paddlepaddle / continuous_evaluation Goto Github PK
View Code? Open in Web Editor NEWMacro Continuous Evaluation Platform for Paddle.
Macro Continuous Evaluation Platform for Paddle.






































































































This version will contain the following enhancement:
This refactor will still be compatible with the original kpi.py and all the tasks.
factor:
train_cost
train_speed
test_acc
CE 框架里面有不少特例情况未打印日志, 异常等没有捕获,, 现在部署的环境机器较多,加上厂内环境各个机器软硬件、网络等情况不一, debug问题较难,
使用的 xonsh等工具,出错后错误信息不准确,容易误导
对于一些高频操作,需要有较严格的机制保证成功率。
希望以后CE框架不会因为修改代码调试难,或担心改坏拖着不能进code,影响正常的功能支持速度。
预计以后CE 框架的迭代速度比现在有较大提升。
job link: http://ce.paddlepaddle.org:8080/viewLog.html?buildId=1966&buildTypeId=PaddleCe_CEBuild&tab=buildLog
[05:28:57]W: [Step 1/1] *** Aborted at 1538285337 (unix time) try "date -d @1538285337" if you are using GNU date ***
[05:28:57]W: [Step 1/1] PC: @ 0x0 (unknown)
[05:28:57]W: [Step 1/1] *** SIGSEGV (@0x58) received by PID 7765 (TID 0x7fc7987af700) from PID 88; stack trace: ***
[05:28:57]W: [Step 1/1] @ 0x7fc82c5a67e0 (unknown)
[05:28:57]W: [Step 1/1] @ 0x7fc82c8b950c PyEval_EvalFrameEx
[05:28:57]W: [Step 1/1] @ 0x7fc82c8c237d PyEval_EvalCodeEx
[05:28:57]W: [Step 1/1] @ 0x7fc82c839905 (unknown)
[05:28:57]W: [Step 1/1] @ 0x7fc82c807d33 PyObject_Call
[05:28:57]W: [Step 1/1] @ 0x7fc82c8bd0a2 PyEval_EvalFrameEx
[05:28:57]W: [Step 1/1] @ 0x7fc82c8bfe9e PyEval_EvalFrameEx
[05:28:57]W: [Step 1/1] @ 0x7fc82c8bfe9e PyEval_EvalFrameEx
[05:28:57]W: [Step 1/1] @ 0x7fc82c8c237d PyEval_EvalCodeEx
[05:28:57]W: [Step 1/1] @ 0x7fc82c839830 (unknown)
[05:28:57]W: [Step 1/1] @ 0x7fc82c807d33 PyObject_Call
[05:28:57]W: [Step 1/1] @ 0x7fc82c81674d (unknown)
[05:28:57]W: [Step 1/1] @ 0x7fc82c807d33 PyObject_Call
[05:28:57]W: [Step 1/1] @ 0x7fc82c8b8897 PyEval_CallObjectWithKeywords
[05:28:57]W: [Step 1/1] @ 0x7fc82c904f32 (unknown)
[05:28:57]W: [Step 1/1] @ 0x7fc82c59eaa1 start_thread
[05:28:57]W: [Step 1/1] @ 0x7fc82bc60bcd clone
[05:28:57]W: [Step 1/1] @ 0x0 (unknown)
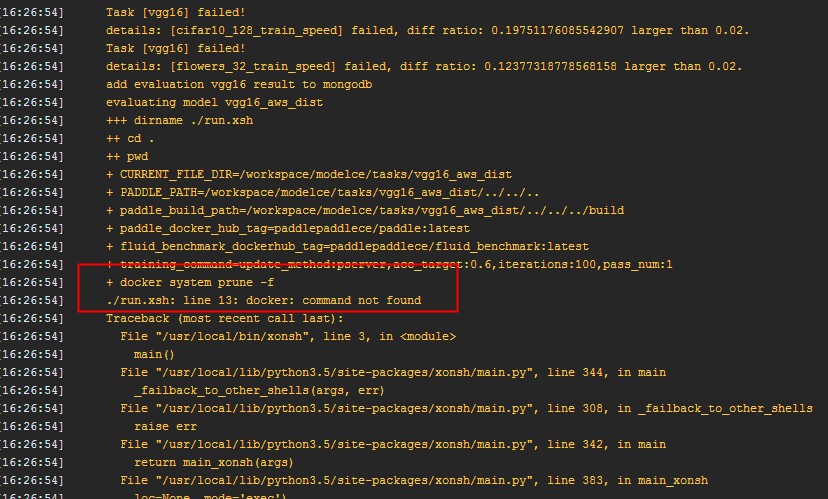
[05:28:58]W: [Step 1/1] ./run.xsh: line 14: 7765 Segmentation fault FLAGS_benchmark=true FLAGS_fraction_of_gpu_memory_to_use=0.0 python model.py --device=GPU --batch_size=${FLOWERS_BATCH_SIZE} --data_set=flowers --iterations=100 --gpu_id=$cudaid
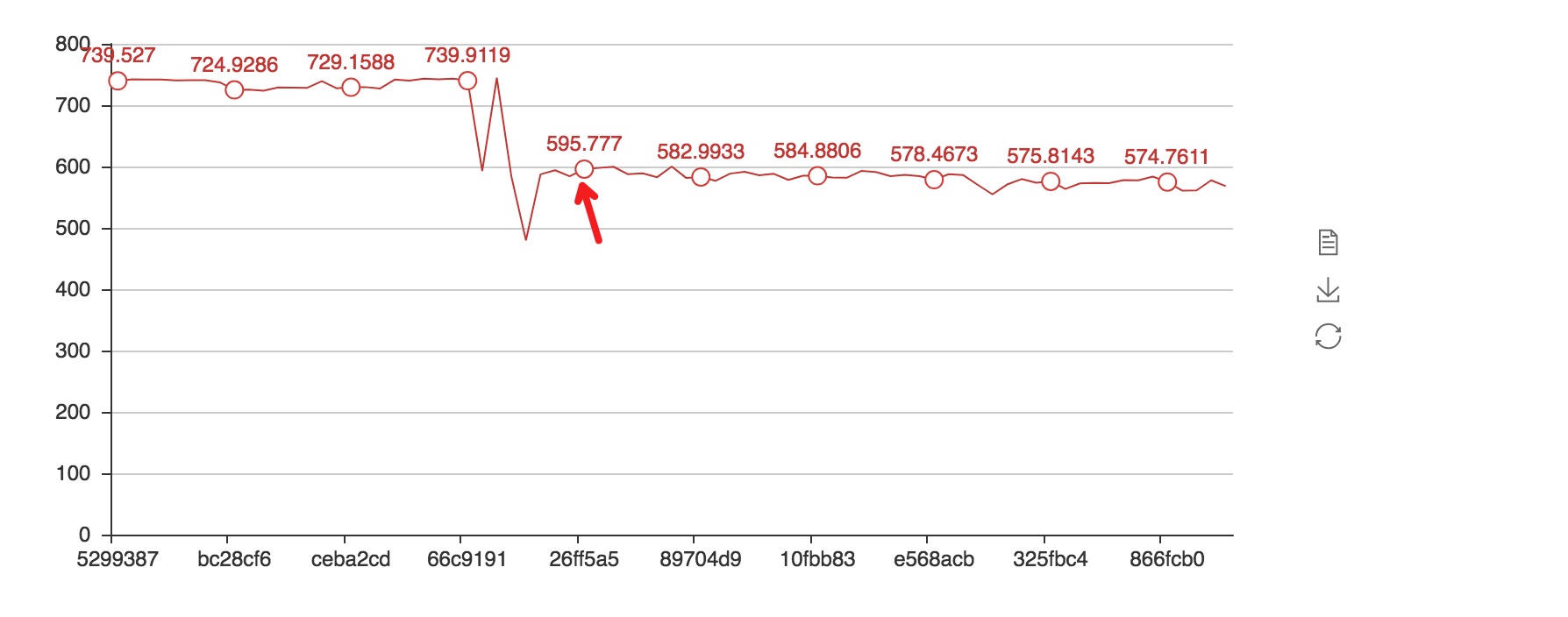
AWS->P40->V100 迁移过程中性能逐渐下降。
目前 有些模型中pass num参数没有用到,
specific_tasks 执行task 不修改db, 不更新基数据。
后面两次是调试的信息,不应该写入db

Build a demo with following features:
确定稳定的模型,如下阈值确定设置合理:
方便值班追踪 Paddle 代码质量
对CE中模型进行梳理(见后面所附表),
模型如下:
image_classification vgg16 mnist object_detection resnet30 resnet50
seq2seq sequence_tagging_for_ner text_classification transformer language_model lstm
需要考虑增加和对齐的内容如下:
模型都改成多卡跑(4卡)(后续,我把指定卡放到外边,单卡、多卡均跑一遍)
每个模型的评价指标需要包含这4个数据(acc/ppl,cost ,mem 和 duration)
目前只监控了上述4个评价指标的diff,我观察到两种非预期情况,1 .跑得时间很短, acc 很低(0.1),2. 跑了很多轮, acc很低(0.1,模型自身有问题)。
暂时方案, 我们将轮数很低的加长(跑30min左右),将acc都统一调到0.5以上。
(后续我加上acc基数阈值告警。)
数据集统一使用现成的(而不是每次都下载), 放在默认的/root/.cache/paddle/dataset目录
| 模型 | 数据集 | Pass 轮数, | 当前执行情况 | 评价指标 | 参数 |
|---|---|---|---|---|---|
| Lstm 影评 Layers:words DynamicRNN | paddle.dataset.imdb as imdb http://ai.stanford.edu/%7Eamaas/data/sentiment/aclImdb_v1.tar.gz | 1轮 | Pass = 0, Iter = 49, Loss = 0.713064, Accuracy = 0.593750 nvidia-smi --id=%s --query-compute-apps=used_memory --format=csv -lms 1 > memory.txt | imdb_32_train_speed imdb_32_gpu_memory | batch_size: 32 device: GPU emb_dim: 512 gpu_id: 0 hidden_dim: 512 iterations: 50 skip_batch_num: 5 |
| object_detection | dataset: pascalvoc 和coco 数据集 指定在/data/目录, 但没有 | Pass轮数:2 | IOError: [Errno 2] No such file or directory: '/data/pascalvoc/label_list' 需要在/data目录防止数据 | train_cost_kpi train_speed_kpi | batch_size: 64 is_toy: 0 iterations: 120 learning_rate: 0.001 num_passes: 2 parallel: True use_gpu: True |
| Resnet50 | Flowers cifar http://www.robots.ox.ac.uk/~vgg/ data/flowers/102/102flowers.tgz | Pass 轮数:29(不收敛) | Pass:2, Loss:3.229035, Train Accuray:0.247656, Test Accuray:0.176471, Handle Images Duration: 63.949636 | cifar10_128_train_acc_kpi, cifar10_128_train_speed_kpi, cifar10_128_gpu_memory_kpi, flowers_64_train_speed_kpi, flowers_64_gpu_memory_kpi, 起了个线程取mem信息, 并没有评价acc等 | batch_size: 64 data_format: NCHW data_set: flowers device: GPU infer_only: False iterations: 80 model: resnet_imagenet pass_num: 3 skip_batch_num: 5 |
| Pass:29, Loss:0.026319, Train Accuray:0.993359, Test Accuray:0.559400, Handle Images Duration: 22.501337 | |||||
| language_model | /root/.cache/paddle/dataset/imikolov/ simple-examples.tgz | ppl:61.667 time_cost(s):18.544248 | |||
| sequence_tagging_for_ner | 数据集 http://cs224d.stanford.edu/assignment2/ assignment2.zip | Pass轮数: 22轮 | download data error! 增加目录data后ok [TestSet] pass_id:2200 【pass num 每次增加100】pass_precision:[0.18181819] pass_recall:[0.125] pass_f1_score:[0.14814815] | train_acc_kpi, pass_duration_kpi, | |
| text_classification | Imdb http://ai.stanford.edu/%7Eamaas/data/sentiment/aclImdb_v1.tar.gz | Pass:14 | avg_acc: 0.999800, avg_cost: 0.002255 | ||
| Vgg16 | flowers/imagelabels.mat http://www.robots.ox.ac.uk/~vgg/data/ flowers/102/imagelabels.mat | 1轮 | cifar10 Pass: 1, Loss: 1.810090, Train Accuray: 0.234375 | cifar10_128_train_speed_kpi, cifar10_128_gpu_memory_kpi, flowers_32_train_speed_kpi, flowers_32_gpu_memory_kpi, 起了个线程取mem信息, 并没有评价acc等 | |
| Pass: 49, Loss: 3.561218, Train Accuray: 0.093750 | |||||
[11:14:00][Publishing artifacts] Collecting files to publish: [output/paddlepaddle*.whl, build/paddle.tgz, build/fluid.tgz]
[11:14:00][Publishing artifacts] Failed to publish artifacts: Artifact file 'fluid.tgz' has size 2654525440 bytes which exceeds maximum allowed size of 2147483648 bytes. Maximum artifact size is configured at the Administration -> Global Settings page.
[11:14:00]Failed to publish artifacts: Artifact file 'fluid.tgz' has size 2654525440 bytes which exceeds maximum allowed size of 2147483648 bytes. Maximum artifact size is configured at the Administration -> Global Settings page.
[11:14:00]
Future: Add more models to CE.
原来CE 只有一个agent , db 在agent 本机上,直接用的127.0.0.1
现在设置了多个agent, 配置文件中127.0.0.1改成环境变量。 在teamcity 上设置该环境变量
http://www.celeryproject.org/
teamcity上只支持3个免费agent。 如果将来需要测试若干种机型task, 需要加若干agent才能支持。
调研了celery 工具
master监测到teamcity 上的queue 中有tasks,
执行相应的调度
@app.task
def V100():
#Run tasks on v100
return {"task_kpis":"kpis_values", "task_type": "v100"}
@app.task
def P40():
#Run tasks on P40
return {"task_kpis":"kpis_values", "task_type": "p40"}
if __name__ == "__main__":
if "task name is startswith v100":
re = V100.delay()
elif "task name is startswith p40":
re = P40.delay()
print(re.result)
print(re.get(timeout=2))
print(re.status)每一个work机器上启动work 监控进程
比如v100 work上
@app.task
def V100():
#Run tasks on v100
return {"task_kpis":"kpis_values", "task_type": "v100"}celery -A download worker -l info -c 5当master执行时, v100 worker上就会收到消息并执行V100函数
[2018-06-13 18:45:00,533: INFO/MainProcess] Received task: download.V100[03a74fb0-df6a-4ec0-b9cc-bc8e4870194e]
[2018-06-13 18:45:00,541: INFO/ForkPoolWorker-3] Task download.V100[03a74fb0-df6a-4ec0-b9cc-bc8e4870194e] succeeded in 0.00594224780798s: {'task_kpis': 'kpis_values'}master上可以拿到各个worker的返回
{u'task_type': u'v100', u'task_kpis': u'kpis_values'}多机时, 每个机器上都要有所有代码, master上并未执行真正逻辑, 依然需要注册该函数。
文档中对于多机使用不清晰,
我们ce中所有步骤都在docker中执行, 采用celery,所有命令都得加上docker run XX, 并且可能会踩坑
这样其实破坏了teamcity 本来的queue 队列和pool池子的 异步调用功能。考虑到优先维护好v100 和 p40 两个场景下tasks功能完备性, 目前agent 数目并不是瓶颈。
和春伟讨论决定继续按照加agent 方式进行, 以后有需要再用工具流

最上面那个任务, 点击进去经常发现只有几个tasks,
将其显示doing状态或者在doing 的不显示在CE web上?
避免用户以为我们只有这几个模型
请闫旭老师帮忙弄下teamcity agent 的docker中需要一些什么设置~
机器:10.255.100.55
docker 容器:teamcity-agent
登录方式我单给你下~
谢谢
commit details 和 compare页面不加cache。
如果用户请求了一个commit detail页面后再请求另一个commit detail页面,因为缓存的存在,会导致用户看到的页面信息和实际对不上。 而且这个响应时间本来比较短,可以不加缓存

compare 显示的commit id信息,目前没有顺序
计划将新的commit 显示在上面,老commit在下面的顺序排列,方便选择
对于后来加的模型,以及后来模型新加的kpis, 需要判断是否两个commit都有相应的task或kpi,否则会key error

例如,选择两个commit 比较,ce server报错:

原来CE模型设置的merge监控,模型需要merge到CE模型库才能暴露问题。
本周增加CE 模型repo PR的监控告警。这样能够保证模型在merge到CE模型库之前 是功能正确,并且阈值在范围内.
栗子:
Superjomn/paddle-ce-latest-kpis#33
效果如下:

点击"details"
http://18.222.34.7:8080/viewLog.html?buildId=450&buildTypeId=Paddle_CeTaskEvaluation
Because my most familiar language is Go, so I conducted my experiments using the Go client library.
If you use Mac, you can install Go using Homebrew. Or, follow the official installation guide.
If you use Emacs, please follow Helin’s configuration.
To access Google API, you need a Gmail account.
Before you can write an application program that access your Google data, you need to register the application so to get a token to identify it. Then, you can write and run your application. Please follow the Google API tutorial for both steps.
The most recent version of Sheets API is v4.
The Go binding is at https://github.com/google/google-api-go-client/blob/master/sheets/v4/sheets-gen.go. The source code is automatically generated from the RESTful format of the API. I use the GoDoc page to understand important services:
From the quick start example program, you might noticed that we need to specify the range in a sheet to read from or to write to. There is no official documentation about it, but we have a version from trial-n-err: https://productforums.google.com/forum/#!topic/docs/8w9TzS7JEQI.
监测model repo的改动, 自动触发变更的model的稳定运行, 通过多次运行结果判断model的变更是否符合预期。
teamcity 地址:
http://18.222.34.7:8080/viewType.html?buildTypeId=Paddle_CeTaskEvaluation
需要验证模型的 CPU 性能,精度,尽量调小阈值,达到可以检测代码库的效果
job: http://ce.paddlepaddle.org:8080/viewLog.html?buildId=1967&buildTypeId=PaddleCe_CEBuild&tab=buildLog
[08:42:15] [Step 1/1] [imikolov_20_pass_duration] failed, diff ratio: 0.02094002761520184 larger than 0.02.
[08:42:15] [Step 1/1] Task is disabled, [imikolov_20_avg_ppl_card4] pass
[08:42:15] [Step 1/1] [imikolov_20_pass_duration_card4] pass
[08:42:15] [Step 1/1] kpis keys ['imikolov_20_avg_ppl', 'imikolov_20_pass_duration', 'imikolov_20_avg_ppl_card4', 'imikolov_20_pass_duration_card4']
[08:42:15] [Step 1/1] kpis values [[[34.16410827636719]], [[33.631132423877716]], [[78.40382385253906]], [[13.359583675861359]]]
CE模型添加多卡支持,待验证Model CE多卡加速比指标
commit details 和 compare页面不加cache。
如果用户请求了一个commit detail页面后再请求另一个commit detail页面,因为缓存的存在,会导致用户看到的页面信息和实际对不上。 而且这个响应时间本来比较短,可以不加缓存
compare 显示的commit id信息,目前没有顺序
计划将新的commit 显示在上面,老commit在下面的顺序排列,方便选择
对于后来模型新加的kpis, 需要判断是否两者均有相应的kpi,否则会key error

比如选择两个commit 比较,ce server报错:
debug时, 可以在teamcity上指定具体模型跑
模型的数据集一般是不更新的, 可以使用之前下载过的数据,不需要每次下载。
目前的很多models 都新下载数据, 看 /root/.cache 下没有, 新下载数据。
还有一部分是使用/data下的数据, 但/data 并没有放数据。
将dataset 标准化, 统一放到/root/.cache 宿主机下。
目前一个模型目录中, 所有gpu,cpu场景都配置在里面。
导致其中kpi相关配置,以及model中记录kpi的变量越来越多。
比如: 加一个4卡和8卡
需要把kpi配置, 启动脚本等,都平铺开来。

PaddlePaddle/paddle-ce-latest-kpis#37
随着我们机器型号和模型场景(Gpu单卡、多卡,cpu等)不断扩充, 维护起来比较费劲。
每一个模型有一个对应的base模型:
resnet50base模型里存放的内容有:
model.py(模型脚本), continuous_evaluation.py (kpi 变量), 所有模型共用。
可以在此基础上定义各种场景模型
resnet50-p40-card8
resnet50-p40-card4
resnet50-p40-card1
resnet50-v100-card4
resnet50-v100-card1每个模型里面的内容是一个启动脚本run.xsh, 一个latest_kpis目录,里面对应的是这个场景的kpi标杆数据。
main.xsh 和 eva.xsh
1.1 base 模型不跑(base模型中不含run.xsh)
1.2 import kpi配置,改为from tasks.%s.continuous_evaluation import tracking_kpis'
% task_name.split('-')[0]
main.xsh需要加入模型匹配跑模型(比如在 aws agent上只跑 '-p40-'的 模型)
./main.xsh --task_pre -p40-
bug fix: delete 模型目录,会计入changed tasks中, 在模型入库时,pr check会失败。需要刨去delete的模型目录(如从 resnet50 改为__resnet50)
由于aws上的CE这台机器成本太高, 计划迁移到厂内机器。 在厂内V100 和P40 上各搭建一个CE agent
同时对目前CE环境的部署结构做了优化。
aws上 teamcity agent 部署在一个docker内,并且和teamcity web, db共用该docker。
有两个问题:
更改后的结构:
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.