A movie recommender system using user-based collaborative filtering algorithm.
User-based collaborative filtering
The dataset consists of 100,000 ratings on different movies by the users of the MovieLens recommender system:
- 100,000 ratings (1-5) from 600 users on 9,000 movies
- Each user has at least 20 movies
- Data about the movies and the users
MovieLens 100K movie ratings dataset created by GroupLens at the University of Minnesota.
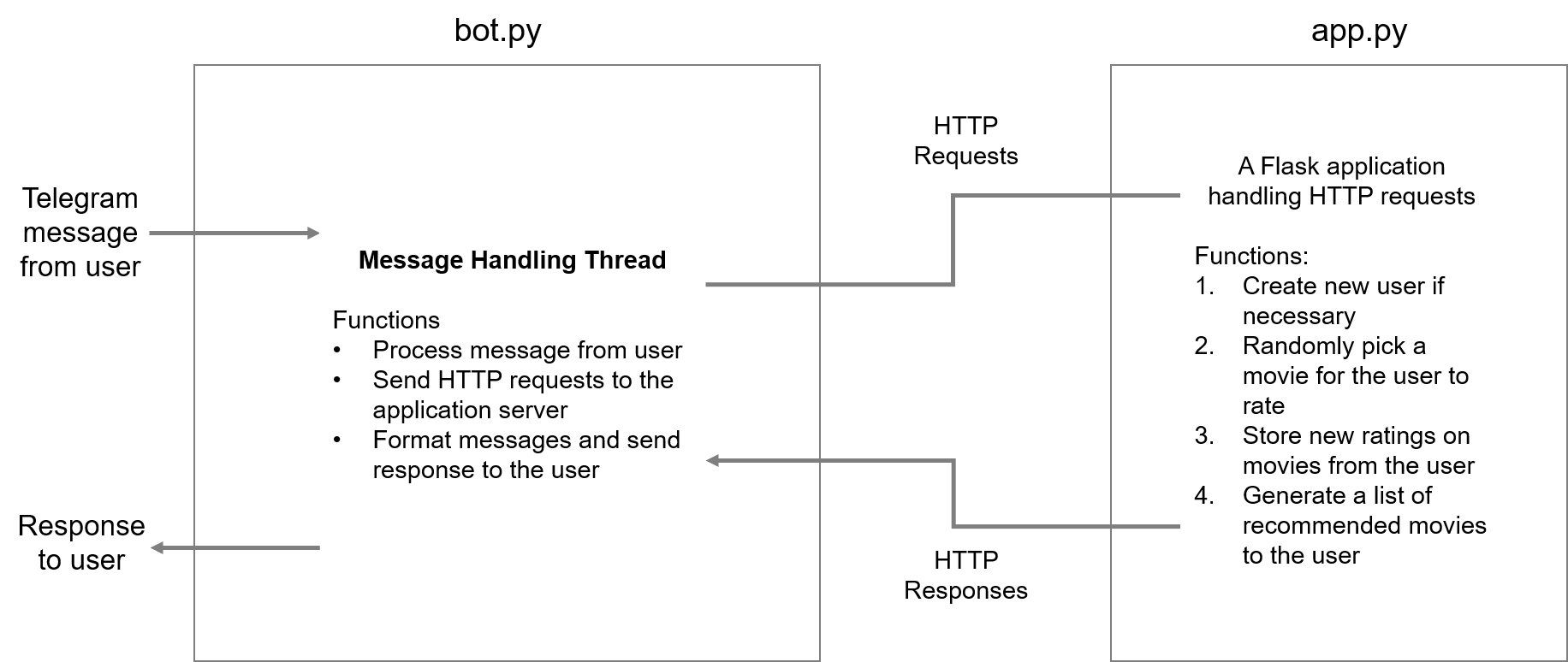
User can use three Telegram bot commands to interact with recommender system.
- /start
- A command to register with the application. If user is new, reply “Welcome!”, otherwise reply “Welcome back!”
- /rate
- A command to ask the application to present a movie for rating. User should receive two messages:
- A message containing the name of the movie, and the URL to the movie’s page on IMDB
- A message asking for the user’s rating on this movie, with a custom keyboard
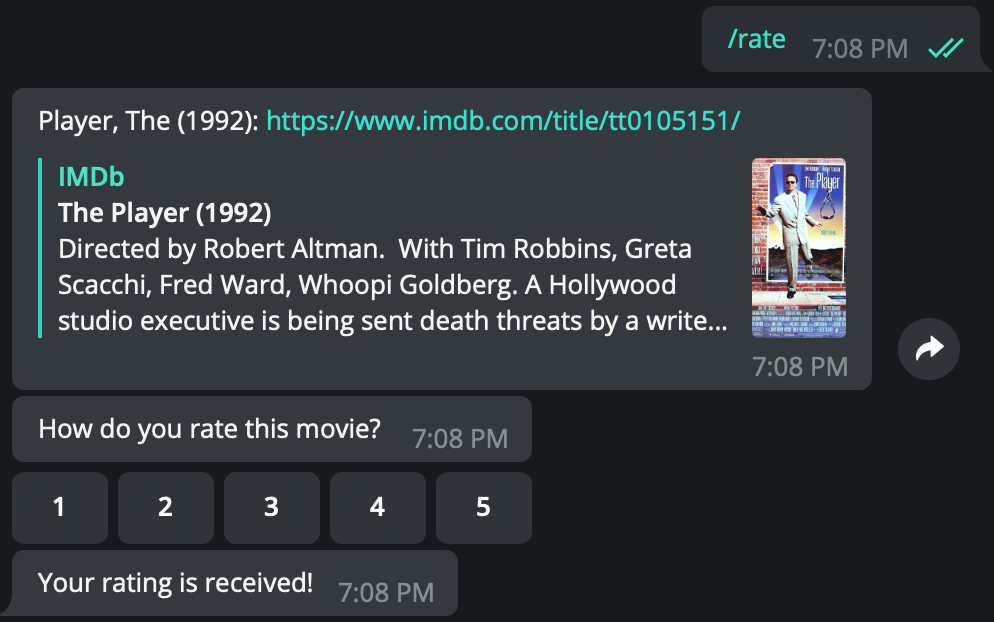
- A command to ask the application to present a movie for rating. User should receive two messages:
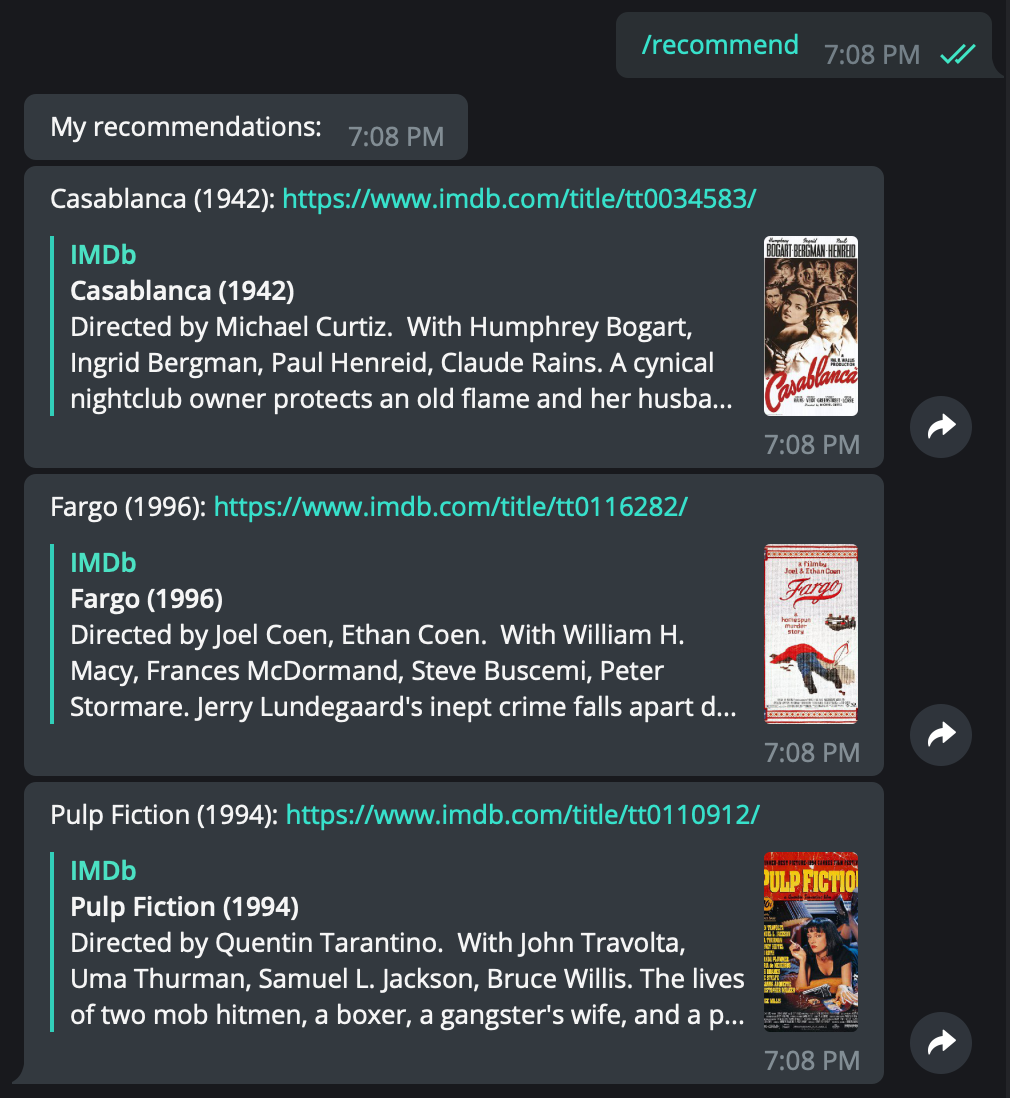
- /recommend
- A command to ask the application to recommend a list of movies based on previous ratings. On receiving this command, the system will send the top 3 recommended movies for the user.
- The server may return two different responses, depending on the number of ratings given by that user:
- If the user has 10 or more ratings, the server will return a list of recommended movies
- If the user has less than 10 ratings, the server will return an empty list and send the following message to the user: “You have not rated enough movies, we cannot generate recommendation for you”.
There is also a Spark ML approach for model training.
In this case, I used Spark 1.6 to train the Model by feeding MovieLens 20M Dataset.
MovieLens 20M Dataset
Train the model:
import sys
from pyspark import SparkContext
from pyspark.mllib.recommendation import ALS, Rating
if __name__ == '__main__':
if len(sys.argv) != 3:
print("Usage: <code> <input file> <partitions>", sys.stderr)
exit(-1)
sc = SparkContext(appName="PythonSparkML")
partitions = int(sys.argv[2])
data = sc.textFile(sys.argv[1], partitions)
ratings = data.map(lambda l: l.split(',')).map(lambda l: Rating(int(l[0]), int(l[1]), float(l[2])))
ratings.partitionBy(partitions)
# Build the recommendation model using Alternating Least Squares
rank = 50
numIterations = 10
model = ALS.train(ratings, rank, numIterations)
model.save(sc, "mr_20m")
sc.stop()Usage: spark-submit <code> <input file> <partitions>
Load movie title & model and do some queries:
from pyspark.mllib.recommendation import MatrixFactorizationModel, Rating
from pyspark.sql import Row, SQLContext
from pyspark import SparkContext
sc = SparkContext(appName="PythonSparkSQLCount")
model = MatrixFactorizationModel.load(sc, "mr_20m")
sqlContext = SQLContext(sc)
lines = sc.textFile("movies_20m.csv")
parts = lines.map(lambda l: l.split(","))
records = parts.map(lambda p: Row(product=p[0], title=p[1]))
df_movies = sqlContext.createDataFrame(records)
top_n = 10
pr1 = model.recommendProducts(1, top_n)
pr2 = model.recommendProducts(1001, top_n)
pr3 = model.recommendProducts(10001, top_n)
df_pr1 = sqlContext.createDataFrame(pr1)
df_pr2 = sqlContext.createDataFrame(pr2)
df_pr3 = sqlContext.createDataFrame(pr3)
df_pr1_title = df_pr1.join(df_movies, "product")
df_pr2_title = df_pr2.join(df_movies, "product")
df_pr3_title = df_pr3.join(df_movies, "product")

