juniortour / blog Goto Github PK
View Code? Open in Web Editor NEWnot only front-end
not only front-end







TODO 正在热火朝天更新中,欢迎催更~
虚拟节点vnode:
vnode = {
"tag": "div",
"children": [
{
"text": "hi, Vue.js"
}
],
}渲染出真实DOM HTML:
<div>hi, Vue.js</div>vm.patch(vm.$el, vnode)方法,传入旧节点和新节点作为参数。第一次渲染的旧节点是一个空的虚拟节点:emptyNodeAt(elm)。nodeOps.createElement(tag, vnode),基于tag等属性,将虚拟节点转化为真实DOM,赋值给vnode.elm。children属性中的子元素,进行遍历,对每个子元素调用this.createElm()递归生成真实DOM,底层基于document.createTextNode(text)等原生DOM API实现。insert(parentElm, vnode.elm, refElm);,将生成的子元素真实DOM树,插入到父元素中;将新节点完整的真实DOM树,插入到body元素中。底层基于parentNode.insertBefore, node.appendChild(child)等原生DOM API实现。this.removeVnodes(oldVnode),删除旧节点对应的真实DOM,基于原生DOM API:node.removeChild(child);实现。数据驱动是Vue.js的核心特性之一,这个特性的创意起源于 github 上 vue.js 仓库的第二个commit,提交于2013年7月:rename · vuejs/vue@871ed91,vue.js的第一个commit是一些 grunt 配置文件,所以这第二个commit可以说是vue.js的起点,下面我和大家一块学习一下这个 commit 里精妙的代码。
从起初的一些 commit 来阅读大型项目的源码,是一种很有益的思路,有助于更好地理解作者的整体思路,还能避免大型海量信息的误导。
我整理并注释了这个commit的主要内容,即ideal.htm,可以访问下文的在线DEMO,或按照注释的序号来阅读这份代码。最好是复制到本地一份,一步步地调试着跑一跑。
<!DOCTYPE html>
<html>
<head>
<title>ideal</title>
<meta charset="utf-8">
</head>
<body>
<div id="test">
<!-- {{propName}} vue.js称之为“文本插值”,angular里叫“插值表达式”,英文都是 interpolation,修改、差值。-->
<p>{{msg}}</p>
<p>{{msg}}</p>
<p>{{msg}}</p>
<p>{{what}}</p>
<p>{{hey}}</p>
</div>
<div>
<button type="buttone" onclick="updateData()">更新数据(data.msg)</button>
</div>
<script>
debugger;
// 1. 声明绑定标记(即后来的“指令”,例如v-bind:title="message")
var bindingMark = 'data-element-binding'
function Element (id, initData) {
debugger;
var self = this,
// 2. 记录下根元素,div#test
el = self.el = document.getElementById(id)
bindings = {} // the internal copy,数据内部拷贝及绑定目标的保存
data = self.data = {} // the external interface,外部数据接口
// 2. 记录下要替换渲染的变量名标记
content = el.innerHTML.replace(/\{\{(.*)\}\}/g, markToken)
// 4. 把bindingMark,'data-element-binding'属性(指令)替换了文本插值后的字符串
// 替换成根元素的html内容
// 至此:{{mustache}} => v-bindingMark
el.innerHTML = content
for (var variable in bindings) {
// 5. 给html中带有bindingMark属性(指令)的元素创建数据绑定
bind(variable)
}
if (initData) {
// 8. 根据一开始声明实例时的data,初始化一次html,
// 后续数据更新后,将继续使用set属性,更新渲染html
// 至此:v-bindingMark => <p>data.msg</p>
for (var variable in initData) {
data[variable] = initData[variable]
}
}
function markToken (match, variable) {
bindings[variable] = {}
// 3. 给每个有文本插值的元素,用bindingMark作为html属性标记(指令)替换掉
// 文本插值标记
// 便于用 querySelectorAll 获取和保存元素的引用到bindings。
return '<span ' + bindingMark + '="' + variable +'"></span>'
}
function bind (variable) {
// 6. 记录下需要重新渲染的html元素的引用,并移除用于标记这些元素的属性(指令)
bindings[variable].els = el.querySelectorAll('[' + bindingMark + '="' + variable + '"]');
[].forEach.call(bindings[variable].els, function (e) {
e.removeAttribute(bindingMark)
})
// 7. 定义绑定的“get和set属性”,用于后续数据更新时,驱动重新渲染更新html模版
Object.defineProperty(data, variable, {
set: function (newVal) {
debugger;
[].forEach.call(bindings[variable].els, function (e) {
bindings[variable].value = e.textContent = newVal
})
},
get: function () {
return bindings[variable].value
}
})
}
}
// 1. 创建Element实例,即后来的Vue实例
var app = new Element('test', {
msg: 'hello'
})
function updateData() {
window.app.data.msg = 'Hello,JuniorTour'
}
</script>
</body>
</html>大致的逻辑如下:
首先,对 Vue 实例所挂载的el.innerHTML用.replace方法进行模板替换(.replace(/\{\{(.*)\}\}/g, markToken)),将文本插值替换成带有绑定标记-bindingMark(指令)的span元素。
例如,
<p>{{msg}}</p>会被修改为<p><span data-element-binding="msg"></span></p>。
之后,将替换后的 HTML富文本字符串 重新赋值回 el.innerHTML,再调用bind()建立绑定关系并储存带有绑定标记的元素。
bind()具体的逻辑是用querySelector('[' + bindingMark + '="' + variable + '"]')得到所有带有绑定标记的元素引用,并保存到内部数据拷贝bindings[variable].els之中。
全文最精妙的地方,就是bind()中通过Object.defineProperty修改属性的 getter, setter 函数拦截属性值的变化,并在属性值变化时触发 HTML 的重新渲染(bindings[variable].value = e.textContent = newVal),实现了数据渲染到模板的功能。
并且,后续data改变时,会触发 setter函数,再做一次 textContent 的替换,实现响应式更新模板的效果。
看完了这个Vue.js的“起点”,我们继续回到数据驱动这个概念上。
数据驱动,驱动什么呢?驱动的是视图,具体地说就是模版、DOM。即根据数据的变化来改变DOM、渲染页面。
作为Vue.js的核心概念之一,在Vue.js的文档中,有多处强调了这个概念,比如:
Vue.js 通常鼓励开发人员沿着“数据驱动”的方式思考,避免直接接触 DOM
在 Vue 中即使是过渡也是数据驱动的!动态过渡最基本的例子是通过 name 特性来绑定动态值。
另一方面,设计$refs主要是提供给 js 程序访问的,并不建议在模板中过度依赖使用它。因为这意味着在实例之外去访问实例状态,违背了 Vue 数据驱动的**。
这种理念致力于用数据实现对视图层的控制,让开发者从繁复的DOM操作从解放出来,Make Life Better。
所谓双向绑定,本质就是数据驱动和语法糖结合,例如:
v-model 语法糖v-model 语法糖实现的双向绑定本质上就是在单向数据绑定的基础上,增加事件监听并赋值给对应的data,即:
<my-component v-model="data.msg"></my-component>
// 等价于
<my-component :value="data.msg" @input="data.msg = $event"></my-component>
// 在线DEMO:https://jsbin.com/zuviwax/edit?html,output继承是面向对象语言的一大特性。通过继承,可以让一种类型拥有其他类型的属性和方法。
JavaScript也有自己实现继承的方式,本文将参考《JavaScript高级程序设计》总结并介绍3种常用常见的继承方式。
这种方法通过将子类的原型重写为父类的实例实现继承。
核心逻辑:
Bird.prototype = new Animal()
//父类:动物
function Animal() {
this.isLife = true
this.characteristic = ['living','eat']
}
Animal.prototype.earnLiving=function () {
console.log('Animal need earn its living.')
}
//子类:鸟类
function Bird() {
this.canFly = true
}
/*原型链继承:通过将子类的原型重写为父类的实例实现继承。*/
Bird.prototype = new Animal()
/*继承后,子类就会拥有父类的属性和方法,
这也是继承和原型链的目的。*/
Bird.prototype.flying = function (){
console.log('I am bird, I am flying.')
}
let sparrow = new Bird()
/*继承后,子类就会拥有父类的属性和方法,
这也是继承/原型链的目的。*/
sparrow.earnLiving()
console.log('After inherit sparrow.isLife = '+sparrow.isLife)
sparrow.flying()
/*原型链继承的弊端:公用引用类型问题*/
sparrow.characteristic.push('grayFeather') // ["living", "eat", "grayFeather"]
let eagle = new Bird()
/*公用引用类型问题是指,子类的所有实例都会共享原型链上的引用类型属性:
eagle也会继承sparrow的grayFeather,这往往不是想要的结果。*/
console.log(eagle.characteristic) // ["living", "eat", "grayFeather"]
// 只有`引用类型`会被共享, 基础类型(String, Number等)并不会这种方法是通过借调父类的构造函数,从而在子类实例的环境下,让子类的实例独立地继承父类的属性和方法,能够避免原型链继承所导致的公用引用类型问题和不能在继承时传递参数的缺点。
核心逻辑:
Animal.call(this,'Bird')
//父类:动物
function Animal(type) {
this.type = type
this.isLife = true
this.characteristic = ['living','eat']
}
//子类:鸟类
function Bird() {
/*借用构造函数继承:通过在Bird类实例的环境下
调用Animal构造函数来实现实例继承属性和方法。
同时可以结局原型链继承所导致的公用引用类型问题,
还能实现传递参数!*/
Animal.call(this,'Bird')
this.canFly = true
}
let sparrow = new Bird()
sparrow.characteristic.push('grayFeather')
console.log(sparrow.characteristic) // ["living", "eat", "grayFeather"]
console.log(sparrow.type) //可以在继承时传递参数
let eagle = new Bird()
/*原型链继承的弊端不会在此出现,
sparrow和eagle都有各自独立的引用类型-数组属性。*/
console.log(eagle.characteristic) //["living", "eat"]这种方式将原型链继承和借用构造函数继承组合在一起,取长补短,既通过在原型上定义方法实现函数复用,又保证每个实例都有自己的属性,避免了公用引用类型问题。是JavaScript中最常用的一种继承方式。
核心逻辑:
Animal.call(this,'Bird')Bird.prototype = new Animal()
//父类:动物
function Animal(type) {
this.type = type
this.isLife = true
this.characteristic = ['living','eat']
}
//原型链继承:
Animal.prototype.earnLiving = function () {
console.log('Animal need earn its living.')
}
//子类:鸟类
function Bird() {
//借用构造函数继承
Animal.call(this,'Bird')
this.canFly = true
}
//原型链继承:
Bird.prototype = new Animal()
Bird.prototype.flying = function (){
console.log('I am bird, I am flying.')
}
let sparrow = new Bird()
sparrow.characteristic.push('grayFeather')
console.log(sparrow.characteristic) // ["living", "eat", "grayFeather"]
console.log(sparrow.type) //可以在继承时传递参数
//继承了父类方法
sparrow.flying()
let eagle = new Bird()
/*解决了原型链继承的公用引用类型弊端,
sparrow和eagle都有各自独立的引用类型-数组属性。*/
console.log(eagle.characteristic) //["living", "eat"]
//继承了父类方法
eagle.earnLiving()原生JavaScript有很多方法可以用来检测原型和实例之间的关系,比如:
Object.prototype.isPrototypeOf({})Object.getPrototypeOf(anInstance) === Object.prototype anInstance instanceof anConstructorfunction A() {}
A.prototype.n=1
var b = new A()
A.prototype={ // 完全重写, 替代掉A的原型
n:2,
m:3
}
var c = new A()
console.log(b.n) // 1
console.log(b.m) // undefined
// 因为 b 用的还是未重写之前的原型
console.log(c.n) // 2
console.log(c.m) // 3本人家里养了一只鸡,一只鸭。当主人向他们发出‘叫’的命令时。鸭子会嘎嘎的叫,而鸡会咯咯的叫。转化成代码形式如下
// Src: https://segmentfault.com/q/1010000003056336
// 非多态代码示例
var makeSound = function(animal) {
if(animal instanceof Duck) {
console.log('嘎嘎嘎');
} else if (animal instanceof Chicken) {
console.log('咯咯咯');
}
}
var Duck = function(){}
var Chiken = function() {};
makeSound(new Chicken());
makeSound(new Duck());
// 多态的代码示例
var makeSound = function(animal) {
animal.sound();
}
var Duck = function(){}
Duck.prototype.sound = function() {
console.log('嘎嘎嘎')
}
var Chiken = function() {};
Chiken.prototype.sound = function() {
console.log('咯咯咯')
}
makeSound(new Chicken());
makeSound(new Duck());Vue.js 并没有什么神秘的魔法,模板渲染、虚拟 DOM diff,也都是一行行代码基于 API 实现的。
本文将用几分钟时间,分章节讲清楚 Vue.js 2.0 的 <template>渲染为 HTML DOM 的原理。
有任何疑问,欢迎通过评论联系我~~
template编译为抽象语法树 AST;
实现「字符串模板<template>编译为 render() 函数」的核心逻辑极其简单,只有 2 部分:
首先用.match()方法,提取字符串中的关键词,例如标签名div,Mustache标签对应的变量msg等。
用 1 行代码就能说明白:
'<div>{{msg}}</div>'.match(/\{\{((?:.|\r?\n)+?)\}\}/)
// ["{{msg}}", "msg"]这个示例用/\{\{((?:.|\r?\n)+?)\}\}/ 正则表达式,提取了字符串'<div>{{msg}}</div>'中的Mustache标签。
暂时不用理解该正则的含义,会用即可。
如果想要理解正则,可以试一试正则在线调试工具:Vue.js 开始标签正则,能够可视化的检查上述正则表达式
获得了"msg"标签对应变量的名称,我们就能在后续拼接出渲染DOM所需要的_vm.msg。
即从我们声明的实例new Vue({data() {return {msg: 'hi'}}})中提取出msg: 'hi',渲染为 DOM 节点。
其次,因为<template>本质上是一段有大量HTML标签的字符串,通常内容较长,为了不遗漏地获取到其中的所有标签、属性,我们需要遍历。
实现方式也很简单,用while(html)循环,不断的html.match()提取模板中的信息。(html变量即template字符串)
每提取一段,再用html = html.substring(n)删除掉n个已经遍历过的字符。
直到html字符串为空,表示我们已经遍历、提取了全部的template。
html = `<div` // 仅遍历一遍,提取开始标签
const advance = (n) => {
html = html.substring(n)
}
while (html) {
match = html.match(/^<([a-zA-Z_]*)/)
// ["<div", "div"]
if (match) {
advance(match[0].length)
// html = '' 跳出循环
}
}理解了这2部分逻辑,就理解了字符串模板template编译为 render() 函数的原理,就是这么简单!
class语法封装我们用 JS 的class语法对代码进行简单的封装、模块化,具体来说就是声明 3 个类:
// 将 Vue 实例的字符串模板 template 编译为 AST
class HTMLParser {}
// 基于 AST 生成渲染函数;
class VueCompiler {
HTMLParser = new HTMLParser()
}
// 基于渲染函数生成虚拟节点和真实 DOM
class Vue {
compiler = new VueCompiler()
}问:为什么要生成
AST?直接把template字符串模板编译为真实 DOM 有什么问题?答:没有问题,技术上也可以实现,
Vue.js 以及众多编译器都采用 AST 做为编译的中间状态,个人理解是为了编译过程中做「转化」(Transform),
例如v-if属性转化为 JS 的if-else判断,有了 AST 做为中间状态,有助于更便捷的实现v-if到if-else
template字符串模板基于我们上述提到的while()和html = html.substring(n),
我们可以实现一套一边解析模板字符串、一边删除已解析部分,直到全部解析完成的逻辑。
很简单,只有几行代码,
我们为class HTMLParser增加一个parseHTML(html, options)方法:
parseHTML(html, options) {
const advance = (n) => {
html = html.substring(n)
}
while(html) {
const startTag = parseStartTag() // TODO 下一步实现 parseStartTag
if (startTag) {
advance(startTag[0].length)
continue
}
}
}html参数即初始化 Vue 实例中的template: '<div>{{msg}}</div>',属性,
在遍历 html 过程中,我们每解析出一个关键词,就调用advance() { html.substring(n) },删去这部分对应的字符串,
示例中我们调用parseStartTag()(下一步实现)解析出开始标签<div>对应的字符串后,就从 html 删除了<div>这5个字符。
<div>接下来让我们实现parseStartTag(),解析出字符串中的开始标签<div>。
也非常简单,用html.match(regularExp)即可,我们可以从Vue.js 源码中的 html-parser.js找到对应的正则表达式startTagOpen。
源码的正则中非常复杂,因为要兼容生产环境的各种标签,我们暂时不考虑,精简后就是:/^<([a-zA-Z_]*)/。
用这个正则调用html.match(),即可得到['<div', 'div']这个数组。
提取出需要的信息后,就把已经遍历的字符调用advance(start[0].length)删除。
const parseStartTag = () => {
let start = html.match(this.startTagOpen);
// ['<div', 'div']
if (start) {
const match = {
tagName: start[1],
attrs: [],
}
advance(start[0].length)
}
}注意,startTagOpen只匹配了开始标签的部分'<div',还需要一次正则匹配,找到开始标签的结束符号>。
找到结束符号后,也要删除对应已遍历的部分。
const end = html.match(this.startTagClose)
debugger
if (end) {
advance(end[0].length)
}
return match两部分组合后,就能完整遍历、解析出模板字符串中的<div>开始标签了。
{{msg}}下一步我们把模板字符串中的文本内容{{msg}}提取出来,仍然是字符串遍历 && 正则匹配
继续补充 while 循环:
while (html) {
debugger
// 顺序对逻辑有影响,startTag 要先于 text,endTag 要先于 startTag
const startTag = parseStartTag()
if (startTag) {
handleStartTag(startTag)
continue
}
let text
let textEnd = html.indexOf('<')
if (textEnd >= 0) {
text = html.substring(0, textEnd)
}
if (text) {
advance(text.length)
}
}因为删除了已解析部分、并且各部分有解析顺序,所以我们只要检测下一个<标签的位置即可获得文本内容在 html 中的结束下标:html.indexOf('<')。
之后就能获得完整的文本内容{{msg}}:text = html.substring(0, textEnd)。
最后,别忘了,删除已经遍历的文本内容:advance(text.length)
</div>到这一步,html 字符串已经只剩下'</div>'了,我们继续用遍历&&正则解析:
while (html) {
debugger
// 顺序对逻辑有影响,startTag 要先于 text,endTag 要先于 startTag
let endTagMatch = html.match(this.endTag)
if (endTagMatch) {
advance(endTagMatch[0].length)
continue
}
}我们暂时不需要从闭合标签中提取信息,所以只需要遍历、匹配后,删除它即可。
到目前为止,我们已经基本实现了class HTMLParser {},多次用正则解析提取出了 template 字符串中的 3 部分信息:
'<div', '>''{{msg}}''</div>'这部分的完整代码,可以访问DEMO -《8分钟学会 Vue.js 原理》:一、template 字符串编译为抽象语法树 AST - JSBin查看。
但为了获得 AST,我们还需要基于这些信息,做一些简单的拼接。
我们继续参考Vue.js 源码中拼接 AST 的实现
完善class VueCompiler,添加HTMLParser = new HTMLParser()实例,以及parse(template)方法。
class VueCompiler {
HTMLParser = new HTMLParser()
constructor() {}
parse(template) {}
}AST 是什么?
先不用去理解晦涩的概念,在 Vue.js 的实现中,AST 就是普通的 JS object,记录了标签名、父元素、子元素等属性:
createASTElement (tag, parent) {
return { type: 1, tag, parent, children: [] }
}我们把createASTElement方法也添加到class VueCompiler中。
并增加parse方法中this.HTMLParser.parseHTML()的调用
parse(template) {
const _this = this
let root
let currentParent
this.HTMLParser.parseHTML(template, {
start(tag) {},
chars (text) {},
})
debugger
return root
}start(tag) {}就是我们提取开始标签对应 AST 节点的回调,
其接受一个参数tag,调用_this.createASTElement(tag, currentParent)来生成 AST 节点。
start(tag) {
let element = _this.createASTElement(tag, currentParent)
if (!root) {
root = element
}
currentParent = element
},调用start(tag)的位置在class HTMLParser中的parseHTML(html, options)方法:
const handleStartTag = (match) => {
if (options.start) {
options.start(match.tagName)
}
}
while(html) {
const startTag = parseStartTag()
if (startTag) {
handleStartTag(startTag)
continue
}
}当我们通过parseStartTag()获取了{tagName: 'div'},就传给options.start(match.tagName),从而生成 AST 的根节点:
// root
'{"type":1,"tag":"div","children":[]}'我们把根节点保存到root变量中,用于最终返回整个AST的引用。
除了根节点,我们还需要继续为 AST 这棵树添加子节点:文本内容节点
仍然是用回调的形式(options.char(text)),提取出文本内容节点所需的信息,
完善VueCompiler.parse()中的chars(text)方法
chars(text) {
debugger
const res = parseText(text)
const child = {
type: 2,
expression: res.expression,
tokens: res.tokens,
text
}
if (currentParent) {
currentParent.children.push(child)
}
},在parseHTML(html, options)的循环中添加options.chars(text)调用:
while (html) {
// ...省略其他标签的解析
let text
let textEnd = html.indexOf('<')
// ...
if (options.chars && text) {
options.chars(text)
}
}Mustache标签语法options.chars(text)接收的text值为字符串'{{msg}}',我们还需要从中剔除{{}},拿到msg字符串。
仍然是用熟悉的正则匹配:
const defaultTagRE = /\{\{((?:.|\r?\n)+?)\}\}/
function parseText(text) {
let tokens = []
let rawTokens = []
const match = defaultTagRE.exec(text)
const exp = match[1]
tokens.push(("_s(" + exp + ")"))
rawTokens.push({ '@binding': exp })
return {
expression: tokens.join('+'),
tokens: rawTokens
}
}结果将是:
{
expression: "_s(msg)",
tokens: {
@binding: "msg"
}
}暂时不必了解expression, tokens及其内容的具体含义,后续到运行时阶段我们会再详细介绍。
template字符串完成,返回 AST完整示例:DEMO -《8分钟学会 Vue.js 原理》:一、template 字符串编译为抽象语法树 AST - JSBin
经过以上步骤,我们将 template 字符串解析后得到这样一个对象:
// root ===
{
"type": 1,
"tag": "div",
"children": [
{
"type": 2,
"expression": "_s(msg)",
"tokens": [
{
"@binding": "msg"
}
],
"text": "{{msg}}"
}
]
}这就是 Vue.js 的 AST,实现就是这么简单,示例中的代码都直接来自 Vue.js 的源码(compiler 部分)
后续我们将基于 AST 生成render()函数,并最终渲染出真实 DOM。
《8分钟学会 Vue.js 原理》系列,共计5部分:
正在热火朝天更新中,欢迎交流~ 欢迎催更~
性能优化不等于体验优化。
以往谈到优化,我们常常关注的是前端性能优化,但性能优化只是我们改善前端项目的方式之一,目标不明确的性能优化并不能真正地优化前端项目,改善用户体验和开发体验才应该是我们优化的根本目的。
所以本书不同于以往的前端性能优化书籍,不是简单的罗列具体优化方法,而是更多的关注方法论,引导读者从宏观的视角,关注前端优化开始前、实施中、生效后的全过程,最终极致地、有效地改善用户体验和开发体验。
从而解决以往前端优化的诸多痛点:
目标不明确: 只会照本宣科,把别人的优化手段生搬硬套到自己的项目;
缺乏量化指标: 无法评估优化效果,拿不出客观、可量化的指标证明优化效果;
没有实质性的改善用户体验: 只优化了测试环境数据,没有真正的改善用户的主观体验;
没有长效化机制: 无法保证优化效果长期稳定、不出现衰退;
不关注开发体验: 没有认识到开发体验和用户体验的正相关性;
本书总结了作者6年多来优化和维护百万日访问量广告管理后台项目、千万日活信息流前端项目以及全球领先的浏览器平台音视频会议等项目的经验,以具体场景和实践经验为例,深入浅出地讲解现代前端工程体验优化的方法论和具体措施。
希望这本书能让读者有所收获,在工作中取的更大的成就。更欢迎通过评论,邮件([email protected]),微信(xinghuamantou)等方式与我交流。
没有量化指标的优化是没有说服力的,不了解优化目标的现状更无法去优化它。
在实施体验优化时,一个常常陷入的误区是没有测量现状,没有建立可以量化优化效果的监控指标就开始优化。这样的方式往往导致自欺欺人的优化,自以为做了效果显著的改进优化,实际上并没有真正的改善用户体验。
例如笔者在刚参加工作时曾做过一次没有量化指标、为了优化而优化的技术改进。
当时计划为内部前端项目的 JS,CSS 等静态资源增加预加载Prefetch ,因为并没有提前建立量化指标、监控优化效果的理念,所以在完成优化,部署上线后,没有得到优化效果的量化数据,只能通过 JS 加载命中了缓存来解释优化的收益,对用户体验有什么影响更是一无所知。
这样没有反馈的技术改进显然不能称之为成功的、有意义的优化。
https://react.dev/ 的预加载 Prefetch 示例:
所以,为了能真正的改善用户体验,我们需要在开始优化前透彻的理解优化目标的现状,建立可量化的指标监控优化前后的变化。
这就需要我们能把主观的用户体验或开发体验量化为客观指标。
体验是非常主观的感受,同样的事物对不同的人,在不同的环境都会有不同的体验。
例如前端页面的加载速度,同一个页面,在不同的地理位置,不同的硬件设备上,都会有不同的表现,给用户的主观体验更是因人而异,所以直接测量用户体验很困难。
业界经过多年的实践,尝试过许多量化用户体验的指标,例如白屏时长、可交互耗时(Time to interact)、总阻塞时间 (Total Blocking Time,TBT)、首次有效绘制 (First Meaningful Paint,FMP) 等指标。
但这些指标往往逻辑复杂、不便于测量,甚至有显著的歧义,所以越来越少见。
近年来最实用的指标是基于 Chrome 官方推出的开源库web-vitals来获取用户访问前端页面时的页面渲染耗时,交互延迟等通用的量化指标。
web-vitals GitHub 地址: https://github.com/GoogleChrome/web-vitals
web-vitals是谷歌的 Chrome 维护团队于 2020 年开源的工具库,能基于浏览器的 Performance API 获取标准化的用户体验指标。
主要有以下6项指标:
FCP测量从页面开始加载到页面中任意部分内容(文本、图像、<svg/>,<canvas/>等类型内容)完成渲染的时长。
其值为浮点数,单位是秒。FCP值越小表示该指标状况越好、页面的渲染越快。
注意,FCP测量的是任意部分DOM渲染的耗时,而非全部内容,更不等于onLoad 事件。
如下图中的例子,FCP指标的值为1200毫秒。在这个时刻页面中首次出现了渲染出了文字和图像。
按照Chrome官方的推荐标准,FCP指标3个等级的评分分别为:
LCP测量从页面开始加载到可视区域内尺寸最大的文字或图像渲染完成的耗时。
其值为浮点数,单位是秒。LCP值越小表示该指标状况越好、最大元素渲染越快。
可以用Chrome浏览器自带 DevTool 中的 Performance Insights 工具来判断页面中什么元素是 最大内容,例如下图中的 img.banner-image 就是掘金首页的 最大内容元素,这个元素渲染的耗时为1.55秒,即LCP的值。
按照Chrome官方的推荐标准,FCP指标3个等级的评分分别为:
FID 测量用户首次交互(点击、触摸)后到浏览器开始响应用户交互之间的间隔耗时。
其值为浮点数,单位是毫秒。FID值越小表示该指标状况越好,用户首次与页面交互时延迟越小。
这一指标只关注页面中首次交互是因为:首次交互时,页面往往处于尚未完全加载的状态,异步响应数据尚未全部返回前端、部分JS和CSS仍在执行、渲染过程中,浏览器的主线程会短暂的处于忙碌状态,不能即时响应用户交互。
同时第一次交互的延迟长短往往决定了用户对网页流畅度的第一印象, 所以这一指标也符合了我们“将用户主观体验的量化”的需求。
按照Chrome官方的推荐标准,FCP指标3个等级的评分分别为:
这一指标因为与 INP 指标测量目标有所重叠,且普适性不及INP,未来可能会被INP替代。
INP测量用户在页面浏览过程中的所有交互(点击、键盘输入、触摸等)与浏览器绘制对应响应的整体延迟情况。
其值为浮点数,单位是毫秒。INP值越小表示该指标状况越好,用户的所有交互延迟卡顿越少。
INP与FID只关注首次交互不同,INP会关注用户浏览网页全过程中的所有交互,所以通常会在页面可视化状态变化或页面卸载时完成计算。
按照Chrome官方的推荐标准,INP指标3个等级的评分分别为:
INP是一项处于实验状态的指标,其评分标准可能会有调整,目前描述的是其2023年5月的标准。
CLS测量页面中所有意外布局变化的累计分值。
其值为浮点数,无单位,值的大小大小表示意外布局变化的多少和影响大小。
所谓 意外布局变化 是指 DOM元素在前后绘制的2帧之间,非用户交互引起DOM元素尺寸、位置的变化。
例如:
这段视频中用户本想点击取消按钮,但是页面元素的布局位置产生了突然的变化,出现了非用户交互导致的意外布局变化,原本取消按钮的位置被确认按钮替代,导致了用户的误操作,严重损害了用户体验。
《意外布局变化》DEMO: https://codesandbox.io/s/cls-demo-qfu8g5?file=/src/App.js
引入 web-vitals 库后调用onCLS API也能检测到对应的意外布局变化的具体来源,如下图中sources字段的2个对象就明确的告诉了我们引起布局变化的来源元素的DOM引用,以及变化前后的尺寸位置状况(sources[i].currentRect, sources[i].previousRect):
按照Chrome官方的推荐标准,CLS指标3个等级的评分分别为:
TTFB测量页面的HTTP请求发送后,响应第一字节数据的耗时。通常包括重定向、DNS查询、服务器响应延迟等耗时。
其值为整数,单位是毫秒。值越小表示该项指标状况越好,响应页面HTTP请求的耗时越短。
除了可以通过web-vitals的onTTFB() API获取,也可以使用 Chrome 自带的 DevTool Network 网络面板计算获取。如下图的例子知乎首页的TTFB耗时即:
文档响应的整体耗时 减去 内容下载耗时(Content Download), 391毫秒 - 57毫秒 = 335毫秒
按照Chrome官方的推荐标准,TTFB指标3个等级的评分分别为:
以上6项指标均可通过web-vitals库内置的API方便的获取,将web-vital库集成到我们提供给用户的前端页面,即可方便地获取用户的真实体验数据,例如:
获取 web-vitals 数据在线 DEMO: https://output.jsbin.com/bizanep (推荐使用Chrome浏览器)
要注意的细节是,这些指标中:
onFCP, onLCP, onTTFB 均为在页面初始化时自动触发。onFID是在用户第一次与页面交互时触发。onCLS, onINP则因为要测量页面的全生命周期,往往无固定触发时间点,在实践中通常会在交互停止一段时间后,或页面可视状态变化(例如切换标签页)后触发。web-vitals 的这些指标是Chrome官方在总结了海量数据后设计出来的,能科学地将主观的用户体验量化为客观的指标。
大量的收集这些指标数据,加以汇总分析便可以实现针对用户体验的“真实用户监控”(https://en.wikipedia.org/wiki/Real_user_monitoring) ,从用户的客户端收集到这些数据要比我们在自己的工作电脑环境上测量出的实验室数据更客观、更有说服力,更有助于我们做出数据驱动的优化决策。
有了获取用户体验指标数据的工具,还需要进一步大量收集、细致分析这些数据,以便了解现状、确定优化方向。
笔者在此推荐一套经过实践检验、开发体验较好的开源工具:Prometheus 和 Grafana。
.....
在上一节《一、template 字符串编译为抽象语法树 AST》中,我们实现了template渲染为AST的逻辑,距离最终目标「渲染为真实DOM」更近了一步!
这一节,我们来继续实现 AST 编译为渲染函数 render() 。
render()也就是将上一节我们编译出来的 AST 对象:
{
"type": 1,
"tag": "div",
"children": [
{
"type": 2,
"expression": "_s(msg)",
"tokens": [
{
"@binding": "msg"
}
],
"text": "{{msg}}"
}
]
}编译为渲染函数render():
function render() {
with(this) {
return _c('div',[_v(_s(msg))])
}
}暂时不必理解渲染函数的含义,后续我们会深入了解。
render()?渲染函数是 AST 到虚拟 DOM 节点的中间媒介,本质上就是 JS 的函数,执行后会基于『运行时』返回虚拟节点的对象。
在 Vue.js 2 中,通过执行「渲染函数」获得了虚拟 DOM 节点,用于虚拟节点 Diff 并最终生成真实 DOM。
Vue.js 源码链接:lifecycle.js#L189-L191
updateComponent = () => {
vm._update(vm._render(), hydrating)
}上述3行源码中,调用的vm._render()即是「渲染函数」,其返回值即为「虚拟 DOM 节点」。
将虚拟 DOM 节点作为参数传给vm._update()后,就开始了著名的『虚拟 DOM Diff』。
写 JS 时,我们可以通过声明或表达式的形式创造函数。
但是在 JS 的执行过程中「创造函数」我们需要new Function() API,即JS中函数的构造函数。
通过调用函数的构造函数,我们可以将「字符串」类型的函数体,转化为一个可执行的JS函数:
const func = new Function('console.log(`新函数`)')
/*
func ===
ƒ anonymous() {
console.log(`新函数`)
}
*/
func() // 打印 `新函数`通过new Function()API,我们就拥有了在 JS 执行过程中生成函数体,并最终声明函数的能力。
有了声明函数的能力,我们就可以把 AST 编译为「字符串格式的函数体」,再将之转化为可执行的函数。
例如,我们有一个<div />对应的 AST:
{
"type": 1,
"tag": "div",
"children": [],
}想要把 AST 编译为渲染函数的函数体:_c('div')。
我们只需要对 AST 进行遍历,根据tag属性就可以拼接出想要的函数体:
function generate(ast) {
if (ast.tag) {
return `_c('${ast.tag}')`
}
}如果 AST 的children属性不为空,我们继续对其进行深度优先递归搜索,就可继续增加渲染函数的函数体,最终生成各种复杂的渲染函数,渲染出复杂的 DOM,例如:
const render = function () {
with (this) {
return _c(
'div', {attrs: {"id": "app"}},
[
_c('h1', [_v("Hello vue-template-babel-compiler")]),
_v(" "),
(optional?.chaining)
? _c('h2', [_v("\\n Optional Chaining enabled: " + _s(optional?.chaining) + "\\n ")])
: _e()
]
)
}
}如果有兴趣,可以找到自己项目中的
node_modules/vue-template-compiler/build.js第4815行:var code = generate(ast, options);
加上console.log(code),npm run serve运行后,就可以在控制台中看到自己写的.vue文件编译出的渲染函数。
这次的代码逻辑更加简单,总共只需要写 41 行代码。
CodeGenerator类及其调用我们用CodeGenerator封装编译AST为渲染函数的逻辑,其带有一个generate(ast)方法,
传入 AST 作为参数,调用后会返回带有 render() 函数作为属性值的对象:
class CodeGenerator {
generate(ast) {
debugger
var code = this.genElement(ast)
return {
render: ("with(this){return " + code + "}"),
}
}
}render时的with(this) {}有什么用?with(this)关键字就是 Vue.js 单文件组件(.vue 文件,SFC)中不用写this关键字,就能渲染出this.msg的秘密。
通过在渲染函数中使用with(this)关键字,可以把this作为其中作用域的全局变量(类似于window, global),{}花括号内的变量都会直接取this对应的属性。
例如:
with (Math) {
val = random()
}
console.log(val) // 调用Math.random()的返回值我们再为类添加一个genElement方法,
这个方法接受一个 AST 节点,做2件事:
childrengenElement(el) {
var children = this.genChildren(el)
const code = `_c('${el.tag}'${children ? `,${children}` : ''})`
return code
}genElement用于将AST:
{
"type": 1,
"tag": "div",
"children": [],
}编译为字符串函数体:_c('div')
接下来我们编译子元素ast.children
children是一个数组,可能有多个子元素,所以我们需要对其进行.map()遍历,分别处理每一个子元素。
genChildren (el, state) {
var children = el.children
if (children.length) {
return `[${children.map(c => this.genNode(c, state)).join(',')}]`
}
}我们再为类添加一个genElement方法,用于调用genChildren:
genElement(el) {
debugger
var children = this.genChildren(el)
const code = `_c('${el.tag}'${children ? `,${children}` : ''})`
return code
}我们用genNode(node)方法处理子元素,
生产环境中,子元素有多种,可能是文本、注释、HTML元素,所以需要用if (node.type === 2)判断类型,在分情况处理。
genNode(node) {
if (node.type === 2) {
return this.genText(node)
}
// TODO else if (node.type === otherType) {}
}我们此次需要处理的只有「文本」(node.type === 2)这一种,所以我们再增加一个genText(text)来处理。
genText(text) {
return `_v(${text.expression})`
}在编译 AST 阶段,我们已经把{{msg}}编译为了一个 JS 对象:
{
"type": 2,
"expression": "_s(msg)",
"tokens": [
{
"@binding": "msg"
}
],
"text": "{{msg}}"
}现在我们只要取expression属性,就是其对应的渲染函数。
简而言之_s()是 Vue.js 内置的一个方法,可以把传入的字符串生成一个对应的虚拟 DOM 节点。
后续我们将详细介绍_s(msg)的含义及其实现。
经过以上各步骤,我们已将 AST 对象解析成了渲染函数的函数体字符串:with(this){return _c('div',[_v(_s(msg))])},
为了将仍然是字符串函数体的render属性,转化为可执行的函数,我们再增加一段new Function(code)逻辑,
并把createFunction (code)声明到VueCompiler类,以便于最终调用:
createFunction (code) {
try {
return new Function(code)
} catch (err) {
throw err
}
}最后我们来统一调用。
在VueCompiler类的compile(template)中添加CodeGenerator实例及this.CodeGenerator.generate(ast)调用:
class VueCompiler {
HTMLParser = new HTMLParser()
CodeGenerator = new CodeGenerator()
compile(template) {
const ast = this.parse(template)
console.log(`一、《template 字符串编译为抽象语法树 AST》`)
console.log(`ast = ${JSON.stringify(ast, null, 2)}`)
const code = this.CodeGenerator.generate(ast)
const render = this.createFunction(code.render)
console.log(`二、《抽象语法树 AST 编译为渲染函数 render()》`)
console.log(`render() = ${render}`)
return render
}
}基于我们前一节已经写好的this.compiler.compile(this.options.template),最终我们就能看到控制台打印出来的渲染函数render() = :
《8分钟学会 Vue.js 原理》系列,共计5部分:
正在热火朝天更新中,欢迎交流~ 欢迎催更~
上一节:《你做的前端优化都错了!《现代前端工程体验优化》前言 && 第一章 数据驱动》
有了获取用户体验指标数据的工具,还需要进一步大量收集、细致分析这些数据,以便了解现状、确定优化方向。
笔者推荐一套经过实践检验、开发体验较好的开源工具:Prometheus 和 Grafana。
Prometheus 是一款开源的数据监控解决方案,包括针对各种编程语言的数据采集SDK(例如面向 Node.js 的NPM包客户端:prom-client)、接收数据上报的后端服务器应用、基于时间序的数据库、以及基础的数据可视化前端应用,具有强大的拓展能力,可以方便快速地融合进已有的项目中,作为数据监控的中台工具。
Grafana 是一款开源的数据可视化工具,主要包括兼容 Prometheus 在内各种数据库的数据查询工具、内置各种图表模板的数据可视化前端应用,并且支持免费的私有化部署。
将 Prometheus 与 Grafana 整合进我们的项目中就能方便地实现强大的数据收集、可视化能力。
下面我们以Node.js为例,演示如何接入这2款工具。
我们将基于:
prom-client演示如何从本地环境收集 web-vitals 数据,并上传到 Grafana,最终创建出数据可视化图表。
首先我们注册并登录 Grafana 官方的云端应用:https://grafana.com/get/?pg=graf&plcmt=hero-btn-1 ,每个账户都有足够的免费试用额度供我们测试。
完成注册后,我们就会进入 Grafana 的看板页面,这里是我们管理数据可视化图表、接入数据源的主要工作区域。
但因为此时我们还没有接入数据,所以内容还是一片空白。接下来我们启动一个基于 prom-client 的 Node.js 服务器作为我们的数据收集应用。
首先我们从左侧侧边栏访问 Connection > Connect data 目录,搜索 node.js 即可找到官方推荐的 Node.js 应用接入基础设施:
不同的数据源有不同的特性,例如:
- 查询语句的格式
- 是否支持日志全文查询
Grafana 支持众多数据源,如果 Prometheus 不适合你的前后端架构,可以参考官方文档选择
Elasticsearch、Graphite等其他数据源:https://grafana.com/docs/grafana/latest/datasources/如果只需要指标收集和存储,建议选择 Prometheus 或 Graphite;
如果需要进行日志收集和分析,对日志全文做可视化,建议选择 Elasticsearch;
点击进入 Node.js Infrastructure 后,接下来我们按照官方文档首先检查必要准备:
安装 Grafana Agent 应用用于收集、转发本地的Prometheus数据:
选择对应系统,输入 API key 的备注名,点击 Generate API token 生成接口令牌,随后会提示生成已完成:Your API token has been generated below.
接下来我们要运行官方提供的命令行从而下载、安装并配置 Grafana Agent 应用,下载和安装可能需要一定时间并克服网络限制:
注意:需要以管理员身份运行 PowerShell,运行方式如下图:
命令执行完成后,点击左下角的 Test agent connection 即可验证安装是否完成。
验证通过、安装完成后,就可以在本地通过Node.js应用收集并上报数据了,让我们新建一个空白 Node.js 项目:
npm init 初始化生成 package.json,并添加启动脚本:"start": "node app.js"npm install express prom-clientapp.js ,将官方的代码示例复制粘贴下来官方示例需要Node.js环境支持 ES module 语法,你也可以参考笔者提供的示例项目,直接使用更方便的 CommonJS module 语法:
《feat: 引入express && prom-client;初始化服务》commit:JuniorTour/node-prometheus-grafana-demo@7ba9148
运行 npm run start 后,prom-client就会自动开始采集一批默认的 Node.js 应用数据。
最后,让我们把预置的可视化图表,添加到我们的看板中,点击下图中的安装 Install 按钮:
安装后,一套监控 Node.js 应用内存用量、CPU使用率等指标的可视化看板就被添加到我们的看板中了:
我们的目标不只是监控这些基础指标,下面让我们试试如何增加自定义指标来。
Grafana 官方 Node.js 集成文档:https://grafana.com/docs/grafana-cloud/data-configuration/integrations/integration-reference/integration-nodejs/
各大云服务供应商也有集成 Grafana:
为了将前端利用 web-vitals 收集的数据,发送到 Grafana,后端服务需要基于 prom-client 的能力,增加一批自定义指标。
让我继续在 app.js 中添加以下代码:
这部分可以参考笔者提供示例中的《feat: 增加自定义计数指标 webVitalsRatingCounter》commit:JuniorTour/node-prometheus-grafana-demo@6c7c57a
// 3. 对所有接口增加 跨域资源共享(CORS)配置
// Enable CORS for all routes
app.use((req, res, next) => {
res.header("Access-Control-Allow-Origin", "*"); // Allow any origin
res.header("Access-Control-Allow-Headers", "Origin, X-Requested-With, Content-Type, Accept"); // Allow these headers
if (req.method === 'OPTIONS') {
res.header("Access-Control-Allow-Methods", "POST"); // Allow POST method
return res.sendStatus(200);
}
next();
});
// 2. 新建一个自定义计数指标webVitalsRatingCounter
// https://www.npmjs.com/package/prom-client#:~:text=()%3B-,Custom%20Metrics,-All%20metric%20types
const webVitalsRatingCounter = new client.Counter({
name: 'webVitalsRatingCounter',
help: 'counter to store web-vitals rating data',
registers: [register],
labelNames: ['name', 'rating'],
});
// 1. 增加一个POST方法的接口
app.post('/post-web-vitals', function(req, res) {
console.log(`req.body=${req.body}`)
const labels = req.body.labels
webVitalsRatingCounter.inc(labels)
const message = `Get web-vitals: labels=${JSON.stringify(labels)}`
console.log(message)
res.status(200).json({ message });
});通过这段代码,我们:
/post-web-vitals,用于接收前端发送来的 web-vitals 数据;webVitalsRatingCounter,用于收到 web-vitals 数据计数、统计数据名称(name)、评分(rating);http://localhost:4001/post-web-vitals接口;基于这段代码我们就可以从前端应用中通过HTTP 异步请求发送 web-vitals 数据到这个后端服务,并借助 prom-client 的自定义计数指标webVitalsRatingCounter将数据上报到 Grafana 供我们查询、创建可视化图表。
接下来我们基于之前的《获取web-vitals数据 DEMO》: https://output.jsbin.com/bizanep 增加上报数据到 Node.js 后端的逻辑:
// 《发送 web-vitals 数据 DEMO》:https://output.jsbin.com/xifudez
async function sendDataToBackend(data) {
if (!data) {
return
}
await fetch('http://localhost:4001/post-web-vitals', {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify({
labels: {
name: data?.name,
rating: data?.rating
}
}),
})
}
function onGetWebVitalsData(data) {
if (!data?.name) {
return
}
const name = data.name
const value = data.value
const rating = data.rating
sendDataToBackend(data)
const msg = (`(已发送到后端)${name}: value=${value}, rating=${rating}`)
console.log(msg)
setInnerHtml(name?.toLowerCase(), msg)
}
onFCP(onGetWebVitalsData);我们的改动主要是:
sendDataToBackend方法,用于接受到web-vitals库的数据后发送HTTP请求到后端接口,并把name, rating这2个字段作为请求体;onGetWebVitalsData方法中增加sendDataToBackend(data)方法的调用,将指标数据作为参数传入;完整示例请参考 《发送 web-vitals 数据 DEMO》:https://output.jsbin.com/xifudez
运行这些新增改动后,我们将能在开发中工具的Network面板中看发送数据的HTTP请求,以及后端的响应信息:
有了这样一套前后端逻辑,我们的web-vitals数据就成功的发送到了 Grafana,接下来我们试着基于这些数据创建几张可视化图表。
下面我们一起来试着创建一张 Grafana 的可视化图表,主要有以下几步:
如果按照上文的接入演示一路操作过来,会有默认的数据源
grafanaclound-yourName-prom
Grafana 中不同的数据源对应不同的查询器面板及语法,我们以前文示例的 Prometheus 数据源为例,其主要有 交互界面选择查询语句(Builder)和 直接输入查询语句文本(Code)2种模式。
推荐使用对新用户更为友好的Builder模式,可以看到包含以下各选项:
分别对应我们调用 prom-client 的 new Counter API 时传入的name,labelNames字段:
const webVitalsRatingCounter = new client.Counter({
name: 'webVitalsRatingCounter',
help: 'counter to store web-vitals rating data',
registers: [register],
labelNames: ['name', 'rating'],
});我们分别输入并选择 webVitalsRatingCounter,name=FCP,rating=good 三项后,
点击刷新仪表盘(Refresh Dashboard)即可看到我们刚刚上传的数据,将对应时段有多少次name=FCP,rating=good 在可视化图表中展示出来:
不同的数据源有各自不同的查询语法
Prometheus 数据源查询语法:https://prometheus.io/docs/prometheus/latest/querying/basics/
ElasticSearch 数据源查询语法:http://lucenetutorial.com/lucene-query-syntax.html
有了数据后,我们就可以进一步完善可视化图表的细节,常用的功能主要有:
图表类型:常用的有折线图、柱状图,纯文本;
标题和描述
提示(Tooltip)和图例(Legend):设置何时显示提示、图例的样式和内容;
度量选项(Standard Options):设置当前查询的值是什么单位,常用的有:
时间间隔:设置将多久的时间间隔内的所有数据,聚合数据为可视化图中的一个数据点。例如截图中5m即表示将5分钟内的数据统一计入可视化图中的一个点。例如下图中时间范围(Time Range)选择最近15分钟(Last 15 minutes),对应折线图就有3个点。
覆盖配置:设置查询语句显示名称、颜色等特殊配置
以上各项配置是个人总结较为常用的配置项,可以随意尝试调整,观察效果。
先后点击:
至此,我们就创建了第一张可视化图表,后续可以在实践中逐步熟悉 Grafana 的强大功能。这只是我们的第一步,接下来我会分享实践中遇到的问题和解决方案。
将数据记录并可视化,非常有成就感,可以让我们明确的感知到工作的产出。
当我们的数据和图表越来越多,我们对维护项目的了解也会越来越深入。
从 web-vitals 获得的数据中比较有统计意义的是:
'good'),待提升('needs-improvement'),差('poor')三类值,可用于对数据进行标准化处理;例如这条从onFCPAPI获取的LCP数据:
{
delta: 382.80000019073486
entries: [
{
duration: 0
element: p
entryType: "largest-contentful-paint"
id: ""
loadTime: 0
name: ""
renderTime: 382.8
size: 8985
startTime: 382.80000019073486
url: ""
}
]
id: "v3-1683034382854-2926018174544"
name: "LCP"
navigationType: "reload"
rating: "good"
value: 382.80000019073486
}笔者更推荐使用评分字段作为可视化图表的主要指标。
原因是直接使用值经常会有异常波动,经常在前端项目没有任何变更的情况下,观察到值产生了显著的变化。
使用评分作为指标,相当于对观测的值做了一次标准化处理,将一定范围内的值处理成统一的评分,有助于规避个别极端值导致的异常波动。
如下图,4/22 前后的 LCP 平均值在我们的前端项目没有变更的情况下就出现了减少11%的变化,这样的异常波动显然不利于评估我们优化的效果:
笔者最初基于 web-vitals 制作数据可视化图时,用的就是值字段,计算了FCP等指标的平均值,观察一段时间后发现即使前后端项目没有上线变更,各指标的平均值也会有10%以上的波动,这显然是不符合预期的,这种波动将会降低我们评估优化效果的准确性。
后来改成基于评分字段制作各评分占比变化图后,数据波动问题就不再出现了,各评分的占比平均值在长时间内都能保持不超过5%的波动。当我们主动进行一些用户优化后就能观察到更客观,更有说服力的指标变化。
下面分享一套基于模拟数据的“堆叠百分比图”示例及配置源码,各位读者可以根据需要复制后粘贴到自己的仪表盘内,并替换为真实数据,从而得到客观稳定的优化效果评估数据。
{
"datasource": {
"type": "testdata",
"uid": "a95c7111-f01f-4e29-b3a6-9b0ac81d9094"
},
"description": "“堆叠百分比图”配置源码,作者:https://github.com/JuniorTour",
"fieldConfig": {
"defaults": {
"custom": {
"drawStyle": "line",
"lineInterpolation": "linear",
"barAlignment": 0,
"lineWidth": 1,
"fillOpacity": 70,
"gradientMode": "none",
"spanNulls": false,
"showPoints": "auto",
"pointSize": 1,
"stacking": {
"mode": "normal",
"group": "A"
},
"axisPlacement": "auto",
"axisLabel": "",
"axisColorMode": "text",
"scaleDistribution": {
"type": "linear"
},
"axisCenteredZero": false,
"hideFrom": {
"tooltip": false,
"viz": false,
"legend": false
},
"thresholdsStyle": {
"mode": "off"
}
},
"color": {
"mode": "palette-classic"
},
"mappings": [],
"thresholds": {
"mode": "absolute",
"steps": [
{
"color": "green",
"value": null
},
{
"color": "red",
"value": 80
}
]
},
"max": 1,
"min": 0,
"unit": "percentunit"
},
"overrides": [
{
"matcher": {
"id": "byName",
"options": "G"
},
"properties": [
{
"id": "color",
"value": {
"fixedColor": "red",
"mode": "fixed"
}
},
{
"id": "displayName",
"value": "差"
}
]
},
{
"matcher": {
"id": "byName",
"options": "E"
},
"properties": [
{
"id": "displayName",
"value": "优"
}
]
},
{
"matcher": {
"id": "byName",
"options": "F"
},
"properties": [
{
"id": "displayName",
"value": "待改进"
}
]
}
]
},
"gridPos": {
"h": 8,
"w": 12,
"x": 0,
"y": 16
},
"id": 4,
"options": {
"tooltip": {
"mode": "multi",
"sort": "none"
},
"legend": {
"showLegend": true,
"displayMode": "table",
"placement": "right",
"calcs": [
"min",
"max",
"mean"
]
}
},
"targets": [
{
"alias": "good",
"datasource": {
"type": "testdata",
"uid": "a95c7111-f01f-4e29-b3a6-9b0ac81d9094"
},
"hide": true,
"refId": "A",
"scenarioId": "csv_metric_values",
"stringInput": "47,57,46,54,54,57,47,46,54,54,55,52,46,53,46"
},
{
"alias": "needsImprove",
"datasource": {
"type": "testdata",
"uid": "a95c7111-f01f-4e29-b3a6-9b0ac81d9094"
},
"hide": true,
"refId": "B",
"scenarioId": "csv_metric_values",
"stringInput": "10,14,11,11,19,13,15,19,15,13,16,17,12,9,19"
},
{
"alias": "poor",
"datasource": {
"type": "testdata",
"uid": "a95c7111-f01f-4e29-b3a6-9b0ac81d9094"
},
"hide": true,
"refId": "C",
"scenarioId": "csv_metric_values",
"stringInput": "15,18,6,12,9,17,10,16,5,8,15,12,11,12,16"
},
{
"datasource": {
"name": "Expression",
"type": "__expr__",
"uid": "__expr__"
},
"expression": "$A+$B+$C",
"hide": true,
"refId": "D",
"type": "math"
},
{
"datasource": {
"name": "Expression",
"type": "__expr__",
"uid": "__expr__"
},
"expression": "$A/$D",
"hide": false,
"refId": "E",
"type": "math"
},
{
"datasource": {
"name": "Expression",
"type": "__expr__",
"uid": "__expr__"
},
"expression": "$B/$D",
"hide": false,
"refId": "F",
"type": "math"
},
{
"datasource": {
"name": "Expression",
"type": "__expr__",
"uid": "__expr__"
},
"expression": "$C/$D",
"hide": false,
"refId": "G",
"type": "math"
}
],
"title": "堆叠百分比统计 WebVitals CLS 指标示例",
"type": "timeseries"
}粘贴图表方式:
创建一张空图表后,点击更多选项-Inspect-Panel JSON,粘贴上述配置源码,点击应用(Apply)后即可立即生效
通过创建多张针对不同指标的堆叠百分比图,我们就能对生产环境的web-vitals各项指标有稳定、客观、可量化的监控,从而:
TODO 正在热火朝天更新中,欢迎催更~
.call、.apply 和 .bind 方法是函数对象的原型方法(Function.prototype),有「改变this指向的」特殊作用,初学 JavaScript 不太容易理解其机制,本文将通过逐步模拟实现这些方法,以加深对这些方法的理解。
call()语法:
func.call(thisArg[, arg1[, arg2[, ...]]])
简单来说,call方法的作用就是:在指定一个this值和若干个指定的参数值的前提下调用某个函数或方法。
因为接下来介绍的函数方法和 this 指针都有很密切的关系,所以我首先向各位推荐一篇文章帮助理解 this 指针:《关于 this 你想知道的一切都在这里》。
举个栗子来说明:
function foo () {
console.log(this.val)
}
let obj = {
val: 1
}
console.log('foo.call(obj) : ')
foo.call(obj) //1我们模拟的步骤是:
call 方法可带任意个参数。null 和 undefined。Function.prototype.myCall=function(context) {
context=context||window //B. 处理参数为 null 和 undefined 的情况
context.fn=this //1. 把调用 myCall 的函数设为对象的方法
let targetArg=[] //A. 注意 call 方法可带“任意个”参数
//处理传入的参数:
for (let i=1; i<arguments.length; i++) {
targetArg.push('arguments['+i+']')
}
let result=eval('context.fn('+targetArg+')') //2. 执行该函数;C.函数可以有返回值
delete context.fn
return result
}targetArg.push('arguments['+i+']')的值是字符串,而非targetArg.push(arguments[i])的值?答:为了兼容字符串类型的值,
例如参数为myCall(obj, "me", 21)时,push(arguments[i])后的targetArg是:["me", 21],经过'context.fn('+targetArg+')'之后,会变成字符串:"context.fn(me,21)",
把me当成了一个变量,而非原本的字符串,但 me 作为一个变量,并未声明过,所以会报错、不可行。
而targetArg.push('arguments['+i+']')的值是字符串,经过'+targetArg+'后,是"context.fn(arguments[1],arguments[2])",对字符串类型不会报错,可行!
eval() 这么 hack 的方式实现?还有别的实现方式吗?首先,因为targetArg最终为「字符串」类型,所以需要通过eval转化为对应的变量
其次,如果不考虑兼容性,不需要 ES3 就支持的eval,也可以用 ES6 的 spread operator:... 替代eval,执行这一步,即:
Function.prototype.myCall=function(context, ...arg) {
// ...
let result = context.fn(...arguments) // ES6这种给内置对象扩展方法的实现形式,通常称为Monkey patching(猴子补丁),可以做一步嗅探来保证兼容:
Function.prototype.myCall=Function.prototype.call || function(context) {/*...*/}
/*这一步的含义是:如果Function.prototype.call存在,就用原生的这个方法,否则用我们自己模拟实现的。*/后续的几个模拟实现,都可以用嗅探兼容保证兼容性。
apply()语法:func.apply(thisArg, [argsArray])
apply 和 call 的用法基本相同,两者的第一个参数都是 func 函数运行时的 this值。
唯一的区别在于,call 可以接受传入多个参数,而 bind 只能接受一个数组传入作为参数。
Function.prototype.myApply = function(context, argArr) {
context = context || window
context.fn = this
let result
if (argArr) {
let targetArg = []
for (let i = 0; i < argArr.length; i++) {
targetArg.push('argArr[' + i + ']')
}
result = eval('context.fn(' + targetArg + ')')
} else {
result = context.fn()
}
return result
}bind()语法:func.bind(thisArg[, arg1[, arg2[, ...]]])
这个方法比较特别,该方法会创建一个新函数并返回,称之为绑定函数,
绑定函数会以创建它时传入bind方法的第一个参数作为 this 值,第二个以及以后的参数,将当做这个新的绑定函数的初始预设参数。
之后调用新绑定函数时,传递给绑定函数的其他参数会跟在预设参数之后传入。
看一个栗子就明白了:
function bindFoo() {
// 用 call 把 arguments 指定为 this 值用于 slice() 处理,
// slice 方法可以把一个类数组(Array-like)对象/集合转换成一个数组。
console.log('[].slice.call(arguments) = ',[].slice.call(arguments))
}
bindFoo(1,2,3); //[1,2,3]
let bindedFoo=bindFoo.bind(undefined,'预先绑定的参数');
bindedFoo(); //[“预先绑定的参数”]
bindedFoo(1,2,3); //[“预先绑定的参数”,1,2,3], '预先绑定的参数' 始终是第一个参数注意 bind() 的几个特点:
new 操作符创建对象。要注意,MDN上对于这种用法有一个警告:“警告 :这部分演示了 JavaScript 的能力并且记录了 bind() 的超前用法。以下展示的方法并不是最佳的解决方案且可能不应该用在任何生产环境中。”
因为模拟构造函数的效果比较不容易理解,且不被推荐,所以在这里我们分别来实现。
Function.prototype.myBind = function (context) {
if (typeof this !== 'function') {
throw new Error('Function.prototype.bind - what is trying to be bound is not callable.')
}
let self = this
// 获取传入的从下标为[1]开始的参数作为「预设参数」:
let args = Array.prototype.slice.call(arguments, 1)
return fBound = function () {
// 预设参数之外传入的参数,即 bind() 返回的新函数调用时传入的『新增参数』
let bindArgs = Array.prototype.slice.call(arguments)
// 改变绑定函数中 this 的指向,并将「预设参数」和『新增参数』合并
self.myApply(context, args.concat(bindArgs))
}
}Function.prototype.myBind = function(context) {
if (typeof this !== 'function') {
throw new Error('Function.prototype.bind - what is trying to be bound is not callable.')
}
let self = this
let args = Array.prototype.slice.call(arguments, 1)
let fBound = function() {
let bindArgs = Array.prototype.slice.call(arguments)
self.myApply(this instanceof self ? this : context, args.concat(bindArgs))
}
/*
如果只是 fBound.prototype = this.prototype,
当我们直接修改 fBound.prototype 的时候,
也会一并顺带修改绑定函数的prototype,这不是我们想要的结果。
这个时候,我们可以通过一个空函数来进行中转:
*/
let fEmpty = function() {}
fEmpty.prototype = self.prototype
fBound.prototype = new fEmpty()
return fBound
} function bar(name, age) {
this.habit = 'shopping';
console.log(this.value);
console.log(name);
console.log(age);
}
bar.prototype.friend = 'kevin';
var bindFoo = bar.myBind(foo, 'daisy');
var obj = new bindFoo('18');使用 new 时,绑定函数内的 this 值会被改成 fBound()(仍然是this指向的基本规则:this 永远指向最后调用它的那个对象),
而外层的 self = this ,self 则会指向调用 myBind() 的对象,即 bar
let fEmpty = function() {}
fEmpty.prototype = self.prototype
fBound.prototype = new fEmpty()通过这3行代码,使 fBound.prototype 指向了 self.prototype,
所以用this instanceof self 可以判断「绑定后函数」是否用作了构造函数。
这部分的内容已经逐步深入到 JavaScript 的内部实现原理之中,确实有些晦涩,可以通过亲手写代码并多多调试观察来加深理解。
JavaScript深入之call和apply的模拟实现,
JavaScript深入之bind的模拟实现,
可能遇到假的面试题:不用call和apply方法模拟实现ES5的bind方法

「闲聊一会~」
《超级马力欧兄弟》是最初发布于1985年的 Nintendo Family Computer(Famicom)游戏机平台的一款平台跳跃类游戏。
风靡全球,售出了超过4000万份,游戏的设定、理念时至今日仍然为我们津津乐道。
承载这款游戏数据的载体:卡带,空间非常有限,只能容纳 256kb 的代码和64kb的精灵图。
所以游戏的开发者在许多方面做了优化,以满足这些限制。

例如:
复用精灵图:

拼接精灵图:
据网上的资料传说,原本运行在NES的游戏里,图像素材只占据了32kb的内存空间
虽然今天的软硬件性能都已今非昔比,很少需要开发者主动优化软件的性能、体积,但是这些优化所展现的思路,仍然很值得我们学习,也非常有趣。
进入游戏后的前30秒、第一个场景,显然经过了精心的设计,既引起人的好奇心,又非常符合直觉,让玩家无需指引,就带着好奇心快速上手游玩:
这个场景:
利用游玩者的好奇心做内容指引。


2D游戏的原理和视频类似,连贯的画面,是由一幅幅静止不动的图片”快速连续交替“形成的,
如上动图所示,动图中的每一张纸就是一”帧”。
通常用 每秒帧数(FPS,Frame Per Second),来计量帧数的高低,电影电视一般是24FPS;游戏也会以一定的的帧数绘制画面、运行。
(也有把“帧”称为“张”的叫法,个人认为,“张”作为帧的单位,确实更容易理解)
浏览器中有文档流的概念,块级元素、行内元素默认都在文档流中,从上到下、从左到右(可能受语言设置影响)排列,
如果给元素声明了float: left; position: fixed; 等特殊属性,会使元素脱离文档流,视觉上的表现就是这些元素会“浮”在文档流中的元素之上,仿佛有2个层次、2张带有透明度的纸叠在了一起一样。
2D游戏为了营造丰富的视觉效果,也会把游戏内的图像区分为不同的层次,通过层叠(composite)各个层次,渲染出最终呈现在的玩家面前的游戏画面。
以此次介绍的超级马力欧游戏DEMO为例,区分出了:
3个层次,请看DEMO:

2D游戏中也经常见到「视差移动」效果,把不同层次的画面,以不同的运动速度,呈现在玩家面前,营造出近似于3D的效果:http://youtube.com/watch?v=MGHudLM7W5U
类似的效果在浏览器中也可以实现,效果也十分两眼。
前端也曾有过精灵图(雪碧图)的概念,早年间,客户端网络带宽较小,为了节约网络资源,会把页面所需的图片资源拼接成一张图片,
一次请求,获取到所有的图片资源,再利用CSS的图片定位功能,把不同的图标呈现在对应的位置。

这个思路和2D游戏异曲同工,2D游戏很久很久以前就一直是这样做的,
基于这种实现方式,还可以把所需的图像切割、重组,实现之前在游戏细节章节所说的体积优化等特殊处理。
下图是超级马力欧 DEMO 中所使用的精灵图:
原版游戏不是这样的,可能是直接用二进制数据储存的,
因为在当时的平台上还没有图片文件这一概念,更没有 jpeg, png 等文件格式(都是90s的产物),
此外为了节约卡带的内存空间,也不会区分这么多颜色,布局也会更紧凑。

游戏中的视角多种多样,现在流行的赛车、枪战等3D游戏往往会有第一人称、第三人称等多重视角,不同的视角会产生截然不同的体验。
游戏视角一般是由镜头(Camera)决定的。
2D游戏的视角在游戏过程中通常是全程固定的,在横版卷轴游戏中,游戏的画面会像卷轴一样徐徐展开,呈现出游戏中的世界。
超级马力欧兄弟就是一个典型的横版卷轴2D游戏。
Demo 中构造了一个 Camera 对象,来记录当前视角所处的二维坐标系位置。
在每一帧中,根据 Camera 当前的位置以及提前配置好的该位置对应图像,绘制出一帧画面、实现卷轴滚动的效果。
2D游戏通常会有自己的坐标体系,用来更方便、高效的构建游戏世界。
DEMO中构建了一个以16px * 16px为一单元格,共计有16*15格的世界,砖块、马力欧、板栗仔都占据一单元格。
当2个实体(entity)所处的单元格重叠时,就会在主循环中,绘制当前帧时,遍历每个实体,进行碰撞检测,根据实体各自的属性,判断、计算将要产生的结果。
function collisionDetect(curEntity) {
allEntities.forEach( entity => {
if (curEntity.collides(entity)) {
// do sth
}
})
}性能问题:用两层循环,在每一帧中遍历所有实体,检测和其他实体是否有碰撞,复杂度是 O(n^2),相当高。
还有一种算法是,构建二维坐标矩阵,遍历一次矩阵,判断同一个坐标中,实体之间是否有碰撞,复杂度预计可以显著降低到 O(n);
但相比之下,开发复杂度显然高得多。对体量比较小(n比较小)的游戏(实体数量几十、几百个),优化效果也很有限。
以下图为例,马力欧所处的红色边线单元格,与板栗仔所处的红色单元格,发生了重叠,主循环在绘制当前帧、进行碰撞检测是,
会根据双方所处的坐标系位置,判断出马力欧“踩在了”板栗仔的头部,板栗仔将被打倒。

游戏通常都有自己独特的的世界观,但又常常要和现实世界对齐。
很多游戏都有模仿现实世界的物理效果,用来改善游戏的手感,增强趣味性。
以超级马力欧这款游戏为例,
DEMO中,通过在人物行走时,计算位移的逻辑中增加加速度系数( acceleration)、摩擦系数 ( dragFactor ),
模拟了奔跑时逐渐加速;快速奔跑后、惯性运动一段距离的物理效果。
import {Trait} from '../Entity.js'
/*extends keyword can be used to inherit all the properties and methods. */
export default class Go extends Trait {
constructor() {
/*super keyword in here means the father class's constructor of this class. */
super('go');
this.dir = 0;
this.acceleration = 400;
this.deceleration = 300;
this.dragFactor = 1/5000;
this.distance = 0;
this.heading = 1;
}
update(entity, { deltaTime }) {
const absX = Math.abs(entity.vel.x);
if (this.dir !== 0) {
entity.vel.x += this.acceleration * deltaTime * this.dir;
if (entity.jump) {
if (!entity.jump.falling) {
this.heading = this.dir;
}
} else {
this.heading = this.dir;
}
} else if (entity.vel.x !== 0) {
const decel = Math.min(absX, this.deceleration * deltaTime);
entity.vel.x += entity.vel.x > 0 ? -decel : decel;
} else {
this.distance = 0;
}
const drag = this.dragFactor * entity.vel.x * absX;
entity.vel.x -= drag;
this.distance += absX * deltaTime;
}
}游戏这样复杂度非常高的项目,很适合用面向对象的思路来构建,DEMO也是这样实现的,大量运用了基于类封装、继承的思路。
DEMO中把 马力欧(Mario.js)、板栗仔(Goomba.js)、行走能力(Go.js)、甚至一整个关卡(Level.js)都视为一个“对象“,封装、抽象出一个类来构建这些实例。
实例各自拥有特殊的属性、方法,用来储存、更新自己的状态(update())。
以玩家操控的人物马力欧为例:
用 createMario() 创建马力欧,每个马力欧都是继承自 Class Entity 的实例,
拥有 pos(位置), vel(速度), traits(特性) 等等属性,用来记录实例的位置、速度等状态。
以及 addTrait , collides, update 等方法,用来调用实例的特性,从而更新状态。
function createMarioFactory(sprite, audio) {
const runAnim = sprite.animations.get("run");
function frameRoute(mario) {
if (mario.jump.falling) {
return 'jump';
}
if (mario.go.distance > 0) {
if ((mario.vel.x > 0 && mario.go.dir < 0) ||
(mario.vel.x < 0 && mario.go.dir > 0)) {
return 'break';
}
return runAnim(mario.go.distance);
}
return 'idle';
}
function drawMario(context) {
sprite.draw(frameRoute(this), context, 0, 0, this.go.heading < 0);
}
return function createMario() {
const mario = new Entity();
mario.audio = audio
mario.size.set(14, 16);
mario.addTrait(new Physics());
mario.addTrait(new Solid());
mario.addTrait(new Go());
mario.addTrait(new Jump());
mario.addTrait(new Stomer());
mario.addTrait(new Killable());
// mario.addTrait(new PlayerController());
mario.killable.removeAfter = 0;
// mario.playerController.setPlayer(mario);
mario.draw = drawMario;
return mario;
}
}游戏“动起来”靠的就是主循环。
DEMO中的实现是用一个基于 requestAnimationFrame API 的 while 循环:
当代码运行积累的时间( accumulatedTime)大于设定的更新一帧的时间(默认是 1/60 === 0.016667秒),
就会调用 level.update 等方法,更新当前关卡的状态、移动镜头,让画面动起来。
export default class Timer {
constructor(deltaTime = 1/60) {
this.animationFrameID = null
let accumulatedTime = 0;
let lastTime = 0;
this.updateProxy = (time) => {
accumulatedTime += (time - lastTime) / 1000;
if (accumulatedTime > 1) {
/* A hack to Solve the time accumulate
* when it is running background.
* So that our computer wont be slow down by this,
* after long time of running this in background.*/
accumulatedTime = 1;
}
while (accumulatedTime > deltaTime) {
this.update(deltaTime);
accumulatedTime -= deltaTime;
}
lastTime = time;
this.enqueue();
}
}
enqueue() {
this.animationFrameID = requestAnimationFrame(this.updateProxy);
}
start() {
this.enqueue();
}
stop() {
if (this.animationFrameID) {
window.cancelAnimationFrame(this.animationFrameID)
}
}
}电子游戏之所以让人着迷,核心原因是它有即时的正向反馈。
按下按键就会有华丽的动画效果、生动的声音特效,立刻就能得到引人入胜的反馈。
不像现实世界,很多事情的结果和反馈不以人的主观意志为转移,例如学习。
游戏的主要反馈就是丰富多彩的画面图像的变化。
DEMO中主要用了 Canvas 2d 上下文的 API 来绘制画面:
折叠源码
const canvas = document.getElementById('screen')
// getContext 在Canvas画布上创建 2D上下文,可选参数有'2d','webgl'等。
// https://developer.mozilla.org/zh-CN/docs/Web/API/HTMLCanvasElement/getContext
const context = canvas.getContext('2d');
// clearRect 指定一片2D 上下文中的矩形区域,清除其中的内容,将区域内的像素设置为透明。
// https://developer.mozilla.org/zhCN/docs/Web/API/CanvasRenderingContext2D/clearRect
context.clearRect(0,0,buffer.width,buffer.height);
// drawImage 把传入的 canvas 图像源绘制到指定的位置
context.drawImage(`buffer, -camera.pos.x % 16, -camera.pos.y);声音在现实生活中也潜移默化的影响着我们,例如吸尘器吹风机以及汽车故意制造的轰鸣声、薯片的弧度以便产生酥脆的感觉。
在游戏中音效也是游戏反馈的核心组成。
DEMO里借助浏览器平台的 window.AudioContext() API 来控制音效的播放。
把异步加载的 .ogg 文件二进制数据,预先储存在内存里的 Map 结构(this.buffers)中,需要播放时从内存中取出即可。
AudioContext 还提供了非常多的特性,可以基于这些特性实现 空间立体声音效、音频裁剪 等功能,
市面上已经有了很多成熟的浏览器平台音效管理框架,可以参考:https://howlerjs.com/
const audioContext = new window.AudioContext()
export default class AudioBoard {
constructor () {
// this.context = context
// not hardcore audioContext, but send it as a param below,
// so than we can change the context easily.
this.buffers = new Map()
}
addAudio(name, buffer) {
this.buffers.set(name, buffer)
}
playAudio(name, audioContext) {
const source = audioContext.createBufferSource()
// TODO Global Volume Setting
// const gainNode = audioContext.createGain();
// gainNode.gain.setValueAtTime(0.3, audioContext.currentTime);
// source.connect(gainNode)
// gainNode.connect(audioContext.destination);
source.connect(audioContext.destination)
source.buffer = this.buffers.get(name)
source.start(0)
}
}一位前端工程师,写过的最多的代码一定是<div>, <span>等填满了文字内容的HTML标签,那么各位有没有想过在这些标签内的文字是如何排布的?
本文将详细介绍line-height、font-size等属性的来龙去脉,以及em框、内容区、行内框和行框等概念,深入剖析这一行文字在毫厘之中的奥秘。
首先,一个字符受字体内置配置以及 font-size 属性影响,会在其周围产生一个不可见的em框(em square)(如下图),font-size属性并不决定实际显示的字符尺寸,只是指定 em框 的高度(宽度则会因字符、字体不同,而不尽相同)。
em框与其中字符的具体大小、相对位置关系由字体内置值决定。
也就是说对于不同的字体,即使是同样 font-size 的同一个字符也会产生不同尺寸的em框,并与em框有不同的相对位置。
一个元素中多个字符的 em 框组合在一起,就形成了内容区,即下图粉色外边框所圈起来的部分。
内容区的高度就是 font-size 的值,而宽度则视内容(如一行中文字的个数)而定。

em 框的概念来自传统印刷行业,以下图为例,为了用活字字模组成一块整齐的印刷板,每个字模的高度必须保持一致,这个高度称为
em,即大写字母M对应字模的高度。
line-height 属性的值规定的是两行文字基线之间的最小距离。
基线也是印刷行业中的术语,维基百科这样描述它:“A baseline is a line that is a base for measurement or for construction.”(基线是一条用于测量和构造的线)。
基线相当于一把尺子,水平地串在 em 框里,一个个字符就以基线为参照,整齐地“站”在基线上(如下图)。

基线的位置因字体而异,由字体内置值决定位于 em 框中特定的位置,如下图:

因为基线无法在浏览器中看到,所以我们以上图中每行文字的 underline 为参照来看基线,上述三行分别为不同的字体,但有相同的 font-size 。
这三行中相同的字,如落、孤,可以明显地看到与基线有着不同的位置关系,第一行字底部与基线有一点重合,而其余两行则和基线几乎没有重合。
因为这三种字体的基线在 em 框之中的位置是不同的。
声明line-height 属性后,两行文字的基线便按照这个值上下分开,行与行也相应的上下分开。
当行高大于字体高度,即line-height的值减去font-size的值大于0时,基线相隔的距离大于该行的行框高度时,两行文字便被分开。

当行高小于字体高度,即 line-height 的值减去 font-size 的值小于0时,基线相隔的距离小于该行的行框高度时,两行文字便会重合在一起。

内容区的上下还会有行间距(leading),具体值为行高减去字符大小的一半,( line-height 减 font-size 除 2 )。
行间距可能是负值(行高小于字符尺寸),这时就会产生上图所呈现的行与行相互重合的现象。
行内框即内容区加行间距,其高度的计算公式是:font-size + (line-height - font-size),去掉括号即 line-height,也就是说行内框的高度就等于 line-height 的值。
同一行中可以有不同高度的行内框(如下图)。
行框的上边界由最高的行内框决定,下边界由最低的行内框决定。

一个行框包含着一整行的内容,各个行框之间上下紧密贴合排列,形成了最终呈现在页面上行与行之间的位置关系。
font-size的值决定一个字符的 em 框的高度,字符的大小由字体内置值决定、又受 em框 高度影响;em框 组合形成内容区,内容区加内边距即行内元素背景颜色所应用的范围;内容区加上行间距( line-height - font-size ),形成行内框;行内框决定了一个行框的高度;行框上下紧密贴合形成了行与行之间的位置关系。《CSS 权威指南(第三版)》,第六章、文本属性和第七章、视觉格式化
W3C规范-9 Visual formatting model(可视化模型)/ 中文版
另一篇同样主题的博文:深入理解CSS中的行高,相互对照,加深理解。
慕课网上张鑫旭老师的两节课:line-height与内联元素的高度机制
当把网址输入到浏览器地址栏,按下回车键后,一段浩瀚的互联网历险就开始了。
本文将结合个人所学并参考《网络是怎样连接的》一书,简要介绍从输入网址到网页最终呈现这个过程中涉及的诸多软硬件的原理及工作方式。
目录
零、URL网址
一、应用层(浏览器、HTTP协议)
(一)Web浏览器的初步工作
浏览器解析URL
查找DNS缓存和hosts:
(二)调用操作系统Socket库进行DNS查询
Socket库
DNS
DNS查询的过程
(三)发送HTTP请求
浏览器生成HTTP请求
协议栈
三握四挥
二、传输层(TCP、UDP)
(四)程序对程序的连接
端口
给数据包加上TCP头部
顺带一提:UDP协议
三、网络层(IP)
(五)确立主机对主机的连接
IP地址和子网掩码
给数据包加上IP头部
给数据包加上MAC头部
四、链接层(网卡、以太网)
(六)在以太网上传输
网卡:数字信号到电/光信号
互联网、因特网、以太网和万维网
在子网络间传输或向路由传输
五、实体层(路由器、调制解调器、网关等)
(七)光信号/电信号经各种设备传输
(八)服务器响应请求
参考资料
网址通常是一个URL,即“统一资源定位符”,是万维网的创造者——蒂姆·伯纳斯·李的发明之一。
就像现实生活中的地址一样,它的用处是规范地在互联网上标识资源的地址。
统一资源定位符URL的标准格式如下:
协议类型:[//服务器地址[:端口号]][/资源层级UNIX文件路径]文件名[?查询][#片段ID]
其中的协议类型://,端口号 ,文件名均可在某些情况下省略。
例如:
因为绝大多数网页内容是HTML文件,默认以HTTP协议传输,所以浏览器通常允许省略协议类型://。
又因为 80 端口也是许多服务器主机默认提供HTTP服务的端口,所以端口号一般也可以省略。
又因为许多服务器会将一些文件(例如:index.html)设置为某个路径的默认文件,所以文件名有时候也可以省略。
而服务器地址出于便于人类记忆的目的,通常会是一个具有语义化的域名,而不是更加精确的标识一台计算机在网络世界中位置的IP地址或MAC地址。
了解完了URL,就该主角们纷纷亮相了。
千里之行始于足下。
首先,浏览器会解析出所输入的URL之中包含的协议,服务器地址,路径,端口号等信息,并根据这些信息决定向谁请求什么资源。
但是因为URL中的服务器地址通常是一串具有一定语义的英文字符:域名,这个地址不够精确,它可能代表不止一台服务器,更无法指明服务器的具体位置,浏览器或者说计算机并不能依靠这个地址在浩瀚的互联网世界中精确地找到目标服务器。
所以还需要进一步借助DNS查询得到IP地址才能定位目标服务器的位置。
在进行DNS查询获取IP地址之前,浏览器会先在内部的DNS缓存中查找是否存在所查询域名的IP地址。
Chrome浏览器可以通过访问
chrome://net-internals/#dns查看浏览器的DNS缓存情况
如果没有通过浏览器的DNS缓存查询到IP,还会进一步借助操作系统查询本地hosts文件看是否有可用的DNS缓存记录
Windows 系统通常位于C:\Windows\System32\drivers\etc 目录下
如果都没有找到目标域名的地址,就要向DNS服务器请求查询了。
浏览器并不能直接找到DNS服务器进行查询,需要操作系统中Socket库的帮助。
Socket库是操作系统提供的一组调用操作系统网络功能的程序组件集合,在计算机网络之中有非常重要的地位,后续我们还会介绍和它相关的内容。
DNS是Domain Name System 即域名系统的缩写。这个系统的主要功能就是根据域名获取IP地址。
DNS服务器是域名系统的具体组成部分,其数量有很多很多,分布在现实世界中的不同位置和网络世界中的不同层次,用于响应不同地区、不同层次域名的查询请求。
DNS服务器的地址需要记录在本机之中,Windows系统中可以在控制面板\网络和 Internet \网络连接中右键进入任意一个连接的属性,双击Internet协议版本4(TCP/IPV4)查看。
在这个面板中可以看到设置如下四项的输入框:
本机IP地址
子网掩码
网关IP地址
DNSIP地址
值得一提的是,因为这四项内容比较复杂,不便于普通用户设置,所以个人电脑中这几项通常都会被设置为自动获得,使用动态分配IP。
这样,当计算机连入网络时,就会利用DHCP协议向负责管理本区域网络所有IP地址的DHCP服务器动态地请求一个IP地址。
调用Socket库发送DNS查询请求时,会向本机中记录的DNS服务器IP地址发送请求,接收到DNS查询请求的DNS服务器会优先在自己缓存的路由表中查询目标域名对应的服务器IP地址。
如果在缓存之中没有找到,DNS服务器则会根据域名的层次分级逐层查询。
例如,查询 https://github.com/JuniorTour 这个域名对应的 IP 时,DNS服务器会逐层向根域名 (.root) 服务器、顶级域名 ( .com ) 服务器、次级域名 ( .github ) 服务器发送查询请求,自顶向下,直到找到域名对应的IP地址。
顺带一提,次级域名 ( .github ) 之下,还有一层可以由用户自己分配的三级域名。
github.com这个域名实际上是省略了www这个三级域名的写法。
知道了URL对应的IP地址后,就可以向这个地址发送HTTP请求,请求所需的网络资源了。
浏览器浏览网页用的是属于应用层的HTTP协议,如果想要获取一个网页,就需要向HTTP服务器发送HTTP请求,在响应的数据中获取网页数据。
通常来说,一个HTTP请求大概长这样子:
GET /JuniorTour HTTP/1.1
Host: github.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
Cookie: authorstyle=no
它主要由以下几部分组成:
<request-line> 请求行
<headers> 请求头
<blank line> 空格
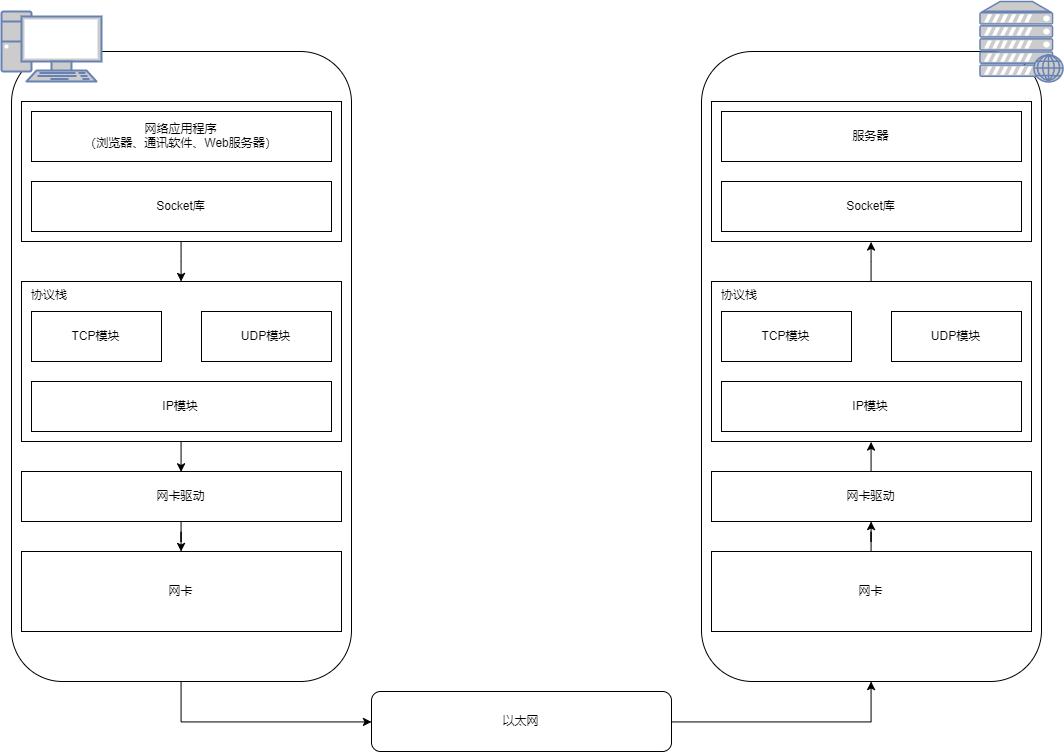
<request-body> 请求数据浏览器在掌握了HTTP服务器的IP地址以及文件名、Cookie、用户代理(User-Agent)等发送请求所需的信息后,就会根据这些信息生成相应的HTTP请求,转交给协议栈,由它来具体执行发送请求。
协议栈是操作系统中的网络控制软件,主要由TCP模块、UDP模块和IP模块组成,分别负责用不同的协议收发数据。
在HTTP请求转交给协议栈发送之前,协议栈或者说是客户端主机首先需要连接上服务器。
这个建立连接的过程就是著名的三次握手,遵循的是TCP协议。
其大致过程如下:
第一次握手:建立连接请求,客户端发送请求报文,将TCP头部的SYN字段标为1,表示连接。
第二次握手:连接建立中,服务器收到客户端的建立连接请求报文后,会发送响应报文,也会将TCP头部的SYN字段和ACK字段标为1。
第三次握手:连接建立,客户端收到服务器的确认连接响应后,会再次向服务器发送一个ACK字段为1的TCP报文,发送完这个报文后,客户端和服务器都会进入“连接已建立”状态,随时准备收发报文。
打一个形象的比喻就是这样的:
客户端告诉服务器:咱们要开始连接了哦~
服务器听到后,回复客户端说:我知道了!
客户端和服务器都确认对方收到消息后就会知道:行了,连接建立了~~
收发数据结束后,还需要断开连接,也就是四次挥手。
以Web为例,服务器会在向浏览器返回响应信息后,由服务器一方发起断开连接。其大致过程如下:
第一次挥手:服务器发送断开连接请求,服务器完成数据响应后,会通过服务器的协议栈向客户端发送一个FIN字段为1的TCP报文。
第二次挥手:客户端确认断开请求,客户端的协议栈接收到服务器的断开连接请求报文后,会向服务器返回一个ACK字段为1的响应报文,表示已收到断开连接请求。
这时客户端的应用程序就会来读取此次响应的数据,客户端的应用程序得到了数据后,也会再向服务器执行一次断开连接操作。
第三次挥手:客户端发送断开连接请求,客户端向服务器发送一个FIN字段为1的TCP报文。
第四次挥手:服务器确认断开连接,收到客户端发来的断开连接请求后,服务器会相应地返回一个ACK字段为1的响应报文,表示已收到断开连接请求。
还是用一个更形象的比喻来描述一次:
服务器发送完数据后对客户端说:数据发完了哦!
客户端得知后回复说:行,我知道了。
客户端检查、储存数据后,又对服务器说:确实都发完了,咱们断开连接吧!
服务器听到后说:好的,我知道了,断开连接吧。
从上述过程也可以看出:TCP协议是一个非常重视可靠性的协议,连接的建立和断开都经历了再三的重复和确认,有效地保证了网络数据传输的可靠性。
发送HTTP请求到一个服务器来获取响应,还有一个问题没有解决。
那就是服务器主机收到HTTP请求后如何判断这个请求是发给这台服务器主机上哪一个程序的,一台服务器主机上可能会运行着多个服务器或程序,该如何判断这个请求是发给哪一个服务器的呢?
同理,当响应传回客户端的个人计算机,又该如何判断这个响应是发给哪一个应用程序,是Chrome,还是微信呢?
这就需要另一个指标来标识一台计算机上运行的不同程序。
这个指标就是端口。
端口(port),其实是每一个使用网卡的程序的编号。
不同的程序占用不同的端口,每个数据包都指定发送到主机的特定端口,不同的程序就能依据端口号收到自己所需要的数据。
在两台主机建立连接之后,建立端口对端口的通信,依据端口号确定数据到底是发送给这台电脑中的哪一个程序,这就是**传输层 **的主要作用。
为了将HTTP请求发送给服务器主机的指定程序,需要委托协议栈中的TCP模块对HTTP请求的数据包进行封装,加上带有端口信息的TCP头部。
这里的端口号也来自一开始在浏览器中输入的URL,通常URL中的端口号可以省略不写,此时就会把事先约定好的HTTP默认端口号: 80或HTTPS默认端口号: 443, 当作目标端口号。
如果指定了端口号,例如:https://github.com:443/JuniorTour ,则会相应地根据指定的端口号附加在HTTP请求上,生成TCP数据包。
大多数应用程序都使用TCP协议来收发数据的,但是有些程序也会使用更简单、更高效的UDP协议。
例如向DNS服务器查询IP用的就是UDP协议。
UDP协议和TCP协议的关键不同点在于,UDP协议为了追求高效率,并不会在收发数据的前后进行确认,也就是前面说的三握四挥,这样的实现相比TCP协议收发数据会更高效。
但是相应的,收发数据的可靠性就会有一定打折,传输过程中发生丢失部分数据包的可能性会更大,即所谓的丢包。
也正是因为效率更高、可靠性较差这两个特点,让UDP协议在短数据收发、多媒体数据收发上有独特的应用。
前面的工作都完成后,就要在两台主机之间建立连接了。
为了实现这一点需要用到明确标识两台主机的标志,就是之前曾多次提及的IP地址。
IP地址的规范主要有两个版本,即 IPv4 和 IPv6 ,他们分别规定了不同长度的IP地址。
以 IPv4 为例,IP地址由32个二进制位组成,例如:11000000.10100010.00000001.00000001,一般习惯用十进制表示,例如:192.168.1.1。
IP地址的作用除了标识一台计算机在网络世界中的地址外,还有判断两台计算机是否属于同一个子网络的功能,这项功能的实现需要子网掩码的辅助。
子网掩码也是一段32位的二进制数,例如:11111111.11111111.11111111.00000000,用十进制表示即为:255.255.255.0,其代表网络部分的全为1,代表主机部分的全为0。
子网掩码的用法是分别和两个IP地址做与运算,如果得出的结果相同,则可以判定两个IP属于同一个子网络。
这两项内容的设置和查看方式已经在前文的DNS一节有所介绍。
为了在两台主机之间建立连接,就需要在数据包中添加带有IP地址的IP头部,并进一步向外传输。
IP模块还会做一件非常重要的事情,就是通过ARP(Address Resolution Protocol,地址解析协议),以广播的形式向同一以太网内的所有设备提问:“ XXX.XXX 这个 IP 地址是谁的?请把你的MAC地址告诉我”,之后就会有同一子网内的其他设备(通常是路由器)回复IP 地址对应的MAC地址。
另外ARP也是有缓存的,会缓存查询结果。
获取到MAC地址之后,IP模块就会再给数据包加上一个带有MAC地址信息的MAC头部并转交给网卡传输。
IP模块的工作完成后,生成的网络包还是不能直接发送给对方,因为此时的网络包还只是内存中的一串数字信号,要在网线上传输,还需要把这些数字转换为电信号或光信号。这个工作是由网卡及其驱动程序完成的。
网卡是计算机上常见的硬件之一,主要功能是信号和数据的编解码、数据包的收发等。
网卡内部有复杂的各种构造,网卡作为一个硬件,和操作它的软件——网卡驱动之间也有多种多样的交互,但在此为了简化这一过程,我们只了解最关键的一小部分细节。
网卡的ROM(只读存储器)中保存着全世界唯一的MAC地址,这个地址是生产网卡时写入的。
以太网上数据包的发送和接收地址都是MAC地址,网卡会将之前IP模块生成的数据包按照一定的规则转换为可在现实世界网线中传输的信号,通过网线发送出去。
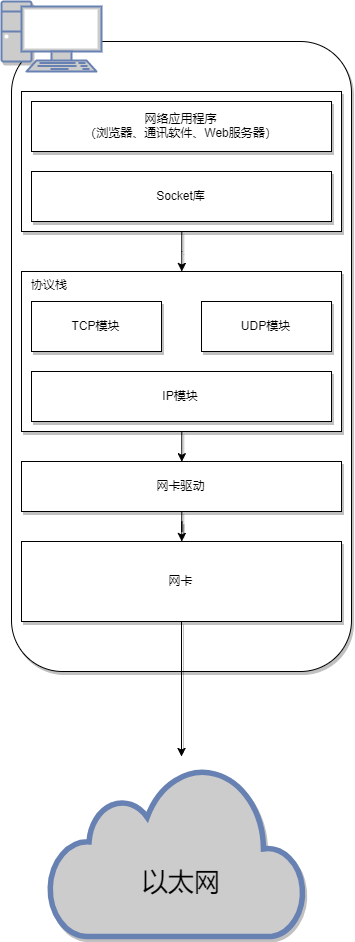
至此,客户端的工作已经完成,数据包进入到了以太网之中进一步传输。
在这一章的开头,我想先介绍四个容易混淆的概念:互联网、因特网、以太网和万维网。
Internet,互联网是意译,因特网是音译,两者在今天都是泛指全球范围内由海量网络相互连接而成的庞大网络。早先,大写开头的Internet专指IP协议架设而成的网络,小写开头的internet则泛指其他各种网络,小写代表的意义包含大写。而今天,在各种网络中,以IP协议架设而成的网络已经占据**地位,是现代人类生活的一部分。小写开头的internet的泛指含义已经没有意义,所以,今天这两个词指的是同一个事物,即全球范围内由海量网络相互连接而成的庞大网络。World Wide Web简称Web,是架构在互联网之上的一项服务,由英国科学家蒂姆·伯纳斯-李于1989年发明,这项服务的核心由统一资源标识符(URI)、超文本传送协议(HTTP)、超文本标记语言(HTML)构成,并借助浏览器等工具为其用户提供各种信息和资源。Ethernet 是一项局域网通信技术,它所涵盖的内容十分丰富,其技术标准是著名的IEEE 802.3标准,某种程度上 IEEE 802.3 就是以太网,其规定了网络连接的规范和电子信号的分组模式等诸多内容。我们要了解的重点是以太网,以太网具体的数据传输方式是:广播,即向整个网络上的每一台设备都发送信号,就像是在一间屋子里喊话一样,一个人喊的话,同一间屋子的所有人都能听到。但是为了明确指出这句话是说给谁的,还需要加上存储在网卡之中标识网络内的每一个节点的MAC地址,就像喊话的时候带上了人名一样。
以太网中以广播的形式向一个MAC地址传输数据的方式有很大的弊端,互联网是由许许多多子网络构成的庞大网络,当两台设备不在同一个子网络之中,却仍采用广播形式时,不仅会有效率上的巨大浪费,也不能准确地传输到目的地。
针对这个弊端,在以太网中传输的数据会依据IP地址和子网掩码判断是否属于同一个子网络。
如果和目标主机不在同一个子网络之中的,会像某一个路由发送数据,由它代理转发到其他子网络之中。相反,当属于同一个子网络时,则仍然采用广播的方式传输数据。
数据被处理成光信号/电信号后,会经过网线、路由器、调制解调器、网关等各种设备的处理转发。
这一部分已经进入了网络硬件的领域,为了保持文章篇幅,不做过多描述。
经历了万水千山、长途跋涉,最初的请求终于到达了目标服务器主机。
服务器主机得到数据包后,会经过网卡、网卡驱动程序、服务器协议栈的层层解析,最终将请求交给服务器处理。服务器处理后,会生成相应的HTTP响应,再将数据包返回给客户端,这个过程几乎就是上文所述的逆向操作。
客户端的浏览器得到了服务器返回的HTTP响应后,将其中的内容解析出来,渲染、呈现在了我们的眼前。
回过头来再看,这几章对应的分别就是互联网的五层模型:
参考资料:
《网络是怎样连接的》-【日】户根勤 著, 周自恒 译
[简析TCP协议中的三次握手和四次挥手](https://segmentfault.com/a/1190000006246996)
TODO 正在热火朝天更新中,欢迎催更~
Watcher第一次调用 updateComponent() 渲染出虚拟DOM:new Watcher(this, updateComponent)Watcher初始化时,constructor中会调用一次Watcher实例的回调this.get()defineProperty()设置的 getterdep.depend()收集当前的Dep.target作为依赖项,添加到dep实例的subs属性中this.subs.push(sub))updateComponent完成后,会卸载Dep.target,设置为null当数据更新后,例如执行:vm._data.msg = "数据驱动 DOM 更新”
defineProperty()设置的settersetter中会调用dep.notify(),遍历所有的依赖(this.subs),并调用依赖的.update()方法Watcher的.update()方法会再次调用其第二个参数 回调函数,执行一次updateComponentupdateComponent,渲染出新的虚拟DOM,并同步到真实DOM中,就完成了一次「数据驱动」的视图更新。A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.
