WordNet - это специальным образом сформированная база данных слов английского языка. WordNet используется в различных задачах компьютерной лингвистики и когнитивистики. Одним из примеров использования является компьютерная система Watson (IBM), разработанная для быстрого нахождения ответов в игре "Jeopardy!" ("Своя игра").
Как организована база WordNet:
Всё множество слов базы разделено на подмножества синонимов (synset). Множество синонимов - это множество слов, представляющих одно и то же понятие. Между некоторыми множествами синонимов может быть установлена семантическая связь одного из двух видов:
- Понятие А является гипонимом (hyponym) понятия В, то есть понятие А выражает частный случай понятия В
- Понятие А является гиперонимом (hypernym) понятия В, то есть понятие В выражает частный случай понятия А
Зададим множество вершин V = {s | s -- это множество синонимов} и множество дуг E = {(a -> b) | a, b - множества синонимов; а является гиперонимом b}. Тогда можно построить граф G = (V, E). G - ориентированный ациклический граф, имеющий одну корневую вершину.
Пример такого графа:
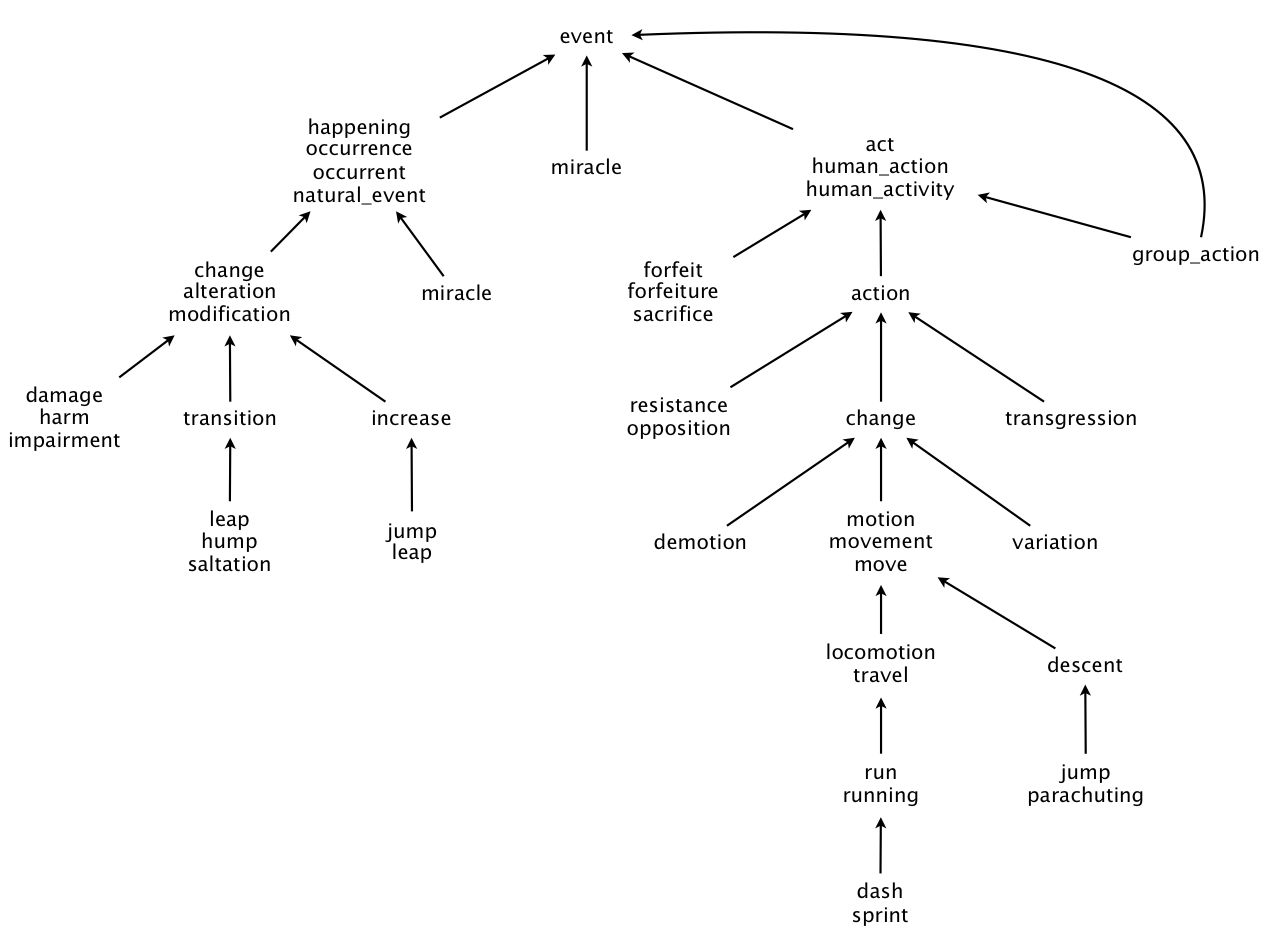
С помощью получившегося графа можно решать следующие две задачи.
-
Определение семантической близости двух заданных слов A и B. Семантическая близость двух слов - это близость понятий, которые эти слова выражают. Задача усложняется тем, что одно и то же слово может выражать несколько понятий.
-
Выделение "лишнего" слова из заданного списка слов. "Лишнее" слово можно определить как слово, которое меньше всего семантически связано с остальными словами.
Для решения этих задач введём следующие понятия.
-
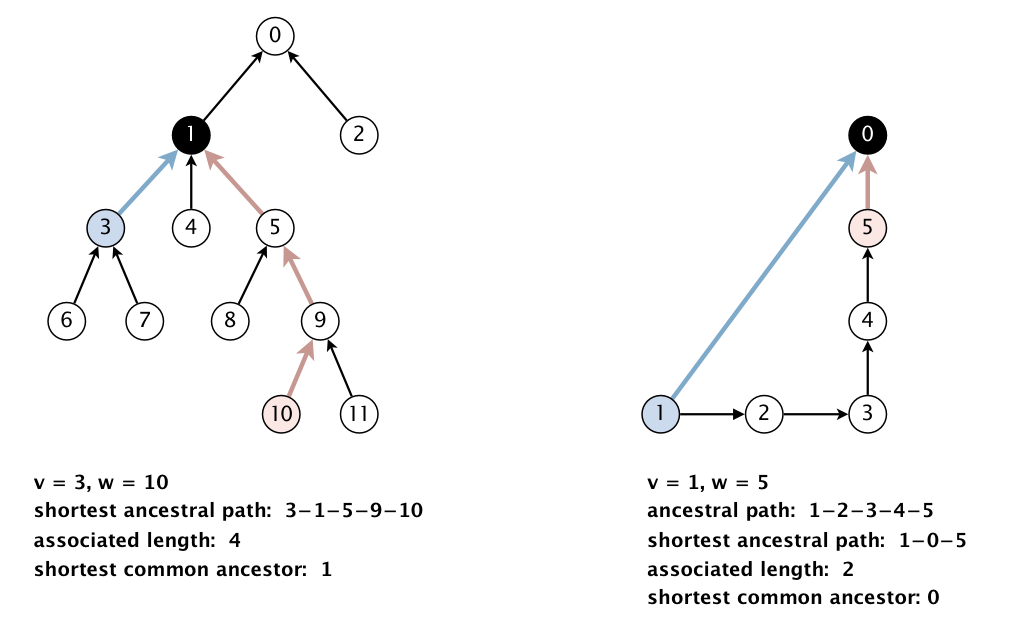
Общий предок (common ancestor) для двух вершин v и w - это вершина, которая достижима из v и w. Так как граф WordNet имеет одну корневую вершину, то общий предок существует для любых двух вершин.
-
Путь из вершины v в вершину w через общего предка x (ancestral path). Это путь, состоящий из двух частей: путь из v в x и путь из w в x.
-
Длина пути (length) - это число дуг, принадлежащих данному пути.
-
Кратчайший путь из вершины v в w через общего предка (shortest ancestral path). Это путь из вершины v в вершину w через общего предка минимальной длины.
-
Ближайший общий предок (shortest common ancestor). Это общий предок x, лежащий на кратчайшем пути из вершины v в w.
-
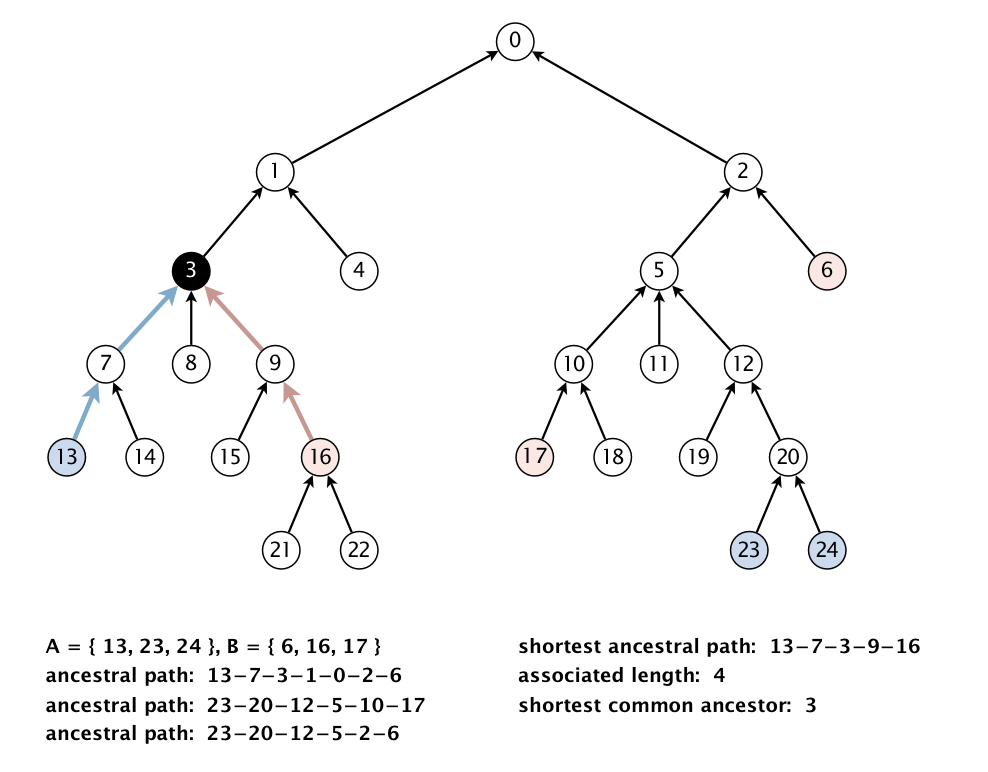
Ближайший общий предок для двух множеств вершин A и В. Между парами вершин
{(a, b) | a из A, b из B}можно построить множество кратчайших путей и выбрать путь P минимальной длины. Тогда ближайший общий предок для двух множеств вершин A и В - это ближайший общий предок пути P.
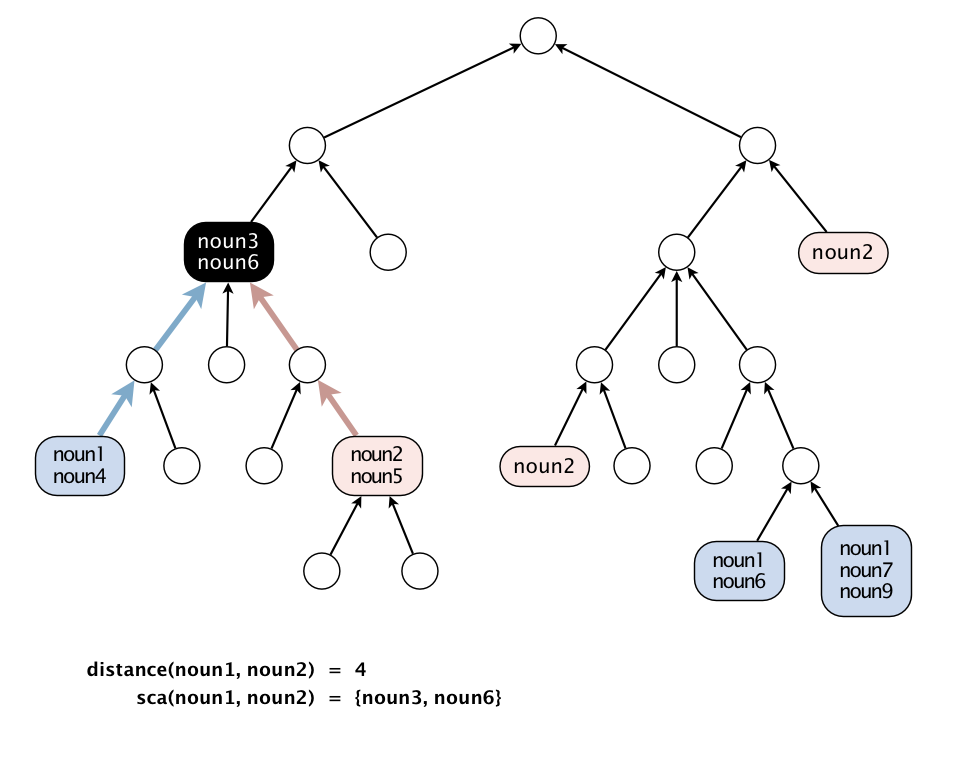
Для двух слов x и y определим
A = множество всех множеств синонимов(synset), содержащие слово x
B = множество всех множеств синонимов(synset), содержащие слово y
и вычислим
distance(x, y) = длина кратчайшего пути между множествами A и B
sca(x, y) = ближайший общий предок между A и B
Дано множество слов X = {x_i | i = 1..n}. Для каждого слова x_i определим его расстояние до множества остальных слов R_i = {x_k | k = 1..n, k != i}:
d_i = distance(x_i, x_1) + distance(x_i, x_2) + ... + distance(x_i, x_n)
Тогда решение задачи - это слово, имеющее наибольшее расстояние до множества остальных слов.
Для решения задач потребуется реализовать следующие классы:
class WordNet
{
WordNet(const std::string & synsets_fn, const std::string & hypernyms_fn);
using Iterator = ...
// get iterator to list all nouns stored in WordNet
Iterator nouns();
Iterator end();
// returns 'true' iff 'word' is stored in WordNet
bool is_noun(const std::string & word) const;
// returns gloss of "shortest common ancestor" of noun1 and noun2
std::string sca(const std::string & noun1, std::string & noun2);
// calculates distance between noun1 and noun2
int distance(const std::string & noun1, const std::string & noun2);
};
Входной файл synsets_fn это CSV файл с тремя колонками:
- идентификатор множества синонимов (synset id)
- множество синонимов (synonyms)
- определение связанного понятия (gloss)

Входной файл hypernyms_fn это CSV файл, имеющий переменное число колонок:
- первая колонка - идентификатор множества синонимов
- оставшиеся колонки - список его гипонимов

Для эффективности реализации класса можно задать ограничение на длину строки слова и длину строки понятия.
Требования по эффективности класса WordNet:
- Конструктор класса должен иметь сложность не хуже
O(N + M), где N и М - размеры входных файлов - Метод
bool is_noun(const std::string & word) constдолжен иметь сложность не хужеO(log N), где N - число слов - Метод
std::string sca(const std::string & noun1, std::string & noun2) constдолжен делать ровно один вызовShortestCommonAncestor::lengthSubset() - Метод
int distance(const std::string & noun1, const std::string & noun2) constдолжен делать ровно один вызовShortestCommonAncestor::ancestorSubset()
class ShortestCommonAncestor
{
ShortestCommonAncestor(const Digraph & G);
// calculates length of shortest common ancestor path from node with id 'v' to node with id 'w'
int length(int v, int w);
// returns node id of shortest common ancestor of nodes v and w
int ancestor(int v, int w);
// calculates length of shortest common ancestor path from node subset 'subset_a' to node subset 'subset_b'
int length_subset(const std::set<int> & subset_a, const std::set<int> & subset_b);
// returns node id of shortest common ancestor of node subset 'subset_a' and node subset 'subset_b'
int ancestor_subset(const std::set<int> & subset_a, const std::set<int> & subset_b);
}
где Digraph - класс, описывающий граф G = (V, E).
Требования по эффективности класса ShortestCommonAncestor: конструктор и методы класса должны выполняться за время O(N_v + N_e), N_v - размер множества вершин V, N_e - размер множества дуг E.
class Outcast
{
public:
Outcast(WordNet & wordnet);
// returns outcast word
std::string outcast(const std::vector<std::string> & nouns);
};