This repo has utilities for AWS cost analysis and optimization. In its initial version, it provides tools that prepare AWS Cost and Usage data, so it can be analyzed using AWS Athena and QuickSight.
For more details, refer to this article in the Concurrency Labs blog:
https://www.concurrencylabs.com/blog/aws-cost-reduction-athena
The repo contains the following files:
The modules in this package execute a number of operations that are required in order to analyze Cost and Usage report files by Athena or QuickSight.
processor.py
Performs the following operations:
- Execute required data preparations before putting files in an S3 bucket that will be queried by Athena.
- Athena doesn't like manifest files or anything that is not a data file, therefore this module only copies .csv files to the destination S3 bucket.
- Place files in Athena S3 bucket using a partition that corresponds to the report date: {aws-cost-usage-bucket}/{prefix}/{period}/{csv-file}.
- Remove 'hash' folder from the object key structure that is used in the Athena S3 bucket. AWS Cost and Usage creates files with the following structure: {aws-cost-usage-bucket}/{prefix}/{period}/{reportID-hash}/{csv-file}. This implementation removes the 'hash' folder when copying the file to the destination S3 bucket, since it interferes with Athena partitions.
- Remove first row in every single file. For some reason, Athena ignores OpenCSVSerde's option to skip first rows.
If you have large Cost and Usage reports, it is recommended that you execute this script from an EC2 instance in the same region as the S3 buckets where you have the AWS Cost and Usage Reports as well as the destination Athena S3 bucket. This way you won't pay data transfer cost out of S3 and out of the EC2 instance into S3. You will also get much better performance when transferring data.
If you run this processes outside of an EC2 instance, you will incur in data transfer costs from S3 out to the internet.
scripts/report_utils.py
This script instantiates class CostUsageProcessor, which executes the operations in
awscostusageprocessor/processor.py
The first step is to make sure that AWS Cost and Usage reports are enabled in your AWS account. These are the necessary steps to enable them:
- Create an S3 bucket to store the reports.
- Enable Cost and Usage Reports
- Go to the "Billing Dashboard" section in the AWS Management Console, navigate to "Reports"
- Click on "Create Report" under "AWS Cost and Usage Reports". A new screen will be displayed.
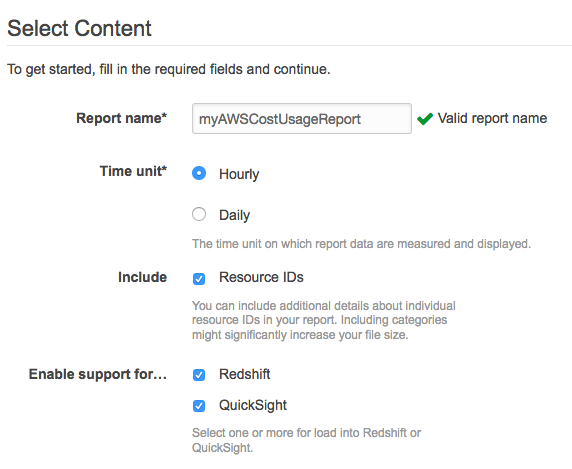
- Set "Time Unit" to "Hourly".
- Check "Include Resource IDs"
- Make sure support for QuickSight and Redshift is enabled.
This is what the "Select Content" screen should look like:
Click on "Next", that should take you to "Select delivery options"
- Specify the S3 bucket where reports will be stored.
- Assign the right permissions to the S3 bucket (there is a link in the console that shows you the bucket policy)
Once you complete these steps, AWS will generate and put Cost and Usage reports in the S3 bucket you specified. These reports are generated approximately once per day and it's hard to predict when exactly they will be copied to S3. This means you'll have to wait approximately one day before you see any reports in your S3 bucket.
There are 3 steps that need to happen before you can run this script the first time:
1. Create a new S3 bucket or folder. First, create a new S3 bucket, or create a folder in your existing bucket where you will place the modified Cost and Usage files.
2. Install the script and create IAM Permissions.
- Clone this repo
- Create a virtualenv (recommended) and activate it.
- Install dependencies
pip install -r requirements.txt - Make sure the AWS CLI is installed in your system, including your AWS credentials.
- Make sure your IAM user or EC2 Instance profile has the required S3 permissions to read files from the source buckets and to put objects into the destination buckets.
3. Setting environment variables
Before executing any script, make sure the following environment variables are set:
export AWS_DEFAULT_PROFILE=<my-aws-default-credentials-profile>
export AWS_DEFAULT_REGION=<us-east-1,eu-west-1, etc.>
Go to the scripts folder.
There are 3 different operations available:
**Prepare files for Athena **
This operation copies files from a destination S3 bucket and prepares the files so they can be queried using Athena (remove reportId hash, remove manifest files, etc.)
python report_utils.py --action=prepare-athena --source-bucket=<s3-bucket-with-cost-usage-reports> --source-prefix=<folder>/ --dest-bucket=<s3-bucket-athena-will-read-files-from> --dest-prefix=<folder>/ --year=<year-in-4-digits> --month=<month-in-1-or-2-digits>
Keep in mind that AWS creates Cost and Usage files daily, therefore you must execute this script daily if you want to have the latest billing data in Athena.
Prepare QuickSight manifest
If you want to upload files to QuickSight, you must provide a manifest file. The manifest file essentially lists the location of the data files, so QuickSight can find them and load them. The source-bucket and source-prefix parameter indicate the S3 location of the Cost and Usage reports that will be used to create the QuickSight manifest.
AWS gives you the option to create QuickSight manifests when you configure Cost and Usage reports in the Billing console. One issue is that AWS creates the QuickSight manifest only at the end of the month. That's why I added this option in the script, so you can generate a QuickSight manifest anytime you want.
python report_utils.py --source-bucket=<s3-bucket-for-quicksight-files> --source-prefix=<folder>/ --action=create-manifest --manifest-type=quicksight --year=<year-in-4-digits> --month=<month-in-1-or-2-digits>
Prepare Redshift manifest
As a bonus, if you want to upload files in QuickSight using a Redshift manifest, the script creates one for you.
python report_utils.py --source-bucket=<s3-bucket-for-quicksight-files> --source-prefix=<folder>/ --action=create-manifest --manifest-type=redshift --year=<year-in-4-digits> --month=<month-in-1-or-2-digits>
1. Enable AWS Cost and Usage reports [see instructions above]. Wait at least one day for the first report to be available in S3.
2. Prepare AWS Cost and Usage data for Athena
python report_utils.py --action=prepare-athena --source-bucket=<s3-bucket-with-cost-usage-reports> --source-prefix=<folder>/ --dest-bucket=<s3-bucket-athena-will-read-files-from> --dest-prefix=<folder>/ --year=<year-in-4-digits> --month=<month-in-1-or-2-digits>
3. Create Athena database
Once your cleaned-up files are in S3, you need to have an Athena database. You can create one from the Athena console by running a SQL statement:
CREATE DATABASE billing;
You can use an existing database if you want, that's up to you. For this example we'll use a new database named 'billing'.
The next step is to create an Athena table. You can do this by running the statement in create_athena_table.sql from the Athena console. We'll create one table per month.
Make sure you update the following parameters with actual values:
- {dbname}
- {tablename}
- {bucket}
- {prefix}
4. Execute queries against your AWS Cost and Usage data! That's it! Now you can query your AWS Cost and Usage data! You can use the sample queries in athena_queries.sql
This repo also has a number of Lambda functions designed to automate the daily processing of Cost and Usage reports for Athena. These functions can be orchestrated by an AWS Step Functions State Machine.
Under the functions folder:
process-cur.py Starts the process that copies and prepares incoming AWS Cost and Usage reports.
create-athena-resources.py Creates Athena databases and tables based on incoming AWS Cost and Usage reports
init-athena-queries.py Initializes common queries, so the results are available in S3. This increases performance and reduces cost.
update-metadata.py Updates a DDB table with the latest execution timestamp. This information is used by:
- The processes that decide whether to query from Athena or from S3.
- Step Function starter, in order to decide if a new execution should be triggered.
- Any application that consumes Cost and Usage data and needs to know when a new report has been processed
s3event-step-function-starter.py This function receives an S3 PUT event when a new AWS Cost and Usage report is generated and it then starts the Step Function workflow. You'll have to manually configure the S3 event so it points to this function.
step-function-athena.json Step Function definition to automate the daily processing of CUR files and creation of Athena resources.
Under the cloudformation folder:
cloudformation/process-cur-sam.yml Serverless Application Model definition to deploy all Lambda functions


