EfficientNetV2 (Efficientnetv2-b2) and quantization int8 and fp32 (QAT and PTQ) on CK+ dataset . fine-tuning, augmentation, solving imbalanced dataset and so on.
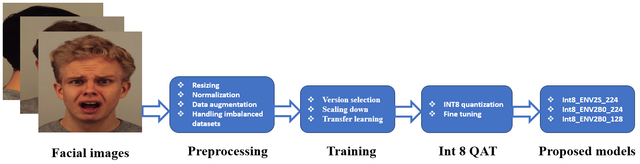
Real-time facial emotion recognition using EfficientNetV2 CNN and quantization on CK+ dataset. This code includes:
1- data loading steps (download and split dataset).
2- preprocessing steps on CK+ dataset (normalization, resizing, augmentation and solving imbalanced dataset problem).
3- fine-tuning (using pre-trained weights from imagenet dataset as initial weights for training step).
4- quantization int8 and fp32 and fin-tuning after quantization ( Quantization-aware training integer8 (QAT) and Post-training quantization float32 (PTQ) ).
5- Macro, Micro, and Weighted for Precision, Recall, F1-score
6- Confusion Matrix
Note that integer computation is much faster than float computation, especially in ARM architecture. Also, the size of Float32 data is four times bigger than Float8. So, quantization int8 has has some benefits in reducing inference time and model size. But, Sometimes, it leads to a lower accuracy (PTQ). If we want to compensate for this loss, we need to use quantization-aware training approach. It means we need fine-tuning after quantization to compensate for lost accuracy. Finally, we compared int8 QAT and fp32 PTQ in terms of accuracy and model size, and inference time. The important point is, it's not the correct inference time. Since, x86 architecture and ARM architecture are varied and our model is appropriate for ARM not x86. Thus, the inference time for int8 tflite model is slower than float32 tflite model or even slower than simple tf model without quantization. In fact, based on our observations on Samsung Galaxy A54 smartphone, int8 tflite model is roughly two times faster than fp32 tflite model.
