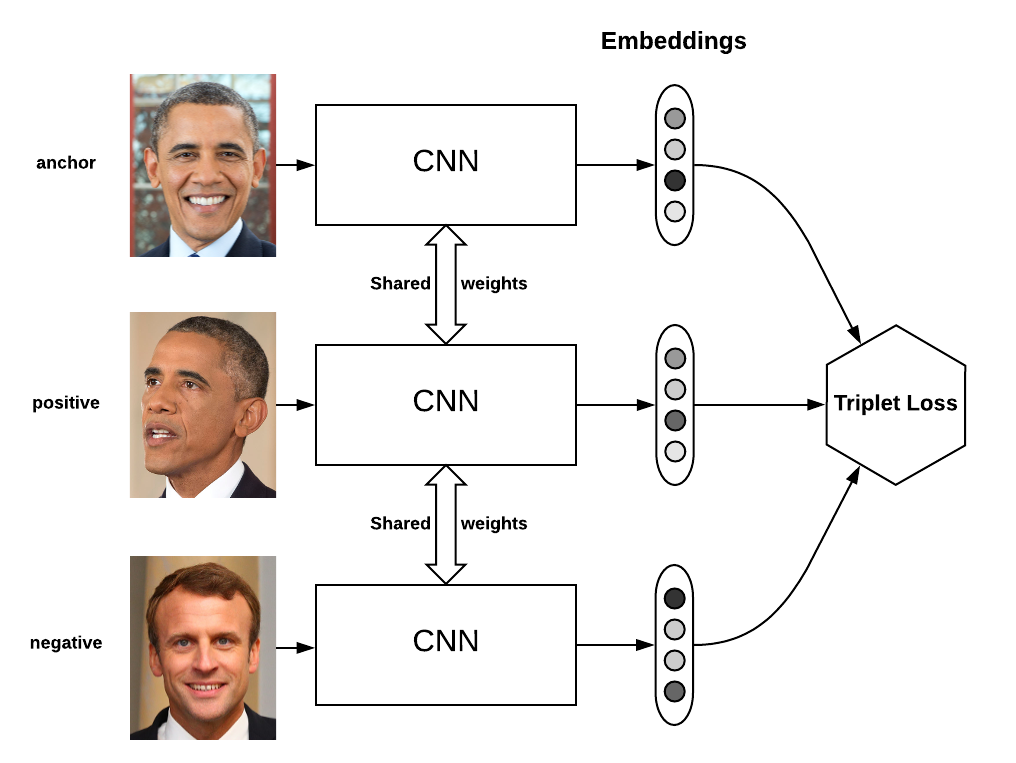
Hi, thanks for sharing your project,
In my own project, I trained the densenet network first, and then used the output as input for the new network, training a very simple DNN network.
def build_model(is_training, images, params):
"""Compute outputs of the model (embeddings for triplet loss).
Args:
is_training: (bool) whether we are training or not
images: (dict) contains the inputs of the graph (features)
this can be `tf.placeholder` or outputs of `tf.data`
params: (Params) hyperparameters
Returns:
output: (tf.Tensor) output of the model
"""
out = images
with tf.variable_scope('fc_1'):
out = tf.layers.dense(out, 1024,activation=tf.nn.relu)
with tf.variable_scope('fc_2'):
out = tf.layers.dense(out, params.embedding_size)
return out
But there were the following bugs:
Traceback (most recent call last):
File "/home/popzq/anaconda3/lib/python3.6/site-packages/tensorflow/python/client/session.py", line 1322, in _do_call
return fn(*args)
File "/home/popzq/anaconda3/lib/python3.6/site-packages/tensorflow/python/client/session.py", line 1307, in _run_fn
options, feed_dict, fetch_list, target_list, run_metadata)
File "/home/popzq/anaconda3/lib/python3.6/site-packages/tensorflow/python/client/session.py", line 1409, in _call_tf_sessionrun
run_metadata)
tensorflow.python.framework.errors_impl.InvalidArgumentError: Incompatible shapes: [64,64,64] vs. [0,0,0]
[[Node: Mul = Mul[T=DT_FLOAT, _device="/job:localhost/replica:0/task:0/device:GPU:0"](ToFloat_1, add_2)]]
[[Node: truediv_1/_77 = _Recvclient_terminated=false, recv_device="/job:localhost/replica:0/task:0/device:CPU:0", send_device="/job:localhost/replica:0/task:0/device:GPU:0", send_device_incarnation=1, tensor_name="edge_168_truediv_1", tensor_type=DT_FLOAT, _device="/job:localhost/replica:0/task:0/device:CPU:0"]]
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "train.py", line 50, in
estimator.train(lambda: train_input_fn('data/val.tfrecords', params))
File "/home/popzq/anaconda3/lib/python3.6/site-packages/tensorflow/python/estimator/estimator.py", line 363, in train
loss = self._train_model(input_fn, hooks, saving_listeners)
File "/home/popzq/anaconda3/lib/python3.6/site-packages/tensorflow/python/estimator/estimator.py", line 843, in _train_model
return self._train_model_default(input_fn, hooks, saving_listeners)
File "/home/popzq/anaconda3/lib/python3.6/site-packages/tensorflow/python/estimator/estimator.py", line 859, in _train_model_default
saving_listeners)
File "/home/popzq/anaconda3/lib/python3.6/site-packages/tensorflow/python/estimator/estimator.py", line 1059, in _train_with_estimator_spec
_, loss = mon_sess.run([estimator_spec.train_op, estimator_spec.loss])
File "/home/popzq/anaconda3/lib/python3.6/site-packages/tensorflow/python/training/monitored_session.py", line 567, in run
run_metadata=run_metadata)
File "/home/popzq/anaconda3/lib/python3.6/site-packages/tensorflow/python/training/monitored_session.py", line 1043, in run
run_metadata=run_metadata)
File "/home/popzq/anaconda3/lib/python3.6/site-packages/tensorflow/python/training/monitored_session.py", line 1134, in run
raise six.reraise(*original_exc_info)
File "/home/popzq/anaconda3/lib/python3.6/site-packages/six.py", line 693, in reraise
raise value
File "/home/popzq/anaconda3/lib/python3.6/site-packages/tensorflow/python/training/monitored_session.py", line 1119, in run
return self._sess.run(*args, **kwargs)
File "/home/popzq/anaconda3/lib/python3.6/site-packages/tensorflow/python/training/monitored_session.py", line 1191, in run
run_metadata=run_metadata)
File "/home/popzq/anaconda3/lib/python3.6/site-packages/tensorflow/python/training/monitored_session.py", line 971, in run
return self._sess.run(*args, **kwargs)
File "/home/popzq/anaconda3/lib/python3.6/site-packages/tensorflow/python/client/session.py", line 900, in run
run_metadata_ptr)
File "/home/popzq/anaconda3/lib/python3.6/site-packages/tensorflow/python/client/session.py", line 1135, in _run
feed_dict_tensor, options, run_metadata)
File "/home/popzq/anaconda3/lib/python3.6/site-packages/tensorflow/python/client/session.py", line 1316, in _do_run
run_metadata)
File "/home/popzq/anaconda3/lib/python3.6/site-packages/tensorflow/python/client/session.py", line 1335, in _do_call
raise type(e)(node_def, op, message)
tensorflow.python.framework.errors_impl.InvalidArgumentError: Incompatible shapes: [64,64,64] vs. [0,0,0]
[[Node: Mul = Mul[T=DT_FLOAT, _device="/job:localhost/replica:0/task:0/device:GPU:0"](ToFloat_1, add_2)]]
[[Node: truediv_1/_77 = _Recvclient_terminated=false, recv_device="/job:localhost/replica:0/task:0/device:CPU:0", send_device="/job:localhost/replica:0/task:0/device:GPU:0", send_device_incarnation=1, tensor_name="edge_168_truediv_1", tensor_type=DT_FLOAT, _device="/job:localhost/replica:0/task:0/device:CPU:0"]]
Caused by op 'Mul', defined at:
File "train.py", line 50, in
estimator.train(lambda: train_input_fn('data/val.tfrecords', params))
File "/home/popzq/anaconda3/lib/python3.6/site-packages/tensorflow/python/estimator/estimator.py", line 363, in train
loss = self._train_model(input_fn, hooks, saving_listeners)
File "/home/popzq/anaconda3/lib/python3.6/site-packages/tensorflow/python/estimator/estimator.py", line 843, in _train_model
return self._train_model_default(input_fn, hooks, saving_listeners)
File "/home/popzq/anaconda3/lib/python3.6/site-packages/tensorflow/python/estimator/estimator.py", line 856, in _train_model_default
features, labels, model_fn_lib.ModeKeys.TRAIN, self.config)
File "/home/popzq/anaconda3/lib/python3.6/site-packages/tensorflow/python/estimator/estimator.py", line 831, in _call_model_fn
model_fn_results = self._model_fn(features=features, **kwargs)
File "/home/popzq/zsl/tensorflow-triplet-loss-master-zsl/model/model_fn.py", line 95, in model_fn
squared=params.squared)
File "/home/popzq/zsl/tensorflow-triplet-loss-master-zsl/model/triplet_loss.py", line 160, in batch_all_triplet_loss
triplet_loss = tf.multiply(mask, triplet_loss)
File "/home/popzq/anaconda3/lib/python3.6/site-packages/tensorflow/python/ops/math_ops.py", line 337, in multiply
return gen_math_ops.mul(x, y, name)
File "/home/popzq/anaconda3/lib/python3.6/site-packages/tensorflow/python/ops/gen_math_ops.py", line 4759, in mul
"Mul", x=x, y=y, name=name)
File "/home/popzq/anaconda3/lib/python3.6/site-packages/tensorflow/python/framework/op_def_library.py", line 787, in _apply_op_helper
op_def=op_def)
File "/home/popzq/anaconda3/lib/python3.6/site-packages/tensorflow/python/framework/ops.py", line 3392, in create_op
op_def=op_def)
File "/home/popzq/anaconda3/lib/python3.6/site-packages/tensorflow/python/framework/ops.py", line 1718, in init
self._traceback = self._graph._extract_stack() # pylint: disable=protected-access
InvalidArgumentError (see above for traceback): Incompatible shapes: [64,64,64] vs. [0,0,0]
[[Node: Mul = Mul[T=DT_FLOAT, _device="/job:localhost/replica:0/task:0/device:GPU:0"](ToFloat_1, add_2)]]
[[Node: truediv_1/_77 = _Recvclient_terminated=false, recv_device="/job:localhost/replica:0/task:0/device:CPU:0", send_device="/job:localhost/replica:0/task:0/device:GPU:0", send_device_incarnation=1, tensor_name="edge_168_truediv_1", tensor_type=DT_FLOAT, _device="/job:localhost/replica:0/task:0/device:CPU:0"]]
I would appreciate it if you could help me!
















































































































































{kind=link}