Background
Substantial progress as been made on the part of the system which is responsible for
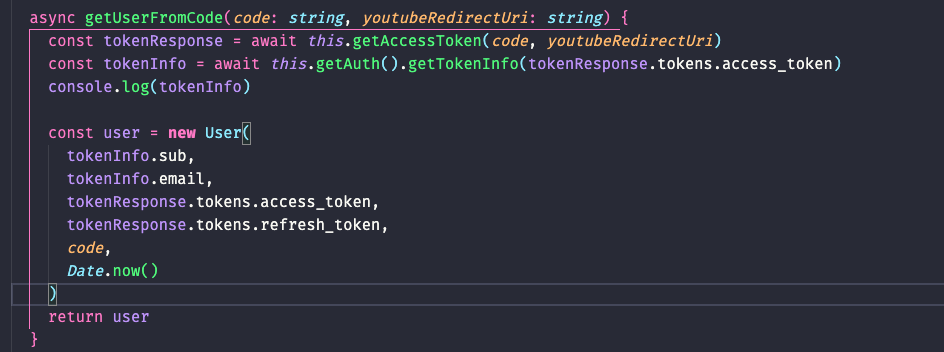
- Accepting & authenticating new claimed YT users.
- Using the API token of a new user to index all of their channels and videos
- Download actual video asset to an S3 placeholder bucket.
- Continuously do steps 2+3 by polling YT for any changed state.
- Exposing a basic API for inspecting the state of the system and interacting with it.
The best summary of the architecture of this system can be found here
https://github.com/Joystream/YT-synch/issues/22#issuecomment-1012282680
It has become clear that the integration with Joystream may infact impact the required architecture in non-trivial ways, as the blockchain and the storage infrastructure will be very plausible sources of both latency and failures. For this reason, the purpose of this issue is to provide some high level perspective and tips on what to keep in mind as we proceed.
Integration
Blockchain Integration
Terminology
- Extrinsic: The Substrate name for transaction, namely state transition message in the ledger
- Atlas: A video consumption, publishing and moneitzation webapp built for the Joystream network. Repo here https://github.com/Joystream/atlas
- Full Node: A node that downlaods and validates all blocks and transactions in the ledger.
- Finalized Block: A block which cannot be removed from the history of the chain.
- Batched Extrinsic calls: A way to do an atomic call to a sequence of extrinsics, with corresponding parameters, where either all succeed of all fail. Is enabled by the runtime pallet
utility, as seen here https://paritytech.github.io/substrate/master/pallet_utility/pallet/enum.Call.html#variant.batch_all.
Joystream SDK
Unfortuantely does not exist yet, hence the best way to understand how to interact with the network in the way which is relevant to the synch infrastruacture is to check out the Atlas code base, which does everything from creating membership, channels, videos to uploading assets to the storage system and reading the state via the query node, in Typescript.
Reading
While it is feasible to read the state of the blockchain from the RPC interface of a full node, both in terms of its current actual storage state, content of blocks and extrinsics, and also recent events like block finalization and transaction finalization, the most practical way to read the state is through the query node, as described here
Joystream/atlas#1577
the most up to date version of the schema the query node exposes, can be seen here.
https://hydra.joystream.org/graphql
For example the memberships query allows you to query all current on-chain memberships.
Writing
Writing to the state of the blockchain is done through extrinsics. Like all account based blockchains, successfully invoking an extrinsic is always done from an account, and it requires:
- The account having sufficient funds to pay for the invocation: be aware that different extrinsics have different fees, and the amount of fees may even depend on the parameter values to the extrinsic.
- That your invocation has a nonce value matching the current on-chain nonce for the account (to avoid replay attacks). The current on-chain nonce value can be recovered by asking a full-node which is in-synch with the chain tip. For each extrinsic invocation that is included in a finalized
- Having the ability to sign with the private key which corresponds to the account.
In particular constraint 2 is has a decisive impact on how the sync infrastructure should write to the chain at scale. Obviously there a need to do extrinsics for membership, channel and video creation, possibly more, and the volume may be quite large eventually. These factors will block the throughput of such calls
- chain throughput: there is one block per 6s, and it only has so much computational weight and physical size.
- query node latency: after an extrinsic invocation has been included in a block, the block has to be finalized, which can take many seconds, and only then will the query node begin to process the content of the block to update its query state. This means that from sending an extrinsic, and even from it being finalized, there is a non-deterministic amount of time until querying the query node will reflect the new changed state. This constraint has to be kept in mind whenever writing to the chain in a way that you hope to see reflected client side in order to proceed.
- non-deterministic latency and faulty extrinsic finalization: simply sending off an extrinsic invocation does not provide any strong guarantee that it will actually be included in any given block that will be finalized. Even if your local full node signals accepting it, this provides no perfect guarantee about the full distributed system. The time it may take for this to happen, or even whether it will happen at all, is not predictable. Extrinsic can be dropped for any reason.
In particular the latter factor can be a source of substantial complication when interacting with requirement 3 above. If a large number of extrinsic invocatins, from the same source account, are issued all at once, then any failure at any point in the sequence of extrinsics will block all subsequent extrinsics, possibly permanently, and complex logic will be needed to detect and recover from this by retransmitting the extrinsic. This is going to be a problem even if the actual Joystream related business logic imposes no dependencies across extrinsics, it will be purely due to nonces. Thus being able to manage nonces and accounts in a way that allows for decent overall throughput, but yet is not brittle to non-deterministic errors, will be critical for the success of the system.
The simplest possible approach I can imagine is:
- Use a dedicated account for simply creating memberships and corresponding channels (see below), and do thisas one batched call. However, only send extrinsic when the prior one has been finalized, and stop if there are no more funds or any other problems. Some sort of queue will be needed probably, and be catious to make sure that if the synch infrastructure fails, there is some graceful way to continue from a queue that was not empty during fault.
- The initial controller and root accounts for a membership (see below) are unique, and thus if credited with some minimal amount of funds, all subsequent publishing of videos under any channel of this member can happen through this unique controller account. This will automatically mean that nonce management across other channels goes away, and you only need to think about each such channel separately. So you can then use the same approach as in the prior point of publishing one video at a time, waiting for one to be finalized before doing the next. The problem here is that eventually the creator will possibly claim the channel back, in which case all future publishing has to be done through a collaborator member. Here there is then a question of whether one should make one global collaborator across all channels, or make a new one per channel. Doing a global one is probably simpler to start with. The benefit of this approach is that, if a large % of channels will be unclaimed a large part of the time, then uploads to these can happen in parallle, so if you are synching thousands of channels, this can really reduce the overall synch latency.
Now, perhaps going even simpler is a good idea, but this is one way to do it.
Storage Integration
The most important storage system interaction will be to publish new assets, for example images or video files. This has two separate components assocaited with it
- An on-chain extrinsic which describes the nature of the asset you want to publish, for example its size and hash. This information is bundled together with the primary action in question, such as creating a channel (in
create_channe) or creating a video (in create_membership).
- Uploading the asset to a first representative in the storage system, which will then replicated to other key storage providers and content delivery nodes (all community operated!). The authentication required here is trivial, you don't even need to authenticate as the member who controls the relevant asset, you only need to be a member (This will be changed). But the infrastructure does validate the content against the hash supplied in step 1.
Membership Creation
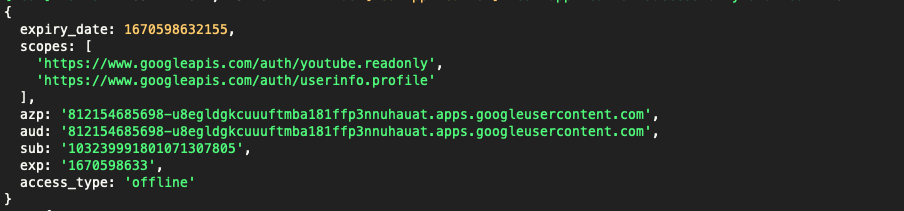
When a YT user is authenticated and added to the system, a corresponding Joystream membership should be made on the Joystream blockchain, using an exterinsic buy_membership. Memberships are described here https://joystream.gitbook.io/joystream-handbook/subsystems/membership. Channels, described below, are owned and operated by members.
The membership allows for a Joystream specific
- handle
- avatar: just a HTTP URL, not hosted on Joystream storage infra natively at this moment.
- description
Each Joystream membership is identified by a unique u64 integer.
It would be ideal for these to somehow mirror whatever is found on YT, however, this may also constitute a privacy issue for the user (for example if they have fragments of their real name in their Google account name). For this reason, the user should probably be offered the option to override these defaults when signing up. For the time being, membership level heavy assets - like image avatars, are not uploaded to the Joystream storage infrastructure, only links are used, but this will change in the future. Lastly, handles on the Joystream side have to be unique, hence the system must deal with a possible conflict that can arise if the YT-handle or the user provided handle are already taken.
Critically, a membership is controlled by two accounts, a root and a controller account, where the former is a recover account and the latter is used for authentication in all extrinsics associated with the account, such as creating a channel, updating membership metadata, etc. Under the assumption that the YT-synch system will not try to automatically detect new YT-channels after signup, it is not needed for the system to know these accounts going forward, however, since we also want the friction for a new user signing up to be minimal, it would be best if the system automaticlly generated such the required keys and stored them until the user was prepared to claim them. This is becuase in order for the user to fully control their membership, they would need to setup a wallet and their frist keys, and this can be difficult. This does however mean that we should at a later time add a way for the user to ask for the system to change the accounts on their behalf to something else that they control, but this will require building some new UIs that are not so urgent.
Channel Creation
Unfortunately the documentation for the content system is for an old version https://joystream.gitbook.io/joystream-handbook/subsystems/content-directory
For each YT channel the user both has, and wishes to synch over to Joystream, a corresponding channel must be created on the Joystream blockchain, using an extrinsic create_channel. Blockchain implementatino can be seen here
https://github.com/Joystream/joystream/blob/master/runtime-modules/content/src/lib.rs#L693
Like YT channel, channels on Joystream have a
- handle: not unique
- avatar image: must be uploaded to the joystrem storage system
- cover image: must be uploaded to the joystrem storage system
- verified status: should be set to Yes.
- description
Each Joystream channel is identified by a unique u64 integer. It is not possible to publish any videos before the channel for that video has first been established, however, it is possible to create videos before the image assets of the channel have been uploaded. Control over a channel is exercised by two means, either by being the member who owns the channel, or being one among a listed set of collaborator members on the channel. These collaborator members can be attached during initial on-chain channel creation with create_channel, or they can be attached later. This notion of a collaborator is probably the best way for the synch infrastructure to retain the ability to publish new videos under a channel, as this is something collaborators can do. For this reason, there should probably be one or more designated synch-infra controlled collaborator members, for which the synch system knows the keys, so that it can retain access to publish, but without control over other asset of the channel, like cash or NFTs. This does mean the user can also kick out the synch collaborator, in which case the synch system must be resilient and not fall over, perhaps pause, or do something else graceful.
Be aware that a channel can be deleted, either by the owning member in Joystream, or by a certain set of curating actors in the on-chian content index (called curators). In which case, the synch system has to not recreate the channel and probably avoid evne looking it up in the future on YT.
Note: as I write this, I am not 100% if curators can actualyl do this, and docs are stale, but the issue still stands.
Video Creation
Unfortunately the documentation for the content system is for an old version https://joystream.gitbook.io/joystream-handbook/subsystems/content-directory
For each YT video video the user has under some YT channel they have signed up for synching, a corresponding video must be created on the Joystrem blockain, using an extrinsic create_video, under the corresponding Joystream channel and membership. Blockchain implementation can be seen here
https://github.com/Joystream/joystream/blob/master/runtime-modules/content/src/lib.rs#L1071
A video on Joystream has
- a title
- a cover photo: must be uploaded to the joystrem storage system
- a video media file: must be uploaded to the joystrem storage system
- some other generic metadata following a standard.
Each Joystream video is identified by a unique u64 integer. Be aware that a video can be deleted, either by the owning member in Joystream, or by a certain set of curating actors in the on-chian content index (called curators). If a channel owner deletes a video from Joystream which was initially added using the synch infra, then it should not be re-uploaded again, hence the synch system needs to somehow track this. An important failure mode here is that a channel runs out of space, there are limits to how much you can upload under a given channel, and the system has to gracefully stop trying to publish new videos until this is resolved, and probably send some alert to someone.
Note: as I write this, I am not 100% if curators can actually do this, and docs are stale, but the issue still stands.