libaudioflux / audioflux Goto Github PK
View Code? Open in Web Editor NEWA library for audio and music analysis, feature extraction.
Home Page: https://audioflux.top
License: MIT License
A library for audio and music analysis, feature extraction.
Home Page: https://audioflux.top
License: MIT License






























































































































Hi
Is there any way to extract all the features in one code? Like the figure you have in your documentation, I need to have a concatenated layer of features and transform each of my audio to a m-dimension space of features.
In the field of deep learning for audio, the mel spectrogram is the most commonly used audio feature. The performance of mel spectrogram features can be benchmarked and compared using audio feature extraction libraries such as the following:
| Library | Language | Version | About |
|---|---|---|---|
| audioFlux | C/Python | 0.1.5 | A library for audio and music analysis, feature extraction |
| torchaudio | Python | 0.11.0 | Data manipulation and transformation for audio signal processing, powered by PyTorch |
| librosa | Python | 0.10.0 | C++ library for audio and music analysis, description and synthesis, including Python bindings |
| essentia | C++/Python | 2.0.1 | Python library for audio and music analysis |
There are many factors that can affect the performance evaluation results, including CPU architecture, operating system, compilation system, selection of basic linear algebra libraries, and usage of project APIs, all of which can have a certain impact on the evaluation results.
For the most common mel features in the audio field, the major performance bottlenecks are FFT computation, matrix computation, and multi-threaded parallel processing, while minor bottlenecks include algorithmic business implementation and Python packaging.
If you want to compare and test multiple libraries, you can use:
$ python run_benchmark.py -p audioflux,torchaudio,librosa -r 1000 -er 10 -t 1,5,10,100,500,1000,2000,3000run_xxx.py calls, numberIf you want to test a single library, you can use:
$ python run_audioflux.py -r 1000 -t 1,5,10,100,500,1000,2000,3000If you want to see more usage instructions, you can execute python run_xxx.py --help
In the field of audio, libraries related to audio feature extraction have their own functional characteristics and provide different types of features. This evaluation does not aim to test all the performance comparisons of their feature extraction in detail. However, as the mel spectrum is one of the most important and fundamental features, all of these libraries support it.
There are many factors that can affect the performance evaluation results, such as CPU architecture, operating system, compilation system, choice of basic linear algebra library, and the usage of project APIs, which will have a certain impact on the evaluation results. In order to be as fair as possible and to better reflect actual business needs, the following conditions are based on in this evaluation:
When the data is short, the first execution time of most libraries may be relatively slow. To reflect actual business needs and to be fair, this first execution time is not counted. If the library API design provides initialization functions, they will be created and repeatedly called in actual business scenarios, and the initialization execution time is also not counted.
⚠️ When using Python scientific computing related libraries such as Conda, PyTorch, TensorFlow, XGBoost, LightGBM, etc., almost all of them use Intel Math Kernel Library (MKL). MKL uses OpenMP for parallel acceleration, but only one instance of OpenMP can exist in the same process. When these libraries are used together, it is best to link all libraries to the same location of libomp, otherwise an error will occur. Modifying the environment variables according to the prompt may result in slower program execution and unreliable results. Relevant tools can be used to rewrite the libomp linking path of the related libraries.
Use audioFlux/torchaudio/librosa script, for AMD/Intel/M1 CPUs and Linux/macOS operating system.
The time required to calculate the mel-spectrogram for 1000 sample data according to a TimeStep of 1/5/10/100/500/1000/2000/3000. Where fft_len=2048, slide_len=512, sampling_rate=32000.
- OS: Ubuntu 20.04.4 LTS
- CPU: AMD Ryzen Threadripper 3970X 32-Core Processor
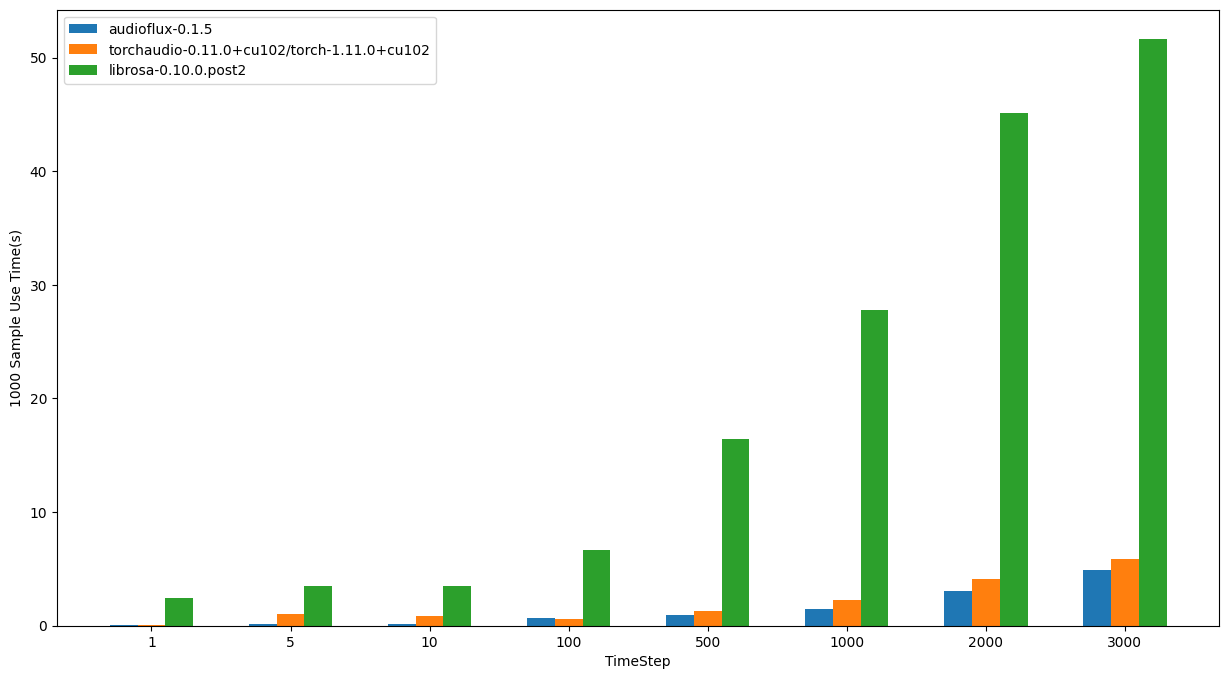
| TimeStep | audioflux | torchaudio | librosa |
|---|---|---|---|
| 1 | 0.04294s | 0.07707s | 2.41958s |
| 5 | 0.14878s | 1.05589s | 3.52610s |
| 10 | 0.18374s | 0.83975s | 3.46499s |
| 100 | 0.67030s | 0.61876s | 6.63217s |
| 500 | 0.94893s | 1.29189s | 16.45968s |
| 1000 | 1.43854s | 2.23126s | 27.78358s |
| 2000 | 3.08714s | 4.10869s | 45.12714s |
| 3000 | 4.90343s | 5.86299s | 51.62876s |
- OS: Ubuntu 20.04.4 LTS
- CPU: Intel(R) Core(TM) i7-6850K CPU @ 3.60GHz
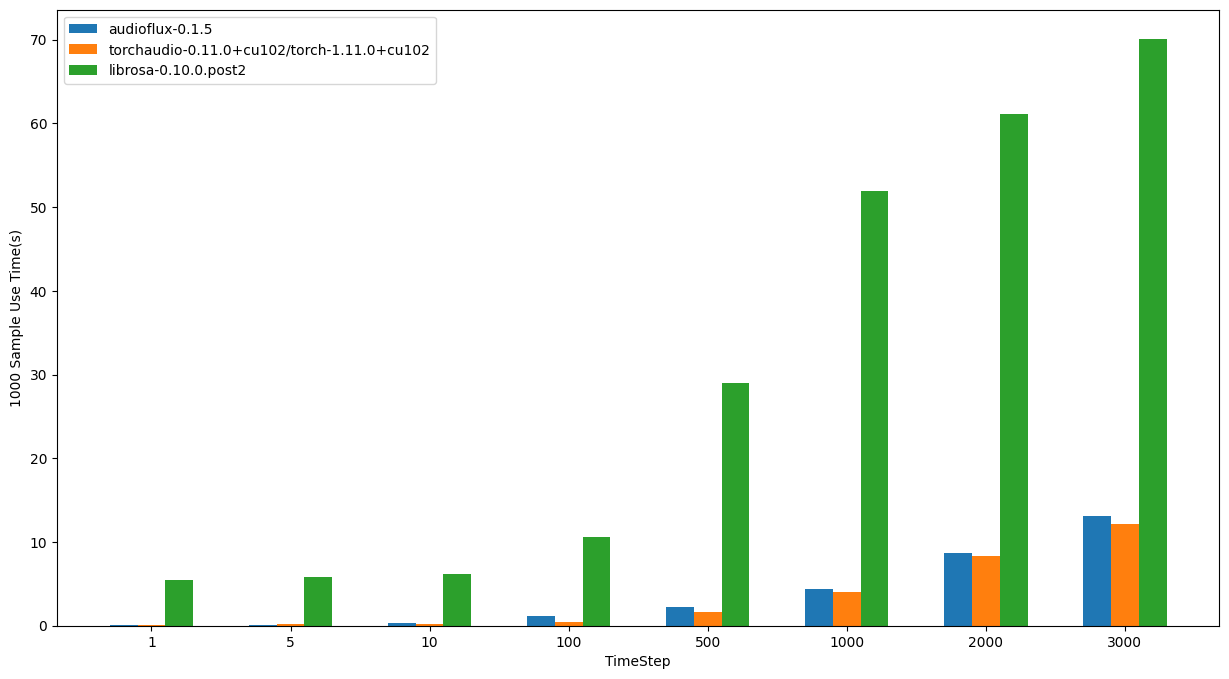
| TimeStep | audioflux | torchaudio | librosa |
|---|---|---|---|
| 1 | 0.08106s | 0.11043s | 5.51295s |
| 5 | 0.11654s | 0.16005s | 5.77631s |
| 10 | 0.29173s | 0.15352s | 6.13656s |
| 100 | 1.18150s | 0.39958s | 10.61641s |
| 500 | 2.23883s | 1.58323s | 28.99823s |
| 1000 | 4.42723s | 3.98896s | 51.97518s |
| 2000 | 8.73121s | 8.28444s | 61.13923s |
| 3000 | 13.07378s | 12.14323s | 70.06395s |
- OS: 12.6.1 (21G217)
- CPU: 3.8GHz 8‑core 10th-generation Intel Core i7, Turbo Boost up to 5.0GHz
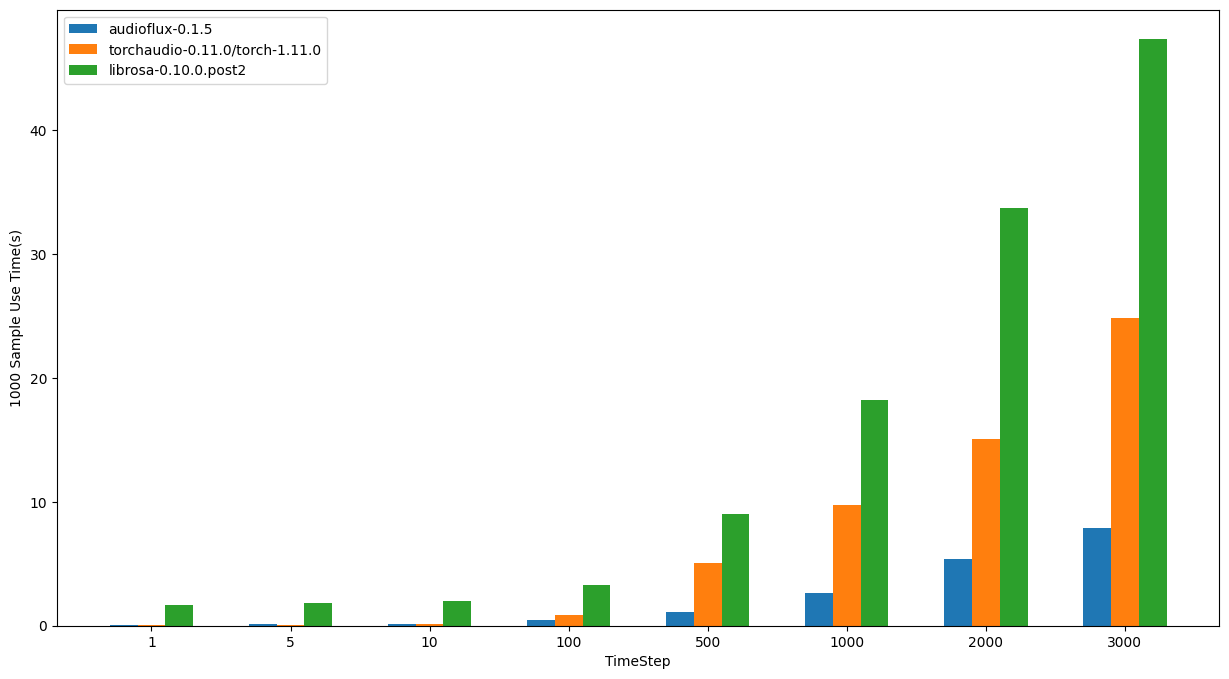
| TimeStep | audioflux | torchaudio | librosa |
|---|---|---|---|
| 1 | 0.07605s | 0.06451s | 1.70139s |
| 5 | 0.14946s | 0.08464s | 1.86964s |
| 10 | 0.16641s | 0.10762s | 2.00865s |
| 100 | 0.46902s | 0.83551s | 3.28890s |
| 500 | 1.08860s | 5.05824s | 8.98265s |
| 1000 | 2.64029s | 9.78269s | 18.24391s |
| 2000 | 5.40025s | 15.08991s | 33.68184s |
| 3000 | 7.92596s | 24.84823s | 47.35941s |
- OS: 12.4 (21F79)
- CPU: Apple M1
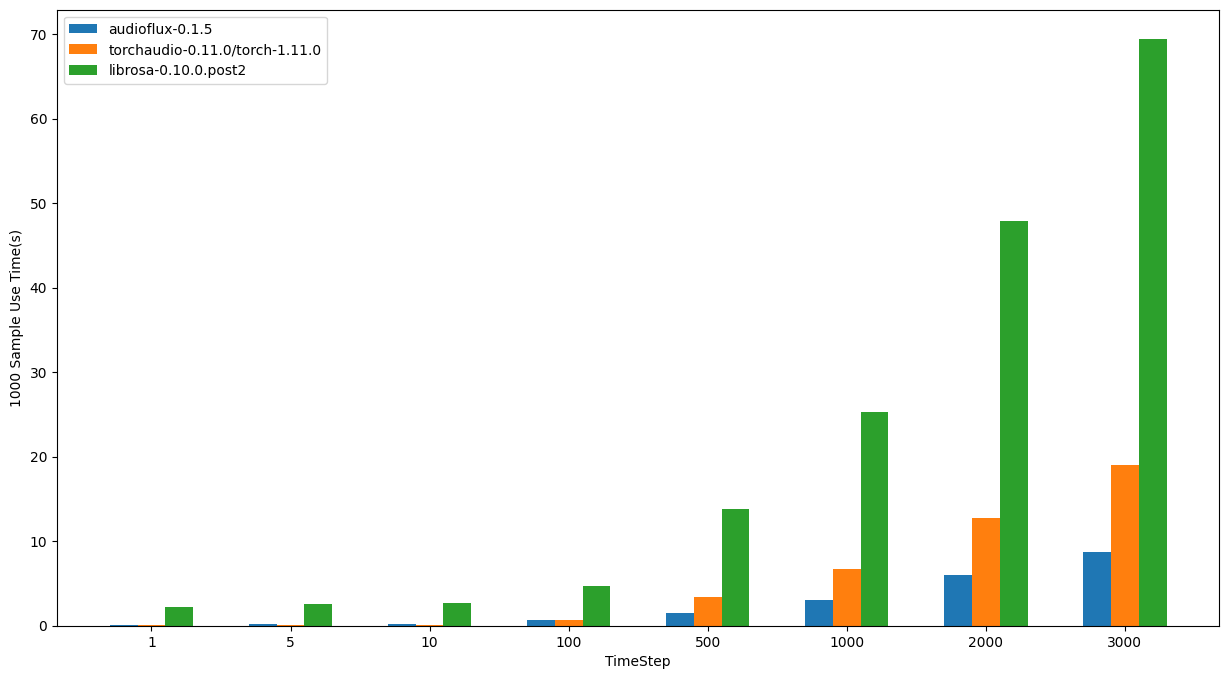
| TimeStep | audioflux | torchaudio | librosa |
|---|---|---|---|
| 1 | 0.06110s | 0.06874s | 2.22518s |
| 5 | 0.23444s | 0.07922s | 2.55907s |
| 10 | 0.20691s | 0.11090s | 2.71813s |
| 100 | 0.68694s | 0.63625s | 4.74433s |
| 500 | 1.47420s | 3.37597s | 13.83887s |
| 1000 | 3.00926s | 6.76275s | 25.24646s |
| 2000 | 5.99781s | 12.69573s | 47.84029s |
| 3000 | 8.76306s | 19.03391s | 69.40428s |
In summary, from the performance comparison results of the three libraries, librosa takes the most time, which is also in line with common sense.
On linux/amd processors, audioflux is slightly faster than torchaudio, but slightly slower on linux/intel.
On the macOS system, for large-size sample data, audioflux is faster than torchaudio, and intel is more obvious than m1; for small-size sample data, torchaudio is faster than audioflux.
I tried using af for audiodata with high sample rates. The resulting spectrograms look correct, however, the y_coords (and underlying fre_band_arr) are not correct. Looks like some too low default is used. Using the high_fre setting does not help.
To reproduce, use e.g. this file: 0170701_213954-MYOMYS-LR_0_0.5.wav with 500 kHz sampling rate.
import audioflux as af
from audioflux.type import SpectralFilterBankScaleType
audio_arr, sr = af.read(
"20170701_213954-MYOMYS-LR_0_0.5.wav"
)
bft_obj = af.BFT(
num=128,
radix2_exp=12,
samplate=sr,
scale_type=SpectralFilterBankScaleType.MEL,
#high_fre=192000, # does not solve the issue
print(sr)
# 500000
print(bft_obj.y_coords()[-1])
# 15948.399 , should be close to 192000 or 250000
print(bft_obj.high_fre)
# 250000 # without high_fre setting, 192 with high_fre setting Same issue with files with 384 kHz sr, and also using audioflux.mel_spectrogram
install:
pip install audioflux
os:
ubuntu18
python3.8
for example
import audioflux
output1 = audioflux.mel_spectrogram(waveform, num=80, radix2_exp=10, samplate=16000)
import torch
import audioflux
output2 = audioflux.mel_spectrogram(waveform, num=80, radix2_exp=10, samplate=16000)
I finally found out that the output1 and output2 is too different just because "import torch", if this is a bug? It'll call difference while inferencing with ONNX (without using torch to extract features).
Extracting audio features on embedded devices needs to run in C environment
你好,我在python中使用pip install audioflux来安装,之后使用import audioflux as af来导入该模块,但是出现了[WinError 126] 找不到指定的模块。
When I create multiple instances of BFT, an exception is raised for access violation writing
Thanks for this great contribution.
Is your implementation of the NSGT transform invertible. If so, could you please provide an example of its usage?
I am trying to use the library with JNI for android. Using example in issue #26 I have run into a problem where it uses a really high amount of memory. using spectrogramObj_spectrogram(...) method to generate Mel spectrograms. For a 3 minute audio track with 15 million samples and a slideLenght of 512 it allocates 1.4GB of memory at the start of spectrogram making process. The slide length appears to scale linearly with the ammount of memory used. Is there a more optimal way to get the melspecs without having such high memory allocations?
用pip install audioflux 安装后运行报错:
Traceback (most recent call last):
File "/Users/***/Downloads/GitHub/AudioAnalysis/test.py", line 1, in <module>
import audioflux as af
File "/Users/***/opt/anaconda3/envs/audio/lib/python3.9/site-packages/audioflux/__init__.py", line 1, in <module>
from .bft import *
File "/Users/***/opt/anaconda3/envs/audio/lib/python3.9/site-packages/audioflux/bft.py", line 5, in <module>
from audioflux.base import Base
File "/Users/***/opt/anaconda3/envs/audio/lib/python3.9/site-packages/audioflux/base.py", line 1, in <module>
from audioflux.fftlib import get_fft_lib
File "/Users/***/opt/anaconda3/envs/audio/lib/python3.9/site-packages/audioflux/fftlib.py", line 129, in <module>
set_fft_lib(None)
File "/Users/***/opt/anaconda3/envs/audio/lib/python3.9/site-packages/audioflux/fftlib.py", line 125, in set_fft_lib
__LIBRARY['_lib'] = load_library(lib_fp)
File "/Users/***/opt/anaconda3/envs/audio/lib/python3.9/ctypes/__init__.py", line 460, in LoadLibrary
return self._dlltype(name)
File "/Users/***/opt/anaconda3/envs/audio/lib/python3.9/ctypes/__init__.py", line 382, in __init__
self._handle = _dlopen(self._name, mode)
OSError: dlopen(/Users/***/opt/anaconda3/envs/audio/lib/python3.9/site-packages/audioflux/lib/libaudioflux.dylib, 0x0006): tried: '/Users/***/opt/anaconda3/envs/audio/lib/python3.9/site-packages/audioflux/lib/libaudioflux.dylib' (mach-o file, but is an incompatible architecture (have (x86_64), need (arm64e)))
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.