Hi~
我使用这个爬虫从Z-library获取数据,并建立了Clibrary.抱着以下目的:
-
为无法翻墙浏览zlib的同志提供帮助网址: https://clibrary.top .
-
如果发生巨大灾难,我将会有一块记录人类文明的硬盘.(好吧我是个生存狂)
也欢迎你使用它为家中Nas下载图书资源,或是和我一样建立国内站点.
为了知识自由!
我并非一个优秀的程序员,因为我一直都有神经衰弱,从初中开始一思考头就晕乎乎.所以这个程序堪称垃圾之王,里面丝毫看不到美丽的逻辑.我写它纯粹只是热爱写代码本身,而并非实用性美观性云云.
因此,如果你要使用它,你只能接着阅读这篇有催吐性质的README,并还要冒着拉肚的风险去修改一些参数.
我并不为您的人身安全负责!
Z-library有以下难爬之处:
-
IP限制
-
图书地址在ISBN后还加了一串随机码(防止遍历ISBN来下载)
-
每一类别只显示10页(防止通过类别全遍历完)
-
国内无法直接访问
-
其他反爬机制
应对之策如下:
-
使用代理IP(我使用的是BrightData).浏览类别页/搜索页不用代理(省钱),到图书页再代理.
-
先通过类别下载,然后到别的网站去爬一份古今中外作者的姓名/著作,挨个搜索来下载.
-
使用selenium去爬,模拟真实浏览器去点击下载按钮.(只在图书页使用selenium,其他搜索之类使用requests)
一个小问题:
- Z-library貌似维护了一份被阻止ip名单,有50%左右的ip被封锁,所以程序每用完一个ip的下载次数,需要尝试得到一个新的没被封锁的ip.
需要两台linux主机,一台在国外,一台在国内(家中NAS开docker).分别运行服务器和本地内的程序.
不要买一般的服务器,划不来.去买轻量服务器,带宽大,每月流量限额2T左右已经够了.
服务器去请求获得下载链接,建立多个下载线程高速搞到资源存到temp文件夹,再用server.js去建立文件服务,然后上传图书信息与下载链接到mysql
本地服务器一直在轮询mysql,如果发现有没被下载的新条目,就去建立多线程的下载任务搞到本地.
适用于慢/烂服务器.
服务器去请求获得下载链接,再下载资源到temp文件夹,再用server.js去建立文件服务,然后上传图书信息与下载链接到mysql
本地服务器一直在轮询mysql,如果发现有没被下载的新条目,就去建立多线程的下载任务搞到本地.
适用于有低价大流量VPN的情况,不过一般VPN都比轻量服务器的流量贵,只有当你服务器带宽很小时才适合选择.
服务器去请求获得下载链接,然后上传图书信息与zlibrary的下载链接到mysql
挂梯子的本地服务器一直在轮询mysql,如果发现有没被下载的新条目,就去建立多线程的下载任务搞到本地.
| 本地 \ #运行在本地NAS上,运行:python3 download.py
| Books #下载得到的图书文件,建议把你存储图书的硬盘挂载到这里
| temp #临时图书数据存储,下载完毕后转移并删除
| database.py #负责与数据库建立联系
| download.py #负责下载
| 服务器 \ #运行在你的海外服务器上
| database.py #负责与数据库建立联系
| main-author #作者索引模式(多下载线程,服务器下载)
| main-server #服务器下载模式(多下载线程)
| main-slow #服务器下载模式(单线程)
| main-vpn #本地VPN下载模式
| net.py #负责请求
| server.js #node服务器,提供文件托管服务
| MysqlData \ #爬取好的数据库
| authorData.json #上文提及的古今中外作者的姓名/著作数据(辅助爬取)
| temp #存储下载好的临时文件
| Upload2Baidu \ #把部分图书文件上传到百度云去省空间
| sliceTemp #百度云要求分片上传,这是分片的临时存储文件夹
| baidu.py #百度云api
| colorPrint.py #彩色输出,纯粹为了好玩
| crypt.py #加密.别以为我会信任你,百度云盘(连文件目录都加密).
| database.py #负责与数据库建立联系
| main.py #主文件
| qr.py #在终端显示二维码,有意思吧
| download.py #下载回来
| download #二进制文件,方便下载 ./download 百度云路径 保存路径
| README.md #这份说明
安装浏览器以及驱动:
wget https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb
dpkg -i google-chrome-stable_current_amd64.deb #报错没关系
apt-get install -f
google-chrome --version #获取版本号
wget https://npm.taobao.org/mirrors/chromedriver/对应版本号/chromedriver_linux64.zip
unzip chromedriver_linux64.zip
mv chromedriver /usr/bin/
chmod +x /usr/bin/chromedriver安装python库:
懒得打了,自己pip install去.
第一次运行:
cd 服务器
nano main-你想要的模式.py #填写serverRoot里的当前服务器ip
nano net.py #填写你代理服务器的信息
nano database.py #填写mysql服务器信息(如果mysql没有暴露给公网,使用frp穿透到服务器这里也行)
nohup node server.js & #长时间运行
python3 main-你想要的模式.py之后运行:
手动恢复类别下载进度:去本地Books文件夹看有多少个类别被下载了(比如有num个),然后再main-xxx.py里修改downloadWebsite()里的bs.select('.subcategory-name a')改为bs.select('.subcategory-name a')[num-1:]
(我知道这很原始,懒得改了)
在mysql里建一个数据表
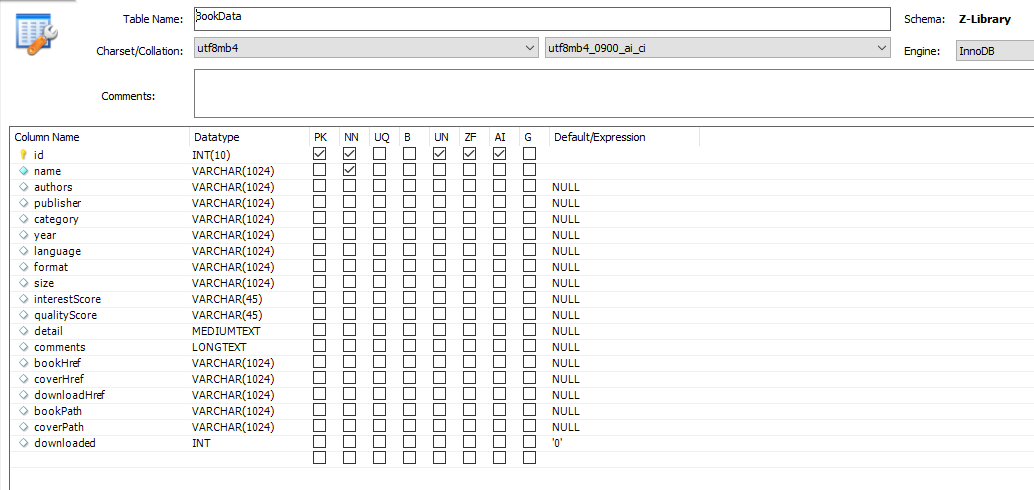
cd 本地
python3 download.pyZ-Library有很多类别,某些类别我们如果不感兴趣,不愿意存在本地占空间,但又不想丢掉,就可以上传到百度云.(比如美术,经济...)
这个功能将书籍信息进行AES加密后存到百度云上,只在数据库里保留链接.(文件名及目录也被加密)
使用方法:
cd Upload2Baidu
nano main.py #去注册百度网盘开发者,填入你的密钥
nano download.py #去注册百度网盘开发者,填入你的密钥;设置你的加密密钥
python #进入python交互模式
import main #第一次使用会要求你扫码授权网盘使用权限
main.uploadSingleCategory('category') #上传单个种类
main.uploadMultiCategory['c1','c2'] #上传多个种类下载:
./download 百度云路径 保存路径
