Language : 🇺🇸 | 🇨🇳
An unofficial PyTorch implementation of VALL-E(Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers).
We can train the VALL-E model on one GPU.



Since VALL-E could synthesize speech that maintains speaker identity, it may carry potential risks in misuse of the model, such as spoofing voice identification or impersonating a specific speaker.
To avoid abuse, Well-trained models and services will not be provided.
To get up and running quickly just follow the steps below:
# PyTorch
pip install torch==1.13.1 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu116
pip install torchmetrics==0.11.1
# fbank
pip install librosa==0.8.1
# phonemizer pypinyin
apt-get install espeak-ng
## OSX: brew install espeak
pip install phonemizer==3.2.1 pypinyin==0.48.0
# lhotse update to newest version
# https://github.com/lhotse-speech/lhotse/pull/956
# https://github.com/lhotse-speech/lhotse/pull/960
pip uninstall lhotse
pip uninstall lhotse
pip install git+https://github.com/lhotse-speech/lhotse
# k2
# find the right version in https://huggingface.co/csukuangfj/k2
pip install https://huggingface.co/csukuangfj/k2/resolve/main/cuda/k2-1.23.4.dev20230224+cuda11.6.torch1.13.1-cp310-cp310-linux_x86_64.whl
# icefall
git clone https://github.com/k2-fsa/icefall
cd icefall
pip install -r requirements.txt
export PYTHONPATH=`pwd`/../icefall:$PYTHONPATH
echo "export PYTHONPATH=`pwd`/../icefall:\$PYTHONPATH" >> ~/.zshrc
echo "export PYTHONPATH=`pwd`/../icefall:\$PYTHONPATH" >> ~/.bashrc
cd -
source ~/.zshrc
# valle
git clone https://github.com/lifeiteng/valle.git
cd valle
pip install -e .
-
English example examples/libritts/README.md
-
Chinese example examples/aishell1/README.md
-
Paper Chapter 5.1 "The average length of the waveform in LibriLight is 60 seconds. During
training, we randomly crop the waveform to a random length between 10 seconds and 20 seconds. For the NAR acoustic prompt tokens, we select a random segment waveform of 3 seconds from the same utterance."
- 0: no acoustic prompt tokens
- 1: random prefix of current batched utterances (This is recommended)
- 2: random segment of current batched utterances
- 4: same as the paper (As they randomly crop the long waveform to multiple utterances, so the same utterance means pre or post utterance in the same long waveform.)
# If train NAR Decoders with prefix_mode 4 python3 bin/trainer.py --prefix_mode 4 --dataset libritts --input-strategy PromptedPrecomputedFeatures ...
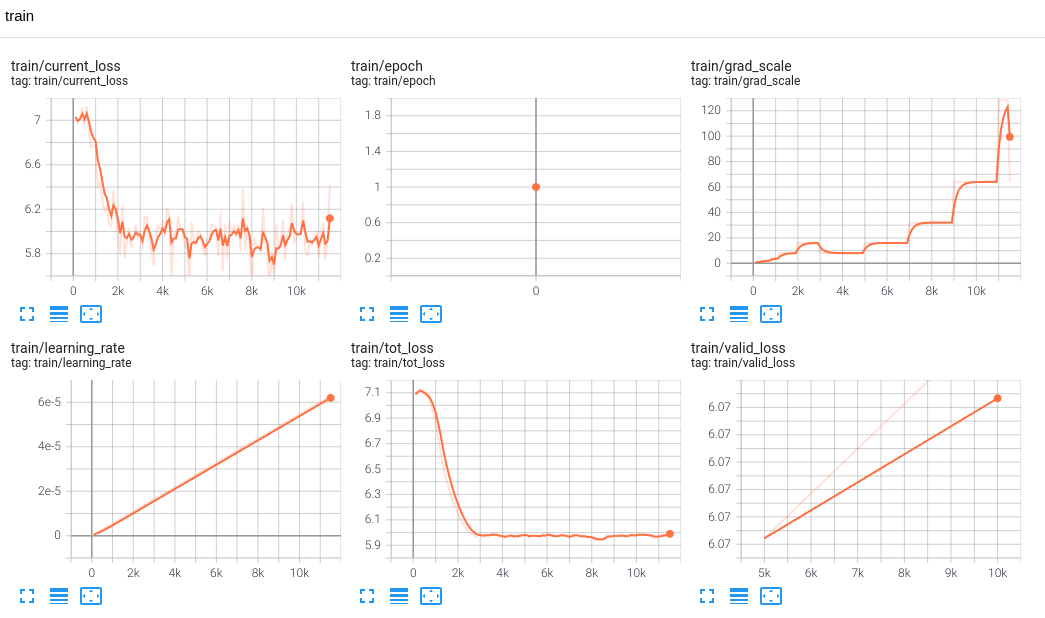
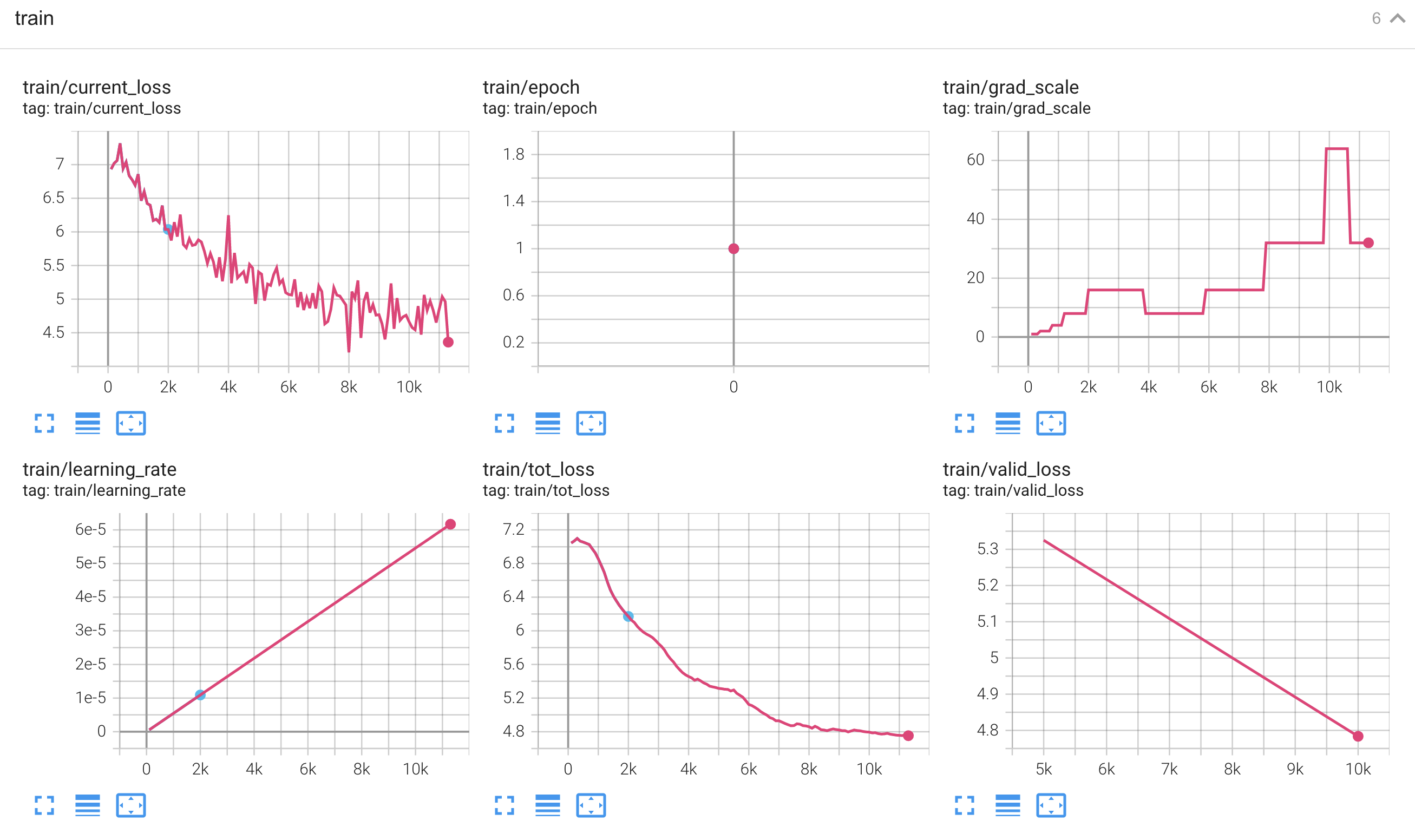
LibriTTS demo Trained on one GPU with 24G memory
cd examples/libritts
# step1 prepare dataset
bash prepare.sh --stage -1 --stop-stage 3
# step2 train the model on one GPU with 24GB memory
exp_dir=exp/valle
## Train AR model
python3 bin/trainer.py --max-duration 80 --filter-min-duration 0.5 --filter-max-duration 14 --train-stage 1 \
--num-buckets 6 --dtype "bfloat16" --save-every-n 10000 --valid-interval 20000 \
--model-name valle --share-embedding true --norm-first true --add-prenet false \
--decoder-dim 1024 --nhead 16 --num-decoder-layers 12 --prefix-mode 1 \
--base-lr 0.05 --warmup-steps 200 --average-period 0 \
--num-epochs 20 --start-epoch 1 --start-batch 0 --accumulate-grad-steps 4 \
--exp-dir ${exp_dir}
## Train NAR model
cp ${exp_dir}/best-valid-loss.pt ${exp_dir}/epoch-2.pt # --start-epoch 3=2+1
python3 bin/trainer.py --max-duration 40 --filter-min-duration 0.5 --filter-max-duration 14 --train-stage 2 \
--num-buckets 6 --dtype "float32" --save-every-n 10000 --valid-interval 20000 \
--model-name valle --share-embedding true --norm-first true --add-prenet false \
--decoder-dim 1024 --nhead 16 --num-decoder-layers 12 --prefix-mode 1 \
--base-lr 0.05 --warmup-steps 200 --average-period 0 \
--num-epochs 40 --start-epoch 3 --start-batch 0 --accumulate-grad-steps 4 \
--exp-dir ${exp_dir}
# step3 inference
python3 bin/infer.py --output-dir infer/demos \
--checkpoint=${exp_dir}/best-valid-loss.pt \
--text-prompts "KNOT one point one five miles per hour." \
--audio-prompts ./prompts/8463_294825_000043_000000.wav \
--text "To get up and running quickly just follow the steps below." \
# Demo Inference
https://github.com/lifeiteng/lifeiteng.github.com/blob/main/valle/run.sh#L68

- SummaryWriter segmentation fault (core dumped)
- LINE
tb_writer = SummaryWriter(log_dir=f"{params.exp_dir}/tensorboard") - FIX https://github.com/tensorflow/tensorboard/pull/6135/files
file=`python -c 'import site; print(f"{site.getsitepackages()[0]}/tensorboard/summary/writer/event_file_writer.py")'` sed -i 's/import tf/import tensorflow_stub as tf/g' $file - LINE
- prepare the dataset to
lhotse manifests- There are plenty of references here lhotse/recipes
python3 bin/tokenizer.py ...python3 bin/trainer.py ...
- Parallelize bin/tokenizer.py on multi-GPUs
To cite this repository:
@misc{valle,
author={Feiteng Li},
title={VALL-E: A neural codec language model},
year={2023},
url={http://github.com/lifeiteng/vall-e}
}@article{VALL-E,
title = {Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers},
author = {Chengyi Wang, Sanyuan Chen, Yu Wu,
Ziqiang Zhang, Long Zhou, Shujie Liu,
Zhuo Chen, Yanqing Liu, Huaming Wang,
Jinyu Li, Lei He, Sheng Zhao, Furu Wei},
year = {2023},
eprint = {2301.02111},
archivePrefix = {arXiv},
volume = {abs/2301.02111},
url = {http://arxiv.org/abs/2301.02111},
}