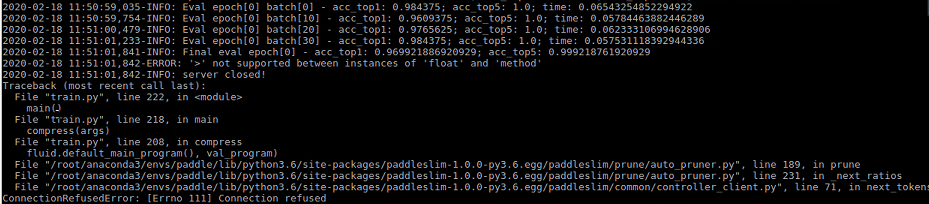
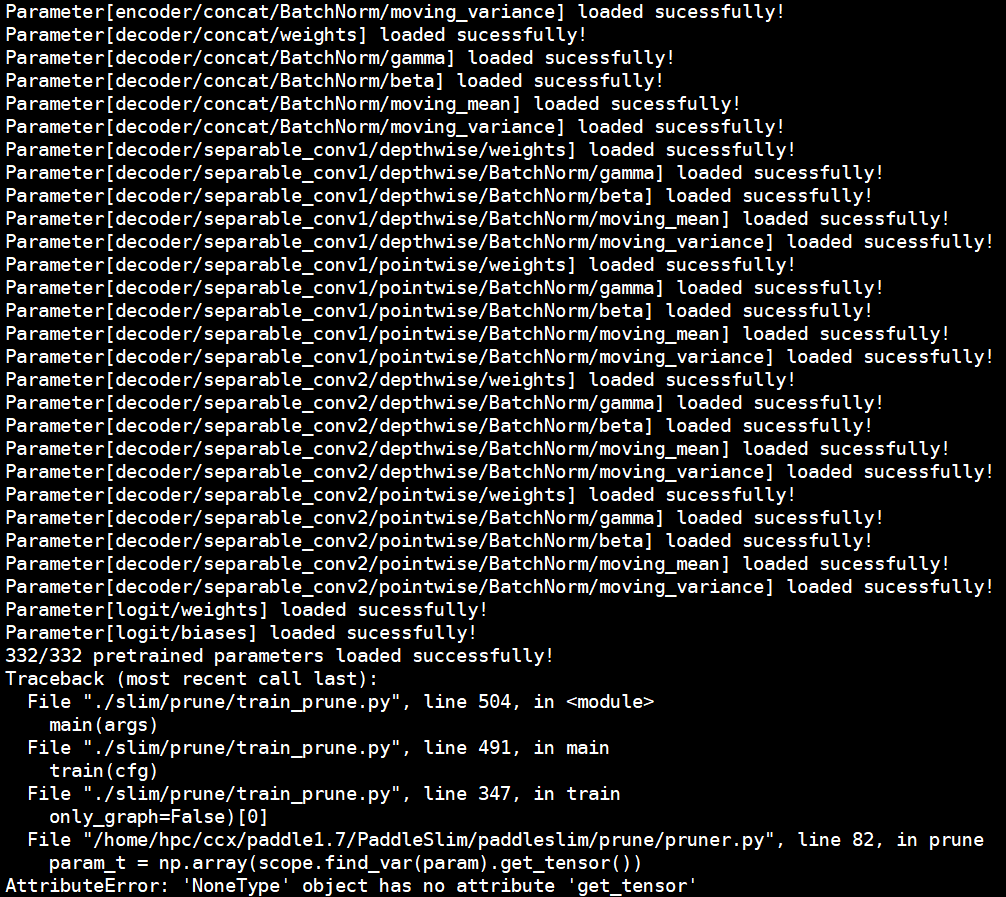
运行时输出如下:
aistudio@jupyter-7623-23204:~/work/PaddleSlim/demo/nas$ python sa_nas_mobilenetv2.py --class_dim 10 --lr 0.01
Namespace(batch_size=256, class_dim=10, data='cifar10', is_server=True, lr=0.01, search_steps=100, use_gpu=True)
2020-01-06 16:57:17,903-INFO: range table: ([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [7, 5, 8, 6, 2, 5, 8, 6, 2, 5, 8, 6, 2, 5, 10, 6, 2, 5, 10, 6, 2, 5, 12, 6, 2])
2020-01-06 16:57:17,903-INFO: ControllerServer - listen on: [172.25.33.199:8989]
2020-01-06 16:57:17,904-INFO: Controller Server run...
Traceback (most recent call last):
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py", line 45, in convert_to_list
value_list = list(value)
TypeError: 'numpy.int64' object is not iterable
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "sa_nas_mobilenetv2.py", line 318, in
search_mobilenetv2(config, args, image_size, is_server=args.is_server)
File "sa_nas_mobilenetv2.py", line 92, in search_mobilenetv2
train_program, startup_program, image_shape, archs, args)
File "sa_nas_mobilenetv2.py", line 49, in build_program
output = archs(data)
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddleslim-0.1-py3.7.egg/paddleslim/nas/search_space/mobilenetv2.py", line 186, in net_arch
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddleslim-0.1-py3.7.egg/paddleslim/nas/search_space/mobilenetv2.py", line 311, in _invresi_blocks
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddleslim-0.1-py3.7.egg/paddleslim/nas/search_space/mobilenetv2.py", line 271, in _inverted_residual_unit
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddleslim-0.1-py3.7.egg/paddleslim/nas/search_space/base_layer.py", line 52, in conv_bn_layer
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/nn.py", line 2721, in conv2d
filter_size = utils.convert_to_list(filter_size, 2, 'filter_size')
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py", line 49, in convert_to_list
value))
ValueError: The filter_size's type must be list or tuple. Received: 3
请问怎么处理下?谢谢
另外, block_sa_nas_mobilenetv2.py 运行也是这个错误