AprioriDemo
Python,两款Apriori算法实践与比较,基于今日头条数据的练习题
Apriori算法是通过限制候选产生发现频繁项集。总的来说,Apriori算法其实效率并不高,大规模数据计算的时候,需要考虑性能问题。 code + data可见:mattzheng/AprioriDemo
盗图盗图:

20200912更新
更新apriori_4.py
新增一些过长时间执行的注释;
新增while(currentLSet != set([])) and k<= tuples :之前的code没有严格按照tuples约束
runApriori(self,data_iter, minSupport, minConfidence,minLift = 0,tuples =2,count = 100000)中的count,如果内容太多break的时候会卡顿
20190705更新
更新了apriori3.py
对数据运行时长可以通过runApriori函数中的count来控制;
支持不等长list的输入,比较适合任意内容的输入与可定制化
20180627更新
新更新了apriori2.py,之前几个库都是只有支持度以及置信度,没有提升度,笔者在第一套关联规则算法上,略微修改了code加了提升度的计算。
目前可以输出三个字段的指标。
20180628更新
发现apriori2.py已经apriori.py 存在一个问题:元组问题,譬如存在:['单词1','单词2','单词3']在一个组中,然后['单词1']与['单词2']有4套以上记录,而且不同记录之间的支持度/置信度不一致。
那么,本次更新在'apriori2.py'中的主函数'runApriori'更新了一个参数:tuples,这个参数就是控制元组数,tuples=2代表只有2元组;tuples=3代表存在2元组+三元组,一次类推。
同时在'transferDataFrame'输出的时候,也会多出:'item'信息以及'item_len',item_len代表其元组数量。
20180725更新
apriori会经常遇到超大集合,一般最耗时的部分在returnItemsWithMinSupport生成关联对环节,有可能一循环就是10W+,导致内存卡爆以及时间不好估计。
笔者这边目前的两个策略是:
- 调整
minSupport,先从大的往下调整,0.8->0.2; - 修改
runApriori中的:
k = 2
while(k < 5):
largeSet[k-1] = currentLSet
currentLSet = joinSet(currentLSet, k)
currentCSet = returnItemsWithMinSupport(currentLSet,
transactionList,
minSupport,
freqSet)
currentLSet = currentCSet
k = k + 1
print('currentLSet len is %s'%len(currentLSet))
通过调整K观察生成关联对,笔者在尝试的时候,K=5,就会 6W+的关联对,基本控制在K=2/3/4即可。
在R语言里面有非常好的package,可见我之前的博客: R语言实现关联规则与推荐算法(学习笔记) 该packages能够实现以下一些可视化:
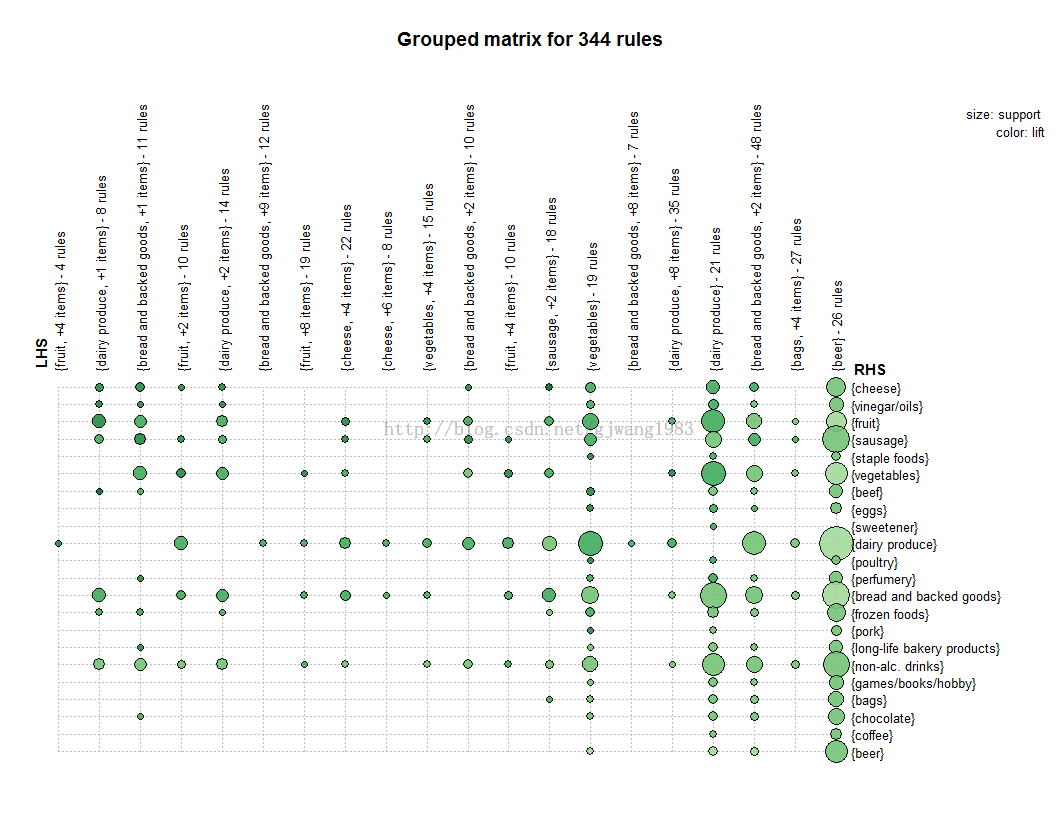
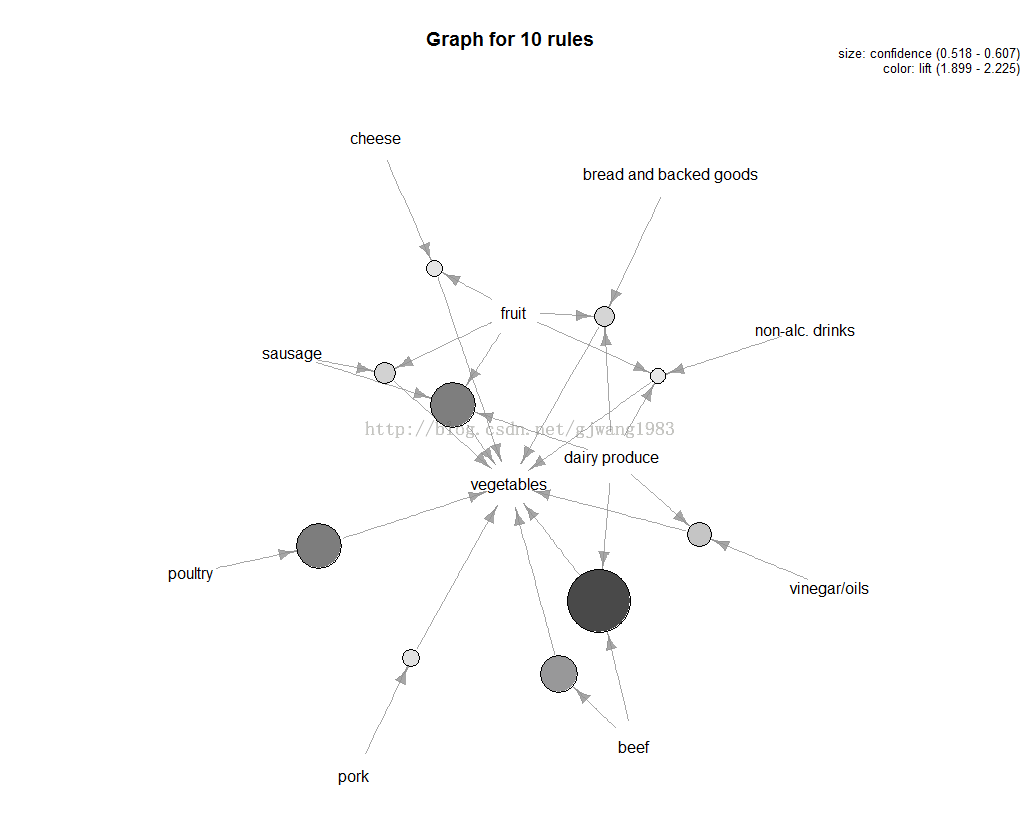
但是好像Python里面没有这样封装比较好的库...搜刮了一下,发现很多人写了,但是没有可视化模块,不过先拿着用呗。 笔者参考这两位大神的作品:
当然也会结合今日头条数据来做,之前做过一个练习,可见我之前博客: 练习题︱基于今日头条开源数据的词共现、新热词发现、短语发现
一、Apriori关联算法一:asaini/Apriori
因为该大神写的时候用得py2,我现在习惯py3;同时对一些细节进行一些调整。主要以介绍案例为主。 整体来看,效率还是很不错的,要比第二款效率高。
1.1 主函数介绍
runApriori(inFile, minSupport, minConfidence)
输入的内容有三样:
- inFile:数据集输入,迭代器
- minSupport:最小支持度阈值,作者推荐:0.1-0.2之间
- minConfidence:最小置信度阈值,作者推荐:0.5-0.7之间
输出内容两样:
- items ,支持度表,形式为:(tuple, support),一个词的支持度、一对词的支持度【无指向】
- rules ,置信度表,形式为((pretuple, posttuple), confidence),(起点词,终点词),置信度【有指向】
1.2 改编两函数:dataFromFile、transferDataFrame
为了更便于使用,同时笔者改编了一个函数 dataFromFile + 新写了一个函数 transferDataFrame。
dataFromFile(fname,extra = False)
作者函数中只能从外部读入,如果笔者要对数据集做点操作,就可以使用extra = True,当然只适用dataframe,可见下面的今日头条数据例子。
transferDataFrame(items, rules,removal = True)
items、rules计算出来之后,作者只是print出来,并没有形成正规的格式输出,这里写了一个变成dataframe的格式。可见下面例子的格式。 同时,这边的removal =True,是因为会出现:‘A->B’,‘B->A’的情况,这边True就是只保留一个。
1.3 作者提供的数据实践
作者的数据为,而且可以支持不对齐、不等长:

inFile = dataFromFile('INTEGRATED-DATASET.csv',extra = False)
minSupport = 0.15
minConfidence = 0.6
items, rules = runApriori(inFile, minSupport, minConfidence)
# ------------ print函数 ------------
printResults(items, rules)
# ------------ dataframe------------
items_data,rules_data = transferDataFrame(items, rules)
这里的支持度、置信度都还挺高的,得出的结果:
items_data的支持度的表格,其中Len,代表词表中的词个数。

rules_data 的置信度表格,指向为word_x->word_y

1.4 今日头条二元组词条
今日头条的数据处理,主要参考上一篇练习题。然后把二元组的内容,截取前800个,放在此处。

其中第一列为共现频数,其他为共现词,在这里面不用第一列共现频数。
data = pd.read_csv('CoOccurrence_data_800.csv',header = None)
inFile = dataFromFile(data[[1,2]],extra = True)
data_iter = dataFromFile(data[[1,2]],extra = True)
#list(inFile)
minSupport = 0.0
minConfidence = 0.0
items, rules = runApriori(inFile, minSupport, minConfidence)
print('--------items number is: %s , rules number is : %s--------'%(len(items),len(rules)))
# ------------ print函数 ------------
printResults(items, rules)
# ------------ dataframe------------
items_data,rules_data = transferDataFrame(items, rules)
此时,因为词语与词语之间的关系很稀疏,支持度与置信度都不会高的,所以练习题中要把两个比例都设置为0比较好。
items_data的支持度的表格,其中Len,代表词表中的词个数。

word_x->word_y

.
二、Apriori关联算法二:Pandas实现高效的Apriori算法
用Pandas写的,效率在生成频繁集的时候会爆炸,所以合理选择支持度很重要。
大神写的很服从中文环境,所以不用改啥,给赞!
2.1 官方案例
所使用的数据比较规则:

# ------------ 官方 ------------
d = pd.read_csv('apriori.txt', header=None, dtype = object)
d = ToD(d)
support = 0.06 #最小支持度
confidence = 0.75 #最小置信度
output = find_rule(d, support, confidence)
output.to_excel('rules.xls')
大神已经整理好结果,可见:

2.2 今日头条数据
今日头条的数据处理,主要参考上一篇练习题。然后把二元组的内容,截取前800个,放在此处。
其中第一列为共现频数,其他为共现词,在这里面不用第一列共现频数。
# ------------自己 ------------
data = pd.read_csv('CoOccurrence_data_800.csv',header = None)
support = 0.002 #最小支持度
confidence = 0.0 #最小置信度
d = ToD(data[[1,2]])
output = find_rule(d, support, confidence)
因为词条之间非常稀疏,支持度与置信度需要设置非常小,如果support设置为0的话,又会超级慢,笔者实验的数据,支持度比较合适在0.002。 最终输出的结果如下:






















