Comp 545 - Natural Language Processing
This project involves fine-tuning a DistilBERT model, a lighter version of BERT, to accurately predict text entailment in natural language inference tasks. Utilizing the Hugging Face transformers library, the model learns from a dataset where the objective is to determine if one sentence logically follows from another.
- Implement a custom neural network module integrating DistilBERT for binary classification.
- Utilize advanced features of PyTorch and the transformers library for efficient model training and evaluation.
- Explore and implement techniques like prompt tuning to enhance model input processing and improve prediction accuracy.
- Benchmark the model's performance using F1 scores and analyze the impact of various tuning techniques.
- Programming Languages: Python
- Frameworks/Libraries: PyTorch, Hugging Face Transformers, NumPy
- Tools: Jupyter Notebook, Kaggle
- Model Customization: Setup of a custom DistilBERT model within a PyTorch framework to handle specific preprocessing and prediction tasks.
- Prompt Engineering: Implementation of soft prompts to refine inputs and enhance model responsiveness to nuanced textual features.
- Performance Evaluation: Use of advanced metrics like F1 score to quantitatively assess model accuracy and effectiveness.
- Model Training and Tuning: Detailed process documentation for training the model, adjusting parameters, and evaluating performance under different configurations.
Train and Validation Accuracy of DistilBERT:

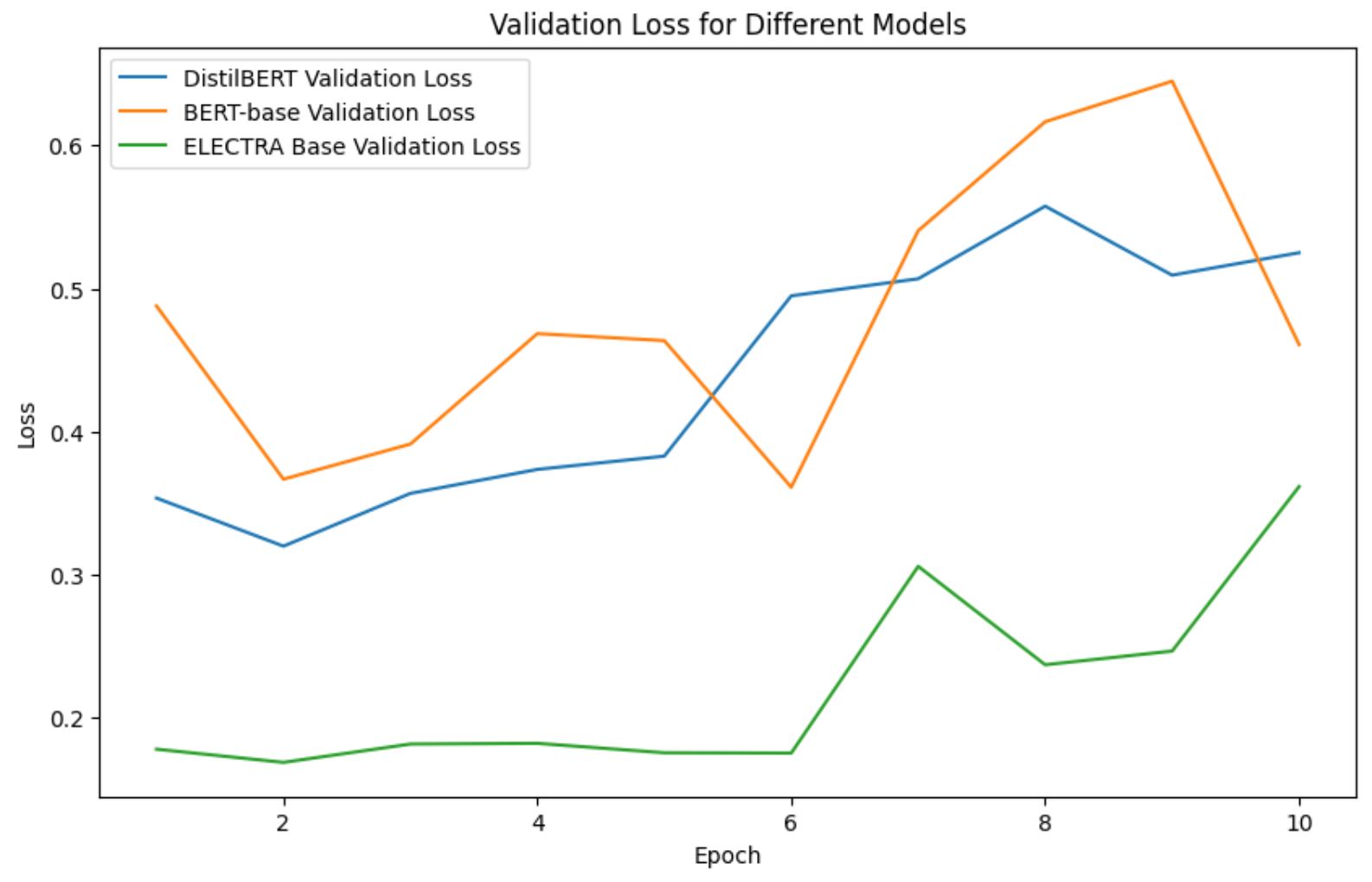
Comparison between different models:

- Clone the GitHub repository.
- Ensure all dependencies are installed as listed in
requirements.txt. - Run the training script
code.pyto fine-tune the model, followed by the evaluation Jupyter notebooks to assess performance.
