English | 简体中文 | हिन्दी | 日本語 | 한국인 | Pу́сский язы́к




PaddleOCR 旨在打造一套丰富、领先、且实用的 OCR 工具库,助力开发者训练出更好的模型,并应用落地。


PaddleOCR 由 PMC 监督。Issues 和 PRs 将在尽力的基础上进行审查。欲了解 PaddlePaddle 社区的完整概况,请访问 community。
-
🔥2024.7 添加 PaddleOCR 算法模型挑战赛冠军方案:
- 赛题一:OCR 端到端识别任务冠军方案——场景文本识别算法-SVTRv2;
- 赛题二:通用表格识别任务冠军方案——表格识别算法-SLANet-LCNetV2。
-
💥2024.6.27 飞桨低代码开发工具 PaddleX 3.0 重磅更新!
- 低代码开发范式:支持 OCR 模型全流程低代码开发,提供 Python API,支持用户自定义串联模型;
- 多硬件训推支持:支持英伟达 GPU、昆仑芯、昇腾和寒武纪等多种硬件进行模型训练与推理。PaddleOCR支持的模型见 模型列表
-
📚直播和OCR实战打卡营预告:《PP-ChatOCRv2赋能金融报告信息智能化抽取,新金融效率再升级》课程上线,破解复杂版面、表格识别、信息抽取OCR解析难题,直播时间:6月6日(周四)19:00。并于6月11日启动【政务采购合同信息抽取】实战打卡营。报名链接:https://www.wjx.top/vm/eBcYmqO.aspx?udsid=197406
-
🔥2024.5.10 上线星河零代码产线(OCR 相关):全面覆盖了以下四大 OCR 核心任务,提供极便捷的 Badcase 分析和实用的在线体验:
同时采用了 全新的场景任务开发范式 ,将模型统一汇聚,实现训练部署的零代码开发,并支持在线服务化部署和导出离线服务化部署包。
-
🔥2023.8.7 发布 PaddleOCR release/2.7
- 发布PP-OCRv4,提供 mobile 和 server 两种模型
- PP-OCRv4-mobile:速度可比情况下,中文场景效果相比于 PP-OCRv3 再提升 4.5%,英文场景提升 10%,80 语种多语言模型平均识别准确率提升 8%以上
- PP-OCRv4-server:发布了目前精度最高的 OCR 模型,中英文场景上检测模型精度提升 4.9%, 识别模型精度提升 2% 可参考快速开始 一行命令快速使用,同时也可在飞桨 AI 套件(PaddleX)中的通用 OCR 产业方案中低代码完成模型训练、推理、高性能部署全流程
- 发布PP-OCRv4,提供 mobile 和 server 两种模型
-
🔨2022.11 新增实现4 种前沿算法:文本检测 DRRG, 文本识别 RFL, 文本超分Text Telescope,公式识别CAN
-
2022.10 优化JS 版 PP-OCRv3 模型:模型大小仅 4.3M,预测速度提升 8 倍,配套 web demo 开箱即用
-
💥 直播回放:PaddleOCR 研发团队详解 PP-StructureV2 优化策略。微信扫描下方二维码,关注公众号并填写问卷后进入官方交流群,获取直播回放链接与 20G 重磅 OCR 学习大礼包(内含 PDF 转 Word 应用程序、10 种垂类模型、《动手学 OCR》电子书等)
-
🔥2022.8.24 发布 PaddleOCR release/2.6
- 发布PP-StructureV2,系统功能性能全面升级,适配中文场景,新增支持版面复原,支持一行命令完成 PDF 转 Word;
- 版面分析模型优化:模型存储减少 95%,速度提升 11 倍,平均 CPU 耗时仅需 41ms;
- 表格识别模型优化:设计 3 大优化策略,预测耗时不变情况下,模型精度提升 6%;
- 关键信息抽取模型优化:设计视觉无关模型结构,语义实体识别精度提升 2.8%,关系抽取精度提升 9.1%。
-
🔥2022.8 发布 OCR 场景应用集合:包含数码管、液晶屏、车牌、高精度 SVTR 模型、手写体识别等9 个垂类模型,覆盖通用,制造、金融、交通行业的主要 OCR 垂类应用。
支持多种 OCR 相关前沿算法,在此基础上打造产业级特色模型PP-OCR、PP-Structure和PP-ChatOCRv2,并打通数据生产、模型训练、压缩、预测部署全流程。
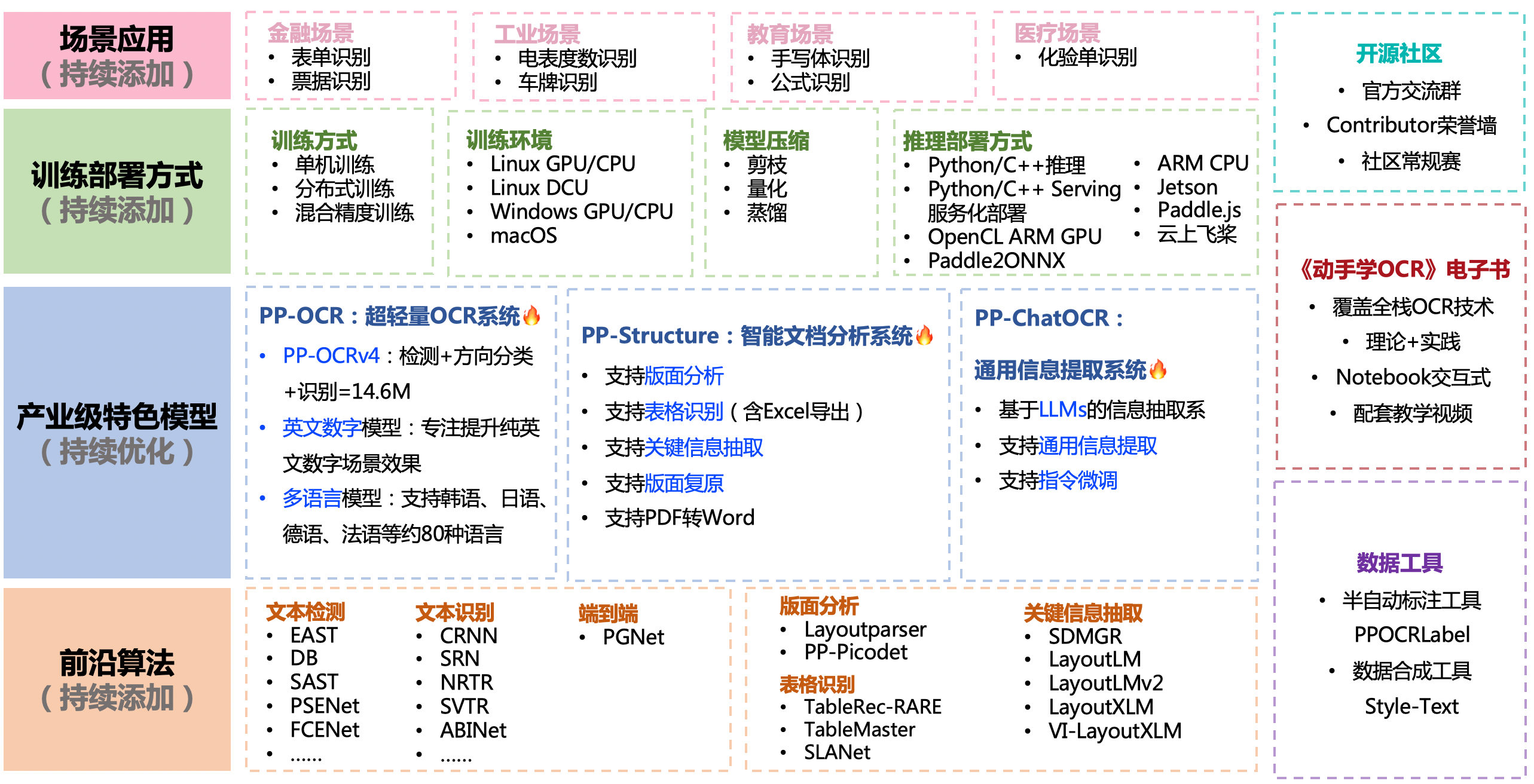
上述内容的使用方法建议从文档教程中的快速开始体验
-
在线免费体验:
- PP-OCRv4 在线体验地址:https://aistudio.baidu.com/community/app/91660
- SLANet 在线体验地址:https://aistudio.baidu.com/community/app/91661
- PP-ChatOCRv2-common 在线体验地址:https://aistudio.baidu.com/community/app/91662
- PP-ChatOCRv2-doc 在线体验地址:https://aistudio.baidu.com/community/app/70303
-
一行命令快速使用:快速开始(中英文/多语言/文档分析)
-
移动端 demo 体验:安装包 DEMO 下载地址(基于 EasyEdge 和 Paddle-Lite, 支持 iOS 和 Android 系统)
- 飞桨低代码开发工具 PaddleX 官方交流频道:https://aistudio.baidu.com/community/channel/610
| 模型简介 | 模型名称 | 推荐场景 | 检测模型 | 方向分类器 | 识别模型 |
|---|---|---|---|---|---|
| 中英文超轻量 PP-OCRv4 模型(15.8M) | ch_PP-OCRv4_xx | 移动端&服务器端 | 推理模型 / 训练模型 | 推理模型 / 训练模型 | 推理模型 / 训练模型 |
| 中英文超轻量 PP-OCRv3 模型(16.2M) | ch_PP-OCRv3_xx | 移动端&服务器端 | 推理模型 / 训练模型 | 推理模型 / 训练模型 | 推理模型 / 训练模型 |
| 英文超轻量 PP-OCRv3 模型(13.4M) | en_PP-OCRv3_xx | 移动端&服务器端 | 推理模型 / 训练模型 | 推理模型 / 训练模型 | 推理模型 / 训练模型 |
- 超轻量 OCR 系列更多模型下载(包括多语言),可以参考PP-OCR 系列模型下载,文档分析相关模型参考PP-Structure 系列模型下载
| 行业 | 类别 | 亮点 | 文档说明 | 模型下载 |
|---|---|---|---|---|
| 制造 | 数码管识别 | 数码管数据合成、漏识别调优 | 光功率计数码管字符识别 | 下载链接 |
| 金融 | 通用表单识别 | 多模态通用表单结构化提取 | 多模态表单识别 | 下载链接 |
| 交通 | 车牌识别 | 多角度图像处理、轻量模型、端侧部署 | 轻量级车牌识别 | 下载链接 |
- 更多制造、金融、交通行业的主要 OCR 垂类应用模型(如电表、液晶屏、高精度 SVTR 模型等),可参考场景应用模型下载
- 运行环境准备
- PP-OCR 文本检测识别🔥
- PP-Structure 文档分析🔥
- 前沿算法与模型🚀
- 场景应用
- 数据标注与合成
- 数据集
- 代码组织结构
- 效果展示
- 《动手学 OCR》电子书📚
- 开源社区
- FAQ
- 参考文献
- 许可证书
👀 效果展示 more
PP-OCRv3 中文模型



PP-OCRv3 英文模型


PP-OCRv3 多语言模型


PP-Structure 文档分析
- 版面分析+表格识别

- SER(语义实体识别)


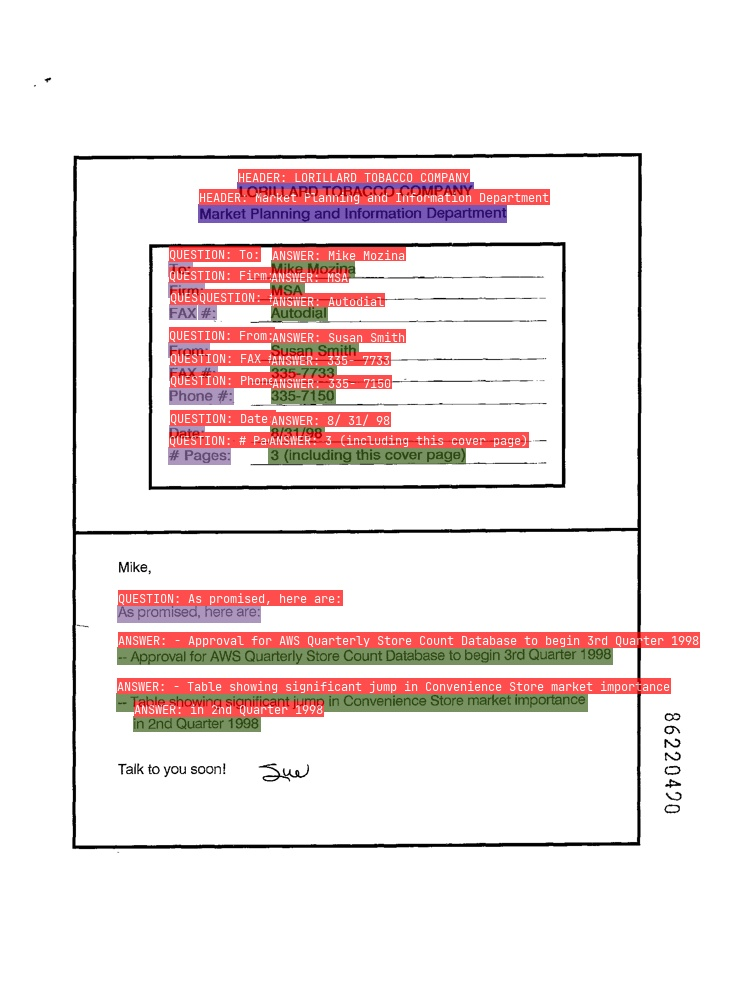
- RE(关系提取)



本项目的发布受Apache 2.0 license许可认证。













































































































































































































































