panchengtao / articles Goto Github PK
View Code? Open in Web Editor NEWArticle Publishment
Article Publishment













这是八月初的一次技术分享,本来是向同事介绍一下公司内第一门自制DSL的前世今生,后来想到这也是一次很好的分享通用型知识的机会,于是就花了一个周末的时间赶制出了这份PPT,加上代码的编写,实际上真不是一件轻松的事情。由于面向对象的基础水平有高有低,本人能力也较有限,因此并没有深入展开编程语言实现的方方面面,也没有很直接的按照词法分析,语法分析等步骤进行讲解,一切内容以简洁,实用为主,同时也保证这些技术在制作DSL的过程中有所使用。
最后整场分享下来,加上互动与板书,竟然花了两个半小时的功夫,PPT制作不是很精致,演讲节奏把握得也不是很好,只能说感谢听讲的同事吧。而内容上则感谢SICP和王垠,以及现成的LISP-JS实现项目。
假期转瞬即逝,在最后一天的下午,我带着本买了很久但是一直没有翻开过的托尔斯泰的《忏悔录》出门去了趟附近的世纪公园。
对于这个降温的午后,公园不是重点,甚至于三个小时的阅读也不是。中间走走停停,勉强看完了前六章,也是整本书的一半内容,再说得确切些,记得下一章的标题是“自杀未遂”,算是承上启下之用。这个“上”,指的就是前六章中持续探讨的“生命的意义”,而这个“下”,我还没来得及启动,只待又一个娴静的午后到来。即便如此,大师的笔触(尽管有些拙劣的翻译)也让我有了些“创作”的冲动。
在描写上一段的内容时,因为用了太多的引号,我不由想起了上次面试 ThoughtWorks 时最终面的技术主管也频繁运用了类似的表示强调的手势,正经地描述下即是——两只手各作出鹰爪功的姿势,在太阳穴两侧比划。当时不明所以,直到很久以后,我才在其他人的口中得知这个手势的真正用意。仅以此,表达我对那位和蔼的相谈甚欢的面试官的歉意。
我不如托尔斯泰,尽管从没有人这么跟我说过,但我知道这是真的。
有时候即便是最熟悉我的人也得花些功夫才能意识到这是我独有的“低级幽默”,为了避免本就不多的读者的误会,我还是提前给出该事实。
我不如他,我也未曾有像他那般的精彩人生,也因此,对于他在前六章中表现出的痛苦和无助,我无法做到感同身受,无法做到共情。对于他追寻的“生命的意义”这一问题的答案,遑论答案,即便是这个问题,也从来不是我 TODO List 中的任何一项。
1828 年生人,年轻的时候接受过大学教育,23 岁入伍参战,但也不像裴多菲那样在战争中杳无音讯,英年早逝。退伍后作为战斗英雄家声名鹊起,又在而立之年组建了自己的幸福家庭。弃武从文,投戎从笔后成就更甚,现在一想到俄国作家大多人想起的名字怕也是列夫托尔斯泰,
更别说文中令我印象深刻的“6000 俄亩农场和300 头马”(注释里写着 “1 俄亩约等于 10900 平方米,略小于标准足球场”,唯一能自我称道的记忆力用在了这里,不免让我唏嘘感叹)。如此功成名就,如此轻马飞扬,却仍在天命之际被一个问题如此折磨,以至于有了自杀的念头。换作是旁人我定会骂一句“矫情”,但对于一位大师,我只能把一大口唾沫唾在手心,当作发蜡抹在头上。

我能理解又不能理解,跟我的幽默一般,我的困扰很“低级”,更好的小猫咪,更好的住房,更好的收入,更好的工作,更好的社会地位,简而言之——更好的生活。比如当前很困扰我的一件小事——更好的学历。我无意承认这代表什么,甚至于因为一直在同家公司,暂时没有因此碰过壁,但是我也不得不承认,这能让我即便不作出任何表现,也有个“高能力”的标签一直挂着。除此之外,作为一个略带浪漫气质的男青年,偶尔也会认真地思考下第二天的发型和穿搭。
这就是我作为一个普通人和大师的距离,但有一点或许是相同的,我们都认为困扰彼此的问题很小。大师已经解决了无数个人生中遇到过的小问题,面对人生的终极问题时折戟沉沙,是的,至少在《忏悔录》前七章的内容里是如此。而我还在经历那些完全不至于自杀,但是影响心情的低级困扰,是的,至少在我前三年的工作生活中是如此。
这些困扰影响我在得空的时候,会去思考一些“我本可以……”的假设,比如上文提到的学历就是一点。
我本可以继续考研,现在应该即将从上交的分布式系统实验室毕业,或能继续读博投身科研。我本可以刚毕业就去大公司转转,而不是继续在当前的公司踯躅,或能 P7 保底,P8 黄袍加身也是未尝不可。我本可以……
“我本可以……”是最懦弱的说辞,寄希望于从未发生过的事情,在这个基础上憧憬着最好的结果,它把你对现状的不满和否定表现得淋漓尽致。更深入反思的话当然也说得出来,但如果只是说,那显然是没有必要了。
而实际的情况又是如何呢?三年的时间里,第一年从事着初创项目 CURD 的工作,第二年因为技术能力相对突出调到了架构组,从事的工作也是相对有技术含量的 DSL 解释器和算法内容,也领导过完整的产品架构设计,在公司内的技术实力和口碑也勉强算是名列前茅。个人时间自由,从没怎么加过班,以至于有不少闲工夫去阅读感兴趣的技术书籍,甚至在前两天,因为对于晶体管有点疑问,我又找了本《穿越计算机的迷雾》通读了几章。虽然待遇不算优厚,但是也到了街薪,公司预期乐观,忍两年上市可能还能套现一笔小钱。家庭和睦,有个明事理的女朋友,还有两只可爱的小猫咪。

这一切不算顶好,但是至少也不算太糟吧。
《忏悔录》还剩下一半的内容,相信大师能够完美应对。而我,也仍将继续寻找解决眼下困境的方法。心理失衡,列举了诸多生活的优点却仍不满足,我明白这些都可以依靠努力和改变解决,我也明白大多数人都明白这些道理。不过写到现在,我也有了个新的认知,追求更好的生活的背后,其实是“证明自己”的欲望,即便有了更好的收入,更大的平台,我也有很大概率仍然是“一箪食,一瓢饮”地生活,对于两只小猫咪,也仍然只能吃到以 go 品牌水平封顶的猫粮,而不能染指 ziwi 巅峰,遑论是日日小罐头,夜夜鸡胸肉。而“证明自己”,才是“自我完善”的目的,这个目的可能仅限于我,向谁证明可能也是无关紧要,但我所描绘的那些“更好的生活”,不正是“证明自己”的体现吗,我要证明我有能力取得那些,也有能力保有那些。
惟进取也,故日新。
通俗且功利。
这是一种十分取巧的做法(至少笔者在网上没找到其他案例),有时候开发者想要在 node 应用中搭建属于自己的执行环境(上下文),同时,也想要支持动态编写和加载自定义函数并在上下文中自由引用。听起来挺复杂,实际上,做到上述的任何一点都不难。例如 node 提供了 vm 模块供开发者在 v8 虚拟机中执行代码。如果不介意传入虚拟机的代码段过长的话,也完全可以通过正则或者其他字符串处理方式将自定义脚本填入代码段中,只是这样未免有些丑陋。所以我们有了下面的方式。
const vm = require('vm');
const compiledFunctions = new Map();
const proxy = new Proxy({}, {
get(target, p, receiver) {
if (compiledFunctions.has(p)) {
return (...args) => {
return compiledFunctions.get(p)(...args)
};
}
}
});
const sandbox = vm.createContext(proxy);
function createVMFunction(args, code) {
let func = `(function (${args.join(',')}){${code}})`;
return vm.runInContext(func, sandbox);
}
const concatFunc = createVMFunction(["x", "y"], "return x + y;");
compiledFunctions.set("concat", concatFunc);
const result = createVMFunction(["x", "y"], "return concat(x,y);");
console.log(result("vm", "proxy"));
最终上述代码将输出 vmproxy。实现原理也很简单,我们将自定义脚本 concatFunc 预先编译到 compiledFunctions 中,当测试代码执行到 concat 方法时,node 将在 Proxy 对应的 {} 对象寻找 concat 对象,这一举动触发 get(target, p, receiver) 方法,再从 compiledFunctions 取出 concat 方法执行。
上述代码工作良好,然而因为上下文 sandbox 的关系,自定义脚本中将无法使用诸如 Promise, JSON 等对象(因为它们毕竟不在所谓的 {} 上),所以我们 Proxy 代理的对象需要做一下变化,例如 const proxy = new Proxy(global, handler),当然更好的做法是,通过 vm 再次创建一个 global 对象,所以最终代码如下。
const vm = require('vm');
global.p = 11;
const compiledFunctions = new Map();
const proxy = new Proxy(vm.runInContext("this", vm.createContext()), {
get(target, p, receiver) {
if (target[p]) {
return target[p];
}
if (compiledFunctions.has(p)) {
return async (...args) => {
return await compiledFunctions.get(p)(...args)
};
}
}
});
const sandbox = vm.createContext(proxy);
function createVMFunction(args, code) {
let func = `(async function (${args.join(',')}){${code}})`;
return vm.runInContext(func, sandbox);
}
const concatFunc = createVMFunction(["x", "y"], "return Promise.resolve(x + y);");
compiledFunctions.set("concat", concatFunc);
const result = createVMFunction(["x", "y"], "return await concat(x,y);");
result("left", "right").then((result) => {
console.log(result);
});
考虑到需要使用 Promise 对象,所以加上了 async 与 await 标识,而在实际场景中,完全可以针对 createVMFunction 做些文章,例如通过正则,解析自定义脚本中是否有同步或异步的标识创建对应的方法。
最近半年时间因为工作关系一直都扎在 nodejs 中,作为一个之前不怎么接触动态语言编程的人来说,倒是没什么膈应的地方,花了几天看了些 ts 的东西,就开始投入项目了。倒不是公司没有写 js 的开发,只是大多是前端,而这个项目相对而言对后端的技能要求更高。其实早前看王垠的文章时,因为看客的立场问题,对王垠批判 js 一直持看热闹的态度,而这段时间下来,才发现王垠讲得真有道理,但是最重要的是——写 js 真的爽啊。
项目核心是一个 dsl 引擎(又被王垠狠狠吐槽过),主要用于数据集成处理(如果公司有开源的打算再好好介绍)。引擎中使用 jison 作为语法解析,后端则沿用 js 语言解析 AST 执行。DSL 语法上和 sql 与 python 相似,目前也实现了诸如自定义执行脚本等高级功能,关键字一直保守地维持在 20 个左右,性能与其他 ETL 工具相比也有优势,虽然中间经历了诸多心酸,但总体来看已经快要毕业了,自己也得到了很多锻炼(独立开发能不得到锻炼吗?)。
刚才算是针对最近小半年没发博客的总结,虽然挺敷衍的,但是对个人来说确实如此。
引擎下一个阶段的工作是要使用 golang 重写,由于原工程中使用了大量的 Promise.all 和 Promise 操作,所以才有以下的代码,也是为了前期批量替换相关操作。
func MapConcurrently(list interface{}, callback func(item interface{}) (interface{}, error)) (interface{}, error) {
src := reflect.ValueOf(list)
switch src.Kind() {
case reflect.Slice, reflect.Array:
l := src.Len()
wg := sync.WaitGroup{}
wg.Add(l)
fin := make(chan int)
errch := make(chan error)
results := make([]interface{}, int(l))
go func() {
for i := 0; i < l; i++ {
go func(j int) {
if result, err := callback(src.Index(j).Interface()); err != nil {
errch <- err
} else {
results[j] = result
}
wg.Done()
}(i)
}
wg.Wait()
close(fin)
}()
select {
case err := <-errch:
close(errch)
return nil, err
case <-fin:
return results, nil
}
default:
return nil, errors.New("")
}
}
相对清晰的名称和参数, list 代表迭代对象集合, callback 代表针对迭代对象的回调操作,但是由于 golang 目前仍然不支持泛型,所以代码中用了大量的 interface 和部分 reflect 代替。为了保持传入传出结果的顺序也用了指定长度的 slice。
代码比较粗略,但总体来看能实现所谓的 Promise.all 功能,不过留了个小坑,当中间任意个 go 程错误时,方法会马上退出,且无法关闭其他正在运行的 go 程。不过这个功能可以用信号可以轻松实现,就当留个小任务吧。
OAuth 2 是一个授权框架,或称授权标准,它可以使第三方应用程序或客户端获得对HTTP服务上(例如 Google,GitHub )用户帐户信息的有限访问权限。OAuth 2 通过将用户身份验证委派给托管用户帐户的服务以及授权客户端访问用户帐户进行工作。综上,OAuth 2 可以为 Web 应用 和桌面应用以及移动应用提供授权流程。
本文将从OAuth 2 角色,授权许可类型,授权流程等几方面进行讲解。
在正式讲解之前,这里先引入一段应用场景,用以与后文的角色讲解对应。
开发者A注册某IT论坛后,发现可以在信息栏中填写自己的 Github 个人信息和仓库项目,但是他又觉得手工填写十分麻烦,直接提供 Github 账户和密码给论坛管理员帮忙处理更是十分智障。
不过该论坛似乎和 Github 有不可告人的秘密,开发者A可以点击“导入”按钮,授权该论坛访问自己的 Github 账户并限制其只具备读权限。这样一来, Github 中的所有仓库和相关信息就可以很方便地被导入到信息栏中,账户隐私信息也不会泄露。
这背后,便是 OAuth 2 在大显神威。
OAuth 2 标准中定义了以下几种角色:
资源所有者是 OAuth 2 四大基本角色之一,在 OAuth 2 标准中,资源所有者即代表授权客户端访问本身资源信息的用户(User),也就是应用场景中的“开发者A”。客户端访问用户帐户的权限仅限于用户授权的“范围”(aka. scope,例如读取或写入权限)。
如果没有特别说明,下文中出现的"用户"将统一代表资源所有者。
资源服务器托管了受保护的用户账号信息,而授权服务器验证用户身份然后为客户端派发资源访问令牌。
在上述应用场景中,Github 既是授权服务器也是资源服务器,个人信息和仓库信息即为资源(Resource)。而在实际工程中,不同的服务器应用往往独立部署,协同保护用户账户信息资源。
在 OAuth 2 中,客户端即代表意图访问受限资源的第三方应用。在访问实现之前,它必须先经过用户者授权,并且获得的授权凭证将进一步由授权服务器进行验证。
如果没有特别说明,下文中将不对"应用",“第三方应用”,“客户端”做出区分。
目前为止你应该对 OAuth 2 的角色有了些概念,接下来让我们来看看这几个角色之间的抽象授权流程图和相关解释。
请注意,实际的授权流程图会因为用户返回授权许可类型的不同而不同。但是下图大体上能反映一次完整抽象的授权流程。
authorization grant。authorization grant。authorization grant,请求访问令牌。authorization grant也被验证通过,授权服务器将为客户端派发access token。授权阶段至此全部结束。access token用于验证并请求资源信息。access token验证通过,资源服务器将向客户端返回资源信息。在应用 OAuth 2 之前,你必须在授权方服务中注册你的应用。如 Google Identity Platform 或者 Github OAuth Setting,诸如此类 OAuth 实现平台中一般都要求开发者提供如下所示的授权设置项。
重定向URI是授权方服务在用户授权(或拒绝)应用程序之后重定向供用户访问的地址,因此也是用于处理授权码或访问令牌的应用程序的一部分。
一旦你的应用注册成功,授权方服务将以client id和client secret的形式为应用发布client credentials(客户端凭证)。client id是公开透明的字符串,授权方服务使用该字符串来标识应用程序,并且还用于构建呈现给用户的授权 url 。当应用请求访问用户的帐户时,client secret用于验证应用身份,并且必须在客户端和服务之间保持私有性。
如上文的抽象授权流程图所示,前四个阶段包含了获取authorization grant和access token的动作。授权许可类型取决于应用请求授权的方式和授权方服务支持的 Grant Type。OAuth 2 定义了四种 Grant Type,每一种都有适用的应用场景。
以下将分别介绍这四种许可类型的相关授权流程。
Authorization Code 是最常使用的一种授权许可类型,它适用于第三方应用类型为server-side型应用的场景。Authorization Code授权流程基于重定向跳转,客户端必须能够与User-agent(即用户的 Web 浏览器)交互并接收通过User-agent路由发送的实际authorization code值。
首先,客户端构造了一个用于请求authorization code的URL并引导User-agent跳转访问。
https://authorization-server.com/auth
?response_type=code
&client_id=29352915982374239857
&redirect_uri=https%3A%2F%2Fexample-client.com%2Fcallback
&scope=create+delete
&state=xcoiv98y2kd22vusuye3kch
Authorization Code授权流程。User-agent的跳转访问地址。CSRF攻击。当用户点击上文中的示例链接时,用户必须已经在授权服务中进行登录(否则将会跳转到登录界面,不过 OAuth 2 并不关心认证过程),然后授权服务会提示用户授权或拒绝应用程序访问其帐户。以下是授权应用程序的示例:
如果用户确认授权,授权服务器将重定向User-agent至之前客户端提供的指向客户端的redirect_uri地址,并附带code和state参数(由之前客户端提供),于是客户端便能直接读取到authorization code值。
https://example-client.com/redirect
?code=g0ZGZmNjVmOWIjNTk2NTk4ZTYyZGI3
&state=xcoiv98y2kd22vusuye3kch
state值将与客户端在请求中最初设置的值相同。客户端将检查重定向中的状态值是否与最初设置的状态值相匹配。这可以防止CSRF和其他相关攻击。
code是授权服务器生成的authorization code值。code相对较短,通常持续1到10分钟,具体取决于授权服务器设置。
现在客户端已经拥有了服务器派发的authorization code,接下来便可以使用authorization code和其他参数向服务器请求access token(POST方式)。其他相关参数如下:
Authorization Code授权流程。authorization code时使用的redirect_uri相同。某些资源(API)不需要此参数。access token的请求只能从客户端发出,而不能从可能截获authorization code的攻击者发出。服务器将会验证第4步中的请求参数,当验证通过后(校验authorization code是否过期,client id和client secret是否匹配等),服务器将向客户端返回access token。
{
"access_token":"MTQ0NjJkZmQ5OTM2NDE1ZTZjNGZmZjI3",
"token_type":"bearer",
"expires_in":3600,
"refresh_token":"IwOGYzYTlmM2YxOTQ5MGE3YmNmMDFkNTVk",
"scope":"create delete"
}
至此,授权流程全部结束。直到access token 过期或失效之前,客户端可以通过资源服务器API访问用户的帐户,并具备scope中给定的操作权限。
Implicit授权流程和Authorization Code基于重定向跳转的授权流程十分相似,但它适用于移动应用和 Web App,这些应用与普通服务器端应用相比有个特点,即client secret不能有效保存和信任。
相比Authorization Code授权流程,Implicit去除了请求和获得authorization code的过程,而用户点击授权后,授权服务器也会直接把access token放在redirect_uri中发送给User-agent(浏览器)。 同时第1步构造请求用户授权 url 中的response_type参数值也由 code 更改为 token 或 id_token 。
客户端构造的URL如下所示:
https://{yourOktaDomain}.com/oauth2/default/v1/authorize?client_id=0oabv6kx4qq6
h1U5l0h7&response_type=token&redirect_uri=http%3A%2F%2Flocalhost%3
A8080&state=state-296bc9a0-a2a2-4a57-be1a-d0e2fd9bb601&nonce=foo'
response_type的response_type参数值为 token 或 id_token 。其他请求参数与Authorization Code授权流程相比没有并什么变化。
假设用户授予访问权限,授权服务器将User-agent(浏览器) 重定向回客户端使用之前提供的redirect_uri。并在 uri 的 #fragment 部分添加access_token键值对。如下所示:
http://localhost:8080/#access_token=eyJhb[...]erw&token_type=Bearer&expires_in=3600&scope=openid&state=state-296bc9a0-a2a2-4a57-be1a-d0e2fd9bb601
response_type设置为 token 时返回,值恒为 Bearer。注意在
Implicit流程中,access_token值放在了 URI 的 #fragment 部分,而不是作为 ?query 参数。
User-agent(浏览器)遵循重定向指令,请求redirect_uri标识的客户端地址,并在本地保留 uri 的 #fragment 部分的access_token信息。
客户端生成一个包含 token 解构脚本的 Html 页面,这个页面被发送给User-agent(浏览器),执行脚本解构完整的redirect_uri并提取其中的access_token(access token信息在第4步中已经被User-agent保存)。
User-agent(浏览器)向客户端发送解构提取的access token。
至此,授权流程全部结束。直到access token 过期或失效之前,客户端可以通过资源服务器API访问用户的帐户,并具备scope中给定的操作权限。
Resource Owner Password Credentials授权流程适用于用户与客户端具有信任关系的情况,例如设备操作系统或同一组织的内部及外部应用。用户与应用交互表现形式往往体现为客户端能够直接获取用户凭据(用户名和密码,通常使用交互表单)。
用户向客户端提供用户名与密码作为授权凭据。
客户端向授权服务器发送用户输入的授权凭据以请求 access token。客户端必须已经在服务器端进行注册。
POST /token HTTP/1.1
Host: server.example.com
Authorization: Basic czZCaGRSa3F0MzpnWDFmQmF0M2JW
Content-Type: application/x-www-form-urlencoded
grant_type=password&username=johndoe&password=A3ddj3w
授权服务器对客户端进行认证并检验用户凭据的合法性,如果检验通过,将向客户端派发 access token>
{
"access_token":"2YotnFZFEjr1zCsicMWpAA",
"token_type":"example",
"expires_in":3600,
"refresh_token":"tGzv3JOkF0XG5Qx2TlKWIA",
"example_parameter":"example_value"
}
Client Credential是最简单的一种授权流程。客户端可以直接使用它的client credentials或其他有效认证信息向授权服务器发起获取access token的请求。
两步中的请求体和返回体分别如下:
POST /token HTTP/1.1
Host: server.example.com
Authorization: Basic czZCaGRSa3F0MzpnWDFmQmF0M2JW
Content-Type: application/x-www-form-urlencoded
grant_type=client_credentials
{
"access_token":"2YotnFZFEjr1zCsicMWpAA",
"token_type":"example",
"expires_in":3600,
"example_parameter":"example_value"
}
说实在的,笔者已经有很长一段时间没有好好地分享心得,发表博客,这固然有工作繁忙,学习充实的原因,但确实也是有些懒,既然认识到了,自然就不希望再堕落下去了。
这一年里读了很多书,做了很多事,虽然自觉在大学时期便接触了部分项目管理和开发的知识,但是工作后的收获仍然十分动心。微服务也好,DDD也好,或是具体的数据库理论和运维工程实践上笔者也有了更深的认识。而时至今日,笔者觉得自己是又到了重新积淀,重新迈向下一个阶段的时候。鉴权服务作为构建健壮微服务必不可少的一环(甚至可以说是第一个工程),所以以 OAuth 2 作为重启的第一篇。当然 OAuth 2 也仍然只是鉴权体系中的授权理论,更基础的认证(Authentication)理论还没有引出,希望在之后的日子里能带来更多关于鉴权相关的博文,如认证体系和功能权限设计在工程上的应用,共勉。
学习和编程都是快乐的。
| 英文 | 中文 |
|---|---|
| Authorization Grant | 授权许可 |
| Authorization Code | 授权码 |
| Access Token | 访问令牌 |
| Authorization | 授权 |
| Authentication | 认证 |
其实最近已经有一段时间没写过 C# 代码了,不过 21 号的时候要去上海大学做一个关于 Golang 编程的技术分享,在 PPT 的最后提到了即将到来的 Golang 2.0 部分特性,其中就包括了泛型,然而 Golang 即便真的要实现泛型,最初的版本中也不会实现协变和逆变性,当然了,对于 Golang 这样一门静态强类型,又没有显式继承和实现的编程语言而言,逆变和协变性其实并没有什么必要。
以下是 Golang 2.0 中介绍泛型草案的原型代码。抛开“泛型”这个功能,唯一的亮点就是只加了规约关键字,依旧保持了简洁的风格。
contract Equal(t T){
t == t
}
func Uniq(type T Equal)(in <- chan T) <-chan T{
out := make(chan T)
go func(){
v := <-in
out <- v
for next := range in{
if v != next {
v = next
out <- v
}
}
}()
}
而对于 C# 和 Java 这类带显式继承关系的静态强类型语言,在设计语言和库功能时,协变和逆变性就是不能绕过的话题了。当然对于大多数开发者而言,这并不是需要深究的话题,所以笔者也只是想对 C# 中协变和逆变做一个简洁的讲解,以泛型接口中的参数类型以及 in 和 out 关键字为例。想解决的其实也只有一个问题——为什么协变针对返回类型,而逆变针对传入参数。
协变和逆变强调的是类型与类型之间的转换,在 C# 中,假如我们定义以下类型:
public class Animal
{
}
public class Dog : Animal
{
}
Animal 是 Dog 的父类,则在代码中我们可以将 Dog 的实例赋值给 Animal 的实例,即 Animal animal = new Dog();,这称为类型的可变性。而对于 Animal 和 Dog 的数组类型而言,同样具有这种表现特征,如以下代码:
Animal[] animals = new Dog[2];
animals[0] = new Cat();
animals[1] = new Dog();
编译时不出错,而运行至第二行时抛出异常。我们将第一行的赋值操作称为“数组对参数类型协变”,即“数组这种与原始类型转换方向相同的可变性就称作协变”(摘自施凡老师的博客)。而诸如 List 等泛型类型却不支持此种特性,只体现了不变性,这也是 C# 被开发者广为诟病的设计缺陷之一,代码的安全性和统一性上都被打破了。
逆变性更不容易理解一些,还是照例看看例子。
从 .NET Framework 4 开始,诸如 IEnumerable、 IEnumerator、 IQueryable 等泛型接口被设计成具有协变类型参数,而 IComparer、 IComparable和 IEqualityComparer 等泛型接口被设计成具有逆变类型参数。源码如下:
public interface IEnumerable<out T> : IEnumerable
{
IEnumerator<T> GetEnumerator();
}
public interface IComparable<in T>
{
int CompareTo(T other);
}
协变和逆变的特性分别通过 out 和 in 关键字标识。前者令编译器保证类型只能出现在那些用于输出的地方,也就是只能给函数或属性的 get 访问器充当返回值。而后者令编译器保证类型只能出现在那些用于输出的位置上面,如 IComparable 接口的 CompareTo 方法。以下笔者定义了几个类型和方法用以说明这些规则的意义和原因。
public class Foo
{
}
public class Bar : Foo
{
}
internal interface ICovariant<out T>
{
//void Method1(T param);
T Method2();
}
internal class Covariant<T> : ICovariant<T> where T : new()
{
public T Method2()
{
return new T();
}
//public void Method1(T param)
//{
// Console.WriteLine(param.GetType().Name);
//}
}
public static void Covariant(ICovariant<Foo> foo)
{
var t = foo.Method2();
//foo.Method1(new Foo());
Console.WriteLine(t.GetType().Name);
}
private static void Main(string[] args)
{
ICovariant<Foo> parent = new Covariant<Foo>();
ICovariant<Bar> sub = new Covariant<Bar>();
Covariant(parent);
Covariant(sub);
}
输出不出所料,分别是 Foo 和 Bar。分析下上文代码,在 ICovariant 接口支持了协变性的条件下,ICovariant 将只能定义 T Method2();。如果还原注释代码,再假设编译能通过,会发生什么情况呢?Covariant 方法参数中的 foo 此时其实是 ICovariant 实例 sub,sub 的 Method1 方法接受一个 Bar 实例,但是 Covariant 方法中却传入了 Foo 实例,违背了只允许子类转换成父类的规则,所以假如一个泛型接口允许对类型 T 的协变,则不能定义诸如 void Method1(T param) 的方法,以免用户自定义的代码(Covariant 类型和 Covariant 方法)中存在父类向子类的转换,索性直接由编译器明令禁止了。
经过刚才的讲解后,其实分析的步骤都是类似的了,不过仍然贴出完整的代码。
internal interface IContravariant<in T>
{
void Method1(T param);
//T Method2();
}
internal class Contravariant<T> : IContravariant<T> where T : new()
{
public T Method2()
{
return new T();
}
public void Method1(T param)
{
Console.WriteLine(param.GetType().Name);
}
}
public static void Contravariant(IContravariant<Bar> contravariant)
{
contravariant.Method1(new Bar());
//var t = contravariant.Method2();
//Bar bar = t;
}
private static void Main(string[] args)
{
IContravariant<Foo> parent = new Contravariant<Foo>();
IContravariant<Bar> sub = new Contravariant<Bar>();
Contravariant(parent);
Contravariant(sub);
}
上述代码能正常编译并运行,输出都是 Bar,说明编译和运行时允许了 IContravariant 向 IContravariant 的转换,因为即便是 IContravariant 实例调用了 Method1 方法,传入的 Bar 类型仍然可以转换成 Foo,逆变性就体现在这里。如果我们再将注释还原,并假设编译全部通过,来看看会发生什么情况。当向 传入 Contravariant 方法传入 parent 对象时,contravariant.Method2() 返回 Foo 实例,随后便赋值给了 bar,又违反了只允许子类转换成父类的规则。所以假如一个泛型接口允许对类型 T 的逆变,则不能定义诸如 T Method2() 的方法,以免用户自定义的代码(Contravariant 类型和 Contravariant 方法)中存在父类向子类的转换,索性直接由编译器继续明令禁止。
我们可以看到,假如泛型接口既要支持可变性,又不添加对输入参数和返回值的限制,那么在开发者编写实现代码或者应用方法代码时,则会很容易地发生安全性方面的问题,泛型委托如 Func 和 Action 大家也可以按照前文的步骤分析。
这篇文章的代码很多,讲解上比较简洁,但是应该已经比较清晰地回答了最初的问题——为什么协变针对返回类型,而逆变针对传入参数。
原来的题目有引战之嫌,同时笔者在写作时,也发现实际内容也没涉及到多少深入的,并且尖锐的对比,所以就改成了现在的《Why PostgreSQL rocks》,但在正文最上方还是保留了之前的说法。实际上我对 Oracle 基本只停留在“由于 Oracle 安装难度过高,所以衍生出了 Oracle 安装收费这样的产业链”的阶段,所以真让我说 Oracle 有什么不好的地方,也是强我所难了。之所以用这个作为题目,纯粹只是我对 C# 的一位大牛,赵姐夫的《Why C# rocks and java sucks》系列的一次致敬而已。技术比不上人家,但是心态上要看看齐。
此次分享的目的,更多的是想让大家了解时下越来越流行的关系型数据库 PostgreSQL 的一些浅薄知识,以及为什么推荐将 PostgreSQL 作为进行项目开发时的数据库第一选择。
基于这个初衷,下面会以 Postgresql 所拥有的强大特性和解决方案作为内容组织条目。在此之前,其实我还想声明一下,从数据上来看,前几年 Postgresql 占比远远不如刚才说的三大数据库,份额上只有五分之一甚至更低。所以出现了这样一种情况,很多开发者之前用过 Oracle,用过 Mysql,用过 Sql Server,唯独没有用过 Postgresql 。当然是很正常的一件事情。不过这也引出了一个普遍问题,因为某项技术没有用过而觉得抗拒,或者因为习惯于某项使用过的技术中而排斥学习,这都是常见但是不提倡的行为。我相信大家既然体验了 .NET CORE,了解了 Docker,K8S 等一系列技术,肯定能感觉身边反馈给你们的工程师文化并不是如此,然后这也推动了今天此次主题的诞生。微软 CEO 萨提亚纳德拉 提出过一个理念,叫作“拥抱变化,更新文化”,说的也是这个道理。
OK,一通嘴炮下来,看起来大家都还能接受,不过也让我们快点进入正题吧。
PostgreSQL 是一个基于 BSD 授权许可的面向 HTAP 场景的开源关系型数据库。很多人应该听过 OLTP 或者 OLAP,而 HTAP 则是时下比较火的概念,可以理解为混合型事务及分析处理,也就是说兼顾优化 OLAP 和 OLTP 场景性能。
PostgreSQL - The world's most advanced open source database
这是挂在 PostgreSQL 官网的一句话,其实仅这一句,就已经违反了**广告法。但是人家就是有这底气。另外有些人也知道 MySQL 的定位,我也贴了出来。
MySQL - The Most Popular Open-Source Database
MySQL,最受欢迎的开源数据库,这是两家数据库背后的团队对自己的认识,其中说明了什么,大家可以自己去体会。单单在功能集上,PostgreSQL 说完爆 MySQL 可能太狂了,但是小爆还是不成问题的。仅仅索引种类支持一项,PostgreSQL 便是 MySQL 的数倍。同时,不像 MySQL 背后仍然有商业性公司 Oracle 作为决策人,尽管 PostgreSQL 已经诞生三十多年,但仍然称得上是社区兴趣使然的产品,尽管现在围绕 PostgreSQL,已经有很多强大的商业产品和商业公司诞生,这个之后会在生态中介绍。然而 PostgreSQL 仍然保持着它的独立性和纯粹性,只由所谓的PostgreSQL全球开发小组领导,不参与商业决策,不受资本控制。同时,社区中的主要贡献者个个都是人才,代码写得好,说话也好听。
当然很多人可能也会担心仅仅由社区推动,是否会对功能,或者代码质量造成损害。那下面就让我来简单介绍下 PG 的发展历程以打消大家的顾虑。
PostgreSQL 的前身是伯克利源于 1977 年的 Ingres 项目,而 Ingres 的作者正是 2014 年图灵奖得主迈克尔·斯通布雷克。值得一提的是,唯一的华人图灵奖得主姚期智院士还是斯通布雷克的普林斯顿校友。迈克尔斯通布雷克在结束 Ingres 项目后,又重启了一个后 Ingres 项目,也就是 Postgres,而 PostgreSQL 正是由两名**研究生在 90 年代重写 Postgres 的产物。尽管未由这位图灵奖得主直接干预,但是从其中继承的全部源码,也解决了诸多难点,如UNIX平台支持,多用户、多进程、两个层次的非过程语言,子查询,宿主语言,交互式算法,存取管理、并发和恢复、部分完整性约束,以及查询修改,还有用于完整性约束和视图,等等。
其实除了 PostgreSQL 之外,Ingres 还衍生出了一系列我们耳熟能详的数据库,比如 SQL Server,Oracle。然而除了 PostgreSQL,其他所有的数据库要么由作者自己开了公司继续做大,要么就由商业公司收购了。
诞生至今的三十多年间,PostgreSQL 一直保持着它旺盛的生命力。活跃的代码贡献者中有来自 VMware,Pivotal 这样的知名企业云服务厂商,也有部分高校的教职人员,当然主要的还是类似于 EnterpriseDB 和 2ndquadrant 这样的基于 PostgreSQL 发展的商业公司。
每年一个主版本,每个季度一个次要版本,目前 PostgreSQL 的最新版本已经来到了 11.1,同时项目组保持对最新对 9.3 版本的支持,所以不用担心数据库的生命周期问题,当然了,PG 也提供了诸如 pg_dump 和 pg_upgrade 等系列迁移升级工具用于使用者升级数据库版本,我们当然是强烈建议尽可能地升级到最新版,因为 PG 每一个大版本的发布都意味着性能,功能,安全性的肉眼可见的提升。
最后让我们来看看截止 2015 年为止,PostgreSQL 的一些主要用户。早前都是一些追求稳定性和安全性的企业或教育机构在使用 PostgreSQL,但是我们也能看到越来越多的知名互联网公司投入了 PostgreSQL 的怀抱。
2014 年至今,PostgreSQL 算是引来了它的黄金期,三十多年的沉淀厚积薄发,才有了这一张图。这图是我从全世界最知名的数据库图库网站 DBEngine 收集的,可以看到如今的 PostgreSQL 气势凶猛,已经接近前三大流行数据库一般的份额,而关键的 2013 后半年节点则是 PostgreSQL 9.3 大版本的发布时间。老实说这个版本亮点不多,主要是增强了垃圾回收和查询优化器性能。
可以看到商业数据库日渐式微,可能在2020年,开源数据库便能实现对商业数据库的完全超车。11 月底亚马逊官方表示,将在 2019 年底全面弃用 Oracle 数据库,报道中还透露亚马逊的数据库已经在 11 月份初就从 Oracle 迁移到了其自主研发的 Redshift 上,当然了,Redshift 也是基于 PostgreSQL 源码修改的。而近年来国内去 O 的趋势也是愈演愈烈,比如 13 年底前阿里便完成了全部的去 O 工作,后面蓬勃诞生的互联网公司更是在最开始的技术选型时便没有考虑过使用 Oracle 数据库。可能有人说这是互联网开发自由的基因天生容不下 Oracle,那让我们来看看传统行业。据有效数据显示,**移动,联通,电信,从 11 年就已经分别开始了去 O 政策。这是在 2015 年第六届**数据库技术大会由浙江移动信息技术部王晓征在他的演讲《运营商去O浅析》中提及的。扩展性差,采购和维护成本高,无法掌握核心技术,技术成长停滞都是企业去 O 的重要动力。
而在一向重度依赖 Oracle 的金融业,其实这股风气也早已经刮了起来。2014 年银监会就发布了一篇名为《关于应用安全可控信息技术加强银行业网络安全和信息化建设的指导意见》,里面提到在保证信息数据安全稳定可靠的情况下,加强技术创新,摆脱在关键信息和网络基础设施领域对单一技术和产品的依赖,并给出了相应的银行信息化技术指标。以小见大,传统行业中,通信也好,金融也好,包括医疗也好,国家对于信息化建设的要求,已经不止停留在安全可靠的程度上,自主可控和知识产权,同样是考量的要点。再说,刚才提到的几款数据库中,难道真的就是 Oracle 最安全了吗?这个问题放到后一节中简要地谈谈。这里先卖个关子。
说完出身和最新的发展态势,在进入 PostgreSQL 功能特性展示前,我还想引入一个有趣的话题。想必大家私下也去找过 PostgreSQL 与其他数据库诸如 MySQL 或者 Oracle 的对比,先不说性能上的较量,很多人都会提到一个名词,叫作代码质量,是的,作为开源数据库,你可以对项目代码一览无余,所以这时候我们常常会听到,MySQL 的代码质量极差,而 PostgreSQL 的代码质量则很高。我前前后后找了一些论证,最后发现国外最大的数据库社区 DZone 上有人做了比对,博文的名字叫作《Code Quality Comparison of Firebird, MySQL, and PostgreSQL》,Firebird 是另一款关系型数据库。文章在这里就不摘抄了,总之最后的评判结果毫无疑问是 PostgreSQL 胜出。后来我也是去 GITHUB 简单翻了下 MySQL 和 PostgreSQL 的源码,也不掺杂主观意见的话,MySQL 在重要的查询优化器以及存储引擎上,单个代码文件行数接近或超过万行也是司空见惯,而 PostgreSQL 很难见到有内容超过两千行的代码文件。但是这种意见,包括刚才的博客中的评判结果,其实都不能算作公论,但是毕竟管中窥豹,可见一斑。
而 Oracle 更是饱受诟病,上个月 14 号国外有人在发了个帖子,标题是“你见过的最糟糕的代码是什么样子”,有个 Oracle 的员工就在下面吐槽,当时就引起了热议,传到**又火了一把,我大概把中文翻译摘抄几段下来。
Oracle 数据库 12.2。它有近 2500 万行 C 代码。
这有多恐怖,简直难以想象!你无法在不破坏成千上万个现有测试的情况下更改产品中的单行代码。好几代程序员在有限的项目期限内编写了这些代码,其中充斥着大量的垃圾代码。
甚至可能需要一两天才能真正理解某个宏命令的作用。
开发一个小功能需要6个月到1年的时间(如果是添加一种新的身份验证模式,比如支持 AD 身份验证,可能需要2年)。
这款产品本身就是一个奇迹!
我不再为 Oracle 工作了。永远不会再为 Oracle 工作了!
看看这种描述,可能有些祖传代码,确实得把老祖宗的棺材给撬开才有读得懂的鬼。
一个数据库是否安全,得从连接的安全性、密码的可管理性、访问的可控制性、数据的
可靠性等多方面衡量。在后面的数据中,大家可以看到,在主流的商业数据库和开源数据库中,PostgreSQL 在这些方面可以说是做得最好的,并且 PG
完整支持 PCI DSS。PCI DSS 全称为第三方支付行业(支付卡行业PCI DSS)数据安全标准,是由PCI安全标准委员会的创始成员(visa、mastercard、American Express、Discover Financial Services、JCB等)制定,主要是为了使目标行业采用一致的数据安全措施。以下是一份国内厂商提供的关于 Oracle 和 PostgreSQL 在数据库功能实现的安全性上的对比。由于 MySQL 在这点上实在是比较吃亏,就没有贴出来了。
| 安全性 | Oracle | PostgreSQL |
|---|---|---|
| 认证支持 | Yes-> LDAP, SSL, RADIUS, PAM, Kerberos, GSSAPI, SSPI | Yes-> LDAP, SSL, RADIUS, PAM, Kerberos, GSSAPI, SSPI |
| 存储加密 | Yes | Yes |
| 链路加密 | Yes | Yes |
| 白名单连接 | Yes | Yes |
| 黑名单连接 | Yes | Yes |
| PROFILES FOR PASSWORDS | Yes | Yes √ |
| SERVER CODE OBFUSCATION | Yes | Yes |
| ANSI STANDARD SQL GRANT/REVOKE | Yes | Yes |
| COLUMN LEVEL PERMISSIONS | Yes | Yes |
| USER/GROUP/ROLE SUPPORT | Yes | Yes √ |
| 虚拟化私有数据库 | Yes | Yes √ |
| VIEW SECURITY BARRIERS | 不可用 | Yes |
| DATA MASKING | Yes | Yes |
| REAL APPLICATION SECURITY | Yes | 只有 DBMS_RLS 功能 |
| DATABASE VAULT | Yes | Yes |
| AUDIT VAULT AND DATABASE FIREWALL | Yes | 数据库防火墙(SQL /Protect) |
| ADVANCED SECURITY | Yes | 多个选项可用 |
| FINE GRAINED AUDITING | Yes | Yes |
| DATA ENCRYPTION TOOLKIT | Yes | Yes √ |
接下来的一份报告是截止目前为止,最新的一份关于数据库漏洞报告的数据。也是由国内知名数据库安全研究厂商安华金和公开。
Oracle 安全漏洞,63个
PostgreSQL 安全漏洞,30个
Mysql 安全漏洞,惨不忍睹了
而在权限管理上,PostgreSQL 和 Oracle 都支持基于角色与用户的权限配置,权限单元的最小粒度也可以锁定到行和列。也就是说,一张完整的表,不同用户看到的只是所有数据的不同子集。
这些都是客观实在的数据,然后再讲一个我们碰到的小故事。上个月参加在苏州举办的“**数字医学前沿论坛”时,有一个 Oracle 的 DBA 说过一个关于触发器使用的安全漏洞。在 Oracle 中,触发器提供的权限是定义者的权限,也就是假如有一个 System 用户定义了一个触发器函数,低权限级别用户就可以写一个恶意函数,比如获取 Sys 用户密码的函数,虽然这个用户不能运行这个函数,但是可以将其放入早先定义好的触发器函数中,从而通过 Sys 用户权限执行函数,逐步地获取对整个数据库的控制权。其他的诸如常见的索引提权等漏洞在目前主流的版本中仍未修复。触发器和索引可能是开发和优化中使用的最多的功能,只希望 Oracle 的开发者能尽快地向那 2500 万行代码中提交补丁吧。
不要小看这些安全漏洞因为不能及时修复带来的影响,前不久国家信息安全漏洞共享平台也发布了一个通告,“Oracle数据库勒索病毒RushQL死灰复燃”。这个RushQL勒索病毒已经不是第一次肆虐Oracle数据库,早在2016年11月就已经在全球掀起了一场血雨腥风。当然,那时候它有个更响亮的名字“比特币勒索病毒”。也就是说,你要么交钱,要么丢数据。两年时间,Oracle 对此仍然是束手无策。
老实说,我觉得对于数据系统是否安全而言,操作系统的安全性和运维人员的素养更要紧一些,比如你硬要把主要的访问端口暴露出来,或者把密码设成全球通用的 admin 和 123456,那不管是什么背景的企业,都有吃亏的时候。然而仅从刚才提到的数据和案例而言,相信大家也有了一些自己的看法。
做完了前面几节的铺垫,这一节里我们将看到 PostgreSQL 为什么如此受欢迎的重要特性和功能。毕竟对于绝大部分开发者而言,所谓的背景,开发流程,代码质量甚至是高级安全特性都不是他们所在意的,数据类型,索引类型,与外部编程语言或者外部数据源的直接集成功能,可靠性以及可用性,往往才是左右开发者是否选择的重点。
PostgreSQL 是所有主流关系型数据库中对 SQL 标准最完善的数据库。目前的 SQL 标准最近的一次更新在 2011 年,在 179 个完整核心符合所要求的强制特性中,PostgreSQL 至少符合 160 个。这也意味着在其他关系型数据库编写的 SQL 语句拿到 PostgreSQL 中,甚至不需要作修改便可以直接运行,提供了强大了可移植性和兼容性。包括你能想得到数据类型,操作符,窗口函数,CTE 表达式,递归和树操作。
XML,键值对,JSON,JSONB,比特,数组,树,地理信息,网络信息,DNA,复合类型等。Transaction DDL,窗口函数,CTE 表达式,表继承等。除此以外, PostgreSQL 还提供了非常多的函数糖,可以这么说的是,PostgreSQL 绝对不会成为业务系统中增删改查和数据库设计的 Runtime 瓶颈。
值得一提的是,PostgreSQL 现在一机多用的能力特别强,不仅能作为关系型数据库,文档存储和键值对操作能力也特别强悍。PG 9.2 引入了 JSON 类型,9.4 引入了JSONB类型,直接对彪 MongoDB 的 BSON,同时内置的函数和操作符支持也远远超过其他几家同样支持 JSON 存储的关系型数据库。在 2014 年刚推出时,国外最大的 PG 厂商之一 EnterpriseDB 发表了一篇关于 PG 9.4 与 MongoDB 2.6 性能对比的文章。
当然了,很多人使用 MongoDB 看中的也是其分布式功能,而一开始 MongoDB 也并未将全部重心放在性能优化上,所以这样的结果也是可以理解的。如今 MongoDB 4.0 也已经发布,除了磁盘空间的消耗仍然比 PostgreSQL 高出很多,性能在各种相对正规的社区评测中也已经能慢慢看到 PostgreSQL 的尾气了。
数据库支持多种数据类型和数据操作方式,为了提供最优的性能,数据库也必须支持
多种类型的索引。PostgreSQL 在这方面有自己的独到之处,不仅提供了在主流关系型数据库最多种类的索引,而且面向的场景基本覆盖了日常和部分特殊领域的需求。
通过对上述索引的组合和使用,很多文章都喊出了诸如“百亿级数据毫秒响应”,“轻松击败搜索引擎”的口号,特别是机器成本可控,案例贴近实际的情况下,一方面不排除有夸大的成分,另一方面却也说明了 PostgreSQL 的性能上限极高。除此以外 PostgreSQL 还通过插件支持其他索引种类或功能性增强。之所以说 PostgreSQL 如此适合 OLAP 场景,种类丰富的索引确实占了很重要的原因。
PostgreSQL 本身的架构设计十分优秀,除了无法更换存储引擎为人诟病意外,其他的开放特性一应俱全。而且由于这种插件式的接口设计,对于性能的损耗在理论上也是微乎其微。
下面先简要提及两个只有 PostgreSQL 才提供的实用功能。
PostgreSQL 支持称为外部数据包装器的功能,简称 FDW。FDW 由 SQL 2003 标准制定。
安装必要的扩展并进行适当的设置后,您可以访问远程服务器上的外部数据,例如我们有一个本地的 PostgreSQL 数据库和一个远程的 MySQL 数据库,在本地写好查询 sql,便能查询到远程数据信息,这对于数据集成,屏蔽多数据源细节,以及数据迁移都有十分重要的意义。目前 PostgreSQL 的数据源支持以及扩展到了市面上所能见到的绝大部分数据库,如 Redis,ElasticSearch 等。值得一提的是,citus,另一个知名 PG 厂商,还利用此功能实现了分布式列存储功能。
但比较遗憾的是,尽管很早就有了这个功能,而且很多数据源的 FDW 开源项目很早也上了马,但是除了由 PG 官方维护的 PostgreSQL FDW,一个直接访问远程 PG 数据库的扩展外,其他的项目并没有得到良好持续的开发。不过随着这几年 PostgreSQL 火箭般的蹿升,相信这种局面已经在慢慢改观。
PostgreSQL允许用户定义的函数使用 SQL 和 C 之外的语言编写。 通常这些额外的语言叫过程语言(PLs)。目前在标准的 PostgreSQL 发布里有四种过程语言可用:PL/pgSQL, PL/Tcl , PL/Perl和 PL/Python 。除了标准的四种,还有以下列出的条目。这些项目在当下都十分活跃,如今 Python,Java,Javascript 如此火爆,直接使用这些语言在 PostgreSQL 中编程其实已经很常见了。
得益于 PostgreSQL 开放的特性和优秀的架构设计,围绕 PostgreSQL 开发的一系列数据库和工具集也是越来越多。图中的这些工具都能以插件的形式集成到 PostgreSQL 数据库中直接使用。
简单介绍几个目前比较流行的开源项目。
讲了这么多 PostgreSQL 本身的特性和功能,接下来让我们来了解一下 PostgreSQL 更直观的几个为 HTAP 设计的特性。其实讲到现在,我们介绍的始终是 PostgreSQL 直接提供的功能,比如数据类型,索引 等等,再往下一步的表结构,进程模型,MVCC,都只是为了实现 PostgreSQL 上层功能的细节,在这个场合中没有探讨的必要,不然只是 MVCC,就我个人而言,又能再写个万字长文了。
下面列出的功能和评测主要针对 OLAP 场景,这和我们的实际场景更切合。
PostgreSQL 9.6 or higher AP
然后下面是对应的性能检测,检测数据使用了全球 OLAP 工业标准 TPC-H,大概 200G 的数据,22 条 AP 相关的 SQL 语句,覆盖了绝大部分场景,所有测试 20 分钟全部跑完。测试环境为 PostgreSQL 11, 64 核 512G 内存云计算主机。
| 场景 | 数据量 | 并发 | 平均计算时间 |
|---|---|---|---|
| 排序 | 1E | 32 | 1.4s |
| 并行建索引 | 1E | 15s | |
| 并行扫描 | 1E | 32 | 0.88s |
| 并行聚合 | 1E | 32 | 0.9s |
| 并行过滤 | 1E | 32 | 1s |
| 并行 join + 聚合 | 1千万 join 1千万 | 32 | 1s |
| 并行 join + 聚合 | 1E join 1E | 32 | 1.2s |
| 多表并行扫描 | 2E | 64 | 0.6s |
| Top n | 100E | 64 | 40s |
从以上数据大家大概能感受到 PostgreSQL 的威力了,而在更多的社区评测中,也可以看到 PG 的单机 AP 性能已经接近了相同成本的 MPP 分布式数据库方案。
无论是高可用性方案还是生态,其实 MySQL 都比 PostgreSQL 或者 Oracle 要强,这没什么要回避的,就跟 C# 与 Java 的困境一般。所以剩下的两个章节也会更注重 PostgreSQL 自身。可以这么说,虽然 PostgreSQL 在各个运维领域的解决方案少,但是都是精品。
首先介绍两个连接池组件。PgBouncer 和 PgPool2。
PgBouncer
PgPool2
两种技术可以一起使用,完全可以把 PoBouncer 放在 PgPool2 之前联合使用。
接下来讲复制,Replication。PostgreSQL 很早就支持了物理流式复制,同时在 9.4 版本后引入了逻辑复制。物理流式复制作用在数据库级别,可以实现容灾库与主库的完全一致。同时也实现了主从同步,主从异步,从库与从库的级联复制模式,保证不同场景下的性能和数据备份要求。物理复制可以保证物理层面的完全一致,同时数据可见延迟低,一致性、可靠性都达到了金融级的需求。但是物理复制要求主备块级完全一致,所以有一些无法覆盖的应用场景,例如备库不仅要只读,还要可写。又比如备库不需要完全和主库一致,只需要复制部分数据,或者备库要从多个数据源复制数据,等等。
PostgreSQL 在 9.4 版本引入的逻辑复制解决了物理复制的不少问题。
当然相对的,逻辑复制对于主库的性能影响也会更大。对于大事务,物理复制的延迟也会比逻辑订阅更低。
剩下的一幅图则是目前针对 PostgreSQL 实现服务和存储高可用的架构图,左侧是我们的 master 节点,右侧是复制节点,两者通过物理流复制或是逻辑流复制交流。Patroni 是一个用于 PostgreSQL 高可用方案的组件,内部使用 etcd 或者 zookeeper 保存监控集群状态并选举 leader 节点。当我们左侧的主库发生宕机,右侧从库自动提升为主库,Patroni 可以自动通知负载均衡节点主库已经发生切换,完全无需人工干预,old master 恢复后又可以自动加入集群。Patroni 和 etcd 在开源社区中都是十分活跃的项目,同时图上的各个组件和 K8s 运维环境可以说是无缝兼容,甚至于负载均衡以及服务注册都可以直接使用 K8s 为我们提供的组件功能。
图中实现了存储层和 PostgreSQL 数据库服务的高可用,至于应用端的高可用,则没有在图上给出方案。
至此,关于《Why PostgreSQL rocks》的所有内容就分享完毕了,在以上的内容中,我们先了解了 PostgreSQL 的前身,发展以及生态,然后分享了 PostgreSQL 的优秀设计和强大的功能特性,在第五节中我们也介绍了 PostgreSQL 在高可用场景下的支持特性以及成熟方案。虽然 PostgreSQL 以及历经数十年的发展,但它并没有像一个迟暮的老人一般,反而依然在社区的支持下不断推陈出新,和目前互联网上的前沿技术仍然配合得很好。
但是上文中我们没有提到的包括,PostgreSQL 设计架构,MVCC 实现,垃圾回收等重要的细节,也是一种遗憾,但是这些话题都要求更深入的探索,有机会的话,希望在之后的分享中带来。
另外值得一提的是,虽然目前 PostgreSQL 暂时不支持更换存储引擎,但是插件化的存储引擎开放接口已经被纳入开发提案了。PG 12 中应该就能看到。
最后,If in doubt, use PostgreSQL。
最近笔者一直没有记录博客,原因是因为卷入了面试,离职,谈判,思考等一系列事件中。不过可以先说明一下的是, 笔者最后还是拒绝了 Thoughtworks 的 Offer,而是继续留在了目前的公司。
去年毕业后,笔者从博客园辗转来到了上海的一家医疗AI公司,从事的依然是后端的工作。由于一开始公司在新产品线上的准备不足,这包括对开发者和开发计划的准备等,在前期的时候,笔者协助主管负责了部分基础架构方面的工作,比如缓存层,日志层,鉴权和测试等等。等之后几个月部门情况慢慢改观后,又投入了紧锣密鼓的开发工作当中。
老实说,从那时候开始,这份工作看起来便不是非常有趣了。虽然用的技术也属前沿(可能并不主流),ASP.NET Core + Angular 的前后端分离架构,GitHub + Jenkins 的 Auto CI 系统,Docker Compose 的 Manual CD 系统等等,但是等你尝了个技术的新鲜后(老实说也不新鲜),反复的业务迭代和不规范的敏捷开发流程仍然会让你备受折磨。更重要的是,开发部门对外没有一个技术上的话事人——技术人员崇尚扁平,但是绝不能是小圈子中的扁平。
这是很正常的一件事,但是会让一些人不可接受。在很长的一段时间内(半年多),笔者基本没有输出过除工作之外的成果,博客也好,开源项目也好。有工作的问题,也有自身的问题。虽然从来没有放弃学习和技术成长,但是或多或少放弃了和更多人交流的欲望。
负面情绪的积累是一方面,这个过程中笔者也直接向上反馈了一些问题,也都得到了解决,情况慢慢地往好的方向发展。在终于完成了新的 Sprint 迭代后,笔者也被调到了公司新成立的基础架构组,和笔者一直很佩服的 CTO 一起共事。
也正是在这个时候,笔者收到了 Thoughtworks 的面试邀请。
粗粗了解 Thoughtworks 的人大概都是因为 Martin Fowler ,著名的《重构》一书的作者。本人也不例外。只是后面在不同的途径上了解到 TW 的更多信息后,就完全是从组织的角度喜欢上了它。这些途径包括知乎的官方 PR,如机构号(笔者也都认真地把文章看了下来);每年两次的技术雷达,让它和普通的技术咨询公司也有了区别(技术服务即外包,这应该是很多人黑的点,见仁见智);一些搜的到员工高认同度,搜不到的与内部员工的交流(也是因为内推结缘,虽然被 HR 抢先了,不过彼此仍然有友好的交流)等等。甚至于在近期的一篇博客里,笔者也狠狠地夸了下 Thoughtworks。技术的包容性和丰富性,管理的扁平化,不同于一般组织的发展理念,都是吸引我的地方。
所以后面的事情基本也就知道了。HR邮件 -> 简历 -> 电话面试 -> 难度适中的 Homework -> 结对编程 -> 技术面试 -> 公司文化面,不算复杂的流程,但是很切合 TW 的气质。老实说当时笔者并没有很强烈的换工作的意愿,所以从头到尾都没有准备过,加上那几天感冒挺严重的,整个人都有点浑浑噩噩。一直到最后一轮文化面,和 MaXu 老师谈了蛮久,也都是随性而言,一来一往都挺有趣的,可能也是在时候才发现,TW 如此适合笔者,笔者也十分地适合 TW(毕竟被马老师“夸赞”了回答都很“标准答案”)。
面试的流程很慢,但是通知很快。第二天,笔者就收到了 HR 的通知,待遇,工作要求也都确定了下来。然后在之后的一周里,便是申请离职 -> 公司 HR 挽留 -> 部门领导交流 -> 技术负责人交流 -> XX交流(笔者算是公司内较早的员工,CTO 对我的技术也比较认可)。所以尽管一开始的时候确实已经坚定了去 TW 的决心,在这么一轮下来后,笔者对目前公司的了解也深入了很多,而对于留下来之后的未来能够开展的工作也有了更多想法,反复的权衡和纠结,最终的结果便是笔者婉拒了 TW 的软件开发工程师的 Offer,重新收拾心情,投入到了现公司基础架构组的工作中去。
工作内容,工作的行程安排(是否出差),选择深入某个领域还是接触不同领域,职业规划,相处性格等等,确实都是笔者考虑的方面,但是没有多少可以分享的地方。不过对于能从基础的业务开发者,转型成基础架构开发和运维,应该也算得上是一件值得满足的事情。之所以如何反复权衡,是因为笔者是真正想从工作中得到满意的感受,同时也希望尽自己能力为工作反馈满意的成果。
尽管如此,笔者对于 TW 仍然十分向往,对于 Thoughtworks 的 HR Ruby 和马老师也是十分感谢,这些话都是发自内心的,没有多少客气的成分,毕竟不是每个人都会和你真诚地谈论你未来的发展。同时也很感谢公司对我的重视和支持,毕竟有时候我略显尖锐的性格确实会攻击到一些人或者制度。希望将来还能有机会和 Thoughtworks 有更多的交流,以更成熟的姿态和更全面的能力,并且仍然保持持续学习和成长的动力。
持续更新中…
原文最新链接
https://github.com/golang/go/wiki/CodeReviewComments/5a40ba36d388ff1b8b2dd4c1c3fe820b8313152f
Github译文链接
#8
对于刚开始学习和使用 Go 的新手来说,有这么几个资源值得关注。
Effective Go 和 Go Code Review Comments 中介绍了很多有助于编写优雅,高效的 Go 代码的指导性原则,前者可以认为是官方权威指南,而后者则可以算是对前者的补充,原文托管在 Github 上,每个月都会做部分 fix,而网上的中文版大多都是历史版本,无法及时更新,所以想由自己在业余时做些额外的工作,水平一般,能力有限,少部分难以翻译的词句将附上原文或给出意译内容。以下是翻译正文。
当前页面收集了在 Go 代码审核期间的常见意见,以便一个详细说明能被快速参考。这是一个常见错误的清单,而非综合性的风格指南。
你也可以将它作为是 Effective Go 的补充。
请在编辑这个页面前先讨论这个变更,就算是一个很小的变更。毕竟许多人都有自己的想法,而这里并不是战场。
在 Go 代码上运行 gofmt 以自动修复大多数的机械性风格问题。几乎所有不正规的 Go 代码都在使用gofmt。本文档的剩余部分涉及非机械性风格问题。
另一种方法是使用 goimports,这是gofmt的超集,gofmt可根据需要额外添加(和删除)导入行。
参见 https://golang.org/doc/effective_go.html#commentary。注释文档声明应该是完整的句子,即使这看起来有些多余。这种方式使注释在提取到 godoc 文档时格式良好。注释应以所描述事物的名称开头,并以句点结束:
// Request represents a request to run a command.type Request struct { ...// Encode writes the JSON encoding of req to w.func Encode(w io.Writer, req *Request) { ...
请注意除了句点之外还有其他符号可以作为句子的有效结尾(但至少也应该是!,?)。除此之外,还有许多工具使用注释来标记类型和方法(如 easyjson:json 和 golint 的 MATCH)。这使得这条规则难以形式化。
context.Context 类型的值包含跨 API 和进程边界的安全凭证,跟踪信息,截止时间和取消信号。比如传入 RPC 请求和 HTTP 请求一直到传出相关请求,Go 程序在整个过程的函数调用链中显式地传递 Context。
大多数使用 Context 的函数都应该接受 Context 作为函数的第一个参数:
func F(ctx context.Context, /* other arguments */) {}
从不特定于请求(request-specific)的函数可以使用 context.Background() 获取 Context,并将 err 与 Context 同时传递,即使你认为不需要。默认情况下只传递 Context ;只在你有充分的理由认为这是错误的,才能直接使用context.Background()。
原文: A function that is never request-specific may use context.Background(), but err on the side of passing a Context even if you think you don't need to. The default case is to pass a Context; only use context.Background() directly if you have a good reason why the alternative is a mistake.
不要将 Context 成员添加到某个 struct 类型中;而是将 ctx 参数添加到该类型的方法上。一个例外情况是当前方法签名必须与标准库或第三方库中的接口方法匹配。
不要在函数签名中创建自定义 Context 类型或使用除了 Context 以外的接口。
如果要传递应用程序数据,请将其放在参数,方法接收器,全局变量中,或者如果它确实应该属于 Context,则放在 Context 的 Value 属性中。
所有的 Context 都是不可变的,因此可以将相同的 ctx 传递给多个共享相同截止日期,取消信号,安全凭据,跟踪等的调用。
为避免意外的别名,从另一个包复制 struct 时要小心。例如,bytes.Buffer 类型包含一个 []byte 的 slice,并且作为短字符串的优化,slice 可以引用一个短字节数组。如果复制一个 Buffer,副本中的 slice 可能会对原始数组进行别名操作,从而导致后续方法调用产生令人惊讶的效果。
通常,如果 T 类型的方法与其指针类型 *T 相关联,请不要复制 T 类型的值。
不要使用包math/rand来生成密钥,即使是一次性密钥。在没有种子(seed)的情况下,生成器是完全可以被预测的。使用time.Nanoseconds()作为种子值,熵只有几位。请使用crypto/rand的 Reader 作为替代,如果你倾向于使用文本,请输出成十六进制或 base64 编码:
import ("crypto/rand"// "encoding/base64"// "encoding/hex""fmt")func Key() string {buf := make([]byte, 16)_, err := rand.Read(buf)if err != nil {panic(err) // out of randomness, should never happen}return fmt.Sprintf("%x", buf)// or hex.EncodeToString(buf)// or base64.StdEncoding.EncodeToString(buf)}
当声明一个空 slice 时,倾向于用
var t []string
代替
t := []string{}
前者声明了一个 nil slice 值,而后者声明了一个非 nil 但是零长度的 slice。两者在功能上等同,len 和 cap 均为零,而 nil slice 是首选的风格。
请注意,在部分场景下,首选非零但零长度的切片,例如编码 JSON 对象时(前者编码为 null,而后者则可以正确编码为 JSON array[])。
在设计 interface 时,避免区分 nil slice 和 非 nil,零长度的 slice,因为这会导致细微的编程错误。
有关 Go 中对于 nil 的更多讨论,请参阅 Francesc Campoy 的演讲 Understanding Nil。
所有的顶级导出的名称都应该有 doc 注释,重要的未导出类型或函数声明也应如此。有关注释约束的更多信息,请参阅 https://golang.org/doc/effective_go.html#commentary。
请参阅 https://golang.org/doc/effective_go.html#errors。不要将 panic 用于正常的错误处理。使用 error 和多返回值。
Error strings should not be capitalized (unless beginning with proper nouns or acronyms) or end with punctuation, since they are usually printed following other context. That is, use fmt.Errorf("something bad") not fmt.Errorf("Something bad"), so that log.Printf("Reading %s: %v", filename, err) formats without a spurious capital letter mid-message. This does not apply to logging, which is implicitly line-oriented and not combined inside other messages.
错误信息字符串不应大写(除非以专有名词或首字母缩略词开头)或以标点符号结尾,因为它们通常是在其他上下文后打印的。即使用fmt.Errorf("something bad")而不要使用fmt.Errorf("Something bad"),因此log.Printf("Reading %s: %v", filename, err)的格式中将不会出现额外的大写字母。否则这将不适用于日志记录,因为它是隐式的面向行,而不是在其他消息中组合。
When adding a new package, include examples of intended usage: a runnable Example, or a simple test demonstrating a complete call sequence.
Read more about testable Example() functions.
添加新包时,请包含预期用法的示例:可运行的示例,或是演示完整调用链的简单测试。
阅读有关 testable Example() functions 的更多信息。
当你生成 goroutines 时,要清楚它们何时或是否会退出。
通过阻塞 channel 的发送或接收可能会引起 goroutines 的内存泄漏:即使被阻塞的 channel 无法访问,垃圾收集器也不会终止 goroutine。
即使 goroutines 没有泄漏,当它们不再需要时却仍然将其留在内存中会导致其他细微且难以诊断的问题。往已经关闭的 channel 发送数据将会引发 panic。在“结果不被需要之后”修改仍在使用的输入仍然可能导致数据竞争。并且将 goroutines 留在内存中任意长时间将会导致不可预测的内存使用。
请尽量让并发代码足够简单,从而更容易地确认 goroutine 的生命周期。如果这不可行,请记录 goroutines 退出的时间和原因。
请参阅 https://golang.org/doc/effective_go.html#errors。不要使用 _ 变量丢弃 error。如果函数返回 error,请检查它以确保函数成功。处理 error,返回 error,或者在真正特殊的情况下使用 panic。
Avoid renaming imports except to avoid a name collision; good package names should not require renaming. In the event of collision, prefer to rename the most local or project-specific import.
避免包重命名导入,防止名称冲突;好的包名称不需要重命名。如果发生命名冲突,则更倾向于重命名最接近本地的包或特定于项目的包。
包导入按组进行组织,组与组之间有空行。标准库包始终位于第一组中。
package mainimport ("fmt""hash/adler32""os""appengine/foo""appengine/user""github.com/foo/bar""rsc.io/goversion/version")
goimports 会为你做这件事。
部分包由于循环依赖,不能作为测试包的一部分进行测试时,以.形式导入它们可能很有用:
package foo_testimport ("bar/testutil" // also imports "foo". "foo")
在这种情况下,测试文件不能位于 foo 包中,因为它使用的 bar/testutil 依赖于 foo 包。所以我们使用import .形式使得测试文件伪装成 foo 包的一部分,即使它不是。除了这种情况,不要在程序中使用 import .。它将使程序更难阅读——因为不清楚如 Quux 这样的名称是否是当前包中或导入包中的顶级标识符。
在 C 和类 C 语言中,通常使函数返回 -1 或 null 之类的值用来发出错误信号或缺少结果:
// Lookup returns the value for key or "" if there is no mapping for key.func Lookup(key string) string// Failing to check a for an in-band error value can lead to bugs:Parse(Lookup(key)) // returns "parse failure for value" instead of "no value for key"
Go 对多返回值的支持提供了一种更好的解决方案。函数应返回一个附加值以指示其他返回值是否有效,而不是要求客户端检查 in-band 错误值。此附加值可能是一个 error,或者在不需要解释时可以是布尔值。它应该是最终的返回值。
// Lookup returns the value for key or ok=false if there is no mapping for key.func Lookup(key string) (value string, ok bool)
这可以防止调用者错误地使用返回结果:
Parse(Lookup(key)) // compile-time error
并鼓励更健壮和可读性强的代码:
value, ok := Lookup(key)if !ok {return fmt.Errorf("no value for %q", key)}return Parse(value)
此规则适用于公共导出函数,但对于未导出函数也很有用。
返回值如 nil,“”,0 和 -1 在他们是函数的有效返回结果时是可接收的,即调用者不需要将它们与其他值做分别处理。
某些标准库函数(如 “strings” 包中的函数)会返回 in-band 错误值。这大大简化了字符串操作,代价是需要程序员做更多事。通常,Go 代码应返回表示错误的附加值。
Try to keep the normal code path at a minimal indentation, and indent the error handling, dealing with it first. This improves the readability of the code by permitting visually scanning the normal path quickly. For instance, don't write:
尝试将正常的代码路径保持在最小的缩进处,优先处理错误并缩进。通过允许快速可视化扫描正常路径来提高代码的可读性。例如,不要写:
if err != nil {// error handling} else {// normal code}
相反,书写以下代码:
if err != nil {// error handlingreturn // or continue, etc.}// normal code
如果 if 语句具有初始化语句,例如:
if x, err := f(); err != nil {// error handlingreturn} else {// use x}
那么这可能需要将短变量声明移动到新行:
x, err := f()if err != nil {// error handlingreturn}// use x
名称中的单词是首字母或首字母缩略词(例如 “URL” 或 “NATO” )需要具有相同的大小写规则。例如,“URL” 应显示为 “URL” 或 “url” (如 “urlPony” 或 “URLPony” ),而不是 “Url”。举个例子:ServeHTTP 不是 ServeHttp。对于具有多个初始化 “单词” 的标识符,也应当显示为 “xmlHTTPRequest” 或 “XMLHTTPRequest”。
当 “ID” 是 “identifier” 的缩写时,此规则也适用于 “ID” ,因此请写 “appID” 而不是“appId”。
由协议缓冲区编译器生成的代码不受此规则的约束。人工编写的代码比机器编写的代码要保持更高的标准。
Go 接口通常属于使用 interface 类型值的包,而不是实现这些值的包。实现包应返回具体(通常是指针或结构)类型:这样一来可以将新方法添加到实现中,而无需进行大量重构。
不要在 API 的实现者端定义 “for mocking” 接口;相反,设计 API 以便可以使用真实实现的公共 API 进行测试。
在使用接口之前不要定义接口:如果没有真实的使用示例,很难看出接口是否是必要的,更不用说它应该包含哪些方法。
package consumer // consumer.gotype Thinger interface { Thing() bool }func Foo(t Thinger) string { … }
package consumer // consumer_test.gotype fakeThinger struct{ … }func (t fakeThinger) Thing() bool { … }…if Foo(fakeThinger{…}) == "x" { … }
// DO NOT DO IT!!!package producertype Thinger interface { Thing() bool }type defaultThinger struct{ … }func (t defaultThinger) Thing() bool { … }func NewThinger() Thinger { return defaultThinger{ … } }
相反,返回一个具体的类型,让消费者模拟生产者实现。
package producertype Thinger struct{ … }func (t Thinger) Thing() bool { … }func NewThinger() Thinger { return Thinger{ … } }
Go代码中没有严格的行长度限制,但避免使用造成阅读障碍的长行。类似的,如果长行的可读性更好,不要为了缩短行而添加换行符——例如,行组成是重复的。
大多数情况下,当人们 “不自然地” 自动换行(wrap lines)时(在函数调用或函数声明的中间,或多或少,比如,虽然有一些例外),如果它们有合理数量的参数并且变量名称较短时,自动换行将是不必要的。长行似乎与长名称有关,避免名称过长有很大帮助。
换句话说,换行是因为你所写的语义(作为一般规则)而不是因为行的长度。如果您发现这会产生太长的行,那么更改名称或语义,可能也会得到一个好结果。
实际上,这与关于函数应该有多长的建议完全相同。没有 “永远不会有超过N行的函数” 这样的规则,但是程序中肯定会存在行数太多,功能过于微弱的函数,而解决方案是改变这个函数边界的位置,而不是执着在行数上。
请参阅 https://golang.org/doc/effective_go.html#mixed-caps。即使 Go 中混合大小写的规则打破了其他语言的惯例,也是适用的。例如,未导出的常量写成 maxLength 而不是MaxLength或MAX_LENGTH。
另见当前页面的 Initialisms 一节。
考虑一下 godoc 中会是什么样子。命名结果参数如:
func (n *Node) Parent1() (node *Node)func (n *Node) Parent2() (node *Node, err error)
将会造成口吃现象(stutter); 最好这样使用:
func (n *Node) Parent1() *Nodefunc (n *Node) Parent2() (*Node, error)
另一方面,如果函数返回两个或三个相同类型的参数,或者如果从上下文中不清楚返回结果的含义,那么在某些上下文中添加命名可能很有用。但是不要仅仅为了避免在函数内做结果参数的声明(var 或者 :=)而命名结果参数;这以牺牲不必要的 API 冗长性为代价,换取了一个微小的实现简洁性。
func (f *Foo) Location() (float64, float64, error)
不如以下代码清晰:
// Location returns f's latitude and longitude.// Negative values mean south and west, respectively.func (f *Foo) Location() (lat, long float64, err error)
如果函数行数较少,那么非命名结果参数是可以的。一旦它是一个中等规模的函数,请明确返回值。推论:仅仅因为它使得能够直接使用预命名返回而命名结果参数是不值得的。文档的清晰度总比在函数中的一行两行更重要。
最后,在某些情况下,您需要命名结果参数,以便在延迟闭包中更改它,这也是可以的。
请参阅当前页面 Named Result Parameters 一节。
与 godoc 呈现的所有注释一样,包注释必须出现在 package 声明的临近位置,无空行。
// Package math provides basic constants and mathematical functions.package math
/*Package template implements data-driven templates for generating textualoutput such as HTML.....*/package template
For "package main" comments, other styles of comment are fine after the binary name (and it may be capitalized if it comes first), For example, for a package main in the directory seedgen you could write:
对于 “package main” 注释,在二进制文件名称之后可以使用其他样式的注释(如果它们放在前面,则可以大写),例如,对于你可以编写 seedgen 目录中下的 main 包注释:
// Binary seedgen ...package main
或是
// Command seedgen ...package main
或是
// Program seedgen ...package main
或是
// The seedgen command ...package main
或是
// The seedgen program ...package main
或是
// Seedgen ..package main
以上是相应示例,它们的合理变体也是可以接受的。
请注意,以小写单词开头的句子不属于包注释的可接受选项,因为注释是公开可见的,应该用适当的英语书写,包括将句子的第一个单词的首字母大写。当二进制文件名称是第一个单词时,即使它与命令行调用的拼写不严格匹配,也需要对其进行大写。
有关评论约定的更多信息,请参阅https://golang.org/doc/effective_go.html#commentary。
包中名称的所有引用都将使用包名完成,因此您可以从标识符中省略该名称。例如,如果有一个 chubby 包,你不应该定义类型名称为 ChubbyFile ,否则使用者将写为 chubby.ChubbyFile。而是应该命名类型名称为 File,使用时将写为 chubby.File。避免使用无意义的包名称,如 util,common,misc,api,types 和 interfaces。有关更多信息,请参阅http://golang.org/doc/effective_go.html#package-names和 http://blog.golang.org/package-names。
不要只是为了节省几个字节就将指针作为函数参数传递。如果一个函数在整个过程中只引用它的参数x作为*x,那么这个参数不应该是一个指针。此常见实例包括将指针传递给 string(*string)或是指向接口值(*io.Reader)的指针。在这两种情况下,值本身都是固定大小,可以直接传递。这个建议不适用于大型 struct ,甚至不适用于可能生长的小型 struct。
方法接收者的名称应该反映其身份;通常,其类型的一个或两个字母缩写就足够了(例如“client”的“c”或“cl”)。不要使用通用名称,例如“me”,“this”或“self”,这是面向对象语言的典型标识符,它们更强调方法而不是函数。名称不必像方法论证那样具有描述性,因为它的作用是显而易见的,不起任何记录目的。名称可以非常短,因为它几乎出现在每种类型的每个方法的每一行上;familiarity admits brevity。使用上也要保持一致:如果你在一个方法中叫将接收器命名为“c”,那么在其他方法中不要把它命名为“cl”。
选择到底是在方法上使用值接收器还是使用指针接收器可能会很困难,尤其是对于 Go 新手程序员。如有疑问,请使用指针接收器,但有时候值接收器是有意义的,通常是出于效率的原因,例如小的不变结构或基本类型的值。以下是一些有用的指导:
相比异步函数更倾向于同步函数——直接返回结果的函数,或是在返回之前已完成所有回调或 channel 操作的函数。
同步函数让 goroutine 在调用中本地化,能够更容易地推断其生命周期并避免泄漏和数据竞争。同步函数也更容易测试:调用者可以传递输入并检查输出,而无需轮询或同步。
如果调用者需要更多的并发性,他们可以定义和调用单独的 goroutine 中的函数来轻松实现。但是在调用者端删除不必要的并发性是非常困难的——有时是不可能的。
失败的测试也应该提供有用的消息,说明错误,展示输入内容,实际内容以及预期结果。编写一堆 assertFoo 帮助程序可能很吸引人,但请确保您的帮助程序能产生有用的错误消息。假设调试失败测试的人不是你,也不是你的团队。典型的 Go 失败测试如:
if got != tt.want {t.Errorf("Foo(%q) = %d; want %d", tt.in, got, tt.want) // or Fatalf, if test can't test anything more past this point}
请注意,此处的命令是 实际结果!=预期结果,并且错误消息也使用该命令格式。然而一些测试框架鼓励倒写输出格式,如 预期结果 != 实际结果,“预期结果为 0,实际结果为 x”,等等。但是 Go 没有这样做。
如果这看起来像是打了很多字,你可能想写一个表驱动的测试。
在使用具有不同输入的测试帮助程序时以消除失败测试歧义的另一种常见技术是使用不同的 TestFoo 函数包装每个调用者,而测试名称也根据对应的输入命名:
func TestSingleValue(t *testing.T) { testHelper(t, []int{80}) }func TestNoValues(t *testing.T) { testHelper(t, []int{}) }
In any case, the onus is on you to fail with a helpful message to whoever's debugging your code in the future.
在任何情况下,你都有责任向可能会在将来调试你的代码的开发者提供有用的消息。
Go 中的变量名称应该短而不是长。对于范围域中的局部变量尤其如此。例如为 line count 定义 c 变量,为 slice index 定义 i 变量。
基本规则:范围域中,越晚使用的变量,名称必须越具有描述性。对于方法接收器,一个或两个字母就足够了。诸如循环索引和读取器(Reader)之类的公共变量可以是单个字母(i,r)。更多不寻常的事物和全局变量则需要更具描述性的名称。
go 中的 cgo 模块可以让 go 无缝调用 c 或者 c++ 的代码,而 python 本身就是个 c 库,自然也可以由 cgo 直接调用,前提是指定正确的编译条件,如 Python.h 头文件(),以及要链接的库文件。本文以 Ubuntu 18.04 作为开发和运行平台进行演示。
其实在使用 cgo 之前,笔者也考虑过使用 grpc 的方式。比如可以将需要调用的 python 代码包装成一个 grpc server 端,然后再使用 go 编写对应的 client 端,这样考虑的前提是,go 调用 python 代码本来就是解一时之困,而且引入语言互操作后,对于项目维护和开发成本控制都有不小的影响,如果直接使用 grpc 生成编程语言无感知的协议文件,将来无论是重构或使用其他语言替换 python 代码,都是更加方便,也是更加解耦的。所以 grpc 也是一种比较好的选择。至于通信延迟,老实说既然已经设计语言互操作,本机中不到毫秒级的损失其实也是可以接受的。
接下来进入正题。
1. 针对 python 版本安装 python-dev
sudo apt install python3.6-dev
系统未默认安装 python3.x 的开发环境,所以假如要通过 cgo 调用 python,需要安装对应版本的开发包。
2. 指定对应的cgo CFLAGS 和 LDFLAGS 选项
对于未由 c 包装的 python 代码,python-dev 包中内置了 python-config 工具用于查看编译选项。
python3.6-config --cflags
python3.6-config --ldflags
以下是对应的输出
-I/usr/include/python3.6m -I/usr/include/python3.6m -Wno-unused-result -Wsign-compare -g -fdebug-prefix-map=/build/python3.6-MtRqCA/python3.6-3.6.6=. -specs=/usr/share/dpkg/no-pie-compile.specs -fstack-protector -Wformat -Werror=format-security -DNDEBUG -g -fwrapv -O3 -Wall
-L/usr/lib/python3.6/config-3.6m-x86_64-linux-gnu -L/usr/lib -lpython3.6m -lpthread -ldl -lutil -lm -xlinker -export-dynamic -Wl,-O1 -Wl,-Bsymbolic-functions
低版本的 python 也可以在安装开发包后,使用对应的 python-config 命令打印依赖配置。由于 cgo 默认使用的编译器不是 gcc ,所以输出中的部分选项并不受支持,所以最后 cgo 代码的配置为
//#cgo CFLAGS : -I./ -I/usr/include/python3.6m
//#cgo LDFLAGS: -L/usr/lib/python3.6/config-3.6m-x86_64-linux-gnu -L/usr/lib -lpython3.6m -lpthread -ldl -lutil -lm
//#include "Python.h"
import "C"
3. 部分示例代码
3.0 映射 PyObject
type PyObject struct {
ptr *C.PyObject
}
func togo(obj *C.PyObject) *PyObject {
if obj == nil {
return nil
}
return &PyObject{ptr: obj}
}
func topy(self *PyObject) *C.PyObject {
if self == nil {
return nil
}
return self.ptr
}
3.1 python 环境的启动与终结
func Initialize() error {
if C.Py_IsInitialized() == 0 {
C.Py_Initialize()
}
if C.Py_IsInitialized() == 0 {
return fmt.Errorf("python: could not initialize the python interpreter")
}
if C.PyEval_ThreadsInitialized() == 0 {
C.PyEval_InitThreads()
}
if C.PyEval_ThreadsInitialized() == 0 {
return fmt.Errorf("python: could not initialize the GIL")
}
return nil
}
func Finalize() error {
C.Py_Finalize()
return nil
}
3.2 包路径与模块导入
func InsertExtraPackageModule(dir string) *PyObject {
sysModule := ImportModule("sys")
path := sysModule.GetAttrString("path")
cstr := C.CString(dir)
defer C.free(unsafe.Pointer(cstr))
C.PyList_Insert(topy(path), C.Py_ssize_t(0), topy(togo(C.PyBytes_FromString(cstr))))
return ImportModule(dir)
}
func ImportModule(name string) *PyObject {
c_name := C.CString(name)
defer C.free(unsafe.Pointer(c_name))
return togo(C.PyImport_ImportModule(c_name))
}
func (self *PyObject) GetAttrString(attr_name string) *PyObject {
c_attr_name := C.CString(attr_name)
defer C.free(unsafe.Pointer(c_attr_name))
return togo(C.PyObject_GetAttrString(self.ptr, c_attr_name))
}
3.3 数据类型转换
func PyStringFromGoString(v string) *PyObject {
cstr := C.CString(v)
defer C.free(unsafe.Pointer(cstr))
return togo(C.PyBytes_FromString(cstr))
}
func PyStringAsGoString(self *PyObject) string {
c_str := C.PyBytes_AsString(self.ptr)
return C.GoString(c_str)
}
...
可以看到形似 C.Py* 的方法都是由 cgo 模块编译调用的,这些方法也是 python 暴露的 C-API,而这里的示例就到此为止,其他诸如调用 python 模块方法的功能文档里也描述得十分详细,尽管实施起来仍然有些麻烦。
但是请注意 C-API 的 2.x 与 3.x 版本仍有不同,比如 2.x 版本中的字符串操作类型 PyString_* 在 3.x 中便被重命名为 PyBytes_*。
关注过 go 与 python 互操作功能的同学应该注意到上述的示例代码部分来自 go-python 这个开源项目,有兴趣的同学也可以关注一下。 这个项目基于 python2.7 ,其中暴露的 api 诸如字符串转换也是基于 python2.x 版本,所以针对于更流行的 python3.x 项目,大家就需要自己按照上文方法做一些修改了。
这里还可以介绍下 pkg-config 工具,在上文我们提到了 python-config 工具,而 pkg-config 可以帮助我们简化提取配置参数,go-python 项目也是这么做的。我们只需要将上文 cgo 配置代码更改为以下形式即可。pkg-config 工具会自动查询编译配置和库文件。
//#cgo pkg-config: python-3.6
//#include "Python.h"
import "C"
实际工作中,语言的互操作场景确实很让人感觉头疼,而 cgo 的文档资料其实并不多,所以希望本文能给大家带来一些帮助。
这是在帮某个业务组同事优化某个数据查询问题时想到的一种做法,大概是绘制某种关于时间的数据量趋势图,如下所示,当前数值为前面所有数值的累加。
https://github.com/percentor/articles/blob/master/Images/DataTrending.png
一个简单的例子,计算某医院某年当前月至起始月所有的就诊量。
create table test(id serial primary key , visit_time date);
do language plpgsql $$
declare
sql text;
date text;
month int;
begin
sql := 'insert into test(visit_time) values ';
for i in 1..10000 loop
month := floor(random() * (12) + 1)::int;
date := '2019-' || month || '-01' ;
sql := sql || '(''' || date || '''),';
end loop;
sql := rtrim(sql,',');
execute sql;
end
$$;
select visit_time,count(*) from test group by visit_time;
| 月份 | 当前就诊量 |
|---|---|
| 2019-06-01 | 800 |
| 2019-02-01 | 841 |
| 2019-01-01 | 870 |
| 2019-11-01 | 805 |
| 2019-08-01 | 832 |
| 2019-12-01 | 784 |
| 2019-09-01 | 870 |
| 2019-10-01 | 806 |
| 2019-07-01 | 858 |
| 2019-04-01 | 840 |
| 2019-05-01 | 843 |
| 2019-03-01 | 851 |
我们最终期望的查询结果应该是如下所示
| 月份 | 总就诊量 |
|---|---|
| 1 | 870 |
| 2 | 1711 |
| 3 | 2562 |
| 4 | 3402 |
| 5 | 4245 |
| 6 | 5045 |
| 7 | 5903 |
| 8 | 6735 |
| 9 | 7605 |
| 10 | 8411 |
| 11 | 9216 |
| 12 | 10000 |
为了实现这个目的,我们用上了 PostgreSQL 提供的 CTE 递归功能(我当时也只是临时去查询的语法,所以就不展开了)
with recursive t(id, p_id, visit_time, total) as (select id, p_id, visit_time, cnt
from (select row_number() over (order by foo.visit_time) as id,
row_number() over (order by foo.visit_time ) - 1 as p_id,
visit_time,
cnt
from (select interl.visit_time, count(*) cnt
from (select extract(month from visit_time) as visit_time
from test) interl
group by visit_time) as foo) bar
where bar.p_id = 0
union all
select bar.id, bar.p_id, bar.visit_time, cnt + c.total
from (select row_number() over (order by foo.visit_time) as id,
row_number() over (order by foo.visit_time ) - 1 as p_id,
visit_time,
cnt
from (select interl.visit_time, count(*) cnt
from (select extract(month from visit_time) as visit_time
from test) interl
group by visit_time) as foo) bar
inner join t c on c.id = bar.p_id)
select *
from t;
这句长 SQL 的核心**在于,所有存在有效数据的月份都是下一个存在有效数据月份的父表,所以我们通过以下语句手动拼凑所谓的父子层级关系,并在每次递归中累加父表的 total count 数据。
select
row_number() over (order by foo.visit_time) as id,
row_number() over (order by foo.visit_time ) - 1 as p_id
from ...
这是一个十分通用的算法,简单变换下,就能解决绝大部分类似的数据累加或累减的问题。唯一不太友好的便是性能,一方面是因为 OLAP 操作很多情况下都不可避免地要扫表,另一方面则是因为发生了非常多次的 loop,但好在一般情况下分组后的键值不会太多,比如我们这里的月份最多也就是 12 而已,数据量也不大,并且查看执行计划时会发现递归操作都是在数据库内存中进行,不会发生反复读盘的情况,所以 CTE 递归工作得还是不错的。
PostgreSQL 的执行计划很详细也很有趣,对于语句调优和性能定位也是最大助力之一。除此之外,PG 还有诸多强大的功能和特性,丰富的索引类型和插件,完善的优化和关联算法,生态中也有诸如 TimescaleDB 和 GreenPlum 这样的强大方案,衷心希望 PG 能够为越来越多的开发者所重视。
可以这么说的是,任何一种非强制性约束同时也没有“标杆”工具支持的开发风格或协议(仅靠文档是远远不够的),最终的实现上都会被程序员冠上“务实”的名头,而不管成型了多少个版本,与最初的设计有什么区别。DDD 是如此,微服务是如此,REST 也是如此。
虽然这也不难理解,风格从一开始被创造出来后,便不再属于作者了。所以仍然把你的符合以下标准
的“不标准” Web API 看作是 RESTful 的,也未尝不可。毕竟,谁在乎呢?
更深层次的讨论参见Why Some Web APIs Are Not RESTful and What Can Be Done About It。什么才是真正的 REST Api 并不是本文的重点(Github Rest API v3),笔者在后文讨论的具体实现,也只是符合目前流行的“RESTful”直觉设计。
| 谓词 | 释义 | 幂等性 | 安全性 |
|---|---|---|---|
| HEAD | 用于获取资源的 HTTP Header 信息 | 是 | 是 |
| GET | 用于检索信息 | 是 | 是 |
| POST | 用于创建资源 | 否 | 否 |
| PUT | 用于更新或替换完整资源或批量更新集合。对于没有 Body 的 PUT 动作,请将 Content-Length 设置为 0 |
是 | 否 |
| DELETE | 用于删除资源 | 是 | 否 |
| PATCH | 用于使用部分 JSON 数据更新资源信息(在一个请求里可搭载多个动作)。PATCH 是一个相对较新的 HTTP 谓词,在客户端或服务器不支持 PATCH 动作时,也可以使用 Post/Put 更新资源 | 否 | 否 |
结合上述 HTTP 谓词,通常情况下,更新部分资源的部分数据时,有以下四种做法:
application/merge-patch+json 来表示)。application/json-patch+json 来表示)我相信大部分系统中,采取的都是第1种和第4种做法,而本文的主题则是第3种做法。
在 RFC 5789(PATCH method for HTTP) 中,有一个关于 PATCH 请求的小例子:
PATCH /file.txt HTTP/1.1
Host: www.example.com
Content-Type: application/example
If-Match: "e0023aa4e"
Content-Length: 100
[description of changes]
[description of changes] 代表对目标资源的一系列操作,而JSON Patch则是描述操作的文档格式。
// 示例 json 文档
{
"a":{
"b":{
"c":"foo"
}
}
}
// JSON Patch 操作
[
{ "op": "test", "path": "/a/b/c", "value": "foo" },
{ "op": "remove", "path": "/a/b/c" },
{ "op": "add", "path": "/a/b/c", "value": [ "foo", "bar" ] },
{ "op": "replace", "path": "/a/b/c", "value": 42 },
{ "op": "move", "from": "/a/b/c", "path": "/a/b/d" },
{ "op": "copy", "from": "/a/b/d", "path": "/a/b/e" }
]
在这个JSON Patch的例子中,op代表操作类型,from和path代表目标 json 的层级路径,value代表操作值。相关语义想必大家都能直接读出来,更多的信息请参考What is JSON Patch?和 RFC JSON Patch。
示例程序引入了swagger,MongoDB,docker-compose等功能,关于 JsonPatch 的部分则使用微软官方的 JsonPatch 编写,该库支持add,remove,replace,move,copy方法,实现并不困难。实际使用时,直接以JsonPatchDocument<T>作为包装即可。
MongoDB 客户端推荐注册为单例。
public interface IMongoDatabaseProvider
{
IMongoDatabase Database { get; }
}
public class MongoDatabaseProvider : IMongoDatabaseProvider
{
private readonly IOptions<Settings> _settings;
public MongoDatabaseProvider(IOptions<Settings> settings)
{
_settings = settings;
}
public IMongoDatabase Database
{
get
{
var client = new MongoClient(_settings.Value.ConnectionString);
return client.GetDatabase(_settings.Value.Database);
}
}
}
/* Startup/ConfigureServices.cs */
public void ConfigureServices(IServiceCollection services)
{
…
services.AddSingleton<IMongoDatabaseProvider, MongoDatabaseProvider>();
…
}
appsettings.json文件中的数据库配置部分则为:
{
"ConnectionString": "mongodb://mongodb",
"Database": "ExampleDb"
}
docker-compose.yml对 web 应用和 MongoDB 的配置如下:
version: '3.4'
services:
aspnetcorejsonpatch:
image: aspnetcorejsonpatch
build:
context: .
dockerfile: AspNetCoreJsonPatch/Dockerfile
depends_on:
- mongodb
ports:
- "8080:80"
mongodb:
image: mongo
ports:
- "27017:27017"
启动时,定位到docker-compose.yml所在文件夹,运行docker-compose up,然后在浏览器访问localhost:8080/swagger,应用在启动后会自动创建ExampleDb数据库并插入一条数据。笔者也写了一个获取信息的接口/api/Persons,返回值如下:
[
{
"name": "LeBron James",
"oId": "5af995a5b8ea8500018d54b7"
}
]
然后再使用返回的oId请求/api/Persons/{id}(UpdateThenAddThenRemoveAsync)接口,body的 JsonPatch 描述则用:
/* body */
[
{
"value": "Daby",
"path": "FirstName",
"op": "replace"
},
{
"value": "Example Address",
"path": "Address",
"op": "add"
},
{
"path": "Mail",
"op": "remove"
}
]
/* PersonsController.cs */
[HttpPatch("{id}")]
public async Task<PersonDto> UpdateThenAddThenRemoveAsync(string id,
[FromBody] JsonPatchDocument<Person> personPatch)
{
var objectId = new ObjectId(id);
var person = await _personRepository.GetAsync(objectId);
personPatch.ApplyTo(person);
await _personRepository.UpdateAsync(person);
return new PersonDto
{
OId = person.Id.ToString(),
Name = $"{person.FirstName} {person.LastName}"
};
}
其他相关代码另请查阅。不过需要再提一点的是,Visual Studio 15.7 版本对docker-compose.yml的文本语法解析有些问题,详见MSBuild failing to parse a valid compose file,比如以下代码将无法编译:
environment:
- ASPNETCORE_ENVIRONMENT=Development
- ASPNETCORE_URLS=http://0.0.0.0:80
- ConnectionString=${MONGODB:-mongodb://mongodb}
- Database=ExampleDb
Keywords: Collector, Processor
| 名称 | Beats | Fluentd-bit |
|---|---|---|
| Introduction | Beats are a collector and processor of lightweight (resource efficient, no dependencies, small) and open source log shippers that act as agents installed on the different servers in your infrastructure for collecting logs or metrics. | Fluent Bit was born to address the need for a high performance and optimized tool that can collect and process data from any input source, unify that data and deliver it to multiple destinations. |
| Owner | Elastic | Treasure Data |
| Open Source | True | True |
| Github Stars | 5742 | 608 |
| License | Apache License v2.0 | Apache License v2.0 |
| Scope | Containers / Servers / K8S | Containers / Servers / K8S |
| Language | Go | C |
| Memory | ~10MB | ~500KB |
| Performance | High | High |
| Dependencies | Zero dependencies, unless some special plugin requires them. | Zero dependencies, unless some special plugin requires them. |
| Category | Auditbeat,Filebeat,Heartbeat,Metricbeat,Packetbeat,Winlogbeat | NaN |
| Configuration | File(.yml)/Cmd | File(custom file extension and syntax)/Cmd |
| Essence | Collector & Processor | Collector & Processor |
| Input/Module | File, Docker, Syslog, Nginx, Mysql, Postgresql, etc | File,CPU, Disk, Docker, Syslog, etc |
| Output | Elasticsearch, Logstash, Kafka, Redis, File, Console | ES, File, Kafka, etc |
| Name | Description | Samples |
|---|---|---|
| Input | Entry point of data. Implemented through Input Plugins, this interface allows to gather or receive data. | Samples |
| Parser | Parsers allow to convert unstructured data gathered from the Input interface into a structured one. Parsers are optional and depends on Input plugins. | Prospector and processors in Filebeat |
| Filter | The filtering mechanism allows to alter the data ingested by the Input plugins. Filters are implemented as plugins. | Prospector and processors in Filebeat |
| Buffer | By default, the data ingested by the Input plugins, resides in memory until is routed and delivered to an Output interface. | |
| Routing | Data ingested by an Input interface is tagged, that means that a Tag is assigned and this one is used to determinate where the data should be routed based on a match rule. | |
| Output | An output defines a destination for the data. Destinations are handled by output plugins. Note that thanks to the Routing interface, the data can be delivered to multiple destinations. | Samples |
Keywords: Collector, Processor, Aggregator
| 名称 | Logstah | Fluentd |
|---|---|---|
| Introduction | Logstash is an open source, server-side data processing pipeline that ingests data from a multitude of sources simultaneously, transforms it, and then sends it to your stash. | Fluentd is an open source data collector, which lets you unify the data. |
| Owner | Elastic | Treasure Data |
| Open Source | True | True |
| Github Stars | 9105 | 6489 |
| License | Apache License v2.0 | Apache License v2.0 |
| Scope | Containers / Servers / K8S | Containers / Servers / K8S |
| Language | JRuby(JVM) | Ruby & C |
| Memory | 200MB+ | ~40MB |
| Performance | Middle | High |
| Dependencies | JVM | Ruby Gem |
| Configuration | File(custom file extension and syntax)/Cmd | File(custom file extension and syntax)/Cmd |
| Essence | Collector, Processor, Aggregator | CCollector, Processor, Aggregator |
| Input/Module | Limited only by your imagination(Serilog) | Limited only by your imagination(Nlog) |
| Output | Limited only by your imagination | Limited only by your imagination |
Further Reading: Fluentd vs. Logstash: A Comparison of Log Collectors
| 比较 | Beats + Logstash | Fluentd bit + Fluentd | 说明 |
|---|---|---|---|
| 功能实现 | √ | √ | 基本一致 |
| 安装与配置简易性 | √ | ||
| 内存占用 | √ | JVM 特性使然 | |
| 可靠性 | √ | √ | 前者使用 registry file + redis 实现可靠性,后者使用内置 buffering 实现可靠性 |
| 可扩展性 | √ | √ | 插件生态和可扩展性基本一致。后者为分布型插件管理 |
| 趋势 | √ | ELK -> EFK | |
| 其他 | √ | √ | 前者更倾向于使用 go & java 技术栈,后者有 docker, k8s 官方 log driver 类型和案例支持 |
Tips: 任一层级都可以自由替换.
Keywords: Query, Analyze, Monitor
| 名称 | Kibana | Grafana |
|---|---|---|
| Introduction | Kibana is an open source data visualization plugin for Elasticsearch. | Data visualization & Monitoring with support for Graphite, InfluxDB, Prometheus, Elasticsearch and many more databases.The leading open source software for time series analytics. |
| Owner | Elastic | Grafana |
| Open Source | True | True |
| Github Stars | 9k+ | 22k+ |
| License | Apache License v2.0 | Apache License v2.0 |
| Scope | ElasticSearch only | ElasticSearch, InfluxDB, PostgreSQL etc |
| Language | Javascript | Go & Typescript |
| Configuration | File(.yml)/Cmd | File(custom file extension and syntax)/Cmd |
| Simple Query | Lucene syntax and filter components | filter components.Different from each other data source |
| Full-Text Query | Yes | No |
| Security | Plugins or libraries | Integration |
| Notification | Plugins or libraries | Integration |
| Advantages | Log, ES | Multiple data source, APM, Timeseries |
Working together.
Keywords:Storage, ES, Postgresql, Zombodb, Arangodb
老实说笔者学习 Go 的时间并不长,积淀也不深厚,这次因缘巧合,同组的同事以前是上海大学的开源社区推动者之一,同时我们也抱着部分宣传公司和技术分享的意图,更进一步的,也是对所学做一个总结,所以拟定了这次分享。另外与会的同学大多都是大二大三的“萌新”,考虑到受众水平和技术分享的性质,所以实际上这次分享涉及到的知识点都相对基础,当然为了寓教于乐,本人也十分讨厌着重介绍基础语法时可能引起的枯燥,所以加了少少的私货,并且也针对 1.11 及之前版本中或优雅,或局限的特性做了发散性的讲解。
总而言之,本次技术分享的初衷不是为了教导大家如何使用 Go 语言,更多的是想让大家在结束分享后,至少能比与会之前更想去了解 Go 这样一门简单优雅的编程语言。我对某些 Gopher 老是将“少即是多”挂在嘴边的做法持保留态度,因为在我看来,强调设计的正交性更能体现 Go 的优雅。下方附上演讲的完整 PPT,包括演讲内容也都包含在了其中,我相信,有需要的同学只需对第二节的开头部分稍作修改,或增加一些介绍 1.11 版本中新的内容和 CSP 的扩展知识,便可以应用到大部分初级的技术分享场景中。
技术一般,水平有限, 欢迎指正。
笔者在上一篇文章中提过,任何一种非“强制性”约束同时也没有“标杆”工具支持的开发风格或协议,最后都会在不同的程序员手中得到不同的诠释,微服务是如此,DDD 是如此,笔者把它称为技术**上的“康威定律”。不出意外的,REST 同样难逃此劫。光是在学习和收集资料的过程中,笔者就已经见过不下十多篇此类理解,甚至于在 url 中使用短划线或下划线连接单词也是众口难调。
尽管这只是小事。
微软也发布过关于如何设计 REST API 的开发指南,但是不幸的是,REST 的创始人 Roy Fielding 认为微软的 REST API 规范与 REST 没有多大关系。
“即使是我最糟糕的 REST 描述也比微软的 API 指南提供的总结或参考要好很多。”
那什么才是正确的 REST 描述呢,或者说,REST 是什么。本文的创作动机便是希冀于解决这样一个问题。
本文假设读者已经具备基本的 REST 和 Web 知识,哪怕你们现在认为 HTTP API 就是 REST API 也可。
REST 英文全称为 Representational State Transfer,又名“表述性状态移交”,是由 Roy Fielding 在《架构风格与基于网络的软件架构设计》一文中提出的一种架构风格(Architectural Style)。而在这篇 REST 圣经问世之前,R.F 博士就已经参与了 HTTP 1.0 协议规范的开发工作(1996年),并且负责了 HTTP 1.1 协议规范的制定(1997年)。
一种架构风格由一组准确命名的,相互协作的架构约束组成。当我们在谈论 REST 本质的时候,我们谈论的其实是架构约束。
REST 用以指导基于网络的分布式超媒体系统的设计和实现,Web(即万维网)就是一种典型的分布式超媒体系统。可以确定的是,在制定 HTTP 协议的过程中,R.F 博士就已经以 REST 架构风格作为指导原则来完成相关工作。论文中提到了以下内容:
“在过去的6年中,我们使用 REST 架构风格来指导现代 Web 架构的设计和开发。这个工作是与我所创作的 HTTP 和 URI 两个互联网规范共同完成的,这两个规范定义了在 Web 上进行交互的所有组件所使用的通用接口。”
“自从1994年起,REST 架构风格就被用来指导现代 Web 架构的设计与开发。”
“开发 REST 的动机是为 Web 的运转方式创建一种架构模型,使之成为 Web 协议标准的指导框架。”
“REST 的第一版开发于1994年10月至1995年8月之间,起初,在我编写 HTTP/1.0 规范和最初的 HTTP/1.1 建议时,将它用来作为表达各种 Web 概念的一种方法……”
Web 架构规范主要包括 HTTP, URI 和 HTML 等。
所以我们也不难理解为什么 REST 与 Web 和 HTTP 能够结合得如此紧密。尽管直到2000年,这只“鸡”才在下完鸡蛋后,出现在了世人面前。
无论是否愿意承认,REST 一开始就是为 Web 而服务的,可以这么说的是,REST 是现代 Web 的架构风格,Web 也是 REST 最典型和最成功的案例。包括在 R.F 博士的论文中,他也是在解决现代 Web 需求(无法控制的可伸缩性和独立部署)的过程中而逐步推导出 REST。前文已经提到一种架构风格是由一组准确命名的,相互协作的架构约束组成。而所谓架构约束,便是这个推导过程中最重要的产物。甚至高于 REST 本身。
早先的 Web 与 REST 所描述的模型有着大量出入,然而正是在对应的 HTTP 和 URI 规范出炉后,才有了所谓“现代 Web”的说法。笔者更愿意把“现代 Web”的定义期限定为1996年后。
在客户端没有发起请求时,服务器并不知道它的存在。同样的,服务器无须维护当前请求之外的客户端状态,从而改善服务器的可伸缩性。Session 和 Cookie 都是“需要”被抛弃的。
如果有些应用状态重要到服务器需要去关心,那它应该成为一个资源。
R.F 博士在论文中针对六大约束中的“统一接口”做了额外的约束分解和说明,但遗憾的是并没有以列表的方式展示出来。但在接下来的内容中你可能就会发现,这几项可能是目前大部分开发者践行 REST 原则时所遵循的全部标准。
REST 对于信息的核心抽象是资源,任何能够被命名的信息都可以称为是资源,只要你的想象力允许。资源一词通常和“可寻址性”绑定,一个或多个 URI 标识一个资源。如果资源的 URI 发生了变化,服务器应该使用超媒体引导客户端访问新的 URI 或提示对应信息。
当客户端对一个资源发起一个请求时,服务器会以一种有效的方式提供一个采集了资源信息的文档作为回应。这就是表述——一种以机器可读的方式对资源当前状态的说明。客户端和服务器之间也可以继续传递表述,从而对资源执行某种操作。客户端从来不会直接看到资源,能看到的都是资源的表述。可以这么说的是,服务器发送的表述用于描述资源当前的状态,客户端发送的表述用于描述客户端希望资源拥有的状态,这就是表述性状态转移/移交。
一个表述由一个“字节序列”和描述这些字节的“表述元数据”构成,且不与服务器端代码绑定,这意味着当服务器端的资源实现和业务操作代码发生变化时,可以选择不更改资源的呈现方式。
值得注意的是,一般人通常会将表述认为成资源的“值”,这虽然可以理解,但是当你请求一个天气服务时,千万不要认为表述一定便是温度等确定的值信息,因为它仍然可能是某次响应中的错误提示。一个表述的具体含义取决于消息中的控制数据。
“控制数据定义了在组件之间移交的消息的用途,例如被请求的动作或相应的含义。它也可用于提供请求的参数,或覆盖某些连接元素的默认行为。例如,可以使用(包含在请求或响应消息中的)控制数据来修改缓存的行为。”
“表述的数据格式称为媒体类型(media type)。发送者能够将一个表述包含在一个消息中,发送给接收者。接收者收到消息之后,根据消息中的控制数据和媒体类型的性质,来对该消息进行处理。”
表述在现代 Web 中的实例包括 HTML,Json,XML,图片等。
一个 (HTTP)消息体包含了所有足以让接收者理解它的必要信息,在现代 Web 中,自描述的消息由一些标准的HTTP方法、可定制的HTTP头信息、可定制的HTTP响应代码组成。扩展开来,它通常有以下三方面的含义。
该约束便是大名鼎鼎的“HATEOAS”(Hypertext/Hypermedia As The Engine Of Application State),但实际上 R.F 博士在论文中并没有对它做过详细的介绍。在目前的共识中(讽刺的是在大多数时候它并没有被应用到设计所谓 REST APIs 中去),HATEOAS 意味着客户端应该使用超文本来作为你在接收到当前的表述后,再进行下一步寻址的方式。更进一步的,客户端需要通过解析超文本理解服务器提供了哪些资源,而不是在客户端事先定义或约定俗成。
“客户端依赖的是超文本的状态迁移语义,而不应该对于是否存在某个URI或URI的某种特殊构造方式作出假设。一切都有可能变化,只有超媒体的状态迁移语义能够长期保持稳定。” —— 《理解本真的REST架构风格》
最终结果便是客户端可以自动化地适应服务器端的变化,服务器也允许在不破坏所有客户端的情况下更改它底层的实现。同样的,我们可以列出几点说明。
看起来,上述四点内容说的多是集中式 Web 应用的情况,在如今多用 Web APIs 进行前后端分离开发的 Web 应用中,HATEOAS 又该做如何理解呢?如今有这么一项技术可以让超文本继续充当驱动应用状态更新流动的引擎,那就是 Web Links,RFC 5988 定义了 HTTP 的这项扩展。
在 Github REST API v3 中,我们可以在很多 apis (如列表翻页)的响应体中看到 Link Header,对应引导的 Uri 同样有相关标准,即 Uri Templates(RFC 6570)
Link: <https://api.github.com/user/repos?page=3&per_page=100>; rel="next",
<https://api.github.com/user/repos?page=50&per_page=100>; rel="last"
至此,想必你也大致清晰了 HATEOAS 的含义。
如果可以的话,你可以将“应用状态”理解为客户端对资源操作后的展示结果。比如“主页”,“博客”,“关于我”,“成功提交”等操作界面。它和“资源状态”有抽象概念上的区分。
你可以放弃对 Hypertext 和 Hypermedia 之间区别的思考,笔者也认为它们在你理解 REST 时并不应该区分。
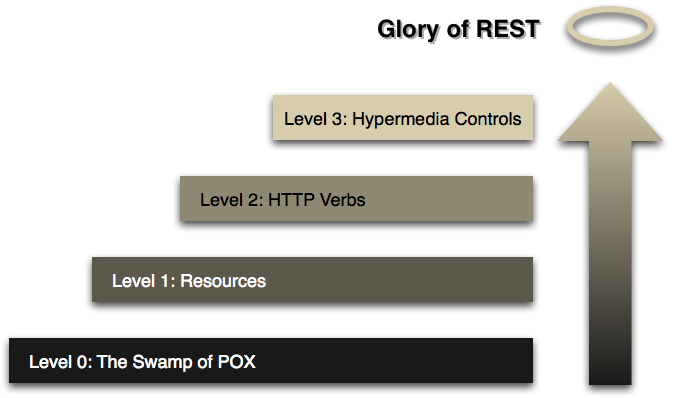
Richardson Maturity Model 是一个可以尝试的甜品,特别是当你在设计自己的 REST APIs 时。和 REST 相似,你也可以把该模型称为指导原则。
笔者无意去解释这几个层级,因为这些层级和“统一接口”的扩展约束都是间接的映射关系。而且正如上文一直在强调的,REST 不依赖于任何单一的通信/传输/移交协议,所以模型中的 HTTP 指示就有些耐人寻味了。
“它是标准吗?”
“当然不是,它只是目前设计 REST APIs 时的一种潜规则。”
对于理解概念性文章的总结总是特别艰难,看起来内容挺丰富,同时结合了 R.F 博士论文及其译者李琨教授相关文章,其实摊开了目录整篇文章也就只涉及到了起源—>约束->模型这样几个方面,实际上 REST 也确实只是一组约束而已。最后,仅用笔者认为的 R.F 博士论文中至关重要的两段话作为结束。
“因此,REST的模型应用是一个引擎,它通过检查和选择当前的表述集合中的状态迁移选项,从一个状态迁移到下一个状态。毫不奇怪,这与一个超媒体浏览器的用户接口完全匹配。然而,REST风格并不假设所有应用都是浏览器。事实上,通用的连接器接口对服务器隐藏了应用的细节,因此各种形式的用户代理都是等价的,无论是为一个索引服务执行信息获取任务的自动化机器人,还是查找匹配特定查询标准的数据的私人代理,或者是忙于巡视破损的引用或被修改的内容的维护爬虫。”
“这个名称“表述性状态转移”是有意唤起人们对于一个良好设计的Web应用如何运转的印象:一个由网页组成的网络(一个虚拟状态机),用户通过选择链接(状态迁移)在应用中前进,导致下一个页面(代表应用的下一个状态)被转移给用户,并且呈现给他们,以便他们来使用。”
Golang 中对于协程池的实现相对简单,以至于开发者去查看比较知名的 Golang 开源协程池库时,会发现代码多是大同小异。本篇文章便是分享一个简版的带有超时和取消功能的协程池。对于一些必备的知识假设读者都已经掌握。
package main
import "fmt"
import (
"time"
"runtime"
)
// 协程池对象,抢占式执行任务
func worker(id int, tasks <-chan int) {
for {
select {
case t, ok := <-tasks:
if ok {
fmt.Println("worker", id, "started task", t)
time.Sleep(time.Second)
fmt.Println("worker", id, "finished task", t)
}
default:
fmt.Println("worker", id, "is waiting for a task")
time.Sleep(time.Second)
}
}
}
func main() {
// 任务队列,非缓冲信道
// 可以将 int 换成其他任意类型,包括 function
tasks := make(chan int)
// 初始化逻辑核心数目的 worker
for wid := 1; wid <= runtime.NumCPU(); wid++ {
go worker(wid, tasks)
}
// 填充任务,由 worker 抢占执行
for t := 1; t <= 100; t++ {
tasks <- t
}
close(tasks)
}
上述 worker 代码中的 for...select... 可以用 range channel 的方式代替,但是这样实现超时和取消功能便有些不美观。
实际生产中我们一般都会为协程池和协程池执行对象分别创建 Pool 和 Worker 对象,然后加入超时和取消属性等,这次由于只是简版,所以统一参数传递和处理。
package main
import "fmt"
import (
"time"
"runtime"
)
// 协程池对象,抢占式执行任务
func worker(done chan interface{}, id int, timeout time.Duration, tasks <-chan int) {
go func() {
select {
// 在 id * 2 秒后传入结束标志
case <-time.After(timeout * time.Second):
done <- struct{}{}
return
}
}()
for {
select {
case t, ok := <-tasks:
if ok {
fmt.Println("worker", id, "started task", t)
time.Sleep(time.Second)
fmt.Println("worker", id, "finished task", t)
}
// 收到结束标志,释放当前 worker
case <-done:
fmt.Println("worker", id, "is canceled")
return
default:
fmt.Println("worker", id, "is waiting for a task")
time.Sleep(time.Second)
}
}
}
func main() {
// 任务队列,非缓冲信道
// 可以将 int 换成其他任意类型,包括 function
tasks := make(chan int)
// 初始化逻辑核心数目的 worker
for wid := 1; wid <= runtime.NumCPU(); wid++ {
done := make(chan interface{})
go worker(done, wid, time.Duration(wid*2), tasks)
}
// 填充任务,由 worker 抢占执行
for t := 1; t <= 100; t++ {
tasks <- t
}
close(tasks)
}
上述代码中可能存在一个小 bug,比如笔者电脑的逻辑核心数目是 12,也就是意味着 24 秒之后所有 worker 将取消,但是此时 tasks 并未全部消化,所以会造成 main goroutine 中的死锁。这里就不予以解决了。
上述代码中使用 done 标识结束每一个 worker,但实际上我们很多时候并不会在意某一或某二执行对象的生命周期,对于整个协程池才是考虑的重点。Golang 在 1.7 之后的版本中加入的 context 包可以很方便的实现这个功能。
package main
import "fmt"
import (
"time"
"runtime"
"context"
)
// 协程池对象,抢占式执行任务
func worker(ctx context.Context, id int, timeout time.Duration, tasks <-chan int) {
for {
select {
case t, ok := <-tasks:
if ok {
fmt.Println("worker", id, "started task", t)
time.Sleep(time.Second)
fmt.Println("worker", id, "finished task", t)
}
// 收到结束标志,释放当前 worker
case <-ctx.Done():
fmt.Println("worker", id, "is canceled")
return
default:
fmt.Println("worker", id, "is waiting for a task")
time.Sleep(time.Second)
}
}
}
func main() {
// 任务队列,非缓冲信道
// 可以将 int 换成其他任意类型,包括 function
tasks := make(chan int)
// 增加 context 信息控制所有 worker 退出
ctx, cancel := context.WithCancel(context.Background())
// 初始化逻辑核心数目的 worker
for wid := 1; wid <= runtime.NumCPU(); wid++ {
go worker(ctx, wid, time.Duration(wid), tasks)
}
// 填充任务,由 worker 抢占执行
for t := 1; t <= 100; t++ {
tasks <- t
}
close(tasks)
// 释放所有 worker
cancel();
// 保证所有的 worker 都能顺利退出
time.Sleep(5 * time.Second)
}
这篇文章的开头,笔者想多说两句,不过也是为了以后再也不多嘴这样的话。
在日常工作中,笔者接触得最多的开发工作仍然是在 .NET Core 平台上,当然因为团队领导的开放性和团队风格的多样性(这和 CTO 以及主管的个人能力也是分不开的),业界前沿的技术概念也都能在上手的项目中出现。所以虽然现在团队仍然处于疾速的发展中,也存在一些奇奇怪怪的事情,工作内容也比较密集,但是总体来说也算有苦有乐,不是十分排斥。
其实这样的环境有些类似于笔者心中的“圣地” Thoughtworks 的 雏形(TW的HR快来找我啊),笔者和女朋友谈到自己最想做的工作也是技术咨询。此类技术咨询公司的开发理念基本可以用一句概括:遵循可扩展开发,可快速迭代,可持续部署,可的架构设计,追求目标应用场景下最优于团队的技术选型决策。
所以语言之争也好,平台之争也好,落到每一个对编程和解决问题感兴趣的开发者身上,便成了最微不足道的问题。能够感受不同技术间的碰撞,领略到不同架构**中的精妙,就已经是一件满足的事情了,等到团队需要你快速应用其他技术选型时,之前的努力也是助力。当然面向工资编程也是一种取舍,笔者思考的时候也会陷入这个怪圈,所以希望在不断的学习和实践中,能够让自己更满意吧。
著名的 DRY 原则告诉我们 —— Don't repeat yourself,而笔者想更进一步的是,Deep Dive And Wide Mind,深入更多和尝试更多。
奇怪的前言就此结束。
作为最新的正式版本,虽然版本号只是小小的提升,但是 .NET Core 2.1 相比 .NET Core 2.0 在性能上又有了大大的提升。无论是项目构建速度,还是字符串操作,网络传输和 JIT 内联方法性能,可以这么说的是,如今的 .NET Core 已经主动为开发者带来抠到字节上的节省体验。具体的介绍还请参看 Performance Improvements in .NET Core 2.1 。
而在这篇文章里,笔者要聊聊的只是关于 async/await 的一些底层原理和 .NET Core 2.1 在异步操作对象分配上的优化操作。
熟悉异步操作的开发者都知道,async/await 的实现基本上来说是一个骨架代码(Template method)和状态机。
从反编译器中我们可以窥见骨架方法的全貌。假设有这样一个示例程序
internal class Program
{
private static void Main()
{
var result = AsyncMethods.CallMethodAsync("async/await").GetAwaiter().GetResult();
Console.WriteLine(result);
}
}
internal static class AsyncMethods
{
internal static async Task<int> CallMethodAsync(string arg)
{
var result = await MethodAsync(arg);
await Task.Delay(result);
return result;
}
private static async Task<int> MethodAsync(string arg)
{
var total = arg.First() + arg.Last();
await Task.Delay(total);
return total;
}
}
为了能更好地显示编译代码,特地将异步操作分成两个方法来实现,即组成了一条异步操作链。这种“侵入性”传递对于开发其实是更友好的,当代码中的一部分采用了异步代码,整个传递链条上便不得不采用异步这样一种正确的方式。接下来让我们看看编译器针对上述异步方法生成的骨架方法和状态机(也已经经过美化产生可读的C#代码)。
[DebuggerStepThrough]
[AsyncStateMachine((typeof(CallMethodAsyncStateMachine)]
private static Task<int> CallMethodAsync(string arg)
{
CallMethodAsyncStateMachine stateMachine = new CallMethodAsyncStateMachine {
arg = arg,
builder = AsyncTaskMethodBuilder<int>.Create(),
state = -1
};
stateMachine.builder.Start<CallMethodAsyncStateMachine>(
(ref stateMachine)=>
{
// 骨架方法启动第一次 MoveNext 方法
stateMachine.MoveNext();
});
return stateMachine.builder.Task;
}
[DebuggerStepThrough]
[AsyncStateMachine((typeof(MethodAsyncStateMachine)]
private static Task<int> MethodAsync(string arg)
{
MethodAsyncStateMachine stateMachine = new MethodAsyncStateMachine {
arg = arg,
builder = AsyncTaskMethodBuilder<int>.Create(),
state = -1
};
// 恢复委托函数
Action __moveNext = () =>
{
stateMachine.builder.Start<CallMethodAsyncStateMachine>(ref stateMachine);
}
__moveNext();
return stateMachine.builder.Task;
}
可以看到,每个由 async 关键字标记的异步操作都会产生相应的骨架方法,而状态机也会在骨架方法中创建并运行。以下是实际的状态机内部代码,让我们用实际进行包含两步异步操作的 CallMethodAsyncStateMachine 做例子。
[CompilerGenerated]
private sealed class CallMethodAsyncStateMachine : IAsyncStateMachine
{
public int state;
public string arg; // 代表变量
public AsyncTaskMethodBuilder<int> builder;
// 代表 result
private int result;
// 代表 var result = await MethodAsync(arg);
private Task<int> firstTaskToAwait;
// 代表 await Task.Delay(result);
private Task secondTaskToAwait;
private void MoveNext()
{
try
{
switch (this.state) // 初始值为-1
{
case -1:
// 执行 await MethodAsync(arg);
this.firstTaskToAwait = AsyncMethods.MethodAsync(this.arg);
// 当 firstTaskToAwait 执行完毕
this.result = firstTaskToAwait.Result;
this.state = 0;
// 调用 this.MoveNext();
this.Builder.AwaitUnsafeOnCompleted(ref this.awaiter, ref this);
case 0:
// 执行 Task.Delay(result)
this.secondTaskToAwait = Task.Delay(this.result);
// 当 secondTaskToAwait 执行完毕
this.state = 1;
// 调用 this.MoveNext();
this.builder.AwaitUnsafeOnCompleted(ref this.awaiter, ref this);
case 1:
this.builder.SetResult(result);
return;
}
}
catch (Exception exception)
{
this.state = -2;
this.builder.SetException(exception);
return;
}
}
[DebuggerHidden]
private void SetStateMachine(IAsyncStateMachine stateMachine)
{
}
}
可以看到一个异步方法内含有几个异步方法,状态机便会存在几种分支判断情况。根据每个分支的执行情况,再通过调用 MoveNext 方法确保所有的异步方法能够完整执行。更进一步,看似是 switch 和 case 组成的分支方法,实质上仍然是一条异步操作执行和传递的Chain。
上述的 CallMethodAsync 方法也可以转化成以下 Task.ContinueWith 形式:
internal static async Task<int> CallMethodAsync(string arg)
{
var result = await (
await MethodAsync(arg).ContinueWith(async MethodAsyncTask =>
{
var methodAsyncTaskResult = await MethodAsyncTask;
Console.Write(methodAsyncTaskResult);
await Task.Delay(methodAsyncTaskResult);
return methodAsyncTaskResult;
}));
return result;
}
可以这样理解的是,总体看来,编译器每次遇到 await,当前执行的方法都会将方法的剩余部分注册为回调函数(当前 await 任务完成后接下来要进行的工作,也可能包含 await 任务,仍然可以顺序嵌套),然后立即返回(return builder.Task)。 剩余的每个任务将以某种方式完成其操作(可能被调度到当前线程上作为事件运行,或者因为使用了 I/O 线程执行,或者在单独线程上继续执行,这其实并不重要),只有在前一个 await 任务标记完成的情况下,才能继续进行下一个 await 任务。有关这方面的奇思妙想,请参阅《通过 Await 暂停和播放》
上节关于编译器生成的内容并不能完全涵盖 async/await 的所有实现概念,甚至只是其中的一小部分,比如笔者并没有提到可等待模式(IAwaitable)和执行上下文(ExecutionContext)的内容,前者是 async/await 实现的指导原则,后者则是实际执行异步代码,返回给调用者结果和线程同步的操控者。包括生成的状态机代码中,当第一次执行发现任务并未完成时(!awaiter.isCompleted),任务将直接返回。
主要原因便是这些内容讲起来怕是要花很大的篇幅,有兴趣的同学推荐去看《深入理解C#》和 ExecutionContext。
异步代码能够显著提高服务器的响应和吞吐性能。但是通过上述讲解,想必大家已经认识到为了实现异步操作,编译器要自动生成大量的骨架方法和状态机代码,应用通常也要分配更多的相关操作对象,线程调度同步也是耗时耗力,这也意味着异步操作运行性能通常要比同步代码要差(这和第一句的性能提升并不矛盾,体重更大的人可能速度降低了,但是抗击打能力也更强了)。
但是框架开发者一直在为这方面的提升作者努力,最新的 .NET Core 2.1 版本中也提到了这点。原本的应用中,一个基于 async/await 操作的任务将分配以下四个对象:
ref标识一开始时,状态机实际以结构的形式存储在栈上,但是不可避免的,状态机运行时,需要被装箱到堆上以保留一些运行状态_moveNext,当链中的一个 Task 完成时,该委托被传递到下一个 Awaiter 执行 MoveNext 方法。据 Performance Improvements in .NET Core 2.1 一文介绍:
for (int i = 0; i < 1000; i++)
{
await Yield();
async Task Yield() => await Task.Yield();
}
当前的应用将分配下图中的对象:
而在 .NET Core 2.1 中,最终的分配对象将只有:
四个分配对象最终减少到一个,分配空间也缩减到了过去的一半。更多的实现信息可以参考 Avoid async method delegate allocation。
本文主要介绍了 async/await 的实现和 .NET Core 2.1 中关于异步操作性能优化的相关内容。因为笔者水平一般,文章篇幅有限,不能尽善尽美地解释完整,还希望大家见谅。
无论是在什么平台上,异步操作都是重要的组成部分,而笔者觉得任何开发者在会用之余,都应该更进一步地适当了解背后的故事。具体发展中,C# 借鉴了 F#中的异步实现,其他语言诸如 js 可能也借鉴了 C# 中的部分内容,当然一些基本术语,比如回调或是 feature,任何地方都是相似的,怎么都脱离不开计算机体系,这也说明了编程基础的重要性。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.

















{kind=link}