![]()
Blazing fast framework for fine-tuning Similarity Learning models

![]()
A dwarf on a giant's shoulders sees farther of the two
Quaterion is a framework for fine-tuning similarity learning models. The framework closes the "last mile" problem in training models for semantic search, recommendations, anomaly detection, extreme classification, matching engines, e.t.c.
It is designed to combine the performance of pre-trained models with specialization for the custom task while avoiding slow and costly training.
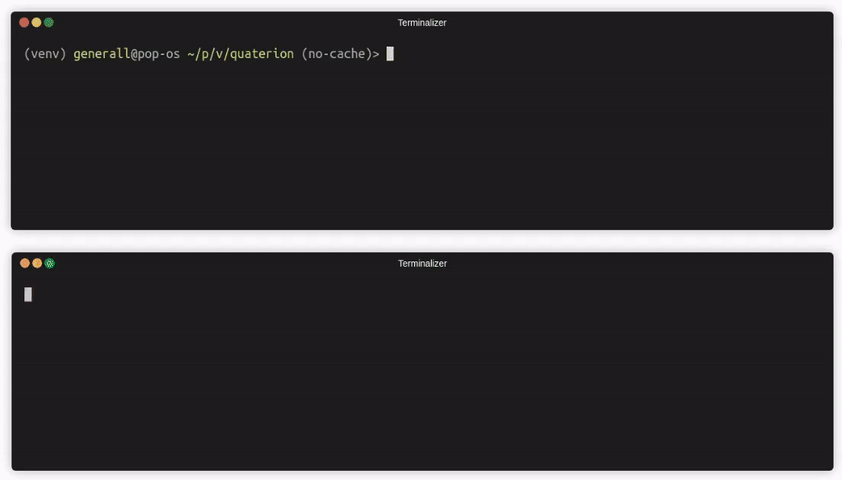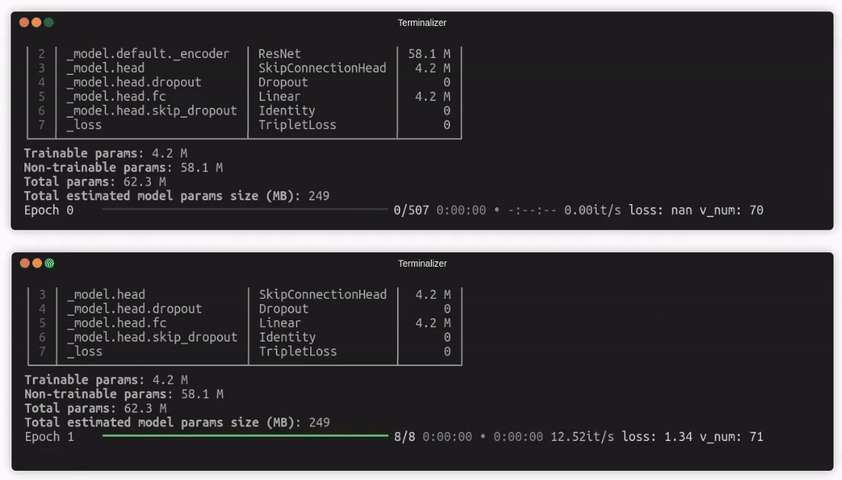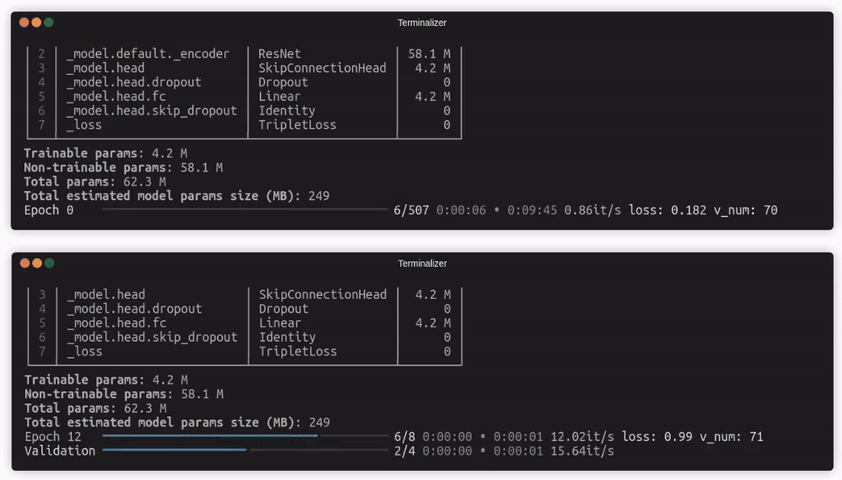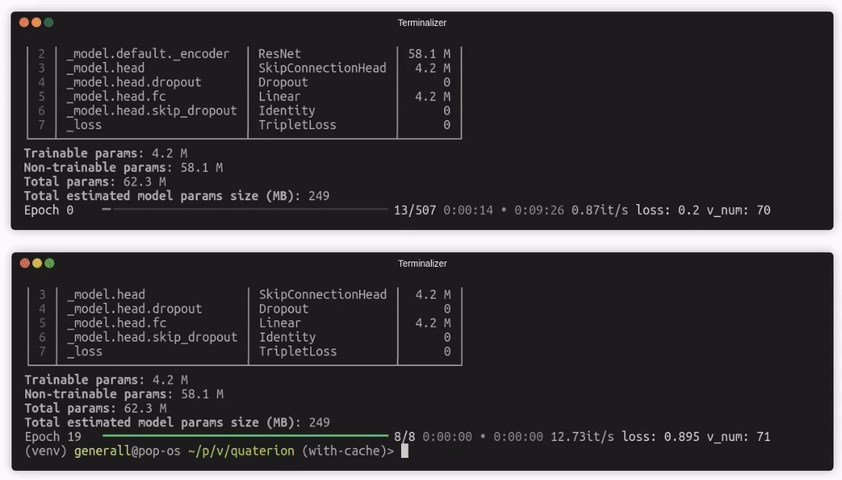
- 🌀 Warp-speed fast: With the built-in caching mechanism, Quaterion enables you to train thousands of epochs with huge batch sizes even on laptop GPU.
-
🐈 Small data compatible: Pre-trained models with specially designed head layers allow you to benefit even from a dataset you can label in one day.
-
🏗️ Customizable: Quaterion allows you to re-define any part of the framework, making it flexible even for large-scale and sophisticated training pipelines.
-
🌌 Scalable: Quaterion is built on top of PyTorch Lightning and inherits all its scalability, cost-efficiency, and reliability perks.
TL;DR:
For training:
pip install quaterionFor inference service:
pip install quaterion-modelsQuaterion framework consists of two packages - quaterion and quaterion-models.
Since it is not always possible or convenient to represent a model in ONNX format (also, it is supported), the Quaterion keeps a very minimal collection of model classes, which might be required for model inference, in a separate package.
It allows avoiding installing heavy training dependencies into inference infrastructure: pip install quaterion-models
At the same time, once you need to have a full arsenal of tools for training and debugging models, it is available in one package: pip install quaterion
- Quick Start Guide
- Minimal working examples
For a more in-depth dive, check out our end-to-end tutorials:
- Fine-tuning NLP models - Q&A systems
- Fine-tuning CV models - Similar Cars Search
Tutorials for advanced features of the framework:
- Cache tutorial - How to make training fast.
- Head Layers: Skip Connection - How to avoid forgetting while fine-tuning
- Embedding Confidence - how do I know that the model is sure about the output vector?
- Vector Collapse Prevention - how to prevent vector space collapse in Triplet Loss
- Join our Discord channel
- Follow us on Twitter
- Subscribe to our Newsletters
- Write us an email [email protected]
Quaterion is licensed under the Apache License, Version 2.0. View a copy of the License file.














































































































