El “Agregador de Indicadores” permite a académicos, multilaterales y otras organizaciones con interés en analizar indicadores de desarrollo, analizar y comparar indicadores de diferentes fuentes y con diversas unidades de medida. Con el esta herramienta es posible buscar con una función los indicadores del Numbers for Development, N4D del Banco Interamericano de Desarrollo, Banco Mundial, y de No Ceilings
Para utilizar la librería en R se debe ejecutar el siguiente codigo:
install.packages('devtools')
library(devtools)
install_github('EL-BID/Libreria-R-Numeros-para-el-Desarrollo')
install_github("arcuellar88/govdata360R")
install_github('EL-BID/Agregador-de-indicadores')
library(agregadorindicadores)library(agregadorindicadores)En este caso buscaremos indicadores relacionados con desempleo.
df<-ind_search(pattern="unemployment")
df[1:5,1:3]
src_id_ind indicator api
1220 SL.UEM.TOTL.ZS Unemployment, total (% of total labor force) (modeled ILO estimate) World Bank
1221 SL.UEM.TOTL.NE.ZS Unemployment, total (% of total labor force) (national estimate) World Bank
1222 SL.UEM.TOTL.MA.ZS Unemployment, male (% of male labor force) (modeled ILO estimate) World Bank
1223 SL.UEM.TOTL.MA.NE.ZS Unemployment, male (% of male labor force) (national estimate) World Bank
1224 SL.UEM.TOTL.FE.ZS Unemployment, female (% of female labor force) (modeled ILO estimate) World BankVerificar las distintas fuentes de informacion
unique(df$api)
[1] "World Bank" "Numbers for Development" "No Ceilings" Con una misma funciono obtuvimos datos de 3 fuentes distintas de informacion.
Para mayor información sobre la buúsqueda de indicadores ejecuta en R:
?ind_searchEn este ejemplo vamos a descargar los datos de dos indicadores para dos países entre el 2014 y el 2015
data<-ai(indicator = c("SL.UEM.TOTL.FE.ZS","SOC_6562"), country = c("CO","PE"),startdate = 2014, enddate=2015)
data[1:8,1:6]
iso2 country year src_id_ind value indicator
1 CO Colombia 2015 SL.UEM.TOTL.FE.ZS 11.843 Unemployment, female (% of female labor force) (modeled ILO estimate)
2 CO Colombia 2014 SL.UEM.TOTL.FE.ZS 11.971 Unemployment, female (% of female labor force) (modeled ILO estimate)
3 PE Peru 2015 SL.UEM.TOTL.FE.ZS 5.004 Unemployment, female (% of female labor force) (modeled ILO estimate)
4 PE Peru 2014 SL.UEM.TOTL.FE.ZS 4.731 Unemployment, female (% of female labor force) (modeled ILO estimate)
5 CO Colombia 2014 SOC_6562 10.253 Unemployment Rate, Female, No quint data, 25-49 age
6 CO Colombia 2015 SOC_6562 10.285 Unemployment Rate, Female, No quint data, 25-49 age
7 PE Peru 2014 SOC_6562 2.845 Unemployment Rate, Female, No quint data, 25-49 age
8 PE Peru 2015 SOC_6562 2.926 Unemployment Rate, Female, No quint data, 25-49 age Para mayor información sobre la descarga de datos de los indicadores ejecuta en R:
?aiUsaremos la librera plotly para los ejemplos
library(plotly)df<-ai(indicator = "AG.LND.AGRI.ZS", country = c("CO", "PE","ZA","US"), startdate = 2014)df$fCountry <- factor(df$country)
p <- ggplot(df, aes(x=fCountry, y=value,colour=fCountry,hover = indicator)) +
geom_point(shape=1)
p <- ggplotly(p)
p
df<-ai(indicator = c("NV.AGR.TOTL.ZS","LMW_403"), country = c("PE"), startdate = 2010)
ay <- list(
tickfont = list(color = "red"),
overlaying = "y",
side = "right",
title = "% of GDP"
)
p <- plot_ly() %>%
add_lines(x = df[df$src_id_ind=="LMW_403",]$year, y = df[df$src_id_ind=="LMW_403",]$value, name = "GDP: (US$ mill.) - Numbers for Development") %>%
add_lines(x = df[df$src_id_ind=="NV.AGR.TOTL.ZS",]$year, y = df[df$src_id_ind=="NV.AGR.TOTL.ZS",]$value, name = "Agriculture, value added (% of GDP) - World Bank", yaxis = "y2") %>%
layout(
title = "Comparación de dos indicadores", yaxis2 = ay,
xaxis = list(title="Year")
)
p

El agregador de indicadores ofrece una funcionalidad adicional para normalizar los indicadores y hacer un raking por país y por año. La normalización consiste en comparar el valor del indicador de cada país contra la media y la desviación de ese mismo indicador para todos los países para cada año. Para cada indicador, país y año se calcula el zscore de la siguiente manera:
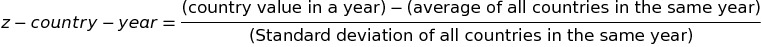
Una de las aplicaciones de esta normalizacion es comparar un conjunto de indicadores en un mismo gráfico. En el siguiente ejemplo se gráfico se muestran más de 1500 indicadores relacionados con género para 8 países para el 2014. En el gráfico se puede ver que Somalia e iraq tienen muchos más indicadores debajo de la media que el resto de países.

Puedes ver una explicación más detallada de esta función en el /ejemplos/normalización El paso a paso de este ejemplo lo pueden ver en /ejemplos/ranking_plot.R
Para mayor información sobre la normalizacioón de datos ejecuta en R:
?ai_normalizePara mejorar el desempeño de la herramienta, esta cuenta con una pequeña base de datos de los metadatos de los indicadores que llamamos caché. Esta fue actualizada por última vez el 1 de Noviembre del 2017. Para utilizar una versión más reciente se puede utilizar el siguiente código:
library(agregadorindicadores)
# Descargamos un nuevo cache en inglés
cache <- ai_cache(lang='en')
# Buscamos indicadores utilizando el cache
df<-ind_search(pattern="poverty", cache=cache)Para ver los datos disponibles en el caché se utiliza el siguiente código
library(agregadorindicadores)
str(ai_cachelist, max.level = 1)
List of 3
$ countries_wb :'data.frame': 304 obs. of 14 variables:
$ countries_idb:'data.frame': 26 obs. of 11 variables:
$ indicators :'data.frame': 19496 obs. of 11 variables:El agregador de indicadores utiliza las siguientes librerias de R:
- dplyr, tidyr , sqldf y gdata se utilizan para manipular los datos (merge, join, agregar columnas, filtrar, etc.)
- wbstats , WDI se utilizan para conectarse con el API del Banco Mundial
- httr , jsonlite se utilizan para leer los resultados del llamodo a los distintos APIs
Adicionalmente se utiliza otras librerias de github:
- 'EL-BID/Libreria-R-Numeros-para-el-Desarrollo' para conectarse con el API del Banco Interamericano de Desarrollo
- 'arcuellar88/govdata360R' para conectarse con el API govdata360 del Banco Mundial
A este repositorio no se le está dando actualmente mantenimiento. Si estás interesado en contribuir al repositorio, ya sea agregando fuentes de datos nuevas, dando mantenimiento o solucionando bugs, escríbenos a code.iadb.org.
Algunas áreas de mejora de esta librería son:
- Agregar filtros a la búsqueda de indicadores
- Verificar duplicados entre distintas fuentes de información
- Mejorar el tiempo de carga par World Bank (reduciendo el número de llamadas al api)link
El software de este repositorio está licenciado bajo una licencia GNU General Public License v3.0.
La documentación de soporte y uso, incluyendo este archivo README.md y el contenido en la carpeta "docs" está licenciado bajo la licencia Creative Commons.
Esta herramienta está basada en las siguientes dos herramientas:


