lmk123 / blog Goto Github PK
View Code? Open in Web Editor NEW个人技术博客,博文写在 Issues 里。
Home Page: https://github.com/lmk123/blog/issues
个人技术博客,博文写在 Issues 里。
Home Page: https://github.com/lmk123/blog/issues






















































































































































当我们开发一个单页应用时,常见的优化做法是生成两个文件:
jQuery、Vue 等然后给这两个文件根据文件内容计算出一个 hash 加在文件名中,并配置一个长达一年的 Cache Control,这样能大大加快应用的访问速度。
因为 vendor.js 的内容基本上很少更新,所以下一次我们更改了 app.js 的内容时,vendor.js 仍然在浏览器的缓存中,那么用户就只需要重新下载 app.js 了。
但为了在 Webpack 中做到这一点,真是费了不少功夫。
为了将项目中的第三方依赖代码抽离出来,官方文档上推荐使用 CommonsChunkPlugin。
当我们在项目里实际使用之后,发现一旦更改了 app.js 内的代码,vendor.js 的 hash 也会改变,那么下次上线时,用户仍然需要重新下载 vendor.js 与 app.js——这样就失去了缓存的意义了。
在网上搜索一番后,发现这是 Webpack 的一个 "Bug": webpack/webpack#1315。
webpack 内部使用数字作为模块的 id,一旦 app.js 的内容发生改变,就会引起 vendor.js 内模块 id 的变化,所以导致了这个 bug 发生。
在刚才那个 issue 里,有人推荐使用 webpack-md5-hash,所以我也试了试,发现在更改了 app.js 的内容后,vendor.js 的 hash 真的没有改变。
看了下源码,原来 webpack-md5-hash 是根据 webpack 编译前的文件内容生成的 hash,所以才能做到 vendor.js 的 hash 不变。本来以为满心欢喜的找到了解决方案,但是在项目上线后却发现整个网页一片空白,并且控制台里报了一个错误。
检查之后才知道,虽然 vendor.js 的 hash 没变,但是 app.js 里的模块 id 仍然变了。举例来说,app.js 里使用的 id 为 40 的模块,在 vendor.js 里的模块 id 为 41,这样就导致 app.js 里使用了错误的模块,于是就报了错。
归根到底,这些问题都是由于模块 id 为数字导致的,所以后来我又试了试 NamedModulesPlugin。顾名思义,它能将模块 id 由数字的形式改为字符串(文件的相对路径)的形式。
虽然这个插件能解决我们的问题,但 app.js 的大小相较于以前大了几乎 60%。虽然 gzip 之后只比以前大了 15%,但我仍然觉得这有点不值得。
踩过这么多次坑之后,我发现根本原因在于 vendor.js 与 app.js 紧耦合了,它们之间的模块 id 会相互影响,所以,如果我们单独打包 vendor.js 和 app.js,问题就解决了。一开始我自己写了一个 CombinePlugin 用来单独打包 vendor.js,然后通过全局变量的方式抛给 app.js 使用,后来翻文档时,才发现官方已经提供了这么一个插件:DLLPlugin。
可后来我又发现,虽然 DLLPlugin 解决了修改 app.js 时 vendor.js hash 会变的问题,但在 app.js 里异步加载的文件(使用 Webpack 的 code split 功能)的 hash 会因为 app.js 里新增/删除模块而改变。
最后,我使用了 Webpack 作者写给 webpack 2.0 的 HashedModuleIdsPlugin,发现它居然完整的解决了上面遇到的所有问题:
修改 app.js 或者在 app.js 里添加新的模块时,vendor.js 的 hash 不会变,在 app.js 里异步加载的 chunk 的 hash 也不会变。
我立刻将它应用在了我自用的 Webpack 模版中:lmk123/webpack-boilerplate
至此,心中的一块大石头总算落地了。
用过 NPM 的朋友可能都有过下面的经历:
你创建了一个项目,用 npm 安装了一些第三方模块。一个月过去了,另外一个人想跟你一起开发这个项目,但他却无法在他的电脑上正常运行你的项目,尽管在你自己的电脑上一切如常。
你可能已经猜到了,这是因为你自己电脑上的第三方模块和他电脑上的第三方模块的版本不一致导致的。
出现这个问题的过程是这样的:当你第一次安装一个模块的时候,假设它的版本号是 1.0.0,但在 package.json 里 npm 会自动帮你设置一个版本范围:^1.0.0。一个月过去了,这个模块已经更新到了 1.1.0,但是你从来没有更新过,可是当别人在安装你的项目的时候,npm 会在他的电脑上安装这个版本范围内的最新版本,也就是 1.1.0,这里面可能会包含一些 「Breaking Changes」,所以就导致了在你电脑上好好的项目,在别人的电脑上却跑不起来。
即使这个项目只有你一个人开发,你也不应该依赖 npm 自动帮你设置的“版本范围”——一旦你一不小心运行了 npm update 来升级你的第三方依赖,你仍然会遇到上面的问题,更糟糕的是,你根本不知道你升级前用的是哪个版本的第三方模块,你可能不得不去挨个翻看你依赖的模块们有哪些 「Breaking Changes」并逐个更改,等你差不多改完的时候也该下班了,然而跟别人说好今天要完成的功能你还一点都没有开始做。
所以,聪明的开发者都会在 package.json 里锁定模块的版本号,以保证在任何情况下大家安装的模块都是一致的。
即使你的项目是用 Yarn 安装模块的,我仍然建议你锁定你的版本号。
在你使用 Yarn 安装模块的时候,这个模块的版本号会被写在 yarn.lock 这个文件里,所以当其他人也使用 Yarn 安装项目里的模块时,Yarn 会优先读取 yarn.lock 里的模块版本号以保证大家安装的模块版本是一致的——
但如果其他人使用 npm 安装了你项目的模块呢?
跟前文说到的情况一样,用 npm 安装你项目模块的人仍然会安装到最新版本的模块—— npm 并不会从 yarn.lock 文件里读取你所安装的模块的版本,这就又会导致前文提到的问题。即使你在项目的 README.md 里提到了要用 Yarn 安装项目的模块,也无法保证会没人使用 npm 安装模块,因为大家都认为,Yarn 和 npm 是兼容的。
所以,无论项目使用的是 npm 还是 Yarn,我都建议锁定模块的版本号,这样一来就可以保证无论大家在何时使用哪种包管理器,所安装的模块都是一致的。
今天在开发 https://github.com/lmk123/t-rex-runner 的过程中,深扒了一下恐龙游戏的源码,居然看到下面这段代码:
Runner.prototype = {
// ...
startListening: function() {
document.addEventListener( 'keydown', this );
// ...
}
};看到这里我惊呆了。一直以来,我都知道 addEventListener 的第二个参数必须是一个函数,但是,上面这段代码直接将 this 作为参数,并且代码没有报错、游戏运行正常!
这时,我注意到 startListening 方法上面还有一个 handleEvent 方法,但它的颜色是灰色的(Webstorm 会把未使用过的方法、函数或变量变为灰色):
Runner.prototype = {
// ...
handleEvent: function(e) {
// ...
},
startListening: function() {
document.addEventListener( 'keydown', this );
// ...
}
};我注释掉这个方法之后再运行游戏,就发现按空格或点鼠标没反应了——吓得我赶紧去谷歌了一下,然后在 MDN 上找到了这段内容:(出处)
var Something = function(element) {
this.name = 'Something Good';
this.handleEvent = function(event) {
console.log(this.name); // 'Something Good', as this is the Something object
switch(event.type) {
case 'click':
// some code here...
break;
case 'dblclick':
// some code here...
break;
}
};
// Note that the listeners in this case are this, not this.handleEvent
element.addEventListener('click', this, false);
element.addEventListener('dblclick', this, false);
// You can properly remove the listeners
element.removeEventListener('click', this, false);
element.removeEventListener('dblclick', this, false);
}这是何等的黑科技,写了三年的 JavaScript,我还是头一回知道这回事!!你要是不相信,可以看看这个在线示例。
简单来说,这个方法的目的是将事件处理函数里的 this 指向另外一个对象。但在 ES 2015 中有了箭头函数,这个方法大概以后也不会有更多人知道了吧。
跟 GitHub Pages 的功能一样,但是:
Bitbucket 旗下的静态网站托管服务。
同样跟 GitHub Pages 的功能一样,但是:
不过,会不会有人像我一样在这里提issues,划词翻译朗读哪里,不能区分是英音还是美音。
第一次知道 Vue.js 是在一个技术群里。按照我的习惯,凡是我没听说过的东西我都会谷歌一下。当时它还没有发布 1.0 正式版(我的另一习惯是只用稳定版),又发现它跟 AngularJS 差不多,所以只是给了颗 Star,然后就干别的去了。
最近因为开发划词翻译 v6.0 的关系,我准备在里面用到我熟悉的 AngularJS 来写一些交互很多的页面,可是想了一下,唯一需要交互的页面就是设置页,为此我要引入 AngularJS 这个“大胖子”,那“性价比”太低了。
随后我就想到了 Vue.js,现在(2015年11月11日)它已经有 9361 个 Star 了,距离我标星的时候(2015年6月26日)涨了近 4000 颗,同时也发布了 1.0 版。我想,是时候深入了解一下它了。
写这篇博文时我刚看完 Vue.js Guide。看完之后,我的感受就是:它真的很简单。想当初学习 AngularJS 的时候我还买了一本书(《AngularJS 权威指南》),看了一个星期才敢用在项目里,而看完 Vue.js 的 Guide 前后不超过一个小时,我就觉得我已经完全理解了它、立刻就能用在项目里了。
AngularJS 里那些让人眼花缭乱的概念(控制器、作用域、模块、指令等等),我到现在也不敢说完全理解了,用起来还是心有戚戚焉,怕随着项目一天天复杂起来,往后会碰到一些不知道的坑,要用各种 "hacks" 才能解决,让项目变得不利于维护;但 Vue.js 唯一需要睁大眼睛看的就是 Reactivity in Depth 这一节。
最后看完 Comparison with Other Frameworks 之后,我更加认同了 Vue.js 的设计理念。没有 AngularJS 的脏值检测,没有 React 的“虚拟 DOM”的奇怪概念(我最受不了的就是它要把 html 写在 js 里),我越来越喜欢它了!
现在我期待的就是 vue-router 能尽快发布稳定版,那我以后可能就不会用 AngularJS 了~
今天在开发一个扩展程序的时候发现了一个很有意思的现象。
官方文档里是这样描述内容脚本的执行环境的:
Content scripts execute in a special environment called an isolated world. They have access to the DOM of the page they are injected into, but not to any JavaScript variables or functions created by the page.
所以我一直认为,内容脚本与网页脚本之间是共享 DOM 树的,而且我的代码也一直是这样写的,没有出过问题,直到今天……
有一个网页给一个元素添加了一个私有属性,就像这样:
const div = document.getElementById('app')
div.textContent = 'hello'
// 一个私有属性
div.__myProp = 'world'然后我在内容脚本里执行了下面这段代码:
const div = document.getElementById('app')
console.log(div.textContent) // 'hello'
console.log(div.__myProp) // 我以为是 'world',但结果是 undefined现在细想一下,内容脚本中的 DOM 跟网页脚本中的 DOM 更像是「双向驱动」,而不是「完全相等」。
每当 DOM 上那些标准属性(例如上面例子里的 textContent)发生变化时,这个变化就会被同步到另一个环境,但如果是添加了一个不属于 DOM 的非标准属性,Chrome 可能就没有检测到——这个行为有点类似于 Vue 的做法:如果你想要检测某个属性的变化,你就一定要把这个属性注册在 data 里,否则 Vue 无法检测到属性发生了变化。
不过也并非没有办法取的网页脚本中的非标准属性,只要从内容脚本里插入一段代码到网页脚本里执行就可以了:
const script = document.createElement('script')
script.textContent = `
var div = document.getElementById('app')
console.log(div.__myProp)
`
document.head.appendChild(script)<script> 元素的脚本会在网页脚本环境里执行,所以可以拿到在内容脚本里拿不到的东西,例如网页脚本的全局变量。另外,在网页脚本中执行的代码也可以同内容脚本通信:Communication with the embedding page
如果代码量很大,也可以直接嵌一个扩展程序中的脚本文件进去:
const script = document.createElement('script')
script.src = chrome.extension.getURL('/path/to/your/js/in/extension.js')
document.head.appendChild(script)写到最后似乎偏题了,就这样吧。
Protractor 是 AngularJS 官方推出的端到端测试工具。本来要安装这个工具非常简单:
npm install -g protractor
webdriver-manager update
webdriver-manager start
但是由于某墙的存在,在执行第二步的时候会报错:
C:\>webdriver-manager update
Updating selenium standalone
downloading https://selenium-release.storage.googleapis.com/2.45/selenium-server-standalone-2.45.0.jar...
Updating chromedriver
downloading https://chromedriver.storage.googleapis.com/2.14/chromedriver_win32.zip...
Error: Got error Error: connect ETIMEDOUT 173.194.38.42:443 from https://selenium-release.storage.googleapis.com/2.
45/selenium-server-standalone-2.45.0.jar
Error: Got error Error: connect ETIMEDOUT 216.58.221.65:443 from https://chromedriver.storage.googleapis.com/2.14/c
hromedriver_win32.zip
C:\>
我电脑上有开启 Shadowscoks 但仍然会报错。谷歌了半天,总算找到了解决方案。
C:\Users\Administrator\AppData\Roaming\npm\node_modules\protractor),将刚才下载的两个文件粘贴到下面的 selenium 文件夹下chromedriver_win32.zip 重命名为 chromedriver_2.14.zip(2.14 替换为你下载的版本号)chromedriver_2.14.zip 里面的 chromedriver.exe 到同级目录完成上面的步骤之后,你的 selenium 文件夹里面应该有三个文件:selenium-server-standalone-2.45.0.jar、chromedriver_2.14.zip 和 chromedriver.exe 。此时再从第二步开始运行就可以了:
webdriver-manager update
webdriver-manager start
如果你直接连接浏览器进行测试的话,可以不用下载 selenium server,只需要下载 chrome driver 并解压到 selenium 文件夹里就可以了,而且测试的时候也不需要使用 webdriver-manager start 命令单独开启一个 selenium 服务器。
考虑到日后可能会在新的电脑上搭建测试环境,所以把这个(坑爹的)过程记录了下来。我只想问,什么时候我们才能推倒那道柏林墙啊。
最近在新项目中使用了 SASS,不得不说,用了它之后,写 css 变得有趣多了,但今天无意中发现了一个小问题:生成的 css 文件中有很多重复的片段。
举例来说:
@mixin error {
color:red;
}
.small-error {
@include error;
font-size:14px;
}
.big-error {
@include error;
font-size:24px;
}因为这两个类用到了同一个片段,所以我想像中应该生成的 css 文件是这样的:
.small-error,.big-error{ /* 共用相同的片段 */
color:red;
}
.small-error {
font-size:14px;
}
.big-error {
font-size:24px;
}但结果它生成的是这样:
.small-error {
color:red; /* 单独插入,没有共用 */
font-size:14px;
}
.big-error {
color:red;
font-size:24px;
}这时我才发现,@mixin 并不会像 @extend 那样共用 css 片段。
那为什么我没有用@extend呢?我一开始确实用到了,是这样写的:
.error {
color:red;
}
.small-error {
@extend .error;
font-size:14px;
}
.big-error {
@extend .error;
font-size:24px;
}但这样写有一个问题:css 文件里面会生成一个 .error ——一个只是被用来 extend 的、并不会在 html 中用到的类。
在查阅相关文档后,问题得到了解决:使用 @extend-Only Selectors。
由此可见,@mixin 主要作用是通过参数生成不同的 css 内容:
@mixin color($color){
color:$color;
}如果是多个类有公用的 css 片段,还是应该使用 @extend-Only Selectors。
最后顺便提一句,我在安装 gulp-sass 的时候总是失败,按照 node-sass 推荐的步骤安装也失败,但是重启电脑后再安装就成功了,不知道这是什么鬼。- -
写 JavaScript 的应该都知道,我们应该避免修改内置对象(例如 Object、Function)的原型链,但今天一个同事问我:为什么要避免这样做?
于是我给他讲了我自己经历过的一件事。
当时我在开发一个工具库的时候,写了如下这段代码:
function Watching (config) {
// config.watch 是一个可选项,所以没有的时候就给一个默认值
var watchingNode = document.querySelector(config.watch || '.watch-node')
watchingNode.addEventListener(...)
// ...
}代码上线之后,有用户反馈在 Firefox 浏览器下点了某个按钮没有反应,然后我就用 Firefox 打开那个网页去调试,发现在执行到上面代码的第三行的时候报了个奇怪的错误,调试了一下,发现 config.watch 被传了一个函数进来。
我心想我知道 watch 这个属性应该传一个字符串,所以不会传个函数进来啊,然后我翻遍了所有调用这个构造函数的代码,愣是没找到给 watch 传了个函数的地方。
后来在我的反复调试之下,我才发现——在 Firefox 里,Object.prototype.watch 居然是一个函数(见 MDN),所以当我不传 config.watch 的时候,读取 config.watch 就读到了原型链上的这个 watch 函数,才有了上面的报错。
从此以后,我就知道为什么要避免修改内置对象的原型链了。
最近我在项目里用到了 David,它能分析你的项目的第三方依赖是否都是最新版,正好最近 Babel 发布了 6.0 版,David 就帮我监测到了,真的非常方便。
我是一个很喜欢追求“最新版”的人,APP、代码、操作系统等都希望用上最新的,因为我认为,最新的总是最好的,会提供新功能、修复 bug 等。这次 Babel 从 5.0 升级到 6.0,最大的改动就是将以往集成的一堆插件全部分开成了一个个小的模块了,使用者需要自行制定要用到哪些插件。
那么问题来了:我已经全局安装了 babel v5.x,如果我升级了 babel ,那么其他依赖 babel 的项目我也要重新配置一遍;但我(和其他大多数人,应该也包括你)认为,别说是项目了,现在连代码都提倡“模块化”——每个代码文件都应该是独立的整体,可是我现在连项目之间都相互“依赖”了;想想看,若你参与两个项目的开发,一个需要全局安装 Babel 5.x,另一个是新项目,用的是 Babel 6.x,那你怎么办,开两个虚拟机吗?
这让我反思出一个道理——我们不应该使用 npm install -g。
这样的话,每个项目都可以有不同版本的 Karma、Babel、gulp、Grunt等;在给项目写说明文件的时候,也不需要额外提示一句“需要先全局安装 balabalabalabala”——因为所有需要的文件都在 package.json 里,所以简单的告诉用户 npm install 就行了。
但是,我担心如果这些模块不全局安装的话会无法使用。可是是我多虑了,npm 早已为我们考虑到了这一点。以 npm i babel-cli --save-dev 为例,我发现项目的 node_modules 文件夹下有一个 .bin/babel.cmd 文件,然后我在 package.json 里定义了一个 script:
{
"scripts":{
"version": "babel -V"
}
}运行 num run version,我发现输出的版本号是 6.1.1 (babel-core 6.0.20),而不是我全局安装的 5.x 版的 Babel。
另外,npm run 可以带参数,例如如果我需要运行 bower install jquery --save,我可以这么做:
{
"scripts":{
"bower":"bower"
},
"devDependencies":{
"bower":"^1.6.0"
}
}然后 npm run bower install jquery -- --save,注意中间使用了 -- 来分隔命令与参数!
这样一来,前面提到的 David 就能监听这些原本没有列在 package.json 里的模块的版本是否有更新,项目与项目之间也能真正做到相互独立了!
对于使用 WebStorm 的开发者,则可以将 Bower 执行脚本的位置指向项目下的 node_modules/.bin/bower.cmd(Mac 用户则需要将脚本位置直接指向 node_modules/bower/bin/bower,其它可执行模块也是一样的)。顺便说一句,我已经升级到 WebStorm 11 了 ;)
看,将全局模块安装到项目本地一点难度也没有,还能解除项目(或者说开发环境)之间的依赖、独立升级,何乐而不为呢?
我在 #2 里曾提到过:Require.js 不是最终解决方案。
为什么这样说呢?想一下这样的场景:
我有很多模块,某一天我更新了其中的 a.js。为了让用户的浏览器不去读缓存,比较 low 的做法是在网页里引用这个脚本的时候,手动带上版本号或时间戳,例如:
<script src="a.js?20150102"></script>但是,模块是由 require.js 来加载的,不需要(也不能)由我们手动添加 script 标签。好在 require.js 提供了一个配置属性 urlArgs,但问题在于:这个设置是全局的,所有被加载的模块都会带上这个 urlArgs。
这意味着它没有_增量更新_的能力:我修改了一个模块,然后更新了这个设置,那么其它所有未修改的模块文件也会被用户的浏览器重新下载一遍。
其实不仅是 require.js ,其它所有在页面上被引用的静态文件都有同样的问题。只是,一些后端语言已经考虑到了这个问题,例如公司项目使用的 Spring 框架,会自动根据页面上引用的静态文件的内容生成一个 md5 字符串,写在文件名里(见 http://spring.io/blog/2014/07/24/spring-framework-4-1-handling-static-web-resources)。
举个例子,我在 jsp 模版里引用了一个脚本:
<script src="require.js"></script>那么 jsp 会把它输出为:
<script src="require-d3jhi6s2.js"></script>实际上,服务器并没有真的生成一个新的文件叫 require-d3jhi6s2.js,它仍然返回的是 require.js文件的内容,只是浏览器(或者 CDN )可能就需要去下载一个“新的”文件了;这种方式对 CSS 以及 CSS 里引用的图片同样有效。
问题似乎已经得到解决了,但这种 jsp 模版并不支持对 require.js 里的模块引用做同样的处理。
于是我找到了 F.I.S,不得不说,它真的是一个非常强大的系统。我花了半天时间去阅读了它的文档,又花了半天时间研究一个基于 require.js 的例子。
在上面的例子里,fis 对前端模块化构建给出了两种解决方案:
paths 设置里。我个人比较喜欢第二种,因为第一种需要改动 html(或 jsp),而把现有项目完全融入 fis 的生态系统中有点困难,况且前面我分析过,我只需要处理 require.js 的模块部分就好了。
于是,在下班之前(也就是现在),我给了自己两种解决方案:
第二种方案似乎是多余的,但考虑到 fis 文档写的太简陋,第一种方式的时间成本可能会比第二种还高。
但 fis 还是值得学习。如果以后开始一个新的项目,我就可以尝试使用它了。
今天项目上线之后,有人反馈部分页面出现了问题,但一刷新就好了。我检查了一下,直接从地址栏进入的时候,html 上加载的是 app.hash-a.js,但一旦刷新,html 加载的就是 app.hash-b.js 了。
简而言之,浏览器将 index.html 这个文件缓存下来了,随后在开发者工具的 Network 面板里也看到,直接在浏览器地址栏进入 index.html 时,HTTP 响应是 200(from cache),但一旦刷新,就变成 200(ok) 了。
于是我打开 chrome://cache/,果然在里面找到了我们项目的网址,点进去看到 HTTP 响应头是:
HTTP/1.1 200 OK
Server: Tengine/2.1.2
Date: Thu, 22 Sep 2016 13:47:55 GMT
Last-Modified: Thu, 22 Sep 2016 12:32:00 GMT
Content-Type: text/html
Vary: Accept-Encoding
Content-Encoding: gzip
我并没有在里面看到 Cache-Control,但为什么 Chrome 会将这个网页缓存下来呢?
在谷歌上搜索了几个关键字“no cache-control but chrome cached”,搜到了这个问题:http://webmasters.stackexchange.com/questions/53942/why-is-this-response-being-cached
简单来说,当一个响应里面有 Last-Modified 但没有 Cache-Control 和 Expires 的时候,浏览器会有自己的一套算法来决定这个文件会被缓存在本地多长时间。
从 Chrome 53 的此处源码(HttpResponseHeaders::GetFreshnessLifetimes)来看,Chrome 的算法是:
(响应头中的 Date - 响应头中的 Last-Modified 的值) * 0.1
所以文章一开始的响应会被 Chrome 缓存大约 7 分钟。在这 7 分钟之内,Chrome 会直接从本地读取缓存,7 分钟之后,Chrome 会请求一次服务器,然后再根据上面的算法缓存一段时间,依此类推。
所以,我们要做的改进就是加上 Cache-Control 响应头,明确的告诉浏览器不要缓存 index.html。
这次这个问题之所以会被发现,是因为后端的一个接口新增了两个必须传的参数,后端上线之后,旧版的 app.js 在请求这个接口的时候没有传这两个新的参数,所以报了错。
这不由得让我想起了另外两个缓存机制:Application Cache 和 Service Worker。这两个缓存机制都是“慢一拍”的:当浏览器检测到缓存更新后,它不会立刻使用新版代码,而是在用户下次访问时才使用新的文件。
所以,后端接口应该做到“向下兼容“——即使使用旧版本的代码也能正常响应,而不是直接抛出一个 400 错误。
自 Babel 6 以后,Babel 将语法转换功能全都拆分成了一个个小模块。这些模块让人眼花缭乱,但官方贴心的提供了 Presets,用的最多的大概就是 ES2015 preset 了吧。再加上大多数项目为了减小项目体积,所以差不多都用了 transform-runtime。
大家的 .babelrc 文件可能就跟我下面这个一样:
{
"presets": ["es2015"],
"plugins": ["transform-runtime"]
}可是,你真的看过 Bebel 处理过的代码吗?
之所以我会关注这个问题,是因为我有一个项目,明明没有用 babel-polyfill,可 Babel 处理后还是加入了 Symbol shim,而我根本没有在代码里使用过它。
我很好奇到底是哪个模块调用了这个函数,于是我在 Babel 生成的 js 文件里顺着模块 id 一路往上找,最后找到了 typeof。
typeof + Symbol,我一下子就想到了 ES2015 preset 里包含的这个插件:ES2015 typeof symbol transform
文档上说,转换后的代码是长这个样子的:
// In
typeof Symbol() === "symbol";
// Out
var _typeof = function (obj) {
return obj && obj.constructor === Symbol ? "symbol" : typeof obj;
};
_typeof(Symbol()) === "symbol";但事实上,当你结合前面提到的 transform-runtime 一起使用时,它就会把整个 Symbol shim 给打包进去,即使你只是用 typeof 检测一个字符串而已。
transform-runtime 提供了配置可以选择要不要使用 polyfill:
{
"plugins": [
["transform-runtime", {
"polyfill": false,
"regenerator": false
}]
]
}但是一点用也没有 😂
所以,为了代码里不要带上根本没有用到过的功能,最好的办法就是——不要偷懒使用 Presets,应该挨个评估项目里到底实际用到了哪些插件,并单独安装。
在接触 AngularJS 之前,我已经深入了解并使用了 RequireJS。我非常喜欢 AMD 的加载方式,因为它做到了模块化与按需加载,促进了代码之间的松耦合。
在接触到 AngularJS 之后,我就开始寻求一种方式——一种将 AngularJS 与 RequireJS 结合起来的方式,使 AngularJS 能借助 RequireJS 做到模块化和按需加载。经过一段时间的努力之后,我成功做到了这一点,并将成果发布到 lmk123/angularjs-requirejs-rjs-md5 。
顾名思义,在此基础上,我还做到了文件合并与 md5 签名,这样就可以将文件安全的放在 CDN 上。
但是还有一点没有做到——给文件路径加上 CDN 的前缀。
按照我那个项目的结构,只有 app/index.html 是不能缓存的,而其它文件:脚本、样式、模板都可以放在 CDN 上。于是我有了这么一个设想:将 AngularJS 应用放在 lmk123.github.io ,然后架设一个 CDN 服务器(比如七牛)dn-lmk123.qbox.me,然后将源镜像地址设为 lmk123.github.io,然后给 AngularJS 应用的所有加载路径加上 cdn 服务器前缀 dn-lmk123.qiniucdn.com。
我不知道我有没有表述清楚,简而言之,用户只有 app/index.html 是访问的 lmk123.github.io 上的,而其它所有文件都是访问的 cdn 服务器上的;当 cdn 服务器找不到对应的文件的时候就会到 lmk123.github.io 抓取并保存下来。
要想做到这一点,我就需要在请求文件的地方加上 cdn 的前缀。虽然 gulp-rev-all 里面有一个 prefix 设置,但它只对以 / 开头的绝对路径才有效,而我的项目里全都是相对路径,所以我只能自己想办法。
思考了一下,我那个项目有三个加载场景:
*.html 里通过浏览器直接加载那现在来逐个击破!
transformPath 函数能轻松的加上前缀data-main的引用地址指向 cdn 后,baseUrl 会自动被设置成 cdn 地址,所以都不需要对文件做特殊处理;如果不是用 data-main 启动应用,就需要自己写代码更新 baseUrl。templateUrl 加上 cdn 前缀,但在实际实施过程中发现这么做无效,可能跟它本身就是一个函数有关,所以还是只能用 $http 拦截器;然而我觉得加一个拦截器有性能问题,还是用 transformPath 写入 cdn 吧。根据上面的分析,其实就是用 transformPath 设置项手动添加前缀。听起来很简单的,于是我试了试:
// CDN_PREFIX 即前缀,例如 http://my.cdn/ ;
// 此项目里使用的是 https://dn-lmk123.qbox.me/angularjs-requirejs-rjs-md5/cdn/
function transformPath( rev , source , file ) {
if ( CDN_PREFIX ) {
return CDN_PREFIX + rev;
} else {
return rev;
}
}上面这段代码成功的给场景一与场景三加上了前缀,但是同时也把通过 RequireJS 加载的文件路径给加上了,即:require( 'path/to/file' ) 变成了 require( 'http://my.cdn/path/to/file' ),于是 cdn 返回了一个 404。
也就是说,我必须有一种方法来区分_用 requirejs 加载的文件_和_其他文件_。
在折腾了很久之后,我发现真的没有太好的办法能使用代码区分这两种文件;然后我还发现,使用 requirejs 加载的 css 文件并不受影响,因为为了让 gulp-rev-all 能正确更新 css 文件的引用,我在写代码时手动带上了 .css 的扩展名,所以变成绝对路径之后仍能正常加载(也就是说,如果我在写代码时手动加上 .js 扩展名,那么就不需要这么麻烦了——但是这种牺牲编码方式的解决方案的兼容性太差了,并且每个路径前都加上前缀的话,或多或少会增加文件的大小)。
考虑到受到影响的实际上只有 js 文件,所以我手动维护了一个列表,列出了所有不是由 requirejs 加载的 js 文件:
paths.jsNotLoadByRequireJS = [ 'bootstrap.js' , 'vendor/require/require.js' ];require.js 是在 index.html 里加载的,所以要列在里面;bootstrap.js 虽然是由 requirejs 加载的,但是因为是 data-main 入口文件,这个文件的路径会影响到 baseUrl 的值,所以为了后面的文件都能从正确的地方加载,这里也必须把它算作“不是由 requirejs 加载的 js 文件”。
最终的(或者说目前的) transformPath 函数是这样的:
function transformPath( rev , source , file ) {
if ( CDN_PREFIX ) {
if ( '.js' === file.revFilenameExtOriginal ) {
if ( paths.jsNotLoadByRequireJS.indexOf( file.revPathOriginal.slice( file.base.length ).replace( /\\/g , '/' ) ) < 0 ) {
return rev;
} else {
return CDN_PREFIX + rev;
}
} else {
return CDN_PREFIX + rev;
}
} else {
return rev;
}
}确实绕的比较头晕 - -
细心的人可能还会发现一个问题:上面在判断一个文件是否在 paths.jsNotLoadByRequireJS 里的时候,没有用 source 变量,而是麻烦的用了 file.revPathOriginal.slice( file.base.length ).replace( /\\/g , '/' )。
这是因为相对路径如 require( '../../directives/index-des' ) 会匹配不上这个列表,所以必须得找到文件真正的相对路径,所以麻烦了点。
总算是告一段落了。
现在我已经把这个功能加到我的 lmk123/angularjs-requirejs-rjs-md5 项目中了。你可以把 cdn/index.html 这个文件下载到本地,然后直接双击打开(即通过 file:// 协议打开),程序仍然能正常运行,因为所有其他的静态文件都托管在 https://dn-lmk123.qbox.me/angualrjs-requirejs-rjs-md5/ 上 :)
前面提到了 gulp-rev-all 的 prefix 设置,其实可以在代码里把文件引用路径全都写成以 / 开头的绝对路径,就不需要这么麻烦了,只是要确保程序是运行在网站根目录下的。为此我们在开发时会需要配置一个本地服务器(例如使用 AveVlad/gulp-connect)
如果你有更好的解决方案,欢迎一起探讨 :)
大家可以用 dart-sass 无缝替换 node-sass 了!dart-sass 兼容 node-sass 的 API,而且安装过程无需下载二进制文件,这样大家就不需要用本篇文章的方式安装 node-sass 了。
安装 node-sass 的时候总是会各种不成功,今天我琢磨了一会儿总算知道要怎么解决了。
首先要知道的是,安装 node-sass 时在 node scripts/install 阶段会从 github.com 上下载一个 .node 文件,大部分安装不成功的原因都源自这里,因为 GitHub Releases 里的文件都托管在 s3.amazonaws.com 上面,而这个网址在国内总是网络不稳定,所以我们需要通过第三方服务器下载这个文件。(顺带一提,你可以看看这个好玩的 commit)
macOS 系统直接运行下面的命令即可:
SASS_BINARY_SITE=https://npm.taobao.org/mirrors/node-sass/ npm install node-sass
我们一般更希望能跨平台、并且直接使用 npm install 安装所有依赖,所以我的做法是在项目内添加一个 .npmrc 文件:
sass_binary_site=https://npm.taobao.org/mirrors/node-sass/
phantomjs_cdnurl=https://npm.taobao.org/mirrors/phantomjs/
electron_mirror=https://npm.taobao.org/mirrors/electron/
registry=https://registry.npm.taobao.org
这样使用 npm install 安装 node-sass、electron 和 phantomjs 时都能自动从淘宝源上下载,但是在使用 npm publish 的时候要把 registry 这一行给注释掉,否则就会发布到淘宝源上去了。
假设你的梯子在你本地机器上开启了一个第三方服务器 127.0.0.1:1080,那么只需按照下面的方法配置一下就能正常安装 node-sass 了(如果你开启的是 PAC 模式而不是全局模式,那还需要将 s3.amazonaws.com 加入 PAC 列表):
npm config set proxy http://127.0.0.1:1080
npm i node-sass
# 下载完成后删除 http 代理
npm config delete proxy
嗯,这样下来就能正常安装了。
给自己的软件打个广告:跨平台 & 一站式划词、截图、网页全文、音视频翻译扩展——划词翻译 https://hcfy.app/docs/guides/summary
最近公司要开发一个内部使用的安卓客户端。我想到 PhoneGap 可以使用网页技术开发手机应用,于是自学了 PhoneGap 。总的来说,除了安装 SDK 麻烦一点,其它跟开发 Chrome 扩展差不多。
开发之前,需要先安装你的目标平台 SDK,而我只需要安装 Android SDK 就够了。
先去下载一个 Android SDK 管理工具;如果官方地址打不开,也可以到这里下载。对于 win7 用户,安装完成后还需要在 PATH 环境变量中追加一段 ;D:\AndroidSDK\tools ,这个地址指向你的 SDK 安装目录下的 tools 目录。
然后在命令行输入 android 打开 SDK 管理工具,它会列出一系列的工具包,但是由于众所周知的原因无法在线下载,所以我在网上找了一个镜像地址,根据说明配置之后就能正常下载了。
之后,需要下载 SDK 中的 Tools/Android SDK Platform-tools 、 Tools/Android SDK Build-tools,以及你想要的安卓版本中的 SDK Platform(我下载的是 Android 5.0.1 (API 21)/SDK Platform)。这些工具用于 PhoneGap 生成 apk。
如果你需要一个安卓模拟器,还需要安装指定安卓版本下面的 System Image (我下载的是 Android 5.0.1 (API 21)/ARM EABI v7a System Image ,安卓版本与上面的一致)。之后,打开 ADV 管理工具(在 Android SDK 安装目录下),切换到 Device Definitions 选项卡,选择一种设备类型并创建就可以了。
首先需要安装 Cordova(看了文档才知道,PhoneGap 首页的 Install PhoneGap 按钮就是一个骗纸,根本就不需要安装)。熟悉 Nodejs 的人很容易就能安装成功了。(说起来直到现在我都不知道 PhoneGap 和 Cordova 是什么关系、有什么不同。)
之后就可以用命令行来创建一个空项目了:
cordova create my_first_phonegap_app io.github.lmk123.FirstApp ThisIsAppTitle完成之后,会在运行命令的目录中创建一个 my_first_phonegap_app 文件夹。里面的 www 目录下有一个 index.html ,这就是程序的“首页”了。按照国际管理,我写下了 hello milk。
之后就可以准备生成对应平台的 app 了。下面的所有命令都是在 /my_first_phonegap_app 这个文件夹里运行的。
首先添加安卓平台:
cordova platform add android然后生成 apk:
cordova build当命令行提示 BUILD SUCCESS 之后,它会给出一个生成的 apk 文件的位置。现在你就可以将这个 apk 发送到自己的手机上安装了。
如果你安装了安卓模拟器,也可以使用 cordova run 命令,这样会直接 build 一个 apk ,然后直接在模拟器里安装并打开。
PhoneGap 插件库 里提供了各种各样的插件,这些插件能通过 javascript 来调用手机的原生功能,例如照相机、震动、通知,以及文件操作等。插件的安装一般都是使用 cordova plugin add 插件名字 命令,但有的插件安装后还需要在 config.xml 里加一些东西,不过这些内容肯定会详细的写在插件说明里的。
至此,PhoneGap 的使用就大致介绍完了,接下来就可以开始愉快的开发了 ;)
这一切都要从我正在开发的非官方的『一个』移动客户端开始说起。
出于对官方的『一个』移动客户端的不满,我萌生了自己开发一个 APP 的想法。在使用 Bootstrap + ui-bootstrap 开发出第一版后,我有点不满意:程序看上去更像一个手机网站,而不是应用程序。
让网站看起来像原生应用程序,指的当然是各种动画效果:滑动、滚动到页面边缘时回弹等等。为此我找到了三种 UI 框架来完成这些事情:
Framework 7 没有与 angularjs 集成,所以我暂时没有考虑使用它。社区里 Star 最多的是 Ionic Framework(并且将另外两个项目远远的甩在身后),所以我首先深入学习了它并用它重写了第二版。这一版并没有写完,因为在使用 Ionic 重写的过程中我发现了一些问题:
第二点可能是我的问题,但这促使我尽快使用下一个 UI 框架,对比看看性能会不会好一点,于是我又学习了 Onsen UI,并着手开发第三个版本——
但现在我准备暂时放弃 Onsen UI:
var 属性的组件,那需要仔细考虑它被初始化的时机,否则会出现各种找不到组件实例的错误)问题看上去并不多,但这是因为仅仅只是一个开始就让我花了很长的时间,让我不太敢继续深入了。
先简述一下 babel-polyfill 与 transform-runtime 是做什么的。
目前浏览器对 ES2015 语法的支持都不太好,所以当我们需要使用 Promise、Set、Map 等功能时就需要 babel-polyfill 来提供。
在转换 ES2015 语法为 ECMAScript 5 的语法时,babel 会需要一些辅助函数,例如 _extend。babel 默认会将这些辅助函数内联到每一个 js 文件里,这样文件多的时候,项目就会很大。
所以 babel 提供了 transform-runtime 来将这些辅助函数“搬”到一个单独的模块 babel-runtime 中,这样做能减小项目文件的大小。
今天我在写一个针对 Chrome 浏览器的项目的时候,使用了 transform-runtime,但没有用 babel-polyfill,因为很多 ES2015 的功能(比如 Promise)Chrome 都已经支持了。可是文件经过 babel 转换之后,文件大小陡增,仔细一看,发现 babel 把 Promise 的 polyfill 给注入进来了。
因为我没有使用 babel-polyfill,所以我本来认为,babel 应该是不会给我注入任何 polyfill 的,但事与愿违。我查看了一下 babel-runtime,发现除了包含 babel 转换时需要用到的辅助函数外,它还包含了 corejs 与 regenerator——而 babel-polyfill 也包含了这两个模块。
当我查阅 transform-runtime 的文档时,才发现 transform-runtime 是可以配置的:
// with options
{
"plugins": [
["transform-runtime", {
"polyfill": false,
"regenerator": true
}]
]
}由此可见,当我们在配置里直接使用 "plugins": ["transform-runtime"] 时,其实就相当于引入了 babel-polyfill。
这可能并不是我们想要的。
最近在做一个 Chrome App ,用来读取电子秤的读数。目前市面上大部分电子秤都是串行接口,在 Chrome App 里读取串行接口设备的数据很容易(见文档),但今天公司给了我一个 USB 接口的设备。
看了下 Chrome App 里连接 USB 设备的文档,上面说如果我要读取一个 USB 设备的数据,我首先得将它的 Vendor ID 与 Product ID 列在 manifest.json 里。但其实不必去找说明书(说明书里也不一定有),Chrome 本身就提供了接口来获取连接到设备的信息。
这个接口就是 chrome.use.getUserSelectedDevices。
这个方法很特殊,就像 HTML5 里让网页全屏的方法一样,它必须写在一个 click 事件的处理函数里、并且这个 click 事件只能是由用户点击按钮产生的。用户点击按钮之后,在处理函数里调用这个方法就会显示一个弹层,列出了现在连接至电脑的所有 USB 设备,用户选择的设备就会作为回调函数的参数,这样就能拿到指定设备的信息了!
你可以使用 NamedStorage 来达成本文提出的优化。
在修改存储在 localStorage 或 sessionStorage 里的数据时,最常用的大概就是下面的步骤了:
function modifyStorage (string) {
// 先读取数据
const data = JSON.parse(localStorage.getItem('arrayData'))
// 修改数据
data.push(string)
// 重新保存
localStorage.setItem('arrayData', JSON.stringify(data))
}
modifyStorage('new data')但是这样做有些问题:
所以,我在修改 storage 内的数据时是这样做的:
// 网页打开时读取一次
const data = JSON.parse(localStorage.getItem('arrayData'))
// 如果你不想让用户知道你存了些什么,那读取完后立刻删除
localStorage.removeItem('arrayData')
// 修改数据时只修改变量
function modifyStorage (string) {
data.push(string)
}
// 重要的一步:网页关闭前将数据写入 storage
window.addEventListener('unload', () => localStorage.setItem('arrayData', JSON.stringify(data)))
modifyStorage('new data')对比一下文章开头的代码,这样做的好处显而易见:
但需要注意的是,在一些奇怪的运行环境中(例如 Native App 的 WebView 里),unload 事件不一定会触发。这种情况下,你还是可以保证读取数据的操作只有一次:
// 网页打开时读取一次
const data = JSON.parse(localStorage.getItem('arrayData'))
// 因为 window.onunload 可能不会被触发,所以每次修改数据时都保存一次
function modifyStorage (string) {
data.push(string)
localStorage.setItem('arrayData', JSON.stringify(data))
}
modifyStorage('new data')完。
在阅读之前,你最好先熟悉 FileSystem API。我强烈向你推荐这篇文章。
最近做一个 PhoneGap 程序要读写手机里的文件,于是深入研究了一番在 PhoneGap 里的文件系统。下面的结论都是在_小米3_手机上测试出来的,在其它手机上可能会有点不同。
首先,必须得安装这个插件:cordova-plugin-file 并仔细阅读这个插件的自述文档。
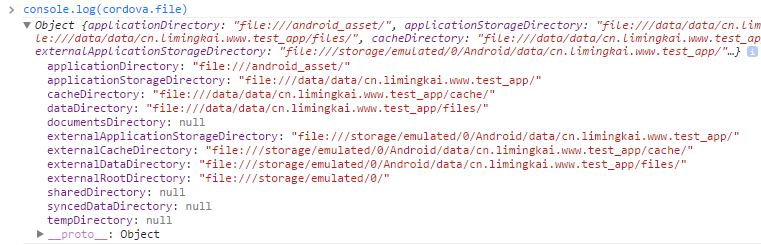
为了看看自述文档里的 cordova.file 到底是个什么东西,我在 GapDebug 把这个对象打印出来了:
由此可以看到,这些关键的目录分为两种:内部存储目录和外部存储(即 SD 卡)目录。
但是目前的许多安卓手机也开始向 iPhone 学习,不允许安装 SD 卡了,比如我使用的小米3就是如此。经过反复测试,发现此时应该使用外部存储目录,即上图中的 external***Directory。一个可能的猜想:如果 external***Directory 不是 null,则应该使用外部存储目录。
在调用 window.requestFileSystem() 函数的时候,请求临时文件系统(window.TEMPORARY)得到的 fs.root 就是 cordova.file.externalRootDirectory 的 DirectoryEntry 对象,请求持久化的文件系统(window.PERSISTENT)得到的 fs.root 就是 cordova.file.externalCacheDirectory 的 DirectoryEntry 对象。实际上,这两种对象都可以通过 window.resolveLocalFileSystemURL() 得到,这意味着你并不需要调用 requestFileSystem 来得到它们。
是的,这篇文章并不长,但是我为此绕了半天的圈子。原因在于我并不知道小米3里所谓的“内部存储”实际上是 cordova.file 的外部存储目录,所以导致我总是读不到文件。另外吐槽一下小米3的 miui 系统真是麻烦,开启个 USB 调试还要绕很大的圈子,你可以参考这篇文章感受一下。
最近开发了 Runner 用来记录我跑步时的进度,但却被一个问题给难住了。
比如下面这段代码:
let sec = 0;
setInterval( ()=> {
sec += 1;
if(sec === 55) { alert('notice me'); } // 在第 55 秒的时候提醒我
}, 1000 );当浏览器处于后台运行时(例如用户关闭了屏幕、切换到了主屏幕或其它 APP),大概经过 17 秒后,浏览器就会停止计时函数。这就导致在经过了很长一段时间后,当用户重新切换回浏览器时,却发现网页上显示的是 17 秒,在这之后,计时函数又重新开始继续运行。
这个行为就好像是被 window.alert() 这一类的函数阻塞了 JavaScript 进程一样。
如果只是要修正计时器的读数其实并不难:
let sec = 0;
let now = Date.now();
setInterval( ()=> {
const diff = Date.now() - now;
if (diff > 1000) { // 具体数值可能有偏差
sec += Math.floor(diff / 1000);
} else {
sec += 1;
}
now = Date.now();
}, 1000 );但我想要的效果是:在某个时间点(比如第 55 秒的时候)播放一段声音提醒我。如果计时开始后手机屏幕被关闭了,那除非解锁手机,否则计时器永远不会到达第 55 秒。
我谷歌了很长时间,看起来唯一的解决方案是使用 NoSleep.js 让手机屏幕常亮,但我在 Runner 里试了好几次也没有成功。
然而有一次在给同事演示计时中断这个现象的时候,却发现最开始的那段代码在微信(iPhone 6s,iOS 9.3.1,微信 6.3.15)里可以正常计时——因为再次打开屏幕的时候,屏幕上出现了 notice me 的 alert 框,秒数正好停在 55 秒(因为 alert 函数也阻塞了 JavaScript 进程)。
现在还不太确定微信的 webview 是否真的不会在后台运行时阻塞 JavaScript 进程——说不定它会在 17 分钟后阻塞呢?但就在我要放弃使用 Runner 的时候,微信无疑成了最后一根稻草。
WebStorm 很早就支持了 *.scss 或 *.less 文件的语法高亮,但偶尔我们会需要在 HTML 文件的 <style> 标签内写 SCSS 或 Less 的语法(例如使用 Vue.js 的朋友应该会需要在 *.vue 文件的 <style> 标签内写 SCSS),其实 WebStorm 也是支持的,但是官方文档上好像并没有提及。
在 <style> 上加 lang="scss"、lang="sass" 和 lang="less" 就可以分别支持 SCSS、Sass 和 Less 的语法了。
在升级到 WebStorm 2017.1 之后,我发现 2016.3 及以前版本的方法已经不起作用了。谷歌了半天也没有找到类似问题,于是尝试了各种方法,还真被我试出来了 😂
WebStorm 2017.1 及之后的版本需要使用 type="text/scss" 或 type="text/sass" 来支持 SCSS 或 Sass 语法,使用 type="text/less" 来支持 Less 语法。
举例来说:
<!-- 下面的 style 块内支持 SCSS 的语法 -->
<style type="text/scss">
body {
$height: 10px;
div {
height: $height;
}
}
</style>
<!-- 下面的 style 块内支持 Sass 的语法 -->
<style type="text/sass">
body
$height: 10px
div
height: $height
</style>
<!-- 下面的 style 块内支持 Less 的语法 -->
<style type="text/less">
body {
@height: 10px;
div {
height: @height;
}
}
</style>在 WebStorm 2016.3 及以前的版本,需要在 <style> 标签上加上 rel="stylesheet/scss",这样 WebStorm 就能正常解析 SCSS 的语法了。如果你使用的是 Sass 的语法,则加上 rel="stylesheet/sass"(只有一个字母不相同)。Less 则是加上 rel="stylesheet/less"。
举例来说:
<!-- 下面的 style 块内支持 SCSS 的语法 -->
<style rel="stylesheet/scss">
body {
$height: 10px;
div {
height: $height;
}
}
</style>
<!-- 下面的 style 块内支持 Sass 的语法 -->
<style rel="stylesheet/sass">
body
$height: 10px
div
height: $height
</style>
<!-- 下面的 style 块内支持 Less 的语法 -->
<style rel="stylesheet/less">
body {
@height: 10px;
div {
height: @height;
}
}
</style>最近迷上了 TypeScript,于是用它重写了 Selection-Translator/translation.js 算是练手。
开发时,我使用了 Rollup + rollup-plugin-typescript2 插件打包模块。
因为 Rollup 是基于 ES2015 的模块语法打包模块的,所以 tsconfig.json 里的 module 会被插件强制设置为 es2015。translation.js 引用了一个 CommonJS 模块 blueimp-md5,当 module 被设置为 es2015 的时候,我没法用 import md5 = require('blueimp-md5') 的方式引用 CommonJS,TypeScript 告诉我只能从 import n from 'mod'、import { n } from 'mod'、import * as n from 'mod'这几种方式中选择一个——但是,我挨个尝试后,发现都不行,因为 blueimp-md5 has no default export.
然后我尝试直接使用 CommonJS 的语法 const md5 = require('blueimp-md5'),打包时是没有问题了,但实际上 rollup 并没有解析这个模块,这条语句直接就输出在最终打包后的文件里了,如果我要在浏览器里用肯定是不行的。
最后,我在 tsconfig.json 里设置了 "allowSyntheticDefaultImports": true,然后使用了 import md5 from 'blueimp-md5',这样总算是没问题了。
可是接下来问题又来了——
在使用 ts-node 跑测试的时候,因为是在 Node.js 环境里运行,所以 module 需要设置成 commonjs,但是此时是没法用 import md5 from 'blueimp-md5' 这种语法的,只能用 TypeScript 专用的语法 import md5 = require('blueimp-md5') 😂
我尝试了各种方式,都没法让其中一种引用 CommonJS 模块的语法既能用在 es2015、也能用在 commonjs,最后只能用一种奇怪的方式解决问题——在跑测试前用代码将 import md5 from 'blueimp-md5' 改成 import md5 = require('blueimp-md5'),测试跑完后再改回来 😂 😂
当 AngularJS 刚问世的时候,我一眼就看到(并认为)它把逻辑写在了模板里:
<button ng-click="edit()">编辑</button>这也是我一直不看好、并且再也没有关注过它的原因。
然而前两天,我买了两本书(《用 AngularJS 开发下一代 Web 应用》与《AngularJS 权威指南》),并准备深入学习它。原因起于一个 PhoneGap 手机 APP。
当我开发这个 APP 的时候,我的**仍然停留在“网站”的层面上。于是我组织代码的形式就跟搭一个网站一样。
可是写到后面,我发现使用“网站”的经验来写手机 APP 有点力不从心了。在构建网站的时候,一般都是已经由服务器构建好了页面,然后再使用 jQuery、doT 等方式操作 dom;但这样让大部分的代码都绑死在了 dom 上,并不能让我真正的关注核心逻辑。
另外,由于手机 APP 里无法依靠服务器来生成 HTML 了,所以假如我要打开一个商品详情页,我要先向服务器请求商品数据,然后再由前端模板(如前面提到的 doT)生成 HTML,然后还得写进 dom 里。如果逻辑再复杂一些,每当商品的数量变动时,我都需要实时计算价格,而显示价格的时候又涉及到了 dom……这个展开已经让我“惶恐不安”了。
这个时候,我才明白AngularJS 为什么这么火了。
在读书的时候我有一个习惯,就是把书上的例子都自己写一遍,并随意的进行一点修改。这样做有两个原因:
果然如我所料,那两本书使用的是 v1.2.x ,而目前最新版本是 v1.3.15,好多代码都失效了——这并不让我感到失望,反而让我觉得有趣:如果代码都按照预期的正常运行,那该少了多少编码的乐趣啊。
深入了解 AngularJS 之后,我发自内心为它折服。但我是一个前端,难免会从“网站”的角度来思考问题,于是我发现:
第一点没有比较好的解决方案,只能用一个折中的办法:文本内容居多的页面不要使用 AngularJS。
第二点在网上已经有解决方案了,可以做到按需加载控制器——虽然不少人觉得这样做并不合适。有的人认为,如果项目真的大到需要按需加载的程度,那么就应该把项目进行合理拆分,分成两个或多个小项目;还有人认为,按需加载的功能应该等待 AngularJS 官方支持,而不应该 “hack” 它。
而我自己觉得,从构建手机 APP 的角度来看,按需加载是没必要的,但如果用来做网站就另当别论了。
有人会说,我可以将所有 js 合并成一个单独的文件,例如 all.js。尽管这个文件可能会比较大,但我们可以给它加上时间戳,然后设一年的缓存,所以只有在用户第一次加载的时候才会觉得比较慢。但这里有一个问题:任何一点小改动,都需要重新合成这个 all.js,这样,用户又得重新加载这个大文件了。
同样的,“all.css” 也有这个问题。
如果将控制器(以及控制器对应的样式)做成按需加载的话,这样的问题就不会有了——虽然实行过程中可能会另有一些问题,但是利大于弊。我们要做的就是在利弊中做一个权衡。
AngularJS 确实是一个很成功的框架,对开发者非常友好。但我还是要做一点破坏气氛的提醒:对开发者和对用户友好,一直都是对立面。在自己代码写的爽的时候,也不要忘了考虑使用者的感受。
关于最后一点,我想引用一下《牧羊少年奇幻之旅》里面的一则小故事,没兴趣的读者可以略过 :)
有一个商店老板叫他的儿子到世界上最有智慧的人那儿,去学习幸福的秘密。少年于是穿越沙漠,跋涉了四十天,终于来到一座盖在山顶上的美丽城堡。那是智者住的地方。
他本以为会遇见一位摆脱尘俗的智者,结果他一踏入城堡大厅,却看见了闹哄哄的聚会,商人来来去去,人们挤在各个角落里聊天,一个小型的乐团正在演奏着抒情音乐,还有一张桌子上摆满了各式各样的美味佳肴。而智者正在跟每个人谈话,少年只好等候了两个小时,直到终于轮到他和智者说话。
智者专心听少年解释他来这里的原因,却说他没时间立刻解释幸福的秘密。他建议少年到四处去逛逛,两个小时后再回来。
“同时我也要你做一件事,”智者递给少年一根汤匙,匙上滴了两滴油。“当你在四处逛的时候,不要让油滴出来。”
男孩开始沿着城堡的楼梯爬上爬下,眼光却一刻未离开汤匙。两个小时后,他回到大厅,找到智者。
“好啦,”智者问,“你有没有看见挂在餐厅里的波斯壁毯?你有没有欣赏那个精心设计的主花园?那可是花了十年才造好的。你有没有注意到图书馆里那张美丽的羊皮纸呀?”
男孩觉得十分尴尬,坦承他根本什么也没注意看。他只全神贯注不让油滴出来。
“那就再回去欣赏这个城堡的美丽壮观吧!”智者说,“你不应该相信一个人,如果你不了解他的房子。”
于是少年就放松心情,开始探索这个城堡。这一次,他仔细地欣赏了天花板、地板,和樯上的绘画,他看了花园,也瞭望了四周的山景、美丽的花朵,还有各个精心挑选的艺术品。等再回到智者身边时,他仔细描述了他所见的一切。
“可是那些油呢?”智者问。
少年低头看汤匙,发现汤匙里的油早就没了。
“我只能提供你一个建议,”这个最有智慧的人说,“幸福的秘密就是去欣赏世界上所有的奇妙景观,但不要忘了汤匙里的油。”
先来说说我对“组件”的定义。
前端开发过程中,可能会用到一些第三方插件,比如 jBox 或者 asDatepicker:这些插件会附带一个 css 文件用来定义样式。于是我们在使用这些插件的时候,页面看上去是这样的:
<link rel="stylesheet" href="jBox.css">
<script src="jBox.js"></script>这里有一个小问题:既然需要加载 jBox.js 的时候总是需要加载 jBox.css 的,那为什么不将 jBox.css 写进 jBox.js 呢?这样可以减少一次 HTTP 请求。
但是总所周知,在 js 里的长文本是很难维护的,所以最好的解决方案是:开发时分成多个文件,但在生产环境时合并成一个文件;相关的文件最好放在一处,比如说放在同一个文件夹下——这就是我所认为的“组件”的定义。
require.js 配合 text插件与 r.js 文件组合工具就可以实现上面的需求了,只是 r.js 的配置有点繁琐:它是奔着将所有的依赖文件都合并在一起的目标去的,而我这里的需求是只想合并组件而已,为此我不得不为每一个组件进行单独配置,这肯定是不利于维护的。
于是,我自己动手写了一个小工具:requirejs-components-combine,它的作用单一而简单,但可以很好的满足我的需求。
举个例子。我有一个组件叫 modal-box,这个组件的作用是取代浏览器的 alert() 与 confirm() 方法,它的文件结构如下:
modal-box/
|----- template.html(模板)
|----- modal.css(样式)
------ index.js (逻辑)
下面简单列出这三个文件的内容:
template.html
<!-- 前略 -->
<body>
<div class="modal-box">Hello World</div>
</body></html>modal.css
.modal-box { color:red; display:none }index.js
define(['jquery', 'text!template.html!strip', 'text!modal.css'], function ($, HTML, CSS) {
var $modal = $( HTML ).appendTo( 'body' );
$('<style>' + CSS + '</style>').appendTo( 'head' );
return {
show: function () { $modal.show(); } ,
hide: function () { $midal.hide(); }
};
} );最后,我们在代码里应该是这样使用它的:
test.js
require( ['modal-box/index'] , function (modal) {
modal.show();
});这样,开发时避免了将模板与样式直接写进 index.js 里,而在上线前,就可以使用我的小工具进行合并了,合并之后的文件结构是这样的:
modal-box/
|----- template.html(模板)
|----- modal.css(样式)
------ index.js (逻辑)
modal-box.js(合并后的文件)
modal-box.js 的内容是:
define('_template.html',function(){return'<div class="modal-box">Hello World</div>'});
define('_modal.css',function(){return'.modal-box { color:red; display:none }'});
define( [ 'jquery' , '_template.html' , '_modal.css' ] , function ( $ , HTML , CSS ) {
var $modal = $( HTML ).appendTo( 'body' );
$('<style>' + CSS + '</style>').appendTo( 'head' );
return {
show:function () { $modal.show(); } ,
hide:function () { $midal.hide(); }
};
} );最后,我们还需要将 test.js 里面的引用从 modal-box/index 改成 modal-box;我们可以在开发时就写一个“代理模块”,避免每次组合完成后都需要更改模块引用:
开发时就先写一个 modal-box.js
define(['modal-box/index'],function (m) { return m; });组件合并工具会覆盖这个“代理模块”,那么在开发时,test.js就可以放心的引用 modal-box ,不需要更改模块引用了。
就是这样了!
使用 ES6(借助了 Babel 的力量)写代码已经很长时间了,中间碰到了几个坑,记录一下。
下面的代码会报错,因为里面的 x 未定义:
new Promise( resolve => resolve( x + 1 ) ).then( ()=> console.log( '一切正常' ) );不过按照标准,浏览器不会给出任何错误提示,因为错误会被传递到 catch() 回调里。上面的代码没有注册这个回调,所以结果就是浏览器没有任何反应:既不会打印 log,也不会报错。
之前我使用的是 jakearchibald/es6-promise,它严格遵循标准,我花了很长时间都不知道为什么 Promise 没执行到 then 里面去,换成了 Babel 的 browser-polyfill.js 才知道 Promise 里面产生了未捕获的错误。Babel 同时也会提示产生了未处理的 rejection,好贴心 :)
const t = {
name:'mk',
yes() { console.log(this.name); },
no:() => console.log( this.name )
};
t.yes(); // 打印出 mk
t.no(); // 报错箭头函数里的 this 指向它外围的那个 this,上面的代码中,yes() 方法里的 this 指向 t,但 no() 方法里的 this 指向全局对象,而由于 babel 默认使用严格模式,this 会被替换为 undefined,所以会报错。
除了 this 以外,箭头函数不能被当做构造函数、不能使用 arguments 对象、不能用 yield ,这三点也是要注意的。
最近一边在做各种 AngularJS 程序,一边完善自己的 AngularJS 项目脚手架。今天想把 $httpBackend 集成到 Protractor 里面去,伤了一会儿脑筋。。
使用这个服务最简单的办法就是直接在项目里依赖它,可是每次项目上线前,我都需要回到源码里删除跟 $httpBackend 有关的代码:删除 angular-mocks.js 的引用、删除 ngMockE2E 的依赖,还要删除配置 $httpBackend 的代码段。
在 Protractor Issues 里有关于这个问题的讨论。
后来我大致看了一遍 Protractor 的文档,看到了两个关键的方法:browser.executeScript 与 browser.addMockModule。(让我吐槽一下这份文档,我网上查了一个小时,就是不知道上哪找 webdriver 来调用 executeScript 方法,后来无意中试了一下 browser.executeScript() 发现居然没报错,大概 browser 本身就是 webdriver 吧……无语了。)
我的思路是:
browser.executeScript() 在测试开始之前用 js 的方式插入 angular-mocks.jsbrowser.addMockModule() 重载启动模块,在这个重载里面加入对 ngMockE2E 的依赖$httpBackend 的配置写在测试代码里我猜想第二步与第三步是最简单的,而事实证明确实如此——第一步怎么折腾都没成功。即使我优先插入了 angular-mocks.js ,但是执行到第二步的时候会报错:ngMockE2E 模块找不到;我猜是因为执行到第二步的时候,第一步插入的脚本没有加载或执行完;本来想在第一步生成的 script 节点里加一个 onload 事件,但是 browser.executeScript() 的执行环境是在浏览器中,所以引用不到 browser 这个(仅在测试文件里才有的)变量。
后来我发现还有 browser.executeAsyncScript() 可以执行异步代码,但同时我也在这里看到,每次调用 browser.get() 的时候,页面都会重新刷新一次,也就是说,每次我都得重新插入一遍脚本,想了想还是算了。
最后只能用一个折中的办法,即在项目里面引用 angular-mocks.js 文件,这样至少每次上线前只需要注释一行代码就可以了。
感觉我的解决方案并不太好,希望以后能在工作过程中找到更好的方式。
在写单元测试的过程中,最痛苦的就是找“监控点”了。
举个栗子,现在有如下代码 source.js:
import { methodA , methodB } from 'third-party';
if( yourCondition ) {
methodA();
} else {
methodB();
}其中 third-party.js 是这个样子的:
const input = document.createElement( 'input' );
document.body.appendChild( input );
export function methodA() {
window.alert( 'hello' );
}
export function methodB() {
input.focus();
}现在我要开始写单元测试了。
为了让 source.js 的代码可被反复执行,我们首先需要将逻辑封装成一个函数(如果 source.js 本身就是一个模块并导出了一些方法,就不需要这一步了):
import { methodA , methodB } from 'third-party';
function main() {
if( yourCondition ) {
methodA();
} else {
methodB();
}
}
if( process.env.NODE_ENV !== 'test' ) {
main();
}
export default main;然后,我开始写单元测试用例 test.js(这里使用 Jasmine 作为示例,你当然可以使用任何其它你喜欢的测试框架):
import main from 'source.js';
describe( 'source.js' , ()=>{
it( '当 yourCondition 为 true 时,会调用 methodA' );
it( '当 yourCondition 为 false 时,会调用 methodB' );
} );现在问题来了,我如何知道 methodA 或 methodB 有没有被调用呢?
我的解决方案是,去查看 methodA 和 methodB 的源码,看看有没有什么“监控点”可以被我劫持。
比如说,methodA 里面会调用 window.alert(),那么单元测试就可以这么写:
it( '当 yourCondition 为 true 时,会调用 methodA' , ()=>{
const yourCondition = true;
spyOn( window , 'alert' );
main();
expect( window.alert ).toHaveBeenCalled(); // window.alert 调用了,就说明 methodA 被调用了
});methodB 里面使用了测试代码访问不到的变量 input,那是不是就没法判断了呢?并不是。
首先我们需要知道的是,input 的 focus() 方法继承自 HTMLElement。当调用 input.focus() 时,其实等同于 HTMLElement.prototype.focus.call( input )。
所以判断 methodB 是否被调用的单元测试可以这样写:
it( '当 yourCondition 为 false 时,会调用 methodB' , ()=>{
const yourCondition = false;
spyOn( HTMLElement.prototype , 'focus' );
main();
expect( HTMLElement.prototype.focus ).toHaveBeenCalled();
});从上面的例子可以看出,我所说的“监控点”,其实就是源码与测试代码都能访问到的作用域(通常是全局作用域)里的某个方法。我可以通过劫持这些方法判断程序的走向,从而完成单元测试。
即使某些情况下找不到监控点,我们也可以创造监控点——你可能已经注意到 source.js 里的 if( process.env.NODE_ENV !== 'test' ) { } 这段代码了。
我就是在创造监控点的过程中发现“依赖注入”这个名词的。
我在划词翻译中使用 Webpack 进行开发,为了给某一个单元测试创建一个监控点,我使用了 Webpack 的 DefinePlugin,而它被归类为 dependency injection,也就是依赖注入了。
但时间一长,我就发现这种方式的弊端了:我需要层层阅读源码去寻找监控点,如果找不到,还得想办法创建一个。
后来我发现,Webpack 还有一个依赖注入插件 RewirePlugin,它正是我想要的解决方案,但可惜的是,它不支持 ES2015 模块语法。
一个 Babel 插件声称支持 ES2015 模块语法,但直到目前(2016年1月21日)为止,它仍然不能正常使用。
在找了很多次监控点之后,我发现我其实可以自己来注入那些依赖。这个方法比起监控点来说,麻烦程度不分上下。
我们可以把 source.js 改写成这个样子:
import { methodA , methodB } from 'third-party';
function main( methodA , methodB ) {
if( yourCondition ) {
methodA();
} else {
methodB();
}
}
if( process.env.NODE_ENV !== 'test' ) {
main( methodA , methodB );
}
export default main;单元测试则可以这样写:
import main from 'source.js';
describe( 'source.js' , ()=>{
let methodA, methodB;
beforeEach(()=>{
methodA = jasmine.createSpy('methodA');
methodB = jasmine.createSpy('methodB');
});
it( '当 yourCondition 为 true 时,会调用 methodA',()=>{
const yourCondition = true;
main( methodA , methodB );
expect( methodA ).toHaveBeenCalled();
} );
it( '当 yourCondition 为 false 时,会调用 methodB' ,()=>{
const yourCondition = false;
main( methodA , methodB );
expect( methodB ).toHaveBeenCalled();
} );
} );这种方法的优点是你不必再寻找“监控点”了,缺点就是,如果你的文件依赖过多,你需要创建的假模块也会很多——取决于程序的分支,你要创建的假模块会比你实际使用了的模块数量多得多。
实际编写单元测试的过程中,“监控点”的方式是用的最多的,但我准备逐步使用“依赖注入”来替代“监控点”了,因为“监控点”有一个致命的缺点:万一第三方库里的内部实现变了呢?
毕业之后,我去的第一家公司使用的前端构建工具是 Ant,使用时需要配置 build.xml 和 ant.properties 文件,构建流程一点也不直观,而且修改时还需要在两个文件之间来回看;后来来到现在这家公司,正好是 Grunt 正火的时候。它最吸引我的地方就在于它使用的是 node.js,对前端来说多么友好啊。
再后来,gulp 横空出世。简单的了解之后,我认为它与 grunt 是同样的工具,不值得再花时间。直到今天,我在网上看到 gulp 4.0 就要发布的消息,于是在 github 上查看了下它的项目主页,发现标星数(11366)居然比 grunt(9050) 多。
我意识到,gulp 后来居上,一定是有更吸引人的地方,所以我稍微研究了下。
gulp 给我的第一印象就是:简单。它的文档居然只有一个页面,要不了多长时间就看完了。读完之后,我发现它是一个“流”构建工具,这正是它与 grunt 最大的区别(虽然我觉得这无非就是减少了构建时间,但这其实无关紧要)。
之后我就开始 Hello World 了。我一直都喜欢追求最新版本,所以使用了暂未发布的 gulp 4.0(实际上它已经开发完成,只是还没更新 API 文档,所以一直没有正式发布)。
作为练习,我对照着项目里面现有的 Gruntfile.js 写了一个 gulpfile.js(查看 Gist)。gulp 写起来很轻松,因为无需像 grunt 那样进行配置,而是像写真正的 nodejs 程序一样。所有的任务都是一个函数,所以无需像 grunt 那样使用 grunt.task.run(['task']) 的方式来调用配置对象里的任务。
学习过程中,唯一遇到的坑就是 gulp.src(globs[, options]) 方法里的 options.base 设置,它的默认值为:
Type: String. Default: everything before a glob starts
我就奇怪我输出的文件位置怎么乱七八糟的。- -
gulp 确实是一个很好用的工具,相比 grunt 这个庞大的“系统”而言,它简单小巧,并易于使用,也难怪会后来居上了。
这两天陆续学习了下 gulp 与 f.i.s。学习 gulp 纯粹是好奇它为什么会比 grunt 流行(我的结论在 #3),而学习 fis 则是为了解决一个_“前端工程”_问题。
我基于一些原因(见 #2),在公司项目里使用了 RequireJS,但我仍需要解决它的增量更新问题。单靠 RequireJS 提供的 urlArgs 是远远不够的,最好的办法应该是这篇文章里所说的那样,给每个静态文件的文件名加上 md5。
在我思考要不要脱离 fis、自己来实现的时候,我在网上搜到了一个 gulp 插件:gulp-rev-all。比起 fis 那种通过更新 RequireJS 中的 paths 设置,这个插件做的事情更符合我的意愿。它能把下面的代码:
requrie(['libs/doT'],function (d) {
// ...
});转换成:
requrie(['libs/doT.dfe5trf3'],function (d) {
// ...
});也就是说,它在给所有文件添加 hash 的同时,还会更改引用过这些文件的地方,无论是 css 里面的图片,还是 js 里面引用的模块:这样就不需要额外加载映射表了。毕竟随着项目的增长,映射表可能会变得越来越庞大。
真是踏破铁鞋无觅处,得来全不费工夫。- -
这种方式仍然有需要注意的地方:如果项目是前后端分离的,那么服务端的模板里面不应该有调用 requrie(['deps']) 的 inline script;如果不是,那就将后端模板也纳入插件的处理范围,当然这样做有点……怎么说呢,low。
那么,关于前端工程的研究总算能告一段落了。最好能做一个 demo 出来。
众所周知,这两个方法用于在字符串与对象之间进行转换。其中用到的最多的场景就是在保存数据到 localStorage 里的时候——因为 localStorage 里只能保存字符串,所以当我们想要保存对象进去时,就会先 JSON.stringify() 一下,读取出来时,再 JSON.parse() 一下。
但是,这样做很可能会产生 bug!
先来看下面这段代码:
JSON.parse('100');一定是我书读的少的缘故,我一直认为上面这段代码会报错——因为字符串 '100' 并不是一个 JSON 字符串。
但是实际上,这段代码不会报错,而是会返回 Number 类型的 100。
同理还有 JSON.stringify(100),这段代码同样不会报错,而是会返回字符串类型的 '100'。查看完整的在线示例
强烈推荐完整的阅读一下 MDN 上关于这两个方法的说明:
上午写了一个小模块,想发布到 npm 里。网上查了查资料,发现发布模块很简单:
npm login
npm publish
结果这两步花了我两小时。
当我运行npm login的时候,它老是提示我用户名或密码不正确,我就纳闷了:我自己在 npmjs.com 上登录了好多次了,为嘛在命令行里就会错误?
这时我发现下面有个提示:
npm ERR! You may need to upgrade your version of npm:
npm ERR! npm install npm -g
升级就升级吧,于是我运行了 npm install npm -g,完成之后输入npm -v一看,仍然是 v2.5.1,但最新的应该是 v2.7.3 才对!
立马我就跑到 npm 开发者文档里去了,可是文档上根本没提到这档子事!于是只好求助于万能的谷歌,结果反倒在 npm 的 Github 项目 wiki 里找到了原因。。win7 好麻烦!
我选了 Option 2,这下版本号总算是最新的了。然后我心满意足的运行 npm login。
还是用户名和密码错误是什么鬼啊!!!唯一不同的是没了升级 npm 的提示信息了!
脑子要浆糊了。
万般无奈之际,我猜想不会是因为我的用户名里面有一个点吧(我的用户名是milk.lee)?
于是在输入 Username 的时候我输入 milk.lee (加了个斜杠转义一下。。),npm 提示我输入了不安全的字符;然后我干脆就不要点了,直接输入 milklee,再输入密码回车。我已经做好看到那一大片的错误信息的心理准备了。
可是居然登录成功了。。登录成功了。。。。
可是事情还没完!!
发布完模块后,我登录进 npmjs.com ,却发现我的个人主页没有列出那个模块。这次我已经有“经验”了,直接退出登录,然后用不带点的 milklee 登录进去,居然也登录成功了 = =而且果然发现了我发布的模块!
无语了 Orz
自从决定将公司的网站改用AMD的方式开发之后,积攒了不少 RequireJS 的使用心得,于是在博客里简单的描述一下。
在为公司开发网站时,一开始的页面结构是很简单的:
<script src="libs/jquery.js"></script>
<script src="app.js"></script>后来,公司要求在页面上加一个图表。自己做不来,只好找一个插件,于是页面变成了这样子:
<script src="libs/jquery.js"></script>
<script src="libs/jquery.chart.js"></script>
<script src="app.js"></script>再后来,公司觉得浏览器的alert()与confirm()样式太丑了,所以我又写了一个公共组件;组件依赖jQuery,并且在每一个网页里都可能用到,于是页面结构成了这样子:
<!-- 组件还带有css -->
<link rel="stylesheet" href="common/alert.css">
<script src="libs/jquery.js"></script>
<script src="common/alert.js"></script>
<script src="libs/jquery.chart.js"></script>
<script src="app.js"></script>那么问题来了。
为了解决上面这两个问题,我找到了 RequireJS :它正是我需要的解决方案。无需手动维护代码之间的依赖关系,并且不会出现变量污染;由 css、html 与 js 组合起来的组件也可以很容易的合并成一个单独的 js 文件,避免发起多次 http 请求。
最终,上面复杂的页面变成了下面这个样子:
<script src="libs/require.js"></script>
<script src="app.js"></script>说起CommonJS就不得不提到NodeJS了,但我仍然认为,在浏览器环境中,AMD才是更合理的开发方式。浏览器毕竟不能像NodeJS那样直接读写硬盘,网页用到的文件都需要下载,所以这必定是一个异步的过程;而var module = require('module');这样的同步加载方式是不适合浏览器环境的。
缓存的重要性不言而喻,浏览器会缓存请求过的静态文件,避免再次下载,这样可以大大提高页面加载速度。但是在RequireJS中,每次更改js文件之后,文件的路径仍然是一样的,这会导致改动不生效;使用它提供的urlArgs设置虽然能解决这个问题,却又会带来一点浪费:其它未改动的文件也会被重新下载--在不考虑其它解决方案的情况下,这大概是唯一能使改动生效的办法了。
在企业级网站的开发过程中,代码开发只是一小部分:部署也同样重要。文件精简、压缩、使用 CDN 都是必不可少的。Grunt、Gulp等工具就是因此被开发出来,但是单靠这些工具仍然不能掌控整个前端开发到部署流程,所以我又开始了新一轮的寻找。
最近了解到了百度开发的 F.I.S ,它解决了企业级网站的很多问题,所以我想,不久之后,我又会写一篇关于FIS的博了 :)
手头有一个需求,要求当手机从竖屏旋转到横屏的时候需要做些处理。设备旋转时可以使用 resize 或是 orientationchange 事件得到通知,但判断当前设备是否是水平状态就有一些麻烦了。
一开始我使用的是 window.innerWidth 与 window.innerHeight 来判断,但在 Android 手机里,当输入法弹出来的时候,会导致 window.innerHeight 变小并触发 resize 事件,此时 window.innerWidth 就会大于 window.innerHeight,但这并不是我想要的。
后来,我开始使用 window.outerWidth 与 window.outerHeight,但在 iOS 下,这两个属性的值始终是 0。
谷歌一番之后,看到有人说使用 window.matchMedia("(orientation: landscape)").matches 来判断,但从 MDN 的文档上得知这个方法会产生跟 innerWidth 与 innerHeight 同样的问题。
同样的,还可以判断 window.orientation,但这个属性已经被弃用了。
还有一个 window.screen.orientation 属性,但是还没有标准化,各家浏览器的实现都不一致,所以也没法用。
思来想去,最后只能尝试一挨个检测了:
let isLandspace
if ('orientation' in window) {
isLandspace = function () {
return window.orientation === 90 || window.orientation === -90
}
} else if (window.outerHeight && window.outerWidth) {
isLandspace = function () {
return window.outerWidth > window.outerHeight
}
} else {
isLandspace = function () {
return window.innerWidth > window.innerHeight
}
}自从接触到 Webpack 之后我就爱上了它。
从 #27 开始,我就在我的项目里全面使用 Webpack 了,无论是写一个小的工具库(如 selection-widget、connect.io)还是一个完整的“产品”(划词翻译)。
说起来,一开始关注 Webpack 是因为我很喜欢 Vue.js,而它就是使用 Webpack 进行开发的,但我一直以来都有一个疑惑:为什么 Vue.js 生成出来的代码如此干净?你可以对比一下我的 connect.io 项目用 Webpack 生成的代码。
然后我发现,Vue.js 在开发时用的是 Webpack,但是最后将文件打包在一起的时候用的是 Rollup(见 vue/build.js)。生成的代码之所以这么干净,是因为 Vue.js 本身除了 ES6 module,几乎没有用到其它 ES6 语法(箭头函数、let const、变量解构之类的)。
类似于 Webpack,Rollup 也是一个模块打包工具,不过它的特色是仅加载模块里用得到的函数以减小文件大小。鉴于这一特性,它特别适合用来写工具库,比如我的 connect.io 就可以用它来生成最终的文件。另外,它生成的代码不会像 Webpack 那样用很多函数来包装模块,这一点我很喜欢——因为所有代码都在同一个函数作用域里,所以 Babel 不需要在每一个模块里都注入辅助函数了(即使用了 transform-runtime 也仍然会留有一点辅助函数。)
但就我来说,如果我要开发一个仅包含 js 文件的模块,我会用 Rollup 生成最终的文件,但如果我要写一个“产品”,我仍然会用 Webpack。Webpack 提供了太多实用的功能来提升开发(及部署)体验,这甚至可以让我忽略打包后文件的大小。而且,类似于 Vue.js,即使是开发一个模块,我仍然会使用 Webpack,只是在最后将模块合并的时候才会用到 Rollup.
首先我得承认,我脑洞很大。- -
在 #8 中,我指出 AngularJS 有一个不好的地方:默认情况下,所有控制器、指令、服务都需要先加载才完毕能启动应用。
但这次我走了另一个极端:所有控制器、指令、服务、甚至样式都做到按需加载。(项目在这里)
我承认我不顾后果的就开始做了,我也知道,这必然会让 HTTP 请求数(疯狂的)攀升。
所以我也没指望谁真的把那个项目用到生产环境里去= =
尽管如此,我仍然觉得这样做是有意义的,至少起了一个抛砖引玉的作用:在两个极端里,我们应该如何找到一个最佳的平衡点呢?
第一个极端是将所有文件都打包成 “all.js” 与 “all.css” ,但是任何一个小改动都会破坏用户的缓存,让用户重新下载这两个大文件。
第二个极端(即我的项目)是将所有文件都做成按需加载的。好处是对小文件的修改不会破坏其他文件的缓存,坏处是用户_每个路由的第一次访问_都要加载两三个甚至更多文件,延迟感比较明显。
为什么我还是觉得我的极端比较合理 = =
为了缓解 HTTP 请求数,我们可以将并不是公用的指令和服务直接写在控制器里,但即使如此,第一次访问一个路由时仍然需要加载三个文件:控制器,模板及样式。
实际上,这个模式就跟传统网站类似。当从一个页面点到另一个页面的时候,也是需要加载这三个文件的,此时模板一般会直接写在 html 里,而且 html 的缓存时间不敢设太长;使用 AngularJS 做到完全的按需加载后,就可以放心的给模板设置长一点的缓存时间了,毕竟模板里面不会引用脚本与样式。
欢迎大家讨论一下到底怎么做比较好 = =
cnpm安装,淘宝做了node-sass的镜像
https://cnodejs.org/topic/5637549fd426a1404cbd0614
有些node包依赖于phantom,安装也会失败,同样解决办法也是cnpm安装
看标题就知道,事情还得从划词翻译说起。
最近我着手准备开发 v6.0 版的划词翻译,这意味着划词翻译将第六次被完全重写。只是这一次我发现,划词翻译实际上可以分解成多个项目:
chrome.storage 的使用可以优化一下,于是有了chrome-storage-wrapper开发 chrome-storage-wrapper 的时候,我就已经用 Jasmine 写了一套测试用例;在开发 selection-widget 的时候,我决定全面启用单元测试。初期写测试用例的时候觉得有点痛苦,写用例的时间几乎要赶上开发时间了,但是测试用例写完之后就发现好处了:下一次更改代码的时候,只需运行一次测试就知道哪些地方做了不兼容的更改,这间接的消灭了很多隐藏的 bug。
我觉得,单元测试就好像是一个项目坚强的后盾,我可以放心的修改代码,单元测试会告诉我还需要改其他哪些地方。
就这样,我一下子就爱上了单元测试。selection-widget 是一个前端项目,使用 Karma 及它丰富的插件可以很容易的运行测试并生成测试覆盖率,完全不需要动脑筋。
现在我着手准备开发 translation.js,我觉得这个项目可以做成浏览器端和 node.js 端通用的模块——除了发起 HTTP 请求的方式不同,其它逻辑实际上是共通的。使用 Browserify 能写浏览器端与 node.js 端通用的代码, superagent 则是一个浏览器端和 node.js 端都能用的 ajax 库,真是感谢万能的开源社区!
那么问题就来了——node.js 的程序如何进行单元测试并生成测试覆盖率呢?
我非常喜欢 Jasmine 的语法,所以首先考虑使用它进行单元测试,而它也提供了一个在 node.js 端使用 Jasmine 的文档,按照上面的做法试了一下,成功!说起来测试 node.js 端的代码比测试浏览器代码简单多了,不需要把文件全都加载到浏览器里,只需在测试用例里 require() 一下就好了!
下一个问题就是如何生成测试覆盖率了,毫无疑问要用到 Istanbul——也就是 karma-coverage 的核心模块。
没想到这个厉害的模块用起来这么简单——当我看到它的项目主页上写着 istanbul cover test.js 的时候吃了一鲸。只是这个命令的参数必须要是一个脚本,所以我不能从命令行运行 jasmine 来测试,需要写成一个启动测试的 js 文件——说起来很高端,其实直接照抄 Jasmine 里的代码就行了:
// test-runner.js
const jasmine = new (require('jasmine'))();
jasmine.loadConfigFile('spec/support/jasmine.json');
jasmine.execute();然后在项目根目录使用 istanbul cover test-runner.js 就行了!
大功告成,只是为了能在项目主页上加一个 coverage | 99% 这样的图标,还需要将覆盖率数据上传到 Coveralls,这个功能参考 karma-coveralls 就知道怎么写了,原理就是把一个 locv.info 文件通过 Coveralls 提供的模块上传上去就行了。
就写这么多了,明天就付诸行动!
来自第二天的我的备注:上面说的功能都完成了,见 lmk123/translation.js
现在可以使用 CSS 中的 all 属性解决这个问题,见 MDN,但这么做还得阻止宿主页面上注册的事件,例如 document.addEventListener('click', ...)。
综合考虑下来,我还是觉得用 iframe 比较好。
对很多前端开发者来说,样式冲突是大部分人都会面对的问题。
以我的划词翻译为例(我知道它最近出镜次数太多),我需要在每一个用户打开的网页里插入一段 HTML 用来显示翻译结果:
const box = document.createElement( 'div' );
box.textContent = '翻译结果!';
box.style.color = 'red';
document.body.appendChild( box );按照我的预期,这段文字应该是红色的,但如果宿主网页有下面一段样式呢?
body { font-size: 50px; }
div { color: green !important; }最终,文字会变成绿色,并且字会很大:这就是我所说的“样式冲突”。在划词翻译中,这都是我不得不解决的问题。
按照 DRY(Don't Repeat Yourself)原则,我先去网上搜索了已有的解决方案。
社区做了很多努力让 Web 组件成为可能(例如 Polymer),其中解决了一个问题就是让组件内的样式不会影响到使用此组件的网页(类似于 Scoped CSS)——但是,本文想要解决的问题正好相反:如何保护组件的样式不会受到宿主网页的影响。
剩下的唯有 <iframe> 了:不仅隔离了样式,还隔离了执行作用域。这确实能解决本文提出的问题,但也带来了更多的问题。
目前,我给所有 HTML 元素加上了自定义的前缀让它们变成了自定义元素,并覆盖掉了宿主里的可继承样式:
const box = document.createElement( 'my-div' );
box.style.display = 'block';
box.style.fontSize = '20px';这确实能规避大部分的样式冲突,但它仍然不能抵挡来自可继承样式的冲突。另外,为了处理用户的输入,我还是得用到浏览器提供的表单元素(select、input、textarea 等),这部分元素正是样式冲突的重灾区。每当宿主上有一条样式会影响到我的表单元素,我都不得不新增一条样式盖过宿主样式。这幅画面就好像每当有一只矛刺过来的时候,我都不得不竖起一面盾来抵挡。
所以,目前最为完整的方案大概就是这样了:插入到宿主中的 HTML 片段全都使用自定义元素(包括表单元素),并且覆盖掉所有的可继承样式。最终,我的 HTML 片段看起来可能就会是这样:
<style>
/* 覆盖掉所有的可继承样式 */
app-container {
text-center: left;
font-size: 14px;
line-height: 14px;
/* and more... */
}
</style>
<template>
<!-- 使用自定义元素避免被宿主的 CSS 选择器匹配到 -->
<app-container>
<my-input></my-input>
</app-container>
</template>看起来真是乱七八糟。
类似于 <iframe>,Shadow DOM 能隔离样式,但与 iframe 不同的是,Shadow DOM 内部仍然与宿主网页处于同一个 document 对象里。
我一度以为 Shadow DOM 会是最终的解决方案,但我发现仍然不够:它确实能隔离一般的样式,但如果是定义在宿主网页的 <body> 元素上的可继承样式,仍然会影响到 Shadow DOM 内部的元素样式。查看在线示例
换句话说,我可以使用 Shadow DOM 来隔离宿主对表单元素的样式,但我仍然要覆盖来自 <body> 的可继承样式。这种方式比起自定义元素 + 样式覆盖的方式并没有很大的改进。
所以,我可能仍然要一条一条样式的打补丁了。
关于 NPAPI 的简介请移步维基百科(英文)。文章中开发的 Chrome App 源码在这里。
前段时间,Google Chrome 禁用了 NPAPI 插件,导致我们公司里原本用 Java 写的读取电子秤读数的浏览器插件失效了,而目前谷歌官方推荐的替代方案是 Native Client,当然对于我这个前端来说,C/C++ 的东西一时半会儿搞不定。
然后我注意到,Chrome Apps 能访问到系统的底层硬件服务,比如串行端口、USB、蓝牙和网络连接,而公司的电子秤是使用串行端口连接到电脑的。
于是我开始考虑使用 Chrome Apps 替代 NPAPI 的可行性了。
假设我能正常使用 Chrome Apps 读取到电子秤的读数,那还需要一种方式,能让普通网页获取到 Chrome Apps 里的数据。在开发 Chrome 扩展程序的时候,普通网页能通过外部消息通信达到这个目的,搜寻一番之后,发现 Chrome Apps 也有这个功能。(只是藏的略深,菜单栏里没有显示出来这个网页,必须到 manifest 文件格式里找到 externally_connectable 这个字段点击进去才看得到。)
作为一名前端,能涉及到系统硬件的开发让我觉得兴奋不已,所以我立刻着手开始开发这个 Chrome Apps 了。
我在公司的电脑是笔记本,本身没有串行端口,但公司有一根转接口,能转接到 USB 插口。这种情况下应该使用串行端口 API 还是 USB API?我也不知道,我先试了试使用串行端口 API,然后就成功接收到电子秤发送过来的数据了!
电子秤发送过来的数据经过 Chrome 处理后都是 ArrayBuffer,要自己转换成 String 类型。电子秤会不停的发送数据,每次只发送一至两个字符,将这些字符打印出来后,发现它们是有规律的:电子秤在稳定时会以换行符作为分隔符发送电子秤的读数。稍作处理,就能读取到一整行的、完整的数据了。
再加上一些外部消息调用的处理,普通网页就能读取到电子秤的读数了!这样看来,使用 Chrome Apps 替代 NPAPI 并非不可能。
本文首发于饿了么大前端知乎专栏:使用缓动函数制作更自然的动画,这里在我的博客再发一遍 😝
自然界中的物体从起点移动到终点时,速度从来不是一成不变的。汽车启动时速度会由慢变快,停止时则由快变慢;篮球落地时会在地上来回反弹,并逐渐停止运动。大家都期待事物的呈现遵循一定的运动规律,所以,在网页中适当的使用动画能让用户得到更舒适的体验。
要制作出更加自然的动画,就需要理解什么是缓动函数。简单来说,缓动函数用于控制动画从初始值运动到最终值的速率。幸运的是,业界已经整理出了一些常用的缓动函数曲线,本文将向读者介绍如何在 CSS 与 JavaScript 里使用这些缓动函数。
CSS 提供了四种基础的缓动函数:
linear 表示线性动画,动画从开始到结束一直是同样的速度,看起来不是很自然。ease-in 表示缓入动画,动画的速度先慢后快,就好像汽车启动时一样。缓入动画会在速度最快时停止,这会让动画结束得很突然,因为自然界中的运动总是慢慢减速后才停止的。ease-out 表示缓出动画,与缓入动画正好相反,缓出动画的速度先快后慢,就好像汽车慢慢停止一样。ease-in-out 表示缓入缓出动画,它的速度由慢变快,最后再变慢,就好像汽车启动、加速、然后停下来一样。总的来说,线性动画与缓入动画不太符合自然运动规律;缓出动画初始速度很快,能给人一种快速反应的感觉;缓入缓出动画更符合自然界的运动规律,但是动画开始时速度很慢,会显得很迟钝,所以运行时间不宜过长,一般最好控制在 300 至 500 毫秒之间。
文章开头提到的常用缓动函数也是以这种规则命名的,所以很容易就能区分。虽然 CSS 不提供这些缓动函数,但可以通过贝塞尔曲线来定义这些缓动函数。例如,要让一个元素的高度用名为 easeInOutCubic 的缓动函数来变化,可以这样写:
div { transition: height 0.2s cubic-bezier(0.645, 0.045, 0.355, 1) }cubic-bezier() 内定义的四个数字实际上是两个点的坐标,用这两个点就可以确定缓动函数的运动曲线了,由于篇幅有限,这里就不深入解释了。
除了使用这些预定义的缓动函数,你也可以使用 cubic-bezier.com 和 matthewlein.com/ceaser 这两个在线工具自定义运动曲线。值得一提的是,你可以在这些工具中把两个点拖动到坐标轴外面来让动画在运动过程中"超出"最终值——想象一下我们在上物理课时做过的关于弹簧的实验,弹簧的一端绑着一个铁球,铁球落到最低点时的水平位置会超过铁球最终停下时所处的水平位置。
如果你仔细看过了前文提到的常用缓动函数的网站,你会发现有一些缓动函数没法在 CSS 中使用,只能用 jQuery 加上 jQuery Easing 插件实现,例如刚才提到的"弹簧"动画:
div.animate({ top: '-=100px' }, 600, 'easeOutElastic', function () { … })仅仅为了制作一个动画就在项目里引入两个依赖太不值得了,所以这里介绍一下如何在不引入任何依赖的情况下使用缓动函数。
查看 jQuery Easing 插件的源码就会发现,JavaScript 里的缓动函数是真的"函数",其中 easeOutElastic 函数的定义如下:
const c4 = (2 * Math.PI) / 3
function easeOutElastic (x) {
return x === 0 ? 0 : x === 1 ? 1 :
Math.pow(2, -10 * x) * Math.sin((x * 10 - 0.75) * c4) + 1
}看不懂?没关系,我也看不懂。一般情况下,我们不需要深入了解每个缓动函数是如何实现的,只需要知道它接收一个参数 x,这个参数代表当前动画的运动时间点,并返回这个时间点动画所处的位置。
简单解释一下这里所说的动画的「运动时间点」与「运动位置」。
我们可以将一个动画的开始到结束理解为动画从 0% 的时间点运动到了 100% 的时间点(即缓动函数曲线的 X 轴),所以动画开始时,x 的值就是 0,运行到一半时,x 的值就是 0.5,结束时,x 的值就是 1,依此类推。当动画的时间点从 0% 运行到 100% 的时候,动画的位置也同样从 0% 运动到了 100%(即缓动函数曲线的 Y 轴),这两个轴从 0 出发运动到 1 时所形成的点就组成了「缓动函数曲线」。
这样理解的话,线性动画的缓动函数曲线是一条直线也就不难理解了——它的运动时间对应的运动位置总是相同的。
现在,假设我们需要使用 easeOutElastic 函数在两秒钟内将一个 div 的高度从 100px 运动到 400px,我们可以这样写(注释可能有一点啰嗦):
const div = document.getElementsByTagName('div')[0] // 要变化高度的 div
const startValue = 100 // div 的初始高度
const endValue = 400 // div 的最终高度
const changeValue = endValue - startValue // div 变化了这么多高度
const during = 2000 // 动画持续 2 秒钟
// 为了让动画足够流畅,我们需要达到 60 帧/每秒的动画速率,
// 即大约 17 毫秒更新一次动画的状态
const updateTime = 1000 / 60
// 计算出两秒内我们需要更新动画的状态多少次
const updateCount = during / updateTime
// 我们需要一个在下一帧更新动画状态的函数
const rAF = window.requestAnimationFrame || function(cb) { setTimeout(cb, updateTime) }
const startPosition = 0 // 动画的开始时间点是 0%
const endPosition = 1 // 动画的结束时间点是 100%
// 因为我们要在动画从 0% 运动到 100% 时更新 `updateCount` 次动画,
// 所以要计算出每次更新动画时动画经过的时间
const perUpdateDistance = endPosition / updateCount
let position = startPosition // 记录动画的当前时间点
function step () {
// 计算 div 在当前时间点的高度
const height = startValue + changeValue * easeOutElastic(position)
div.style.height = height + 'px' // 更新 div 的高度
position += perUpdateDistance
// 如果动画还没结束,则准备在下一帧更新动画
if (position < endPosition) {
rAF(step)
} else {
console.log('动画结束')
}
}
step() // 开始运行动画你可以查看这段代码的运行效果。
理解了动画运行的过程之后,上面的代码很容易就可以封装成一个可以重复使用的 tween 函数:
const updateTime = 1000 / 60
const rAF = window.requestAnimationFrame || function(cb) { setTimeout(cb, updateTime) }
/**
* 简单的执行缓动函数的方法
* @param {number} startValue - 初始值
* @param {number} endValue - 最终值
* @param {number} during - 持续时间
* @param {function} easingFunc - 缓动函数
* @param {function} stepCb - 每次更新动画状态后执行的函数
* @return {Promise}
*/
function tween (startValue, endValue, during, easingFunc, stepCb) {
const changeValue = endValue - startValue
const updateCount = during / updateTime
const perUpdateDistance = 1 / updateCount
let position = 0
return new Promise(function(resolve) {
function step () {
const state = startValue + changeValue * easingFunc(position)
stepCb(state)
position += perUpdateDistance
if (position < 1) {
rAF(step)
} else {
resolve()
}
}
step()
})
}使用 tween 函数实现同样的弹簧效果可以这样写:
const div = document.getElementsByTagName('div')[0]
tween(100, 400, 2000, easeOutElastic, height => div.style.height = height + 'px')
.then(() => console.log('动画结束'))这样,你就可以代入 jQuery Easing 插件中所有的缓动函数并尝试不同的动画效果了。
jQuery Easing 插件在 v1.3.2 及之前的版本实现的缓动函数有五个参数,但这种实现方式参杂了运动的过程所以无法细粒度的控制动画的进度,不建议使用。
另外,文中实现的 tween 函数比较粗糙,并且一次只能变化一个属性,在实际项目中可以使用开源社区的其它实现,例如 Shifty。
最后,希望这篇文章能帮助大家更好的理解和制作动画,谢谢。
NPM 3 发布之后,我发现 node_modules 原本的树状结构变成了平级结构(不知道描述是否准确),这进一步让我思考该不该用 NPM 替代 Bower 了。
一个项目里要维护两份结构相差无几的配置文件(package.json 与 bower.json)比较繁琐,而且流行的前端项目会同时发布到 Bower 和 NPM 里。其中,package.json 是必不可少的,而 Bower 更适合前端项目的原因就在于这几点:
而如果使用 NPM 替代 Bower 有以下几点优势:
bower install 一下了)也就是说,如果我想用 NPM 替代 Bower,那我得自己想一个办法,将前端的第三方库复制到另一个路径里。这一点并不难,但这样做的话我还是得维护一份要从 node_modules 复制到自定义路径的文件列表,并且每次安装前端依赖时都要执行一次。
啊,让我再考虑一下吧。
第一次通读 Vue.js 的文档的时候是 v1.0.12。现在 Vue.js 已经 v1.0.24,虽然仍然没有到 v1.1,但添加了很多新的功能,所以今天花了点时间重新通读了一遍文档,顺便将其中容易遗漏的细节记录一下。
在 1.0.19+ 中,可以在数组语法中使用对象语法:
<div v-bind:class="[classA, { classB: isB, classC: isC }]">
1.0.16 添加了两个额外的修饰符:
<!-- 添加事件侦听器时使用 capture 模式 --> <div v-on:click.capture="doThis">...</div> <!-- 只当事件在该元素本身(而不是子元素)触发时触发回调 --> <div v-on:click.self="doThat">...</div>
<input type="checkbox" v-model="toggle" v-bind:true-value="a" v-bind:false-value="b">// 当选中时 vm.toggle === vm.a // 当没有选中时 vm.toggle === vm.b
一直不知道 Checkbox 可以分别指定 true 和 false 时的值。
当需要和第三方的 CSS 动画库,比如 Animate.css 配合时会非常有用。
和 Framework7 配合也挺有用的,它用的是 .modal-in、.modal-out 这一类的命名。
文档上说 v-show 也能使用过渡,但在开发 vue-framework7 的时候,v-if 能触发过渡,但是替换成 v-show 的话总是不正常。有空深入研究一下。
type也可以是一个自定义构造器,使用instanceof检测。
感觉没有什么场景会用到这一点,但作为以前不知道的事情还是记录一下。
这个做法挺好,以后就这么干了。
可以 <router-view transition="iOS-switch" transition-mode="out-in"></router-view> 实现类似于 iOS 风格的页面切换效果。
一旦全局注册混合,它会影响所有之后创建的 Vue 实例。
文档上把上句中的“所有”两个字加粗了,但是我加粗了“之后”这两个字,因为碰到了一个小坑:vuejs/vue-router#410
名字以 _ 或 $开始的属性不会被 Vue 实例代理,因为它们可能与 Vue 的内置属性与 API 方法冲突。用 vm.$data._property 访问它们。
一开始我以为可以通过这个办法来避免 Vue 将一些常量属性变成 getter/setter。
我所说的“常量属性”是指一些模版里要用到、但永远不会发生变化的数据——将这种数据的所有属性转换成 getter/setter 太浪费性能了。
举个例子,下面的 options 属性仅仅是用来渲染一个下拉框的,永远不会发生变化:
<select>
<option v-for="option in options" v-text="option.name" :value='option.value'></option>
</select>new Vue({
data: {
options: [{ name:'选项一', value: 1 }, { name: '选项二', value: 2 }]
},
ready () {
console.log(this.options)
}
})查看控制台,你会发现 Vue.js 会遍历 options 里的每一个对象并将它们的属性转换成 getter/setter。
本来我以为,如果我们这样写,那 Vue 就会“放过” _options:
<select>
<option v-for="option in $data._options" v-text="option.name" :value='option.value'></option>
</select>new Vue({
data: {
_options: [{ name:'选项一', value: 1 }, { name: '选项二', value: 2 }]
},
ready () {
console.log(this._options) // undefined
console.log(this.$data._options)
}
})可是查看控制台,我发现 Vue 仍然遍历了 _options ,其中的每个对象属性都变成了 getter/setter。改变了 this.$data._options,DOM 仍然是会更新的!说白了仅仅只是没法用 this._options 访问到而已。查看在线示例
不过我们可以这么写:
<select>
<option v-for="option in $data._options" v-text="option.name" :value='option.value'></option>
</select>new Vue({
data () {
this._options = [{ name:'选项一', value: 1 }, { name: '选项二', value: 2 }]
},
ready () {
console.log(this._options) // 数组能在模版里使用,但没有被转换成 getter/setter
}
})这个新加的配置挺有意思。
完。
在 Windows 下安装 Node.js 时,若启用了 Add to PATH 选项(默认启用),但当前账号又没有足够的权限读写环境变量时,在安装过程中会弹出警告,安装结束后运行命令行 node -v 和 npm -v 都会提示“命令不存在”。
这种情况下,我需要手动将 node 与 npm 这两个路径添加到环境变量中。
首先需要知道安装 Node.js 时的安装路径。默认情况下,Node.js 会被安装到 C:\Program Files\nodejs。
依次打开“控制面板”->“系统”->“高级系统设置”,切换到“高级”选项卡,点击下方的“环境变量”按钮,在用户变量里或者系统变量里找到名为 PATH 的变量,然后单击它并点击下方的“编辑”,在值里面追加上面说的 Node.js 的安装路径,并用分号(;)隔开,例如 ;C:\Program Files\nodejs。
点击“确定”后不要关闭“高级系统设置”,现在只添加了 node 命令,后面还需要添加 npm 命令。
打开一个命令提示符,输入 node -v 与 npm -v,现在就能显示安装的 Node.js 的版本号了。
然后安装最新版的 npm:
npm i npm -g
安装完成后会显示 npm 的安装路径,一般情况下是 C:\Users\你的用户名\AppData\Roaming\npm。将这个路径以同样的方法追加到上面说的 PATH 环境变量里。
然后再安装全局模块(特别是附带命令行的模块)时,就能正确找到命令了。
现在是凌晨三点三十八分 :)
本来我一点钟的时候是准备睡的,然而正准备关灯的时候,我一不小心瞟到了角落的《数据结构与算法 JavaScript 描述》(下面简称《算法》)。
这本书刚买回来时,我简单翻了一下前两章,然后就后悔买这本书了:书上讲的都是很基础的内容,第一章完全就是给 JavaScript 新手看的,第二章讲了 Array 的一些方法,而这些内容我早在《JavaScript 权威指南》里面就看过了。
这也是这本书一直被我放在角落的原因。
为了避免自己去睡觉(明明很困但就是不想睡),我翻了翻这本书,发现第二章有四个习题,粗略看了看也不难,正好拿来清醒一下大脑。
前三题没什么难度,轻松完成。但是第四题却让我意识到,这本书可能没我想像中的那么简单:
创建这样一个对象,它将字母存储在数组中,并且用一个方法可以将字母连在一起,显示成一个单词。
我先试着理解了一下题目。它似乎是要实现这样一个函数,我们假设它叫 word:
word( 'o', 'n' ); // 输出单词 no
word( 's' , 'y' , 'e' ); // 输出单词 yes
word( 'j', 'v', 'a', 'a' ); // 输出单词 java
word( 'c', 'i', 's', 't', 'p', 'r' ); // 输出单词 script这道题跟前面三题、跟前两章给 js 新手看的内容根本不是一个级别啊!!
按照我的思路,我首先得列出输入的这几个字母所能组合成的所有字符串,然后再验证它是不是一个有效的单词。例如上面的 ['s','y','e'] 可以组合成:
sye sey
yse yes
esy eys
而其中只有 yes 是英文单词。
……好难!我只是一个前端,在工作中从来没碰到这样的场景啊!!但这却激起了我的兴趣,我的瞌睡一下子就没了。
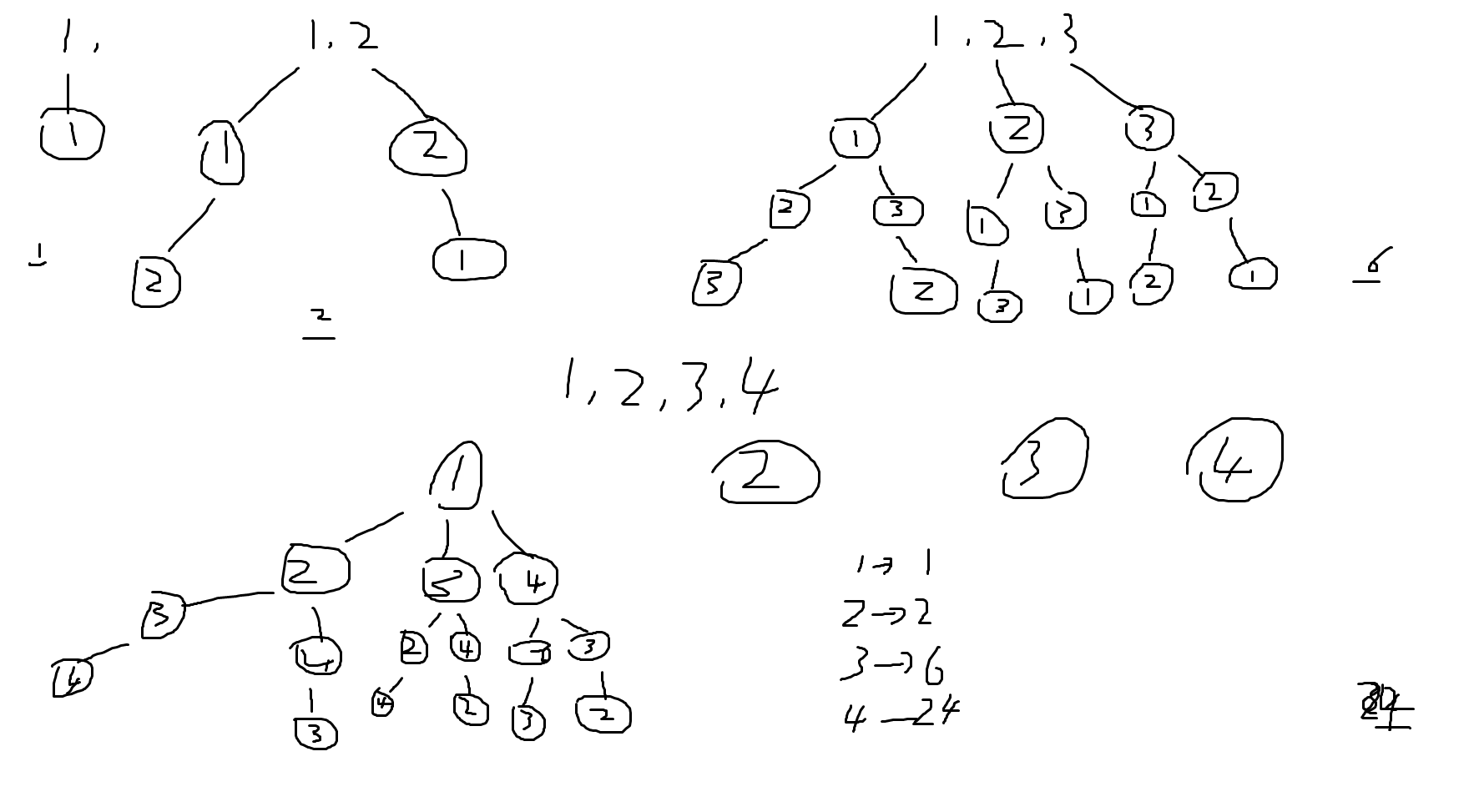
为了方便我理解字母组合成单词的过程,我专门画了一张图:
(我知道这图很 low,将就看一下吧 - -)
如图所示,单词的组建过程其实就是一个树状结构。即使我知道了这一点,可是我怎么知道它所有的路径呢?
我尝试从字母个数与组合结果这两个数据之间寻找联系。我注意到这么个规律:
字母的个数 组合结果
1 1
2 2
3 6
4 24
虽然我算不出其中的规律,但是我总觉得这种结构在哪见过,我记得《JavaScript 语言精粹》里面好像讲到过一个斐什么那什么的数列,而这本《算法》好像也在哪提到过。往书的前面翻了翻,果然,它在第 1.2.7 节里讲解“递归”的时候用到了这个函数(虽然书上没说这个函数跟一个数列有关,但函数的名字我还是记得的):
function factorial(number) {
if (number == 1) {
return number;
} else {
return number * factorial(number -1);
}
}由此可以算出,当字母的个数有 5 个时,最终组合出来的结果有 1 * 2 * 3 * 4 * 5 = 120 个。
可是知道这一点对我没有任何帮助,我需要一个遍历这颗“树”的方法,从而得到最终这 120 个组合结果。
我把这棵树从“分层”的角度来看,每一层都要比上一层少一个节点,而这一层就是由从上一层里面剩余的几个节点组成的(我知道很绕口)。根据这个想法,半小时后,我的第一版出来了:
// 复制(或将类数组转换为真)数组的辅助函数
function copyArr( arr ) {
return [].slice.call( arr , 0 );
}
function list() {
var args = copyArr( arguments ) ,
length = args.length ,
tree = [];
for ( var i = 0 ; i < length ; i += 1 ) {
var layer = [];
layer.push( args[ i ] ); // 依次抽出元素
args.forEach( function ( v , index ) {
if ( i !== index ) {
layer.push( v ); // 将剩余元素加到层中
}
} );
tree.push( layer );
}
console.log( tree );
return tree;
}很明显这是不对的……执行 list( 's', 'y', 'e') 之后,控制台只输出了三个结果:
[ [ 's', 'y', 'e' ], [ 'y', 's', 'e' ], [ 'e', 's', 'y' ] ]苦思冥想一番,发现真是没什么头绪,就像一头狼看到了一个刺猬,不知道从哪里下嘴。终于,半个小时过后我放弃了,把书往旁边一扔,关灯睡觉。
我躺下之后,脑海里仍然还想着上面那幅图,突然大脑里灵光一闪:当我躺下来的时候,那幅图也跟着逆时针旋转了 90 度,原本的树结构变成了很容易理解的“对象”。例如 [ 's', 'y', 'e' ] 的样子变成了下面这样:
{
s:{
y:{
e:{} // sye
},
e:{
y:{} // sey
}
}
// ...下面类似,不再列出
}从这个角度看的话,思路一下就明了了:我只需要一层层生成这棵树就可以了!就如上面所说,下一层比上一层少一个元素,所以我需要一个将某个元素从数组中抽离的方法,而一层层的生成树肯定要用到递归!
我一下子从床上弹了起来,赶紧重新开了电脑(关闭了还没半分钟),然后写下了第二版:
// 将 arr 中的 element 抽离,并返回抽离之后的新数组
function spliceFormArr( arr , element ) {
var i = arr.indexOf( element ) ,
c;
if ( i >= 0 ) {
c = copyArr( arr );
c.splice( i , 1 );
}
return c;
}
function list() {
var args = copyArr( arguments ) ,
root = {};
subTree( root , args );
console.log( root );
return root;
// 生成子树的方法
function subTree( root , arr ) {
// 当子树里最终一个节点都没有的时候,这里就不会执行 forEach 了
arr.forEach( function ( v , i , a ) {
// 为子树上的每一个节点创建一个对象,并在下一层中抽离父节点
subTree( root[ v ] = {} , spliceFormArr( a , v ) );
} );
}
}信心满满的执行了 list( 's', 'y', 'e'),结果如下:

真是太棒了!!关键点攻破之后,重复字母、性能优化、单词匹配等问题也就不难了——一步步解开一个题目的感觉真是太好了!!
(第二天我发现我高兴的太早了,即使我生成了这棵树,我还是不知道怎么拿到最终的组合结果……)
我一下子喜欢上了这本书。
这是我第一次深刻理解到“算法”两字的含义。
解完题后,我意犹未尽,谷歌了一下“算法”,在知乎上看到一个人将《算法导论》里 99% 的题目做完了,结果却因为是本科生,所以被人认为只是纸上谈兵而找不到好工作的故事。
我真正被作者感动的是他在评论里留下的一句话:“我会变强的,哪天变得足够强,以至于有人愿意为我一个人破例,以至于这些规则不再成为束缚。"
作为公司里唯一的前端,代码组织方式一直是我在考虑的事情,而文章的标题就是我一步步实践过来的路程。
最开始的时候,我毫无例外的使用最普遍的 <script> 方式加载代码,我做的网页看起来就像这样:
<link rel="stylesheet" href="bootstrap.css">
<link rel="stylesheet" href="common1.css">
<link rel="stylesheet" href="common2.css">
<link rel="stylesheet" href="page.css">
<script src="jquery.js"></script>
<script src="common1.js"></script>
<script src="common2.js"></script>
<script src="page.js"></script>就像大多数人做的那样,整个网站都用到的 style 与 script 放在最上面,某些页面之间公用的文件次之,最后是单个页面用到的文件。
后来我发现,这样做会有一些问题:
<script> 标签就失控了。window.MyApp.module1,但时间长了就不知道这个命名空间里有些什么模块、这里面的模块相互之间是怎么依赖的了<script> 标签的加载方式无法做到按需加载;defer 与 async 只是延迟加载了,并没有做到按需加载。为了彻底杜绝不可控的 <script> 标签,我在后来开始使用 RequireJS 并从此爱上了它(当然,我也专门为 RequireJS 写过一篇博文):
<script> 标签就够了require() 函数的使用就可以了button.onclick = () => require(['beautiful-alert'], myAlert => myAlert('Hello World.'));基于上面的这些理由,我一直以来都坚决“拥护” AMD 的加载方式,即使是用 AngularJS 做的单页网站,我还是会使用它,并为此研究了如何异步加载 AngularJS 的控制器、指令、模块等(这是因为开发时会将代码分成很多块,而我需要一种方式在生产环境中将它们合理的合并在一起,最大化的提高网页加载速度。顺带一提,jQuery 也是用它来组织代码的,你可以在源码里找到熟悉的 define())。
即使后来 Browserify 的横空出世也没有改变我的立场。我发现 Browserify 在开发浏览器/ NodeJS 端的通用模块时很有用,并用它开发了 translation.js,但如果让我选择,我依然会在以后的项目中使用 RequrieJS 而不是 Browserify ——我甚至在开发划词翻译 v5.x 时也用了 RequireJS,而实际上由于 manifest.json 里的内容脚本不允许异步加载扩展里的脚本,所以 Chrome 扩展更适合用命名空间的方式组织代码。
最近开发划词翻译 v6.x 时,我考虑再三,还是决定使用命名空间而不是 RequireJS 来组织代码。一来扩展里文件也不多,用 RequireJS 有种大材小用,二来文件合并之后其实 RequireJS 作为加载器就不需要存在了,感觉有点占用空间(我不是处女座)。
但是在开发的时候,有一点让我很不爽——我的项目里除了 package.json ,还要加一个 bower.json。我在 #22 说明了为什么我不想再用 bower.json 了,而这时我发现,Vue.js (我的新宠)使用 webpack 来组织代码,还写了 vue-loader 用于加载 vue 组件。
虽说没有哪个工具能替代另一个工具,只有最适合的工具——但 Webpack 完全能替代 Browserify,并为开发模块、单页网站或是多页网站提供了更强大的功能。实际上我很早就 Star 了它,但在简单的看了文档之后觉得学习成本有点高,所以就先放着了。
然而今天,我花了一个下午的时间提交了一个 PR,并最终成功用它取代了命名空间的代码组织方式。我发现如果我不去看它生成的那一坨代码,在浏览器端使用 CMD 来组织代码的方式我还是能接收的。
并且,我顺利的删除了跟 Bower 有关的所有文件,项目里只有一个 package.json 的感觉舒服多了。
不过我想说的是,webpack 虽然能很好的支持多页网站,但这会让配置变得很复杂(主要的复杂度体现在将多个文件的通用模块分割开来),并且为了让输出的文件在不同的文件夹下,你需要使用多个 webpack.config.js(我暂时没有找到其他将文件输出在不同文件夹的方法)。但在如今这个 AngularJS 与 Vue.js 越来越流行的时代,webpack 在单页网站及模块开发上还是很有用的。
最近我正在开发公司网站的移动端网站——考虑到功能繁多且无需服务端渲染,也许用 “Web App” 来形容会更准确一点。
公司希望这个 Web App 能运行在微信里,并使用微信 SDK 提供的各种功能(特别是“扫描条形码”的功能)。也就是说,公司想要一个“微信 only” 的网站。
但实际上,我更倾向于“渐进增强”的做法。
以“扫描条形码”举例来说,除了微信,PhoneGap 也有插件提供这个功能。我的想法是:开发一个基本的 Web App,这个 Web App 应该能在任何浏览器环境(普通浏览器、微信内置浏览器或者 PhoneGap)里使用,但如果用户点击了“扫描条形码”的按钮:
也就是说,我们可以把这部分逻辑独立出来,并在不同的环境引用不同的功能:
let api;
if( isWeixin ) {
api = {
scan() {
wx.scanQRCode();
}
};
}
if ( isPhoneGap ) {
api = {
scan() {
// 插件提供的某个方法
scanFuncProviedByPlugin();
}
};
}
if ( isNormal ) {
api = {
scan() { alert( '无法使用扫一扫功能,请在微信中打开此链接,或者下载我们的手机客户端。' ); }
};
}
api.scan();这样做的好处是,如果以后又有新的运行环境出现了(例如在 Chrome App 中运行),那我们只需要多添加一个 api 就可以无缝迁移了。
在新的项目里,我已经开始全面使用 Babel 与 SASS 了。本来 WebStorm 里自带 File Watcher 功能,但我认为项目本身应该尽可能的脱离编辑器环境,这样每个人都可以使用通用的方法进行开发,所以自己写了一个 gulp 任务:lmk123/gulp-es6-sass。
然而,我现在决定使用 WebStorm 里的 File Watcher 了,原因如下:
不得不说,用 WebStorm 编程真是一种享受,项目的单元测试也能使用 WebStorm 执行。也许以后我会越来越依赖 WebStorm 了。
附上使用 WebStorm 编译 es6 与 scss 的教程:
http://blog.jetbrains.com/webstorm/2015/05/ecmascript-6-in-webstorm-transpiling/
https://www.jetbrains.com/webstorm/help/transpiling-sass-less-and-scss-to-css.html
其中 scss 要用 gem 安装,遇到安装错误可以参考此链接。
简单记录一下解决过程:
$ gem sources -r https://rubygems.org/
$ gem sources -a https://ruby.taobao.org/
$ gem install sass
不过 File Watcher 只在文件改变的时候触发,但也可以用这种方式手动触发:
run file w,此时出来的第一个选项就是 Run File Watcher你也可以给这个动作分配一个自定义的快捷键,见这里。
新建 Watcher 的时候,WebStrom 的默认设置就已经能运行了,但还是推荐将 Show Console 设为 Never,否则每次编辑文件到一半就会弹出一个语法错误的消息。
WebStorm 默认的 Scss File Watcher 配置需要改进一下:
.scss 文件归为一组,需要在 Output paths to refresh 选项后面加上一段 :$FileNameWithoutExtension$.css.map,变成 $FileNameWithoutExtension$.css:$FileNameWithoutExtension$.css.mapInvalid GBK character "\xE8" on line 1 的错误,解决方法是在每个文件第一行加上 @charset "utf-8";Track only root files的勾,否则编辑以下划线开头的.scss文件时,引用了这个文件的那些文件不会被重新编译。A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.