用来记录平时的日常总结
olifer655 / randomnotes Goto Github PK
View Code? Open in Web Editor NEW用来记录平时的日常总结
用来记录平时的日常总结
用来记录平时的日常总结


最早在使用源生js或jq类库时,我们需要在各个事件方法中直接操作DOM来达到修改视图的目的。但是当应用一大就会变得难以维护。
那我们是不是可以把真实DOM树抽象成一棵以JavaScript对象构成的抽象树,在修改抽象树数据后将抽象树转化成真实DOM重绘到页面上呢?于是虚拟DOM出现了,它是真实DOM的一层抽象,用 属性 描述真实DOM的各个特性。当它发生变化的时候,就会去修改视图。
但是这样的JavaScript操作DOM进行重绘整个视图层是相当消耗性能的,我们是不是可以每次只更新它的修改呢?所以Vue.js将DOM抽象成一个以JavaScript对象为节点的虚拟DOM树,以VNode节点模拟真实DOM,可以对这颗抽象树进行创建节点、删除节点以及修改节点等操作,在这过程中都不需要操作真实DOM,只需要操作JavaScript对象,大大提升了性能。修改以后经过diff算法得出一些需要修改的最小单位,再将这些小单位的视图进行更新。这样做减少了很多不需要的DOM操作,大大提高了性能。
Vue就使用了这样的抽象节点VNode,它是对真实Dom的一层抽象,而不依赖某个平台,它可以是浏览器平台,也可以是weex,甚至是node平台也可以对这样一棵抽象Dom树进行创建删除修改等操作,这也为前后端同构提供了可能。
var VNode = function VNode (
tag,
data,
children,
text,
elm,
ns,
context,
componentOptions
) {
/* 当前节点的标签名 */
this.tag = tag
/* 当前节点对应的对象,包含了具体的一些数据信息,是一个VNodeData类型,可以参考VNodeData类型中的数据信息 */
this.data = data
/* 当前节点的子节点,是一个数组 */
this.children = children
/* 当前节点的文本 */
this.text = text
/* 当前虚拟节点对应的真实dom节点 */
this.elm = elm
/* 当前节点的名字空间 */
this.ns = ns
/* 编译作用域 */
this.context = context
/*函数化组件作用域*/
this.functionalContext = undefined
/* 节点的key属性,被当作节点的标志,用以优化 */
this.key = data && data.key
/* 组件的option选项 */
this.componentOptions = componentOptions
/* 当前节点对应的组件的实例 */
this.child = undefined
/* 当前节点的父节点 */
this.parent = undefined
/* 简而言之就是是否为原生HTML或只是普通文本,innerHTML的时候为true,textContent的时候为false */
this.raw = false
/* 静态节点标志 */
this.isStatic = false
/* 是否作为跟节点插入 */
this.isRootInsert = true
/* 是否为注释节点 */
this.isComment = false
/* 是否为克隆节点 */
this.isCloned = false
};DOM是文档对象模型(Document Object Model)的简写,在浏览器中我们可以通过js来操作DOM,
但是这样的操作性能很差,于是Virtual Dom应运而生。
Virtual Dom就是在js中模拟DOM对象树来优化DOM操作的一种技术或思路。
children: 数组类型,包含了当前节点的子节点
text: 当前节点的文本,一般文本节点或注释节点会有该属性
elm: 当前虚拟节点对应的真实的dom节点
ns: 节点的namespace
context: 编译作用域
functionalContext: 函数化组件的作用域
componentOptions: 创建组件实例时会用到的选项信息
key: 节点的key属性,用于作为节点的标识,有利于patch的优化
child: 当前节点对应的组件实例
parent: 组件的占位节点
raw: raw html
isStatic: 静态节点的标识
isRootInsert: 是否作为根节点插入,被包裹的节点,该属性的值为false
isComment: 当前节点是否是注释节点
isCloned: 当前节点是否为克隆节点
function createElement (
tag,
data,
children
) {
// 兼容不传data的情况
if (data && (Array.isArray(data) || typeof data !== 'object')) {
children = data
data = undefined
}
// make sure to use real instance instead of proxy as context
// 调用_createElement创建虚拟节点
return _createElement(this._self, tag, data, children)
}项目的运行时依靠一个makefile ,下面列出其相关代码,并做简单分析
.PHONY: dist
default: helper
include $(shell test -x "$$(which finite)" || sudo npm install finite -g > /dev/null; finite lib)
include $(shell find node_modules/finite-git/Makefile.d -type f 2>/dev/null)
helper:
@echo " \033[4m WaiMai.h5 Make Helper \033[0m"
@echo " \033[1;32m make install \033[0m Install node_modules"
@echo " \033[1;32m make lint \033[0m Run lint"
@echo " \033[1;32m make cleandist \033[0m Delete dist folder"
@echo " \033[1;32m make build \033[0m Build"
@echo " \033[1;32m make dev\033[0m \033[1;35me=alpha/beta/ppe/product \033[0m Start dev server"
@echo " \033[1;35m module=example1[,example2] \033[0m"
@echo " \033[1;35m [port=80] \033[0m"
@echo " \033[1;32m make alpha/beta/ppe/product\033[0m Shorthand of 'make dev'"
install: node_modules
lint:
@npm run lint
cleandist:
rm -rf ./dist
build: cleandist install
@npm run build
deploy: cleandist install
@npm run deploy
@cp -r dist fe.h5
@cp site-icon/* fe.h5/dist
@cp src/index.html fe.h5/dist
dev:
@echo "\033[1;32m dev-server will listen to module '$(module)' \033[0m"
@echo "\033[1;32m server starting... \033[0m"
@sudo module=$(module) npm run dev -- $(e)
alpha:
@make dev e=alpha
beta:
@make dev e=beta
ppe:
@make dev e=ppe
product:
@make dev e=product
make default后,输出
https://billie66.github.io/TLCL/book/zh/chap14.html
make dev module=login,profile,ordersuccess e=alpha后,输出
通过make dev可以看出,起需要两个参数: module 和 e
alpha: @make dev e=alpha 因此,make alpha module=login,profile,ordersuccess也可以达到同样的效果。

npm run dev究竟执行了什么呢?在先说明一下此项目是采webpake打包的。
来看一下package.json文件的内容:
{
"name": "h5",
"version": "0.0.0",
"private": true,
"scripts": {
"dev": "node ./build/server.js",
"build": "webpack --config ./build/webpack.prod.config.js",
"deploy": "npm run build",
"lint": "eslint src"
},
"dependencies": {
....(省略了跟本Issues无关的部分内容)
},
"devDependencies": {
"babel-core": "^6.0.0",
....(省略了跟本Issues无关的部分内容)
}
}
重点看一下我们的scripts对象。npm dev 执行的是./build/server.js 文件 内容。
http://www.ruanyifeng.com/blog/2016/10/npm_scripts.html
顺便再撸一把 server.js 吧
'use strict'
const fs = require('fs')
const childProcess = require('child_process')
const app = require('express')()
const webpack = require('webpack')
const webpackDevMiddleware = require('webpack-dev-middleware')
const webpackHotMiddleware = require('webpack-hot-middleware')
const proxy = require('http-proxy-middleware')
const webpackConfig = require('./webpack.dev.config')
const proxyMap = require('./proxy-map')
const proxyFactory = require('./proxy-factory')
const PORT = process.env.port || 80
const ENVIRONMENT = process.argv[2] || 'alpha'
if (!proxyMap.mainsite[ENVIRONMENT]) {
console.error('Unavailable environment')
process.exit()
}
let compiler = webpack(webpackConfig)
app.use(webpackDevMiddleware(compiler, {
stats: {
colors: true,
chunks: false,
children: false,
},
lazy: false,
publicPath: '/',
}))
app.use(webpackHotMiddleware(compiler))
try {
if (fs.statSync('./proxy.config.js')) {
let userProxyConfig = require('../proxy.config')
let routerConfig = {}
Object.keys(userProxyConfig).forEach(path => {
let newPath = path
if (path[path.length - 1] === '/') {
newPath = path.slice(0, -1)
}
if (newPath[0] !== '/') {
newPath = '/' + newPath
}
let targetUrl = userProxyConfig[path].replace('https://', 'http://')
if (!targetUrl.match(/^http:\/\//)) {
targetUrl = 'http://' + targetUrl
}
routerConfig[newPath] = targetUrl
})
mainProxy.router = routerConfig
}
} catch (error) {}
app.use((req, res, next) => {
let proxyConfig = proxyFactory(ENVIRONMENT)[req.hostname]
if (proxyConfig)
proxy(proxyConfig)(req, res, next)
else
next()
})
module.exports = app.listen(PORT, () => {
console.log(`Dev server listen on port PORT ${PORT}`)
console.log(`Server environment: ${ENVIRONMENT}`)
childProcess.exec(`open http://h5.test.ele.me/${webpackConfig.moduleGroup[0]}/`)
})
在此,重点强求一下,const app = require('express')()
http://expressjs.jser.us/3x_zh-cn/api.html
http://acgtofe.com/posts/2016/02/full-live-reload-for-express-with-webpack
let reg = /^\d{4}(\-|\/|\.)\d{1,2}\1\d{1,2}$/
密码的强度必须是包含大小写字母和数字的组合,不能使用特殊字符,长度在8-10之间。
let reg = /^(?=.*\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$/
字符串仅能是中文。
let reg = /^[\u4e00-\u9fa5]{0,}$/
let reg = /^\w+$/
同密码一样,下面是E-mail地址合规性的正则检查语句。
let reg = /[\w!#$%&'*+/=?^_`{|}~-]+(?:\.[\w!#$%&'*+/=?^_`{|}~-]+)*@(?:[\w](?:[\w-]*[\w])?\.)+[\w](?:[\w-]*[\w])?/
下面是身份证号码的正则校验。15 或 18位。
let reg = /^[1-9]\d{7}((0\d)|(1[0-2]))(([0|1|2]\d)|3[0-1])\d{3}$/
let reg = /^[1-9]\d{5}[1-9]\d{3}((0\d)|(1[0-2]))(([0|1|2]\d)|3[0-1])\d{3}([0-9]|X)$/
let reg = /^(?:(?!0000)[0-9]{4}-(?:(?:0[1-9]|1[0-2])-(?:0[1-9]|1[0-9]|2[0-8])|(?:0[13-9]|1[0-2])-(?:29|30)|(?:0[13578]|1[02])-31)|(?:[0-9]{2}(?:0[48]|[2468][048]|[13579][26])|(?:0[48]|[2468][048]|[13579][26])00)-02-29)$
/
金额校验,精确到2位小数。
let reg = /^[0-9]+(.[0-9]{2})?$/
(可根据目前国内收集号扩展前两位开头号码)
let reg = /^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\d{8}$/
IE目前还没被完全取代,很多页面还是需要做版本兼容,下面是IE版本检查的表达式。
let reg = /^.*MSIE [5-8](?:\.[0-9]+)?(?!.*Trident\/[5-9]\.0).*$/
IP4 正则语句。
let reg = /\b(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\b/
应用开发中很多时候需要区分请求是HTTPS还是HTTP,通过下面的表达式可以取出一个url的前缀然后再逻辑判断。
if (!s.match(/^[a-zA-Z]+:\/\/)) {
s = 'http://' + s;
}
下面的这个表达式可以筛选出一段文本中的URL。
let reg = /^(f|ht){1}(tp|tps):\/\/([\w-]+\.)+[\w-]+(\/[\w- ./?%&=]*)?/
假若你想提取网页中所有图片信息,可以利用下面的表达式。
let reg = /\< *[img][^\>]*[src] *= *[\"\']{0,1}([^\"\'\ >]*)/
${document.domain.replace(/^h5\./, 'restapi.')}`
Vue使用的是Getter/Setter机制, 或者说基于proxy() 的原理。下面详细的说一下我个人的理解。
一个简单的双向绑定的例子,下面列出他的html和js
<p>{{ model }}</p>
<input v-model="model">
<script>
var app = new Vue({
el: '#app',
data: {
model: 'Hello Vue!'
}
})
</script> 经过 vue 处理后,模板实际是编译成了下面的 render 函数
(function() {
with (this) {
return _h('div', {
attrs: {
"id": "app"
}
}, [_h('p', [_s(model)]), " ", _h('input', {
// 自定义指令. 注意事项:不能对绑定的旧值设值
// Vue 会为您持续追踪
directives: [{
name: "model",
value: (model),
expression: "model"
}],
// DOM 属性
domProps: {
"value": _s(model)
},
// 事件监听器基于 `on`
// 所以不再支持如 `v-on:keyup.enter` 修饰器
// 需要手动匹配 keyCode。
on: {
"input": function($event) {
// https://segmentfault.com/a/1190000009246058
if ($event.target.composing)
return;
model = $event.target.value
}
}
}), " "])
}
}
)这里稍微强调一下with 函数的特点:“破坏”作用域。
function withTest() {
var userName = "jeff wong";
//暂时修改作用域链
with (document) {
writeln("Hello,");
writeln(userName);
}//with内的语句执行完之后,作用域链恢复原状
alert(userName);
}
withTest();函数withTest在定义的时候,就确定了withTest的作用域链,我们暂且认为这条作用域链的最顶端是window对象,当withTest被执行的时候,js引擎生成了一个call object(调用对象)并将其添加到作用域链尾部上(window对象之后),语句运行到with(document)时,将生成新的作用域(实质上这个作用域和普通function的作用域一样,只不过它在with子句执行完,该作用域也随之消失)并添加到作用域链的尾部,所以with之内的变量查找,就会优先从这条链的with(document)作用域上查找,然后从withTest的call object中查找,最后查找window。with内的语句执行完之后,作用域链恢复原状(with(document)生成的作用域被移出作用域链)。
缩写对应的函数
Vue.prototype._h = createElement
Vue.prototype._s = _toString
Vue.prototype._n = toNumber
Vue.prototype._e = emptyVNode
Vue.prototype._q = looseEqual
Vue.prototype._i = looseIndexOf当修改 input 的内容时,vue 通过 model = $event.target.value; 开始了他的这一趟旅程。
整个 render 函数建立在一个 proxy 的基础上,先判断。vue实例是否包含含有 model 属性。
proxyHandlers = {
has: function has (target, key) {
var has = key in target
var isAllowed = allowedGlobals(key) || key.charAt(0) === '_'
if (!has && !isAllowed) {
warn(..)
}
return has || !isAllowed
}
}model = $event.target.value; 对model 赋值时,会自动的调用proxy.set()
function proxy (vm, key) {
if (!isReserved(key)) {
Object.defineProperty(vm, key, {
configurable: true,
enumerable: true,
get: function proxyGetter () {
return vm._data[key]
},
set: function proxySetter (val) {
vm._data[key] = val
}
})
}
}vm._data[model] = val 修改响应式数据model,所以调用 defineReactive$$1.set()
function defineReactive$$1 (
obj,
key,
val,
customSetter
) {
var dep = new Dep()
var property = Object.getOwnPropertyDescriptor(obj, key)
...
var getter = property && property.get
var setter = property && property.set
var childOb = observe(val)
Object.defineProperty(obj, key, {
enumerable: true,
configurable: true,
get: function reactiveGetter () {
...
return value
},
set: function reactiveSetter (newVal) {
var value = getter ? getter.call(obj) : val
if (newVal === value) {
return
}
if (setter) {
setter.call(obj, newVal)
} else {
val = newVal
}
childOb = observe(newVal) // newVal为对象时,对其建立新监控
dep.notify() // 通知执行订阅者watcher更新数据
}
})
}childOb = observe(newVal) 对新值建立监控
function observe (value) {
if (!isObject(value)) { //只对obj建立监控, isObject() 判断value是否为对象
return
}
var ob
if (hasOwn(value, '__ob__') && value.__ob__ instanceof Observer) {
// 已经建立监控的情况
ob = value.__ob__
} else if (
observerState.shouldConvert &&
!config._isServer &&
(Array.isArray(value) || isPlainObject(value)) &&
Object.isExtensible(value) &&
!value._isVue
) {
ob = new Observer(value)
}
return ob
}
dep.notify() 通知数据变更
Dep.prototype.notify = function notify () {
var subs = this.subs.slice()
for (var i = 0, l = subs.length; i < l; i++) {
// 执行订阅者的update更新函数
subs[i].update()
}
};this 代表依赖集合。
Def {
id: 14,
subs: [watcher]
}subs是由执行订阅者watcher组成的数组,所以,subs[i].update() 其实就是 watcher.update()
Watcher.prototype.update = function update () {
if (this.lazy) { // 默认false
this.dirty = true
} else if (this.sync) {
this.run()
} else {
queueWatcher(this)
}
};queueWatcher(this) 实现了API中的下面的解释
Vue 异步执行 DOM 更新。只要观察到数据变化,Vue 将开启一个队列,并缓冲在同一事件循环中发生的所有数据改变。如果同一个 watcher 被多次触发,只会一次推入到队列中。
function queueWatcher (watcher) {
var id = watcher.id
if (has$1[id] == null) {
has$1[id] = true
if (!flushing) { // 默认情况flushing = waiting = false,是否重置了 queue
queue.push(watcher)
} else {
// if already flushing, splice the watcher based on its id
// if already past its id, it will be run next immediately.
var i = queue.length - 1
while (i >= 0 && queue[i].id > watcher.id) {
i--
}
queue.splice(Math.max(i, index) + 1, 0, watcher)
}
// queue the flush
if (!waiting) {
waiting = true
nextTick(flushSchedulerQueue)
}
}
}nextTick 是异步执行的Defer的一个任务,触发Promise.then()后的行为
var nextTick = (function () {
var callbacks = []
var pending = false // queue 队列收集完成
var timerFunc
function nextTickHandler () {
pending = false
var copies = callbacks.slice(0)
callbacks.length = 0
for (var i = 0; i < copies.length; i++) {
copies[i]()
}
}
// 判断是浏览器是否支持Promise,否者MutationObserver,都不支持使用timerFunc = setTimeout
if (typeof Promise !== 'undefined' && isNative(Promise)) {
if (typeof Promise !== 'undefined' && isNative(Promise)) {
var p = Promise.resolve()
timerFunc = function () {
p.then(nextTickHandler)
if (isIOS) { setTimeout(noop) }
}
} else if (typeof MutationObserver !== 'undefined' && (
isNative(MutationObserver) || MutationObserver.toString() === '[object MutationObserverConstructor]'
)) {
var counter = 1
var observer = new MutationObserver(nextTickHandler)
var textNode = document.createTextNode(String(counter))
observer.observe(textNode, {
characterData: true
})
timerFunc = function () {
counter = (counter + 1) % 2
textNode.data = String(counter)
}
} else {
timerFunc = setTimeout
}
return function queueNextTick (cb, ctx) {
var func = ctx
? function () { cb.call(ctx) }
: cb
callbacks.push(func)
if (!pending) {
pending = true
timerFunc(nextTickHandler, 0)
}
}
})()注意timerFunc(nextTickHandler, 0) , timerFunc 是一个promise(promise不存在时是setTimeout),所以 nextTickHandler 的内容会在Watcher.prototype.update、dep.notify()执行完毕,即proxy.set() 结束后调用。
nextTickHandler 运行时宣告pending状态结束,最终运行的就是callbacks中的回调函数,本例运行flushSchedulerQueue .
function flushSchedulerQueue () {
flushing = true // 开始重置queue
// 按照watcher.id 进行排序
// This ensures that:
// 1. Components are updated from parent to child.
// (because parent is always created before the child)
// 2. A component's user watchers are run before its render watcher
// (because user watchers are created before the render watcher)
// 3. If a component is destroyed during a parent component's
// watcher run, its watchers can be skipped.
queue.sort(function (a, b) { return a.id - b.id; })
// ⚠ 这里作者并没有这样写index = 0, l = queue.length;因为运行过程中可能queue会不断的变大
for (index = 0; index < queue.length; index++) {
var watcher = queue[index]
var id = watcher.id
has$1[id] = null
watcher.run()
// in dev build, check and stop circular updates.
if ("development" !== 'production' && has$1[id] != null) {
circular[id] = (circular[id] || 0) + 1
if (circular[id] > config._maxUpdateCount) {
warn(...),
watcher.vm
)
break
}
}
}
// devtool hook
/* istanbul ignore if */
if (devtools && config.devtools) {
devtools.emit('flush')
}
resetSchedulerState()
}运行watcher.run() 和 resetSchedulerState() , 先看一下watcher.run()
Watcher.prototype.run = function run () {
if (this.active) {
var value = this.get() // Watcher.prototype.get()
if (
value !== this.value ||
// Deep watchers and watchers on Object/Arrays should fire even
// when the value is the same, because the value may
// have mutated.
isObject(value) ||
this.deep
) {
// set new value
var oldValue = this.value
this.value = value
if (this.user) {
try {
this.cb.call(this.vm, value, oldValue)
} catch (e) {
"development" !== 'production' && warn(
("Error in watcher \"" + (this.expression) + "\""),
this.vm
)
/* istanbul ignore else */
if (config.errorHandler) {
config.errorHandler.call(null, e, this.vm)
} else {
throw e
}
}
} else {
this.cb.call(this.vm, value, oldValue)
}
}
}
};
Watcher.prototype.get 主要作用是用来收集依赖的。
Watcher.prototype.get = function get () {
// 如果dep.target, 向targetStack中推入dep.target,
// 不存在的话,dep.target = watcher
pushTarget(this)
var value = this.getter.call(this.vm, this.vm) // 不明白,怎么指向的是vm._watcher????
// "touch" every property so they are all tracked as
// dependencies for deep watching
if (this.deep) {
traverse(value)
}
popTarget()
this.cleanupDeps() // 把newDepIds 值赋给depIds,newDeps 值赋给deps,并清空newDepIds 和 newDeps
return value
};vm._watcher = new Watcher(vm, function () {
vm._update(vm._render(), hydrating)
}, noop)vm._render() 方法生成一个vnode,并开始安装 render 函数编译html
Vue.prototype._render = function () {
var vm = this
var ref = vm.$options;
var render = ref.render;
var staticRenderFns = ref.staticRenderFns;
var _parentVnode = ref._parentVnode;
....
var vnode
try {
// 调用 经过 vue 编译的 html-> js 的 render 函数
//在支持proxyde 浏览器 ,
//vm._renderProxy = new Proxy(vm, proxyHandlers)
// 开始调用 render 函数,渲染html
vnode = render.call(vm._renderProxy, vm.$createElement)
} catch (e) {
{
warn(...)
}
/* istanbul ignore else */
if (config.errorHandler) {
config.errorHandler.call(null, e, vm)
} else {
if (config._isServer) {
throw e
} else {
setTimeout(function () { throw e }, 0)
}
}
// return previous vnode to prevent render error causing blank component
vnode = vm._vnode
}
// return empty vnode in case the render function errored out
if (!(vnode instanceof VNode)) {
if ("development" !== 'production' && Array.isArray(vnode)) {
warn(
'Multiple root nodes returned from render function. Render function ' +
'should return a single root node.',
vm
)
}
vnode = emptyVNode()
}
// set parent
vnode.parent = _parentVnode
return vnode
}
Vue.prototype._update = function (vnode, hydrating) {
var vm = this
if (vm._isMounted) {
callHook(vm, 'beforeUpdate')
}
var prevEl = vm.$el
var prevActiveInstance = activeInstance
activeInstance = vm
var prevVnode = vm._vnode
vm._vnode = vnode
if (!prevVnode) {
// Vue.prototype.__patch__ is injected in entry points
// based on the rendering backend used.
vm.$el = vm.__patch__(vm.$el, vnode, hydrating)
} else {
vm.$el = vm.__patch__(prevVnode, vnode)
}
activeInstance = prevActiveInstance
// update __vue__ reference
if (prevEl) {
prevEl.__vue__ = null
}
if (vm.$el) {
vm.$el.__vue__ = vm
}
// if parent is an HOC, update its $el as well
if (vm.$vnode && vm.$parent && vm.$vnode === vm.$parent._vnode) {
vm.$parent.$el = vm.$el
}
if (vm._isMounted) {
callHook(vm, 'updated')
}
}
先来看一下 _h(), _h() 指向的是createElement(tag, data, children), 观察 render 模版函数可以发现,vue采用 " " 代表标签结束和开始。
function createElement (
tag,
data,
children
) {
if (data && (Array.isArray(data) || typeof data !== 'object')) {
children = data
data = undefined
}
return _createElement(this._self, tag, data, children)
}
function _createElement (
context,
tag,
data,
children
) {
if (data && data.__ob__) {
"development" !== 'production' && warn(...)
return
}
if (!tag) {
return emptyVNode()
}
if (typeof tag === 'string') {
var Ctor
var ns = config.getTagNamespace(tag) // 是否是保留标签html或svg
if (config.isReservedTag(tag)) {
return new VNode(
tag, data, normalizeChildren(children, ns),
undefined, undefined, ns, context
)
} else if ((Ctor = resolveAsset(context.$options, 'components', tag))) {
// component
return createComponent(Ctor, data, context, children, tag)
} else {
// unknown or unlisted namespaced elements
// check at runtime because it may get assigned a namespace when its
// parent normalizes children
return new VNode(
tag, data, normalizeChildren(children, ns),
undefined, undefined, ns, context
)
}
} else {
// direct component options / constructor
return createComponent(tag, data, context, children)
}
}在看一下 _s()
function _toString (val) {
return val == null
? ''
: typeof val === 'object'
? JSON.stringify(val, null, 2)
: String(val)
}至于如何根据render函数渲染,需要自己一步一步看了。。。
原本出自饿了么的小伙伴,王亦斯。
Object.getOwnPropertyDescriptors()
Shared memory and atomics
共享内存与原子操作run to completion(RTC)
async/await
sharedArrayBuffe: 编译到js
nodejs 里面没有worker的概念,目前只有多个进程的概念。但是他们已经在考虑将worder 加入。
import export 经过js 编译后,会
import() 按需加载
import(./ada.js)
.then()
.catch()
async iteratior

regExp

global 指向本地,现代浏览器都支持了
class

后现代的


接下来可能会出现的

pattern matching



webassembly
二进制的形式,web上的汇编语言
ps -ef | grep ngin
//从容停止Nginx:
kill -QUIT 主进程号
//快速停止Nginx:
kill -TERM 主进程号
//强制停止Nginx:
pkill -9 nginx
nginx -s reload
如果更改了配置就要重启Nginx,要先关闭Nginx再打开?不是的,可以向Nginx 发送信号,平滑重启。 平滑重启命令:kill -HUP 主进称号或进程号文件路径 或者使用 /usr/nginx/sbin/nginx -s reload
注意:修改了配置文件后最好先检查一下修改过的配置文件是否正 确,以免重启后Nginx出现错误影响服务器稳定运行。判断Nginx配置是否正确命令如下:
//检查指定的nginx配置文件,是否正确
nginx -t -c /usr/nginx/conf/nginx.conf
//检查默认的nginx配置文件
/usr/nginx/sbin/nginx -t
比较任何两个相邻项。 如果第一个比第二大,则交换他们。
function(){
var length = array.length;
for (var i=0; i<length; i++){
for (var j=0; j<length-1-i; j++ ){
if (array[j] > array[j+1]){
swap(j, j+1);
}
}
}
};
function swap(index1, index2){
var aux = array[index1];
array[index1] = array[index2];
array[index2] = aux;
};
示意图:

一种原值比较排序法。找到数据结构中最小的,放在第一的位置,再找到第二小的,放在第二的位置,依此类退。
this.selectionSort = function(){
var length = array.length,
indexMin;
for (var i=0; i<length-1; i++){
indexMin = i;
for (var j=i; j<length; j++){
if(array[indexMin]>array[j]){
indexMin = j;
if (i !== indexMin){
swap(i, indexMin);
}
}
}
}
};
示意图:

假定第一项已经排好了,接着和第二项进行比较,如果第二项比第一项小泽交换位置。以此类推。
this.insertionSort = function(){
var length = array.length,
j, temp;
for (var i=1; i<length; i++){
j = i;
temp = array[i];
while (j>0 && array[j-1] > temp){
array[j] = array[j-1];
j--;
}
array[j] = temp;
}
};
示意图:

是一种分治算法。将原始数组切分成较小的数组,直到每个数组只有一个位置。然后再讲小数组和并成一个大数组。
function mergeSortRec(array){
var length = array.length;
if(length === 1) {
return array;
}
var mid = Math.floor(length / 2),
left = array.slice(0, mid),
right = array.slice(mid, length);
return merge(mergeSortRec(left), mergeSortRec(right));
};
function merge(left, right){
var result = [],
il = 0,
ir = 0;
while(il < left.length && ir < right.length) {
if(left[il] < right[ir]) {
result.push(left[il++]);
} else{
result.push(right[ir++]);
}
}
while (il < left.length){
result.push(left[il++]);
}
while (ir < right.length){
result.push(right[ir++]);
}
return result;
};
示意图:

最复杂也是最常用的一种排序法。
示意图:

给定的数组 [3, 5, 1, 6, 4, 7, 2], 前面示例了第一次的执行过程。


示意图:
示意图:
在 Express 或者 Koa 等服务端框架中,middleware 是指可以被嵌入在框架接收请求到产生响应过程之中的代码。例如,Express 或者 Koa 的 middleware 可以完成添加 CORS headers、记录日志、内容压缩等工作。middleware 最优秀的特性就是可以被链式组合。你可以在一个项目中使用多个独立的第三方 middleware。
首先,webpack已经想到了开发流程中的自动刷新,这就是webpack-dev-server。它是一个静态资源服务器,只用于开发环境。
一般来说,对于纯前端的项目(全部由静态html文件组成),简单地在项目根目录运行webpack-dev-server,然后打开html,修改任意关联的源文件并保存,webpack编译就会运行,并在运行完成后通知浏览器刷新。
和直接在命令行里运行webpack不同的是,webpack-dev-server会把编译后的静态文件全部保存在内存里,而不会写入到文件目录内。这样,少了那个每次都在变的webpack输出目录,会不会觉得更清爽呢?
如果在请求某个静态资源的时候,webpack编译还没有运行完毕,webpack-dev-server不会让这个请求失败,而是会一直阻塞它,直到webpack编译完毕。这个对应的效果是,如果你在不恰当的时候刷新了页面,不会看到错误,而是会在等待一段时间后重新看到正常的页面,就好像“网速很慢”。
Express本质是一系列middleware的集合,因此,适合Express的webpack开发工具是webpack-dev-middleware和webpack-hot-middleware。
webpack-dev-middleware是一个处理静态资源的middleware。前面说的webpack-dev-server,实际上是一个小型Express服务器,它也是用webpack-dev-middleware来处理webpack编译后的输出。
webpack-hot-middleware是一个结合webpack-dev-middleware使用的middleware,它可以实现浏览器的无刷新更新(hot reload)。这也是webpack文档里常说的HMR(Hot Module Replacement)。
make code smaller
压缩器其实本身也是一个编译器。目前市面的压缩器:
uglifyJs、 closure Compiler、babili(基于babel的)
过程:
source code - > parser -> AST -> Tagert Code
import { foo } from './foo.js'
import { bar } from './bar.js'
foo(bar)export function foo() {
}export const bar = 123// foo.js
function() {
//...
}
// bar.js
const bar = 123
// main.js
foo(bar)聪明的压缩器会将不需要的一些函数去掉。
<div>
<p class="foo">
{{ msg }}
</p>
</div>编译后:
return h('div', [
h(
'p',
{ staticClass: 'foo'},
[....]
)
])对于变化的模版
<ul>
<li v-for="i in 10>
{{ i }}
</li>
</ul>
编译后:
return h('ul', [
renderList(10, i => {
return h('li', i)
})
])不得不说virtual Dom 是有好处实在太多,对于手写render function ,对于自定义组件啊, 但是其性能肯定是比不上 直接的字符串拼接,因为它首先创建那么多对象后,再进行stringfy(). 所以ract ssr,它深深的受制于这种over head ,性能方面受到了很大的限制。
首先 vue底层是用了virtual Dom 的,找到所有可以不变的部分写成字符串,但是对于自定义组建使用render function。
在编译的时,首先要加载main.js , 在渲染main.js 后发现需要a.js ,此时再去加载a.js这期间是有等待的,所以vue在进行首屏加载的时候,会有一个 manifist 纪录首屏都需要什么。一次性取得。
基于virtual Dom 进行服务端渲染时,肯定比不上模版语言的,直接字符串拼接的。因为它首先创建那么多对象后,再进行stringfy(). react 服务端渲染受制于这个原因。有一些小众的marko.js他们也做了服务端渲染,并且性能非常好,因为他们限制了只能使用 模版 语言。
css 是在该组建被构建的时候,当他的生命周期的钩子被触发时,加载对应钩子所需要的css.


二叉树-> 字符串 序列化
字符串-> 二叉树 反序列化



node 中有个叫 n 的模块专门用来管理node版本的。
先分享一下node 下的常用命令:
npm install -g n
如果报下面的错误:

可以尝试:
sudo npm install -g n
看到下面这行命令,代表你已经安装成功。

n stable
报下面的错,

请试着尝试:
sudo n stable
出现下面的,代表你已经更新成功!也可以 node -v 进行检测

另外n后面也可以跟随版本号比如:n v3.8.0 或 n 6.8.0
把一个普通 JavaScript 对象传给 Vue 实例的 data 选项,Vue 将遍历此对象所有的属性,并使用 Object.defineProperty 把这些属性全部转为 getter/setter。
function initData (vm) {
//这里的data通过策略合并对象变成了函数mergedInstanceDataFn
var data = vm.$options.data;
data = vm._data = typeof data === 'function'
? getData(data, vm) //getData就是执行mergedInstanceDataFn函数,返回data对象
: data || {};
//当data函数返回的不是对象时
if (!isPlainObject(data)) {
data = {};
"development" !== 'production' && warn(
'data functions should return an object:\n' +
'https://vuejs.org/v2/guide/components.html#data-Must-Be-a-Function',
vm
);
}
// proxy data on instance
// 在实例vm上代理data中各项,作用同props的代理
var keys = Object.keys(data);
var props = vm.$options.props;
var methods = vm.$options.methods;
var i = keys.length;
while (i--) {
var key = keys[i];
// data中属性不能和methods中同名
if (methods && hasOwn(methods, key)) {
warn(
("method \"" + key + "\" has already been defined as a data property."),
vm
);
}
// data中属性不能和props中同名
if (props && hasOwn(props, key)) {
"development" !== 'production' && warn(
"The data property \"" + key + "\" is already declared as a prop. " +
"Use prop default value instead.",
vm
);
} else if (!isReserved(key)) { //data中属性不能以_或$开头
proxy(vm, "_data", key);
}
}
// observe data
observe(data, true /* asRootData */); // 对data进行观测
}//给value添加一个observer,保存在value.__ob__属性上。
function observe (value, asRootData) {
//不对普通类型观测
if (!isObject(value)) {
return
}
var ob;
if (hasOwn(value, '__ob__') && value.__ob__ instanceof Observer) {
ob = value.__ob__;
} else if (
observerState.shouldConvert &&
!isServerRendering() &&
(Array.isArray(value) || isPlainObject(value)) &&
Object.isExtensible(value) &&
!value._isVue //当有_isVue属性时,该value不会被观测
) {
ob = new Observer(value); //主要函数,实例化一个Observer
}
if (asRootData && ob) {
ob.vmCount++;
}
return ob
}var Observer = function Observer (value) {
this.value = value;
this.dep = new Dep(); //每个observer都实例化一个Dep,用于收集依赖
this.vmCount = 0;
def(value, '__ob__', this); //将__ob__放在value上,值为observer对象
if (Array.isArray(value)) { //当value是数组
var augment = hasProto
? protoAugment
: copyAugment;
augment(value, arrayMethods, arrayKeys);
this.observeArray(value);
} else {
this.walk(value); //当value是对象
}
};Observer.prototype.walk = function walk (obj) {
var keys = Object.keys(obj); //这里__ob__不会出现在keys里
for (var i = 0; i < keys.length; i++) {
//对obj中每一项进行响应式定义
defineReactive$$1(obj, keys[i], obj[keys[i]]);
}
};function defineReactive$$1 (obj, key, val, customSetter, shallow) {
var dep = new Dep();
var property = Object.getOwnPropertyDescriptor(obj, key);
if (property && property.configurable === false) {
return
}
// cater for pre-defined getter/setters
// 引用预先定义的getter/setters
var getter = property && property.get;
var setter = property && property.set;
//val可能是对象,故继续观测
var childOb = !shallow && observe(val);
Object.defineProperty(obj, key, {
enumerable: true,
configurable: true,
get: function reactiveGetter () {
var value = getter ? getter.call(obj) : val;
if (Dep.target) {
dep.depend();
//子对象也收集父对象的依赖
if (childOb) {
childOb.dep.depend();
}
//对数组的依赖处理
if (Array.isArray(value)) {
dependArray(value);
}
}
return value
},
set: function reactiveSetter (newVal) {
var value = getter ? getter.call(obj) : val;
/* eslint-disable no-self-compare */
if (newVal === value || (newVal !== newVal && value !== value)) {
return
}
/* eslint-enable no-self-compare */
if ("development" !== 'production' && customSetter) {
customSetter(); //报错用
}
if (setter) {
setter.call(obj, newVal);
} else {
val = newVal;
}
childOb = !shallow && observe(newVal); //设置新值后,对新值进行观测
dep.notify(); //触发观测器的回调或get函数
}
});
}每个组件实例都有相应的 watcher 实例对象,它会在组件渲染的过程中把属性记录为依赖,之后当依赖项的 setter 被调用时,会通知 watcher 重新计算,从而致使它关联的组件得以更新。
| 代码/语法 | 说明 |
|---|---|
| . | 匹配除换行符以外的任意字符 |
| \w or [a-z0-9A-Z] | 匹配字母或数字 |
| \s | 匹配任意的空白符 |
| \d or [0-9] | 匹配数字 |
| \b | 匹配单词的开始或结束 |
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的结束 |
| 代码/语法 | 说明 |
|---|---|
| * | 重复零次或更多次 |
| + | 重复一次或更多次 |
| ? | 重复零次或一次 |
| {n} | 重复 n 次 |
| {n,} | 重复大于等于 n 次 |
| {n,m} | 重复 n 到 m 次 |
| 代码/语法 | 说明 |
|---|---|
| \W | 匹配任意不是字母和数字的字符 |
| \S | 匹配任意不是空白符的字符 |
| \D | 匹配任意非数字的字符 |
| \B | 匹配不是单词开头或结束的位置 |
| [^x] | 匹配除了x以外的任意字符 |
| [^aeiou] | 匹配除了aeiou这几个字母以外的任意字符 |
| 捕获 | 说明 |
|---|---|
| (exp) | 匹配exp,并捕获文本到自动命名的组里 |
| (?exp) | 匹配exp,并捕获文本到名称为name的组里 |
| (?:exp) | 匹配exp,不捕获匹配的文本 |
| 位置指定 | |
| (?=exp) | 匹配exp前面的位置 |
| (?<=exp) | 匹配exp后面的位置 |
| (?!exp) | 匹配后面跟的不是exp的位置 |
| (?<!exp) | 匹配前面不是exp的位置 |
| 注释 | |
| (?#comment) | 这种类型的组不对正则表达式的处理产生任何影响,只是为了提供让人阅读注释 |
| 懒惰量词 | 说明 |
|---|---|
| *? | 重复任意次,但尽可能少重复 |
| +? | 重复1次或更多次,但尽可能少重复 |
| ?? | 重复0次或1次,但尽可能少重复 |
| {n,m}? | 重复n到m次,但尽可能少重复 |
| {n,}? | 重复n次以上,但尽可能少重复 |
| 其他 | 说明 |
|---|---|
| \a | 报警字符(打印它的效果是电脑嘀一声) |
| \b | 通常是单词分界位置,但如果在字符类里使用代表退格 |
| \t | 制表符,Tab |
| \r | 回车 |
| \v | 竖向制表符 |
| \f | 换页符 |
| \n | 换行符 |
| \e | Escape |
| \0nn | ASCII代码中八进制代码为nn的字符 |
| \xnn | ASCII代码中十六进制代码为nn的字符 |
| \unnnn | Unicode代码中十六进制代码为nnnn的字符 |
| \cN | ASCII控制字符。比如\cC代表Ctrl+C |
| \A | 字符串开头(类似^,但不受处理多行选项的影响) |
| \Z | 字符串结尾或行尾(不受处理多行选项的影响) |
| \z | 字符串结尾(类似$,但不受处理多行选项的影响) |
| \G | 当前搜索的开头 |
| \p{name} | Unicode中命名为name的字符类,例如\p{IsGreek} |
| (?>exp) | 贪婪子表达式 |
| (?-exp) | 平衡组 |
| (?-exp) | 平衡组 |
| (?im-nsx:exp) | 在子表达式exp中改变处理选项 |
| (?im-nsx) | 为表达式后面的部分改变处理选项 |
| (?(exp)yes | no) |
| (?(exp)yes) | 同上,只是使用空表达式作为no |
| (?(name)yes | no) |
| (?(name)yes) | 同上,只是使用空表达式作为no |
| 字符 | 替换文本 |
|---|---|
| $& | 与正则相匹配的字符串 |
| $` | 匹配字符串左边的字符 |
| $' | 匹配字符串右边的字符 |
| $1,$2,$3,…,$n | 匹配结果中对应的分组匹配结果 |
var sStr='讨论一下正则表达式中的replace的用法';
sStr.replace(/正则表达式/,'{$&}');
//讨论一下{正则表达式}中的replace的用法
'abc'.replace(/b/,"$`"); //aac
'abc'.replace(/b/,"$'"); //acc
var str = 'hello world!';
var result = /^hello/.test(str);
console.log(result); // truevar str = '123456789'
var reg = /(\w{3})\1*/g
arr = str.match(reg) // ["123", "456", "789"]3.search
var str = "hey JudE";
var re = /[A-Z]/g;
str.search(re); // 4 4.replace
var str = 'Twas the night before Xmas...';
var newstr = str.replace(/xmas/i, 'Christmas');
console.log(newstr); // Twas the night before Christmas...1、数组
2、栈
3、队列
4、链表
5、集合
6、字典和散列表
7、树
8、排序和搜索算法
其中1、2、3、4 是顺序数据结构。
//加法
Number.prototype.add = function(arg){
var r1,r2,m;
try{r1=this.toString().split(".")[1].length}catch(e){r1=0}
try{r2=arg.toString().split(".")[1].length}catch(e){r2=0}
m=Math.pow(10,Math.max(r1,r2))
return (this*m+arg*m)/m
}
//减法
Number.prototype.sub = function (arg){
return this.add(-arg);
}
//乘法
Number.prototype.mul = function (arg)
{
var m=0,s1=this.toString(),s2=arg.toString();
try{m+=s1.split(".")[1].length}catch(e){}
try{m+=s2.split(".")[1].length}catch(e){}
return Number(s1.replace(".",""))*Number(s2.replace(".",""))/Math.pow(10,m)
}
//除法
Number.prototype.div = function (arg){
var t1=0,t2=0,r1,r2;
try{t1=this.toString().split(".")[1].length}catch(e){}
try{t2=arg.toString().split(".")[1].length}catch(e){}
with(Math){
r1=Number(this.toString().replace(".",""))
r2=Number(arg.toString().replace(".",""))
return (r1/r2)*pow(10,t2-t1);
}
}
最近使用Webpack遇到了一个坑。
我们构建前端项目的时候,往往希望第三方库(vendors)和自己写的代码可以分开打包,因为第三方库往往不需要经常打包更新。对此Webpack的文档建议用CommonsChunkPlugin来单独打包第三方库。
entry: {
vendor: ["jquery", "other-lib"],
app: "./entry"
}
new CommonsChunkPlugin({
name: "vendor",
// filename: "vendor.js"
// (Give the chunk a different name)
minChunks: Infinity,
// (with more entries, this ensures that no other module
// goes into the vendor chunk)
})通常为了对抗缓存,我们会给售出文件的文件名中加入hash的后缀——但是——我们编辑了app部分的代码后,重新打包,发现vendor的hash也变化了!

这么一来,意味着每次发布版本的时候,vendor代码都要刷新,即使我并没有修改其中的代码。这样并不符合我们分开打包的初衷。
带着问题我浏览了Github上的讨论,发现了一个神器:dll。
Dll是Webpack最近新加的功能,我在网上并没有找到什么中文的介绍,所以在这里我就简单介绍一下。
Dll这个概念应该是借鉴了Windows系统的dll。一个dll包,就是一个纯纯的依赖库,它本身不能运行,是用来给你的app引用的。
打包dll的时候,Webpack会将所有包含的库做一个索引,写在一个manifest文件中,而引用dll的代码(dll user)在打包的时候,只需要读取这个manifest文件,就可以了。
这么一来有几个好处:
Dll打包以后是独立存在的,只要其包含的库没有增减、升级,hash也不会变化,因此线上的dll代码不需要随着版本发布频繁更新。
App部分代码修改后,只需要编译app部分的代码,dll部分,只要包含的库没有增减、升级,就不需要重新打包。这样也大大提高了每次编译的速度。
假设你有多个项目,使用了相同的一些依赖库,它们就可以共用一个dll。
如何使用呢?
首先要先建立一个dll的配置文件,entry只包含第三方库:
const webpack = require('webpack');
const vendors = [
'antd',
'isomorphic-fetch',
'react',
'react-dom',
'react-redux',
'react-router',
'redux',
'redux-promise-middleware',
'redux-thunk',
'superagent',
];
module.exports = {
output: {
path: 'build',
filename: '[name].[chunkhash].js',
library: '[name]_[chunkhash]',
},
entry: {
vendor: vendors,
},
plugins: [
new webpack.DllPlugin({
path: 'manifest.json',
name: '[name]_[chunkhash]',
context: __dirname,
}),
],
};webpack.DllPlugin的选项中,path是manifest文件的输出路径;name是dll暴露的对象名,要跟output.library保持一致;context是解析包路径的上下文,这个要跟接下来配置的dll user一致。
运行Webpack,会输出两个文件一个是打包好的vendor.js,一个就是manifest.json,长这样:
{
"name": "vendor_ac51ba426d4f259b8b18",
"content": {
"./node_modules/antd/dist/antd.js": 1,
"./node_modules/react/react.js": 2,
"./node_modules/react/lib/React.js": 3,
"./node_modules/react/node_modules/object-assign/index.js": 4,
"./node_modules/react/lib/ReactChildren.js": 5,
"./node_modules/react/lib/PooledClass.js": 6,
"./node_modules/react/lib/reactProdInvariant.js": 7,
"./node_modules/fbjs/lib/invariant.js": 8,
"./node_modules/react/lib/ReactElement.js": 9,
............Webpack将每个库都进行了编号索引,之后的dll user可以读取这个文件,直接用id来引用。
Dll user的配置:
const webpack = require('webpack');
module.exports = {
output: {
path: 'build',
filename: '[name].[chunkhash].js',
},
entry: {
app: './src/index.js',
},
plugins: [
new webpack.DllReferencePlugin({
context: __dirname,
manifest: require('./manifest.json'),
}),
],
};DllReferencePlugin的选项中,context需要跟之前保持一致,这个用来指导Webpack匹配manifest中库的路径;manifest用来引入刚才输出的manifest文件。
运行Webpack之后,结果如下:

对比一下不做分离的情况下打包的结果:

速度快了,文件也小了。
平时开发的时候,修改代码后重新编译的速度会大大减少,节省时间。
如果有多个项目,使用相同的一套库,你可以在打包的时候引用相同的manifest文件,这样就可以在项目之间共享了。
SVG实现图片圆角效果
SVG实现图片圆角关键是借助元素 <pattern>,举个板栗,如果实现名为test.jpg的图片圆形效果,大小100px * 100px, 则SVG代码如下:
<svg width="100" height="100">
<desc>SVG圆角效果</desc>
<defs>
<pattern id="raduisImage" patternUnits="userSpaceOnUse" width="100" height="100">
<image xlink:href="test.jpg" x="0" y="0" width="625" height="605" />
</pattern>
</defs>
<circle cx="50" cy="50" r="50" fill="url(#raduisImage)"></circle>
</svg>
图形元素都有一个fill属性,让其值url锚向<pattern>的id就可以了。
Canvas实现图片圆角的关键是使用“纹理填充”。Canvas中有个名为createPattern的方法,可以让已知尺寸的图片元素转换成纹理对象,作填充用。举个板栗,如果实现名为test.jpg的图片圆形效果,大小100px * 100px, 则主要JS代码如下:
// canvas元素, 图片元素
var canvas = document.querySelector("#canvas"), image = new Image();
var context = canvas.getContext("2d");
image.onload = function() {
// 创建图片纹理 http://www.manongjc.com/article/1214.html
var pattern = context.createPattern(image, "no-repeat");
// 绘制一个圆
context.arc(50, 50, 50, 0, 2 * Math.PI);
// 填充绘制的圆
context.fillStyle = pattern;
context.fill();
};
image.src = "test.jpg";
让Canvas上下文的fillStyle属性值等于这个纹理对象就可以了。
position 方式代替,但是 position 在不同的IE版本中存在着多种兼容性问题。另见 position 以及 position and z-index属性
没有定位,元素出现在正常的流中(忽略 top, bottom, left, right z-index 声明)。
absolute
生成绝对定位的元素,相对于值不为 static的第一个父元素进行定位(原文档流中的位置不做保留)。
fixed (老IE不支持)
生成绝对定位的元素,相对于浏览器窗口进行定位。
relative
生成相对定位的元素,相对于其正常位置进行定位(原文档流中的位置依然保留)。
inherit
规定从父元素继承 position 属性的值。
| 属性值 | 空白符 | 换行符 | 自动换行 | 最早出现于 |
|---|---|---|---|---|
| normal | 合并 | 忽略 | 允许 | CSS 1 |
| nowrap | 合并 | 忽略 | 不允许 | CSS 1 |
| pre | 保留 | 保留 | 不允许 | CSS 1 |
| pre-wrap | 保留 | 保留 | 允许 | CSS 2.1 |
| pre-line | 合并 | 保留 | 允许 | CSS 2.1 |
IE6-8下
.content {
white-space: pre-wrap;
*white-space: pre;
*word-wrap: break-word;
}
有些朋友利用ps导出的jpg图片在浏览器显示不了,但我们打开又能正常打开,后来我想了很多可能出现在ps导出ps的问题上。
把这个图片在photoshop里打开,这时突然发现图片的模式是CMYK:
原来是图片的模式搞错了,应该是RGB格式,CMYK模式保存的JPEG图片无法在IE6,IE7,IE8中显示(好长时间没遇到这个问题,一时没想到),非IE内核浏览器可正常渲染,接下来就简单了,在photoshop里点击菜单栏—图像—RGB模式就行了,然后把图片上传上去就正常显示了。
在浏览器中通过js来操作DOM,这样的操作性能很差,于是Virtual Dom应运而生。Virtual Dom就是在js中模拟DOM对象树来优化DOM操作的一种技术或思路。
var VNode = function VNode (
tag,
data,
children,
text,
elm,
ns,
context,
componentOptions
) {
this.tag = tag
this.data = data
this.children = children
this.text = text
this.elm = elm
this.ns = ns
this.context = context
this.key = data && data.key
this.componentOptions = componentOptions
this.child = undefined
this.parent = undefined
this.raw = false
this.isStatic = false
this.isRootInsert = true
this.isComment = false
this.isCloned = false
};DOM是文档对象模型(Document Object Model)的简写,在浏览器中我们可以通过js来操作DOM,
但是这样的操作性能很差,于是Virtual Dom应运而生。
Virtual Dom就是在js中模拟DOM对象树来优化DOM操作的一种技术或思路。
children: 数组类型,包含了当前节点的子节点
text: 当前节点的文本,一般文本节点或注释节点会有该属性
elm: 当前虚拟节点对应的真实的dom节点
ns: 节点的namespace
context: 编译作用域
functionalContext: 函数化组件的作用域
componentOptions: 创建组件实例时会用到的选项信息
key: 节点的key属性,用于作为节点的标识,有利于patch的优化
child: 当前节点对应的组件实例
parent: 组件的占位节点
raw: raw html
isStatic: 静态节点的标识
isRootInsert: 是否作为根节点插入,被包裹的节点,该属性的值为false
isComment: 当前节点是否是注释节点
isCloned: 当前节点是否为克隆节点



下载完成后,在手机 设置 --> 通用 --> 描述文件中查看安装的证书



https 内容也需要配置证书

安装成功

通常情况下,打开charles,然后菜单栏选择Proxy -> Mac OS X Proxy 即可,接着所有访问的请求都可以在charles中看到。
但是楼主发现,选择了这个,却还是抓不到请求。查阅资料发现,原因是我系统设置了vpn代理导致。

为了不让程序员费心分配内存,JavaScript 在定义变量时就完成了内存分配。JavaScript 的变量类型分为两种:基本类型和引用类型。而在JavaScript 中内存也分为栈内存和堆内存两种。
基本类型包括:Undefined,Null,Number,String,Boolean类型的值。
引用类型包括: Object,Function,Array等类型。
一般来说,栈内存中存放的是存储对象的地址,而堆内存中存放的是存储对象的具体内容。对于原始类型的值而言,其地址和具体内容都存在与栈内存中;而基于引用类型的值,其地址存在栈内存,其具体内容存在堆内存中。堆内存与栈内存是有区别的,栈内存运行效率比堆内存高,空间相对推内存来说较小,反之则是堆内存的特点。
var str = "Hello World"; // str:"Hello World"存在栈中
var obj = {value:"Hello World"}; // obj存在栈中,{value:"Hello World"}存在堆中,通过栈中的变量名obj(访问地址)访问1.当对象将被需要的时候为其分配内存
2.使用已分配的内存(读、写操作)
3.当对象不在被需要的时候,释放存储这个对象的内存
var str_a = "a"; // 为str_a分配栈内存:str_a:"a"
var str_b = str_a; // 原始类型直接访问值,so,为str_b新分配栈内存:str_b:"a"
str_b = "b"; // 栈内存中:str_b:"b"。str_b的值为"b",而str_a的值仍然是"a"
// 分隔 str 和 obj -----------------------------------------------------------//
var obj_a = {v:"a"}; // 为obj_a分配栈内存访问地址:obj_a,堆内存中存对象值:{v:"a"};
var obj_b = obj_a; // 为obj_b分配栈内存访问地址:obj_b,引用了堆内存的值{v:"a"}
obj_b.v = "b"; // 通过obj_b访问(修改)堆内存的变量,这时候堆内存中对象值为:{v:"b"},由于obj_a和obj_b引用的是堆内存中同一个对象值,所以这时候打印都是{v:"b"}
obj_b = {v:"c"}; // 因为改的是整个对象,这里会在堆内存中创建一个新的对象值:{v:"c"},而现在的obj_b引用的是这个对象,所以这里打印的obj_a依旧是{v:"b"},而obj_b是{v:"c"}(两者在内存中引用的是不同对象了)。js引擎线程 无论什么时候都只有一个 JS 线程在运行 JS 程序, 想象一下,如果js 也是多线程的,就会出现这种情况:A 线程 在一个 DOM 节点插入一个元素,此时 B 线程 要删除这个节点,那么这个时候就会出现错乱的现象。
js线程——>http线程——>事件触发线程(把回调插入js线程尾部)——>js线程

setTimeout/setInterval
定时触发器线程(完成之后插入js线程尾部)——>js线程
垃圾回收的目的是,当内存不再需要使用时释放,并回收。
这是最简单的垃圾收集算法。
因为GET请求只能进行url编码,所以在使用get方法发送请求的时候,如果参数是数组的情况,需要注意转码问题。例如:
let params = {
refundArry: [1,2],
statusArry: [1,2]
}
$http({
'method': 'GET',
'url': babala,
'params': params,
})refundArry:1
refundArry:0
statusArry:0
statusArry:-1
type:1
uid:64这一定不是我们想要的,所以一定要经过下面的方式转换:
let params = {
refundArry: [1,2],
statusArry: [1,2]
}
// 将数组转化成字符串,但是形似数组,例如:[1,2]=> "[1,2]"
let param = {}
for(var key in params) {
if (angular.isArray(params[key])) {
param[key] = `[ ${params[key]} ]`
} else {
param[key] = params[key]
}
}
$http({
'method': 'GET',
'url': babala,
'params': param,
})refundArry:[1,2]
statusArry: [1,2]
type:1
uid:64这样就是我们想要的结果了
参数大小的限制又是从哪来的呢?
GET和POST还有一个重大区别,GET产生一个TCP数据包;POST产生两个TCP数据包。
对于GET方式的请求,浏览器会把http header和data一并发送出去,服务器响应200(返回数据);
而对于POST,浏览器先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200 ok(返回数据)。
据研究,在网络环境好的情况下,发一次包的时间和发两次包的时间差别基本可以无视。而在网络环境差的情况下,两次包的TCP在验证数据包完整性上,有非常大的优点。
并不是所有浏览器都会在POST中发送两次包,Firefox就只发送一次。


xcodeXcode


Xcode虽好,但是毕竟太大,如果只想简单的发现页面的css或是其他的简单功能,可以直接利用Safari
手机连接电脑,打开iPhone的Safari,输入要访问的页面的 URL,在 Mac 的 Safari 下选中要看的页面即可
chrome 地址栏输入 chrome://inspect/#devices, 即可直接进行真机调试
Document.styleSheets 是一个只读属性,返回一个由 StyleSheet 对象组成的 StyleSheetList,每个 StyleSheet 对象都是文档中链接或嵌入的样式表。
1、浏览器缓存机制
2、Dom Storgage(Web Storage)
3、Web SQL Database 存储机制(不再维护,被5取代了)
4、Application Cache(manifest)(不再维护)
5、Indexed Database (IndexedDB)
6、File System API
由于http 1.0是无状态的,在发起网络请求时,发送第一个请求和第二个请求时浏览器是不知道他们之间的关系的。所以我们目前来说通常是利用 cookie 来记录一些信息。
当浏览器加载 HTML 文件中引用的静态资源 —— 如图片、外部 CSS、外部 JS 等时,若该资源所属域与当前页面相同,则会在 HTTP 头请求中加载当前域的 cookie 信息。
换句话说,如果一个页面上有50张图片,即使一个 cookie 1KB,但是如果你要加载 50 个图片(或其它静态文件),这样发送的 cookie 总量就多达 50KB 了。
这也就是为什么我之前很多人很喜欢把 cdn 域名划到主域外,这样就减少了cookie 等不必要的数据量。或者合并请求、启用 Cookie-Free 域名。但http2 就没有必要担心了,http2做了首部压缩。
补充http2的内容
通过存储字符串的 Key/Value 对来提供的,并提供 `5MB `(不同浏览器可能不同,分 HOST)的存储空间。不像 Cookies,每次请求一次页面,Cookies 都会发送给服务器。
sessionStorage 用来存储与页面相关的数据,它在页面关闭后无法使用。
localStorage 则持久存在,在页面关闭后也可以使用
IndexedDB 也是一种数据库的存储机制,但又不是传统的关系数据库,可归为 SQL 数据库。IndexedDB 类似于 Dom Storage 的 key-value 的存储方式,但功能更强大,且存储空间更大。
IndexedDB 中Key 是必需,且要唯一;Key 可以自己定义,也可由系统自动生成。Value 也是必需的,但 Value 非常灵活,可以是任何类型的对象。一般 Value 都是通过 Key 来存取的。
IndexedDB 提供了一组 API,可以进行数据存、取以及遍历。这些 API 都是异步的,操作的结果都是在回调中返回。
File System API 是 H5 新加入的存储机制。它为 Web App 提供了一个虚拟的文件系统,就像 Native App 访问本地文件系统一样。Web App 在虚拟的文件系统中,可以进行文件(夹)的创建、读、写、删除、遍历等操作。
优势:
临时的存储空间是由浏览器自动分配的,但可能被浏览器回收;
持久性的存储空间需要显示的申请,申请时浏览器会给用户一提示,需要用户进行确认。
持久性的存储空间是 WebApp 自己管理,浏览器不会回收,也不会清除内容。持久性的存储空间大小是通过配额来管理的,首次申请时会一个初始的配额,配额用完需要再次申请。
虚拟的文件系统是运行在沙盒中。不同 WebApp 的虚拟文件系统是互相隔离的,虚拟文件系统与本地文件系统也是互相隔离的。
网络应用可通过调用 window.requestFileSystem() 请求对沙盒文件系统的访问权限
蓝图
• 有上传器的应用
◦ 当你选择一个文件或目录进行上传时,你可以赋值文件到一个本地沙盒并一次上传一个块。
◦ 应用可以在一次中断后重新上传,中断可能包括浏览器被关闭或崩溃,连接中断,或电脑被关闭。
• 视频游戏或其他使用大压缩包并在本地将他们解压到一个文件目录中。
◦ 应用能在后台预取资源,从而让用户能够进入下一项工作或游戏等级,而不需要等待下载。
• 音频或照片编辑器使用线下访问或本地缓存(有助于表现和速度)
◦ 应用可以分段写入文件(例如只覆盖ID3/EXIF标签而不是整个文件)。
• 线下视频浏览
◦ 应用可以下载大文件(>1GB)用于以后浏览。
◦ 应用可以访问只下载了部分的文件(因此你可以查看你的DVD的第一章,即使应用仍在下载剩余部分,或者当你需要取赶火车而没有完成下载时)。
• 线下网络邮件客户端
◦ 客户端下载附件并在本地存储它们。
◦ 客户端缓存附件用于稍后的上传。
缓存分很多种:服务器缓存,第三方缓存,浏览器缓存等。其中浏览器缓存是代价最小的,因为浏览器缓存依赖的是客户端,而几乎不耗费服务器端的资源。
我们先在chrome浏览器下看看到底缓存了什么东西
查看所有的缓存文件
随便点开一个,可以看到这个缓存文件所有的信息,包括访问url,http请求的头信息,和缓存文件正文内容
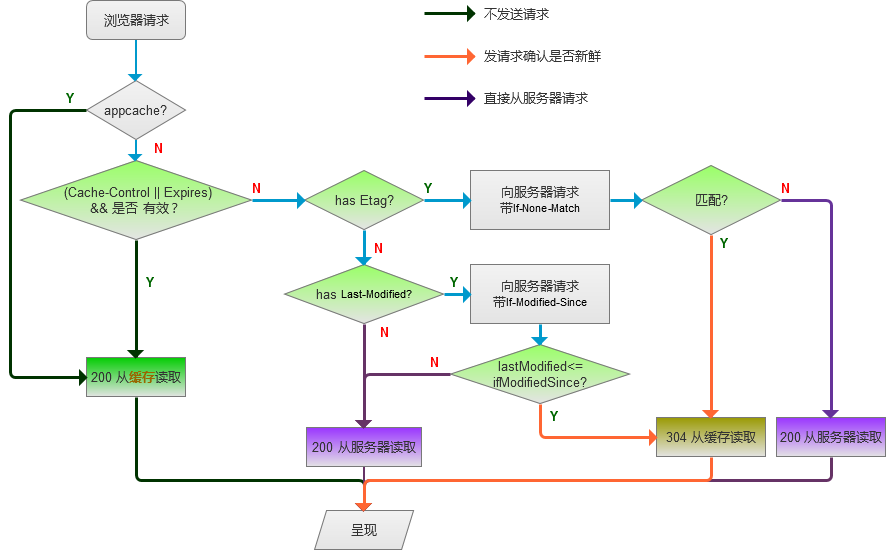
有两种,强缓存 和 协商缓存
1.强缓存:不会向服务器发送请求,直接从缓存中读取资源,在chrome控制台的network选项中可以看到该请求返回200的状态码,并且size显示from disk cache或from memory cache;
2.协商缓存:向服务器发送请求,服务器会根据这个请求的request header的一些参数来判断是否命中协商缓存,如果命中,则返回304状态码并带上新的response header通知浏览器从缓存中读取资源;
浏览器第一次加载资源,服务器返回200,浏览器将资源文件从服务器上请求下载下来,并把response header及该请求的返回时间一并缓存;
下一次加载资源时,先比较当前时间和上一次返回200时的时间差,如果没有超过cache-control设置的max-age,则没有过期,命中强缓存,不发请求直接从本地缓存读取该文件(如果浏览器不支持HTTP1.1,则用expires判断是否过期);如果时间过期,则向服务器发送header带有If-None-Match和If-Modified-Since的请求;
服务器收到请求后,优先根据Etag的值判断被请求的文件有没有做修改,Etag值一致则没有修改,命中协商缓存,返回304;如果不一致则有改动,直接返回新的资源文件带上新的Etag值并返回200;
如果服务器收到的请求没有Etag值,则将If-Modified-Since和被请求文件的最后修改时间做比对,一致则命中协商缓存,返回304;不一致则返回新的last-modified和文件并返回200;

优点:Expires属性告诉浏览器相关副本可以保存在缓存器中的时间。在此时间内,浏览器在访问相关内容的时候,不发任何请求。
缺点:
是牵扯到了日期,这样Web服务器的时间和缓存服务器的时间必须是同步的,如果有些不同步, 要么是应该缓存的内容提前过期了,要么是过期结果没及时更新。
如果在固定时间前服务器更新了内容浏览器并不知道(此时,刷新会请求,地址栏敲回车【模拟新开webview】不会请求 )。
过期时间头信息属性值只能是HTTP格式的日期时间,其他的都会被解析成当前时间“之前”,副本会过期,记住:HTTP的日期时间必须是**格林威治时* 间(GMT),而不是本地时间。举例:Expires: Fri, 30 Oct 1998 14:19:41
例:Cache-Control: max-age=3600, must-revalidate
Expires和Cache-Control:max-age=*** 的作用是差不多的,区别就在于 Expires 是http1.0的产物,Cache-Control是http1.1的产物,两者同时存在的话,Cache-Control优先级高于Expires;在某些不支持HTTP1.1的环境下,Expires就会发挥用处。所以Expires其实是过时的产物,现阶段它的存在只是一种兼容性的写法
Expires和Cache-Control的区别还有一个:Expires是一个具体的服务器时间,这就导致一个问题,如果客户端时间和服务器时间相差较大,缓存命中与否就不是开发者所期望的。Cache-Control是一个时间段,控制就比较容易。


Etag是上一次加载资源时,服务器返回的response header,是对该资源的一种唯一标识,只要资源有变化,Etag就会重新生成。浏览器在下一次加载资源向服务器发送请求时,会将上一次返回的Etag值放到request header里的If-None-Match里,服务器接受到If-None-Match的值后,会拿来跟该资源文件的Etag值做比较,如果相同,则表示资源文件没有发生改变,命中协商缓存。
Last-Modified和If-Modified-Since:这两个也要一起说。Last-Modified是该资源文件最后一次更改时间,服务器会在response header里返回,同时浏览器会将这个值保存起来,在下一次发送请求时,放到request header里的If-Modified-Since里,服务器在接收到后也会做比对,如果相同则命中协商缓存。
ETag和Last-Modified的作用和用法也是差不多,说一说他们的区别。
首先在精确度上,Etag要优于Last-Modified。Last-Modified的时间单位是秒,如果某个文件在1秒内改变了多次,那么他们的Last-Modified其实并没有体现出来修改,但是Etag每次都会改变确保了精度;如果是负载均衡的服务器,各个服务器生成的Last-Modified也有可能不一致。
第二在性能上,Etag要逊于Last-Modified,毕竟Last-Modified只需要记录时间,而Etag需要服务器通过算法来计算出一个hash值。
第三在优先级上,服务器校验优先考虑Etag。
地址栏访问,链接跳转是正常用户行为,将会触发浏览器缓存机制;
F5刷新,浏览器会设置max-age=0,跳过强缓存判断,会进行协商缓存判断;
ctrl+F5刷新,跳过强缓存和协商缓存,直接从服务器拉取资源。
Date:Date头域表示消息发送的时间,时间的描述格式由rfc822定义。例如,Date: Mon, 04 Jul 2011 05:53:36 GMT。
Age:当代理服务器用自己缓存的实体去响应请求时,用该头部表明该实体从产生到现在经过多长时间了。

上面这种交互,相信大家都不陌生吧。致于这种交互的名称是什么,Skeleton Screen? 加载占位图? I don't know ! 暂且就叫它Skeleton Screen吧。最初是在支付宝上看见的这种效果,感觉这种交互效果很好,便查了很多这方面的信息,现在总结一下。
简而言之:
在 CSS2 时代,伪元素和伪类均是以一个冒号开头的;在 CSS2.1 之后,为了对伪元素和伪类加以区分,规定伪类继续以一个冒号开头,而伪元素改为以两个冒号开头。但是为了向前兼容,浏览器同样接受 CSS2 时代已经存在的伪元素(它们包括:before, :after, :first-line, :first-letter)的单冒号写法。但是对于 CSS2 之后所有新增的伪元素(例如::selection),必须采用双冒号写法。
angular的脏检查机制(dirty-checking)是指,ng在指定事件触发后,才进入$digest cycle:
angular是进入$digest cycle,等待所有model都稳定后,才批量一次性更新UI。这种机制能减少浏览器repaint次数,从而提高性能。
$scope.$watch(watchExpression, modelChangeCallback), watchExpression可以是String或Function。
<p>plain text other {{variable}} plain text other</p>
//改为:
<p>plain text other <span ng-bind='variable'></span> plain text other</p>
//或
<p>plain text other <span>{{variable}}</span> plain text other</p>
$http.get('http://path/to/url').success(function(data){
$scope.name = data.name;
$timeout(function(){
//do sth later, such as log
}, 0, false);
});
我们都知道angular建议一个页面最多2000个双向绑定,但在列表页面通常很容易超标。
譬如一个滑动到底部加载下页的表格,一行20+个绑定, 展示个100行就超标了。
如果指令需要展示的内容之变一次的话,我们可以使用自定义的指令来代替 bindonce
1、JSON 的全称 Javascript Object Notation (javascript 对象表示法),是一种将不同编程语言链接q的数起来的数据交换格式。
2、JSON 的媒体类型: application/json
3、JSON Schema(验证):
{
// 声明的名称必须是$schema,值必须为所用草拟版本的链接
"$schema": "http://json-schema.org/draft-04/schema#",
"title": "Cat",
// 定义猫的属性
"properties": {
"name": {
"type": "string",
"minlength": 3, // 最小长度
"maslength": 20 // 最大长度,不在这个返回,不予以验证通过
},
"age": {
"type": "number",
"description": "your cat's age in years",
"minlength": 0
},
"declawed": {
"type": "boolean",
"description": ""
}
},
"required": [ // 必填项
"name",
"age",
"declawed"
]
}
JSON 中的安全性问题[
{
"user": "bshdfiadhlf"
},
{
"phone": "55-55-55"
}
]
像上面这类最外层没有花括号的 json 成为 顶层 JSON 数组,同时这也是 JavaScript 字面量的一种表现形式,如果一个网址使用 GET 请求 (get 请求到的内容可以通过一个URL 地址获得,自然也就可以通过script标签伪造获取), 同时又使用 顶层 JSON 数组 形式,那他的网址就很容易被攻击。因为只要此时 cookie 处于会话中,黑客可以像是使用JavaScript 脚本nei内容一样,获取所需信息。因此银行几乎不用此类方式传输信息。而改用合法的json 和 POST 方式传输。
如果黑客拦截脚本内容,恶意篡改,客户端并不知道,使用 JSON.parse()函数,仅解析 JSON,并不执行脚本。接下再做判断。另外,数据传输中,有使用JavaScript标签的内容,应该先做 encode(),防止其会运作中执行。
用 gitLab clone 新项目的时候,报错如下:
Cloning into 'uiloop'...
Username for 'http://code.kaipao.cc': ziran
Password for 'http://[email protected]':
fatal: Authentication failed for 'http://code.kaipao.cc/dongjia/uiloop.git/'
原以为和 SSH 有关,后来才知道,公司修改了gitLab 的默认端口号,
使用终端,~/.ssh/config 后,修改端口号
host code.kaipao.cc
port 10022
后才可以。
initDate() 时,observe 监控如果是object则进下面的步骤:
var Observer = function Observer (value) {
this.value = value
this.dep = new Dep()
this.vmCount = 0
def(value, '__ob__', this)
if (Array.isArray(value)) {
var augment = hasProto
? protoAugment
: copyAugment
<!-- arrayKeys: push、pop、shift、unshift、splice、sort、reverse -->
augment(value, arrayMethods, arrayKeys)
this.observeArray(value)
} else {
this.walk(value)
}
};Observer.prototype.observeArray = function observeArray (items) {
for (var i = 0, l = items.length; i < l; i++) {
observe(items[i])
}
};经常能在博客或者论坛上看到很多有关前端性能优化的文章,但是却很少看到如何分析一个网页的性能的文章。到底什么样的指标(或者说是标准)代表这个网页性能好或者不好,通过什么方式来得到这些指标呢?因此,本文来讲述下如何分析一个网页的性能的好与差。本文用到的工具:chrome浏览器。下面我们一一来看。
首先要说明的是,运行性能是指你的网页在运行的时候的性能,而不是加载的时候的性能。RAIL(Response-Animation-Idle-Load)模型是一种以用户为中心的性能模型,每个网络应用均具有与其生命周期相关的四个不同方面,且这些方面以不同的方式影响着性能。用官网图来镇压一下:

下面分别从四个方面阐述RAIL模型:
任何网站的终极目标不是让其在任何特定设备上都能运行很快,而是让使用该网站的用户满意。用户花在网站上的大多数时间不是等待加载,而是在使用过程中等待响应。那么怎样评价延迟?让我们来看下面的表:

在用户注意到滞后之前网站有100毫秒的时间可以响应用户输入。这适用于大多数输入,比如点击按钮、切换表单控件或是启动动画。但是不适用于触摸拖动或滚动(因为触摸拖动或滚动属于动画范畴)。如果网站未响应,操作与反应之间的连接就会中断,用户会注意到。因此,对于需要超过500毫秒才能完成的操作,需要始终提供反馈。
其实,有些动作可以不等到用户操作了才响应。网站可以使用此100毫秒时间在后台来执行其他开销大的工作,但前提是不影响用户当前的操作。
动画不止是奇特的UI效果,例如滚动和触摸拖动也属于动画类型。如果动画帧率发生变化,用户便会注意到。网站的目标是每秒生成60帧,每一帧必须完成以下所有步骤:

从纯粹的数学角度而言,每帧的预算约为16毫秒(1000毫秒/60帧=16.66毫秒/帧)。但将新帧渲染到屏幕上也是需要花费时间的,因此实际上浏览器只有10毫秒的时间来执行代码,如果无法符合此估算,帧率将下降,并且内容会在屏幕上抖动,也就是卡顿,会对用户体验产生负面影响。因此,如果可能,最好利用好100毫秒响应预先计算开销大的工作,这样网站就更有可能实现60fps的性能。
可以利用空闲来完成推迟的工作。例如:尽可能减少预加载的数据,以便网站能够快速加载,并利用空闲时间加载剩余数据。推迟的工作应分成每个耗时约50毫秒的多个块。如果用户开始交互,优先级最高的事项是响应用户。要实现小于100毫秒的响应,应用必须在每50毫秒内将控制返回给主线程,这样网站就可以执行其他像素管道、对用户输入作出反应等命令。
因此,以50毫秒块工作既可以完成任务,又能确保即时的响应。
在1秒钟内加载网站,否则,用户的注意力会分散,他们处理任务的感觉会中断。其实也无需在1秒内加载所有内容以让用户产生完整加载的感觉。应该启用渐进式渲染和在后台执行一些工作,将非必需的加载推迟到空闲时间段再来加载。
要根据RAIL指标评估您的网站,可使用Chrome的DevTools的performance面板(旧版本chrome可以用TimeLine工具)记录用户操作(具体可见下面一节讲解如何记录性能数据)。然后根据这些关键RAIL指标检查面板中的记录时间。

下面的教程指引了如何利用chrome开发车工具(DevTools)的performance面板来分析运行时性能。
注意:下面的指引基于chrome 62版本,如果你用了其他版本的chrome,其UI界面和特征会有些许的不同。
首先我们打开官网提供的demo,请确保用浏览器隐身模式打开,以保证浏览器是在一个纯净的环境中。否则,如果你安装了很多浏览器扩展,会对你性能分析的数据产生一定的干扰。接着打开DevTools,具体方法:Command+Option+I (Mac) or Control+Shift+I (Windows, Linux)。

手机设备具有比台式机和笔记本更小的CPU频率,无论何时评估你的网页,你都必须使用CPU限制来模拟网页在手机设备上表现。

注意:如果测试其他页面,如果想测试在低端机上的性能,可以选择更低的倍数。这个只是为了更好的演示,选择了小一点的限制。
注意:如果你没有观察到明显变慢,尝试点击几次Subtract 10按钮再尝试前面步骤。否则如果你添加了太多的蓝色方框,就会耗尽CPU资源。
当你页面运行网页的优化版本,蓝色方框移动速度会变快。为了更好的检测出性能问题,我们记录网页非优化的版本。


关键的性能指标是FPS,其值如果是60FPS,用户体验会很好,使用网站的感受也是愉悦的。
查看FPS图表(图中蓝色方框框住的部分),如果看到了红色长条,就代表帧率太低并已经影响到用户体验了。一般情况下,绿色长条越高,FPS越高。

在FPS下面就是CPU图表,图表中的颜色和面板底部的Summarytab中的颜色是匹配的。CPU颜色越丰富,代表在录制过程中CPU已经最大化了。如果这段丰富颜色的长条比较长,这就暗示网站应该想办法让CPU做更少的工作了,也就是说代码逻辑需要做优化了。

顺便提一下的就是,无论鼠标移动到FPS,CPU或者NET图表上,DevTools都会显示在该时间节点上的屏幕截图,将你的鼠标左右移动,可以重放录制画面,这被称为擦洗,对于手动分析动画进程很有用。

在Frames部分,如果将你的鼠标移动至绿色方块部分,会显示在该特定帧上的FPS值,此例中每帧可能远低于60FPS的目标。的确,在这个例子中,这个页面的性能很差并且能很明显地被观察到,但是在实际场景中,可能并不是那么的容易,所以,要用所有这些工具来进行综合测量。

现在你已经通过上面的各种方式了解并确信了这个网页的性能不好,那么为什么会差呢?是什么导致它运行的这么差的呢?
当没有选择任何事件的时候,Summary tab显示了网页进程活动的分类。从图中可以看出,这个网页花费了太多的时间在渲染(rendering)上了。因此,你的目标就是减少渲染工作花费的时间。

展开Main部分,DevTools将显示主线程上的随着时间推移的活动火焰图。x轴代表随时间推移的记录,每个长条代表一个事件,长条越宽,代表这个事件花费的时间越长。y轴代表调用堆栈,当你看到堆叠在一起的事件时,意味着上层事件发起了下层事件。

可以通过单击、鼠标滚动或者拖动来选中FPS,CPU或NET图标中的一部分,Main部分和Summary Tab就会只显示选中部分的录制信息。注意Animation Frame Fired事件右上角的红色三角形图标,该红色三角图标是这个事件有问题的警告。
单击Animation Frame Fired事件,Summary tab会显示该事件相关的信息。

注意reveal,点击它,会高亮触发Animation Frame Fired事件的事件。

注意app.js:95,点击它,会跳转到source面板对应的源码及其对应的行号。
当选中了一个事件之后,可以使用键盘上的箭头来选择前面或者后面的事件
在Animation Frame Fired事件下面有一群紫色的事件。如果把它们放宽一点,会看到几乎每个紫色事件的右上角都有红色三角形图标。点击其中一个紫色事件(其实就是Layout事件),Summary tab会显示该事件更详细的信息。确实,这里有一个强制reflow的警告。

在Summary tab,点击Recalculation Forced下面的app.js:71,DevTools会跳转到触发强制reflow的代码行。

这个代码的问题在于,在动画的每一帧都改变了蓝色方块的样式并计算了每个方块在页面的位置。因为样式改变了,浏览器却不确定是否是每一个方块的位置都改变了,因此浏览器为了计算方块的位置,只能对方块重新布局。可以查看Avoid forced synchronous layouts这篇文来了解如何避免大型、复杂的布局和布局抖动。
更多的时间线事件参考,请点击这里

如同评估运行时性能一样设置了CPU限制,你也可以在设置里面设置network控制,来调整你想要的网络速度环境。
可以使用chrome浏览器DevTools中的Performance面板来得到网页的加载性能和运行时的性能数据,根据上文介绍的分析方法,结合RAIL模型来评估网页性能的好与差。这是一个很有效的方法。具体如何提高网页的性能呢?这又是一个大课题,相信网上也有不少与之相关的博文可以参考,笔者后续有时间也出相关博文。
转载自:
前端静径
缘起一段这样的代码:
fs.readFile('./docs/use.md', function (err, buffer) {
if (err) {
return console.log('error: ', err);
}
console.log('OK');
});本地运行时一切 OK,线上部署时却死活找不到 ./docs/use.md 这个文件,后来才发现是因为线上启动应用时不是从当前目录启动了,不过为什么启动脚本的位置也会影响这个路径呢,且往下看。
Node 中的文件路径大概有 __dirname, __filename, process.cwd(), ./ 或者 ../,前三个都是绝对路径,为了便于比较,./ 和 ../ 我们通过 path.resolve('./')来转换为绝对路径。
先看一个简单的栗子:
假如我们有这样的文件结构:
app/
-lib/
-common.js
-model
-task.js
-test.js在 task.js 里编写如下的代码:
var path = require('path');
console.log(__dirname);
console.log(__filename);
console.log(process.cwd());
console.log(path.resolve('./'));
在 model 目录下运行 node task.js 得到的输出是:
/Users/guo/Sites/learn/app/model
/Users/guo/Sites/learn/app/model/task.js
/Users/guo/Sites/learn/app/model
/Users/guo/Sites/learn/app/model
然后在 app 目录下运行 node model/task.js,得到的输出是:
/Users/guo/Sites/learn/app/model
/Users/guo/Sites/learn/app/model/task.js
/Users/guo/Sites/learn/app
/Users/guo/Sites/learn/app
那么,不好意思不是问题来了~T_T,我们可以得出一些肤浅的结论了:
我明明记得在 require('../lib/common') 里一直都是各种相对路径写,也没见报什么错啊,我们还在再来个栗子吧,还是上面的结构,'model/task.js' 里的代码改成:
var fs = require('fs');
var common = require('../lib/common');
fs.readFile('../lib/common.js', function (err, data) {
if (err) return console.log(err);
console.log(data);
});在 model 目录下运行 node task.js,一切 Ok,没有报错。然后在 app 目录下运行 node model/task.js,然后很果断滴报错了:
那么这下问题真的都是来了,按照上面的理论,在 app 下运行时,../lib/common.js 会被转成 /Users/guo/Sites/learn/lib/common.js,这个路径显然是不存在的,但是从运行结果可以看出 require('../lib/common') 是 OK 的,只是 readFile 时报错了。
那么关于 ./ 正确的结论是:
在 require() 中使用是跟 __dirname 的效果相同,不会因为启动脚本的目录不一样而改变,在其他情况下跟 process.cwd() 效果相同,是相对于启动脚本所在目录的路径。
只有在 require() 时才使用相对路径(./, ../) 的写法,其他地方一律使用绝对路径,如下:
// 当前目录下
path.dirname(__filename) + '/test.js';
// 相邻目录下
path.resolve(__dirname, '../lib/common.js');
首先不得不说,fetch的出现确实在前端圈子里一石激起了千层浪。超前的ReadableStream **让人眼前一亮。但是在使用过程中难免还是发现了一些问题。
出于兼容性考虑,大部分的项目在发送 POST 请求时都会使用 application/x-www-form-urlencoded 这种 Content-Type,下面我们来看一下,向服务器发送请求,ajax 和 fetch 的区别
$.post('/api/add', {name: 'test'});fetch('/api/add', {
method: 'POST',
headers: {
'Content-Type': 'application/x-www-form-urlencoded;charset=UTF-8'
},
body: Object.keys({name: 'test'}).map((key) => {
return encodeURIComponent(key) + '=' + encodeURIComponent(params[key]);
}).join('&')
});** fetch 是一个 low-level 的 API,所以你需要自己 encode HTTP 请求的 payload,还要自己指定 HTTP Header 中的 Content-Type 字段。此外, fetch 在发送请求时默认不会带上 Cookie!,所以我们需要自己加上去。**
fetch('/api/add', {
method: 'POST',
credentials: 'include',
...
});同理,如果你需要 POST 一个 JSON 到服务端,你需要这样做:
fetch('/api/add', {
method: 'POST',
credentials: 'include',
headers: {
'Content-Type': 'application/json;charset=UTF-8'
},
body: JSON.stringify({name: 'test'})
});fetch('xx.png')
.then(() => {
console.log('ok');
})
.catch(() => {
console.log('error');
});
我们期待的结果是:error,但是有图有真相的输出了 ok 。
原来,**按照 MDN 的说法,fetch 只有在遇到网络错误的时候才会 reject 这个 promise,比如用户断网或请求地址的域名无法解析等。只要服务器能够返回 HTTP 响应(甚至只是 CORS preflight 的 OPTIONS 响应),promise 一定是 resolved 的状态。 **
所以,fetch 的成功与否需要我们自己去判断:
const resolveFetch = response => {
const json = response.json()
if (response.status >= 200 && response.status < 300) return json
return json.then(Promise.reject.bind(Promise))
}
fetch('xx.png')
.then(resolveFetch)
.then(res => {
console.log('ok');
})
.catch(() => {
console.log('error');
});
ok,终于输出error了。
每个团队在实际工作中对错处处理是不一样呀的,例如,我们团队在请求发送成功(服务器能够返回 HTTP 响应),但是请求内容有误(如参数传递有误等),会返回如下的json:
{
"success":false,
"errorMsg":"用户不存在",
"errorCode":"40000",
"model":null,
"attributes":null,
"attributesJson":null,
"exception":null
}我们期望这种情况也进入catch,因为fetch的返回内容response.json()其实就是一个Promise,所以改进上面的resolveFetch如下
const resolveFetch = response => {
const json = response.json()
if (response.status >= 200 && response.status < 300) {
return new Promise((resolve, reject) => {
json.then(data => {
if (data.success) {
resolve(data.model);
} else {
reject(data)
}
});
});
}
return json.then(Promise.reject.bind(Promise))
}
ok ,好了。
<img src="data: image/gif;base64,B01GOD1HFUAIDHF;AOHF;ADH;FDF;ADHF;DOIFHOAI;AIF;ADIFOAD;IF;AD="> computed: {
captchaImage() {
return `//mainsite-restapi/v1/captchas/`
}
}
<img :src="captchaImage">
如果应用程序Web服务器离用户很近,则一个HTTP请求所花费的时间将缩短(最早,很多网站都会提供电信 / 网通等不同二级域名,供不同运营商用户选择,这无疑增加了使用成本。当前,一般网站都使用 DNS 服务来解决这个问题:按地域、运营商等条件,将用户 DNS 请求解析到最合适的 IP),如果组件Web服务器离用户很近,则多个HTTP请求响应时间将会缩短。而且增加组件Web服务器相对于增加应用程序Web服务器而言简单很多,因此CDN非常的实用。
CDN是一组分布在不同地理位置的Web服务器,用于有效的向用户发布内容。
优势:
Web服务器,所以响应时间受其他网站的影响。Web客户端通过Accept-Encoding: gzip deflate头来表示其支持压缩,服务器端从中选择一种压缩方式,通过Content-Encoding告诉客户端。最通用的压缩方式是gzip格式。压缩通常是压缩脚本和样式表,甚至是HTML和JSON ,对用图片和 PDF 一般不会压缩。因为不必要的压缩会给服务器端带来额外的CPU消耗,客户端也需要消耗资源来解压缩。
Web服务器的响应头中添加Vary头。Web服务器告诉代理根据一个或多个请求头来改变缓存的响应。服务器的Vary头中包含Accept-Encoding,这将使得服务器端的响应有多种选择,即:Vary: Accept-Encoding
首先介绍两篇关于 DNS 的文章,感觉写的好棒!
http://www.ruanyifeng.com/blog/2016/06/dns.html
https://imququ.com/post/http-alt-svc.html
请求支持keep-alive特性,同时可以覆盖TTL(time-to-live)和浏览器的时间限制。换句话说,质押浏览器的服务器可以愉快的聊天,就没有必要去查询DNS。
webP1、https://segmentfault.com/a/1190000005898538
2、http://isux.tencent.com/introduction-of-webp.html
使用时,检测浏览器是否支持 webp 即可
const VueImg = Object.create(null)
VueImg.canWebp = false
const img = new Image()
img.onload = () => { VueImg.canWebp = true }
浏览器可以使用 Accept-Encodeing头来声明它支持压缩的格式。 服务器使用 Content-Encoding 头确认响应已经被压缩。ps: 请求体是被压缩的。
如果浏览器在缓存中保留了资源的一个副本,但不确定 它是否有效,就会发送一个 get请求。如果缓存有效,浏览器就会从缓存中获取所需内容。
缓存的副本有效性,来自于最后修改时间。基于 Last-Modofied头,浏览器可以知道最后修改时间。他会使用If-Modofied-Since头将最后修改时间发送给服务器。其实浏览器是在说:“我拥有这个资源版本,这是它的最后修改时间,我可以使用它嘛?”如果响应没有发生过修改,那么服务器会返回一个“ 304 Not Modofied”的状态码,并不在发生实体,浏览器缓存中的内容。
User-Agent 或 Accept-Language头而改变、明确指出浏览器在过期时间之前都可以使用缓存中的内容,无需发送任何请求验证。
弊端:
HTTP 1.1 引入了Cache-Control头来克服Expires头的限制。Cache-Control使用max-age指令指定资源被保存对酒。如果资源从被请求开始过去的时间不少于max-age(这是一个相对于被请求时间的时间,是被请求后的max-age秒),浏览器就会使用缓存的版本,不再发送任何HHTP请求。
可以同时指定Expires和Cache-Control两个请求头。如果两个同时出现,HTTP规定max-age指令会复写Expires头。
Cache-Control:Private 禁用一切缓存
ps: 可以通过在文件发布时,添加一个变量或者hash来告诉浏览器,资源已被修改,需要重新下载,这样就防止了服务器端资源改变但客户端并不知道的情况发生。
解决了多对一请求服务器导致的socket 链接低效的问题。她使得浏览器可以在一个单独的链接上进行多个请求。浏览器和服务器同时使用Connection头来指出对Keep-Alive的支持。默认情况下,一个持久的TCP链接将会一直使用,直到其闲置超过5分钟为止。由于链接是持久的,所以不需要重复的DNS查询。
浏览器或者服务器可以发送Connection: Close来关闭持久链接。
做H5开发的小伙伴们一直很关心的问题就是首屏。一般大家都知道,从纯前端角度讲,dom树的深度 会很影响加载速度,但是产品和设计的需求不会降低,尽量减少对 dom 的操作方面现有的框架 vue 、angular
react 等框架对尽其所能的对他们做了优化,所以,其实这方面的改动就很小了。所以从另一方面将,我们只能从网络方面入手。
思路主要就是两个方面:
有两个方面对此影响:
1、tcp慢启动。
2、数据源所在地。例如我们在杭州,如果服务器在北京,那么每次获取信息都是在北京与杭州之间来回传输,肯定比杭州到杭州的服务器之间慢很多。
我们知道HTTP 1.0 的请求是无状态的,且每次链接都需要 TCP 3次握手后才可以得以链接。费事又费力。
对于问题一,目前大多数的解决办法是CND, 这里涉及到一些httphttp-cache 和缓存的知识。对于问题二,有 keep-alive , socket 等等方式。但是都会有一定的负面代价。比如说,http 本来是短链接,我们通过timeout 限制它在多少时间内不进行3次握手校验,势必 要增加server内存,预先扩容 。即使这样实际提升也只有200毫秒左右。
http 1.0 是1999年开始使用的,一直沿用到现在。但是随着web应该不断的在更新,地位不断的在上升,各个框架不断的在优化,但是如果协议方面不做任何的优化,其实还是指标不治本。我们的服务性能还是会被底层服务所限制。
http 是基于文本的协议,分为 header 和 body 。由于http 1.0是无状态的,在我们发送第一个请求和第二个请求时浏览器是不知道他们之间的关系的。所以我们目前来说通常是利用 cookie 来记录一些信息。
当浏览器加载 HTML 文件中引用的静态资源 —— 如图片、外部 CSS、外部 JS 等 —— 时,若该资源所属域与当前页面相同,则会在 HTTP 头请求中加载当前域的 cookie 信息。
换句话说,如果一个页面上有50张图片,即使一个 cookie 1KB,但是如果你要加载 50 个图片(或其它静态文件),这样发送的 cookie 总量就多达 50KB 了。
不要忘记除了cookie 外还有user Agent.
这也就是为什么我之前很多人很喜欢把 cdn 域名划到主域外,这样就减少了cookie 等不必要的数据量。或者合并请求、启用 Cookie-Free 域名。但http2 就没有必要担心了,http2做了首部压缩。
http2 是有两个指针,一个是头部针和数据针。
在第一次发送http求的时候,它会有以键值队的形式建立一个表

| 键 | 值 |
|---|---|
| :method | GET |
| :scheme | https |
| :host | www |
| :path | fdaf |
在接下来的每次请求时都会对比这个头部指针所对应,如果没有变化则发送data指针所指的数据。
如果有变更,则发生有变更的数据指针。


注意
借用他文章中的一图:

解释:
多路复用和链路复用不同。
链路复用是说在tcp链路已建立的前提下,那么我就可以不用在建立新的链接了,但是原有的请求还是要按照顺序一条一条的发送。
多路复用是指在建立了一个tcp连接后,在这个连接上我可以双工的进行发送请求、接收请求等。
----->
server <----- client
而且是可以乱序等,不必再等一个请求结束再开始收另一个请求。这样就不会什么雪碧图啊,减少请求数量等等一系列的问题。它会高效的利用这条链路。
以前我们再请求一个页面时,以前会先返回一个html 文件,再返回css 和js 资源。浏览器再根据css 和js 解析html 。请注意css 和js 资源和html 文件这之间是有时间差的。
而服务器推送,服务器是知道那个html引用了哪个js,css 的,那么它一起返回给我们,前端就可以立刻渲染了。
虽然HTTP 2.0 没有明确指明它必须是 https (SSL),但是 就目前来看 chrome 等大多都是https的,苹果17年1月的新审核规定也要求所有 session 必须是https。
* 因为增加了TSL验证一来一回又增加了200ms * 3 = 600ms的时间
* tcp慢启动,一般的服务器初始化最多可以发送10 个 TCP 包,老一点的有6-4个,首个数据传输来回(RTT)可传输的数据上线是14kb,(前面也说了,即使带宽再大,一开始加载的速度也不会很快)。所以如果要加载的数据大于14kb,接下来它必须等待客户端应答这些数据,然后才能增加它的拥塞窗口并继续发送更多数据。。所以压缩文件体积至关重要。而http2 依旧受此限制。
尤大大 讲编译时优化
但是据腾讯开发者统计,虽然使用了https,但是用了http 2.0 后还是节约了 200-400ms的时间。
现在的模式是,先请求html,再请求js、css ,再发ajax请求取回json,来渲染,最乐观的情况也需要3个RTT来回。服务端的渲染就是它发一次请求同时返回html、js、css 、json ,这都是渲染好的。
Vue.js 2.4.0 版本提供了内置的服务端渲染与异步组件支持,从而保证了在服务端渲染中也能使用异步组件,而不再是局限于路由中使用。
4 Important Changes In Vue.js 2.4.0
webview 本身会初始化 webkit 内核和app本身的一些东西,目前很多公司的做法是跨过webview本身,先发送请求到服务器,等webview初始化后,就已经取到了数据。
图片是占带宽最大的,所以针对图片存多种格式的。webP虽然对iphone的支持率低,但是我觉得还是有必要的。
# 无其他办法怎么办?
与用户的交流,目前比较新颖的方式是Skeleton Screen
输出下列结果:
promise()
.then(() => {
console.log('1')
})
.then(() => {
console.log('2')
})
.catch(() => {
console.log('3')
})
.then(() => {
console.log('4')
})实现方式:
function one(resolve, reject){
console.log('1');
setTimeout(()=>{
reject('3');
}, 2000);
}
function two(clothes){
console.log('2');
setTimeout(()=>{
console.log('4');
}, 3000);
}
new Promise(one)
.catch(two())var promise = new Promise(function(resolve, reject) {
if (/* 异步操作成功 */){
resolve(value);
} else {
reject(error);
}
});
promise
.then(function(value) {
// 如果调用了resolve方法,执行此函数
}, function(value) {
// 如果调用了reject方法,执行此函数
});其实Promise函数的使命,就是构建出它的实例,并且负责帮我们管理这些实例。而这些实例有以下三种状态:
new Promise 只接受一个函数为参数,这个函数在创建的时候就立即执行了。
promise 从设计模式上来讲,是观察者模式
观察者模式是基于订阅-发布模式的,但是又有些许区别, 发布 emit 和订阅 on 两者没有直接关系, 观察者模式把 观察者 放到被观察者中,二者都是 一种一对多的关系 [fn,fn,fn]。
举个生活中的例子: 一天 A 去售楼处看房子,到了售楼处才发现楼盘都售光了,但是值得高兴的是下周可能会有一批尾楼盘放出,于是 A 请售楼小姐记下他的信息,等楼盘放出后给他发信息。 不久后 B 、C 、D 都来看房子都遇见同样的问题,售楼小姐依次记录了他们的信息。一周后,楼盘放出了,售楼小姐拿出手机依次给 A、B 、C 、D... 客人发了信息(发完崩溃了。。。)。
这就是订阅-发布模式。
后来售楼小姐认识了一个程序猿小哥哥,和他说了这件事,程序猿小哥哥说,你把 A、B 、C 、D... 的信息给我,我帮你操作,这样你就不用一个一个发信息了。
下面看看程序猿小哥哥的操作:
// 观察者模式: 把 观察者 放到被观察者中
class Subject { // 被观察者
constructor() {
this.stack = [];
this.name = '';
}
attach = (observer) => {
this.stack.push(observer);
}
setName = (newName) => {
this.name = newName;
this.stack.map( o => o.mobile(newName))
}
}
class Observer { // 观察者
constructor(username) {
this.username = username;
}
mobile = (name) => {
console.log('尊敬的用户' + this.username + '您好!您关注的'+ name + '开售了,快来看看吧')
}
}
let o1 = new Observer('A');
let o2 = new Observer('B');// 收集 A、B ... 的信息
let s = new Subject();
s.attach(o1);
s.attach(o2); // 将 A、B ... 的信息放入待执行队列中
s.setName('万科楼盘') // 当楼盘信息出来后,主动给 A、B... 发信息
下面我们手写一版 promise,如下:
const SUCCESS = 'fulfilled'
const FAIL = 'rejected';
const PENDING = 'pending'
class Promise {
constructor(executor) {
this.status = PENDING;
this.value = undefined; // 成功返回
this.reason = undefined; // 失败返回
this.onResolvedCallbacks = []; // 存储成功的所有的回调 只有pending的时候才存储
this.onRejectedCallbacks = []; // 存储所有失败的
try {
executor(this.resolve, this.reject);
} catch(e){
reject(e);
}
}
then = (onFulfilled, onRejected) => {
if(this.status === SUCCESS){
onFulfilled(this.value);
}
if(this.status === FAIL){
onRejected(this.reason);
}
if(this.status === PENDING){
this.onResolvedCallbacks.push(()=>{
onFulfilled(this.value);
});
this.onRejectedCallbacks.push(()=>{
onRejected(this.reason);
})
}
}
resolve = (value) => {
if(this.status === PENDING){
this. value = value;
this.status = SUCCESS;
this.onResolvedCallbacks.forEach((fn) => {
fn(value)
})
}
}
reject = (reason) => {
if(this.status === PENDING){
this. reason = reason;
this.status = FAIL;
this.onRejectedCallbacks.forEach((fn) => {
fn(reason)
})
}
}
}promise 和 fetch 简单结合一下:
let fetchData = new Promise((resovle, reject) => {
fetch(url)
.then(data => data.json())
.then(data => {
if(data.success) {
return resovle(data)
}
else {
return reject(data)
}
})
}) 当我们使用链式调用法,如下:
fetchData
.then(res => {
console.log(res)
})
.then(res => {
console.log(this.userInfo)
})当进去第二个then后,我们发现,程序因为找不到then方法而导致报错。

promise的链式操作关键是: Promise.prototype.then方法接受一个函数为参数,并返回的是一个新的Promise对象,因此可以采用链式写法。
想让then方法支持链式调用,其实也是很简单的:
then(onFulfilled, onRejected) {
....
return this
}没错,就是这么简单的一句,就可以很魔法的实现链式调用。
问题1:
如果用户再then函数里面注册的仍然是一个Promise,该如何解决?
Page({
onShow: function() {
HTTP.GET('v2/user/invest/info')
.then(res => {
this.userInfo = res
console.log(this.userInfo)
return HTTP.GET('v2/report/invest/do/list')
})
.then(data => {
console.log(data)
})
}
})如果继续使用上面的promise,HTTP.GET('v2/report/invest/do/list')返回内容无法是无法获取的:

如图,data 和 res 返回内容一致,这显然不是我们想要的。
链式Promise是指在当前promise达到fulfilled状态后,即开始进行下一个promise(后邻promise)。那么我们如何衔接当前promise和后邻promise呢?
我们可以说尝试着在 then 方法里面 return 一个 promise, 事实上Promises/A+规范中的2.2.7就是这么说哒~
继续改造我们的promise:
// 在Promise类外添加一个resolvePromise方法
function resolvePromise(promise2, x,resolve,reject) { // 考虑的非常全面
if(promise2 === x){
return reject(new TypeError('TypeError: Chaining cycle detected for promise #<Promise>'));
}
// 判断x的类型
// promise 有n种实现 都符合了这个规范 兼容别人的promise
// 怎么判断 x是不是一个promise 看他有没有then方法
if(typeof x === 'function' || (typeof x === 'object' && x != null)){
try{
let then = x.then; // 去then方法可能会出错
if(typeof then === 'function'){ // 我就认为他是一个promise
then.call(x,y=>{ // 如果promise是成功的就把结果向下传,如果失败的就让下一个人也失败
resolvePromise(promise2,y,resolve,reject); // 递归
},r=>{
reject(r);
}) // 不要使用x.then否则会在次取值
}else{ // {then:()=>{}}
resolve(x);
}
}catch(e){
reject(e);
}
}else{ // x是个? 常量
resolve(x);
}
}
...
then(onFulfilled, onRejected) {
let promise2;
// 可以不停的调用then方法,返还了一个新的promise
// 异步的特点 等待当前主栈代码都执行后才执行
promise2 = new Promise((resolve, reject) => {
if (this.status === SUCCESS) {
setTimeout(() => {
try {
// 调用当前then方法的结果,来判断当前这个promise2 是成功还是失败
let x = onFulfilled(this.value);
// 这里的x是普通值还是promise
// 如果是一个promise呢?
resolvePromise(promise2, x, resolve, reject);
} catch (err) {
reject(err);
}
});
}
if (this.status === FAIL) {
setTimeout(() => {
try {
let x = onRejected(this.reason);
resolvePromise(promise2, x, resolve, reject);
} catch (err) {
reject(err);
}
});
}
if (this.status === PENDING) {
this.onResolvedCallbacks.push(()=>{
setTimeout(() => {
try {
let x = onFulfilled(this.value);
resolvePromise(promise2, x, resolve, reject);
} catch (err) {
reject(err);
}
});
});
this.onRejectedCallbacks.push(()=> {
setTimeout(() => {
try {
let x = onRejected(this.reason);
resolvePromise(promise2, x, resolve, reject);
} catch (err) {
reject(err);
}
});
});
}
});
return promise2; // 之前例子中的this
}
...现在回顾下Promise的实现过程,其主要使用了设计模式中的观察者模式:
通过Promise.then和Promise.catch方法将观察者方法注册到被观察者Promise对象中,同时返回一个新的Promise对象,以便可以链式调用。
被观察者管理内部pending、fulfilled和rejected的状态转变,同时通过构造函数中传递的resolve和reject方法以主动触发状态转变和通知观察者。
本文是关于表单上传的知识点,主要围绕表单相关知识点接受。
首先,大家都知道通过 HTTP + form表单向服务器发送POST,代码如下:
提交时会向服务器端发出这样的数据(已经去除部分不相关的头信息),数据如下:
Accept:*/*
Accept-Encoding:gzip, deflate
Accept-Language:zh-CN,zh;q=0.8,en;q=0.6
Cache-Control:no-cache
Connection:keep-alive
Content-Length:21
Content-Type:application/x-www-form-urlencoded
Host:abbla.com
Origin:http://abbla.com
Pragma:no-cachename:11
age:22
button:对于普通的HTML Form POST请求,它会在头信息里使用 Content-Length 注明内容长度。它的 Content-Type 是application/x-www-form-urlencoded,这意味着消息内容会经过`URL`编码,就像在GET请 求时URL里的QueryString那样。txt1=hello&txt2=world
最早的HTTP POST是不支持文件上传的,在1995年,ietf出台了rfc1867,也就是《RFC 1867 -Form-based File Upload in HTML》,用以支持文件上传。所以Content-Type的类型扩充了multipart/form-data用以支持向服务器发送二进制数据。因此发送post请求时候,表单<form>属性enctype共有二个值可选,这个属性管理的是表单的MIME编码:
①application/x-www-form-urlencoded(默认值)
②multipart/form-data
其实form表单在你不写enctype属性时,也默认为其添加了`enctype属性值,默认值是enctype="application/x- www-form-urlencoded".
通过form表单提交文件操作如下:
<form method="post" action="/file/add?name=_pics" enctype="multipart/form-data">
<input type="text" name="name">
<input type="text" name="age">
<button type="submit" name="button">提交</button>
</form>Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
Accept-Encoding:gzip, deflate
Accept-Language:zh-CN,zh;q=0.8,en;q=0.6
Cache-Control:no-cache
Connection:keep-alive
Content-Length:322
Content-Type:multipart/form-data; boundary=----WebKitFormBoundaryX6nJzxcGuGRVzdlw
Host:abbla.com
Origin:http://abbla.com
Pragma:no-cache
Referer:http://abbla.com
Upgrade-Insecure-Requests:1------WebKitFormBoundaryX6nJzxcGuGRVzdlw
Content-Disposition: form-data; name="name"
12
------WebKitFormBoundaryX6nJzxcGuGRVzdlw
Content-Disposition: form-data; name="age"
12
------WebKitFormBoundaryX6nJzxcGuGRVzdlw
Content-Disposition: form-data; name="button"
------WebKitFormBoundaryX6nJzxcGuGRVzdlw--根据RFC 1867定义,我们需要选择一段数据作为“分割边界”( boundary属性),这个“边界数据”不能在内容其他地方出现,一般来说使用一段从概率上说“几乎不可能”的数据即可。 不同浏览器的实现不同,例如火狐某次post的 boundary=---------------------------32404670520626 , opera为boundary=----------E4SgDZXhJMgNE8jpwNdOAX ,每次post浏览器都会生成一个随机的30-40位长度的随机字符串,浏览器一般不会遍历这次post的所有数据找到一个不可能出现在数据中的字符串,这样代价太大了。一般都是随机生成,如果你遇见boundary值和post的内容一样,那样的话这次上传肯定失败,不过我建议你去买彩票,你太幸运了。Rfc1867这样说明{A boundary is selected that does not occur in any of the data. (This selection is sometimes done probabilisticly.)}。
<form method="post" action="/file/add?name=_pics" enctype="multipart/form-data">
<input type="text" name="name">
<input type="text" name="age">
<button type="submit" name="button">提交</button>
</form>用js的方式实现如下:
htlm
<form>
<input type="file">
</form>let img = new Image()
let form = document.getElementsByName('form')[0]
let files = form.file.files || []
let formData = new FormData()
formData.append('_pics', scope.file)
$http({
'method': 'POST',
'url': scope.uploadUrl,
'data': formData,
'headers': {
'Content-Type': undefined
}
})
.then( (res) => {
var data = res.data.id
scope.uploading = false
scope.value = data || 'Upload Fail'
}, function(e) {
scope.uploading = false
alert('系统异常!')
})你可以自己创建一个FormData对象,可以使用append()方法添加字段属性,append() 方法 会添加一个新值到 FormData 对象内的一个已存在的键中,如果键不存在则会添加该键。
FormData.set 和 append() 的区别在于,如果指定的键已经存在, FormData.set 会使用新值覆盖已有的值,而 append() 会把新值添加到已有值集合的后面。
'Content-Type': undefined这句话的作用时,生成随机字符串`boundary` 值
https://segmentfault.com/a/1190000002784857
:root {
--mainColor: red;
}
a {
color: var(--mainColor);
}
:root {
--danger-theme: {
color: white;
background-color: red;
};
}
.danger {
@apply --danger-theme;
}
:root {
--fontSize: 1rem;
}
h1 {
font-size: calc(var(--fontSize) * 2);
}
其他的见: http://cssnext.io/features/
.container{
display: flex;
}
编译后:
.container{
display: -webkit-box;
display: -webkit-flex;
display: -ms-flexbox;
display: flex;
}
自定义变量
:root {
--text-color: black;
}
body {
color: var(--text-color);
}
编译后:
body {
color: black;
}
自定义选择器
@custom-selector :--heading h1, h2, h3, h4, h5, h6;
:--heading {
font-weight: bold;
}
编译后:
h1,
h2,
h3,
h4,
h5,
h6 {
font-weight: bold;
}
样式规则嵌套
.message {
font-weight: normal;
& .header {
font-weight: bold;
}
@nest .body & {
color: black;
}
}
编译后:
.message {
font-weight: normal
}
.message .header {
font-weight: bold;
}
.body .message {
color: black;
}
使用 resolve 的 CSS 样式声明
.logo {
background-image: resolve('logo.png');
}
编译后:
.logo {
background-image: url('/assets/images/logo.png');
}
为了理解 HTTP,我们先了解一下 TCP/IP 协议族
通常我们使用的网络是在 TCP/IP 协议族的基础上工作的,而 HTTP 属于它内部的一个自集。
为什么叫协议族?
计算机与网络之间要相互通讯,就要基于相同的方法。不同的硬件、网络之间需要沟通,就需要一种统一的规则,我们称这种规则为协议(protocal).
TCP/IP 是互联网相关的各类协议族的总称
协议中存在各式各样的内容,从电缆的规格到IP地址的选定方法,寻找异地用户的方法,双方建立通讯的顺序,以及web 页面的显示需要处理的步骤,等等。
TCP/IP 协议族按层次分,分别为:应用层、传输层、网络层和数据链路层。
分层管理的好处
各就其职,每一层只需要处理本层的任务就可,整体设计好后,每一层内的内部可以自由的设计,而对整体没有任何的影响。
TCP/IP 各层的作用
应用层
应用层决定了向用户提供应用服务时的通讯服务。
TCP/IP 协议族内预存了各类通讯的应用服务。如:FTP和DNS,HTTP也属于该层。
传输层
提供处于网络连接中的两台计算机之间的数据传输。
在传输中有两个性质不同的协议:TCP 和 UDP (User Data Protocol, 用户数据报协议)
网络层
处理在网络中流动的数据包。数据包是网络传输的最小数据单位。该层规定了通过怎样的路径到达对方的电脑,并把数据传给对方。
数据链路层
用来处理链接网络的硬件部分, 包括操作系统、硬件驱动、NIC(网卡)、光纤等物理可见部分。

发送端在发送数据时,必会在每一层打上一个专所属该层的头部标签,反之,接收端在层与层传输中,每经过一层则去掉对用的首部。这种吧数据包装起来的方式叫做封装。
IP不等于IP地址
IP 的作用是把数据传输给对方。而准确无误的传给对方,需要两个重要的条件:IP地址和MAC地址(Media Access Control Address)。MAC地址是指网卡的固定地址。 IP地址和MAC地址进行配对,IP地址易变,但MAC一般是不会变的。
IP地址通讯依赖MAC地址。在网络中,双方在同一局域网的情况非常少见,一般都是通过多台计算机和中转设备才能建立联系。在中转时,会利用下一站中转设备的MAC地址来搜索下一站中转的目标,这时会采用APR协议(Address Resolution Protocol)。APR协议是解析地址的一种协议,根据通讯方的IP地址返查出MAC地址。
TCP 位于传输层,提供可靠的字节服务。
所谓字节服务是指,为了方便运输,将大块数据分割成以报文段为单位的数据包进行管理。
如何确认数据准确到达对方 -- 三次握手

存在于应用层。负责IP于域名之间的映射关系。
ps: 本文是《图解http》一书的总结
2017-05-08日,腾讯公司正式向国家知识产权局提交了一份关于图片编码技术的专利申请—— TPG(Tiny Portable Graphics),在数据上TPG图片格式产生的文件大小明显小于JPG/JPEG、PNG、GIF、WEBP等业界主流的图片格式,处于世界领先水平。
此项专利技术由 腾讯音视频实验室 发出,资料显示,
TPG比PNG小50%以上,
比GIF小90%以上,
比JPG/JPEG格式图片小40%以上,
比WEBP格式,文件大小可以减少近30%。
但是众所周知,目前业内的图片处理格式有
无损:gif << png < webp << FLIF (Free Lossless Image Format)
有损:jpg << webp < BPG
优点
缺点
区别
对于现阶段的视频帧编码来说,通常都有帧内预测。即利用图像已编码部分预测未编码部分。
它通常有多种预测方法,将图像细分来进行预测处理,细分级别也有多种,如:4x4 16x16 等,分块越细预测越准确。获取数值后将 原图像数据 减去 预测数据 得到差值,仅对差值进行编码,以此控制大小。同时编码阶段可能还存在 去块滤波,进行像素差抹平。以此来取得图像大小以及平滑度兼顾的目的。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.