Galera Operator
Project overview
Galera Operator makes it easy to manage highly-available galera clusters deployed to Kubernetes and automates tasks related to operating a galera cluster.
Galera is a popular, free, open-source, multi-master system for mySQL, MariaDB and Percona XtraDB databases. Galera Operator is tested and build for MariaDB.
Today, Galera Operator can:
- Create and Destroy
- Resize cluster size (number of nodes in a galera cluster)
- Resize Containers and Persistent Volumes (Vertical Scalability)
- Failover
- Rolling upgrade
- Backup and Restore
Please read the full documentation in ./doc/user to view all features.
30 000 ft view
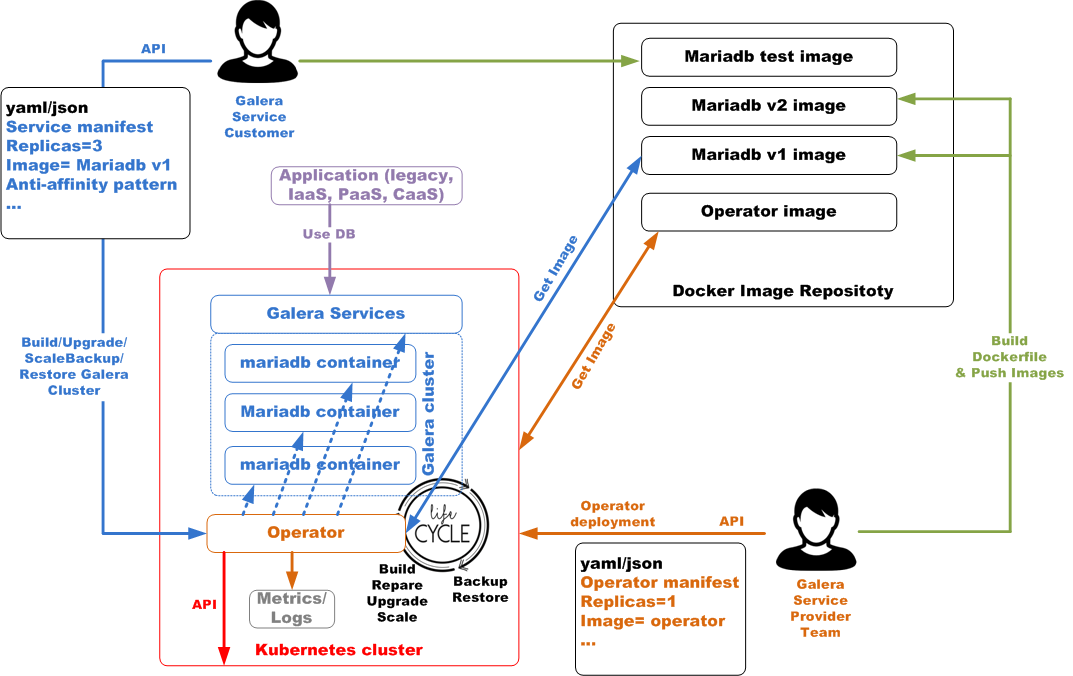
Requirements
- Kubernetes 1.12+
- MariaDB 10.1.23 for Backup and Restore, only mariabackup is currently implemented
- S3 storage for Backup and Restore, S3 is currently the only object storage implemented
Note: Operator image provided for example purpose are build for Kubernetes 1.15+. If you want to use it on an older Kubernetes you need to rebuild the image
Features
Deploy Galera Operator
First, we need to deploy new kind of resources used to describe galera cluster and galera backup, note upgrade-config and upgrade-rule is a forthcoming feature used to validate if a cluster can be upgraded:
$ kubectl apply -f ./example-manifests/galera-crd/galera-crd.yaml
$ kubectl apply -f ./example-manifests/galera-crd/galerabackup-crd.yaml
$ kubectl apply -f ./example-manifests/galera-crd/upgrade-config-crd.yaml
$ kubectl apply -f ./example-manifests/galera-crd/upgrade-rule-crd.yamlNow we can create a Kubernetes namespace in order to host Galera Operator.
$ kubectl apply -f ./example-manifests/galera-operator/00-namespace.yamlGalera Operator needs to have some rights on the Kubernetes cluster if RBAC (recommended) is set:
$ kubectl apply -f ./example-manifests/galera-operator/10-operator-sa.yaml
$ kubectl apply -f ./example-manifests/galera-operator/20-role.yaml
$ kubectl apply -f ./example-manifests/galera-operator/30-role-binding.yaml
$ kubectl apply -f ./example-manifests/galera-operator/40-cluster-role.yaml
$ kubectl apply -f ./example-manifests/galera-operator/60-cluster-role-binding.yamlDeploy the operator using a deployment:
$ kubectl apply -f ./example-manifests/galera-operator/70-operator-deployment.yamlNOTE: do not deploy ./example-manifests/galera-operator/50-cluster-role-clusterwide.yaml, it is only used if you want to deploy the operator to manage galera objects clusterwide, see full documentation for that.
Galera Operator also have some options configured by flags (have a look by starting Galerator Operator with help flag)
Finally if Prometheus Operator is deployed, you can use it to collect Galera Operator metrics
$ kubectl apply -f ./example-manifests/galera-monitoring/operator-monitor.yamlManaged Galera Cluster
A galera cluster is made of several nodes, each galera node is mapped on a kubernetes pod (be carefull between galera nodes and kubernetes nodes, it is not the same thing). All galera nodes are not the same, labels are set to specify which pod is the galera node for read, write of be the backup.
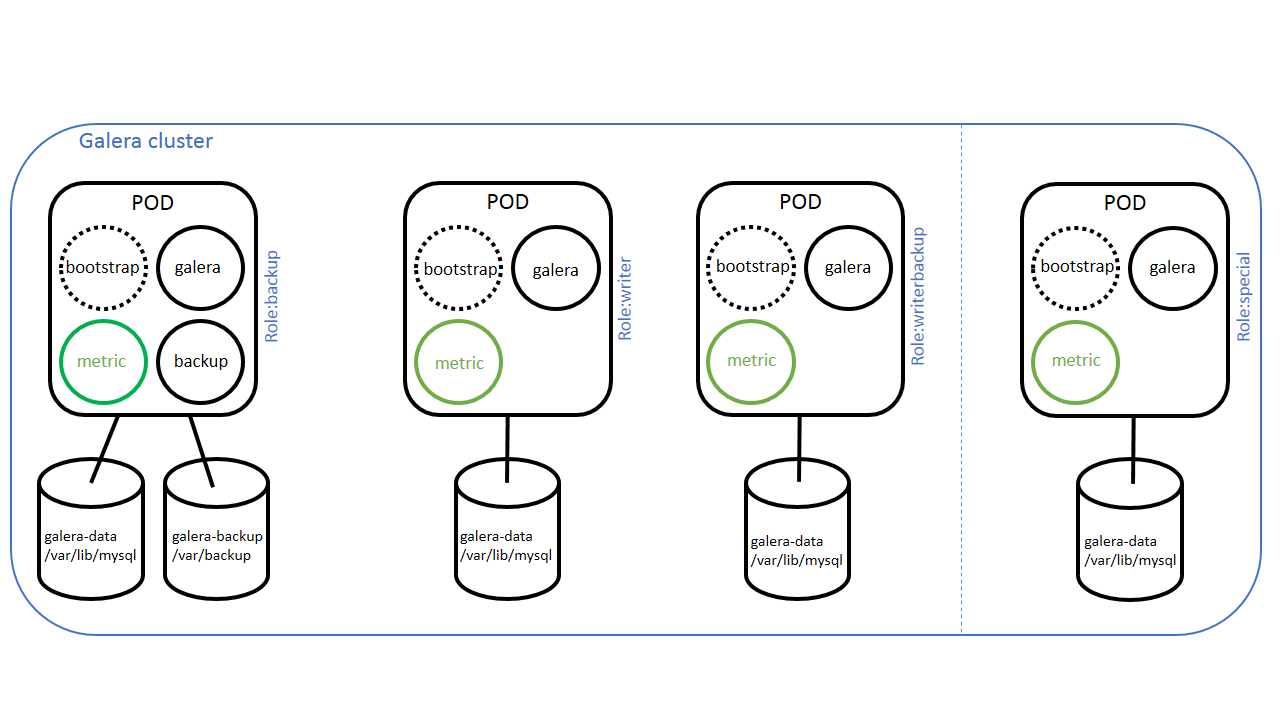
We can find on each pod an initcontainer called bootstrap and a container called galera. Metric container is optional and is used to have metrics collected by external system (as prometheus). On each pod we find a persistant volume claim mapping /var/lib/mysql.
The backup pod is not the same as other pods, because there is an extra container (backup) and an extra persistant volume claim. Backup container is designed to expose an API to manage restore and backup operation from the operator. This API is missing today as all operations are done through cli.
Special pod is used for adding large amount of data on existing cluster (like adding tables). It is designed to be used for a limited time, adding or removing this pod does not change the controller revision used to follow change during the galera cluster lifecycle.
For a deeper undestanding of galera cluster object, please read ./doc/design/design_overview.md
Create Galera Cluster
Once Galera Operator is deployed, Galera can be deployed. You need to deploy a ConfigMap to specify the my.cnf configuration. Operator will overwrite some parameters or add it if not present. A Secret is used to provide access to Galera Operator to interact with the managed galera cluster.
$ kubectl apply -f ./example-manifests/galera-cluster/10-priority-class.yaml
$ kubectl apply -f ./example-manifests/galera-cluster/20-galera-config.yaml
$ kubectl apply -f ./example-manifests/galera-cluster/30-galera-secret.yaml
$ kubectl apply -f ./example-manifests/galera-cluster/40-galera.yamlIf Prometheus Operator is deployed and if a metric image is provided, you can collect metrics:
$ kubectl apply -f ./example-manifests/galera-monitoring/galera-monitor.yamlResize Galera Cluster
Galera cluster can be resized in different ways:
1 by changing the number of replicas
2 by specifing new resource requirements
3 by changing volume claim spec, using different storage classes or a new specifying storage request, for example by changing request resource size
Note that each time a modification on the Galera object is made (except if it is the number of replicas), a controllerRevisions is created.
Rolling upgrade
Simply specify a new container image, today the rolling upgrade is done if the new version is greater that the current on deployed. Image must follow the semver format, for example "10.4.5"
TODO : new CRDs provided to the operator will be used to implement plugins and check if upgrade can be done with the provided my.cnf.
Backup Galera Cluster
Galera clusters can be backuped:
$ kubectl apply -f ./example-manifests/galera-backup/10-backup-secret.yaml
$ kubectl apply -f ./example-manifests/galera-backup/20-galera-backup.yamlNOTE: change $YOURKEY, $YOURSECRET and $YOURENDPOINT to the credentials and url of your S3 solution.
Restore Galera Cluster
Galera clusters can be restored (you need to specify the name of the gzip file) :
$ kubectl -n galera get gl
NAME TIMESTARTED TIMECOMPLETED LOCATION METHOD PROVIDER
galera-backup 14m gal-galera-backup.20200128172501.sql.gz mariabackup S3
$ kubectl apply -f ./example-manifests/galera-restore/restore-galera.yamlCollect Metrics
If Prometheus Operator is deployed, collect the metrics by deploying the service monitor:
$ kubectl apply -f ./example-manifests/galera-monitoring/galera-monitor.yamlBuilding the operator
Kubernetes version: 1.13+
This project uses Go modules to manage its dependencies, so feel free to work from outside of your GOPATH. However, if you'd like to continue to work from within your GOPATH, please export GO111MODULE=on.
k8s.io/kubernetes is not primarily intended to be consumed as a module. Only the published subcomponents are (and go get works properly with those). We need to add require directives for matching versions of all of the subcomponents, rather than using go get. Please read carefully Installing client-go and have a look to go.mod. To help you find the matchind dependency you can also use ./hack/dependencies.sh
This operator use the kubernetes code-generator for:
- clientset: used to manipulate objects defined in the CRD (GaleraCluster)
- informers: cache for registering to events on objects defined in the CRD
- listers
- deep copy
To get code-generator, you need to explicitly git clone the branch matching the kubernetes version to ./vendor/k8s.io/code-generator
The clientset can be generated using the ./hack/update-codegen.sh script or using the makefile codegen.
The update-codegen script will automatically generate the following files and directories:
pkg/apis/apigalera/v1beta2/zz_generated.deepcopy.go
pkg/client/
The following code-generators are used:
deepcopy-gen - creates a method func (t* T) DeepCopy() *T for each type T
client-gen - creates typed clientsets for CustomResource APIGroups
informer-gen - creates informers for CustomResources which offer an event based interface to react on changes of CustomResources on the server
lister-gen - creates listers for CustomResources which offer a read-only caching layer for GET and LIST requests.
Changes should not be made to these files manually, and when creating your own controller based off of this implementation you should not copy these files and instead run the update-codegen script to generate your own.















































