
SDK Reference: https://python-sdk-docs.kili-technology.com/
Kili Documentation: https://docs.kili-technology.com/docs
App: https://cloud.kili-technology.com/label/
Website: https://kili-technology.com/
Kili is a platform that empowers a data-centric approach to Machine Learning through quality training data creation. It provides collaborative data annotation tools and APIs that enable quick iterations between reliable dataset building and model training. More info here.
| Named Entities Extraction and Relation | PDF classification and bounding-box | Object detection (bounding-box) |
|---|---|---|
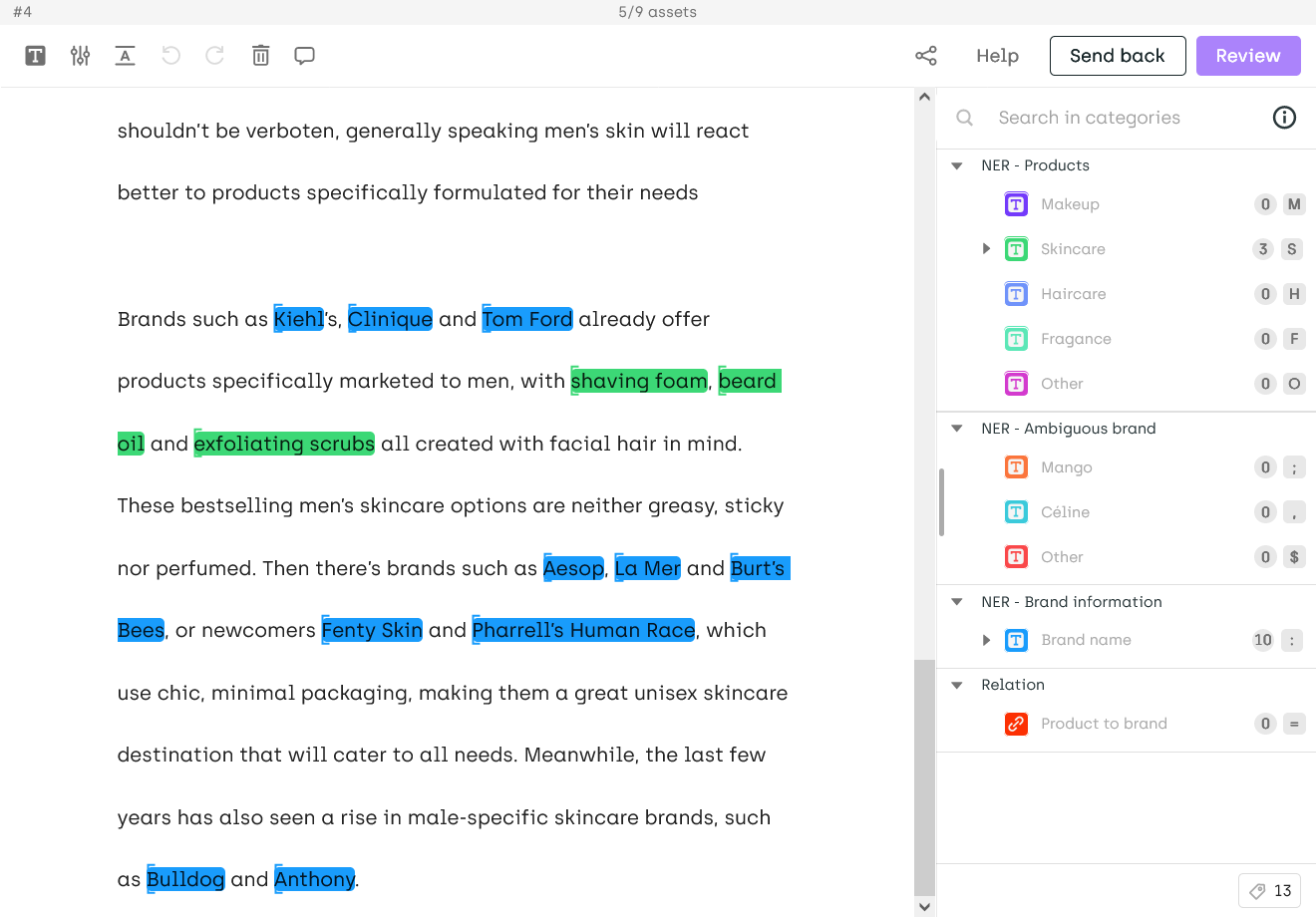 |
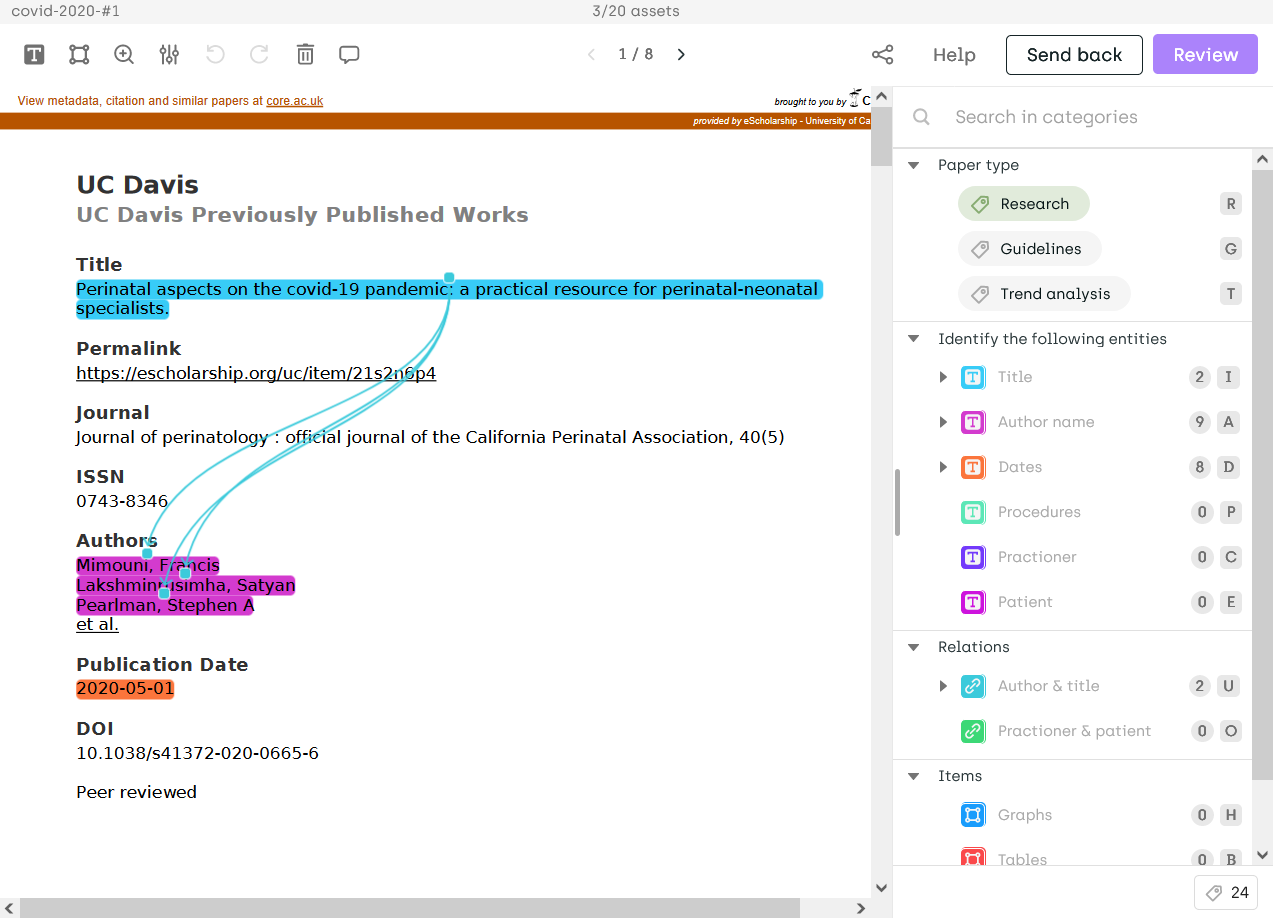 |
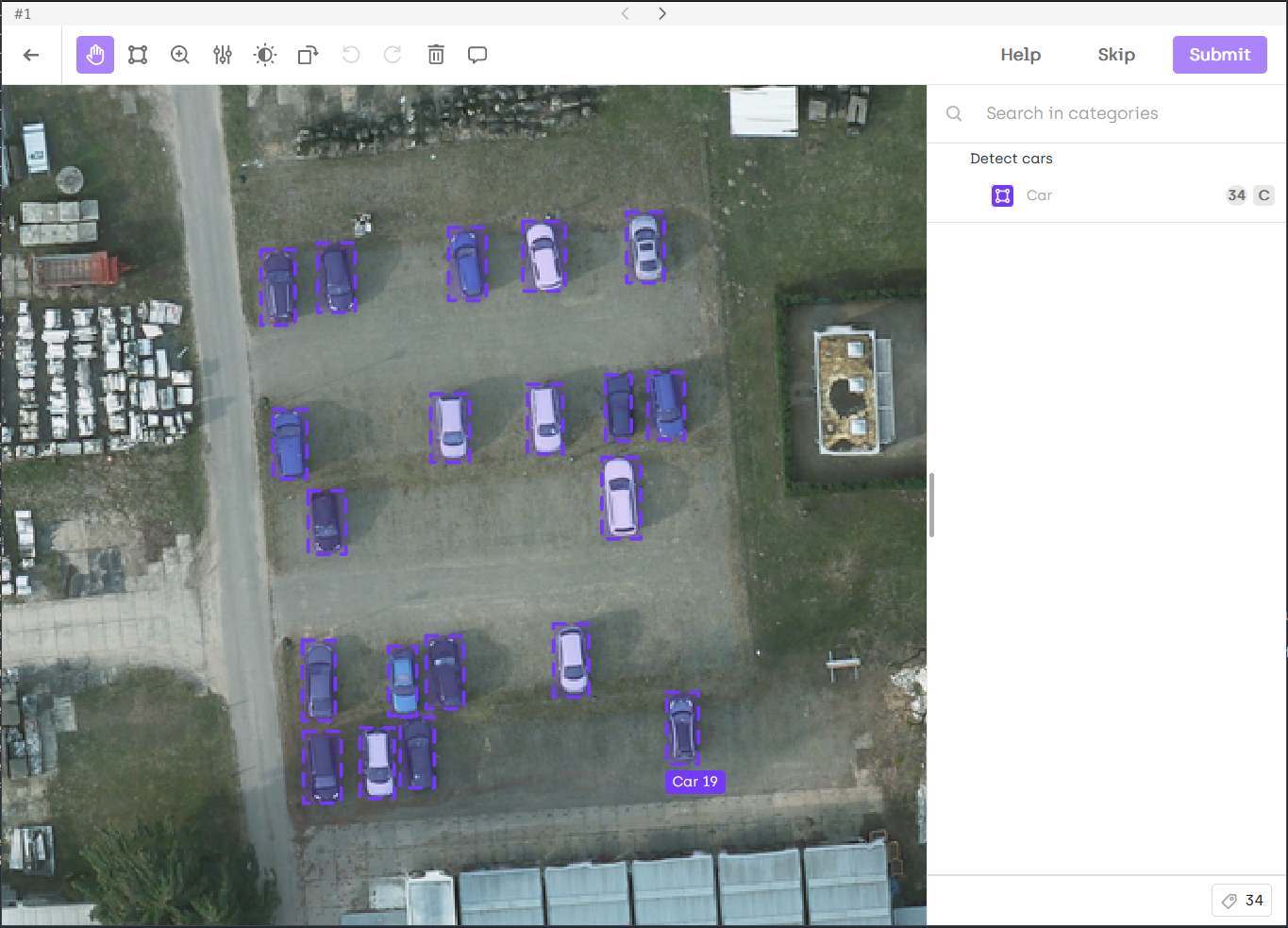 |
and many more.
Kili Python SDK is the Python client for the Kili platform. It allows to query and manipulate the main entities available in Kili, like projects, assets, labels, api keys...
It comes with several tutorials that demonstrate how to use it in the most frequent use cases.
- Python >= 3.8
- Create and copy a Kili API key
- Add the
KILI_API_KEYvariable in your bash environment (or in the settings of your favorite IDE) by pasting the API key value you copied above:
export KILI_API_KEY='<your api key value here>'Install the Kili client with pip:
pip install kiliIf you want to contribute, here are the installation steps.
Instantiate the Kili client:
from kili.client import Kili
kili = Kili()
# You can now use the Kili client!Note that you can also pass the API key as an argument of the Kili initialization:
kili = Kili(api_key='<your api key value here>')For more details, read the SDK reference or the Kili documentation.
Check out our tutorials! They will guide you through the main features of the Kili client.
You can find several other recipes in this folder.
Here is a sample of the operations you can do with the Kili client:
json_interface = {
"jobs": {
"CLASSIFICATION_JOB": {
"mlTask": "CLASSIFICATION",
"content": {
"categories": {
"RED": {"name": "Red"},
"BLACK": {"name": "Black"},
"WHITE": {"name": "White"},
"GREY": {"name": "Grey"}},
"input": "radio"
},
"instruction": "Color"
}
}
}
project_id = kili.create_project(
title="Color classification",
description="Project ",
input_type="IMAGE",
json_interface=json_interface
)["id"]assets = [
{
"externalId": "example 1",
"content": "https://images.caradisiac.com/logos/3/8/6/7/253867/S0-tesla-enregistre-d-importantes-pertes-au-premier-trimestre-175948.jpg",
},
{
"externalId": "example 2",
"content": "https://img.sportauto.fr/news/2018/11/28/1533574/1920%7C1280%7Cc096243e5460db3e5e70c773.jpg",
},
{
"externalId": "example 3",
"content": "./recipes/img/man_on_a_bike.jpeg",
},
]
external_id_array = [a.get("externalId") for a in assets]
content_array = [a.get("content") for a in assets]
kili.append_many_to_dataset(
project_id=project_id,
content_array=content_array,
external_id_array=external_id_array,
)See the detailed example in this tutorial.
prediction_examples = [
{
"external_id": "example 1",
"json_response": {
"CLASSIFICATION_JOB": {
"categories": [{"name": "GREY", "confidence": 46}]
}
},
},
{
"external_id": "example 2",
"json_response": {
"CLASSIFICATION_JOB": {
"categories": [{"name": "WHITE", "confidence": 89}]
}
},
}
]
kili.create_predictions(
project_id=project_id,
external_id_array=[p["external_id"] for p in prediction_examples],
json_response_array=[p["json_response"] for p in prediction_examples],
model_name="My SOTA model"
)See detailed examples in this recipe.
kili.export_labels("your_project_id", "export.zip", "yolo_v4")See a detailed example in this tutorial.












![github-actions[bot] avatar](https://avatars.githubusercontent.com/in/15368?v=4 "github-actions[bot]")












![renovate[bot] avatar](https://avatars.githubusercontent.com/in/2740?v=4 "renovate[bot]")









































































































