This document mainly works as an paper List in categories 🐱 Also, our notes for read papers are linked beside, which could hFelp us recall the main idea in paper more quickly.
🎫 Note that
The paper Information is listed at such format
"Paper Name" Conference/Journal/Arxiv, year month, MethodsAbbreviation Authors(optional) [paper link]() [code link]() [paper website link]() [the Note link, which we makde summary based on our understanding]() short discription(optional)If only the paper website is listed, it denotes the paper link and code link could be found in the website page.
The priority order of papers in each category is based on paper importance(based on our task) and then paper-release time.
emoji meaning :warning: : no official code. :construction: code is obscure :statue_of_liberty: / :star:: canonical paper. :bulb:: novel thoughts. :+1:: recommend to see this first. :baby_chick: : has only skimmed through
Here is Table Of Content! 📖
[TOC]
- "Bringing Old Photos Back to Life" CVPR oral, 2020 Apr ⭐ paper(CVPR version) paper(TPAMI version) code website note
Pascal VOC 上合成噪声(DA & 噪声模板 collect 62 scratch texture images and 55 paper texture image);可以参考消除合成数据和真实数据之间 domain gap 的方法。
Face Enhancement 模块用 FFHQ 数据
无监督方式!!将灰度图人脸修复为彩色图 >> Sibling 概念,使用预训练 stylegan 的优良颜色特征,用 StyleGAN 生成先弄一个类似的人脸(颜色ok,人不像),然后另外训一个 decoder 生成结构和原图相似的人脸,Color Transfer,contextual loss 训练。无监督方式训练:模拟一个老相机的退化,将 RGB 转为灰度图,与原图做 reconstruction loss (这里前提是数据集本身的噪声并不多,没有扭曲很多情况下)
-
"Pik-Fix: Restoring and Colorizing Old Photo" WACV, 2022 May paper code pdf
有数据集,发邮件回复下载 GoogleDrive >> Runsheng Xu
RealOld 200个老照片,有 Expert 修复过的 GT!
-
"Modernizing Old Photos Using Multiple References via Photorealistic Style Transfer" CVPR, 2023 Apr, MROPM paper code website note
从风格迁移的角度做,修复完划痕看起来还很旧,修改风格
Dataset: 从韩国 3 个博物馆收集到的文物照片,拍摄样式老旧,但没有明显的划痕
-
"Self-Prior Guided Pixel Adversarial Networks for Blind Image Inpainting" TAPMI, 2023 June paper pdf
-
"Focusing on Persons: Colorizing Old Images Learning from Modern Historical Movies" 2021 Aug, HistoryNet paper code
-
"DeOldify: A Review and Implementation of an Automatic Colorization Method" IPOL, 2022 Apr,
DeOldifypaper code pdf -
"Towards Robust Blind Face Restoration with Codebook Lookup Transformer" NeurIPS, 2022 Jun, CodeFormer 🗽 paper code website
Blind Face Restoration SOTA, 老照片修复
预测划痕、雨水区域,伪影问题的处理
- "DeSRA: Detect and Delete the Artifacts of GAN-based Real-World Super-Resolution Models" ICML, 2023 Jul
paper code blog_explanation
⚠️
解决 GAN-SR 的伪影问题,分析 L1 Loss 细节过于突兀,Gan Loss 容易产生伪影但细节很自然,关注如何融合两个 loss 能写成一个工作
-
"Sparse Sampling Transformer with Uncertainty-Driven Ranking for Unified Removal of Raindrops and Rain Streaks" ICCV, 2023 Aug paper code pdf note Authors: Sixiang Chen, Tian Ye, Jinbin Bai, Erkang Chen, Jun Shi, Lei Zhu
-
"Restoring Degraded Old Films with Recursive Recurrent Transformer Networks" code
-
"CLIP-DINOiser: Teaching CLIP a few DINO tricks"Sakuga-42M Dataset: Scaling Up Cartoon Research paper code note
CLIP lack of spatial awareness makes it unsuitable for dense computer vision tasks && self-supervised representation methods have demonstrated good localization properties
take the best of both worlds and propose a zero-shot open-vocabulary semantic segmentation method, which does not require any annotations
🎯 Current Working Direction!
- "DeOldify" open-sourced toolbox to restore image and video code
strong baseline in multi papers 👍
-
"DeepRemaster: Temporal Source-Reference Attention Networks for Comprehensive Video Enhancement" SIGGRAPH, 2019 Nov 🗽 paper website note
baseline in "Bringing Old Films Back to Life"
-
"Bringing Old Films Back to Life" CVPR, 2022 Mar ⭐ paper code website note
crop 256 patches from REDS dataset and apply the proposed video degradation model(DA & noise template) on the fly
REDS
sharp data: train 240 video and each has 100 Frame collect 63 old films from the internet for evaluation -
[x]
-
"DSTT-MARB: Multi-scale Attention Based Spatio-Temporal Transformers for Old Film Restoration" Master Thesis report, 2022 Sep thesis-report local pdf
硕士论文,里面整合了上面 3 个文章Unsupervised Model-Based Learning for Simultaneous Video Deflickering and Deblotching
-
"Stable Remaster: Bridging the Gap Between Old Content and New Displays" Arxiv, 2023 Jun ⭐ paper code note
针对视频 aspect ratio 调整,对画面两边 black bar 背景区域用其他帧的背景补充。用 image-stitching 方法,对于缺失区域的小图像用 pretrained Stable-diffusion 生成(
diffusers.StableDiffusionInpaintPipelineAPI 可以传入prompt="animated background",和 mask)类似实验报告,可以学习下 pipline 各个模块API,例如: image-stitching(cv2), torchvision 用 MaskRCNN 做前景分割,
diffusers.StableDiffusionInpaintPipeline -
"VRT: A Video Restoration Transformer" ArXiv, 2022 Jun, VRT paper code
an unified framework for video SR, deblurring and denoising
-
"Recurrent Video Restoration Transformer with Guided Deformable Attention" NeurlPS, 2022 June, RVRT 🗽 paper code note
Video SR, deblurring, Denoising
dataset: 30 frames for REDS [53], 14 frames for Vimeo-90K [87], and 16 frames for DVD [63], GoPro [54] as well as DAVIS [31]
-
"Blind Video Deflickering by Neural Filtering with a Flawed Atlas" CVPR, 2023 Mar ⭐ paper code website note
用 Nerf 类似的 atlas 处理视频一致性问题
有公布数据 60 * old_movie, 大多为 350 帧图像; 21* old_cartoon, 大多为 50-100 帧; 用 RE:VISION. De:flicker 去用软件人工修复(存在新手修的质量差的问题)
-
"RTTLC: Video Colorization with Restored Transformer and Test-time Local" CVPR, 2023 Mar paper
NTIRE23(CVPR) video colorization competition 2nd rank, post their result, qualities result no so astounding
evolved from RTN [23] in "Bringing Old Films Back to Life"
-
"Exemplar-based Video Colorization with Long-term Spatiotemporal Dependency" Arxiv, 2023 Mar paper
Reference based video colorization, use DeepRemaster, DeepExemplar as baseline
Train Datset: DAVIS[22], FVI[46] and Videvo [47].2090 training videos
randomly select a video clips with max length of 20 frames, and use the first frame as reference
All the experiments are implemented on a single NVIDIA 3090 GPU 😮
-
"BiSTNet: Semantic Image Prior Guided Bidirectional Temporal Feature Fusion for Deep Exemplar-based Video Colorization" ArXiv, 2022 Dec ⭐ paper website
NTIRE2023 Video Colorization Challenge Champion
synthetic datasets and real-world videos
adopt the DAVIS dataset [17] and the Videvo dataset [8] as the benchmark datasets for training and testing
- evaluate the proposed method on real-world grayscale videos, where the ground truth colors videos are not available
four RTX-A6000 GPUs
-
"SVCNet: Scribble-based Video Colorization Network with Temporal Aggregation" Arxiv, 2023 Mar paper code
use ImageNet, DAVIS, and Videvo datasets as our training set. all the used data could be downloaded on paper's github repo.
-
"AddCR: a data-driven cartoon remastering" Arxiv, 2023 Jul paper code note
-
"Bitstream-Corrupted Video Recovery: A Novel Benchmark Dataset and Method" NeurIPS, 2023 Sep 🗽 paper code note
VHS 类似的噪声合成数据
⚠️ -
"Restoring Degraded Old Films with Recursive Recurrent Transformer Networks" WACV, 2024 paper code pdf
-
"Unsupervised Model-based Learning for Simultaneous Video Deflickering and Deblotching" WACV, 2024 paper pdf
-
"Scratch detection of archival flms: modeling and trajectory calculation" paper
paper with code VHS 老录像带修复
- "BasicVSR++: Improving video super-resolution with enhanced propagation and alignment" CVPR, 2021 Apr 🗿 paper code note
- "Memory-Augmented Non-Local Attention for Video Super-Resolution" CVPR, 2021 Aug, MANA paper code
- "Multi-Scale Memory-Based Video Deblurring" CVPR, 2022 Apr paper code
- "Restoration of Analog Videos Using Swin-UNet" ACM-ICM, 2022 Oct paper ACM-paper code
- "Reference-based Restoration of Digitized Analog Videotapes" WACV, 2023 Oct, TAPE paper code note Authors: Lorenzo Agnolucci, Leonardo Galteri, Marco Bertini, Alberto Del Bimbo
paper with code searching 'diffusion video' 👍
- Awesome Video Diffusion
- "A Survey on Video Diffusion Models" paper code
-
"Video Diffusion Models" CVPR, 2022 Apr paper
-
"Imagen Video: High Definition Video Generation with Diffusion Models" Arxiv, 2022 Oct ⭐ paper
-
"Diffusion Video Autoencoders: Toward Temporally Consistent Face Video Editing via Disentangled Video Encoding" CVPR oral, 2022 Dec, DVA paper code noteCoDeF
人脸编辑
-
"Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation" ICCV, 2022 Dec paper code
consistency between origin and generation
-
"Structure and Content-Guided Video Synthesis with Diffusion Models" Arxiv, 2023 Feb, Gen-1 🔥 Runway Research paper website
video2video, using multi-modality (text, image) as input
Gen-2 create 4s video based on text prompt / image
-
"LDMVFI: Video Frame Interpolation with Latent Diffusion Models" Arxiv, 2023 Mar 👍 LDMVFI paper code note
video Interpolation, first diffusion used in video interpolation
-
"Pix2Video: Video Editing using Image Diffusion" ICCV, 2023 Mar paper code website note
存在闪烁问题
-
"Zero-Shot Video Editing Using Off-The-Shelf Image Diffusion Models" Arxiv, 2023 Mar, vid2vid-zero ⭐ paper code [note](./2023_03_Arxiv_ Zero-shot-video-editing-using-off-the-shelf-image diffusion-models_Note.md)
- Video editing with off-the-shelf image diffusion models.
- No training on any video.
cost lots of GPU memory, video with 1s 8fps>>24G,10s 30fps 48G++
-
"Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models" CVPR, 2023 Apr, VideoLDM ⭐
⚠️ paper website code: unofficial implementation notediffusion 用于 text2video 生成,用预训练的 stable-diffusion,对 U-net 加 temporal layer 实现时序一致性
-
"Gen-L-Video: Multi-Text to Long Video Generation via Temporal Co-Denoising" Arxiv, 2023 May paper code
-
"Control-A-Video: Controllable Text-to-Video Generation with Diffusion Models" Arxiv, 2023 May ⭐ paper code [website](https://controlavideo.github.io /)note
视频风格编辑,引入深度图
-
"VideoComposer: Compositional Video Synthesis with Motion Controllability" Arxiv, 2023 Jun, VideoComposer arXiv Website note
Video LDM 上加入各种样式的 condition 实现可控视频生成
-
"Make-Your-Video: Customized Video Generation Using Textual and Structural Guidance" Arxiv, 2023 Jun 🗽 paper website code
-
"Representing Volumetric Videos as Dynamic MLP Maps" CVPR, 2023 Apr Sida Peng∗ Yunzhi Yan∗ Qing Shuai Hujun Bao Xiaowei Zhou† paper code website author blog explanation note
Neural Volumes,用一组小型MLP网络表示体积视频
-
"MCVD: Masked Conditional Video Diffusion for Prediction, Generation, and Interpolation" paper code
-
"MagicEdit: High-Fidelity and Temporally Coherent Video Editing" paper
-
"ModelScope Text-to-Video Technical Report" CVPR, 2023 Aug paper
-
"GAIA-1: A Generative World Model for Autonomous Driving" Arxiv, 2023 Sep paper
视频帧序列作为输入,生成自动驾驶视频
-
"StableVideo: Text-driven Consistency-aware Diffusion Video Editing" ICCV, 2023 Aug 18 paper code pdf note Authors: Wenhao Chai, Xun Guo, Gaoang Wang, Yan Lu
-
"SimDA: Simple Diffusion Adapter for Efficient Video Generation" paper
text2video task, 提出 temporal adapter 和 attention adapter 把 image SD 调整为 video SD

-
"CoDeF: Content Deformation Fields for Temporally Consistent Video Processing" Arxiv, 2023 Aug ⭐ paper code website note
视频一致性编辑,效果非常好! as a new type of video representation, which consists of a canonical content field
-
"FreeNoise: Tuning-Free Longer Video Diffusion Via Noise Rescheduling" Arxiv, 2023 Oct paper code website note
-
"VideoCrafter1: Open Diffusion Models for High-Quality Video Generation" Arxiv, 2023 Oct paper code note
-
"Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets" Arxiv, 2023 Nov 25,
SVDpaper code pdf note Authors: Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram Voleti, Adam Letts, Varun Jampani, Robin Rombach -
"MagicAnimate: Temporally Consistent Human Image Animation using Diffusion Model" CVPR, 2023 Nov 🗽 paper code website note
human image animation task, which aims to generate a video of a certain reference identity
-
"VIDiff: Translating Videos via Multi-Modal Instructions with Diffusion Models" paper website
-
"Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets" Arxiv, 2023 Nov 25 paper code pdf note Authors: Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram Voleti, Adam Letts, Varun Jampani, Robin Rombach
-
"VideoBooth: Diffusion-based Video Generation with Image Prompts" CVPR, 2023 Dec paper code website note
-
"Upscale-A-Video: Temporal-Consistent Diffusion Model for Real-World Video Super-Resolution" CVPR, 2023 Dec,
Upscale-A-Videopaper code website note

将整个视频按 8 帧切为各个 clip,模仿 SD x4 upscaler 将输入 LR 加噪作为 SD latent space 特征。改造了一下 UNet 加了一点 temporal layer 微调了一下,然后对 z0 对于不同clip 传播一下。更新后的特征输入 VAE decoder 得到 x4 的 HR。这里的 VAE Decoder 加入了 conv3d 微调了一下作为 decoder.
- "Control-A-Video: Controllable Text-to-Video Generation with Diffusion Models" Arxiv, 2023 May ⭐ paper code [website](https://controlavideo.github.io /) note
- "VideoComposer: Compositional Video Synthesis with Motion Controllability" Arxiv, 2023 Jun, VideoComposer arXiv Website note
- "I2VGen-XL: High-Quality Image-to-Video Synthesis via Cascaded Diffusion Models" Arxiv, 2023 Nov 7 paper code pdf note Authors: Shiwei Zhang, Jiayu Wang, Yingya Zhang, Kang Zhao, Hangjie Yuan, Zhiwu Qin, Xiang Wang, Deli Zhao, Jingren Zhou
- "Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets" Arxiv, 2023 Nov 25 paper code pdf note Authors: Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram Voleti, Adam Letts, Varun Jampani, Robin Rombach
- "Pix2Gif: Motion-Guided Diffusion for GIF Generation" Arxiv, 2024 Mar 7 paper code pdf note Authors: Hitesh Kandala, Jianfeng Gao, Jianwei Yang
- "Ctrl-Adapter: An Efficient and Versatile Framework for Adapting Diverse Controls to Any Diffusion Model" Arxiv, 2024 Apr 15 paper code pdf note Authors: Han Lin, Jaemin Cho, Abhay Zala, Mohit Bansal
- "ConsistI2V: Enhancing Visual Consistency for Image-to-Video Generation" Arxiv, 2024 Feb 6 paper code website pdf note Authors: Weiming Ren, Harry Yang, Ge Zhang, Cong Wei, Xinrun Du, Stephen Huang, Wenhu Chen
- "Make Your Actor Talk: Generalizable and High-Fidelity Lip Sync with Motion and Appearance Disentanglement" Arxiv, 2024 Jun 12 paper code pdf note Authors: Runyi Yu, Tianyu He, Ailing Zeng, Yuchi Wang, Junliang Guo, Xu Tan, Chang Liu, Jie Chen, Jiang Bian
paper List repo Awesome-Diffusion-Models contains introductory lectures for canonical papers! 👨🏫 awesome-diffusion-low-level-vision image-to-image-papers
- VAE 博客 提供了一个将概率图跟深度学习结合起来的一个非常棒的案例 code
- lujianqing,zhangmingxuan,chengqifeng, zhenglei 老师:low level
- Daniel Cohen-Or
- Diffusion Blog
- 苏剑林老师 DDPM 理解博客
- "Understanding Diffusion Models: A Unified Perspective" Arxiv, 2022 Aug paper [note](./2022_08_Arxiv_Understanding Diffusion Models-A Unified Perspective_Note.md)
the basic math for diffusion model
-
"Denoising Diffusion Implicit Models" ICLR, 2020 Oct 6,
DDIMpaper code pdf note Authors: Jiaming Song, Chenlin Meng, Stefano Ermon -
"Progressive Distillation for Fast Sampling of Diffusion Models" ICLR, 2022 Feb 1,
v-predictionpaper code pdf note Authors: Tim Salimans, Jonathan Ho
-
"Image-to-Image Translation with Conditional Adversarial Networks" CVPR, 2016 Nov, Pix2pix 🗿 paper code website
-
"Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks" ICCV, 2017 Mar 30,
CycleGAN⭐ paper code website pdf note blog Authors: Jun-Yan Zhu, Taesung Park, Phillip Isola, Alexei A. Efros
无监督方式实现非配对数据训练,用两组生成鉴别器形成一个 cycle;回环的 cycle 用 consistency loss (L1 Loss 足够) 来约束内容一致;用 Identity loss 保证不需要转换的数据输出还是不变

-
"Interpreting the Latent Space of GANs for Semantic Face Editing" CVPR&TPAMI, 2019 Jul, InterFaceGAN paper code website pdf
-
"A Style-Based Generator Architecture for Generative Adversarial Networks" CVPR, 2019 Dec, StyleGAN paper code note
-
"Denoising Diffusion Implicit Models", Arxiv, 2020 Oct, DDIM paper code
DDIM inversion
-
"Score-Based Generative Modeling through Stochastic Differential Equations" Arxiv, 2020 Nov, Score-based 🗽 paper
-
"Taming Transformers for High-Resolution Image Synthesis" CVPR, 2020 Dec, VQ-GAN ⭐
-
"Denoising Diffusion Probabilistic Models" NeurIPS, 2020 Dec, DDPM 🗽 paper
-
"StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery" ICCV, 2021 Mar, StyleCLIP paper code pdf
-
"CogView: Mastering Text-to-Image Generation via Transformers" NeurIPS, 2021 May, GLID paper code
text2Image
-
"Diffusion Models Beat GANs on Image Synthesis" NeurIPS, 2021 May 🗽 paper code
classifier guidance
-
"Vector Quantized Diffusion Model for Text-to-Image Synthesis" CVPR, 2021 Nov, VQ-diffusion paper
-
"Classifier-Free Diffusion Guidance" NIPS, 2022 Jul paper blog
-
"Null-text Inversion for Editing Real Images using Guided Diffusion Models" CVPR, 2022 Nov paper website code Google github repo for null-text inversion ⭐
Null-text Inversion
-
"Wavelet Diffusion Models are fast and scalable Image Generators" CVPR, 2022 Nov, WaveDiff 💡 paper code
novel wavelet-based diffusion scheme
-
"High-Resolution Image Synthesis with Latent Diffusion Models" CVPR, 2022 Dec,
StableDiffusion🗽 paper github [note](./2022_CVPR_High-Resolution Image Synthesis with Latent Diffusion Models_Note.md) -
"MultiDiffusion: Fusing Diffusion Paths for Controlled Image Generation" ICML, 2023 Feb ⭐ paper website code

-
"Diffusion Models Beat GANs on Image Classification" Arxiv, 2023 Jul paper
-
"SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis" Arxiv, 2023 Jul 🗽 paper code blog_explanation pdf
-
"Diffusion Models for Image Restoration and Enhancement -- A Comprehensive Survey" Arxiv, 2023 Aug ⭐ paper code
survey
-
"Residual Denoising Diffusion Model" paper
将残差认为
$\mu$ ,用两个网络分别估计残差和噪声$\epsilon$ 总结出 DIffusion 用于去噪和生成应该分开处理
-
"DynaGAN: Dynamic Few-shot Adaptions of GAN"
Clip Loss 对比 loss
-
"Are Diffusion Models Vision-And-Language Reasoners" code
使用预训练 diffusion,设计一个image-text matching module可以完成绝大多数image-text-matching task
-
"Consistency Models" Arxiv, 2023 Mar paper Authors: Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever
-
"Diffusion Model for Camouflaged Object Detection" ECAI, 2023 Aug paper code note
应用 DDPM 到目标检测;验证了输入图像提取多尺度特征&融合,到 diffusion attn 一起有效

-
"Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference" paper website Authors: Simian Luo, Yiqin Tan, Longbo Huang, Jian Li, and Hang Zhao
-
"Accelerating Diffusion Models for Inverse Problems through Shortcut Sampling" Arxiv, 2023 May paper note
-
"LCM-LoRA: A Universal Stable-Diffusion Acceleration Module" Arxiv, 2023 Nov paper code pdf note Authors: Simian Luo, Yiqin Tan, Suraj Patil, Daniel Gu, Patrick von Platen, Apolinário Passos, Longbo Huang, Jian Li, Hang Zhao
Stable Diffusion 加速
-
- "Fast Diffusion EM: a diffusion model for blind inverse problems with application to deconvolution" code
- Rerender A Video"Accelerating Diffusion Models for Inverse Problems through Shortcut Sampling" code
-
"Make Pre-trained Model Reversible: From Parameter to Memory Efficient Fine-Tuning" NeurIPS, 2023 Jun paper code note
提出降低显存的 finetune 方法,比 LoRA 方式显存降低很多

- "PowerInfer: Fast Large Language Model Serving with a Consumer-grade GPU" code
单卡 4090 推理 17B 模型
-
"Distribution-Aware Prompt Tuning for Vision-Language Models" ICCV, 2023 Sep paper code
-
"Nested Diffusion Processes for Anytime Image Generation" Arxiv, 2023 May paper code
show that the generation scheme can be recomposed as two nested diffusion processes, enabling fast iterative refinement of a generated image
- "Adversarial Diffusion Distillation" Arxiv, 2023 Nov 28,
SD-Turbo⭐ paper code pdf note Authors: Axel Sauer, Dominik Lorenz, Andreas Blattmann, Robin Rombach
提出 ADD 蒸馏方法,使用此方法蒸馏 SD-v21 得到 SD-turbo
- "One-Step Image Translation with Text-to-Image Models" Arxiv, 2024 Mar 18 paper code pdf note Authors: Gaurav Parmar, Taesung Park, Srinivasa Narasimhan, Jun-Yan Zhu
验证了 one-step SD-turbo 有足够的能力做 image 合成Adversarial Diffusion Distillation任务 && low-level 任务中,在 VAE Decoder 中加入 Encoder 特征能够减轻信息丢失问题

- "SDXS: Real-Time One-Step Latent Diffusion Models with Image Conditions" Arxiv, 2024 Mar 25 paper code pdf note Authors: Yuda Song, Zehao Sun, Xuanwu Yin
- "DigGAN: Discriminator gradIent Gap Regularization for GAN Training with Limited Data" NeurIPS, 2022 Nov ⭐ paper
发现训练数据量减少后,FID 指标变差很多,发现 discriminator 对真实or生成图的梯度差距加大,然后相应的设计了一个discriminator的regularization(做实验多观察),验证了一种 unstable training 的原因
To improve the training of GANs with limited data, it is natural to reduce the DIG. We propose to use Eq. (2) as a regularizer so as to control the DIG during training. In turn, this aids to balance the discriminator’s learning speed.
训练完发现效果差,去检查可能的原因!

- "FreeU: Free Lunch in Diffusion U-Net" CVPR, 2023 Sep paper
improves diffusion model sample quality at no costs: no training, no additional parameter introduced, and no increase in memory or sampling time.
可视化发现 U-Net Encoder 的残差主要是高频信息,含有较多噪声。因此先用 FFT 和 IFFT 变换降低高频信息,将 UNet decoder 特征乘个系数(加大权重)再 concat
Video Diffusion 噪声图
- 怎么加 temporal layer
Findings
text2video inference 时候基于随机选取的高斯噪声开始,这里面的高频信息很乱,造成生成的不一致。因此先用训练的 text2video 模型得到更新的 z0 特征图(也认为是一种噪声),提取里面比较好的低频特征,高频信息替换为新的高斯噪声,优化初始噪声,重新进行去噪。
对 Video Diffusion 的 noise

Framework

- "The Blessing of Randomness: SDE Beats ODE in General Diffusion-based Image Editing" ICLR, 2023 Nov 2 paper code web pdf note Authors: Shen Nie, Hanzhong Allan Guo, Cheng Lu, Yuhao Zhou, Chenyu Zheng, Chongxuan Li
发现 diffusion 去噪过程,对于 latent 图像编辑后特征分布改变的情况,导致了编辑结果的变差,而先前ODE方法认为仍是同一分布,没考虑此问题; 在数学推导上发现 SDE 去噪过程噪声有益处,能够逐渐拉进编辑后特征的分布 & 原始图像空间特征的分布;而 ODE 去噪过程的分布是不变的,若 xT 分布改变则无法拉近特征分布距离;
get prior info from large-scale model Kelvin C.K. Chan Yuval Alaluf
-
"Exploiting Deep Generative Prior for Versatile Image Restoration and Manipulation" ECCV oral&PAMI, 2020 Mar, DGP(Deep Generative Prior) 🗽 🐤 paper video 👍
DGP exploits the image prior of an off-the-shelf GAN for various image restoration and manipulation. DGP effective way to exploit the image prior captured by a generative adversarial network (GAN) trained on large-scale natural images. we allow the generator to be fine-tuned on-the-fly in a progressive manner.
GAN-inversion 由于 model capacity 等限制,只能修复大致的 latent code 但生成效果并不好;类似 Bring Old Photo 论文,GT 和 GAN 生成的数据分布类似,但还有距离
- 因为要对 generator finetune,使用 MSR + perceptual loss 会 wipe out image prior 损害先验信息,生成的效果不行。
- **用 discriminator loss 来表示和 GT 分布的距离。**直接 finetune 整个 encoder 会导致
information lingering artifact(上色区域和物体不一致), 分析因为深层的 encoder 没处理好 low-level 细节,就去 align high-level 的颜色
提出 Progressive Reconstruction 一种 finetune 策略 >> 由浅到深依次解冻 encoder 去 finetune
-
Experiment
BigGANon ImageNet 用于 finetune。Colorization, inpainting, SRRemove most adversarial perturbation (adversarial defense)
映射到 latent space 来进行修改,除了修复也可以加 random noise 实现 jittering、Image Morphing(融合两幅图像,类似插值)
-
"PULSE: Self-Supervised Photo Upsampling via Latent Space Exploration of Generative Models" CVPR, 2020 Mar 🗽 paper code blog_explanation
对 LR 图像做超分,给定一堆 HR 图像(Manifold),如果有 HR 图像下采样后能近似输入的 LR 图像,则认为这个 HR 为输入 LR图像超分的结果。作者用预训练的 latent space 生成模型
$G$ (本文中使用 StyleGAN)的 latent space 去近似这个 Manifold,转化问题为:去 latent space 找与 LR 接近的 latent code。 PULSE seeks for for a latent vector $z\in \cal{L}(latentspace)$ that minimizes $downscalingloss = \abs{\abs{DS(G(z)) - I_{LR}}}p^p < \epsilon(1e{-3})$ ,$I{SR}=G(z)$ 生成模型结果,$DS$ 代表下采样- 缺点:推理很慢,需要不停迭代 latent space 去找合适的 latent code
-
"Blind Face Restoration via Deep Multi-scale Component Dictionaries"
-
"PriorGrad: Improving Conditional Denoising Diffusion Models with Data-Dependent Adaptive Prior" Arxiv, 2021 Jun paper website
-
"Diffusion models as plug-and-play priors" NeurIPS, 2022 Jun paper code
-
"GLEAN: Generative Latent Bank for Image Super-Resolution and Beyond" TAPMI, 2022 Jul ⭐ paper code note
使用 StyleGAN 大模型先验,从里面抽一些特征辅助进行 SR。参考同样方式做 Diffusion
-
"Adaptive Diffusion Priors for Accelerated MRI Reconstruction" Arxiv, 2022 Jul paper
-
"ShadowDiffusion: When Degradation Prior Meets Diffusion Model for Shadow Removal" CVPR, 2022 Dec
⚠️ paper code -
"Zero-shot Generation of Coherent Storybook from Plain Text Story using Diffusion Models" paper
-
"CLIP-Driven Universal Model for Organ Segmentation and Tumor Detection" ICCV, 2023 Jan paper code
-
"Generative Diffusion Prior for Unified Image Restoration and Enhancement" CVPR, 2023 Apr paper website
参考如何使用退化信息作为先验
-
"Learning a Diffusion Prior for NeRFs" Arxiv, 2023 Apr paper
-
"Exploiting Diffusion Prior for Real-World Image Super-Resolution" Arxiv, 2023 May paper website code note
-
"Hierarchical Integration Diffusion Model for Realistic Image Deblurring" NIPS-spotlight, 2023 May paper code note
使用主干网络 Encoder-Decoder 的主干网络(Restormer),在每个 scale 开头加上 diffusion 的先验特征,当作 KV 融入主干网络(提出的 HIM block);两阶段训练,stage1 先训练用于 diffusion 的图像编码器 LE Encoder, 不训diffusion 把特征 z 输入主干网络,在图像空间约束;stage2 zT 的编码器不训,训练 condition 的编码器 + diffusion + HIM

-
"ConceptLab: Creative Generation using Diffusion Prior Constraints" Arxiv, 2023 Aug paper website
-
"DiffBIR: Towards Blind Image Restoration with Generative Diffusion Prior" Arxiv, 2023 Aug 🗽 paper code website note
diffusion 先验实现 real-world 修复
-
"Are Diffusion Models Vision-And-Language Reasoners" code
使用预训练diffusion,设计一个image-text matching module可以完成绝大多数image-text-matching task 👍
-
"Learning Dual Memory Dictionaries for Blind Face Restoration" paper code
-
"DreamCraft3D: Hierarchical 3D Generation with Bootstrapped Diffusion Prior" CVPR, 2023 Oct paper website note
训练合成新视角的 diffusion 出图,辅助生成 3D 模型;用 stable diffusion 用 VSD loss 细化细节?
-
"Text-to-Image Generation for Abstract Concepts" AAAI, 2023 Sep paper note
抽象概念的 text2image,分解为理解层次(object,form) 优化 prompt
-
"Unifying Diffusion Models' Latent Space, with Applications to CycleDiffusion and Guidance" 2022 Oct paper code
-
"Localizing Object-level Shape Variations with Text-to-Image Diffusion Models" Arxiv, 2023 Mar paper code note pdf Authors: Or Patashnik, Daniel Garibi, Idan Azuri, Hadar Averbuch-Elor, Daniel Cohen-Or
通过调整去噪步数,实现指定物体的编辑,同时不改变其余物体
-
"Diffusion in the Dark: A Diffusion Model for Low-Light Text Recognition" WACV, 2023 Mar paper code note
参考如何解决图像修复中,文字模糊的问题 ⭐
-
"LaDI-VTON: Latent Diffusion Textual-Inversion Enhanced Virtual Try-On" ACMM, 2023 May paper code
保持区域背景Improving Diffusion Models for Virtual Try-on

-
"TF-ICON: Diffusion-Based Training-Free Cross-Domain Image Composition" ICCV, 2023 Jul paper code website blog
基于扩散的免训练跨域图像合成
-
"Editing Implicit Assumptions in Text-to-Image Diffusion Models" CVPR, 2023 Aug,
TIMEpaper code note
输入原始 prompt 和增加编辑属性的 prompt (例如加一个形容词),修改stable diffusion 的 QKV 映射矩阵实现编辑,用 loss function 约束两个 text embedding 接近。
通过这种编辑来调整 SD 原始 text-prompt 的 QKV mapping 矩阵来实现消除训练数据 bias 的目的
例如原始 SD 训练数据 “A CEO” 都是男士,“A female CEO” 去调整 mapping 矩阵来达到降低 bias 目的
学习对 Loss 计算闭合全局最优解,就不用再去训练了

-
"Stable Diffusion Reference Only: Image Prompt and Blueprint Jointly Guided Multi-Condition Diffusion Model for Secondary Painting" Arxiv, 2023 Nov paper code note
-
"DiffiT: Diffusion Vision Transformers for Image Generation" CVPR, 2023 Dec 🐤 paper code
引入了一种新的时间依赖的自注意力模块,允许注意力层以高效的方式适应其在去噪过程中的不同阶段的行为

-
"Reference-based Image Composition with Sketch via Structure-aware Diffusion Model" Arxiv, 2023 Mar paper code pdf note Authors: Kangyeol Kim, Sunghyun Park, Junsoo Lee, Jaegul Choo
-
"Ablating Concepts in Text-to-lmage Diffusion Models" paper
大模型生成的内容存在版权问题,例如生成 snoopy。想要删除此类受版权保护的概念或图像,因此从头开始重新训练模型。
图像动作编辑
- "The Blessing of Randomness: SDE Beats ODE in General Diffusion-based Image Editing" ICLR, 2023 Nov 2 paper code web pdf note Authors: Shen Nie, Hanzhong Allan Guo, Cheng Lu, Yuhao Zhou, Chenyu Zheng, Chongxuan Li
从 diffusion 去噪公式上(SDE, ODE)分析验证,**存在 zt 特征编辑后会改变特征分布的情况,SDE 由于噪声的存在,能够在去噪过程中弥补这个特征分布的差距!**而 ODE 加噪去噪前后特征分布是一致的,导致编辑后特征分布不同后,去噪得到的分布也不同,导致了图像烂;
- "COVE: Unleashing the Diffusion Feature Correspondence for Consistent Video Editing" Arxiv, 2024 Jun 13 paper code pdf note Authors: Jiangshan Wang, Yue Ma, Jiayi Guo, Yicheng Xiao, Gao Huang, Xiu Li
- "PhotoMaker: Customizing Realistic Human Photos via Stacked ID Embedding" Arxiv, 2023 Dec,
PhotoMakerpaper code notepdf Authors: (TencentARC) Zhen Li, Mingdeng Cao, Xintao Wang, Zhongang Qi, Ming-Ming Cheng, Ying Shan
- "DiFaReli: Diffusion Face Relighting" ICCV, 2023 Apr paper website code pdf note Authors: Puntawat Ponglertnapakorn, Nontawat Tritrong, Supasorn Suwajanakorn

-
DiffAE + DDIM 可以将图像解耦为 high-level 特征
$z_{sem}$ ,由图像确定地得到的 low-level 特征 xT(DDIM 性质,图像能够唯一映射到 xT),有出色的重建效果 -
编辑任务,缺少数据时候,可以用特征分解 + 自重建方式训练;在测试时候对特征进行编辑即可(这个编辑怎么做到?)
-
类似 StyleGAN style-feature, Semantic Encoder 出来的特征 1x512 含有足够多的信息?
The reverse process to obtain xT is key to reproducing high-frequency details from the input image ⭐
condition 只能起到辅助,需要 xT 保留了很多 low-level 信息,xT 是重建质量的关键!
-
condition 方式
- 预训练模型提取有效的图像特征 ⭐
- 用类似 ControlNet 方式(复制一个 UNet 的 encoder )去预测一个权重,乘到 res-block 的输出上(AdaIN 方式)
- 直接 condat 使用 MLP + SiLU 组合去提取特征向量 ok

-
"SketchFFusion: Sketch-guided image editing with diffusion model" CVPR, 2023 Apr paper
-
"SinDDM: A Single Image Denoising Diffusion Model" ICML, 2022 Nov paper code
多尺度 DDPM 去噪

-
"Understanding Object Dynamics for Interactive Image-to-Video Synthesis" Arxiv, 2021 Jun paper code
-
"iPOKE: Poking a Still Image for Controlled Stochastic Video Synthesis" Arxiv, 2021 Jul paper code
-
Conditional Image-to-Video Generation with Latent Flow Diffusion Models CVPR, 2023 Mar paper note
latent flow diffusion models (LFDM)
-
DreamPose: Fashion Image-to-Video Synthesis via Stable Diffusion (Apr., 2023) note
-
"VideoCrafter1: Open Diffusion Models for High-Quality Video Generation" Arxiv, 2023 Oct paper code note
-
"Any-to-Any Generation via Composable Diffusion" NIPS, 2023 May paper website
实现多个模态的转换
-
"Adding 3D Geometry Control to Diffusion Models" Arxiv, 2023 Jun paper
Understanding the underlying 3D world of 2D images, existing challenge:
- inability to control the 3D properties of the object
- difficulty in obtaining ground-truth 3D annotations of objects
用 edge map 作为 visual condition;文本用 tag 和 类别,将类别标签用 LLM 描述丰富一些,再使用。使用 ContolNet 来引导

-
"Diffusion in the Dark: A Diffusion Model for Low-Light Text Recognition" WACV, 2023 Mar paper code note
参考如何解决图像修复中,文字模糊的问题 ⭐
-
"AnyText: Multilingual Visual Text Generation And Editing" ICLR-Spotlight, 2023 Nov paper code pdf note
Authors: (Alibaba Group) Yuxiang Tuo, Wangmeng Xiang, Jun-Yan He, Yifeng Geng, Xuansong Xie
-
参考一下针对具体任务,如何设计任务相关的模块:生成文字图像,先直接把文字排好弄成一张图;
-
特定任务的预训练好的 Encoder (OCR Encoder ) 加上一个 MLP 来与原先文本特征融合,或理解成把原先特征中的一些不好的特征,用现有特征替换掉! ⭐
pre-trained visual model, specifically the recognition model of PP-OCRv3 Li et al.
-
ConrtolNet 初始 condition 比较少:增加一些额外的条件(文本的位置 mask,文本简单排列)!
-
-
针对任务设计 Loss!

- "WaterGAN: Unsupervised Generative Network to Enable Real-time Color Correction of Monocular Underwater Images" Arxiv, 2017 Feb,
WaterGANpaper
解决水下图像色差 color correction;结合相机模型训练一个 GAN generator 生成水下风格的合成图像(绿色背景),少部分真实水下照片只用于测试;先预测图像 depth 得到 RGB-D 图像,再训练了一个 UNet 进行颜色矫正

- "MSG-GAN: Multi-Scale Gradients for Generative Adversarial Networks" CVPR, 2020 paper
多尺度提取 GAN generator 特征,增强生成图像的 details
genetic algorithm
- "EvoGAN: An Evolutionary Computation Assisted GAN" paper
- "Evolutionary Generative Adversarial Networks",
E-GANpaper - "Annealing Genetic GAN for Minority Oversampling" paper
- "CDE-GAN: Cooperative dual evolution-based generative adversarial network" website
Awesome-diffusion-model-for-image-processing Awesome-CVPR2023-Low-Level-Vision
-
"Low-Dose CT with a Residual Encoder-Decoder Convolutional Neural Network (RED-CNN)" TMI, 2017 Feb 🗿 paper code
医学 CT 去噪(噪声 GT 对),模型结构很简单
-
"Deep Image Prior" CVPR, 2017 Nov 29,
DIPpaper code website pdf note blog Authors: Dmitry Ulyanov, Andrea Vedaldi, Victor Lempitsky
无监督,发现 NN 去拟合单张低质图像的过程中,中间的迭代步数可以接近输出修复好的图像;NN 对噪声越强的图像,越难拟合(阻抗性)

- ""Double-DIP": Unsupervised Image Decomposition via Coupled Deep-Image-Priors" CVPR, 2018 Dec 2,
Double-DIPpaper code website pdf note Authors: Yossi Gandelsman, Assaf Shocher, Michal Irani
DIP 中提出用 NN 本身在训练过程中的先验信息,只去拟合单张低质图像就可以做图像恢复任务,这个方法可以应用到超分,inpainting 各种任务上;
DoubleDIP 把各种 low-level 任务看作图层分解任务,将图像看作多层 layer 的叠加,每一个图层取用 DIP 方式学习。可以用于很多下游任务,例如去雾任务分解为一张清晰和雾气图;将视频转场效果分解,视频分割

-
"The Perception-Distortion Tradeoff" CVPR, 2017 Nov 🗽 🐤 paper code blog_explanation note
指标好不代表结果好(从数学角度证明了distortion和perceptual quality之间是矛盾的,并且存在一条tradeoff曲线。所有图像复原类任务的表现只能逼近这个曲线). 作者提出评价一个图像复原算法的新的标准:评价算法时同时用一对 NR(No-reference) and FR metrics(full reference, PSNR, SSIM), 也就是考虑算法在perception-distortion曲线中的位置.
-
"EdgeConnect: Generative Image Inpainting with Adversarial Edge Learning" Arxiv, 2019 Jan paper code blog explanation
-
"Image Super-Resolution via Iterative Refinement" TPAMI, 2021 Apr, SR3 paper code
-
"Palette: Image-to-Image Diffusion Models" SIGGRAPH, 2021 Nov
⚠️ paper website code-unofficial note1st diffusion in image restoration
训练好的 DDPM 做 inpainting
-
"Denoising Diffusion Restoration Models" ICLRW, 2022 Jan, DDRM 🗽 paper code website
-
"RePaint: Inpainting using Denoising Diffusion Probabilistic Models" CVPR, 2022 Jan, RePaint paper code
-
"MAXIM: Multi-Axis MLP for Image Processing"
CVPR 2022 Oral, Best Paper Nomination, 2022 Jan, MAXIM:statue_of_liberty: paper code -
"Restoring Vision in Adverse Weather Conditions with Patch-Based Denoising Diffusion Models" TPAMI, 2022 Jul 🐤 paper code note
将 DDPM 用于多种退化的 adverse weather conditions 去噪。提出用 patch-based diffusive restoration 方法,推理时候对重叠 patch 预测的噪声取平均,实现任意分辨率图像的修复,解决 DDPM 噪声图尺寸受限问题。
训练时候随机 crop 去训,在 test 时候,对任意尺寸图像通过 crop 后输入,在去噪过程预测的噪声进行拼接效果更好!
-
"JPEG Artifact Correction using Denoising Diffusion Restoration Models" Arxiv, 2022 Sep, DDRM-jpeg paper code
-
"DriftRec: Adapting diffusion models to blind JPEG restoration" Arxiv, 2022 Nov paper
mean reverting diffusion
-
"Zero-Shot Image Restoration Using Denoising Diffusion Null-Space Model" ICLR(Notable-Top-25%), 2022 Dec, DDNM 👍 paper website code note
将图像修复任务的数学模型,转换到 Range-Null space 分解,对于分解的其中一项替换为 Diffusion 的 noise 实现修复操作,融入 diffusion 的方式值得借鉴。
-
"Image Restoration with Mean-Reverting Stochastic Differential Equations" ICML, 2023 Jan ⭐ Ziwei Luo, Fredrik K. Gustafsson, Zheng Zhao, Jens Sjölund, Thomas B. Schön paper code website note
从高质量图像,加噪声到低质量图像,而不是到纯高斯噪声 》》加速
-
"DiffIR: Efficient Diffusion Model for Image Restoration" ICCV, 2023 Mar paper code
-
"DR2: Diffusion-based Robust Degradation Remover for Blind Face Restoration" CVPR, 2023 Mar ⭐ 🐤 paper code note
预训练 DDPM,从退化图开始,用高斯噪声模拟退化,去噪时候加上“加噪时候的低频部分”去学高频信息
-
"Efficient and Explicit Modelling of Image Hierarchies for Image Restoration" CVPR, 2023 Mar, GRL 🗽 paper code pdf
20M 参数,在多个任务上 SOTA
-
"Learning A Sparse Transformer Network for Effective Image Deraining" CVPR, 2023 Mar, DRSformer ⭐ paper code
image de-raining 提出了一个新的 Transformer. 认为 QK 不匹配,取 topk 的 Query 特征,分解特征多次用注意力
torch.topk(attn, k=int(C/2), dim=-1, lagest=True) -
"Generative Diffusion Prior for Unified Image Restoration and Enhancement" CVPR, 2023 Apr ⭐ paper code website note
Multi-task Restoration, 有权重
-
"Refusion: Enabling Large-Size Realistic Image Restoration With Latent-Space Diffusion Models" CVPRW, 2023 Apr ⭐ paper code note
Multi-task Restoration, image-sde 改进,比赛 trick:去噪步数;patch >> 越大越好,crop 大patch 再下采样 >> 让patch有全局性
-
"A Unified Conditional Framework for Diffusion-based Image Restoration" Arxiv, 2023 May
⚠️ paper code website pdf -
"Fourmer: An Efficient Global Modeling Paradigm for Image Restoration" PMLR, 2023 Jun paper [pdf](./2023_06_PMLR_Fourmer-An Efficient Global Modeling Paradigm for Image Restoration.pdf)
Wavelet
-
"Let Segment Anything Help Image Dehaze" Arxiv, 2023 Jun paper note
将 SAM 分割结果作为通道扩展到 U-net 模块中,进行去雾
-
"ResShift: Efficient Diffusion Model for Image Super-resolution by Residual Shifting" Arxiv, 2023 Jul paper code 8.5
-
"Lighting Every Darkness in Two Pairs: A Calibration-Free Pipeline for RAW Denoising" ICCV, 2023 Aug 🗽 ⭐ paper code blog_explanation
极简标定流程下的 RAW 去噪 & 少量配对数据(6对)和快速微调即可适应目标相机, 0.2% 原来训练时间实现 SOTA blog 相机标定基础知识
-
"Single Image Reflection Separation via Component Synergy" ICCV, 2023 Aug, DSR-net paper code
8.22 图像反射分解 single image reflection separation task,重新定义数学模型
$I = W ◦ T + \bar{W} ◦ R$ ; dual 网络出来的分支,再去用一个网络预测残差 dual-stream, reconstruction loss with residual correction -
"Exploiting Diffusion Prior for Real-World Image Super-Resolution" Arxiv, 2023 May, StableSR paper code website pdf
-
"Pixel-Aware Stable Diffusion for Realistic Image Super-resolution and Personalized Stylization" CVPR, 2023 Aug, PASD paper code note
-
"SeeSR: Towards Semantics-Aware Real-World Image Super-Resolution" Arxiv, 2023 Nov ⭐ paper code note
微调 stable diffusion
- "Deep Image Prior" CVPR, 2017 Nov 29 ⭐ paper code pdf note blog Authors: Dmitry Ulyanov, Andrea Vedaldi, Victor Lempitsky
用随机初始化的 NN 只去拟合单张低质量图像,发现神经网络本身在迭代过程的先验,只要控制指定迭代步数就能得到较好的修复结果(一开始输出乱的,100it 出了个接近修复的图;1kiteration学的太好了输出含有噪声的原图);
- "Deep Exemplar-based Colorization" SIGGRAPH, 2018 Jul 🗽 paper code
- "DeOldify: A Review and Implementation of an Automatic Colorization Method" IPOL, 2022 Apr,
DeOldifypaper - "DDColor: Towards Photo-Realistic Image Colorization via Dual Decoders" ICCV, 2022 Dec,
DDColorpaper code note
-
"Towards Unsupervised Deep Image Enhancement with Generative Adversarial Network" TIP, 2020 Dec, UEGAN paper note
unsupervised image enhancement GAN
参考 Encoder Decoder 如何设计
-
"Time-Travel Rephotography" SIGGRAPH, 2020 Dec ⭐ paper website code talk 👍 pdf
无监督方式!!将灰度图人脸修复为彩色图 >> Sibling 概念,使用预训练 stylegan 的优良颜色特征,用 StyleGAN 生成先弄一个类似的人脸(颜色ok,人不像),然后另外训一个 decoder 生成结构和原图相似的人脸,
Color Transfer,contextual loss训练。无监督方式训练:模拟一个老相机的退化,将 RGB 转为灰度图,与原图做 reconstruction loss (这里前提是数据集本身的噪声并不多,没有扭曲很多情况下)HWFD 数据集,100多张名人人脸灰度照片,可以下载
- ❓ Color Transfer Loss
-
"RefineDNet: A Weakly Supervised Refinement Framework for Single Image Dehazing" TIP, 2021 Mar,
RefineDNetpaper code pdf note Authors: Shiyu Zhao; Lin Zhang; Ying Shen; Yicong Zhou
融入感知到图像融合中,参考设计特征融合
-
"Modernizing Old Photos Using Multiple References via Photorealistic Style Transfer" CVPR, 2023 Apr, MROPM paper code website note
从风格迁移的角度做,修复完划痕看起来还很旧,修改风格
Dataset: 从韩国 3 个博物馆收集到的文物照片,拍摄样式老旧,但没有明显的划痕
-
"Denoising Diffusion Models for Plug-and-Play Image Restoration" CVPRW, 2023 May, DiffPIR⭐ paper code website note
Multi-task Restoration
-
"Deep Optimal Transport: A Practical Algorithm for Photo-realistic Image Restoration" Arxiv, 2923 Jun,DOT-Dmax paper code
后处理方法,进一步提升指标:control the perceptual quality and/or the mean square error (MSE) of any pre-trained model, trading one over the other at test time
Survey
-
"Blind Face Restoration via Deep Multi-scale Component Dictionaries" ECCV, 2020 Aug paper
-
"Towards Robust Blind Face Restoration with Codebook Lookup Transformer" NeurIPS, 2022 Jun, CodeFormer 🗽 paper code website
Blind Face Restoration SOTA, 老照片修复
-
"CodeTalker: Speech-Driven 3D Facial Animation with Discrete Motion Prior" Arxiv, 2023 Jan paper website
-
"RIDCP: Revitalizing Real Image Dehazing via High-Quality Codebook Priors" CVPR, 2023 Apr ⭐ paper
-
"RestoreFormer++: Towards Real-World Blind Face Restoration from Undegraded Key-Value Pairs" TPAMI, 2023 Aug code
-
"Context-Aware Pretraining for Efficient Blind Image Decomposition" CVPR, 2023 Jun, CPNet
⚠️ paper code note- 避免信息泄露,GT 的 pretext 分支用 masked noisy image 代替 gt image
-
"Rethinking Image Inpainting via a Mutual Encoder-Decoder with Feature Equalizations" ECCV oral, 2020 Jul paper code
浅层网络特征提取细节特征(纹理);深度网络感受野逐渐加大,主要提取语义信息(semantic)。类似 Transformer 的特征融合模块,融合 Encoder 得到的细节和语义特征。关注 Encoder、Decoder 设计
-
"SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations" 2021 Aug paper
- "Restormer: Efficient transformer for high-resolution image restoration" CVPR, 2021 Nov,
Restormer🐤 paper
UNet 结构不变,每个 block 换为 Transformer block. 两个 Attention,第一个把 MLP 换为 Depth-conv 说是不同通道分别处理,空间HxW上的特征更丰富;第二个相当于做一个 CBAM 时空注意力。

- "Stripformer: Strip transformer for fast image deblurring" ECCV, 2022 Apr, 🐤 paper
在 pixel-space 竖着 & 横着逐像素做 attn. 再竖着 & 横着逐条做 attn


- "Hierarchical Integration Diffusion Model for Realistic Image Deblurring" NIPS-spotlight, 2023 May paper code note
使用主干网络 Encoder-Decoder 的主干网络(Restormer),在每个 scale 开头加上 diffusion 的先验特征,当作 KV 融入主干网络(提出的 HIM block);两阶段训练,stage1 先训练用于 diffusion 的图像编码器 LE Encoder, 不训diffusion 把特征 z 输入主干网络,在图像空间约束;stage2 zT 的编码器不训,训练 condition 的编码器 + diffusion + HIM
-
"Single image haze removal using dark channel prior" CVPRBestPaper&TPAMI, 2009,
DCPpaper blog code -
"Aerial Image Dehazing with Attentive Deformable Transformers" WACV, 2023 ⭐ paper code
Self-atten QKV 特征都单独过 SE 空间注意力 + Deformable 偏移(自己计算偏移);对比了不同类型 deformable,针对不同任务稍微修改一下 deformable ,psnr 能高 1 db
- "RefineDNet: A Weakly Supervised Refinement Framework for Single Image Dehazing" TIP, 2021 Mar paper code note
融入感知到图像融合中,参考设计特征融合

- "RIDCP: Revitalizing Real Image Dehazing via High-Quality Codebook Priors" CVPR, 2023 Apr ⭐ paper
- "RealFill: Reference-Driven Generation for Authentic Image Completion" Arxiv, 2023 Sep 28 paper code pdf note Authors: Luming Tang, Nataniel Ruiz, Qinghao Chu, Yuanzhen Li, Aleksander Holynski, David E. Jacobs, Bharath Hariharan, Yael Pritch, Neal Wadhwa, Kfir Aberman, Michael Rubinstein
类似 DreamBooth, 用几张图去微调 Diffusion 学习 target image 的场景; 参考图 & target 图做 mask 去微调 Diffusion; Diffusion 出图原始区域模糊,对 mask blur & 用 alpha 把生成的和原图融合; diffusion 每次推理不同随机种子随机性太大,用预训练的 dense correspondence 去筛选生成较好的图
- "AnyDoor: Zero-shot Object-level Image Customization" CVPR, 2023 Jul 18 paper code pdf note Authors: Xi Chen, Lianghua Huang, Yu Liu, Yujun Shen, Deli Zhao, Hengshuang Zhao
- 使用预训练的 DINOv2 提供细节特征,DINOv2 有全局 和 patch 的特征,发现 concat 起来过可学习的 MLP,可以与 UNet 特征空间对齐 ⭐
- 贴图的时候使用高频特征,而不是放图像,避免生成图像不搭的情况
- 各个 trick,细节一致性还是不足,例如文字扭曲了
- DNIO or CLIP 特征很重要,作为图像物体生成的基本盘,不加物体直接不一样;细节不一致的问题要再用高频特征约束一下
- 发现训练早期多用视频中多姿态物体训练,能够增强生成物体的细节一致性,缓解色偏的问题
- 对比 DINO, CLIP 提取物体特征
- DINO 特征对于物体细节的特征比 CLIP 特征更优秀,但 DINO 特征要处理下才能好:用分割图提取物体再去提取特征才能得到接近原始物体的结果
- CLIP 特征有点离谱,可能是背景干扰很大
- "Zero-shot Image Editing with Reference Imitation" Arxiv, 2024 Jun 11,
MimicBrushpaper code pdf note Authors: Xi Chen, Yutong Feng, Mengting Chen, Yiyang Wang, Shilong Zhang, Yu Liu, Yujun Shen, Hengshuang Zhao
ControlNet 有学习 dense correspondence 的能力,基于 correspondence 去做 inpaint
-
"Perceptual Losses for Real-Time Style Transfer and Super-Resolution" ECCV, 2016 Mar paper note
提出了 perceptual loss
-
"Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization" ICCV, 2017 Mar, AdaIN 🗽 blog code
风格迁移,Instance normalization 公式
$IN(x) = \gamma *(\frac{x-\mu(x)}{\sigma(x)}) + \beta$ 修改,用 style-image 的均值、方差替换$\gamma,\beta$ -
"High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs" CVPR, 2017 Nov, pix2pix-HD paper website
-
"Free-Form Image Inpainting with Gated Convolution" ICCV, 2018 Jun paper code note
-
"Semantic Image Synthesis with Spatially-Adaptive Normalization" CVPR, 2019 Mar, SPADE 🗽 🐤 paper code
分割图引导修改,feature 先 batchNorm, SPADE 用于去归一化,将分割图过两个 Conv 分别得到两个去归一化参数,先乘再加
SPADE layer 实现 edit clue 融合;backbone 使用 pix2pix-HD
- SFT layer
-
"CoCosNet v2: Full-Resolution Correspondence Learning for Image Translation" CVPR oral, 2020 Dec 🗽 paper code
-
"Parser-Free Virtual Try-on via Distilling Appearance Flows" CVPR, 2021 Mar 🐤 paper code
estimate the appearance flow; knowledge distillation appearance flow is good at flexibly distort the image but cannot generate new contents Limit: origin & target image has domain gap
-
"SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations" ICLR, 2021 Aug paper code website
用预训练 stable diffusion 做 Image Synthesis and Editing
image modification with Stable Diffusion.
-
"DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation" CVPR, 2022 Aug ⭐ paper code note
DreamBooth is a method to personalize text-to-image models like Stable Diffusion given just a few images (3~5 images) of a subject. && 生成结果保留了参考照片的主体部分
-
"Prompt-to-Prompt Image Editing with Cross Attention Control" Arxiv, 2022 Aug ⭐ paper code blog_explanation
specific object editing by replacing the correspondence
-
"MIDMs: Matching Interleaved Diffusion Models for Exemplar-based Image Translation" AAAI, 2022 Sep paper website
-
"Imagic: Text-Based Real Image Editing with Diffusion Models" CVPR, 2022 Oct
⚠️ paper websitediffusion finetune,加上优化 text-embedding 实现图像编辑
-
"Sketch-Guided Text-to-Image Diffusion Models" Arxiv, 2022 Nov
⚠️ paper website code:unofficialperform a spatial guidance with gradients of a small model (we call it Latent Edge Predictor) that operates on intermediate DDPM activations.
- Latent Edge Predictor >> see methods image which is a per-pixel MLP, is trained to map each pixel in the concatenated features to the corresponding pixel in the encoded edge map.
-
"Adding Conditional Control to Text-to-Image Diffusion Models" Arxiv, 2023 Feb, ControlNet 🗽 paper code note
-
"Zero-shot Image-to-Image Translation" Arxiv, 2023 Feb, pix2pix-zero paper code local pdf
-
"Drag Your GAN: Interactive Point-based Manipulation on the Generative Image Manifold" SIGGRAPH, 2023 May, DragGAN 🗽 paper code website
-
"DragDiffusion: Harnessing Diffusion Models for Interactive Point-based Image Editing" Arxiv, 2023 Jun ⭐ paper website code
-
"Diffusion Self-Guidance for Controllable Image Generation" Arxiv, 2023 Jun paper code
-
"AnyDoor: Zero-shot Object-level Image Customization" Arxiv, 2023 Jul
⚠️ paper websiteDiffusion 做 Object Moving, Object Swapping (23.7.21 Ni recommend)
可以用到老照片上增加可编辑性
-
"DragonDiffusion: Enabling Drag-style Manipulation on Diffusion Models" Arxiv, 2023 Jul ⭐
⚠️ Chong Mou1 Xintao Wang2 Jiechong Song1 Ying Shan2 Jian Zhang†1 paper website Blog explanation note多个分支 U-net 针对重建 or 编辑根据 loss 区分,U-net decoder Transformer 重建分支的 KV 替换到编辑分支的 KV 增加 consistency. (类似 UniAD 多个 Transformer 共享 KV) 这样多个分支同步 denoise,U-net decoder 的特征有对应关系,实验发现用 U-net decoder layer2,3 特征的效果最好
-
"T2I-Adapter: Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models" Arxiv, 2023 Feb:star: paper code
Zhang jian 老师组,对扩散模型生成内容进行精准控制。**已经用于 Stability Al 的涂鸦生图工具 **Stable Doodle
-
"DatasetDM: Synthesizing Data with Perception Annotations Using Diffusion Models" Arxiv, 2023 Aug
⚠️ paper code website notedataset generation model, 用 diffusion 造数据
-
"FaceChain: A Playground for Identity-Preserving Portrait Generation" Arxiv, 2023 Aug paper
Stable Diffusion 人脸编辑 Recurrent Video Restoration Transformer with Guided Deformable Attention
-
"Image Super-Resolution Using Very Deep Residual Channel Attention Networks" ECCV, 2018 Jul, RCAN 🗽 paper
-
"SRDiff: Single image super-resolution with diffusion probabilistic models" Neurocomputing, 2021 Apr paper code
-
"OSRT: Omnidirectional Image Super-Resolution with Distortion-aware Transformer" CVPR, 2023 Feb paper code
Deformable attn 用于图像 SR
-
"DeSRA: Detect and Delete the Artifacts of GAN-based Real-World Super-Resolution Models" ICML, 2023 Jul paper code blog_explanation
解决 GAN-SR 的伪影问题,分析 L1 Loss 细节过于突兀,Gan Loss 容易产生伪影但细节很自然,关注如何融合两个 loss 能写成一个工作
-
"MultiDiffusion: Fusing Diffusion Paths for Controlled Image Generation" ICML, 2023 Feb 16 paper code pdf note Authors: Omer Bar-Tal, Lior Yariv, Yaron Lipman, Tali Dekel
-
"Mixture of diffusers for scene composition and high resolution image generation"
-
"Orthogonal Adaptation for Modular Customization of Diffusion Models" CVPR, 2023 Dec paper
-
"Zero-Painter: Training-Free Layout Control for Text-to-Image Synthesis" CVPR, 2023 Unknown paper
-
"Inf-DiT: Upsampling Any-Resolution Image with Memory-Efficient Diffusion Transformer" Arxiv, 2024 May 7 paper code pdf note Authors: Zhuoyi Yang, Heyang Jiang, Wenyi Hong, Jiayan Teng, Wendi Zheng, Yuxiao Dong, Ming Ding, Jie Tang
解决任意分辨率,多个 patch 一致性问题
-
"Exploiting Diffusion Prior for Real-World Image Super-Resolution" Arxiv, 2023 May, StableSR paper code website pdf
-
"Pixel-Aware Stable Diffusion for Realistic Image Super-resolution and Personalized Stylization" CVPR, 2023 Aug, PASD paper code note
-
"SeeSR: Towards Semantics-Aware Real-World Image Super-Resolution" Arxiv, 2023 Nov ⭐ paper code note
微调 stable diffusion
-
"Scaling up to excellence: Practicing model scaling for photo-realistic image restoration in the wild" 24.01
-
"Beyond Subspace Isolation: Many-to-Many Transformer for Light Field Image Super-resolution" 24.01
-
"Photo-Realistic Image Restoration in the Wild with Controlled Vision-Language Models" 24.04 paper
-
"AddSR: Accelerating Diffusion-based Blind Super-Resolution with Adversarial Diffusion Distillation" 24.05.23
-
"CDFormer: When Degradation Prediction Embraces Diffusion Model for Blind Image Super-Resolution" paper
-
"Layered Neural Atlases for Consistent Video Editing" SIGGRAPH, 2021 Sep 🗽 paper website
Nerf representation for video "Blind Video Deflickering by Neural Filtering with a Flawed Atlas" video deblurin
-
"Stitch it in Time: GAN-Based Facial Editing of Real Videos" SIGGRAPH, 2019 Jan, STIT paper code website note
-
"Pix2Video: Video Editing using Image Diffusion" Arxiv, 2023 Mar
⚠️ paper code website -
"ControlVideo: Adding Conditional Control for One Shot Text-to-Video Editing" Arxiv, 2023 May paper code website
-
"Style-A-Video: Agile Diffusion for Arbitrary Text-based Video Style Transfer" Arxiv, 2023 May
⚠️ paper code -
"TokenFlow: Consistent Diffusion Features for Consistent Video Editing" Arxiv, 2023 Jul ⭐
⚠️ paper code websitegenerated video is temporal consistent, 效果很不错 使用 video atlas
-
"StableVideo: Text-driven Consistency-aware Diffusion Video Editing" ICCV. 2023 Aug paper code
-
"CoDeF: Content Deformation Fields for Temporally Consistent Video Processing" Arxiv, 2023 Aug ⭐ paper code website
note
视频一致性编辑,效果非常好! as a new type of video representation, which consists of a canonical content field
-
"Generative Image Dynamics" Arxiv, 2023 Sep paper website
LDM 交互方式模拟图像中物体的物理运动
-
"Learning Joint Spatial-Temporal Transformations for Video Inpainting" ECCV, 2020 Jul, STTN 🗽 🐤 paper code pdf note
第一个将 transformer 用于 video inpainting,构建了时空 transformer 从而实现视频修复
-
"Decoupled Spatial-Temporal Transformer for Video Inpainting" Arxiv, 2021 Apr, DSTT paper code
-
"FuseFormer: Fusing Fine-Grained Information in Transformers for Video Inpainting" ICCV, 2021 Sep 🗽 🐤 paper code pdf
FuseFormer在 patch 角度做融合,提取有重叠的 patch。 主要提出了SoftSplit+SoftComposite方式替换了 Transformer 的FeedForward。Figure1 展示了重叠取 patch (SS+SC 操作) 很好地融合了相邻 patch,overlapped区域聚合了很多tokens的信息,这对于平滑的边界以及增加感受野很有用。 SS 分解 patch,SC将原始重叠区域特征直接相加 (要 Normalize)- Encoder-Decoder, Discriminator 参考 STTN,区别在 Encoder 和第一个 Transformer Block 之间加了几层卷积
- 任意分辨率上测试 issue
-
"Towards An End-to-End Framework for Flow-Guided Video Inpainting" CVPR, 2022 Apr, E2FGVI 🗽 ⭐ paper code note
End2End: optical-flow completion + feature propagation + content hallucination(Focal transformer 实现)
-
"PS-NeRV: Patch-wise Stylized Neural Representations for Videos" ICIP, 2022 Aug paper
-
"Deficiency-Aware Masked Transformer for Video Inpainting" Arxiv, 2023 Jul 🗽
⚠️ paper code -
"Hierarchical Masked 3D Diffusion Model for Video Outpainting" Arxiv, 2023 Sep paper website note
-
"ProPainter: Improving Propagation and Transformer for Video Inpainting" ICCV, 2023 Sep 🗽 paper code pdf
- Encoder: We use an image encoder with the same structure as previous works (E2FGVI, FuseFormer)
- Feature Propagation 增加一致性筛选机制,只 warp 筛选后的区域,其余区域用原来的特征
-
"CIRI: Curricular Inactivation for Residue-aware One-shot Video Inpainting" ICCV, 2023
⚠️ paper codeOne-shot Inpainting(要 mask 的区域只给在第一帧中的信息), propagate the initial target to the other frames
-
curricular inactivation to replace the hard masking mechanism 动态预测 mask
对于不同帧的 mask 区域存在细节区域不一致,使用 Contextual loss 约束:star:
-
对于只 inpainting 部分区域的问题,提出 online residue removal method
-
-
"XVFI: eXtreme Video FFrame Interpolation" ICCV Oral, 2021 Mar 🗽 paper code
optical-flow based VFI methods
-
"LDMVFI: Video Frame Interpolation with Latent Diffusion Models" Arxiv, 2023 Mar 👍 LDMVFI paper code note
video Interpolation, first diffusion used in video interpolation
-
"Clearer Frames, Anytime: Resolving Velocity Ambiguity in Video Frame Interpolation" Arxiv, 2023 Nov paper website note
-
SparseCtrl
-
DynamiCrafter
-
review
-
"waifu2x " a tool for Image Super-Resolution for Anime-style art using Deep CNN. code
-
"ReBotNet: Fast Real-time Video Enhancement" AeXiv, 2023 Mar
⚠️ paper website note30 FPS 实时的方法,主要针对 video deblur,用 ConvNext + Mixer 代替 Transformer 减小计算量;根据 Talkingheads 数据集,筛选+处理针对视频会议场景的数据集 (没开源)
❓ ConvNext & MLP-mixer 原理
-
"Depth-Aware Video Frame Interpolation" CVPR, 2019 Apr, DAIN paper code
-
"EDVR: Video Restoration with Enhanced Deformable Convolutional Networks" CVPR NTIRE 1st, 2019 May
-
"ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks" ECCV, 2018 Sep, ESRGAN(Enhanced SRGAN) ⭐ paper code
-
"Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data" ICCV, 2021 Aug 🚀 paper code
General Image/Video Restoration(SR).
-
BasicSR (Basic Super Restoration) is an open-source image and video restoration toolbox github repo
-
"Recurrent Video Restoration Transformer with Guided Deformable Attention" NeurlPS, 2022 June, RVRT 🗽 paper code note
-
"SB-VQA: A Stack-Based Video Quality Assessment Framework for Video Enhancement" CVPR, 2023 May paper
mention
old film restoration -
"DiffSynth: Latent In-Iteration Deflickering for Realistic Video Synthesis" Arxiv, 2023 Aug ⭐ 🐤 paper website code note
Multi-task in video diffusion, include video restoration
阿里 NLP
-
"Video Adverse-Weather-Component Suppression Network via Weather Messenger and Adversarial Backpropagation" ICCV, 2023 Sep
⚠️ paper code噪声和老电影很类似
-
"Neural Compression-Based Feature Learning for Video Restoration" paper code
-
"Video generation models as world simulators" 2024 Feb, Sora OpenAI_report note
-
"FastDVDnet: Towards Real-Time Deep Video Denoising Without Flow Estimation" CVPR, 2019 Jul paper code
-
"Recurrent Video Restoration Transformer with Guided Deformable Attention" NeurlPS, 2022 June, RVRT 🗽 paper code note
-
"Learning Task-Oriented Flows to Mutually Guide Feature Alignment in Synthesized and Real Video Denoising" 2022 Aug, ReViD
⚠️ paper -
"Real-time Controllable Denoising for Image and Video" CVPR, 2023 Mar paper website code
video/image Denoising!
-
"A Differentiable Two-stage Alignment Scheme for Burst Image Reconstruction with Large Shift" CVPR, 2022 Mar paper code
-
"Joint Video Multi-Frame Interpolation and Deblurring under Unknown Exposure Time" CVPR, 2023 Mar ⭐ paper code
参考如何进行多帧融合
-
"Deep Exemplar-based Video Colorization" CVPR, 2019 Jun paper code note
Bring old films 张博老师的工作Self-augmented Unpaired Image
T 帧结合作者选取的 reference image,输入VGG19提取关联性矩阵。上色模块结合 t-1 时刻的输出,实现 temporal consistency
-
"Video Colorization with Pre-trained Text-to-Image Diffusion Models" Arxiv, 2023 Jun ⭐
-
"Temporal Consistent Automatic Video Colorization via Semantic Correspondence" CVPR, 2023 May paper
-
Interactive Deep Colorization
-
Improved Diffusion-based Image Colorization via Piggybacked Models Apr 2023
-
"Video super-resolution based on spatial-temporal recurrent residual networks" CVIU, 2018 Mar paper
按 H264 考虑关键帧 & offset 作为输入实现超分 takes not only the LR frames but also the differences of these adjacent LR frames as the input
-
"EDVR: Video Restoration with Enhanced Deformable Convolutional Networks" CVPR NTIRE 1st, 2019 May
-
"BasicVSR: The Search for Essential Components in Video Super-Resolution and Beyond" CVPR, 2020 Dec, BasicVSR 🗿 paper code note
Authors: Kelvin C. K. Chan, Xintao Wang, Ke Yu, Chao Dong, Chen Change Loy
-
"Memory-Augmented Non-Local Attention for Video Super-Resolution" CVPR, 2021 Aug paper code
memory mechanism
-
"BasicVSR++: Improving video super-resolution with enhanced propagation and alignment" CVPR, 2021 Apr 🗿 paper code note
Deformable Transformer
-
"Investigating Tradeoffs in Real-World Video Super-Resolution" CVPR, 2021 Nov, RealBasicVSR paper code note
盲视频超分,基于2个发现进行改进:长时序反而会降低性能,有噪声没有特殊处理;iteration L=10 太少了会造成颜色伪影,20->30 会好一些 基于 BasicVSR 加入动态预处理模块,改进训练数据策略降低计算量
-
"TR-MISR: Multiimage Super-Resolution Based on Feature Fusion With Transformers" STAEOR, 2022 Jan 🗽 paper'
-
"AnimeSR: Learning Real-World Super-Resolution Models for Animation Videos" NIPS, 2022 Jul ⭐ paper code
如何去设计 LR,HR 配对数据集,思考是否可以用生成模型去学习退化;模型学习缩放尺度(缩放的尺度适合动画),实现任意分辨率超分;使用单向传播; 提出真实动画数据集,参考 LICENSE AGREEMENT.pdf
-
"Can SAM Boost Video Super-Resolution?" Arxiv, 2023 May
⚠️ paper -
"Recurrent Video Restoration Transformer with Guided Deformable Attention" NeurlPS, 2022 June, RVRT 🗽 paper code note
-
"STDAN: Deformable Attention Network for Space-Time Video Super-Resolution" NNLS, 2023 Feb 🗽 paper code note
Deformable Attention 视频 SR
-
"Towards High-Quality and Efficient Video Super-Resolution via Spatial-Temporal Data Overfitting" CVPR_highlight, 2023 Mar paper code note
对视频分 patch 再按 PSNR 分组再去训练
-
"Expanding Synthetic Real-World Degradations for Blind Video Super Resolution" CVPR, 2023 May paper
-
"Mitigating Artifacts in Real-World Video Super-resolution Models" AAAI, 2023 Jun
⚠️ paper code note -
"Motion-Guided Latent Diffusion for Temporally Consistent Real-world Video Super-resolution" Arxiv, 2023 Dec,
MGLD-VSRpaper code note pdf Authors: Xi Yang, Chenhang He, Jianqi Ma, Lei Zhang

- "Upscale-A-Video: Temporal-Consistent Diffusion Model for Real-World Video Super-Resolution" CVPR, 2023 Dec,
Upscale-A-Videopaper code website note
将整个视频按 8 帧切为各个 clip,模仿 SD x4 upscaler 将输入 LR 加噪作为 SD latent space 特征。改造了一下 UNet 加了一点 temporal layer 微调了一下,然后对 z0 对于不同clip 传播一下。更新后的特征输入 VAE decoder 得到 x4 的 HR。这里的 VAE Decoder 加入了 conv3d 微调了一下作为 decoder.
- "EvTexture: Event-driven Texture Enhancement for Video Super-Resolution" Arxiv, 2024 Jun 19 paper code pdf note Authors: Dachun Kai, Jiayao Lu, Yueyi Zhang, Xiaoyan Sun
光流传播的方法类似 basicVSR;增加了额外的 event signals ,搞了一个 event signals 的传播分支,得到传播后的 event signal;
把每一帧各自传播后的光流特征
- Event signals 含有更多细节的纹理的特征,但需要 event camera
- 按 badcase 找出来分别计算指标hhh
- 参考实验设计 ⭐
3D ResNets for Action Recognition
参考这个将 2D CNN 改成 3D
-
"Long-Term Feature Banks for Detailed Video Understanding" CVPR, 2018 Decf paper code
use 3D volumes to solve long-video understanding
-
"Learning to Cut by Watching Movies" ICCV, 2021 Aug paper code website pdf
-
"EVA: Exploring the Limits of Masked Visual Representation Learning at Scale" CVPR, 2022 Nov, EVA-CLIP paper code
feature extractor
-
"BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models" Arxiv, 2023 Jan paper code
feature extractor Qformer
-
"Siamese Masked Autoencoders" NeurIPS, 2023 May paper website
-
"Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models" Arxiv, 2023 Jun, Video-ChatGPT 🗽 paper code
-
"MeMViT: Memory-Augmented Multiscale Vision Transformer for Efficient Long-Term Video Recognition" CVPR oral, 2022 Jan ⭐ 🐤 paper code paper_local_pdf
高效处理长视频,将 KV 每次压缩(可学 layer)存到 memory(列表存 tensor),和之前 memory concat 起来输入 KV 和当前特征 Q 一起 attn
-
tips: 为了不让 memory 和先前 iteration 的梯度关联起来 >>
detach -
code 可以学习
读取视频方式:perform sequential reading of consecutive chunks of frames (clips) to process videos in an online fashion
learnable pooling 对 memory 降维
relative positional embedding
-
长视频15min 数据集:AVA spatiotemporal action
-
PySlowFast: provides state-of-the-art video classification models with efficient training
-
-
"Pin the Memory: Learning to Generalize Semantic Segmentation" CVPR, 2022 Apr paper code
-
"Multi-Scale Memory-Based Video Deblurring" CVPR, 2022 Oct ⭐ code
多尺度
-
"Make-A-Story: Visual Memory Conditioned Consistent Story Generation" CVPR, 2022 Nov 🐤 🚧 paper code note
给 story 文本合成图,在 StableDiffusion U-net 的 cross-attn 后面加上一层 memory attn 用先前生成结果替换 QKV ( latent code 作为 V, ...) ,能够提升 LDM 生成一致性。
原来 LDM 效果已经很好,替换指代对数据集加难度,体现 memory 机制的有效性
-
"MovieChat: From Dense Token to Sparse Memory for Long Video Understanding" Arxiv, 2023 Jul, MovieChat🗽 paper code pdf
designed for ultra-long videos (>10K frames) understanding through interactive dialogue with the user
- frame-wise visual feature extractor, memory mechanism, projection layer, LLM
- feature-extract in sliding window: EVA-CLIP + Qformer
-
"Memory-and-Anticipation Transformer for Online Action Understanding" ICCV, 2023 Aug paper website
-
"Memory-Aided Contrastive Consensus Learning for Co-salient Object Detection" AAAI, 2023 Feb paper
-
"Memory-guided Image De-raining Using Time-Lapse Data"
-
"Memory Encoding Model" code
可变形卷积 >> transformer 做视频帧的特征对齐 各帧之间有差异,直接用 CNN。可变形 transformer 对非对其特征融合
-
"Cross Attention-guided Dense Network for Images Fusion" Arxiv, 2021 Sep paper code
-
"TransforMatcher: Match-to-Match Attention for Semantic Correspondence" CVPR, 2022 May paper code
-
"Neural Matching Fields: Implicit Representation of Matching Fields for Visual Correspondence" NeurIPS, 2022 Oct paper code website note
INR 隐式网络用于特征点匹配,SOTA & 推理一张图要 8-9s
-
"DreamSim: Learning New Dimensions of Human Visual Similarity using Synthetic Data" Arxiv, 2023 Jun paper code website
-
"Learning to Fuse Monocular and Multi-view Cues for Multi-frame Depth Estimation in Dynamic Scenes" CVPR, 2023 Apr paper code
多特征融合,去除部分特征干扰
-
"DiffMatch: Diffusion Model for Dense Matching" Arxiv, 2023 May
⚠️ paper websiteNeural Matching Fields 同个组
-
"GMFlow: Learning Optical Flow via Global Matching" CVPR oral, 2022 Nov
比 RAFT 更高效的光流预测网络,关注光流预测 & 特征对齐
- 前反向光流只要一次前向
-
RefSR
-
"Robust Reference-based Super-Resolution via C2-Matching" CVPR, 2021 Jun, C2-Matching 🗽 paper code
-
"Reference-based Image Super-Resolution with Deformable Attention Transformer" ECCV, 2022 Jul, DATSR 🗽 paper code note
-
"DARTS: Double Attention Reference-based Transformer for Super-resolution" Arxiv, 2023 Jul paper code
-
-
"Dual-Camera Super-Resolution with Aligned Attention Modules" ICCV oral, 2021 Sep, DCSR paper code note
reference images 按相似度筛选提取信息
-
"EFENet: Reference-based Video Super-Resolution with Enhanced Flow Estimation" paper code
-
"Reference-based Video Super-Resolution Using Multi-Camera Video Triplets" CVPR, 2022 Mar, RefVSR 🗽 paper website code [pdf](./2022_03_Reference-based-Video -Super-Resolution-Using-Multi-Camera-Video-Triplets.pdf)
cosine similarity, reference alignment, and propagative temporal fusion module
-
"NeuriCam: Key-Frame Video Super-Resolution and Colorization for IoT Cameras" MobiCom, 2022 Jul paper code
-
"Generating Aligned Pseudo-Supervision from Non-Aligned Data for Image Restoration in Under-Display Camera" paper website code
-
"Efficient Reference-based Video Super-Resolution (ERVSR): Single Reference Image Is All You Need" WACV, 2023 Jan, ERVSR paper code
-
"RefVSR++: Exploiting Reference Inputs for Reference-based Video Super-resolution" Arxiv, 2023 Jul RefVSR++ paper
-
"STDAN: Deformable Attention Network for Space-Time Video Super-Resolution" NNLS, 2023 Feb 🗽 paper code note
Deformable Attention 视频 SR,每一帧和多个参考帧加权平均来融合(在像素点角度,用 QK 乘积得到的相似度,去做加权平均是否合理?:question:) 12帧显存占用只有 8 G,但搭配后续 Residual Swim Transformer Block 显存直接到 20 G
-
"Store and Fetch Immediately: Everything Is All You Need for Space-Time Video Super-resolution" AAAI, 2023 Jun paper note
-
"InternVideo: General Video Foundation Models via Generative and Discriminative Learning" Arxiv, 2022 Dec paper code note
视频基础大模型,39个数据集的 SOTA, 6B 参数。
- 验证了 masked video learning (VideoMAE) and video-language contrastive modeling 对于下游任务的有效性;用两个分支的 Encoder
- 高效训练,相比之前 Coca 只要 23% power costs
- 无法处理长视频
-
"VideoChat: Chat-Centric Video Understanding" Arxiv, 2023 May ⭐ paper code
结合 InternVideo, 长视频的视频理解,可以类似 chatgpt 交互
researcher: Prune Truong working on dense correspondence
-
dense correspondence
- "Probabilistic Warp Consistency for Weakly-Supervised Semantic Correspondences" CVPR, 2022 Mar paper
-
"Temporal FiLM: Capturing Long-Range Sequence Dependencies with Feature-Wise Modulations" NIPS, 2019 Sep paper code
-
"Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks" TPAMI, 2021 May paper code_attn_series ⭐
-
"Bi-level Feature Alignment for Versatile Image Translation and Manipulation" ECCV, 2021 Jul paper code
-
"Relational Embedding for Few-Shot Classification" ICCV, 2021 Aug paper code
-
"Monte Carlo denoising via auxiliary feature guided self-attention" SIGGRAPH, 2021 Dec, MC-deoise:baby_chick: paper code pdf
非对齐特征融合 Denoising via Auxiliary Feature 很贴近
-
"Vision Transformer with Deformable Attention" CVPR, 2022 Jan, DAT paper code blog_explanation code_improvement note
特征融合部分可以考虑使用这个deformable attention,此前deformable convolution经常用于非对齐的特征融合,local reference 7和5帧特征就是非对齐的特征融合,考虑使用这种 deformable attention
2D deformable attention
-
"Rethinking Alignment in Video Super-Resolution Transformers" NIPS, 2022 Jul paper code note
探索 deformable,optical flow 用来 warp 的优缺点和使用场景 👍
-
"Blur Interpolation Transformer for Real-World Motion from Blur" CVPR, 2022 Nov paper code
-
"DFA3D: 3D Deformable Attention For 2D-to-3D Feature Lifting" ICCV, 2023 Jul paper code
3D deformable attn
-
"DDT: Dual-branch Deformable Transformer for image denoising" ICME, 2023 Apr paper code
融合非对齐特征
-
"Recurrent Video Restoration Transformer with Guided Deformable Attention" NeurlPS, 2022 June, RVRT 🗽 paper code note
-
"Dual-Camera Super-Resolution with Aligned Attention Modules" ICCV oral, 2021 Sep, DCSR paper code note
reference images 按相似度筛选提取信息
-
A Toolbox for Video Restoration: VR-Baseline. CVPR NTIRE 3rd award 👶 paper code
-
"STDAN: Deformable Attention Network for Space-Time Video Super-Resolution" NNLS, 2023 Feb 🗽 paper code note
Deformable Attention 视频 SR
-
"An Implicit Alignment for Video Super-Resolution" Arxiv, 2023 Apr paper code note
对 deformable 中 bilinear 采样方式,使用 NN 优化
-
"LightGlue: Local Feature Matching at Light Speed" 2023 Jun paper code note
-
"Multi-view Self-supervised Disentanglement for General Image Denoising" ICCV, 2023 Sep paper code website note
-
"Fix the Noise: Disentangling Source Feature for Controllable Domain Translation" paper code
-
"Align and Prompt: Video-and-Language Pre-training with Entity Prompts" CVPR, 2021 Dec paper code note
-
"Open-Vocabulary Semantic Segmentation with Mask-adapted CLIP" CVPR, 2022 Oct paper code note
-
"Iterative Prompt Learning for Unsupervised Backlit Image Enhancement" ICCV, 2023 Mar paper code website
背光图像增强,CLIP 锁住,初始化 prompt,和图片得到 loss 梯度回传去更新 prompt。得到新的 prompt 去更新优化器
-
"PromptIR: Prompting for All-in-One Blind Image Restoration" Arxiv, 2023 Jul paper code
Blind Restoration
HDR(High-Dynamic Range), LLIE(Low-Light Image Enhancement) paper with code rank
-
"Invertible Denoising Network: A Light Solution for Real Noise Removal" CVPR, 2021 Apr paper code
LLI 使用小波变换提取低频高频特征,对高频信息映射到高斯分布,对高频重新采样,再恢复
-
"Toward Fast, Flexible, and Robust Low-Light Image Enhancement" CVPR(oral), 2022 Apr, SCI paper code
-
"BokehMe: When Neural Rendering Meets Classical Rendering" CVPR oral, 2022 Jun paper website
对图像实现可控的模糊,调整焦距,光圈等效果。发布了数据集
-
"DNF: Decouple and Feedback Network for Seeing in the Dark" CVPR Highlight, 2023 paper code note
Single stage(RAW space 的噪声映射到未知分布的 color space) & multi-stage (多阶段 pipeline 存在累积 loss ) 的问题
domain-specific decoupled & feedback info : 分解为 noisy-to-clean and RAW-to-sRGB 任务。将 Denoise Decoder 的中间特征,经过 GFM 模块过滤后,返回去融合到 Encoder 中。
同一个 Encoder 融合 denoise 的中间特征进行 colorization 代替使用去噪不准确的结果作为输入。用一个 RSM 模块调节是否加入残差跳连,区分 noise 和 signal (denoise, color)
-
"Iterative Prompt Learning for Unsupervised Backlit Image Enhancement" ICCV, 2023 Mar, ⭐ CLIP-LIT paper code website 8.10
引入 CLIP 文本特征的先验,能够有助于低光增强,能用于视频
-
"Inverting the Imaging Process by Learning an Implicit Camera Model" CVPR, 2023, Apr paper website
⚠️ noteRepresent the visual signal using implicit coordinate-based neural networks is recent trend in CV. Existing methods directly conider using the whole NN to represent the scene, and not consider the camera separately. The paper proposed a new implicit camera model (using implicit neural network) to represent the physical imaging process. 使用 NeRF 单独模拟相机模型和 scene,实现解耦,增加可调节能力
-
"DC2: Dual-Camera Defocus Control by Learning to Refocus" CVPR, 2023 Apr website
image refocus requires deblurring and blurring different regions of the image at the same time, that means that image refocus is at least as hard as DoF Control
-
"Low-Light Image Enhancement with Wavelet-based Diffusion Models" Arxiv, 2023 Jun paper pdf
-
"Lighting Every Darkness in Two Pairs: A Calibration-Free Pipeline for RAW Denoising" ICCV, 2023 Aug 🗽 ⭐ paper code blog_explanation
极简标定流程下的 RAW 去噪 & 少量配对数据(6对)和快速微调即可适应目标相机, 0.2% 原来训练时间实现 SOTA blog 相机标定基础知识
-
"Efficient Multi-exposure Image Fusion via Filter-dominated Fusion and Gradient-driven Unsupervised Learning, Supplementary Material" paper
HDR
-
SpatialCrossAttentionmodule 两个 feature 互相加权一下 两个 featurex1,x2, 先 concat 过 Conv 压缩通道再还原原来通道数,chunk 出来再和原来x1,x2相乘 -
L1 梯度 Loss: 梯度最大值相减 L1,抑制伪影的产生
I0 LDR 梯度亮处很清晰,HDR 暗处很清晰,组合一下
-
-
"TransMEF: A Transformer" paper
多曝光融合:伪影
自监督方式:GT 图构造不同的噪声,构造低质量图
-
"Multi-Exposure Image Fusion via Deformable Self-attention"
deformable attention in feature fusion
-
"Alignment-free HDR Deghosting with Semantics Consistent" Arxiv, 2023 May
⚠️ paper website融合 3 个曝光图(内容有差距,例如人在移动)的特征
$f_1, f_2,f_3$ 特征过Transformer 融合一下 + chunk 分解回去代替原来 Transformer 进行 alignment 方式可以参考多个曝光不同位置的图,如何 alignment
-
"CLE Diffusion: Controllable Light Enhancement Diffusion Model" code
模型最后
[-1, 1]>> Decoder 不用 tanh 直接 conv 出来也是可以的Decoder 最后一层卷积 后面 bias 是否有用,需要做实验去验证
bias 可能会学到训练集的先验
-
"Opening the Black Box of Deep Neural Networks via Information" paper
Information Bottleneck (IB) tradeoff 加深对 DNN 的理解
-
"Half Wavelet Attention on M-Net+ for Low-Light Image Enhancement" paper
U-Net decoder 部分每一层的特征,和最终结果 concat 处理,提点很有用
-
"Learning Enriched Features for Fast Image Restoration and Enhancement" TPAMI, 2022 May, MIRNetv2 🗽 paper code note
各种 low level 的 trick
集成了各种 Trick:关注 Encoder,(多尺度)特征融合,上下文信息融合,训练策略;消融实验很有参考价值:moneybag:
-
"Deep Learning Tricks links repo" code
-
"A ConvNet for the 2020s" paper
当作卷积
-
"Learning to Upsample by Learning to Sample" ICCV, 2023 Aug paper code
对特征进行上采样方式,先前都是 bilinear+Conv; PixelShuffle
-
"Editing Implicit Assumptions in Text-to-Image Diffusion Models" CVPR, 2023 Aug,
TIMEpaper code note对 loss function 按目标变量求导,看看是否有闭合解(直接能求出来使得导数=0),也就不用训练了!

paper-list: Awesome-Segment-Anything
https://www.sainingxie.com/pdf/CVPR_t4vworkshop_clean.pdf 基础模型的总结
- "Densely Connected Convolutional Networks" CVPRBestPaper, 2016 Aug 25 paper code pdf note blog Authors: Gao Huang, Zhuang Liu, Laurens van der Maaten, Kilian Q. Weinberger

-
"Shunted Self-Attention via Multi-Scale Token Aggregation" CVPR, 2021 Nov ⭐ paper code 8.2
backbone, 对 KV 下采样多次
-
"DLGSANet: Lightweight Dynamic Local and Global Self-Attention Networks for Image Super-Resolution" Arxiv, 2023 Jan paper 8.2
-
"Deep Discriminative Spatial and Temporal Network for Efficient Video Deblurring" CVPR, 2023 paper code 8.2
-
"Learning A Sparse Transformer Network for Effective Image Deraining" CVPR, 2023 Mar paper code 8.2
-
"Simple but Effective: CLIP Embeddings for Embodied AI" CVPR, 2021 Nov paper code
-
"Rethinking Breast Lesion Segmentation in Ultrasound: A New Video Dataset and A Baseline Network" paper
ultrasound video segmentation
- propose a dynamic selection scheme to effectively sample the most relevant frames from all the past frames
Awesome-Transformer-Attention Flighting-CV attention_usage GNN survey
- "Attention Is All You Need" NIPS, 2017 Jun 12 ⭐⭐ paper code pdf note Authors: Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin
- Q:$\sqrt{d_k}$ 是干嘛的?
dk 为 Q,K,V 特征的通道数 or 维度 ⭐ ,用于做 scaling 的,不加会导致 Dot products 值很大,做完 softmax 梯度太小
We suspect that for large values of dk, the dot products grow large in magnitude, pushing the softmax function into regions where it has extremely small gradients
-
multi-head 就是在一开始 MLP ,把 C 拆成
nH, C/nH,单独做 attention;最后做完再 reshape 回去;认为对应到了子空间中的不同位置,能够得到更丰富特征 -
"Swin Transformer: Hierarchical Vision Transformer using Shifted Windows" ICCV_best_paper, 2021 Mar paper code note

-
"Focal Self-attention for Local-Global Interactions in Vision Transformers" NeurIPS, 2021 Jul paper code video-explanation
E2FGVI basVideo Swineline modified
-
"Top-Down Visual Attention from Analysis by Synthesis" CVPR, 2023 Mar, AbSViT paper code website
-
"SVFormer: Semi-supervised Video Transformer for Action Recognition" CVPR, 2022 Nov paper code
-
"MAGVIT: Masked Generative Video Transformer" CVPR, 2022 Dec paper
-
"Eventful Transformers: Leveraging Temporal Redundancy in Vision Transformers" Arxiv, 2023 Aug 🐤 paper code
exploit temporal redundancy between subsequent inputs && significant computational savings
$2 - 4\times$ implementing a fused CUDA kernel for our gating logic, further improve-
Token Gating: Detecting Redundancy
每次存一个 reference 图的 tokens, 下一帧进来比较 token 和 ref 的差异,差异大则更新 reference 的 tokens
-
-
On the Expressivity Role of LayerNorm in Transformer's Attention
https://github.com/tech-srl/layer_norm_expressivity_role 这个工作可以加深对 transformer 的一些理解 ⭐ -
"Scaling Local Self-Attention for Parameter Efficient Visual Backbones" CVPR, 2021 Mar, HaloNet paper
对特征图进行窗口注意力(分成 bxb 的patch),patch 之间没有交互,信息有丢失。对 patch 设置为 bxb+2*halo_size 增大 patch 大小 & 让 patch 之间有重叠
-
SpectFormer: Frequency and Attention is what you need in a Vision Transformer
https://github.com/badripatro/SpectFormers -
Learning A Sparse Transformer Network for Effective Image Deraining https://github.com/cschenxiang/DRSformer
-
FEDformer: Frequency Enhanced Decomposed Transformer for Long-term Series Forecasting ⭐ 时序数据 https://github.com/MAZiqing/FEDformer
-
Permuted AdaIN: Reducing the Bias Towards Global Statistics in Image Classification https://github.com/onuriel/PermutedAdaIN 这个工作很简单但是对于提升模型鲁棒性很有效,大家都可以看一下
理解核心的那一小段代码即可
-
"A ConvNet for the 2020s" paper
-
MobileViT blog
-
"CrossFormer: A Versatile Vision Transformer Based on Cross-scale Attention" code
现有的方法存在着缺乏对不同尺度的特征进行交互的能力
参考模型设计
-
"Vision Transformer with Super Token Sampling" code
加速训练
-
"SG-Former: Self-guided Transformer with Evolving Token Reallocation" code
-
"Global Context Vision Transformers" ICML, 2022 Jun, GCViT paper code note
-
"PVT v2: Improved Baselines with Pyramid Vision Transformer" paper
-
Survey
-
"Deformable ConvNets v2: More Deformable, Better Results" CVPR, 2018 Nov, DCNv2 🗽 paper note
- 相比 DCNv1 增加更多卷积层
- Modulation mechanism 就是对区域点的特征加权平均 👍
$y(p) = \sum_{k=1}^{K}{w_k}\cdot x(p+p_k+\triangle{p_k})\cdot \triangle{m_k}$
-
从结果上看
输入图像越小,感受也越大,物体上的点更为密集 & 但会存在很多 offset 到其他物体上的点;随着输入图尺度增加,点会更分散 & 更为准确,偏移错的点比例减少
从 ROI 区域来看,DCNv2 还是有偏差,说明要按相似度再筛选一下,只加权还是有可能把错的信息拉进来
-
⚠️ 相比 DCNv1 参数量和 FLOPS 都增加接近 10%
-
"Deformable Kernel Networks for Joint Image Filtering" 2019 Oct paper code
-
"Deformable 3D Convolution for Video Super-Resolution" Trans, 2020 Jul paper code
deformable 代替 inaccurate optical flow
-
"Is Space-Time Attention All You Need for Video Understanding?" ICML, 2021 Feb,
TimeSFormerpaper code note对每一帧在空间维度划分 patch,没有在 t 维度设置窗口;此时提取的特征是按空间维度的,没对 t 维度一起提取特征,造成 spatial&temporal 效果每 divided 好;
-
"ViViT: A Video Vision Transformer" ICCV, 2021 Mar paper code note
在 t 维度也设置一个窗口,每个窗口为一个长方体
t,h,w;用 3D 卷积同时提取t,h,w维度的特征,此时 spatial&temporal 效果更好 -
"Video Swin Transformer" CVPR, 2021 Jun paper code blog note
类似 vivit 设置 tube 形式的窗口
-
"Multiscale Vision Transformers" ICCV, 2021 Apr,
MViTpaper code note对 attention QKV 使用 conv-pooling 降低 spatial 尺寸的同时升高 channel,实现多尺度融合 从浅层到深层根据channel 的维度划分成多个stage,channel维度逐渐增大,空间分辨率逐渐变小(变得更coarse)
参数只有 vivit 的 1/4,准确率更高
-
"MViTv2: Improved Multiscale Vision Transformers for Classification and Detection" CVPR, 2021 Dec,
MViTv2paper code note -
"Vision Transformer with Deformable Attention" CVPR, 2022 Jan, DAT paper code blog_explanation code_improvement
-
"UniFormer: Unified Transformer for Efficient Spatiotemporal Representation Learning" ICLR+TPAMI, 2022 Jan paper code blog note Authors: Kunchang Li, Yali Wang, Peng Gao, Guanglu Song, Yu Liu, Hongsheng Li, Yu Qiao
发现 Encoder 全部用 attn,也只是在相邻帧的对应位置左右做注意力,用 attn 浪费计算资源,因此浅层用 CNN 代替
-
"Multiview transformers for video recognition" CVPR, 2022 Jan,
MTV🗽 paper note -
"Rethinking Alignment in Video Super-Resolution Transformers" NeurIPS, 2022 Jul paper code
-
"Reference-based Image Super-Resolution with Deformable Attention Transformer" ECCV, 2022 Jul, DATSR paper code note
-
"DOVE: Learning Deformable 3D Objects by Watching Videos" IJCV, 2022 Jul paper code
-
"UniFormerV2: Spatiotemporal Learning by Arming Image ViTs with Video UniFormer" ICCV, 2022 Nov ⭐ paper code note
InternVideo 视觉基础模型 masked visual encoder 的 backbone
-
"InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions" CVPR highlight, 2022 Nov, INTERN-2.5 ⭐ paper code blog_explanation pdf
SOTA
-
"PointAvatar: Deformable Point-based Head Avatars from Videos" CVPR, 2022 Dec paper
Deformable 用于视频
-
"InternVideo: General Video FoundatioMViTv2n Models via Generative and Discriminative Learning" Arxiv, 2022 Dec paper code note
视频基础大模型,39个数据集的 SOTA, 6B 参数。
- 验证了 masked video learning (VideoMAE) and video-language contrastive modeling 对于下游任务的有效性;用两个分支的 Encoder
- 高效训练,相比之前 Coca 只要 23% power costs
- 无法处理长视频
-
"OSRT: Omnidirectional Image Super-Resolution with Distortion-aware Transformer" CVPR, 2023 Feb paper code
Deformable attn 用于图像 SR
-
"STDAN: Deformable Attention Network for Space-Time Video Super-Resolution" NNLS, 2023 Feb 🗽 paper code note
Deformable Attention 视频 SR
-
"An Efficient Accelerator Based on Lightweight Deformable 3D-CNN for Video Super-Resolution" CS, 2023 Mar paper
Deformable Attention 视频 SR
-
"Eventful Transformers: Leveraging Temporal Redundancy in Vision Transformers" Arxiv, 2023 Aug paper
-
"DAT++: Spatially Dynamic Vision Transformer with Deformable Attention" paper code
Extended version of "Vision Transformer with Deformable Attention"
关注 deformable 可视化 code
-
"Aerial Image Dehazing with Attentive Deformable Transformers" WACV, 2023 ⭐ paper code
Self-atten QKV 特征都单独过 SE 空间注意力 + Deformable 偏移(自己计算偏移);对比了不同类型 deformable,针对不同任务稍微修改一下 deformable ,psnr 能高 1 db
-
"Video-FocalNets: Spatio-Temporal Focal Modulation for Video Action Recognition" ICCV, 2023 Jul paper code
-
"Revisiting Deformable Convolution for Depth Completion" IROS, 2023 Aug paper code
-
Motivation:most of the propagation refinement methods require several iterations and suffer from a fixed receptive field, which may contain irrelevant and useless information
address these two challenges simultaneously by revisiting the idea of deformable convolution. 增大感受野降低迭代数
studied its best usage on depth completion with very sparse depth maps: first generate a coarse depth map Dˆ from the backbone. Then, we pass it through our deformable refinement module.
-
- "MnasNet: Platform-Aware Neural Architecture Search for Mobile" CVPR, 2018 Jul paper
用 NAS 搜出来一个网络,可以参考借鉴一下搜出来的 CNN block;3x3 Conv Block 搭配 5x5 有 SE 的 ConvBlock

- "EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks" ICML, 2019 May,
EfficientNetpaper code pdf note Authors: Mingxing Tan, Quoc V. Le
- 验证了组合地去增加模型深度&通道数&分辨率,能够比只加一个更好;每一个维度只加 1.3 倍左右就足够,能比单一一个维度加 4 倍效果更好
- 每个维度 scale 多少用 NAS 方式去搜索,能有接近 4 % Acc 的提升

ViT 等方法使用 MLP 将图像分为多个 patch,每个 patch 都用同一个 MLP 映射没考虑到 patch 内的特殊性。aim to improve the representation way of tokens for dynamically aggregating them according to their semantic contents,对比 ViT-L 参数量小一半,Flops 约 1/4,对比 Swin-T 同样 Flops 下准确率更高。 wave function(幅值代表强度,相位代表在 wave 中的相对位置) 分解图像为幅值(特征)和相位(平衡 token 和 MLP 权值之间的关系);
提出 (PATM) for aggregating tokens,分解幅值、相位进行融合(区别于加权平均,phase
- "EfficientViT: Memory Efficient Vision Transformer with Cascaded Group Attention" CVPR, 2023 May paper note
-
"Fast Segment Anything" Arxiv, 2023 Jun 21 paper code
FPS25 !
-
"Faster Segment Anything: Towards Lightweight SAM for Mobile Applications" Arxiv, 2023 Jun 25, MobileSAM paper code blog
-
"Segment and Track Anything" Arxiv, 2023 May, SAM-Track code
视频实例分割,和 E2FGVI 结合一下实现 object removal
-
"Segment Anything Meets Point Tracking" Arxiv, 2023 Jul, VideoSAM paper code blog
Self-Supervised Learning awesome-self-supervised-learning
- "EMP-SSL: Towards Self-Supervised Learning in One Training Epoch" Arxiv, 2023 Apr, EMP-SSL ⭐ paper code blog_explanation note
一个 loss 提升自监督学习效率,30个epoch实现SOTA;提出的 TCR loss 约束特征表示,将相近特征拉的更近,避免噪声干扰
$$
Loss = \max{\frac{1}{n}\sum_{i=1}^{n}{(R(Z_i) +\lambda\cdot D(Z_i, \bar{Z}))}}\
\bar{Z} = \frac{1}{n}\sum_{i=1}^{n}{Z_i}\
\text{where
-
Siamese Masked Autoencoders
Masked Siamese Networks for Label-Efficient Learning https://github.com/facebookresearch/msn
MixMask: Revisiting Masking Strategy for Siamese ConvNets https://github.com/LightnessOfBeing/MixMask 这几个半监督/自监督的工作很有意思,大家好好看下
-
SimMIM: a Simple Framework for Masked Image Modeling
可以应用到 video MAE
-
Hard Patches Mining for Masked Image Modeling https://mp.weixin.qq.com/s/YJFDjcTqtX_hzy-FXt-F6w
-
Masked-Siamese-Networks-for-Label-Efficient-Learning
-
"Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks" ICCV, 2017 Mar, CycleGAN 🗿 paper code website
-
"Unifying Diffusion Models' Latent Space, with Applications to CycleDiffusion and Guidance" paper code
-
"RefineDNet: A Weakly Supervised Refinement Framework for Single Image Dehazing" TIP, 2021 Mar paper code note
自监督去雾,多个预测结果通SeeSR过感知融合
- "Multi-view Self-supervised Disentanglement for General Image Denoising" ICCV, 2023 Sep paper code website note
NLP & 多模态
- Multimodal Prompting with Missing Modalities for Visual Recognition https://github.com/YiLunLee/Missing_aware_prompts 训练或者测试是多模态非完美情况
- Is GPT-4 a Good Data Analyst https://github.com/damo-nlp-sg/gpt4-as-dataanalyst
对比学习
- CCPL: Contrastive Coherence Preserving Loss for Versatile Style Transfer https://github.com/JarrentWu1031/CCPL
-
2023_CVPR_Inverting-the-Imaging-Process-by-Learning-an-Implicit-Camera-Model_Note.md
-
Neural Volume Super Resolution https://github.com/princeton-computational-imaging/Neural-Volume-Super-Resolution NeRF+SR
-
LERF: Language Embedded Radiance Fields https://github.com/kerrj/lerf NeRF + 3D CLIP
-
iNeRF: Inverting Neural Radiance Fields for Pose Estimation
-
ViP-NeRF: Visibility Prior for Sparse Input Neural Radiance Fields
-
AdaNeRF: Adaptive Sampling for Real-time Rendering of Neural Radiance Fields
-
2022_CVPR_Aug-NeRF--Training-Stronger-Neural-Radiance-Fields-with-Triple-Level-Physically-Grounded-Augmentations >> 输入增加扰动
-
"Anything-3D: Towards Single-view Anything Reconstruction in the Wild" code
将SAM,BLIP,stable diffusion,NeRF结合到一起
-
"Implicit Neural Representations with Periodic Activation Functions" NeurIPS, 2020 Jun paper code
-
"Learning Continuous Image Representation with Local Implicit Image Function" CVPR oral, 2020 Dec, LIIF ⭐ 🗽 paper code note
表示任意分辨率图像
-
"UltraSR: Spatial Encoding is a Missing Key for Implicit Image Function-based Arbitrary-Scale Super-Resolution" Arxiv, 2021 Mar paper code
-
"An Arbitrary Scale Super-Resolution Approach for 3D MR Images via Implicit Neural Representation"
Biomedical and Health Informatics, 2021 Oct, ArSSR paper code实现任意分辨率 SR,基于 LIIF 改进
-
"Implicit Neural Representations for Image Compression" ECCV, 2021 Dec code
-
"MINER: Multiscale Implicit Neural Representations" ECCV, 2022 Feb, MINER paper code
-
"Signal Processing for Implicit Neural Representations" NeurIPS, 2022 Oct paper code website
-
"TITAN: Bringing the deep image prior to implicit representations" Arxiv, 2022 Nov paper code
-
"CiaoSR: Continuous Implicit Attention-in-Attention Network for Arbitrary-Scale Image Super-Resolution" CVPR, 2022 Dec paper code
-
"WIRE: Wavelet Implicit Neural Representations" CVPR, 2023 Jan, WIRE ⭐ paper code note
通过坐标来取得像素值的颜色 RGB 信息
- 提出一个 Gabor Activation Layer 激活层
-
"Local Implicit Normalizing Flow for Arbitrary-Scale Image Super-Resolution" CVPR, 2023 Mar paper
-
"Cascaded Local Implicit Transformer for Arbitrary-Scale Super-Resolution" CVPR, 2023 Mar paper code
-
"Implicit Diffusion Models for Continuous Super-Resolution" CVPR, 2023 Mar paper code
-
"Super-Resolution Neural Operator" CVPR, 2023 Mar paper code
-
"Implicit Neural Representation for Cooperative Low-light Image Enhancement" ICCV, 2023 Mar paper code
-
"Inverting the Imaging Process by Learning an Implicit Camera Model" CVPR, 2023, Apr, NeuCam paper code website
⚠️ notesimulate camera model
-
"Revisiting Implicit Neural Representations in Low-Level Vision" Arxiv, 2023 Apr, LINR paper code website note
-
"Enhanced Invertible Encoding for Learned Image Compression" ACMM, 2021 Aug paper code
Zhangyang 现在用的可逆网络
-
"reversible ViT"
刷性能
- Factorized Fourier Neural Operators https://github.com/alasdairtran/fourierflow
- Super-Resolution Neural Operator https://github.com/2y7c3/Super-Resolution-Neural-Operator
- Adaptive Fourier Neural Operators: Efficient Token Mixers for Transformers https://github.com/NVlabs/AFNO-transformer
- Fourier Neural Operator for Parametric Partial Differential Equations https://github.com/neuraloperator/neuraloperator
❔ what is IQA CVPR IQA 博客 IQA(image quality assessment) Task target: quantification of human perception of image quality
- Application 想对某一项视觉任务评估图像能否满足需要,比如针对人脸识别的质量评价,看一幅图像是否应该拒绝还是输入到人脸识别系统中;texture classification;texture retrieval (texture similarity);texture recovery
- 对于图像下游任务:denoising, deblurring, super-resolution, compression,能够提升图像质
- Full Reference, No-reference
- "Image Quality Assessment: Unifying Structure and Texture Similarity" TPAMI, 2020 Dec, DISTS paper note
针对有明显纹理的原图,让模型对 JPEG 压缩后、resample 的图像打分(实际上肉眼看上去 JPEG 更加模糊),之前方法对于 JPEG 图像质量评分错误地高于 resample 图。
-
"Re-IQA: Unsupervised Learning for Image Quality Assessment in the Wild" CVPR, 2023 Apr paper our noted pdf
一种 NR-IQA 算法,使用对比学习的方式,使用 2 个 Res50 去学习 content & image-quality-aware features. 最后加一个 regressor 输出 image quality scores. 对于 quality feature 一路,模仿 MoCoV2 ,修改了构造正负样本的方式进行训练。
-
Full-reference IQA方法 对于 images in the wild 场景,没有 reference 应用受限FR-IQA 需要参考图像(undistorted) & distorted 图像,一起才能输出评分。
-
high-level content representation using MoCoV2
2 crops from same image -> similar scores, but not the case for some human viewers.
-
-
"Half of an image is enough for quality assessment"
-
"MaxVQA"
-
FastIQA 提取视频 VQA 特征,没考虑失真信息
-
-
"REQA: Coarse-to-fine Assessment of Image Quality to Alleviate the Range Effect" CVPR&IVP, 2022 Sep paper code
Blind image quality assessment (BIQA) of User Generated Content (UGC) suffers from the range effect 发现: overall quality range, mean opinion score (MOS) and predicted MOS (pMOS) are well correlated while focusing on a particular range, the correlation is lower
- utilize global context features and local detailed features for the multi-scale distortion perception
- Feedback Mechanism
统计发现 mos 分布具有一定的特性,然后针对性设计了 curriculum learning 提升性能

-
https://lilianweng.github.io/posts/2023-06-23-agent/
https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/
https://lilianweng.github.io/posts/2023-01-27-the-transformer-family-v2/
https://lilianweng.github.io/posts/2023-01-10-inference-optimization/
https://lilianweng.github.io/posts/2022-06-09-vlm/
https://lilianweng.github.io/posts/2021-07-11-diffusion-models/
put the works not classified or read below
Problem Formulation: It's quite slow to read a paper just to get enlightenment for ideas. This would attribute to not being able to read much paper in one field to get whole picture and forget previous paper's idea after 1-2 weeks. Not able to generate ideas is caused by little accumulation. Some modules in paper are proposed to make up 2 novelties and may have not much enlightenment on our work. In this case, it's not worth it to spend much time read it and find not that helpful when finished.
In order to solve that problem, we should scan the paper within 30mins at maximum at first read and it's ok not to understand every details at first time! In this section, we could record the meaningful papers and corresponding problems to remind us figure out some problems that we met later.
Also, we should read paper with purpose, like when we need to solve scratch detection problems then we search paper with this objective. First read collected paper coarsely and understand the methods(whole pipeline) at minimum level. If find helpful, then check the code and read in details. And quickly apply the idea to our framework, which is the objective and most significant stuff! 💰 If find not much enlightenment, then quickly turn to search other papers.
However, In these cases, some paper includes some basics knowledge, formulations, like DDPM, or the paper we need further modify. It's worth it to spend 1-2 days to understand every little details or line of code.
-
Self-Supervised Learning with Random-Projection Quantizer for Speech Recognition
参考 random-projection 操作
-
Locally Hierarchical Auto-Regressive Modeling for Image Generation 👍
-
Scalable Diffusion Models with Transformers
-
All are Worth Words: A ViT Backbone for Diffusion Models
-
LayoutDM: Transformer-based Diffusion Model for Layout Generation
-
Vector Quantized Diffusion Model for Text-to-Image Synthesis
-
Image Super-Resolution via Iterative Refinement
-
Real-World Denoising via Diffusion Model
-
Diffusion in the Dark A Diffusion Model for Low-Light Text Recognition
-
Privacy Leakage of SIFT Features via Deep Generative Model based Image Reconstruction
-
"DreamDiffusion: Generating High-Quality Images from Brain EEG Signals" Arxiv, 2023 Jun, DreamDiffusion paper code blog
-
SWAGAN: A Style-based Wavelet-driven Generative Model 23.7.14
-
Shifted Diffusion for Text-to-image generation 23.7.15
-
Generative image inpainting with contextual attention ⭐
类似 non-local attention
-
"Towards Explainable In-the-Wild Video Quality Assessment: a Database and a Language-Prompted Approach" code 7.29
AIGC IQA
-
"Intelligent Grimm - Open-ended Visual Storytelling via Latent Diffusion Models" 7.29 code website
Our results have superior style and content consistency, text-image alignment, and image quality
-
"Learning with noisy correspondence for cross-modal matching" NeurIPS, 2021 paper code
类似偏多标签
-
"A Unified HDR Imaging Method with Pixel and Patch Level"
-
"Perception prioritized training of diffusion models" 8.2 ⭐
Diffusion 去噪过程,对 loss 加权实现 初步加噪和纯高斯噪声附近的权值小(避免训练难以察觉的细节),学习中间 content
- InvBlock 替换 U-net >> 实现完全复原
- 隐式网络
- 8.2
-
"End-to-End Diffusion Latent Optimization Improves Classifier Guidance" 8.2
-
"GSURE-Based Diffusion Model Training with Corrupted Data" 8.2 paper code
-
"Zero-Shot Noise2Noise: Efficient Image Denoising without any Data" 8.2
-
"Invertible Image Rescaling" ECCV, 2020 May 8.2 paper "Invertible Rescaling Network and Its Extensions" IJCV 2022 Oct paper code
可逆网络代替 U-net,实现无损恢复
-
MediaPipe Diffusion插件 7.25 blog
推理效率比ControlNet高20+倍!谷歌发布MediaPipe Diffusion插件
-
"Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles" code
如何训练一个对任务有效的模型,不是越复杂越好
-
"Bytes Are All You Need: Transformers Operating Directly On File Bytes" code 8.9
以前有些工作直接操作metadata,这个工作直接操作byte
-
"Self-Guided Diffusion Models" code
-
"RGB no more: Minimally Decoded JPEG Vision Transformers" code
-
DRHDR: A Dual branch Residual Network for Multi-Bracket High Dynamic Range Imaging
-
Networks are Slacking Off: Understanding Generalization Problem in Image Deraining
-
Image-based CLIP-Guided Essence Transfer
-
Luminance Attentive Networks for HDR Image and Panorama Reconstruction https://github.com/LWT3437/LANet
-
Perceptual Attacks of No-Reference Image Quality Models with Human-in-the-Loop
-
Perception-Oriented Single Image Super-Resolution using Optimal Objective Estimation
-
8.8
- Quality Aware Generative Adversarial Networks
- Generating Images with Perceptual Similarity Metrics based on Deep Networks
- Perceptual Adversarial Networks for Image-to-Image Transformation
-
8.11
Prompt 工作
From Images to Textual Prompts: Zero-shot VQA with Frozen Large Language Models https://github.com/salesforce/LAVIS/tree/main/projects/img2llm-vqa
PromptIR: Prompting for All-in-One Blind Image Restoration https://github.com/va1shn9v/promptir
Prompt-to-Prompt Image Editing with Cross-Attention Control https://github.com/google/prompt-to-prompt
Iterative Prompt Learning for Unsupervised Backlit Image Enhancement https://github.com/ZhexinLiang/CLIP-LIT
https://github.com/raoyongming/DenseCLIP DenseCLIP: Language-Guided Dense Prediction with Context-Aware Prompting
LANIT: Language-Driven Image-to-Image Translation for Unlabeled Data https://github.com/KU-CVLAB/LANIT
-
"Pyramid Diffusion Models For Low-light Image Enhancement" code
多尺度 diffusion
-
9.1
matching "Pin the Memory: Learning to Generalize Semantic Segmentation" paper code "Knowing Where to Focus: Event-aware Transformer for Video Grounding" Arxiv, 2023 Aug
"Neural Matching Fields: Implicit Representation of Matching Fields for Visual Correspondence" NeurIPS, 2022 Oct paper code
"Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks" TPAMI, 2021 May paper code_attn_series
-
9.5
Perception Prioritized Training of Diffusion Models https://github.com/jychoi118/P2-weighting
General Image-to-Image Translation with One-Shot Image Guidance https://github.com/crystalneuro/visual-concept-translator
Elucidating the Design Space of Diffusion-Based Generative Models https://github.com/NVlabs/edm
Diffusion Probabilistic Model Made Slim https://github.com/CompVis/latent-diffusion
Diffusion Models already have a Semantic Latent Space https://github.com/kwonminki/Asyrp_official
Restoring Vision in Adverse Weather Conditions with Patch-Based Denoising Diffusion Models https://github.com/igitugraz/weatherdiffusion
Unsupervised Representation Learning from Pre-trained Diffusion Probabilistic Models https://github.com/ckczzj/pdae
Self-Guided Diffusion Models https://github.com/dongzhuoyao/self-guided-diffusion-models
Unleashing Text-to-Image Diffusion Models for Visual Perception https://github.com/wl-zhao/VPD
Ablating Concepts in Text-to-Image Diffusion Models https://github.com/nupurkmr9/concept-ablation
FreeDoM: Training-Free Energy-Guided Conditional Diffusion Model https://github.com/vvictoryuki/FreeDoM
Guided Motion Diffusion for Controllable Human Motion Synthesis https://github.com/korrawe/guided-motion-diffusion
-
DPF: Learning Dense Prediction Fields with Weak Supervision https://github.com/cxx226/DPF
-
Reference-guided Controllable Inpainting of Neural Radiance Fields
-
9.20
-
9.21
- "Towards Efficient SDRTV-to-HDRTV by Learning from Image Formation" code
- "CNN Injected Transformer for Image Exposure Correction" paper
- "Pixel-Aware Stable Diffusion for Realistic Image Super-resolution and Personalized Stylization" code
- "Exploring Overcomplete Representations for Single Image Deraining using CNNs"
-
10.6
ICCV 工作
-
10.12
-
10.20
"CLIPascene: Scene Sketching with Different Types and Levels of Abstraction" paper website
-
11.22
-
"Self-augmented Unpaired Image Dehazing via Density and Depth Decomposition" CVPR, 2022 ⭐ code
改进cycleGAN做无监督/非配对的去雾任务
-
Distribution-Flexible Subset Quantization for Post-Quantizing Super-Resolution Networks https://github.com/zysxmu/DFSQ
Dynamic Dual Trainable Bounds for Ultra-low Precision Super-Resolution Networks https://github.com/zysxmu/DDTB
Fine-grained Data Distribution Alignment for Post-Training Quantization https://github.com/zysxmu/FDDA
MBQuant: A Novel Multi-Branch Topology Method for Arbitrary Bit-width Network Quantization https://github.com/zysxmu/MBQuant
CADyQ: Content-Aware Dynamic Quantization for Image Super Resolution https://github.com/Cheeun/CADyQ
-
-
11.24
- "Controlling Text-to-Image Diffusion by Orthogonal Finetuning" paper note
- "Accelerating Diffusion Models for Inverse Problems through Shortcut Sampling" Arxiv, 2023 May
- "Neural Compression-Based Feature Learning for Video Restoration" paper
- "Memory Encoding Model" code
- "Memory-guided Image De-raining Using Time-Lapse Data"
- "Hypercorrelation Squeeze for Few-Shot Segmentation" code
- "Accelerating Video Object Segmentation with Compressed Video" code
- "Video-FocalNets: Spatio-Temporal Focal Modulation for Video Action Recognition" code
- "Bi-level Feature Alignment for Versatile Image Translation and Manipulation" code
- "Temporal FiLM: Capturing Long-Range Sequence Dependencies with Feature-Wise Modulation" code
-
12.6
-
"DropKey for Vision Transformer" paper blog
研究出推key进行dropout可以提升鲁棒性,两行代码发cvpr
regards Key as the drop unit and exploits decreasing schedule for drop ratio, improving ViTs in a general way
-
"HINet: Half Instance Normalization Network for Image Restoration"
对 C 一半做 IN
-
"Batch-Instance Normalization for Adaptively Style-Invariant Neural Networks"
IN+BN
-
"U-GAT-IT: Unsupervised Generative Attentional Networks with Adaptive Layer Instance Normalization for Image-to-Image Translation"
LN+IN
-
"MixFormer: Mixing Features across Windows and Dimensions"
将transformer与cnn融合的方法,类似的方法很多
- combining local-window self-attention with depth-wise convolution across branches models connections across windows, addressing the limited receptive fields issue
"Global Context Vision Transformers"
将q使用se方式获得所谓的全局特性
倪哥用
-
"Feature Shrinkage Pyramid for Camouflaged Object Detection with Transformers" CVPR, 2023 Mar paper code
-
"Memory-Aided Contrastive Consensus Learning for Co-salient Object Detection" paper
-
"Deep Spectral Methods: A Surprisingly Strong Baseline for Unsupervised Semantic Segmentation and Localization"
-
"Extracting Training Data from Diffusion Models"
-
"Self-conditioned Image Generation via Generating Representations" paper
-
-
12.13
-
"Diffusion Model for Camouflaged Object Detection"
-
"Discrete Cosine Transform Network for Guided Depth Map Super-Resolution"
-
"UC-Net: Uncertainty Inspired RGB-D Saliency Detection via Conditional Variational Autoencoders" code
-
"Attend-and-Excite: Attention-Based Semantic Guidance for Text-to-Image Diffusion Models" SIGGRAPH, 2023 Jan paper code
很简单明了的idea,分析stable diffusion的一些特性,解决方案是推理过程中smooth attention map
-
"Physics-Driven Turbulence Image Restoration with Stochastic Refinement" ICCV, 2023 Jul paper code
-
"Solving 3D Inverse Problems using Pre-trained 2D Diffusion Models" paper code
-
"SinDDM: A Single Image Denoising Diffusion Model" paper code
-
"CABM: Content-Aware Bit Mapping for Single Image Super-Resolution Network with Large Input" code
-
"MulT: An End-to-End Multitask Learning Transformer" code
-
"MED-VT: Multiscale Encoder-Decoder Video Transformer with Application to Object Segmentation"
-
"Cross-Modal Learning with 3D Deformable Attention for Action Recognition"
-
"Memory-Aided Contrastive Consensus Learning for Co-salient Object Detection" code
-
-
12.17
-
"DigGAN: Discriminator gradIent Gap Regularization for GAN Training with Limited Data" NeurIPS, 2022 Nov paper
发现训练数据量减少后,FID 指标变差很多,发现 discriminator 对真实or生成图的梯度差距加大,然后相应的设计了一个discriminator的regularization(做实验多观察)
To improve the training of GANs with limited data, it is natural to reduce the DIG. We propose to use Eq. (2) as a regularizer so as to control the DIG during training. In turn, this aids to balance the discriminator’s learning speed.
-
-
1.4
合成数据训练 & 自监督
完全合成数据训练自监督模型获得超过监督学习的性能,使用合成数据训练大模型的idea在24年可能会出现很多工作
- "Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models"
- "Learning Vision from Models Rivals Learning Vision from Data"
- "ReST (DeepMind): Reinforced Self-Training (ReST) for Language Modeling"
- "ReST-EM (follow-up): Beyond Human Data: Scaling Self-Training for Problem-Solving with Language Models"
- "GAILGenerative Adversarial Imitation Learning"
Diffusion 处理文本
-
"PV3D: A 3D Generative Model for Portrait Video Generation" code
-
"T2I-Adapter: Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models" code
-
"Adding 3D Geometry Control to Diffusion Models"
参考 pipeline
-
"InstructPix2Pix: Learning to Follow Image Editing Instructions" code
-
"Editing Implicit Assumptions in Text-to-Image Diffusion Models" code
-
"LooseControl: Lifting ControlNet for Generalized Depth Conditioning"
-
"HandRefiner: Refining Malformed Hands in Generated Images by Diffusion-based Conditional Inpainting" paper
-
"DreaMoving: A Human Video Generation Framework based on Diffusion Models"
Finetune SD
- "Parameter-efficient Tuning of Large-scale Multimodal Foundation Model" code
- "Distribution-Aware Prompt Tuning for Vision-Language Models" code
- "Make Pre-trained Model Reversible: From Parameter to Memory Efficient Fine-Tuning" code
- "TIP: Text-Driven lmage Processing with Semantic and Restoration Instructions" blog
- "Hydra: Multi-head Low-rank Adaptation for Parameter Efficient Fine-tuning" code
- "A Survey of Reasoning with Foundation Models.Concepts,Methodologies, and Outlook" blog
非对齐图像处理
- "Semantic similarity metrics for learned image registration" code
Color shift
- "GamutMLP: A Lightweight MLP for Color Loss Recovery" code
Prompt
- "RSPrompter: Learning to Prompt for Remote Sensing Instance Segmentation based on Visual Foundation Model" code
预测划痕
-
"Restoring Degraded Old Films with Recursive Recurrent Transformer Networks" code
-
"CLIP-DINOiser: Teaching CLIP a few DINO tricks" paper code note
CLIP lack of spatial awareness makes it unsuitable for dense computer vision tasks && self-supervised representation methods have demonstrated good localization properties
take the best of both worlds and propose a zero-shot open-vocabulary semantic segmentation method, which does not require any annotations
模型结构
-
"U-Net v2: RETHINKING THE SKIP CONNECTIONS OF U-NET FOR MEDICAL IMAGE SEGMENTATION" code
-
"ResNeSt: Split-Attention Networks" code
学习如何改模型
大语言模型应用于low level task
-
1.11
SD bias
-
1.15
-
"Location-Free Camouflage Generation Network" Transactions-on-Multimedia, 2022 Mar, paper code
-
"Towards Smooth Video Composition" Arxiv, 2022 Dec, paper code website note
-
"Pik-Fix: Restoring and Colorizing Old Photos" code
-
"Improving the Stability of Diffusion Models for Content Consistent Super-Resolution" Arxiv, 2024 Jan, CCSR paper note
propose a non-uniform timestep learning strategy to train a compact diffusion network; finetune the pre-trained decoder of variational auto-encoder (VAE) by adversarial training for detail enhancement
发现去噪
-
"Sparse Sampling Transformer with Uncertainty-Driven Ranking for Unified Removal of Raindrops and Rain Streaks" code
-
"Nested Diffusion Processes for Anytime Image Generation" Arxiv, 2023 May paper code note
-
-
1.28
-
"A Complete Recipe for Diffusion Generative Models"
-
"The Bias Amplification Paradox in Text-to-Image Generation" code
-
"Reference-based Image Composition with Sketch via Structure-aware Diffusion Model" Arxiv, 2023 Apr paper code note
目标区域编辑
-
"Iterative α-(de)Blending: a Minimalist Deterministic Diffusion Model" ⭐ paper code note
-
"Diffusion in the Dark: A Diffusion Model for Low-Light Text Recognition" code
-
"Image Super-resolution via Latent Diffusion: a Sampling-space Mixture of Experts and Frequency-augmented Decoder Approach" code note
-
"Hierarchical Integration Diffusion Model for Realistic Image Deblurring" NIPS-spotlight, 2023 May paper code note
-
"Unleashing Text-to-Image Diffusion Models for Visual Perception" ICCV, 2023 Mar paper code note
-
"Diverse Data Augmentation with Diffusions for Effective Test-time Prompt Tuning" ICCV, 2023 Aug,
DiffTPT, paper code note -
"pix2gestalt: Amodal Segmentation by Synthesizing Wholes" ⭐ paper note
ICCV 2023 diffusion
-
-
2.1
-
"Depicting Beyond Scores: Advancing Image Quality Assessment through Multi-modal Language Models"
-
"Scaling Up to Excellence: Practicing Model Scaling for Photo-Realistic Image Restoration In the Wild"
-
"Regression Metric Loss: Learning a Semantic Representation Space for Medical Images"
参考特征约束
-
"Learning Vision from Models Rivals Learning Vision from Data" paper note
使用合成数据,达到 SOTA 性能
-
"Multiscale structure guided diffusion for image deblurring" ICCV, 2023 paper note
去模糊任务,用多尺度信息(需要结构信息,把一张 RGB 转为灰度 再 resize 8 倍,用)

参考可视化证明模块有效
-
-
2.22
-
"PromptIR: Prompting for All-in-One Blind Image Restoration" paper code
-
"High-Quality Image Restoration Following Human Instructions" paper code
把大部分常见图像处理任务都刷了一遍
-
"EfficientViT-SAM: Accelerated Segment Anything Model Without Performance Loss" paper
-
"Scalable diffusion models with transformers"
-
"Prompt-In-Prompt (PIP) Learning for Universal Image Restoration" code note
-
"Video generation models as world simulators" 2024 Feb, Sora OpenAI_report note
-
"Towards Effective Multiple-in-One Image Restoration: A Sequential and Prompt Learning Strategy" paper code
-
"Motion-Guided Latent Diffusion for Temporally Consistent Real-world Video Super-resolution" Arxiv, 2023 Dec,
MGLD-VSRpaper code note pdf Authors: Xi Yang, Chenhang He, Jianqi Ma, Lei Zhang -
"VIDiff: Translating Videos via Multi-Modal Instructions with Diffusion Models" paper
-
-
24.02.26
简单 idea:3D-SwinTransformer 改进为 deformable,做到 SOTA
从数据存储角度做恢复
- "Recaptured Raw Screen Image and Video Demoiréing via Channel and Spatial Modulations" NIPS, 2023 Oct paper code note pdf
- "Bitstream-Corrupted JPEG Images are Restorable: Two-stage Compensation and Alignment Framework for Image Restoration" CVPR, 2023 May paper note pdf
补充 video SOTA 文章做改进
- "A Simple Baseline for Video Restoration with Grouped Spatial-temporal Shift"
- "Exploring Temporal Frequency Spectrum in Deep Video Deblurring"
- "Deep Video Demoireing via Compact Invertible Dyadic Decomposition"
- "Dancing in the Dark: A Benchmark towards General Low-light Video Enhancement"
- "MGMAE: Motion Guided Masking for Video Masked Autoencoding"
- "Semantic-Aware Dynamic Parameter for Video Inpainting Transformer"
- "ProPainter: Improving Propagation and Transformer for Video Inpainting"
- "Learning Data-Driven Vector-Quantized Degradation Model for Animation Video Super-Resolution"
- DiffMatch: Diffusion Model for Dense Matching https://github.com/KU-CVLAB/DiffMatch
- A Unified Conditional Framework for Diffusion-based Image Restoration https://github.com/zhangyi-3/UCDIR
搭建一个基于mamba的重建网络,然后融入diffusion的先验刷性能或者鲁棒性
-
24.03.06
- "GIM: LEARNING GENERALIZABLE IMAGE MATCHER FROM INTERNET VIDEOS" paper website
- "Multi-granularity Correspondence Learning from Long-term Noisy Videos" code
- "Towards Real-World HDR Video Reconstruction: A Large-Scale Benchmark Dataset and A Two-Stage Alignment Network"
Mamba
- "Weak-Mamba-UNet: Visual Mamba Makes CNN and ViT Work Better for Scribble-based Medical Image Segmentation" paper code
- "Vivim: a Video Vision Mamba for Medical Video Object Segmentation" Arxiv, 2024 Jan paper code pdf note Authors: Yijun Yang, Zhaohu Xing, Lei Zhu
diffusion
-
"InteractDiffusion: Interaction Control in Text-to-Image Diffusion Models" code
text2image, 可以手动指定生成物体的位置 bbox,来控制生成的图像
-
"ControlVideo: Training-free Controllable Text-to-Video Generation" code
-
"Solving 3D Inverse Problems using Pre-trained 2D Diffusion Models" paper note
-
"Improving 3D Imaging with Pre-Trained Perpendicular 2D Diffusion Models"
diffusion 插值(类似 GAN inversion)
-
"TF-ICON: Diffusion-Based Training-Free Cross-Domain Image Composition" ICCV, 2023 Jul paper code website blog
基于扩散的免训练跨域图像合成
-
"DiffuseMorph: Unsupervised Deformable Image Registration Using Diffusion Model"
对 Lora 参数,z0 进行插值
VSR
-
"Real-World Image Super-Resolution as Multi-Task Learning" NIPS, 2023 Sep,
TGSRpaper code pdf note Authors: Wenlong Zhang, Xiaohui Li, Guangyuan SHI, Xiangyu Chen, Yu Qiao, Xiaoyun Zhang, Xiao-Ming Wu, Chao Dong多任务**,分解 LR 为多种退化修复任务,再集成
codebook
-
"Learning Data-Driven Vector-Quantized Degradation Model for Animation Video Super-Resolution" code
学习一下 codebook
-
"DAEFR: Dual Associated Encoder for Face Restoration"
网络结构经验
- "RAMiT: Reciprocal Attention Mixing Transformer for Lightweight Image Restoration" code
Diffusion Cross attention 修正
-
"Training-Free Structured Diffusion Guidance for Compositional Text-to-Image Synthesis"
-
03.11 先前遗留
- "Perceptual Losses for Real-Time Style Transfer and Super-Resolution" Arxiv, 2016 Mar paper code pdf Authors: Justin Johnson, Alexandre Alahi, Li Fei-Fei
- "Understanding Object Dynamics for Interactive Image-to-Video Synthesis" Arxiv, 2021 Jun paper code pdf Authors: Andreas Blattmann, Timo Milbich, Michael Dorkenwald, Björn Ommer
- "iPOKE: Poking a Still Image for Controlled Stochastic Video Synthesis" Arxiv, 2021 Jul paper code pdf Authors: Andreas Blattmann, Timo Milbich, Michael Dorkenwald, Björn Ommer
- "CLIPascene: Scene Sketching with Different Types and Levels of Abstraction" Arxiv, 2022 Nov paper code website pdf Authors: Yael Vinker, Yuval Alaluf, Daniel Cohen-Or, Ariel Shamir
- "Effective Data Augmentation With Diffusion Models" NIPS, 2023 Feb paper code pdf Authors: Brandon Trabucco, Kyle Doherty, Max Gurinas, Ruslan Salakhutdinov
- "Localizing Object-level Shape Variations with Text-to-Image Diffusion Models" Arxiv, 2023 Mar paper code pdf Authors: Or Patashnik, Daniel Garibi, Idan Azuri, Hadar Averbuch-Elor, Daniel Cohen-Or
- "Reference-based Image Composition with Sketch via Structure-aware Diffusion Model" Arxiv, 2023 Mar paper code pdf Authors: Kangyeol Kim, Sunghyun Park, Junsoo Lee, Jaegul Choo
- "Unmasked Teacher: Towards Training-Efficient Video Foundation Models" Arxiv, 2023 Mar paper code pdf Authors: Kunchang Li, Yali Wang, Yizhuo Li, Yi Wang, Yinan He, Limin Wang, Yu Qiao
- "Feature Shrinkage Pyramid for Camouflaged Object Detection with Transformers" CVPR, 2023 Mar paper code pdf Authors: Zhou Huang, Hang Dai, Tian-Zhu Xiang, Shuo Wang, Huai-Xin Chen, Jie Qin, Huan Xiong
- "Modality-invariant Visual Odometry for Embodied Vision" Arxiv, 2023 Apr paper code pdf Authors: Marius Memmel, Roman Bachmann, Amir Zamir
- "Rerender A Video: Zero-Shot Text-Guided Video-to-Video Translation" SIGGRAPH, 2023 Jun paper code pdf Authors: Shuai Yang, Yifan Zhou, Ziwei Liu, Chen Change Loy
- "StableVideo: Text-driven Consistency-aware Diffusion Video Editing" Arxiv, 2023 Aug paper code pdf Authors: Wenhao Chai, Xun Guo, Gaoang Wang, Yan Lu
- "CoSeR: Bridging Image and Language for Cognitive Super-Resolution" Arxiv, 2023 Nov paper code pdf Authors: Haoze Sun, Wenbo Li, Jianzhuang Liu, Haoyu Chen, Renjing Pei, Xueyi Zou, Youliang Yan, Yujiu Yang
- "SparseCtrl: Adding Sparse Controls to Text-to-Video Diffusion Models" Arxiv, 2023 Nov paper code pdf Authors: Yuwei Guo, Ceyuan Yang, Anyi Rao, Maneesh Agrawala, Dahua Lin, Bo Dai
- "Annual Review of Vision Science Mobile Computational Photography A Tour.pdf"
贴图
-
"BrushNet: A Plug-and-Play Image Inpainting Model with Decomposed Dual-Branch Diffusion" Arxiv, 2024 Mar 11 paper code pdf note Authors: Xuan Ju, Xian Liu, Xintao Wang, Yuxuan Bian, Ying Shan, Qiang Xu
-
ST"AnyText: Multilingual Visual Text Generation And Editing" ICLR-Spotlight, 2023 Nov paper code pdf note
-
"RMT: Retentive Networks Meet Vision Transformers"
-
3.22
- "MIGC: Multi-Instance Generation Controller for Text-to-Image Synthesis"
指定区域 && 控制生成内容
enables precise position control while ensuring the correctness of various attributes
-
"LocalMamba: Visual State Space Model with Windowed Selective Scan"
-
"VmambaIR: Visual State Space Model for Image Restoration"
-
"FRESCO: Spatial-Temporal Correspondence for Zero-Shot Video Translation" ⭐
视频风格迁移,解决生成内容与输入的一致性
-
StreamingT2V: Consistent, Dynamic, and Extendable Long Video Generation from Text
-
"One-Step Image Translation with Text-to-Image Models" Arxiv, 2024 Mar 18 paper code pdf note Authors: Gaurav Parmar, Taesung Park, Srinivasa Narasimhan, Jun-Yan Zhu
-
"SDXS: Real-Time One-Step Latent Diffusion Models with Image Conditions" Arxiv, 2024 Mar 25 paper code pdf note Authors: Yuda Song, Zehao Sun, Xuanwu Yin
-
"UniEdit: A Unified Tuning-Free Framework for Video Motion and Appearance Editing"
4.1
- "Self-Rectifying Diffusion Sampling with Perturbed-Attention Guidance" Arxiv, 2024 Mar 26 paper code pdf note Authors: Donghoon Ahn, Hyoungwon Cho, Jaewon Min, Wooseok Jang, Jungwoo Kim, SeonHwa Kim, Hyun Hee Park, Kyong Hwan Jin, Seungryong Kim
- 使用 diffusion 进行 image deblur,inpainting (想办法弄到视频上提升 diffusion condition)
- 学习一下查看 diffusion 生成效果的特征可视化怎么做 👍
-
"EfficientVMamba: Atrous Selective Scan for Light Weight Visual Mamba" code
学习一下被人怎么进一步对 Mamba Block 进行优化
-
"LITA: Language Instructed Temporal-Localization Assistant" 学习一下视频文本关联,如何定位到某一帧(找干净的帧)
-
"Mastering Text-to-Image Diffusion: Recaptioning, Planning, and Generating with Multimodal LLMs" Arxiv, 2024 Jan 22,
RPGpaper code pdf note Authors: Ling Yang, Zhaochen Yu, Chenlin Meng, Minkai Xu, Stefano Ermon, Bin CuiVideoCaption && Diffusion 不同 patch 一致性
-
"PGDiff: Guiding Diffusion Models for Versatile Face Restoration via Partial Guidance" paper
-
"Iterative Token Evaluation and Refinement for Real-World Super-Resolution" paper
-
"Beyond Text: Frozen Large Language Models in Visual Signal Comprehension" Arxiv, 2024 Mar 12,
V2T-Tokenizerpaper code pdf note Authors: Lei Zhu, Fangyun Wei, Yanye Lu
用 LLM token 来表示图像,发现具有 low-level restoration 的能力 && 不需要 finetune;支持多种下游任务 caption, VQA, denoising; 学习 codebook;
Low-Level 任务给一张完全的人脸,只是移一个位置 or 旋转,输出的人脸修复很烂
LLM gains the ability not only for visual comprehension but also for image denoising and restoration in an auto-regressive fashion

- "The Hidden Attention of Mamba Models" paper
可视化 Mamba 如何做 attention
-
"Multi-granularity Correspondence Learning from Long-term Noisy Videos" Arxiv, 2024 Jan 30 paper code pdf note Authors: Yijie Lin, Jie Zhang, Zhenyu Huang, Jia Liu, Zujie Wen, Xi Peng
-
"Cross-Attention Makes Inference Cumbersome in Text-to-Image Diffusion Models" paper
-
"Adversarial Diffusion Distillation" Arxiv, 2023 Nov 28,
SD-Turbo⭐ paper code pdf note Authors: Axel Sauer, Dominik Lorenz, Andreas Blattmann, Robin Rombach -
"MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies" code
图像中获取写了什么文字
4.20
-
"Magic Clothing: Controllable Garment-Driven Image Synthesis"
提出对齐 loss
-
OmniParser
-
"Unifying Correspondence, Pose and NeRF for Pose-Free Novel View Synthesis from Stereo Pairs"
-
"State Space Model for New-Generation Network Alternative to Transformers: A Survey" paper
4.26
- "QLoRA: Efficient Finetuning of Quantized LLMs"
finetune LLM
- "SEED-X: Multimodal Models with Unified Multi-granularity Comprehension and Generation" paper
- "Improving Diffusion Models for Virtual Try-on" paper
BrushNet
- "ControlNet++: Improving Conditional Controls with Efficient Consistency Feedback" Arxiv, 2024 Apr 11 paper code pdf note Authors: Ming Li, Taojiannan Yang, Huafeng Kuang, Jie Wu, Zhaoning Wang, Xuefeng Xiao, Chen Chen
5.1
Diffusion 细节补足
-
"MultiBooth: Towards Generating All Your Concepts in an Image from Text" paper
-
"ID-Animator: Zero-Shot Identity-Preserving Human Video Generation" paper
-
"ConsistentID: Portrait Generation with Multimodal Fine-Grained Identity Preserving" Arxiv, 2024 Apr 25 paper code pdf note Authors: Jiehui Huang, Xiao Dong, Wenhui Song, Hanhui Li, Jun Zhou, Yuhao Cheng, Shutao Liao, Long Chen, Yiqiang Yan, Shengcai Liao, Xiaodan Liang
-
"Efficient Multimodal Learning from Data-centric Perspective" paper

- "StoryDiffusion: Consistent Self-Attention for Long-Range Image and Video Generation" Arxiv, 2024 May 2 paper code pdf note Authors: Yupeng Zhou, Daquan Zhou, Ming-Ming Cheng, Jiashi Feng, Qibin Hou
Zero-shot 保持 batch 一致性
- "DoRA: Weight-Decomposed Low-Rank Adaptation"
- "KAN: Kolmogorov-Arnold Networks" code
- OpenSoRA
- "Factorized Diffusion: Perceptual Illusions by Noise Decomposition"
5.11
- "ImageInWords: Unlocking Hyper-Detailed Image Descriptions" Arxiv, 2024 May 5 paper code pdf note Authors: Roopal Garg, Andrea Burns, Burcu Karagol Ayan, Yonatan Bitton, Ceslee Montgomery, Yasumasa Onoe, Andrew Bunner, Ranjay Krishna, Jason Baldridge, Radu Soricut
Prompt 细节描述,提升细节生成能力
- "Improving Diffusion Models for Virtual Try-on" Arxiv, 2024 Mar 8 paper code pdf note Authors: Yisol Choi, Sangkyung Kwak, Kyungmin Lee, Hyungwon Choi, Jinwoo Shin
reference 在需要对齐的情况下,保持细节一致
- "ID-Animator: Zero-Shot Identity-Preserving Human Video Generation" Arxiv, 2024 Apr 23 paper code pdf note Authors: Xuanhua He, Quande Liu, Shengju Qian, Xin Wang, Tao Hu, Ke Cao, Keyu Yan, Man Zhou, Jie Zhang
ID 保持能力
基础
-
SDXL 怎么做
-
ComfyUI 如何加入节点?
-
SD-webui
-
"Vision Mamba: A Comprehensive Survey and Taxonomy" Arxiv, 2024 May 7 paper code pdf note Authors: Xiao Liu, Chenxu Zhang, Lei Zhang
-
"SoccerNet Game State Reconstruction: End-to-End Athlete Tracking and Identification on a Minimap" Arxiv, 2024 Apr 17 paper code pdf note Authors: Vladimir Somers, Victor Joos, Anthony Cioppa, Silvio Giancola, Seyed Abolfazl Ghasemzadeh, Floriane Magera, Baptiste Standaert, Amir Mohammad Mansourian, Xin Zhou, Shohreh Kasaei, Bernard Ghanem, Alexandre Alahi, Marc Van Droogenbroeck, Christophe De Vleeschouwer
-
"Emergent Correspondence from Image Diffusion" NIPS, 2023,
DIFTcode
Diffusion 特征点匹配, Dense correspondence
-
DragonDiffusion
-
Drag Your GAN: Interactive Point-based Manipulation on the Generative Image Manifold
-
Q:什么是 DDIM-inversion?
"Denoising Diffusion Implicit Models", Arxiv, 2020 Oct, DDIM paper code
-
"Seeing the Unseen: A Frequency Prompt Guided Transformer for Image Restoration" Arxiv, 2024 Mar 30 paper code pdf note Authors: Shihao Zhou, Jinshan Pan, Jinglei Shi, Duosheng Chen, Lishen Qu, Jufeng Yang
-
"Emergent Correspondence from Image Diffusion" NIPS, 2023 Jun 6 paper code pdf note Authors: Luming Tang, Menglin Jia, Qianqian Wang, Cheng Perng Phoo, Bharath Hariharan
-
"Quality-Aware Image-Text Alignment for Real-World Image Quality Assessment" Arxiv, 2024 Mar 17 paper code pdf note Authors: Lorenzo Agnolucci, Leonardo Galteri, Marco Bertini
-
"Lumiere: A Space-Time Diffusion Model for Video Generation" paper
-
"LayoutGPT: Compositional Visual Planning and Generation with Large Language Models" paper
-
"Muse Pose: a Pose-Driven Image-to-Video Framework for Virtual Human Generation."
24.06.06
- "MOFA-Video: Controllable Image Animation via Generative Motion Field Adaptions in Frozen Image-to-Video Diffusion Model" Arxiv, 2024 May 30 paper code pdf note Authors: Muyao Niu, Xiaodong Cun, Xintao Wang, Yong Zhang, Ying Shan, Yinqiang Zheng
- "ZeroSmooth: Training-free Diffuser Adaptation for High Frame Rate Video Generation" paper
- "VITON-DiT: Learning In-the-Wild Video Try-On from Human Dance Videos via Diffusion Transformers" Arxiv, 2024 May 28 paper code pdf note Authors: Jun Zheng, Fuwei Zhao, Youjiang Xu, Xin Dong, Xiaodan Liang
- "LeftRefill: Filling Right Canvas based on Left Reference through Generalized Text-to-Image Diffusion Model" Arxiv, 2023 May 19 paper code pdf note Authors: Chenjie Cao, Yunuo Cai, Qiaole Dong, Yikai Wang, Yanwei Fu
- "EchoReel: Enhancing Action Generation of Existing Video Diffusion Models" paper
基于参考视频生成动漫
一致性
- "Diffusion Hyperfeatures: Searching Through Time and Space for Semantic Correspondence" paper
- "Looking Backward: Streaming Video-to-Video Translation with Feature Banks" paper
- "Training-Free Consistent Text-to-Image Generation" Arxiv, 2024 Feb 5 paper code pdf note Authors: Yoad Tewel, Omri Kaduri, Rinon Gal, Yoni Kasten, Lior Wolf, Gal Chechik, Yuval Atzmon
- "Diffusion Hyperfeatures: Searching Through Time and Space for Semantic Correspondence" NIPS, 2023 May 23 paper code pdf note Authors: Grace Luo, Lisa Dunlap, Dong Huk Park, Aleksander Holynski, Trevor Darrell
- "EchoReel: Enhancing Action Generation of Existing Video Diffusion Models" Arxiv, 2024 Mar 18 paper code pdf note Authors: Jianzhi liu, Junchen Zhu, Lianli Gao, Jingkuan Song
- "Video Interpolation with Diffusion Models"
24.06.11
- "DiM: Diffusion Mamba for Efficient High-Resolution Image Synthesis" paper
- "StableVideo: Text-driven Consistency-aware Diffusion Video Editing" ICCV, 2023 Aug 18 paper code pdf note Authors: Wenhao Chai, Xun Guo, Gaoang Wang, Yan Lu
- "ConsistI2V: Enhancing Visual Consistency for Image-to-Video Generation" Arxiv, 2024 Feb 6 paper code website pdf note Authors: Weiming Ren, Harry Yang, Ge Zhang, Cong Wei, Xinrun Du, Stephen Huang, Wenhu Chen
- "AdaptBIR: Adaptive Blind Image Restoration with latent diffusion prior for higher fidelity" paper Authors: Chao Dong
- "Temporally consistent video colorization with deep feature propagation and self-regularization learning" 03 January 2024 paper
- "Misalignment-Robust Frequency Distribution Loss for Image Transformation"
- "The Blessing of Randomness: SDE Beats ODE in General Diffusion-based Image Editing" ICLR, 2023 Nov 2 paper code pdf note Authors: Shen Nie, Hanzhong Allan Guo, Cheng Lu, Yuhao Zhou, Chenyu Zheng, Chongxuan Li
- "COVE: Unleashing the Diffusion Feature Correspondence for Consistent Video Editing" Arxiv, 2024 Jun 13 paper code pdf note Authors: Jiangshan Wang, Yue Ma, Jiayi Guo, Yicheng Xiao, Gao Huang, Xiu Li
融入 correspondence
- "OmniTokenizer: A Joint Image-Video Tokenizer for Visual Generation" paper
- "Zero-shot Image Editing with Reference Imitation"
MimicBrush⭐ paper code
cross-attn KV concat 融合实现匹配
24.06.18
-
"One-Step Effective Diffusion Network for Real-World Image Super-Resolution" paper
-
Stable Diffusion 3 Medium
"Scaling Rectified Flow Transformers for High-Resolution Image Synthesis" Arxiv, 2024 Mar 5,
SD3paper code weights pdf note Authors: Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, Kyle Lacey, Alex Goodwin, Yannik Marek, Robin Rombach -
"I2VEdit: First-Frame-Guided Video Editing via Image-to-Video Diffusion Models"
-
"Generative Image Dynamics" CVPR_best_paper paper
-
"ToonCrafter: Generative Cartoon Interpolation" Arxiv, 2024 May 28 paper code pdf note Authors: Jinbo Xing, Hanyuan Liu, Menghan Xia, Yong Zhang, Xintao Wang, Ying Shan, Tien-Tsin Wong
24.06.25
- "Inf-DiT: Upsampling Any-Resolution Image with Memory-Efficient Diffusion Transformer" Arxiv, 2024 May 7 paper code pdf note Authors: Zhuoyi Yang, Heyang Jiang, Wenyi Hong, Jiayan Teng, Wendi Zheng, Yuxiao Dong, Ming Ding, Jie Tang
超大分辨率超分,patch 之间关联
- "MAVIN: Multi-Action Video Generation with Diffusion Models via Transition Video Infilling" paper
插帧
- "Edit-Your-Motion: Space-Time Diffusion Decoupling Learning for Video Motion Editing" paper
视频动作编辑
- "OmniSSR: Zero-shot Omnidirectional Image Super-Resolution using Stable Diffusion Model" paper
RealSR
-
"Autoregressive Image Generation without Vector Quantization" paper
-
"Hunyuan-DiT : A Powerful Multi-Resolution Diffusion Transformer with Fine-Grained Chinese Understanding" paper
-
"Scaling the Codebook Size of VQGAN to 100,000 with a Utilization Rate of 99%"
增大 VQGAN codebook 看看效果
-
"VideoGPT+: Integrating Image and Video Encoders for Enhanced Video Understanding"
获取文本!
24.06.28
-
2309.07906
-
2406.16863
-
"Zero-shot Image Editing with Reference Imitation" Arxiv, 2024 Jun 11,
MimicBrushpaper code pdf note Authors: Xi Chen, Yutong Feng, Mengting Chen, Yiyang Wang, Shilong Zhang, Yu Liu, Yujun Shen, Hengshuang Zhao
ControlNet 有学习 dense correspondence 的能U力,基于 correspondence 去做 inpaint
- "ExVideo: Extending Video Diffusion Models via Parameter-Efficient Post-Tuning"
设计方法https://arxiv.org/pdf/2406.14130提升当前 video synthesis 生成的时序长度,显存更低
, we propose a novel post-tuning methodology fMicmicBrushor video synthesis models, called ExVideo. This approach is designed to enhance the capability of current video synthesis models, allowing them to produce content over extended temporal durations while incurring lower training expenditures. I
- "AnyDoor: Zero-shot Object-level Image Customization" CVPR, 2023 Jul 18 paper code pdf note Authors: Xi Chen, Lianghua Huang, Yu Liu, Yujun Shen, Deli Zhao, Hengshuang Zhao
- 使用预训练的 DINOv2 提供细节特征,DINOv2 有全局 和 patch 的特征,发现 concat 起来过可学习的 MLP,可以与 UNet 特征空间对齐 ⭐
- 贴图的时候使用高频特征,而不是放图像,避免生成图像不搭的情况
- 各个 trick,细节一致性还是不足,例如文字扭曲了
- DNIO or CLIP 特征很重要,作为图像物体生成的基本盘,不加物体直接不一样;细节不一致的问题要再用高频特征约束一下
- 发现训练早期多用视频中多姿态物体训练,能够增强生成物体的细节一致性,缓解色偏的问题
- 对比 DINO, CLIP 提取物体特征
- DINO 特征对于物体细节的特征比 CLIP 特征更优秀,但 DINO 特征要处理下才能好:用分割图提取物体再去提取特征才能得到接近原始物体的结果
- CLIP 特征有点离谱,可能是背景干扰很大
-
"ExVideo: Extending Video Diffusion Models via Parameter-Efficient Post-Tuning" Arxiv, 2024 Jun 20 paper code pdf note Authors: Zhongjie Duan, Wenmeng Zhou, Cen Chen, Yaliang Li, Weining Qian
-
"EvTexture: Event-driven Texture Enhancement for Video Super-Resolution" Arxiv, 2024 Jun 19 paper code pdf note Authors: Dachun Kai, Jiayao Lu, Yueyi Zhang, Xiaoyan Sun
Mask 制作
- "Masked Autoencoders Are Scalable Vision Learners" CVPR, 2021 Nov,
MAEpaper - "SimMIM: A Simple Framework for Masked Image Modeling" CVPR, 2021 Nov 18 paper code pdf note Authors: Zhenda Xie, Zheng Zhang, Yue Cao, Yutong Lin, Jianmin Bao, Zhuliang Yao, Qi Dai, Han Hu

24.07.08
kuaishou 可图,keling
- https://github.com/Kwai-Kolors/Kolors/blob/master/imgs/Kolors_paper.pdf
- "Kolors: Effective Training of Diffusion Model for Photorealistic Text-to-Image Synthesis" Arxiv, 2024 Jul 7 paper code pdf note website Authors: Kolors Team
- "LivePortrait: Efficient Portrait Animation with Stitching and Retargeting Control" Arxiv, 2024 Jul 3 paper code pdf note Authors: Jianzhu Guo, Dingyun Zhang, Xiaoqiang Liu, Zhizhou Zhong, Yuan Zhang, Pengfei Wan, Di Zhang
Fancy Stuff, efficiency
-
"Learning to (Learn at Test Time): RNNs with Expressive Hidden States" paper
-
"StreamMultiDiffusion: Real-Time Interactive Generation with Region-Based Semantic Control" paper
24.07.15
- "Explore the Limits of Omni-modal Pretraining at Scale" Arxiv , 2024 Jun 13,
MiCo, paper code [pdf](./2024_06_Arxiv _Explore-the-Limits-of-Omni-modal-Pretraining-at-Scale.pdf) [note](./2024_06_Arxiv _Explore-the-Limits-of-Omni-modal-Pretraining-at-Scale_Note.md) Authors: Yiyuan Zhang, Handong Li, Jing Liu, Xiangyu Yue
多模态
- "MambaVision: A Hybrid Mamba-Transformer Vision Backbone" Arxiv , 2024 Jul 10,
MambaVisionpaper code [pdf](./2024_07_Arxiv _MambaVision--A-Hybrid-Mamba-Transformer-Vision-Backbone.pdf) [note](./2024_07_Arxiv _MambaVision--A-Hybrid-Mamba-Transformer-Vision-Backbone_Note.md) Authors: Ali Hatamizadeh, Jan Kautz
Backbone
-
SEED-Story: Multimodal Long Story Generation with Large Language Model
-
"MoSca: Dynamic Gaussian Fusion from Casual Videos via 4D Motion Scaffolds" https://arxiv.org/pdf/2405.17421
视频直接到 4D
- "FoleyCrafter: Bring Silent Videos to Life with Lifelike and Synchronized Sounds" paper
视频生成音频
- "Image Neural Field Diffusion Models" paper
高分辨率输出逼真细节
- "A Comprehensive Survey on Human Video Generation: Challenges, Methods, and Insights" paper
- "Video Diffusion Alignment via Reward Gradients" Arxiv , 2024 Jul 11 paper code web [pdf](./2024_07_Arxiv _Video-Diffusion-Alignment-via-Reward-Gradients.pdf) [note](./2024_07_Arxiv _Video-Diffusion-Alignment-via-Reward-Gradients_Note.md) Authors: Mihir Prabhudesai, Russell Mendonca, Zheyang Qin, Katerina Fragkiadaki, Deepak Pathak
24.07.21
- "Visual Geometry Grounded Deep Structure From Motion" CVPR, 2023 Dec 7 paper code pdf note Authors: Jianyuan Wang, Nikita Karaev, Christian Rupprecht, David Novotny
predict camera pose
- "BlazeBVD: Make Scale-Time Equalization Great Again for Blind Video Deflickering" Arxiv, 2024 Mar 10 paper code pdf note Authors: Xinmin Qiu, Congying Han, Zicheng Zhang, Bonan Li, Tiande Guo, Pingyu Wang, Xuecheng Nie
- "LightenDiffusion: Unsupervised Low-Light Image Enhancement with Latent-Retinex Diffusion Models" Arxiv, 2024 Jul 12 paper code pdf note Authors: Hai Jiang, Ao Luo, Xiaohong Liu, Songchen Han, Shuaicheng Liu
-
论文笔记
主要看懂方法;总结学到了啥(总结创新点,分析如何能用到自己的任务;提到的典型方法;...)
Key-point
- Task
- Background
- 🏷️ Label:
Contributions
Related Work
methods
Experiment
ablation study 看那个模块有效,总结一下
Limitations
Summary 🌟
learn what & how to apply to our task
-
文章阅读建议
每周 5 篇精读,一篇文章要看多次的,第一次看完不懂没关系,但要记录下来后面再看!一定要整理 code,进性总结 ⭐⭐
https://gaplab.cuhk.edu.cn/cvpapers/#home 这里整理分类了近几年计算机视觉方面重要会议(CVPR,ICCV,ECCV,NeurIPS,ICLR)的文章和代码,大家可以多看看
https://openaccess.thecvf.com/menu 这是CVF的官网,一些计算机视觉一些重要会议(CVPR,ICCV,WACV)的所有文章附录等材料
https://www.ecva.net/index.php 这是ECCV的官网,历年的文章附录都有
建议这些会议(CVPR,ICCV,ECCV,NeurIPS,ICLR,ICML,AAAI,IJCAI,ACMMM等)的文章以及一些重要期刊(T-PAMI,T-IP,TOG,TVCG,IJCV,T-MM,T-CSVT等)大家多阅读,相同或者相近任务的文章至少全部粗读一遍,然后选择性精读,需要学会使用Google学术和GitHub查询有用资料
-
复现方法时,检查正确性:先看数据输入是否正确(dataloader,learning-rate, batchsize不要是1),再去看框架
-
至少想 2 个创新点,做实验看为什么不 work,分析问题&看文献;
Possible direction
-
diffusion 稳定 or 加速训练
-
ControlNet >> 能否借鉴到 video editing ⭐
-
GAN 之前存在的问题,一些**能否用到 diffusion 中
-
模式崩塌:多样性很差,只生产几个类别,质量比较好
-
Limited Data 看**
-
wavelet diffusion models
-
-
Rado, 张雷老师组 >> diffusion model in low level
-
https://orpatashnik.github.io/ 看一下这个组的工作 >> StyleCLIP, StyleGAN-NADA Daniel Cohen-Or Blog
-
-
关注自己的研究方向,作为主线:diffusion model 用于老电影修复。 当这周的论文阅读量没做完,优先看自己的主线方向论文和项目进展!
-
主线方向,和视频相关方向都要看,只不过要学会某些进行略读。不要局限于技术细节,识别哪些可以暂时跳过,记录下来后面看。
- Chao Dong 中科大
- Xintao Wang Kuaishou
- Chen Change Loy NTU
- Zhangkai NI TJ
- Q:DDPM 采样原理;
- Q:DDIM 的区别?
- Q:ControlNet reference-only 处理残差的方式?
- Q:手写一下 self-attention 公式和代码 ⭐
"Attention Is All You Need" NIPS, 2017 Jun 12 paper code pdf note Authors: Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin
youtube-dl is a command-line program to download videos from YouTube.com
-
FFHQ(Flickr-Faces-Hight-Quality)
FFHQ是一个高质量的人脸数据集,包含1024x1024分辨率的70000张PNG格式高清人脸图像,在年龄、种族和图像背景上丰富多样且差异明显,在人脸属性上也拥有非常多的变化,拥有不同的年龄、性别、种族、肤色、表情、脸型、发型、人脸姿态等,包括普通眼镜、太阳镜、帽子、发饰及围巾等多种人脸周边配件,因此该数据集也是可以用于开发一些人脸属性分类或者人脸语义分割模型的。(人脸图像恢复)
-
the first large-scale dataset for video instance segmentation 大部分视频为 human & one item 互动。
提供分割图
several video super-resolution, deblurring, and denoising datasets like REDS [49], DVD [69], GoPro [50], DAVIS [35], Set8 [72] quote from "ReBotNet: Fast Real-time Video Enhancement"
-
DDPD(Dual-pixel defocus deblurring.)
350 images for training, 74 images for validation and 76 images for testing. 每个场景有 2 张 blur 的图,一张 all-in-focus 图
-
The Densely Annotation Video Segmentation dataset (DAVIS)
There are 50 video sequences with 3455 densely annotated frames in pixel level. 可用于 Video inpaint, denoising, interactive segmentation 任务
-
Talking-Heads (video deblur, heads video)
"One-Shot Free-View Neural Talking-Head Synthesis for Video Conferencing" CVPR, 2021 Apr paper code:unofficial
public dataset that uses Youtube videos and processes them using face detectors to obtain just the face.
-
GoPro (video deblur)
"Deep Multi-scale Convolutional Neural Network for Dynamic Scene Deblurring"
作者使用GOPRO4 HERO Black相机拍摄了240fps的视频,然后对连续的7到13帧取平均获得模糊程度不一的图像。每张清晰图像的快门速度为1/240s,对15帧取平均相当于获得了一张快门速度为1/16s的模糊图像。作者将模糊图像对应的清晰图像定义为处于中间位置的那一帧图像。最终,一共生成了3214对模糊-清晰图像,分辨率为1280×720
-
DVD (video deblur)
"Deep Video Deblurring for Hand-held Cameras" CVPR 2017
拍摄了 71 个 240 FPS 视频,含有多个场景:合成 Long Exposure 来得到 blur video,最后处理得到 2Million training patches
-
"ReBotNet: Fast Real-time Video Enhancement" 从 Youtube Talking-Head数据集处理,针对视频会议构造的两个数据集,没开源 (video deblur, heads video)
-
PortraitVideo 关注人脸区域:,筛选&抠出人脸区域视频;resolution of the faces to 384 × 384. The videos are processed at 30 frames per second (FPS) with a total of 150 frames per video. 加上退化操作
-
FullVideo 关注说话人的身体和其他周围场景:从 Talking-Head 数据集筛选,没用 Talking-Head 的预处理方法。132 training videos and 20 testing videos, and all videos are 720 × 1280, 30 FPS and 128 frames long. We apply similar degradations as PortraitVideo
-
-
Set8 (usually used as test set)
Set8 is composed of 8 sequences: 4 sequences from the Derf 480p testset ("tractor", "touchdown", "park_joy", "sunflower") plus other 4 540p sequences. You can find these under the test_sequences folder here.
-
Vimeo-90K
"Video Enhancement with Task-Oriented Flow" IJCV 2019 website sample-clip-from-viemo-90K
build a large-scale, high-quality video dataset, Vimeo90K. This dataset consists of 89,800 video clips downloaded from vimeo.com, which covers large variaty of scenes and actions. It is designed for the following four video processing tasks: temporal frame interpolation, video denoising, video deblocking, and video super-resolution.
-
Youtube-VOS
-
WebVid10M subset code
335K video-text pair 336×596
下载工具 video2dataset
-
YouHQ
- "Sakuga-42M Dataset: Scaling Up Cartoon Research" Arxiv, 2024 May 13
⚠️ (Withdraw) paper code pdf note Authors: Zhenglin Pan
老照片修复中心 https://www.ancientfaces.com/photo/george-roberts/1328388 old photos textures
-
"Time-Travel Rephotography" SIGGRAPH, 2021 Dec ⭐
HWFD 数据集,100多张名人人脸照片,可以下载
-
"Bringing Old Photos Back to Life" CVPR oral, 2020 Apr ⭐
Pascal VOC, DIV2K 上合成的照片(DA 看论文,退化模板没给要去网上找),真实老照片只用来测试(ancient face)
-
"Modernizing Old Photos Using Multiple References via Photorealistic Style Transfer" CVPR, 2023 Apr
644 old color photos produced in 20th century >> 3个韩国博物馆找的文物图
-
"Pik-Fix: Restoring and Colorizing Old Photo" WACV, 2023
Div2K [1], Pascal [17], and RealOld
-
hired Photoshop experts to mimic the degradation patterns in real old photos (but not from our newly created RealOld dataset) on images from the Pascal dataset, using alpha compositing with randomized transparency levels, thereby generating synthetic old photos.
-
Real-World Old Photos (RealOld)
we collected digitized copies of 200 real old black & white photographs. Each of these photos were digitally manually restored and colorized by Photoshop experts.
the first real-world old photo dataset that has aligned “ground truth”
-
old movie, old cartoon 都可以! How Old Movies Are Professionally Restored | Movies Insider **电影修复馆 Baidu 智感超清服务 修复流程
网上按
film noise关键字查询噪声模板example 35mm胶带
-
Commercial Old films https://www.britishpathe.com/ 老电影商店 75英镑下载一个。。
-
Youtube Denis Shiryaev Youtuber permit other to use the video for research in his video comment. 有给出 source video Youtube url
[4k, 60 fps] A Trip Through New York City in 1911 already restore by several algorithms
⚠️ [4k, 60 fps] San Francisco, a Trip down Market Street, April 14, 1906 >> tell what methods used to restore -
Youtube guy jones 1902c - Crowd Ice Skating in Montreal (stabilized w/ added sound)
-
Youtube Old cartoon
[A Day at the Zoo (1939) goland-2022.2.1.exe ](https://www.youtube.com/watch?v=RtblQQvT2Nk&list=PL-F4vmhdMdiXIXZEDNQ3UFLXmQqjHguBA)
-
优酷搜索老电影
-
B 站博主
https://www.bilibili.com/video/BV1dT411u7Hu/?spm_id_from=333.788&vd_source=eee3c3d2035e37c90bb007ff46c6e881 https://www.bilibili.com/video/BV1oG41187Rp/?spm_id_from=333.999.0.0&vd_source=eee3c3d2035e37c90bb007ff46c6e881
https://github.com/leiurayer/downkyi b站视频下载工具
The Dataset that used in old video restoration related paper
-
Deepremaster👍作者从 Youtube-8M dataset 数据集,筛选了一些合适用于合成的视频,共 1569 个youtube 视频,给出了视频 url 和退化模板(网上按
film noise关键字搜索 )。按 DA 方式对视频帧进行退化
-
"Bringing Old Films Back to Life" CVPR, 2022 Mar
crop 256 patches from REDS dataset and apply the proposed video degradation model(DA & noise template) on the fly
REDS
sharp data: train 240 video and each has 100 Frame -
"Blind flickering" 提供自己构造的 flickering 数据 (Link to paper info)
-
真实数据 evaluation
60 * old_movie clip,存储为
%05d.jpg大多为 350 帧图像,若 fps=25,约为 10-14s的视频。21* old_cartoon clip,图像格式存储,大多为 50-100 帧,约为 1 - 4s 视频
-
合成数据 train
用软件自己修复的视频
-
-
"DSTT-MARB: Multi-scale Attention Based Spatio-Temporal Transformers for Old Film Restoration" Master Thesis
没看文章里面有 release 数据的 url
参考 Deepremaster 使用合成数据,a subset of 103845 images is selected from
YouTube-VOSDataset- 找 Noise 模板,增加到 5770 个
- noise 模板预处理:几个模板融合起来
- Noise-level:原图和 noise 模板,使用图形学 Grain-merge 等方法融合
- frame-level >> pdf Page 51
-
"RTTLC: Video Colorization with Restored Transformer and Test-time Local" CVPR, 2023 Mar
LDV Dataset contains 240 high-quality videos and exhibits a high degree of diversity. Specifically, we select 200 color videos with a resolution of 960×536 as the training set. The validation set contains 15 videos
trained for 4 days on four NVIDIA GeForce RTX 3090 GPUs.
DeOldify [1], RTN [23] and BasicVSR++
VHS recordings videos given from Mr.Jorvan contacted under the blog: Can I upload a dataset of old VHS recordings of music videos? You’ll probably need to do some trimming and velocity adjustments here and there, and some videos don’t have audio for some reason.
What is VHS? VHS(Video Home System) is a standard for consumer-level analog video recording on tape cassettes invented in 1976 by the Victor Company of Japan and was the competitor to the ill-fated Sony Betamax system.
没有 GT 但有相似的?
How to Convert Your Old VHS Tapes to DVD with honestech VHS to DVD 4.0 Deluxe
如何合成 old VHS video vaporwave 通过抽象虚拟信号影像展现过程中的各种可能性、实现了九十年代影像风格的重现。
-
accept file transfer
-
❓ have old music videos (with blur, noise, artifacts, etc.) that nowadays are on youtube in HD
At least some of them have GT!
- 确定视频 degradation 类型 Sade - Is It A Crime (Live Video from San Diego) Mariah Carey - Emotions

-
可以模仿类似方法找老视频数据!去影像店找那种旧的录像带 如何把图片处理成VHS录像带的效果?
PR software VHS template video1
image VHS like vaporwave
video VHS
Creating faux analogue video imagery with python ntscqt 👍 python rewrite of https://github.com/joncampbell123/composite-video-simulator
The ultimate goal is to reproduce all of the artifacts described here https://bavc.github.io/avaa/tags.html#video ⭐ >> Video artifact 社区标准
v ba









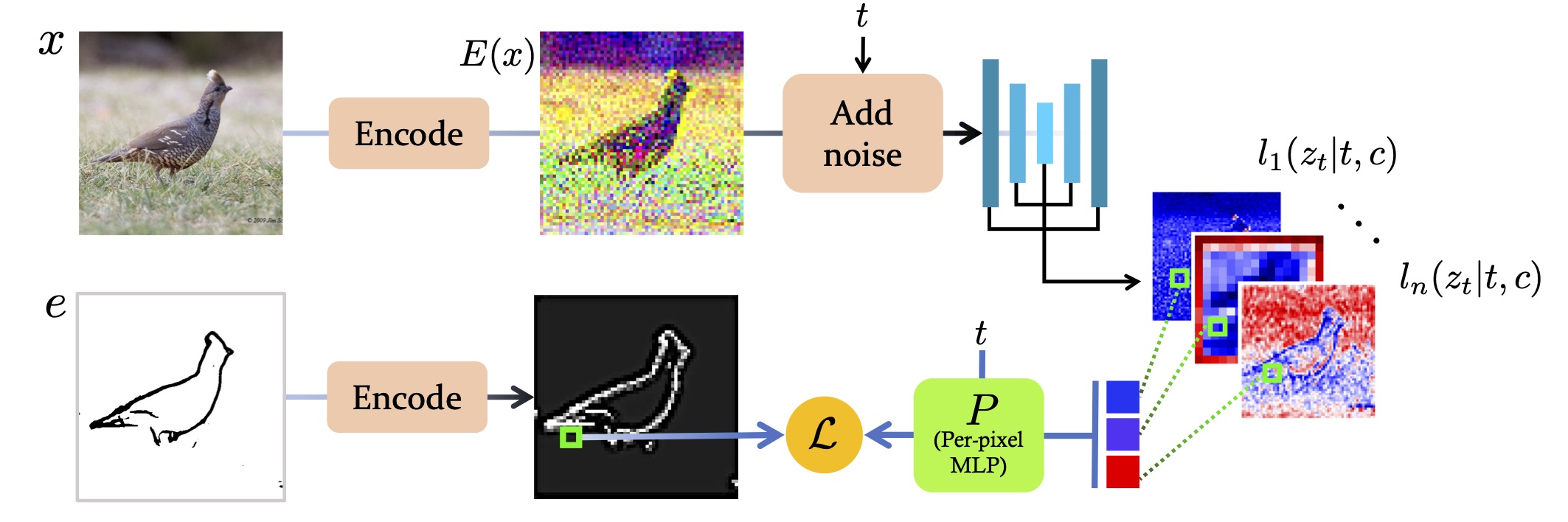{kind=link}