I'm Tom. I do open-source! 1.9K stars on GitHub
About me
- 💼 working as a software engineer for self-driving
- 📈 building open source LLM tools and more

Run any Llama 2 locally with gradio UI on GPU or CPU from anywhere (Linux/Windows/Mac). Use `llama2-wrapper` as your local llama2 backend for Generative Agents/Apps.
License: MIT License

































































































































As bitsandybytes is required by ll2ma2-webui, but on win10 platform, it can not work.
It seems that bitsanndbytes can not find some .so library.
PS C:\Users\PC> python -m bitsandbytes
False
===================================BUG REPORT===================================
C:\Users\PC\AppData\Local\Programs\Python\Python311\Lib\site-packages\bitsandbytes\cuda_setup\main.py:166: UserWarning: Welcome to bitsandbytes. For bug reports, please run
python -m bitsandbytes
CUDA_SETUP: WARNING! libcudart.so not found in any environmental path. Searching in backup paths...
The following directories listed in your path were found to be non-existent: {WindowsPath('/usr/local/cuda/lib64')}
DEBUG: Possible options found for libcudart.so: set()
CUDA SETUP: PyTorch settings found: CUDA_VERSION=118, Highest Compute Capability: 8.6.
CUDA SETUP: To manually override the PyTorch CUDA version please see:https://github.com/TimDettmers/bitsandbytes/blob/main/how_to_use_nonpytorch_cuda.md
CUDA SETUP: Loading binary C:\Users\PC\AppData\Local\Programs\Python\Python311\Lib\site-packages\bitsandbytes\libbitsandbytes_cuda118.so...
argument of type 'WindowsPath' is not iterable
CUDA SETUP: Problem: The main issue seems to be that the main CUDA runtime library was not detected.
CUDA SETUP: Solution 1: To solve the issue the libcudart.so location needs to be added to the LD_LIBRARY_PATH variable
CUDA SETUP: Solution 1a): Find the cuda runtime library via: find / -name libcudart.so 2>/dev/null
CUDA SETUP: Solution 1b): Once the library is found add it to the LD_LIBRARY_PATH: export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:FOUND_PATH_FROM_1a
CUDA SETUP: Solution 1c): For a permanent solution add the export from 1b into your .bashrc file, located at ~/.bashrc
CUDA SETUP: Solution 2: If no library was found in step 1a) you need to install CUDA.
CUDA SETUP: Solution 2a): Download CUDA install script: wget https://github.com/TimDettmers/bitsandbytes/blob/main/cuda_install.sh
CUDA SETUP: Solution 2b): Install desired CUDA version to desired location. The syntax is bash cuda_install.sh CUDA_VERSION PATH_TO_INSTALL_INTO.
CUDA SETUP: Solution 2b): For example, "bash cuda_install.sh 113 ~/local/" will download CUDA 11.3 and install into the folder ~/local
Traceback (most recent call last):
File "", line 189, in run_module_as_main
File "", line 148, in get_module_details
File "", line 112, in get_module_details
File "C:\Users\PC\AppData\Local\Programs\Python\Python311\Lib\site-packages\bitsandbytes_init.py", line 6, in
from . import cuda_setup, utils, research
File "C:\Users\PC\AppData\Local\Programs\Python\Python311\Lib\site-packages\bitsandbytes\research_init.py", line 1, in
from . import nn
File "C:\Users\PC\AppData\Local\Programs\Python\Python311\Lib\site-packages\bitsandbytes\research\nn_init.py", line 1, in
from .modules import LinearFP8Mixed, LinearFP8Global
File "C:\Users\PC\AppData\Local\Programs\Python\Python311\Lib\site-packages\bitsandbytes\research\nn\modules.py", line 8, in
from bitsandbytes.optim import GlobalOptimManager
File "C:\Users\PC\AppData\Local\Programs\Python\Python311\Lib\site-packages\bitsandbytes\optim_init_.py", line 6, in
from bitsandbytes.cextension import COMPILED_WITH_CUDA
File "C:\Users\PC\AppData\Local\Programs\Python\Python311\Lib\site-packages\bitsandbytes\cextension.py", line 20, in
raise RuntimeError('''
RuntimeError:
CUDA Setup failed despite GPU being available. Please run the following command to get more information:
python -m bitsandbytes
Inspect the output of the command and see if you can locate CUDA libraries. You might need to add them
to your LD_LIBRARY_PATH. If you suspect a bug, please take the information from python -m bitsandbytes
and open an issue at: https://github.com/TimDettmers/bitsandbytes/issues
On Macbook CPU inference,run in Docker,user Chinese Error
models GGML:
https://huggingface.co/LinkSoul/Chinese-Llama-2-7b-ggml/blob/main/Chinese-Llama-2-7b.ggmlv3.q4_1.bin

llama.cpp: loading model from /app/model/llama-2-7b-chat.ggmlv3.q4_1.bin
llama_model_load_internal: format = ggjt v3 (latest)
llama_model_load_internal: n_vocab = 32000
llama_model_load_internal: n_ctx = 4000
llama_model_load_internal: n_embd = 4096
llama_model_load_internal: n_mult = 256
llama_model_load_internal: n_head = 32
llama_model_load_internal: n_head_kv = 32
llama_model_load_internal: n_layer = 32
llama_model_load_internal: n_rot = 128
llama_model_load_internal: n_gqa = 1
llama_model_load_internal: rnorm_eps = 1.0e-06
llama_model_load_internal: n_ff = 11008
llama_model_load_internal: freq_base = 10000.0
llama_model_load_internal: freq_scale = 1
llama_model_load_internal: ftype = 3 (mostly Q4_1)
llama_model_load_internal: model size = 7B
llama_model_load_internal: ggml ctx size = 0.08 MB
llama_model_load_internal: mem required = 4537.35 MB (+ 2000.00 MB per state)
llama_new_context_with_model: kv self size = 2000.00 MB
AVX = 1 | AVX2 = 0 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | VSX = 0 |
Llama.generate: prefix-match hit
Llama.generate: prefix-match hit
Llama.generate: prefix-match hit
Llama.generate: prefix-match hit
Llama.generate: prefix-match hit
Llama.generate: prefix-match hit
Llama.generate: prefix-match hit
Llama.generate: prefix-match hit
Running on CPU with llama.cpp.
Caching examples at: '/app/gradio_cached_examples/19'
Caching example 1/5
Caching example 2/5
Caching example 3/5
Caching example 4/5
Caching example 5/5
Caching complete
Running on local URL: http://0.0.0.0:7860
Could not create share link. Missing file: /usr/local/lib/python3.9/site-packages/gradio/frpc_linux_amd64_v0.2.
Please check your internet connection. This can happen if your antivirus software blocks the download of this file. You can install manually by following these steps:
Hi,
I'm trying to add the llama_index to a llama-2 model using llama-webui, but I'm not sure how to do it. I've read the documentation, but it doesn't seem to cover this specific case.
Could you please provide some instructions on how to add the llama_index to a llama-2 model in llama-webui? I would really appreciate it.
Running python app.py
(llama2-webui) [09:10:56] houge (llama2-webui) ~/llama2-webui [main ●1…4]
$ python app.py
Running on GPU with backend torch transformers.
Loading checkpoint shards: 0%| | 0/2 [00:00<?, ?it/s]
Traceback (most recent call last):
File "/home/houge/llama2-webui/app.py", line 418, in <module>
main()
File "/home/houge/llama2-webui/app.py", line 60, in main
llama2_wrapper = LLAMA2_WRAPPER(
^^^^^^^^^^^^^^^
File "/home/houge/llama2-webui/llama2_wrapper/model.py", line 99, in __init__
self.init_model()
File "/home/houge/llama2-webui/llama2_wrapper/model.py", line 103, in init_model
self.model = LLAMA2_WRAPPER.create_llama2_model(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/houge/llama2-webui/llama2_wrapper/model.py", line 146, in create_llama2_model
model = AutoModelForCausalLM.from_pretrained(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/houge/llama2-webui/lib/python3.11/site-packages/transformers/models/auto/auto_factory.py", line 493, in from_pretrained
return model_class.from_pretrained(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/houge/llama2-webui/lib/python3.11/site-packages/transformers/modeling_utils.py", line 2903, in from_pretrained
) = cls._load_pretrained_model(
^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/houge/llama2-webui/lib/python3.11/site-packages/transformers/modeling_utils.py", line 3246, in _load_pretrained_model
state_dict = load_state_dict(shard_file)
^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/houge/llama2-webui/lib/python3.11/site-packages/transformers/modeling_utils.py", line 447, in load_state_dict
with safe_open(checkpoint_file, framework="pt") as f:
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
safetensors_rust.SafetensorError: Error while deserializing header: HeaderTooLarge
[09:11:31] [cost 9.708s] python app.py
I am using Collab Pro, running on the GPU, executing the following code to ask a question, and responding for 50 seconds, which is too slow. Is there any way to accelerate?
`prompt = get_prompt("Please help me explain the TCP handshake")
res = llama2_wrapper(prompt)
print(res)`
Getting an error when launching the app with the standard, unmodified, env file : OSError: [Errno 30] Read-only file system: '/tmpcjgwfixw'
python -m venv venvsource venv/bin/activate.fishpip install -r requirements.txtpython app.pyApp downloads the model then fails with OSError: [Errno 30] Read-only file system: '/tmpcjgwfixw'

| llama-2-7b-chat.ggmlv3.q4_0 | 4 bit | Intel i7-8700 | 5.4 GB RAM | 6.27 | 173.15 |
|---|---|---|---|---|---|
| llama-2-7b-chat.ggmlv3.q4_0 | 4 bit | Intel i7-9700 | 4.8 GB RAM | 4.2 | 87.9 |
Hey,
locally both of these work with llama.cpp. I also am approved for llama v2, but don't really want to upload manually or redownload that. However when I try to use the ggml models by the bloke, I always get a verification error.
CUDA not found.
Traceback (most recent call last):
File "/home/user/project/llama2-webui/app.py", line 61, in <module>
llama2_wrapper.init_tokenizer()
File "/home/user/project/llama2-webui/model.py", line 21, in init_tokenizer
self.tokenizer = LLAMA2_WRAPPER.create_llama2_tokenizer(self.config)
File "/home/user/project/llama2-webui/model.py", line 65, in create_llama2_tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name)
File "/home/user/.local/share/virtualenvs/llama2-webui-NwPLNNNA/lib/python3.10/site-packages/transformers/models/auto/tokenization_auto.py", line 652, in from_pretrained
tokenizer_config = get_tokenizer_config(pretrained_model_name_or_path, **kwargs)
File "/home/user/.local/share/virtualenvs/llama2-webui-NwPLNNNA/lib/python3.10/site-packages/transformers/models/auto/tokenization_auto.py", line 496, in get_tokenizer_config
resolved_config_file = cached_file(
File "/home/user/.local/share/virtualenvs/llama2-webui-NwPLNNNA/lib/python3.10/site-packages/transformers/utils/hub.py", line 417, in cached_file
resolved_file = hf_hub_download(
File "/home/user/.local/share/virtualenvs/llama2-webui-NwPLNNNA/lib/python3.10/site-packages/huggingface_hub/utils/_validators.py", line 110, in _inner_fn
validate_repo_id(arg_value)
File "/home/user/.local/share/virtualenvs/llama2-webui-NwPLNNNA/lib/python3.10/site-packages/huggingface_hub/utils/_validators.py", line 158, in validate_repo_id
raise HFValidationError(
huggingface_hub.utils._validators.HFValidationError: Repo id must be in the form 'repo_name' or 'namespace/repo_name': '/path-to/Llama-2-7b-chat-hf'. Use `repo_type` argument if needed.
My models are stored in models/ (within the llama2-webui folder). I suspect it is some path problem, but I double checked multiple times and also used the full path as well as a partial path, with similar results. Still probably some mistake by me, but would be great if you have any idea.
I cannot run Llama-2-70b-hf. The backend type is transformers.
I tried to use multiple GPUs.
If anyone knows how to solve this problem, please let me know.
import os
from llama2_wrapper import LLAMA2_WRAPPER, get_prompt
os.environ["CUDA_VISIBLE_DEVICES"]="4,5,6,7"
llama2_wrapper = LLAMA2_WRAPPER(
model_path = "/home/takizawa/model/Llama-2-70b-hf",
backend_type = "transformers",
load_in_8bit = False
)
prompt = get_prompt("Hi do you know Pytorch?")
print(llama2_wrapper(prompt))
../aten/src/ATen/native/cuda/IndexKernel.cu:92: operator(): block: [0,0,0], thread: [0,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/IndexKernel.cu:92: operator(): block: [0,0,0], thread: [1,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/IndexKernel.cu:92: operator(): block: [0,0,0], thread: [2,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
( ... )
../aten/src/ATen/native/cuda/IndexKernel.cu:92: operator(): block: [0,0,0], thread: [95,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
Cell In[5], line 4
1 from llama2_wrapper import get_prompt
3 prompt = get_prompt("Hi do you know Pytorch?")
----> 4 print(llama2_wrapper(prompt))
File ~/Projects/test_llama2wrapper/.venv/lib/python3.11/site-packages/llama2_wrapper/model.py:363, in LLAMA2_WRAPPER.__call__(self, prompt, stream, max_new_tokens, temperature, top_p, top_k, repetition_penalty, **kwargs)
361 return streamer
362 else:
--> 363 output_ids = self.model.generate(
364 **generate_kwargs,
365 )
366 output = self.tokenizer.decode(output_ids[0])
367 return output.split("[/INST]")[1].split("</s>")[0]
File ~/Projects/test_llama2wrapper/.venv/lib/python3.11/site-packages/torch/utils/_contextlib.py:115, in context_decorator.<locals>.decorate_context(*args, **kwargs)
112 @functools.wraps(func)
113 def decorate_context(*args, **kwargs):
114 with ctx_factory():
--> 115 return func(*args, **kwargs)
File ~/Projects/test_llama2wrapper/.venv/lib/python3.11/site-packages/transformers/generation/utils.py:1538, in GenerationMixin.generate(self, inputs, generation_config, logits_processor, stopping_criteria, prefix_allowed_tokens_fn, synced_gpus, assistant_model, streamer, **kwargs)
1532 raise ValueError(
1533 "num_return_sequences has to be 1 when doing greedy search, "
1534 f"but is {generation_config.num_return_sequences}."
1535 )
1537 # 11. run greedy search
-> 1538 return self.greedy_search(
1539 input_ids,
1540 logits_processor=logits_processor,
1541 stopping_criteria=stopping_criteria,
1542 pad_token_id=generation_config.pad_token_id,
1543 eos_token_id=generation_config.eos_token_id,
1544 output_scores=generation_config.output_scores,
1545 return_dict_in_generate=generation_config.return_dict_in_generate,
1546 synced_gpus=synced_gpus,
1547 streamer=streamer,
1548 **model_kwargs,
1549 )
1551 elif is_contrastive_search_gen_mode:
1552 if generation_config.num_return_sequences > 1:
File ~/Projects/test_llama2wrapper/.venv/lib/python3.11/site-packages/transformers/generation/utils.py:2362, in GenerationMixin.greedy_search(self, input_ids, logits_processor, stopping_criteria, max_length, pad_token_id, eos_token_id, output_attentions, output_hidden_states, output_scores, return_dict_in_generate, synced_gpus, streamer, **model_kwargs)
2359 model_inputs = self.prepare_inputs_for_generation(input_ids, **model_kwargs)
2361 # forward pass to get next token
-> 2362 outputs = self(
2363 **model_inputs,
2364 return_dict=True,
2365 output_attentions=output_attentions,
2366 output_hidden_states=output_hidden_states,
2367 )
2369 if synced_gpus and this_peer_finished:
2370 continue # don't waste resources running the code we don't need
File ~/Projects/test_llama2wrapper/.venv/lib/python3.11/site-packages/torch/nn/modules/module.py:1501, in Module._call_impl(self, *args, **kwargs)
1496 # If we don't have any hooks, we want to skip the rest of the logic in
1497 # this function, and just call forward.
1498 if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks or self._forward_pre_hooks
1499 or _global_backward_pre_hooks or _global_backward_hooks
1500 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1501 return forward_call(*args, **kwargs)
1502 # Do not call functions when jit is used
1503 full_backward_hooks, non_full_backward_hooks = [], []
File ~/Projects/test_llama2wrapper/.venv/lib/python3.11/site-packages/accelerate/hooks.py:165, in add_hook_to_module.<locals>.new_forward(*args, **kwargs)
163 output = old_forward(*args, **kwargs)
164 else:
--> 165 output = old_forward(*args, **kwargs)
166 return module._hf_hook.post_forward(module, output)
File ~/Projects/test_llama2wrapper/.venv/lib/python3.11/site-packages/transformers/models/llama/modeling_llama.py:806, in LlamaForCausalLM.forward(self, input_ids, attention_mask, position_ids, past_key_values, inputs_embeds, labels, use_cache, output_attentions, output_hidden_states, return_dict)
803 return_dict = return_dict if return_dict is not None else self.config.use_return_dict
805 # decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
--> 806 outputs = self.model(
807 input_ids=input_ids,
808 attention_mask=attention_mask,
809 position_ids=position_ids,
810 past_key_values=past_key_values,
811 inputs_embeds=inputs_embeds,
812 use_cache=use_cache,
813 output_attentions=output_attentions,
814 output_hidden_states=output_hidden_states,
815 return_dict=return_dict,
816 )
818 hidden_states = outputs[0]
819 if self.pretraining_tp > 1:
File ~/Projects/test_llama2wrapper/.venv/lib/python3.11/site-packages/torch/nn/modules/module.py:1501, in Module._call_impl(self, *args, **kwargs)
1496 # If we don't have any hooks, we want to skip the rest of the logic in
1497 # this function, and just call forward.
1498 if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks or self._forward_pre_hooks
1499 or _global_backward_pre_hooks or _global_backward_hooks
1500 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1501 return forward_call(*args, **kwargs)
1502 # Do not call functions when jit is used
1503 full_backward_hooks, non_full_backward_hooks = [], []
File ~/Projects/test_llama2wrapper/.venv/lib/python3.11/site-packages/transformers/models/llama/modeling_llama.py:693, in LlamaModel.forward(self, input_ids, attention_mask, position_ids, past_key_values, inputs_embeds, use_cache, output_attentions, output_hidden_states, return_dict)
685 layer_outputs = torch.utils.checkpoint.checkpoint(
686 create_custom_forward(decoder_layer),
687 hidden_states,
(...)
690 None,
691 )
692 else:
--> 693 layer_outputs = decoder_layer(
694 hidden_states,
695 attention_mask=attention_mask,
696 position_ids=position_ids,
697 past_key_value=past_key_value,
698 output_attentions=output_attentions,
699 use_cache=use_cache,
700 )
702 hidden_states = layer_outputs[0]
704 if use_cache:
File ~/Projects/test_llama2wrapper/.venv/lib/python3.11/site-packages/torch/nn/modules/module.py:1501, in Module._call_impl(self, *args, **kwargs)
1496 # If we don't have any hooks, we want to skip the rest of the logic in
1497 # this function, and just call forward.
1498 if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks or self._forward_pre_hooks
1499 or _global_backward_pre_hooks or _global_backward_hooks
1500 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1501 return forward_call(*args, **kwargs)
1502 # Do not call functions when jit is used
1503 full_backward_hooks, non_full_backward_hooks = [], []
File ~/Projects/test_llama2wrapper/.venv/lib/python3.11/site-packages/accelerate/hooks.py:165, in add_hook_to_module.<locals>.new_forward(*args, **kwargs)
163 output = old_forward(*args, **kwargs)
164 else:
--> 165 output = old_forward(*args, **kwargs)
166 return module._hf_hook.post_forward(module, output)
File ~/Projects/test_llama2wrapper/.venv/lib/python3.11/site-packages/transformers/models/llama/modeling_llama.py:408, in LlamaDecoderLayer.forward(self, hidden_states, attention_mask, position_ids, past_key_value, output_attentions, use_cache)
405 hidden_states = self.input_layernorm(hidden_states)
407 # Self Attention
--> 408 hidden_states, self_attn_weights, present_key_value = self.self_attn(
409 hidden_states=hidden_states,
410 attention_mask=attention_mask,
411 position_ids=position_ids,
412 past_key_value=past_key_value,
413 output_attentions=output_attentions,
414 use_cache=use_cache,
415 )
416 hidden_states = residual + hidden_states
418 # Fully Connected
File ~/Projects/test_llama2wrapper/.venv/lib/python3.11/site-packages/torch/nn/modules/module.py:1501, in Module._call_impl(self, *args, **kwargs)
1496 # If we don't have any hooks, we want to skip the rest of the logic in
1497 # this function, and just call forward.
1498 if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks or self._forward_pre_hooks
1499 or _global_backward_pre_hooks or _global_backward_hooks
1500 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1501 return forward_call(*args, **kwargs)
1502 # Do not call functions when jit is used
1503 full_backward_hooks, non_full_backward_hooks = [], []
File ~/Projects/test_llama2wrapper/.venv/lib/python3.11/site-packages/accelerate/hooks.py:165, in add_hook_to_module.<locals>.new_forward(*args, **kwargs)
163 output = old_forward(*args, **kwargs)
164 else:
--> 165 output = old_forward(*args, **kwargs)
166 return module._hf_hook.post_forward(module, output)
File ~/Projects/test_llama2wrapper/.venv/lib/python3.11/site-packages/transformers/models/llama/modeling_llama.py:330, in LlamaAttention.forward(self, hidden_states, attention_mask, position_ids, past_key_value, output_attentions, use_cache)
327 key_states = repeat_kv(key_states, self.num_key_value_groups)
328 value_states = repeat_kv(value_states, self.num_key_value_groups)
--> 330 attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)
332 if attn_weights.size() != (bsz, self.num_heads, q_len, kv_seq_len):
333 raise ValueError(
334 f"Attention weights should be of size {(bsz, self.num_heads, q_len, kv_seq_len)}, but is"
335 f" {attn_weights.size()}"
336 )
RuntimeError: CUDA error: CUBLAS_STATUS_EXECUTION_FAILED when calling `cublasGemmStridedBatchedExFix( handle, opa, opb, m, n, k, (void*)(&falpha), a, CUDA_R_16F, lda, stridea, b, CUDA_R_16F, ldb, strideb, (void*)(&fbeta), c, CUDA_R_16F, ldc, stridec, num_batches, CUDA_R_32F, CUBLAS_GEMM_DEFAULT_TENSOR_OP)`
Python 3.11.3
llama2-wrapper==0.1.8
torch==2.0.1
transformers==4.31.0
NVIDIA-SMI 465.19.01
Driver Version: 465.19.01
CUDA Version: 11.3
This huggingface/transformers issue may be related to this issue.
error loading model: llama.cpp: tensor 'layers.0.attention.wk.weight' has wrong shape; expected 8192 x 8192, got 8192 x 1024
The exact same settings and quantization works for 7B and 13B. Here is my .env
MODEL_PATH = ""
#MODEL_PATH = "./models/llama-2-7b-chat.ggmlv3.q4_0.bin"
MODEL_PATH = "./models/llama-2-70b-chat.ggmlv3.q4_0.bin"
#MODEL_PATH = "./models/llama-2-13b-chat.ggmlv3.q4_0.bin"
BACKEND_TYPE = "llama.cpp"
LOAD_IN_8BIT = False
MAX_MAX_NEW_TOKENS = 2048
DEFAULT_MAX_NEW_TOKENS = 1024
MAX_INPUT_TOKEN_LENGTH = 4000
DEFAULT_SYSTEM_PROMPT = ""
Is there any way where this could be exposed as Rest API instead of a WebUI default
Hey, this is really great, and I have got it working. I have a gaming laptop with 2 GPUs: an AMD with 512 MB VRAM, and a RTX 4080 with 12 GB VRAM. The model is running pretty well, but it is hitting the AMD, not the RTX. When launched, I am getting "CUDA not found". I am doing all this on Win11/WSL2. I think I have cuda installed and enabled properly for python in WSL:
torch.cuda.is_available()
True
Here is my .env:
MODEL_PATH = "TheBloke/Llama-2-7b-Chat-GPTQ"
LOAD_IN_8BIT = False
LOAD_IN_4BIT = True
LLAMA_CPP = FalseMAX_MAX_NEW_TOKENS = 2048
DEFAULT_MAX_NEW_TOKENS = 1024
MAX_INPUT_TOKEN_LENGTH = 4000
(Note: I had to tweak MODEL_PATH from example - this value above worked for me. I also removed DEFAULT_SYSTEM_PROMPT for now, because it was crashing the app with "everett.ConfigurationError: Env file line missing = operator")
Do you have any suggestions on what I might need to do to get the app to recognize and use the RTX? Thanks!
Trying to run this with CPU only and followed the instruction to install and run this on Linux.
Here is what I get:
$ python3 ./app.py
Running on backend llama.cpp.
Model path is empty.
Use default llama.cpp model path: ./models/llama-2-7b-chat.ggmlv3.q4_0.bin
Model exists in ./models/llama-2-7b-chat.ggmlv3.q4_0.bin.
Traceback (most recent call last):
File "/opt/Data/Personal/NextCloud/Documents/IT/repos/llama2-webui/./app.py", line 325, in <module>
main()
File "/opt/Data/Personal/NextCloud/Documents/IT/repos/llama2-webui/./app.py", line 56, in main
llama2_wrapper = LLAMA2_WRAPPER(
^^^^^^^^^^^^^^^
File "/opt/Data/Personal/NextCloud/Documents/IT/repos/llama2-webui/llama2_wrapper/model.py", line 99, in __init__
self.init_model()
File "/opt/Data/Personal/NextCloud/Documents/IT/repos/llama2-webui/llama2_wrapper/model.py", line 103, in init_model
self.model = LLAMA2_WRAPPER.create_llama2_model(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/Data/Personal/NextCloud/Documents/IT/repos/llama2-webui/llama2_wrapper/model.py", line 125, in create_llama2_model
model = Llama(
^^^^^^
File "/home/edavison/.local/lib/python3.11/site-packages/llama_cpp/llama.py", line 323, in __init__
assert self.model is not None
^^^^^^^^^^^^^^^^^^^^^^
AssertionError
My environment:
$ pip3 freeze | grep -E '(llama|bitsand)'
bitsandbytes==0.40.2
llama-cpp-python==0.1.85
llama2-wrapper==0.1.12
$ python3 -V
Python 3.11.5
Hello, when I'm using gradio framework, the chatbot text occasionally got stuck after I submit some inputs.
The debug info given by the Chrome is as follows, looking like a javascript error:

Can you give some help? Thanks.
When running the 4bit model on CPU, receiving the below error
raise HFValidationError(huggingface_hub.utils._validators.HFValidationError: Repo id must be in the form 'repo_name' or 'namespace/repo_name': '/model/q4/llama-2-7b-chat.ggmlv3.q4_0.bin'. Use `repo_type` argument if needed.
Running on backend llama.cpp.
Traceback (most recent call last):
File "/root/llama2-webui/app.py", line 325, in
main()
File "/root/llama2-webui/app.py", line 56, in main
llama2_wrapper = LLAMA2_WRAPPER(
^^^^^^^^^^^^^^^
File "/root/llama2-webui/llama2_wrapper/model.py", line 99, in init
self.init_model()
File "/root/llama2-webui/llama2_wrapper/model.py", line 103, in init_model
self.model = LLAMA2_WRAPPER.create_llama2_model(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/root/llama2-webui/llama2_wrapper/model.py", line 125, in create_llama2_model
model = Llama(
^^^^^^
File "/root/llama2-webui/new1/lib/python3.11/site-packages/llama_cpp/llama.py", line 323, in init
assert self.model is not None
^^^^^^^^^^^^^^^^^^^^^^
AssertionError
Running the benchmark a couple of times to take the average results, the default can be set as --iter 1.
Is there a way to enable sharing on gradio when launching the app? Apologies if this is a newbie question. Thanks.
There is a major error as the picture show.

.env is
`
MODEL_PATH = "/data/model/llama2/Llama-2-13b-chat-hf"
LOAD_IN_8BIT = False
LOAD_IN_4BIT = False
LLAMA_CPP = False
MAX_MAX_NEW_TOKENS = 2048
DEFAULT_MAX_NEW_TOKENS = 1024
MAX_INPUT_TOKEN_LENGTH = 4000
DEFAULT_SYSTEM_PROMPT = "You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature. If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information."
`
Hey There, I am new to this so please consider that while writing you response.
So I read the readme and followed it... I didn't want to download the model "Llama-2-7b-Chat-GPTQ" through the terminal so I downloaded it manually and put it in the folder "./models" and then I ran the "app.py" file I got the following errors:
GPU CUDA not found.
Traceback (most recent call last):
File "...\llama2-webui\app.py", line 325, in
main()
File "...\llama2-webui\app.py", line 56, in main
llama2_wrapper = LLAMA2_WRAPPER(
File "...\llama2-webui\llama2_wrapper\model.py", line 98, in init
self.init_tokenizer()
File "...\llama2-webui\llama2_wrapper\model.py", line 116, in init_tokenizer
self.tokenizer = LLAMA2_WRAPPER.create_llama2_tokenizer(self.model_path)
File "...\llama2-webui\llama2_wrapper\model.py", line 160, in create_llama2_tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_path)
File "...\llama2-webui\venv\lib\site-packages\transformers\models\auto\tokenization_auto.py", line 652, in from_pretrained
tokenizer_config = get_tokenizer_config(pretrained_model_name_or_path, **kwargs)
File "...\llama2-webui\venv\lib\site-packages\transformers\models\auto\tokenization_auto.py", line 496, in get_tokenizer_config
resolved_config_file = cached_file(
File "...\llama2-webui\venv\lib\site-packages\transformers\utils\hub.py", line 417, in cached_file
resolved_file = hf_hub_download(
File "....\llama2-webui\venv\lib\site-packages\huggingface_hub\utils_validators.py", line 110, in _inner_fn
validate_repo_id(arg_value)
File "...\llama2-webui\venv\lib\site-packages\huggingface_hub\utils_validators.py", line 158, in validate_repo_id
raise HFValidationError(
huggingface_hub.utils._validators.HFValidationError: Repo id must be in the form 'repo_name' or 'namespace/repo_name': './models/Llama-2-7b-Chat-GPTQ'. Userepo_typeargument if needed.
When I searched online some people said to download the CUDA Drivers so I did but still it didn't fix the problem. I tried to put the absolute path of the model but still no luck. here is my ".env" file:
MODEL_PATH = "./models/Llama-2-7b-Chat-GPTQ"
BACKEND_TYPE = "gptq"
LOAD_IN_8BIT = True
MAX_MAX_NEW_TOKENS = 2048
DEFAULT_MAX_NEW_TOKENS = 1024
MAX_INPUT_TOKEN_LENGTH = 4000DEFAULT_SYSTEM_PROMPT = "You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature. If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information."
I have Intel HD Graphics 540 GPU with no clue to how much Vram it has and I also have Nvidia M2000M with 4GB of Vram and 16GB of Ram Running on Windows 11
Hi!
Code sample first:
from llama2_wrapper import LLAMA2_WRAPPER, get_prompt
from IPython.display import display, Markdown
chat_history = []
llama2_wrapper = LLAMA2_WRAPPER(
backend_type="gptq",
)
user_input = input("You: ")
response_generator = llama2_wrapper.run(user_input, chat_history=chat_history, max_new_tokens = 1000, temperature = 0.15, system_prompt = "")
Prompt: How was Tupac Shakur influenced by Nirvana?
Wrapper initialization output:
Running on GPU with backend torch transformers.
Model path is empty.
Use default gptq model path: ./models/Llama-2-7b-Chat-GPTQ
Model exists in ./models/Llama-2-7b-Chat-GPTQ
The safetensors archive passed at ./models/Llama-2-7b-Chat-GPTQ\model.safetensors does not contain metadata. Make sure to save your model with the `save_pretrained` method. Defaulting to 'pt' metadata.
skip module injection for FusedLlamaMLPForQuantizedModel not support integrate without triton yet.
Issue: no matter how I change the temperature parameter (changed to 0, 1, -1, 0.1 etc), it does not change the response (the prompt is just a sample: I have the same issue with any other prompt). Simplifying the code to print(llama2_wrapper(prompt, temperature = 0.15)) also doesn't help. All other parameters work just fine.
At the same time, when I am using Llama 2 UI on Replicate and change the temperature, answers change too, and the model stops hallucinating when temperature is set to ~0.8 or less. Is this something I am doing wrong, or the parameter does not through the wrapper?
I would appreciate any advice.
Thanks!
Ilya
Running on backend llama.cpp.
Model path is empty.
Use default llama.cpp model path: ./models/llama-2-7b-chat.ggmlv3.q4_0.bin
Model exists in ./models/llama-2-7b-chat.ggmlv3.q4_0.bin.
Traceback (most recent call last):
File "C:\llama2-webui\app.py", line 325, in
main()
File "C:\llama2-webui\app.py", line 56, in main
llama2_wrapper = LLAMA2_WRAPPER(
^^^^^^^^^^^^^^^
File "C:\llama2-webui\llama2_wrapper\model.py", line 99, in init
self.init_model()
File "C:\llama2-webui\llama2_wrapper\model.py", line 103, in init_model
self.model = LLAMA2_WRAPPER.create_llama2_model(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\llama2-webui\llama2_wrapper\model.py", line 125, in create_llama2_model
model = Llama(
^^^^^^
File "C:\Python311\Lib\site-packages\llama_cpp\llama.py", line 323, in init
assert self.model is not None
AssertionError
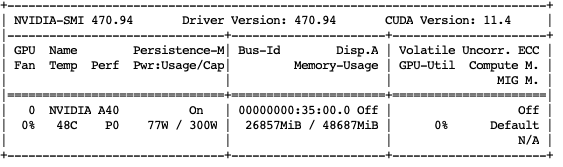
Cloud platform: matpool.com
Machine used: NVIDIA A40
Model used: Llama-2-13b-chat-hf
After the model is loaded, it takes up video memory: about 26G
Inference memory usage: about 26G GPU utilization: about 80%

Memory usage: about 2G

If hhhh cannot be written, it will also be filled with characters

How to load. bin file weights ?
file in /mnt/Llama-2-13b-chat-hf/

Win10 rtx3090
im running this on a machine with Nvidia A100 but it doesnt seem to make use of the gpu.
System Specs :
4x Nvidia A100 80Gb
540 Gigs of ram
Benchmarks :
Initialization time: 0.2208 seconds.
Average generation time over 5 iterations: 31.0348 seconds.
Average speed over 5 iterations: 5.0459 tokens/sec.
Average memory usage during generation: 4435.30 MiB
This is my problem, i need help!!
root@autodl-container-66e0119cac-10ae5257:~/autodl-tmp/llama2-webui# python app.py
Traceback (most recent call last):
File "app.py", line 8, in
from llama2_wrapper import LLAMA2_WRAPPER
File "/root/autodl-tmp/llama2-webui/llama2_wrapper/init.py", line 1, in
from .model import LLAMA2_WRAPPER, get_prompt
File "/root/autodl-tmp/llama2-webui/llama2_wrapper/model.py", line 7, in
class LLAMA2_WRAPPER:
File "/root/autodl-tmp/llama2-webui/llama2_wrapper/model.py", line 163, in LLAMA2_WRAPPER
chat_history: list[tuple[str, str]] = [],
TypeError: 'type' object is not subscriptable
Failed to build llama-cpp-python
ERROR: Could not build wheels for llama-cpp-python, which is required to install pyproject.toml-based projects
we build a WebUi to use llama,llama2, vicuna, falcon, etc. It's pretty good, if someone wants to run llama2, and maybe this project also can use it. 😊

Thank you for your outstanding work. I have already incorporated it as a primary tool for researching LLM. Additionally, I noticed that some of the backends for the GGML models use ctransformers. Could we consider adding support for ctransformers in LLAMA2-webui in the future? Thanks again.
Since openai/triton still not worked on windows yet, and with torch.compile heavily relying on triton.
Traceback (most recent call last):
File "E:\Projects\GPT\llama2-webui\app.py", line 62, in
llama2_wrapper.init_model()
File "E:\Projects\GPT\llama2-webui\llama2_wrapper\model.py", line 13, in init_model
self.model = LLAMA2_WRAPPER.create_llama2_model(
File "E:\Projects\GPT\llama2-webui\llama2_wrapper\model.py", line 52, in create_llama2_model
model = AutoModelForCausalLM.from_pretrained(
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python310\lib\site-packages\transformers\models\auto\auto_f
actory.py", line 492, in from_pretrained
model_class = _get_model_class(config, cls._model_mapping)
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python310\lib\site-packages\transformers\models\auto\auto_f
actory.py", line 376, in _get_model_class
supported_models = model_mapping[type(config)]
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python310\lib\site-packages\transformers\models\auto\auto_f
actory.py", line 666, in getitem
return self._load_attr_from_module(model_type, model_name)
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python310\lib\site-packages\transformers\models\auto\auto_f
actory.py", line 680, in _load_attr_from_module
return getattribute_from_module(self._modules[module_name], attr)
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python310\lib\site-packages\transformers\models\auto\auto_f
actory.py", line 625, in getattribute_from_module
if hasattr(module, attr):
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python310\lib\site-packages\transformers\utils\import_utils
.py", line 1089, in getattr
module = self._get_module(self._class_to_module[name])
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python310\lib\site-packages\transformers\utils\import_utils
.py", line 1101, in _get_module
raise RuntimeError(
RuntimeError: Failed to import transformers.models.llama.modeling_llama because of the following error (look up to see i
ts traceback):
DLL load failed while importing libtriton: The specified module could not be found.
Hi,
the Huggingface download page for GGML models remarks:
The GGML format has now been superseded by GGUF. As of August 21st 2023, [llama.cpp](https://github.com/ggerganov/llama.cpp) no longer supports GGML models. Third party clients and libraries are expected to still support it for a time, but many may also drop support.
Please use the GGUF models instead.
Does this repo also support GGUF already?
Support https://github.com/karpathy/llama2.c to rum small llama2 models.
Hi, testing this great tool. Noticed bot ignored last questions and responded with previous question details, along with it crossed out. Have any idea why? Could it just be the model? Maybe not supported, tried it anyway. Tried -> Wizard-Vicuna-13B-Uncensored.ggmlv3.q2_K

Why can't llama understand Chinese so much and can't reply directly in Chinese?
I tested Llama-2-7b-chat-hf again today.
Test using GPU platform: matpool.com
Memory usage:
Open 8BIT occupies 8G+, GPU utilization: 13-20%
If 8BIT is not enabled, it takes up 14G+, GPU utilization: 55-70%



Hi,
I experienced a memory leak issue that could probably be connected to Gradio and to the issue discussed here:
gradio-app/gradio#3321
In the last messages they write that the issue might be solved with Gradio 4.x - I couldn't try that yet and in that issue it was also not yet tested.
I guess you can replicate the memory leak by just using a server for a longer while and making several requests to it without restarting.
Dear llama2-webui developer,
Greetings! I am vansinhu, a community developer and volunteer at InternLM. Your work has been immensely beneficial to me, and I believe it can be effectively utilized in InternLM as well. Welcome to add Discord https://discord.gg/gF9ezcmtM3 . I hope to get in touch with you.
Best regards,
vansinhu
I am running this on Mac M1 16GB RAM using app.py for simple text generation. Using the llama.cpp from terminal is much faster but when I use the backend through app.py is very slow. Any ideas?
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.