nereuschen / blog Goto Github PK
View Code? Open in Web Editor NEWblog
blog


















































写整洁代码很难;原因在于不仅要掌握原则和模式,还需要付之大量的实践,形成“代码感”
花时间保持代码整洁不但有关效率,还有关生存
破窗理论
童子军规
The Boy Scout Rule
http://programmer.97things.oreilly.com/wiki/index.php/The_Boy_Scout_Rule
每次check in的代码都比check out的代码都整洁
目的:没法保证你读过之后就有“代码感”,但是可以让你了解到好的程序员是
通过哪些技巧、技术和工具写出整洁代码的
一条sql更新500W+数据导致数据库变慢
监控MySQL的关键指标数据
通过监控实时了解MySQL的性能问题
内部的事务计算器(Trx id counter)是如何变化的
history list的长度表明最老的未被清除的事务有多老。如果这个值变大了,说明有些事务开启了很长时间。这意味着InnoDB不能够清除旧的行版本。最后数据库会变慢。所以要尽可能快递提交事务
Active Transactions
活跃的事务就是当前被开启的事务,它介于开始(BEGIN)和提交(COMMIT)之间。如果设置为 auto-commit,正在运行的query,即时它立即提交,也是一个活跃的事务。
Locked Transactions
locked事务是正处于 LOCK WAIT 状态的事务。通常情况下它正在等待一个行锁,但有时候有可能是在等待获取一个表锁或者自增长锁。
可以通过 SHOW INNODB STATUS 执行的结果去查找“LOCK WAIT”正在等待哪种类型的锁。
导致锁等待的因素有很多,比如,都在获取热表、通过扫描不同的索引来查询数据、或者使用SELECT .. FOR UPDATE这种错误的查询模式
Current Transactions
当前事务的总个数,包含所有状态状态(ACTIVE, LOCK WAIT, not started等)的事务;是通过SHOW INNODB STATUS执行的结果统计“---TRANSACTION”出现的总次数
Read views
其个数显示了多少个事务对于DB上下文有一致的快照
案例
某次DB磁盘被写满(磁盘I/O使用率到100%)时,观察到的监控
可以看出Active Transactions飙高

显示了每秒钟InnoDB事务等待锁的个数。它和InnoDB Active/Locked Transactions有一定的关系
如果Lock Waits出现的次数比较多,那么就应该去排查一下LOCK WAIT状态的事务;如果事务一直是处于LOCK WAIT状态,那么最悲催的情况下是,等待时间达到innodb_lock_wait_timeout(默认50秒)时才会放弃获取锁;
如果innodb_lock_wait_timeout设置过大,即使只有一个处于LOCK WAIT的事务,它也很可能等待一个比较长的时间
innodb_lock_wait_timeout
表示在获取锁时等待的最长时间,默认值是50秒
如果超过这个时间,应用会收到如下异常信息java.lang.Exception: ### Error updating database. Cause: java.sql.SQLException: Lock wait timeout exceeded; try restarting transaction ### The error may involve defaultParameterMap ### The error occurred while setting parameters ### Cause: java.sql.SQLException: Lock wait timeout exceeded; try restarting transaction; SQL []; Lock wait timeout exceeded; try restarting transaction; nested exception is java.sql.SQLException: Lock wait timeout exceeded; try restarting transaction
案例
某次发生deadlock时的监控信息

这些handler记录了MySQL通过存储引擎的API的操作记录
案例
某次出现一条sql在一个从库上的执行计划中没有使用到索引时导致的监控飙升
Handler Read Rnd Next飙高
显示了各种select类型的执行次数:full join, full range join, range, range check, and scan
这些显示了执行计划的各种类型的执行次数,尤其要注意
尽可能将Select_full_join的出现次数控制在0
尤其要注意aborted clients和connections,一般很少出现这两个值飙高的情况
以下这几种场景会导致该监控的值飙高
1. 由于client挂掉而没有正确关闭连接导致被终止的连接数;
2. 或者client sleep的时间超过了wait_timeout(默认28800秒)或者interactive_timeout(默认28800秒),并且这期间没有向server发送任何请求;
3. 或者client在传输数据的过程中突然终止
参考:
Aborted_clients
Communication Errors and Aborted Connections
尝试连接MySQL的失败次数;
导致的原因:
1. client没有访问权限
2. client访问密码错误
3. 连接包不合法
4. 发送连接包的时间超过了connect_timeout(默认10秒)
网络相关原因也会导致这2种异常
logical read requests 表示InnoDB已经处理过的数量
logical reads 表示InnoDB并不能从buffer pool读取数据,不得不直接从磁盘中读取
案例
某次出现一条sql在一个从库上的执行计划中没有使用到索引时导致的监控飙升
显示了buffer pool中的活动信息:创建、读和写pages
它和Handler是一致的
显示InnoDB的同步和异步的pending I/O.
Pending I/O是不理想的;理想情况下,InnoDB后台线程(background thread)能够和写保持同步,并且希望buffer pool足够大能解决读的问题;
如果出现大量的pending I/O,那么需要加内存,或者一个更大的buffer pool(或者使用O_DIRECT来double-buffering),或者比较快的磁盘系统
表明InnoDB内部有多少锁结构;这个和事务持有的行锁的个数相当;
并没有硬性该规定多少个锁结构是好还是坏,不过当很多事务正在等待锁时,很显然这个值越小越好
通过SHOW INNODB STATUS可以查看锁信息
23 lock struct(s), heap size 3024, undo log entries 27
LOCK WAIT 12 lock struct(s), heap size 3024, undo log entries 5
LOCK WAIT 2 lock struct(s), heap size 368
显示了InnoDB Log的活动
If transactions need to write to the log buffer and it’s either not big enough or is currently being flushed, they’ll stall.
当日志被清理时,size会发生变化,比如设置了expire_logs_days。
如果size突然增大了,可以看看是不是清除(purge)的时候出了问题,有可能是配置发生了变化,或者有人手动删除了文件触发了自动清除从而导致MySQL停止工作
显示了复制线程的状态。有2种方式衡量复制延时
1.通过SHOW SLAVE STATUS去查看Seconds_behind_master信息
2.通过心跳表去check
当复制正在工作的时候,绿色区域的大小就是复制延时。当复制停止的时候,也有个红色的区域,其大小也是复制延时;所以通过观察区域的颜色就能知道复制是否被终止了。如果复制没有延时,那么看不到绿色或者红色的区域
大致看明白这个方法的业务逻辑,需要话多长时间
2分钟?1分钟?20秒?
Dirty
public void renderWebPage() {
StringBuilder content = getContentBuilder(); content.append("<html>");
content.append("<head>");
for (HeaderElement headerElement : getHeaderElements()) {
String headerEntry = headerElement.getStartTag() +
headerElement.getContent() + headerElement.getEndTag();
content.append(headerEntry); }
content.append("</head>");
content.append("<body>");
for (BodyElement bodyElement : getBodyElements()) {
String bodyEntry = content.append(bodyElement);
}
content.append("</body>");
content.append("</html>");
OutputStream output = new OutputStream(response);
output.write(content.toString().getBytes());
output.close();
}
简单重构之后,看懂这个方法的业务逻辑需要多长时间?
10秒钟?5秒钟?
Clean
public void renderWebPage() {
buildStartPage();
buildHeaderContent();
buildBodyContent();
buildEndPage();
flushPageToResponse();
}
private void buildStartPage() { /* ... */ }
private void includeHeaderContent() { /* ... */ }
private void includeBodyContent() { /* ... */ }
private void buildEndPage() { /* ... */ }
private void flushPageToResponse() { /* ... */ }
重构后的代码肯定比重构前的代码更容易阅读和理解
如何做到的呢?
掌握以下内容,你也可以做到
短小的好处如下
多小才算小呢?看看大牛们怎么说的
听起来好像不可能,是不是还有点疯狂!!
方法只应该做一件事情;说起来简单,实际做起来不容易
首先要能够判断出一个方法是否只做一件事情
通常的判断标准是看这个方法中的每一步是否都是同一抽象级别的方法,如果是我们可以判断该方法只做了一件事情,只是包含多个步骤而已
比如,重构后的renderWebPage方法,含5个步骤(startPage,includeHeaderContent...),每个步骤执行自己的逻辑,并且是在同一个抽象级别,所以该方法只做了一件事情
注意是同一抽象级别;如果一个方法里面包含了高抽象级别或者低抽象级别的
比如,这段代码
public void renderWebPage() {
startPage();
includeHeaderContent();
includeBodyContent();
content.append("</html>");
flushPageToResponse();
}
可以很明显的看出
content.append("</html>");
和其他方法不在同一个抽象级别上,这段代码是低抽象级别的代码
使用描述性的名字,更容易表达出业务含义
不要太在意起个描述性的名字会导致方法名过长,即使是描述性过长的名称也好过长注释的方法
article.calculate();
article.calculatePrice();
article.calculatePriceWithDiscount();
article.calculatePriceNetOfTax();
多少个参数比较合适
当一个方法的参数超过3个的时候,就需要将一些参数封装为对象,来替代这次参数
Dirty
public List<Article> searchArticles(String articleName,String articleNumber,
String articleCategory, int pageSize, int pageOffset, int order) {
/* ... */
}
Clean
public List<Article> searchArticles(ArticleSearchCriteria criteria) {
/* ... */
}
critera = new ArticleSearchCriteria() .withArticleName("cleancode")
.withArticleNumber("abc123") .withArticleCategory("softwareengineering")
.withPageSize(10);
因为违反了单一职责原则,一个方法只该作一件事情
Dirty
public void rotate(double degrees, boolean left)
Clean
public void rotateLeft(double degrees)
public void rotateRight(double degrees)
if(!el.offsetWidth || !el.offsetHeight) {
}
var isVisible = el.offsetWidth && el.offsetHeight;
if(!isVisible) {
}
Dirty
public static Map<String, Object> buildFaxContentMap(Command faxCommand) {
Map<String, Object> faxContentMap = Maps.newHashMap();
if (Command.BOOKING_NOTIFY == faxCommand || Command.MANUAL_NOTIFY == faxCommand) {
faxContentMap.put("titleName", "预订通知单");
faxContentMap.put("faxType", "预订");
} else if (Command.CANCEL_NOTIFY == faxCommand) {
faxContentMap.put("titleName", "取消通知单");
faxContentMap.put("faxType", "取消");
} else if (Command.CHANGE_NOTIFY == faxCommand) {
faxContentMap.put("titleName", "变更通知单");
faxContentMap.put("faxType", "变更");
} else if (Command.OCNC_NOTIFY == faxCommand) {
faxContentMap.put("titleName", "现付转预付通知单");
faxContentMap.put("faxType", "");
} else if (Command.REJECTED_NOTIFY == faxCommand) {
faxContentMap.put("titleName", "拒单通知单");
faxContentMap.put("faxType", "拒单");
} else {
faxContentMap.put("titleName", "订单详情");
faxContentMap.put("faxType", "");
}
return faxContentMap;
}
Clean
private static Map<Command, FaxTitle> faxTitleMap = Maps.newHashMap();
static {
faxTitleMap.put(Command.BOOKING_NOTIFY, new FaxTitle("预订通知单", "预订"));
faxTitleMap.put(Command.MANUAL_NOTIFY, new FaxTitle("预订通知单", "预订"));
faxTitleMap.put(Command.CANCEL_NOTIFY, new FaxTitle("取消通知单", "取消"));
faxTitleMap.put(Command.CHANGE_NOTIFY, new FaxTitle("变更通知单", "变更"));
faxTitleMap.put(Command.OCNC_NOTIFY, new FaxTitle("现付转预付通知单", ""));
faxTitleMap.put(Command.REJECTED_NOTIFY, new FaxTitle("拒单通知单", "拒单"));
}
public static Map<String, Object> buildFaxContentMap(Command faxCommand) {
Map<String, Object> faxContentMap = Maps.newHashMap();
FaxTitle faxTitle = faxTitleMap.get(faxCommand);
if(faxTitle==null){
faxTitle = new FaxTitle("订单详情","");
}
faxContentMap.put("titleName", faxTitle.getTitleName());
faxContentMap.put("faxType", faxTitle.getFaxTypeDesc());
return faxContentMap;
}
让应届生童鞋做了一个批量修改业务数据的工具,目的是代替人工通过系统重复处理这些业务数据。工具的输入是业务模型id,然后根据约定的业务逻辑处理这些数据。当在批量一次性提交5000条id执行后,出现了一系列异常现象。
SQL QPS飙高
SQL QPS从100飙到700,涨了6倍
处理时间过长,响应时间高于平时一个数量级
处理5000条业务数据耗时20min,QPS是4(=5000条/(20min*60s)),处理一条数据的响应时间是250ms(=1000ms/4),但日常人工处理1条数据的响应时间是30ms,大致相差10倍。
页面显示504 Gateway Time-out
说明NG处理超时了
出了问题,首先应该看日志
Tomcat日志
主要查看biz.log和access.log,记业务日志和tomcat的http请求日志
biz.log
代码执行过程中,记录了处理失败的业务数据Id;grep 日志信息发现这个集群中的每个tomcat实例的业务日志中都出现了部分相同的业务数据Id。让该童鞋merge了一下日志文件,给出的结论是Id的记录总数超过1W。1W 这数据明细不对,不可能大于输入的Id数5000才对。看了一下去重的shell使用不当导致,正确统计后是2900+。
[xxxxx~0][xxx:24:03.396][INFO][xxxImpl:117] 执行到id=XXX
[xxxxx~0][xxx:25:03.443][INFO][xxxImpl:117] 执行到id=XXX
[xxxxx~0][xxx:26:03.340][INFO][xxxImpl:117] 执行到id=XXX
[xxxxx~0][xxx:27:03.363][INFO][xxxImpl:117] 执行到id=XXX
access.log
grep POST的URL后,发现在集群环境中每个Tomcat实例的access.log中都有这个URL。
[xxx:17:38:55 +0800] "POST /xxx/batch/update HTTP/1.0" 200 65493 "http://xxx/api/batch/update/rules" "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36" "-"
[xxx:17:39:53 +0800] "POST /xxx/batch/update HTTP/1.0" 200 65493 "http://xxx/api/batch/update/rules" "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36" "-"
[xxx:17:40:20 +0800] "POST /xxx/batch/update HTTP/1.0" 200 65493 "http://xxx/api/batch/update/rules" "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36" "-" 192.168.114.144
[xxx:17:42:02 +0800] "POST /xxx/batch/update HTTP/1.0" 200 65493 "http://xxx/api/batch/update/rules" "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36" "-" 192.168.114.144
从日志上看,请求都提交到集群中每个Tomcat实例上,只是相差60S而已
Nginx日志
有无无查看NG的权限,日后再补上
NG配置代码
通过日志不难发现请求被NG依次做了转发,导致每个tomcat实例都执行了1次
导致NG超时的根本原因是请求处理时间过长,超时导致,因此以下是比较常见的应用场景
修改NG配置文件,在发生timeout时,勿将请求再次转发到机器中的其他的节点
将响应时间长(>60s)的请求异步化,请求提交后,通过后台task去执行
http://www.nginxtips.com/504-gateway-time-out-using-nginx/
http://wiki.nginx.org/HttpProxyModule#proxy_connect_timeout
http://saiyaren.iteye.com/blog/1914865
绝境长城(冰与火之歌)
通常限流主要是限制并发数以及QPS,从而避免异常流量对系统的冲击;
并发数和QPS是紧密相关的,可以参考Little's Law(律特法则):L = λW (proven 1961)
一个排队系统在稳定状态下,在系统里面的个体的数量的平均值 L, 等于
平均个体到达率λ (单位是λ个每单位时间)乘以 个体的平均逗留时间W数学定理(严格的数学推理,非经验公式)
排队论的理论
最粗暴的实现方式是每执行一次delay一定时间,从而达到限制QPS的效果
比如,我们想以最大的QPS为10去处理1000个业务逻辑,那么代码很可能这么写
for (int i = 0; i < 1000; i++) {
doSomething();
Thread.sleep(100);
}
这种写法有什么弊端?
delay的预估时间不精确
为什么是100ms呢?其实QPS还依赖于doSomething的执行时间;
如果doSomething的执行时间短,比如是1ms,那么QPS最接近10;
如果doSomething的执行时间长,比如是500,那么QPS还不到2
通常情况下,doSomething的执行时间是非常不确定的,所以我们很难给出一个相对精确的delay时间
多线程下如何控制呢?
显然,由于doSomething的执行时间不确定,会导致没法在较短的时间内处理完1000个业务逻辑
所以必须借助线程池,通过并行去处理,但是QPS也必须控制在10以内
WorkThread的代码很有可能这么写,然后启多少个线程合适呢?
@Override
public void run() {
doSomething();
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
因此,采用delay这种粗暴的实现方式很难将QPS稳定地控制在10
要想解决这个问题,就必须做到
固定速率
在1秒这个时间窗口内,将执行的次数控制在10,这样速率是固定的
不允许突发情况
在任何1秒时间窗口内,不能超过10个
所以不能出现以下突发情况:比如QPS=2,0.0s到1.0s和1.0s到2.0s分别指允许执行2次,
但是在0.08秒、0.09秒、1.01秒、1.02秒执行了4次,所以在0.5秒到1.5秒这期间的1秒,
QPS是4并且超过了2
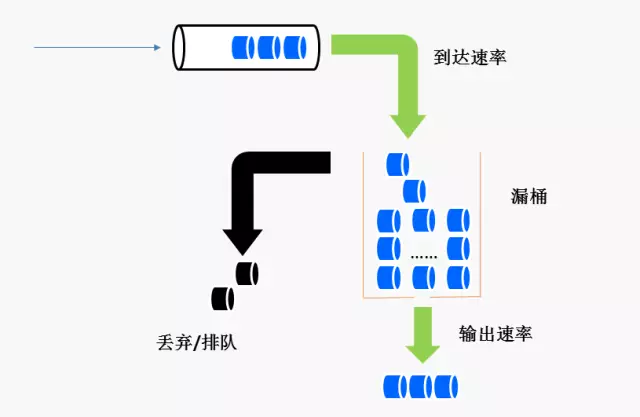
Leaky bucket(漏桶算法)正好解决了这些问题
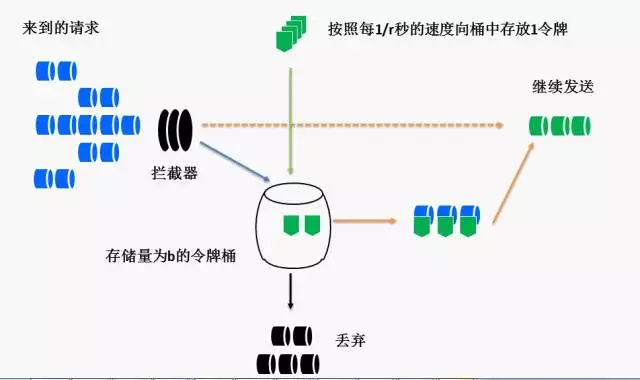
Token bucket(令牌桶算法)和它一样,都是最常见的两种限流算法
不断的往桶里面注水,无论注水的速度是大还是小,水都是按固定的速率往外漏水;
如果桶满了,水会溢出;
令牌发送:每秒往桶里面发送r个令牌(token)
桶的容量:桶中最多可以存放b个token;当放入的token数量超过b时,新放入的token会被丢弃
请求访问:每次请求访问时先check桶中有没有剩余的令牌
由于每秒会不断地往桶中放r个token,所以当无业务请求需处理时,桶中的token数量会不断增加,止到达到桶的容量b为止
令牌可以积累
桶中最大的令牌数是b,也是可以积累的最大令牌数
允许突发流量
桶中token可以积累到n(b<=n<=0),此时如果有n个突发请求同时到达,这n个请求是可以同时允许处理的
| 对比项 | Leakly bucket | Token bucket | Token bucket的备注 |
|---|---|---|---|
| 依赖token | 否 | 是 | |
| 立即执行 | 是 | 否 | 有足够的token才能执行 |
| 堆积token | 否 | 是 | |
| 速率恒定 | 是 | 否 | 可以大于设定的QPS |
在Guava中RateLimiter的实现有两种:SmoothBursty和SmoothWarmUp
补充类图
RateLimiter rateLimiter = RateLimiter.create(permitsPerSecond);//创建一个SmoothBursty实例
rateLimiter.acquire();//获取1个permit;可能会被阻塞止到获取到为止
以下场景,调用acquire()时何时有返回值?
QPS=1,4个线程在以下时间点依次调用acquire()方法
T0 at 0 seconds --> 0 excute
T1 at 1.05 seconds --> 1.05
T2 at 2 seconds --> 2.05(=1.05+1)
T3 at 3 seconds --> 3.05(=2.05+1)
存储token,具备处理突发请求的能力
当RateLimiter空闲时(无请求需处理),可以积累一定时间内的permits(token)
比如,当QPS=2,maxBurstSeconds=10时,也就意味着如果RateLimiter空闲,那么可以积累
10秒的permits,也就是10*2=20个(maxPermits = maxBurstSeconds *permitsPerSecond),
当下次有请求过来时,可以立即取走这20个permits,从而可以达到突发请求的效果
注意:SmoothBursty中maxBurstSeconds的默认值是1,并且不可以修改,所以SmoothBursty最多只能积累permitsPerSecond个permits
//创建一个SmoothWarmingUp实例;warmupPeriod是指预热的时间
RateLimiter rateLimiter =
RateLimiter.create(permitsPerSecond,warmupPeriod,timeUnit);
rateLimiter.acquire();//获取1个permit;可能会被阻塞止到获取到为止
预热期间QPS会平滑地逐步加速到最大的速率(也就是QPS)
public class RateLimiterUseCase {
private Logger logger = LoggerFactory.getLogger(RateLimiterUseCase.class);
private int qps;
private int requestCount;
private RateLimiter rateLimiter;
public RateLimiterUseCase(int qps, int requestCount) {
this.qps = qps;
this.requestCount = requestCount;
}
private void buildRateLimiter(RateLimiter rateLimiter) {
this.rateLimiter = rateLimiter;
}
private void processRequest(int requestCount) {
logger.info("RateLimiter 类型:{}", rateLimiter.getClass());
long startTimeMillis = System.currentTimeMillis();
for (int i = 0; i < requestCount; i++) {
rateLimiter.acquire();
}
long usedTimeMillis = System.currentTimeMillis() - startTimeMillis;
logger.info("处理请求数:{},耗时:{},限流的qps:{},实际的qps:{}", requestCount, usedTimeMillis, rateLimiter.getRate(), Math.ceil(requestCount / (usedTimeMillis / 1000.00)));
logger.info("");
}
private void sleep(int sleepTimeSeconds) {
logger.info("等待{}秒后,继续处理下一批{}个请求", sleepTimeSeconds, requestCount);
try {
Thread.sleep(sleepTimeSeconds * 1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public void processWithTokenBucket() {
buildRateLimiter(RateLimiter.create(qps));
doProcess();
}
public void processWithLeakBucket() {
buildRateLimiter(RateLimiter.create(qps, 0, TimeUnit.MILLISECONDS));
doProcess();
}
private void doProcess() {
sleep(0);
processRequest(requestCount);
sleep(1);
processRequest(requestCount);
sleep(5);
processRequest(requestCount);
sleep(10);
processRequest(requestCount);
}
public static void main(String[] args) {
RateLimiterUseCase test = new RateLimiterUseCase(10, 100);
test.processWithLeakBucket();
test.processWithTokenBucket();
test = new RateLimiterUseCase(10, 15);
test.processWithLeakBucket();
test.processWithTokenBucket();
}
}
运行结果
09:55:47.662 [main] INFO c.n.guava.RateLimiterUseCase - 等待0秒后,继续处理下一批100个请求
09:55:47.668 [main] INFO c.n.guava.RateLimiterUseCase - RateLimiter 类型:class com.google.common.util.concurrent.SmoothRateLimiter$SmoothWarmingUp
09:55:57.573 [main] INFO c.n.guava.RateLimiterUseCase - 处理请求数:100,耗时:9904,限流的qps:10.0,实际的qps:11.0
09:55:57.574 [main] INFO c.n.guava.RateLimiterUseCase -
09:55:57.574 [main] INFO c.n.guava.RateLimiterUseCase - 等待1秒后,继续处理下一批100个请求
09:55:58.578 [main] INFO c.n.guava.RateLimiterUseCase - RateLimiter 类型:class com.google.common.util.concurrent.SmoothRateLimiter$SmoothWarmingUp
09:56:08.481 [main] INFO c.n.guava.RateLimiterUseCase - 处理请求数:100,耗时:9903,限流的qps:10.0,实际的qps:11.0
09:56:08.481 [main] INFO c.n.guava.RateLimiterUseCase -
09:56:08.481 [main] INFO c.n.guava.RateLimiterUseCase - 等待5秒后,继续处理下一批100个请求
09:56:13.486 [main] INFO c.n.guava.RateLimiterUseCase - RateLimiter 类型:class com.google.common.util.concurrent.SmoothRateLimiter$SmoothWarmingUp
09:56:23.388 [main] INFO c.n.guava.RateLimiterUseCase - 处理请求数:100,耗时:9902,限流的qps:10.0,实际的qps:11.0
09:56:23.388 [main] INFO c.n.guava.RateLimiterUseCase -
09:56:23.388 [main] INFO c.n.guava.RateLimiterUseCase - 等待10秒后,继续处理下一批100个请求
09:56:33.391 [main] INFO c.n.guava.RateLimiterUseCase - RateLimiter 类型:class com.google.common.util.concurrent.SmoothRateLimiter$SmoothWarmingUp
09:56:43.293 [main] INFO c.n.guava.RateLimiterUseCase - 处理请求数:100,耗时:9902,限流的qps:10.0,实际的qps:11.0
09:56:43.294 [main] INFO c.n.guava.RateLimiterUseCase -
09:56:43.294 [main] INFO c.n.guava.RateLimiterUseCase - 等待0秒后,继续处理下一批100个请求
09:56:43.294 [main] INFO c.n.guava.RateLimiterUseCase - RateLimiter 类型:class com.google.common.util.concurrent.SmoothRateLimiter$SmoothBursty
09:56:53.195 [main] INFO c.n.guava.RateLimiterUseCase - 处理请求数:100,耗时:9901,限流的qps:10.0,实际的qps:11.0
09:56:53.196 [main] INFO c.n.guava.RateLimiterUseCase -
09:56:53.196 [main] INFO c.n.guava.RateLimiterUseCase - 等待1秒后,继续处理下一批100个请求
09:56:54.197 [main] INFO c.n.guava.RateLimiterUseCase - RateLimiter 类型:class com.google.common.util.concurrent.SmoothRateLimiter$SmoothBursty
09:57:03.194 [main] INFO c.n.guava.RateLimiterUseCase - 处理请求数:100,耗时:8997,限流的qps:10.0,实际的qps:12.0
09:57:03.194 [main] INFO c.n.guava.RateLimiterUseCase -
09:57:03.194 [main] INFO c.n.guava.RateLimiterUseCase - 等待5秒后,继续处理下一批100个请求
09:57:08.198 [main] INFO c.n.guava.RateLimiterUseCase - RateLimiter 类型:class com.google.common.util.concurrent.SmoothRateLimiter$SmoothBursty
09:57:17.102 [main] INFO c.n.guava.RateLimiterUseCase - 处理请求数:100,耗时:8904,限流的qps:10.0,实际的qps:12.0
09:57:17.103 [main] INFO c.n.guava.RateLimiterUseCase -
09:57:17.103 [main] INFO c.n.guava.RateLimiterUseCase - 等待10秒后,继续处理下一批100个请求
09:57:27.107 [main] INFO c.n.guava.RateLimiterUseCase - RateLimiter 类型:class com.google.common.util.concurrent.SmoothRateLimiter$SmoothBursty
09:57:36.012 [main] INFO c.n.guava.RateLimiterUseCase - 处理请求数:100,耗时:8905,限流的qps:10.0,实际的qps:12.0
09:57:36.012 [main] INFO c.n.guava.RateLimiterUseCase -
09:57:36.012 [main] INFO c.n.guava.RateLimiterUseCase - 等待0秒后,继续处理下一批15个请求
09:57:36.013 [main] INFO c.n.guava.RateLimiterUseCase - RateLimiter 类型:class com.google.common.util.concurrent.SmoothRateLimiter$SmoothWarmingUp
09:57:37.416 [main] INFO c.n.guava.RateLimiterUseCase - 处理请求数:15,耗时:1403,限流的qps:10.0,实际的qps:11.0
09:57:37.416 [main] INFO c.n.guava.RateLimiterUseCase -
09:57:37.416 [main] INFO c.n.guava.RateLimiterUseCase - 等待1秒后,继续处理下一批15个请求
09:57:38.417 [main] INFO c.n.guava.RateLimiterUseCase - RateLimiter 类型:class com.google.common.util.concurrent.SmoothRateLimiter$SmoothWarmingUp
09:57:39.820 [main] INFO c.n.guava.RateLimiterUseCase - 处理请求数:15,耗时:1402,限流的qps:10.0,实际的qps:11.0
09:57:39.821 [main] INFO c.n.guava.RateLimiterUseCase -
09:57:39.821 [main] INFO c.n.guava.RateLimiterUseCase - 等待5秒后,继续处理下一批15个请求
09:57:44.825 [main] INFO c.n.guava.RateLimiterUseCase - RateLimiter 类型:class com.google.common.util.concurrent.SmoothRateLimiter$SmoothWarmingUp
09:57:46.228 [main] INFO c.n.guava.RateLimiterUseCase - 处理请求数:15,耗时:1403,限流的qps:10.0,实际的qps:11.0
09:57:46.229 [main] INFO c.n.guava.RateLimiterUseCase -
09:57:46.229 [main] INFO c.n.guava.RateLimiterUseCase - 等待10秒后,继续处理下一批15个请求
09:57:56.233 [main] INFO c.n.guava.RateLimiterUseCase - RateLimiter 类型:class com.google.common.util.concurrent.SmoothRateLimiter$SmoothWarmingUp
09:57:57.636 [main] INFO c.n.guava.RateLimiterUseCase - 处理请求数:15,耗时:1403,限流的qps:10.0,实际的qps:11.0
09:57:57.636 [main] INFO c.n.guava.RateLimiterUseCase -
09:57:57.636 [main] INFO c.n.guava.RateLimiterUseCase - 等待0秒后,继续处理下一批15个请求
09:57:57.636 [main] INFO c.n.guava.RateLimiterUseCase - RateLimiter 类型:class com.google.common.util.concurrent.SmoothRateLimiter$SmoothBursty
09:57:59.037 [main] INFO c.n.guava.RateLimiterUseCase - 处理请求数:15,耗时:1400,限流的qps:10.0,实际的qps:11.0
09:57:59.037 [main] INFO c.n.guava.RateLimiterUseCase -
09:57:59.037 [main] INFO c.n.guava.RateLimiterUseCase - 等待1秒后,继续处理下一批15个请求
09:58:00.038 [main] INFO c.n.guava.RateLimiterUseCase - RateLimiter 类型:class com.google.common.util.concurrent.SmoothRateLimiter$SmoothBursty
09:58:00.539 [main] INFO c.n.guava.RateLimiterUseCase - 处理请求数:15,耗时:501,限流的qps:10.0,实际的qps:30.0
09:58:00.540 [main] INFO c.n.guava.RateLimiterUseCase -
09:58:00.540 [main] INFO c.n.guava.RateLimiterUseCase - 等待5秒后,继续处理下一批15个请求
09:58:05.542 [main] INFO c.n.guava.RateLimiterUseCase - RateLimiter 类型:class com.google.common.util.concurrent.SmoothRateLimiter$SmoothBursty
09:58:05.945 [main] INFO c.n.guava.RateLimiterUseCase - 处理请求数:15,耗时:403,限流的qps:10.0,实际的qps:38.0
09:58:05.946 [main] INFO c.n.guava.RateLimiterUseCase -
09:58:05.946 [main] INFO c.n.guava.RateLimiterUseCase - 等待10秒后,继续处理下一批15个请求
09:58:15.947 [main] INFO c.n.guava.RateLimiterUseCase - RateLimiter 类型:class com.google.common.util.concurrent.SmoothRateLimiter$SmoothBursty
09:58:16.350 [main] INFO c.n.guava.RateLimiterUseCase - 处理请求数:15,耗时:403,限流的qps:10.0,实际的qps:38.0
09:58:16.350 [main] INFO c.n.guava.RateLimiterUseCase -
对于SmoothBurst [RateLimiter.create(permitsPerSecond)] 而言,是基于Token bucket算法,因此
速率不是固定的,因为允许出现burst突发情况,实际的QPS会出现大于permitsPerSecond的情况;
设定的QPS越大,需要处理的request越小时,实际的QPS越大;
设定的QPS越小,需要处理的request越大时,实际的QPS越平稳,越接近设定的QPS
对于SmoothWarmingUp [RateLimiter.create(permitsPerSecond,warmupPeriod,timeUnit)]而言,是基于Leaky bucket算法,因此
速率是固定的,因此QPS也是固定的,不会出现burst突发情况
获取permit时是否会block线程
acquire()会block线程
/** * Acquires a single permit from this {@code RateLimiter}, blocking until the * request can be granted. Tells the amount of time slept, if any. * * <p>This method is equivalent to {@code acquire(1)}. * * @return time spent sleeping to enforce rate, in seconds; 0.0 if not rate-limited * @since 16.0 (present in 13.0 with {@code void} return type}) */ public double acquire() { return acquire(1); }tryAcquire() 不会block线程
/** * Acquires a permit from this {@link RateLimiter} if it can be acquired immediately without * delay. * * <p> * This method is equivalent to {@code tryAcquire(1)}. * * @return {@code true} if the permit was acquired, {@code false} otherwise * @since 14.0 */ public boolean tryAcquire() { return tryAcquire(1, 0, MICROSECONDS); }
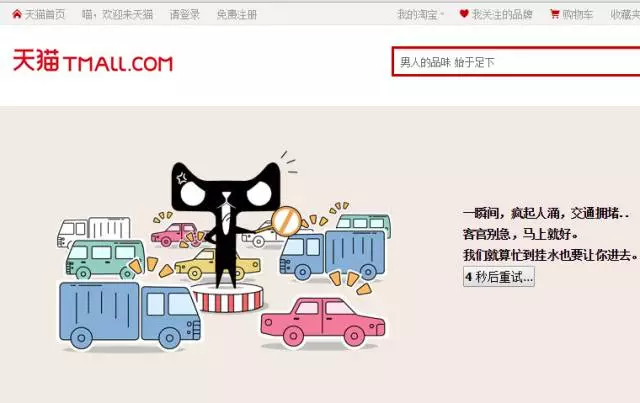
如果你在双十一0点0分之后,购物的时候遇到这个页面,那么亲,你被限流了,必须排到等待
特点:
为了提升用户体验,需要支持爆发量,所以采用令牌桶算法
允许最大的访问速率:b+r
爆发持续时间:T=b/(m-2r)
爆发量:L=T*r
特点:
采用漏桶算法
分成几个主要模块
监控模块
收集数据、实时监控和反馈分析
决策模块
什么场景使用什么限流方式;比如,用户洪峰采用令牌桶算法,
系统回调使用漏桶算法
规则变更模块
动态调整令牌桶容量和产生令牌的速率
限流模块
如何处理被限流的请求,是排队还是丢弃
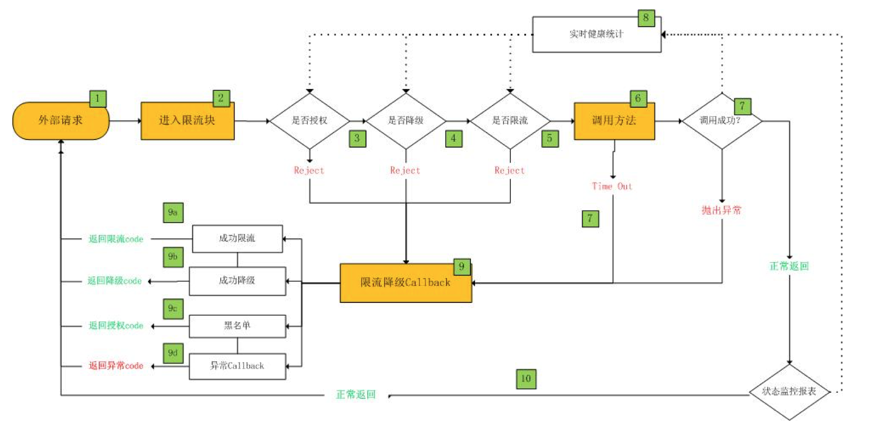
限流框架的处理流程
TODO
vi /etc/nginx/conf.d/default.conf
......
upstream myapp {
server 127.0.0.1:8081;
}
limit_req_zone $binary_remote_addr zone=login:10m rate=10r/s;
server {
server_name _;
location / {
proxy_pass http://myapp;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $http_host;
}
location /account/login/ {
# apply rate limiting
limit_req zone=login burst=5 nodelay;
# boilerplate copied from location /
proxy_pass http://myapp;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $http_host;
}
}
参数说明
$binary_remote_addr
采用二进制表示访问的IP地址
zone=login:10m
表示定义了一个名为login的内存共享区,其占用内存大小为10M。
10M的内存可以存放16W个二进制表示的IP地址。
rate=1r/s
就是QPS;对同一个IP地址而言,速率被限制为每秒1次请求
burst
如果同一个IP访问的请求超过rate后,没有超过桶上限burst的请求会被放入桶中,等待被处理。
这个例子中桶的容量是5。
nodelay
单个IP的在某时间段内平均QPS未超过设定的rate,那么桶中的请求会立即被处理,
此时的瞬间QPS高于设定的rate;如果在某时间段内平均的QPS超过rate,那么超过
rate的请求会直接被拒绝,直接返回503
从示例配置信息中可以看出:
对访问/account/login/的请求根据访问的IP进行了限速,QPS是10;
对于同一个IP地址只允许每秒10个请求访问该URL;
如果请求量大于QPS(10),会立即返回503(因为配置了参数nodelay);
如果没有配置参数nodelay,那么超过QPS访问量的请求会先积压到桶中(可以积压5个),
如果桶满了,就返回503。
nginx限流模块默认使用的是漏桶算法,而当配置了nodelay时采用的是令牌算法,此时允许burst请求
重点说明一下对burst+nodelay的理解
limit_req_zone $binary_remote_addr zone=login:10m rate=1r/s;
......
location /account/login/ {
# apply rate limiting
limit_req zone=login burst=15 nodelay;
}
| 时间点 | 并发请求量 | 拒绝的请求次数 | 成功的请求次数 |
|---|---|---|---|
| 10:00:01 | 15 | 0 | 15 |
| 10:00:15 | 15 | 0 | 15 |
| 10:00:30 | 15 | 0 | 15 |
| 10:00:45 | 15 | 0 | 15 |
| 11:00:01 | 15 | 0 | 15 |
| 11:00:02 | 15 | 14 | 1 |
| 11:00:03 | 15 | 14 | 1 |
| 11:00:04 | 15 | 14 | 1 |
针对这个case的理解:
(1)在[10:00:01到10:00:45]期间,每隔15秒会有15个并发请求,虽然在这些时间点上并发
请求大于rate,但在每个15秒内其QPS是1,依旧未超过rate,所以每次的15个并发请求能够
被成功处理
(2)在[11:00:01到11:00:05]期间,每秒15个并发请求,在11:00:01时,请求量未超过burst,
并且由于配置了nodelay,所以当时15个请求立即被执行了;而在其他的时间点上QPS大于
rate,所以超出rate的请求直接被拒绝
http://redis.io/commands/INCR#pattern-rate-limiter
https://github.com/UsedRarely/spring-rate-limit
https://github.com/colley/spring-ratelimiter
https://github.com/nlap/dropwizard-ratelimit
https://github.com/sudohippie/throttle
https://github.com/coveo/spillway
https://github.com/marcosbarbero/spring-cloud-starter-zuul-ratelimit
可以借助在filter中通过RateLimiter来实现正对单机的限流
秒杀特点:瞬时并发高、数据一致性高、热点更新频率高
大量更新DB中的同一条记录时,会产生锁等待,导致DB性能急剧下降
当大量的并发更新同一条记录时,使用排队的方式来保证高并发下热点记录更新依然能保持
较好的性能,为threads_running设置一个硬上线,当并发超过此值是,拒绝执行sql,
保护MySQL,我们将这个称之为高水位限流,这样就给数据库加上了一层限流的功能,使得
数据库不被瞬间的高爆发请求打爆。
高水位限流实现:
监控系统status变量threads_running,当满足拒绝条件,拒绝执行sql,返回用户:
MySQL Server is too busy,判断逻辑在dispatch_command中,sql解析之后。
增加的系统variables:
1.threads_running_ctl_mode: 限流的sql类型,有两个取值:[ALL | SELECTS],
默认SELECTS,设置为ALL需谨慎。
2.threads_running_high_watermark: 限流水位值,只有threads_running
超过此值才会触发,默认值为max_connections,当set global
threads_running_high_watermark=0时自动设置为max_connections
拒绝必要条件:
1.threads_running超过threads_running_high_watermark
2.threads_running_ctl_mode与sql类型相符
以下情况不拒绝:
1.用户具有super权限
2.sql所在事务已经开启
3.sql为commit/rollback
sudo yum -y install gcc make
sudo yum -y install gcc gcc-c++
wget http://download.savannah.gnu.org/releases/libunwind/libunwind-0.99-beta.tar.gz
./configure
make
sudo make install
make clean
wget http://gperftools.googlecode.com/files/google-perftools-1.9.1.tar.gz
./configure --prefix=/home/q/google-perftools
sudo make
sudo make install
make clean
以tomcat为例,启动
导致CPU飙高,部分进程使用到的CPU接近100%
text
text
X - Y = X + (-Y)
简历投递邮箱:[email protected]
从日常工作中遇到的问题中总结出来的若干点,内容有点分散,先记录下来,日后再整理成稍有体系的内容
1 2015-08-30 13:30:53 7f7b33410700
2 *** (1) TRANSACTION:
3 TRANSACTION 20966501047, ACTIVE 0 sec starting index read
4 mysql tables in use 1, locked 1
5 LOCK WAIT 3 lock struct(s), heap size 1184, 1 row lock(s), undo log entries 2
6 MySQL thread id 10985893, OS thread handle 0x7f7b31cb4700, query id 17850878553 192.168.1.11 h_rw updating
7 delete
8 from order
9 where order_no=123456789
10 *** (1) WAITING FOR THIS LOCK TO BE GRANTED:
11 RECORD LOCKS space id 609 page no 4 n bits 720 index `uniq_order_no` of table `orders`.`order` trx id 20966501047 lock_mode X waiting
12 Record lock, heap no 492 PHYSICAL RECORD: n_fields 2; compact format; info bits 32
13 0: len 8; hex 80000017683ff2ab; asc h? ;;
14 1: len 4; hex 048ede55; asc U;;
15 *** (2) TRANSACTION:
16 TRANSACTION 20966501042, ACTIVE 0 sec starting index read, thread declared inside InnoDB 1
17 mysql tables in use 1, locked 1
18 4 lock struct(s), heap size 1184, 2 row lock(s), undo log entries 2
19 MySQL thread id 10975858, OS thread handle 0x7f7b33410700, query id 17850878537 192.168.1.15 h_rw updating
20 delete
21 from order
22 where order_no=123456789
23 *** (2) HOLDS THE LOCK(S):
24 RECORD LOCKS space id 609 page no 4 n bits 720 index `uniq_order_no` of table `orders`.`order` trx id 20966501042 lock_mode X locks rec but not gap
25 Record lock, heap no 492 PHYSICAL RECORD: n_fields 2; compact format; info bits 32
26 0: len 8; hex 80000017683ff2ab; asc h? ;;
27 1: len 4; hex 048ede55; asc U;;
28 *** (2) WAITING FOR THIS LOCK TO BE GRANTED:
29 RECORD LOCKS space id 609 page no 4 n bits 720 index `uniq_order_no` of table `orders`.`order` trx id 20966501042 lock_mode X waiting
30 Record lock, heap no 492 PHYSICAL RECORD: n_fields 2; compact format; info bits 32
31 0: len 8; hex 80000017683ff2ab; asc h? ;;
32 1: len 4; hex 048ede55; asc U;;
33 *** WE ROLL BACK TRANSACTION (1)
亲,load怎么了?已经飙到了20+
load是如何计算的
load = run queue length (运行队列中的等待进程和正在执行的进程数)
参考资料:
Understanding Linux CPU Load - when should you be worried? 中文版
正确认识物理CPU、多核和逻辑CPU
查看逻辑CPU
逻辑CPU个数=物理CPU个数_cores个数_2(开启超程)
查看物理CPU、多核和逻辑CPU
cat /proc/cpuinfo
load到底多大比较合适?
逻辑CPU个数*0.7
Linux Scheduler
参考资料
Scheduling in Linux
Inside the Linux scheduler
Linux Scheduler算法演示
相关算法在线演示
进程状态
R running or runnable (on run queue)
D uninterruptible sleep (usually IO)
S interruptible sleep (waiting for an event to complete)
Z defunct/zombie, terminated but not reaped by its parent
T stopped, either by a job control signal or because it is being traced
参考资料:
Linux进程状态
Linux进程的三种状态
OS中定义的进程状态
参考资料
Operating system concepts
load实例
high load & cpu
high load low cpu (todo)
上下文切换频繁
常用命令
好的命名是要能直接体现出意图,表达具体的业务含义,不需要通过补充注释来说明命名的含义,能让人更容易理解和修改代码;名字是自描述的,不需要额外的注释来说明
我们在命名时需要想想团队的新成员是否能理解这个名字的含义?
这些内容看起来确实简单,但实施起来并非易事,因为需要知道哪些地方有问题以及如何正确使用
变量名、方法名、参数名、类名、包名、文件名
Dirty
int d; // elapsed time in days
int process();
Clean
这些名称更能让人容易理解
int elapsedTimeInDays;
int daysSinceCreation;
int daysSinceModification;
int fileAgeInDays;
int parseCustomerIdFromFile();
Dirty
这些代码想表达什么含义?
模糊度:上下文在代码中未能被明确体现的程度
public List <int[]> getThem() {
List <int[]> list1 = new ArrayList <int[]>();
for (int[] x : theList)
if (x[0] == 4)
list1.add(x);
return list1;
}
Clean
public List <int[]> getFlaggedCells() {
List <int[]> flaggedCells = new ArrayList <int[]>();
for (int[] cell : gameBoard)
if (cell[STATUS_VALUE] == FLAGGED)
flaggedCells.add(cell);
return flaggedCells;
}
Dirty
CreateCache(int size)
Start(int delay)
int delayTime = getDelayTime(orderPending, inEBWhiteList, inHotelExceptionFax, mainOrder, sHotel);
Clean
CreateCache(int sizeMb)
Start(int delaySeconds)
int delayTimeMinutes = getDelayTime(orderPending, inEBWhiteList, inHotelExceptionFax, mainOrder, sHotel);
时间相关
delayTimeNanos
delayTimeMicros
delayTimeMillis
delayTimeSeconds
delayTimeMinutes
delayTimeHours
delayTimeDays
java.util.concurrent.TimeUnit
Dirty
if (isEBWhiteList) {
delayTime = 30;
} else if (isHotelExceptionFax) {
delayTime = 10;
}
Clean
int EB_WHITE_LIST_DEALY_TIME_MINUTES = 30 ;
int HOTEL_EXCEPTION_FAX_DEALY_TIME_MINUTES = 10 ;
.....
if (isEBWhiteList) {
delayTime = EB_WHITE_LIST_DEALY_TIME_MINUTES;
} else if (isHotelExceptionFax) {
delayTime = HOTEL_EXCEPTION_FAX_DEALY_TIME_MINUTES;
}
More clean
if (isEBWhiteList) {
delayTimeMinutes = EB_WHITE_LIST_DEALY_TIME_MINUTES;
} else if (isHotelExceptionFax) {
delayTimeMinutes = HOTEL_EXCEPTION_FAX_DEALY_TIME_MINUTES;
}
Dirty
Customer[] customerList;
Clean
Customer[] customers;
Dirty
a1,a2能体现出什么业务含义?
public static void copyChars(char a1[], char a2[]) {
for (int i = 0; i < a1.length; i++) {
a2[i] = a1[i];
}
}
Clean
public static void copyChars(char source[], char destination[]) {
for (int i = 0; i < source.length; i++) {
destination[i] = source[i];
}
}
http://www.slideshare.net/CleanestCode/naming-standards-clean-code
Dirty
class DtaRcrd102 {
private Date genymdhms; // generationdate, year, month, day, hour,
//minute,and second (you can notread this)
private Date modymdhms;
private final String pszqint = "102";
}
Clean
class Customer {
private Date generationTimestamp;
private Date modificationTimestamp;
private final String recordId = "102";
}
在命名变量时,如果这些变量有相关性,可以给这些变量加上前缀
Dirty
firstName
lastName
street
houseNumber
city
state
zipcode
Clean
addrFirstName
addrLastName
addrStreet
addrHouseNumber
addrCity
addrState
addrZipcode
类名应该是名词或者名词短语
Dirty
Clean
Customer
Account
AddressParser
方法名应该是动词或者动词短语
Dirty
Clean
postPayment
deletePage
save
Dirty
Clean
Dirty
Clean
Dirty
Clean
Dirty
Clean
Dirty
Clean
Dirty
Clean
Dirty
Clean
Dirty
Clean
GRANT SELECT, INSERT, UPDATE, DELETE ON db_%.* TO 'test_rw'@'*'
GRANT CREATE ON test_db1.* TO 'test_rw'@'192.168.11.11'
导致该IP没有SELECT, INSERT, UPDATE, DELETE 权限
Server version: 5.6.16-64.2-log Percona Server (GPL)
近期遇到一个堆外内存导致swap飙高的问题,这类问题比较罕见,因此将整个排查过程记录下来了
最近1周线上服务器时不时出现swap报警(swap超过内存10%时触发报警,内存是4G,因此swap超过400M会触发报警),每次都是童鞋们通过重启tomcat解决的;
但导致的根本原因是什么呢?必须找到根本原因才行,总是这么重启就有点low了
于是找了1台占用了swap但还未触发报警的服务器进行了排查
以下是当时通过top命令观察到的结果
23:03:22 swap占用了354M的内存

23:55:42 swap占用了398M的内存

到底是什么原因导致swap飙高呢?肯定是tomcat,因为每次重启tomcat就解决了;但根本原因是?
通过以下脚本 swap.sh
#!/bin/bash
# Get current swap usage for all running processes
# Erik Ljungstrom 27/05/2011
do_swap () {
SUM=0
OVERALL=0
for DIR in `find /proc/ -maxdepth 1 -type d | egrep "^/proc/[0-9]"` ; do
PID=`echo $DIR | cut -d / -f 3`
PROGNAME=`ps -p $PID -o comm --no-headers`
for SWAP in `grep Swap $DIR/smaps 2>/dev/null| awk '{ print $2 }'`
do
let SUM=$SUM+$SWAP
done
echo "PID=$PID - Swap used: $SUM - ($PROGNAME )"
let OVERALL=$OVERALL+$SUM
SUM=0
done
echo "Overall swap used: $OVERALL"
}
do_swap |awk -F[\ \(] '{print $5,$1,$8}' | sort -n | tail -3
可以看出PID=19911这个进程使用了324M的swap

通过grep进程号19911可以看出确实是tomcat占用swap最多

进程19911占用总的物理内存是3.1G,java占用的堆内内存大小为2.78G,剩下的320M是堆外内存占用的
Max memory = [-Xmx] + [-XX:MaxPermSize] + number_of_threads * [-Xss]
2779M=2048M+268M+463*1M
sudo -u tomcat ./jinfo -flag MaxPermSize 19911
-XX:MaxPermSize=268435456
java -XX:+PrintFlagsFinal -version | grep ThreadStackSize
intx CompilerThreadStackSize = 0 {pd product}
intx ThreadStackSize = 1024 {pd product}
intx VMThreadStackSize = 1024 {pd product}
java version "1.7.0_45"
Java(TM) SE Runtime Environment (build 1.7.0_45-b18)
Java HotSpot(TM) 64-Bit Server VM (build 24.45-b08, mixed mode)
java -XX:+PrintFlagsFinal -version | grep -i permsize
uintx AdaptivePermSizeWeight = 20 {product}
uintx MaxPermSize = 85983232 {pd product}
uintx PermSize = 21757952 {pd product}
java version "1.7.0_45"
Java(TM) SE Runtime Environment (build 1.7.0_45-b18)
Java HotSpot(TM) 64-Bit Server VM (build 24.45-b08, mixed mode)
堆内内存溢出可以直接通过MAT分析堆信息就可以定位到具体的代码,但是对于堆外内存就必须通过BTrace来解决
如何安装和使用google-perftools见这里
由于要启动google-perftools需要重启tomcat,所以重启tomcat后,PID从19911变成了9176
重启tomcat后,会自动生成heap文件,文件名的命名规范是gperf_pid.xxx.heap,所以我们只需要关注gperf_9176.*即可
[xxxx@xxxx /home/xxx/logs]$ ll *.heap
…...
-rw-r--r-- 1 tomcat tomcat 5048 May 6 10:46 gperf_9171.0001.heap
-rw-r--r-- 1 tomcat tomcat 5036 May 6 10:46 gperf_9173.0001.heap
-rw-r--r-- 1 tomcat tomcat 5055 May 6 10:46 gperf_9174.0001.heap
-rw-r--r-- 1 tomcat tomcat 5352 May 6 10:46 gperf_9175.0001.heap
-rw-r--r-- 1 tomcat tomcat 1048563 May 6 10:46 gperf_9176.0001.heap
-rw-r--r-- 1 tomcat tomcat 1048564 May 6 10:46 gperf_9176.0002.heap
-rw-r--r-- 1 tomcat tomcat 1048563 May 6 10:47 gperf_9176.0003.heap
-rw-r--r-- 1 tomcat tomcat 1048565 May 6 10:47 gperf_9176.0004.heap
-rw-r--r-- 1 tomcat tomcat 1048574 May 6 10:49 gperf_9176.0005.heap
-rw-r--r-- 1 tomcat tomcat 1048574 May 6 10:50 gperf_9176.0006.heap
-rw-r--r-- 1 tomcat tomcat 1048568 May 6 10:51 gperf_9176.0007.heap
-rw-r--r-- 1 tomcat tomcat 1048572 May 6 10:53 gperf_9176.0008.heap
-rw-r--r-- 1 tomcat tomcat 1048564 May 6 10:55 gperf_9176.0009.heap
-rw-r--r-- 1 tomcat tomcat 1048560 May 6 10:58 gperf_9176.0010.heap
-rw-r--r-- 1 tomcat tomcat 1048563 May 6 11:00 gperf_9176.0011.heap
-rw-r--r-- 1 tomcat tomcat 1048564 May 6 11:03 gperf_9176.0012.heap
…...
分析heap文件
/home/google-perftools/bin/pprof --text /home/java /home/logs/gperf_9176.0010.heap
Using local file /home/java.
Using local file /home/logs/gperf_9176.0010.heap.
Total: 186.4 MB
91.2 48.9% 48.9% 91.2 48.9% updatewindow
52.5 28.2% 77.1% 52.5 28.2% os::malloc
38.0 20.4% 97.4% 38.0 20.4% inflateInit2_
3.0 1.6% 99.0% 3.0 1.6% init
0.8 0.4% 99.5% 0.8 0.4% ObjectSynchronizer::omAlloc
0.4 0.2% 99.7% 0.4 0.2% readCEN
0.3 0.2% 99.9% 38.3 20.5% Java_java_util_zip_Inflater_init
0.1 0.1% 100.0% 0.1 0.1% _dl_allocate_tls
0.0 0.0% 100.0% 0.0 0.0% _dl_new_object
0.0 0.0% 100.0% 1.1 0.6% Thread::Thread
0.0 0.0% 100.0% 0.0 0.0% CollectedHeap::CollectedHeap
0.0 0.0% 100.0% 0.0 0.0% Events::init
0.0 0.0% 100.0% 0.4 0.2% ZIP_Put_In_Cache0
0.0 0.0% 100.0% 0.0 0.0% read_alias_file
0.0 0.0% 100.0% 0.0 0.0% _nl_intern_locale_data
可以看出是java.util.zip.Inflater的init()占用了比较多的内存
编写代码BtracerInflater.java对init方法进行拦截
import static com.sun.btrace.BTraceUtils.*;
import com.sun.btrace.annotations.*;
import java.nio.ByteBuffer;
import java.lang.Thread;
@BTrace public class BtracerInflater{
@OnMethod(
clazz="java.util.zip.Inflater",
method="/.*/"
)
public static void traceCacheBlock(){
println("Who call java.util.zip.Inflater's methods :");
jstack();
}
}
运行BTrace
[[email protected] /home/xxx/btrace-bin/bin]$ sudo -u tomcat ./btrace -cp ../build 9176 BtracerInflater.java|more
Who call java.util.zip.Inflater's methods :
java.util.zip.Inflater.<init>(Inflater.java:102)
java.util.zip.GZIPInputStream.<init>(GZIPInputStream.java:76)
java.util.zip.GZIPInputStream.<init>(GZIPInputStream.java:90)
com.xxx.OrderDiffUtil.ungzip(OrderDiffUtil.java:54)
com.xxx.OrderDiffUtil.parse(OrderDiffUtil.java:32)
com.xxx.FaxOrderEventListener.takeSectionChangedInfo(FaxOrderEventListener.java:87)
com.xxx.FaxOrderEventListener.onMessage(FaxOrderEventListener.java:46)
.......
可以看出是OrderDiffUtil的ungzip()调用了java.util.zip.Inflater的init()
看看OrderDiffUtil.ungzip()
private static String ungzip(String encodeJson) {
ByteArrayOutputStream out = new ByteArrayOutputStream(encodeJson.length() * 5);
ByteArrayInputStream in = null;
try {
in = new ByteArrayInputStream(Base64.decode(encodeJson));
} catch (UnsupportedEncodingException e) {
return "{}";
}
try {
GZIPInputStream gunzip = new GZIPInputStream(in);
byte buffer[] = new byte[1024];
int len = 0;
while ((len = gunzip.read(buffer)) != -1) {
out.write(buffer, 0, len);
}
} catch (IOException e) {
return "{}";
}
try {
return out.toString("ISO-8859-1");
} catch (UnsupportedEncodingException e) {
}
return "{}";
}
可见gunzip未被close
所以根本原因是未调用GZIPInputStream的close()关闭流导致堆外内存占用
http://m.blog.csdn.net/blog/whuoyunshen88/19508075
http://itindex.net/detail/11709-perftools-内存-hbase
http://outofmemory.cn/code-snippet/1713/Btrace-usage-introduction
一台线上的应用服务器突然不可用,紧急下线该tomcat应用之后,发现已经OOM了,自动生成了oom.hprof文件,通过这个文件可以分析出什么原因导致OOM.
需要在java启动参数中配置-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/path
究竟是什么原因导致突然OOM呢?下面通过MAT工具简要进行分析
由于hprof文件比较大,所以需要修改MAT的JVM参数,防止MAT分析该文件时自己产生OOM





通过分析占用对象最大的dubbo线程的堆栈,可以看这次调用的Request对象中url的path=ProductRemote,methodName=query,所以可以断定是调用了ProductRemot服务的query方法导致OOM的

我们可以看看query这个方法的调用参数arugments,这个参数的值是QueryInput,它使用了一个ArrayList对象,size大小是88;结合业务代码来看,这个方法是要一次性查询88个酒店的相关信息,导致这个dubbo服务的线程在返回时占用了94M+的堆空间

线上某个业务应用的SQL的QPS监控发生了报警,QPS都飙到1.4w,平时才100不到,这节奏...
发布导致的?让童靴查了一下果然在这个点有发布,先果断回滚发布将风险降到最低
为了彻查原因,在回滚发布之前将一台服务器从线上摘下来,保留现场
当时的关键性监控


SQL执行次数持续飙高,说明这些TOP3的SQL一直在被执行,只要定位出是哪些线程一直处于RUNNABLE状态,这个问题就初步定位了。所以可以先使用jstack dump出线程堆栈信息
在JAVA的bin目录下通过以下命令dump线程栈信息
$ sudo -u tomcat ./jstack -l pid >~/threadDump1.log
可以每隔2秒dump一次,然后对比这些线程栈,看看哪些线程的一直是RUNNABLE状态
发现这个thread比较可疑
"pool-12-thread-2" prio=10 tid=0x00007f7818006800 nid=0x2227 runnable [0x00007f779e2c4000]
java.lang.Thread.State: `RUNNABLE`
at java.lang.Throwable.fillInStackTrace(Native Method)
- locked <0x00007f7892778a20> (a java.sql.SQLException)
at java.lang.Throwable.<init>(Throwable.java:196)
at java.lang.Exception.<init>(Exception.java:41)
at java.sql.SQLException.<init>(SQLException.java:52)
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:1074)
......
at org.apache.ibatis.executor.statement.PreparedStatementHandler.query(PreparedStatementHandler.java:57)
at org.apache.ibatis.executor.statement.RoutingStatementHandler.query(RoutingStatementHandler.java:70)
......
at org.apache.ibatis.binding.MapperProxy.invoke(MapperProxy.java:43)
at $Proxy33.queryXxxName(Unknown Source)
at com.XXX.queryXxxName(XXXImpl.java:361)
at com.XXX.queryXxxListByUserId(XXXImpl.java:405)
at sun.reflect.GeneratedMethodAccessor433.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:25)
at java.lang.reflect.Method.invoke(Method.java:597)
at org.springframework.aop.support.AopUtils.invokeJoinpointUsingReflection(AopUtils.java:317)
......
at $Proxy37.queryXxxListByUserId(Unknown Source)
at com.XXX.saveXxxPrivList(XXXImpl.java:238)
at com.XXX.changeXxxByXxxIds(XXXImpl.java:170)
at com.XXXThread.run(XXXThread.java:72)
at java.util.concurrent.ThreadPoolExecutor$Worker.runTask(ThreadPoolExecutor.java:886)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:908)
at java.lang.Thread.run(Thread.java:619)
通过看业务代码,DAO中涉及到的SQL正是上面说到的TOP3的SQL
最后...FIX BUG呗,重新发布上线
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.