BeatNet is the state-of-the-art AI-based Python library for joint music beat, downbeat, tempo, and meter tracking. This repo includes the BeatNet neural structure along with the efficient two-stage cascade particle filtering algorithm that is proposed in the paper. It offers four distinct working modes, as follows:
- Streaming mode: This mode captures streaming audio directly from the microphone.
- Real-time mode: In this mode, audio files are read and processed in real-time, yielding immediate results.
- Online mode: Similar to Real-time mode, Online mode employs the same causal algorithm for track processing. However, rather than reading the files in real-time, it reads them faster, while still producing identical outcomes to the real-time mode.
- Offline mode: Inferes beats and downbeats in an offline fashion.
To gain a better understanding of each mode, please refer to the Usage examples provided in this document.

This repository contains the user package and the source code of the Monte Carlo particle flitering inference model of the "BeatNet" music online joint beat/downbeat/tempo/meter tracking system. The arxiv version of the original ISMIR-2021 paper:
In addition to the proposed online inference, we added madmom's DBN beat/downbeat inference model for the offline usages. Note that, the offline model still utilize BeatNet's neural network rather than that of Madmom which leads to better performance and significantly faster results.
Note: All models are trained using pytorch and are included in the models folder. In order to recieve the training script and the datasets data/feature handlers, shoot me an email at mheydari [at] ur.rochester.edu
Raw audio waveform object or directory.
- By using the audio directory as the system input, the system automatically resamples the audio file to 22050 Hz. However, in the case of using an audio object as the input, make sure that the audio sample rate is equal to 22050 Hz.
A vector including beats and downbeats columns, respectively with the following shape: numpy_array(num_beats, 2).
model: An scalar in the range [1,3] to select which pre-trained CRNN models to utilize.
mode: An string to determine the working mode. i.e. 'stream', 'realtime', 'online' and 'offline'.
inference model: A string to choose the inference approach. i.e. 'PF' standing for Particle Filtering for causal inferences and 'DBN' standing for Dynamic Bayesian Network for non-causal usages.
plot: A list of strings to plot. It can include 'activations', 'beat_particles' and 'downbeat_particles' Note that to speed up plotting the figures, rather than new plots per frame, the previous plots get updated. However, to secure realtime results, it is recommended to not plot or have as less number of plots as possible at the time.
thread: To decide whether accomplish the inference at the main thread or another thread.
device: Type of device being used. Cuda or cpu (by default).
Approach #1: Installing binaries from the pypi website:
pip install BeatNet
Approach #2: Installing directly from the Git repository:
pip install git+https://github.com/mjhydri/BeatNet
- Note: Before installing the BeatNet make sure Librosa and Madmom packages are installed. Also, pyaudio is a python binding for Portaudio to handle audio streaming. If Pyaudio is not installed in your machine, depending on your machine type either install it thorugh pip (Mac OS and Linux) or download an appropriate version for your machine (Windows) from here. Then, navigate to the file location through commandline and use the following command to install the wheel file locally:
pip install <Pyaduio_file_name.whl>
from BeatNet.BeatNet import BeatNet
estimator = BeatNet(1, mode='stream', inference_model='PF', plot=[], thread=False)
Output = estimator.process()
*In streaming usage cases, make sure to feed the system with as loud input as possible to leverage the maximum streaming performance, given all models are trained on the datasets containing mastered songs.
from BeatNet.BeatNet import BeatNet
estimator = BeatNet(1, mode='realtime', inference_model='PF', plot=['beat_particles'], thread=False)
Output = estimator.process("audio file directory")
from BeatNet.BeatNet import BeatNet
estimator = BeatNet(1, mode='online', inference_model='PF', plot=['activations'], thread=False)
Output = estimator.process("audio file directory")
from BeatNet.BeatNet import BeatNet
estimator = BeatNet(1, mode='offline', inference_model='DBN', plot=[], thread=False)
Output = estimator.process("audio file directory")
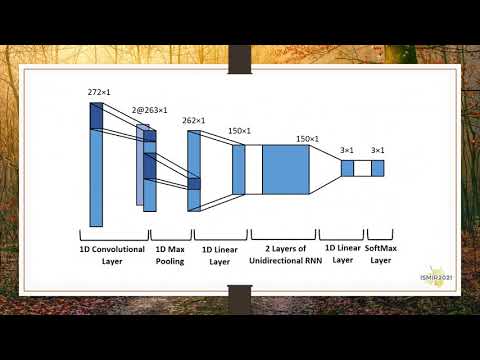
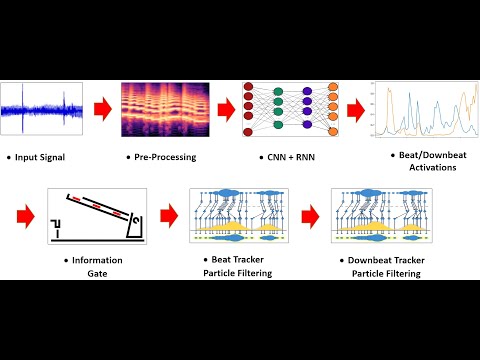
1: In this tutorial, we explain the BeatNet mechanism.
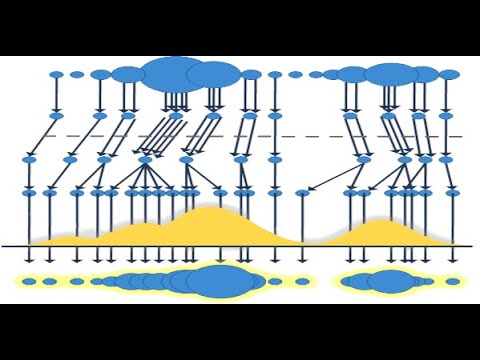
In order to demonstrate the performance of the system for different beat/donbeat tracking difficulties, here are three video demo examples :
1: Song Difficulty: Easy
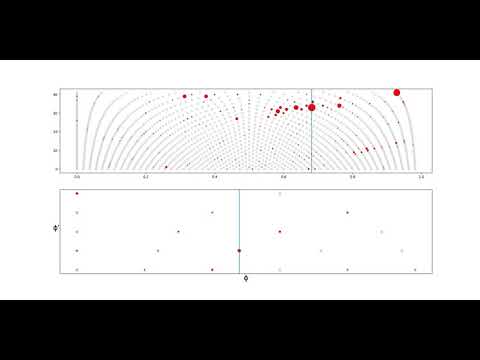
2: Song difficulty: Medium
3: Song difficulty: Veteran
For the input feature extraction and the raw state space generation, Librosa and Madmom libraries are ustilzed respectively. Many thanks for their great jobs. This work has been partially supported by the National Science Foundation grants 1846184 and DGE-1922591.
@inproceedings{heydari2021beatnet,
title={BeatNet: CRNN and Particle Filtering for Online Joint Beat Downbeat and Meter Tracking},
author={Heydari, Mojtaba and Cwitkowitz, Frank and Duan, Zhiyao},
journal={22th International Society for Music Information Retrieval Conference, ISMIR},
year={2021}
}
@inproceedings{heydari2021don,
title={Don’t look back: An online beat tracking method using RNN and enhanced particle filtering},
author={Heydari, Mojtaba and Duan, Zhiyao},
booktitle={ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
pages={236--240},
year={2021},
organization={IEEE}
}


















































































































