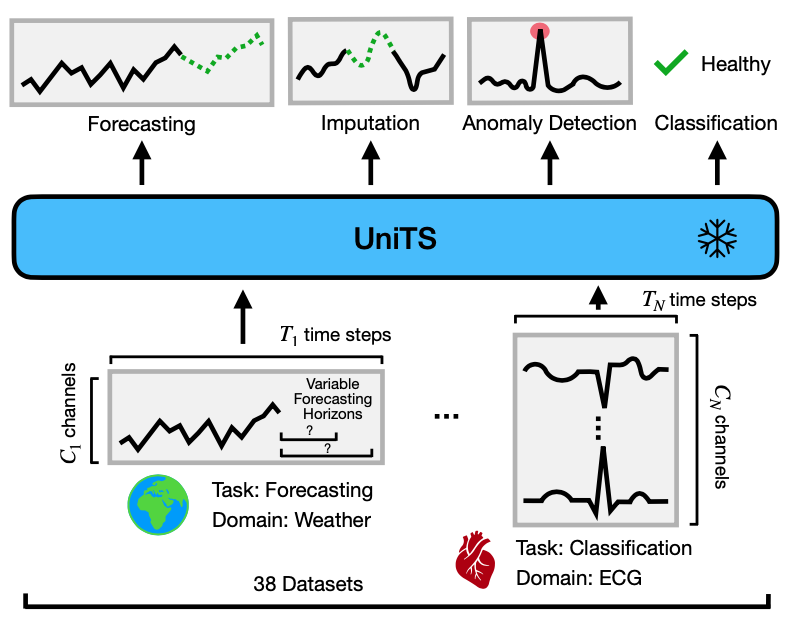
UniTS is a unified time series model that can process various tasks across multiple domains with shared parameters and does not have any task-specific modules.
Authors: Shanghua Gao Teddy Koker Owen Queen Thomas Hartvigsen Theodoros Tsiligkaridis Marinka Zitnik
Foundation models, especially LLMs, are profoundly transforming deep learning. Instead of training many task-specific models, we can adapt a single pretrained model to many tasks via few-shot prompting or fine-tuning. However, current foundation models apply to sequence data but not to time series, which present unique challenges due to the inherent diverse and multi-domain time series datasets, diverging task specifications across forecasting, classification and other types of tasks, and the apparent need for task-specialized models.
We developed UniTS, a unified time series model that supports a universal task specification, accommodating classification, forecasting, imputation, and anomaly detection tasks. This is achieved through a novel unified network backbone, which incorporates sequence and variable attention along with a dynamic linear operator and is trained as a unified model.
Across 38 multi-domain datasets, UniTS demonstrates superior performance compared to task-specific models and repurposed natural language-based LLMs. UniTS exhibits remarkable zero-shot, few-shot, and prompt learning capabilities when evaluated on new data domains and tasks.
Install Pytorch2.0+ and the required packages.
pip install -r requirements.txt
bash download_data_all.sh
Datasets configs for different multi-task settings are shown in .ymal files of the data_provider folder.
By default, all experiments follow the multi-task setting where one UniTS model is jointly trained on mulitple datasets.
- Pretraining + Prompt learning
bash ./scripts/pretrain_prompt_learning/UniTS_pretrain_x128.sh
- Supervised learning
bash ./scripts/supervised_learning/UniTS_supervised.sh
Note: Please follow the instruction in following training scripts to get the pretrained ckpt first.
- Finetuning
# please set the pretrianed model path in the script.
bash ./scripts/few_shot_newdata/UniTS_finetune_few_shot_newdata_pct20.sh
- Prompt tuning
# please set the pretrianed model path in the script.
bash ./scripts/few_shot_newdata/UniTS_prompt_tuning_few_shot_newdata_pct20.sh
- Finetuning
# please set the pretrianed model path in the script.
bash ./scripts/few_shot_anomaly_detection/UniTS_finetune_few_shot_anomaly_detection.sh
- Prompt tuning
# please set the pretrianed model path in the script.
bash ./scripts/few_shot_anomaly_detection/UniTS_prompt_tuning_few_shot_anomaly_detection.sh
- Finetuning
# please set the pretrianed model path in the script.
bash ./scripts/few_shot_imputation/UniTS_finetune_few_shot_imputation_mask050.sh
- Prompt tuning
# please set the pretrianed model path in the script.
bash ./scripts/few_shot_imputation/UniTS_prompt_tuning_few_shot_imputation_mask050.sh
# please set the pretrianed model path in the script.
bash ./scripts/zero_shot/UniTS_forecast_new_length_unify.sh
# A special verison of UniTS with shared prompt/mask tokens needs to be trained for this setting.
bash ./scripts/zero_shot/UniTS_zeroshot_newdata.sh
UniTS is a highly flexible unified time series model, supporting tasks such as forecasting, classification, imputation, and anomaly detection with a single shared model and shared weights. We provide a Tutorial to assist you in using your own data with UniTS.
We provide the pretrained weights for models mentioned above in checkpoints.
@article{gao2024building,
title={UniTS: Building a Unified Time Series Model},
author={Gao, Shanghua and Koker, Teddy and Queen, Owen and Hartvigsen, Thomas and Tsiligkaridis, Theodoros and Zitnik, Marinka},
journal={arXiv},
url={https://arxiv.org/pdf/2403.00131.pdf},
year={2024}
}
This codebase is built based on the Time-Series-Library. Thanks!
DISTRIBUTION STATEMENT: Approved for public release. Distribution is unlimited.
This material is based upon work supported by the Under Secretary of Defense for Research and Engineering under Air Force Contract No. FA8702-15-D-0001. Any opinions, findings, conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the Under Secretary of Defense for Research and Engineering.
© 2024 Massachusetts Institute of Technology.
Subject to FAR52.227-11 Patent Rights - Ownership by the contractor (May 2014)
The software/firmware is provided to you on an As-Is basis
Delivered to the U.S. Government with Unlimited Rights, as defined in DFARS Part 252.227-7013 or 7014 (Feb 2014). Notwithstanding any copyright notice, U.S. Government rights in this work are defined by DFARS 252.227-7013 or DFARS 252.227-7014 as detailed above. Use of this work other than as specifically authorized by the U.S. Government may violate any copyrights that exist in this work.



















































































































