10000 例/天,且随着页面访问量的上升而增加。
另外,监控资源加载失败的方式不止这些,上述两种方式都属于较好的方案,其他的方式就不再展开。
有了监控数据后,便可着手优化。当资源加载失败时,刷新页面可能是最简单直接的尝试恢复方式。于是当监控到资源加载失败时,我们通过 location.reload(true) 强制浏览器刷新重新加载资源,并且为了防止出现一直刷新的情况,结合了 SessionStorage 限制自动刷新次数。

通过监控数据发现,通过自动刷新页面,最终能恢复正常加载占异常总量 30%,优化比例不高,且刷新页面导致了出现多次的页面全白,用户体验不好。
只对加载失败的文件进行重加载。并且,为了防止域名劫持等导致加载失败的原因,对加载失败文件采用替换域名的方式进行重加载。替换域名的方式可以采用重试多个 cdn 域名,并最终重试到页面主域名的静态服务器上(主域名被劫持的可能性小)

然而,失败资源重加载成功后,页面原有的加载顺序可能发生变化,最终执行顺序发现变化也将导致执行异常。

在不需要考虑兼容性的情况下,资源加载失败时通过 document.write 写入新的 script 标签,可以阻塞后续 script 脚本的执行,直到新标签加载并执行完毕,从而保证原来的顺序。但它在IE、Edge却无法正常工作,满足不了我们项目的兼容性。
于是我们需要增加 “管理 JS 执行顺序” 的逻辑。使 JS 文件加载完成后,先检查所依赖的文件是否都加载完成,再执行业务逻辑。当存在加载失败时,则会等待文件加载完成后再执行,从而保证正常执行。

手动管理模块文件之间的依赖和执行时机存在着较大的维护成本。而实际上现代的模块打包工具,如 webpack ,已经天然的处理好这个问题。通过分析构建后的代码可以发现,构建生成的代码不仅支持模块间的依赖管理,也支持了上述的等待加载完成后再统一执行的逻辑。
// 检查是否都加载完成,如是,则开始执行业务逻辑
function checkDeferredModules() {
// ...
if(fulfilled) {
// 所有都加载,开始执行
result = __webpack_require__(__webpack_require__.s = deferredModule[0]);
}
}
然而,在默认情况下,业务代码的执行不会判断配置的 external 模块是否存在。所以当 external 文件未加载完成或加载失败时,使用对应模块将会导致报错。
"react": (function(module, exports) {
eval("(function() { module.exports = window[\"React\"]; }());");
})所以我们需要在业务逻辑执行前,保证所依赖的 external 都加载完成。最终通过开发 wait-external-webpack-plugin webpack 插件,在构建时分析所依赖的 external,并注入监控代码,等待所有依赖的文件都加载完成后再统一顺序执行。(详见:Webpack 打包后代码执行时机分析与优化)
至此,针对加载失败资源重试的逻辑最终都通过构建工具自动完成,对开发者透明。重试后存在加载失败的情况优化了 99%。减少了大部分原先加载失败导致异常的情况。
用户网络千变万化,或临时断网、或浏览器突然异常,那些始终加载失败的情况,我们又该如何应对呢?
一个友好的提醒弹框或是最后的稻草,避免用户的无效等待,缓解用户感受。
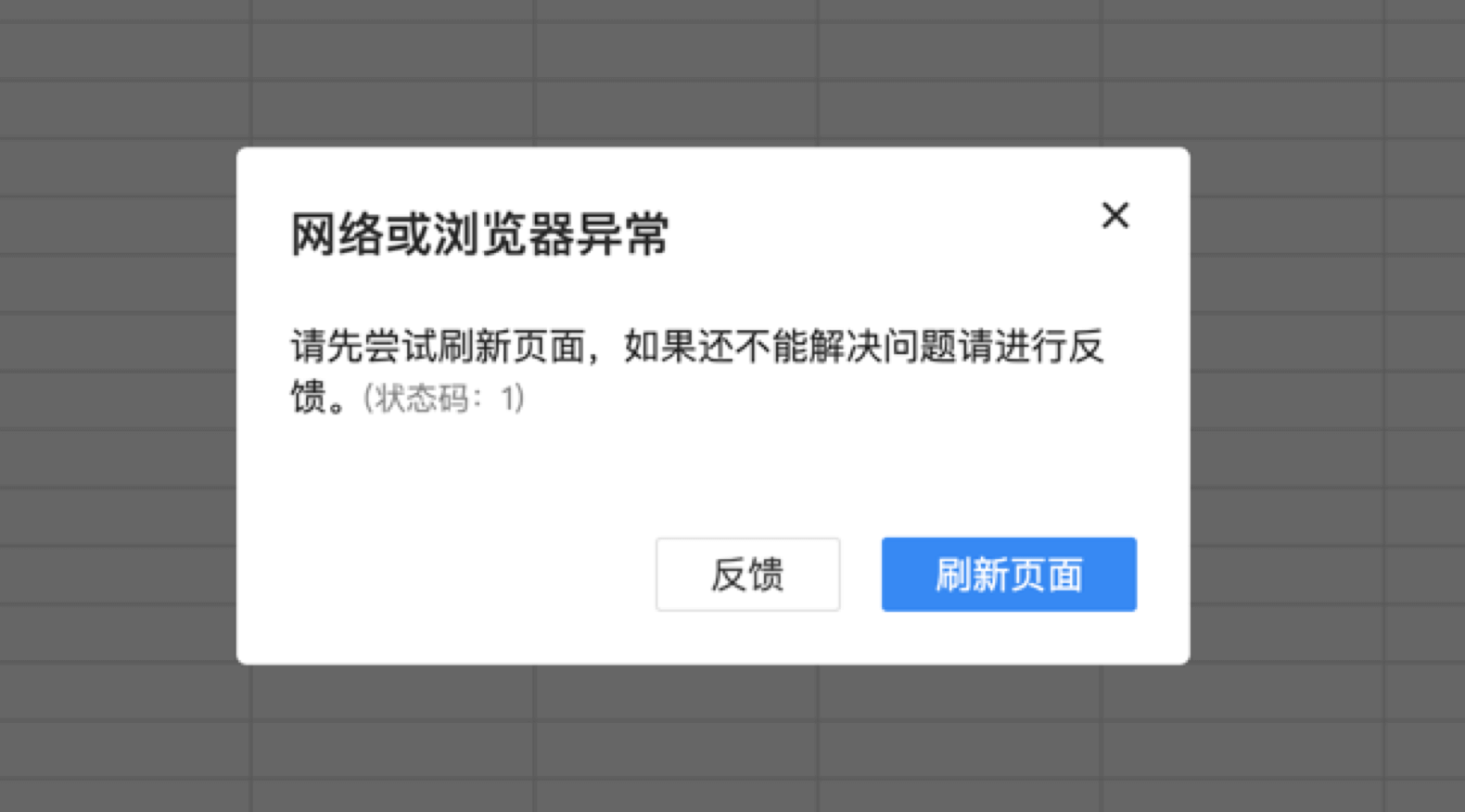
以上,便是对资源加载失败优化的整体方案,从如何监控加载失败、加载失败时重试、重试失败后的提醒等方面。大幅优化修正了加载失败的问题,也缓解着实遇到异常的用户使用体验。
如有不妥,恳请斧正,谢谢。
直出是什么?到底是怎样的性能优化?本文将结合从在浏览器输入url,到展示最终页面的过程来对其进行一步步分析,并将在手Q web 中的实际应用实践进行总结。
从用户输入 url 到展示最终页面的过程,这种模式可简单的分为以下 5 部分
具体流程图如下

这种处理形式应该占据大多数,然而也很容易发现一个问题就是请求数多,前后依赖大,如必须等待 JS 加载完成后执行时才会发起 数据请求,等待数据回来用户才可以展示最终页面,这种强依赖的关系使得整个应用的首屏渲染耗时增加不少。
数据请求在server端上提前获取,并和html一同返回,页面模板和数据的渲染在浏览器端上执行
在模式 1 中,第 1 点用户输入 url 时 server 端不做其他处理直接返回 html ,在第 4 点向 server 请求获取数据。那么,同样都是向 server 请求获取,如果在第 1 点中将请求数据放在 server 上,将拿到的数据拼接到 HTML 上一并返回,那么可减少在前端页面上的一次数据请求时间。 这就是模式 2 - 数据直出所做的事,处理方式也很简单
具体可下面的流程图看出这种模式下

这种模式与模式1 相比,减少了这两种模式请求数据的耗时差距。这块差距有多少呢?
DNS解析(100~200ms可以缓存)
|
|
建立TCP链接 (三次握手100~200ms )
|
|
HTTP Request( 半个RTT )
|
|
HTTP Response( RTT 不确定优化空间 )
注: RTT 为 Round-trip time 缩写,表示一个数据包从发出到返回所用的时间。
由上面对 HTTP 的网络请求过程可看到建立一次完整的请求返回在耗时上明显的,特别是外网用户在进行 HTTP 请求时,由于网络等因素的影响,在网络连接及传输上将花费很多时间。而在服务端进行数据拉取,即使同样是 HTTP 请求,由于后端之间是处于同一个内网上的,所以传输十分高效,这是差距来源的大头,是优化的刚需。
数据请求在server端上提前获取,页面模板结合数据的渲染处理也在server上完成,输出最终 HTML
模式 2 中将依赖于JS文件加载回来才能去发起的数据请求挪到 server 中,数据随着 HTML 一并返回。然后等待 JS 文件加载完成,JS 将服务端已给到的数据与HTML结合处理,生成最终的页面文档。
数据请求能放到 server 上,对于数据与HTML结合处理也可以在server上做,从而减少等待 JS 文件的加载时间。 这就是模式3 - 直出 (服务端渲染),主要处理如下
可以从下图看出,页面的首屏展示不再需要等待 JS 文件回来,优化减少了这块时间

通过以上模式,将模式 1 - 常用模式中的第 3 和 4 点耗时进行了优化,那么可以再继续优化吗?
在页面文档不大情况下,可将CSS内联到HTML中,这是优化请求量的做法。直出稍微不同的是需要考虑的是服务端最终渲染出来的文档的大小,在范围内也可将 CSS 文件内联到 HTML 中。这样的话,便优化了 CSS 的获取时间,如下图

直出能够将常用模式优化到剩下了一次 HTML 请求,加快首屏渲染时间,使用服务端渲染,还能够优化前端渲染难以克服的 SEO 问题。而不管是简单的 数据直出 或是 服务端渲染直出 都能使页面的性能优化得到较大提高,以下将从实际应用中进行说明。
由于项目上线时间紧,所以在第一次优化上使用了数据直出的简单方式来优化首屏渲染时间。具体处理与 模式 2 数据直出方式 一致,与其不同的是这里使用了由 AlloyTeam 开发的 基于KOA的玄武直出服务 来作为前端与服务端间的中间层。形式如下

使用这种中间层的方式,在项目的开发过程中依然可使用前后端分离的方式,开发完后再将页面请求指向这个中间层服务上。中间层服务主要做了上述 模式 2 - 数据直出 中的处理
由于该中间层服务与具体server部署在相同的内网上,所以它们直接的数据交互是十分高效的,从而可达到 模式 2 - 数据直出 中所述的优化。
另一点,做为中间层玄武直出服务通过公司的L5负载均衡服务,完美兼容直出与非直出版本,即当直出服务挂掉了,也可以顺利走非直出版本,确保基本的用户体验,也能够更好的支持 A/BTest。
简单的数据方式直出同样迎来了较大的性能提升,手Q家校群列表页在首屏渲染完成时间上,相比于优化前的版本,数据直出有大概 650ms 的优化,提升约 35% 的性能。

在前后端没有分离时 使用后端渲染出模板的方式是与文中所述的直出方案效果是一致的,前后端分离后淡化了这种**,Node 的发展让更多的前端开始做后端事情,直出的方式也越来越被重视了。
历史的车轮滚滚向前,直出方案看似回到了服务端渲染的原点,实际上是在以前的基础上盘旋上升。有了更多的能力,便可以有更多的思考。期待前端会越来越强大,这不,react-native也让前端开始着手客户端的事儿了 ~
手Q家校群使用 React + Redux + Webpack架构,既然是 React,肯定不可忽略 React 同构 (服务端渲染) 关于React 同构直出的具体实践,我将其总结在另外一篇文章上,可点击查看 React同构直出优化总结
对于文章一开始提及的前端路由,对路由的实现原理感兴趣的也可点击查看 前端路由实现与 react-router 源码分析
感谢指教!
前端路由实现与 react-router 源码分析
在单页应用上,前端路由并不陌生。很多前端框架也会有独立开发或推荐配套使用的路由系统。那么,当我们在谈前端路由的时候,还可以谈些什么?本文将简要分析并实现一个的前端路由,并对 react-router 进行分析。
一个极简前端路由实现
说一下前端路由实现的简要原理,以 hash 形式(也可以使用 History API 来处理)为例,当 url 的 hash 发生变化时,触发 hashchange 注册的回调,回调中去进行不同的操作,进行不同的内容的展示。直接看代码或许更直观。
function Router() {
this.routes = {};
this.currentUrl = '';
}
Router.prototype.route = function(path, callback) {
this.routes[path] = callback || function(){};
};
Router.prototype.refresh = function() {
this.currentUrl = location.hash.slice(1) || '/';
this.routesthis.currentUrl;
};
Router.prototype.init = function() {
window.addEventListener('load', this.refresh.bind(this), false);
window.addEventListener('hashchange', this.refresh.bind(this), false);
}
window.Router = new Router();
window.Router.init();
上面路由系统 Router 对象实现,主要提供三个方法
init 监听浏览器 url hash 更新事件
route 存储路由更新时的回调到回调数组routes中,回调函数将负责对页面的更新
refresh 执行当前url对应的回调函数,更新页面
Router 调用方式以及呈现效果如下:点击触发 url 的 hash 改变,并对应地更新内容(这里为 body 背景色)
react-router 分析
react-router 与 history 结合形式
react-router 是基于 history 模块提供的 api 进行开发的,结合的形式本文记为 包装方式。所以在开始对其分析之前,先举一个简单的例子来说明如何进行对象的包装。
// 原对象
var historyModule = {
listener: [],
listen: function (listener) {
this.listener.push(listener);
console.log('historyModule listen..')
},
updateLocation: function(){
this.listener.forEach(function(listener){
listener('new localtion');
})
}
}
// Router 将使用 historyModule 对象,并对其包装
var Router = {
source: {},
init: function(source){
this.source = source;
},
// 对 historyModule的listen进行了一层包装
listen: function(listener) {
return this.source.listen(function(location){
console.log('Router listen tirgger.');
listener(location);
})
}
}
// 将 historyModule 注入进 Router 中
Router.init(historyModule);
// Router 注册监听
Router.listen(function(location){
console.log(location + '-> Router setState.');
})
// historyModule 触发回调
historyModule.updateLocation();
返回:
22
可看到 historyModule 中含有机制:historyModule.updateLocation() -> listener( ),Router 通过对其进行包装开发,针对 historyModule 的机制对 Router 也起到了作用,即historyModule.updateLocation() 将触发 Router.listen 中的回调函数 。点击查看完整代码
这种包装形式能够充分利用原对象(historyModule )的内部机制,减少开发成本,也更好的分离包装函数(Router)的逻辑,减少对原对象的影响。
react-router 使用方式
react-router 以 react component 的组件方式提供 API, 包含 Router,Route,Redirect,Link 等等,这样能够充分利用 react component 提供的生命周期特性,同时也让定义路由跟写 react component 达到统一,如下
render((
), document.body)
就这样,声明了一份含有 path to component 的各个映射的路由表。
react-router 还提供的 Link 组件(如下),作为提供更新 url 的途径,触发 Link 后最终将通过如上面定义的路由表进行匹配,并拿到对应的 component 及 state 进行 render 渲染页面。
从点击 Link 到 render 对应 component ,路由中发生了什么
为何能够触发 render component ?
主要是因为触发了 react setState 的方法从而能够触发 render component。
从顶层组件 Router 出发(下面代码从 react-router/Router 中摘取),可看到 Router 在 react component 生命周期之组件被挂载前 componentWillMount 中使用 this.history.listen 去注册了 url 更新的回调函数。回调函数将在 url 更新时触发,回调中的 setState 起到 render 了新的 component 的作用。
Router.prototype.componentWillMount = function componentWillMount() {
// .. 省略其他
var createHistory = this.props.history;
this.history = _useRoutes2['default'](createHistory)({
routes: _RouteUtils.createRoutes(routes || children),
parseQueryString: parseQueryString,
stringifyQuery: stringifyQuery
});
this._unlisten = this.history.listen(function (error, state) {
_this.setState(state, _this.props.onUpdate);
});
};
上面的 _useRoutes2 对 history 操作便是对其做一层包装,所以调用的 this.history 实际为包装以后的对象,该对象含有 _useRoutes2 中的 listen 方法,如下
function listen(listener) {
return history.listen(function (location) {
// .. 省略其他
match(location, function (error, redirectLocation, nextState) {
listener(null, nextState);
});
});
}
可看到,上面代码中,主要分为两部分
使用了 history 模块的 listen 注册了一个含有 setState 的回调函数(这样就能使用 history 模块中的机制)
回调中的 match 方法为 react-router 所特有,match 函数根据当前 location 以及前面写的 Route 路由表匹配出对应的路由子集得到新的路由状态值 state,具体实现可见 react-router/matchRoutes ,再根据 state 得到对应的 component ,最终执行了 match 中的回调 listener(null, nextState) ,即执行了 Router 中的监听回调(setState),从而更新了展示。
以上,为起始注册的监听,及回调的作用。
如何触发监听的回调函数的执行?
这里还得从如何更新 url 说起。一般来说,url 更新主要有两种方式:简单的 hash 更新或使用 history api 进行地址更新。在 react-router 中,其提供了 Link 组件,该组件能在 render 中使用,最终会表现为 a 标签,并将 Link 中的各个参数组合放它的 href 属性中。可以从 react-router/ Link 中看到,对该组件的点击事件进行了阻止了浏览器的默认跳转行为,而改用 history 模块的 pushState 方法去触发 url 更新。
Link.prototype.render = function render() {
// .. 省略其他
props.onClick = function (e) {
return _this.handleClick(e);
};
if (history) {
// .. 省略其他
props.href = history.createHref(to, query);
}
return _react2['default'].createElement('a', props);
};
Link.prototype.handleClick = function handleClick(event) {
// .. 省略其他
event.preventDefault();
this.context.history.pushState(this.props.state, this.props.to, this.props.query);
};
对 history 模块的 pushState 方法对 url 的更新形式,同样分为两种,分别在 history/createBrowserHistory 及 history/createHashHistory 各自的 finishTransition 中,如 history/createBrowserHistory 中使用的是 window.history.replaceState(historyState, null, path); 而 history/createHashHistory 则使用 window.location.hash = url,调用哪个是根据我们一开始创建 history 的方式。
更新 url 的显示是一部分,另一部分是根据 url 去更新展示,也就是触发前面的监听。这是在前面 finishTransition 更新 url 之后实现的,调用的是 history/createHistory 中的 updateLocation 方法,changeListeners 中为 history/createHistory 中的 listen 中所添加的,如下
function updateLocation(newLocation) {
// 示意代码
location = newLocation;
changeListeners.forEach(function (listener) {
listener(location);
});
}
function listen(listener) {
// 示意代码
changeListeners.push(listener);
}
总结
可以将以上 react-router 的整个包装闭环总结为
回调函数:含有能够更新 react UI 的 react setState 方法。
注册回调:在 Router componentWillMount 中使用 history.listen 注册的回调函数,最终放在 history 模块的 回调函数数组 changeListeners 中。
触发回调:Link 点击触发 history 中回调函数数组 changeListeners 的执行,从而触发原来 listen 中的 setState 方法,更新了页面
至于前进与后退的实现,是通过监听 popstate 以及 hashchange 的事件,当前进或后退 url 更新时,触发这两个事件的回调函数,回调的执行方式 Link 大致相同,最终同样更新了 UI ,这里就不再说明。
react-router 主要是利用底层 history 模块的机制,通过结合 react 的架构机制做一层包装,实际自身的内容并不多,但其包装的**笔者认为很值得学习,有兴趣的建议阅读下源码,相信会有其他收获。
最近在 Alloyteam Conf 2016 分享了《使用RxJS构建流式前端应用》,会后在线上线下跟大家交流时发现对于 RxJS 的态度呈现出两大类:有用过的都表达了 RxJS 带来的优雅编码体验,未用过的则反馈太难入门。所以,这里将结合自己对 RxJS 理解,通过 RxJS 的实现原理、基础实现及实例来一步步分析,提供 RxJS 较为全面的指引,感受下使用 RxJS 编码是怎样的体验。
做一个搜索功能在前端开发中其实并不陌生,一般的实现方式是:监听文本框的输入事件,将输入内容发送到后台,最终将后台返回的数据进行处理并展示成搜索结果。
<input id="text"></input>
<script>
var text = document.querySelector('#text');
text.addEventListener('keyup', (e) =>{
var searchText = e.target.value;
// 发送输入内容到后台
$.ajax({
url: `search.qq.com/${searchText}`,
success: data => {
// 拿到后台返回数据,并展示搜索结果
render(data);
}
});
});
</script>上面代码实现我们要的功能,但存在两个较大的问题:
多余的请求
当想搜索“爱迪生”时,输入框可能会存在三种情况,“爱”、“爱迪”、“爱迪生”。而这三种情况将会发起 3 次请求,存在 2 次多余的请求。
已无用的请求仍然执行
一开始搜了“爱迪生”,然后马上改搜索“达尔文”。结果后台返回了“爱迪生”的搜索结果,执行渲染逻辑后结果框展示了“爱迪生”的结果,而不是当前正在搜索的“达尔文”,这是不正确的。
减少多余请求数,可以用 setTimeout 函数节流的方式来处理,核心代码如下
<input id="text"></input>
<script>
var text = document.querySelector('#text'),
timer = null;
text.addEventListener('keyup', (e) =>{
// 在 250 毫秒内进行其他输入,则清除上一个定时器
clearTimeout(timer);
// 定时器,在 250 毫秒后触发
timer = setTimeout(() => {
console.log('发起请求..');
},250)
})
</script>已无用的请求仍然执行的解决方式,可以在发起请求前声明一个当前搜索的状态变量,后台将搜索的内容及结果一起返回,前端判断返回数据与当前搜索是否一致,一致才走到渲染逻辑。最终代码为
<input id="text"></input>
<script>
var text = document.querySelector('#text'),
timer = null,
currentSearch = '';
text.addEventListener('keyup', (e) =>{
clearTimeout(timer)
timer = setTimeout(() => {
// 声明一个当前所搜的状态变量
currentSearch = '书';
var searchText = e.target.value;
$.ajax({
url: `search.qq.com/${searchText}`,
success: data => {
// 判断后台返回的标志与我们存的当前搜索变量是否一致
if (data.search === currentSearch) {
// 渲染展示
render(data);
} else {
// ..
}
}
});
},250)
})
</script>上面代码基本满足需求,但代码开始显得乱糟糟。我们来使用 RxJS 实现上面代码功能,如下
var text = document.querySelector('#text');
var inputStream = Rx.Observable.fromEvent(text, 'keyup')
.debounceTime(250)
.pluck('target', 'value')
.switchMap(url => Http.get(url))
.subscribe(data => render(data));可以明显看出,基于 RxJS 的实现,代码十分简洁!
RxJS 是 Reactive Extensions for JavaScript 的缩写,起源于 Reactive Extensions,是一个基于可观测数据流在异步编程应用中的库。RxJS 是 Reactive Extensions 在 JavaScript 上的实现,而其他语言也有相应的实现,如 RxJava、RxAndroid、RxSwift 等。学习 RxJS,我们需要从可观测数据流(Streams)说起,它是 Rx 中一个重要的数据类型。
流是在时间流逝的过程中产生的一系列事件。它具有时间与事件响应的概念。

下雨天时,雨滴随时间推移逐渐产生,下落时对水面产生了水波纹的影响,这跟 Rx 中的流是很类似的。而在 Web 中,雨滴可能就是一系列的鼠标点击、键盘点击产生的事件或数据集合等等。
对流的概念有一定理解后,我们来讲讲 RxJS 是怎么围绕着流的概念来实现的,讲讲 RxJS 的基础实现原理。RxJS 是基于观察者模式和迭代器模式以函数式编程思维来实现的。
观察者模式在 Web 中最常见的应该是 DOM 事件的监听和触发。
document.body.addEventListener('click', function listener(e) {
console.log(e);
},false);
document.body.click(); // 模拟用户点击将上述例子抽象模型,并对应通用的观察者模型

迭代器模式可以用 JavaScript 提供了 Iterable Protocol 可迭代协议来表示。Iterable Protocol 不是具体的变量类型,而是一种可实现协议。JavaScript 中像 Array、Set 等都属于内置的可迭代类型,可以通过 iterator 方法来获取一个迭代对象,调用迭代对象的 next 方法将获取一个元素对象,如下示例。
var iterable = [1, 2];
var iterator = iterable[Symbol.iterator]();
iterator.next(); // => { value: "1", done: false}
iterator.next(); // => { value: "2", done: false}
iterator.next(); // => { value: undefined, done: true}元素对象中:value 表示返回值,done 表示是否已经到达最后。
遍历迭代器可以使用下面做法。
var iterable = [1, 2];
var iterator = iterable[Symbol.iterator]();
while(true) {
let result;
try {
result = iterator.next(); // <= 获取下一个值
} catch (err) {
handleError(err); // <= 错误处理
}
if (result.done) {
handleCompleted(); // <= 无更多值(已完成)
break;
}
doSomething(result.value);
}主要对应三种情况:
获取下一个值
调用 next 可以将元素一个个地返回,这样就支持了返回多次值。
无更多值(已完成)
当无更多值时,next 返回元素中 done 为 true。
错误处理
当 next 方法执行时报错,则会抛出 error 事件,所以可以用 try catch 包裹 next 方法处理可能出现的错误。
RxJS 中含有两个基本概念:Observables 与 Observer。Observables 作为被观察者,是一个值或事件的流集合;而 Observer 则作为观察者,根据 Observables 进行处理。
Observables 与 Observer 之间的订阅发布关系(观察者模式) 如下:
下面为 Observable 与 Observer 的伪代码
// Observer
var Observer = {
next(value) {
alert(`收到${value}`);
}
};
// Observable
function Observable (Observer) {
setTimeout(()=>{
Observer.next('A');
},1000)
}
// subscribe
Observable(Observer);上面实际也是观察者模式的表现,那么迭代器模式在 RxJS 中如何体现呢?
在 RxJS 中,Observer 除了有 next 方法来接收 Observable 的事件外,还可以提供了另外的两个方法:error() 和 complete(),与迭代器模式一一对应。
var Observer = {
next(value) { /* 处理值*/ },
error(error) { /* 处理异常 */ },
complete() { /* 处理已完成态 */ }
};结合迭代器 Iterator 进行理解:
next()
Observer 提供一个 next 方法来接收 Observable 流,是一种 push 形式;而 Iterator 是通过调用 iterator.next() 来拿到值,是一种 pull 的形式。
complete()
当不再有新的值发出时,将触发 Observer 的 complete 方法;而在 Iterator 中,则需要在 next 的返回结果中,当返回元素 done 为 true 时,则表示 complete。
error()
当在处理事件中出现异常报错时,Observer 提供 error 方法来接收错误进行统一处理;Iterator 则需要进行 try catch 包裹来处理可能出现的错误。
下面是 Observable 与 Observer 实现观察者 + 迭代器模式的伪代码,数据的逐渐传递传递与影响其实就是流的表现。
// Observer
var Observer = {
next(value) {
alert(`收到${value}`);
},
error(error) {
alert(`收到${error}`);
},
complete() {
alert("complete");
},
};
// Observable
function Observable (Observer) {
[1,2,3].map(item=>{
Observer.next(item);
});
Observer.complete();
// Observer.error("error message");
}
// subscribe
Observable(Observer);有了上面的概念及伪代码,那么在 RxJS 中是怎么创建 Observable 与 Observer 的呢?
RxJS 提供 create 的方法来自定义创建一个 Observable,可以使用 next 来发出流。
var Observable = Rx.Observable.create(observer => {
observer.next(2);
observer.complete();
return () => console.log('disposed');
});Observer 可以声明 next、err、complete 方法来处理流的不同状态。
var Observer = Rx.Observer.create(
x => console.log('Next:', x),
err => console.log('Error:', err),
() => console.log('Completed')
);最后将 Observable 与 Observer 通过 subscribe 订阅结合起来。
var subscription = Observable.subscribe(Observer);RxJS 中流是可以被取消的,调用 subscribe 将返回一个 subscription,可以通过调用 subscription.unsubscribe() 将流进行取消,让流不再产生。
看了起来挺复杂的?换一个实现形式:
// @Observables 创建一个 Observables
var streamA = Rx.Observable.of(2);
// @Observer streamA$.subscribe(Observer)
streamA.subscribe(v => console.log(v));将上面代码改用链式写法,代码变得十分简洁:
Rx.Observable.of(2).subscribe(v => console.log(v));Rx.Observable.of(2).subscribe(v => console.log(v));上面代码相当于创建了一个流(2),最终打印出2。那么如果想将打印结果翻倍,变成4,应该怎么处理呢?
方案一?: 改变事件源,让 Observable 值 X 2
Rx.Observable.of(2 * 2 /* <= */).subscribe(v => console.log(v));方案二?: 改变响应方式,让 Observer 处理 X 2
Rx.Observable.of(2).subscribe(v => console.log(v * 2 /* <= */));优雅方案: RxJS 提供了优雅的处理方式,可以在事件源(Observable)与响应者(Observer)之间增加操作流的方法。
Rx.Observable.of(2)
.map(v => v * 2) /* <= */
.subscribe(v => console.log(v));map 操作跟数组操作的作用是一致的,不同的这里是将流进行改变,然后将新的流传出去。在 RxJS 中,把这类操作流的方式称之为 Operators(操作)。RxJS提供了一系列 Operators,像map、reduce、filter 等等。操作流将产生新流,从而保持流的不可变性,这也是 RxJS 中函数式编程的一点体现。关于函数式编程,这里暂不多讲,可以看看另外一篇文章 《谈谈函数式编程》
到这里,我们知道了,流从产生到最终处理,可能经过的一些操作。即 RxJS 中 Observable 将经过一系列 Operators 操作后,到达 Observer。
Operator1 Operator2
Observable ----|-----------|-------> ObserverRxJS 提供了非常多的操作,像下面这些。
Aggregate,All,Amb,ambArray,ambWith,AssertEqual,averageFloat,averageInteger,averageLong,blocking,blockingFirst,blockingForEach,blockingSubscribe,Buffer,bufferWithCount,bufferWithTime,bufferWithTimeOrCount,byLine,cache,cacheWithInitialCapacity,case,Cast,Catch,catchError,catchException,collect,concatWith,Connect,connect_forever,cons,Contains,doAction,doAfterTerminate,doOnComplete,doOnCompleted,doOnDispose,doOnEach,doOnError,doOnLifecycle,doOnNext,doOnRequest,dropUntil,dropWhile,ElementAt,ElementAtOrDefault,emptyObservable,fromNodeCallback,fromPromise,fromPublisher,fromRunnable,Generate,generateWithAbsoluteTime,generateWithRelativeTime,Interval,intervalRange,into,latest (Rx.rb version of Switch),length,mapTo,mapWithIndex,Materialize,Max,MaxBy,mergeArray,mergeArrayDelayError,mergeWith,Min,MinBy,multicastWithSelector,nest,Never,Next,Next (BlockingObservable version),partition,product,retryWhen,Return,returnElement,returnValue,runAsync,safeSubscribe,take_with_time,takeFirst,TakeLast,takeLastBuffer,takeLastBufferWithTime,windowed,withFilter,withLatestFrom,zipIterable,zipWith,zipWithIndex关于每一个操作的含义,可以查看官网进行了解。operators 具有静态(static)方法和实例( instance)方法,下面使用 Rx.Observable.xx 和 Rx.Observable.prototype.xx 来简单区分,举几个例子。
Rx.Observable.of
of 可以将普通数据转换成流式数据 Observable。如上面的 Rx.Observable.of(2)。
Rx.Observable.fromEvent
除了数值外,RxJS 还提供了关于事件的操作,fromEvent 可以用来监听事件。当事件触发时,将事件 event 转成可流动的 Observable 进行传输。下面示例表示:监听文本框的 keyup 事件,触发 keyup 可以产生一系列的 event Observable。
var text = document.querySelector('#text');
Rx.Observable.fromEvent(text, 'keyup')
.subscribe(e => console.log(e));Rx.Observable.prototype.map
map 方法跟我们平常使用的方式是一样的,不同的只是这里是将流进行改变,然后将新的流传出去。上面示例已有涉及,这里不再多讲。
Rx.Observable.of(2)
.map(v => 10 * v)
.subscribe(v => console.log(v));Rx 提供了许多的操作,为了更好的理解各个操作的作用,我们可以通过一个可视化的工具 marbles 图 来辅助理解。如 map 方法对应的 marbles 图如下

箭头可以理解为时间轴,上面的数据经过中间的操作,转变成下面的模样。
Rx.Observable.prototype.mergeMap
mergeMap 也是 RxJS 中常用的接口,我们来结合 marbles 图(flatMap(alias))来理解它

上面的数据流中,产生了新的分支流(流中流),mergeMap 的作用则是将分支流调整回主干上,最终分支上的数据流都经过主干的其他操作,其实也是将流中流进行扁平化。
Rx.Observable.prototype.switchMap
switchMap 与 mergeMap 都是将分支流疏通到主干上,而不同的地方在于 switchMap 只会保留最后的流,而取消抛弃之前的流。
除了上面提到的 marbles,也可以 ASCII 字符的方式来绘制可视化图表,下面将结合 Map、mergeMap 和 switchMap 进行对比来理解。
@Map @mergeMap @switchMap
↗ ↗ ↗ ↗
-A------B--> a2 b2 a2 b2
-2A-----2B-> / / / /
/ / / /
a1 b1 a1 b1
/ / / /
-A-B-----------> -A-B---------->
--a1-b1-a2-b2--> --a1-b1---b2-->
mergeMap 和 switchMap 中,A 和 B 是主干上产生的流,a1、a2 为 A 在分支上产生,b1、b2 为 B 在分支上产生,可看到,最终将归并到主干上。switchMap 只保留最后的流,所以将 A 的 a2 抛弃掉。
Rx.Observable.prototype.debounceTime
debounceTime 操作可以操作一个时间戳 TIMES,表示经过 TIMES 毫秒后,没有流入新值,那么才将值转入下一个操作。

RxJS 中的操作符是满足我们以前的开发思维的,像 map、reduce 这些。另外,无论是 marbles 图还是用 ASCII 字符图这些可视化的方式,都对 RxJS 的学习和理解有非常大的帮助。
RxJS 提供许多创建流或操作流的接口,应用这些接口,我们来一步步将搜索的示例进行 Rx 化。
使用 RxJS 提供的 fromEvent 接口来监听我们输入框的 keyup 事件,触发 keyup 将产生 Observable。
var text = document.querySelector('#text');
Rx.Observable.fromEvent(text, 'keyup')
.subscribe(e => console.log(e));这里我们并不想输出事件,而想拿到文本输入值,请求搜索,最终渲染出结果。涉及到两个新的 Operators 操作,简单理解一下:
Rx.Observable.prototype.pluck('target', 'value')
将输入的 event,输出成 event.target.value。
Rx.Observable.prototype.mergeMap()
将请求搜索结果输出回给 Observer 上进行渲染。
var text = document.querySelector('#text');
Rx.Observable.fromEvent(text, 'keyup')
.pluck('target', 'value') // <--
.mergeMap(url => Http.get(url)) // <--
.subscribe(data => render(data))上面代码实现了简单搜索呈现,但同样存在一开始提及的两个问题。那么如何减少请求数,以及取消已无用的请求呢?我们来了解 RxJS 提供的其他 Operators 操作,来解决上述问题。
Rx.Observable.prototype.debounceTime(TIMES)
表示经过 TIMES 毫秒后,没有流入新值,那么才将值转入下一个环节。这个与前面使用 setTimeout 来实现函数节流的方式有一致效果。
Rx.Observable.prototype.switchMap()
使用 switchMap 替换 mergeMap,将能取消上一个已无用的请求,只保留最后的请求结果流,这样就确保处理展示的是最后的搜索的结果。
最终实现如下,与一开始的实现进行对比,可以明显看出 RxJS 让代码变得十分简洁。
var text = document.querySelector('#text');
Rx.Observable.fromEvent(text, 'keyup')
.debounceTime(250) // <- throttling behaviour
.pluck('target', 'value')
.switchMap(url => Http.get(url)) // <- Kill the previous requests
.subscribe(data => render(data))本篇作为 RxJS 入门篇到这里就结束,关于 RxJS 中的其他方面内容,后续再拎出来进一步分析学习。
RxJS 作为一个库,可以与众多框架结合使用,但并不是每一种场合都需要使用到 RxJS。复杂的数据来源,异步多的情况下才能更好凸显 RxJS 作用,这一块可以看看民工叔写的《流动的数据——使用 RxJS 构造复杂单页应用的数据逻辑》 相信会有更好的理解。
附:
RxJS(JavaScript) https://github.com/Reactive-Extensions/RxJS
RxJS(TypeScript ) https://github.com/ReactiveX/rxjs
在前端开发工作中,除了项目开发保质保量上线以外,项目的数据监控也应该配套起来,确保线上的正常运转。如上报 pv 监控项目是否正常运转;测速上报反应项目质量;脚本错误监控作为监控中重要一环,当页面发生报错的时候,通过上报错误信息,能及时发现存在问题,修复优化、减少损失。
本文基于在手Q家校群前端脚本错误量优化的方案,致力于打造极致的脚本错误优化。
作为首篇,主要讲解基础的脚本错误监控和上报方式,以及常会遇到的 Script error. 的产生原因和处理方法。
脚本错误主要有两类:语法错误、运行时错误。
监控的方式主要有两种:try-catch、window.onerror。
try {
test // <- throw error
} catch(e){
console.log('运行时错误信息 ↙');
console.log(e);
}
通过给代码块进行 try-catch 包装,当代码块出错时 catch 将能捕获到错误信息,页面也将继续执行。
当发生语法错误或异步错误时,则无法正常捕捉。
try {
function empty() // <- throw error 语法错误
} catch(e){
console.log('语法错误信息 ↙');
console.log(e);
}无法捕捉错误

try {
setTimeout(function() {
test // <- throw error 异步错误
},0)
} catch(e){
console.log('异步错误信息 ↙');
console.log(e);
}无法捕捉错误

语法错误无法在 try-catch 中进行捕抓、而异步报错则可以通过为异步函数块再包装一层 try-catch,增加标识信息来配合定位,可以用工具来进行处理,这里不展开。
/**
* @param {String} msg 错误信息
* @param {String} url 出错文件
* @param {Number} row 行号
* @param {Number} col 列号
* @param {Object} error 错误详细信息
*/
window.onerror = function (msg, url, row, col, error) {
console.log('onerror 错误信息 ↙');
console.log({
msg, url, row, col, error
})
};
test // <- throw error
window.onerror 能捕捉到当前页面的语法错误或运行时报错,是十分强大的。
那么try-catch 是否不再需要呢?其实并不是。
在使用过程中的体会:onerror 主要用来捕获预料之外的错误,而 try-catch 则可以用在预知情况下监控特定错误,两种形式结合使用更加高效。
监控错误拿到了报错信息,接下来则是将捕抓的错误信息发送到信息收集平台上,发送的形式主要有两种:
function report(msg, level) {
var reportUrl = "http://localhost:8055/report";
new Image().src = reportUrl + '?msg=' + msg;
}监控报错,并将捕捉到的错误信息上报给数据收集平台,如下图

有了监控了后,就可以在收集平台上进行查看脚本错误量的日志统计。

发现占据榜首的错误信息 “Script error.” 具有非常高的比例,没有无具体的错误信息,无法定位问题,而这是怎么产生的呢?
翻看在 webkit 的源码可以看到 “Script error.” 是浏览器在同源策略限制下所产生的。浏览器出于安全上的考虑,当页面引用的非同域的外部脚本中抛出了异常,此时本页面无权限获得这个异常详情, 将输出 Script error 的错误信息。

Script error 来自同源策略的影响,那么解决的方案之一是进行资源的同源化,另外也可以利用跨源资源共享机制( CORS )。
以上两种方式能够简单直接地解决问题,但也可能带来其他影响,如内联资源不好利用文件缓存,同域无法充分利用cdn优势等等。
跨源资源共享 ( CORS )机制让Web应用服务器能支持跨站访问控制,从而能够安全地跨站数据传输。主要是通过给请求带上特定头信息,服务器实现了CORS接口,就可以跨源通信,从而能够看到具体报错信息。
<script src="http://127.0.0.1:8077/main.js" crossorigin></script>增加 crossorigin 属性后,浏览器将自动在请求头中添加一个 Origin 字段,发起一个 跨来源资源共享 请求。Origin 向服务端表明了请求来源,服务端将根据来源判断是否正常响应。


Access-Control-Allow-Origin: * 表示通过该跨域请求,且该资源可以被任意站点跨站访问。而当该资源仅允许来自 http://127.0.0.1:8066 的跨站请求,其它站点都不能跨站访问时,将可以返回:
Access-Control-Allow-Origin:http://127.0.0.1:8066
Vary 字段的作用在于为缓存服务器提供缓存规则及缓存筛选的依据。当增加 Vary:Origin 响应头后,缓存服务器将会按照 Origin 字段的内容,缓存不同版本,在请求响应时根据请求头中的 Origin 决定是否能够使用缓存响应。

举例 · 不加 Vary 将存在错误命中缓存的问题

上图中,第一个请求(Origin: 127.0.0.1:8066)响应被浏览器缓存了,当第二个请求(Origin: 127.0.0.1:8888)发起,被错误命中了前一个请求的缓存,收到了 Access-Control-Allow-Origin:http://127.0.0.1:8066 的响应时,将导致资源加载失败。
所以当 Access-Control-Allow-Origin 不是返回为 * 时,需要加上 Vary 返回头来避免引缓存导致的权限问题。
跨域脚本报错产生 Script error. 通过以上方式进行处理后将能够捕获到具体的报错信息了。在 NodeJS 的实现中主要通过添加以下代码:
app.use(function *(next){
// 拿到请求头中的 Origin
var requestOrigin = this.get('Origin');
if (!requestOrigin) { // 不存在则忽略
return yield next;
}
// 设置 Access-Control-Allow-Origin: Origin
this.set('Access-Control-Allow-Origin', requestOrigin);
// 设置 Vary: Origin
this.vary('Origin');
return yield next;
});以上为本文所有内容,兄弟篇:脚本错误量极致优化-让脚本错误一目了然
代码执行时机将决定着是否能够正常执行,当依赖文件没加载完成就开始执行、使用对应模块,那么将会导致执行异常。这在“存在资源加载失败时,加载重试影响原来文件的执行顺序”的场景下尤为常见。
webpack 构建除了进行模块依赖管理,实际上,也天然地管理了 entry 与 chunk 多文件的执行时机,但缺少了对 external 文件管理,当 external 文件加载失败或未完成时,执行、使用对应模块同样将导致异常。为此,wait-external-webpack-plugin 应运而生,以 webpack 插件的形式,补充 external 的执行管理。本文将进行简要说明。
将 webpack 打包后的代码进行简化,其实就是一个立即调用函数;传入“模块”,使用 webpack_require 进行调用。在单文件下,文件加载后将立即执行业务逻辑。
(function(modules) { // webpackBootstrap
function __webpack_require__(moduleId) {
// ...
// 执行模块代码
modules[moduleId].call(module.exports, module, module.exports, __webpack_require__);
}
// 引用入口
return __webpack_require__(__webpack_require__.s = "./src/entryB.js");
})({
"./entryB.js": (function(module, __webpack_exports__, __webpack_require__) {
// ...
})
});为了 “抽取公共模块进行单独打包避免重复加载” 或 “增加并发请求数减少总加载时间” 等原因,一般会将代码拆分成多文件,可使用如下形式:
拆分成多个文件后,为了避免业务逻辑执行时相关文件还没加载完成导致执行出错,需要等待相关文件都加载完成后再开始执行。
entry 与 其他 chunk 文件的 “等待-执行” 的逻辑,webpack 其实已经帮我们自动生成了。
// # entry.js
// 声明依赖列表
deferredModules.push(["./src/entryA.js","commons"]);
// 缓存已完成的加载
var installedChunks = {
"entryA": 0
};
function webpackJsonpCallback(data) {
// 加载后标记完成
installedChunks[chunkId] = 0;
}
// 检查是否都加载完成,如是,则开始执行业务逻辑
function checkDeferredModules() {
// 判断 installedChunks 是否完整
// ...
if(fulfilled) {
// 所有都加载,开始执行
result = __webpack_require__(__webpack_require__.s = deferredModule[0]);
}
}
// 提供给 chunk 的全局回调方法
var jsonpArray = window["webpackJsonp"] = window["webpackJsonp"] || [];
jsonpArray.push = webpackJsonpCallback;chunk 文件加载后,正常情况下将调用 entry 提供的全局回调方法,标记加载完成。而当 chunk 文件先于 entry 加载完成,则会先缓存记录,等 entry 文件加载后读取缓存并将其标记完成。
// # chunk.js
(window["webpackJsonp"] = window["webpackJsonp"] || []).push([["commons"],{
"./src/moduleA.js": (function(module, __webpack_exports__, __webpack_require__) {
// ...
})
}]);基于以上分析,可以看出 entry 和 chunk 文件加载顺序不会影响执行时机,只有在都加载完成后,才会执行业务逻辑。如下图示

项目引用第三方库,一般会配置 external 让库单独加载。通过 webpack 生成的代码可以看出,配置 external 的模块在业务代码执行前将被当作已存在环境中,不做任何判断。所以当 external 文件未加载完成或加载失败时,使用对应模块将会导致执行出错。
"react": (function(module, exports) {
eval("(function() { module.exports = window[\"React\"]; }());");
})为了避免使用时出错,在执行前需先保证 external 文件已经加载完成。处理方式如下
示意代码:
(function () {
var entryInit = function () {
(function(modules) {
// webpackBootstrap
// ...
})({})
};
if (window["React"]) {
entryInit();
} else {
var hasInit = false;
var callback = function () {
if(hasInit) return;
if (window["React"]) {
hasInit = true;
document.removeEventListener('load', callback, true);
entryInit();
}
};
document.addEventListener('load', callback, true);
}
})();等待 external 加载完成逻辑是统一的,差异在于依赖的 external 或有不同。为了避免手动添加出错,我们可以通过以 webpack 插件的形式自动分析依赖,并生成相关代码。
具体实现可见插件 wait-external-webpack-plugin
通过 wait-external-webpack-plugin 插件,能够自动生成等待依赖的 external 文件加载完成再执行逻辑,对开发者透明,保证文件对正常执行。
欢迎使用,欢迎任何意见或建议,谢谢。
CSP 全称为 Content Security Policy,即内容安全策略。主要以白名单的形式配置可信任的内容来源,在网页中,能够使白名单中的内容正常执行(包含 JS,CSS,Image 等等),而非白名单的内容无法正常执行,从而减少跨站脚本攻击(XSS),当然,也能够减少运营商劫持的内容注入攻击。
示例:在 HTML 的 Head 中添加如下 Meta 标签,将在符合 CSP 标准的浏览器中使非同源的 script 不被加载执行。
<meta http-equiv="Content-Security-Policy" content="script-src 'self'">不支持 CSP 的浏览器将自动会忽略 CSP 的信息,不会有什么影响。具体兼容性可在caniuse查看
CSP 有两种策略类型:
这两种策略类型的主要区别也可以从命名上看出,第一种对不安全的资源会进行阻止执行,而第二种只会进行数据上报,不会有实际的阻止。
当定义多个策略的时候,浏览器会优先采用最先定义的。
CSP 的指令是组成内容来源白名单的关键,上面两种策略类型含有以下众多指令,可以通过搭配得到满足网站资源来源的白名单。
| 指令 | 取值示例 | 说明 |
|---|---|---|
| default-src | 'self' cdn.example.com | 定义针对所有类型(js/image/css/web font/ajax/iframe/多媒体等)资源的默认加载策略,某类型资源如果没有单独定义策略,就使用默认。 |
| script-src | 'self' js.example.com | 定义针对JavaScript的加载策略 |
| object-src | 'self' | 针对,, 等标签的加载策略 |
| style-src | 'self' css.example.com | 定义针对样式的加载策略 |
| img-src | 'self' image.example.com | 定义针对图片的加载策略 |
| media-src | 'media.example.com' | 针对或者 |
| frame-src | 'self' | 针对iframe的加载策略 |
| connect-src | 'self' | 针对Ajax、WebSocket等请求的加载策略。不允许的情况下,浏览器会模拟一个状态为400的响应 |
| font-src | font.qq.com | 针对Web Font的加载策略 |
| sandbox | allow-forms allow-scripts | 对请求的资源启用sandbox |
| report-uri | /some-report-uri | 告诉浏览器如果请求的资源不被策略允许时,往哪个地址提交日志信息。不阻止任何内容,可以改用Content-Security-Policy-Report-Only头 |
| base-uri | 'self' | 限制当前页面的url(CSP2) |
| child-src | 'self' | 限制子窗口的源(iframe、弹窗等),取代frame-src(CSP2) |
| form-action | 'self' | 限制表单能够提交到的源(CSP2) |
| frame-ancestors | 'none' | 限制了当前页面可以被哪些页面以iframe,frame,object等方式加载(CSP2) |
| plugin-types | application/pdf | 限制插件的类型(CSP2) |
| 指令值 | 示例 | 说明 |
|---|---|---|
| * | img-src * | 允许任何内容 |
| 'none' | img-src 'none' | 不允许任何内容 |
| 'self' | img-src 'self' | 允许同源内容 |
| data: | img-src data: | 允许data:协议(如base64编码的图片) |
| www.a.com | img-src www.a.com | 允许加载指定域名的资源 |
| *.a.com | img-src *.a.com | 允许加载a.com任何子域的资源 |
| https://img.com | img-src https://img.com | 允许加载img.com的https资源 |
| https: | img-src https: | 允许加载https资源 |
| 'unsafe-inline' | script-src 'unsafe-inline' | 允许加载inline资源(style属性,onclick,inline js和inline css等等) |
| 'unsafe-eval' | script-src 'unsafe-eval' | 允许加载动态js代码,例如eval() |
在这种形式中,Meta 标签主要含有两部分的 key-value:
http-equiv 的 value 为 CSP 的策略类型,而 content 则是声明指令集合,即白名单。如
<meta http-equiv="Content-Security-Policy" content="script-src 'self'">在HTML 的 head 中 添加上面的 Meta 标签,那么当浏览器支持 CSP 标准时,由于使用的是 Content-Security-Policy 实际阻止的策略,所以将会使得非同源的 script(根据指令集合来定)不会被加载及执行。
Meta 标签的 Content-Security-Policy-Report-Only 方式在当前(2016/5/19)多数移动端浏览器上表现正常,但是 不推荐 这样做,如 chrome 50 会产生如下的提示
The report-only Content Security Policy xxxxxxx was delivered via a element,which is disallowed. The policy has been ignored.
通过 Meta 的方式很是简单,但当涉及到的页面较多时,使用 Meta 标签的方式需要在每个页面都各自加上。而如果通过服务端配置 HTML 返回的响应头 HTTP header 带上 CSP 的指令的话,那将能够一劳永逸,同时支持多个页面。下图为响应头

不仅如此,这种形式的 Content-Security-Policy-Report-Only 方式能够得到更好的兼容支持,也是推荐方式。
CSP 的阻止加载及执行的方式相当强大,也因为它如此强大,所以在使用时更是要小心谨慎,毕竟,如一个不小心制定了错误的指令集合方案,那将可能导致阻止了正常文件的加载,影响业务功能,这是相当危险的。
这种方式实现成本低,只对当前的 HTML 有效,从而能够进行逐步灰度。当然也存在上面提及的兼容性问题,但如果现在是在移动端上,或者在可预期的浏览器内核上跑的话,在兼容性满足的情况下,那还是可以通过这个方式进行 Report-Only。结合自己业务的资源情况以及在 Chrome 上调试制定初步方案。
由于上面的 Meta 标签存在一定的兼容问题,所以当我们制定了初步方案后,就可以开始使用 HTTP Header 的形式,小心驶得万年船,这里还是建议先使用 Report-Only 的方式,并指定上报的 url 来收集阻止的内容,通过上报的数据进行方案的优化,从而进一步确定具体方案。
具体的 CSP 方案经过上面两轮洗礼,在分析完上报的数据,确定百无疏漏后,可将HTTP Header 改用 Content-Security-Policy 策略,从而进行实际拦截阻止。
笔者在实际项目中的进行了 CSP 上报拦截,通过上报的数据可以看到日均劫持达到 20000+ 的量,这对于页面本身 PV 并非很高的情况,在线 PV 占比竟达到了 4%;另一方面,从数据上也可以看出 拦截的主要来源(如下表)
3月1日-4月4日,CSP 拦截量
| 日期 | CSP阻止量 | 在线PV | 占比 |
|---|---|---|---|
| 2016.03.31 | 23431 | 545872 | 4.31% |
| 2016.04.01 | 24459 | 619979 | 3.95% |
| 2016.04.02 | 20398 | 525055 | 3.88% |
| 2016.04.03 | 19938 | 475985 | 4.19% |
| 2016.04.04 | 23140 | 507329 | 4.56% |
4月4日,CSP 拦截的 URL 前5名
| 排名 | 被 拦截的 URL | CSP拦截量 |
|---|---|---|
| 1 | http://wap.zjtoolbarc60.10086.cn:8080 | 5410 |
| 2 | http://wap.toolbar.sd.chinamobile.com:8080 | 2690 |
| 3 | http://119.188.105.1:8080 | 1498 |
| 4 | http://211.137.132.89:9090 | 947 |
| 5 | http://n.cosbot.cn | 675 |
从上面数据也可以看出,每天被攻击的情况呈现出一种稳定持续的倾向,而且这类攻击一般不是针对某个业务的,具备了普遍性,这样的影响范围可想而知。
不过,这也侧面烘托出 CSP 的强大,简单处理就能够阻止如此多的攻击,赶紧接入吧。
https://www.w3.org/TR/CSP/#changes-from-level-1
http://w3c.github.io/webappsec-csp/
http://content-security-policy.com/
https://www.w3.org/TR/2012/CR-CSP-20121115/
下一版本的 Firefox OS 移动操作系统将通过使用其多核处理器来充分利用设备的性能,JavaScript虽然在单线程上执行,但通过使用web workers可以实现代码的并行执行,这样将释放浏览器中任何可能阻塞主线程的程序,UI动画也将因此更顺畅的执行。
有几种类型的web workers:
他们各自拥有不同特性,但有着相似的设计形式,worker中代码将在自己开辟的独立线程上执行,与主线程及其他worker并行执行,不同类型的workers维护着一个共同的接口。
专用的web workers将在主线程上被实例化,并且其他worker将只能通过它来进行通信
Shared workers 允许同源中的所有页面或脚本(包含不同的浏览器标签, iframes或者其他 shared workers)之间进行通信.
近期,Service workers 得到了大量的关注,他可以作为web代理服务器(开发者能够对页面请求进行控制)将内容传递给请求者(如主线程)。不仅如此,它还能够支持离线应用。Service workers是一个非常新的API,现在仍没有兼容所有的浏览器,本文将不对其详细介绍。
为了验证web workers让Firefox OS运行得更快,我们通过对其进行基准测试来验证他的速度。
本文主要针对Firefox OS。所有的数据都在Flame手机上所测量。
第一组测试是创建 web workers所花费的时间,为此,我们创建一个script文件,该script文件实例化了一个web worker并发送一个最小的消息。发现web worker快速对其回复。当主线程接收到响应后,我们将得到这个过程所花费的时间。
然后销毁web worker并对上面所述的实验进行多次重复操作,我们将能够得到创建web worker所花费的平均时间,可以通过如下代码简单地实例化一个web worker
// Start a worker.
var worker = new Worker('worker-script.js');
// Terminate a worker.
worker.terminate();同样的方式来创建广播通道
// Open a broadcast channel.
var channel = new window.BroadcastChannel('channel-name');
// Close a broadcast channel.
channel.close();Shared workers 无法在这里进行基准测试,因为他们一旦被创建,开发者将不能够销毁他们,它们将由浏览器接管。鉴于此,我们不能通过创建和销毁
Shared workers来得到有意义的基准测试。
Web workers大约使用40毫秒被实例化。这个时间相当稳定的,波动只有几毫秒。创建一个broadcast channel 通常是在1毫秒内完成。
正常情况下,浏览器的刷新频率为60帧/秒(fps),这意味着没有JavaScript代码运行应该超过一帧所需时间,即16.66毫秒(60帧/秒)。否则页面的渲染就会出现卡顿效果,也就是常说的jankiness。
实例化web workers非常高效的,但是仍可能不适合单帧所用的时间。这就是为什么要创造尽可能少的web workers并且重用它们的重要原因。
web workers的关键之一,是它能够在主线程及workers之间进行快速通信,以下列出主线程与web worker之间两种不同的通信方式。
这个API是默认及首选的,用来web worker发送和接收消息。如下:
// Send a message to the worker.
worker.postMessage(myMessage);
// Listen to messages from the worker.
worker.onmessage = evt => {
var message = evt.data;
};这是一个新的API,现在只能在Firefox中使用。Broadcast Channel能够所有同源的上下文进行广播消息。包含同源的页面,iframes,或workers都能够发送和接收消息:
// Send a message to the broadcast channel.
channel.postMessage(myMessage);
// Listen to messages from the broadcast channel.
channel.onmessage = evt => {
var message = evt.data;
};这里的基准测试,我们使用类似于上述代码,不同之处在于web worker将不被销毁,并在每一个操作都重复使用它。所以,得到的往返响应时间应除以2。
可能你已想到,简单的postMessage是很快的,它通常只需要在0至1毫秒来发送一个消息,不管是对一个web还是shared worker。Broadcast channel的API大约需要1至2毫秒。
在正常情况下,workers之间通信很快,你不需要担心这里的通信速度,当然,发送更大的消息将会使用较长的时间。
有两种形式能够给web workers发送消息
在第一种情况下,该消息将被序列化,复制然后发送。在后者,数据将被传送,这意味着消息发送出去后,发送者将不再使用它。数据传送几乎是瞬时的,所以不能基准测试。然而,只有ArrayBuffer是可传送的。
正如预期,序列化、复制和反序列化数据对消息传输增加了显著的开销。消息越大,时间越长。
在这个基准测试中,我们发送一个 typed array 给 web worker。 它的大小在每个迭代中逐步增加。传送消息的大小跟传输时间呈线性相关。对于每次测量,我们可以把数据大小(kb)除以时间(ms)来得到传输速度(kb/ms)。
通常,在Flame手机中,postMessage的传输速度在80 kB/ms,而broadcast channel则为12kB/ms,这意味着,如果你想你的消息适应单个帧,那么当使用postMessage时,让消息的大小保持在1300kB内;在使用broadcast channel时,使其大小小于200kB。否则,可能会出现丢帧的情况。
在这个基准测试中,我们使用typed array,因为它使我们能够以千字节为单位确定其大小。你也可以传输JavaScript对象,但由于序列化的过程,他们需要更长的时间去发送。对于小的对象,这其实并不重要,但如果你需要发送巨大的对象,你不妨将其序列化成二进制格式。并且使用类似于协议缓冲区的方式。
以下是在Flame 手机中对web workers的各种基准测试的总结:
操作 -> 值
基准测试用来确保你所使用的解决方案是非常快的。这个过程将大量的猜测从web开发中消除。
在 《XSS终结者-CSP理论与实践》 中,讲述了 CSP 基础语法组成与使用方式。通过一步步的方案制定,最终我们利用 CSP 提供的域名白名单机制,有效地将异常的外联脚本拦在门外。然而在线上环境千千万万,虽然我们限制了外联脚本,但却仍被内联脚本钻了空子。
CSP 的默认策略是不允许 inline 脚本执行,所以当我们没有必要进行脚本 inline 时,CSP 域名白名单的机制足以防范注入脚本的问题。然而在实际项目中,我们还是会因为一些场景需要将部分脚本进行 inline。于是需要在 CSP 的规则中增加 script-src 'unsafe-inline' 配置,允许了 inline 资源执行。但也带来了新的安全隐患。
允许 inline 资源执行,也意味着当恶意代码通过 inline 的方式注入到页面中执行时,页面将变得不再安全。如富文本中被插入一段 script 代码(没被转义),或者是通过浏览器插件的方式进行代码注入等方式。
Content-Security-Policy: script-src 'unsafe-inline'为了避免上述问题,我们可以使用 nonce 方式加强的 CSP 策略。nonce 方式是指每次页面访问都产生一个唯一 id,通过给内联脚本增加一个 nonce 属性,并且使其属性值(id) 与返回的 CSP nonce-{id} 对应。只有当两者一致时,对应的内联脚本才被允许执行。于是,即使网页被注入异常的脚本,因为攻击者不知道当时 nonce 的随机 id 值,所以注入的脚本不会被执行。从而让网页变得更加安全。
Content-Security-Policy: script-src 'nonce-5fAifFSghuhdf'
<script nonce="5fAifFSghuhdf">
// ...
</script>那么,当我们通过动态生成脚本并进行插入时,nonce 也会将我们的正常代码拦截在外。所以在这种场景下,我们需要配套使用 CSP 提供的 'strict-dynamic','strict-dynamic' 模式允许让被信任的脚本插入并放行正常脚本执行。
Content-Security-Policy: script-src 'nonce-5fAifFSghuhdf' 'strict-dynamic'scirpt 标签增加 nonce 属性
我们可以通过构建的方式为页面中 script 标签添加 nonce 属性,并添加一个占位符,如
<script nonce="NONCE_TOKEN">
// ...
</script>生产唯一id,在 CSP 返回头中添加 nonce-{id} 并将 id 替换 html 上的 nonce 占位符
方式一:服务端处理
方式二:Nginx 处理
当然,为了避免攻击者提前注入一段脚本,并在 script 标签上同样添加了 nonce="NONCE_TOKEN" ,后端的“误”替换,导致这段提前注入的脚本进行执行。我们需要保密好项目的占位符,取一个特殊的占位符,并行动起来吧!
CSP 的应用场景越来越多,逐步地优化策略才能更好地守护我们的项目安全。
雪碧图并不陌生,将多张图片合在一起来减少请求数,从而提升网站的性能。在你的网站未支持 HTTP2 前,还是值得这么处理。
为了适应不同的设备分辨率,一般会做几套不同大小的图去适配,那如何用一套图来自适应缩放呢?
本文对等比缩放的雪碧图动画的原理进行分步讲解,并使用 gka 进行一键生成。
GitHub: https://github.com/gkajs/gka
当背景图片设置 background-size:100% 100% 时,百分比是以元素宽高为基准的,应用到雪碧图上会将整张雪碧图拉伸填充整个元素

虽然上面并不是我们希望的效果,但也可以发现设置了百分比后,背景图被拉伸填充整个元素且随着元素长宽而改变。所以只需再解决以下三个问题就能达到我们希望的自适应等比缩放。
雪碧图中,每张单图的宽高一致,设置 background-size: 100% 100% 后,可以看到上图元素展示区域中宽含4张图,高含有5张图,所以如果将雪碧图宽度4倍放大(即每张图片宽度都4倍放大),此时元素在宽中将只能展示1张。同理,雪碧图的高放大5倍后,那么元素的展示就被一张图片填充满了。

background-size: 400% 500%所以,通过放大宽高对应的倍数设置 background-size,能让元素只展示一张图片。
雪碧图可以通过调整 background-position 来展示不同区域。由于此时图片的具体大小未知,无法通过 px 直接定位出来。background-position 同样支持百分比,不同的是其百分比的值是根据元素宽高与背景图宽高计算得出的,公式如下
x百分比 = (x偏移量 / ((元素宽度 - 背景图片宽度) || 1)) * 100 + '%'
y百分比 = (y偏移量 / ((元素高度 - 背景图片高度) || 1)) * 100 + '%'
已知对 background-size 相应放大后,元素只展示一张图片,背景图片宽高为单图宽高倍数。所以,每张单图对应的位置百分比都可以通过对应x、y的偏移值和宽高来计算获得。

由于背景图片根据元素的宽高及进行填充展示,所以为了保持背景图片的正常宽高比,需要让元素的宽高比保持一致。元素 padding 设置的百分比是依据父容器的宽度计算的,padding-top/padding-bottom 也是如此,且 padding 能影响元素的展示区域。所以依据宽度来设置 padding-bottom 的百分比从而调整元素高度;另一方面,当元素的宽度为百分比时,同样是依据父容器的宽度计算的。
所以,保持元素的宽高比,只需要将 width 和 padding-bottom 按宽高比设置百分比即可。如单张图片的宽高比为 1: 2 时,只需要这样设置
.gka-base {
width: 100%;
height: 0;
padding-bottom: 200%;
}通过以上一步步实践就可以做一个可自适应等比缩放的雪碧图帧动画了,大体有以下几个工作
使用 gka 仅一行命令,自动化完成以上所有工作。
gka imageDir -t percentgka 最终输出自适应的雪碧图帧动画套装:雪碧图、css文件及预览文件。

欢迎试用 gka ,欢迎任何意见或建议,谢谢 :D
GitHub: https://github.com/gkajs/gka

最近,项目用了 React,配套使用了 Webpack,毕竟热替换(react-hot-loader)吸引力确实高,开发模式下使用 webpack 构建其实也够用,并且相对 gulp-webpack 来说,模块的编译等待时间大大缩小,这是生命啊! 发布时,借助 gulp 来进行其他方面的处理,如合图,打包等。或许把这些边幅修一修、支持下,Webpack 估计就要逆天了吧?
仰望天空,还是脚踏实地,Webpack 虽非新鲜之物,但也没有多成熟。对应的 Plugin 及 Loader 的量并不多,还是有很多轮子没造,很多坑没踩呢。从源码中似乎看到了一些可能在接下来会暴漏出来的新接口,想想还有点小激动,期待下一代 Webpack 吧。
碎碎念完毕,以下讲讲如何开发一个基础的 Webpack Loader 及一些心得。
Loader 是支持链式执行的,如处理 sass 文件的 loader,可以由 sass-loader、css-loader、style-loader 组成,由 compiler 对其由右向左执行,第一个 Loader 将会拿到需处理的原内容,上一个 Loader 处理后的结果回传给下一个接着处理,最后的 Loader 将处理后的结果以 String 或 Buffer 的形式返回给 compiler。
这种链式的处理方式倒是和 gulp 有点儿类似,固然也是希望每个 loader 只做该做的事,纯粹的事,而不希望一箩筐的功能都集成到一个 Loader 中。
{
module: {
loaders: [{
test: /\.scss$/,
loader: 'style!css!sass'
}]
}
};另一方面,虽然链式之间可以依赖其前一个Loader所返回的结果来执行自己的内容。但这并不支持两个 Loader 之间进行数据交流的做法,一个标准的 Loader 应该是要求着 强独立性、以及输入什么,就输出什么的可预见性。
官网说了,A loader is a node module exporting a function.
既然是 node module,那么基本的写法可以是
// base loader
module.exports = function(source) {
return source;
};如果你所写的 Loader 需要依赖其他模块的话,那么同样以 module 的写法,将依赖放在文件的顶部声明,让人清晰看到
// Module dependencies.
var fs = require("fs");
module.exports = function(source) {
return source;
};上面使用返回 return 返回,是因为是同步类的 Loader 且返回的内容唯一,如果你希望将处理后的结果(不止一个)返回给下一个 Loader,那么就需要调用 Webpack 所提供的 API。 一般来说,构建系统都会提供一些特有的 API 供开发者使用。Webpack 也如此,提供了一套 Loader API,可以通过在 node module 中使用 this 来调用,如 this.callback(err, value...),这个 API 支持返回多个内容的结果给下一个 Loader 。
// return multiple result
module.exports = function(source, other) {
// do whatever you want
// ...
this.callback(null, source, other);
};以上的内容,稍总结下
而实际上,掌握上面所介绍的内容及**,就可以开始写一个简单的 Loader 了,不是吗? 由上所说的,在你的 Loader 中,你可以拿到需要处理的文件内容,并且知道了处理后的结果应该怎么去返回,在中间部分,你可以以正常使用 node 的姿态对内容进行怎样的处理,Do Whatever You Want,Loader 没有其他特殊要求。
上半部分的介绍虽然确实能搭建起一个普通的 Loader 了,但这样就够了吗?
从提高执行效率上,如何处理利用缓存是极其重要的。 Mac OS 会让内存充分使用、尽量占满来提高交互效率。回到 Webpack,Hot-Replace 以及 React Hot Loader 也充分地利用缓存来提高编译效率。 Webpack Loader 同样可以利用缓存来提高效率,并且只需在一个可缓存的 Loader 上加一句 this.cacheable(); 就是这么简单
// 让 Loader 缓存
module.exports = function(source) {
this.cacheable();
return source;
};很多 Loader 都是可以缓存的,但也有例外。可以缓存的 Loader 需要具备可预见性,不变性等等。
异步并不陌生,当一个 Loader 无依赖,可异步的时候我想都应该让它不再阻塞地去异步。在一个异步的模块中,回传时需要调用 Loader API 提供的回调方法 this.async(),使用起来也很简单
// 让 Loader 缓存
module.exports = function(source) {
var callback = this.async();
// 做异步的事
doSomeAsyncOperation(content, function(err, result) {
if(err) return callback(err);
callback(null, result);
});
};前面所述的 Loader 从右到左链式执行。这种说法实际说的是 Loader 中 module.exports 出来的执行方法顺序。在一些场景下,Loader 并不依赖上一个 Loader 的结果,而只关心原输入内容。这时候,从左到右执行并没有什么问题。在 Loader 的 module 中,可使用 module.exports.pitch = function(); pitch 方法在 Loader 中便是从左到右执行的,并且可以通过 data 这个变量来进行 pitch 和 normal 之间传递。
module.exports.pitch = function(remaining, preceding, data) {
if(somothingFlag()) {
return "module.exports = require(" + JSON.stringify("-!" + remaining) + ");";
}
data.value = 1;
};具体的实践可以查看 style-loader,里面就有使用到 pitch。
默认的情况,原文件是以 UTF-8 String 的形式传入给 Loader,而在上面有提到的,module 可使用 buffer 的形式进行处理,针对这种情况,只需要设置 module.exports.raw = true; 这样内容将会以 raw Buffer 的形式传入到 loader 中了
module.exports = function(content) {
};
module.exports.raw = true;Loader API 将提供给每一个 Loader 的 this 中,API 可以让我们的调用方式更加地方便,更加灵活。
data pitch loader 中可以通过 data 让 pitch 和 normal module 进行数据共享。
query 则能获取到 Loader 上附有的参数。 如 require("./somg-loader?ls"); 通过 query 就可以得到 "ls" 了。
emitFile emitFile 能够让开发者更方便的输出一个 file 文件,这是 webpack 特有的方法,使用的方法也很直接
emitFile(name: string, content: Buffer|String, sourceMap: {...})在 file-loader 中有调用到 this.emitFile(url, content); 这个方法,具体可以查看其源码了解。
更多的 API 就不在此 一 一 说明了,建议查看官网文档了解。最后推荐一个工具模块 loader-utils,大多数的 Loader 都会用上它来解析或者使用它提供的一些 util 方法,很方便。
针对 Loader 的基础介绍大致就到这了,不多,希望这篇文章能够对 Webpack Loader 有一个大致的了解。 更多进阶的方案及实战经验容我再整理整理,迟些输出。
在上篇《脚本错误量极致优化-监控上报与Script error》 中,主要提到了js脚本错误上报的方式,并讲解了如何使用 crossorigin 来解决 Script error 报错信息的方案,于是我们就可以查看到脚本报错信息了。而此时可能会遇到另一个问题:”JS 代码压缩后,定位具体出错代码困难!“。本篇《脚本错误量极致优化-让脚本错误一目了然》 将结合示例,通过多种解决方案逐一分析,让脚本错误 一目了然。
1.源代码(存在错误)
function test() {
noerror // <- 报错
}
test();2.经 webpack 打包压缩后产生如下代码
!function(n){function r(e){if(t[e])return t[e].exports;var o=t[e]={i:e,l:!1,exports:{}};return n[e].call(o.exports,o,o.exports,r),o.l=!0,o.exports}var t={};r.m=n,r.c=t,r.i=function(n){return n},r.d=function(n,t,e){r.o(n,t)||Object.defineProperty(n,t,{configurable:!1,enumerable:!0,get:e})},r.n=function(n){var t=n&&n.__esModule?function(){return n.default}:function(){return n};return r.d(t,"a",t),t},r.o=function(n,r){return Object.prototype.hasOwnProperty.call(n,r)},r.p="",r(r.s=0)}([function(n,r){function t(){noerror}t()}]);3.代码如期报错,并上报相关信息
{ msg: 'Uncaught ReferenceError: noerror is not defined',
url: 'http://127.0.0.1:8077/main.min.js',
row: '1',
col: '515' }
此时,错误信息中行列数为 1 和 515。 结合压缩后的代码,肉眼观察很难定位出具体问题。
这种方式简单粗暴,但存在明显问题:1. 源代码泄漏,2. 文件的大小大大增加。
uglifyjs 有一个叫 semicolons 配置参数,设置为 false 时,会将压缩代码中的分号替换为换行符,提高代码可读性, 如
!function(n){function r(e){if(t[e])return t[e].exports
var o=t[e]={i:e,l:!1,exports:{}}
return n[e].call(o.exports,o,o.exports,r),o.l=!0,o.exports}var t={}
r.m=n,r.c=t,r.i=function(n){return n},r.d=function(n,t,e){r.o(n,t)||Object.defineProperty(n,t,{configurable:!1,enumerable:!0,get:e})},r.n=function(n){var t=n&&n.__esModule?function(){return n.default}:function(){return n}
return r.d(t,"a",t),t},r.o=function(n,r){return Object.prototype.hasOwnProperty.call(n,r)},r.p="",r(r.s=0)}([function(n,r){function t(){noerror}t()}])此时,错误信息中行列数为 5 和 137,查找起来比普通压缩方便不少。但仍会出现一行中有很多代码,不容易定位的问题。
uglifyjs 的另一配置参数 beautify 设置为 true 时,最终代码将呈现压缩后进行格式化的效果(保留空格和换行),如
!function(n) {
// ...
// ...
}([ function(n, r) {
function t() {
noerror;
}
t();
} ]);此时,错误信息中行列数为 32 和 9,能够快速定位到具体位置,进而对应到源代码。但由于增加了换行和空格,所以文件大小有所增加。
SourceMap 是一个信息文件,存储着源文件的信息及源文件与处理后文件的映射关系。
在定位压缩代码的报错时,可以通过错误信息的行列数与对应的 SourceMap 文件,处理后得到源文件的具体错误信息。

SourceMap 文件中的 sourcesContent 字段对应源代码内容,不希望将 SourceMap 文件发布到外网上,而是将其存储到脚本错误处理平台上,只用在处理脚本错误中。
通过 SourceMap 文件可以得到源文件的具体错误信息,结合 sourcesContent 上源文件的内容进行可视化展示,让报错信息一目了然!
基于 SourceMap 快速定位脚本报错方案

整套方案的代码实现可以在这 noerror 查看,效果如下

1.左边的为线上页面,上报脚本错误
2.右边的为 noerror 脚本错误监控系统
此时,错误信息中行列数为 1 和 515。 结合 sourcemap,经处理(source-map)后,拿到对应的源文件上的具体错误信息,并进行展示。
sentry 是一个实时的错误日志追踪和聚合平台,包含了上面 sourcemap 方案,并支持更多功能,如:错误调用栈,log 信息,issue管理,多项目,多用户,提供多种语言客户端等,具体介绍可以查看 getsentry/sentry,sentry.io,这里暂不展开。

以上的方案都有各自使用场景,能够解决问题的方案都是好方案。可以先快速支持,然后逐渐过渡到完整的方案。除了本篇文章 提到的方案外,社区还有不少其他的优秀方案。
关于 sourceMap 文件的生成,通过 gulp,webpack 都可以很好支持, noerror 的示例使用的是 webpack,只需要设置 devtool: "source-map",具体示例可以查看这里 。
继 Facebook 提出 Flux 架构来管理 React 数据流后,相关架构开始百花齐放,本文简单分析 React 中管理数据流的方式,以及对 Redux 进行较为仔细的介绍。
A JAVASCRIPT LIBRARY FOR BUILDING USER INTERFACES
在 React 中,UI 以组件的形式来搭建,组件之间可以嵌套组合。另,React 中组件间通信的数据流是单向的,顶层组件可以通过 props 属性向下层组件传递数据,而下层组件不能向上层组件传递数据,兄弟组件之间同样不能。这样简单的单向数据流支撑起了 React 中的数据可控性。
前两种形式其实也足够在小应用中跑起来。但当项目越来越大的时候,管理数据的事件或回调函数将越来越多,也将越来越不好管理了。 对于后两种形式,个人经过对比后,可以看出 Redux 对 Flux 架构的一些简化。如 Redux 限定一个应用中只能有单一的 store,这样的限定能够让应用中数据结果集中化,提高可控性。当然,不仅如此。
Redux 主要分为三个部分 Action、Reducer、及 Store
在 Redux 中,action 主要用来传递操作 State 的信息,以 Javascript Plain Object 的形式存在,如
{
type: 'ADD_FILM',
name: 'Mission: Impossible'
}在上面的 Plain Object 中,type 属性是必要的,除了 type 字段外,action 对象的结构完全取决于你,建议尽可能简单。type 一般用来表达处理 state 数据的方式。如上面的 'ADD_FILM' 表达要增加一个电影。而 name 表达了增加这个电影的电影名为 'Mission: Impossible'。那么,当我们需要表达增加另一部电影时,就需要另外一个action,如
{
type: 'ADD_FILM',
name: 'Minions'
}上面写法没有任何问题,但细想,当我们增加的电影越来越多的时候,那这种直接声明的 Plain Object 将越来越多,不好组织。实际上,我们可以通过创建函数来生产 action,这类函数统称为 Action Creator,如
function addFilm(name) {
return { type: 'ADD_FILM', name: name };
}这样,通过调用 addFilm(name) 就可以得到对应的 Action,非常直接。
有了 Action 来传达需要操作的信息,那么就需要有根据这个信息来做对应操作的方法,这就是 Reducer。 Reducer 一般为简单的处理函数,通过传入旧的 state 和指示操作的 action 来更新 state,如
function films(state = initialState, action) {
switch (action.type) {
case 'ADD_FILM':
// 更新 state 中的 films 字段
return [{
id: state.films.reduce((maxId, film) => Math.max(film.id, maxId), -1) + 1,
name: action.name
}, ...state];
case 'DELETE_FILM':
return state.films.filter(film =>
film.id !== action.id
);
case 'SHOW_ALL_FILM':
return Object.assign({}, state, {
visibilityFilter: action.filter
});
default:
return state;
}上面代码展示了 Reducer 根据传入的 action.type 来匹配 case 进行不同的 state 更新。显然,当项目中存在越来越多的 action.type 时,上面的 films 函数( Reducer )将变得越来越大,越来越多的 case 将导致代码不够清晰。所以在代码组织上,通常会将 Reducer 拆分成一个个小的 reducer,每个 reducer 分别处理 state 中的一部分数据,最终将处理后的数据合并成为整个 state。
在上面的代码中,我们可以把 'ADD_FILM' 和 'DELETE_FILM' 归为操作 state.films 的类,而 'SHOW_ALL_FILM' 为过滤显示类,所以可以把大的 film Reducer 拆分成 filmReducer 和 filterReducer,如
1 filmReducer
function filmReducer(state = [], action) {
switch (action.type) {
case 'ADD_FILM':
// 更新 state 中的 films 字段
return [{
id: state.films.reduce((maxId, film) => Math.max(film.id, maxId), -1) + 1,
name: action.name
}, ...state];
case 'DELETE_FILM':
return state.films.filter(film =>
film.id !== action.id
);
default:
return state;
}
}2 filterReducer
function filterReducer(state, action) {
switch (action.type) {
case 'SHOW_ALL_FILM':
return Object.assign({}, state, {
visibilityFilter: action.filter
});
default:
return state;
}
}最后,通过组合函数将上面两个 reducers 组合起来,如
function rootReducer(state = {}, action) {
return {
films: filmReducer(state.films, action),
filter: filterReducer(state.filter, action)
};
}上面的 rootReducer 将不同部分的 state 传给对应的 reducer 处理,最终合并所有 reducer 的返回值,组成整个state。
实际上,Redux 提供了 combineReducers() 方法来做 rootReducer 所做的事情。使用 combineReducers 来重构 rootReducer,如
var rootReducer = combineReducers({
films: filmReducer,
filter: filterReducer
});combineReducers() 将调用一系列 reducer,并根据对应的 key 来筛选出 state 中的一部分数据给相应的 reducer,这样也意味着每一个小的 reducer 将只能处理 state 的一部分数据,如:filterReducer 将只能处理及返回 state.filter 的数据,如果需要使用到其他 state 数据,那还是需要为这类 reducer 传入整个 state。
在 Redux 中,一个 action 可以触发多个 reducer,一个 reducer 中也可以包含多种 action.type 的处理。属于多对多的关系。
Action 用来表达操作消息,Reducer 根据 Action 来更新 State。
在 Redux 项目中,Store 是单一的。维护着一个全局的 State,并且根据 Action 来进行事件分发处理 State。可以看出 Store 是一个把 Action 和 Reducer 结合起来的对象。
Redux 提供了 createStore() 方法来 生产 Store,并提供三个 API,如
var store = createStore(rootReducer); // 其中 rootReducer 为顶级的 Reducerstore 对象可以简单的理解为如下形式
function createStore(reducer, initialState) {
//闭包私有变量
var currentReducer = reducer;
var currentState = initialState;
var listeners = [];
function getState() {
return currentState;
}
function subscribe(listener) {
listeners.push(listener);
return function unsubscribe() {
var index = listeners.indexOf(listener);
listeners.splice(index, 1);
};
}
function dispatch(action) {
currentState = currentReducer(currentState, action);
listeners.slice().forEach(listener => listener());
return action;
}
//返回一个包含可访问闭包变量的公有方法
return {
dispatch,
subscribe,
getState
};
}store.getState() 用来获取 state 数据。
store.subscribe(listener) 用于注册监听函数。每当 state 数据更新时,将会触发监听函数。
而 store.dispatch(action) 是用于将一个 action 对象发送给 reducer 进行处理。如
store.dispatch({
type: 'ADD_FILM',
name: 'Mission: Impossible'
}); store 对象使得我们可以通过 store.dispatch(action) 来减少对 reducer 的直接调用,并且能够更好地对 state 进行统一管理。没有 store,可能会出现 reducer(currentState, action) 这样的频繁地传入 state 参数的更新形式。
从上面的 Action 相关介绍中可知,我们使用了 ActionCreator 来生产 action。所以在实际的 store.dispatch(action) 中,我们需要这样调用 store.dispatch(actionCreator(…args))。
借鉴 Store 对 reducer 的封装(减少传入 state 参数)。可以对 store.dispatch 进行再一层封装,将多参数转化为单参数的形式。 Redux 提供的 bindActionCreators 就做了这件事。如
var actionCreators = bindActionCreators(actionCreators, store.dispatch);现在,经 bindActionCreators 包装过后的 action Creator 形成了具有改变全局 state 数据的多个函数,将这些函数分发到各个地方,即能通过调用这些函数来改变全局的 state。
Redux 中的函数传递及原理
当调用了具备操作全局 state 的函数时,将经过一系列的函数传递及调用,如

问:为什么不直接使用 reducer(currentState, {type:'ADD_FILM', name: 'Minions'})) 呢?
答:这样做除了在代码组织和扩展维护上提供了便利,同时也涵盖了函数式编程的许多优点。
Redux 并不依赖于 React,它支持多种框架 Ember、Angular、jQuery 甚至纯 JavaScript。但实际上,它更合适由 数据更新 UI 的框架。如 React、Deku。
上面的章节最终通过 bindActionCreators 得到具有操作全局 state 的函数集合,在与 React 搭配时,就会将这些函数分发到各个对应的组件中,从而组件具备了操作全局的 state 的功能。在上节中可以得到,调用操作全局 state 的函数,最终将更新 state。当 redux 与 react 结合,在更新 state 时,将会触发 重新渲染 组件的函数,进而组件得到更新。
react-redux 主要提供两个组件来实现上述功能。
Connect 组件主要为 React 组件提供 store 中的部分 state 数据 及 dispatch 方法,这样 React 组件就可以通过 dispatch 来更新全局 state。在 React 组件中,如果你希望让组件通过调用函数来更新 state,可以通过使用 const actions = bindActionCreators(FilmActions, dispatch); 将 actions 和 dispatch 揉在一起,成为具备操作 store.state 的 actions。最终将 actions 和 state(state.films)以 props 形式传入子组件中。如
import { connect } from 'react-redux';
import * as flimActions from '../actions/films';
// 其他模块引入..
class FilmApp extends Component {
render() {
// 从 react-redux 注入
const { films, dispatch } = this.props;
// 生成具有操作 state 能力的 actions
const actions = bindActionCreators(flimActions, dispatch);
// 为各个 React 组件提供 state 数据 及 actions
return (
<div>
<Header films={films} actions={actions}/>
<Section films={films} deleteFilm={actions.deleteFilm}/>
</div>
);
}
}
// state 将由 store 提供
function select(state) {
return {
films: state.films
};
}
// 最终暴露 经 connect 处理后的组件
export default connect(select)(FilmApp);由上,在 redux 提供的 connect 函数中,select 函数用于筛选 state 的部分数据,最终和 dispatch 以 props 的形式传给 React 组件(FilmApp)。FilmApp 就可通过 this.props 来得到 store 中的 state 及 dispatch。
在 redux 中,没有与 redux 有直接关联的组件称为木偶组件,如 FilmApp 下的子组件,不理外面纷纷扰扰,只知道自己拥有了 state 及 具备操作 state 数据的 actions 方法。
当木偶组件使用 actions 方法,更新了 store.state 的数据时,将会触发 store 中的 subscribe 所注册的函数。而其中一个注册函数,就在 Connect 组件中静默注册了。
// 在 Connect 中
this.store.subscribe(this.handleChange.bind(this));即当 actions 更改了 state 时,会调用注册函数 handleChange。从而进行 “阿米诺骨牌式” 的函数执行连锁反应。更新了 state,并使用新的数据重新 render 组件。实际上是为智能组件 FilmApp(传入 connect 的组件)传入新的 props,因为各个子元素是通过引用父级组件的 props,所以将进行一级一级的差异数据更新,最终效果就是页面更新了。
实际上,这里与简单的发布订阅模式类似。使用 store.subscribe(cb); 来订阅一个回调函数,子组件进行 action 操作 store.state 时进行发布,执行了回调函数。
在 react-redux 中,数据的流向及对应的反应,如

Connect 组件需要 store。这个需求由 Redux 提供的另一个组件 Provider 来提供。源码中,Provider 继承了 React.Component,所以可以以 React 组件的形式来为 Provider 注入 store,从而使得其子组件能够在上下文中得到 store 对象。如
<Provider store={store}>
{() => <FilmApp /> }
</Provider>在 React 0.13 及以前的版本中,Provider 渲染子组件是通过执行 children(),如
Provider.prototype.render = function render() {
var children = this.props.children;
return children();
};编辑状态的实时预览 redux-dev-tools https://github.com/gaearon/redux-devtools
大量的相关参考 awesome-redux https://github.com/xgrommx/awesome-redux
ERROR in ./src/js/modules/header/index.jsx
Module not found: Error: Cannot resolve module 'index.less' in C:\Users\Desktop\src\js\modules\header
@ ./src/js/modules/header/index.jsx 5:0-21
ERROR in ./src/js/modules/header/index.less
Module not found: Error: Cannot resolve 'file' or 'directory' ./../../../../node_modules/css-loader/index.js in C:\Users\Desktop/src\js\modules\header
@ ./src/js/modules/header/index.less 4:14-134ERROR in ./src/js/modules/header/index.less
Module not found: Error: Cannot resolve 'file' or 'directory' ./../../../../node_modules/style-loader/addStyles.js in C:\Users\Desktop/src\js\modules\header
@ ./src/js/modules/header/index.less 7:13-77
var path = require('path');
module.exports = {
context: path.join(__dirname, 'src'),
resolve: {
root: path.resolve(__dirname, "src"),
// root: __dirname + '/src',
}
}两者的不同,可看一下输出
console.log(path.resolve(__dirname, "src")); // 输出: C:\Users\joeyguo\Desktop\src
console.log(__dirname + '/src'); // 输出: C:\Users\joeyguo\Desktop/src
ERROR in Cannot find module 'less'
@ ./src/js/modules/header/index.less 4:14-134
npm install less less-loader --save-dev
CreateJS 是基于 HTML5 开发的一套模块化的库和工具,用于快捷地开发基于HTML5的游戏、动画和交互应用。
gka 为 createjs 开发定制模板 gka-tpl-createjs ,仅需一行命令,优化图片资源,生成雪碧图及 createjs 动画文件。欢迎 star : D https://github.com/gkajs/gka
为了减小图片大小、减少http请求,可以对图片集进行合图,如下(图片来自 createjs 官方示例)

使用 createjs 让雪碧图动起来。
var spriteSheet = new createjs.SpriteSheet({
framerate: 30,
images: ["./sprites.png"],
frames: {"regX": 82, "height": 292, "count": 64, "regY": 0, "width": 165},
animations: {
"run": [0, 25, "run"]
}
});
var grant = new createjs.Sprite(spriteSheet, "run");
stage.addChild(grant);上述代码使用 createjs 完成雪碧图动画的声明,从而能够进行播放。
上述示例可能存在以下问题
使用 gka,仅需一行命令,优化图片、生成雪碧图及 createjs 动画文件。
gka <dir> -t createjs # dir 为帧图片目录优化后的雪碧图

对比两张雪碧图的压缩后大小,可发现优化了40+KB,约 40% !
gka 是一款简单的、高效的帧动画生成工具,图片处理工具。
只需一行命令,快速图片优化、生成动画文件,支持效果预览。
相同帧图片复用✓,图片空白裁剪✓,合图模式✓,图片压缩✓官方文档:https://gka.js.org
Github 地址: https://github.com/gkajs/gka
gka createjs 模板:https://github.com/gkajs/gka-tpl-createjs
如果你觉得不错,请点个 star : D
欢迎使用,欢迎任何意见或建议,谢谢。
函数式编程 ( Functional Programming ) 是一种以函数为基础的编程方式和代码组织方式,能够带来更好的代码调试及项目维护的优势。本篇主要结合笔者在实际项目开发中的一些应用,简要谈谈函数式编程。
在函数式编程中,任何代码可以都是函数,且要求具有返回值,如下示例
// 非函数式
var title = "Functional Programming";
var saying = "This is not";
console.log(saying + title); // => This is not Functional Programming// 函数式
var say = title => "This is " + title;
var text = say("Functional Programming"); // => This is Functional Programming纯函数在这里指函数内外间是“无”关联的。主要有下面两点
// 非纯函数(函数内依赖函数外的变量值)
var title = "Functional Programming";
var say = ()=> "This is not" + title; // <= 依赖了全局变量 title// 纯函数
var say = (title)=>"This is " + title; // <= 依赖了以参数 title 传入
say("Functional Programming");这里主要是指变量值的不可变。当需要基于原变量值改变时,可通过产生新的变量来确保原变量的不变性,如下
// 可变数据
var arr = ["Functional", "Programming"];
arr[0] = "Other"; // <= 修改了arr[0]的值
console.log(arr) // => ["Other", "Programming"] // 变量arr值已经被修改// 不可变数据
var arr = ["Functional", "Programming"];
// 得到新的变量,不修改了原来的值
var newArr = arr.map(item => {
if(item === "Functional"){
return "Other";
} else {
return item;
}
})
console.log(arr); // => ["Functional", "Programming"] 变量arr值不变
console.log(newArr); // => ["Other", "Programming"] 产生新的变量newArr之所以使用这种不变值,除了更好的函数式编程外,还能够维持线程安全可靠,落地在业务中,实际上也能让代码更加清晰。
设想,如果你定义了一个变量A,A在其他地方被其他人修改了,这样是不方便定位A的当前值的。关于定义多个变量引发的内存等问题,可以通过重用结构或部分引用的方式来减轻,可参考 immutable.js
强大的 JavaScript 有着越来越多的高能处理数据函数,其中包含了 map、 reduce、 filter 等。
map 能够对原数组中的值进行逐个处理并产生新的数组,一个简单例子
// map
var data = [1, 2, 3];
var squares = data.map( (item, index, array) => item * item );
console.log(squares); // => [1, 4, 9]
console.log(data);// => [1, 2, 3] data 还是那个 data reduce 能够对原数组中的各个值进行结合处理,来产生新的值,如下面例子中,previous 代表上一个结果值,current 代表当前值,reduce 函数可以传入第二个参数作为 previous 初始值,不传时则 previous 初始值为数组中第一个值。
// reduce
var sum = [1, 2, 3].reduce( (previous, current, index, array) => previous + current );
console.log(sum); // => 6柯里化 是将多参函数转换成一系列的单参函数。结合下面例子来说明下
// 一个多参函数
var add = (a, b) => a + b;
add(1, 2); // => 3将上面的多参函数进行柯里化,如下
// 柯里化函数
var add = a => b => a + b;上面柯里化后的函数调用方式也有所转变,第一次传入一个参数返回了一个函数,再传入参数则完成整体的调用,这也是利用的闭包的特性
var add1 = add(1);
add1(2); // => 3柯里化后的函数,也可以应用在生产 “ 函数 ” 上,如下示例
var say = title => type => title + " is " + type;
var sayFP = say("Functional Programming");
var sayOther = say("Other Programming");
sayFP("good"); // => Functional Programming is good
sayOther("good"); // => Other Programming is good顾名思义,组合函数是将多个函数进行组合成一个函数。举个例子
var compose = (fn1, fn2) => (arg) => fn1(fn2(arg));
var a = arg => arg + 'a';
var b = arg => arg + 'b';
var c = compose(a, b); // 将a,b函数进行组合
c('c'); // => cba上面示例中,当调用组合函数 c 时,传入的参数会经过 b 函数,接着将 b 函数的返回值作为 a 函数的参数值,从而输出最终结果。
组合函数 c 就像管道一样,将水流( 返回值 )流经各个函数中进行处理。
当想要组合很多函数成一条很长很长的“管道”时,那么显然上面的 compose 函数已经不够用了。下面看看 redux 是怎么做这个 compose 工具函数的。
// 源自: redux/src/compose.js
export default function compose(...funcs) {
if (funcs.length === 0) {
return arg => arg
} else {
const last = funcs[funcs.length - 1]
const rest = funcs.slice(0, -1)
return (...args) => rest.reduceRight((composed, f) => f(composed), last(...args))
}
}代码很简洁,主要利用了递归方式和数组的 reduceRight 方法来处理,reduceRight 跟上边提到的 reduce 方法功能是一样的,不同的是 reduceRight 是从数组的末尾向前逐个处理。就这样,想拼多长的就多长。
以上,便是笔者在项目实践中应用较多的函数式编程内容,如有不妥,请斧正。
附: 一些可供学习函数式编程的内容
React 的实践从去年在 PC QQ家校群开始,由于 PC 上的网络及环境都相当好,所以在使用时可谓一帆风顺,偶尔遇到点小磕绊,也能够快速地填补磨平。而最近一段时间,我们将手Q的家校群重构成 React,除了原有框架上存在明显问题的原因外,选择React也是因为它确实有足够的吸引力以及优势,加之在PC家校群上的实践经验,斟酌下便开始了,到现在已有页面在线上正常跑起。
由于移动端上的网络及环境迥异,性能偏差。所以在移动端上用 React 时,遇到了不少的坑点,也花了一些力气在上面。关于在移动端上的优化,可看我们团队的另一篇文章的 React移动端web极致优化
一提到优化,不得不提直出
关于这块可以查看 Node直出理论与实践总结,这篇文章较详细的分析直出的概念及一步步优化,也结合了 手Q家校群使用快速的数据直出方式来优化性能的总结与性能数据分析
一提到 React,不得不提同构
同构基于服务端渲染,却不止是服务端渲染。
服务端渲染的方案早在后台程序前后端包办的时代上就有了,那时候使用JSP、PHP等动态语言将数据与页面模版整合后输出给浏览器,一步到位

这个时候,前端开发跟后端揉为一体,项目小的时候,前后端的开发和调试还真可以称为一步到位。但当项目庞大起来的时候,无论是修改某个样式要起一个庞大服务的尴尬,还是前后端糅合的地带变得越来越难以维护,都很难过。
前后端分离后,服务端渲染的模式就开始被淡化了。这时候的服务端渲染比较尴尬,由于前后端的编码语言不同,连页面模板都不能复用,只能让在前后端开发完成后,再将前端代码改为给后端使用的页面模板,增大了工作量。最终也还是跟后台包办殊途同归。
Node 驾着祥云腾空而来,谷歌 V8 引擎给力支持,众前端拿着看家本领(JavaScript)开始涉足服务端,于是服务端渲染上又一步进阶

由于前后端时候的相同的语言,所以前后端在代码的共用上达到了新的高度,页面模版、node modules 都可以做成前后通用。同构的雏形,只是共用的代码还是有局限。
有了Node 后,前端便有了更多的想象空间。前端框架开始考虑兼容服务端渲染,提供更方便的 API,前后端共用一套代码的方案,让服务端渲染越来越便捷。当然,不只是 React 做了这件事,但 React 将这种**推向高潮,同构的概念也开始广为人传。

关于 React 网上已有大多教程,可以查看阮老师的react-demos。关于 React 上的数据流管理方案,现在最为火热的 Redux 应该是首选,具体可以查看另一篇文章 React 数据流管理架构之Redux,此篇就不再赘述,下面讲讲 React 同构的理论与在手Q家校群上的具体实践总结。
React 的虚拟 Dom 以对象树的形式保存在内存中,并存在前后端两种展露原型的形式

完善的 Component 属性及生命周期与客户端的 render 时机是 React 同构的关键。
DOM 的一致性
在前后端渲染相同的 Component,将输出一致的 Dom 结构。
不同的生命周期
在服务端上 Component 生命周期只会到 componentWillMount,客户端则是完整的。
客户端 render 时机
同构时,服务端结合数据将 Component 渲染成完整的 HTML 字符串并将数据状态返回给客户端,客户端会判断是否可以直接使用或需要重新挂载。
以上便是 React 在同构/服务端渲染的提供的基础条件。在实际项目应用中,还需要考虑其他边角问题,例如服务器端没有 window 对象,需要做不同处理等。下面将通过在手Q家校群上的具体实践,分享一些同构的 Tips 及优化成果
手Q家校群使用 React + Redux + Webpack 的架构
ReactDOMServer 提供 renderToString 和 renderToStaticMarkup 的方法,大多数情况使用 renderToString,这样会为组件增加 checksum

React 在客户端通过 checksum 判断是否需要重新render
相同则不重新render,省略创建DOM和挂载DOM的过程,接着触发 componentDidMount 等事件来处理服务端上的未尽事宜(事件绑定等),从而加快了交互时间;不同时,组件将客户端上被重新挂载 render。
renderToStaticMarkup 则不会生成与 react 相关的data-*,也不存在 checksum,输出的 html 如下

在客户端时组件会被重新挂载,客户端重新挂载不生成 checknum( 也没这个必要 ),所以该方法只当服务端上所渲染的组件在客户端不需要时才使用

服务端上的产生的数据需要随着页面一同返回,客户端使用该数据去 render,从而保持状态一致。服务端上使用 renderToString 而在客户端上依然重新挂载组件的情况大多是因为在返回 HTML 的时候没有将服务端上的数据一同返回,或者是返回的数据格式不对导致,开发时可以留意 chrome 上的提示如

平台上的差异,服务端渲染只会执行到 compnentWillMount 上,所以为了达到同构的目的,可以把拉取数据的逻辑写到 React Class 的静态方法上,一方面服务端上可以通过直接操作静态方法来提前拉取数据再根据数据生成 HTML,另一方面客户端可以在 componentDidMount 时去调用该静态方法拉取数据
这里指影响组件 render 结果的数据,举个例子,下面的组件由于在服务端与客户端渲染上会因为组件上产生不同随机数的原因而导致客户端将重新渲染。
Class Wrapper extends Component {
render() {
return (<h1>{Math.random()}</h1>);
}
};可以将 Math.random() 封装至Component 的 props 中,在服务端上生成随机数并传入到这个component中,从而保证随机数在客户端和服务端一致。如
Class Wrapper extends Component {
render() {
return (<h1>{this.props.randomNum}</h1>);
}
};服务端上传入randomNum
let randomNum = Math.random()
var html = ReacDOMServer.renderToString(<Wrapper randomNum={randomNum} />);当前后端共用一套代码的时候,像前端特有的 Window 对象,Ajax 请求 在后端是无法使用上的,后端需要去掉这些前端特有的对象逻辑或使用对应的后端方案,如后端可以使用 http.request 替代 Ajax 请求,所以需要进行平台区分,主要有以下几种方式
1.代码使用前后端通用的模块,如 isomorphic-fetch
2.前后端通过webpack 配置 resolve.alias 对应不同的文件,如
客户端使用 /browser/request.js 来做 ajax 请求
resolve: {
alias: {
'request': path.join(pathConfig.src, '/browser/request'),
}
}服务端 webpack 上使用 /server/request.js 以 http.request 替代 ajax 请求
resolve: {
alias: {
'request': path.join(pathConfig.src, '/server/request'),
}
}3.使用 webpack.DefinePlugin 在构建时添加一个平台区分的值,这种方式的在 webpack UglifyJsPlugin 编译后,非当前平台( 不可达代码 )的代码将会被去掉,不会增加文件大小。如
在服务端的 webpack 加上下面配置
new webpack.DefinePlugin({
"__ISOMORPHIC__": true
}),在JS逻辑上做判断
if(__ISOMORPHIC__){
// do server thing
} else {
// do browser thing
}4.window 是浏览器上特有的对象,所以也可以用来做平台区分
var isNode = typeof window === 'undefined';
if (isNode) {
// do server thing
} else {
// do browser thing
}这是为了减少服务端的负担,也是加快首屏展示时间,如在手Q家校群列表中存在 “我发布的” 和 “全部” 两个 tab,内容都为作业列表,此次实践在服务端上只处理首屏可视内容,即只输出 “我发布的” 的完整HTML,另外一个tab的内容在客户端上通过 react 的 dom diff 机制来动态挂载,无页面刷新的感知。

举个例子,identity 默认为 UNKOWN,从后台拉取到数据后,更新其值,从而触发 setButton 方法
componentWillReceiveProps(nextProps) {
if (nextProps.role.get('identity') !== UNKOWN &&
nextProps.role.get('identity') !== this.props.role.get('identity'))) {
this.setButton();
}
}同构时,由于服务端上已做了第一次数据拉取,所以上面代码在客户端上将由于 identity 已存在而导致永不执行 setButton 方法,解决方式可在 componentDidMount 做兼容处理
componentDidMount() {
// .. 判断是否为同构
if (identity !== UNKOWN) {
this.setButton(identity);
}
} 下图为其中一种形式,先进行数据请求,再将请求到的数据 dispatch 一个 action,通过在reducer将数据进行 redux 的 state 化。还有其他方式,如直接 dispatch 一个 action,在action里面去做数据请求,后续是一样的,不过这样就要求请求数据的模块是 isomorphism 即前后端通用的。

设计好 store state 是使用 redux 的关键,而在服务端上,合理的扁平化 state 能在其被序列化时,减少 CPU 消耗
客户端上,由于 react 中 setState 的异步机制,所以在同个component中触发多个action,会出现一种情况是:第一个 action 对 state 的改变还没来得及更新component时,第二个action便开始执行,即第二个 action 将使用到未更新的值。
而在同构中,如果第一个 action (如下的 fetchData)是在服务端执行了,第二个 action 在客户端执行时将使用到的是第一个 action 对 state 改变后的值,即更新后的值。这时,同构需要做兼容处理。
fetchData() {
this.props.setCourse(lastCourseId, lastCourseName);
}
render() {
this.props.updateTab(TAB);
}手Q家校群上使用了 immutable 来保证数据的不可变,提高数据对比速度,而在同构时需要注意两点
1.服务端上,从 store 中拿到的 state 为immutable对象,需转成 string 再同HTML返回
2.客户端上,从服务端注入到HTML上的 state 数据,需要将其转成 immutable对象,再放到 configureStore 中,如
var __serverData__ = Immutable.fromJS(window.__serverData__);
var store = configureStore(__serverData__);实际上,如果是一个单独的服务的话,可以使用babel提供的方式来让node环境兼容好 E6
require("babel-register")({
extensions: [".jsx"],
presets: ['react']
});
require("babel-polyfill");但如果是以同一个直出服务器,多个项目的直出代码都放在这个服务上,那么,还是建议使用 webpack 的方式去兼容 ES6,减少 babel 对全局环境的影响。使用 webpack 的话,在项目完成后,可将 es6 代码编译成 es5 再放到真正的 server 上,这样也可以减少动态编译耗时。
使用webpack时,默认是将css文件以 css in js 的方式打包起来,这种情况将增加服务端运行耗时,通过将 css 外链,或在webpack打包成独立的css文件后再inline进去,可以减少服务端的处理耗时及负荷。
上面提及使用webpack编译后的代码放到真正的server上去跑,在前端发布前一般会进行代码uglify,而后端实际上没多大必要,在实际应用中发现,使用 UglifyJsPlugin 后运行服务端会报错,需慎用。
当服务端代码需要使用到 __dirname 时,需在 webpack.config.js 配置 target 为 node,并在 node 中声明__filename和__dirname为true,否则拿不到准确值,如在服务端代码上添加 console.log(__dirname); 和 console.log(__filenam );
在服务端使用的 webpack 上指定 target 为 node,如下
target: 'node',
node: {
__filename: true,
__dirname: true
}经 webpack 编译后输出如下代码,可看出 __dirname 和 __filename 将正确输出(注:需考虑生成的路径是否能在不同系统上跑,如下图是在window下,使用的是双斜杠)

而不在webpack上配置时,__dirname则为 / ,__filename则为文件名,这是不正确的

使用 webpack 将一个模块编译后将形成一个立即执行函数,函数中返回对象。如果需要将编译后的代码也作为一个模块供其他地方使用时,那么需要重新将该模块暴露出去( 如当业务上的直出代码只是作为直出服务器的其中一个任务时,那么需要将编译后的代码作为一个模块 exports 出去,即在编译后代码前重新加上 module.exports =,从而直出服务将能够使用到这个编译后的模块代码 )。写了一个 webpack 插件来自动添加 module.exports,比较简单,有兴趣的欢迎使用 webpack-add-module-expors,效果如下
编译前

编译后

使用 webpack-add-module-expors编译后将带上module.exports

当服务端上不想处理样式模块或一些浏览器才需要的模块(如前端上报)时,需要在服务端上将其忽略。尝试 webpack 自带的 webpack.IgnorePlugin 插件后出现一些奇奇怪怪的问题,重温 如何开发一个 Webpack Loader ( 一 ) 时想起 webpack 在执行时会将原文件经webpack loaders进行转换,如 jsx 转成 js等。所以想法是将在服务端上需要忽略的模块,在loader前执行前就将其忽略。写了个 ignored-loader,可以将需要忽略的模块在 loader 执行前直接返回空,所以后续就不再做其他处理,简单但也满足现有需求。
服务端上的耗时增加了,但整体上的首屏渲染完成时间大大减少
服务端渲染方案将数据的拉取和模板的渲染从客户端移到了服务端,由于服务端的环境以及数据拉取存在优势(详见 Node直出理论与实践总结),所以在相比下,这块耗时大大减少,但确实存在,这两块耗时是服务端渲染相比于客户端渲染在服务端上多出来。所以本次也做了耗时的数据统计,如下图

从统计的数据上看,服务端上数据拉取的时间约 61.75 ms,服务端render耗时为16.32 ms,这两块时间的和为 78 ms,这耗时还是比较大。所以此次在同构耗时在计算上包含了服务端数据拉取与模板渲染的时间
服务端渲染时由于不需要等待 JS 加载和 数据请求(详见 Node直出理论与实践总结),在首屏展示时间耗时上将大大减少,此次在手Q家校群列表页首屏渲染完成时间上,优化前平均耗时约1643.914 ms,而同构优化后平均耗时为 696.62 ms,有了 947ms 的优化,提升约 57.5% 的性能,秒开搓搓有余!


1.优化前

2.优化后(同构直出)

可明显看出同构直出后,白屏时间大大减少,可交互时间也得到了提前,产品体验将变得更好。
服务端渲染的方式能够很好的减少首屏展示时间,React 同构的方式让前后端模板、类库、以及数据模型上共用,大大减少的服务端渲染的工作量。
由于在服务端上渲染模板,render 时过多的调用栈增加了服务端负载,也增加了 CPU 的压力,所以可以只直出首屏可视区域,减少Component层级,减少调用栈,最后,做好容灾方案,如真的服务端挂了( 虽然情况比较少 ),可以直接切换到普通的客户端渲染方案,保证用户体验。
以上,便是近期在 React 同构上的实践总结,如有不妥,恳请斧正,谢谢。
”JS 代码压缩后,定位具体出错代码困难!“ 的问题,我们可以通过 SourceMap 快速定位,处理得到源文件的具体错误信息。具体方式可以查看 《脚本错误量极致优化-让脚本错误一目了然》
然而当项目外链第三方资源或公共库时,这种压缩且无提供 SourceMap 的文件出现异常,又该如何更好的定位错误位置呢?
我们可以将压缩代码进行格式化,当错误出现时,错误信息也就有了具体的行列数,更够方便定位到错误位置。
!function(n) {
// ...
// ...
}([ function(n, r) {
function t() {
noerror;
}
t();
} ]);而此时,格式化后的代码由于增加了换行和空格,增加了文件的大小,所以并不推荐这种方式。 但这种试图 “通过压缩代码的出错行列位置转换成格式化代码对应的出错行列位置” 的思路我们可以接着进行优化。将格式化代码的转换进行后置处理。借助工具,避免提前格式化导致的文件增大问题。

我们可以将压缩代码进行格式化,并结合原来的压缩代码匹配生成“映射文件” - SourceMap 文件。
有了 SourceMap 文件后,就能够通过压缩代码的行列数找到对应格式化后代码的行列数了。

当遇到压缩且无源码 SourceMap 的文件出错时,借助上面提到的“工具”,能够找到其对应格式化后的代码及出错位置,更好的定位具体问题。具体工具的使用与实现方式可见 https://github.com/joeyguo/js-beautify-sourcemap
以上为本文所有内容,相关文章:
脚本错误量极致优化-监控上报与Script error
脚本错误量极致优化-让脚本错误一目了然
在单页应用上,前端路由并不陌生。很多前端框架也会有独立开发或推荐配套使用的路由系统。那么,当我们在谈前端路由的时候,还可以谈些什么?本文将简要分析并实现一个的前端路由,并对 react-router 进行分析。
说一下前端路由实现的简要原理,以 hash 形式(也可以使用 History API 来处理)为例,当 url 的 hash 发生变化时,触发 hashchange 注册的回调,回调中去进行不同的操作,进行不同的内容的展示。直接看代码或许更直观。
function Router() {
this.routes = {};
this.currentUrl = '';
}
Router.prototype.route = function(path, callback) {
this.routes[path] = callback || function(){};
};
Router.prototype.refresh = function() {
this.currentUrl = location.hash.slice(1) || '/';
this.routes[this.currentUrl]();
};
Router.prototype.init = function() {
window.addEventListener('load', this.refresh.bind(this), false);
window.addEventListener('hashchange', this.refresh.bind(this), false);
}
window.Router = new Router();
window.Router.init();上面路由系统 Router 对象实现,主要提供三个方法
Router 调用方式以及呈现效果如下:点击触发 url 的 hash 改变,并对应地更新内容(这里为 body 背景色)
<ul>
<li><a href="#/">turn white</a></li>
<li><a href="#/blue">turn blue</a></li>
<li><a href="#/green">turn green</a></li>
</ul> var content = document.querySelector('body');
// change Page anything
function changeBgColor(color) {
content.style.backgroundColor = color;
}
Router.route('/', function() {
changeBgColor('white');
});
Router.route('/blue', function() {
changeBgColor('blue');
});
Router.route('/green', function() {
changeBgColor('green');
});
以上为一个前端路由的简单实现,点击查看完整代码,虽然简单,但实际上很多路由系统的根基都立于此,其他路由系统主要是对自身使用的框架机制的进行配套及优化,如与 react 配套的 react-router。
react-router 是基于 history 模块提供的 api 进行开发的,结合的形式本文记为 包装方式。所以在开始对其分析之前,先举一个简单的例子来说明如何进行对象的包装。
// 原对象
var historyModule = {
listener: [],
listen: function (listener) {
this.listener.push(listener);
console.log('historyModule listen..')
},
updateLocation: function(){
this.listener.forEach(function(listener){
listener('new localtion');
})
}
}
// Router 将使用 historyModule 对象,并对其包装
var Router = {
source: {},
init: function(source){
this.source = source;
},
// 对 historyModule的listen进行了一层包装
listen: function(listener) {
return this.source.listen(function(location){
console.log('Router listen tirgger.');
listener(location);
})
}
}
// 将 historyModule 注入进 Router 中
Router.init(historyModule);
// Router 注册监听
Router.listen(function(location){
console.log(location + '-> Router setState.');
})
// historyModule 触发回调
historyModule.updateLocation();返回:

可看到 historyModule 中含有机制:historyModule.updateLocation() -> listener( ),Router 通过对其进行包装开发,针对 historyModule 的机制对 Router 也起到了作用,即historyModule.updateLocation() 将触发 Router.listen 中的回调函数 。点击查看完整代码
这种包装形式能够充分利用原对象(historyModule )的内部机制,减少开发成本,也更好的分离包装函数(Router)的逻辑,减少对原对象的影响。
react-router 以 react component 的组件方式提供 API, 包含 Router,Route,Redirect,Link 等等,这样能够充分利用 react component 提供的生命周期特性,同时也让定义路由跟写 react component 达到统一,如下
render((
<Router history={browserHistory}>
<Route path="/" component={App}>
<Route path="about" component={About}/>
<Route path="users" component={Users}>
<Route path="/user/:userId" component={User}/>
</Route>
<Route path="*" component={NoMatch}/>
</Route>
</Router>
), document.body)就这样,声明了一份含有 path to component 的各个映射的路由表。
react-router 还提供的 Link 组件(如下),作为提供更新 url 的途径,触发 Link 后最终将通过如上面定义的路由表进行匹配,并拿到对应的 component 及 state 进行 render 渲染页面。
<Link to={`/user/89757`}>'joey'</Link>这里不细讲 react-router 的使用,详情可见:https://github.com/reactjs/react-router
主要是因为触发了 react setState 的方法从而能够触发 render component。
从顶层组件 Router 出发(下面代码从 react-router/Router 中摘取),可看到 Router 在 react component 生命周期之组件被挂载前 componentWillMount 中使用 this.history.listen 去注册了 url 更新的回调函数。回调函数将在 url 更新时触发,回调中的 setState 起到 render 了新的 component 的作用。
Router.prototype.componentWillMount = function componentWillMount() {
// .. 省略其他
var createHistory = this.props.history;
this.history = _useRoutes2['default'](createHistory)({
routes: _RouteUtils.createRoutes(routes || children),
parseQueryString: parseQueryString,
stringifyQuery: stringifyQuery
});
this._unlisten = this.history.listen(function (error, state) {
_this.setState(state, _this.props.onUpdate);
});
};上面的 _useRoutes2 对 history 操作便是对其做一层包装,所以调用的 this.history 实际为包装以后的对象,该对象含有 _useRoutes2 中的 listen 方法,如下
function listen(listener) {
return history.listen(function (location) {
// .. 省略其他
match(location, function (error, redirectLocation, nextState) {
listener(null, nextState);
});
});
}可看到,上面代码中,主要分为两部分
以上,为起始注册的监听,及回调的作用。
这里还得从如何更新 url 说起。一般来说,url 更新主要有两种方式:简单的 hash 更新或使用 history api 进行地址更新。在 react-router 中,其提供了 Link 组件,该组件能在 render 中使用,最终会表现为 a 标签,并将 Link 中的各个参数组合放它的 href 属性中。可以从 react-router/ Link 中看到,对该组件的点击事件进行了阻止了浏览器的默认跳转行为,而改用 history 模块的 pushState 方法去触发 url 更新。
Link.prototype.render = function render() {
// .. 省略其他
props.onClick = function (e) {
return _this.handleClick(e);
};
if (history) {
// .. 省略其他
props.href = history.createHref(to, query);
}
return _react2['default'].createElement('a', props);
};
Link.prototype.handleClick = function handleClick(event) {
// .. 省略其他
event.preventDefault();
this.context.history.pushState(this.props.state, this.props.to, this.props.query);
};对 history 模块的 pushState 方法对 url 的更新形式,同样分为两种,分别在 history/createBrowserHistory 及 history/createHashHistory 各自的 finishTransition 中,如 history/createBrowserHistory 中使用的是 window.history.replaceState(historyState, null, path); 而 history/createHashHistory 则使用 window.location.hash = url,调用哪个是根据我们一开始创建 history 的方式。
更新 url 的显示是一部分,另一部分是根据 url 去更新展示,也就是触发前面的监听。这是在前面 finishTransition 更新 url 之后实现的,调用的是 history/createHistory 中的 updateLocation 方法,changeListeners 中为 history/createHistory 中的 listen 中所添加的,如下
function updateLocation(newLocation) {
// 示意代码
location = newLocation;
changeListeners.forEach(function (listener) {
listener(location);
});
}
function listen(listener) {
// 示意代码
changeListeners.push(listener);
}可以将以上 react-router 的整个包装闭环总结为
至于前进与后退的实现,是通过监听 popstate 以及 hashchange 的事件,当前进或后退 url 更新时,触发这两个事件的回调函数,回调的执行方式 Link 大致相同,最终同样更新了 UI ,这里就不再说明。
react-router 主要是利用底层 history 模块的机制,通过结合 react 的架构机制做一层包装,实际自身的内容并不多,但其包装的**笔者认为很值得学习,有兴趣的建议阅读下源码,相信会有其他收获。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.
{kind=link}
{kind=link}