onizukalab / conferenceproceedings Goto Github PK
View Code? Open in Web Editor NEWNLP 班論文読み会用のリポジトリ
NLP 班論文読み会用のリポジトリ





























テキスト生成に entity のベクトル表現を用いたモデルを提案し、3つのタスクで評価した。
https://homes.cs.washington.edu/~eaclark7/www/naacl2018.pdf
Elizabeth Clark, Yangfeng Ji, Noah A. Smith
(Paul G. Allen School of Computer Science & Engineering University of Washington Seattle, WA, USA)
現在生成している文の前の単語のRNNの隠れ状態・以前の文のベクトル表現・entityのベクトル表現を考慮した文脈ベクトルを用いることで、narrative text(小説、ニュースなど)にとって必要である entity を考慮した文の生成を行う。
評価は 1)mention generation、2)sentence selection、3)sentence generation の3つのタスクで行い、1)、2) では既存のモデルよりも高い精度を達成した。また3) では人手での評価を行い、既存のモデルと提案モデルが生成した文の優劣だけでなく、「なぜその文が優れていると判断したか?」を答えてもらうことで、生成した文の問題とこれからの課題を明らかにした。
既存手法では entity を考慮した LM を提案しており、それまでの手法と比較すると perplexity が低下していた。これは、entity のベクトル表現がうまく行えているということを示している。提案手法ではこの entity のベクトル表現手法を用いたモデルを提案している。
context from previous sentence
普通のattentionメカニズムと同じで、現在の文のある単語の隠れ状態と1つ前の文の隠れ状態から attention を計算し、1つ前の文の各単語の隠れ状態と attention の重み付き和で文のベクトル表現を作る。
context from entity
entity のベクトル表現を用いてどの entity が参照されるかの重みを計算し、重みが一番大きい entity を1つ選ぶ(このベクトルが現在の context を表す)。
これらと前の単語での隠れ状態を用いて、文脈ベクトルを決定する。文脈ベクトルの各次元の値は、3つのベクトルの同じ次元のあたいのうち一番大きいものである(max-pooling)。このベクトルから class-factored softmax を用いて単語を出力していく。
ベースラインをS2SA、既存手法をENTITYNLM、提案手法をENGENとする、
mention generation
entity が入るべきスロットに、これまで出てきた entity のうちどの entity を入れるかを当てる問題。

2行目と4行目から、entity のベクトル表現が有効であり、3行目と4行目から局所的な文脈を用いることで(ちょっとだけだが)精度が上がる。1行目は最後に出てきたものを選ぶ手法だが、heuristic な手法は効果がなかった。
sentence selection
49文が示された後、次に入る50番目の文としてどちらがいいかを、2つの文から選ぶ問題。

mention generation(上のタスク)と違って、S2SAの方が精度がいい。これは、局所的な文脈が重要であることを示している。
sentence generation
60単語以上の文章を読んで、次に続くべき文を生成する問題。このタスクは人手での評価を行った。
結果としては、「以前の entity がある文だから選ぶ」というより「以前出てきていない entity がある文だから選ばない」という人が多かった。また以前出てきていない entity が新しく出てきていても、それで話が続きそうというような、テーマや雰囲気に沿ったような文を選ぶ人もいた。
人手を使って数値では表せない部分の問題点も洗い出しており、しっかり分析しているなと思いました。特に「新しい entity が生成されていて、物語が進みそうな文なので評価した」という意見はすごい面白いなと思いました(以前の entity を参照した方がいいという考えしか持っていなかったので)。
PBSMTとNMTで教師なし機械翻訳手法を提案
https://aclweb.org/anthology/D18-1549
Guillaume Lample†‡, Myle Ott†, Alexis Conneau†§, Ludovic Denoyer‡, Marc' Aurelio Ranzato†
†) Facebook AI Research ‡) Sorbonne Universités §) Université Le Mans
近年の教師なし機械翻訳の提案手法から、翻訳に必要なステップとして
翻訳に必要なステップを定め、PBSMTとNMTで実際に教師なし機械翻訳を行なったところ。
翻訳は
Unsupervised NMTでは
Unsupervised PBSMTでは
既存の教師なし機械翻訳手法を上回るBLEU値を達成、またPBSMTの方がNMTよりもBLEU値が高くなるという結果に。英露翻訳のような文字の異なる言語対でもちゃんと翻訳の学習ができている。また、PBSMTとNMTを組み合わせることでさらにBLEU値が上昇した。
English-Urduの結果だけ表にないのがちょっと気になる。英日対だとどうなるのか試してみたい。
RNNとTransformerを比べた.(bilingual / multilingual / zero-shotで)
http://aclweb.org/anthology/C18-1054
Surafel M. Lakew, Mauro Cettolo, Marcello Federico
COLING2018
bilingual, multilingual, zero-shotで定量的な評価を行った.
TransformerとRNNの翻訳性能について調査した.
zero-shotにおいて言語の近さがどう影響するか調べた.

属性変換タスク(広義のスタイル変換)において、よりシンプルでつよいモデルを提案。
https://arxiv.org/pdf/1804.06437.pdf
Juncen Li∗1 Robin Jia2 He He2 Percy Liang2 1 WeChat Search Application Department, Tencent
2 Computer Science Department, Stanford University
2018.04.17
属性(sentimentなど)に依存しないコンテンツを保持しながら、特定の属性を変換するタスクにおいて、1.DELETE:文からソース属性特有の表現を削除する
2.RETRIEVE:ターゲット属性を持つ文集合から似た文を検索する
3.GENERATE:最終的な出力を生成する
という3ステップに分けて行うことで、よりシンプルで・学習しやすくて・つよくて・制御しやすいモデルを提案した。
提案モデルをYelpレビュー(pos/neg)・Amazonレビュー(pos/neg)・Image Caption(factual/romantic/humorous)のデータセットで評価した。
↑っょぃ
| 提案手法(DELETEANDRETRIEVE)
| ベースライン(RETRIEVEONLY、TEMPLATEBASED)、提案手法(DELETEONLY)
| GANベースの先行研究3つ(CROSSALIGNED、MULTIDECODER、STYLEEMBEDDING)
↓ょゎぃ
属性の情報が現れるのは文中のほんの一部分である、という知識を利用して、コンテンツと属性情報を明示的に分離しているところ。
どれぐらい変換するかを再学習なしで制御可能。(ソース属性マーカーの域値やターゲット属性マーカーの選び方を制御すればよいので)



DELETEすると"Fish is delicious."と"Fish is cute."の区別がつかなくなって困りそう。
人間が作ったリファレンスでさえ75%,45%,56%しか成功してなくて絶望した。
画像説明文生成において,画像へのアテンションとトピックへのアテンションをうまいこと組み合わせた.
http://aclweb.org/anthology/D18-1013
Fenglin Liu, Xuancheng Ren, Yuanxin Liu, Houfeng Wang, Xu Sun
School of ICE, Beijing University of Posts and Telecommunications
MOE Key Laboratory of Computational Linguistics, School of EECS, Peking University
画像説明文生成タスクにおいて,画像へのアテンションとテキストへのアテンションを同時に考慮する Image-Topic Merging Network (simNet) を提案.デコード時の各タイムステップごとに,トピックと画像それぞれにアテンションを張って特徴抽出.生成文の文脈を元にバランスを決めてマージすることで,意味的な情報と画像情報とをいい感じに組み合わせた.
意味的な情報と画像情報とを組み合わせて画像説明文生成を改善した研究は(著者らによれば)これが最初.
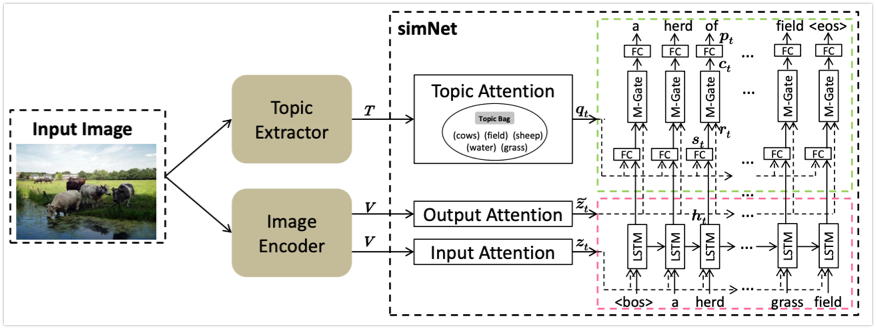
提案モデルは画像エンコーダー・トピック抽出器・マージングデコーダの3つからなる.
画像の特徴量を抽出し、ベクトルとして表現する.ResNet152 を利用.
デコーダーに意味的なコンセプト(以降ではこれをトピックと呼ぶ)を与えることを目的とし,トピック抽出器は,画像からトピック候補リストを決定する.正例説明文内の名詞全てを正解のトピック候補リストとする.

画像アテンション・トピックアテンション・マージングゲートの3つのコンポーネントからなる LSTM.
画像アテンションは画像中の注目すべき部分への誘導を目的とする.直前のタイムステップの隠れ状態および画像特徴量を元に画像特徴量へのアテンションを張る入力アテンションと,現在の隠れ状態(これは直前の出力単語を反映していると考えられる)および画像特徴量を元に画像特徴量へのアテンションを張る出力アテンションから成る.
トピックアテンションは現在の隠れ状態とトピック候補リストを元にトピックへのアテンションを張る.
マージングゲートは現在の隠れ状態を元に画像アテンションの結果得られたベクトルとトピックアテンションの結果得られたベクトルのバランスを決定しマージする.こうして得られたベクトルから単語を決定する.
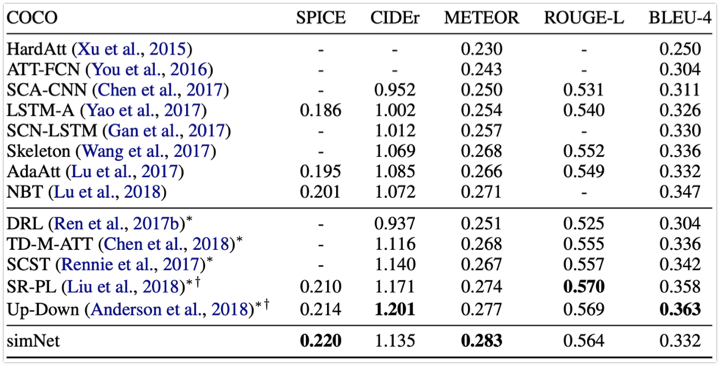
直接比較できる比較手法には BLEU 以外で優っている.特に,画像説明文生成において最も人手評価と強く相関する指標である SPICE で勝っているので強い.SPICE は特に詳細な記述の評価に強い.
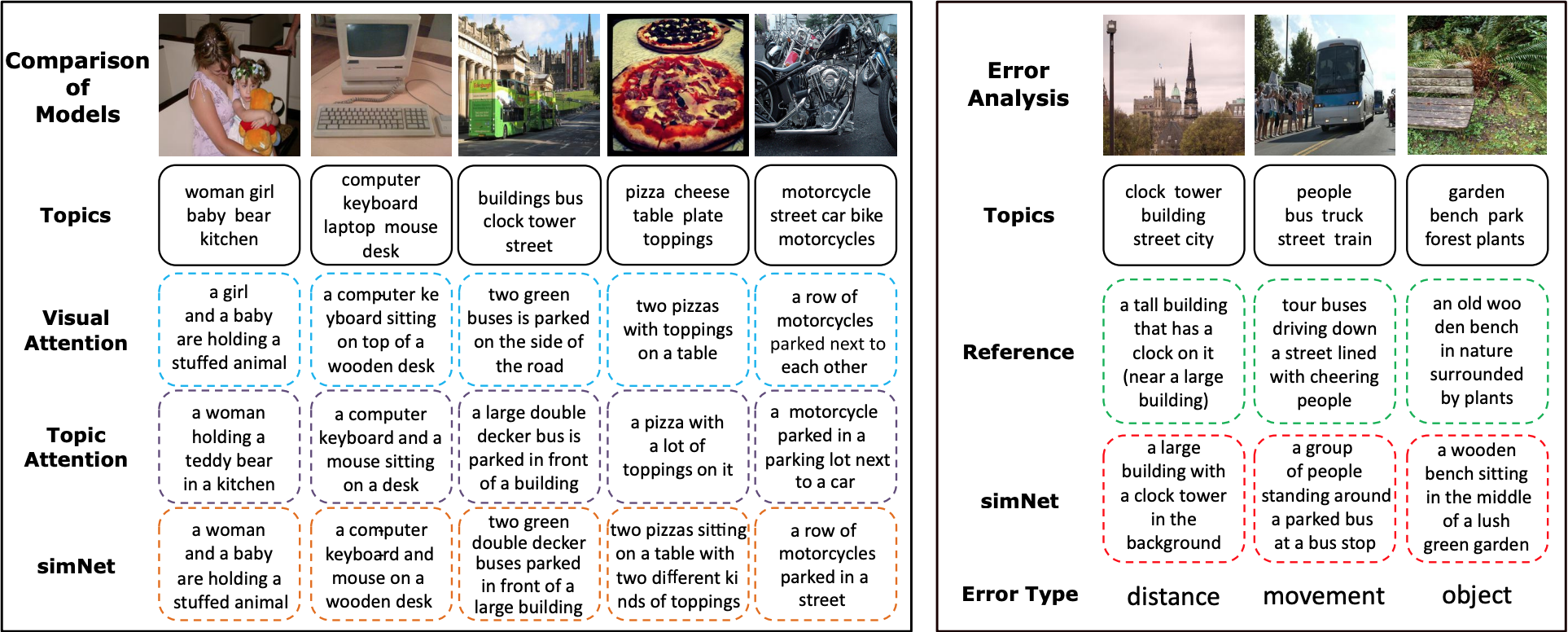
トピックアテンションと画像アテンションがいい感じに組み合わせられていることがわかる.

綺麗な結果だなと思いました.出力例とかも,順当で綺麗.
ネコチャン 可愛い.
ところでなぜ私はこれの発表準備をしているのでしょう?(本読み会2本目)
応答生成における特殊性をデコーダ部で制御する
http://aclweb.org/anthology/P18-1102
Ruqing Zhang, Jiafeng Guo, Yixing Fan, Yanyan Lan, Jun Xu and Xueqi Cheng
University of Chinese Academy of Sciences, Beijing, China
CAS Key Lab of Network Data Science and Technology, Institute of Computing Technology,
Chinese Academy of Sciences, Beijing, China
2018/07/
応答生成における特殊性をデコーダ部で制御する。
デコード時に各単語の出現確率に操作をし、応答を多様にして欲しい時ほどありきたりでない単語の出現確率を大きくする。
文及び単語のデータ中の出現数を数え、少ないものほど多様であると仮定し、発話応答対に特殊性を表す数値を予め付与する。
追加データ、アノテーションなしで応答生成の多様性の制御を実現

応答文レベルで決定(NIRF)
データ全体に出現する数が少ない応答文ほどSが高くなる
応答文中の単語レベルで決定(NIWF)
データ全体に出現する数が少ない単語を持つ応答文ほどSが高くなる

distinct-nは全ての生成文で一度だけ出現したngram/それを全ての生成文で出現したngram数で除算した物
応答の特殊性を制御できていることがわかる
NMTを効果的に且つ素早く新しいlow-resourceの言語に適用させる。
http://aclweb.org/anthology/D18-1103
Graham Neubig, Junjie Hu/CMU
Cross-lingual transfer (fine-tuning)を用いて様々な設定でNMTを新しいlow-resourceの言語に適用させる。


自分のmixed fine tuningを比較してほしい。
スタイル変換(Formality Transfer)とスタイル気にする機械翻訳(Formality-Sensitive MT)をマルチタスク学習した。
http://aclweb.org/anthology/C18-1086
Xing Niu, Sudha Rao, Marine Carpuat, University of Maryland, MD, USA
2018/06/12
スタイル変換(Formality Transfer)とスタイル気にする機械翻訳(Formality-sensitive MT)をマルチタスク学習した。
FT:SOTA更新
FSMT:FSMT側のデータに制約(事前にデータ選別が必要)つけなくても、それなりの結果に
・FTとFSMTマルチタスク学習した
・FTと一緒に学習することで、事前にデータ選別することなくFSMTできた






※めっちゃねむい
すっごい深いBi-LSTM言語モデルの内部状態から Word Embedding を獲得する
http://aclweb.org/anthology/N18-1202
Matthew E. Peters†, Mark Neumann†, Mohit Iyyer†, Matt Gardner†
Christopher Clark*, Kenton Lee*, Luke Zettlemoyer†*
†Allen Institute for Artificial Intelligence
*Paul G. Allen School of Computer Science & Engineering, University of Washington
従来の単語分散表現のほとんどは文脈に依らず単語と分散表現は一対一対応しているが,本提案手法では言語モデルを用いて単語分散表現を動的に獲得しており,これによって文法特性や多義性を扱うことができるようになった.
深くスタックした LSTM のうちどの層を重視するかを応用タスクごとに学習することで,様々なタスクへの転移学習が可能に.
Bi-LSTM 言語モデルの学習
多層 Bi-LSTM を用いた言語モデルを大規模なコーパスで学習させる.
ELMo

簡単なベースラインに ELMo を追加するだけで,質問応答(Question Answering),テキスト含意認識(Textual Entailment),感情分析(Sentiment Analysis)など多くのタスクで SOTA モデルに匹敵もしくはそれ以上のスコアを達成.

エンドタスクへの転移において ELMo そのものを再学習する必要がない(線形結合の重みだけ学習すれば良い)という点で使いやすいのではないかと感じた.
日本語で試したい(計算資源をたくさん持ってるひとたちがやって公開してくれると良いなー)
multi labelingを別の見方でやってみた
http://aclweb.org/anthology/C18-1330
Multi Label classificationはsingle labelより複雑であり、ラベル間に相関があることが多い。
また、文中のどの部分が判断材料になるかも、ラベルごとに変わってくる。
しかし、先行研究のモデルではこれらを全て無視している。
この論文では、Multi label classificationをsequence generation問題として捉え、新たなdecoder構造を
適用したsequence generationモデルを使うことにより、上の問題に対処した
Attention機構を備えたseq2seq。decoder部分には、新たにmask vectorとglobal embeddingが使用されている


細かいところまで説明されていたので、読みやすかったです
解釈可能な文の離散表現を得るためにVAEやGumbel-Softmaxトリックを使って色々とやってみました
https://aclanthology.info/papers/P18-1101/p18-1101
Tiancheng Zhao , Kyusong Lee and Maxine Eskenazi
Language Technologies Institute, Carnegie Mellon University
Recognition network (R) によって文 x を K-classes × M の離散的な潜在変数 z = {z1, z2, ... ,zM} に変換する.訓練時には Gumbel-Softmax トリックを用いる.
Generation network (G) は潜在表現 z を元に,VAEモデルにおいては入力文を復元,VSTモデルにおいては隣接文を予測するように学習する.




2名のエキスパートが,各潜在クラスに属する文からそれぞれ5文ずつサンプリングしたものに対し,その5文に共通するような性質を示すようにラベル付けを行う.
その後AMTを用いて5名のワーカーを雇い,各クラスに属する他の文がエキスパートのつけたラベルの説明にマッチするかどうかを判定してもらう.この時ネガティブサンプリングを行うことで不正を防ぐ.
結果:

アノテーション例:

与えたラベルと生成例:

非常に多くの実験を行っており丁寧な論文だった(誤記は多いが)
教師なしで対話行為等のカテゴライズされた情報を得られるのは非常にありがたい
FastTextとGaussianMixtureを組み合わせると精度の高い分散表現(の分布)が得られる。多義語・未知語・低頻度語に強い。
Probabilistic Fast Text for Multi-Sense Word Embeddings
2018/07/15
SGNSやCBOWでは多義語や低頻度語・未知語に対応できない。それらに対応するため様々な手法が提案されてきた。例えば、単語をサブワードに分割して学習するFastTextを用いると、低頻度語・未知語に対応できる。また、点ではなく分布で単語を表現するGaussianMixtureが存在する。
この論文では上記二つの手法を組み合わせることで、低頻度語・未知語に対して高い性能を発揮し、さらに多義語にも頑強な手法を提案している。



発話単位の関係を捉えることができるSeq2Seqを提案
Liangchen Luo, Jingjing Xu, Junyang Lin, Qi Zeng, Xu Sun
2018/11
発話生成は対話分野において重要なタスクである.
発話生成の既存手法のほとんどはSeq2Seqをベースとしている.
しかし,Seq2Seqは文単位での意味関係を捉えることができるが,
発話単位の意味関係を捉えることができない課題がある.
そこで,本研究では発話単位の意味関係を捉えるSeq2Seqモデルを提案する.
Seq2Seqモデルと比較した結果,BLEU, Distinct, 人手評価において良い性能を示した.
発話単位の意味関係を捉える新しいSeq2Seqモデル,Auto-Encoder Matching modelを提案
応答の一貫性,流暢性,多様性においてSeq2Seqモデルと比較して良い性能を示した
Daily Dialogue Corpus
train: 36.3k, valid: 11.1k, test: 11.1k [pairs]
BLEU-(1, 2, 3, 4)
Distinct-(1, 2, 3, 4)
10段階人手評価 (Fluency, Coherence)
Seq2Seq
Seq2Seq + Attention
提案手法
提案手法 + Attention
単語分散表現を画像に基づいて獲得する手法を提案
http://aclweb.org/anthology/P18-1085
J. Kiros, W. Chan, G. Hinton
Google Brain Toronto
単語分散表現の獲得に画像を用いること






コンセプトは順当でスッキリしたものだと思いました.220万の単語に対して,少なくとも10枚/語彙 の画像を CNN モデルに突っ込むので結構重たい処理だと思うのですが,さすが Google だけあってやっている実験の量が違いますね.数の暴力.
今回はそれぞれの手法は単純なものですが,各タスクに対してこれらの手法はどんどん最適化され洗練されていくと思うので,今後の発展が楽しみです.
従来の教師なし学習を用いた機械翻訳ではエンコーダが一つ,デコーダが二つだったが,提案手法ではエンコーダの最後からn層とデコーダの最初からm層のweightをシェアすることで精度を向上させた.
http://aclweb.org/anthology/P18-1005
Zhen Yang, Wei Chen, Feng Wang, Bo Xu
Institute of Automation, Chinese Academy of Sciences
University of Chinese Academy of Sciences
2018/07
AEを二つ用意し真ん中の層の重みをシェアすることで,二言語が同じ潜在空間にマッピングされるように学習する.
中間のシェアされている層をみて,言語Sと言語Tでどちらの言語からマッピングされたかを識別する識別器D_lと
出力をみてどちらの言語から翻訳されたかを識別する識別器D_gを用いる.




いろいろ実装していてすごい.
Ablation Studyはたくさんの機構を実装している人向けであり,今後使っていきたいかも.
ただ,重みシェアという考えは順当.
機構を変えるならもう少しBLEUの改善が望まれるのでは?(ブーメラン)
NLP におけるマルチモーダル研究のサーベイ論文.マルチモーダルの分類からマルチモーダル研究の最新動向まで幅広く議論されている.
Multimodal Grounding for Language Processing
COLING 2018
NLP におけるマルチモーダル研究を情報フローの観点から議論する.
サーベイ論文は流し読みができないのでつらかった.
機械翻訳に通すとスタイル情報を落とせるので、それを使ってスタイル変換をする。
https://arxiv.org/pdf/1804.09000.pdf
Shrimai Prabhumoye, Yulia Tsvetkov, Ruslan Salakhutdinov, Alan W Black Carnegie Mellon University, Pittsburgh, PA, USA
2018/05/24
機械翻訳を使用することによって、スタイル情報を落とした潜在変数zを得ることができる。
このzから目的のスタイルの文を生成するようにする。
3つのタスクGender・Political Slant・Sentimentにおいて、だいたいSOTAベースライン(Closs-Aligned AE)を上回る性能を発揮。
・機械翻訳を使った新しいスタイル変換のアプローチを提案
・スタイル変換のタスクとして、政治的立場を変更するタスクを提案

分類器(システムの分類器の訓練に使わなかったデータで訓練したもの)による評価

人手による評価(ABテスト)

人手による評価(1(判読不能)~4(完璧)でスコアリング)

著者「sentiment transferは無理ゲー。スタイル変換の評価には適していない」
「おはようございます」だと「Good morning」になって、「おはよー」だと「Hi」に訳されたりしない?
本当に翻訳を通すとスタイルが消えるの?もしくはほとんどがそうなるのか?
転移学習的な手法を使ってParallelコーパスがほとんどない言語のNMTを作ってみた。
Universal Neural Machine Translation for Extremely Low Resource Languages
Jiatao Gu†∗ Hany Hassan‡ Jacob Devlin§∗ Victor O.K. Li†
† The University of Hong Kong
‡ Microsoft Research
§ Google Research
2018/04/17
Neural MTのトレーニングには膨大な量の対訳コーパスが必要で、マイナー言語や特定ドメインだとコーパス足りない問題に直面する。
本研究では、この問題に対処するため多言語NMTの枠組みを利用している。コーパスの少ないターゲット言語のmonolingual dataに、複数のメジャーな言語の語彙/文章表現をuniversalなtokenとして共有させencodeすることにより、コーパスの少なさを補っている。
その結果、6k程度の僅少なコーパスでもBLEUスコアで20を超える程度のモデルを作ることができた。
多言語のモデルからuniversalなrepresentation spaceを作り、転移学習の枠組みを作っているところ
語彙レベルと文章レベルのマッピングを両立させているところ

EQ:ターゲット言語のembedding
EK:Universal tokenのembedding
EU:NMT embeddingの行列
点線の囲いはuniversalなモデルになっているところ
語彙のlexiconを考慮したマッピング
各メジャー言語のmonolingual embeddingと統合
言語ごとのexpertsと、その入出力をコントロールするゲートを設置
文レベルのuniversal modelを作る

Multi language source ごとのBLEUスコア。
単なるMulti-lingualモデルに対して、ULRとMoLEを導入することによってスコアが上昇している。

Ablation studyの結果。ULRとMoLE、さらにback translation (BT)を追加することでBLEUは23近くまで改善されている。
凝ったシステムやなあ...
Reading comprehension (RC) データセットが本当にRCの評価に適したものになっているか調査
5種類のデータセット、3種類のNNベースのモデルを使用
データセット作成論文、提案モデル論文でレポートすべき要件について提案
https://aclanthology.info/papers/D18-1546/d18-1546
Divyansh Kaushik, Zachary C. Lipton (CMU)
EMNLP2018 (Short paper)
個々のデータセットに対する分析はあるが、5種類のデータセットを横断的に分析したのは初めて?
“Corrupt Data” を準備
Q-only: Assign random passages (For SQuAD, create passages that contain the candidates in random locations)
P-only: Assign random questions
Full data/Corrupt dataでのモデルの性能を比較
Q-only, P-onlyでも高い性能が出るなら、PassageとQuestionを関連付けられていなくても解ける問題
CNN: “anonymization of entities which prevents models from building entity-specific information”
SQuAD: “is an unusually carefully-designed and challenging RC task.”
他のデータセットは問題アリ
Q-only, P-onlyでも結構正解できちゃう
Passageの最後の一文だけでも正解できるものも
結果を報告するときは、Q-only, P-onlyでの性能も報告しよう。でないとRCのタスクを本当にやっているのか、passage の正解に対する分類問題を解いているのか分からない。
加えて、正解するのに必要だったコンテキスト(passageの分量)についても報告しよう。
resource-richの言語対(X, Y)を用いてresource-poorの言語対(X, Z), (Y, Z)の翻訳精度を上げるのに、triangular architectureを提案。
http://aclweb.org/anthology/P18-1006
Shuo Ren1,2*, Wenhu Chen3, Shujie Liu4, Mu Li4, Ming Zhou4 and Shuai Ma1,2
1SKLSDE Lab, Beihang University, China
2Beijing Advanced Innovation Center for Big Data and Brain Computing
3University of California, Santa Barbara, CA, USA
4Microsoft Research Asia, Beijing, China
2018/05/13
Neural Machine Translation (NMT) performs poor on the low-resource language pair (X, Z), especially when Z is a rare language. By introducing another rich language Y , we propose a novel triangular training architecture (TA-NMT) to leverage bilingual data (Y, Z) (may be small) and (X, Y ) (can be rich) to improve the translation performance of low-resource pairs. In this triangular architecture, Z is taken as the intermediate latent variable, and translation models of Z are jointly optimized with a unified bidirectional EM algorithm under the goal of maximizing the translation likelihood of (X, Y ). Empirical results demonstrate that our method significantly improves the translation quality of rare languages on MultiUN and IWSLT2012 datasets, and achieves even better performance combining back-translation methods.


Multilingual MTと実験的に比べてない
NMTにおける(サブ)ワードレベルとキャラクターレベルの融合
http://www.aclweb.org/anthology/N18-1116
Huadong Chen, Shujian Huang, David Chiang*, Xinyu Dai and Jiajun Chen
State Key Laboratory for Novel Software Technology, Nanjing University
*Department of Computer Science and Engineering, University of Notre Dame
細かい粒度の文字のEmbeddingを用いてword representationをよくする.
Encoder側もDecoder側もソースサイドの文字列と単語列の情報を使用する.
Encoderで文字列情報をembeddingするときに,単語の内側と外側,それぞれの情報を使ってrepresentationを作成する.
Encoder側,Decoder側単体でも性能が向上する言語対もあるが,組み合わせると全てを上回る.
文字だけを使う手法に比べて,シンプルに単語の表現を強化する
文字と単語情報を組み合わせる手法は単語レベルの情報を無視している

Encoder:
character-levelのembeddingとword-levelのembeddingを組み合わせる.
Decoder:

少し単純?
あまり手法のすごさがわからない
グラフ表現を使ってRNNなしで言語生成すると、既存手法以上のパフォーマンスが出ました
多くのNLPアプリケーションはGraph-to-Sequenceの問題と捉えられる。
既存手法では、Neural Architectureを使って、文法ベースより良い結果が得られているが、未だに
線形化ヒューリスティックやRNNなどに頼っている。
この論文ではグラフに含まれる構造化された情報を全て利用するモデルを提案する。
実験から、この論文の提案手法は、AMRからの生成タスク、機械翻訳両方においてs2sを上回った。
Levi Graph変換を用いて、パラメータ数爆発問題の解決と、各グラフに適したエッジのベクトル表現の
取得を実現している
seq2seqのenocder部分に、Gated Graph Neural Networkを適用。
入力グラフは、有向非巡回グラフをLevi Graphに変換したものを使用



Noun-compounds の constituency 間に存在するimplicit relationをパラフレーズすることで明らかにする手法を提案。学習コーパスに存在しないnoun-compoundsも取り扱える一般性を実現。
https://aclanthology.info/papers/P18-1111/p18-1111
Vered Shwartz, Ido Dagan (Bar-Ilan University, Israel)
ACL2018
Noun-compounds の constituency 間に存在するimplicit relationをパラフレーズすることで明らかにする手法を提案している。constituencyのペアからrelationを予測するタスク、constituency の一つとrelationから残りのconstituencyを予測するタスクのマルチタスク学習を行う。
定性的評価により、未知の noun-compounds についてもパラフレーズできることを示した。また厳密には別タスクとなるがSemEvalやTratz (2011) のデータを用いた定量評価(既存研究との比較)も丁寧に行っている。
既存研究では、implicit relationをラベル付けする分類問題、もしくは人手で作ったパラフレーズのランキング問題として定式化していた。前者はラベルセットの設計が困難であり、また複数ラベルを持ちうるケースに対応できない。後者は学習データに存在しないnoun-compoundsを取り扱えない問題があった。
提案手法ではこの問題を解決し、未知のnoun-compoundsでもパラフレーズできる一般性を実現している。

定性的分析の結果

丁寧な分析が興味深い論文
「○○といえば△△」のような情報推薦にも応用できそう。
ベーシックなCNNを(Wieting et al. 2016)に適用したらSTSタスクで性能が上がる(ケースもある)ことを示した。
Wieting et al. Towards Universal Paraphrastic Sentence Embeddings (ICLR 2016)
https://aclanthology.info/papers/C18-1209/c18-1209
Xiaoqi Jiao, Fang Wang, Dan Feng
COLING2018
Paraphraseを使った学習フレームワーク、ロス関数などベースは(Wieting et al. 2016)。
Sentence Embeddingを作る部分にベーシックなCNNを適用。
STS2012-2015, SICKデータセットによる実験で性能向上を示し、フィルタサイズ、学習コーパスの影響も調査。
(Wieting et al. 2016)にCNNによるSentence embedding生成を適用。
Sentence embedding生成はベーシックなCNN。PoolingはSum-poolingを適用。

Transfer learning設定でのSTS2015、Supervised learning設定(SICK利用)でGRANモデル(Wieting and Gimpel 2017) に比べて性能向上。
Supervised のSICKではInferSentやQuickThoughtには敵わず。
Wieting & Gimpel. Revisiting Recurrent Networks for Paraphrastic Sentence Embeddings. (ACL 2017).
This paper proposed a neural sequence to sequence model which allows one to edit text by marking unwanted tokens.
http://aclweb.org/anthology/N18-1025
David Grangier, Michael Auli
Facebook AI Research
2017/11/13
QuickEdit allows a user to reformulate a sentence by marking tokens which they don't want to include in the new sentence. QuickEdit can be applied to both machine translation post-editing and paraphrasing. It is built upon a neural sequence to sequence model and takes a sentence with change markers as inputs. The model is trained on translation bitext by simulating post-edits. The trained model is shown to perform significantly better in machine translation tasks than post-editing baseline and in paraphrasing tasks than a strong model proposed by Mallinson et al. (http://aclweb.org/anthology/E17-1083).
http://www.emnlp2015.org/proceedings/EMNLP/pdf/EMNLP120.pdf
In Touch-Based Pre-Post-Editing of Machine Translation Output, Marie and Max proposed a similar interaction model where users label each span from the output of machine translation positive or negative. The system only keeps positively marked spans and use phrases which generate these spans to explain corresponding source phrases. QuickEdit simplifies the interaction procedure by letting the users only label unwanted tokens.

Post-edit QuickEdit improves post-edit baseline BLEU scores on the above evaluation tasks.

Monolingual editing QuickEdit outperforms ParaNet model(Mallinson et al., 2017) in a human evaluation on the MTC dataset.

Paraphrasing is evaluated on a relatively small dataset.
Post-edit QuickEdit performance is not compared to other translation/post-edit models.
Model parameters and implementation details are not shared.
人間の認知メカニズムを想定した構文解析モデルを作り、実際に脳神経活動との相関性を調べた。
Finding Syntax in Human Encephalography with Beam Search
John Hale, Chris Dyer, Adhiguna Kuncoro, Jonathan R. Brennan
DeepMind, London, UK
2018/06/11
著者は明示的な句構造モデリングの手法としてRNNG (recurrent neural network grammar) を提唱している。この研究では、被験者の脳波を記録し、RNNGにおける各単語ごとの統計量(=文中でその単語がどの程度の複雑さを持っているか)と、脳波のピーク(聞き手にとっての理解しにくさ)との相関性を調べた。その結果、ベースラインのLSTMに対してRNNGは有意に脳波ピークとの相関性が高く、より人間の認知をモデル化した手法として妥当であることが示された。
実際に生体データを記録し、相関性を調べたこと
認知モデリングとして複雑性の指標を構築したこと

P600領域のDictanceでRNNG-comp>LSTM、ANT領域のSurprisalでRNNG>RNNG-compとなり、RNNGはERPとの相関性が有意に高い

回帰係数のプロット。濃い色の領域で統計学的に有意

RNNGの構造
Natural language generation using a deep ensemble model considering aligned Meaning Representation (MR)
A Deep Ensemble Model with Slot Alignment for Sequence-to-Sequence Natural Language Generation
Juraj Juraska, Panagiotis Karagiannis, Kevin K. Bowden, Marilyn A. Walker
Natural Language and Dialogue Systems Lab, University of California, Santa Cruz
2018/05/18
自然言語生成をする際,Meaning Representation (MR)を考慮して生成することは文の意味的整合性と構造的整合性をとることができる.(MRとは複数の対話行為(DA)から成り,DAは情報のタイプ(slot)と発話中の表現(value)の対から成る.) しかし,従来の統計的手法では人手でルールを定める必要があり,ニューラル的手法ではslotの対応をとるために膨大なデータが必要であり,生成された文は流暢性を損なう.よって,MRの情報を用いた新しい生成器の提案,slotの対応を自動でとるシステムの構築を目的とする.
評価指標
BLEU, NIST, METEOR, ROUGE
結果
前処理を行わないデータと前処理を行ったデータとで比較した結果,前処理を行ったデータの方が良い結果が出た.
3種類のモデルそれぞれとアンサンブルモデルとで性能評価した結果,BLEUとNISTではエポック数が少ないBi-LSTMモデルが最も高い値を示し,METEORとROUGEではアンサンブルモデルが最も高い値を示した.
竹林さんのインターン内容に実装が似ていると思いました.
VQA(画像をみて質問に答えるタスク)は CNN と RNN を組み合わせた end-to-end なものが主流である.そのようなモデルでは,特に解答が間違えていた場合,なぜそのエラーが生じたのかを分析しにくいという問題がある.本研究では VQA を 説明ステップ と 解答予測ステップ に分けることで,中間結果を人間が理解しやすいようにして分析しやすくした.
https://aclanthology.info/papers/D18-1164/d18-1164
Q. Li, J. Fu, D. Yu, T. Mei, J. Luo
University of Science and Technology of China, Microsoft Research, Beijing, China, JD AI Research, Beijing 100105, China, University of Rochester, Rochester, NY
Visual QA は CNN とかを使って結構いい感じに実現している.しかしながらその過程はブラックボックスである.本研究では VQA を説明と推論の2つのステップに分ける.こうすることで,システムが画像からどのような情報を抽出しているのかを確認することができる.また,このような中間結果は予想された回答が間違いだった場合それがなぜ起こったのかを知る手がかりとなる.
本研究の3つの貢献

実際の例

見通しのいい綺麗な研究だと思いました。精度はそこそこでも実用上ありがたい特性を持つこっちのほうが使いたいなって思いました。
ユーザーのレベルに合わせた語彙平易化システムの提案
Personalizing Lexical Simplification
2018/08/20-26
既存のLexical Simplification(LS)はユーザーによらず難解な単語と平易な単語を区別してきた。しかし、ユーザーによってその単語の難易度は異なるため、真に必要なLSはユーザー依存でなければいけない。
そこで、40の単語の既知未知をユーザーにつけてもらうことでユーザーのレベルを推定し(全4段階)それらを元にユーザー依存の「平易」「難解」を決定する。
LSシステムに組み込むことで


A Word-Complexity Lexicon and A Neural Readability Ranking Model
2018/10/31-11/04
Lexical Simplification(LS)のための新たなモデルの提案とデータセットの作成。
平易な順に並べ替えるタスクで既存手法より高い性能を示し、作成した単語の難易度辞書を用いることで、文中の難解な単語を特定する精度が上がった。
単語を平易な順に並べ替えるタスク
難解な単語から、平易な言い換え候補を生成する
文中から難解な単語を特定する



RNNを計算論的?に分析した。
http://aclweb.org/anthology/N18-1205
1)Yining Chen, 2)Sorcha Gilroy, 3)Andreas Maletti, 4)Jonathan May, 4)Kevin Knight
( 1)Dartmouth College, 2)ILCC University of Edinburgh, 3)Institute of Computer Science Universität Leipzig, 4)Information Sciences Institute University of Southern California)
RNNを「文が入力されるとその文に対応した数値」を返す計算機構として捉えることで、RNNを計算論的?に分析した。
特にこの論文では
の4つの問題について分析している。
None
None
(著者のConclusionから)

とのことでした。
すみません、全然分からなかったので、もし興味がある人は自分で読んでみてください(内容をご教授頂ければ幸いです)
単純に学習を行った機械学習モデルは、入力を少し変化すると出力が大きく変化してしまうことが知られており、NMTも例外ではない。この論文では入力に対して頑健なNMTの訓練法を提案する。
http://aclweb.org/anthology/P18-1163
1)Yong Cheng, 1)Zhaopeng Tu, 1)Fandong Meng, 1)Junjie Zhai, 2)Yang Liu
1)Tencent AI Lab, China
2)State Key Laboratory of Intelligent Technology and Systems Beijing National Research Center for Information Science and Technology Department of Computer Science and Technology, Tsinghua University, Beijing, China Beijing Advanced Innovation Center for Language Resources
Attentionモデルをベースに、元の入力xと少し変えたx'の隠れ層の表現が近づくようにadversarial stability trainingを行う。中英、英独、英仏翻訳タスクで精度が向上することを示した。
NMTの関連研究ではadversarial attackに関する分析などが主にされているが、他のタスクでは頑健性を高めるような訓練が提案されている。この論文ではNMTに対してadversarial stability trainingを用いて頑健なモデルの訓練を行うことを提案している。
Attentionrモデルをベースにして学習を行う。Encoderの隠れ層表現を用いて、Decoderはxとx'に対する正解の翻訳yを学習する。Discriminatorはxとx'のEncoderでの隠れ層表現を区別するように学習を行う。x'は、似た単語に置き換える手法、embeddingに小さな値を加える方法の2種類を用いている。このような学習を行うことで、xとx'の翻訳が同じになり、かつ内部表現も似たものとなる。
NMTの性能が上がり、頑健さも向上した。
embeddingに与える値を適当なサンプリングによる値ではなく、勾配など計算して与えたい気持ちになった(けど、とても難しそう)。事前並び替えの学習で使えそう。対話とかの学習でも使えるかも?(ただ、多対一での学習となっている気がするので、使うならもうちょっと方法を変えた方がいい気がする)
Transformer を応答選択の分野に応用すると良い結果が得られた.
Multi-turn Response Selection for Chatbots with Deep Attention Matching Network
Xiangyang Zhou, Lu Li, Daxiang Dong, Yi Liu, Ying Chen,Wayne Xin Zhaoy, Dianhai Yu and Hua Wu
Baidu Inc., Beijing, China
2018/07
人の会話は文脈に依存するが,その依存の仕方には2種類ある.1つは名詞の複数形などの表層的な依存性.もう1つは共参照などの文の構造的な依存性である.RNNベースの手法では表層的な依存性のみを考慮できているが構造的な依存性を考慮しきれておらず,学習コストも高い.そこで,本研究ではそれらの問題を解決する新しい応答選択モデルの提案を目的とし,既存のRNNベースの手法と比較した結果,最も優れた結果を達成した.

アテンション機構を用いて文の表現を得る.
このアテンションを以後AttentiveModule(Q, K, V)と表す.
self-attention

cross-attention

scoring
self-attentionとcross-attentionを連結して3D Matching Imageを得る.
Maxpooling によって3D Matching Image 2次元に落とし込み,NNを用いてスコアリングをする.
Rn@k

Transformer 万能説
http://www.aclweb.org/anthology/N18-1018
Shuming Ma, Xu Sun, Wei Li, Sujian Li, Wenjie Li, Xuancheng Ren
MOE Key Lab of Computational Linguistics, School of EECS, Peking University
Deep Learning Lab, Beijing Institute of Big Data Research, Peking University
Department of Computing, The Hong Kong Polytechnic University
NAACL2018
Seq2Seq の decoder における output layer で softmax に代えて軽量なベクトル類似度計算による出力単語の決定手法を提案。具体的には hidden layer の出力ベクトルと encoder へのattentionで計算したコンテキストベクトル から計算したベクトルと、単語ベクトルとの類似度を計算しスコア最大の単語を出力する。
Strongness:
疑問点:
Output layerの新たな設計(シンプルかつSoftmaxに比べ軽量)を提案。

Text simplification で顕著な性能改善


手法やコーパスの違う事前学習した単語分散表現を組み合わせることでいい分散表現を生成
http://aclweb.org/anthology/C18-1140
Cong Bao and Danushka Bollegala
Department of Computer Science
University of Liverpool
2018/
単語分散表現はword2vec等の手法によって大規模コーパスから事前学習される。
手法、コーパスによって分散表現に含まれる情報が異なるので、それらの情報を
共有する分散表現(meta-embedding)を作りたい
meta-embeddingを作ることで既存の分散表現より性能向上
オートエンコーダーを利用することで既存のmeta-embeddingより性能向上
オートエンコーダーを利用してmeta-embeddingを生成する手法を提案

E1,E2,D1,D2は一層のfeed-forward、デコーダに入る中間層はそれぞれ別


デコーダへの入力は共通


2つの分散表現の特徴をうまく合わせることでよりいい分散表現を生成
オートエンコードを利用することでさらにいい結果
性能があまり良くならなかったと感じた
言い換え生成モデルを改良していい感じの文 Embedding が得られるようにしたよ(Sentiment Analysis で SOTA)
https://aclanthology.info/papers/C18-1230/c18-1230
Badri Narayana Patro, Vinod Kumar Kurmi, Sandeep Kumar, Vinay Namboodiri
Indian Institute of Technology
2018
Seq2Seq を用いたベーシックな言い換え生成モデルに対して,生成文の Embedding が参照文の Embedding に近くなるように学習する機構(Discriminator)を追加することで,意味的に類似する文同士が似た Embedding になるように改良.

ロス関数は local(通常の Seq2Seq の Construction-loss)と global(Discriminator 部分のロス)の足し合わせ.
global loss は下式の通りで,生成文と参照文の類似度の最大化・生成文と擬似負例(バッチ内の参照文以外の文)の類似度の最小化を同時に行う(類似度は Embedding 同士の内積で定義).

Sentiment Analysis (Stanford Sentiment Treebank fine-grained) で SOTA
Discriminator 機構の提案
VAE にこの Discriminator 的な機構を付け足したら KL collapse 対策になりそう?(エンコーダがそんなにサボらなくなりそう)
SST データセットで SOTA と報告されているが,なぜ binary-classification の結果は載せずに fine-grained だけ載せたのかが疑問
QuickThought あたりとの比較が見たかった(QuickThought の論文は SST-binary で実験している)
機械翻訳において翻訳元にアテンションを張り,翻訳元の文脈を大域的に考慮することは一般に行われる.
提案手法では訳出済みの文の要約を用いて次の単語を予測することで翻訳先の文脈も大域的に考慮する.
3つの言語対において類似の手法を超える翻訳性能を達成.
https://arxiv.org/abs/1709.04849
Lesly Miculicich Werlen, Nikolaos Pappas, Dhananjay Ram, Andrei Popescu-Belis
2017/09/14

機械翻訳においてデコーダはアテンション機構を通じて全ての翻訳元の文脈にアクセスするが,
翻訳先における文脈情報は隠れ状態の固定長のベクトルで表現される.これが長期の情報保持を学習する上でボトルネックになる.
seq2seqでは,直近の単語にバイアスがかかることと構造的な組成を十分に捉えられないことがネックである.
これを避けるために著者らはself-attentive residual recurrent decoderを提案している.
この論文における貢献は以下である.
翻訳先の文脈情報を考慮する簡潔なモデル Self-attentive residual connections を提案
過去の全訳出語という可変長の入力を扱うために,ターゲット側の要約ベクトルd_tを定義.
d_tはtまでの訳出文の表現と見ることができる.
d_tの構成の仕方には以下の2つがある
tまでの訳出語{y_1, ..., y_t}の平均
tまでの訳出語{y_1, ..., y_t}の重み付き平均
重みはアテンション機構 (shared self-attention mechanism) によって決定される
アテンション機構は単語間の非連続的な依存関係をモデル化することを目的とし,recurrent層の補完的なメモリとして機能する.

memory RNN はベースラインとほとんど同じBLEUを示し,また,アテンションはほとんどt-1に張られる.
self-attentive RNN はベースラインに劣る.
これは隠れ層が反復表現とアテンションを同時に学習しなければならないというオーバーヘッドに起因すると考えられる.
提案手法はベースラインを超え,self-attentive residual connections が最高スコアを出している.
手法が単純でパラメータ数がほとんど増えていないことにも注目すべきである.
意外とただ平均をとっただけでもいいスコアが出ているのは面白いと思った.
テキスト分割したい
semantic parser と NMT 両方使ったら既存研究より良くなった
https://aclanthology.info/papers/P18-1016/p18-1016 [PDF]
Elior Sulem, Omri Abend, Ari Rappoport
Department of Computer Science, The Hebrew University of Jerusalem
2018/07
structural semantics と neural methods を 組み合わせた
意味で分割して、
NTS built using the OpenNMT


複数単位のsubwordを使ってNMTのembedding層をよくする
http://aclweb.org/anthology/C18-1052
Makoto Morishita, Jun Suzuki, Masaaki Nagata/NTT
BPEのmerge操作数を予め複数決めて、粒度の違う複数単位のsubwordをNMTで使わせる
複数単位のsubwordを使うのが新しい

encoderに複数単位のsubwordを入れた方が良い

タイトルは階層的と書いてあるが、手法的には階層的になっていない
木構造をしたラベル空間をrootから探索することで、任意の数のラベル付けを行った。
http://aclweb.org/anthology/D18-1308
木構造を出力するようなseq2seqモデルを提案
encoderとdecoderからなる

MTの品質推定(Quality Estimation, QE)を neural network-based で手軽にやるためにいろいろと試してみた。
deepQuest: A Framework for Neural-based Quality Estimation
Julia Ive, Frederic Blain, Lucia Specia
King’s College London, IoPPN, UK
Department of Computer Science, University of Sheffield, UK
COLING 2018




Sequential Matching Network (SMN)の改良版
Modeling Multi-turn Conversation with Deep Utterance Aggregation
Zhuosheng Zhang, Jiangtong Li, Pengfei Zhu, Hai Zhao, Gongshen Liu
2018/08/20-26
対話システムにおいて応答選択のタスクは重要である.
文脈を考慮する応答選択において既存研究ではノイズとなる冗長な発話に弱い.
よって,発話ごとに重みを付けて学習させるモデルの構築を目的とする.
Ubuntu Dialogue Corpus
Douban Conversation Corpus
E-commerce-Dataset
Rn@k, MAP, MRR, P@1
SMN, Multi-view, etc...
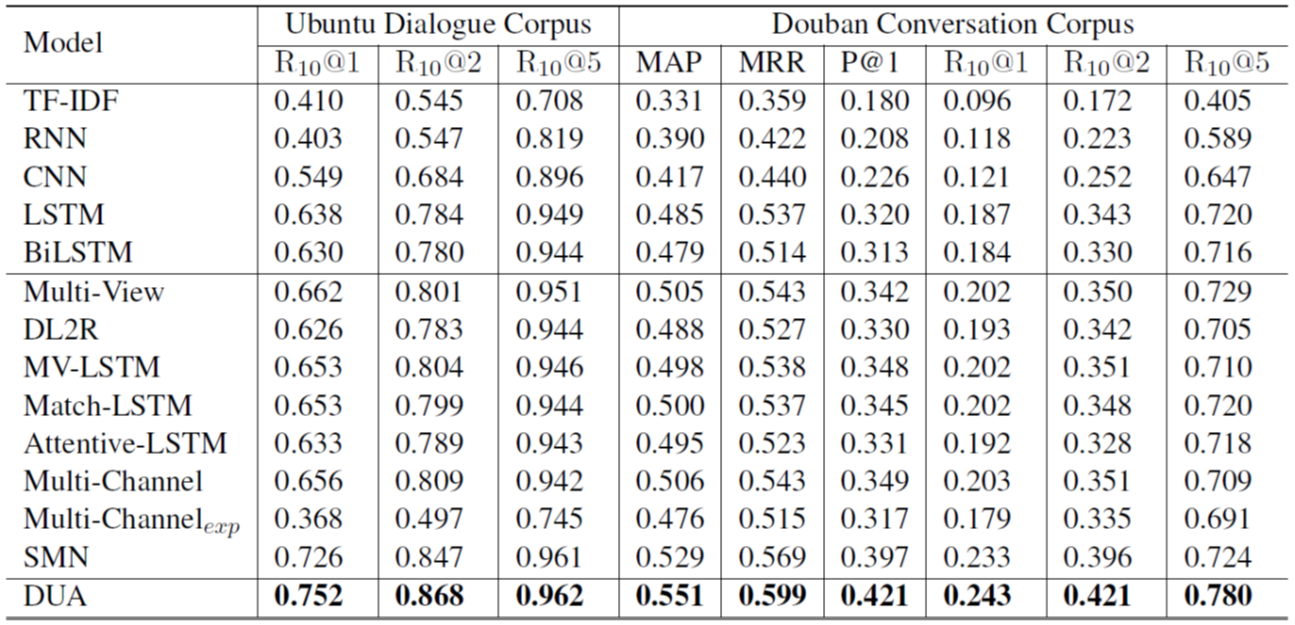
ACL読み会で紹介した,Transformer を応答選択に使用した手法に負けていた…
結果としてデータ公開のみが貢献となってしまった悲しき論文
アテンション付きseq2seqの目的関数をいろいろ比較してみました。
Classical Structured Prediction Losses for Sequence to Sequence Learning
Sergey Edunov, Myle Ott,
Michael Auli, David Grangier, Marc’Aurelio Ranzato
Facebook AI Research
Menlo Park, CA and New York, NY
2018/05/18
ビームサーチを行うアテンション付きseq2seqの目的関数をいろいろ比較してみました。
MaxMargin等の目的関数もseq2seqに当てはめて再定義しました。
独英翻訳のデータセットであるIWSLT'14で翻訳のタスクで評価しました。
MaxMargin等の古典的な目的関数をSeq2Seq用に変換して性能を評価するという点で新規性がある。
TokNLL
普通に正解データの尤度を最大化するような目的関数。
seq2seqの論文で目的関数に言及されていなければこれが使われているというくらい基本的な目的関数。本論文のベースライン
TokLS
TokNLLだと正解の語の尤度だけが高くなるという問題があるので、語彙の分布と正解の分布のKLdivergenceも考慮する
SeqNLL
TokNLLみたいに正解文の尤度を最大化する目的関数。u*の尤度-候補文全部の尤度
Risk
コスト関数を最小化する目的関数。今回は1-BLEU値。ただし重みとして文の尤度をかけている
MaxMargin
u*のスコアと候補文中の最大の尤度を持つ文のスコアの差を最小化する。スコアはコスト関数とソフトマックス関数の和で計算される
MultiMargin
MaxMarginでは最大の尤度を持つ文のみu*とスコアを比較したが、MultiMarginでは全ての候補文とスコアを比較、差の和が最小になるように学習
SoftmaxMargin
高すぎる尤度をコスト関数の値に合わせるように目的関数を設定
u*の尤度-候補文全部のコスト関数とソフトマックス関数の和
単語の尤度に基づいた目的関数より文の尤度に基づいた目的関数の方がいい結果になった。
また、両方を組み合わせることでよりいい結果になった。
単語の尤度に基いた目的関数でパラメータを初期化してから文に基づいた目的関数で学習させても、両方を組み合わせた場合と同じような結果になった。
目的関数難しい。ただ目的関数を決めるための着想みたいなのが理解できれば今後役に立つなと思った。この論文だと、古典的な目的関数をseq2seqに応用したというところが着想にあたるのでは
Beam Search時にRescoringする手法をいくつか考え,BLEU向上に繋がった.
http://aclweb.org/anthology/D18-1342
Yilin Yang (1), Liang Huang (1, 2), Mingbo Ma (1, 2)
(1) Oregon State University Corvallis, OR, USA
(2) Baidu Research Sunnyvale, CA, USA
一般にNMTでBeam sizeをあげると翻訳の質を下げてしまうので,Beam sizeは3や5にする.
(これをBeam searchの呪いと呼ぶ)
Beam searchの呪いの原因を突き止め,新たなリスコアリング手法を提案した.
Chinese-Englishタスクでhyperparameter-freeな手法で比べ+2.0 BLEUを示した.
この論文では






文字ベースNMTにおけるwhite-boxのアプローチで単語を消すor単語を変えた翻訳を狙うことができる。またadversarial exampleを用いて頑健なNMTを訓練できる。
http://aclweb.org/anthology/C18-1055
Javid Ebrahimi, Daniel Lowd, Dejing Dou
Computer and Information Science Department, University of Oregon, USA
white-boxなアプローチである文字を{変えた|削除した|挿入した}adversarial exampleを作って翻訳をすることで、特定の単語を削除したり違う単語に変えた翻訳を出力させることができた。またそのようなadversarial exampleを用いて訓練を行うことで頑健なNMTができた。
これまでのNMTに対するadversarial attackではblack-boxな手法がr多く用いられていた。この論文ではwhite-boxな手法を用いることでより翻訳を変化させるようなadversarial exampleを作れる。
また翻訳文中の単語を{削除した|違う単語にした}ものを出力させるようにする手法も提案している。削除したい場合は翻訳文中の削除したい単語に対するロスが大きくなるような操作が選択され、違う単語にしたい場合は置き換え後の単語に対するロスが小さくなるような操作が選択される。
white-boxなアプローチはblack-boxなアプローチよりも強い。翻訳文中の特定の単語に対するアプローチもうまくいってる(のか?)
またadversarial exampleを提案手法で作成して訓練させると頑健性が高まり、ほかのadversarial attackの作成手法と比較して一番いい結果になった。
white-boxなアプローチがblack-boxよりもうまくadversarial attackをできるのは当たり前だと思うが、翻訳文中の特定の単語を削除、変換するような手法を提案している部分が面白いと思う。
ユーザ発話(request)からqueryを生成するために、発話とqueryの履歴を利用し言語理解を深める。
http://aclweb.org/anthology/N18-1203
Alane Suhr, Yoav Artzi: Cornell University
Srinivasan Iyer: Univ. of Washington
2018/04/18
We propose a context-dependent model to map utterances within an interaction to executable
formal queries. To incorporate interaction history, the model maintains an interaction-level encoder that updates after each turn, and can copy sub-sequences of previously predicted queries during generation. Our approach combines implicit and explicit modeling of references between utterances. We evaluate our model on the ATIS flight planning interactions, and demonstrate the benefits of modeling context and explicit references.
発話からqueryを生成するend-to-endのモデルに


NAACL 2018 Outstanding Paper
テキスト平易化の評価にBLEUを使うのは適当ではない
http://aclweb.org/anthology/D18-1081
Elior Sulem, Omri Abend, Ari Rappoport
Department of Computer Science, The Hebrew University of Jerusalem
BLEUは平易性や構造平易性において人手評価と相関がない
特に文分割を含む場合、文法性や意味保存性においても相関がない
文分割を考慮したリファレンスで測ればいいとかそういう話でもない
4つの項目 (文法性 (G)・意味保存性 (M)・平易性 (S)・構造平易性 (StS))において、以下の自動評価指標によるスコアと人手評価によるスコアの相関 (スピアマンの順位相関係数)を見る
出力を比較するシステムは
Nisioi et al. (2017)のTSシステム(SOTA)の4バリエーション、Moses、SBMT-SARI
特に文分割を主に行うもの:DSS、DSSm、SEMoses、SEMosesm、SEMosesLM、SEMosesmLM
標準のテストセットのリファレンスを使ったときのシステムレベルの相関

Hsplitをリファレンスとしたときの文レベルの相関

wordベクトルとcontextベクトルを用いて単語間のsimilarityとrelatednessの精度を確かめる。
Querying Word Embeddings for Similarity and Relatedness
2018/06/01
単語間の類似度を考えるとき、主にsimilarityとrelatednessの観点がある。similarityは基本的に双方向性であるが、relatednessは片方向性である。(「コウノトリ」は「赤ちゃん」に関連するが、「赤ちゃん」はそこまで「コウノトリ」に関連しない。)
word2vecでは基本的に最終出力はwordベクトルであり、学習段階で生成されたcontextベクトルは学習後に破棄される。
wordベクトルとcontextベクトルをうまく組み合わせることで、similarityとrelatednessの観点から類似性を判断できるのでは。
wordベクトル・contextベクトルを用いて単語w1とw2の類似度を下記手法で求め、人手でアノテーションしたデータを元にsimilarity・relatednessの観点から評価する。
similarityの観点ではWWの手法が最もよい結果が出た。relatednessの観点からはWCが最もよい結果が出た。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.