pedro-r-marques / keras-opt Goto Github PK
View Code? Open in Web Editor NEWKeras Scipy optimize interface
License: Apache License 2.0
Keras Scipy optimize interface
License: Apache License 2.0

















I think the following is not supported anymore:
from tensorflow.python.keras.engine import data_adapter'
it gives an error, as .keras.engine does not exist anymore.
Nevermind, I had a dependency issue. I got rid of the error
Hello, thank you for publishing these codes. I have an issue which is related to my problem where I have trained a Keras model in TensorFlow 2.7 using float32 precision in order to have fast performance. Now I would like to continue the training using scipy L-BFGS-B optimizer using your codes.
In my code I first load the trained model (using ADAM optimizer) then I define a customized loss function, and then I compile the model with the customized loss function. When I run the model I got the following error
ValueError: failed to initialize intent(inout) array -- expected elsize=8 but got 4
The last error message is shown just after running one iteration of the scipy optimizer. I think it is related to the fact that my model weights are in float32 precision while my loss is in float64 precision.
Could you tell me how shall I solve this issue.
Hi @pedro-r-marques,
Thanks very much for contributing this repo and sharing under MIT!
I had a use case in which I wanted to use a scipy solver, and found this as part of my search. Unfortunately I wasn't able to use keras-opt, but I wanted to share my implementation of same interface, since I believe it has several improvements that increase the robustness and the problem size that may be solved.
keras-opt Issues Encounteredkeras-opt implementation and Pi-Yeuh Chuang's example; my python process exceeded the available memory on my laptop and was killed, even after adjusting the batch_sizekeras-opt the tf.GradientTape() is registered outside of the loop over mini-batches of training data, cf (scipy_optimizer.py#L64)[https://github.com/pedro-r-marques/keras-opt/blob/master/keras_opt/scipy_optimizer.py#L64]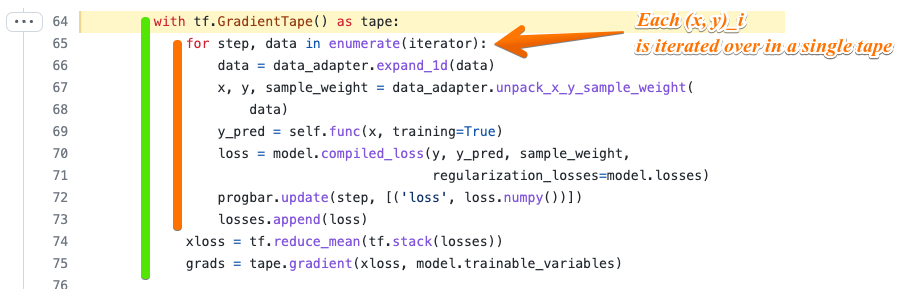
tf.reduce_mean and Regularization Terms in Mini-Batchestf.reduce_mean step in the gradient calculation has a (small) bug when the compiled_loss has a reduction=tf.keras.losses.Reduction.SUM_OVER_BATCH_SIZE (or tf.keras.losses.Reduction.AUTO). If the training dataset is distributed into batches of unequal size, the unweighted mean of the means [for each mini-batch] doesn't equal the mean of the sums [for each mini-batch] (e.g. if the last batch is the remainder and has fewer elements).make_train_function losses per-iteration validation metricsscipy.optimize.minimize routine will be entered into in the first epoch (and the user needs to be aware that epochs=1 is the only valid value for epochs) and the validation trace values (e.g. validation loss, validation metrics) will only be evaluated at the conclusion of the optimization routine.Changes to the interface to remove the above issues were relatively straightforward, but a little long.
The biggest difference was that rather than override make_train_function I created a class that overrode fit, which is a large discretionary change (which has some drawbacks of its own of course).
I decided to make these available in a separate package linked above rather than a PR here since the code changes were pretty substantive at the end of the day.
If you still actively use keras-opt let me know if you'd like to try the kormos package on the same problem for benchmarking!
I've included 2 comparable usage examples, by adapting the Keras MNIST covnet over at the kormos.readthedocs.io example here.
I think this is a pretty reasonable benchmark of a small but large enough model (35k parameters, 600k examples). I found that the gradient calculations run much faster with the reversal of the (tape, data iterator) loop as mentioned above, and the memory burden on the system is greatly reduced for the same batch_size. Depending on what other memory consumption I have on my laptop, the keras-opt snippet will OOM or write a lot of swap files, increasing the program runtime pretty substantially.
keras-opt Example## keras-opt
import numpy as np
from tensorflow import keras
from tensorflow.keras import layers
# Model / data parameters
num_classes = 10
input_shape = (28, 28, 1)
# Load the data and split it between train and test sets
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
# Scale images to the [0, 1] range
x_train = x_train.astype("float32") / 255
x_test = x_test.astype("float32") / 255
# Make sure images have shape (28, 28, 1)
x_train = np.expand_dims(x_train, -1)
x_test = np.expand_dims(x_test, -1)
print("x_train shape:", x_train.shape)
print(x_train.shape[0], "train samples")
print(x_test.shape[0], "test samples")
# convert class vectors to binary class matrices
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
x_train = np.repeat(x_train, 10, axis=0)
y_train = np.repeat(y_train, 10, axis=0)
# build the convolutional model
model = keras.Sequential(
[
keras.Input(shape=input_shape),
layers.Conv2D(32, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Conv2D(64, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Flatten(),
layers.Dropout(0.5),
layers.Dense(num_classes, activation="softmax"),
]
)
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
from keras_opt import scipy_optimizer
model.train_function = scipy_optimizer.make_train_function(model, maxiter=5)
history = model.fit(x_train, y_train, batch_size=2**12, epochs=1, validation_split=0.1)kormos Example# equivalent convnet in kormos
import numpy as np
from tensorflow import keras
from tensorflow.keras import layers
# Model / data parameters
num_classes = 10
input_shape = (28, 28, 1)
# Load the data and split it between train and test sets
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
# Scale images to the [0, 1] range
x_train = x_train.astype("float32") / 255
x_test = x_test.astype("float32") / 255
# Make sure images have shape (28, 28, 1)
x_train = np.expand_dims(x_train, -1)
x_test = np.expand_dims(x_test, -1)
print("x_train shape:", x_train.shape)
print(x_train.shape[0], "train samples")
print(x_test.shape[0], "test samples")
# convert class vectors to binary class matrices
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
x_train = np.repeat(x_train, 10, axis=0)
y_train = np.repeat(y_train, 10, axis=0)
# build the convolutional model
import kormos
model = kormos.models.BatchOptimizedSequentialModel(
[
keras.Input(shape=input_shape),
layers.Conv2D(32, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Conv2D(64, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Flatten(),
layers.Dropout(0.5),
layers.Dense(num_classes, activation="softmax"),
]
)
model.compile(loss=keras.losses.CategoricalCrossentropy(), optimizer="l-bfgs-b", metrics=["accuracy"])
history = model.fit(x_train, y_train, batch_size=2**12, epochs=5, validation_split=0.1)It seems, the current version does only work in eager mode. Are there plans to get it running in graph mode? I think, all .numpy() calls are then "illegal".
This works with the tensorflow 2.0 (beta), but it appears changes have been made to the api and it now fails with tensorflow-nightly with the following message,
File "...\keras\optimizer_v2\optimizer_v2.py", line 539, in getattribute
return super(OptimizerV2, self).getattribute(name)
AttributeError: 'GradientObserver' object has no attribute '_create_slots'
There is an issue in a couple parts of the code, which I believe is dependant on which version of numpy you have installed.
In init and _update_weights methods of ScipyOptimizer
File "...keras_opt\scipy_optimizer.py", line 132, in _collect_weights
x_values = np.empty(self._weights_size)
TypeError: 'numpy.float64' object cannot be interpreted as an integer
Depending on which version, you appear to need to have for example:
w_size = np.prod(shape).astype(int)
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.