blog's People
Contributors

Stargazers





























Watchers

blog's Issues
【Spark学习笔记】Hadoop&Spark基本操作与第一次运行
一、HDFS 上传文件
HDFS可以看作一个文件管理系统,和普通PC的本地文件系统很相似。还有图形化的网页界面可供查看。HDFS的原理还需要学习。
以下命令需要在Hadoop开启之后才能使用。
- 创建目录命令
HDFS有一个默认的工作目录/user/$USER,其中$USER是用户的登录用户名。不过目录不会自动建立,需要mkdir建立它
命令格式:hadoop dfs -mkdir
如在home目录下创建pc目录:
hadoop dfs -mkdir /home/pc
注意:Hadoop的mkdir命令会自动创建父目录,类似于带-p的UNIX命令
2. 上传文件命令
put命令从本地文件系统中复制单个或多个源路径到目标文件系统,也支持从标准输入设备中读取输入并写入目标文件系统。分为本地上传和上传到HDFS中。
命令格式:hadoop fs -put filename
如放本地文件系统的一个文件进去
hadoop fs -put example.txt
最后一个参数是句点,相当于放入了默认的工作目录,等价于hadoop fs -put example.txt /home/pc。
- 上传文件到HDFS
上传文件时,文件首先复制到DataNode上,只有所有的DataNode都成功接收完数据,文件上传才是成功的。
命令格式:hadoop dfs put filename newfilename
如:
通过“-put 文件1 文件2 ”命令将Hadoop目录下的test1文件上传到HDFS上并重命名为test2
hadoop dfs -put test1 test2
- 列出HDFS目录下某个文档的文件
通过“-ls 文件夹名” 命令浏览HDFS下文件夹中的文件
命令格式:hadoop dfs -ls 文件夹名
如:
浏览HDFS中in文件夹中的文件
hadoop dfs -ls in
通过该命令可以查看in文件夹中的所有文档文件

查看HDFS下某个文件的内容
通过“-cat 文件名”命令查看HDFS下文件夹中某个文件的内容
命令格式:hadoop$ bin/hadoop dfs -cat 文件名
如:
查看HDFS下in 目录中的内容
hadoop$ bin/hadoop dfs -cat in/*
通过这个命令可以查看in文件夹中所有文件的内容将HDFS中的文件复制到本地系统中
通过“-get 文件按1 文件2”命令将HDFS中某目录下的文件复制到本地系统的某文件中,并对该文件重新命名。
命令格式:hadoop dfs -get 文件名 新文件名
如:
将HDFS中的in文件复制到本地系统并重命名为IN1
hadoop dfs -get in IN1
-get 命令与-put命令一样,既可以操作目录,也可以操作文件删除HDFS下的文档
通过“-rmr 文件”命令删除HDFS下的文件
命令格式:hadoop$ bin/hadoop dfs -rmr 文件
如:
删除HDFS下的out文档
hadoop dfs -rmr out
-rmr 删除文档命令相当于delete的递归版本。格式化HDFS
通过-format命令实现HDFS格式化
命令格式:user@NameNode:hadoop$ bin/hadoop NameNode -format
进入http://localhost:50070/后可以看到:

二、集群运行自带GraphX程序
这里直接使用已经打包在spark/example/jars/目录下的spark-example的jar包。
在命令行下使用
spark-submit --class org.apache.spark.examples.graphx.ComprehensiveExample /usr/local/spark/examples/jars/spark-examples_2.11-2.2.0.jar
运行结果

【待解决】
但是有个问题,在spark Web UI 没有任务显示出来:

三、我的第一个程序
我的提交命令:
【==========================】
【待解决:找不到对象???】

【Scala学习笔记 · 一】基础、控制结构和函数、数组操作
第一章 基础
1、声明值和变量
声明变量:
scala> val a = 8*8
a: Int = 64
scala> var hhh = "hello world"
hhh: String = hello world以val定义的值实际上是一个常量——你无法改变它的内容。而var就可以改变。在scala中,鼓励使用val。
在scala中,变量或函数的类型总卸载变量或函数的后面。
var a,b:String = "as"这是将两个值放在一起声明。
跟java不同,scala的类型(int,char等)都是类,也就是说,可以对数字执行方法。
scala> 666.toString
res1: String = 666更有意思的是:
scala> 2.to(10)
res4: scala.collection.immutable.Range.Inclusive = Range 2 to 10在这里,Int值首先被转换为RichInt(具有int所不具备的便捷方法),再应用to方法。
2、算术和操作符重载
scala> val a = 1+2*3/6-1
a: Int = 1算术符号用法其实与其他语言相同,但需要注意的是这些操作符其实是方法,例如:
a + b是如下方法的简写:
a.+(b)也就是说,这里的+是一个方法名。
和java或C++相比,scala有个显著的不同:没有++和--操作符,需要使用+=1或-=1。
ans+=1还有大数对象:
scala> val x:BigInt = 99999999
x: BigInt = 99999999
scala> x*x*x
res6: scala.math.BigInt = 999999970000000299999999可见操作起来比java方便
3、调用函数和方法
scala> import scala.math._
import scala.math._
scala> sqrt(2)
res8: Double = 1.4142135623730951调用一些函数时,需要引入特定包。
而不带参数的scala方法通常不使用圆括号。例如以下distinct方法,是获取字符串中不重复的字符:
scala> "ddddhello".distinct
res9: String = dhelo如果s是一个字符串,那么在C++中,会写s[i]来获取第i个字符,在Java中是s.charAt(i),而scala是这样:
scala> var s = "hello"
s: String = hello
scala> s(4)
res10: Char = o
scala> "hello"(4)
res11: Char = o可以把这种用法当作是()操作符的重载形式,他的背后是一个apply方法:
def apply(n: Int): Char也就是说,“hello”(4)是如下语句的简写:
"hello".apply(4)练习
- scala允许用数字去乘字符串:
scala> "crazy"*3
res15: String = crazycrazycrazy- res变量是val还是var?
scala> res15+"asd"
res17: String = crazycrazycrazyasd
scala> res17 = "asdasdasdas"
<console>:15: error: reassignment to val
res17 = "asdasdasdas"答:res变量是val,一个不可改变的常量。
- 用BigInt计算2的1024次方。
scala> val x:BigInt = 2
x: scala.math.BigInt = 2
scala> x.pow(1024)
res22: scala.math.BigInt = 179769313486231590772930519078902473361797697894230657273430081157732675805500963132708477322407536021120113879871393357658789768814416622492847430639474124377767893424865485276302219601246094119453082952085005768838150682342462881473913110540827237163350510684586298239947245938479716304835356329624224137216- 在Scala中如何获取字符串的首字符和尾字符?
scala> val a="123456789"
a: String = 123456789
scala> a.head
res24: Char = 1
scala> a.last
res25: Char = 9- take, drop, takeRight, dropRight这些字符串函数是做什么用的?和substring相比,它们的优点和缺点都有哪些?
scala> val a="123456789"
a: String = 123456789
scala> a.take(2)
res26: String = 12
scala> a.drop(2)
res27: String = 3456789
scala> a.takeRight(2)
res28: String = 89
scala> a.dropRight(2)
res29: String = 1234567【Linux】从Linux文件系统看文件读写过程
从Linux文件系统看文件读写过程
提问: 在一个 txt 文件中,修改其中一个字,然后保存,这期间计算机内部到底发生了什么?
1. 答案:文件读写基本流程
1.1 读文件
-
进程调用库函数向内核发起读文件请求;
-
内核通过检查进程的文件描述符定位到虚拟文件系统的已打开文件列表表项;
-
调用该文件可用的系统调用函数read()
-
read()函数通过文件表项链接到目录项模块,根据传入的文件路径,在目录项模块中检索,找到该文件的inode;
-
在inode中,通过文件内容偏移量计算出要读取的页;
-
通过inode找到文件对应的address_space;
-
在address_space中访问该文件的页缓存树,查找对应的页缓存结点:
- 如果页缓存命中,那么直接返回文件内容;
- 如果页缓存缺失,那么产生一个页缺失异常,创建一个页缓存页,同时通过inode找到文件该页的磁盘地址,读取相应的页填充该缓存页;重新进行第6步查找页缓存;
-
文件内容读取成功。
1.2 写文件
前6步和读文件一致,在address_space中查询对应页的页缓存是否存在:
-
如果页缓存命中,直接把文件内容修改更新在页缓存的页中。写文件就结束了。这时候文件修改位于页缓存,并没有写回到磁盘文件中去。
-
如果页缓存缺失,那么产生一个页缺失异常,创建一个页缓存页,同时通过inode找到文件该页的磁盘地址,读取相应的页填充该缓存页。此时缓存页命中,进行第6步。
-
一个页缓存中的页如果被修改,那么会被标记成脏页。脏页需要写回到磁盘中的文件块。有两种方式可以把脏页写回磁盘:
- 手动调用sync()或者fsync()系统调用把脏页写回
- pdflush进程会定时把脏页写回到磁盘
同时注意,脏页不能被置换出内存,如果脏页正在被写回,那么会被设置写回标记,这时候该页就被上锁,其他写请求被阻塞直到锁释放。
这里出现了几个概念:系统调用、虚拟文件系统中的innode、页缓冲Page Cache和Address Space
2.1 系统调用
操作系统的主要功能是为管理硬件资源和为应用程序开发人员提供良好的环境,但是计算机系统的各种硬件资源是有限的,因此为了保证每一个进程都能安全的执行。处理器设有两种模式:“用户模式”与“内核模式”。一些容易发生安全问题的操作都被限制在只有内核模式下才可以执行,例如I/O操作,修改基址寄存器内容等。而连接用户模式和内核模式的接口称之为系统调用。
应用程序代码运行在用户模式下,当应用程序需要实现内核模式下的指令时,先向操作系统发送调用请求。操作系统收到请求后,执行系统调用接口,使处理器进入内核模式。当处理器处理完系统调用操作后,操作系统会让处理器返回用户模式,继续执行用户代码。
进程的虚拟地址空间可分为两部分,内核空间和用户空间。内核空间中存放的是内核代码和数据,而进程的用户空间中存放的是用户程序的代码和数据。不管是内核空间还是用户空间,它们都处于虚拟空间中,都是对物理地址的映射。
应用程序中实现对文件的操作过程就是典型的系统调用过程。
附:linux的用户模式和内核模式
在Linux机器上,CPU要么处于受信任的内核模式,要么处于受限制的用户模式。除了内核本身处于内核模式以外,所有的用户进程都运行在用户模式之中。
处理器总处于以下状态中的一种:
1、内核态,运行于进程上下文,内核代表进程运行于内核空间;
2、内核态,运行于中断上下文,内核代表硬件运行于内核空间;
3、用户态,运行于用户空间。
用户空间的应用程序,通过系统调用,进入内核空间。这个时候用户空间的进程要传递很多变量、参数的值给内核,内核态运行的时候也要保存用户进程的一些寄存器值、变量等。所谓的“进程上下文”,可以看作是用户进程传递给内核的这些参数以及内核要保存的那一整套的变量和寄存器值和当时的环境等。
硬件通过触发信号,导致内核调用中断处理程序,进入内核空间。这个过程中,硬件的一些变量和参数也要传递给内核,内核通过这些参数进行中断处理。所谓的“中断上下文”,其实也可以看作就是硬件传递过来的这些参数和内核需要保存的一些其他环境(主要是当前被打断执行的进程环境)。
2.2 虚拟文件系统
一个操作系统可以支持多种底层不同的文件系统(比如NTFS, FAT, ext3, ext4),为了给内核和用户进程提供统一的文件系统视图,Linux在用户进程和底层文件系统之间加入了一个抽象层,即虚拟文件系统(Virtual File System, VFS),进程所有的文件操作都通过VFS,由VFS来适配各种底层不同的文件系统,完成实际的文件操作。
通俗的说,VFS就是定义了一个通用文件系统的接口层和适配层,一方面为用户进程提供了一组统一的访问文件,目录和其他对象的统一方法,另一方面又要和不同的底层文件系统进行适配。如图所示:
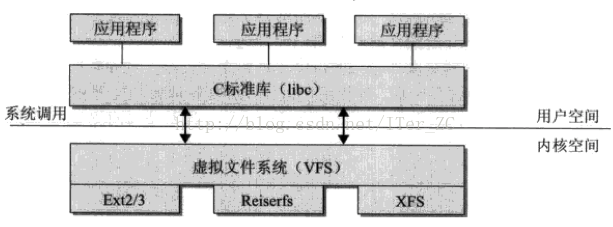
Linux的EXT2文件系统
对于一个磁盘分区来说,在被指定为相应的文件系统后,整个分区被分为 1024,2048 和 4096 字节大小的块。根据块使用的不同,可分为:
-
超级块(Superblock): 这是整个文件系统的第一块空间。包括整个文件系统的基本信息,如块大小,inode/block的总量、使用量、剩余量,指向空间 inode 和数据块的指针等相关信息。
-
inode块(文件索引节点) : 文件系统索引,记录文件的属性。它是文件系统的最基本单元,是文件系统连接任何子目录、任何文件的桥梁。每个子目录和文件只有唯一的一个 inode 块。它包含了文件系统中文件的基本属性(文件的长度、创建及修改时间、权限、所属关系)、存放数据的位置等相关信息. 在 Linux 下可以通过 "ls -li" 命令查看文件的 inode 信息。硬连接和源文件具有相同的 inode 。
-
数据块(Block) :实际记录文件的内容,若文件太大时,会占用多个 block。为了提高目录访问效率,Linux 还提供了表达路径与 inode 对应关系的 dentry 结构。它描述了路径信息并连接到节点 inode,它包括各种目录信息,还指向了 inode 和超级块。
就像一本书有封面、目录和正文一样。在文件系统中,超级块就相当于封面,从封面可以得知这本书的基本信息; inode 块相当于目录,从目录可以得知各章节内容的位置;而数据块则相当于书的正文,记录着具体内容。
进程和虚拟文件系统交互
-
内核使用task_struct来表示单个进程的描述符,其中包含维护一个进程的所有信息。task_struct结构体中维护了一个 files的指针(和“已打开文件列表”上的表项是不同的指针)来指向结构体files_struct,files_struct中包含文件描述符表和打开的文件对象信息。
-
file_struct中的文件描述符表实际是一个file类型的指针列表(和“已打开文件列表”上的表项是相同的指针),可以支持动态扩展,每一个指针指向虚拟文件系统中文件列表模块的某一个已打开的文件。
-
file结构一方面可从f_dentry链接到目录项模块以及inode模块,获取所有和文件相关的信息,另一方面链接file_operations子模块,其中包含所有可以使用的系统调用函数,从而最终完成对文件的操作。这样,从进程到进程的文件描述符表,再关联到已打开文件列表上对应的文件结构,从而调用其可执行的系统调用函数,实现对文件的各种操作。
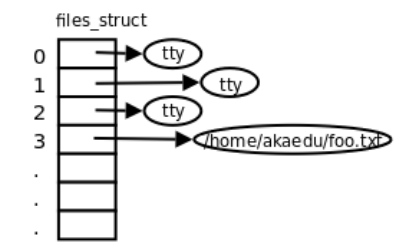
进程、文件列表与Inode
-
多个进程可以同时指向一个打开文件对象(文件列表表项),例如父进程和子进程间共享文件对象;
-
一个进程可以多次打开一个文件,生成不同的文件描述符,每个文件描述符指向不同的文件列表表项。但是由于是同一个文件,inode唯一,所以这些文件列表表项都指向同一个inode。通过这样的方法实现文件共享(共享同一个磁盘文件);
2.3 I/O 缓冲区
概念
如高速缓存(cache)产生的原理类似,在I/O过程中,读取磁盘的速度相对内存读取速度要慢的多。因此为了能够加快处理数据的速度,需要将读取过的数据缓存在内存里。而这些缓存在内存里的数据就是高速缓冲区(buffer cache),下面简称为“buffer”。
具体来说,buffer(缓冲区)是一个用于存储速度不同步的设备或优先级不同的设备之间传输数据的区域。一方面,通过缓冲区,可以使进程之间的相互等待变少,从而使从速度慢的设备读入数据时,速度快的设备的操作进程不发生间断。另一方面,可以保护硬盘或减少网络传输的次数。
Buffer和Cache
buffer和cache是两个不同的概念:cache是高速缓存,用于CPU和内存之间的缓冲;buffer是I/O缓存,用于内存和硬盘的缓冲;简单的说,cache是加速“读”,而buffer是缓冲“写”,前者解决读的问题,保存从磁盘上读出的数据,后者是解决写的问题,保存即将要写入到磁盘上的数据。
Buffer Cache和 Page Cache
buffer cache和page cache都是为了处理设备和内存交互时高速访问的问题。buffer cache可称为块缓冲器,page cache可称为页缓冲器。在linux不支持虚拟内存机制之前,还没有页的概念,因此缓冲区以块为单位对设备进行。在linux采用虚拟内存的机制来管理内存后,页是虚拟内存管理的最小单位,开始采用页缓冲的机制来缓冲内存。Linux2.6之后内核将这两个缓存整合,页和块可以相互映射,同时,页缓存page cache面向的是虚拟内存,块I/O缓存Buffer cache是面向块设备。需要强调的是,页缓存和块缓存对进程来说就是一个存储系统,进程不需要关注底层的设备的读写。
buffer cache和page cache两者最大的区别是缓存的粒度。buffer cache面向的是文件系统的块。而内核的内存管理组件采用了比文件系统的块更高级别的抽象:页page,其处理的性能更高。因此和内存管理交互的缓存组件,都使用页缓存。
2.4 页缓存Page Cache
页缓存是面向文件,面向内存的。通俗来说,它位于内存和文件之间缓冲区,文件IO操作实际上只和page cache交互,不直接和内存交互。page cache可以用在所有以文件为单元的场景下,比如网络文件系统等等。page cache通过一系列的数据结构,比如inode, address_space, struct page,实现将一个文件映射到页的级别:
-
struct page结构标志一个物理内存页,通过page + offset就可以将此页帧定位到一个文件中的具体位置。同时struct page还有以下重要参数:
- 标志位flags来记录该页是否是脏页,是否正在被写回等等;
- mapping指向了地址空间address_space,表示这个页是一个页缓存中页,和一个文件的地址空间对应;
- index记录这个页在文件中的页偏移量;
-
文件系统的inode实际维护了这个文件所有的块block的块号,通过对文件偏移量offset取模可以很快定位到这个偏移量所在的文件系统的块号,磁盘的扇区号。同样,通过对文件偏移量offset进行取模可以计算出偏移量所在的页的偏移量。
-
page cache缓存组件抽象了地址空间address_space这个概念来作为文件系统和页缓存的中间桥梁。地址空间address_space通过指针可以方便的获取文件inode和struct page的信息,所以可以很方便地定位到一个文件的offset在各个组件中的位置,即通过:文件字节偏移量 --> 页偏移量 --> 文件系统块号 block --> 磁盘扇区号
-
页缓存实际上就是采用了一个基数树结构将一个文件的内容组织起来存放在物理内存struct page中。一个文件inode对应一个地址空间address_space。而一个address_space对应一个页缓存基数树。
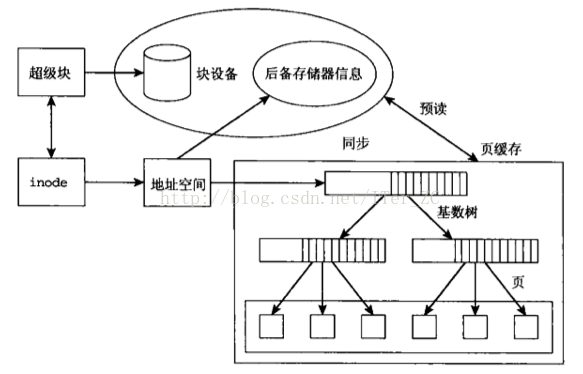
2.5 Address Space
下面我们总结已经讨论过的address_space所有功能。address_space是Linux内核中的一个关键抽象,它被作为文件系统和页缓存的中间适配器,用来指示一个文件在页缓存中已经缓存了的物理页。因此,它是页缓存和外部设备中文件系统的桥梁。如果将文件系统可以理解成数据源,那么address_space可以说关联了内存系统和文件系统。
由图中可以看到,地址空间address_space链接到页缓存基数树和inode,因此address_space通过指针可以方便的获取文件inode和page的信息。那么页缓存是如何通过address_space实现缓冲区功能的?我们再来看完整的文件读写流程。
3 回顾
应用程序需要修改文件A中的部分字段,首先应用程序将待写数据存放在其user buffer结构中,user buffer 通过MMU 映射,数据实际存放在物理内存中。现在应用程序需要将待写数据写入硬盘。
-
程序进程调用内核函数write(),将待写文件标识(句柄)、待写数据相对文件首部的字节偏移量(offset xx)、待写数据长度(2KB)和待写数据的位置一并传给内核 ;
注:在程序打开文件时,内核在PageCache中创建一个虚拟的文件 A’,这个文件A’从文件系统inode结构(下文讲)中映射出来,由若干个page组成,初始情况下文件A’存在与逻辑地址空间内,不占用物理内存。文件A’的逻辑长度参考文件实际长度占用page的整数倍,这里假设page 大小为4KB。
-
内核根据文件字节偏移量和上文提到的虚拟文件A’计算出待写数据占用的page1;(这里面待写数据只有2KB,小于page大小,因此待写数据落入page1中)
-
计算出page号后,内核尝试找到page1对应的物理地址,以进行下一步操作。此时发现page1对应的数据并没有调入内存中,产生缺页,此时需要内核将page1对应的数据完整的从磁盘调入内存;(注意:此处和内存换页没有关系,这里可以看到使用操作系统Pagecache的写IO可能会产生IO读惩罚)
注:文件系统的主要功能就是组织文件在磁盘上的分布,文件是连续的结构,但其在磁盘上却是离散分布的。文件系统将磁盘格式化成若干个块,每个块由若干个连续物理扇区组成,这个真实存在的块叫做物理块。为了提高利用率,同一个文件映射出的物理块可能在磁盘的任何位置,不一定是连续的。因此文件系统需要一个链表来记录文件对应的物理块位置,这个结构在linux中就是inode
-
文件系统将page号映射到对应的块,然后根据inode可查到文件块对应的真实物理地址LBA,内核将请求封装后转给设备驱动层(此步内核需要将Page所包含的所有字节都调入内存——”Page对齐“)。
-
设备驱动将请求翻译成若干各个SCSI指令,驱动SAS控制器通过SAS总线向磁盘发送指令:
SCSI Read() LBA0x****** Len=N N=读取字节大小/扇区大小注:上述过程主要发生在CPU与内存之间,CPU从内存中读出指令并执行,最后CPU将指令通过PCIe总线发送给了SAS控制器,SAS控制器将指令发送到SAS总线上
-
磁盘收到SCSI指令后,找到LBA对应的实际盘面和柱面,读出对应的扇区,发回SAS控制器;
-
从磁盘读出的数据(这里是4KB大小)从原路返回,最后写入到page1对应的物理内存中;
-
内核用代写2KB数据替换掉Page1对应的2KB待替换数据;
-
此时内核向程序进程反馈:写入成功;
-
内核在合适时机将内存中的脏页刷入磁盘。
注:9、10两步表示 Write Back模式,内核在没有将数据写入磁盘时就返回写入成功,以提高效率,相当于内核“欺骗”了应用程序。实际上不光内核会这样做,底层的很多环节也会有这样的情况,比如磁盘也会“欺骗”SAS控制器。如果此时发生系统掉电,所有易失性存储中的数据全部丢失,并未写入磁盘,而应用程序认为写IO已经完成了,下次开机时就会产生数据不一致。程序可以设置Write Through 模式,此时内核会等底层层层上报写入成功后,才会反馈写入成功。
参考链接
【Linux】关于空洞文件
【问题】:文件在初始地方放1字节,在K位置放1字节(一块的大小就是4K),整文件大小多少?占用硬盘物理空间多大?
【答】文件大小2字节,占用硬盘物理空间4K。
在日常的常识中,我们使用的文件存放在硬盘分区上的时候,有多大的内容就会占用多大的空间,但Linux为了便于管理文件,文件系统都是按块大小来分配给文件的,假如这个文件系统一个块是4096的话,那么这个文件就会占用一个块的,无论实际的内容是1B还是4000B.如果我们有一个4MB的文件,那么它会在分区中占用:4MB/4096B=1000个块.
但在Linux文件读写时,如果文件指针偏移很大一段,然后写入1byte,这样这个文件实际占用1byte空间,但是stat查看文件大小,或者读写时,都会发现文件很大,所有没有写内容的都填充0,且不占用空间,这样的文件叫
sparse file,即空洞文件。文件储存在硬盘上,硬盘的最小存储单位叫做"扇区"(
Sector)。每个扇区储存512字节(相当于0.5KB)。操作系统读取硬盘的时候,不会一个个扇区地读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个"块"(block)。这种由多个扇区组成的"块",是文件存取的最小单位。"块"的大小,最常见的是4KB,即连续八个sector组成一个block。举个生活中的例子吧,很多人一起吃饭,这个分配单元就相当于碗的大小,这个文件就好比碗里的饭,每个人的饭量不一样,有人吃的多,就需要两个碗来盛饭,但是有的人吃的少,但也是要占一个碗。了解这个概念以后,理解起来文件大小和占用空间的关系就简单多了。
其实可以实际测试一下,为了效果更佳明显,我没有按照题目一样只放一个字节。
对于
testfile1,我从一个tar文件那里复制1000个块,每块大小4096字节。通过ls –l命令我们可以看到文件大小4M,通过du –h命令可以看到占用硬盘物理空间同样是4M。而对于
testfile2,我只复制了最后的一个块,前面的999个都跳过了,也就是创建了一个空洞文件。可以看到文件大小虽然是4M,但占用硬盘物理空间只有4K。实际中的空洞文件会在哪里用到呢?常见的场景有两个:
- 在下载电影的时候,发现刚开始下载,文件的大小就已经到几百M了.
- 在创建虚拟机的磁盘镜像的时候,你创建了一个100G的磁盘镜像,但是其实装起来系统之后,开始也不过只占用了3,4G的磁盘空间,如果一开始把100G都分配出去的话,无疑是很大的浪费.

【Scala学习笔记 · 二】映射和元组、类、对象
第四章 映射和元组
1. 映射
Scala中映射是对偶的集合,也就是两个值构成的组,这两个值不一定是一个类型的。
//建立映射的两种方式
val sc = Map("A"->99, "B"-> 80)
val sc2 = Map(("Alice",10), ("Bob",8))
//获取映射的值
val Asc = sc.get("A")
//Asc: Option[Int] = Some(99)
val Bobsc = sc2.getOrElse("Bob",0)
//如果映射包含键“Bob”,返回相应值,否则返回0
//Bobsc: Int = 8
//映射的更新
val newsc = sc+("C"->88, "D"->77)
//映射迭代之键值交换
for((k, v) <- sc) yield (v,k)
//res0: scala.collection.immutable.Map[Int,String] = Map(99 -> A, 80 -> B)2. 元组
映射是对偶的集合,对偶是元组(tuple)的最简单形式——元组是不同类型的值的聚集。
//创建一个元组
val t = (1,2.2,"sadf")
//t: (Int, Double, String) = (1,2.2,sadf)
//如下方法访问组元,这里将第二个组元传给变量second
val second = t._2
//second: Double = 2.2
//也可以一起访问并赋值
val (fir, sec, thi) = t
//fir: Int = 1
//sec: Double = 2.2
//thi: String = sadf
//当然也可以不全部获取
val (fir1, sec1, _) = t
//fir1: Int = 1
//sec1: Double = 2.2拉链操作:
val symbol = Array("<", "-", ">")
val count = Array(2, 10, 2)
val pairs = symbol.zip(count)
//pairs: Array[(String, Int)] = Array((<,2), (-,10), (>,2))练习
- 设置一个映射,其中包含你想要的一些装备,以及它们的价格。然后构建另一个映射,采用同一组键,但在价格上打9折。
val p :Map[String, Int] = Map("t1"->10, "t2"->12, "t3"->20)
val ans = (for((k, v) <- p) yield {(k,v*0.9)})
//p: Map[String,Int] = Map(t1 -> 10, t2 -> 12, t3 -> 20)
//ans: scala.collection.immutable.Map[String,Double] = Map(t1 -> 9.0, t2 -> 10.8, t3 -> 18.0)- 编写一段程序,从文件中读取单词。用一个可变映射来清点每一个单词出现的频率。
import java.io.File
import java.util.Scanner
val in = new Scanner(new File("/text.txt"))
val map = new scala.collection.mutable.HashMap[String, Int]()
while(in.hasNext()){
val str = in.next()
map(str) = map.getOrElse(str,0) + 1
}
println(map.mkString(","))
//(alpha) -> 1,PageRank -> 1,Collaborative -> 1 .......................- 重复前一个练习,这次用不可变的映射。
import java.io.File
import java.util.Scanner
val in = new Scanner(new File("C:/Users/67329/Desktop/text.txt"))
val map = Map[String, Int]()
var m = map //不可变(val)映射
while(in.hasNext()){
val str = in.next()
m += (str -> (m.getOrElse(str,0) + 1))
//添加一对映射
}
println(m.mkString(","))
//abstraction -> 1,At -> 1,GraphX -> 4,for -> 1................- 重复前一个练习,这次用已排序的映射,以便单词可以按顺序打印出来。
import java.io.File
import java.util.Scanner
val in = new Scanner(new File("/text.txt"))
val map = scala.collection.immutable.SortedMap[String, Int]()
var m = map //不可变(val)映射
while(in.hasNext()){
val str = in.next()
m += (str -> (m.getOrElse(str,0) + 1))
//添加一对映射
}
println(m.mkString(","))
//(alpha) -> 1,(e.g., -> 3,API -> 1,API. -> 1............................- 编写一个函数minmax(values: Array[Int]),返回数组中最小值和最大值的对偶。
val t =Array(1,2,3,4,5)
val min = t.min
val max = t.max
printf("%d, %d\n",min,max)
//1, 5- 编写一个函数lteqgt(values: Array[Int], v: Int),返回数组中小于v,等于v和大于v的数量,要求三个值一起返回。
def iteqgt(values: Array[Int], v: Int) = {
var l,e,r = 0;
for (i <- values){
if (i<v)
l += 1
else if(i == v)
e += 1
else
r += 1
}
(l,e,r)
}
val a = Array(1,2,3,4,5,6)
val ans = iteqgt(a,3)
println(ans)
//(2,1,3)- 当你将两个字符串拉链在一起,比如”Hello”.zip(“World”),会是什么结果?想出一个讲得通的用例。
val t1 = "hello".zip("world")
val t2 = "ab".zip("cde")
val t3 = "abc".zip("d")
println(t1)
println(t2)
println(t3)
//Vector((h,w), (e,o), (l,r), (l,l), (o,d))
//Vector((a,c), (b,d))
//Vector((a,d))【Java】HashMap工作原理
HashMap工作原理
先抛出几个问题:
1.什么是HashMap?你为什么用到它?
2.你知道HashMap的工作原理吗?
3.你知道get和put的原理吗?equals()和hashCode()的都有什么作用?
4.你知道hash的实现吗?为什么要这样实现?
5.如果HashMap的大小超过了负载因子(load factor)定义的容量,怎么办?
1.HashMap是什么
简而言之,就是一种基于哈希的键值对数据结构。
在java官方文档中是这样描述HashMap的:
Hash table based implementation of the Map interface. This implementation provides all of the optional map operations, and permits null values and the null key. (The HashMap class is roughly equivalent to Hashtable, except that it is unsynchronized and permits nulls.) This class makes no guarantees as to the order of the map; in particular, it does not guarantee that the order will remain constant over time.
基于Map接口实现、允许null键/值、非同步(synchronized)、不保证有序(比如插入的顺序)、也不保证序不随时间变化。
【疑问】
null和非同步是怎么体现的?有什么作用?
2.HashMap 工作原理
2.1 结构与参数
系统在初始化HashMap时,会创建一个 长度为 capacity 的 Entry 数组,这个数组里可以存储元素的位置被称为“桶(bucket)”,每个 bucket 都有其指定索引,系统可以根据其索引快速访问该 bucket 里存储的元素。
在HashMap中有两个很重要的参数,容量(Capacity)和负载因子(Load factor):
Capacity就是buckets的数目,Load factor就是buckets填满程度的最大比例。如果对迭代性能要求很高的话不要把
capacity设置过大,也不要把load factor设置过小。当bucket填充的数目(即hashmap中元素的个数)大于capacity*load factor时就需要调整buckets的数目为当前的2倍。
无论何时,HashMap 的每个“桶”只存储一个元素(也就是一个 Entry),由于 Entry 对象可以包含一个引用变量(就是 Entry 构造器的的最后一个参数)用于指向下一个 Entry,
因此可能出现的情况是:HashMap 的 bucket 中只有一个 Entry,但这个 Entry 指向另一个 Entry ——这就形成了一个 Entry 链。(也就是冲突了)

当 HashMap 的每个 bucket 里存储的 Entry 只是单个 Entry ——也就是没有通过指针产生 Entry 链时(没有哈希冲突),此时的 HashMap 具有最好的性能:当程序通过 key 取出对应 value 时,系统只要先计算出该 key 的 hashCode() 返回值,在根据该 hashCode 返回值找出该 key 在 table 数组中的索引,然后取出该索引处的 Entry,最后返回该 key 对应的 value 即可。
在发生“Hash 冲突”的情况下,单个 bucket 里存储的不是一个 Entry,而是一个 Entry 链,系统只能必须按顺序遍历每个 Entry,直到找到想搜索的 Entry 为止——如果恰好要搜索的 Entry 位于该 Entry 链的最末端(该 Entry 是最早放入该 bucket 中),那系统必须循环到最后才能找到该元素。
当创建 HashMap 时,有一个默认的负载因子(load factor),其默认值为 0.75,这是时间和空间成本上一种折衷:增大负载因子可以减少 Hash 表(就是那个 Entry 数组)所占用的内存空间,但会增加查询数据的时间开销,而查询是最频繁的的操作(HashMap 的 get() 与 put() 方法都要用到查询);减小负载因子会提高数据查询的性能,但会增加 Hash 表所占用的内存空间。 通常情况下,程序员无需改变负载因子的值。
2.2 put()函数的实现
put函数大致的思路为:
- 对key的hashCode()做hash,然后再计算index;
- 如果没碰撞直接放到bucket里;
- 如果碰撞了,以链表的形式存在buckets后;
- 如果碰撞导致链表过长(大于等于TREEIFY_THRESHOLD),就把链表转换成红黑树参考此链接:Java 8:HashMap的性能提升;
- 如果节点已经存在就替换old value(保证key的唯一性)
- 如果bucket满了(超过load factor*current capacity),就要resize。
public V put(K key, V value) {
// 对key的hashCode()做hash
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// tab为空则创建
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 计算index,并对null做处理
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
// 节点存在
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 该链为树
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// 该链为链表
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
// 写入
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
// 超过load factor*current capacity,resize
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}2.3 get()函数的实现
大致思路如下:
- bucket里的第一个节点,直接命中;
- 如果有冲突,则通过key.equals(k)去查找对应的entry
- 若为树,则在树中通过key.equals(k)查找,O(logn);
- 若为链表,则在链表中通过key.equals(k)查找,O(n)。
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// 直接命中
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
// 未命中
if ((e = first.next) != null) {
// 在树中get
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
// 在链表中get
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}2.4 hash函数的实现
过程如下图:

static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}高16bit不变,低16bit和高16bit做了一个异或。
这样的一个hash函数实现,主要是权衡了速度与碰撞率。
设计者还解释到因为现在大多数的hashCode的分布已经很不错了,就算是发生了碰撞也用
O(logn)的tree去做了。仅仅异或一下,既减少了系统的开销,也不会造成的因为高位没有参与下标的计算(table长度比较小时),从而引起的碰撞。
如果发生了碰撞:
在Java 8之前的实现中是用链表解决冲突的,在产生碰撞的情况下,进行get时,两步的时间复杂度是O(1)+O(n)。因此,当碰撞很厉害的时候n很大,O(n)的速度显然是影响速度的。
因此在Java 8中,利用红黑树替换链表,这样复杂度就变成了O(1)+O(logn)了,这样在n很大的时候,能够比较理想的解决这个问题,在Java 8:HashMap的性能提升一文中有性能测试的结果。
注意:hash和计算下标是不一样的,hash是计算下标过程的一部分
2.5 RESIZE 的实现
当put时,如果发现目前的bucket占用程度已经超过了Load Factor所希望的比例,为了减少碰撞率,就会执行resize。resize的过程,简单的说就是把bucket扩充为2倍,之后重新计算index,把节点再放到新的bucket中。
怎么理解呢?例如我们从16扩展为32时,具体的变化如下所示:
因此元素在重新计算hash之后,因为n变为2倍,那么n-1的mask范围在高位多1bit(红色),因此新的index就会发生这样的变化:
因此,我们在扩充HashMap的时候,不需要重新计算hash,只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成“原索引+oldCap”。可以看看下图为16扩充为32的resize示意图:
这个设计确实非常的巧妙,既省去了重新计算hash值的时间,而且同时,由于新增的1bit是0还是1可以认为是随机的,因此resize的过程,均匀的把之前的冲突的节点分散到新的bucket了。



Hashmap为什么容量是2的幂次
最理想的效果是,Entry数组中每个位置都只有一个元素,这样,查询的时候效率最高,不需要遍历单链表,也不需要通过equals去比较K,而且空间利用率最大。那如何计算才会分布最均匀呢?我们首先想到的就是%运算,哈希值%容量=bucketIndex。
static int indexFor(int h, int length) {
return h & (length-1);
} 这个等式实际上可以推理出来,2^n转换成二进制就是1+n个0,减1之后就是0+n个1,如16 -> 10000,15 -> 01111,那根据&位运算的规则,都为1(真)时,才为1,那0≤运算后的结果≤15,假设h <= 15,那么运算后的结果就是h本身,h >15,运算后的结果就是最后三位二进制做&运算后的值,最终,就是%运算后的余数,我想,这就是容量必须为2的幂的原因。
3. 总结
1. 什么是HashMap?你为什么用到它?
是基于Map接口的实现,存储键值对时,它可以接收null的键值,是非同步的,HashMap存储着Entry(hash, key, value, next)对象。
2. 你知道HashMap的工作原理吗?
通过hash的方式,以键值对<K,V>的方式存储(put)、获取(get)对象。存储对象时,我们将K/V传给put方法时,它调用hashCode计算hash从而得到bucket位置,进一步存储,HashMap会根据当前bucket的占用情况自动调整容量(超过Load Facotr则resize为原来的2倍)。获取对象时,我们将K传给get,它调用hashCode计算hash从而得到bucket位置,并进一步调用equals()方法确定键值对。如果发生碰撞的时候,Hashmap通过链表将产生碰撞冲突的元素组织起来,在Java 8中,如果一个bucket中碰撞冲突的元素超过某个限制(默认是8),则使用红黑树来替换链表,从而提高速度。
3. 你知道get和put的原理吗?equals()和hashCode()的都有什么作用?
通过对key的hashCode()进行hashing,并计算下标( n-1 & hash),从而获得buckets的位置。如果产生碰撞,则利用key.equals()方法去链表或树中去查找对应的节点。
4. 你知道hash的实现吗?为什么要这样实现?
在Java 1.8的实现中,是通过hashCode()的高16位异或低16位实现的:(h = k.hashCode()) ^ (h >>> 16),主要是从速度、功效、质量来考虑的,这么做可以在bucket的n比较小的时候,也能保证考虑到高低bit都参与到hash的计算中,同时不会有太大的开销。
5. 如果HashMap的大小超过了负载因子(load factor)定义的容量,怎么办?
如果超过了负载因子(默认0.75),则会重新resize一个原来长度两倍的HashMap,并且重新调用hash方法。
6. 什么是哈希冲突?如何解决的?
以Entry[]数组实现的哈希桶数组,用Key的哈希值取模桶数组的大小可得到数组下标。
插入元素时,如果两条Key落在同一个桶(比如哈希值1和17取模16后都属于第一个哈希桶),我们称之为哈希冲突。
JDK的做法是链表法,Entry用一个next属性实现多个Entry以单向链表存放。查找哈希值为17的key时,先定位到哈希桶,然后链表遍历桶里所有元素,逐个比较其Hash值然后key值。
在JDK8里,新增默认为8的阈值,当一个桶里的Entry超过閥值,就不以单向链表而以红黑树来存放以加快Key的查找速度。
当然,最好还是桶里只有一个元素,不用去比较。所以默认当Entry数量达到桶数量的75%时,哈希冲突已比较严重,就会成倍扩容桶数组,并重新分配所有原来的Entry。扩容成本不低,所以也最好有个预估值。
7. HashMap在高并发下引起的死循环
- HashMap进行存储时,如果size超过当前最大容量*负载因子时候会发生resize。
- 而这段代码中又调用了transfer()方法,而这个方法实现的机制就是将每个链表转化到新链表,并且链表中的位置发生反转,而这在多线程情况下是很容易造成链表回路,从而发生get()死循环
- 链表头插法的会颠倒原来一个散列桶里面链表的顺序。在并发的时候原来的顺序被另外一个线程a颠倒了,而被挂起线程b恢复后拿扩容前的节点和顺序继续完成第一次循环后,又遵循a线程扩容后的链表顺序重新排列链表中的顺序,最终形成了环。
- 假如有两个线程P1、P2,以及链表 a=》b=》null
- P1先执行,执行完"Entry<K,V> next = e.next;"代码后发生阻塞,或者其他情况不再执行下去,此时e=a,next=b
- 而P2已经执行完整段代码,于是当前的新链表newTable[i]为b=》a=》null
- P1又继续执行"Entry<K,V> next = e.next;"之后的代码,则执行完"e=next;"后,newTable[i]为a《=》b,则造成回路,while(e!=null)一直死循环
参考资料
HashMap的工作原理
HashMap 里的“bucket”、“负载因子” 介绍
Java 8:HashMap的性能提升
HashMap和Hashtable的区别
【Camera】Camera2Basic 源码阅读
Camera2Basic 源码阅读
本文将通过对 android-Camera2Basic 的源码分析,学习安卓相机的基本开发。
【TODO】getSupportFragmentManager() 这系列的语句是做什么用的?
【TODO】安卓基础:inflater
【TODO】Java 信号量 Semaphore
【TODO】camera:TextureView是什么?
【TODO】OpenGL相关:OpenGL ES texture是什么?
一、CameraActivity
public class CameraActivity extends AppCompatActivity {
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_camera);
if (null == savedInstanceState) {
getSupportFragmentManager().beginTransaction()
.replace(R.id.container, Camera2BasicFragment.newInstance())
.commit();
}
}
}首先肯定要看这个相机应用是怎么诞生的。
onCreate很简短,主要是实例化一个 Camera2BasicFragment,也是整个项目的重头戏。
【TODO】getSupportFragmentManager() 这系列的语句是做什么用的?
二、Camera2BasicFragment
public static Camera2BasicFragment newInstance() {
return new Camera2BasicFragment();
}通过这个方法,之前的活动 CameraActivity 实例化了Fragment:
【此处应有张截图】代码界面贴一张图片
由上图可以看到,整个 com.example.android.camera2basic.Camera2BasicFragment.java 总共有 25 个方法、一个图片保存类、一个比较类以及两个日志类。
根据本app的拍照流程,这25个方法可以分为以下几类:
创建界面 - 打开相机 - 显示预览 - 拍摄 - 保存图片 - 关闭服务
2.1 创建界面
(1) 导入视图的xml
@Override
public View onCreateView(LayoutInflater inflater, ViewGroup container,
Bundle savedInstanceState) {
return inflater.inflate(R.layout.fragment_camera2_basic, container, false);
}【TODO】 安卓基础:inflater
(2)配置按钮
@Override
public void onViewCreated(final View view, Bundle savedInstanceState) {
// 下方蓝底和拍摄按钮
view.findViewById(R.id.picture).setOnClickListener(this);
// 右侧感叹号 信息按钮
view.findViewById(R.id.info).setOnClickListener(this);
mTextureView = (AutoFitTextureView) view.findViewById(R.id.texture);
}设置拍摄按钮以及info按钮的点击事件
(3)相关配置初始化
@Override
public void onActivityCreated(Bundle savedInstanceState) {
super.onActivityCreated(savedInstanceState);
// 为拍摄得到的图片定义输出路径文件
mFile = new File(getActivity().getExternalFilesDir(null), "pic.jpg");
}mFile是图片的输出目标文件
2.2 打开相机
2.2.1 通过API2调用
app层次的代码肯定是无法直接调用硬件层面的摄像头配置的,所以需要使用API2提供的接口来对相机进行打开和关闭,以及异常情况的处理:
/**
* {@link CameraDevice.StateCallback} is called when {@link CameraDevice} changes its state.
*/
private final CameraDevice.StateCallback mStateCallback = new CameraDevice.StateCallback() {
// 打开摄像头
@Override
public void onOpened(@NonNull CameraDevice cameraDevice) {
// This method is called when the camera is opened. We start camera preview here.
mCameraOpenCloseLock.release();
mCameraDevice = cameraDevice;
// 创建预览绘画
createCameraPreviewSession();
}
@Override
public void onDisconnected(@NonNull CameraDevice cameraDevice) {
// 关闭相机连接时 解锁(此处省略代码)
}
@Override
public void onError(@NonNull CameraDevice cameraDevice, int error) {
//(此处省略代码)
};对于摄像头这个独占资源的使用,采用了
private Semaphore mCameraOpenCloseLock = new Semaphore(1);
信号量进行控制。 【TODO】Java 信号量 Semaphore
并创建了之后为用户提供画面的预览会话。
这部分API的使用,会在之后的app调用中通过 CameraManager 来使用。
2.2.2 获得相机权限
回到app层面,要使用相机,肯定需要获得Android的相机权限:
private void requestCameraPermission() {
if (shouldShowRequestPermissionRationale(Manifest.permission.CAMERA)) {
new ConfirmationDialog().show(getChildFragmentManager(), FRAGMENT_DIALOG);
} else {
requestPermissions(new String[]{Manifest.permission.CAMERA}, REQUEST_CAMERA_PERMISSION);
}
}2.2.3 相机输出设置
获得所有摄像头的特性,并根据长度宽度这两个参数,设置预览与输出的分辨率大小。
private void setUpCameraOutputs(int width, int height) {
Activity activity = getActivity();
CameraManager manager = (CameraManager) activity.getSystemService(Context.CAMERA_SERVICE);
try {
// 0. 可能有多个摄像头,比如前置后置,遍历每个摄像头进行设置
for (String cameraId : manager.getCameraIdList()) {
// 1. 获得描述摄像头的各种特性
// 通过CameraManager的getCameraCharacteristics(String cameraId)方法来获取
CameraCharacteristics characteristics
= manager.getCameraCharacteristics(cameraId);
// 2. 跳过前置摄像头
Integer facing = characteristics.get(CameraCharacteristics.LENS_FACING);
if (facing != null && facing == CameraCharacteristics.LENS_FACING_FRONT) {
continue;
}
// 3. 获得该摄像头支持的分辨率信息
StreamConfigurationMap map = characteristics.get(
CameraCharacteristics.SCALER_STREAM_CONFIGURATION_MAP);
if (map == null) {
continue;
}
// 4. 使用可行的最大的尺寸来输出照片
Size largest = Collections.Arrays.asList(map.getOutputSizes(ImageFormat.JPEG)),new CompareSizesByArea());
。。。
// Find out if we need to swap dimension to get the preview size relative to sensor coordinate.
int displayRotation = activity.getWindowManager().getDefaultDisplay().getRotation();
//noinspection ConstantConditions
// 5. 获取摄像头方向,按照顺时针来衡量角度
mSensorOrientation = characteristics.get(CameraCharacteristics.SENSOR_ORIENTATION);
boolean swappedDimensions = false;
switch (displayRotation) {
。。。
}
// 6. 通过点的坐标获得预览显示区域的像素大小
Point displaySize = new Point();
activity.getWindowManager().getDefaultDisplay().getSize(displaySize);
。。。
// 7. 将TextureView的宽高与预览的大小匹配,并且会与手机横置与否匹配
int orientation = getResources().getConfiguration().orientation;
。。。
// 8. 检查闪光灯是否支持
Boolean available = characteristics.get(CameraCharacteristics.FLASH_INFO_AVAILABLE);
。。。
return;
}
} catch (CameraAccessException e) {
e.printStackTrace();
} catch (NullPointerException e) {
// Currently an NPE is thrown when the Camera2API is used but not supported on the
// device this code runs.
ErrorDialog.newInstance(getString(R.string.camera_error))
.show(getChildFragmentManager(), FRAGMENT_DIALOG);
}
}2.2.4 通过CameraManager管理相机
CameraManager manager = (CameraManager) activity.getSystemService(Context.CAMERA_SERVICE);
CameraManager是一个系统服务,将相机硬件相关的功能封装成接口供调用。
2.2.* 整体流程代码
整体流程封装如下,在最后的打开相机时,会使用Lock.tryAcquire() 检测锁是否被占用。
/**
* Opens the camera specified by {@link Camera2BasicFragment#mCameraId}.
*/
private void openCamera(int width, int height) {
// 1. 获取权限
if (ContextCompat.checkSelfPermission(getActivity(), Manifest.permission.CAMERA)
!= PackageManager.PERMISSION_GRANTED) {
requestCameraPermission();
return;
}
// 设置相机输出格式:长宽,并配置好预览的长宽、闪光灯配置等
setUpCameraOutputs(width, height);
//
configureTransform(width, height);
Activity activity = getActivity();
// 2. 获取CameraManager:"摄像头管理器,用于打开和关闭系统摄像头"
CameraManager manager = (CameraManager) activity.getSystemService(Context.CAMERA_SERVICE);
try {
// 请求摄像头时检测锁是否被占用
if (!mCameraOpenCloseLock.tryAcquire(2500, TimeUnit.MILLISECONDS)) {
throw new RuntimeException("Time out waiting to lock camera opening.");
}
// 调用时内部还会有同步锁进行控制
manager.openCamera(mCameraId, mStateCallback, mBackgroundHandler);
} catch (CameraAccessException e) {
e.printStackTrace();
} catch (InterruptedException e) {
throw new RuntimeException("Interrupted while trying to lock camera opening.", e);
}
}【TODO】TextureView是什么? 旋转?
2.3 显示预览
// 打开摄像头
@Override
public void onOpened(@NonNull CameraDevice cameraDevice) {
// This method is called when the camera is opened. We start camera preview here.
mCameraOpenCloseLock.release();
mCameraDevice = cameraDevice;
// 创建预览会话
createCameraPreviewSession();
}打开摄像头之后,就要在应用界面显示预览画面。
预览画面时动态且实时的,所以需要摄像头持续不断的获取数据:
所以创建了一个拍摄会话,通过一个重复请求源源不断的获取图片,并以数组形式传递给surface用以显示预览
surface是什么?
是一个接受数据的原始缓冲
经常被SurfaceTexture、MediaRecorder等图片缓冲消费者(consumer of image buffers)创建
或者被生产者如opengl.EGL14、MediaPlayer等调用通过SurfaceTexture创建
【TODO】OpenGL相关:OpenGL ES texture是什么?({@link SurfaceTexture}: Captures frames from an image stream as an OpenGL ES texture.)
/**
* Creates a new {@link CameraCaptureSession} for camera preview.
*/
private void createCameraPreviewSession() {
try {
SurfaceTexture texture = mTextureView.getSurfaceTexture();
assert texture != null;
// 我们将默认缓冲区的大小配置为我们想要的相机预览的大小。
texture.setDefaultBufferSize(mPreviewSize.getWidth(), mPreviewSize.getHeight());
// 这是需要开始预览的输出surface
Surface surface = new Surface(texture);
// 通过surface配置CaptureRequest.Builder
mPreviewRequestBuilder
= mCameraDevice.createCaptureRequest(CameraDevice.TEMPLATE_PREVIEW);
mPreviewRequestBuilder.addTarget(surface);
// Here, we create a CameraCaptureSession for camera preview.
// 创建CaptureSession会话。
// 第一个参数 outputs 是一个 List 数组,相机会把捕捉到的图片数据传递给该参数中的 Surface 。
// 第二个参数 StateCallback 是创建会话的状态回调。
// 第三个参数描述了 StateCallback 被调用时所在的线程,这里为 null
mCameraDevice.createCaptureSession(Arrays.asList(surface, mImageReader.getSurface()),
new CameraCaptureSession.StateCallback() {
@Override
public void onConfigured(@NonNull CameraCaptureSession cameraCaptureSession) {
// The camera is already closed
if (null == mCameraDevice) {
return;
}
// When the session is ready, we start displaying the preview.
mCaptureSession = cameraCaptureSession;
try {
// Auto focus should be continuous for camera preview.
mPreviewRequestBuilder.set(CaptureRequest.CONTROL_AF_MODE,
CaptureRequest.CONTROL_AF_MODE_CONTINUOUS_PICTURE);
// Flash is automatically enabled when necessary.
setAutoFlash(mPreviewRequestBuilder);
// Finally, we start displaying the camera preview.
mPreviewRequest = mPreviewRequestBuilder.build();
// 为预览会话持续不断的重复获取捕捉到的图片
// 并且mPreviewRequest由之前的代码定义:设置为连续自动对焦模式,并在必要时自动开启闪光
mCaptureSession.setRepeatingRequest(mPreviewRequest,
mCaptureCallback, mBackgroundHandler);
} catch (CameraAccessException e) {
e.printStackTrace();
}
}
@Override
public void onConfigureFailed(
@NonNull CameraCaptureSession cameraCaptureSession) {
showToast("Failed");
}
}, null
);
} catch (CameraAccessException e) {
e.printStackTrace();
}
}2.4 拍摄
2.4.1 点击拍摄按钮拍照:
public void onClick(View view) {
switch (view.getId()) {
case R.id.picture: {
// 点击拍摄键拍照
takePicture();
break;
}
case R.id.info: {
。。。
}
break;
}
}
}
private void takePicture() {
lockFocus();
}2.4.2 对焦曝光要正确
拍照,肯定要对焦,并且对焦要稳定不能拉风箱,对于对焦的状态,可通过mState = STATE_WAITING_LOCK;进行控制。
private void lockFocus() {
try {
// This is how to tell the camera to lock focus.
// 告诉摄像头 配置自动对焦
mPreviewRequestBuilder.set(CaptureRequest.CONTROL_AF_TRIGGER,
CameraMetadata.CONTROL_AF_TRIGGER_START);
// Tell #mCaptureCallback to wait for the lock.
mState = STATE_WAITING_LOCK;
mCaptureSession.capture(mPreviewRequestBuilder.build(), mCaptureCallback,
mBackgroundHandler);
} catch (CameraAccessException e) {
e.printStackTrace();
}
}通过RequestBuilder配置好自动对焦后,等待对焦稳定,通过session拍摄,此时会调用一个回调进行拍摄,也就是mCaptureCallback。
而拍摄的处理过程就是靠这个回调定义的。
这个回调mCaptureCallback,会分为四种不同的情况:
预览时需要调用摄像头的数据但并不做拍摄操作;
mState = STATE_WAITING_LOCK时表示要准备拍照了,此时会根据【对焦状态】进行拍摄或尝试进行预拍摄(precapture);
根据【曝光状态】如“需要闪光灯补光”,将mstate由等待预拍摄(STATE_WAITING_PRECAPTURE)转换为等待非预拍摄(STATE_WAITING_NON_PRECAPTURE)
曝光稳定后拍摄
/**
* A {@link CameraCaptureSession.CaptureCallback} that handles events related to JPEG capture.
*/
private CameraCaptureSession.CaptureCallback mCaptureCallback
= new CameraCaptureSession.CaptureCallback() {
private void process(CaptureResult result) {
// 按下拍照键后根据设置的不同,有不同的拍摄方式
switch (mState) {
case STATE_PREVIEW: {
// 预览
// We have nothing to do when the camera preview is working normally.
break;
}
case STATE_WAITING_LOCK: {
// 对焦稳定后拍摄或尝试拍摄
Integer afState = result.get(CaptureResult.CONTROL_AF_STATE);
if (afState == null) {
captureStillPicture();
} else if (CaptureResult.CONTROL_AF_STATE_FOCUSED_LOCKED == afState ||
CaptureResult.CONTROL_AF_STATE_NOT_FOCUSED_LOCKED == afState) {
// CONTROL_AE_STATE can be null on some devices
Integer aeState = result.get(CaptureResult.CONTROL_AE_STATE);
if (aeState == null ||
aeState == CaptureResult.CONTROL_AE_STATE_CONVERGED) {
// 对焦状态无特殊情况或与当前场景契合 正常拍照
mState = STATE_PICTURE_TAKEN;
captureStillPicture();
} else {
runPrecaptureSequence();
}
}
break;
}
case STATE_WAITING_PRECAPTURE: {
// CONTROL_AE_STATE can be null on some devices
// 曝光,等待曝光稳定,比如需要闪光灯
Integer aeState = result.get(CaptureResult.CONTROL_AE_STATE);
if (aeState == null ||
aeState == CaptureResult.CONTROL_AE_STATE_PRECAPTURE ||
aeState == CaptureRequest.CONTROL_AE_STATE_FLASH_REQUIRED) {
mState = STATE_WAITING_NON_PRECAPTURE;
}
break;
}
case STATE_WAITING_NON_PRECAPTURE: {
// CONTROL_AE_STATE can be null on some devices
// 曝光稳定后拍摄
Integer aeState = result.get(CaptureResult.CONTROL_AE_STATE);
if (aeState == null || aeState != CaptureResult.CONTROL_AE_STATE_PRECAPTURE) {
mState = STATE_PICTURE_TAKEN;
captureStillPicture();
}
break;
}
}
}2.4.3 拍照
真正获得静态图像的是captureStillPicture()这个方法。
/**
* Capture a still picture. This method should be called when we get a response in
* {@link #mCaptureCallback} from both {@link #lockFocus()}.
* 拍照获得静态图像并保存
*/
private void captureStillPicture() {
try {
final Activity activity = getActivity();
if (null == activity || null == mCameraDevice) {
return;
}
// 和预览界面相似的一系列设置,包括自动曝光自动对焦等
// This is the CaptureRequest.Builder that we use to take a picture.
final CaptureRequest.Builder captureBuilder =
mCameraDevice.createCaptureRequest(CameraDevice.TEMPLATE_STILL_CAPTURE);
captureBuilder.addTarget(mImageReader.getSurface());
// Use the same AE and AF modes as the preview.
captureBuilder.set(CaptureRequest.CONTROL_AF_MODE,
CaptureRequest.CONTROL_AF_MODE_CONTINUOUS_PICTURE);
setAutoFlash(captureBuilder);
// Orientation
int rotation = activity.getWindowManager().getDefaultDisplay().getRotation();
captureBuilder.set(CaptureRequest.JPEG_ORIENTATION, getOrientation(rotation));
// 通过保存了拍摄设置的session,调用拍摄回调,将图片保存到文件中,并toast路径
CameraCaptureSession.CaptureCallback CaptureCallback
= new CameraCaptureSession.CaptureCallback() {
@Override
public void onCaptureCompleted(@NonNull CameraCaptureSession session,
@NonNull CaptureRequest request,
@NonNull TotalCaptureResult result) {
showToast("Saved: " + mFile);
Log.d(TAG, mFile.toString());
// 拍摄结束时结束等待对焦状态,回到预览状态
unlockFocus();
}
};
// 中断传输给预览界面的循环
mCaptureSession.stopRepeating();
// 放弃当前所有任务,如果是循环任务如预览,会放弃之前缓存的数据
mCaptureSession.abortCaptures();
// 根据之前设置的参数,拍照获取当前帧
mCaptureSession.capture(captureBuilder.build(), CaptureCallback, null);
} catch (CameraAccessException e) {
e.printStackTrace();
}
}拍摄时,会中断为预览画面执行的循环任务,并放弃之前缓存的数据,然后拍照获取当前帧。
2.5 保存图片
图片的保存是通过一个实现了runnable的内部类,异步保存
private static class ImageSaver implements Runnable {
/**
* The JPEG image
*/
private final Image mImage;
/**
* The file we save the image into.
*/
private final File mFile;
ImageSaver(Image image, File file) {
mImage = image;
mFile = file;
}
// 使用另一个线程保存照片
@Override
public void run() {
ByteBuffer buffer = mImage.getPlanes()[0].getBuffer();
byte[] bytes = new byte[buffer.remaining()];
buffer.get(bytes);
FileOutputStream output = null;
try {
output = new FileOutputStream(mFile);
output.write(bytes);
} catch (IOException e) {
e.printStackTrace();
} finally {
mImage.close();
if (null != output) {
try {
// 在finally里面调用close,如果在try中close,可能会因为出现异常,导致无法执行到close语句
output.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}2.6 关闭服务
使用juc中的信号量Semaphore控制并发,依次关闭相机相关服务
private void closeCamera() {
// 使用juc中的信号量Semaphore控制并发,依次关闭相机相关服务
try {
mCameraOpenCloseLock.acquire();
if (null != mCaptureSession) {
mCaptureSession.close();
mCaptureSession = null;
}
if (null != mCameraDevice) {
mCameraDevice.close();
mCameraDevice = null;
}
if (null != mImageReader) {
mImageReader.close();
mImageReader = null;
}
} catch (InterruptedException e) {
throw new RuntimeException("Interrupted while trying to lock camera closing.", e);
} finally {
mCameraOpenCloseLock.release();
}
}2.7 特殊情况的处理
在阅读代码的过程中,经常会出现一些变量,与“Background”有关,比如mBackgroundThread。最开始看到很疑惑这个东西是干什么的。
/**
* An additional thread for running tasks that shouldn't block the UI.
* 一个额外的线程用以运行维持UI的任务
*/
private HandlerThread mBackgroundThread;搜寻了一番发现在 onResume() 中有段注释:
@Override
public void onResume() {
super.onResume();
// TODO:什么是HandlerThread,关于BackgroundThread是做什么的:见line224
startBackgroundThread();
// When the screen is turned off and turned back on, the SurfaceTexture is already
// available, and "onSurfaceTextureAvailable" will not be called. In that case, we can open
// a camera and start preview from here (otherwise, we wait until the surface is ready in
// the SurfaceTextureListener).
if (mTextureView.isAvailable()) {
openCamera(mTextureView.getWidth(), mTextureView.getHeight());
} else {
mTextureView.setSurfaceTextureListener(mSurfaceTextureListener);
}
}也就是说,但屏幕关闭之后又开启,相机应用可以通过这个“后台线程”快速可用。
同时可以注意到该线程是一个HandleThread类,似乎是个Android独有的线程实现方式。
private void startBackgroundThread() {
mBackgroundThread = new HandlerThread("CameraBackground");
mBackgroundThread.start();
// 在Android开发中,不熟悉多线程开发的人一想到要使用线程,可能就用new Thread(){…}.start()这样的方式。
//实质上在只有单个耗时任务时用这种方式是可以的,但若是有多个耗时任务要串行执行呢?
//那不得要多次创建多次销毁线程,这样导致的代价是很耗系统资源,容易存在性能问题。那么,怎么解决呢?
//我们可以只创建一个工作线程,然后在里面循环处理耗时任务,
mBackgroundHandler = new Handler(mBackgroundThread.getLooper());
}那么如何关闭这个线程?
在onPause()中调用:
@Override
public void onPause() {
closeCamera();
stopBackgroundThread();
super.onPause();
}HandlerThread既然是一个循环线程,那么怎么退出呢?有两种方式,分别是不安全的退出方法quit()和安全的退出方法quitSafely();
具体有关HandlerThread的内容可以看另一篇博文。
private void stopBackgroundThread() {
// HandlerThread既然是一个循环线程,那么怎么退出呢?有两种方式,分别是不安全的退出方法quit()和安全的退出方法quitSafely():
mBackgroundThread.quitSafely();
try {
mBackgroundThread.join();
mBackgroundThread = null;
mBackgroundHandler = null;
} catch (InterruptedException e) {
e.printStackTrace();
}
}三、总结
整体代码就是按照拍照应该有的流程进行,包括创建界面 - 打开相机 - 显示预览 - 拍摄 - 保存图片 - 关闭服务,以及特殊情况的处理。
通过功能来梳理源码,结构很清晰,同时了解了拍摄前后的一些细节,比如对焦曝光检测。
同时编码过程中也有很多trick,比如信号量在相机开关时的使用,以及handlerThread实现的后台线程,应该会对以后的编码有所启发。
DONE
【Scala学习笔记 · 三】包和引入、继承、文件和正则表达式
第七章 包和引入
1. 包
下面的代码定义了一个cn.scala.xtwy包
在程序的任何地方都可以通过cn.scala.xtwy.Teacher来使用Teacher这个类
package cn{
package scala{
package xtwy{
class Teacher {
}
}
}
}2. 包的作用域
包可以和其他作用域嵌套,可以访问上层作用域的名称。
package cn{
package scala{
//在包cn.scala下创建了一个Utils单例
object Utils{
def toString(x:String){
println(x)
}
//外层包无法直接访问内层包,下面这一行代码编译通不过
//def getTeacher():Teacher=new Teacher("john")
//如果一定要使用的话,可以引入包
import cn.scala.xtwy._
def getTeacher():Teacher=new Teacher("john")
}
//定义了cn.scala.xtwy
package xtwy{
class Teacher(var name:String) {
//演示包的访问规则
//内层包可以访问外层包中定义的类或对象,无需引入
def printName()={Utils.toString(name)}
}
}
}
}
object Test{
//scala允许在任何地方进行包的引入,_的意思是引入该包下的所有类和对象
import cn.scala._
import cn.scala.xtwy._
def main(args: Array[String]): Unit = {
Utils.toString(new Teacher("john").name)
new Teacher("john").printName()
}
}但在Scala中包名是相对的(Java中是绝对的),也就是说:比如创建com.horstmann.collection包,那么编译器在寻找collection.mutable时就不能找到,因为本意是向使用顶级的scala包的collection包,而不是随便什么存在与可访问作用域中的子包。
而这个解决方法之一就是使用包名,以_root_开始:
val subordinates = new _root_.scala.collection.mutable.ArrayBuffer[Employee]3. 包对象
package cn{
package scala{
object Utils{
def toString(x:String){
println(x)
}
import cn.scala.xtwy._
def getTeacher():Teacher=new Teacher("john")
}
package xtwy{
class Teacher(var name:String) {
def printName()={Utils.toString(name)}
}
}
}
}
//利用package关键字定义单例对象
package object Math {
val PI=3.141529
val THETA=2.0
val SIGMA=1.9
}
class Coputation{
def computeArea(r:Double)=Math.PI*r*r
}
//PI: Double = 3.141529
//THETA: Double = 2.0
//SIGMA: Double = 1.94. 包可见性
package cn{
package scala{
object Utils{
def toString(x:String){
println(x)
}
import cn.scala.xtwy._
def getTeacher():Teacher=new Teacher("john")
}
package xtwy{
class Teacher(var name:String) {
def printName()={Utils.toString(name)}
}
}
}
}
class Teacher(var name: String) {
private def printName(tName:String="") :Unit= { println(tName) }
//可以访问
def print(n:String)=this.printName(n)
}
object Teacher{
//伴生对象可以访问
def printName=new Teacher("john").printName()
}
object appDemo {
def main(args: Array[String]): Unit = {
//不能访问
//new Teacher("john").printName()
}
}5. import高级特性
重命名与隐藏方法
import java.util.{ HashMap => JavaHashMap }
//将java.util.HashMap重命名为JavaHashMap
import java.util.{HashMap=> _,_}
//通过HashMap=> _,这样类便被隐藏起来了隐式引入
每个Scala程序都隐式的引入了以下代码:
import java.lang._
import scala._
import Predef._
练习
- 编写一段让你的Scala朋友们感到困惑的代码,使用一个不在顶部的com包。
package com.horstmann.impatient {
object Funcy {
def foo {
println("top level com");
}
}
}
package scala.com.horstmann.impatient {
object Funcy {
def foo {
println("not top level com");
}
}
}
import scala._ // 如果去掉用输出 "top level com" , 否则输出 "not top level com"
object Test {
def main(args : Array[String]) {
com.horstmann.impatient.Funcy.foo
}
}- 编写一个包random,加入函数nextInt():Int、nextDouble: Double和setSeed(seed:Int):Unit。生成随机数的算法使用线性同余生成器:
后值=(前值 x * a + b) mod 2^n
其中,a=1664525,b=1013904223,n=32,前值的初始值为seed。
package random {
package object random {
val a : Long = 1664525;
val b : Long = 1013904223;
val n : Int = 32;
var prev : Int = 1;
def nextInt() : Int = {
val rand = (prev * a + b) % n
setSeed(rand.toInt)
rand.toInt
}
def setSeed(seed : Int) : Unit = {
this.prev = seed
}
def nextDouble() : Double = {
nextInt.toDouble / n
}
}
}
object Test {
def main(args : Array[String]) {
import random._ //导入包
random.setSeed(1);
for (_ <- 1.to(10, 1)) {
println(random.nextInt);
}
for (_ <- 1.to(10, 1)) {
println(random.nextDouble);
}
}
}【Java】由几个多线程并发的失效案例出发
[toc]
一、多线程并发
1. synchronized的对象定义为final
【例子】对于一个变量mA,将其作为synchronized的对象,但是没有定义为final,而且在函数1中有改变其值,那么对于函数2和3来讲就有可能sync不同的对象,从而起不到同步作用。
【分析】使用该变量作为锁对象本来就是不正规的,应该为此private final new Object(),使用final的同步对象作为synchronized的对象,然后再各个函数内操作改变变量mA
【原理】
概括:【TODO】
参考链接
- final关键词在多线程环境中的使用
- 从Java内存模型理解synchronized、volatile和final关键字
- volatile、synchronized、final原理浅析
- 额外深入: 深入理解 Java 内存模型(六)——final
- 延申: 为什么要指令重排序?
2. 同步锁对象不明确
【例子】使用this对象锁时,this指向的可能是其内部类对象。下面的例子为同一个类,this为三个不同的对象
【分析】这个问题体现的是同步锁的不是一个对象;使用同步锁对象时需要将其声明为final,并确保同步锁的是同一对象
【原理】使用自定义任意对象进行同步锁 不同线程必须为同一对象,否则仍旧是异步运行的。而存在内部类时,使用this会导致指向内部类,使得多个线程之间,一个持有大类,一个持有内部类,并不是同一个锁(同一个对象)
参考链接:
3. 同步锁范围过大导致死锁
【例子】同步锁范围过大有可能导致两个线程试图以不同的顺序来获得相同的锁,进而死锁
public void funA() {
synchronized(mA) {
//...
funcB();
}
}
void funcB() {
synchronized(mB) {
}
}【分析】在log中(暂无图),会出现
thread-1先拿到mA的锁,在等待mB,thread-2可能在别处先拿到mB的锁,在等待mA即2个thread死锁
【解决】缩小同步锁范围,不要出现两个锁嵌套
public void funA() {
synchronized(mA) {
//...
}
funcB();
}
void funcB() {
synchronized(mB) {
}
}4. 多线程环境下单例模式的规范写法
编写的单例模式不够规范,下面介绍两种规范写法供大家参考
【写法一】
- 参考代码
public class Singleton {
private static volatile Singleton singleton;
private Singleton() {}
public static Singleton getInstance() {
if (singleton == null) {
synchronized (Singleton.class) {
if (singleton == null) {
singleton = new Singleton(); // 参考代码第8行
}
}
}
return singleton;
}
}- 注意事项(WHY):
- private构造函数:以确保无法通过该类的构造函数来实例化该类的对象,只能通过该类提供的静态方法getInstance()来得到该类的唯一实例。
- private、static 、volatile关键字:其中volatile的作用是防止重排序
参考代码第8行有可能发生如下重排序。
重排序前
memory = allocate(); // 1. 分配对象的内存空间
ctorInstance(memory); // 2. 初始化对象
instance = memory; // 3. 设置instance指向刚分配的内存地址可能发生重排序后:
memory = allocate(); // 1. 分配对象的内存空间
instance = memory; // 3. 设置instance指向刚分配的内存地址
// 注意,此时对象还没有被初始化!
ctorInstance(memory); // 2. 初始化对象比如线程A在参考代码第8行执行了步骤1和步骤3,但步骤2还没有执行完
这时线程B执行到了第5行,判断sInstance不为空,就直接返回了一个未初始化完的sInstance
-
double check提高执行效率:
- 第1次判空:单例模式只需要创建一次实例,如果后面再次调用getInstance()时,则直接返回之前创建的实例,因此大部分时间不需要执行同步块里的代码,提高了性能
- 第2次判空:防止创建多个实例
-
synchronized块:保证线程安全
-
懒加载:延迟加载,只在getInstance()第一次被调用时才实例化
- 参考链接:
【写法二】
- 参考代码:
public class Singleton() {
private Singleton() {}
public static Singleton getInstance() {
return SingletonInstance.INSTANCE;
}
private static class SingletonInstance {
private final static Singleton INSTANCE = new Singleton();
}
}- 注意事项(WHY):
- private构造函数:作用同上
- 线程安全:静态内部类变量INSTANCE只会在第一次调用getInstance(),加载类SingletonInstance时初始化,保证了线程安全
- 懒加载:作用同上
5. 多线程更新list后,获取数据为空
关键: ArrayList 并不是线程安全
【案例】
代码场景:两个线程,两处代码,一处代码是Arraylist.add(),由线程1执行,另一处代码是ArrayList.get(),由线程2执行。发生空指针。
【分析】
How ? 线程如何调用才会导致出现箭头处的空指针呢??
估计是Add操作并不是原子操作,看下JDK的实现:
// java.util.ArrayList#add(E)
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}出现了一个问题, 即操作的时候是先将size增加了1,还是先将值赋值进正确的位置?
看下Java字节码是如何执行的
- 首先准备demo代码
public class incre {
public void test() {
int[] list = new int[32];
int i = 8;
list[i++] = 10; // 主要看自增操作与赋值操作的先后顺序,直觉来说应该是自增
}
}- 编译并查看
javac Increment.java
javap -verbose Increment- 得到字节码的执行序列:
Classfile /D:/My Documents/Desktop/javademo/incre.class
Last modified 2020年4月22日; size 258 bytes
MD5 checksum aeecc843a0de5a71613407b83abf58cf
Compiled from "incre.java"
public class incre
minor version: 0
major version: 55
flags: (0x0021) ACC_PUBLIC, ACC_SUPER
this_class: #2 // incre
super_class: #3 // java/lang/Object
interfaces: 0, fields: 0, methods: 2, attributes: 1
Constant pool:
#1 = Methodref #3.#11 // java/lang/Object."<init>":()V
#2 = Class #12 // incre
#3 = Class #13 // java/lang/Object
#4 = Utf8 <init>
#5 = Utf8 ()V
#6 = Utf8 Code
#7 = Utf8 LineNumberTable
#8 = Utf8 test
#9 = Utf8 SourceFile
#10 = Utf8 incre.java
#11 = NameAndType #4:#5 // "<init>":()V
#12 = Utf8 incre
#13 = Utf8 java/lang/Object
{
public incre();
descriptor: ()V
flags: (0x0001) ACC_PUBLIC
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
LineNumberTable:
line 1: 0
public void test();
descriptor: ()V
flags: (0x0001) ACC_PUBLIC
Code:
stack=3, locals=3, args_size=1
0: bipush 32
2: newarray int
4: astore_1
5: bipush 8 // 赋值 i = 8
7: istore_2
8: aload_1
9: iload_2
10: iinc 2, 1 // 自增 i++
13: bipush 10 // 赋值 = 10
15: iastore
16: return
LineNumberTable:
line 3: 0
line 4: 5
line 5: 8
line 6: 16
}
SourceFile: "incre.java"测试结论是先增加Size,再放元素进数组。
因此回到本案例,线程1 add 元素,执行到将size++ 后,CPU切成线程2执行,去取list.size(), 此时取到的是线程1 将Size增大1 的Size。但是元素并没有就位。线程2继续get元素,所以get到空了。
【修复】
- 将线程抛至同一个线程操作,使得其能同步处理
- 将ArrayList修改成线程安全的CopyOnWriteArrayList,保证数据的安全性
【结论】
- 多线程场景下,尽量使用线程安全的对象进行数据操作,如
vector,CopyOnWriteArrayList - 多线程场景下,需要考虑一下加锁,线程同步等措施,保证无稳定性的前提下,确保业务数据正确。
【参考链接】
- 读多写少的场景,使用基于synchronized修饰的vector效率就不高了,所以需要基于读写分离**实现的juc容器:并发容器之CopyOnWriteArrayList
【操作系统实验笔记】进程控制与GDB多线程调试
本文基于最基础的Linux下创建子进程的程序,了解GDB在多线程下的调试。
参考链接: 100个gdb小技巧
操作系统:Ubuntu 16.04/bash on ubuntu on windows
实验内容
编写一段程序,使用系统调用 fork( )创建两个子进程,在系统中有一个父进程和两个子进程 活动。让每个进程在屏幕上显示一个字符;父进程显示字符“a”,子进程分别显示字符“b” 和“c”。 试观察记录屏幕上的显示结果,并分析原因。
实现代码
#include
#include
int main(){
int p1,p2;
while((p1=fork())==-1);
if(p1==0)
putchar('b');
else {
while((p2=fork())==-1);
if(p2==0){
putchar('c');
printf("\n");
}
else putchar('a');
}
return 0;
}
其中,a、b、c 的显示顺序是随机的,取决与进程的调度顺序。fork()创建进程之后,各 个进程的时间片的获得不一定是顺序的,所以输出的顺序会变化。
GDB多进程调试
调试子进程
在调试多进程程序时,gdb 默认会追踪父进程。如果要调试子进程,要使用如下命 令:
set follow-fork-mode child
(gdb) set follow-fork-mode child
(gdb) start
Temporary breakpoint 1 at 0x40056e: file 1.c, line 5.
Starting program: /root/tst
Temporary breakpoint 1, main () at 1.c:5
5 while((p1=fork())==-1);
(gdb) n
[New process 24]
ac
[Switching to process 24]
main () at 1.c:6
6 if(p1==0)
(gdb)
7 putchar('b');
(gdb)
16 return 0;
(gdb)
17 }
(gdb)
__libc_start_main (main=0x400566 , argc=1, argv=0x7ffffffde398, init=,
fini=, rtld_fini=, stack_end=0x7ffffffde388)
at ../csu/libc-start.c:325
325 ../csu/libc-start.c: No such file or directory.
(gdb)
b[Inferior 2 (process 24) exited normally]
(gdb)
The program is not being run.
可以看到执行到第5行,父进程打印“a” 并创建了子进程 24,子进程打印“c”。正常退出后打印“b”。
(但这里是不是只监视了一个子进程24 ?)
同时调试父进程和子进程
如果要同时调试父进程和子进程,可以使用
set detach-on-fork off(默 认detach-on-fork是on)命令,这样 gdb 就能同时调试父子进程,并且在调试一 个进程时,另外一个进程处于挂起状态。在使用set detach-on-fork off命令 后,用i inferiors(i 是 info 命令缩写)查看进程状态,可以看到父子进程都 在被 gdb 调试的状态,前面显示“*”是正在调试的进程。当父进程退出后,用inferior infno切换到子进程去调试。
(gdb) set detach-on-fork off
(gdb) start
Reading symbols from /usr/lib/debug/lib/x86_64-linux-gnu/libc-2.23.so...done.
Reading symbols from /usr/lib/debug/lib/x86_64-linux-gnu/ld-2.23.so...done.
Reading symbols from /usr/lib/debug/lib/x86_64-linux-gnu/libc-2.23.so...done.
Reading symbols from /usr/lib/debug/lib/x86_64-linux-gnu/ld-2.23.so...done.
Temporary breakpoint 2 at 0x40056e: main. (3 locations)
Starting program: /root/tst
Thread 1.1 "tst" hit Temporary breakpoint 2, main () at 1.c:5
5 while((p1=fork())==-1);
(gdb) n
[New process 26]
6 if(p1==0)
(gdb) i inferior
Num Description Executable
* 1 process 25 /root/tst
2 process 23 /root/tst
3 process 24 /root/tst
4 process 26 /root/tst
(gdb) n
9 while((p2=fork())==-1);
(gdb)
[New process 27]
10 if(p2==0){
(gdb)
14 else putchar('a');
(gdb)
16 return 0;
(gdb)
17 }
(gdb)
__libc_start_main (main=0x400566 , argc=1, argv=0x7ffffffde398, init=,
fini=, rtld_fini=, stack_end=0x7ffffffde388)
at ../csu/libc-start.c:325
325 ../csu/libc-start.c: No such file or directory.
(gdb)
a[Inferior 1 (process 25) exited normally]
(gdb)
The program is not being run.
(gdb) inferior 2
[Switching to inferior 2 [process 23] (/root/tst)]
[Switching to thread 2.1 (process 23)]
#0 0x00007fffff0fc41a in __libc_fork () at ../sysdeps/nptl/fork.c:145
145 ../sysdeps/nptl/fork.c: No such file or directory.
(gdb)
[Switching to inferior 2 [process 23] (/root/tst)]
[Switching to thread 2.1 (process 23)]
#0 0x00007fffff0fc41a in __libc_fork () at ../sysdeps/nptl/fork.c:145
145 in ../sysdeps/nptl/fork.c
.
.
.
168 in ../sysdeps/nptl/fork.c
(gdb) bt
#0 __libc_fork () at ../sysdeps/nptl/fork.c:168
#1 0x0000000000400573 in main () at 1.c:5
(gdb) n
169 in ../sysdeps/nptl/fork.c
.
.
.
(gdb)
264 in ../sysdeps/nptl/fork.c
(gdb)
main () at 1.c:6
6 if(p1==0)
(gdb) i inferior
Num Description Executable
1 /root/tst
* 2 process 23 /root/tst
3 process 24 /root/tst
4 process 26 /root/tst
5 process 27 /root/tst
(gdb) inferior 3
[Switching to inferior 3 [process 24] (/root/tst)]
[Switching to thread 3.1 (process 24)]
#0 0x00007fffff0fc41a in __libc_fork () at ../sysdeps/nptl/fork.c:145
145 ../sysdeps/nptl/fork.c: No such file or directory.
(gdb) i inferior
Num Description Executable
1 /root/tst
2 process 23 /root/tst
* 3 process 24 /root/tst
4 process 26 /root/tst
5 process 27 /root/tst
(gdb) n
152 in ../sysdeps/nptl/fork.c
.
.
.
(gdb)
264 in ../sysdeps/nptl/fork.c
(gdb)
main () at 1.c:10
10 if(p2==0){
(gdb)
11 putchar('c');
(gdb)
12 printf("\n");
(gdb)
c
16 return 0;
(gdb)
17 }
(gdb)
__libc_start_main (main=0x400566 , argc=1, argv=0x7ffffffde398, init=,
fini=, rtld_fini=, stack_end=0x7ffffffde388)
at ../csu/libc-start.c:325
325 ../csu/libc-start.c: No such file or directory.
(gdb)
[Inferior 3 (process 24) exited normally]
(gdb)
7 putchar('b');
(gdb)
16 return 0;
(gdb)
17 }
(gdb)
__libc_start_main (main=0x400566 , argc=1, argv=0x7ffffffde398, init=,
fini=, rtld_fini=, stack_end=0x7ffffffde388)
at ../csu/libc-start.c:325
325 ../csu/libc-start.c: No such file or directory.
(gdb)
b[Inferior 2 (process 23) exited normally]
(gdb)
The program is not being run.
在使用“set detach-on-fork off”命令后,用“i inferiors”(i是info命令缩写)查看进程状态,可以看到父子进程都在被gdb调试的状态,前面显示“*”是正在调试的进程。当父进程退出后,用“inferior infno”切换到子进程去调试。
此外,如果想让父子进程都同时运行,可以使用“set schedule-multiple on”(默认schedule-multiple是off)命令,仍以上述代码为例:
(gdb) set detach-on-fork off
(gdb) set schedule-multiple on
(gdb) start
Temporary breakpoint 1 at 0x40056e: file 1.c, line 5.
Starting program: /root/tst
Temporary breakpoint 1, main () at 1.c:5
5 while((p1=fork())==-1);
(gdb) n
[New process 32]
b6 if(p1==0)
(gdb)
[Inferior 2 (process 32) exited normally]
(gdb)
9 while((p2=fork())==-1);
(gdb)
[New process 33]
c
10 if(p2==0){
(gdb)
[Inferior 3 (process 33) exited normally]
(gdb)
14 else putchar('a');
(gdb)
16 return 0;
(gdb)
17 }
(gdb)
__libc_start_main (main=0x400566 , argc=1, argv=0x7ffffffde398, init=, fini=,
rtld_fini=, stack_end=0x7ffffffde388) at ../csu/libc-start.c:325
325 ../csu/libc-start.c: No such file or directory.
(gdb)
a[Inferior 1 (process 28) exited normally]
(gdb)
The program is not being run.
父进程Inferior 1(process 28)创建Inferior 2(process 32)打印 b ,并正常退出;再创建Inferior 3(process 33)打印c,并正常退出,之后父进程打印a,退出。
总结
第一次上手GDB调试,有助于对进程控制的理解
【Java】《深入理解Java虚拟机》笔记 · 一 Java内存区域
一. Java内存区域
原书第二章
1. 运行时区域
原书2.2节
书上讲的很难理解,这里有一张图:Link1

- java堆(Heap):Heap区域被所有线程共享,用于存储对象实例。
- 方法区:被各个线程共享,用于存储已经被虚拟机加载的类型西、常量、静态变量等数据。
如果想查阅书上原文(P38-43),这篇博客 整理的很好。
2. 方法区和运行时常量池溢出
原书2.4.3节
书中进行了一个String.intern()返回引用的测试。
分别在JDK1.6和JDK1.7分别运行会产生不同的结果。产生差异的原因:JDK1.6中,intern()方法会把首次遇到的字符串实例复制到永久代上,返回的就是永久代上的实例引用,而StringBuilder创建的字符串实例在java堆上,所以两者不会是一个引用。
而在JDK1.7上intern()只是在常量池中记录首次出现的实例引用,也就是和StringBuilder创建的实例是同一个。
PermGen(永久代)
这里的 “PermGen space”其实指的就是方法区。不过方法区和“PermGen space”又有着本质的区别。前者是 JVM 的规范,而后者则是 JVM 规范的一种实现,并且只有 HotSpot 才有 “PermGen space”,而对于其他类型的虚拟机,如 JRockit(Oracle)、J9(IBM) 并没有“PermGen space”。由于方法区主要存储类的相关信息,所以对于动态生成类的情况比较容易出现永久代的内存溢出。最典型的场景就是,在 jsp 页面比较多的情况,容易出现永久代内存溢出。
Metaspace(元空间)
在 JDK 1.8 中, HotSpot 已经没有 “PermGen space”这个区间了,取而代之是一个叫做 Metaspace(元空间) 的东西。
元空间的本质和永久代类似,都是对JVM规范中方法区的实现。不过元空间与永久代之间最大的区别在于:元空间并不在虚拟机中,而是使用本地内存。因此,默认情况下,元空间的大小仅受本地内存限制。
参考链接
《深入理解Java虚拟机》读书笔记
《深入理解Java虚拟机》读书笔记1:Java技术体系、Java内存区域和内存溢出异常
《Java虚拟机原理图解》3、JVM运行时数据区
JVM内存结构---《深入理解Java虚拟机》学习总结
Java8内存模型—永久代(PermGen)和元空间(Metaspace)
【测试】与其感慨路难行,不如马上出发
【整理】知识图谱整理
一、算法
1. 贪心
- 一个n位的数,去掉其中的k位,问怎样去使得留下来的(n-k)位数按原来的前后顺序组成的数最小
思路:去除降序数列中的第一个 思路
2. 动态规划
-
你有很多硬币,面额为1,2,4,8,....,2^k,每种面额的硬币有两个,要求凑出n元来,输出不同的凑硬币方案的数目。
动态规划 -
最长回文子序列 dp 相反之后做LCS
for(int i=1;i<=X.length;i++){
for (int j=1;j<=Y.length;j++){
if(X[i-1]==Y[j-1]){
c[i][j] = c[i-1][j-1]+1;
}
else{
c[i][j] = max(c[i][j-1],c[i-1][j]);
}
}
}- 找零钱问题:
// 假设只有 1 分、 2 分、五分、 1 角、二角、 五角、 1 元的硬币。
// 在超市结账时,如果需要找零钱,收银员希望将最少的硬币数找给顾客。
// 那么,给定需要找的零钱数目,如何求得最少的硬币数呢?
public class zhaolingqian {
public int caldp(int n,int[] money){
// dp[i] 金额为i时找的零钱数目
int[] dp = new int[n + 5];
for (int i = 1; i<dp.length; i++){
dp[i] = Integer.MAX_VALUE; //!!!!!!!!!!!!
}
dp[0] = 0;
for (int i = 0; i < money.length; i++){
for (int j = money[i]; j <= n; j++){
dp[j] = Math.min(dp[j - money[i]] + 1 , dp[j]);
}
}
return dp[n];
}
public static void main(String[] args) {
int[] money = {1,2,5,10,20,50,100};
zhaolingqian zq = new zhaolingqian();
System.out.println(zq.caldp(625, money)); //8
}
}3. 排序算法
查找是在大量的信息中寻找一个特定的信息元素,在计算机应用中,查找是常用的基本运算,例如编译程序中符号表的查找。本文简单概括性的介绍了常见的七种查找算法,说是七种,其实二分查找、插值查找以及斐波那契查找都可以归为一类——插值查找。插值查找和斐波那契查找是在二分查找的基础上的优化查找算法。树表查找和哈希查找会在后续的博文中进行详细介绍。 >
查找定义:根据给定的某个值,在查找表中确定一个其关键字等于给定值的数据元素(或记录)。
查找算法分类:
- 静态查找和动态查找;
注:静态或者动态都是针对查找表而言的。动态表指查找表中有删除和插入操作的表。
- 无序查找和有序查找。
无序查找:被查找数列有序无序均可;
有序查找:被查找数列必须为有序数列。平均查找长度(Average Search Length,ASL):需和指定key进行比较的关键字的个数的期望值,称为查找算法在查找成功时的平均查找长度。
对于含有n个数据元素的查找表,查找成功的平均查找长度为:ASL = Pi*Ci的和。
Pi:查找表中第i个数据元素的概率。
Ci:找到第i个数据元素时已经比较过的次数。
不仅详细介绍了诸如树表查找、分块查找等查找方式,还引申了B树红黑树等数据结构的优缺点与使用场景
- O(N)查找有哪些数据结构?
- 答:顺序查找
- O(logN)查找有哪些数据结构?
- 答:二分查找、斐波那契查找、二叉查找树(最坏有O(n)的复杂度)、红黑树。
- O(1)查找有哪些数据结构?
- 答:hash(无冲突的情况)
- 其他:插值查找时间复杂度均为O(log2(log2n))。
堆排序
- 堆排序(使用大堆,升序)从基本实现原理来说也是一种选择排序。
- 所谓大根堆,就是根节点大于子节点的完全二叉树。
- 首先将所有元素都构建在一个初始堆中,并重建为大堆。这时当前堆中的最大元素就在堆的顶部,也就是数组a[0],这时将该最大元素与数组中的最后一个元素交换,使其移到最末尾,表明该元素已经到应该在得位置了,之后的堆重建也不需要管他,所以last--,对缩小后的目标堆重建。就这样,将顶端最大的元素与最后一个元素不断的交换,交换后又不断的调用堆以重新维持最大堆的性质,最后,一个一个的,从大到小的,把堆中的所有元素都清理掉,也就形成了一个有序的序列。这就是堆排序的全部过程。
#include <bits/stdc++.h>
using namespace std;
int a[100];
void rebuild(int a[], int size, int rt)
{
int left_child = 2*rt+1;
if(left_child < size)
{
int right_child = left_child+1;
if(right_child < size)
{
if(a[left_child] > a[right_child]) // < shengxu
left_child = right_child;
}
if(a[rt] > a[left_child]) // 用 < 代表大根堆 升序
{
swap(a[rt], a[left_child]);
rebuild(a, size, left_child);
}
//注意rebuild的if框
}
}
void heapSort(int a[], int size)
{
//第一步 构造初始堆
for(int i=size-1 ;i>=0 ;i--)
{
rebuild(a,size, i);
}
int last = size - 1;
for(int i=1; i<=size; i++, last--)
{
swap(a[0],a[last]);
rebuild(a,last, 0);//把最大的元素沉入堆底之后就可以不用管了,last--
}
}
int main()
{
int n;
cin>>n;
for(int i=0 ;i<n; i++)
{
cin>>a[i];
}
heapSort(a,n);
for(int i=0; i<n; i++)
cout<<a[i]<<" ";
cout<<endl;
return 0;
}- 快排
#include <bits/stdc++.h>
using namespace std;
int a[100],n;
void hqsort(int* a, int left, int right) {
if(left+1 >= right) return ;
int i = left, j = right-1, key = a[left];
while(i < j) {
while(i < j && key <= a[j]) j--;
a[i] = a[j];
while(i < j && a[i] <= key) i++;
a[j] = a[i];
}
a[i] = key;
hqsort(a, left, i);
hqsort(a, i+1, right);
}
int main()
{
cin>>n;
for(int i=0; i<n; i++)
{
cin>>a[i];
}
hqsort(a,0,n);
for(int i=0; i<n; i++)
{
cout<<a[i]<<" ";
}
return 0;
}-
不同条件下,排序方法的选择
- 若n较小(如n≤50),可采用直接插入或直接选择排序。
当记录规模较小时,直接插入排序较好;否则因为直接选择移动的记录数少于直接插人,应选直接选择排序为宜。 - 若文件初始状态基本有序(指正序),则应选用直接插人、冒泡或随机的快速排序为宜;
- 若n较大,则应采用时间复杂度为O(nlgn)的排序方法:快速排序、堆排序或归并排序。
- 快速排序是目前基于比较的内部排序中被认为是最好的方法,当待排序的关键字是随机分布时,快速排序的平均时间最短;
- 堆排序所需的辅助空间少于快速排序,并且不会出现快速排序可能出现的最坏情况。这两种排序都是不稳定的。
- 若要求排序稳定,则可选用归并排序。但本章介绍的从单个记录起进行两两归并的 排序算法并不值得提倡,通常可以将它和直接插入排序结合在一起使用。先利用直接插入排序求得较长的有序子文件,然后再两两归并之。因为直接插入排序是稳定 的,所以改进后的归并排序仍是稳定的。
优先队列通常用堆排序来实现
- 若n较小(如n≤50),可采用直接插入或直接选择排序。
4. 图论
图的遍历和图的连通性**
即BFS、DFS和Kruskal、Prim 算法
拓扑排序
由AOV网构造拓扑序列的拓扑排序算法主要是循环执行以下两步,直到不存在入度为0的顶点为止。
(1) 选择一个入度为0的顶点并输出之;
(2) 从网中删除此顶点及所有出边。
循环结束后,若输出的顶点数小于网中的顶点数,则输出“有回路”信息,否则输出的顶点序列就是一种拓扑序列。
5. 数据结构
5.1 栈
import java.util.Stack;
public class TwoStackQueue {
Stack<Integer> s1 = new Stack<>();
Stack<Integer> s2 = new Stack<>();
public static void main(String[] args) {
TwoStackQueue twoStackQueue = new TwoStackQueue();
twoStackQueue.push(1);
twoStackQueue.push(2);
System.out.println(twoStackQueue.pop());
}
private int pop() {
while(!s1.empty()){
s2.push(s1.pop());
}
int res = s2.pop();
//重新pop回去
while(!s2.empty()){
s1.push(s2.pop());
}
return res;
}
private void push(int i) {
s1.push(i);
}
}5.2 链表
- 链表反转
链接
//遍历反转法:递归反转法是从后往前逆序反转指针域的指向,而遍历反转法是从前往后反转各个结点的指针域的指向。
// 基本思路是:将当前节点cur的下一个节点 cur.getNext()缓存到temp后,然后更改当前节点指针指向上一结点pre。也就是说在反转当前结点指针指向前,先把当前结点的指针域用tmp临时保存,以便下一次使用,其过程可表示如下:
// pre:上一结点
// cur: 当前结点
// tmp: 临时结点,用于保存当前结点的指针域(即下一结点)
public class LinkedListReverse {
private void Display(Node node){
while (null != node){
System.out.println(node.getData() + " ");
node = node.getNext();
}
System.out.println("====");
}
private Node Reverse(Node head){
if (head == null)
return head;
Node pre = head;
Node cur = head.getNext();
Node tmp;
while(null != cur){
tmp = cur.getNext();
cur.setNext(pre);
pre = cur;
cur = tmp;
}
head.setNext(null);
return pre;
}
public static void main(String[] args) {
Node head = new Node(0);Node n1 = new Node(1);
Node n2 = new Node(2);Node n3 = new Node(3);
head.setNext(n1);n1.setNext(n2);
n2.setNext(n3);n3.setNext(null);
LinkedListReverse linkedListReverse = new LinkedListReverse();
linkedListReverse.Display(head);
Node rvs = linkedListReverse.Reverse(head);
linkedListReverse.Display(rvs);
}
}
class Node{
private int data;
private Node next;
}-
判断一个单链表是否有环
最常用方法:定义两个指针,同时从链表的头节点出发,一个指针一次走一步,另一个指针一次走两步。如果走得快的指针追上了走得慢的指针,那么链表就是环形链表;如果走得快的指针走到了链表的末尾(next指向 NULL)都没有追上第一个指针,那么链表就不是环形链表。 -
使用异或交换两个整数或者字符串
public static String reverse(String s){ char[] a = s.toCharArray(); int first = 0, last = a.length-1; while(first < last){ a[first] = (char)(a[first] ^ a[last]); a[last] = (char)(a[last] ^ a[first]); a[first] = (char)(a[last] ^ a[first]); first ++; last --; } return new String(a); }
5.3 树
- 红黑树
-
节点是红色或黑色。
-
根是黑色。
-
所有叶子都是黑色(叶子是NIL节点)。
-
每个红色节点必须有两个黑色的子节点。(从每个叶子到根的所有路径上不能有两个连续的红色节点。)
-
从任一节点到其每个叶子的所有简单路径都包含相同数目的黑色节点。
-
- 2-3 查找树需要用到 2- 节点和 3- 节点,红黑树使用红链接来实现 3- 节点。指向一个节点的链接颜色如果为红色,那么这个节点和上层节点表示的是一个 3- 节点,而黑色则是普通链接。
-
2-3查找树能保证在插入元素之后能保持树的平衡状态,最坏情况下即所有的子节点都是2-node,树的高度为lgN,从而保证了最坏情况下的时间复杂度。但是2-3树实现起来比较复杂,本文介绍一种简单实现2-3树的数据结构,即红黑树(Red-Black Tree)
-
红黑树的主要是想对2-3查找树进行编码,尤其是对2-3查找树中的3-nodes节点添加额外的信息。红黑树中将节点之间的链接分为两种不同类型,红色链接,他用来链接两个2-nodes节点来表示一个3-nodes节点。黑色链接用来链接普通的2-3节点。特别的,使用红色链接的两个2-nodes来表示一个3-nodes节点,并且向左倾斜,即一个2-node是另一个2-node的左子节点。这种做法的好处是查找的时候不用做任何修改,和普通的二叉查找树相同。
-
链接中还有动画演示。
-
5.4. 哈希表
-
哈希表就是一种以 键-值(key-indexed) 存储数据的结构,我们只要输入待查找的值即key,即可查找到其对应的值。
-
使用哈希查找有两个步骤:
- 使用哈希函数将被查找的键转换为数组的索引。在理想的情况下,不同的键会被转换为不同的索引值,但是在有些情况下我们需要处理多个键被哈希到同一个索引值的情况。所以哈希查找的第二个步骤就是处理冲突
- 处理哈希碰撞冲突。有很多处理哈希碰撞冲突的方法,本文后面会介绍拉链法和线性探测法。
-
实现哈希函数:以正整数与字符串为例
- 获取正整数哈希值最常用的方法是使用除留余数法。即对于大小为素数M的数组,对于任意正整数k,计算k除以M的余数。M一般取素数。
- 我们可以将组成字符串的每一个字符取值然后进行哈希
for (int i = 0; i < value.length; i++) {h = 31 * h + val[i];}
-
避免哈希冲突
- 拉链法:其实就是将冲突后的数据依次存入链表中。
- 线性探测法;开放寻址法中最简单的是线性探测法:当碰撞发生时即一个键的散列值被另外一个键占用时,直接检查散列表中的下一个位置即将索引值加1
6. 经典问题
Top k 问题
-
堆排序方法
按照堆排序的方法排序之后输出前K个即可。
时间复杂度
n*logK
适用场景
实现的过程中,我们先用前K个数建立了一个堆,然后遍历数组来维护这个堆。这种做法带来了三个好处:(1)不会改变数据的输入顺序(按顺序读的);(2)不会占用太多的内存空间(事实上,一次只读入一个数,内存只要求能容纳前K个数即可);(3)由于(2),决定了它特别适合处理海量数据。这三点,也决定了它最优的适用场景。
-
快排方法
用快排的partition**,对数组进行不断分治,使得基准点pos刚好在K-1的位置上,此时前面的K个数字(0,K-1)就是要找的前K个数。
时间复杂度
n适用场景
对照着堆排的解法来看,partition函数会不断地交换元素的位置,所以它肯定会改变数据输入的顺序;既然要交换元素的位置,那么所有元素必须要读到内存空间中,所以它会占用比较大的空间,至少能容纳整个数组;数据越多,占用的空间必然越大,海量数据处理起来相对吃力。但是,它的时间复杂度很低,意味着数据量不大时,效率极高。
string 反转
除了普通的交换,还可以用异或的方法减少空间复杂度。
public static String reverse(String s){
char[] a = s.toCharArray();
int first = 0, last = a.length-1;
while(first < last){
a[first] = (char)(a[first] ^ a[last]);
a[last] = (char)(a[last] ^ a[first]);
a[first] = (char)(a[last] ^ a[first]);
first ++;
last --;
}
return new String(a);
}7. 大数据相关
二、操作系统
1. 进程与线程
进程是资源分配的基本单位。
进程控制块 (Process Control Block, PCB) 描述进程的基本信息和运行状态,所谓的创建进程和撤销进程
1.1 进程与线程的区别
- 线程是独立调度的基本单位。
- 一个进程中可以有多个线程,它们共享进程资源。
进程和线程的主要差别在于它们是不同的操作系统资源管理方式。进程有独立的地址空间,一个进程崩溃后,在保护模式下不会对其它进程产生影响,而线程只是一个进程中的不同执行路径。线程有自己的堆栈和局部变量,但线程之间没有单独的地址空间,一个线程死掉就等于整个进程死掉,所以多进程的程序要比多线程的程序健壮,但在进程切换时,耗费资源较大,效率要差一些。但对于一些要求同时进行并且又要共享某些变量的并发操作,只能用线程,不能用进程。
例:QQ 和浏览器是两个进程,浏览器进程里面有很多线程,例如 HTTP 请求线程、事件响应线程、渲染线程等等,线程的并发执行使得在浏览器中点击一个新链接从而发起 HTTP 请求时,浏览器还可以响应用户的其它事件。
进程和线程的区别?
- 线程里面有什么是独立的
栈:是个线程独有的,保存其运行状态和局部自动变量的。栈在线程开始的时候初始化,每个线程的栈互相独立,因此,栈是 thread safe的。操作系统在切换线程的时候会自动的切换栈,就是切换 SS/ESP寄存器。
线程独享资源:程序计数器,寄存器,栈,状态字.
1.2 并发与并行的区别
并发和并行的区别就是一个处理器同时处理多个任务和多个处理器或者是多核的处理器同时处理多个不同的任务。
前者是逻辑上的同时发生(simultaneous),而后者是物理上的同时发生.
2. 进程
2.1 现代操作系统的进程内存分布
一个linux进程分为几个部分(从一个进程的地址空间的低地址向高地址增长):
- text段,就是存放代码,可读可执行不可写,也称为正文段,代码段。
- data段,存放已初始化的全局变量和已初始化的static变量(不管是局部static变量还是全局static变量)
- bss段,存放全局未初始化变量和未初始化的static变量(也是不区分局部还是全局static变量)
以上这3部分是确定的,也就是不同的程序,以上3部分的大小都各不相同,因程序而异,若未初始化的全局变量定义的多了,那么bss区就大点,反之则小点。 - heap,也就是堆,堆在进程空间中是自低地址向高地址增长,你在程序中通过动态申请得到的内存空间(c中一般为malloc/free,c++中一般为new/delete),就是在堆中动态分配的。
- stack,栈,程序中每个函数中的局部变量,都是存放在栈中,栈是自高地址向低地址增长的。起初,堆和栈之间有很大一段空间,然后随着,程序的运行,堆不断向高地址增长,栈不断向高地址增长,这样,堆跟栈之间的空间总有一个最大界限,超过这个最大界限,就会出现堆跟栈重叠,就会出错,所以一般来说,Linux下的进程都有其最大空间的。
- 再往上,也就是一个进程地址空间的顶部,存放了命令行参数和环境变量。
2.2 Linux进程的状态转换图

-
运行状态(TASK_RUNNING)
当进程正在被CPU执行,或已经准备就绪随时可由调度程序执行,则称该进程为处于运行状态(running)。进程可以在内核态运行,也可以在用户态运行。当系统资源已经可用时,进程就被唤醒而进入准备运行状态,该状态称为就绪态。这些状态(图中中间一列)在内核中表示方法相同,都被成为处于TASK_RUNNING状态。
-
可中断睡眠状态(TASK_INTERRUPTIBLE)
当进程处于可中断等待状态时,系统不会调度该进程执行。当系统产生一个中断或者释放了进程正在等待的资源,或者进程收到一个信号,都可以唤醒进程转换到就绪状态(运行状态)。
-
不可中断睡眠状态(TASK_UNINTERRUPTIBLE)
与可中断睡眠状态类似。但处于该状态的进程只有被使用wake_up()函数明确唤醒时才能转换到可运行的就绪状态。
-
暂停状态(TASK_STOPPED)
当进程收到信号SIGSTOP、SIGTSTP、SIGTTIN或SIGTTOU时就会进入暂停状态。可向其发送SIGCONT信号让进程转换到可运行状态。在Linux 0.11中,还未实现对该状态的转换处理。处于该状态的进程将被作为进程终止来处理。
-
僵死状态(TASK_ZOMBIE)
当进程已停止运行,但其父进程还没有询问其状态时,则称该进程处于僵死状态。
当一个进程的运行时间片用完,系统就会使用调度程序强制切换到其它的进程去执行。另外,如果进程在内核态执行时需要等待系统的某个资源,此时该进程就会调用sleep_on()或sleep_on_interruptible()自愿地放弃CPU的使用权,而让调度程序去执行其它进程。进程则进入睡眠状态(TASK_UNINTERRUPTIBLE或TASK_INTERRUPTIBLE)。
只有当进程从“内核运行态”转移到“睡眠状态”时,内核才会进行进程切换操作。在内核态下运行的进程不能被其它进程抢占,而且一个进程不能改变另一个进程的状态。为了避免进程切换时造成内核数据错误,内核在执行临界区代码时会禁止一切中断。
2.3 孤儿进程,僵尸进程
-
孤儿进程
一个父进程退出,而它的一个或多个子进程还在运行,那么这些子进程将成为孤儿进程。孤儿进程将被 init 进程(进程号为 1)所收养,并由 init 进程对它们完成状态收集工作。
由于孤儿进程会被 init 进程收养,所以孤儿进程不会对系统造成危害。
-
僵死进程
一个子进程的进程描述符在子进程退出时不会释放,只有当父进程通过 wait 或 waitpid 获取了子进程信息后才会释放。如果子进程退出,而父进程并没有调用 wait 或 waitpid,那么子进程的进程描述符仍然保存在系统中,这种进程称之为僵死进程。
通过 ps 命令显示出来的状态为 Z。
系统所能使用的进程号是有限的,如果大量的产生僵死进程,将因为没有可用的进程号而导致系统不能产生新的进程。
要消灭系统中大量的僵死进程,只需要将其父进程杀死,此时所有的僵死进程就会变成孤儿进程,从而被 init 所收养,这样 init 就会释放所有的僵死进程所占有的资源,从而结束僵死进程。
2.4 进程间通信方式
- 同一主机上的进程通信方式
- UNIX进程间通信方式: 包括管道(PIPE), 有名管道(FIFO), 和信号(Signal)
- System V进程通信方式:包括信号量(Semaphore), 消息队列(Message Queue), 和共享内存(Shared Memory)
- 网络主机间的进程通信方式
- RPC: Remote Procedure Call 远程过程调用
- Socket: 当前最流行的网络通信方式, 基于TCP/IP协议的通信方式.
- 各自的特点如下:
- 管道(PIPE):管道是一种半双工的通信方式,数据只能单向流动,而且只能在 具有亲缘关系(父子进程)的进程间使用 。另外管道传送的是无格式的字节流,并且管道缓冲区的大小是有限的(管道缓冲区存在于内存中,在管道创建时,为缓冲区分配一个页面大小)。
- 有名管道 (FIFO): 有名管道也是半双工的通信方式,但是它允许无亲缘关系进程间的通信。
- 信号(Signal): 信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生。
- 信号量(Semaphore):信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
- 消息队列(Message Queue):消息队列是由消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。
- 共享内存(Shared Memory ):共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号量,配合使用,来实现进程间的同步和通信。
- 套接字(Socket): 套解口也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同主机间的进程通信。
2.4.1 管道(TODO)
2.4.2 信号量、互斥体和自旋锁(TODO)
2.5 进程间如何同步(Synchronization)
-
进程的互斥、同步、通信都是基于这两种基本关系而存在的,为了解决进程间竞争关系(间接制约关系)而引入进程互斥;为了解决进程间松散的协作关系( 直接制约关系)而引入进程同步;为了解决进程间紧密的协作关系而引入进程通信。
-
某些进程为完成同一任务需要分工协作,由于合作的每一个进程都是独立地以不可预知的速度推进,这就需要相互协作的进程在某些协调点上协 调各自的工作。当合作进程中的一个到达协调点后,在尚未得到其伙伴进程发来的消息或信号之前应阻塞自己,直到其他合作进程发来协调信号或消息后方被唤醒并继续执行。这种协作进程之间相互等待对方消息或信号的协调关系称为进程同步。
-
进程的同步(Synchronization)是解决进程间协作关系( 直接制约关系) 的手段。进程同步指两个以上进程基于某个条件来协调它们的活动。一个进程的执行依赖于另一
个协作进程的消息或信号,当一个进程没有得到来自于另一个进程的消息或信号时则需等待,直到消息或信号到达才被唤醒。 -
不难看出,进程互斥关系是一种特殊的进程同步关系,即逐次使用互斥共享资源,也是对进程使用资源次序上的一种协调。
-
进程同步的方法
-
Linux下
- Linux 下常见的进程同步方法有:SysVIPC 的 sem(信号量)、file locking / record locking(通过 fcntl 设定的文件锁、记录锁)、futex(基于共享内存的快速用户态互斥锁)。针对线程(pthread)的还有 pthread_mutex 和 pthread_cond(条件变量)。
- Linux 下常见的进程通信的方法有 :pipe(管道),FIFO(命名管道),socket(套接字),SysVIPC 的 shm(共享内存)、msg queue(消息队列),mmap(文件映射)。以前还有 STREAM,不过现在比较少见了(好像)。
-
Windows下
- 在Windwos中,进程同步主要有以下几种:互斥量、信号量、事件、可等计时器等几种技术。
- 在Windows下,进程通信主要有以下几种:内存映射、管道、消息等,但是内存映射是最基础的,因为,其他的进程通信手段在内部都是考内存映射来完成的。
-
2.6 死锁
死锁产生的原因?
-
因竞争资源发生死锁 现象:系统中供多个进程共享的资源的数目不足以满足全部进程的需要时,就会引起对诸资源的竞争而发生死锁现象
-
进程推进顺序不当发生死锁
死锁的四个必要条件
(1)互斥条件:进程对所分配到的资源不允许其他进程进行访问,若其他进程访问该资源,只能等待,直至占有该资源的进程使用完成后释放该资源
(2)请求和保持条件:进程获得一定的资源之后,又对其他资源发出请求,但是该资源可能被其他进程占有,此事请求阻塞,但又对自己获得的资源保持不放
(3)不可剥夺条件:是指进程已获得的资源,在未完成使用之前,不可被剥夺,只能在使用完后自己释放
(4)环路等待条件:是指进程发生死锁后,必然存在一个进程--资源之间的环形链
处理死锁的基本方法
预防死锁(破坏四个必要条件):
-
资源一次性分配:(破坏请求和保持条件)
-
可剥夺资源:即当某进程新的资源未满足时,释放已占有的资源(破坏不可剥夺条件)
-
资源有序分配法:系统给每类资源赋予一个编号,每一个进程按编号递增的顺序请求资源,释放则相反(破坏环路等待条件)
避免死锁(银行家算法)
预防死锁的几种策略,会严重地损害系统性能。因此在避免死锁时,要施加较弱的限制,从而获得 较满意的系统性能。由于在避免死锁的策略中,允许进程动态地申请资源。因而,系统在进行资源分配之前预先计算资源分配的安全性。若此次分配不会导致系统进入不安全状态,则将资源分配给进程;否则,进程等待。其中最具有代表性的避免死锁算法是银行家算法。
在银行中,客户申请贷款的数量是有限的,每个客户在第一次申请贷款时要声明完成该项目所需的最大资金量,在满足所有贷款要求时,客户应及时归还。银行家在客户申请的贷款数量不超过自己拥有的最大值时,都应尽量满足客户的需要。在这样的描述中,银行家就好比操作系统,资金就是资源,客户就相当于要申请资源的进程。
检测死锁
首先为每个进程和每个资源指定一个唯一的号码;
然后建立资源分配表和进程等待表,例如:
解除死锁
当发现有进程死锁后,便应立即把它从死锁状态中解脱出来,常采用的方法有:
剥夺资源:从其它进程剥夺足够数量的资源给死锁进程,以解除死锁状态;
撤消进程:可以直接撤消死锁进程或撤消代价最小的进程,直至有足够的资源可用,死锁状态.消除为止;所谓代价是指优先级、运行代价、进程的重要性和价值等。
3. 线程
3.1 线程间如何通讯
-
线程通信
- 线程互斥
互斥意味着“排它”,即两个线程不能同时进入被互斥保护的代码。Linux下可以通过pthread_mutex_t 定义互斥体机制完成多线程的互斥操作,该机制的作用是对某个需要互斥的部分,在进入时先得到互斥体,如果没有得到互斥体,表明互斥部分被其它线程拥有,此时欲获取互斥体的线程阻塞,直到拥有该互斥体的线程完成互斥部分的操作为止。 - 线程同步
同步就是线程等待某个事件的发生。只有当等待的事件发生线程才继续执行,否则线程挂起并放弃处理器。当多个线程协作时,相互作用的任务必须在一定的条件下同步。
- 线程互斥
-
Linux系统中的线程间通信方式主要以下几种:
- 锁机制:包括互斥锁、条件变量、读写锁
互斥锁提供了以排他方式防止数据结构被并发修改的方法。
读写锁允许多个线程同时读共享数据,而对写操作是互斥的。
条件变量可以以原子的方式阻塞进程,直到某个特定条件为真为止。对条件的测试是在互斥锁的保护下进行的。条件变量始终与互斥锁一起使用。 - 信号量机制(Semaphore):包括无名线程信号量和命名线程信号量
- 信号机制(Signal):类似进程间的信号处理
- 锁机制:包括互斥锁、条件变量、读写锁
3.2 线程间同步
- 同步就是线程等待某个事件的发生。只有当等待的事件发生线程才继续执行,否则线程挂起并放弃处理器。当多个线程协作时,相互作用的任务必须在一定的条件下同步
3.3 是否需要线程安全
3.4 线程间的同步和互斥是怎么做的
- Posix中两种线程同步机制,分别为互斥锁和信号量。这两个同步机制可以通过互相调用对方来实现,但互斥锁更适用于同时可用的资源是唯一的情况;信号量更适用于同时可用的资源为多个的情况。
4. 锁(TODO)
自旋锁
自旋锁它是为为实现保护共享资源而提出一种锁机制。其实,自旋锁与互斥锁比较类似,它们都是为了解决对某项资源的互斥使用。无论是互斥锁,还是自旋锁,在任何时刻,最多只能有一个保持者,也就说,在任何时刻最多只能有一个执行单元获得锁。但是两者在调度机制上略有不同。对于互斥锁,如果资源已经被占用,资源申请者只能进入睡眠状态。但是自旋锁不会引起调用者睡眠,如果自旋锁已经被别的执行单元保持,调用者就一直循环在那里看是否该自旋锁的保持者已经释放了锁,"自旋"一词就是因此而得名。
-
自旋锁一般原理
跟互斥锁一样,一个执行单元要想访问被自旋锁保护的共享资源,必须先得到锁,在访问完共享资源后,必须释放锁。如果在获取自旋锁时,没有任何执行单元保持该锁,那么将立即得到锁;如果在获取自旋锁时锁已经有保持者,那么获取锁操作将自旋在那里,直到该自旋锁的保持者释放了锁。由此我们可以看出,自旋锁是一种比较低级的保护数据结构或代码片段的原始方式,这种锁可能存在两个问题:死锁和过多占用cpu资源。
-
自旋锁适用情况
自旋锁比较适用于锁使用者保持锁时间比较短的情况。正是由于自旋锁使用者一般保持锁时间非常短,因此选择自旋而不是睡眠是非常必要的,自旋锁的效率远高于互斥锁。信号量和读写信号量适合于保持时间较长的情况,它们会导致调用者睡眠,因此只能在进程上下文使用,而自旋锁适合于保持时间非常短的情况,它可以在任何上下文使用。如果被保护的共享资源只在进程上下文访问,使用信号量保护该共享资源非常合适,如果对共享资源的访问时间非常短,自旋锁也可以。但是如果被保护的共享资源需要在中断上下文访问(包括底半部即中断处理句柄和顶半部即软中断),就必须使用自旋锁。自旋锁保持期间是抢占失效的,而信号量和读写信号量保持期间是可以被抢占的。自旋锁只有在内核可抢占或SMP(多处理器)的情况下才真正需要,在单CPU且不可抢占的内核下,自旋锁的所有操作都是空操作。另外格外注意一点:自旋锁不能递归使用。
信号量、互斥体和自旋锁
5. 内存管理 段式页式
5.1 存储方式:页式段式(TODO)
5.2 页面置换算法
在地址映射过程中,若在页面中发现所要访问的页面不在内存中,则产生 缺页中断。当发生缺页中断时,如果操作系统内存中没有空闲页面,则操作系统必须在内存选择一个页面将其移出内存,以便为即将调入的页面让出空间。而用来选择淘汰哪一页的规则叫做页面置换算法。
5.3 缺页中断
页缺失指的是当软件试图访问已映射在虚拟地址空间中,但是目前并未被加载在物理内存中的一个分页时,由**处理器的内存管理单元所发出的中断。
通常情况下,用于处理此中断的程序是操作系统的一部分。如果操作系统判断此次访问是有效的,那么操作系统会尝试将相关的分页从硬盘上的虚拟内存文件中调入内存。而如果访问是不被允许的,那么操作系统通常会结束相关的进程。
5.4 常见的置换算法
- 先进先出置换算法(FIFO)
最简单的页面置换算法是先入先出(FIFO)法。这种算法的实质是,总是选择在主存中停留时间最长(即最老)的一页置换,即先进入内存的页,先退出内存。理由是:最早调入内存的页,其不再被使用的可能性比刚调入内存的可能性大。建立一个FIFO队列,收容所有在内存中的页。被置换页面总是在队列头上进行。当一个页面被放入内存时,就把它插在队尾上。
- 最近最久未使用(LRU)算法
它的实质是,当需要置换一页时,选择在之前一段时间里最久没有使用过的页面予以置换。
其问题是怎么确定最后使用时间的顺序,对此有两种可行的办法:
- 计数器。最简单的情况是使每个页表项对应一个使用时间字段,并给CPU增加一个逻辑时钟或计数器。每次存储访问,该时钟都加1。每当访问一个页面时,时钟寄存器的内容就被复制到相应页表项的使用时间字段中。这样我们就可以始终保留着每个页面最后访问的“时间”。在置换页面时,选择该时间值最小的页面。这样做, [1] 不仅要查页表,而且当页表改变时(因CPU调度)要 [1] 维护这个页表中的时间,还要考虑到时钟值溢出的问题。
- 栈。用一个栈保留页号。每当访问一个页面时,就把它从栈中取出放在栈顶上。这样一来,栈顶总是放有目前使用最多的页,而栈底放着目前最少使用的页。由于要从栈的中间移走一项,所以要用具有头尾指针的双向链连起来。在最坏的情况下,移走一页并把它放在栈顶上需要改动6个指针。每次修改都要有开销,但需要置换哪个页面却可直接得到,用不着查找,因为尾指针指向栈底,其中有被置换页。
6. IO多路复用
6.0 IO五种模型(阻塞IO、非阻塞IO、多路复用IO、信号驱动IO、异步IO)
同步就是当一个进程发起一个函数(任务)调用的时候,一直等待直到函数(任务)完成,而进程继续处于激活状态。而异步情况下是当一个进程发起一个函数(任务)调用的时候,不会等函数返回,而是继续往下执行当,函数返回的时候通过状态、通知、事件等方式通知进程任务完成。
阻塞是当请求不能满足的时候就将进程挂起,而非阻塞则不会阻塞当前进程,即阻塞与非阻塞针对的是进程或线程而同步与异步所针对的是功能函数。
IO复用:为了解释这个名词,首先来理解下复用这个概念,复用也就是共用的意思,这样理解还是有些抽象,为此,咱们来理解下复用在通信领域的使用,在通信领域中为了充分利用网络连接的物理介质,往往在同一条网络链路上采用时分复用或频分复用的技术使其在同一链路上传输多路信号,到这里我们就基本上理解了复用的含义,即公用某个“介质”来尽可能多的做同一类(性质)的事,那IO复用的“介质”是什么呢?为此我们首先来看看服务器编程的模型,客户端发来的请求服务端会产生一个进程来对其进行服务,每当来一个客户请求就产生一个进程来服务,然而进程不可能无限制的产生,因此为了解决大量客户端访问的问题,引入了IO复用技术,即:一个进程可以同时对多个客户请求进行服务。
同步 : 自己亲自出马持银行卡到银行取钱(使用同步IO时,Java自己处理IO读写);
异步 : 委托一小弟拿银行卡到银行取钱,然后给你(使用异步IO时,Java将IO读写委托给OS处理,需要将数据缓冲区地址和大小传给OS(银行卡和密码),OS需要支持异步IO操作API);
阻塞 : ATM排队取款,你只能等待(使用阻塞IO时,Java调用会一直阻塞到读写完成才返回);
非阻塞 : 柜台取款,取个号,然后坐在椅子上做其它事,等号广播会通知你办理,没到号你就不能去,你可以不断问大堂经理排到了没有,大堂经理如果说还没到你就不能去(使用非阻塞IO时,如果不能读写Java调用会马上返回,当IO事件分发器会通知可读写时再继续进行读写,不断循环直到读写完成)
IO五种模型(阻塞IO、非阻塞IO、多路复用IO、信号驱动IO、异步IO):
select,poll,epoll都是IO多路复用的机制。I/O多路复用就通过一种机制,可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。
6.1 前言:系统层面概念说明
在进行解释之前,首先要说明几个概念:
- 用户空间和内核空间
- 进程切换
- 进程的阻塞
- 文件描述符
- 缓存 I/O
6.1.1 用户空间与内核空间
现在操作系统都是采用虚拟存储器,那么对32位操作系统而言,它的寻址空间(虚拟存储空间)为4G(2的32次方)。操作系统的核心是内核,独立于普通的应用程序,可以访问受保护的内存空间,也有访问底层硬件设备的所有权限。为了保证用户进程不能直接操作内核(kernel),保证内核的安全,操心系统将虚拟空间划分为两部分,一部分为内核空间,一部分为用户空间。针对linux操作系统而言,将最高的1G字节(从虚拟地址0xC0000000到0xFFFFFFFF),供内核使用,称为内核空间,而将较低的3G字节(从虚拟地址0x00000000到0xBFFFFFFF),供各个进程使用,称为用户空间。
6.1.2 进程切换
为了控制进程的执行,内核必须有能力挂起正在CPU上运行的进程,并恢复以前挂起的某个进程的执行。这种行为被称为进程切换。因此可以说,任何进程都是在操作系统内核的支持下运行的,是与内核紧密相关的。
从一个进程的运行转到另一个进程上运行,这个过程中经过下面这些变化:
- 保存处理机上下文,包括程序计数器和其他寄存器。
- 更新PCB信息。
- 把进程的PCB移入相应的队列,如就绪、在某事件阻塞等队列。
- 选择另一个进程执行,并更新其PCB。
- 更新内存管理的数据结构。
- 恢复处理机上下文。
注:总而言之就是很耗资源。
6.1.3 进程的阻塞
正在执行的进程,由于期待的某些事件未发生,如请求系统资源失败、等待某种操作的完成、新数据尚未到达或无新工作做等,则由系统自动执行阻塞原语(Block),使自己由运行状态变为阻塞状态。可见,进程的阻塞是进程自身的一种主动行为,也因此只有处于运行态的进程(获得CPU),才可能将其转为阻塞状态。
当进程进入阻塞状态,是不占用CPU资源的。
6.1.4 文件描述符
文件描述符(File descriptor)是计算机科学中的一个术语,是一个用于表述指向文件的引用的抽象化概念。
**文件描述符在形式上是一个非负整数。**实际上,它是一个索引值,指向内核为每一个进程所维护的该进程打开文件的记录表。当程序打开一个现有文件或者创建一个新文件时,内核向进程返回一个文件描述符。在程序设计中,一些涉及底层的程序编写往往会围绕着文件描述符展开。但是文件描述符这一概念往往只适用于UNIX、Linux这样的操作系统。
6.1.5 缓存 I/O
缓存 I/O 又被称作标准 I/O,大多数文件系统的默认 I/O 操作都是缓存 I/O。在 Linux 的缓存 I/O 机制中,操作系统会将 I/O 的数据缓存在文件系统的页缓存( page cache )中,也就是说,数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间。
- 缓存 I/O 的缺点:
数据在传输过程中需要在应用程序地址空间和内核进行多次数据拷贝操作,这些数据拷贝操作所带来的 CPU 以及内存开销是非常大的。
6.2 I/O 多路复用
I/O 多路复用(IO multiplexing)就是我们说的select,poll,epoll,有些地方也称这种IO方式为事件驱动(event driven IO)。select/epoll的好处就在于单个process就可以同时处理多个网络连接的IO。它的基本原理就是select,poll,epoll这个function会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程。
所以,I/O 多路复用的特点是通过一种机制一个进程能同时等待多个文件描述符,而这些文件描述符(套接字描述符)其中的任意一个进入读就绪状态,select()函数就可以返回。
所以,如果处理的连接数不是很高的话,使用select/epoll的web server不一定比使用多线程multi-threading + 阻塞blocking IO的web server性能更好,可能延迟还更大。select/epoll的优势并不是对于单个连接能处理得更快,而是在于能处理更多的连接。)
在IO多路复用中,实际中,对于每一个socket,一般都设置成为非阻塞non-blocking,但是,整个用户的process其实是一直被阻塞block的。只不过process是被select这个函数block,而不是被socket IO给block。
6.3 select、poll、epoll详解
6.3.1 select
select的工作流程:
单个进程就可以同时处理多个网络连接的io请求(同时阻塞多个io操作)。基本原理就是程序呼叫select,然后整个程序就阻塞了,这时候,select会将需要监控的readfds集合拷贝到内核空间(假设监控的仅仅是socket可读),kernel就会轮询检查所有select负责的fd,当找到一个client中的数据准备好了,select就会返回,这个时候程序就会系统调用,将数据从kernel复制到进程缓冲区。
通过上面的select逻辑过程分析,相信大家都意识到,select存在两个问题:
- 被监控的fds需要从用户空间拷贝到内核空间。为了减少数据拷贝带来的性能损坏,内核对被监控的fds集合大小做了限制,并且这个是通过宏控制的,大小不可改变(限制为1024)。
- 被监控的fds集合中,只要有一个有数据可读,整个socket集合就会被遍历一次调用sk的poll函数收集可读事件。由于当初的需求是朴素,仅仅关心是否有数据可读这样一个事件,当事件通知来的时候,由于数据的到来是异步的,我们不知道事件来的时候,有多少个被监控的socket有数据可读了,于是,只能挨个遍历每个socket来收集可读事件。
6.3.2 Poll
poll的原理与select非常相似,差别如下:
- 描述fd集合的方式不同,poll使用 pollfd 结构而不是select结构fd_set结构,所以poll是链式的,没有最大连接数的限制
- poll有一个特点是水平触发,也就是通知程序fd就绪后,这次没有被处理,那么下次poll的时候会再次通知同个fd已经就绪。
poll机制虽然改进了select的监控大小1024的限制,但以下两个性能问题还没有解决。略显鸡肋。
- fds集合需要从用户空间拷贝到内核空间的问题,我们希望不需要拷贝
- 当被监控的fds中某些有数据可读的时候,我们希望通知更加精细一点,就是我们希望能够从通知中得到有可读事件的fds列表,而不是需要遍历整个fds来收集。
6.3.3 epoll 解决问题
假设现实中,有1百万个客户端同时与一个服务器保持着tcp连接,而每一个时刻,通常只有几百上千个tcp连接是活跃的,这时候我们仍然使用select/poll机制,kernel必须在搜寻完100万个fd之后,才能找到其中状态是active的,这样资源消耗大而且效率低下。
(a) fds集合拷贝问题的解决
对于IO多路复用,有两件事是必须要做的(对于监控可读事件而言):1. 准备好需要监控的fds集合;2. 探测并返回fds集合中哪些fd可读了。细看select或poll的函数原型,我们会发现,每次调用select或poll都在重复地准备(集中处理)整个需要监控的fds集合。然而对于频繁调用的select或poll而言,fds集合的变化频率要低得多,我们没必要每次都重新准备(集中处理)整个fds集合。
于是,epoll引入了epoll_ctl系统调用,将高频调用的epoll_wait和低频的epoll_ctl隔离开。同时,epoll_ctl通过(EPOLL_CTL_ADD、EPOLL_CTL_MOD、EPOLL_CTL_DEL)三个操作来分散对需要监控的fds集合的修改,做到了有变化才变更,将select/poll高频、大块内存拷贝(集中处理)变成epoll_ctl的低频、小块内存的拷贝(分散处理),避免了大量的内存拷贝。
(b) 按需遍历就绪的fds集合
为了做到只遍历就绪的fd,我们需要有个地方来组织那些已经就绪的fd。为此,epoll引入了一个中间层,一个双向链表(ready_list),一个单独的睡眠队列(single_epoll_wait_list),并且,与select或poll不同的是,epoll的process不需要同时插入到多路复用的socket集合的所有睡眠队列中,相反process只是插入到中间层的epoll的单独睡眠队列中,process睡眠在epoll的单独队列上,等待事件的发生。
6.3.4 小结
- select, poll是为了解決同时大量IO的情況(尤其网络服务器),但是随着连接数越多,性能越差
- epoll是select和poll的改进方案,在 linux 上可以取代 select 和 poll,可以处理大量连接的性能问题
7. 文件系统
7.1 Linux的EXT2文件系统
-
这部分就是inode牵扯到的相关知识
-
对于一个磁盘分区来说,在被指定为相应的文件系统后,整个分区被分为 1024,2048 和 4096 字节大小的块。根据块使用的不同,可分为:
-
超级块(Superblock): 这是整个文件系统的第一块空间。包括整个文件系统的基本信息,如块大小,inode/block的总量、使用量、剩余量,指向空间 inode 和数据块的指针等相关信息。
-
inode块(文件索引节点) : 文件系统索引,记录文件的属性。它是文件系统的最基本单元,是文件系统连接任何子目录、任何文件的桥梁。每个子目录和文件只有唯一的一个 inode 块。它包含了文件系统中文件的基本属性(文件的长度、创建及修改时间、权限、所属关系)、存放数据的位置等相关信息. 在 Linux 下可以通过 "ls -li" 命令查看文件的 inode 信息。硬连接和源文件具有相同的 inode 。
-
数据块(Block) :实际记录文件的内容,若文件太大时,会占用多个 block。为了提高目录访问效率,Linux 还提供了表达路径与 inode 对应关系的 dentry 结构。它描述了路径信息并连接到节点 inode,它包括各种目录信息,还指向了 inode 和超级块。
就像一本书有封面、目录和正文一样。在文件系统中,超级块就相当于封面,从封面可以得知这本书的基本信息; inode 块相当于目录,从目录可以得知各章节内容的位置;而数据块则相当于书的正文,记录着具体内容。
- 磁盘 I/O 那些事:从硬件到Linux文件系统
从硬盘构造,到Linux文件系统的优化,再到其他开源系统(HDFS、Kafka)基于磁盘IO的设计
7.2 Inode是什么
- 文件储存在硬盘上,硬盘的最小存储单位叫做"扇区"(Sector)。每个扇区储存512字节(相当于0.5KB)。
操作系统读取硬盘的时候,不会一个个扇区地读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个"块"(block)。这种由多个扇区组成的"块",是文件存取的最小单位。"块"的大小,最常见的是4KB,即连续八个 sector组成一个 block。
文件数据都储存在"块"中,那么很显然,我们还必须找到一个地方储存文件的元信息,比如文件的创建者、文件的创建日期、文件的大小等等。这种储存文件元信息的区域就叫做inode,中文译名为"索引节点"。
每一个文件都有对应的inode,里面包含了与该文件有关的一些信息。 - 链接
三、计算机网络
1. 七层网络结构
- 物理层,数据链路层,网络层,传输层,会话层,表示层,应用层。
计算机网络基础知识总结

- 物理层
- 数据链路层
- 数据链路层为网络层提供可靠的数据传输;
- 基本数据单位为帧;
- 主要的协议:以太网协议;
- 网络层
网络层中涉及众多的协议,其中包括最重要的协议,也是TCP/IP的核心协议——IP协议。IP协议非常简单,仅仅提供不可靠、无连接的传送服务。IP协议的主要功能有:无连接数据报传输、数据报路由选择和差错控制。与IP协议配套使用实现其功能的还有地址解析协议ARP、逆地址解析协议RARP、因特网报文协议ICMP、因特网组管理协议IGMP。具体的协议我们会在接下来的部分进行总结,有关网络层的重点为:- IP协议(Internet Protocol,因特网互联协议);
- ICMP协议(Internet Control Message Protocol,因特网控制报文协议);
- ARP协议(Address Resolution Protocol,地址解析协议);
- RARP协议(Reverse Address Resolution Protocol,逆地址解析协议)。
- 传输层
- 传输层负责将上层数据分段并提供端到端的、可靠的或不可靠的传输以及端到端的差错控制和流量控制问题;
- TCP协议(Transmission Control Protocol,传输控制协议)
- UDP协议(User Datagram Protocol,用户数据报协议);
- 会话层
- 表示层
- 应用层
- 数据传输基本单位为报文;
- 包含的主要协议:FTP(文件传送协议)、Telnet(远程登录协议)、DNS(域名解析协议)、SMTP(邮件传送协议),POP3协议(邮局协议),HTTP协议(Hyper Text Transfer Protocol)。
2. TCP/IP协议
TCP/IP协议是Internet最基本的协议、Internet国际互联网络的基础,由网络层的IP协议和传输层的TCP协议组成。通俗而言:TCP负责发现传输的问题,一有问题就发出信号,要求重新传输,直到所有数据安全正确地传输到目的地。而IP是给因特网的每一台联网设备规定一个地址。
IP层接收由更低层(网络接口层例如以太网设备驱动程序)发来的数据包,并把该数据包发送到更高层---TCP或UDP层;相反,IP层也把从TCP或UDP层接收来的数据包传送到更低层。IP数据包是不可靠的,因为IP并没有做任何事情来确认数据包是否按顺序发送的或者有没有被破坏,IP数据包中含有发送它的主机的地址(源地址)和接收它的主机的地址(目的地址)。
TCP是面向连接的通信协议,通过三次握手建立连接,通讯完成时要拆除连接,由于TCP是面向连接的所以只能用于端到端的通讯。TCP提供的是一种可靠的数据流服务,采用“带重传的肯定确认”技术来实现传输的可靠性。TCP还采用一种称为“滑动窗口”的方式进行流量控制,所谓窗口实际表示接收能力,用以限制发送方的发送速度。

2.1 TCP重要知识点
2.1.1 三次握手
TCP连接建立过程:首先Client端发送连接请求报文,Server段接受连接后回复ACK报文,并为这次连接分配资源。Client端接收到ACK报文后也向Server段发生ACK报文,并分配资源,这样TCP连接就建立了。
为什么要三次挥手?
在只有两次“握手”的情形下,假设Client想跟Server建立连接,但是却因为中途连接请求的数据报丢失了,故Client端不得不重新发送一遍;这个时候Server端仅收到一个连接请求,因此可以正常的建立连接。但是,有时候Client端重新发送请求不是因为数据报丢失了,而是有可能数据传输过程因为网络并发量很大在某结点被阻塞了,这种情形下Server端将先后收到2次请求,并持续等待两个Client请求向他发送数据...问题就在这里,Cient端实际上只有一次请求,而Server端却有2个响应,极端的情况可能由于Client端多次重新发送请求数据而导致Server端最后建立了N多个响应在等待,因而造成极大的资源浪费!所以,“三次握手”很有必要!
2.1.2 四次挥手
TCP连接断开过程:假设Client端发起中断连接请求,也就是发送FIN报文。Server端接到FIN报文后,意思是说"我Client端没有数据要发给你了",但是如果你还有数据没有发送完成,则不必急着关闭Socket,可以继续发送数据。所以你先发送ACK,"告诉Client端,你的请求我收到了,但是我还没准备好,请继续你等我的消息"。这个时候Client端就进入FIN_WAIT状态,继续等待Server端的FIN报文。当Server端确定数据已发送完成,则向Client端发送FIN报文,"告诉Client端,好了,我这边数据发完了,准备好关闭连接了"。Client端收到FIN报文后,"就知道可以关闭连接了,但是他还是不相信网络,怕Server端不知道要关闭,所以发送ACK后进入TIME_WAIT状态,如果Server端没有收到ACK则可以重传。“,Server端收到ACK后,"就知道可以断开连接了"。Client端等待了2MSL后依然没有收到回复,则证明Server端已正常关闭,那好,我Client端也可以关闭连接了。Ok,TCP连接就这样关闭了!
为什么要四次挥手?
试想一下,假如现在你是客户端你想断开跟Server的所有连接该怎么做?第一步,你自己先停止向Server端发送数据,并等待Server的回复。但事情还没有完,虽然你自身不往Server发送数据了,但是因为你们之前已经建立好平等的连接了,所以此时他也有主动权向你发送数据;故Server端还得终止主动向你发送数据,并等待你的确认。其实,说白了就是保证双方的一个合约的完整执行!
2.1.3 TIME-WAIT 和 CLOSE-WAIT 的区别
TCP协议规定,对于已经建立的连接,网络双方要进行四次握手才能成功断开连接,如果缺少了其中某个步骤,将会使连接处于假死状态,连接本身占用的资源不会被释放。网络服务器程序要同时管理大量连接,所以很有必要保证无用连接完全断开,否则大量僵死的连接会浪费许多服务器资源。在众多TCP状态中,最值得注意的状态有两个:CLOSE_WAIT和TIME_WAIT。
TIME_WAIT
TIME_WAIT 是主动关闭链接时形成的,等待2MSL时间,约4分钟。主要是防止最后一个ACK丢失。 由于TIME_WAIT 的时间会非常长,因此server端应尽量减少主动关闭连接
CLOSE_WAIT
CLOSE_WAIT是被动关闭连接是形成的。根据TCP状态机,服务器端收到客户端发送的FIN,则按照TCP实现发送ACK,因此进入CLOSE_WAIT状态。但如果服务器端不执行close(),就不能由CLOSE_WAIT迁移到LAST_ACK,则系统中会存在很多CLOSE_WAIT状态的连接。此时,可能是系统忙于处理读、写操作,而未将已收到FIN的连接,进行close。此时,recv/read已收到FIN的连接socket,会返回0。
为什么需要 TIME_WAIT 状态?
假设最终的ACK丢失,server将重发FIN,client必须维护TCP状态信息以便可以重发最终的ACK,否则会发送RST,结果server认为发生错误。TCP实现必须可靠地终止连接的两个方向(全双工关闭),client必须进入 TIME_WAIT 状态,因为client可能面 临重发最终ACK的情形。
为什么 TIME_WAIT 状态需要保持 2MSL 这么长的时间?
如果 TIME_WAIT 状态保持时间不足够长(比如小于2MSL),第一个连接就正常终止了。第二个拥有相同相关五元组的连接出现,而第一个连接的重复报文到达,干扰了第二个连接。TCP实现必须防止某个连接的重复报文在连接终止后出现,所以让TIME_WAIT状态保持时间足够长(2MSL),连接相应方向上的TCP报文要么完全响应完毕,要么被丢弃。建立第二个连接的时候,不会混淆。
TIME_WAIT 和CLOSE_WAIT状态socket过多
如果服务器出了异常,百分之八九十都是下面两种情况:
- 服务器保持了大量TIME_WAIT状态
- 服务器保持了大量CLOSE_WAIT状态,简单来说CLOSE_WAIT数目过大是由于被动关闭连接处理不当导致的。
因为linux分配给一个用户的文件句柄是有限的,而TIME_WAIT和CLOSE_WAIT两种状态如果一直被保持,那么意味着对应数目的通道就一直被占着,而且是“占着茅坑不使劲”,一旦达到句柄数上限,新的请求就无法被处理了,接着就是大量Too Many Open Files异常,Tomcat崩溃。
2.1.4 流量控制和拥塞控制
利用滑动窗口实现流量控制
定义: 流量控制往往指的是点对点通信量的控制,是个端到端的问题。流量控制所要做的就是控制发送端发送数据的速率,以便使接收端来得及接受。如果发送方把数据发送得过快,接收方可能会来不及接收,这就会造成数据的丢失。所谓流量控制就是让发送方的发送速率不要太快,要让接收方来得及接收。
设A向B发送数据。在连接建立时,B告诉了A:“我的接收窗口是 rwnd = 400 ”(这里的 rwnd 表示 receiver window) 。因此,发送方的发送窗口不能超过接收方给出的接收窗口的数值。请注意,TCP的窗口单位是字节,不是报文段。TCP连接建立时的窗口协商过程在图中没有显示出来。再设每一个报文段为100字节长,而数据报文段序号的初始值设为1。大写ACK表示首部中的确认位ACK,小写ack表示确认字段的值ack。

从图中可以看出,B进行了三次流量控制。第一次把窗口减少到 rwnd = 300 ,第二次又减到了 rwnd = 100 ,最后减到 rwnd = 0 ,即不允许发送方再发送数据了。这种使发送方暂停发送的状态将持续到主机B重新发出一个新的窗口值为止。B向A发送的三个报文段都设置了 ACK = 1 ,只有在ACK=1时确认号字段才有意义。
拥塞控制
定义: 在某段时间,若对网络中某资源的需求超过了该资源所能提供的可用部分,网络的性能就要变坏。

- 慢开始:在主机刚刚开始发送报文段时可先将拥塞窗口 cwnd 设置为一个最大报文段 MSS 的数值。在每收到一个对新的报文段的确认后,将拥塞窗口增加至多一个 MSS 的数值。用这样的方法逐步增大发送端的拥塞窗口 cwnd,可以使分组注入到网络的速率更加合理。每经过一个传输轮回,拥塞窗口(发送端)就加倍。
- 拥塞避免:让拥塞窗口缓慢增大,每经过一个往返时间就加1,而不是加倍,按线性规律缓慢增长。拥塞窗口大于慢开始门限,就执行拥塞避免算法。“乘法减小”:指不论在慢开始还是拥塞避免阶段,只要出现超时重传就把慢开始门限值减半。"加分增大“:指执行拥塞避免算法后,使拥塞窗口缓慢增大,以防止网络过早出现拥塞。合起来叫AIMD算法。
- 快重传算法:发送方只要一连收到三个重复确认就应当重传对方尚未收到的报文。而不必等到该分组的重传计时器到期。
- 快恢复算法:(1)当发送端收到连续三个重复的确认时,就执行“乘法减小”算法,把慢开始门限 ssthresh 减半。但接下去不执行慢开始算法。(2)由于发送方现在认为网络很可能没有发生拥塞,因此现在不执行慢开始算法,即拥塞窗口 cwnd 现在不设置为 1,而是设置为慢开始门限 ssthresh 减半后的数值,然后开始执行拥塞避免算法(“加法增大”),使拥塞窗口缓慢地线性增大.
3. UDP协议
UDP与TCP位于同一层,但它不管数据包的顺序、错误或重发。因此,UDP不被应用于那些使用虚电路的面向连接的服务,UDP主要用于那些面向查询---应答的服务,例如NFS。相对于FTP或Telnet,这些服务需要交换的信息量较小。
3.1 TCP 与 UDP 的区别
TCP是面向连接的,可靠的字节流服务;UDP是面向无连接的,不可靠的数据报服务。

TCP的优点
- 可靠,稳定
- TCP的可靠体现在TCP在传递数据之前,会有三次握手来建立连接,而且在数据传递时,有确认、窗口、重传、拥塞控制机制,在数据传完后,还会断开连接用来节约系统资源。
TCP的缺点
- 慢,效率低,占用系统资源高,易被攻击
- TCP在传递数据之前,要先建连接,这会消耗时间,而且在数据传递时,确认机制、重传机制、拥塞控制机制等都会消耗大量的时间,而且要在每台设备上维护所有的传输连接,事实上,每个连接都会占用系统的CPU、内存等硬件资源。
- 而且,因为TCP有确认机制、三次握手机制,这些也导致TCP容易被人利用,实现DOS、DDOS、CC等攻击。
UDP的优点
- 快,比TCP稍安全
- UDP没有TCP的握手、确认、窗口、重传、拥塞控制等机制,UDP是一个无状态的传输协议,所以它在传递数据时非常快。没有TCP的这些机制,UDP较TCP被攻击者利用的漏洞就要少一些。但UDP也是无法避免攻击的,比如:UDP Flood攻击……
UDP的缺点
- 不可靠,不稳定
- 因为UDP没有TCP那些可靠的机制,在数据传递时,如果网络质量不好,就会很容易丢包。
4. HTTP协议
4.1 POST 与 GET 的区别
TCP在传输层,HTTP在应用层。
所有的WWW文件都必须遵守HTTP。建立一个到服务器指定端口(默认是80端口)的TCP连接。
4.1.1 HTTP 协议包括哪些请求?
- GET:请求读取由URL所标志的信息。
- POST:给服务器添加信息(如注释)。
- PUT:在给定的URL下存储一个文档。
- DELETE:删除给定的URL所标志的资源。
4.1.2 POST 与 GET 的区别
- Get是从服务器上获取数据,Post是向服务器传送数据
- Get是把参数数据队列加到提交表单的Action属性所指向的URL中,值和表单内各个字段一一对应,在URL中可以看到。
- Get传送的数据量小,不能大于2KB;Post传送的数据量较大,一般被默认为不受限制。
- 根据HTTP规范,GET用于信息获取,而且应该是安全的和幂等的。
I. 所谓 安全的 意味着该操作用于获取信息而非修改信息。换句话说,GET请求一般不应产生副作用。就是说,它仅仅是获取资源信息,就像数据库查询一样,不会修改,增加数据,不会影响资源的状态。
II. 幂等 的意味着对同一URL的多个请求应该返回同样的结果。
- GET在浏览器回退时是无害的,而POST会再次提交请求。
- GET请求会被浏览器主动cache,而POST不会,除非手动设置。
- GET请求只能进行url编码,而POST支持多种编码方式。
- GET请求参数会被完整保留在浏览器历史记录里,而POST中的参数不会被保留
- GET请求在URL中传送的参数是有长度限制的,而POST么有。
- GET参数通过URL传递,POST放在Request body中。
但GET和POST本质上没有区别
GET和POST是什么?HTTP协议中的两种发送请求的方法。
HTTP是什么?HTTP是基于TCP/IP的关于数据如何在万维网中如何通信的协议。
TCP就像汽车,我们用TCP来运输数据,它很可靠,从来不会发生丢件少件的现象。但是如果路上跑的全是看起来一模一样的汽车,那这个世界看起来是一团混乱,送急件的汽车可能被前面满载货物的汽车拦堵在路上,整个交通系统一定会瘫痪。为了避免这种情况发生,交通规则HTTP诞生了。HTTP给汽车运输设定了好几个服务类别,有GET, POST, PUT, DELETE等等,HTTP规定,当执行GET请求的时候,要给汽车贴上GET的标签(设置method为GET),而且要求把传送的数据放在车顶上(url中)以方便记录。如果是POST请求,就要在车上贴上POST的标签,并把货物放在车厢里。当然,你也可以在GET的时候往车厢内偷偷藏点货物,但是这是很不光彩;也可以在POST的时候在车顶上也放一些数据,让人觉得傻乎乎的。HTTP只是个行为准则,而TCP才是GET和POST怎么实现的基本。
GET和POST本质上就是TCP链接,并无差别。但是由于HTTP的规定和浏览器/服务器的限制,导致他们在应用过程中体现出一些不同。
GET和POST还有一个重大区别,简单的说:
GET产生一个TCP数据包;POST产生两个TCP数据包。
-
对于GET方式的请求,浏览器会把http header和data一并发送出去,服务器响应200(返回数据);
-
而对于POST,浏览器先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200 ok(返回数据)。
也就是说,GET只需要汽车跑一趟就把货送到了,而POST得跑两趟,第一趟,先去和服务器打个招呼“嗨,我等下要送一批货来,你们打开门迎接我”,然后再回头把货送过去。
因为POST需要两步,时间上消耗的要多一点,看起来GET比POST更有效。因此Yahoo团队有推荐用GET替换POST来优化网站性能。但这是一个坑!跳入需谨慎。为什么?
-
GET与POST都有自己的语义,不能随便混用。
-
据研究,在网络环境好的情况下,发一次包的时间和发两次包的时间差别基本可以无视。而在网络环境差的情况下,两次包的TCP在验证数据包完整性上,有非常大的优点。
-
并不是所有浏览器都会在POST中发送两次包,Firefox就只发送一次。
4.2 HTTP流程
HTTP 把客户端浏览器的请求发送到服务器,并把相应的网页内容由服务器返回客户端浏览器。
1. 地址解析
如用客户端浏览器请求这个页面:http://localhost.com:8080/index.htm
从中分解出协议名、主机名、端口、对象路径等部分,对于我们的这个地址,解析得到的结果如下:
- 协议名:http
- 主机名:localhost.com
- 端口:8080
- 对象路径:/index.htm
在这一步,需要 域名系统DNS 解析域名 localhost.com,得主机的IP地址。
2. 封装HTTP请求数据包
把以上部分结合本机自己的信息,封装成一个HTTP请求数据包
3. 封装成TCP包,建立TCP连接(TCP的三次握手)
在HTTP 工作开始之前,客户机(Web浏览器)首先要通过网络与服务器建立连接,该连接是通过TCP来完成的,该协议与IP协议共同构建Internet,即著名 的TCP/IP协议族,因nternet又被称作是TCP/IP网络。HTTP是比TCP更高层次的应用层协议,根据规则,只有低层协议建立之后才 能,才能进行更层协议的连接,因此,首先要建立TCP连接,一般TCP连接的端口号是80。这里是8080端口
4. 客户机发送请求命令
建立连接后,客户机发送一个请求给服务器,请求方式的格式为:统一资源标识符(URL)、协议版本号,后边是MIME信息包括请求修饰符、客户机信息和可内容。
5. 服务器响应
服务器接到请求后,给予相应的响应信息,其格式为一个状态行,包括信息的协议版本号、一个成功或错误的代码,后边是MIME信息包括服务器信息、实体信息和可能的内容。
实体消息是服务器向浏览器发送头信息后,它会发送一个空白行来表示头信息的发送到此为结束,接着,它就以Content-Type应答头信息所描述的格式发送用户所请求的实际数据
6. 服务器关闭TCP连接
一般情况下,一旦Web服务器向浏览器发送了请求数据,它就要关闭TCP连接,然后如果浏览器或者服务器在其头信息加入了这行代码
Connection:keep-alive
TCP连接在发送后将仍然保持打开状态,于是,浏览器可以继续通过相同的连接发送请求。保持连接节省了为每个请求建立新连接所需的时间,还节约了网络带宽。
客户机发起一次请求的时候:
客户机会将请求封装成http数据包-->封装成Tcp数据包-->封装成Ip数据包--->封装成数据帧--->硬件将帧数据转换成bit流(二进制数据)-->最后通过物理硬件(网卡芯片)发送到指定地点。
服务器硬件首先收到bit流....... 然后转换成ip数据包。于是通过ip协议解析Ip数据包,然后又发现里面是tcp数据包,就通过tcp协议解析Tcp数据包,接着发现是http数据包通过http协议再解析http数据包得到数
小结:输入一个网站执行后的过程
事件顺序
- 浏览器获取输入的域名 www.baidu.com
- 浏览器向DNS请求解析www.baidu.com的IP地址
- 域名系统DNS解析出百度服务器的IP地址
- 客户端浏览器通过DNS解析到www.baidu.com的IP地址220.181.27.48,通过这个IP地址找到客户端到服务器的路径。客户端浏览器发起一个HTTP会话到220.161.27.48,然后通过TCP进行封装数据包,输入到网络层。
- 浏览器与该服务器建立TCP连接(默认端口号80)
- 在客户端的传输层,把HTTP会话请求分成报文段,添加源和目的端口,如服务器使用80端口监听客户端的请求,客户端由系统随机选择一个端口如5000,与服务器进行交换,服务器把相应的请求返回给客户端的5000端口。然后使用IP层的IP地址查找目的端。
- 浏览器发出HTTP请求,请求百度首页
- 客户端的网络层不用关系应用层或者传输层的东西,主要做的是通过查找路由表确定如何到达服务器,期间可能经过多个路由器,这些都是由路由器来完成的工作,不作过多的描述,无非就是通过查找路由表决定通过那个路径到达服务器。
- 客户端的链路层,包通过链路层发送到路由器,通过邻居协议查找给定IP地址的MAC地址,然后发送ARP请求查找目的地址,如果得到回应后就可以使用ARP的请求应答交换的IP数据包现在就可以传输了,然后发送IP数据包到达服务器的地址。
- 服务器通过HTTP响应把首页文件发送给浏览器
- TCP连接释放
- 浏览器将首页文件进行解析,并将Web页显示给用户。
涉及到的协议
- 应用层:HTTP(WWW访问协议),DNS(域名解析服务)DNS解析域名为目的IP,通过IP找到服务器路径,客户端向服务器发起HTTP会话,然后通过运输层TCP协议封装数据包,在TCP协议基础上进行传输
- 传输层:TCP(为HTTP提供可靠的数据传输),UDP(DNS使用UDP传输) HTTP会话会被分成报文段,添加源、目的端口;TCP协议进行主要工作
- 网络层:IP(IP数据数据包传输和路由选择),ICMP(提供网络传输过程中的差错检测),ARP(将本机的默认网关IP地址映射成物理MAC地址)为数据包选择路由,IP协议进行主要工作
4.3. HTTP与HTTPS的关系
HTTPS是在HTTP上建立SSL加密层,并对传输数据进行加密,是HTTP协议的安全版。http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
https = http + ssl
SSL介于应用层和TCP层之间。应用层数据不再直接传递给传输层,而是传递给SSL层,SSL层对从应用层收到的数据进行加密,并增加自己的SSL头。
有两种基本的加解密算法类型:
-
对称加密(symmetrcic encryption):密钥只有一个,加密解密为同一个密码,且加解密速度快,典型的对称加密算法有DES、AES,RC5,3DES等;
- 对称加密主要问题是共享秘钥,除你的计算机(客户端)知道另外一台计算机(服务器)的私钥秘钥,否则无法对通信流进行加密解密。解决这个问题的方案非对称秘钥。
-
非对称加密:使用两个秘钥:公共秘钥和私有秘钥。私有秘钥由一方密码保存(一般是服务器保存),另一方任何人都可以获得公共秘钥。
- 这种密钥成对出现(且根据公钥无法推知私钥,根据私钥也无法推知公钥),加密解密使用不同密钥(公钥加密需要私钥解密,私钥加密需要公钥解密),相对对称加密速度较慢,典型的非对称加密算法有RSA、DSA等。

过程大致如下:
-
SSL客户端通过TCP和服务器建立连接之后(443端口),并且在一般的tcp连接协商(握手)过程中请求证书。
- 即客户端发出一个消息给服务器,这个消息里面包含了自己可实现的算法列表和其它一些需要的消息,SSL的服务器端会回应一个数据包,这里面确定了这次通信 所需要的算法,然后服务器向客户端返回证书。(证书里面包含了服务器信息:域名。申请证书的公司,公共秘钥)。
-
Client在收到服务器返回的证书后,判断签发这个证书的公共签发机构,并使用这个机构的公共秘钥确认签名是否有效,客户端还会确保证书中列出的域名就是它正在连接的域名。
-
如果确认证书有效,那么生成对称秘钥并使用服务器的公共秘钥进行加密。然后发送给服务器,服务器使用它的私钥对它进行解密,这样两台计算机可以开始进行对称加密进行通信。
4.4 HTTP错误代码
- 2xx -- 成功
- 这类状态代码表明服务器成功地接受了客户端请求。
- 3xx -- 重定向
- 客户端浏览器必须采取更多操作来实现请求。例如,浏览器可能不得不请求服务器上的不同的页面,或通过代理服务器重复该请求。
- 4xx -- 客户端错误
- 发生错误,客户端似乎有问题。例如,客户端请求不存在的页面,客户端未提供有效的身份验证信息。
- 5xx -- 服务器错误
- 服务器由于遇到错误而不能完成该请求。
HTTP错误代码详细介绍
- 服务器由于遇到错误而不能完成该请求。
四、数据库
1. 底层原理
1.1 B树 B+树
B-树,这类似普通的平衡二叉树,不同的一点是B-树允许每个节点有更多的子节点。下图是 B-树的简化图
B+树是B-树的变体,也是一种多路搜索树, 它与 B- 树的不同之处在于:

- 所有关键字存储在叶子节点出现,内部节点(非叶子节点并不存储真正的 data)
- 为所有叶子结点增加了一个链指针
简化 B+树 如下图
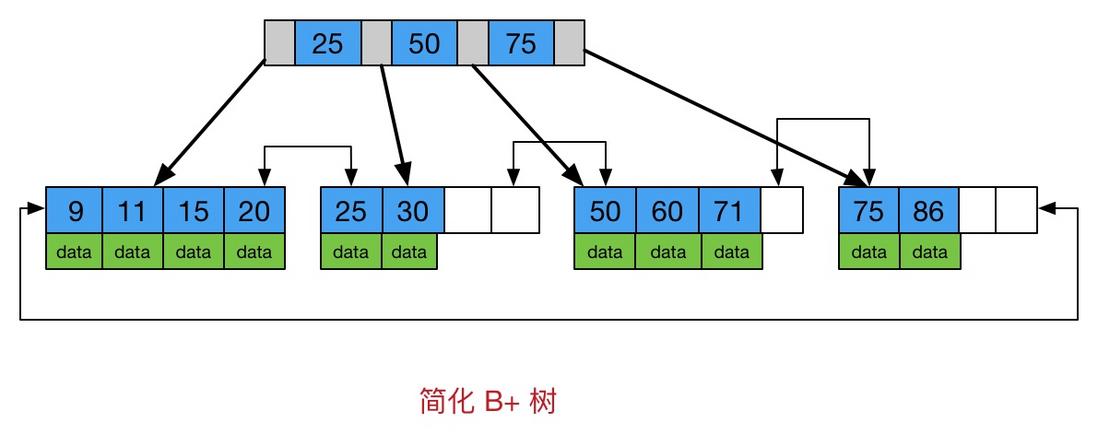
1.2 为什么使用B-/B+ Tree
红黑树等数据结构也可以用来实现索引,但是文件系统及数据库系统普遍采用B-/+Tree作为索引结构。MySQL 是基于磁盘的数据库系统,索引往往以索引文件的形式存储的磁盘上,索引查找过程中就要产生磁盘I/O消耗,相对于内存存取,I/O存取的消耗要高几个数量级,索引的结构组织要尽量减少查找过程中磁盘I/O的存取次数。为什么使用B-/+Tree,还跟磁盘存取原理有关。
由于存储介质的特性,磁盘本身存取就比主存慢很多,再加上机械运动耗费,磁盘的存取速度往往是主存的几百分分之一,因此为了提高效率,要尽量减少磁盘I/O。为了达到这个目的,磁盘往往不是严格按需读取,而是每次都会预读,即使只需要一个字节,磁盘也会从这个位置开始,顺序向后读取一定长度的数据放入内存。这样做的理论依据是计算机科学中著名的局部性原理:当一个数据被用到时,其附近的数据也通常会马上被使用。程序运行期间所需要的数据通常比较集中。
由于磁盘顺序读取的效率很高(不需要寻道时间,只需很少的旋转时间),因此对于具有局部性的程序来说,预读可以提高I/O效率。预读的长度一般为页(page)的整倍数。页是计算机管理存储器的逻辑块,硬件及操作系统往往将主存和磁盘存储区分割为连续的大小相等的块,每个存储块称为一页(在许多操作系统中,页得大小通常为4k),主存和磁盘以页为单位交换数据。当程序要读取的数据不在主存中时,会触发一个缺页异常,此时系统会向磁盘发出读盘信号,磁盘会找到数据的起始位置并向后连续读取一页或几页载入内存中,然后异常返回,程序继续运行。
由于磁盘的存取速度与内存之间鸿沟,为了提高效率,要尽量减少磁盘I/O.磁盘往往不是严格按需读取,而是每次都会预读,磁盘读取完需要的数据,会顺序向后读一定长度的数据放入内存。而这样做的理论依据是计算机科学中著名的局部性原理:当一个数据被用到时,其附近的数据也通常会马上被使用,程序运行期间所需要的数据通常比较集中
1.3 索引为什么使用 B+树
一般来说,索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上。这样的话,索引查找过程中就要产生磁盘I/O消耗,相对于内存存取,I/O存取的消耗要高几个数量级,所以评价一个数据结构作为索引的优劣最重要的指标就是在查找过程中磁盘I/O操作次数的渐进复杂度。换句话说,索引的结构组织要尽量减少查找过程中磁盘I/O的存取次数。而B-/+/*Tree,经过改进可以有效的利用系统对磁盘的块读取特性,在读取相同磁盘块的同时,尽可能多的加载索引数据,来提高索引命中效率,从而达到减少磁盘IO的读取次数。
Mysql是一种关系型数据库,区间访问是常见的一种情况,B+树叶节点增加的链指针,加强了区间访问性,可使用在范围区间查询等,而B-树每个节点 key 和 data 在一起,则无法区间查找。
由 B-/B+树看 MySQL索引结构
数据库索引为什么使用B+树?
2. 索引
索引优化是对查询性能优化的最有效手段,它能够轻松地将查询的性能提高几个数量级。
InnoDB 存储引擎在绝大多数情况下使用 B+ 树建立索引,这是关系型数据库中查找最为常用和有效的索引,但是 B+ 树索引并不能找到一个给定键对应的具体值,它只能找到数据行对应的页,然后正如上一节所提到的,数据库把整个页读入到内存中,并在内存中查找具体的数据行。
B+ 树是平衡树,它查找任意节点所耗费的时间都是完全相同的,比较的次数就是 B+ 树的高度;
2.1 聚集索引和辅助索引
数据库中的 B+ 树索引可以分为聚集索引(clustered index)和辅助索引(secondary index),它们之间的最大区别就是,聚集索引中存放着一条行记录的全部信息,而辅助索引中只包含索引列和一个用于查找对应行记录的『书签』。
2.1.1 聚集索引
InnoDB 存储引擎中的表都是使用索引组织的,也就是按照键的顺序存放;该索引中键值的逻辑顺序决定了表中相应行的物理顺序。 聚集索引就是按照表中主键的顺序构建一颗 B+ 树,并在叶节点中存放表中的行记录数据。
在数据库中创建一张表,B+ 树就会使用 id 作为索引的键,并在叶子节点中存储一条记录中的所有信息。
聚集索引对于那些经常要搜索范围值的列特别有效。使用聚集索引找到包含第一个值的行后,便可以确保包含后续索引值的行在物理相邻。例如,如果应用程序执行 的一个查询经常检索某一日期范围内的记录,则使用聚集索引可以迅速找到包含开始日期的行,然后检索表中所有相邻的行,直到到达结束日期。这样有助于提高此 类查询的性能。同样,如果对从表中检索的数据进行排序时经常要用到某一列,则可以将该表在该列上聚集(物理排序),避免每次查询该列时都进行排序,从而节 省成本。
当索引值唯一时,使用聚集索引查找特定的行也很有效率。例如,使用唯一雇员 ID 列 emp_id 查找特定雇员的最快速的方法,是在 emp_id 列上创建聚集索引或 PRIMARY KEY 约束。
2.1.2 辅助索引(非聚集索引)
该索引中索引的逻辑顺序与磁盘上行的物理存储顺序不同。
- 聚集索引一个表只能有一个,而非聚集索引一个表可以存在多个,这个跟没问题没差别,一般人都知道。
- 聚集索引存储记录是物理上连续存在,而非聚集索引是逻辑上的连续,物理存储并不连续,这个大家也都知道。
2.2 索引使用策略及优化
MySQL的优化主要分为结构优化(Scheme optimization)和查询优化(Query optimization)。本章的内容完全基于上文的理论基础,实际上一旦理解了索引背后的机制,那么选择高性能的策略就变成了纯粹的推理,并且可以理解这些策略背后的逻辑。
2.2.1 联合索引及最左前缀原理
a. 联合索引(复合索引)
首先介绍一下联合索引。联合索引其实很简单,相对于一般索引只有一个字段,联合索引可以为多个字段创建一个索引。它的原理也很简单,比如,我们在(a,b,c)字段上创建一个联合索引,则索引记录会首先按照A字段排序,然后再按照B字段排序然后再是C字段,因此,联合索引的特点就是:
- 第一个字段一定是有序的
- 当第一个字段值相等的时候,第二个字段又是有序的,比如下表中当A=2时所有B的值是有序排列的,依次类推,当同一个B值得所有C字段是有序排列的
其实联合索引的查找就跟查字典是一样的,先根据第一个字母查,然后再根据第二个字母查,或者只根据第一个字母查,但是不能跳过第一个字母从第二个字母开始查。这就是所谓的最左前缀原理。
b. 前缀索引
除了联合索引之外,对mysql来说其实还有一种前缀索引。前缀索引就是用列的前缀代替整个列作为索引key,当前缀长度合适时,可以做到既使得前缀索引的选择性接近全列索引,同时因为索引key变短而减少了索引文件的大小和维护开销。
一般来说以下情况可以使用前缀索引:
- 字符串列(varchar,char,text等),需要进行全字段匹配或者前匹配。也就是=‘xxx’ 或者 like ‘xxx%’
- 字符串本身可能比较长,而且前几个字符就开始不相同。比如我们对**人的姓名使用前缀索引就没啥意义,因为**人名字都很短,另外对收件地址使用前缀索引也不是很实用,因为一方面收件地址一般都是以XX省开头,也就是说前几个字符都是差不多的,而且收件地址进行检索一般都是like ’%xxx%’,不会用到前匹配。相反对外国人的姓名可以使用前缀索引,因为其字符较长,而且前几个字符的选择性比较高。同样电子邮件也是一个可以使用前缀索引的字段。
- 前一半字符的索引选择性就已经接近于全字段的索引选择性。如果整个字段的长度为20,索引选择性为0.9,而我们对前10个字符建立前缀索引其选择性也只有0.5,那么我们需要继续加大前缀字符的长度,但是这个时候前缀索引的优势已经不明显,没有太大的建前缀索引的必要了。
2.2.2 索引优化策略
- 最左前缀匹配原则,上面讲到了
- 主键外键一定要建索引
- 对 where,on,group by,order by 中出现的列使用索引
- 尽量选择区分度高的列作为索引,区分度的公式是count(distinct col)/count(*),表示字段不重复的比例,比例越大我们扫描的记录数越少,唯一键的区分度是1,而一些状态、性别字段可能在大数据面前区分度就是0
- 对较小的数据列使用索引,这样会使索引文件更小,同时内存中也可以装载更多的索引键
- 索引列不能参与计算,保持列“干净”,比如from_unixtime(create_time) = ’2014-05-29’就不能使用到索引,原因很简单,b+树中存的都是数据表中的字段值,但进行检索时,需要把所有元素都应用函数才能比较,显然成本太大。所以语句应该写成create_time = unix_timestamp(’2014-05-29’);
- 为较长的字符串使用前缀索引
- 尽量的扩展索引,不要新建索引。比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可
- 不要过多创建索引, 权衡索引个数与DML之间关系,DML也就是插入、删除数据操作。这里需要权衡一个问题,建立索引的目的是为了提高查询效率的,但建立的索引过多,会影响插入、删除数据的速度,因为我们修改的表数据,索引也需要进行调整重建
- 对于like查询,”%”不要放在前面。
SELECT * FROMhoudunwangWHEREunameLIKE'后盾%' -- 走索引
SELECT * FROMhoudunwangWHEREunameLIKE "%后盾%" -- 不走索引 - 查询where条件数据类型不匹配也无法使用索引
字符串与数字比较不使用索引;
CREATE TABLEa(achar(10));
EXPLAIN SELECT * FROMaWHEREa="1" – 走索引
EXPLAIN SELECT * FROM a WHERE a=1 – 不走索引
正则表达式不使用索引,这应该很好理解,所以为什么在SQL中很难看到regexp关键字的原因
2.2.3 索引使用的注意点
- 一般说来,索引应建立在那些将用于JOIN,WHERE判断和ORDER BY排序的字段上。尽量不要对数据库中某个含有大量重复的值的字段建立索引。对于一个ENUM类型的字段来说,出现大量重复值是很有可能的情况。
- 应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描。最好不要给数据库留NULL,尽可能的使用 NOT NULL填充数据库.
- 应尽量避免在 where 子句中使用 != 或 <> 操作符,否则将引擎放弃使用索引而进行全表扫描。
- 应尽量避免在 where 子句中使用 or 来连接条件,如果一个字段有索引,一个字段没有索引,将导致引擎放弃使用索引而进行全表扫描。
- 一般情况下不鼓励使用like操作,如果非使用不可,如何使用也是一个问题。like “%aaa%” 不会使用索引,而like “aaa%”可以使用索引。
数据库索引原理及优化
MySQL优化系列(三)--索引的使用、原理和设计优化
3. 锁
3.1 乐观锁与悲观锁
乐观锁和悲观锁其实都是并发控制的机制,同时它们在原理上就有着本质的差别;
悲观锁
正如其名,它指的是对数据被外界(包括本系统当前的其他事务,以及来自外部系统的事务处理)修改持保守态度(悲观),因此,在整个数据处理过程中,将数据处于锁定状态。 悲观锁的实现,往往依靠数据库提供的锁机制 (也只有数据库层提供的锁机制才能真正保证数据访问的排他性,否则,即使在本系统中实现了加锁机制,也无法保证外部系统不会修改数据)
- 悲观锁的流程
在对任意记录进行修改前,先尝试为该记录加上排他锁(exclusive locking。
如果加锁失败,说明该记录正在被修改,那么当前查询可能要等待或者抛出异常。 具体响应方式由开发者根据实际需要决定。
如果成功加锁,那么就可以对记录做修改,事务完成后就会解锁了。
其间如果有其他对该记录做修改或加排他锁的操作,都会等待我们解锁或直接抛出异常。 - 优点与不足
悲观并发控制实际上是“先取锁再访问”的保守策略,为数据处理的安全提供了保证。但是在效率方面,处理加锁的机制会让数据库产生额外的开销,还有增加产生死锁的机会;另外,在只读型事务处理中由于不会产生冲突,也没必要使用锁,这样做只能增加系统负载;还有会降低了并行性,一个事务如果锁定了某行数据,其他事务就必须等待该事务处理完才可以处理那行数
乐观锁
乐观锁是一种**,它其实并不是一种真正的『锁』,它会先尝试对资源进行修改,在写回时判断资源是否进行了改变,如果没有发生改变就会写回,否则就会进行重试,在整个的执行过程中其实都没有对数据库进行加锁;
它假设多用户并发的事务在处理时不会彼此互相影响,各事务能够在不产生锁的情况下处理各自影响的那部分数据。在提交数据更新之前,每个事务会先检查在该事务读取数据后,有没有其他事务又修改了该数据。如果其他事务有更新的话,正在提交的事务会进行回滚。
- 相对于悲观锁,在对数据库进行处理的时候,乐观锁并不会使用数据库提供的锁机制。一般的实现乐观锁的方式就是记录数据版本。
数据版本,为数据增加的一个版本标识。当读取数据时,将版本标识的值一同读出,数据每更新一次,同时对版本标识进行更新。当我们提交更新的时候,判断数据库表对应记录的当前版本信息与第一次取出来的版本标识进行比对,如果数据库表当前版本号与第一次取出来的版本标识值相等,则予以更新,否则认为是过期数据。
CAS
-
CAS 是项乐观锁技术,当多个线程尝试使用 CAS 同时更新同一个变量时,只有其中一个线程能更新变量的值,而其它线程都失败,失败的线程并不会被挂起,而是被告知这次竞争中失败,并可以再次尝试。
-
CAS 操作包含三个操作数 —— 内存位置(V)、预期原值(A)和新值 (B)。如果内存位置的值与预期原值相匹配,那么处理器会自动将该位置值更新为新值。否则,处理器不做任何操作。无论哪种情况,它都会在 CAS 指令之前返回该位置的值。(在 CAS 的一些特殊情况下将仅返回 CAS 是否成功,而不提取当前值。)CAS 有效地说明了“我认为位置 V 应该包含值 A;如果包含该值,则将 B 放到这个位置;否则,不要更改该位置,只告诉我这个位置现在的值即可。” 这其实和乐观锁的冲突检查 + 数据更新的原理是一样的。
这里再强调一下,乐观锁是一种**。CAS 是这种**的一种实现方式。
-
ABA 问题
-
CAS 算法实现一个重要前提需要取出内存中某时刻的数据,而在下时刻比较并替换,那么在这个时间差类会导致数据的变化。
-
比如说一个线程 one 从内存位置 V 中取出 A,这时候另一个线程 two 也从内存中取出 A,并且 two 进行了一些操作变成了 B,然后 two 又将 V 位置的数据变成 A,这时候线程 one 进行 CAS 操作发现内存中仍然是 A,然后 one 操作成功。尽管线程 one 的 CAS 操作成功,但是不代表这个过程就是没有问题的。
-
部分乐观锁的实现是通过版本号(version)的方式来解决 ABA 问题,乐观锁每次在执行数据的修改操作时,都会带上一个版本号,一旦版本号和数据的版本号一致就可以执行修改操作并对版本号执行+1操作,否则就执行失败。因为每次操作的版本号都会随之增加,所以不会出现 ABA 问题,因为版本号只会增加不会减少。
-
3.2 锁的种类: 共享锁和互斥锁
对数据的操作其实只有两种,也就是读和写,而数据库在实现锁时,也会对这两种操作使用不同的锁;InnoDB 实现了标准的行级锁,也就是共享锁(Shared Lock)和互斥锁(Exclusive Lock);共享锁和互斥锁的作用其实非常好理解:
- 共享锁(读锁):允许事务对一条行数据进行读取;
- 互斥锁(写锁):允许事务对一条行数据进行删除或更新;
而它们的名字也暗示着各自的另外一个特性,共享锁之间是兼容的,而互斥锁与其他任意锁都不兼容:
因为共享锁代表了读操作、互斥锁代表了写操作,所以我们可以在数据库中并行读,但是只能串行写,只有这样才能保证不会发生线程竞争,实现线程安全。
4. 事务与隔离级别
4.1 事务的四个特性 ACID
(1)原子性Atomicity:指整个数据库事务是不可分割的工作单位。只有使据库中所有的操作执行成功,才算整个事务成功;事务中任何一个SQL语句执行失败,那么已经执行成功的SQL语句也必须撤销,数据库状态应该退回到执行事务前的状态。
(2)一致性Correspondence:指数据库事务不能破坏关系数据的完整性以及业务逻辑上的一致性。例如对银行转帐事务,不管事务成功还是失败,应该保证事务结束后ACCOUNTS表中Tom和Jack的存款总额为2000元。
(3)隔离性Isolation:指的是在并发环境中,当不同的事务同时操纵相同的数据时,每个事务都有各自的完整数据空间。由并发事务所做的修改必须与任何其他并发事务所做的修改隔离。事务查看数据更新时,数据所处的状态要么是另一事务修改它之前的状态,要么是另一事务修改它之后的状态,事务不会查看到中间状态的数据。
(4)持久性Durability:指的是只要事务成功结束,它对数据库所做的更新就必须永久保存下来。即使发生系统崩溃,重新启动数据库系统后,数据库还能恢复到事务成功结束时的状态。
4.2 事务实现原理
事务原理可以分几个部分说:acid,事务ACID的实现,事务的隔离级别,InnoDB的日志。
-
隔离性的实现:事务的隔离性由存储引擎的锁来实现。
-
原子性和持久性的实现:
redo log 称为重做日志(也叫事务日志),用来保证事务的原子性和持久性.
redo恢复提交事务修改的页操作,redo是物理日志,页的物理修改操作. -
一致性的实现:
undo log 用来保证事务的一致性. undo 回滚行记录到某个特定版本,undo 是逻辑日志,根据每行记录进行记录.
undo 存放在数据库内部的undo段,undo段位于共享表空间内.
undo 只把数据库逻辑的恢复到原来的样子.
4.3 事务隔离级别
数据库事务的隔离级别有4个,由低到高依次为Read uncommitted(读未提交)、Read committed(读提交)、Repeatable read(重复读)、Serializable(序列化),这四个级别可以逐个解决脏读、不可重复读、幻读这几类问题。
1. READ UNCOMMITTED(未提交读)
事务中的修改,即使没有提交,对其它事务也是可见的. 脏读(Dirty Read).
2. READ COMMITTED(提交读)
一个事务开始时,只能"看见"已经提交的事务所做的修改. 这个级别有时候也叫不可重复读(nonrepeatable read).
3. REPEATABLE READ(可重复读)
该级别保证了同一事务中多次读取到的同样记录的结果是一致的. 但理论上,该事务级别还是无法解决另外一个幻读的问题(Phantom Read).
4. SERIALIZABLE (可串行化)
强制事务串行执行,避免了上面说到的 脏读,不可重复读,幻读 三个的问题.
什么是脏读,不可重复读,幻读
-
脏读 :脏读就是指当一个事务正在访问数据,并且对数据进行了修改,而这种修改还没有提交到数据库中,这时,另外一个事务也访问这个数据,然后使用了这个数据。
公司发工资了,领导把5000元打到长贵的账号上,但是该事务并未提交,而长贵的正好去查看账户,发现工资已经到账,是5000元整,非常高兴。可是不幸的是,领导发现发给长贵的工资金额不对,是2000元,于是迅速回滚了事务,修改金额后,将事务提交,最后长贵实际的工资只有2000元,长贵空欢喜一场。
出现上述情况,即我们所说的脏读,两个并发的事务,“事务A:领导给长贵发工资”、“事务B:长贵查询工资账户”,事务B读取了事务A尚未提交的数据。
-
不可重复读 :是指在一个事务内,多次读同一数据。在这个事务还没有结束时,另外一个事务也访问该同一数据。那么,在第一个事务中的两 次读数据之间,由于第二个事务的修改,那么第一个事务两次读到的的数据可能是不一样的。这样就发生了在一个事务内两次读到的数据是不一样的,因此称为是不 可重复读。例如,一个编辑人员两次读取同一文档,但在两次读取之间,作者重写了该文档。当编辑人员第二次读取文档时,文档已更改。原始读取不可重复。如果 只有在作者全部完成编写后编辑人员才可以读取文档,则可以避免该问题。
长贵拿着工资卡去消费,系统读取到卡里确实有2000元,而此时她的老婆谢大脚也正好在网上转账,把谢大脚把工资卡的2000元转到自己的账户,并在长贵之前提交了事务,当长贵扣款时,系统检查到长贵的工资卡已经没有钱,扣款失败,长贵十分纳闷,明明卡里有钱,为何……
出现上述情况,即我们所说的不可重复读,两个并发的事务,“事务A:长贵消费”、“事务B:长贵的老婆谢大脚网上转账”,事务A事先读取了数据,事务B紧接了更新了数据,并提交了事务,而事务A再次读取该数据时,数据已经发生了改变。
当隔离级别设置为Read committed时,避免了脏读,但是可能会造成不可重复读。大多数数据库的默认级别就是Read committed,比如Sql Server , Oracle。如何解决不可重复读这一问题,请看下一个隔离级别。
当隔离级别设置为Repeatable read时,可以避免不可重复读。当长贵拿着工资卡去消费时,一旦系统开始读取工资卡信息(即事务开始),长贵的老婆就不可能对该记录进行修改,也就是长贵的老婆不能在此时转账。
虽然Repeatable read避免了不可重复读,但还有可能出现幻读。
-
幻读 : 是指当事务不是独立执行时发生的一种现象,例如第一个事务对一个表中的数据进行了修改,这种修改涉及到表中的全部数据行。 同时,第二个事务也修改这个表中的数据,这种修改是向表中插入一行新数据。那么,以后就会发生操作第一个事务的用户发现表中还有没有修改的数据行,就好象 发生了幻觉一样。例如,一个编辑人员更改作者提交的文档,但当生产部门将其更改内容合并到该文档的主复本时,发现作者已将未编辑的新材料添加到该文档中。 如果在编辑人员和生产部门完成对原始文档的处理之前,任何人都不能将新材料添加到文档中,则可以避免该问题。
谢大脚查看长贵的工资卡消费记录。有一天,她正在查询到长贵当月信的总消费金额(select sum(amount) from transaction where month = 本月)为80元,而长贵此时正好在外面胡吃海塞后在收银台买单,消费1000元,即新增了一条1000元的消费记录(insert transaction … ),并提交了事务,随后谢大脚将长贵当月消费的明细打印到A4纸上,却发现消费总额为1080元,谢大脚很诧异,以为出现了幻觉,幻读就这样产生了。
简单的说,幻读指当用户读取某一范围的数据行时(不是同一行数据),另一个事务又在该范围内插入了新行,当用户再读取该范围的数据行时,会发现有新的“幻影” 行。
5. MVCC(TODO)
https://blog.csdn.net/tangkund3218/article/details/47704527
6. 其他基本概念
-
第一范式(1NF)
数据库表中的字段都是单一属性的,不可再分。这个单一属性由基本类型构成,包括整型、实数、字符型、逻辑型、日期型等。在当前的任何关系数据库管理系统(DBMS)中,傻瓜也不可能做出不符合第一范式的数据库,因为这些DBMS不允许你把数据库表的一列再分成二列或多列。因此,你想在现有的DBMS中设计出不符合第一范式的数据库都是不可能的。 -
第二范式(2NF)
首先我们考虑,把所有这些信息放到一个表中(学号,学生姓名、年龄、性别、课程、课程学分、系别、学科成绩,系办地址、系办电话)下面存在如下的依赖关系。
(学号, 课程名称) → (姓名, 年龄, 成绩, 学分)- 问题分析
因此不满足第二范式的要求,会产生如下问题:
数据冗余:同一门课程由n个学生选修,"学分"就重复n-1次;同一个学生选修了m门课程,姓名和年龄就重复了m-1次。 - 更新异常:
1)若调整了某门课程的学分,数据表中所有行的"学分"值都要更新,否则会出现同一门课程学分不同的情况。
2)假设要开设一门新的课程,暂时还没有人选修。这样,由于还没有"学号"关键字,课程名称和学分也无法记录入数据库。 - 删除异常 :假设一批学生已经完成课程的选修,这些选修记录就应该从数据库表中删除。但是,与此同时,课程名称和学分信息也被删除了。很显然,这也会导致插入异常。
- 解决方案
把选课关系表SelectCourse改为如下三个表:
学生:Student(学号,姓名,年龄,性别,系别,系办地址、系办电话);
课程:Course(课程名称,学分);
选课关系:SelectCourse(学号,课程名称,成绩)。
- 问题分析
-
第三范式(3NF)
接着看上面的学生表Student(学号,姓名,年龄,性别,系别,系办地址、系办电话),关键字为单一关键字"学号",因为存在如下决定关系:
(学号)→ (姓名,年龄,性别,系别,系办地址、系办电话
但是还存在下面的决定关系:
(学号) → (系别)→(系办地点,系办电话)
即存在非关键字段"系办地点"、"系办电话"对关键字段"学号"的传递函数依赖。
它也会存在数据冗余、更新异常、插入异常和删除异常的情况。
根据第三范式把学生关系表分为如下两个表就可以满足第三范式了:
学生:(学号,姓名,年龄,性别,系别);
系别:(系别,系办地址、系办电话)。
上面的数据库表就是符合I,Ⅱ,Ⅲ范式的,消除了数据冗余、更新异常、插入异常和删除异常。 -
笛卡儿积
假设集合A={a,b},集合B={0,1,2},则两个集合的笛卡尔积为{(a,0),(a,1),(a,2),(b,0),(b,1), (b,2)}。 -
binlog
Mysql binlog 查看方法 -
varchar和char 的区别
char是一种固定长度的类型,varchar则是一种可变长度的类型,它们的区别是: char(M)类型的数据列里,每个值都占用M个字节,如果某个长度小于M,MySQL就会在它的右边用空格字符补足.(在检索操作中那些填补出来的空格字符将被去掉)在varchar(M)类型的数据列里,每个值只占用刚好够用的字节再加上一个用来记录其长度的字节(即总长度为L+1字节). -
数据库连接池实现原理
-
一个数据库连接对象均对应一个物理数据库连接,每次操作都打开一个物理连接,使用完都关闭连接,这样造成系统的 性能低下。 数据库连接池的解决方案是在应用程序启动时建立足够的数据库连接,并讲这些连接组成一个连接池(简单说:在一个“池”里放了好多半成品的数据库联接对象),由应用程序动态地对池中的连接进行申请、使用和释放。对于多于连接池中连接数的并发请求,应该在请求队列中排队等待。并且应用程序可以根据池中连接的使用率,动态增加或减少池中的连接数。
-
连接池的工作原理主要由三部分组成,分别为连接池的建立、连接池中连接的使用管理、连接池的关闭。
第一、连接池的建立。一般在系统初始化时,连接池会根据系统配置建立,并在池中创建了几个连接对象,以便使用时能从连接池中获取。连接池中的连接不能随意创建和关闭,这样避免了连接随意建立和关闭造成的系统开销。Java中提供了很多容器类可以方便的构建连接池,例如Vector、Stack等。
第二、连接池的管理。连接池管理策略是连接池机制的核心,连接池内连接的分配和释放对系统的性能有很大的影响。其管理策略是:
当客户请求数据库连接时,首先查看连接池中是否有空闲连接,如果存在空闲连接,则将连接分配给客户使用;如果没有空闲连接,则查看当前所开的连接数是否已经达到最大连接数,如果没达到就重新创建一个连接给请求的客户;如果达到就按设定的最大等待时间进行等待,如果超出最大等待时间,则抛出异常给客户。
当客户释放数据库连接时,先判断该连接的引用次数是否超过了规定值,如果超过就从连接池中删除该连接,否则保留为其他客户服务。
该策略保证了数据库连接的有效复用,避免频繁的建立、释放连接所带来的系统资源开销。第三、连接池的关闭。当应用程序退出时,关闭连接池中所有的连接,释放连接池相关的资源,该过程正好与创建相反。
-
7. Mysql性能提升
7.1 sql语句效率提升(TODO)
https://jianshu.com/p/5dd73a35d70f
7.2 其他
- 搜索引擎的选取,MySQL默认innodb(支持事务),可以选择MYISAM(有b-tree算法查询)还有其他不同引擎
- 服务器的硬件提升
- 索引方面
- 建表的时候尽量使用notnull
- 字段尽量固定长度
- 垂直分隔(将很多字段多分成几张表),水平分隔(将大数据的表分成几个小的数量级,分成几张表,还可以分开放在几个数据库中,利用集群的**)
- 优化sql语句(查询执行速度比较慢的sql语句))
- 添加适当存储过程,触发器,事务等
- 表的设计要符合三范式。
- 读写分离(主从数据库)
8. NOSQL
8.1 MongoDB
- mongodb的缺点
mongodb不支持事务操作;mongodb占用空间过大;无法进行关联表查询,不适用于关系多的数据; - 优点:更能保证用户的访问速度;文档结构的存储方式,能够更便捷的获取数据;内置GridFS,支持大容量的存储
8.2 Redis
五、Java
5.1 基本知识
Java的Integer和int有什么区别
-
最基本的一点区别是:Ingeter是int的包装类,int的初值为0,Ingeter的初值为null。
-
无论如何,Integer与new Integer不会相等。不会经历拆箱过程,new出来的对象存放在堆,而非new的Integer常量则在常量池(在方法区),他们的内存地址不一样,所以为false。
-
两个都是非new出来的Integer,如果数在-128到127之间,则是true,否则为false。因为java在编译Integer i2 = 128的时候,被翻译成:Integer i2 = Integer.valueOf(128);而valueOf()函数会对-128到127之间的数进行缓存。
-
两个都是new出来的,都为false。还是内存地址不一样。
-
int和Integer(无论new否)比,都为true,因为会把Integer自动拆箱为int再去比。
Java中equals和==的区别
- ==可以用来比较基本类型和引用类型,判断内容和内存地址
- equals只能用来比较引用类型,它只判断内容。该函数存在于老祖宗类 java.lang.Object
java中的数据类型,可分为两类:
1.基本数据类型,也称原始数据类型。byte,short,char,int,long,float,double,boolean
他们之间的比较,应用双等号(==),比较的是他们的值。
2.复合数据类型(类)
当他们用(==)进行比较的时候,比较的是他们在内存中的存放地址,
所以,除非是同一个new出来的对象,他们的比较后的结果为true,否则比较后结果为false。
java在静态类中能引用非静态方法吗
- 不能,但main是个例外
- 首先static的成员是在类加载的时候初始化的,JVM的CLASSLOADER的加载,首次主动使用加载,而非static的成员是在创建对象的时候,即new 操作的时候才初始化的;
- 先后顺序是先加载,才能初始化,那么加载的时候初始化static的成员,此时非static的成员还没有被加载必然不能使用,而非static的成员是在类加载之后,通过new操作符创建对象的时候初始化,此时static 已经分配内存空间,所以可以访问!
- 简单点说:静态成员属于类,不需要生成对象就存在了.而非静态需要生成对象才产生.所以静态成员不能直接访问非静态.
面向对象的三个基本特征
-
面向对象的三个基本特征是:封装、继承、多态。
-
封装,也就是把客观事物封装成抽象的类,并且类可以把自己的数据和方法只让可信的类或者对象操作,对不可信的进行信息隐藏。
-
继承是指这样一种能力:它可以使用现有类的所有功能,并在无需重新编写原来的类的情况下对这些功能进行扩展。
继承概念的实现方式有三类:实现继承、接口继承和可视继承。- 实现继承是指使用基类的属性和方法而无需额外编码的能力;
- 接口继承是指仅使用属性和方法的名称、但是子类必须提供实现的能力;
- 可视继承是指子窗体(类)使用基窗体(类)的外观和实现代码的能力。
在考虑使用继承时,有一点需要注意,那就是两个类之间的关系应该是“属于”关系。例如,Employee 是一个人,Manager 也是一个人,因此这两个类都可以继承 Person 类。但是 Leg 类却不能继承 Person 类,因为腿并不是一个人。
-
多态,有二种方式,覆盖,重载。
- 覆盖,是指子类重新定义父类的虚函数的做法。
- 重载,是指允许存在多个同名函数,而这些函数的参数表不同(或许参数个数不同,或许参数类型不同,或许两者都不同)。
重载的实现是:编译器根据函数不同的参数表,对同名函数的名称做修饰,然后这些同名函数就成了不同的函数。对于这两个函数的调用,在编译器间就已经确定了,是静态的。
-
我们知道,封装可以隐藏实现细节,使得代码模块化;继承可以扩展已存在的代码模块(类);它们的目的都是为了——代码重用。而 多态 则是为了实现另一个目的——接口重用!多态的作用,就是为了类在继承和派生的时候,保证使用“家谱”中任一类的实例的某一属性时的正确调用。

构造器的调用顺序
- 父类静态代码块
- 子类静态代码块
- 父类代码块
- 父类构造
- 子类代码块
- 子类构造
java 子类继承父类运行顺序
抽象类和接口的区别
- 抽象类是用来捕捉子类的通用特性的 。它不能被实例化,只能被用作子类的超类。抽象类是被用来创建继承层级里子类的模板。
- 接口是抽象方法的集合。如果一个类实现了某个接口,那么它就继承了这个接口的抽象方法。这就像契约模式,如果实现了这个接口,那么就必须确保使用这些方法。
- 什么时候使用抽象类和接口
- 如果你拥有一些方法并且想让它们中的一些有默认实现,那么使用抽象类吧。
- 如果你想实现多重继承,那么你必须使用接口。由于Java不支持多继承,子类不能够继承多个类,但可以实现多个接口。因此你就可以使用接口来解决它。
- 如果基本功能在不断改变,那么就需要使用抽象类。如果不断改变基本功能并且使用接口,那么就需要改变所有实现了该接口的类。
- 抽象类和接口有什么区别,什么情况下会使用抽象类和什么情况你会使用接口
匿名内部类
-
类名规则 定位$1
- test方法中的匿名内部类的名字被起为 Test$1
-
Anonymous Inner Class (匿名内部类)是否可以extends(继承)其它类,是否可以implements(实现)interface(接口)?
- 可以继承其他类或实现其他接口。不仅是可以,而是必须!
匿名内部类
- 可以继承其他类或实现其他接口。不仅是可以,而是必须!
5.2 String相关
String、StringBuffer以及StringBuilder的区别
-
for(int i=0;i<10000;i++){string += "hello";这句 string += “hello”;的过程相当于将原有的string变量指向的对象内容取出与”hello”作字符串相加操作再存进另一个新的String对象当中,再让string变量指向新生成的对象。整个循环的执行过程,并且每次循环会new出一个StringBuilder对象,然后进行append操作,最后通过toString方法返回String对象。也就是说这个循环执行完毕new出了10000个对象,试想一下,如果这些对象没有被回收,会造成多大的内存资源浪费。 -
那么有人会问既然有了StringBuilder类,为什么还需要StringBuffer类?查看源代码便一目了然,事实上,StringBuilder和StringBuffer类拥有的成员属性以及成员方法基本相同,区别是StringBuffer类的成员方法前面多了一个关键字:synchronized,不用多说,这个关键字是在多线程访问时起到安全保护作用的,也就是说StringBuffer是线程安全的。
在java中String类为什么要设计成final
首先String类是用final关键字修饰,这说明String不可继承。再看下面,String类的主力成员字段value是个char[ ]数组,而且是用final修饰的。final修饰的字段创建以后就不可改变。
1. 为了安全
在hashmap等映射时体现。
2. 不可变性支持线程安全
还有一个大家都知道,就是在并发场景下,多个线程同时读一个资源,是不会引发竟态条件的。只有对资源做写操作才有危险。不可变对象不能被写,所以线程安全。
3. 不可变性支持字符串常量池
最后别忘了String另外一个字符串常量池的属性。像下面这样字符串one和two都用字面量"something"赋值。它们其实都指向同一个内存地址。
String.GetHashCode()复杂度
-
如果两个字符串对象是否相等,GetHashCode方法返回相同的值。 但是,有不为每个唯一字符串值是唯一的哈希代码值。 不同的字符串可以返回相同的哈希代码。
-
Java的实现
- 可以看到String的hashCode还是很简单的 复杂度为O(n)
public int hashCode() { int h = hash; if (h == 0 && value.length > 0) { char val[] = value; for (int i = 0; i < value.length; i++) { h = 31 * h + val[i]; } hash = h; } return h; }
科普:为什么 String hashCode 方法选择数字31作为乘子
31可以被 JVM 优化,31 * i = (i << 5) - i
String不变性
-
一旦字符串在内存(堆)中创建就不会被改变。记住:所有的String方法都不是改变字符串本身,而是创建一个新的字符串。
-
如果需要自身可以改变的字符串则可以使用StringBuilder和StringBuffer,否则就会浪费大量的时间在垃圾回收上。
String驻留池
对于以下代码:
String s1="abc"; String s2="abc";总共创建了几个对象?答案是一个,这两个字符串,我们在使用的时候,它们在内容上没有任何区别,更没有理由使用两份对象,所以 JVM对字符串对象的创建作了一个优化,即使用了驻留池技术,当String s1="abc";时,JVM首先会在驻留池寻找,是否存在“abc”这样的一个值,当然刚开始显然是不存在的,所以JVM会在驻留池创建一个对象保存这个字符串,当再次出现String s2="abc";时,这是JVM会在驻留池寻找是否存在“abc”这样的一个值,当然,这个时候已经存在了,所以JVM会把保存该字符串对象的引用直接返回给s2,这样就避免了重复创建对象,减少了内存的开销。
那么对于这句代码:Sting str=new String("abc");
不妨这样写
String s="abc"; String str=new String(s);先定义一个字符串常量,然后用这个字符串常量作为字符串构造方法的参数再new出一个字符串出来。在定义字符串常量“abc”时,JVM会在 驻留池里创建出一个对象 来保存“abc”(注意这个对象 不是被new出来的,所以不会被放在堆中 )当再用s作为构造参数new出一个对象时,会被放在堆内存中,所以一共创建了两个对象。
-
习题:
String str = new String ("King");问: 这句话创建了几个对象?- 答案:2个;一个由new 在堆区产生,另一个在驻留池中产生。
5.3 数据结构
List --> ArrayList / LinkedList / Vector
在Java中List接口有3个常用的实现类,分别是ArrayList、LinkedList、Vector。
-
ArrayList内部存储的数据结构是数组存储。数组的特点:元素可以快速访问。每个元素之间是紧邻的不能有间隔,缺点:数组空间不够元素存储需要扩容的时候会开辟一个新的数组把旧的数组元素拷贝过去,比较消性能。从ArrayList中间位置插入和删除元素,都需要循环移动元素的位置,因此数组特性决定了数组的特点:适合随机查找和遍历,不适合经常需要插入和删除操作。
-
Vector内部实现和ArrayList一样都是数组存储,最大的不同就是它支持线程的同步,所以访问比ArrayList慢,但是数据安全,所以对元素的操作没有并发操作的时候用ArrayList比较快。
-
LinkedList内部存储用的数据结构是链表。链表的特点:适合动态的插入和删除。访问遍历比较慢。另外不支持get,remove,insertList方法。可以当做堆栈、队列以及双向队列使用。LinkedList是线程不安全的。所以需要同步的时候需要自己手动同步,比较费事,可以使用提供的集合工具类实例化的时候同步:具体使用List springokList=Collections.synchronizedCollection(new 需要同步的类)
Map --> HashMap / ConcurrentHashMap / TreeMap / LinkedHashMap
1. HashMap
1.1 结构与参数
系统在初始化HashMap时,会创建一个 长度为 capacity 的 Entry 数组,这个数组里可以存储元素的位置被称为“桶(bucket)”,每个 bucket 都有其指定索引,系统可以根据其索引快速访问该 bucket 里存储的元素。
在HashMap中有两个很重要的参数,容量(Capacity)和负载因子(Load factor):
Capacity就是buckets的数目,Load factor就是buckets填满程度的最大比例。如果对迭代性能要求很高的话不要把
capacity设置过大,也不要把load factor设置过小。当bucket填充的数目(即hashmap中元素的个数)大于capacity*load factor时就需要调整buckets的数目为当前的2倍。
无论何时,HashMap 的每个“桶”只存储一个元素(也就是一个 Entry),由于 Entry 对象可以包含一个引用变量(就是 Entry 构造器的的最后一个参数)用于指向下一个 Entry,
因此可能出现的情况是:HashMap 的 bucket 中只有一个 Entry,但这个 Entry 指向另一个 Entry ——这就形成了一个 Entry 链。(也就是冲突了)
当 HashMap 的每个 bucket 里存储的 Entry 只是单个 Entry ——也就是没有通过指针产生 Entry 链时(没有哈希冲突),此时的 HashMap 具有最好的性能:当程序通过 key 取出对应 value 时,系统只要先计算出该 key 的 hashCode() 返回值,在根据该 hashCode 返回值找出该 key 在 table 数组中的索引,然后取出该索引处的 Entry,最后返回该 key 对应的 value 即可。
在发生“Hash 冲突”的情况下,单个 bucket 里存储的不是一个 Entry,而是一个 Entry 链,系统只能必须按顺序遍历每个 Entry,直到找到想搜索的 Entry 为止——如果恰好要搜索的 Entry 位于该 Entry 链的最末端(该 Entry 是最早放入该 bucket 中),那系统必须循环到最后才能找到该元素。
当创建 HashMap 时,有一个默认的负载因子(load factor),其默认值为 0.75,这是时间和空间成本上一种折衷:增大负载因子可以减少 Hash 表(就是那个 Entry 数组)所占用的内存空间,但会增加查询数据的时间开销,而查询是最频繁的的操作(HashMap 的 get() 与 put() 方法都要用到查询);减小负载因子会提高数据查询的性能,但会增加 Hash 表所占用的内存空间。 通常情况下,程序员无需改变负载因子的值。
1.2 put()函数的实现
put函数大致的思路为:
- 对key的hashCode()做hash,然后再计算index;
- 如果没碰撞直接放到bucket里;
- 如果碰撞了,以链表的形式存在buckets后;
- 如果碰撞导致链表过长(大于等于TREEIFY_THRESHOLD),就把链表转换成红黑树参考此链接:Java 8:HashMap的性能提升;
- 如果节点已经存在就替换old value(保证key的唯一性)
- 如果bucket满了(超过load factor*current capacity),就要resize。
1.3 get()函数的实现
大致思路如下:
- bucket里的第一个节点,直接命中;
- 如果有冲突,则通过key.equals(k)去查找对应的entry
- 若为树,则在树中通过key.equals(k)查找,O(logn);
- 若为链表,则在链表中通过key.equals(k)查找,O(n)。
1.4 hash函数的实现
过程如下图:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}高16bit不变,低16bit和高16bit做了一个异或。
这样的一个hash函数实现,主要是权衡了速度与碰撞率。
设计者还解释到因为现在大多数的hashCode的分布已经很不错了,就算是发生了碰撞也用
O(logn)的tree去做了。仅仅异或一下,既减少了系统的开销,也不会造成的因为高位没有参与下标的计算(table长度比较小时),从而引起的碰撞。
如果发生了碰撞:
在Java 8之前的实现中是用链表解决冲突的,在产生碰撞的情况下,进行get时,两步的时间复杂度是O(1)+O(n)。因此,当碰撞很厉害的时候n很大,O(n)的速度显然是影响速度的。
因此在Java 8中,利用红黑树替换链表,这样复杂度就变成了O(1)+O(logn)了,这样在n很大的时候,能够比较理想的解决这个问题,在Java 8:HashMap的性能提升一文中有性能测试的结果。
注意:hash和计算下标是不一样的,hash是计算下标过程的一部分
1.5 RESIZE 的实现
当put时,如果发现目前的bucket占用程度已经超过了Load Factor所希望的比例,为了减少碰撞率,就会执行resize。resize的过程,简单的说就是把bucket扩充为2倍,之后重新计算index,把节点再放到新的bucket中。
怎么理解呢?例如我们从16扩展为32时,具体的变化如下所示:
因此元素在重新计算hash之后,因为n变为2倍,那么n-1的mask范围在高位多1bit(红色),因此新的index就会发生这样的变化:
因此,我们在扩充HashMap的时候,不需要重新计算hash,只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成“原索引+oldCap”。可以看看下图为16扩充为32的resize示意图:
这个设计确实非常的巧妙,既省去了重新计算hash值的时间,而且同时,由于新增的1bit是0还是1可以认为是随机的,因此resize的过程,均匀的把之前的冲突的节点分散到新的bucket了。
1.6 Hashmap为什么容量是2的幂次
最理想的效果是,Entry数组中每个位置都只有一个元素,这样,查询的时候效率最高,不需要遍历单链表,也不需要通过equals去比较K,而且空间利用率最大。那如何计算才会分布最均匀呢?我们首先想到的就是%运算,哈希值%容量=bucketIndex。
static int indexFor(int h, int length) {
return h & (length-1);
} 这个等式实际上可以推理出来,2^n转换成二进制就是1+n个0,减1之后就是0+n个1,如16 -> 10000,15 -> 01111,那根据&位运算的规则,都为1(真)时,才为1,那0≤运算后的结果≤15,假设h <= 15,那么运算后的结果就是h本身,h >15,运算后的结果就是最后三位二进制做&运算后的值,最终,就是%运算后的余数,我想,这就是容量必须为2的幂的原因。
1.7 总结
1. 什么是HashMap?你为什么用到它?
是基于Map接口的实现,存储键值对时,它可以接收null的键值,是非同步的,HashMap存储着Entry(hash, key, value, next)对象。
2. 你知道HashMap的工作原理吗?
通过hash的方式,以键值对<K,V>的方式存储(put)、获取(get)对象。存储对象时,我们将K/V传给put方法时,它调用hashCode计算hash从而得到bucket位置,进一步存储,HashMap会根据当前bucket的占用情况自动调整容量(超过Load Facotr则resize为原来的2倍)。获取对象时,我们将K传给get,它调用hashCode计算hash从而得到bucket位置,并进一步调用equals()方法确定键值对。如果发生碰撞的时候,Hashmap通过链表将产生碰撞冲突的元素组织起来,在Java 8中,如果一个bucket中碰撞冲突的元素超过某个限制(默认是8),则使用红黑树来替换链表,从而提高速度。
3. 你知道get和put的原理吗?equals()和hashCode()的都有什么作用?
通过对key的hashCode()进行hashing,并计算下标( n-1 & hash),从而获得buckets的位置。如果产生碰撞,则利用key.equals()方法去链表或树中去查找对应的节点。
4. 你知道hash的实现吗?为什么要这样实现?
在Java 1.8的实现中,是通过hashCode()的高16位异或低16位实现的:(h = k.hashCode()) ^ (h >>> 16),主要是从速度、功效、质量来考虑的,这么做可以在bucket的n比较小的时候,也能保证考虑到高低bit都参与到hash的计算中,同时不会有太大的开销。
5. 如果HashMap的大小超过了负载因子(load factor)定义的容量,怎么办?
如果超过了负载因子(默认0.75),则会重新resize一个原来长度两倍的HashMap,并且重新调用hash方法。
6. 什么是哈希冲突?如何解决的?
以Entry[]数组实现的哈希桶数组,用Key的哈希值取模桶数组的大小可得到数组下标。
插入元素时,如果两条Key落在同一个桶(比如哈希值1和17取模16后都属于第一个哈希桶),我们称之为哈希冲突。
JDK的做法是链表法,Entry用一个next属性实现多个Entry以单向链表存放。查找哈希值为17的key时,先定位到哈希桶,然后链表遍历桶里所有元素,逐个比较其Hash值然后key值。
在JDK8里,新增默认为8的阈值,当一个桶里的Entry超过閥值,就不以单向链表而以红黑树来存放以加快Key的查找速度。
当然,最好还是桶里只有一个元素,不用去比较。所以默认当Entry数量达到桶数量的75%时,哈希冲突已比较严重,就会成倍扩容桶数组,并重新分配所有原来的Entry。扩容成本不低,所以也最好有个预估值。
7. HashMap在高并发下引起的死循环
- HashMap进行存储时,如果size超过当前最大容量*负载因子时候会发生resize。
- 而这段代码中又调用了transfer()方法,而这个方法实现的机制就是将每个链表转化到新链表,并且链表中的位置发生反转,而这在多线程情况下是很容易造成链表回路,从而发生get()死循环
- 链表头插法的会颠倒原来一个散列桶里面链表的顺序。在并发的时候原来的顺序被另外一个线程a颠倒了,而被挂起线程b恢复后拿扩容前的节点和顺序继续完成第一次循环后,又遵循a线程扩容后的链表顺序重新排列链表中的顺序,最终形成了环。
- 假如有两个线程P1、P2,以及链表 a=》b=》null
- P1先执行,执行完"Entry<K,V> next = e.next;"代码后发生阻塞,或者其他情况不再执行下去,此时e=a,next=b
- 而P2已经执行完整段代码,于是当前的新链表newTable[i]为b=》a=》null
- P1又继续执行"Entry<K,V> next = e.next;"之后的代码,则执行完"e=next;"后,newTable[i]为a《=》b,则造成回路,while(e!=null)一直死循环
2. ConcurrentHashMap
ConcurrentHashMap 同样也分为 1.7 、1.8 版,两者在实现上略有不同。
【1.7】
原理上来说:ConcurrentHashMap 采用了分段锁技术,其中 Segment 继承于 ReentrantLock。不会像 HashTable 那样不管是 put 还是 get 操作都需要做同步处理,理论上 ConcurrentHashMap 支持 CurrencyLevel (Segment 数组数量)的线程并发。每当一个线程占用锁访问一个 Segment 时,不会影响到其他的 Segment。

PUT
在put时,首先是通过 key 定位到 Segment,之后在对应的 Segment 中进行具体的 put。
虽然 HashEntry 中的 value 是用 volatile 关键词修饰的,但是并不能保证并发的原子性,所以 put 操作时仍然需要加锁处理。
首先第一步的时候会尝试获取锁,如果获取失败肯定就有其他线程存在竞争,则利用 scanAndLockForPut() 自旋获取锁
GET
get 逻辑比较简单:
只需要将 Key 通过 Hash 之后定位到具体的 Segment ,再通过一次 Hash 定位到具体的元素上。
由于 HashEntry 中的 value 属性是用 volatile 关键词修饰的,保证了内存可见性,所以每次获取时都是最新值。
ConcurrentHashMap 的 get 方法是非常高效的,因为整个过程都不需要加锁。
【1.8】
看起来是不是和 1.8 HashMap 结构类似?
其中 抛弃了原有的 Segment 分段锁 ,而采用了 CAS + synchronized 来保证并发安全性。

PUT
- 根据 key 计算出 hashcode 。
- 判断是否需要进行初始化。
- f 即为当前 key 定位出的 Node,如果为空表示当前位置可以写入数据,利用 CAS 尝试写入,失败则自旋保证成功。
- 如果当前位置的 hashcode == MOVED == -1,则需要进行扩容。
- 如果都不满足,则利用 synchronized 锁写入数据。
- 如果数量大于 TREEIFY_THRESHOLD 则要转换为红黑树
GET
- 根据计算出来的 hashcode 寻址,如果就在桶上那么直接返回值。
- 如果是红黑树那就按照树的方式获取值。
- 就不满足那就按照链表的方式遍历获取值。
3. 使用LinkedHashMap设计实现一个LRU Cache
实际上就是 HashMap 和 LinkedList 两个集合类的存储结构的结合。在 LinkedHashMapMap 中,所有 put 进来的 Entry 都保存在哈希表中,但它又额外定义了一个 head 为头结点的空的双向循环链表,每次 put 进来 HashMapEntry ,除了将其保存到对哈希表中对应的位置上外,还要将其插入到双向循环链表的尾部。
public class LRUCache{
private int capacity;
private Map<Integer, Integer> cache;
public LRUCache(int capacity) {
this.capacity = capacity;
this.cache = new LinkedHashMap<Integer, Integer> (capacity, (float) 0.75, true){
@Override
protected boolean removeEldestEntry(Map.Entry<Integer, Integer> eldest) {
return size() > capacity;
}
};
}
public void set(int key, int value){
cache.put(key, value);
}
public int get(int key){
if(cache.containsKey(key))
return cache.get(key);
return -1;
}Set --> HashSet / TreeSet(TODO)
5.4 多线程 并发
JAVA多线程之线程间的通信方式
- 同步
这里讲的同步是指多个线程通过synchronized关键字这种方式来实现线程间的通信。
由于线程A和线程B持有同一个MyObject类的对象object,尽管这两个线程需要调用不同的方法,但是它们是同步执行的,比如:线程B需要等待线程A执行完了methodA()方法之后,它才能执行methodB()方法。这样,线程A和线程B就实现了 通信。
这种方式,本质上就是“共享内存”式的通信。多个线程需要访问同一个共享变量,谁拿到了锁(获得了访问权限),谁就可以执行。 - while轮询的方式
这种方式下,线程A不断地改变条件,线程ThreadB不停地通过while语句检测这个条件(list.size()==5)是否成立 ,从而实现了线程间的通信。但是这种方式会浪费CPU资源。 - wait/notify机制
A,B之间如何通信的呢?也就是说,线程A如何知道 list.size() 已经为5了呢?
这里用到了Object类的 wait() 和 notify() 方法。
当条件未满足时(list.size() !=5),线程A调用wait() 放弃CPU,并进入阻塞状态。---不像②while轮询那样占用CPU
当条件满足时,线程B调用 notify()通知 线程A,所谓通知线程A,就是唤醒线程A,并让它进入可运行状态。
这种方式的一个好处就是CPU的利用率提高了。
但是也有一些缺点:比如,线程B先执行,一下子添加了5个元素并调用了notify()发送了通知,而此时线程A还执行;当线程A执行并调用wait()时,那它永远就不可能被唤醒了。因为,线程B已经发了通知了,以后不再发通知了。这说明:通知过早,会打乱程序的执行逻辑。 - 管道通信
而管道通信,更像消息传递机制,也就是说:通过管道,将一个线程中的消息发送给另一个。
线程池ThreadPoolExecutor参数设置
- ThreadPoolExecutor类可设置的参数主要有:
- corePoolSize
核心线程数,核心线程会一直存活,即使没有任务需要处理。当线程数小于核心线程数时,即使现有的线程空闲,线程池也会优先创建新线程来处理任务,而不是直接交给现有的线程处理。核心线程在allowCoreThreadTimeout被设置为true时会超时退出,默认情况下不会退出。
- maxPoolSize
当线程数大于或等于核心线程,且任务队列已满时,线程池会创建新的线程,直到线程数量达到maxPoolSize。如果线程数已等于maxPoolSize,且任务队列已满,则已超出线程池的处理能力,线程池会拒绝处理任务而抛出异常。
- keepAliveTime
当线程空闲时间达到keepAliveTime,该线程会退出,直到线程数量等于corePoolSize。如果allowCoreThreadTimeout设置为true,则所有线程均会退出直到线程数量为0。
- allowCoreThreadTimeout
是否允许核心线程空闲退出,默认值为false。
- queueCapacity
任务队列容量。从maxPoolSize的描述上可以看出,任务队列的容量会影响到线程的变化,因此任务队列的长度也需要恰当的设置。
内存可见性与volatile 关键字
线程在工作时,需要将主内存中的数据拷贝到工作内存中。这样对数据的任何操作都是基于工作内存(效率提高),并且不能直接操作主内存以及其他线程工作内存中的数据,之后再将更新之后的数据刷新到主内存中。
这里所提到的主内存可以简单认为是堆内存,而工作内存则可以认为是栈内存。
所以在并发运行时可能会出现线程 B 所读取到的数据是线程 A 更新之前的数据。
显然这肯定是会出问题的,因此 volatile 的作用出现了:
当一个变量被 volatile 修饰时,任何线程对它的写操作都会立即刷新到主内存中,并且会强制让缓存了该变量的线程中的数据清空,必须从主内存重新读取最新数据。
volatile 修饰之后并不是让线程直接从主内存中获取数据,依然需要将变量拷贝到工作内存中。
-
内存可见性的应用
当我们需要在两个线程间依据主内存通信时,通信的那个变量就必须的用 volatile 来修饰:
主线程在修改了标志位使得线程 A 立即停止,如果没有用 volatile 修饰,就有可能出现延迟。
这里要重点强调,volatile 并不能保证线程安全性! -
指令重排
内存可见性只是 volatile 的其中一个语义,它还可以防止 JVM 进行指令重排优化。
举一个伪代码:int a=10 ;//1int b=20 ;//2int c= a+b ;//3
一段特别简单的代码,理想情况下它的执行顺序是:1>2>3。但有可能经过 JVM 优化之后的执行顺序变为了 2>1>3。
可以发现不管 JVM 怎么优化,前提都是保证单线程中最终结果不变的情况下进行的。
这里就能看出问题了,当 flag 没有被 volatile 修饰时,JVM 对 1 和 2 进行重排,导致 value 都还没有被初始化就有可能被线程 B 使用了。
所以加上 volatile 之后可以防止这样的重排优化,保证业务的正确性。
synchronized的实现原理
- synchronized可以保证方法或者代码块在运行时,同一时刻只有一个方法可以进入到临界区,同时它还可以保证共享变量的内存可见性
- 当一个线程访问同步代码块时,它首先是需要得到锁才能执行同步代码,当退出或者抛出异常时必须要释放锁.
- 锁的机制可以参考互斥锁自旋锁。
- 链接
- Java中synchronized的实现原理与应用(详细)
应用方式
- synchronized关键字最主要有以下3种应用方式,下面分别介绍
- 修饰实例方法,作用于当前实例加锁,进入同步代码前要获得当前实例的锁
- 修饰静态方法,作用于当前类对象加锁,进入同步代码前要获得当前类对象的锁
- 修饰代码块,指定加锁对象,对给定对象加锁,进入同步代码库前要获得给定对象的锁。
- 修饰实例方法: 由于i++;操作并不具备原子性,该操作是先读取值,然后写回一个新值,相当于原来的值加上1,分两步完成,如果第二个线程在第一个线程读取旧值和写回新值期间读取i的域值,那么第二个线程就会与第一个线程一起看到同一个值,并执行相同值的加1操作,这也就造成了线程安全失败,因此对于increase方法必须使用synchronized修饰,以便保证线程安全。
- 修饰静态方法: 由于synchronized关键字修饰的是静态increase方法,与修饰实例方法不同的是,其锁对象是当前类的class对象。注意代码中的increase4Obj方法是实例方法,其对象锁是当前实例对象,如果别的线程调用该方法,将不会产生互斥现象,毕竟锁对象不同,但我们应该意识到这种情况下可能会发现线程安全问题(操作了共享静态变量i)。
- 修饰代码块在某些情况下,我们编写的方法体可能比较大,同时存在一些比较耗时的操作,而需要同步的代码又只有一小部分,如果直接对整个方法进行同步操作,可能会得不偿失,此时我们可以使用同步代码块的方式对需要同步的代码进行包裹,这样就无需对整个方法进行同步操作了
实现原理
-
Java对象头
- 在JVM中,对象在内存中的布局分为三块区域:对象头、实例数据和对齐填充。
- synchronized使用的锁是存放在Java对象头里面,具体位置是对象头里面的MarkWord,MarkWord里默认数据是存储对象的HashCode等信息,但是会随着对象的运行改变而发生变化,不同的锁状态对应着不同的记录存储方式
-
Java虚拟机对synchronized的优化
- 锁的状态总共有四种,无锁状态、偏向锁、轻量级锁和重量级锁。随着锁的竞争,锁可以从偏向锁升级到轻量级锁,再升级的重量级锁,但是锁的升级是单向的,也就是说只能从低到高升级,不会出现锁的降级。
- 偏向锁
- 偏向锁是Java 6之后加入的新锁,它是一种针对加锁操作的优化手段,经过研究发现,在大多数情况下,锁不仅不存在多线程竞争,而且总是由同一线程多次获得,因此为了减少同一线程获取锁(会涉及到一些CAS操作,耗时)的代价而引入偏向锁。偏向锁的核心**是,如果一个线程获得了锁,那么锁就进入偏向模式,此时Mark Word 的结构也变为偏向锁结构,当这个线程再次请求锁时,无需再做任何同步操作,即获取锁的过程,这样就省去了大量有关锁申请的操作,从而也就提供程序的性能。所以,对于没有锁竞争的场合,偏向锁有很好的优化效果,毕竟极有可能连续多次是同一个线程申请相同的锁。但是对于锁竞争比较激烈的场合,偏向锁就失效了,因为这样场合极有可能每次申请锁的线程都是不相同的,因此这种场合下不应该使用偏向锁,否则会得不偿失,需要注意的是,偏向锁失败后,并不会立即膨胀为重量级锁,而是先升级为轻量级锁。下面我们接着了解轻量级锁。
- 轻量级锁
- 倘若偏向锁失败,虚拟机并不会立即升级为重量级锁,它还会尝试使用一种称为轻量级锁的优化手段(1.6之后加入的),此时Mark Word 的结构也变为轻量级锁的结构。轻量级锁能够提升程序性能的依据是“对绝大部分的锁,在整个同步周期内都不存在竞争”,注意这是经验数据。需要了解的是,轻量级锁所适应的场景是线程交替执行同步块的场合,如果存在同一时间访问同一锁的场合,就会导致轻量级锁膨胀为重量级锁。
- 自旋锁
- 轻量级锁失败后,虚拟机为了避免线程真实地在操作系统层面挂起,还会进行一项称为自旋锁的优化手段。这是基于在大多数情况下,线程持有锁的时间都不会太长,如果直接挂起操作系统层面的线程可能会得不偿失,毕竟操作系统实现线程之间的切换时需要从用户态转换到核心态,这个状态之间的转换需要相对比较长的时间,时间成本相对较高,因此自旋锁会假设在不久将来,当前的线程可以获得锁,因此虚拟机会让当前想要获取锁的线程做几个空循环(这也是称为自旋的原因),一般不会太久,可能是50个循环或100循环,在经过若干次循环后,如果得到锁,就顺利进入临界区。如果还不能获得锁,那就会将线程在操作系统层面挂起,这就是自旋锁的优化方式,这种方式确实也是可以提升效率的。最后没办法也就只能升级为重量级锁了。
- 锁消除
- 消除锁是虚拟机另外一种锁的优化,这种优化更彻底,Java虚拟机在JIT编译时(可以简单理解为当某段代码即将第一次被执行时进行编译,又称即时编译),通过对运行上下文的扫描,去除不可能存在共享资源竞争的锁,通过这种方式消除没有必要的锁,可以节省毫无意义的请求锁时间,如下StringBuffer的append是一个同步方法,但是在add方法中的StringBuffer属于一个局部变量,并且不会被其他线程所使用,因此StringBuffer不可能存在共享资源竞争的情景,JVM会自动将其锁消除。
Synchronized 与 ReentrantLock 的区别
相似点
这两种同步方式有很多相似之处,它们都是加锁方式同步,而且都是阻塞式的同步,也就是说当如果一个线程获得了对象锁,进入了同步块,其他访问该同步块的线程都必须阻塞在同步块外面等待,而进行线程阻塞和唤醒的代价是比较高的(操作系统需要在用户态与内核态之间来回切换,代价很高,不过可以通过对锁优化进行改善)。
区别
这两种方式最大区别就是:
-
对于Synchronized来说,它是java语言的关键字,是原生语法层面的互斥,需要jvm实现,不但可以通过一些监控工具监控synchronized的锁定,而且在代码执行时出现异常,JVM会自动释放锁定。
-
而ReentrantLock它是JDK 1.5之后提供的API层面的互斥锁,需要lock()和unlock()方法配合try/finally语句块来完成。
| 类别 | synchronized | Lock |
|---|---|---|
| 存在层次 | Java的关键字,在jvm层面上 | 是一个类 |
| 锁的释放 | 1、以获取锁的线程执行完同步代码,释放锁 2、线程执行发生异常,jvm会让线程释放锁 | 在finally中必须释放锁,不然容易造成线程死锁 |
| 锁的获取 | 假设A线程获得锁,B线程等待。如果A线程阻塞,B线程会一直等待 | 分情况而定,Lock有多个锁获取的方式,具体下面会说道,大致就是可以尝试获得锁,线程可以不用一直等待 |
| 锁状态 | 无法判断 | 可以判断 |
| 锁类型 | 可重入 不可中断 非公平 | 可重入 可判断 可公平(两者皆可) |
| 性能 | 少量同步 | 大量同步 |
在资源竞争不是很激烈的情况下,Synchronized的性能要优于ReetrantLock,但是在资源竞争很激烈的情况下,Synchronized的性能会下降几十倍,但是ReetrantLock的性能能维持常态;
1. Synchronized
Synchronized经过编译,会在同步块的前后分别形成monitorenter和monitorexit这个两个字节码指令。在执行monitorenter指令时,首先要尝试获取对象锁。如果这个对象没被锁定,或者当前线程已经拥有了那个对象锁,把锁的计算器加1,相应的,在执行monitorexit指令时会将锁计算器就减1,当计算器为0时,锁就被释放了。如果获取对象锁失败,那当前线程就要阻塞,直到对象锁被另一个线程释放为止。
2. ReentrantLock
由于ReentrantLock是java.util.concurrent包(J.U.C)下提供的一套互斥锁,相比Synchronized,ReentrantLock类提供了一些高级功能,主要有以下3项:
-
等待可中断,持有锁的线程长期不释放的时候,正在等待的线程可以选择放弃等待,这相当于Synchronized来说可以避免出现死锁的情况。
-
公平锁,多个线程等待同一个锁时,必须按照申请锁的时间顺序获得锁,Synchronized锁非公平锁,ReentrantLock默认的构造函数是创建的非公平锁,可以通过参数true设为公平锁,但公平锁表现的性能不是很好。
-
锁绑定多个条件,一个ReentrantLock对象可以同时绑定对个对象。
public class SynDemo{
public static void main(String[] arg){
Runnable t1=new MyThread();
new Thread(t1,"t1").start();
new Thread(t1,"t2").start();
}
}
class MyThread implements Runnable {
private Lock lock=new ReentrantLock();
public void run() {
lock.lock(); //加锁
try{
for(int i=0;i<5;i++)
System.out.println(Thread.currentThread().getName()+":"+i);
}finally{
lock.unlock(); //解锁
}
}
}java的两种同步方式, Synchronized与ReentrantLock的区别
Synchronized与Lock锁的区别
Callable、Future和FutureTask(TODO)
JDK8 的 CompletableFuture(TODO)
5.5 Java 中的锁
锁
- Java 中的锁
- 包括:1.公平锁和非公平锁、2.自旋锁、3.锁消除、4.锁粗化、5.可重入锁、6.类锁和对象锁、7.偏向锁、轻量级锁和重量级锁、8.悲观锁和乐观锁、9.共享锁和排它锁、10.读写锁、11.互斥锁、12.无锁
锁的粒度
- 并发性能优化 : 降低锁粒度
- 当我们需要使用并发时, 常常有一个资源必须被两个或多个线程共享。在这种情况下,就存在一个竞争条件,也就是其中一个线程可以得到锁(锁与特定资源绑定),其他想要得到锁的线程会被阻塞。这个同步机制的实现是有代价的,为了向你提供一个好用的同步模型,JVM 和操作系统都要消耗资源。有三个最重要的因素使并发的实现会消耗大量资源,它们是:
- 上下文切换
- 内存同步
- 阻塞
- 介绍一种通过降低锁粒度的技术来减少这些因素。让我们从一个基本原则开始:不要长时间持有不必要的锁。
- 在获得锁之前做完所有需要做的事,只把锁用在需要同步的资源上,用完之后立即释放它。详情见链接。
5.6 NIO
概述
- NIO本身是基于事件驱动**来完成的,
- 其主要想解决的是BIO的大并发问题: 在使用同步I/O的网络应用中,如果要同时处理多个客户端请求,或是在客户端要同时和多个服务器进行通讯,就必须使用多线程来处理。也就是说,将每一个客户端请求分配给一个线程来单独处理。这样做虽然可以达到我们的要求,但同时又会带来另外一个问题。由于每创建一个线程,就要为这个线程分配一定的内存空间(也叫工作存储器),而且操作系统本身也对线程的总数有一定的限制。如果客户端的请求过多,服务端程序可能会因为不堪重负而拒绝客户端的请求,甚至服务器可能会因此而瘫痪。
- NIO基于Reactor,当socket有流可读或可写入socket时,操作系统会相应的通知引用程序进行处理,应用再将流读取到缓冲区或写入操作系统。 也就是说,这个时候,已经不是一个连接就要对应一个处理线程了,而是有效的请求,对应一个线程,当连接没有数据时,是没有工作线程来处理的。
- NIO的最重要的地方是当一个连接创建后,不需要对应一个线程,这个连接会被注册到多路复用器上面,所以所有的连接只需要一个线程就可以搞定,当这个线程中的多路复用器进行轮询的时候,发现连接上有请求的话,才开启一个线程进行处理,也就是一个请求一个线程模式。
IO和NIO的关键就在你读取的过程中,假设一个情况,你正在读取一个数据,它的长度是500字节,但是目前传输而来的数据只有200字节,还有300在路上。这时候你有两种方式,一种是继续阻塞,等待那些数据到达。不过这显然不是个好方法,因为你不知道那些数据还有多久到达(有可能网络中断了,它们永远不会到达了)。另外一种方法是将已经读取的数据先记录到缓冲中,然后继续等待运行(一般就是再等待接口可读),等数据到达了再拼接起来。而NIO就是帮你搭建了第二种方法的基础,帮你把缓冲等问题处理好了,这样虽然两个读取都是阻塞的,但是第一种阻塞是网络IO的阻塞,第二种阻塞是本地缓冲IO的阻塞,显然第二种更有确定性、更可靠。特别实在读取数据到下一次等等套接字可读的过程中,你还需要做一些其他的响应或处理时,这个线程就要保障不能长时间阻塞,所以NIO是个很好的解决办法。
总的来说NIO只是在BIO上做一个简单封装,让你专注到实现功能中去,不用再考虑网络IO阻塞的问题。
NIO是怎么工作的
所有的系统I/O都分为两个阶段:等待就绪和操作。举例来说,读函数,分为等待系统可读和真正的读;同理,写函数分为等待网卡可以写和真正的写。
需要说明的是等待就绪的阻塞是不使用CPU的,是在“空等”;而真正的读写操作的阻塞是使用CPU的,真正在"干活",而且这个过程非常快,属于memory copy,带宽通常在1GB/s级别以上,可以理解为基本不耗时。
以socket.read()为例子:
传统的BIO里面socket.read(),如果TCP RecvBuffer里没有数据,函数会一直阻塞,直到收到数据,返回读到的数据。
对于NIO,如果TCP RecvBuffer有数据,就把数据从网卡读到内存,并且返回给用户;反之则直接返回0,永远不会阻塞。
最新的AIO(Async I/O)里面会更进一步:不但等待就绪是非阻塞的,就连数据从网卡到内存的过程也是异步的。
换句话说,BIO里用户最关心“我要读”,NIO里用户最关心"我可以读了",在AIO模型里用户更需要关注的是“读完了”。
NIO一个重要的特点是:socket主要的读、写、注册和接收函数,在等待就绪阶段都是非阻塞的,真正的I/O操作是同步阻塞的(消耗CPU但性能非常高)。
结合事件模型使用NIO同步非阻塞特性
回忆BIO模型,之所以需要多线程,是因为在进行I/O操作的时候,一是没有办法知道到底能不能写、能不能读,只能"傻等",即使通过各种估算,算出来操作系统没有能力进行读写,也没法在socket.read()和socket.write()函数中返回,这两个函数无法进行有效的中断。所以除了多开线程另起炉灶,没有好的办法利用CPU。
NIO的读写函数可以立刻返回,这就给了我们不开线程利用CPU的最好机会:如果一个连接不能读写(socket.read()返回0或者socket.write()返回0),我们可以 把这件事记下来,记录的方式通常是在Selector上注册标记位,然后切换到其它就绪的连接(channel)继续进行读写。
下面具体看下如何利用事件模型单线程处理所有I/O请求:
NIO的主要事件有几个:读就绪、写就绪、有新连接到来。
我们首先需要注册当这几个事件到来的时候所对应的处理器。然后在合适的时机告诉事件选择器:我对这个事件感兴趣。对于写操作,就是写不出去的时候对写事件感兴趣;对于读操作,就是完成连接和系统没有办法承载新读入的数据的时;对于accept,一般是服务器刚启动的时候;而对于connect,一般是connect失败需要重连或者直接异步调用connect的时候。
其次,用一个死循环选择就绪的事件,会执行系统调用(Linux 2.6之前是select、poll,2.6之后是epoll(这几个概念后文专门解释),Windows是IOCP),还会阻塞的等待新事件的到来。新事件到来的时候,会在selector上注册标记位,标示可读、可写或者有连接到来。
注意,select是阻塞的,无论是通过操作系统的通知(epoll)还是不停的轮询(select,poll),这个函数是阻塞的。所以你可以放心大胆地在一个while(true)里面调用这个函数而不用担心CPU空转。
程序大概的模样是:
//IO线程主循环:
class IoThread extends Thread{
public void run(){
Channel channel;
while(channel=Selector.select()){//选择就绪的事件和对应的连接
if(channel.event==accept){
registerNewChannelHandler(channel);//如果是新连接,则注册一个新的读写处理器
}
if(channel.event==write){
getChannelHandler(channel).channelWritable(channel);//如果可以写,则执行写事件
}
if(channel.event==read){
getChannelHandler(channel).channelReadable(channel);//如果可以读,则执行读事件
}
}
}
Map<Channel,ChannelHandler> handlerMap;//所有channel的对应事件处理器
}这个程序很简短,也是最简单的Reactor模式:注册所有感兴趣的事件处理器,单线程轮询选择就绪事件,执行事件处理器。
BIO、NIO两者的主要区别
| BIO(IO) | NIO |
|---|---|
| 面向流 | 面向缓冲 |
| 阻塞IO | 非阻塞IO |
| 无 | 选择器(selector) |
面向流与面向缓冲
Java BIO面向流意味着每次从流中读一个或多个字节,直至读取所有字节,它们没有被缓存在任何地方。此外,它不能前后移动流中的数据。如果需要前后移动从流中读取的数据,需要先将它缓存到一个缓冲区。
Java NIO的缓冲导向方法略有不同。数据读取到一个它稍后处理的缓冲区,需要时可在缓冲区中前后移动。这就增加了处理过程中的灵活性。但是,还需要检查是否该缓冲区中包含所有您需要处理的数据。而且,需确保当更多的数据读入缓冲区时,不要覆盖缓冲区里尚未处理的数据。
阻塞与非阻塞IO
Java BIO的各种流是阻塞的。这意味着,当一个线程调用read() 或 write()时,该线程被阻塞,直到有一些数据被读取,或数据完全写入。该线程在此期间不能再干任何事情了。
Java NIO的非阻塞模式,使一个线程从某通道发送请求读取数据,但是它仅能得到目前可用的数据,如果目前没有数据可用时,就什么都不会获取。而不是保持线程阻塞,所以直至数据变的可以读取之前,该线程可以继续做其他的事情。 非阻塞写也是如此。一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时可以去做别的事情。 线程通常将非阻塞IO的空闲时间用于在其它通道上执行IO操作,所以一个单独的线程现在可以管理多个输入和输出通道(channel)。
NIO的核心部分
NIO主要有三大核心部分:Channel(通道),Buffer(缓冲区), Selector。传统IO基于字节流和字符流进行操作,而NIO基于Channel和Buffer(缓冲区)进行操作,数据总是从通道读取到缓冲区中,或者从缓冲区写入到通道中。Selector(选择区)用于监听多个通道的事件(比如:连接打开,数据到达)。因此,单个线程可以监听多个数据通道Channel。
2.1 Channel
首先说一下Channel,国内大多翻译成“通道”。Channel和IO中的Stream(流)是差不多一个等级的。只不过Stream是单向的,譬如:InputStream, OutputStream.而Channel是双向的,既可以用来进行读操作,又可以用来进行写操作。
NIO中的Channel的主要实现有:
- FileChannel
- DatagramChannel
- SocketChannel
- ServerSocketChannel
这里看名字就可以猜出个所以然来:分别可以对应文件IO、UDP和TCP(Server和Client)。
2.2 Buffer
通常情况下,操作系统的一次写操作分为两步:
将数据从用户空间拷贝到系统空间。
从系统空间往网卡写。同理,读操作也分为两步:
- 将数据从网卡拷贝到系统空间;
- 将数据从系统空间拷贝到用户空间。
对于NIO来说,缓存的使用可以使用DirectByteBuffer和HeapByteBuffer。如果使用了DirectByteBuffer,一般来说可以减少一次系统空间到用户空间的拷贝。但Buffer创建和销毁的成本更高,更不宜维护,通常会用内存池来提高性能。
如果数据量比较小的中小应用情况下,可以考虑使用heapBuffer;反之可以用directBuffer。
2.3 Selectors 选择器
Java NIO的选择器允许一个单独的线程同时监视多个通道,可以注册多个通道到同一个选择器上,然后使用一个单独的线程来“选择”已经就绪的通道。这种“选择”机制为一个单独线程管理多个通道提供了可能。
Selector运行单线程处理多个Channel,如果你的应用打开了多个通道,但每个连接的流量都很低,使用Selector就会很方便。例如在一个聊天服务器中。要使用Selector, 得向Selector注册Channel,然后调用它的select()方法。这个方法会一直阻塞到某个注册的通道有事件就绪。一旦这个方法返回,线程就可以处理这些事件,事件的例子有如新的连接进来、数据接收等。
2.4 Proactor与Reactor
I/O 复用机制需要事件分发器(event dispatcher)。 事件分发器的作用,即将那些读写事件源分发给各读写事件的处理者,就像送快递的在楼下喊: 谁谁谁的快递到了, 快来拿吧!开发人员在开始的时候需要在分发器那里注册感兴趣的事件,并提供相应的处理者(event handler),或者是回调函数;事件分发器在适当的时候,会将请求的事件分发给这些handler或者回调函数。
- 在Reactor模式中,事件分发器等待某个事件或者可应用或个操作的状态发生(比如文件描述符可读写,或者是socket可读写),事件分发器就把这个事件传给事先注册的事件处理函数或者回调函数,由后者来做实际的读写操作。
- 在Proactor模式中,事件处理者(或者代由事件分发器发起)直接发起一个异步读写操作(相当于请求),而实际的工作是由操作系统来完成的。发起时,需要提供的参数包括用于存放读到数据的缓存区、读的数据大小或用于存放外发数据的缓存区,以及这个请求完后的回调函数等信息。事件分发器得知了这个请求,它默默等待这个请求的完成,然后转发完成事件给相应的事件处理者或者回调。举例来说,在Windows上事件处理者投递了一个异步IO操作(称为overlapped技术),事件分发器等IO Complete事件完成。这种异步模式的典型实现是基于操作系统底层异步API的,所以我们可称之为“系统级别”的或者“真正意义上”的异步,因为具体的读写是由操作系统代劳的。
NIO存在的问题
-
使用NIO != 高性能,当连接数<1000,并发程度不高或者局域网环境下NIO并没有显著的性能优势。
-
NIO并没有完全屏蔽平台差异,它仍然是基于各个操作系统的I/O系统实现的,差异仍然存在。使用NIO做网络编程构建事件驱动模型并不容易,陷阱重重。
-
推荐大家使用成熟的NIO框架,如Netty,MINA等。解决了很多NIO的陷阱,并屏蔽了操作系统的差异,有较好的性能和编程模型。
适用范围
-
BIO方式适用于连接数目比较小且固定的架构,这种方式对服务器资源要求比较高,并发局限于应用中,JDK1.4以前的唯一选择,但程序直观简单易理解。
-
NIO方式适用于连接数目多且连接比较短(轻操作)的架构,比如聊天服务器,并发局限于应用中,编程比较复杂,JDK1.4开始支持。
六、JVM
6.1 JVM 内存模型
- java堆(Heap):Heap区域被所有线程共享,用于存储对象实例。java堆是垃圾回收器管理的主要区域,所以也叫gc堆。java堆可以分为:新生代和老年代
- 方法区:被各个线程共享,用于存储已经被虚拟机加载的类型西、常量、静态变量等数据。
JVM中堆和栈
栈:
- 简单理解:堆栈(stack)是操作系统在建立某个进程或者线程(在支持多线程的操作系统中是线程)为这个线程建立的存储区域,该区域具有先进后出的特性。
- 特点:存取速度比堆要快,仅次于直接位于CPU中的寄存器。栈中的数据可以共享(意思是:栈中的数据可以被多个变量共同引用)。
- 缺点:存在栈中的数据大小与生存期必须是确定的,缺乏灵活性。
- 相关存放对象:①一些基本类型的变量(,int, short, long, byte, float, double, boolean, char)和对象句柄【例如:在函数中定义的一些基本类型的变量和对象的引用变量】。②方法的形参 直接在栈空间分配,当方法调用完成后从栈空间回收。
- 特殊:①方法的引用参数,在栈空间分配一个地址空间,并指向堆空间的对象区,当方法调用完成后从栈空间回收。②局部变量new出来之后,在栈控件和堆空间中分配空间,当局部变量生命周期结束后,它的栈空间立刻被回收,它的堆空间等待GC回收。
堆:
- 简单理解:每个Java应用都唯一对应一个JVM实例,每一个JVM实例唯一对应一个堆。应用程序在运行中所创建的所有类实例或者数组都放在这个堆中,并由应用所有的线程共享。Java中分配堆内存是自动初始化的,Java中所有对象的存储控件都是在堆中分配的,但这些对象的引用则是在栈中分配,也就是一般在建立一个对象时,堆和栈都会分配内存。
- 特点:可以动态地分配内存大小、比较灵活,生存期也不必事先告诉编译器,Java的垃圾收集器会自动收走这些不再使用的数据。在堆中分配的内存,由Java虚拟机的自动垃圾回收器来管理。
- 缺点:由于要在运行时动态分配内存,存取速度较慢。
- 主要存放:①由new创建的对象和数组 ;②this
- 特殊:引用数据类型(需要用new来创建),既在栈控件分配一个地址空间,又在堆空间分配对象的类变量。
Java中的内存泄漏
什么是java的内存泄漏
在Java中,内存泄漏就是存在一些被分配的对象,这些对象有下面两个特点,首先,这些对象是可达的,即在有向图中,存在通路可以与其相连;其次,这些对象是无用的,即程序以后不会再使用这些对象。如果对象满足这两个条件,这些对象就可以判定为Java中的内存泄漏,这些对象不会被GC所回收,然而它却占用内存。

因此,通过以上分析,我们知道在Java中也有内存泄漏,但范围比C++要小一些。因为Java从语言上保证,任何对象都是可达的,所有的不可达对象都由GC管理。
Java内存泄漏引起的原因
Java内存泄漏的根本原因是什么呢?长生命周期的对象持有短生命周期对象的引用就很可能发生内存泄漏,尽管短生命周期对象已经不再需要,但是因为长生命周期持有它的引用而导致不能被回收,这就是Java中内存泄漏的发生场景。具体主要有如下几大类:
(1)静态集合类引起内存泄漏:
- 像HashMap、Vector等的使用最容易出现内存泄露,这些静态变量的生命周期和应用程序一致,他们所引用的所有的对象Object也不能被释放,因为他们也将一直被Vector等引用着。
(2)当集合里面的对象属性被修改后,再调用remove()方法时不起作用。
public static void main(String[] args)
{
Set<Person> set = new HashSet<Person>();
Person p1 = new Person("唐僧","pwd1",25);
Person p2 = new Person("孙悟空","pwd2",26);
Person p3 = new Person("猪八戒","pwd3",27);
set.add(p1);
set.add(p2);
set.add(p3);
System.out.println("总共有:"+set.size()+" 个元素!"); //结果:总共有:3 个元素!
p3.setAge(2); //修改p3的年龄,此时p3元素对应的hashcode值发生改变
set.remove(p3); //此时remove不掉,造成内存泄漏
set.add(p3); //重新添加,居然添加成功
System.out.println("总共有:"+set.size()+" 个元素!"); //结果:总共有:4 个元素!
for (Person person : set)
{
System.out.println(person);
}
}(3)单例模式
不正确使用单例模式是引起内存泄漏的一个常见问题,单例对象在初始化后将在JVM的整个生命周期中存在(以静态变量的方式),如果单例对象持有外部的引用,那么这个对象将不能被JVM正常回收,导致内存泄漏,考虑下面的例子:
class A{
public A(){
B.getInstance().setA(this);
}
....
}
//B类采用单例模式
class B{
private A a;
private static B instance=new B();
public B(){}
public static B getInstance(){
return instance;
}
public void setA(A a){
this.a=a;
}
//getter...
}
显然B采用singleton模式,它持有一个A对象的引用,而这个A类的对象将不能被回收。想象下如果A是个比较复杂的对象或者集合类型会发生什么情况6.2 JVM 堆
堆内存 分布
Java 中的堆是 JVM 所管理的最大的一块内存空间,主要用于存放各种类的实例对象。
在 Java 中,堆被划分成两个不同的区域:新生代 ( Young )、老年代 ( Old )。新生代 ( Young ) 又被划分为三个区域:Eden、From Survivor、To Survivor。
这样划分的目的是为了使 JVM 能够更好的管理堆内存中的对象,包括内存的分配以及回收。
堆的内存模型大致为:

从图中可以看出: 堆大小 = 新生代 + 老年代。其中,堆的大小可以通过参数 –Xms、-Xmx 来指定。
链接:Java 堆内存
为什么需要把堆分代
- 新生代Eden与两个Survivor区的解释
- 我们先来捋捋,为什么需要把堆分代?不分代不能完成他所做的事情么?其实不分代完全可以,分代的唯一理由就是优化GC性能。你先想想,如果没有分代,那我们所有的对象都在一块,GC的时候我们要找到哪些对象没用,这样就会对堆的所有区域进行扫描。而我们的很多对象都是朝生夕死的,如果分代的话,我们把新创建的对象放到某一地方,当GC的时候先把这块存“朝生夕死”对象的区域进行回收,这样就会腾出很大的空间出来。
- 【为什么新生代内存需要有两个Survivor区】
- 为什么要设置两个Survivor区?设置两个Survivor区最大的好处就是解决了碎片化。
我们知道了必须设置Survivor区。假设现在只有一个survivor区,我们来模拟一下流程:
- 刚刚新建的对象在Eden中,一旦Eden满了,触发一次Minor GC,Eden中的存活对象就会被移动到Survivor区。这样继续循环下去,下一次Eden满了的时候,问题来了,此时进行Minor GC,Eden和Survivor各有一些存活对象,如果此时把Eden区的存活对象硬放到Survivor区,很明显这两部分对象所占有的内存是不连续的,也就导致了内存碎片化。

碎片化带来的风险是极大的,严重影响JAVA程序的性能。堆空间被散布的对象占据不连续的内存,最直接的结果就是,堆中没有足够大的连续内存空间.
那么,顺理成章的,应该建立两块Survivor区,刚刚新建的对象在Eden中,经历一次Minor GC,Eden中的存活对象就会被移动到第一块survivor space S0,Eden被清空;等Eden区再满了,就再触发一次Minor GC,Eden和S0中的存活对象又会被复制送入第二块survivor space S1(这个过程非常重要,因为这种复制算法保证了S1中来自S0和Eden两部分的存活对象占用连续的内存空间,避免了碎片化的发生)

- 其中色块代表对象,白色框分别代表Eden区(大)和Survivor区(小)。Eden区理所当然大一些,否则新建对象很快就导致Eden区满,进而触发Minor GC,有悖于初衷。
- 上述机制最大的好处就是,整个过程中,永远有一个survivor space是空的,另一个非空的survivor space无碎片。
6.3 垃圾回收
什么时候回收
如何判断一个对象需要被回收?
GC的两种判定方法:引用计数与引用链
-
引用计数:给一个对象设置一个计数器,当被引用一次就加1,当引用失效的时候就减1,如果该对象长时间保持为0值,则该对象将被标记为回收。优点:算法简单,效率高,缺点:很难解决对象之间的相互循环引用问题。
-
引用链(可达性分析):现在主流的gc都采用可达性分析算法来判断对象是否已经死亡。可达性分析:通过一系列成为GC Roots的对象作为起点,从这些起点向下搜索,搜索所走过的路径成为引用链,当一个对象到引用链没有相连时,则判断该对象已经死亡。
Java虚拟机GC根节点的选择
- 虚拟机栈(栈帧中的本地变量表)中引用的对象
- 本地方法栈中JNI(即一般说的Native方法)引用的对象
- 方法区中类静态属性引用的对象
- 方法区中常量引用的对象
垃圾回收算法
标记清除、标记整理、复制算法的原理:
-
标记清除:直接将要回收的对象标记,发送gc的时候直接回收:特点回收特别快,但是回收以后会造成很多不连续的内存空间,因此适合在老年代进行回收,CMS(current mark-sweep),就是采用这种方法来会后老年代的。
-
标记整理:就是将要回收的对象移动到一端,然后再进行回收,特点:回收以后的空间连续,缺点:整理要花一定的时间,适合老年代进行会后,parallel Old(针对parallel scanvange gc的) gc和Serial old就是采用该算法进行回收的。
-
复制算法:将内存划分成原始的是相等的两部分,每次只使用一部分,这部分用完了,就将还存活的对象复制到另一块内存,将要回收的内存全部清除。这样只要进行少量的赋值就能够完成收集。比较适合很多对象的回收,同时还有老年代对其进行担保。(serial new和parallel new和parallel scanvage)
Minor GC、Major GC(或称为 Major GC)之间的区别
Java 中的堆也是 GC 收集垃圾的主要区域。GC 分为两种:Minor GC、Full GC ( 或称为 Major GC )。
Minor GC
- 是发生在新生代中的垃圾收集动作,所采用的是复制算法。
- 新生代几乎是所有 Java 对象出生的地方,即 Java 对象申请的内存以及存放都是在这个地方。Java 中的大部分对象通常不需长久存活,具有朝生夕灭的性质。
- 当一个对象被判定为 "死亡" 的时候,GC 就有责任来回收掉这部分对象的内存空间。新生代是 GC 收集垃圾的频繁区域。
- 当对象在 Eden ( 包括一个 Survivor 区域,这里假设是 from 区域 ) 出生后,在经过一次 Minor GC 后,如果对象还存活,并且能够被另外一块 Survivor 区域所容纳
- ( 上面已经假设为 from 区域,这里应为 to 区域,即 to 区域有足够的内存空间来存储 Eden 和 from 区域中存活的对象 ),则使用复制算法将这些仍然还存活的对象复制到另外一块 Survivor 区域 ( 即 to 区域 ) 中,然后清理所使用过的 Eden 以及 Survivor 区域 ( 即 from 区域 ),并且将这些对象的年龄设置为1,以后对象在 Survivor 区每熬过一次 Minor GC,就将对象的年龄 + 1,当对象的年龄达到某个值时 ( 默认是 15 岁,可以通过参数 -XX:MaxTenuringThreshold 来设定 ),这些对象就会成为老年代。
- 但这也不是一定的,对于一些较大的对象 ( 即需要分配一块较大的连续内存空间 ) 则是直接进入到老年代。
Full GC
- 是发生在老年代的垃圾收集动作,所采用的是标记-清除算法。
- 老年代里面的对象几乎个个都是在 Survivor 区域中熬过来的,它们是不会那么容易就 "死掉" 了的。因此,Full GC 发生的次数不会有 Minor GC 那么频繁,并且做一次 Full GC 要比进行一次 Minor GC 的时间更长。
- 另外,标记-清除算法收集垃圾的时候会产生许多的内存碎片 ( 即不连续的内存空间 ),此后需要为较大的对象分配内存空间时,若无法找到足够的连续的内存空间,就会提前触发一次 GC 的收集动作。
6.4 垃圾收集器
JVM垃圾收集器-对比Serial、Parallel、CMS和G1
-
串行收集器Seiral Collector
串行收集器是最简单的,它设计为在单核的环境下工作(32位或者windows),你几乎不会使用到它。它在工作的时候会暂停整个应用的运行,因此在所有服务器环境下都不可能被使用。
使用方法:-XX:+UseSerialGC
-
并行/吞吐优先收集器Parallel/Throughput Collector
这是JVM默认的收集器,跟它名字显示的一样,它最大的优点是使用多个线程来扫描和压缩堆。缺点是在minor和full GC的时候都会暂停应用的运行。并行收集器最适合用在可以容忍程序停滞的环境使用,它占用较低的CPU因而能提高应用的吞吐(throughput)。
使用方法:-XX:+UseParallelGC
-
CMS收集器CMS Collector
CMS 收集器的 GC 周期由 6 个阶段组成。其中 4 个阶段 (名字以 Concurrent 开始的) 与实际的应用程序是并发执行的,而其他 2 个阶段需要暂停应用程序线程。
初始标记 :在这个阶段,需要虚拟机停顿正在执行的任务,官方的叫法STW(Stop The Word)。这个过程从垃圾回收的”根对象”开始,只扫描到能够和”根对象”直接关联的对象,并作标记。所以这个过程虽然暂停了整个JVM,但是很快就完成了。
并发标记 :这个阶段紧随初始标记阶段,在初始标记的基础上继续向下追溯标记。并发标记阶段,应用程序的线程和并发标记的线程并发执行,所以用户不会感受到停顿。
并发预清理 :并发预清理阶段仍然是并发的。在这个阶段,虚拟机查找在执行并发标记阶段新进入老年代的对象(可能会有一些对象从新生代晋升到老年代, 或者有一些对象被分配到老年代)。通过重新扫描,减少下一个阶段”重新标记”的工作,因为下一个阶段会Stop The World。
重新标记 :这个阶段会暂停虚拟机,收集器线程扫描在CMS堆中剩余的对象。扫描从”跟对象”开始向下追溯,并处理对象关联。
并发清理 :清理垃圾对象,这个阶段收集器线程和应用程序线程并发执行。
并发重置 :这个阶段,重置CMS收集器的数据结构,等待下一次垃圾回收。
接下来是CMS收集器,CMS是Concurrent-Mark-Sweep的缩写,并发的标记与清除。这个算法使用多个线程并发地(concurrent)扫描堆,标记不使用的对象,然后清除它们回收内存。在两种情况下会使应用暂停(Stop the World, STW):1. 当初次开始标记根对象时initial mark。2. 当在并行收集时应用又改变了堆的状态时,需要它从头再确认一次标记了正确的对象final remark。
这个收集器最大的问题是在年轻代与老年代收集时会出现的一种竞争情况(race condition),称为提升失败promotion failure。对象从年轻代复制到老年代称为提升promotion,但有时侯老年代需要清理出足够空间来放这些对象,这需要一定的时间,它收集的速度可能赶不上不断产生的要提升的年轻代对象的速度,这时就需要做STW的收集。STW正是CMS想避免的问题。为了避免这个问题,需要增加老年代的空间大小或者增加更多的线程来做老年代的收集以赶上从年轻代复制对象的速度。
除了上文所说的内容之外,CMS最大的问题就是内存空间碎片化的问题。CMS只有在触发FullGC的情况下才会对堆空间进行compact。如果线上应用长时间运行,碎片化会非常严重,会很容易造成promotion failed。为了解决这个问题线上很多应用通过定期重启或者手工触发FullGC来触发碎片整理。
对比并行收集器它的一个坏处是需要占用比较多的CPU。对于大多数长期运行的服务器应用来说,这通常是值得的,因为它不会导致应用长时间的停滞。但是它不是JVM的默认的收集器。
使用CMS需要仔细分析自己的应用对象生命周期,尤其是在应用要求高性能,高吞吐。需要仔细分析自己应用所需要的heap大小,老年代,新生代的分配比例,以及survival区的大小。设置不合理会很容易造成性能问题。后续会有专门的文章来介绍。
使用方法:-XX:+UseConcMarkSweepGC,此时可同时使用-XX:+UseParNewGC将并行收集作用于年轻代,新的JVM自动打开这一配置
-
G1收集器Garbage First Collector
如果你的堆内存大于4G的话,那么G1会是要考虑使用的收集器。它是为了更好支持大于4G堆内存在JDK 7 u4引入的。G1收集器把堆分成多个区域,大小从1MB到32MB,并使用多个后台线程来扫描这些区域,优先会扫描最多垃圾的区域,这就是它名称的由来,垃圾优先Garbage First。
如果在后台线程完成扫描之前堆空间耗光的话,才会进行STW收集。它另外一个优点是它在处理的同时会整理压缩堆空间,相比CMS只会在完全STW收集的时候才会这么做。
使用过大的堆内存在过去几年是存在争议的,很多开发者从单个JVM分解成使用多个JVM的微服务(micro-service)和基于组件的架构。其他一些因素像分离程序组件、简化部署和避免重新加载类到内存的考虑也促进了这样的分离。
除了这些因素,最大的因素当然是避免在STW收集时JVM用户线程停滞时间过长,如果你使用了很大的堆内存的话就可能出现这种情况。另外,像Docker那样的容器技术让你可以在一台物理机器上轻松部署多个应用也加速了这种趋势。
使用方法:-XX:+UseG1GC
6.5 从实际案例聊聊Java应用的GC优化
发生Stop-The-World的GC
- GC日志如下图(在GC日志中,Full GC是用来说明这次垃圾回收的停顿类型,代表STW类型的GC,并不特指老年代GC),根据GC日志可知本次Full GC耗时1.23s。这个在线服务同样要求低时延高可用。本次优化目标是降低单次STW回收停顿时间,提高可用性。
- 首先,什么时候可能会触发STW的Full GC呢?
- Perm空间不足;
- CMS GC时出现promotion failed和concurrent mode failure(concurrent mode failure发生的原因一般是CMS正在进行,但是由于老年代空间不足,需要尽快回收老年代里面的不再被使用的对象,这时停止所有的线程,同时终止CMS,直接进行Serial Old GC);
- 统计得到的Young GC晋升到老年代的平均大小大于老年代的剩余空间;
- 主动触发Full GC(执行jmap -histo:live [pid])来避免碎片问题。
然后,我们来逐一分析一下:
- 排除原因2:如果是原因2中两种情况,日志中会有特殊标识,目前没有。
- 排除原因3:根据GC日志,当时老年代使用量仅为20%,也不存在大于2G的大对象产生。
- 排除原因4:因为当时没有相关命令执行。
- 锁定原因1:根据日志发现Full GC后,Perm区变大了,推断是由于永久代空间不足容量扩展导致的。
找到原因后解决方法有两种:
- 通过把-XX:PermSize参数和-XX:MaxPermSize设置成一样,强制虚拟机在启动的时候就把永久代的容量固定下来,避免运行时自动扩容。
- CMS默认情况下不会回收Perm区,通过参数CMSPermGenSweepingEnabled、CMSClassUnloadingEnabled ,可以让CMS在Perm区容量不足时对其回收。
由于该服务没有生成大量动态类,回收Perm区收益不大,所以我们采用方案1,启动时将Perm区大小固定,避免进行动态扩容。
请求高峰期发生GC,导致服务可用性下降
-
GC日志显示,高峰期CMS在重标记(Remark)阶段耗时1.39s。Remark阶段是Stop-The-World(以下简称为STW)的,即在执行垃圾回收时,Java应用程序中除了垃圾回收器线程之外其他所有线程都被挂起,意味着在此期间,用户正常工作的线程全部被暂停下来,这是低延时服务不能接受的。本次优化目标是降低Remark时间。
-
解决问题前,先回顾一下CMS的四个主要阶段,以及各个阶段的工作内容。下图展示了CMS各个阶段可以标记的对象,用不同颜色区分。
- Init-mark初始标记(STW) ,该阶段进行可达性分析,标记GC ROOT能直接关联到的对象,所以很快。
- Concurrent-mark并发标记,由前阶段标记过的绿色对象出发,所有可到达的对象都在本阶段中标记。
- Remark重标记(STW) ,暂停所有用户线程,重新扫描堆中的对象,进行可达性分析,标记活着的对象。因为并发标记阶段是和用户线程并发执行的过程,所以该过程中可能有用户线程修改某些活跃对象的字段,指向了一个未标记过的对象,如下图中红色对象在并发标记开始时不可达,但是并行期间引用发生变化,变为对象可达,这个阶段需要重新标记出此类对象,防止在下一阶段被清理掉,这个过程也是需要STW的。特别需要注意一点,这个阶段是以新生代中对象为根来判断对象是否存活的。
- 并发清理,进行并发的垃圾清理。
- 原因如下:
- 新生代对象持有老年代中对象的引用,这种情况称为“跨代引用”。因它的存在,Remark阶段必须扫描整个堆来判断对象是否存活,包括图中灰色的不可达对象。
- 对于这种情况,CMS提供CMSScavengeBeforeRemark参数,用来保证Remark前强制进行一次Minor GC。
GC频繁
- 思路1:通过jmap分析出占用内存占用最多的类,进行代码优化以减少内存使用

- 从上图可以知道,内存占用最多的是HashMap$Entry。所以,可以在代码上看看什么地方用到HashMap并往里面put了很多对象,针对这个代码进行优化
6.6 类的加载
6.6.1 类加载的五个过程:加载、验证、准备、解析、初始化
-
加载:加载有两种情况,①当遇到new关键字,或者static关键字的时候就会发生(他们对应着对应的指令)如果在常量池中找不到对应符号引用时,就会发生加载 ,②动态加载,当用反射方法(如class.forName(“类名”)),如果发现没有初始化,则要进行初始化。(注:加载的时候发现父类没有被加载,则要先加载父类)
-
验证:这一阶段的目的是确保class文件的字节流中包含的信息符合当前虚拟机的要求,并不会危害虚拟机自身的安全(虽然编译器会严格的检查java代码并生成class文件,但是class文件不一定都是通过编译器编译,然后加载进来的,因为虚拟机获取class文件字节流的方式有可能是从网络上来的,者难免不会存在有人恶意修改而造成系统崩溃的问题,class文件其实也可以手写16进制,因此这是必要的)
-
准备:该阶段就是为对象分派内存空间,然后初始化类中的属性变量,但是该初始化只是按照系统的意愿进行初始化,也就是初始化时都为0或者为null。因此该阶段的初始化和我们常说初始化阶段的初始化时不一样的
-
解析:解析就是虚拟机将常量池中的符号引用替换成直接引用的过程。符号引用其实就是class文件常量池中的各种引用,他们按照一定规律指向了对应的类名,或者字段,但是并没有在内存中分配空间,因此符号因此就理解为一个标示,而在直接引用直接指向内存中的地址。
-
初始化:简单讲就是执行对象的构造函数,给类的静态字段按照程序的意愿进行初始化,注意初始化的顺序。(此处的初始化由两个函数完成,一个是,初始化所有的类变量(静态变量),该函数不会初始化父类变量,还有一个是实例初始化函数,对类中实例对象进行初始化,此时要如果有需要,是要初始化父类的)
-
《深入了解Java虚拟机》 pdf P231 《深入理解Java虚拟机》读书笔记5:类加载机制与字节码执行引擎
6.6.2 双亲委派模型
三个类加载器
- 根加载器 Bootstrap ClassLoader 一般用本地代码实现,负责加载JVM基础核心类库(rt.jar);
- 扩展加载器 Extension ClassLoader 从java.ext.dirs系统属性所指定的目录中加载类库,它的父加载器是Bootstrap;
- 系统加载器 ApplicationClassLoader。又叫应用类加载器,其父类是Extension。它是应用最广泛的类加载器。它从环境变量classpath或者系统属性java.class.path所指定的目录中记载类,是用户自定义加载器的默认父加载器。
类加载器的工作过程:如果一个类加载器收到类类加载的请求,他首先不会自己去加载这个类,而是把类委派个父类加载器去完成,因此所有的请求最终都会传达到顶 层的启动类加载器中,只有父类反馈无法加载该类的请求(在自己的搜索范围类没有找到要加载的类)时候,子类才会试图去加载该类。
七、Spring
Spring IOC、DI、AOP原理和实现
1. Spring IOC原理
IOC的意思是控件反转也就是由容器控制程序之间的关系,这也是spring的优点所在,把控件权交给了外部容器,之前的写法,由程序代码直接操控,而现在控制权由应用代码中转到了外部容器,控制权的转移是所谓反转。换句话说之前用new的方式获取对象,现在由spring给你至于怎么给你就是di了。
IOC的意思是控件反转也就是由容器控制程序之间的关系,把控件权交给了外部容器,之前的写法,由程序代码直接操控,而现在控制权由应用代码中转到了外部容器,控制权的转移是所谓反转。网上有一个很形象的比喻:
我们是如何找女朋友的?常见的情况是,我们到处去看哪里有长得漂亮身材又好的mm,然后打听她们的兴趣爱好、qq号、电话号、ip号、iq号………,想办法认识她们,投其所好送其所要,然后嘿嘿……这个过程是复杂深奥的,我们必须自己设计和面对每个环节。传统的程序开发也是如此,在一个对象中,如果要使用另外的对象,就必须得到它(自己new一个,或者从JNDI中查询一个),使用完之后还要将对象销毁(比如Connection等),对象始终会和其他的接口或类藕合起来。那么IoC是如何做的呢?有点像通过婚介找女朋友,在我和女朋友之间引入了一个第三者:婚姻介绍所。婚介管理了很多男男女女的资料,我可以向婚介提出一个列表,告诉它我想找个什么样的女朋友,比如长得像李嘉欣,身材像林熙雷,唱歌像周杰伦,速度像卡洛斯,技术像齐达内之类的,然后婚介就会按照我们的要求,提供一个mm,我们只需要去和她谈恋爱、结婚就行了。简单明了,如果婚介给我们的人选不符合要求,我们就会抛出异常。整个过程不再由我自己控制,而是有婚介这样一个类似容器的机构来控制。Spring所倡导的开发方式就是如此,所有的类都会在spring容器中登记,告诉spring你是个什么东西,你需要什么东西,然后spring会在系统运行到适当的时候,把你要的东西主动给你,同时也把你交给其他需要你的东西。所有的类的创建、销毁都由 spring来控制,也就是说控制对象生存周期的不再是引用它的对象,而是spring。对于某个具体的对象而言,以前是它控制其他对象,现在是所有对象都被spring控制,所以这叫控制反转。
2. 什么是DI机制?
这里说DI又要说到IOC,依赖注入(Dependecy Injection)和控制反转(Inversion of Control)是同一个概念,具体的讲:当某个角色 需要另外一个角色协助的时候,在传统的程序设计过程中,通常由调用者来创建被调用者的实例。但在spring中 创建被调用者的工作不再由调用者来完成,因此称为控制反转。创建被调用者的工作由spring来完成,然后注入调用者 因此也称为依赖注入。
spring以动态灵活的方式来管理对象 , 注入的四种方式: 1. 接口注入 2. Setter方法注入 3. 构造方法注入 4.注解注入(@autowire)
IoC的一个重点是在系统运行中,动态的向某个对象提供它所需要的其他对象。这一点是通过DI(Dependency Injection,
依赖注入)来实现的。比如对象A需要操作数据库,以前我们总是要在A中自己编写代码来获得一个Connection对象,有了
spring我们就只需要告诉spring,A中需要一个Connection,至于这个Connection怎么构造,何时构造,A不需要知道。
在系统运行时,spring会在适当的时候制造一个Connection,然后像打针一样,注射到A当中,这样就完成了对各个对象之间关系
的控制。A需要依赖 Connection才能正常运行,而这个Connection是由spring注入到A中的,依赖注入的名字就这么来的。
3. 什么是 AOP 面向切面编程
- AOP,即面向切面编程,采用横向抽取机制,取代了传统的纵向继承体系重复性代码。是什么意思呢?
- 我们知道,使用面向对象编程有一些弊端,当需要为多个不具有继承关系的对象引入同一个公共行为是,例如日志,安全检测等,我们只有在每一个对象中引入公共行为,这样程序中就出现了很多重复代码,加大了程序的维护难度。所以有了面向对象编程的补充AOP,它关注的方向是横向的,而不是面向对象那样的纵向。
IOC依赖注入,和AOP面向切面编程,这两个是Spring的灵魂。
主要用到的设计模式有工厂模式和代理模式。
- IOC就是典型的工厂模式,通过sessionfactory去注入实例。
- AOP就是典型的代理模式的体现。
- 在Spring中使用AspecJ实现AOP
- 我们一个需要被拦截增强的bean(也就是需要面向的切入点,切面),这个bean可能是满足业务需要的核心逻辑,例如其中的test方法封装这核心业务,如果我们想在这个test前后加入日志调试,那直接修改源码肯定是不合适的。但spring的aop能做到这点。
public class Book { public void test(){ System.out.println("Book test....."); } }
- 创建增强类,采用的是基于
@AspectJ的注解,例如前置增强@Before、后置增强,环绕增强等。public class MyBook { public void before1(){ System.out.println("前置增强....."); }//预计先输出这个,再输出Book中的test
- 之后再在xml配置文件中作出声明,测试就能成功。
Spring IoC容器的初始化(TODO)
Spring AOP 的实现机制(TODO)
实现的两种代理实现机制,JDK动态代理和CGLIB动态代理。
代理机制-CGLIB
- 静态代理
- 静态代理在使用时,需要定义接口或者父类
- 被代理对象与代理对象一起实现相同的接口或者是继承相同父类
但是我们知道,实现接口,则必须实现它所有的方法。方法少的接口倒还好,但是如果恰巧这个接口的方法有很多呢,例如List接口。 更好的选择是: 使用动态代理!
- JDK动态代理
- 动态代理对象特点:
- 代理对象,不需要实现接口
- 代理对象的生成,是利用JDK的API,动态的在内存中构建代理对象(需要我们指定创建代理对象/目标对象实现的接口的类型)
- JDK实现代理只需要使用newProxyInstance方法
- JDK动态代理局限性
- 其代理对象必须是某个接口的实现,它是通过在运行期间床i教案一个接口的实现类来完成目标对象的代理。但事实上并不是所有类都有接口,对于没有实现接口的类,便无法使用该方方式实现动态代理。
如果Spring识别到所代理的类没有实现Interface,那么就会使用CGLib来创建动态代理,原理实际上成为所代理类的子类。
-
Cglib动态代理
- 上面的静态代理和动态代理模式都是要求目标对象是实现一个接口的目标对象,Cglib代理,也叫作子类代理,是基于asm框架,实现了无反射机制进行代理,利用空间来换取了时间,代理效率高于jdk ,它是在内存中构建一个子类对象从而实现对目标对象功能的扩展. 它有如下特点:
- JDK的动态代理有一个限制,就是使用动态代理的对象必须实现一个或多个接口,如果想代理没有实现接口的类,就可以使用Cglib实现.
- Cglib是一个强大的高性能的代码生成包,它可以在运行期扩展java类与实现java接口.它广泛的被许多AOP的框架使用,例如Spring AOP和synaop,为他们提供方法的interception(拦截)
- Cglib包的底层是通过使用一个小而块的字节码处理框架ASM来转换字节码并生成新的类.不鼓励直接使用ASM,因为它要求你必须对JVM内部结构包括class文件的格式和指令集都很熟悉.
- 目标对象的方法如果为final/static,那么就不会被拦截,即不会执行目标对象额外的业务方法.
对比JDK动态代理和CGLib代理,在实际使用中发现CGLib在创建代理对象时所花费的时间却比JDK动态代理要长,所以CGLib更适合代理不需要频繁实例化的类。
Bean的加载
整个bean加载的过程步骤相对繁琐,主要步骤有以下几点:
-
转换beanName
要知道平时开发中传入的参数name可能只是别名,也可能是FactoryBean,所以需要进行解析转换,一般会进行以下解析:
(1)消除修饰符,比如name="&test",会去除&使name="test";
(2)取alias表示的最后的beanName,比如别名test01指向名称为test02的bean则返回test02。 -
从缓存中加载实例
实例在Spring的同一个容器中只会被创建一次,后面再想获取该bean时,就会尝试从缓存中获取;如果获取不到的话再从singletonFactories中加载。 -
实例化bean
缓存中记录的bean一般只是最原始的bean状态,这时就需要对bean进行实例化。如果得到的是bean的原始状态,但又要对bean进行处理,这时真正需要的是工厂bean中定义的factory-method方法中返回的bean,上面源码中的getObjectForBeanInstance就是来完成这个工作的。 -
检测parentBeanFacotory
从源码可以看出如果缓存中没有数据会转到父类工厂去加载,源码中的!containsBeanDefinition(beanName)就是检测如果当前加载的xml配置文件中不包含beanName所对应的配置,就只能到parentBeanFacotory去尝试加载bean。 -
存储XML配置文件的GernericBeanDefinition转换成RootBeanDefinition之前的文章介绍过XML配置文件中读取到的bean信息是存储在GernericBeanDefinition中的,但Bean的后续处理是针对于RootBeanDefinition的,所以需要转换后才能进行后续操作。
-
初始化依赖的bean
这里应该比较好理解,就是bean中可能依赖了其他bean属性,在初始化bean之前会先初始化这个bean所依赖的bean属性。 -
创建bean
Spring容器根据不同scope创建bean实例。
整个流程就是如此,下面会讲解一些重要步骤的源码。
Bean生命周期(TODO)
Spring Bean的生命周期
Bean的生命周期
Spring中Bean的生命周期是怎样的?zhihu

1. 实例化Bean
对于BeanFactory容器,当客户向容器请求一个尚未初始化的bean时,或初始化bean的时候需要注入另一个尚未初始化的依赖时,容器就会调用createBean进行实例化。 对于ApplicationContext容器,当容器启动结束后,便实例化所有的bean。 容器通过获取BeanDefinition对象中的信息进行实例化。并且这一步仅仅是简单的实例化,并未进行依赖注入。 实例化对象被包装在BeanWrapper对象中,BeanWrapper提供了设置对象属性的接口,从而避免了使用反射机制设置属性。
2. 设置对象属性(依赖注入)
实例化后的对象被封装在BeanWrapper对象中,并且此时对象仍然是一个原生的状态,并没有进行依赖注入。 紧接着,Spring根据BeanDefinition中的信息进行依赖注入。 并且通过BeanWrapper提供的设置属性的接口完成依赖注入。
3. 注入Aware接口
紧接着,Spring会检测该对象是否实现了xxxAware接口,并将相关的xxxAware实例注入给bean。
4. BeanPostProcessor
当经过上述几个步骤后,bean对象已经被正确构造,但如果你想要对象被使用前再进行一些自定义的处理,就可以通过BeanPostProcessor接口实现。 该接口提供了两个函数:postProcessBeforeInitialzation( Object bean, String beanName ) 当前正在初始化的bean对象会被传递进来,我们就可以对这个bean作任何处理。 这个函数会先于InitialzationBean执行,因此称为前置处理。 所有Aware接口的注入就是在这一步完成的。postProcessAfterInitialzation( Object bean, String beanName ) 当前正在初始化的bean对象会被传递进来,我们就可以对这个bean作任何处理。 这个函数会在InitialzationBean完成后执行,因此称为后置处理。
5. InitializingBean与init-method
当BeanPostProcessor的前置处理完成后就会进入本阶段。 InitializingBean接口只有一个函数:afterPropertiesSet()这一阶段也可以在bean正式构造完成前增加我们自定义的逻辑,但它与前置处理不同,由于该函数并不会把当前bean对象传进来,因此在这一步没办法处理对象本身,只能增加一些额外的逻辑。 若要使用它,我们需要让bean实现该接口,并把要增加的逻辑写在该函数中。然后Spring会在前置处理完成后检测当前bean是否实现了该接口,并执行afterPropertiesSet函数。当然,Spring为了降低对客户代码的侵入性,给bean的配置提供了init-method属性,该属性指定了在这一阶段需要执行的函数名。Spring便会在初始化阶段执行我们设置的函数。init-method本质上仍然使用了InitializingBean接口。
6. DisposableBean和destroy-method
和init-method一样,通过给destroy-method指定函数,就可以在bean销毁前执行指定的逻辑。
Spring是如果解决循环依赖
-
第1种,解决构造器中对其它类的依赖,创建A类需要构造器中初始化B类,创建B类需要构造器中初始化C类,创建C类需要构造器中又要初始化A类,因而形成一个死循环,Spring的解决方案是,把创建中的Bean放入到一个“当前创建Bean池”中,在初始化类的过程中,如果发现Bean类已存在,就抛出一个“BeanCurrentInCreationException”的异常
-
第2种,解决setter对象的依赖,就是说在A类需要设置B类,B类需要设置C类,C类需要设置A类,这时就出现一个死循环,spring的解决方案是,初始化A类时把A类的初始化Bean放到缓存中,然后set B类,再把B类的初始化Bean放到缓存中,然后set C类,初始化C类需要A类和B类的Bean,这时不需要初始化,只需要从缓存中取出即可.该种仅对single作用的Bean起作用,因为prototype作用的Bean,Spring不对其做缓存
八、Spring Boot
源码解读@SpringBootApplication与SpringApplication.run
一. @SpringBootApplication
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@SpringBootConfiguration // 从源代码中得知 @SpringBootApplication 被 @SpringBootConfiguration、@EnableAutoConfiguration、@ComponentScan 注解
@EnableAutoConfiguration // 所修饰,换言之 Springboot 提供了统一的注解来替代以上三个注解,简化程序的配置。下面解释一下各注解的功能。
@ComponentScan(excludeFilters = {
@Filter(type = FilterType.CUSTOM, classes = TypeExcludeFilter.class),
@Filter(type = FilterType.CUSTOM, classes = AutoConfigurationExcludeFilter.class) })
public @interface SpringBootApplication {
@AliasFor(annotation = EnableAutoConfiguration.class)
Class<?>[] exclude() default {};
@AliasFor(annotation = EnableAutoConfiguration.class)
String[] excludeName() default {};
@AliasFor(annotation = ComponentScan.class, attribute = "basePackages")
String[] scanBasePackages() default {};
@AliasFor(annotation = ComponentScan.class, attribute = "basePackageClasses")
Class<?>[] scanBasePackageClasses() default {};
}1. @SpringBootConfiguration
进入之后可以看到这个注解是继承了 @Configuration 的,二者功能也一致,标注当前类是配置类,并会将当前类内声明的一个或多个以@bean注解标记的方法的实例纳入到srping容器中,并且实例名就是方法名。
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Configuration
public @interface SpringBootConfiguration {
}- 以下摘自Spring文档翻译
@Configuration是一个类级注释,指示对象是一个bean定义的源。@Configuration类通过@Bean注解的公共方法声明bean。
@Bean注释是用来表示一个方法实例化,配置和初始化是由 Spring IoC 容器管理的一个新的对象。
通俗的讲 @Configuration 一般与 @Bean 注解配合使用,用 @Configuration 注解类等价与 XML 中配置 beans,用 @Bean 注解方法等价于 XML 中配置 bean 。举例说明:
- XML配置代码如下:
<beans>
<bean id = "userService" class="com.user.UserService">
<property name="userDAO" ref = "userDAO"></property>
</bean>
<bean id = "userDAO" class="com.user.UserDAO"></bean>
</beans>- 等价于
@Bean注释
@Configuration
public class Config {
@Bean
public UserService getUserService(){
UserService userService = new UserService();
userService.setUserDAO(null);
return userService;
}
@Bean
public UserDAO getUserDAO(){
return new UserDAO();
}
}2. @EnableAutoConfiguration
@EnableAutoConfiguration的作用启动自动的配置,@EnableAutoConfiguration注解的意思就是Springboot根据你添加的jar包来配置你项目的默认配置,比如根据spring-boot-starter-web ,来判断你的项目是否需要添加了webmvc和tomcat,就会自动的帮你配置web项目中所需要的默认配置。
- 以下摘自Spring文档翻译
启用 Spring 应用程序上下文的自动配置,试图猜测和配置您可能需要的bean。自动配置类通常采用基于你的 classpath 和已经定义的 beans 对象进行应用。
被 @EnableAutoConfiguration 注解的类所在的包有特定的意义,并且作为默认配置使用。例如,当扫描 @entity类的时候它将本使用。通常推荐将 @EnableAutoConfiguration 配置在 root 包下,这样所有的子包、类都可以被查找到。
Auto-configuration类是常规的 Spring 配置 Bean。它们使用的是 SpringFactoriesLoader 机制(以 EnableAutoConfiguration 类路径为 key)。通常 auto-configuration beans 是 @conditional beans(在大多数情况下配合 @ConditionalOnClass 和 @ConditionalOnMissingBean 注解进行使用)。
- SpringFactoriesLoader 机制:
SpringFactoriesLoader会查询包含 META-INF/spring.factories 文件的JAR。 当找到spring.factories文件后,SpringFactoriesLoader将查询配置文件命名的属性。EnableAutoConfiguration的 key 值为org.springframework.boot.autoconfigure.EnableAutoConfiguration。根据此 key 对应的值进行 spring 配置。在 spring-boot-autoconfigure.jar文件中,包含一个 spring.factories 文件
3. @componentscan
@ComponentScan,扫描当前包及其子包下被@Component,@Controller,@Service,@Repository注解标记的类并纳入到spring容器中进行管理。是以前的<context:component-scan>(以前使用在xml中使用的标签,用来扫描包配置的平行支持)。举个例子,这就是为什么常见入门项目中User类会被Spring容器管理的原因。
- 以下摘自Spring文档翻译
为 @configuration注解的类配置组件扫描指令。同时提供与 Spring XML’s 元素并行的支持。
无论是 basePackageClasses() 或是 basePackages() (或其 alias 值)都可以定义指定的包进行扫描。如果指定的包没有被定义,则将从声明该注解的类所在的包进行扫描。
注意, 元素有一个 annotation-config 属性(详情:http://www.cnblogs.com/exe19/p/5391712.html),但是 @componentscan 没有。这是因为在使用 @componentscan 注解的几乎所有的情况下,默认的注解配置处理是假定的。此外,当使用 AnnotationConfigApplicationContext, 注解配置处理器总会被注册,以为着任何试图在 @componentscan 级别是扫描失效的行为都将被忽略。
通俗的讲,@componentscan 注解会自动扫描指定包下的全部标有 @component注解 的类,并注册成bean,当然包括 @component 下的子注解@service、@repository、@controller。@componentscan 注解没有类似的属性。
4. 更多
根据上面的理解,HelloWorld的入口类SpringboothelloApplication,我们可以使用:
@ComponentScan
//@SpringBootApplication
public class SpringboothelloApplication {
public static void main(String[] args) {
SpringApplication.run(SpringboothelloApplication.class, args);
}
}使用@ComponentScan注解代替@SpringBootApplication注解,也可以正常运行程序。原因是@SpringBootApplication中包含@ComponentScan,并且springboot会将入口类看作是一个@SpringBootConfiguration标记的配置类,所以定义在入口类Application中的SpringboothelloApplication也可以纳入到容器管理。
参考链接
二. SpringApplication.run
run方法主要用于创建或刷新一个应用上下文,是 Spring Boot的核心。
2.1 入口 run 方法执行流程
- 创建计时器,用于记录SpringBoot应用上下文的创建所耗费的时间。
- 开启所有的SpringApplicationRunListener监听器,用于监听Sring Boot应用加载与启动信息。
- 创建应用配置对象(main方法的参数配置) ConfigurableEnvironment
- 创建要打印的Spring Boot启动标记 Banner
- 创建 ApplicationContext应用上下文对象,web环境和普通环境使用不同的应用上下文。
- 创建应用上下文启动异常报告对象 exceptionReporters
- 准备并刷新应用上下文,并从xml、properties、yml配置文件或数据库中加载配置信息,并创建已配置的相关的单例bean。到这一步,所有的非延迟加载的Spring bean都应该被创建成功。
- 打印Spring Boot上下文启动耗时到Logger中
- Spring Boot启动监听
- 调用实现了*Runner类型的bean的callRun方法,开始应用启动。
- 如果在上述步骤中有异常发生则日志记录下才创建上下文失败的原因并抛出IllegalStateException异常。
public ConfigurableApplicationContext run(String... args) {
// 1. 创建计时器,用于记录SpringBoot应用上下文的创建所耗费的时间
StopWatch stopWatch = new StopWatch();
stopWatch.start();//stopWatch就是计时器
ConfigurableApplicationContext context = null;
Collection<SpringBootExceptionReporter> exceptionReporters = new ArrayList<>();
configureHeadlessProperty();
// 2. 开启所有的SpringApplicationRunListener监听器,用于监听Sring Boot应用加载与启动信息。
SpringApplicationRunListeners listeners = getRunListeners(args);
listeners.starting();// 监听器启动 主要用在log方面?
try {
ApplicationArguments applicationArguments = new DefaultApplicationArguments(
args);
// 3. 创建应用配置对象(main方法的参数配置) ConfigurableEnvironment
ConfigurableEnvironment environment = prepareEnvironment(listeners,
applicationArguments);
configureIgnoreBeanInfo(environment);
// 4. 创建要打印的Spring Boot启动标记 Banner
Banner printedBanner = printBanner(environment);
// 5. 创建 ApplicationContext应用上下文对象,web环境和普通环境使用不同的应用上下文。
context = createApplicationContext();
// 6. 创建应用上下文启动异常报告对象 exceptionReporters
exceptionReporters = getSpringFactoriesInstances(
SpringBootExceptionReporter.class,
new Class[] { ConfigurableApplicationContext.class }, context);
// 7. 准备并创建刷新应用上下文,并从xml、properties、yml配置文件或数据库中加载配置信息,并创建已配置的相关的单例bean。到这一步,所有的非延迟加载的Spring bean都应该被创建成功。
prepareContext(context, environment, listeners, applicationArguments,
printedBanner);
refreshContext(context);// 刷新上下文
afterRefresh(context, applicationArguments);
stopWatch.stop();//计时结束
// 8. 打印Spring Boot上下文启动耗时到Logger中
if (this.logStartupInfo) {
new StartupInfoLogger(this.mainApplicationClass)
.logStarted(getApplicationLog(), stopWatch);
}
// 9. Spring Boot启动监听
listeners.started(context);
// 10. 调用实现了*Runner类型的bean的callRun方法,开始应用启动。
callRunners(context, applicationArguments);
}
catch (Throwable ex) {
handleRunFailure(context, ex, exceptionReporters, listeners);
throw new IllegalStateException(ex);
}
try {
listeners.running(context); //完成listeners监听
}
// 11. 如果在上述步骤中有异常发生则日志记录下才创建上下文失败的原因并抛出IllegalStateException异常。
catch (Throwable ex) {
handleRunFailure(context, ex, exceptionReporters, null);
throw new IllegalStateException(ex);
}
return context;
}2.2 运行事件 深入各方法
事件就是Spring Boot启动过程的状态描述,在启动Spring Boot时所发生的事件一般指:
- 开始启动事件
- 环境准备完成事件
- 上下文准备完成事件
- 上下文加载完成
- 应用启动完成事件
2.2.1 开始启动运行监听器 SpringApplicationRunListeners
上一层调用代码:SpringApplicationRunListeners listeners = getRunListeners(args);
顾名思意,运行监听器的作用就是为了监听 SpringApplication 的run方法的运行情况。在设计上监听器使用观察者模式,以总信息发布器 SpringApplicationRunListeners 为基础平台,将Spring启动时的事件分别发布到各个用户或系统在 META_INF/spring.factories文件中指定的应用初始化监听器中。使用观察者模式,在Spring应用启动时无需对启动时的其它业务bean的配置关心,只需要正常启动创建Spring应用上下文环境。各个业务'监听观察者'在监听到spring开始启动,或环境准备完成等事件后,会按照自己的逻辑创建所需的bean或者进行相应的配置。观察者模式使run方法的结构变得清晰,同时与外部耦合降到最低。
spring-boot-2.0.3.RELEASE-sources.jar!/org/springframework/boot/context/event/EventPublishingRunListener.java
class SpringApplicationRunListeners {
...
// 在run方法业务逻辑执行前、应用上下文初始化前调用此方法
public void starting() {
for (SpringApplicationRunListener listener : this.listeners) {
listener.starting();
}
}
// 当环境准备完成,应用上下文被创建之前调用此方法
public void environmentPrepared(ConfigurableEnvironment environment) {}
// 在应用上下文被创建和准备完成之后,但上下文相关代码被加载执行之前调用。因为上下文准备事件和上下文加载事件难以明确区分,所以这个方法一般没有具体实现。
public void contextPrepared(ConfigurableApplicationContext context) {}
// 当上下文加载完成之后,自定义bean完全加载完成之前调用此方法。
public void contextLoaded(ConfigurableApplicationContext context) {}
public void started(ConfigurableApplicationContext context) {}
public void running(ConfigurableApplicationContext context) {}
// 当run方法执行完成,或执行过程中发现异常时调用此方法。
public void failed(ConfigurableApplicationContext context, Throwable exception) {
for (SpringApplicationRunListener listener : this.listeners) {
callFailedListener(listener, context, exception);
}
}
private void callFailedListener(SpringApplicationRunListener listener,
ConfigurableApplicationContext context, Throwable exception) {}
}
}
}默认情况下Spring Boot会实例化EventPublishingRunListener作为运行监听器的实例。在实例化运行监听器时需要SpringApplication对象和用户对象作为参数。其内部维护着一个事件广播器(被观察者对象集合,前面所提到的在META_INF/spring.factories中注册的初始化监听器的有序集合 ),当监听到Spring启动等事件发生后,就会将创建具体事件对象,并广播推送给各个被观察者。
2.2.2 环境准备 创建应用配置对象 ConfigurableEnvironment
上一层调用代码:ConfigurableEnvironment environment = prepareEnvironment(listeners
将通过ApplicationArguments将环境Environment配置好,并与SpringApplication绑定
private ConfigurableEnvironment prepareEnvironment(
SpringApplicationRunListeners listeners,
ApplicationArguments applicationArguments) {
// 获取或创建环境 Create and configure the environment
ConfigurableEnvironment environment = getOrCreateEnvironment();
configureEnvironment(environment, applicationArguments.getSourceArgs());
// 持续监听
listeners.environmentPrepared(environment);
// 将环境与SpringApplication绑定(调用到 binder.java 未看)
bindToSpringApplication(environment);
if (this.webApplicationType == WebApplicationType.NONE) {
environment = new EnvironmentConverter(getClassLoader())
.convertToStandardEnvironmentIfNecessary(environment);
}
ConfigurationPropertySources.attach(environment);
return environment;
}- 略过Banner的创建
2.2.3 创建应用上下文对象 ApplicationContext
context = createApplicationContext();
根据this.webApplicationType来判断是什么环境,web环境和普通环境使用不同的应用上下文。再使用反射相应实例化。
spring-boot-2.0.3.RELEASE-sources.jar!/org/springframework/boot/SpringApplication.java
protected ConfigurableApplicationContext createApplicationContext() {
Class<?> contextClass = this.applicationContextClass;
if (contextClass == null) {
try {
switch (this.webApplicationType) {
case SERVLET:// 判断
contextClass = Class.forName(DEFAULT_WEB_CONTEXT_CLASS); // 反射
break;
case REACTIVE:
contextClass = Class.forName(DEFAULT_REACTIVE_WEB_CONTEXT_CLASS);
break;
default:
contextClass = Class.forName(DEFAULT_CONTEXT_CLASS);
}
}
catch (ClassNotFoundException ex) {
throw new IllegalStateException(
"Unable create a default ApplicationContext, "
+ "please specify an ApplicationContextClass",
ex);
}
}
return (ConfigurableApplicationContext) BeanUtils.instantiateClass(contextClass);
}================================
Class.forName() 的作用
-
Class.forName:返回与给定的字符串名称相关联类或接口的 Class 对象。
- Class.forName(className) 实际上是调用 Class.forName(className,true, this.getClass().getClassLoader())。第二个参数,是指 Class 被 loading 后是不是必须被初始化。可以看出,使用 Class.forName(className)加载类时则已初始化。
- 所以 Class.forName(className) 可以简单的理解为:获得字符串参数中指定的类,并初始化该类。
-
首先你要明白在 java 里面任何 class 都要装载在虚拟机上才能运行
- forName 这句话就是装载类用的 (new 是根据加载到内存中的类创建一个实例,要分清楚)。
- 至于什么时候用,可以考虑一下这个问题,给你一个字符串变量,它代表一个类的包名和类名,你怎么实例化它?
两者是一样的效果。
A a = (A)Class.forName("pacage.A").newInstance(); A a = new A();
- jvm 在装载类时会执行类的静态代码段,要记住静态代码是和 class 绑定的,class 装载成功就表示执行了你的静态代码了,而且以后不会再执行这段静态代码了。
- Class.forName(xxx.xx.xx) 的作用是要求 JVM 查找并加载指定的类,也就是说 JVM 会执行该类的静态代码段。
- 动态加载和创建 Class 对象,比如想根据用户输入的字符串来创建对象
String str = 用户输入的字符串 Class t = Class.forName(str); t.newInstance();
2.2.4 创建上下文启动异常报告对象 exceptionReporters
上一层调用:
exceptionReporters = getSpringFactoriesInstances(SpringBootExceptionReporter.class,
new Class[] { > ConfigurableApplicationContext.class }, context);
通过getSpringFactoriesInstances创建SpringBootExceptionReporter接口的实现,而该接口的实现的就是FailureAnalyzers——上下文启动失败原因分析对象。
spring-boot-2.0.3.RELEASE-sources.jar!/org/springframework/boot/diagnostics/FailureAnalyzers.java
final class FailureAnalyzers implements SpringBootExceptionReporter {
...
FailureAnalyzers(ConfigurableApplicationContext context, ClassLoader classLoader) {}
private List<FailureAnalyzer> loadFailureAnalyzers(ClassLoader classLoader) {}
private void prepareFailureAnalyzers(List<FailureAnalyzer> analyzers,
ConfigurableApplicationContext context) {}
private void prepareAnalyzer(ConfigurableApplicationContext context,
FailureAnalyzer analyzer) {}
@Override
public boolean reportException(Throwable failure) {}
private FailureAnalysis analyze(Throwable failure, List<FailureAnalyzer> analyzers) {}
private boolean report(FailureAnalysis analysis, ClassLoader classLoader) {}
}2.2.5 准备上下文 prepareContext
上一层调用:prepareContext(context, environment, listeners, applicationArguments,printedBanner);
xml、properties、yml配置文件或数据库中加载的配置信息封装到applicationArguments中,并创建已配置的相关的单例bean。到这一步,所有的非延迟加载的Spring bean都应该被创建成功。
private void prepareContext(ConfigurableApplicationContext context,
ConfigurableEnvironment environment, SpringApplicationRunListeners listeners,
ApplicationArguments applicationArguments, Banner printedBanner) {
context.setEnvironment(environment);
postProcessApplicationContext(context);
applyInitializers(context);
listeners.contextPrepared(context);
if (this.logStartupInfo) {
logStartupInfo(context.getParent() == null);
logStartupProfileInfo(context);
}
// 创建已配置的相关的单例 bean
// Add boot specific singleton beans
context.getBeanFactory().registerSingleton("springApplicationArguments",
applicationArguments);
if (printedBanner != null) {
context.getBeanFactory().registerSingleton("springBootBanner", printedBanner);
}
// Load the sources
Set<Object> sources = getAllSources();
Assert.notEmpty(sources, "Sources must not be empty");
load(context, sources.toArray(new Object[0]));
listeners.contextLoaded(context);
}2.2.6
上一层调用:refreshContext(context);
2.2.7
上一层调用:
参考链接
九、设计模式(TODO)
十、Linux命令行使用
【操作系统实验笔记】Hello World程序在Linux下的诞生与消亡
一、从源代码到可执行文件
#include<stdio.h>
int main()
{
printf("hello world\n");
return 0;
}1. 编译全过程解析
自C,C++等高级语言诞生之后,程序的编写基本脱离了硬件系统,使人更能读懂与理解。但对于机器来说,源代码需要经过多个步骤,转换为一系列低级机器语言指令,然后将这些指令按照可执行程序的格式打包,并以二进制文件形式储存起来。
命令:
gcc -o h hello.c
作用:在Linux下,可用gcc的命令编译hello.c,使其转化为可执行文件h。
gcc 编译器驱动程序读取源文件hello.c,经过预处理、编译、汇编、链接(分别使用预处理器、编译器、汇编器、链接器,这四个程序构成了编译系统)四个步骤,将其翻译成可执行目标程序hello。如下图所示:

2. 预处理
预处理器(CPP)根据源程序中以字符”#”开头的命令,修改源程序,得到另一个源程序,常以.i作为文件扩展名。修改主要包括#include、#define和条件编译三个方面。
命令:
gcc -o hello.i -E hello.c
作用:编译器将C源代码中的包含的头文件如stdio.h编译进来,将hello.c预处理输出hello.i文件。
查看hello.i,如下图所示:

3. 编译
第二步,编译器(CCL)将经过预处理器处理得到的文本文件hello.i翻译成hello.s,在这个阶段中,gcc首先要检查代码的规范性、是否有语法错误等,以确定代码的实际要做的工作,在检查无误后,gcc把代码翻译成汇编语言。汇编语言程序以一种标准的文本格式确切描述一条低级机器语言指令。
命令:
gcc -S hello.c
作用:将预处理输出文件hello.i汇编成hello.s文件。
.file "hello.c"
.section .rodata
.LC0:
.string "hello world"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
movl $.LC0, %edi
call puts
movl $0, %eax
popq %rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (Ubuntu 5.4.0-6ubuntu1~16.04.5) 5.4.0 20160609"
.section .note.GNU-stack,"",@progbits 4. 汇编
汇编阶段是把编译阶段生成的”.s”文件转成二进制目标代码。汇编器(AS)将hello.s翻译成机器语言指令,并打包成可重定位目标程序,一般以.o为文件扩展名。可重定位目标程序是二进制文件,它的字节编码是机器语言指令而不是字符。
命令:
gcc -c hello.s
作用:将汇编输出文件hello.s编译输出hello.o文件。
vim打开hello.o发现文件是乱码,说明此时已经是二进制文件。
5. 链接
链接程序(LD)将hello.o以及一些其他必要的目标文件组合起来,创建可执行目标文件。
命令:
gcc -o he hello.o
作用:生成可执行文件he
root@Treee:~# ./he
hello world
在这里涉及到一个重要的概念:函数库。
读者可以重新查看这个小程序,在这个程序中并没有定义”printf”的函数实现,且在预编译中包含进的”stdio.h”中也只有该函数的声明,而没有定义函数的实现,那么,是在哪里实现”printf”函数的呢?最后的答案是:系统把这些函数实现都被做到名为libc.so.6的库文件中去了,在没有特别指定时,gcc会到系统默认的搜索路径”/usr/lib”下进行查找,也就是链接到libc.so.6库函数中去,这样就能实现函数”printf” 了,而这也就是链接的作用。
你可以用ldd命令查看动态库加载情况:
[root]# ldd hello.exe
libc.so.6 => /lib/tls/libc.so.6 (0x42000000)
/lib/ld-linux.so.2 => /lib/ld-linux.so.2 (0x40000000)
函数库一般分为静态库和动态库两种。静态库是指编译链接时,把库文件的代码全部加入到可执行文件中,因此生成的文件比较大,但在运行时也就不再需要库文件了。其后缀名一般为”.a”。动态库与之相反,在编译链接时并没有把库文件的代码加入到可执行文件中,而是在程序执行时由运行时链接文件加载库,这样可以节省系统的开销。动态库一般后缀名为”.so”,如前面所述的libc.so.6就是动态库。gcc在编译时默认使用动态库。
参考链接
二、可执行程序的加载及执行
1. 可执行文件的存储器映像
通过链接,我们获得了可执行文件,可执行文件是保存在磁盘中的。

在可执行文件中,有一个程序头表。在程序头表当中,描述了可执行文件中的只读代码(图中的 .text )和数据 (.data 和 .bss) 的存储映像。
而它在Linux系统下的虚拟地址结构如上图右侧所示,分为两个空间:
- 最上面1GB是内核的虚存区,即从
0xC00000000向上的区域。- 下面的3GB空间是用户的虚存区。在用户的虚存区中又分为栈区(用户栈)和堆区,栈向下生长,堆向上生长,中间是共享库的区域。
- 最下面是可读可写的数据段和只读代码。
读写数据段与左图中的.data和.bss相映射。
从0x08048000开始的只读代码段与左图中从0开始的.text以及最终的只读数据节.rodata相映射。
如下图所示:

2. 程序的加载与运行
-
可执行文件通过调用execve系统调用函数来调用加载器。
-
加载器(loader)根据可执行文件的程序头表中的信息,将可执行文件的代码和数据从磁盘“拷贝”到存储器中(实际上不会真正拷贝,而是经过一系列复杂的数据结构等建立一种映射)。
-
加载后,将PC(EIP)设定指向
Entry point即符号_start处,最后执行可执行文件中的main函数,以启动程序执行。
execve系统调用函数:
- UNIX/Linux系统中,可通过调用
execve()函数来启动加载器。execve()函数的功能是在当前进程上下文中加载并运行一个新程序。
execve()函数的用法如下:
int execve(char *filename, char *argv[], *envp[]);
filename是加载并运行的可执行文件名(/.hello),可带参数列表argv和环境变量列表envp。若错误(如找不到指定文件filename),则返回-1,并将控制权交给调用程序;若函数执行成功,则不返回,最终将控制权传递到可执行目标中的主函数main。- 主函数
main()的原型形式如下:
int main(int argc, char **argv, char **envp);或者:
int main(int argc, char *argv[], char *envp[])- 而
main函数中的参数是由execve()函数传递下来的。argc指定参数个数,参数列表中第一个总是命令名(可执行文件名)。
例如:命令行为ld -o test main.o test.o时,argc=6。
回到 hello world 程序
hello程序的加载与运行过程:
- 在shell命令行提示符后输入命令:
./hello后回车 - shell命令行解释器构造
argv和enpv
shell命令行解释器先从键盘接受这些字符,然后碰到最后一个回车之后,就分割这个命令行。而。/hello只有一个字符串,因此构造的数组实际上是这样的:

它的第一个元素指向的是这个字符串的首地址,然后是一个以空结尾的一个指针类型数组。其中每一个数组都是一个指针,里面实际只有一个字符串,所以只有第一个数组元素是有意义的,指针指向这个字符串。 - 调用
fork()函数,创建一个子进程,与父进程shell完全相同(只读/共享,就是shell命令行解释器),包括只读代码段、可读写数据段、堆以及用户栈等。 - 调用
execve()函数,在当前进程(新创建的子进程)的上下文中加载并运行hello程序。将hello中的.text节、.data节 、.bss节等内容加载到当前进程的虚拟地址空间(仅修改当前进程上下文中关于存储映像的一些数据结构,不从磁盘中拷贝代码,数据等内容) - 调用
hello程序的main()函数,hello程序开始在一个进程的上下文中运行。
如下图所示:

三、Hello在内存中的镜像
可执行文件在内存中的加载已经在 二.1 可执行文件的存储器映像 中简单介绍过了。
在Linux操作系统加载程序是,将程序所使用的内存分为5段:text(程序段),data(数据段),bss(bbs数据段),heap(堆),stack(栈)。
1. text segment(程序段)
程序段用于存放程序指令本身,Linux为程序代码分配长度固定的内存,且程序段内存位于整个程序所占内存的最上方。
2. data segment(数据段)
数据段用于存放代码中已经被赋值的全局变量和静态变量,因为这类变量的所需内存(这点由变量数据类型决定)和其数值都已经在代码中确定了,因此data segment 紧跟 text segment ,并且操作系统清楚的知道数据段需要多少内存,从而赋予长度固定的内存。
这里可以使用ll命令查看:

第一个栏位,表示文件的属性。Linux的文件基本上分为三个属性:可读(r),可写(w),可执行(x)。 详情
第二个栏位,表示文件个数。如果是文件的话,那这个数目自然是1了,如果是目录的话,那它的数目就是该目录中的文件个数了。
第三个栏位,表示该文件或目录的拥有者。若使用者目前处于自己的Home,那这一栏大概都是它的账号名称。
第四个栏位,表示所属的组(group)。每一个使用者都可以拥有一个以上的组,不过大部分的使用者应该都只属于一个组,只有当系统管理员希望给予某使用者特殊权限时,才可能会给他另一个组。
第五栏位,表示文件大小。文件大小用byte来表示,而空目录一般都是1024byte,当然可以用其它参数 使文件显示的单位不同,如使用ls –k就是用kb莱显示一个文件的大小单位,不过一般我们还是以byte为主。
第六个栏位,表示最后一次修改时间。以“月,日,时间”的格式表示,如Aug 15 5:46表示8月15日早上5:46分。
第七个栏位,表示文件名。我们可以用ls –a显示隐藏的文件名。
3. bss segment(bss数据段)
此处引用一篇博客的内容:
bss segment用于存放未赋值的全局变量和静态变量。这块挨着data segment,长度固定。
bss是指那些没有初始化的和初始化为0的全局变量int bss_array[1024 * 1024] = {0}; int main(int argc, char* argv[]) { return 0; }[root@localhost bss]# gcc -g bss.c -o bss.exe [root@localhost bss]# ll total 12 -rw-r--r-- 1 root root 84 Jun 22 14:32 bss.c -rwxr-xr-x 1 root root 5683 Jun 22 14:32 bss.exe变量bss_array的大小为4M,而可执行文件的大小只有5K。 由此可见,bss类型的全局变量只占运行时的内存空间,而不占文件空间。
4. heap(堆)
用于存放程序所需的动态内存空间,如malloc()函数申请的内存空间。这块内存挨着bss,并向上生长。
5. stack(栈)
用于存放局部变量,当程序调用一个函数(包括main函数)时,将函数内部的变量入栈,当调用完成之后,函数内的局部变量就没用了,故要出栈。所以在递归的程序中,若函数调用次数(递归深度)过多,会有爆栈风险。
四、系统调用
本节主要介绍
printf()函数的调用。
1. printf()的代码在哪里?
在一.2 预处理中,预处理器预编译源代码,得到另一个源程序,可以发现printf()函数的声明。

然后如一.3 编译所示,编译成汇编:
.file "hello.c"
.section .rodata
.LC0:
.string "hello world"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
movl $.LC0, %edi
**call puts**
movl $0, %eax
popq %rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (Ubuntu 5.4.0-6ubuntu1~16.04.5) 5.4.0 20160609"
.section .note.GNU-stack,"",@progbits 我们发现
printf()函数调用被转化为call puts指令,而不是call printf指令,这好像有点出乎意料。不过不用担心,这是编译器对printf()的一种优化。实践证明,对于printf()的参数如果是以\n结束的纯字符串,printf会被优化为puts函数,而字符串的结尾\n符号被消除。除此之外,都会正常生成call printf指令。
编译阶段之后就是汇编了,但hello.o文件我们并不能通过vim等工具查看,这时候就需要gcc工具链的objdump命令查看二进制信息。
命令:
objdump -d hello.o。
作用:查看二进制文件。
hello.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <main>:
0: 55 push %rbp
1: 48 89 e5 mov %rsp,%rbp
4: bf 00 00 00 00 mov $0x0,%edi
**9: e8 00 00 00 00 callq e <main+0xe>**
e: b8 00 00 00 00 mov $0x0,%eax
13: 5d pop %rbp
14: c3 retq
而链接器最终会将puts的符号地址修正。由于链接方式分为静态链接和动态链接两种,此处callq e <main+0xe>应该是动态链接。虽然链接方式不同,但是不影响最终代码对库函数的调用。
我们这里关注printf函数背后的原理,因此使用更易说明问题的静态链接的方式阐述。这里引用原文内容
$/usr/lib/gcc/i686-linux-gnu/4.7/collect2 \ -static -o main \ /usr/lib/i386-linux-gnu/crt1.o \ /usr/lib/i386-linux-gnu/crti.o \ /usr/lib/gcc/i686-linux-gnu/4.7/crtbeginT.o \ main.o \ --start-group \ /usr/lib/gcc/i686-linux-gnu/4.7/libgcc.a \ /usr/lib/gcc/i686-linux-gnu/4.7/libgcc_eh.a \ /usr/lib/i386-linux-gnu/libc.a \ --end-group \ /usr/lib/gcc/i686-linux-gnu/4.7/crtend.o \ /usr/lib/i386-linux-gnu/crtn.o $objdump –sd mainDisassembly of section .text: ... 08048ea4 <main>: 8048ea4: 55 push %ebp 8048ea5: 89 e5 mov %esp,%ebp 8048ea7: 83 e4 f0 and $0xfffffff0,%esp 8048eaa: 83 ec 10 sub $0x10,%esp 8048ead: c7 04 24 e8 86 0c 08 movl $0x80c86e8,(%esp) 8048eb4: e8 57 0a 00 00 call 8049910 <_IO_puts> 8048eb9: b8 00 00 00 00 mov $0x0,%eax 8048ebe: c9 leave 8048ebf: c3 ret静态链接时,链接器将C语言的运行库(CRT)链接到可执行文件,其中crt1.o、crti.o、crtbeginT.o、crtend.o、crtn.o便是这五个核心的文件,它们按照上述命令显示的顺序分居在用户目标文件和库文件的两侧。由于我们使用了库函数puts,因此需要库文件libc.a,而libc.a与libgcc.a和libgcc_eh.a有相互依赖关系,因此需要使用-start-group和-end-group将它们包含起来。
链接后,call puts的地址被修正,但是反汇编显示的符号是_IO_puts而不是puts!难道我们找的文件不对吗?当然不是,我们使用readelf命令查看一下main的符号表。竟然发现puts和_IO_puts这两个符号的性质是等价的!objdump命令只是显示了全局的符号_IO_puts而已。
2. printf()的调用轨迹
我们知道对于"Hello World !\n"的printf调用被转化为puts函数,并且我们找到了puts的实现代码是在库文件libc.a内的,并且知道它是以二进制的形式存储在文件ioputs.o内的,那么我们如何寻找printf函数的调用轨迹呢?换句话说,printf函数是如何一步步执行,最终使用Linux的int 0x80软中断进行系统调用陷入内核的呢?
如果让我们向终端输出一段字符串信息,我们一般会使用系统调用write()。那么打印Helloworld的printf最终是这样做的吗?我们借助于gdb来追踪这个过程,不过我们需要在编译源文件的时候添加-g选项,支持调试时使用符号表。
gdb ./main (gdb)break main (gdb)run (gdb)stepi在main函数内下断点,然后调试执行,接着不断的使用stepi指令执行代码,直到看到Hello World !输出为止。这也是为什么我们使用puts作为示例而不是使用printf的原因。
(gdb) 0xb7fff419 in __kernel_vsyscall () (gdb) Hello World!我们发现Hello World!打印位置的上一行代码的执行位置为0xb7fff419。我们查看此处的反汇编代码。
(gdb)disassembleDump of assembler code for function __kernel_vsyscall: 0xb7fff414 <+0>: push %ecx 0xb7fff415 <+1>: push %edx 0xb7fff416 <+2>: push %ebp 0xb7fff417 <+3>: mov %esp,%ebp 0xb7fff419 <+5>: sysenter 0xb7fff41b <+7>: nop 0xb7fff41c <+8>: nop 0xb7fff41d <+9>: nop 0xb7fff41e <+10>: nop 0xb7fff41f <+11>: nop 0xb7fff420 <+12>: nop 0xb7fff421 <+13>: nop 0xb7fff422 <+14>: int $0x80 => 0xb7fff424 <+16>: pop %ebp 0xb7fff425 <+17>: pop %edx 0xb7fff426 <+18>: pop %ecx 0xb7fff427 <+19>: ret End of assembler dump.我们惊奇的发现,地址0xb7fff419正是指向sysenter指令的位置!这里便是系统调用的入口。如果想了解这里为什么不是int 0x80指令,请参考文章《Linux 2.6 对新型 CPU 快速系统调用的支持》。或者参考Linus在邮件列表里的文章《Intel P6 vs P7 system call performance》。
系统调用的位置已经是printf函数调用的末端了,我们只需要按照函数调用关系便能得到printf的调用轨迹了。
(gdb)backtrace#0 0xb7fff424 in __kernel_vsyscall () #1 0x080588b2 in __write_nocancel () #2 0x0806fa11 in _IO_new_file_write () #3 0x0806f8ed in new_do_write () #4 0x080708dd in _IO_new_do_write () #5 0x08070aa5 in _IO_new_file_overflow () #6 0x08049a37 in puts () #7 0x08048eb9 in main () at main.c:4我们发现系统调用前执行的函数是__write_nocancel,它执行了系统调用__write!
五、程序卸载
在二. 2程序的加载与运行已经讲过,hello world程序需要调度fork()函数创建一个子进程,而main结束并返回后,就需要调用系统调用终止当前进程。
当进程执行完它的工作后,就需要执行退出操作,释放进程占用的资源。ucore分了两步来完成这个工作,首先由进程本身完成大部分资源的占用内存回收工作,然后由此进程的父进程完成剩余资源占用内存的回收工作。为何不让进程本身完成所有的资源回收工作呢?这是因为进程要执行回收操作,就表明此进程还存在,还在执行指令,这就需要内核栈的空间不能释放,且表示进程存在的进程控制块不能释放。所以需要父进程来帮忙释放子进程无法完成的这两个资源回收工作。
为此在用户态的函数库中提供了
exit函数,此函数最终访问sys_exit系统调用接口让操作系统来帮助当前进程执行退出过程中的部分资源回收。我们来看看ucore是如何做进程退出工作的。首先,
exit函数会把一个退出码error_code传递给ucore,ucore通过执行内核函数do_exit来完成对当前进程的退出处理,主要工作简单地说就是回收当前进程所占的大部分内存资源,并通知父进程完成最后的回收工作,具体流程如下:
- 如果
current->mm != NULL,表示是用户进程,则开始回收此用户进程所占用的用户态虚拟内存空间;a) 首先执行
lcr3(boot_cr3),切换到内核态的页表上,这样当前用户进程目前只能在内核虚拟地址空间执行了,这是为了确保后续释放用户态内存和进程页表的工作能够正常执行;
b) 如果当前进程控制块的成员变量mm的成员变量mm_count减1后为0(表明这个mm没有再被其他进程共享,可以彻底释放进程所占的用户虚拟空间了。),则开始回收用户进程所占的内存资源:i. 调用
exit_mmap函数释放current->mm->vma链表中每个vma描述的进程合法空间中实际分配的内存,然后把对应的页表项内容清空,最后还把页表所占用的空间释放并把对应的页目录表项清空;
ii. 调用put_pgdir函数释放当前进程的页目录所占的内存;
iii. 调用mm_destroy函数释放mm中的vma所占内存,最后释放mm所占内存;
c) 此时设置current->mm为NULL,表示与当前进程相关的用户虚拟内存空间和对应的内存管理成员变量所占的内核虚拟内存空间已经回收完毕;
这时,设置当前进程的执行状态
current->state=PROC_ZOMBIE,当前进程的退出码current-> exit_code=error_code。此时当前进程已经不能被调度了,需要此进程的父进程来做最后的回收工作(即回收描述此进程的内核栈和进程控制块);如果当前进程的父进程
current->parent处于等待子进程状态:
current->parent->wait_state==WT_CHILD,则唤醒父进程(即执行
wakup_proc(current->parent)),让父进程帮助自己完成最后的资源回收;
如果当前进程还有子进程,则需要把这些子进程的父进程指针设置为内核线程
initproc,且各个子进程指针需要插入到initproc的子进程链表中。如果某个子进程的执行状态是PROC_ZOMBIE,则需要唤醒initproc来完成对此子进程的最后回收工作。执行
schedule()函数,选择新的进程执行。那么父进程如何完成对子进程的最后回收工作呢?这要求父进程要执行
wait用户函数或wait_pid用户函数,这两个函数的区别是,wait函数等待任意子进程的结束通知,而wait_pid函数等待进程id号为pid的子进程结束通知。这两个函数最终访问sys_wait系统调用接口让ucore来完成对子进程的最后回收工作,即回收子进程的内核栈和进程控制块所占内存空间,具体流程如下:
如果
pid!=0,表示只找一个进程id号为pid的退出状态的子进程,否则找任意一个处于退出状态的子进程;如果此子进程的执行状态不为
PROC_ZOMBIE,表明此子进程还没有退出,则当前进程只好设置自己的执行状态为PROC_SLEEPING,睡眠原因为WT_CHILD(即等待子进程退出),调用schedule()函数选择新的进程执行,自己睡眠等待,如果被唤醒,则重复跳回步骤1处执行;如果此子进程的执行状态为
PROC_ZOMBIE,表明此子进程处于退出状态,需要当前进程(即子进程的父进程)完成对子进程的最终回收工作,即首先把子进程控制块从两个进程队列proc_list和hash_list中删除,并释放子进程的内核堆栈和进程控制块。自此,子进程才彻底地结束了它的执行过程,消除了它所占用的所有资源。
可以这样概括:
- 调用系统调用终止当前进程
- 回收用户态空间分页
- 销毁进程句柄
- 通知父进程,该进程结束。
【Java】从BIO、NIO到Linux下的IO多路复用
从传统的阻塞I/O和线程池模型面临的问题讲起,然后对比几种常见I/O模型,一步步分析NIO怎么利用事件模型处理I/O,解决线程池瓶颈处理海量连接,包括利用面向事件的方式编写服务端/客户端程序。再延展到一些高级主题,如Reactor与Proactor模型的对比、Buffer的选择等。最后还会参考一下Linux的IO多路复用,映照着理解。
一、传统BIO、NIO对比
1.1 传统BIO模型分析
让我们先回忆一下传统的服务器端同步阻塞I/O处理(也就是BIO,Blocking I/O)的经典编程模型,服务器为每个客户端启动一个线程,这个线程会全心全意为这个客户端服务,但这个模式有一个重大弱点,它倾向于让CPU进行IO等待:
{// 以下为伪代码
ExecutorService executor = Excutors.newFixedThreadPollExecutor(100);//线程池
ServerSocket serverSocket = new ServerSocket();
serverSocket.bind(8088);
while(!Thread.currentThread.isInturrupted()){//主线程死循环等待新连接到来
Socket socket = serverSocket.accept();
executor.submit(new ConnectIOnHandler(socket));//为新的连接创建新的线程
}
class ConnectIOnHandler extends Thread{
private Socket socket;
public ConnectIOnHandler(Socket socket){
this.socket = socket;
}
public void run(){
while(!Thread.currentThread.isInturrupted()&&!socket.isClosed()){// 死循环处理读写事件
String someThing = socket.read()....//读取数据
if(someThing!=null){
......//处理数据
socket.write()....//写数据
}
}
}
}这是一个经典的一个链接一个线程的IO模型。这里以多线程为例,主要是因为socket.accept()、socket.read()、socket.write()三个主要函数都是同步阻塞的,当一个链接在处理IO时,系统是阻塞的。这时候我们可以利用多线程的本质:
- 利用多核
- 当I/O阻塞系统,但CPU空闲的时候,可以利用多线程使用CPU资源。
并且现在的多线程一般使用线程池,可以让线程的创建回收成本相对较低。线程池本身就是一个天然的漏斗,可以缓冲一些系统处理不了的连接或请求。
不过,这个模型最本质的问题在于,严重依赖于线程。但线程是很"贵"的资源,主要表现在:
- 线程的创建和销毁成本很高,在Linux这样的操作系统中,线程本质上就是一个进程。创建和销毁都是重量级的系统函数。
- 线程本身占用较大内存,像Java的线程栈,一般至少分配512K~1M的空间,如果系统中的线程数过千,恐怕整个JVM的内存都会被吃掉一半。
- 线程的切换成本是很高的。操作系统发生线程切换的时候,需要保留线程的上下文,然后执行系统调用。如果线程数过高,可能执行线程切换的时间甚至会大于线程执行的时间,这时候带来的表现往往是系统load偏高、CPU sy使用率特别高(超过20%以上),导致系统几乎陷入不可用的状态。
- 容易造成锯齿状的系统负载。因为系统负载是用活动线程数或CPU核心数,一旦线程数量高但外部网络环境不是很稳定,就很容易造成大量请求的结果同时返回,激活大量阻塞线程从而使系统负载压力过大。
所以,当面对十万甚至百万级连接的时候,传统的BIO模型是无能为力的。随着移动端应用的兴起和各种网络游戏的盛行,百万级长连接日趋普遍,此时,必然需要一种更高效的I/O处理模型。
1.2 NIO是怎么工作的
所有的系统I/O都分为两个阶段:等待就绪和操作。举例来说,读函数,分为等待系统可读和真正的读;同理,写函数分为等待网卡可以写和真正的写。
需要说明的是等待就绪的阻塞是不使用CPU的,是在“空等”;而真正的读写操作的阻塞是使用CPU的,真正在"干活",而且这个过程非常快,属于memory copy,带宽通常在1GB/s级别以上,可以理解为基本不耗时。
以socket.read()为例子:
传统的BIO里面socket.read(),如果TCP RecvBuffer里没有数据,函数会一直阻塞,直到收到数据,返回读到的数据。
对于NIO,如果TCP RecvBuffer有数据,就把数据从网卡读到内存,并且返回给用户;反之则直接返回0,永远不会阻塞。
最新的AIO(Async I/O)里面会更进一步:不但等待就绪是非阻塞的,就连数据从网卡到内存的过程也是异步的。
换句话说,BIO里用户最关心“我要读”,NIO里用户最关心"我可以读了",在AIO模型里用户更需要关注的是“读完了”。
NIO一个重要的特点是:socket主要的读、写、注册和接收函数,在等待就绪阶段都是非阻塞的,真正的I/O操作是同步阻塞的(消耗CPU但性能非常高)。
1.2.1 结合事件模型使用NIO同步非阻塞特性
回忆BIO模型,之所以需要多线程,是因为在进行I/O操作的时候,一是没有办法知道到底能不能写、能不能读,只能"傻等",即使通过各种估算,算出来操作系统没有能力进行读写,也没法在socket.read()和socket.write()函数中返回,这两个函数无法进行有效的中断。所以除了多开线程另起炉灶,没有好的办法利用CPU。
NIO的读写函数可以立刻返回,这就给了我们不开线程利用CPU的最好机会:如果一个连接不能读写(socket.read()返回0或者socket.write()返回0),我们可以 把这件事记下来,记录的方式通常是在Selector上注册标记位,然后切换到其它就绪的连接(channel)继续进行读写。
下面具体看下如何利用事件模型单线程处理所有I/O请求:
NIO的主要事件有几个:读就绪、写就绪、有新连接到来。
我们首先需要注册当这几个事件到来的时候所对应的处理器。然后在合适的时机告诉事件选择器:我对这个事件感兴趣。对于写操作,就是写不出去的时候对写事件感兴趣;对于读操作,就是完成连接和系统没有办法承载新读入的数据的时;对于accept,一般是服务器刚启动的时候;而对于connect,一般是connect失败需要重连或者直接异步调用connect的时候。
其次,用一个死循环选择就绪的事件,会执行系统调用(Linux 2.6之前是select、poll,2.6之后是epoll(这几个概念后文专门解释),Windows是IOCP),还会阻塞的等待新事件的到来。新事件到来的时候,会在selector上注册标记位,标示可读、可写或者有连接到来。
注意,select是阻塞的,无论是通过操作系统的通知(epoll)还是不停的轮询(select,poll),这个函数是阻塞的。所以你可以放心大胆地在一个while(true)里面调用这个函数而不用担心CPU空转。
程序大概的模样是:
interface ChannelHandler{
void channelReadable(Channel channel);
void channelWritable(Channel channel);
}
class Channel{
Socket socket;
Event event;//读,写或者连接
}
//IO线程主循环:
class IoThread extends Thread{
public void run(){
Channel channel;
while(channel=Selector.select()){//选择就绪的事件和对应的连接
if(channel.event==accept){
registerNewChannelHandler(channel);//如果是新连接,则注册一个新的读写处理器
}
if(channel.event==write){
getChannelHandler(channel).channelWritable(channel);//如果可以写,则执行写事件
}
if(channel.event==read){
getChannelHandler(channel).channelReadable(channel);//如果可以读,则执行读事件
}
}
}
Map<Channel,ChannelHandler> handlerMap;//所有channel的对应事件处理器
}这个程序很简短,也是最简单的Reactor模式:注册所有感兴趣的事件处理器,单线程轮询选择就绪事件,执行事件处理器。
1.3. 小结:两者的主要区别
| BIO(IO) | NIO |
|---|---|
| 面向流 | 面向缓冲 |
| 阻塞IO | 非阻塞IO |
| 无 | 选择器(selector) |
1.3.1 面向流与面向缓冲
Java BIO面向流意味着每次从流中读一个或多个字节,直至读取所有字节,它们没有被缓存在任何地方。此外,它不能前后移动流中的数据。如果需要前后移动从流中读取的数据,需要先将它缓存到一个缓冲区。
Java NIO的缓冲导向方法略有不同。数据读取到一个它稍后处理的缓冲区,需要时可在缓冲区中前后移动。这就增加了处理过程中的灵活性。但是,还需要检查是否该缓冲区中包含所有您需要处理的数据。而且,需确保当更多的数据读入缓冲区时,不要覆盖缓冲区里尚未处理的数据。
1.3.2 阻塞与非阻塞IO
Java BIO的各种流是阻塞的。这意味着,当一个线程调用read() 或 write()时,该线程被阻塞,直到有一些数据被读取,或数据完全写入。该线程在此期间不能再干任何事情了。
Java NIO的非阻塞模式,使一个线程从某通道发送请求读取数据,但是它仅能得到目前可用的数据,如果目前没有数据可用时,就什么都不会获取。而不是保持线程阻塞,所以直至数据变的可以读取之前,该线程可以继续做其他的事情。 非阻塞写也是如此。一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时可以去做别的事情。 线程通常将非阻塞IO的空闲时间用于在其它通道上执行IO操作,所以一个单独的线程现在可以管理多个输入和输出通道(channel)。
二、NIO的核心部分
NIO主要有三大核心部分:Channel(通道),Buffer(缓冲区), Selector。传统IO基于字节流和字符流进行操作,而NIO基于Channel和Buffer(缓冲区)进行操作,数据总是从通道读取到缓冲区中,或者从缓冲区写入到通道中。Selector(选择区)用于监听多个通道的事件(比如:连接打开,数据到达)。因此,单个线程可以监听多个数据通道Channel。
2.1 Channel
首先说一下Channel,国内大多翻译成“通道”。Channel和IO中的Stream(流)是差不多一个等级的。只不过Stream是单向的,譬如:InputStream, OutputStream.而Channel是双向的,既可以用来进行读操作,又可以用来进行写操作。
NIO中的Channel的主要实现有:
- FileChannel
- DatagramChannel
- SocketChannel
- ServerSocketChannel
这里看名字就可以猜出个所以然来:分别可以对应文件IO、UDP和TCP(Server和Client)。
2.2 Buffer
通常情况下,操作系统的一次写操作分为两步:
将数据从用户空间拷贝到系统空间。
从系统空间往网卡写。同理,读操作也分为两步:
- 将数据从网卡拷贝到系统空间;
- 将数据从系统空间拷贝到用户空间。
对于NIO来说,缓存的使用可以使用DirectByteBuffer和HeapByteBuffer。如果使用了DirectByteBuffer,一般来说可以减少一次系统空间到用户空间的拷贝。但Buffer创建和销毁的成本更高,更不宜维护,通常会用内存池来提高性能。
如果数据量比较小的中小应用情况下,可以考虑使用heapBuffer;反之可以用directBuffer。
2.3 Selectors 选择器
Java NIO的选择器允许一个单独的线程同时监视多个通道,可以注册多个通道到同一个选择器上,然后使用一个单独的线程来“选择”已经就绪的通道。这种“选择”机制为一个单独线程管理多个通道提供了可能。
Selector运行单线程处理多个Channel,如果你的应用打开了多个通道,但每个连接的流量都很低,使用Selector就会很方便。例如在一个聊天服务器中。要使用Selector, 得向Selector注册Channel,然后调用它的select()方法。这个方法会一直阻塞到某个注册的通道有事件就绪。一旦这个方法返回,线程就可以处理这些事件,事件的例子有如新的连接进来、数据接收等。
2.4 Proactor与Reactor
I/O 复用机制需要事件分发器(event dispatcher)。 事件分发器的作用,即将那些读写事件源分发给各读写事件的处理者,就像送快递的在楼下喊: 谁谁谁的快递到了, 快来拿吧!开发人员在开始的时候需要在分发器那里注册感兴趣的事件,并提供相应的处理者(event handler),或者是回调函数;事件分发器在适当的时候,会将请求的事件分发给这些handler或者回调函数。
- 在Reactor模式中,事件分发器等待某个事件或者可应用或个操作的状态发生(比如文件描述符可读写,或者是socket可读写),事件分发器就把这个事件传给事先注册的事件处理函数或者回调函数,由后者来做实际的读写操作。
- 在Proactor模式中,事件处理者(或者代由事件分发器发起)直接发起一个异步读写操作(相当于请求),而实际的工作是由操作系统来完成的。发起时,需要提供的参数包括用于存放读到数据的缓存区、读的数据大小或用于存放外发数据的缓存区,以及这个请求完后的回调函数等信息。事件分发器得知了这个请求,它默默等待这个请求的完成,然后转发完成事件给相应的事件处理者或者回调。举例来说,在Windows上事件处理者投递了一个异步IO操作(称为overlapped技术),事件分发器等IO Complete事件完成。这种异步模式的典型实现是基于操作系统底层异步API的,所以我们可称之为“系统级别”的或者“真正意义上”的异步,因为具体的读写是由操作系统代劳的。
2.5 NIO存在的问题
-
使用NIO != 高性能,当连接数<1000,并发程度不高或者局域网环境下NIO并没有显著的性能优势。
-
NIO并没有完全屏蔽平台差异,它仍然是基于各个操作系统的I/O系统实现的,差异仍然存在。使用NIO做网络编程构建事件驱动模型并不容易,陷阱重重。
-
推荐大家使用成熟的NIO框架,如Netty,MINA等。解决了很多NIO的陷阱,并屏蔽了操作系统的差异,有较好的性能和编程模型。
2.6 适用范围
-
BIO方式适用于连接数目比较小且固定的架构,这种方式对服务器资源要求比较高,并发局限于应用中,JDK1.4以前的唯一选择,但程序直观简单易理解。
-
NIO方式适用于连接数目多且连接比较短(轻操作)的架构,比如聊天服务器,并发局限于应用中,编程比较复杂,JDK1.4开始支持。
三、Linux系统IO多路复用 select、poll与epoll
select,poll,epoll都是IO多路复用的机制。I/O多路复用就通过一种机制,可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。
3.1 前言:系统层面概念说明
在进行解释之前,首先要说明几个概念:
- 用户空间和内核空间
- 进程切换
- 进程的阻塞
- 文件描述符
- 缓存 I/O
3.1.1 用户空间与内核空间
现在操作系统都是采用虚拟存储器,那么对32位操作系统而言,它的寻址空间(虚拟存储空间)为4G(2的32次方)。操作系统的核心是内核,独立于普通的应用程序,可以访问受保护的内存空间,也有访问底层硬件设备的所有权限。为了保证用户进程不能直接操作内核(kernel),保证内核的安全,操心系统将虚拟空间划分为两部分,一部分为内核空间,一部分为用户空间。针对linux操作系统而言,将最高的1G字节(从虚拟地址0xC0000000到0xFFFFFFFF),供内核使用,称为内核空间,而将较低的3G字节(从虚拟地址0x00000000到0xBFFFFFFF),供各个进程使用,称为用户空间。
3.1.2 进程切换
为了控制进程的执行,内核必须有能力挂起正在CPU上运行的进程,并恢复以前挂起的某个进程的执行。这种行为被称为进程切换。因此可以说,任何进程都是在操作系统内核的支持下运行的,是与内核紧密相关的。
从一个进程的运行转到另一个进程上运行,这个过程中经过下面这些变化:
- 保存处理机上下文,包括程序计数器和其他寄存器。
- 更新PCB信息。
- 把进程的PCB移入相应的队列,如就绪、在某事件阻塞等队列。
- 选择另一个进程执行,并更新其PCB。
- 更新内存管理的数据结构。
- 恢复处理机上下文。
注:总而言之就是很耗资源。
3.1.3 进程的阻塞
正在执行的进程,由于期待的某些事件未发生,如请求系统资源失败、等待某种操作的完成、新数据尚未到达或无新工作做等,则由系统自动执行阻塞原语(Block),使自己由运行状态变为阻塞状态。可见,进程的阻塞是进程自身的一种主动行为,也因此只有处于运行态的进程(获得CPU),才可能将其转为阻塞状态。
当进程进入阻塞状态,是不占用CPU资源的。
3.1.4 文件描述符
文件描述符(File descriptor)是计算机科学中的一个术语,是一个用于表述指向文件的引用的抽象化概念。
**文件描述符在形式上是一个非负整数。**实际上,它是一个索引值,指向内核为每一个进程所维护的该进程打开文件的记录表。当程序打开一个现有文件或者创建一个新文件时,内核向进程返回一个文件描述符。在程序设计中,一些涉及底层的程序编写往往会围绕着文件描述符展开。但是文件描述符这一概念往往只适用于UNIX、Linux这样的操作系统。
3.1.5 缓存 I/O
缓存 I/O 又被称作标准 I/O,大多数文件系统的默认 I/O 操作都是缓存 I/O。在 Linux 的缓存 I/O 机制中,操作系统会将 I/O 的数据缓存在文件系统的页缓存( page cache )中,也就是说,数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间。
- 缓存 I/O 的缺点:
数据在传输过程中需要在应用程序地址空间和内核进行多次数据拷贝操作,这些数据拷贝操作所带来的 CPU 以及内存开销是非常大的。
3.2 I/O 多路复用
I/O 多路复用(IO multiplexing)就是我们说的select,poll,epoll,有些地方也称这种IO方式为事件驱动(event driven IO)。select/epoll的好处就在于单个process就可以同时处理多个网络连接的IO。它的基本原理就是select,poll,epoll这个function会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程。
所以,I/O 多路复用的特点是通过一种机制一个进程能同时等待多个文件描述符,而这些文件描述符(套接字描述符)其中的任意一个进入读就绪状态,select()函数就可以返回。
所以,如果处理的连接数不是很高的话,使用select/epoll的web server不一定比使用多线程multi-threading + 阻塞blocking IO的web server性能更好,可能延迟还更大。select/epoll的优势并不是对于单个连接能处理得更快,而是在于能处理更多的连接。)
在IO多路复用中,实际中,对于每一个socket,一般都设置成为非阻塞non-blocking,但是,整个用户的process其实是一直被阻塞block的。只不过process是被select这个函数block,而不是被socket IO给block。
3.3 select、poll、epoll详解
3.3.1 select
select的工作流程:
单个进程就可以同时处理多个网络连接的io请求(同时阻塞多个io操作)。基本原理就是程序呼叫select,然后整个程序就阻塞了,这时候,select会将需要监控的readfds集合拷贝到内核空间(假设监控的仅仅是socket可读),kernel就会轮询检查所有select负责的fd,当找到一个client中的数据准备好了,select就会返回,这个时候程序就会系统调用,将数据从kernel复制到进程缓冲区。
通过上面的select逻辑过程分析,相信大家都意识到,select存在两个问题:
- 被监控的fds需要从用户空间拷贝到内核空间。为了减少数据拷贝带来的性能损坏,内核对被监控的fds集合大小做了限制,并且这个是通过宏控制的,大小不可改变(限制为1024)。
- 被监控的fds集合中,只要有一个有数据可读,整个socket集合就会被遍历一次调用sk的poll函数收集可读事件。由于当初的需求是朴素,仅仅关心是否有数据可读这样一个事件,当事件通知来的时候,由于数据的到来是异步的,我们不知道事件来的时候,有多少个被监控的socket有数据可读了,于是,只能挨个遍历每个socket来收集可读事件。
3.3.2 Poll
poll的原理与select非常相似,差别如下:
- 描述fd集合的方式不同,poll使用 pollfd 结构而不是select结构fd_set结构,所以poll是链式的,没有最大连接数的限制
- poll有一个特点是水平触发,也就是通知程序fd就绪后,这次没有被处理,那么下次poll的时候会再次通知同个fd已经就绪。
poll机制虽然改进了select的监控大小1024的限制,但以下两个性能问题还没有解决。略显鸡肋。
- fds集合需要从用户空间拷贝到内核空间的问题,我们希望不需要拷贝
- 当被监控的fds中某些有数据可读的时候,我们希望通知更加精细一点,就是我们希望能够从通知中得到有可读事件的fds列表,而不是需要遍历整个fds来收集。
3.3.3 epoll 解决问题
假设现实中,有1百万个客户端同时与一个服务器保持着tcp连接,而每一个时刻,通常只有几百上千个tcp连接是活跃的,这时候我们仍然使用select/poll机制,kernel必须在搜寻完100万个fd之后,才能找到其中状态是active的,这样资源消耗大而且效率低下。
(a) fds集合拷贝问题的解决
对于IO多路复用,有两件事是必须要做的(对于监控可读事件而言):1. 准备好需要监控的fds集合;2. 探测并返回fds集合中哪些fd可读了。细看select或poll的函数原型,我们会发现,每次调用select或poll都在重复地准备(集中处理)整个需要监控的fds集合。然而对于频繁调用的select或poll而言,fds集合的变化频率要低得多,我们没必要每次都重新准备(集中处理)整个fds集合。
于是,epoll引入了epoll_ctl系统调用,将高频调用的epoll_wait和低频的epoll_ctl隔离开。同时,epoll_ctl通过(EPOLL_CTL_ADD、EPOLL_CTL_MOD、EPOLL_CTL_DEL)三个操作来分散对需要监控的fds集合的修改,做到了有变化才变更,将select/poll高频、大块内存拷贝(集中处理)变成epoll_ctl的低频、小块内存的拷贝(分散处理),避免了大量的内存拷贝。
(b) 按需遍历就绪的fds集合
为了做到只遍历就绪的fd,我们需要有个地方来组织那些已经就绪的fd。为此,epoll引入了一个中间层,一个双向链表(ready_list),一个单独的睡眠队列(single_epoll_wait_list),并且,与select或poll不同的是,epoll的process不需要同时插入到多路复用的socket集合的所有睡眠队列中,相反process只是插入到中间层的epoll的单独睡眠队列中,process睡眠在epoll的单独队列上,等待事件的发生。
3.3.4 小结
- select, poll是为了解決同时大量IO的情況(尤其网络服务器),但是随着连接数越多,性能越差
- epoll是select和poll的改进方案,在 linux 上可以取代 select 和 poll,可以处理大量连接的性能问题
参考链接
【python爬虫笔记】校各部门网站模拟登录与数据获取
环境:chrome,python 3.5
一、正方教务管理系统
1. 目标分析

首先可以看到我们需要填写以下字段:
- 用户名
- 密码
- 验证码
- 身份选择
需要注意的就是验证码:
可以知道验证码是以图片的方式浮现在文本框上的。这里选择找到验证码的图片链接,并下载到本地,通过用户手动输入验证码来完成登录。
之后可以尝试一下图像识别的第三方库,实现自动填写验证码。
2. 数据抓取
(1) 抓取验证码
对验证码右键单击检查,可直接定位在验证码的相应信息上。

得到验证码的图片链接:
jw.****.edu.cn/default2.aspx/CheckCode.aspx
(2) 抓取post数据
在chrome下按F12打开开发者工具
这里给一个技巧,我们可以先故意输入一个 错误的值
来追踪一下我们究竟post了哪些值
打开 Chrome开发者工具 --- Networks --- 勾选 Preserve log
输入一些值,点击 登录按钮,
在点开右边的 Headers 拉倒最后的 FromData:
这里就是我们提交数据:

这个字典里,我们很容易可以看到我们需要自己填写的值:
post的数据一般是通过键值对的形式传到服务器的,一般是字典或json格式
- txtUserName: 用户名
- TextBox2: 密码
- txtSecretCode: 验证码
- RadioButtonList1 :选择按钮 学生(这里需要我们手动编码成gbk编码)
而第一个数据是如何得到的?在登录界面的html页面中。

可见第一个数据在登录界面html中,我们模拟登录时把这个数据提出来。就行了。
这一长串随机的值,实际上是正方系统的一个简单的验证手段。
(3) 获取课表
通过浏览器登录之后,进入 /xs_main.aspx?xh=********** 页面,再转入课表页面,地址栏的网页链接并没有变化,但真正的课表链接藏在html里面。同理在课表处右键检查定位到html中

(4) 代码
#-*-coding:utf-8-*-
import os
import re
from lxml import etree
import requests
import sys
from bs4 import BeautifulSoup
from PIL import Image
#初始参数,自己输入的学号,密码。
studentnumber = input("学号: ")
password = input("密码: ")
#得到__VIEWSTATE的值。
s = requests.session()
url = "http://jw.****.edu.cn/default2.aspx"
response = s.get(url)
selector = etree.HTML(response.content)
__VIEWSTATE = selector.xpath('//*[@id="form1"]/input/@value')[0]
#获取验证码并下载到本地
imgUrl = "http://jw.****.edu.cn/CheckCode.aspx?"
imgresponse = s.get(imgUrl, stream=True)
#print (s.cookies)
image = imgresponse.content
DstDir = os.getcwd()+"\\"
try:
with open(DstDir+"tcode.jpg" ,"wb") as jpg:
jpg.write(image)
except IOError:
print("IO Error\n")
finally:
jpg.close
# 打开验证码图片
image = Image.open('{}/tcode.jpg'.format(os.getcwd()))
image.show()
#手动输入验证码
code = input("验证码: ")
#构建post数据
data = {
"__VIEWSTATE":__VIEWSTATE,
"txtUserName":studentnumber,
"TextBox2":password,
"txtSecretCode":code,
"Button1":"",
}
#提交表头,里面的参数是电脑各浏览器的信息。模拟成是浏览器去访问网页。
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.110 Safari/537.36",
}
#登陆教务系统
response = s.post(url,data=data,headers=headers)
print ("成功进入")
#得到登录信息
def getInfor(response,xpath):
content = response.content.decode('gb2312') #网页源码是gb2312要先解码
selector = etree.HTML(content)
infor = selector.xpath(xpath)[0]
return infor
#获取学生基本信息
text = getInfor(response,'//*[@id="xhxm"]/text()')
text = text.replace(" ","")
print (text)
#获取课表,kburl是课表页面url,为什么有个Referer参数,这个参数代表你是从哪里来的。就是登录后的主界面参数。这个一定要有。
kburl = "http://jw.****.edu.cn/xskbcx.aspx?xh="+studentnumber+"&xm=%D5%C5%B8%DB&gnmkdm=N121603"
headers = {
"Referer":"http://jw.****.edu.cn/xs_main.aspx?xh="+studentnumber,
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.110 Safari/537.36",
}
response = s.get(kburl,headers=headers)
#html代表访问课表页面返回的结果就是课表。下面做的就是解析这个html页面。
html = response.content.decode("gb2312")
selector=etree.HTML(html)
content = selector.xpath('//*[@id="Table1"]/tr/td/text()')
for each in content:
print (each)(5) 结果


TODO: 3. 验证码的自动识别
二、校体育部网站
校体育部这个网站有点非主流,与csdn等博客上最常见的教务系统登录不太一样,是个很好的练手对象。
1. 模拟登录
首先是通过Fiddler 4对目标网站进行登录抓包(应该是这个词吧)。

关键点1:
体育部的登陆页面并不是/security/login.do,而是/login.do。
关键点2:
在输入账号密码之后,还有btnlogin.x与btnlogin.y这两个属性,大胆猜测这是点击按钮的动作,而后面值就是横纵坐标。
登录成功并获取首页html
import urllib.request, urllib.parse, urllib.error
import http.cookiejar
import requests
from bs4 import BeautifulSoup
import bs4
LOGIN_URL = 'http://211.69.129.116:8501/login.do'
# ===========关键点:体育部网站的真正登陆页面并不是网站那栏,在fiddler中显示为该网址===========
get_url = 'http://211.69.129.116:8501/jsp/menuForwardContent.jsp?url=stu/StudentSportModify.do'
#get_url = 'http://211.69.129.116:8501/' # 利用cookie请求访问另一个网址
values = {'action': 'username', 'username': '2016317200113', 'password': '888888', 'btnlogin.x': '30', 'btnlogin.y': '11'}
# ===========关键点:在fiddler的action中还有两行btnlogin的信息,将这个点击按钮的动作加入到values中===========
postdata = urllib.parse.urlencode(values).encode()
user_agent = r'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36'
headers = {'User-Agent': user_agent}
cookie_filename = 'cookie_jar.txt'
cookie_jar = http.cookiejar.MozillaCookieJar(cookie_filename)
handler = urllib.request.HTTPCookieProcessor(cookie_jar)
opener = urllib.request.build_opener(handler)
request = urllib.request.Request(LOGIN_URL, postdata, headers)
try:
response = opener.open(request)
html = response.read().decode()
#print(response.read().decode())
except urllib.error.URLError as e:
print(e.code, ':', e.reason)
#================html格式化================
soup = BeautifulSoup(html)
print(soup.prettify())
#==========================================
# TODO: Creat List
ulist = []
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
ulist.append([tds[0].string, tds[1].string])
print("==================LIST======================")
for i in range(5):
u = ulist[i]
print("{:^10}\t{:^6}", format(u[0], u[1]))
#=================unfinished=================数据提取
但是获取的还是原始的html文本,没有依据标签进行数据提取。
未完待续
参考链接: 从零开始写Python爬虫、 抓取课程表
【SpringBoot】@SpringBootApplication 与 SpringApplication.run 源码分析
Spring Boot 启动、事件通知与配置加载原理
spring-boot\2.0.3.RELEASE\spring-boot-2.0.3.RELEASE-sources.jar
一. @SpringBootApplication
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@SpringBootConfiguration // 从源代码中得知 @SpringBootApplication 被 @SpringBootConfiguration、@EnableAutoConfiguration、@ComponentScan 注解
@EnableAutoConfiguration // 所修饰,换言之 Springboot 提供了统一的注解来替代以上三个注解,简化程序的配置。下面解释一下各注解的功能。
@ComponentScan(excludeFilters = {
@Filter(type = FilterType.CUSTOM, classes = TypeExcludeFilter.class),
@Filter(type = FilterType.CUSTOM, classes = AutoConfigurationExcludeFilter.class) })
public @interface SpringBootApplication {
@AliasFor(annotation = EnableAutoConfiguration.class)
Class<?>[] exclude() default {};
@AliasFor(annotation = EnableAutoConfiguration.class)
String[] excludeName() default {};
@AliasFor(annotation = ComponentScan.class, attribute = "basePackages")
String[] scanBasePackages() default {};
@AliasFor(annotation = ComponentScan.class, attribute = "basePackageClasses")
Class<?>[] scanBasePackageClasses() default {};
}1. @SpringBootConfiguration
进入之后可以看到这个注解是继承了 @Configuration 的,二者功能也一致,标注当前类是配置类,并会将当前类内声明的一个或多个以@bean注解标记的方法的实例纳入到srping容器中,并且实例名就是方法名。
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Configuration
public @interface SpringBootConfiguration {
}- 以下摘自Spring文档翻译
@Configuration是一个类级注释,指示对象是一个bean定义的源。@Configuration类通过@Bean注解的公共方法声明bean。
@Bean注释是用来表示一个方法实例化,配置和初始化是由 Spring IoC 容器管理的一个新的对象。
通俗的讲 @Configuration 一般与 @Bean 注解配合使用,用 @Configuration 注解类等价与 XML 中配置 beans,用 @Bean 注解方法等价于 XML 中配置 bean 。举例说明:
- XML配置代码如下:
<beans>
<bean id = "userService" class="com.user.UserService">
<property name="userDAO" ref = "userDAO"></property>
</bean>
<bean id = "userDAO" class="com.user.UserDAO"></bean>
</beans>- 等价于
@Bean注释
@Configuration
public class Config {
@Bean
public UserService getUserService(){
UserService userService = new UserService();
userService.setUserDAO(null);
return userService;
}
@Bean
public UserDAO getUserDAO(){
return new UserDAO();
}
}2. @EnableAutoConfiguration
@EnableAutoConfiguration的作用启动自动的配置,@EnableAutoConfiguration注解的意思就是Springboot根据你添加的jar包来配置你项目的默认配置,比如根据spring-boot-starter-web ,来判断你的项目是否需要添加了webmvc和tomcat,就会自动的帮你配置web项目中所需要的默认配置。
- 以下摘自Spring文档翻译
启用 Spring 应用程序上下文的自动配置,试图猜测和配置您可能需要的bean。自动配置类通常采用基于你的 classpath 和已经定义的 beans 对象进行应用。
被 @EnableAutoConfiguration 注解的类所在的包有特定的意义,并且作为默认配置使用。例如,当扫描 @entity类的时候它将本使用。通常推荐将 @EnableAutoConfiguration 配置在 root 包下,这样所有的子包、类都可以被查找到。
Auto-configuration类是常规的 Spring 配置 Bean。它们使用的是 SpringFactoriesLoader 机制(以 EnableAutoConfiguration 类路径为 key)。通常 auto-configuration beans 是 @conditional beans(在大多数情况下配合 @ConditionalOnClass 和 @ConditionalOnMissingBean 注解进行使用)。
- SpringFactoriesLoader 机制:
SpringFactoriesLoader会查询包含 META-INF/spring.factories 文件的JAR。 当找到spring.factories文件后,SpringFactoriesLoader将查询配置文件命名的属性。EnableAutoConfiguration的 key 值为org.springframework.boot.autoconfigure.EnableAutoConfiguration。根据此 key 对应的值进行 spring 配置。在 spring-boot-autoconfigure.jar文件中,包含一个 spring.factories 文件
3. @componentscan
@ComponentScan,扫描当前包及其子包下被@Component,@Controller,@Service,@Repository注解标记的类并纳入到spring容器中进行管理。是以前的<context:component-scan>(以前使用在xml中使用的标签,用来扫描包配置的平行支持)。举个例子,这就是为什么常见入门项目中User类会被Spring容器管理的原因。
- 以下摘自Spring文档翻译
为 @configuration注解的类配置组件扫描指令。同时提供与 Spring XML’s 元素并行的支持。
无论是 basePackageClasses() 或是 basePackages() (或其 alias 值)都可以定义指定的包进行扫描。如果指定的包没有被定义,则将从声明该注解的类所在的包进行扫描。
注意, 元素有一个 annotation-config 属性(详情:http://www.cnblogs.com/exe19/p/5391712.html),但是 @componentscan 没有。这是因为在使用 @componentscan 注解的几乎所有的情况下,默认的注解配置处理是假定的。此外,当使用 AnnotationConfigApplicationContext, 注解配置处理器总会被注册,以为着任何试图在 @componentscan 级别是扫描失效的行为都将被忽略。
通俗的讲,@componentscan 注解会自动扫描指定包下的全部标有 @component注解 的类,并注册成bean,当然包括 @component 下的子注解@service、@repository、@controller。@componentscan 注解没有类似的属性。
4. 更多
根据上面的理解,HelloWorld的入口类SpringboothelloApplication,我们可以使用:
@ComponentScan
//@SpringBootApplication
public class SpringboothelloApplication {
public static void main(String[] args) {
SpringApplication.run(SpringboothelloApplication.class, args);
}
}使用@ComponentScan注解代替@SpringBootApplication注解,也可以正常运行程序。原因是@SpringBootApplication中包含@ComponentScan,并且springboot会将入口类看作是一个@SpringBootConfiguration标记的配置类,所以定义在入口类Application中的SpringboothelloApplication也可以纳入到容器管理。
二. SpringApplication.run
run方法主要用于创建或刷新一个应用上下文,是 Spring Boot的核心。
2.1 入口 run 方法执行流程
- 创建计时器,用于记录SpringBoot应用上下文的创建所耗费的时间。
- 开启所有的SpringApplicationRunListener监听器,用于监听Sring Boot应用加载与启动信息。
- 创建应用配置对象(main方法的参数配置) ConfigurableEnvironment
- 创建要打印的Spring Boot启动标记 Banner
- 创建 ApplicationContext应用上下文对象,web环境和普通环境使用不同的应用上下文。
- 创建应用上下文启动异常报告对象 exceptionReporters
- 准备并刷新应用上下文,并从xml、properties、yml配置文件或数据库中加载配置信息,并创建已配置的相关的单例bean。到这一步,所有的非延迟加载的Spring bean都应该被创建成功。
- 打印Spring Boot上下文启动耗时到Logger中
- Spring Boot启动监听
- 调用实现了*Runner类型的bean的callRun方法,开始应用启动。
- 如果在上述步骤中有异常发生则日志记录下才创建上下文失败的原因并抛出IllegalStateException异常。
public ConfigurableApplicationContext run(String... args) {
// 1. 创建计时器,用于记录SpringBoot应用上下文的创建所耗费的时间
StopWatch stopWatch = new StopWatch();
stopWatch.start();//stopWatch就是计时器
ConfigurableApplicationContext context = null;
Collection<SpringBootExceptionReporter> exceptionReporters = new ArrayList<>();
configureHeadlessProperty();
// 2. 开启所有的SpringApplicationRunListener监听器,用于监听Sring Boot应用加载与启动信息。
SpringApplicationRunListeners listeners = getRunListeners(args);
listeners.starting();// 监听器启动 主要用在log方面?
try {
ApplicationArguments applicationArguments = new DefaultApplicationArguments(
args);
// 3. 创建应用配置对象(main方法的参数配置) ConfigurableEnvironment
ConfigurableEnvironment environment = prepareEnvironment(listeners,
applicationArguments);
configureIgnoreBeanInfo(environment);
// 4. 创建要打印的Spring Boot启动标记 Banner
Banner printedBanner = printBanner(environment);
// 5. 创建 ApplicationContext应用上下文对象,web环境和普通环境使用不同的应用上下文。
context = createApplicationContext();
// 6. 创建应用上下文启动异常报告对象 exceptionReporters
exceptionReporters = getSpringFactoriesInstances(
SpringBootExceptionReporter.class,
new Class[] { ConfigurableApplicationContext.class }, context);
// 7. 准备并创建刷新应用上下文,并从xml、properties、yml配置文件或数据库中加载配置信息,并创建已配置的相关的单例bean。到这一步,所有的非延迟加载的Spring bean都应该被创建成功。
prepareContext(context, environment, listeners, applicationArguments,
printedBanner);
refreshContext(context);// 刷新上下文
afterRefresh(context, applicationArguments);
stopWatch.stop();//计时结束
// 8. 打印Spring Boot上下文启动耗时到Logger中
if (this.logStartupInfo) {
new StartupInfoLogger(this.mainApplicationClass)
.logStarted(getApplicationLog(), stopWatch);
}
// 9. Spring Boot启动监听
listeners.started(context);
// 10. 调用实现了*Runner类型的bean的callRun方法,开始应用启动。
callRunners(context, applicationArguments);
}
catch (Throwable ex) {
handleRunFailure(context, ex, exceptionReporters, listeners);
throw new IllegalStateException(ex);
}
try {
listeners.running(context); //完成listeners监听
}
// 11. 如果在上述步骤中有异常发生则日志记录下才创建上下文失败的原因并抛出IllegalStateException异常。
catch (Throwable ex) {
handleRunFailure(context, ex, exceptionReporters, null);
throw new IllegalStateException(ex);
}
return context;
}2.2 运行事件 深入各方法
事件就是Spring Boot启动过程的状态描述,在启动Spring Boot时所发生的事件一般指:
- 开始启动事件
- 环境准备完成事件
- 上下文准备完成事件
- 上下文加载完成
- 应用启动完成事件
2.2.1 开始启动运行监听器 SpringApplicationRunListeners
上一层调用代码:SpringApplicationRunListeners listeners = getRunListeners(args);
顾名思意,运行监听器的作用就是为了监听 SpringApplication 的run方法的运行情况。在设计上监听器使用观察者模式,以总信息发布器 SpringApplicationRunListeners 为基础平台,将Spring启动时的事件分别发布到各个用户或系统在 META_INF/spring.factories文件中指定的应用初始化监听器中。使用观察者模式,在Spring应用启动时无需对启动时的其它业务bean的配置关心,只需要正常启动创建Spring应用上下文环境。各个业务'监听观察者'在监听到spring开始启动,或环境准备完成等事件后,会按照自己的逻辑创建所需的bean或者进行相应的配置。观察者模式使run方法的结构变得清晰,同时与外部耦合降到最低。
spring-boot-2.0.3.RELEASE-sources.jar!/org/springframework/boot/context/event/EventPublishingRunListener.java
class SpringApplicationRunListeners {
...
// 在run方法业务逻辑执行前、应用上下文初始化前调用此方法
public void starting() {
for (SpringApplicationRunListener listener : this.listeners) {
listener.starting();
}
}
// 当环境准备完成,应用上下文被创建之前调用此方法
public void environmentPrepared(ConfigurableEnvironment environment) {}
// 在应用上下文被创建和准备完成之后,但上下文相关代码被加载执行之前调用。因为上下文准备事件和上下文加载事件难以明确区分,所以这个方法一般没有具体实现。
public void contextPrepared(ConfigurableApplicationContext context) {}
// 当上下文加载完成之后,自定义bean完全加载完成之前调用此方法。
public void contextLoaded(ConfigurableApplicationContext context) {}
public void started(ConfigurableApplicationContext context) {}
public void running(ConfigurableApplicationContext context) {}
// 当run方法执行完成,或执行过程中发现异常时调用此方法。
public void failed(ConfigurableApplicationContext context, Throwable exception) {
for (SpringApplicationRunListener listener : this.listeners) {
callFailedListener(listener, context, exception);
}
}
private void callFailedListener(SpringApplicationRunListener listener,
ConfigurableApplicationContext context, Throwable exception) {}
}
}
}默认情况下Spring Boot会实例化EventPublishingRunListener作为运行监听器的实例。在实例化运行监听器时需要SpringApplication对象和用户对象作为参数。其内部维护着一个事件广播器(被观察者对象集合,前面所提到的在META_INF/spring.factories中注册的初始化监听器的有序集合 ),当监听到Spring启动等事件发生后,就会将创建具体事件对象,并广播推送给各个被观察者。
2.2.2 环境准备 创建应用配置对象 ConfigurableEnvironment
上一层调用代码:ConfigurableEnvironment environment = prepareEnvironment(listeners
将通过ApplicationArguments将环境Environment配置好,并与SpringApplication绑定
private ConfigurableEnvironment prepareEnvironment(
SpringApplicationRunListeners listeners,
ApplicationArguments applicationArguments) {
// 获取或创建环境 Create and configure the environment
ConfigurableEnvironment environment = getOrCreateEnvironment();
configureEnvironment(environment, applicationArguments.getSourceArgs());
// 持续监听
listeners.environmentPrepared(environment);
// 将环境与SpringApplication绑定(调用到 binder.java 未看)
bindToSpringApplication(environment);
if (this.webApplicationType == WebApplicationType.NONE) {
environment = new EnvironmentConverter(getClassLoader())
.convertToStandardEnvironmentIfNecessary(environment);
}
ConfigurationPropertySources.attach(environment);
return environment;
}- 略过Banner的创建
2.2.3 创建应用上下文对象 ApplicationContext
context = createApplicationContext();
根据this.webApplicationType来判断是什么环境,web环境和普通环境使用不同的应用上下文。再使用反射相应实例化。
spring-boot-2.0.3.RELEASE-sources.jar!/org/springframework/boot/SpringApplication.java
protected ConfigurableApplicationContext createApplicationContext() {
Class<?> contextClass = this.applicationContextClass;
if (contextClass == null) {
try {
switch (this.webApplicationType) {
case SERVLET:// 判断
contextClass = Class.forName(DEFAULT_WEB_CONTEXT_CLASS); // 反射
break;
case REACTIVE:
contextClass = Class.forName(DEFAULT_REACTIVE_WEB_CONTEXT_CLASS);
break;
default:
contextClass = Class.forName(DEFAULT_CONTEXT_CLASS);
}
}
catch (ClassNotFoundException ex) {
throw new IllegalStateException(
"Unable create a default ApplicationContext, "
+ "please specify an ApplicationContextClass",
ex);
}
}
return (ConfigurableApplicationContext) BeanUtils.instantiateClass(contextClass);
}Class.forName() 的作用
-
Class.forName:返回与给定的字符串名称相关联类或接口的 Class 对象。
- Class.forName(className) 实际上是调用 Class.forName(className,true, this.getClass().getClassLoader())。第二个参数,是指 Class 被 loading 后是不是必须被初始化。可以看出,使用 Class.forName(className)加载类时则已初始化。
- 所以 Class.forName(className) 可以简单的理解为:获得字符串参数中指定的类,并初始化该类。
-
首先你要明白在 java 里面任何 class 都要装载在虚拟机上才能运行
- forName 这句话就是装载类用的 (new 是根据加载到内存中的类创建一个实例,要分清楚)。
- 至于什么时候用,可以考虑一下这个问题,给你一个字符串变量,它代表一个类的包名和类名,你怎么实例化它?
两者是一样的效果。
A a = (A)Class.forName("pacage.A").newInstance(); A a = new A();
- jvm 在装载类时会执行类的静态代码段,要记住静态代码是和 class 绑定的,class 装载成功就表示执行了你的静态代码了,而且以后不会再执行这段静态代码了。
- Class.forName(xxx.xx.xx) 的作用是要求 JVM 查找并加载指定的类,也就是说 JVM 会执行该类的静态代码段。
- 动态加载和创建 Class 对象,比如想根据用户输入的字符串来创建对象
String str = 用户输入的字符串 Class t = Class.forName(str); t.newInstance();
2.2.4 创建上下文启动异常报告对象 exceptionReporters
上一层调用:
exceptionReporters = getSpringFactoriesInstances(SpringBootExceptionReporter.class,
new Class[] { > ConfigurableApplicationContext.class }, context);
通过getSpringFactoriesInstances创建SpringBootExceptionReporter接口的实现,而该接口的实现的就是FailureAnalyzers——上下文启动失败原因分析对象。
spring-boot-2.0.3.RELEASE-sources.jar!/org/springframework/boot/diagnostics/FailureAnalyzers.java
final class FailureAnalyzers implements SpringBootExceptionReporter {
...
FailureAnalyzers(ConfigurableApplicationContext context, ClassLoader classLoader) {}
private List<FailureAnalyzer> loadFailureAnalyzers(ClassLoader classLoader) {}
private void prepareFailureAnalyzers(List<FailureAnalyzer> analyzers,
ConfigurableApplicationContext context) {}
private void prepareAnalyzer(ConfigurableApplicationContext context,
FailureAnalyzer analyzer) {}
@Override
public boolean reportException(Throwable failure) {}
private FailureAnalysis analyze(Throwable failure, List<FailureAnalyzer> analyzers) {}
private boolean report(FailureAnalysis analysis, ClassLoader classLoader) {}
}2.2.5 准备上下文 prepareContext
上一层调用:prepareContext(context, environment, listeners, applicationArguments,printedBanner);
xml、properties、yml配置文件或数据库中加载的配置信息封装到applicationArguments中,并创建已配置的相关的单例bean。到这一步,所有的非延迟加载的Spring bean都应该被创建成功。
private void prepareContext(ConfigurableApplicationContext context,
ConfigurableEnvironment environment, SpringApplicationRunListeners listeners,
ApplicationArguments applicationArguments, Banner printedBanner) {
context.setEnvironment(environment);
postProcessApplicationContext(context);
applyInitializers(context);
listeners.contextPrepared(context);
if (this.logStartupInfo) {
logStartupInfo(context.getParent() == null);
logStartupProfileInfo(context);
}
// 创建已配置的相关的单例 bean
// Add boot specific singleton beans
context.getBeanFactory().registerSingleton("springApplicationArguments",
applicationArguments);
if (printedBanner != null) {
context.getBeanFactory().registerSingleton("springBootBanner", printedBanner);
}
// Load the sources
Set<Object> sources = getAllSources();
Assert.notEmpty(sources, "Sources must not be empty");
load(context, sources.toArray(new Object[0]));
listeners.contextLoaded(context);
}2.2.6
上一层调用:refreshContext(context);
2.2.7
上一层调用:
参考链接
【Spring】Spring相关学习总结
Spring 学习笔记
目录
一、Spring框架
二、Spring Boot
之后的文章,均是我围绕Spring Security添加功能所实现的。记录一下我的学习过程。
【Java】《深入理解Java虚拟机》笔记 · 二 垃圾收集器与内存分配策略
分为两部分:大篇幅介绍垃圾收集,最后会介绍内存分配策略。
垃圾回收算法
原书第三章。
- 哪些内存需要回收?
- 什么时候回收?
- 如何回收?
这三个问题,就是垃圾收集的关键点。
1. 第一个问题:哪些内存需要回收?
只有判断那些对象是“活的”还是“死的”,才能决定是否回收。
引用计数算法
很多教科书判断对象是否存活的算法是这样的:给对象添加引用计数器,当有地方引用它时就加1,引用失效就减1,为0时就认为对象不再被使用可回收。
该算法实现简单,判断高效,但并不被主流虚拟机采用,主要原因是它很难解决对象之间相互循环引用的问题。
形象点说,循环引用就是两个对象相互之间引用,但是如果将这两个对象看成一个整体,这个整体是没有被别处引用的,那么这个整体在引用计数算法下计数为0,是需要被收回的,但两个对象的计数都为1,即不可收回。
可达性分析算法
java是通过可达性分析算法判断对象是否存活。
通过一系列的称为“GC Roots”的对象作为起点,从这些节点开始向下搜索,搜索所走过的路径称为引用链(Reference Chain),如果一个对象到GC Roots没有引用链相连,则该对象是不可用的。

2. 第二个问题:什么时候回收?
此处引用这篇博客 的内容:
次收集(Minor GC)和全收集(Full GC)
当这三个分代的堆空间比较紧张或者没有足够的空间来为新到的请求分配的时候,垃圾回收机制就会起作用。有两种类型的垃圾回收方式:次收集和全收集。当新生代堆空间满了的时候,会触发次收集将还存活的对象移到年老代堆空间。当年老代堆空间满了的时候,会触发一个覆盖全范围的对象堆的全收集。
次收集
- 当新生代堆空间紧张时会被触发
- 相对于全收集而言,收集间隔较短
全收集
- 当老年代或者持久代堆空间满了,会触发全收集操作
- 可以使用System.gc()方法来显式的启动全收集
- 全收集一般根据堆大小的不同,需要的时间不尽相同,但一般会比较长。不过,如果全收集时间超过3到5秒钟,那就太长了
以下为原书内容:
回收方法区
永久代的垃圾收集主要回收两部分内容:废弃常量和无用的类。
一个无用的类需要满足以下三个条件:
- 该类的所有实例都已经被回收;
- 加载该类的ClassLoader已经被回收;
- 该类对象的java.lang.Class对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法;
3. 第三个问题:如何回收?
主要介绍一些垃圾收集算法。
1.标记-清除算法
算法分为标记和清除两个阶段:首先标记出所有需要回收的对象,在标记完成后统一回收所有被标记的对象,它的标记过程就是使用可达性算法进行标记的。
主要缺点有两个:
- 效率问题,标记和清除两个过程的效率都不高
- 空间问题,标记清除之后会产生大量不连续的内存碎片

2.复制算法
复制算法:将可用内存按照容量分为大小相等的两块,每次只使用其中的一块。当这一块的内存用完了,就将还存活着的对象复制到另一块上面,然后把已使用过的内存空间一次清理掉。
内存分配时不用考虑内存碎片问题,只要一动堆顶指针,按顺序分配内存即可,实现简单,运行高效。代价是将内存缩小为原来的一半。

3.标记-整理算法
标记整理算法(Mark-Compact),标记过程仍然和“标记-清除”一样,但后续不走不是直接对可回收对象进行清理,而是让所有存活对象向一端移动,然后直接清理掉端边界以外的内存。

4.分代收集算法
根据对象存活周期的不同将内存分为几块。一般把Java堆分为新生代和老年代,根据各个年代的特点采用最合适的收集算法。在新生代中,每次垃圾收集时有大批对象死去,只有少量存活,可以选用复制算法。而老年代对象存活率高,使用标记清理或者标记整理算法。
垃圾收集器
垃圾收集算法是内存回收的方法论,垃圾收集器就是内存回收的具体实现。
原书这里出现了新生代、老年代与永久代的概念:
下图是Sun HotSpot虚拟机的Heap区的分区,分为三个区:分别是Young Gereration新生代、Old Gerenation老年代、Permanent Generation持久区。

垃圾收集器有Serial收集器、ParNew收集器、Parallel Scavenge收集器、Serial Old收集器、Parallel Old收集器、CMS收集器和G1收集器。这里不再赘述,查阅参考链接。
内存分配与回收策略
原书3.6节
- 对象优先在新生代分配
- 大对象直接进入老年代
- 长期存活的对象将进入老年代
- 动态对象年龄判断:如果在Survivor空间中相同年龄所有对象大小总和大于Survivor空间的一半,大于或等于该年龄的对象直接进入老年代;
- 空间分配担保:发生Minor GC前,虚拟机会先检查老年代最大可用连续空间是否大于新生代所有对象总空间,如果不成立,虚拟机会查看HandlePromotionFailure设置值是否允许担保失败,如果允许继续检查老年代最大可用的连续空间是否大于历次晋升到老年代的平均大小,如果大于会尝试进行一次Minor GC;如果小于或者不允许冒险,会进行一次Full GC;
理论结合代码
JVM垃圾收集器-对比Serial、Parallel、CMS和G1
1. 串行收集器Seiral Collector
串行收集器是最简单的,它设计为在单核的环境下工作(32位或者windows),你几乎不会使用到它。它在工作的时候会暂停整个应用的运行,因此在所有服务器环境下都不可能被使用。
> 使用方法:-XX:+UseSerialGC
2. 并行/吞吐优先收集器Parallel/Throughput Collector
这是JVM默认的收集器,跟它名字显示的一样,它最大的优点是使用多个线程来扫描和压缩堆。缺点是在minor和full GC的时候都会暂停应用的运行。并行收集器最适合用在可以容忍程序停滞的环境使用,它占用较低的CPU因而能提高应用的吞吐(throughput)。
使用方法:-XX:+UseParallelGC
3. CMS收集器CMS Collector
接下来是CMS收集器,CMS是Concurrent-Mark-Sweep的缩写,并发的标记与清除。这个算法使用多个线程并发地(concurrent)扫描堆,标记不使用的对象,然后清除它们回收内存。在两种情况下会使应用暂停(Stop the World, STW):1. 当初次开始标记根对象时initial mark。2. 当在并行收集时应用又改变了堆的状态时,需要它从头再确认一次标记了正确的对象final remark。
这个收集器最大的问题是在年轻代与老年代收集时会出现的一种竞争情况(race condition),称为提升失败promotion failure。对象从年轻代复制到老年代称为提升promotion,但有时侯老年代需要清理出足够空间来放这些对象,这需要一定的时间,它收集的速度可能赶不上不断产生的要提升的年轻代对象的速度,这时就需要做STW的收集。STW正是CMS想避免的问题。为了避免这个问题,需要增加老年代的空间大小或者增加更多的线程来做老年代的收集以赶上从年轻代复制对象的速度。
除了上文所说的内容之外,CMS最大的问题就是内存空间碎片化的问题。CMS只有在触发FullGC的情况下才会对堆空间进行compact。如果线上应用长时间运行,碎片化会非常严重,会很容易造成promotion failed。为了解决这个问题线上很多应用通过定期重启或者手工触发FullGC来触发碎片整理。
对比并行收集器它的一个坏处是需要占用比较多的CPU。对于大多数长期运行的服务器应用来说,这通常是值得的,因为它不会导致应用长时间的停滞。但是它不是JVM的默认的收集器。
使用CMS需要仔细分析自己的应用对象生命周期,尤其是在应用要求高性能,高吞吐。需要仔细分析自己应用所需要的heap大小,老年代,新生代的分配比例,以及survival区的大小。设置不合理会很容易造成性能问题。
使用方法:-XX:+UseConcMarkSweepGC,此时可同时使用-XX:+UseParNewGC将并行收集作用于年轻代,新的JVM自动打开这一配置
4. G1收集器Garbage First Collector
如果你的堆内存大于4G的话,那么G1会是要考虑使用的收集器。它是为了更好支持大于4G堆内存在JDK 7 u4引入的。G1收集器把堆分成多个区域,大小从1MB到32MB,并使用多个后台线程来扫描这些区域,优先会扫描最多垃圾的区域,这就是它名称的由来,垃圾优先Garbage First。
如果在后台线程完成扫描之前堆空间耗光的话,才会进行STW收集。它另外一个优点是它在处理的同时会整理压缩堆空间,相比CMS只会在完全STW收集的时候才会这么做。
使用过大的堆内存在过去几年是存在争议的,很多开发者从单个JVM分解成使用多个JVM的微服务(micro-service)和基于组件的架构。其他一些因素像分离程序组件、简化部署和避免重新加载类到内存的考虑也促进了这样的分离。
除了这些因素,最大的因素当然是避免在STW收集时JVM用户线程停滞时间过长,如果你使用了很大的堆内存的话就可能出现这种情况。另外,像Docker那样的容器技术让你可以在一台物理机器上轻松部署多个应用也加速了这种趋势。
使用方法:-XX:+UseG1GC
参考链接
《深入理解Java虚拟机》读书笔记
《深入理解Java虚拟机》读书笔记2:垃圾收集器与内存分配策略
深入理解java虚拟机(六):java垃圾收集分析实战(内存分配与回收策略)
【Spark学习笔记】Hadoop+Scala+Spark 分布式集群环境搭建
硬件环境:3台搭载 Ubuntu14.04 的计算机。
一台Ubuntu主机系统作Master,一台Ubuntu主机系统做slave01,一台Ubuntu主机系统做slave02。三台主机机器处于同一局域网下。
所有环境配置与权限设置都是在各台Ubuntu下的pc用户下完成的,也可以专门为三台电脑创建一个用户(如hadoop)进行管理。
一、Hadoop 2.7 分布式环境搭建
在配置Spark之前,需要先配置Hadoop。
0. 初始设置
本小节的内容可以根据需要自己设定。
本节内容:修改配置三台电脑的host。
为了更好的在Shell中区分三台主机,修改其显示的主机名,执行如下命令:
sudo vim /etc/hostname在你想要当作主机(master)的电脑的/etc/hostname修改为如下内容:
master
同理,配置两台slave(此处只写了slave01):
slave01
重启之后,在终端shell中就会看到变化,说明配置成功。
之后在每台电脑上输入:
ifconfig
可以获得当前电脑的局域网地址。尝试一下这三台电脑之间能不能 ping 通。
ping 192.168.1.1
不一定是192的本地地址,如果ip显示的是公网ip,那在之后的配置中要使用公网ip。
修改三台机器的/etc/hosts文件,添加三台电脑的host配置:
sudo vim /etc/hosts
配置类似如下:
127.0.0.1 localhost
192.168.1.1 master
192.168.1.2 slave01
192.168.1.3 slave02
1. 配置ssh无密码登录本机和访问集群机器
什么是SSH?
简单说,SSH是一种网络协议,用于计算机之间的加密登录。
如果一个用户从本地计算机,使用SSH协议登录另一台远程计算机,我们就可以认为,这种登录是安全的,即使被中途截获,密码也不会泄露。
最早的时候,互联网通信都是明文通信,一旦被截获,内容就暴露无疑。1995年,芬兰学者Tatu Ylonen设计了SSH协议,将登录信息全部加密,成为互联网安全的一个基本解决方案,迅速在全世界获得推广,目前已经成为Linux系统的标准配置。
三台主机电脑分别运行如下命令,测试能否连接到本地localhost
ssh localhost
登录成功会显示如下结果:
Last login: Mon Nov 17 18:29:55 2017 from ::1
如果不能登录本地,请运行如下命令,安装openssh-server,并生成ssh公钥。
sudo apt-get openssh-serverssh-keygen -t rsa -P ""cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys
在保证了三台主机电脑都能连接到本地localhost后,还需要让master主机免密码登录slave01和slave02主机。在master执行如下命令,将master的id_rsa.pub传送给两台slave主机。(下文的pc可以被替换为自定义的用户名)
scp ~/.ssh/id_rsa.pub pc@slave01:/home/pc/
scp ~/.ssh/id_rsa.pub pc@slave02:/home/pc/
在slave01,slave02主机上分别运行 ls 命令,可以看到他们分别接收到了 id_rsa.pub 文件。
接着在slave01、slave02主机上将master的公钥加入各自的节点上,在slave01和slave02执行如下命令:
cat ~/id_rsa.pub >> ~/.ssh/authorized_keysrm ~/id_rsa.pub
rm ~/id_rsa.pub
如果master主机和slave01、slave02主机的用户名一样,那么在master主机上直接执行如下测试命令,即可让master主机免密码登录slave01、slave02主机。
ssh slave01
这样我们可以在master这台电脑上对两台slave进行操作,就不用跑来跑去啦。

2. JDK和Hadoop的安装配置
分别在master主机和slave01、slave02主机上安装JDK和Hadoop,并加入环境变量。
安装 JDK
JDK可以直接使用一行命令 sudo apt-get install default-jdk 就能获取,但是使用这种方法会在之后的Hadoop启动过程中因无法找到一些Java方法而报错(至少我在报错上是这么看到的)。之后我换用 JDK 8【链接】才成功。这里给上安装配置方法。
分别在master主机和slave01,slave02主机上执行安装JDK的操作:
下载完成后:
sudo tar -zxf ~/下载/jdk-8u151-linux-x64.tar.gz -C /usr/local/
cd /usr/local
sudo mv ./jdk-8u151-linux-x64.tar.gz/ ./java
sudo chown -R pc ./java
编辑~/.bashrc文件:
vim ~/.bashrc
添加如下内容:
export JAVA_HOME=/usr/local/java/jdk1.8.0_151
接着让环境变量生效,执行如下代码:
source ~/.bashrc
查看是否成功配置:
java -version
安装 Hadoop
先在master主机上做安装Hadoop(选择下载hadoop-2.7.4),暂时不需要在slave01,slave02主机上安装Hadoop.稍后会把master配置好的Hadoop发送给slave01,slave02.
在master主机执行如下操作:
sudo tar -zxf ~/下载/hadoop-2.7.4.tar.gz -C /usr/local # 解压到/usr/local中
cd /usr/local/
sudo mv ./hadoop-2.7.4/ ./hadoop # 将文件夹名改为hadoop
sudo chown -R pc ./hadoop # 修改文件权限
编辑~/.bashrc文件:
vim ~/.bashrc
添加如下内容:
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
接着让环境变量生效,执行如下代码:
source ~/.bashrc
3. Hadoop集群配置
修改master主机修改Hadoop如下配置文件,这些配置文件都位于 /usr/local/hadoop/etc/hadoop 目录下。
- slaves
这里把DataNode的主机名写入该文件,每行一个。这里让master节点主机仅作为NameNode使用。
slave01
slave02
- core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value><!-- <value>file:/usr/local/hadoop/tmp</value> -->
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
- hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
</configuration>
- mapred-site.xml(复制mapred-site.xml.template,再修改文件名)
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
- yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
</configuration>
配置好后,将 master 上的 /usr/local/hadoop 文件夹复制到各个节点上。之前有跑过伪分布式模式,建议在切换到集群模式前先删除之前的临时文件。在 master 节点主机上执行:
cd /usr/local/
rm -rf ./hadoop/tmp # 删除临时文件
rm -rf ./hadoop/logs/* # 删除日志文件
tar -zcf ~/hadoop.master.tar.gz ./hadoop
cd ~
scp ./hadoop.master.tar.gz slave01:/home/pc
scp ./hadoop.master.tar.gz slave02:/home/pc
在slave01,slave02节点上执行:
sudo rm -rf /usr/local/hadoop/
sudo tar -zxf ~/hadoop.master.tar.gz -C /usr/local
sudo chown -R pc /usr/local/hadoop
4. 启动Hadoop集群测试
在master主机上执行如下命令:
cd /usr/local/hadoop
bin/hdfs namenode -format
sbin/start-all.sh
运行后,在master,slave01,slave02运行jps命令,查看:
jps
master运行jps后,slave01、slave02运行jps,如下图:

在这里,master一定要看到NameNode,slave要看到DataNode,不然不算成功。我在配置的时候遇见了这个问题,我是这么解决的:
Hadoop启动不了Namenode进程
最终的core-site.xml和hdfs-site.xml配置内容就在上文。
二、 Scala 配置
我选择的是scala-2.12.4,我们把它安装在与Java和Hadoop相同的路径下。
首先在master主机下安装,之后ssh至两个分机。
sudo tar -zxf ~/下载/scala-2.12.4.tgz -C /usr/local # 解压到/usr/local中
cd /usr/local/
sudo mv ./scala-2.12.4/ ./scala # 将文件夹名改为scala
sudo chown -R pc ./scala # 修改文件权限
编辑~/.bashrc文件:
vim ~/.bashrc
添加如下内容:
export SCALA_HOME=/usr/local/scala
export PATH=$PATH:$SCALA_HOME/bin
接着让环境变量生效,执行如下代码:
source ~/.bashrc
检测安装是否成功
scala -version
将 master 上的 /usr/local/scala 文件夹复制到各个节点上。在 master 节点主机上执行:
cd /usr/local/
tar -zcf ~/hadoop.master.tar.gz ./scala
cd ~
scp ./scala.master.tar.gz slave01:/home/pc
scp ./scala.master.tar.gz slave02:/home/pc
在slave01,slave02节点上执行:
sudo tar -zxf ~/scala.master.tar.gz -C /usr/local
sudo chown -R pc /usr/local/scala
最后记得在slave上配置环境变量,检查是否安装成功。
scala -version
三、 Spark 2.2 分布式环境搭建
1. 下载安装
在master节点上,下载spark,如下图:

下载完成后,执行如下命令:
sudo tar -zxf ~/下载/spark-2.2.0-bin-hadoop2.7.tgz -C /usr/local/
cd /usr/local
sudo mv ./spark-2.2.0-bin-hadoop2.7.tgz/ ./spark
sudo chown -R pc ./spark
2. 配置环境变量
在master节点主机的终端中执行如下命令:
vim ~/.bashrc
在~/.bashrc添加如下配置:
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
记得生效:
source ~/.bashrc
3. Spark 配置
把master 作为 Master 节点,两个slave01、slave02作为Worker节点。
在master节点主机上进行如下操作:
- slaves
将 slaves.template 拷贝到 slaves
cd /usr/local/spark/
cp ./conf/slaves.template ./conf/slaves
slaves文件设置Worker节点。编辑slaves内容,把默认内容localhost替换成如下内容:
slave01
slave02
- spark-env.sh
将 spark-env.sh.template 拷贝到 spark-env.sh
cp ./conf/spark-env.sh.template ./conf/spark-env.sh
编辑spark-env.sh,添加如下内容:
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
###
export SPARK_MASTER_IP=master
export SPARK_LOCAL_IP=172.16.121.12
#export SPARK_MASTER_IP=172.16.121.12
export JAVA_HOME=/usr/local/java/jdk1.8.0_151
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
export SCALA_HOME=/usr/local/scala
SPARK_MASTER_IP 指定 Spark 集群 master 节点的 IP 地址;
配置好后,将master主机上的/usr/local/spark文件夹复制到各个节点上。在master主机上执行如下命令:
cd /usr/local/
tar -zcf ~/spark.master.tar.gz ./spark
cd ~
scp ./spark.master.tar.gz slave01:/home/pc
scp ./spark.master.tar.gz slave02:/home/pc
在slave01,slave02节点上执行:
sudo rm -rf /usr/local/spark/
sudo tar -zxf ~/spark.master.tar.gz -C /usr/local
sudo chown -R hadoop /usr/local/spark
4. 启动Spark集群
启动Hadoop集群
启动Spark集群前,要先启动Hadoop集群。在master节点主机上运行如下命令:
cd /usr/local/hadoop/
sbin/start-all.sh
启动Spark集群
- 启动master节点
在master节点主机上运行如下命令:
cd /usr/local/spark/
sbin/start-master.sh
在master节点上运行jps命令,可以看到多了个Master进程:

- 启动所有slave节点
在master节点主机上运行如下命令:
cd /usr/local/spark/
sbin/start-slaves.sh
分别slave01、slave02节点上运行jps命令,可以看到多了个Worker进程:

- 在浏览器上查看独立集群管理器Spark集群信息
在master主机上打开浏览器,访问http://master:8080,如下图:

如果在浏览器下看不到worker,可以参考这篇文章
简单总结一下博客就是:删掉hosts里面的127.0.0.1 localhost。
其中的spark-env.sh已在上文给出。
之后在master的终端中输入spark-shell就可以进入,看到spark的字符画。
5. 关闭 Spark 集群
关闭master节点
sbin/stop-master.sh
关闭worker节点
sbin/stop-slaves.sh
关闭Hadoop集群
cd /usr/local/hadoop/
sbin/stop-all.sh
【Spring】IoC控制反转、DI依赖注入、AOP面向切面编程
1. Spring IOC原理
IOC的意思是控件反转也就是由容器控制程序之间的关系,这也是spring的优点所在,把控件权交给了外部容器,之前的写法,由程序代码直接操控,而现在控制权由应用代码中转到了外部容器,控制权的转移是所谓反转。换句话说之前用new的方式获取对象,现在由spring给你至于怎么给你就是di了。
IOC的意思是控件反转也就是由容器控制程序之间的关系,把控件权交给了外部容器,之前的写法,由程序代码直接操控,而现在控制权由应用代码中转到了外部容器,控制权的转移是所谓反转。网上有一个很形象的比喻:
我们是如何找女朋友的?常见的情况是,我们到处去看哪里有长得漂亮身材又好的mm,然后打听她们的兴趣爱好、qq号、电话号、ip号、iq号………,想办法认识她们,投其所好送其所要,然后嘿嘿……这个过程是复杂深奥的,我们必须自己设计和面对每个环节。传统的程序开发也是如此,在一个对象中,如果要使用另外的对象,就必须得到它(自己new一个,或者从JNDI中查询一个),使用完之后还要将对象销毁(比如Connection等),对象始终会和其他的接口或类藕合起来。那么IoC是如何做的呢?有点像通过婚介找女朋友,在我和女朋友之间引入了一个第三者:婚姻介绍所。婚介管理了很多男男女女的资料,我可以向婚介提出一个列表,告诉它我想找个什么样的女朋友,比如长得像李嘉欣,身材像林熙雷,唱歌像周杰伦,速度像卡洛斯,技术像齐达内之类的,然后婚介就会按照我们的要求,提供一个mm,我们只需要去和她谈恋爱、结婚就行了。简单明了,如果婚介给我们的人选不符合要求,我们就会抛出异常。整个过程不再由我自己控制,而是有婚介这样一个类似容器的机构来控制。Spring所倡导的开发方式就是如此,所有的类都会在spring容器中登记,告诉spring你是个什么东西,你需要什么东西,然后spring会在系统运行到适当的时候,把你要的东西主动给你,同时也把你交给其他需要你的东西。所有的类的创建、销毁都由 spring来控制,也就是说控制对象生存周期的不再是引用它的对象,而是spring。对于某个具体的对象而言,以前是它控制其他对象,现在是所有对象都被spring控制,所以这叫控制反转。
2. 什么是DI机制?
这里说DI又要说到IOC,依赖注入(Dependecy Injection)和控制反转(Inversion of Control)是同一个概念,具体的讲:当某个角色 需要另外一个角色协助的时候,在传统的程序设计过程中,通常由调用者来创建被调用者的实例。但在spring中 创建被调用者的工作不再由调用者来完成,因此称为控制反转。创建被调用者的工作由spring来完成,然后注入调用者 因此也称为依赖注入。
spring以动态灵活的方式来管理对象 , 注入的四种方式: 1. 接口注入 2. Setter方法注入 3. 构造方法注入 4.注解注入(@autowire)
IoC的一个重点是在系统运行中,动态的向某个对象提供它所需要的其他对象。这一点是通过DI(Dependency Injection,
依赖注入)来实现的。比如对象A需要操作数据库,以前我们总是要在A中自己编写代码来获得一个Connection对象,有了
spring我们就只需要告诉spring,A中需要一个Connection,至于这个Connection怎么构造,何时构造,A不需要知道。
在系统运行时,spring会在适当的时候制造一个Connection,然后像打针一样,注射到A当中,这样就完成了对各个对象之间关系
的控制。A需要依赖 Connection才能正常运行,而这个Connection是由spring注入到A中的,依赖注入的名字就这么来的。
3. 什么是 AOP 面向切面编程
- AOP,即面向切面编程,采用横向抽取机制,取代了传统的纵向继承体系重复性代码。是什么意思呢?
- 我们知道,使用面向对象编程有一些弊端,当需要为多个不具有继承关系的对象引入同一个公共行为是,例如日志,安全检测等,我们只有在每一个对象中引入公共行为,这样程序中就出现了很多重复代码,加大了程序的维护难度。所以有了面向对象编程的补充AOP,它关注的方向是横向的,而不是面向对象那样的纵向。
IOC依赖注入,和AOP面向切面编程,这两个是Spring的灵魂。
主要用到的设计模式有工厂模式和代理模式。
- IOC就是典型的工厂模式,通过sessionfactory去注入实例。
- AOP就是典型的代理模式的体现。
在Spring中使用AspecJ实现AOP
- 我们一个需要被拦截增强的bean(也就是需要面向的切入点,切面),这个bean可能是满足业务需要的核心逻辑,例如其中的test方法封装这核心业务,如果我们想在这个test前后加入日志调试,那直接修改源码肯定是不合适的。但spring的aop能做到这点。
public class Book { public void test(){ System.out.println("Book test....."); } }
- 创建增强类,采用的是基于
@AspectJ的注解,例如前置增强@Before、后置增强,环绕增强等。public class MyBook { public void before1(){ System.out.println("前置增强....."); }//预计先输出这个,再输出Book中的test
- 之后再在xml配置文件中作出声明,测试就能成功。
Spring AOP 的实现机制
实现的两种代理实现机制,JDK动态代理和CGLIB动态代理。
代理机制-CGLIB
- 静态代理
- 静态代理在使用时,需要定义接口或者父类
- 被代理对象与代理对象一起实现相同的接口或者是继承相同父类
但是我们知道,实现接口,则必须实现它所有的方法。方法少的接口倒还好,但是如果恰巧这个接口的方法有很多呢,例如List接口。 更好的选择是: 使用动态代理!
- JDK动态代理
- 动态代理对象特点:
- 代理对象,不需要实现接口
- 代理对象的生成,是利用JDK的API,动态的在内存中构建代理对象(需要我们指定创建代理对象/目标对象实现的接口的类型)
- JDK实现代理只需要使用newProxyInstance方法
- JDK动态代理局限性
- 其代理对象必须是某个接口的实现,它是通过在运行期间床i教案一个接口的实现类来完成目标对象的代理。但事实上并不是所有类都有接口,对于没有实现接口的类,便无法使用该方方式实现动态代理。
如果Spring识别到所代理的类没有实现Interface,那么就会使用CGLib来创建动态代理,原理实际上成为所代理类的子类。
-
Cglib动态代理
- 上面的静态代理和动态代理模式都是要求目标对象是实现一个接口的目标对象,Cglib代理,也叫作子类代理,是基于asm框架,实现了无反射机制进行代理,利用空间来换取了时间,代理效率高于jdk ,它是在内存中构建一个子类对象从而实现对目标对象功能的扩展. 它有如下特点:
- JDK的动态代理有一个限制,就是使用动态代理的对象必须实现一个或多个接口,如果想代理没有实现接口的类,就可以使用Cglib实现.
- Cglib是一个强大的高性能的代码生成包,它可以在运行期扩展java类与实现java接口.它广泛的被许多AOP的框架使用,例如Spring AOP和synaop,为他们提供方法的interception(拦截)
- Cglib包的底层是通过使用一个小而块的字节码处理框架ASM来转换字节码并生成新的类.不鼓励直接使用ASM,因为它要求你必须对JVM内部结构包括class文件的格式和指令集都很熟悉.
- 目标对象的方法如果为final/static,那么就不会被拦截,即不会执行目标对象额外的业务方法.
对比JDK动态代理和CGLib代理,在实际使用中发现CGLib在创建代理对象时所花费的时间却比JDK动态代理要长,所以CGLib更适合代理不需要频繁实例化的类。
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.