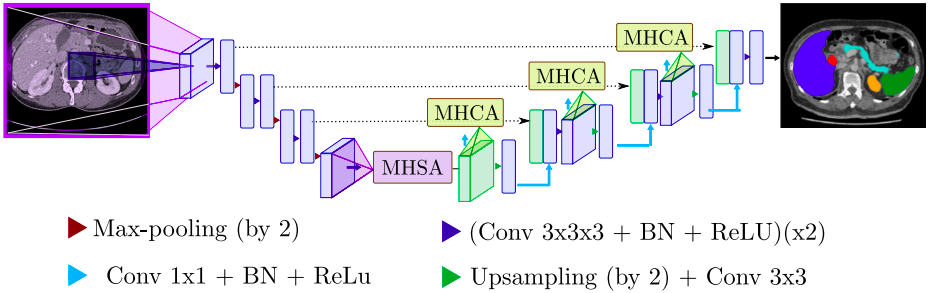
Implementation of the U-Net Transformer and comparison with Attention U-Net and baseline U-Net
- Create Environment
conda create -n <environment_name> python=3.8
conda activate <enviroment_name>
pip install -r requirements.txt- Download dataset as mentioned in Data section
- Run the following commands only one time to place data (If you have already run this command once make the
is_rawflag toFalse):
train_ratio = 0.65
val_ratio = 0.20
batch_size = 256
size = (128, 128)
num_workers = 2
is_raw = True
train_loader, val_loader, test_loader = get_loaders(f'../data/{"raw" if is_raw else "processed"}/lgg-mri-segmentation/kaggle_3m', train_ratio, val_ratio, batch_size, size, num_workers, is_raw)
print(f'Train samples: {len(train_loader.dataset)}')
print(f'Val samples: {len(val_loader.dataset)}')
print(f'Test samples: {len(test_loader.dataset)}')- These commands are written in provided notebooks in
notebooks/directory Solver.pyclass trains and evaluate model(s)
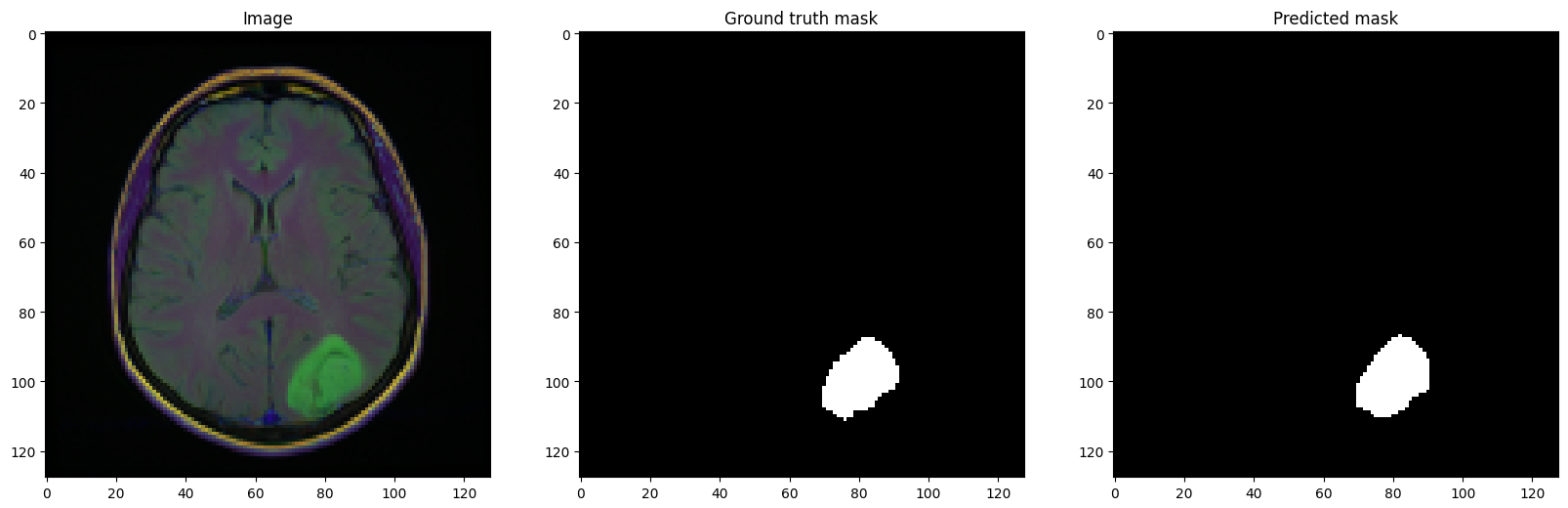
This model was trained on Brain MRI Segmentation Kaggle dataset and scored a Dice Score of 0.8925 on validation data and 0.8868 on test data.
This model can easily be extended for multiclass classification. Moreover, I wrote U-Net generlized implementation which can be easily be extended for different types of U-Nets.
| Model | Params | Batch Size | Time (20 epochs) | CPU Workers | GPU(s) |
|---|---|---|---|---|---|
| UNet | ~2.02M | 256 | ~5m | 2 | 1 Tesla v100 (32GB) |
| Attention UNet | ~8.47M | 256 (2 GPUs) | ~6m | 2 | 2 Tesla v100 (32GB each = 64GB) |
| UTransformer | ~8.82M | 8 | ~4h | 4 | 8 Tesla k80 (12GB each = 96GB) |
- Attention UNet was run on 2 GPUs such that batch was divided in half (128 on each)
- UTransformer was run on 8 GPUs such that I had to run certain layers manually on each GPU:
- Input, output, loss, and PE on cuda:0
- Encoder layers on cuda:6
- Decoder layers on cuda:7
- MHSA on cuda:1
- Each (4)MHCA on cuda:2 through cuda:5
| Model (ᵩ Res) | Accuracy | Dice | F1 Score | IoU | Precision | Recall | Specificity |
|---|---|---|---|---|---|---|---|
| UNet | 0.9912 | 0.8492 | 0.8492 | 0.8644 | 0.8656 | 0.8333 | 0.9960 |
| UNetᵩ | 0.9920 | 0.8567 | 0.8567 | 0.8705 | 0.9106 | 0.8087 | 0.9976 |
| Attention UNet | 0.9864 | 0.7318 | 0.7318 | 0.7816 | 0.8862 | 0.6233 | 0.9975 |
| Attention UNetᵩ | 0.9911 | 0.8340 | 0.8340 | 0.8531 | 0.9343 | 0.7532 | 0.9984 |
| UTransformer | 0.9931 | 0.8818 | 0.8818 | 0.8908 | 0.9026 | 0.8619 | 0.9972 |
| UTransformerᵩ | 0.9939 | 0.8925 | 0.8925 | 0.8998 | 0.9289 | 0.8589 | 0.9980 |
Brain MRI Segmentation can be downloaded from Kaggle.
- Place the
lgg-mri-segmentationfolder with its contents intodata/rawfolder - Run
ETL.py
Olivier Petit, Nicolas Thome, Clément Rambour, Luc Soler:
U-Net Transformer: Self and Cross Attention for Medical Image Segmentation