Please note: If you are new to Prefect, we strongly recommend starting with Prefect 2 and Prefect Cloud 2, as they are in General Availability.
Prefect 1 Core, Server, and Cloud are our first-generation workflow and orchestration tools. You can continue to use them and we'll continue to support them while migrating users to Prefect 2. Prefect 2 can also be self-hosted and does not depend on this repository in any way.
If you're ready to start migrating your workflows to Prefect 2, see our migration guide.
Please note: this repo is for Prefect Server development. If you want to run Prefect Server, the best first step is to install Prefect and run prefect server start.
If you want to install Prefect Server on Kubernetes, take a look at the Server Helm Chart.
If you would like to work on the Prefect UI or open a UI-specific issue, please visit the Prefect UI repository.
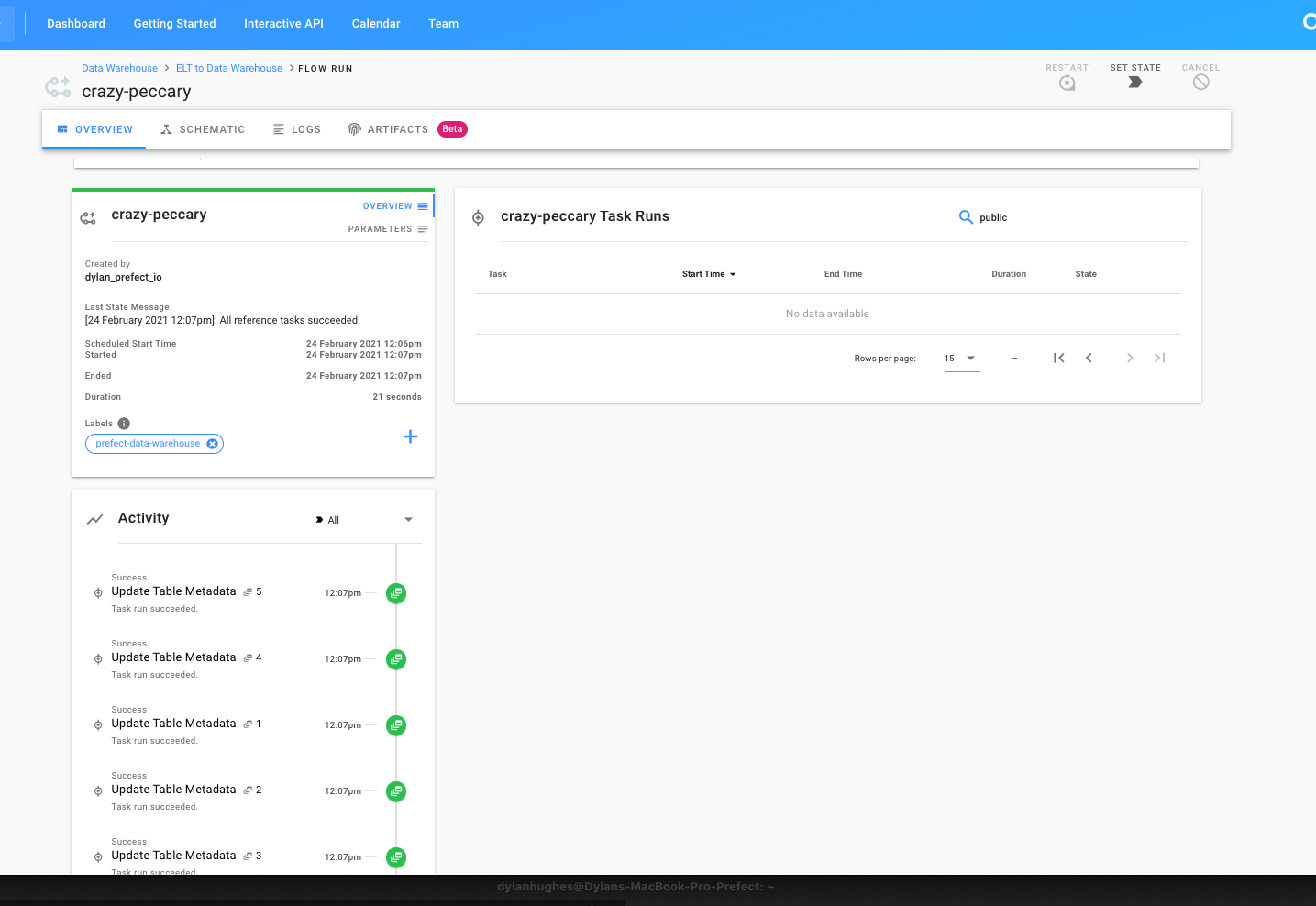
Prefect Server is an open source backend that makes it easy to monitor and execute your Prefect flows.
Prefect Server consists of a number of related services including:
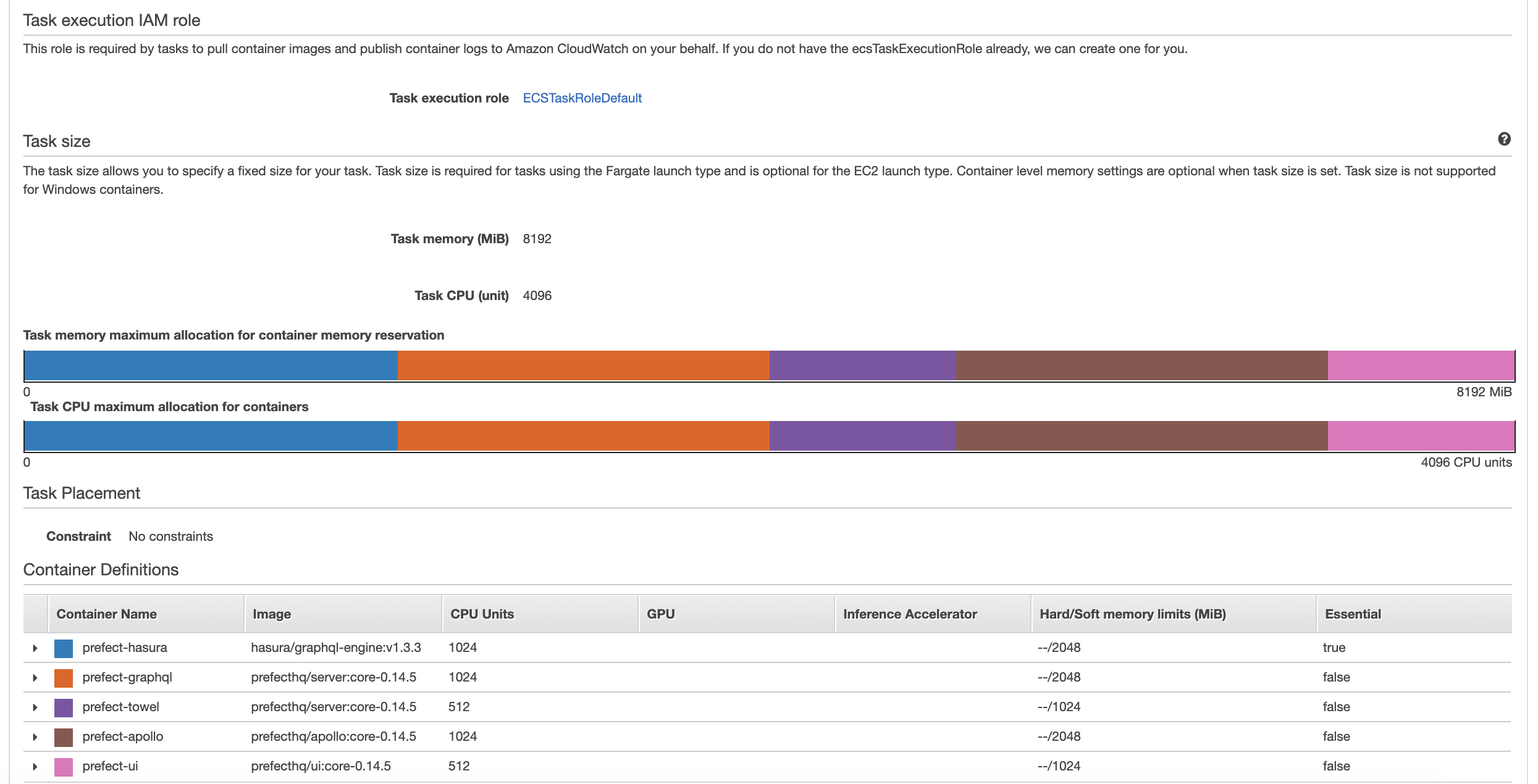
postgres: the database persistence layerhasura: a GraphQL API for Postgres (http://hasura.io)graphql: a Python-based GraphQL server that exposes mutations (actions) representing Prefect Server's logicapollo: an Apollo Server that serves as the main user interaction endpoint, and stitches together thehasuraandgraphqlAPIstowel: a variety of utility services that provide maintenance routines, because a towel is just about the most massively useful thing an interstellar hitchhiker can carryscheduler: a service that searches for flows that need scheduling and creates new flow runslazarus: a service that detects when flow runs ended abnormally and should be restartedzombie_killer: a service that detects when task runs ended abnormally and should be failed
These services are intended to be run within Docker and some CLI commands require docker-compose which helps orchestrate running multiple Docker containers simultaneously.
-
Don't Panic.
-
Make sure you have Python 3.7+ and Prefect installed:
pip install prefect -
Clone this repo, then install Prefect Server and its dependencies by running:
pip install -e . cd services/apollo && npm install
Note: if installing for local development, it is important to install using the -e flag with [dev] extras: pip install -e ".[dev]"
Note: for deploying Prefect Server, please use the prefect server start CLI command in Prefect Core 0.13.0+.
If you are doing local development on Prefect Server, it is best to run most services as local processes. This allows for hot-reloading as code changes, setting debugging breakpoints, and generally speeds up the pace of iteration.
In order to run the system:
-
Start the database and Hasura in Docker:
prefect-server dev infrastructure
If when starting the infrastructure, you receive an error message stating
infrastructure_hasura_1 exited with code 137, it is likely a memory issue with Docker. Bumping Docker Memory to 8GB should solve this. -
Run the database migrations and apply Hasura metadata:
prefect-server database upgrade
-
In a new terminal, start the services locally:
prefect-server dev services
You can use the -i (include) or -e (exclude) flags to choose specific services:
# run only apollo and graphql
prefect-server dev services -i apollo,graphql
# run all except graphql
prefect-server dev services -e graphqlPrefect Server has three types of tests:
unit tests: used to validate individual functionsservice tests: used to verify functionality throughout Prefect Serverintegration tests: used to verify functionality between Prefect Core and Server
Prefect Server uses pytest for testing. Tests are organized in a way that generally mimics the src directory. For example, in order to run all unit tests
for the API and the GraphQL server, run:
pytest tests/api tests/graphqlUnit tests can be run with only prefect-server dev infrastructure running. Service and
integration tests require Prefect Server's services to be running as well.
Whether you'd like a feature or you're seeing a bug, we welcome users filing issues. Helpful bug issues include:
- the circumstances surrounding the bug
- the desired behavior
- a minimum reproducible example
Helpful feature requests include:
- a description of the feature
- how the feature could be helpful
- if applicable, initial thoughts about feature implementation
Please be aware that Prefect Server feature requests that might compete with propriety Prefect Cloud features will be rejected.
Prefect Server is lovingly made by the team at Prefect and licensed under the Prefect Community License. For information on how you can use, extend, and depend on Prefect Server to automate your data, take a look at our license or contact us.