













This is a mono repository for my home infrastructure and Kubernetes cluster. I try to adhere to Infrastructure as Code (IaC) and GitOps practices using tools like Ansible, Terraform, Kubernetes, Flux, Renovate, and GitHub Actions.
My Kubernetes cluster is deploy with Talos. This is a semi-hyper-converged cluster, workloads and block storage are sharing the same available resources on my nodes while I have a separate server with ZFS for NFS/SMB shares, bulk file storage and backups.
There is a template over at onedr0p/cluster-template if you want to try and follow along with some of the practices I use here.
- actions-runner-controller: Self-hosted Github runners.
- cert-manager: Creates SSL certificates for services in my cluster.
- cilium: Internal Kubernetes container networking interface.
- cloudflared: Enables Cloudflare secure access to certain ingresses.
- external-dns: Automatically syncs ingress DNS records to a DNS provider.
- external-secrets: Managed Kubernetes secrets using 1Password Connect.
- ingress-nginx: Kubernetes ingress controller using NGINX as a reverse proxy and load balancer.
- rook: Distributed block storage for peristent storage.
- sops: Managed secrets for Kubernetes and Terraform which are commited to Git.
- spegel: Stateless cluster local OCI registry mirror.
- tf-controller: Additional Flux component used to run Terraform from within a Kubernetes cluster.
- volsync: Backup and recovery of persistent volume claims.
Flux watches the clusters in my kubernetes folder (see Directories below) and makes the changes to my clusters based on the state of my Git repository.
The way Flux works for me here is it will recursively search the kubernetes/${cluster}/apps folder until it finds the most top level kustomization.yaml per directory and then apply all the resources listed in it. That aforementioned kustomization.yaml will generally only have a namespace resource and one or many Flux kustomizations (ks.yaml). Under the control of those Flux kustomizations there will be a HelmRelease or other resources related to the application which will be applied.
Renovate watches my entire repository looking for dependency updates, when they are found a PR is automatically created. When some PRs are merged Flux applies the changes to my cluster.
This Git repository contains the following directories under Kubernetes.
📁 kubernetes
├── 📁 main # main cluster
│ ├── 📁 apps # applications
│ ├── 📁 bootstrap # bootstrap procedures
│ ├── 📁 flux # core flux configuration
│ └── 📁 templates # re-useable components
└── 📁 storage # storage cluster
├── 📁 apps # applications
├── 📁 bootstrap # bootstrap procedures
└── 📁 flux # core flux configurationThis is a high-level look how Flux deploys my applications with dependencies. Below there are 3 apps postgres, glauth and authelia. postgres is the first app that needs to be running and healthy before glauth and authelia. Once postgres and glauth are healthy authelia will be deployed.
graph TD;
id1>Kustomization: cluster] -->|Creates| id2>Kustomization: cluster-apps];
id2>Kustomization: cluster-apps] -->|Creates| id3>Kustomization: postgres];
id2>Kustomization: cluster-apps] -->|Creates| id6>Kustomization: glauth]
id2>Kustomization: cluster-apps] -->|Creates| id8>Kustomization: authelia]
id2>Kustomization: cluster-apps] -->|Creates| id5>Kustomization: postgres-cluster]
id3>Kustomization: postgres] -->|Creates| id4[HelmRelease: postgres];
id5>Kustomization: postgres-cluster] -->|Depends on| id3>Kustomization: postgres];
id5>Kustomization: postgres-cluster] -->|Creates| id10[Postgres Cluster];
id6>Kustomization: glauth] -->|Creates| id7(HelmRelease: glauth);
id8>Kustomization: authelia] -->|Creates| id9(HelmRelease: authelia);
id8>Kustomization: authelia] -->|Depends on| id5>Kustomization: postgres-cluster];
id9(HelmRelease: authelia) -->|Depends on| id7(HelmRelease: glauth);
Click to see a high-level network diagram
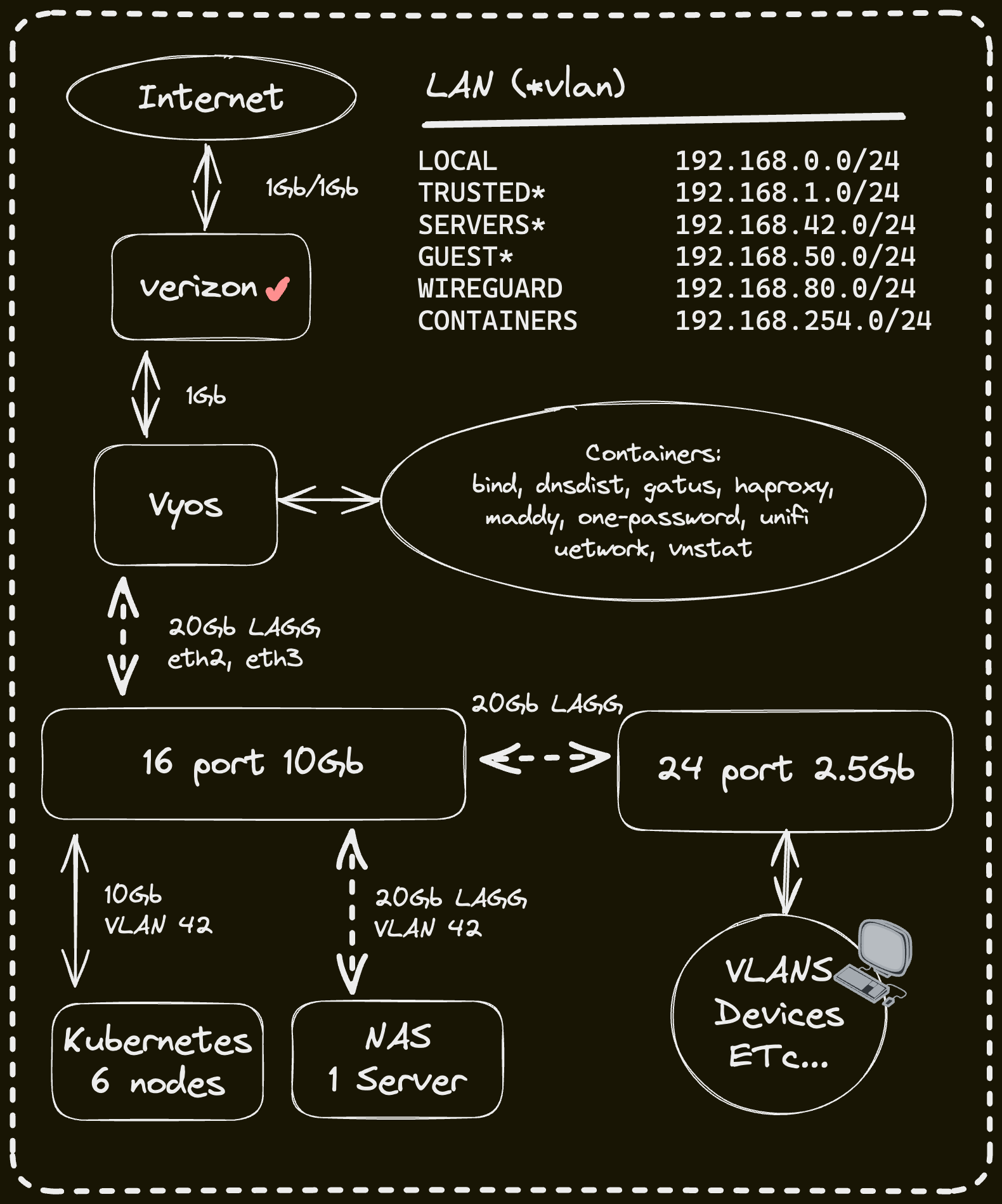
While most of my infrastructure and workloads are self-hosted I do rely upon the cloud for certain key parts of my setup. This saves me from having to worry about two things. (1) Dealing with chicken/egg scenarios and (2) services I critically need whether my cluster is online or not.
The alternative solution to these two problems would be to host a Kubernetes cluster in the cloud and deploy applications like HCVault, Vaultwarden, ntfy, and Gatus. However, maintaining another cluster and monitoring another group of workloads is a lot more time and effort than I am willing to put in.
| Service | Use | Cost |
|---|---|---|
| 1Password | Secrets with External Secrets | ~$65/yr |
| Cloudflare | Domain and S3 | ~$30/yr |
| Frugal | Usenet access | ~$35/yr |
| GCP | Voice interactions with Home Assistant over Google Assistant | Free |
| GitHub | Hosting this repository and continuous integration/deployments | Free |
| Migadu | Email hosting | ~$20/yr |
| Pushover | Kubernetes Alerts and application notifications | $5 OTP |
| Terraform Cloud | Storing Terraform state | Free |
| UptimeRobot | Monitoring internet connectivity and external facing applications | ~$60/yr |
| Total: ~$20/mo |
On my Vyos router I have Bind9, blocky and dnsdist deployed as containers. In my cluster external-dns is deployed with the RFC2136 provider which syncs DNS records to bind9.
dnsdist is a DNS loadbalancer and has "downstream" DNS servers configured such as bind9 and blocky. All my clients use dnsdist as the upstream DNS server, this allows for more granularity with configuring DNS across my networks such as having all requests for my domain forward to bind9 on certain networks, or only using 1.1.1.1 instead of blocky on certain networks where adblocking isn't required.
Outside the external-dns instance mentioned above another instance is deployed in my cluster and configured to sync DNS records to Cloudflare. The only ingress this external-dns instance looks at to gather DNS records to put in Cloudflare are ones that have an ingress class name of external and contain an ingress annotation external-dns.alpha.kubernetes.io/target.
Click to see the rack!

| Device | Count | OS Disk Size | Data Disk Size | Ram | Operating System | Purpose |
|---|---|---|---|---|---|---|
| Intel NUC8i5BEH | 3 | 1TB SSD | 1TB NVMe (rook-ceph) | 64GB | Talos | Kubernetes Controllers |
| Intel NUC8i7BEH | 3 | 1TB SSD | 1TB NVMe (rook-ceph) | 64GB | Talos | Kubernetes Workers |
| PowerEdge T340 | 1 | 2TB SSD | 64GB | Ubuntu LTS | NFS + Backup Server | |
| Lenovo SA120 | 1 | - | 10x22TB ZFS (mirrored vdevs) | - | - | DAS |
| Raspberry Pi 4 | 1 | 32GB (SD) | - | 4GB | PiKVM (Arch) | Network KVM |
| TESmart 8 Port KVM Switch | 1 | - | - | - | - | Network KVM (PiKVM) |
| HP EliteDesk 800 G3 SFF | 1 | 256GB NVMe | - | 8GB | Vyos (Debian) | Router |
| Unifi US-16-XG | 1 | - | - | - | - | 10Gb Core Switch |
| Unifi USW-Enterprise-24-PoE | 1 | - | - | - | - | 2.5Gb PoE Switch |
| Unifi UNVR | 1 | - | 4x8TB HDD | - | - | NVR |
| Unifi USP PDU Pro | 1 | - | - | - | - | PDU |
| APC SMT1500RM2U w/ NIC | 1 | - | - | - | - | UPS |
Thanks to all the people who donate their time to the Home Operations Discord community. Be sure to check out kubesearch.dev for ideas on how to deploy applications or get ideas on what you may deploy.






















































































































